TubeDETR:基于Transformer的空间-时间视频定位
摘要
我们考虑在一个视频中定位与给定文本查询相对应的时空管的问题。 这是一项具有挑战性的任务,需要对时间、空间和多模态交互进行联合和高效的建模。 为了解决这个问题,我们提出了TubeDETR,这是一种基于Transformer的架构,其灵感来自最近这类模型在文本条件下物体检测方面的成功。 我们的模型主要包括: (i) 一个高效的视频和文本编码器,它对稀疏采样的帧进行空间多模态交互建模,以及 (ii) 一个时空解码器,它联合执行时空定位。 通过广泛的消融研究,我们证明了我们提出的组件的优势。 我们还在时空视频定位任务上评估了我们的完整方法,并在具有挑战性的VidSTG和HC-STVG基准上展示了比现有技术更好的性能。
1 引言
将自然语言基础在视觉内容中是一项基本技能,可以构建强大且可解释的视觉和语言模型。 尤其,理解语言与视频中空间区域和时间边界的关联对于分析和改进多模态视频模型尤为重要。 这超出了将全局视觉表示与文本表示关联[62, 57],因为它需要推理关于详细的时空视觉表示及其与自然语言的关联,如图1所示。
时空视频定位,最近在[102]中引入,是一项有趣且具有挑战性的任务,它位于视觉定位[33, 59, 74]和时间定位[30, 25, 9]的交叉点。 给定未修剪的视频和对象的文本描述,时空视频接地旨在定位时空管(即。,一系列边界框)输入文本描述的目标对象。 此任务尤其具有挑战性,因为视频高度多样化,并且通常呈现出具有挑战性的场景,其中不同的实体具有相似的外观或在一个场景中执行相似的动作。
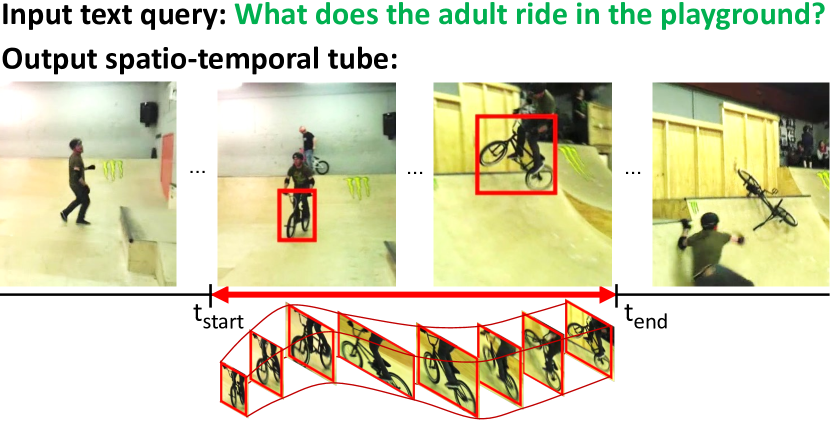
基于注意力的模型在自然语言处理中的成功 [75, 21] 近年来启发了将 Transformer 集成到计算机视觉任务中的方法,例如图像分类 [22]、目标检测 [8]、语义分割 [52] 或动作识别 [3, 7, 100, 60]。 值得注意的是,DETR [8] 在目标检测方面展现出具有竞争力的性能,同时消除了对多个手工设计的组件的需求,这些组件编码了关于此任务的先验知识。 最近,MDETR [37] 将此框架扩展到图像域中的各种文本条件目标检测任务,例如短语定位、参照表达式理解和分割。
受这些工作的启发,以及基于注意力的架构是为视频中的多模态和时空上下文关系建模的直观选择的这一事实,我们开发了一个时空视频定位的 Transformer 编码器-解码器模型,如图 2 所示。 虽然现有的针对此任务的方法依赖于预提取的对象建议 [102]、管式建议 [72] 或上采样层 [68],但我们的架构只是对称为 时间查询 的抽象进行推理,以共同执行时间定位和视觉定位。 我们的框架能够使用相同的表示来完成这两个子任务,从而学习强大的上下文表示。
更具体地说,我们的架构包括用于共同建模时间、空间和多模态交互的关键组件。 我们的视频-文本编码器通过对稀疏采样帧计算这些交互来有效地编码空间和多模态交互,并通过轻量级快速分支分别恢复时间局部信息。 我们的时空解码器通过时间自注意力层对时间交互进行建模,并通过时间对齐的交叉注意力层对空间和多模态交互进行建模。 时空视频定位然后通过解码器输出顶部的多个头来解决,这些头预测对象框和时间开始和结束概率。 我们进行了各种消融研究,其中我们特别展示了我们的视频-文本编码器在性能-内存权衡方面的优势,以及我们的时空解码器在时空定位结果方面的效率。 最后,我们表明,我们的方法在两个基准测试 VidSTG [102] 和 HC-STVG [72] 上显著优于最先进的方法。
总之,我们的贡献有三方面:
(i) 我们提出了一种用于时空视频定位的新架构,它使用时空 Transformer 解码器来执行此任务。
(ii) 我们提出了一种双流编码器,它基于慢速多模态流和轻量级快速视觉流,有效地编码了空间和多模态交互。 (iii) 我们在两个基准数据集 VidSTG 和 HC-STVG 上进行了综合实验,结果表明我们的框架在时空视频定位任务中非常有效。 我们的方法被称为 TubeDETR,在所有最先进的方法中取得了显著的性能提升。
代码和训练模型可在 [1] 公开获取。
2 相关工作
时空视频定位。 视觉定位是指在给定指代表达式的条件下,对物体进行空间定位,一直是图像领域 [18, 33, 32, 59, 83, 91, 97, 107, 51, 77] 和视频领域 [35, 66, 74] 的研究热点。 一个标准的范式是使用预先提取的物体建议 [48, 49, 78, 84, 86, 87, 90],而一些最近的工作 [46, 37, 19, 34, 56, 89, 88] 提出了一种不需要此类建议的单阶段方法。 我们的工作遵循 MDETR [37] 的单阶段框架,但将其扩展到时空视频定位,并加入了时间定位损失(见公式 3.4)、慢速-快速编码(见图 3)和时空解码(见图 4)。
另一条研究路线侧重于在给定自然语言查询的情况下,在视频中定位时间片段 [9, 10, 30, 31, 25, 47, 58, 64, 80, 101, 96, 99, 98, 95, 76, 92, 12, 27]。 这些工作构建了能够推断时间的架构,但没有保留空间信息。 时空视频定位位于时间定位和视觉定位的交叉点。 虽然一些方法 [15, 72, 84] 依赖于预先提取的管状建议,或物体建议 [102],但我们的方法不需要任何预先提取的建议。 最近的一项工作 [68] 提出了一种名为 STVGBert 的单阶段方法,它将 VilBERT 模型 [54] 在概念字幕 [65] 上进行预训练后,应用于这项任务。 STVGBert 使用反卷积进行视觉定位,并对时间和空间交互进行对称建模。 相比之下,我们的架构使用 Transformer 解码器进行视觉定位,并分别推断时间和空间维度。
视频理解中的时间建模。 像 ViT [22] 或 DETR [8] 这样的用于图像理解的强大模型的兴起,促进了将这些模型扩展到视频领域的研究 [3, 7, 100, 41, 29, 60]。 特别是,Lei et al. [41] 提出了一种架构,将时刻检索视为一个直接的集合预测问题,但它不适合视觉定位,因为它不保留空间信息。 He et al. [29] 将 DETR 框架扩展到视频,并提出了一种在可变形 DETR [106] 之上添加了顺序模块的架构,而我们的架构是基于对预训练的编码器和解码器的内部修改构建的,并且还推理语言。 我们的双分支编码器也与 SlowFast 网络 [23, 82] 相关,后者结合了快慢视频流。 相比之下,在我们的情况下,两个流都对从同一骨干网络提取的特征进行操作,我们的双流架构的灵感来自于与多模态建模相关的计算复杂度。
视觉和语言。 基于 Transformer 的架构已成为各种视觉和语言任务中无处不在的工具 [69, 71, 54, 14, 20, 36, 43, 45, 55, 103, 11, 38, 17]。 大多数视频文本 Transformer 依赖于预提取的对象特征 [105],或者空间池化特征 [70, 44, 26, 85, 24, 104],这些特征不保留详细的空间信息。 相比之下,我们的架构旨在保留空间信息以执行视觉定位。 一些最新研究提出基于 Transformer 的架构,对保留空间信息的视频和文本进行推理 [42, 94, 2, 5]。 但是,这些研究通常旨在学习全局视频表示以解决视频级预测任务,而我们专注于学习详细的帧级表示以解决需要空间和时间定位的密集预测任务。
3 方法
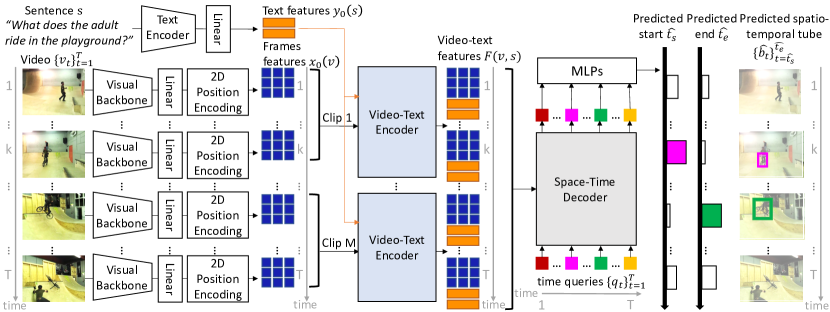
我们首先在第 3.1 节中概述了我们的模型。 接下来,我们将详细介绍我们模型的两个主要部分:视频文本编码器(第 3.2 节)和时空解码器(第 3.3 节)。 然后在第 3.4 节中,我们将解释用于训练我们模型的损失。 最后,在第 3.5 节中,我们将介绍我们如何初始化模型权重。
3.1 概述
我们的目标是,给定一个视频和一个语言查询,输出一个时空管,即。 一个具有时间边界的一系列边界框,将语言查询定位到视频中。 这很有挑战性,因为它需要对语言查询和视频之间的长程 空间 和 时间 交互进行建模,其中视频可能具有数百帧,由数万个时空视频特征表示。 因此,效率是一个主要挑战。 为了解决这个问题,我们设计了一个编码器-解码器架构,如图 2 所示,它能够在整个视频中准确而有效地对视频语言空间和时间交互进行建模。 特别是,我们的双流视频文本编码器(第 3.2 节)仅对大约一秒的短片段建模视频语言交互,但允许详细的空间定位。 我们的时空解码器(第 3.3 节)然后在整个视频上对长程时间交互进行建模,以产生时间上一致的输出和对输出时空管的开始和结束时间的准确预测。
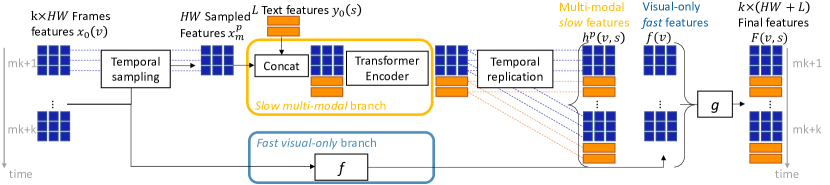
3.2 视频-文本编码器
我们的编码器如图3所示,并在下面描述。 它的目标是模拟语言查询和视频之间的空间和多模态交互,以准确地将查询在空间上定位到每一帧。 为此,我们利用自注意力层联合建模空间和视觉语言交互的能力[37, 42, 36]。 但是,计算每一帧的视觉特征和文本特征之间的自注意力的计算成本很高。 出于这个原因,我们建议仅针对每帧计算空间和多模态交互。 我们将产生的流称为慢多模态分支。 我们使用一个单独的轻量级快速视觉专用分支,它保留了原始的帧速率,并使我们能够恢复慢分支稀疏采样丢失的一些高频时空细节。
形式上,我们的编码器将来自视觉主干的所有输入视频帧的一组 2D 平坦图像特征以及文本编码器从查询句子中提取的一组文本特征作为输入,并输出一组视频文本特征,每帧一个。 接下来我们将详细介绍慢速和快速分支,以及最终的特征聚合模块。
慢多模态分支。 这个分支的目标(见图3的顶部)是对视觉和文本表示之间的交互进行建模。 这条分支首先从 一个 帧中采样特征,用于 个连续帧的短剪辑。 典型的剪辑长度为一秒,即. 标准帧率为每秒 5 帧 [102]。 形式上,得到的特征图被写成 ,其中 是剪辑的数量, 是剪辑的长度, 是整个视频的长度。 然后,我们为每个剪辑 连接其视觉特征 和文本特征 ,并将其转发到 N 层 Transformer 编码器。 输出是上下文化的视觉文本表示 ,它有效地结合了输入视频 和查询句 中的信息。
快速仅视觉分支。 前面解释的时间稀疏采样方案显着减少了视频文本编码器的内存需求,但会导致时空细节的丢失,而这些细节对于时空视频定位很重要。 为了缓解这个问题,我们引入了模块 (见图 3 底部),该模块对 所有帧的 2D 平铺图像特征 进行操作。 形式上,给定特征图 ,该模块输出视觉特征 。 这个 快速 分支保留了特征的空间和时间分辨率,但计算量很小,因为它不计算任何多模态或空间交互。 为了提高效率,在训练时,该分支不会将梯度反向传播到视觉主干。 此外,我们在第 4.2 节中展示,当与从慢分支获得的时间稀疏特征相结合时,它能够恢复在时间采样过程中丢失的一些时间信息。
慢速-快速特征聚合。 现在我们来描述 慢速 和 快速 分支聚合模块(见图 3,右侧),它融合了来自两个分支的信息并输出最终的视频文本特征。 为了匹配来自 快速 分支 的输出的时间维度,慢速 多模态分支 的输出在时间上被复制了 次,每个剪辑得到一个视频文本编码 。 这些编码是文本上下文化的视觉编码 和视觉上下文化的文本编码 的串联。 将文本语境化的视觉编码 与 快速 分支的输出相结合,并通过一个额外的聚合模块 和一个残差连接,得到聚合后的视觉编码 。 我们视频文本编码器的最终输出是通过将这些聚合后的视觉编码与视觉语境化的文本编码 即 连接起来得到的。 具体来说,模块 是通过一个求和操作,然后是一个线性层实现的,即 。
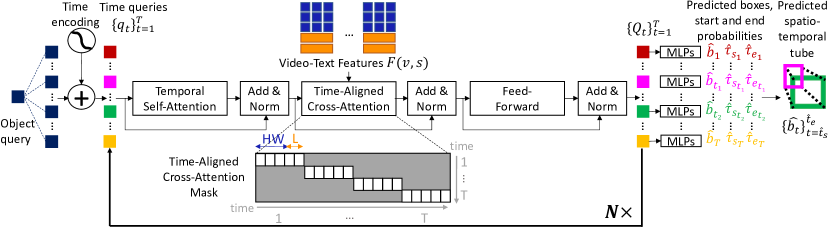
3.3 时空解码器
我们的解码器如图 4 所示,并将在下面详细介绍。 它的目标是对 帧整个视频中的时间交互进行建模,并将编码器中的多模态特征解码成具有准确起始和结束时间的时序一致的输出管。 这是通过一个高效的解码器架构实现的,该架构交替使用 (i) 时间自注意力 层,它对整个视频中的 时间 交互进行建模,以及 (ii) 时间对齐交叉注意力 层,它有效地将从编码器获得的单个帧的视频文本特征合并到一起。 具体来说,解码器对 个位置编码 进行操作,每个帧一个,称为时间查询。 每个时间查询的初始编码是通过对所有帧通用的学习到的对象编码和一个冻结的正弦时间编码进行求和得到的。 解码器还将 视频-语言嵌入 作为输入,这些嵌入是由视频-文本编码器输出的。 解码器是 解码器块的连续序列。 每个块都由时间自注意力、时间对齐交叉注意力和前馈层组成,并与归一化 [4] 交织在一起,如图 4 所示。 解码器输出经过细化的时间查询 ,这些查询在视频中的所有帧以及编码器生成的视频-文本特征之间进行上下文化。 然后,将经过细化的时间查询联合用于输出时空视频管,该视频管将输入句子与视频联系起来。 接下来将详细描述各个层。
时间自注意力。 输入时间查询 使用时间自注意力层相互关注。 该层位于解码器中的每个 块中,负责对整个视频中的长程时间交互进行建模。 这是因为该层的复杂度相对较低,它不依赖于输入视频的空间分辨率。
时间对齐交叉注意力。 由于视频帧数量 很多,并且视频特征的空间分辨率 很大,因此允许每个时间查询交叉关注所有 视频-文本特征在计算上可能非常昂贵。 相反,在我们的交叉注意力模块中,每个时间查询 只交叉关注帧 处与其时间对应多模态特征 。 请注意,使用我们的时间对齐交叉注意力公式,时间编码和时间自注意力层变得更加重要,因为它们负责整个视频的时间建模。 没有它们,我们的解码器将独立解码每一帧。 它们的重要性在第 4.2 节中被消除。
预测头。 解码器的输出是一组细化的时间查询 。 它们被联合用于视觉定位和时间定位,以同时获得对 视频所有帧 的预测。 详细地说,所有边界框的归一化坐标(二维中心和大小) 由一个三层 MLP 预测。 输出视频管的开始和结束的概率,分别为 和 ,由两层 MLP 预测。 在推理时,输出管的开始和结束时间,分别为 和 ,通过选择联合开始和结束概率分布 的最大值来计算,其中无效组合 被屏蔽。 预测的时空管 由在选择的开始和结束时间 和 内预测的边界框 组成。
3.4 训练损失
输入训练数据以一组视频的形式给出,其中每个视频都用一个查询句子 和相应的视频管 进行标注,该视频管由一组边界框和相应的开始和结束时间 和 组成。
受 [64] 的启发,我们构建了一个目标开始(分别为结束)分布 (分别为 ),它遵循以 (分别为 )为中心的量化高斯分布,标准差为 1。
我们用四个损失的线性组合来训练我们的架构
| (1) |
其中 表示归一化的地面真实框坐标, 表示预测的边界框, 表示时间自注意力矩阵。 最后,不同的 是各个损失的标量权重。 是一个关于边界框坐标的 损失。 是一个关于边界框的广义“交并比”(IoU)损失 [63]。 和 都用于空间定位。 是 Kullback-Leibler 散度损失,用于衡量预测的开始分布与目标开始分布之间的距离,以及预测的结束分布与目标结束分布之间的距离 [64]。 是一种引导注意力损失 [64],它鼓励时间边界之外的时间查询对应的权重低于这些边界内的权重。 和 都用于时间定位。 损失是在解码器每一层计算的,遵循 [8]。
3.5 权重初始化
我们使用 MDETR [37] 在 Flickr30k [61]、MS COCO [13] 和 Visual Genome [40] 上预训练的权重来初始化我们的架构。 详细来说,我们视频-文本编码器的权重从 MDETR 多模态编码器初始化,除了快速模块和聚合模块。 我们还使用 MDETR 单图像多目标解码器的权重来初始化我们多帧单目标时空解码器,除了时间定位头。 我们通过将其与 ImageNet 初始化进行比较来展示这种初始化的好处, i.e. 使用在 ImageNet 上预训练的视觉主干和随机初始化的 Transformer,在第 4.2 节。 我们还在第 4.2 节评估了 MDETR 等效基线。
4 实验
本节展示了我们架构的有效性,并将我们的方法与最先进的方法进行了比较。 我们首先在第 4.1 节介绍了数据集、评估指标和实现细节。 然后,我们在第 4.2 节中展示了消融研究。 第 4.3 节给出了时空视频定位中与最先进方法的比较。 最后,我们在第 4.4 节展示了定性结果。
4.1 实验设置
数据集.
我们在 VidSTG [102] 和 HC-STVG [72] 数据集上评估了我们的方法. 两者都用与文本查询相对应的时空管道进行标注. VidSTG 包含 99,943 个句子描述,其中包含 44,808 个陈述句和 55,135 个疑问句,描述了出现在 10,303 个不同视频中的 79 种类型的物体. 该数据集被划分为训练、验证和测试子集,分别包含 80,684、8,956 和 10,303 个不同的句子,以及 5,436、602 和 732 个不同的视频. HC-STVG 包含多人场景中的视频,每个视频都用一个指代某个人的句子进行标注. 为了消融,我们使用该数据集的第二个改进版本 HC-STVG2.0,该版本被划分为训练和验证子集,分别包含 10,131 和 2,000 个视频-句子对. 在撰写本文时,测试集尚未公开发布. 为了与以前的工作进行比较,我们使用该数据集的第一个版本 HC-STVG1,该版本被划分为训练和测试子集,分别包含 4,500 和 1,160 个视频-句子对.
评估指标.
我们遵循 [102] 并定义 为 ,其中 (分别为 )是地面实况 (GT) 和预测时间戳之间并集(分别为交集)中的帧集. (分别为 )是时间 t 处的预测(分别为 GT)框. 为了评估时空视频接地,我们使用 ,它是 的平均值. 我们还使用 ,即 的样本比例. 为了隔离时间定位的评估,我们使用 ,它是 GT 开始和结束与预测开始和结束之间的时间 IoU 的平均值. 同样,为了仅评估空间接地,我们使用 ,它是通过使用 GT 开始和结束时间来计算的. 对于消融,我们报告所有样本的平均结果. 更详细的消融结果分别针对 VidSTG 中的陈述句和疑问句,在附录部分 C 中给出。我们还报告了训练期间的峰值 GPU 内存使用量 (Mem.). 用于衡量替代模型的内存占用。
实现细节。
视觉主干网络是 ResNet-101 [28],文本编码器是 RoBERTa [50],快速模块 是一个线性层。 遵循 [102],我们每秒采样 5 帧视频,对于超过 200 帧采样的视频,我们均匀地采样 200 帧。 我们使用超参数 、 、 、 、 、 和 。 我们分别在 VidSTG、HC-STVG2.0 和 HC-STVG1 上训练我们的网络 10、20 和 40 个 epoch。 最终模型是根据验证集上最佳的时空视频定位性能选择的。 对于最大的数据集 VidSTG,优化在 16 个 Tesla V100 GPU 上需要 2 天时间。 更多细节包含在附录部分 B 中。
4.2 消融研究
| Time Encoding | Self Attention | m_tIoU | m_vIoU | vIoU @0.3 | vIoU @0.5 | m_sIoU | |
| 1. | ✗ | - | 23.9 | 12.2 | 15.3 | 6.1 | 47.0 |
| 2. | ✗ | Temporal | 25.2 | 13.0 | 16.9 | 6.5 | 47.3 |
| 3. | ✓ | - | 41.7 | 21.3 | 28.7 | 17.4 | 46.5 |
| 4. | ✓ | Temporal | 45.9 | 24.3 | 33.2 | 22.0 | 47.7 |
| Pre- Training | Decoder Self- Attention Transfer | m_tIoU | m_vIoU | vIoU @0.3 | vIoU @0.5 | m_sIoU | |
| 1. | ✗ | ✗ | 42.8 | 18.8 | 25.1 | 15.6 | 38.5 |
| 2. | ✓ | ✗ | 43.8 | 22.4 | 29.9 | 19.1 | 46.5 |
| 3. | ✓ | Temporal | 45.9 | 24.3 | 33.2 | 22.0 | 47.7 |
| Fast | Res. | Temp. Stride | m_tIoU | m_vIoU | vIoU@0.3 | vIoU@0.5 | m_sIoU | Mem. (GB) | |
| 1. | — | 224 | 1 | 46.5 | 25.2 | 34.1 | 23.0 | 49.1 | 23.9 |
| 2. | ✓ | 224 | 2 | 46.0 | 25.0 | 34.3 | 22.9 | 49.0 | 16.2 |
| 3. | ✓ | 224 | 5 | 45.9 | 24.3 | 33.2 | 22.0 | 47.7 | 11.8 |
| 4. | ✓ | 288 | 2 | 46.4 | 25.9 | 35.0 | 23.9 | 50.5 | 23.7 |
| 5. | ✓ | 320 | 3 | 46.4 | 25.9 | 35.7 | 23.7 | 50.7 | 23.6 |
| 6. | ✓ | 352 | 4 | 46.9 | 26.2 | 36.1 | 24.1 | 50.7 | 24.4 |
| 7. | ✗ | 352 | 4 | 46.6 | 24.8 | 34.0 | 21.6 | 48.3 | 18.1 |
| 8. | ✓ | 384 | 5 | 46.8 | 26.0 | 35.5 | 24.0 | 50.4 | 26.1 |
| Fast | Res. | Temp. Stride | m_tIoU | m_vIoU | vIoU@0.3 | vIoU@0.5 | m_sIoU | Mem. (GB) | |
| 1. | — | 224 | 1 | 52.8 | 35.0 | 55.3 | 28.3 | 63.9 | 14.3 |
| 2. | ✓ | 224 | 2 | 53.7 | 35.8 | 56.7 | 29.6 | 64.3 | 10.2 |
| 3. | ✓ | 224 | 5 | 53.2 | 35.0 | 54.5 | 29.0 | 63.2 | 8.0 |
| 4. | ✓ | 288 | 2 | 53.9 | 36.4 | 58.1 | 30.7 | 65.4 | 13.9 |
| 5. | ✓ | 320 | 3 | 53.6 | 36.2 | 57.5 | 30.4 | 65.2 | 13.8 |
| 6. | ✓ | 352 | 4 | 53.9 | 36.4 | 58.8 | 30.6 | 64.9 | 14.3 |
| 7. | ✗ | 352 | 4 | 53.1 | 34.7 | 55.9 | 27.4 | 63.0 | 11.3 |
| 8. | ✓ | 384 | 5 | 53.6 | 36.3 | 57.5 | 30.4 | 65.3 | 15.2 |
| Method | Pretraining Data | VidSTG | HC-STVG1 | ||||||||||
| Declarative Sentences | Interrogative Sentences | ||||||||||||
| m_tIoU | m_vIoU | vIoU@0.3 | vIoU@0.5 | m_tIoU | m_vIoU | vIoU@0.3 | vIoU@0.5 | m_vIoU | vIoU@0.3 | vIoU@0.5 | |||
| 1. | STGRN [102] | Visual Genome | 48.5 | 19.8 | 25.8 | 14.6 | 47.0 | 18.3 | 21.1 | 12.8 | — | — | — |
| 2. | STGVT [72] | Visual Genome + Conceptual Captions | — | 21.6 | 29.8 | 18.9 | — | — | — | — | 18.2 | 26.8 | 9.5 |
| 3. | STVGBert [68] | ImageNet + Visual Genome + Conceptual Captions | — | 24.0 | 30.9 | 18.4 | — | 22.5 | 26.0 | 16.0 | 20.4 | 29.4 | 11.3 |
| 4. | TubeDETR (Ours) | ImageNet | 43.1 | 22.0 | 29.7 | 18.1 | 42.3 | 19.6 | 26.1 | 14.9 | 21.2 | 31.6 | 12.2 |
| 5. | TubeDETR (Ours) | ImageNet + Visual Genome + Flickr + COCO | 48.1 | 30.4 | 42.5 | 28.2 | 46.9 | 25.7 | 35.7 | 23.2 | 32.4 | 49.8 | 23.5 |
在本节中,我们消融了模型的超参数,并评估了编码器和解码器的替代设计选择。 除非另有说明,否则我们使用 224 像素的空间帧分辨率和时间步长 。
时空解码器。 我们首先消融了所提出的时空解码器的设计选择。 我们将完整的解码器模型与没有时间编码、没有时间自注意力以及两者都没有的变体进行比较。 没有两者都对应于空间专用解码器,类似于独立应用于每一帧的 MDETR [37]。 表 1 显示,在使用时间编码和时间自注意力时,与空间专用解码器相比有实质性改进(行 1 和 4 之间的 上 +17.9%)。 收益主要来自时间定位( 上 +22.0%),而空间接地则适度提高( 上 +0.7%)。 此外,我们可以观察到时间编码带来了大部分收益(行 1 和 3 之间的 上 +13.4%)。 最后,时间自注意力在仅使用时间编码的基础上取得了额外的改进(第 3 行和第 4 行之间的 提高了 +4.5%)。
初始化。 我们现在将分析使用预训练的 MDETR [37] 权重初始化模型的重要性。 在表 2 中,我们将此初始化与 ImageNet 初始化进行比较,以及一个变体,该变体不将 MDETR 解码器的空间自注意力权重迁移到我们时空解码器中的时间自注意力。 在预训练时,此自注意力用于模拟同一图像中不同对象之间的空间关系,而我们解码器中的时间自注意力模拟视频不同帧中同一对象之间的时序关系。 我们发现预训练非常有利(第 1 行和第 3 行之间的 提高了 +8.1%),尤其对于空间定位性能( 提高了 +9.2%)。 此外,我们观察到将 MDETR 解码器的空间自注意力权重用于初始化我们解码器中的时间自注意力(第 2 行和第 3 行之间的 提高了 +3.3%)的优势。
空间分辨率和时间步长的影响 。 在本节中,我们分析了帧分辨率和时间步长 的影响。 在表 3 中,我们展示了提高分辨率是时空视频定位性能的重要因素,无论是在 VidSTG 还是 HC-STVG2.0 数据集上(见第 2 行和第 4 行)。 但是,它也会导致内存使用量显着增加(16.2GB 对 23.7GB)。 因此,使用时间步长 的变体在 Tesla V100 32GB GPU 上难以在 VidSTG 上以高于 224 的分辨率进行训练。 在固定的 224 分辨率下,将时间步长 增加到 2 或 5 会分别将峰值内存使用量减少 7.7GB 或 12.1GB(见第 1 行与第 2 行或第 3 行的比较)。 我们提出的视频-文本编码器使我们能够在给定内存使用量的情况下以更高的分辨率进行训练。 这比使用时间步长 的基线变体(第 1 行)实现了更好的性能-内存权衡(第 4、5、6、8 行)。 特别地,在两个数据集上获得的最佳时空视频定位结果( 和 )是使用时间步长 和 352 分辨率(第 6 行)得到的。
我们注意到,随着分辨率的提高,通过进一步提高分辨率获得的性能提升预计会更低,因为它们受原始视频分辨率的限制。 例如,VidSTG 和 HCSTVG2.0 中的平均视频像素高度分别为 440 像素和 490 像素。
快速分支的影响。 最后,我们通过比较最佳变体的时态步幅 和分辨率 352 的慢速-快速视频-文本编码器与对应于 和 的仅慢速变体来验证快速分支的重要性。 在这种情况下,视频-文本特征是慢速视频-文本特征。 通过比较表 3 中的第 6 行和第 7 行,我们的快速分支显着提高了时空视频接地性能(VidSTG 上提高 +2.1% ,HC-STVG2.0 上提高 +2.9% ),同时计算内存开销很低。 这表明快速分支恢复了慢速分支中时态采样操作丢失的有用时空细节。 我们进一步消融了快速和聚合模块 和 的设计,如附录部分 D 所示。

4.3 与最先进技术的比较
在本节中,我们将我们的方法与时空视频接地领域的最新方法进行比较。 我们报告了在之前的消融研究中获得最佳验证结果的模型的结果,即 i.e.,我们的时空解码器,具有时间编码和时态自注意力机制,时态步幅 和分辨率 352。 我们工作重点是时空视频接地指标( 和 )。 如表 4 所示,仅使用 ImageNet 初始化视觉主干(第 4 行),我们的 TubeDETR 表现出色,尽管使用了较少的注释。 此外,如果我们使用 MDETR 初始化(第 5 行),我们的 TubeDETR 在两个数据集上都大幅超过了所有以前的方法(第 1、2 和 3 行)。 STGRN [102] 达到了类似的 (仅测量时间定位),但它定义了一组手工制作的可能窗口宽度来解决时间定位问题,而我们考虑所有可能的窗口,即。 任何开始帧 和结束帧 ,。 这些结果证明了我们架构在时空视频接地方面的优异性能。
4.4 定性示例
5 结论
我们提出了 TubeDETR,这是一种新颖的基于 Transformer 的时空视频接地架构。 TubeDETR 利用时空 Transformer 解码器结合视频文本编码器来解决此任务,该编码器有效地编码了空间和多模态交互。 我们已经证明了我们的时空解码器的有效性,以及我们的视频文本编码器在性能内存权衡方面的优势。 最后,我们的方法在两个基准 VidSTG 和 HC-STVG 上优于最先进的方法。 未来的工作可以扩展我们的时空解码器,以检测每帧中的多个对象或每个视频中的多个事件。 研究更有效的自注意力替代方案,例如为自然语言研究的那些 [39, 81, 79, 6, 73, 16, 93],是未来研究的另一个有希望的方向。
致谢。 这项工作获得了 IDRIS 的 HPC 资源访问权限,分配由 GENCI 授予,分配号为 2021-AD011011670R1。 该工作由 Google 赠款、法国政府资助,作为“未来投资”计划的一部分,由法国国家研究署 (Agence Nationale de la Recherche) 管理,参考号为 ANR-19-P3IA-0001 (PRAIRIE 3IA Institute)、路易威登 ENS 人工智能主席、欧洲区域发展基金资助,项目为 IMPACT (注册号 CZ.02.1.01/0.0/0.0/15 003/0000468)。
我们感谢 S. Chen 和 J. Chen 的宝贵讨论,以及 O. Bounou 和 P.-L. Guhur 的校对。
参考文献
- [1] TubeDETR project webpage. https://antoyang.github.io/tubedetr.html.
- [2] Hassan Akbari, Linagzhe Yuan, Rui Qian, Wei-Hong Chuang, Shih-Fu Chang, Yin Cui, and Boqing Gong. VATT: Transformers for multimodal self-supervised learning from raw video, audio and text. arXiv preprint arXiv:2104.11178, 2021.
- [3] Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, and Cordelia Schmid. ViViT: A video vision transformer. In ICCV, 2021.
- [4] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- [5] Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. In ICCV, 2021.
- [6] Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020.
- [7] Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? In ICML, 2021.
- [8] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, 2020.
- [9] Jingyuan Chen, Xinpeng Chen, Lin Ma, Zequn Jie, and Tat-Seng Chua. Temporally grounding natural sentence in video. In EMNLP, 2018.
- [10] Jingyuan Chen, Lin Ma, Xinpeng Chen, Zequn Jie, and Jiebo Luo. Localizing natural language in videos. In AAAI, 2019.
- [11] Shizhe Chen, Pierre-Louis Guhur, Cordelia Schmid, and Ivan Laptev. History aware multimodal transformer for vision-and-language navigation. In NeurIPS, 2021.
- [12] Shaoxiang Chen and Yu-Gang Jiang. Semantic proposal for activity localization in videos via sentence query. In AAAI, 2019.
- [13] Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick. Microsoft COCO captions: Data collection and evaluation server. arXiv preprint arXiv:1504.00325, 2015.
- [14] Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. UNITER: Universal image-text representation learning. In ECCV, 2020.
- [15] Zhenfang Chen, Lin Ma, Wenhan Luo, and Kwan-Yee K Wong. Weakly-supervised spatio-temporally grounding natural sentence in video. In ACL, 2019.
- [16] Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers. In ICLR, 2021.
- [17] Marcella Cornia, Matteo Stefanini, Lorenzo Baraldi, and Rita Cucchiara. Meshed-memory transformer for image captioning. In CVPR, 2020.
- [18] Chaorui Deng, Qi Wu, Qingyao Wu, Fuyuan Hu, Fan Lyu, and Mingkui Tan. Visual grounding via accumulated attention. In CVPR, 2018.
- [19] Jiajun Deng, Zhengyuan Yang, Tianlang Chen, Wengang Zhou, and Houqiang Li. TransVG: End-to-end visual grounding with transformers. In ICCV, 2021.
- [20] Karan Desai and Justin Johnson. VirTex: Learning visual representations from textual annotations. In CVPR, 2021.
- [21] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL-HLT, 2019.
- [22] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
- [23] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In ICCV, 2019.
- [24] Valentin Gabeur, Chen Sun, Karteek Alahari, and Cordelia Schmid. Multi-modal transformer for video retrieval. In ECCV, 2020.
- [25] Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. TALL: Temporal activity localization via language query. In ICCV, 2017.
- [26] Simon Ging, Mohammadreza Zolfaghari, Hamed Pirsiavash, and Thomas Brox. COOT: Cooperative hierarchical transformer for video-text representation learning. In NeurIPS, 2020.
- [27] Dongliang He, Xiang Zhao, Jizhou Huang, Fu Li, Xiao Liu, and Shilei Wen. Read, watch, and move: Reinforcement learning for temporally grounding natural language descriptions in videos. In AAAI, 2019.
- [28] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. In CVPR, 2016.
- [29] Lu He, Qianyu Zhou, Xiangtai Li, Li Niu, Guangliang Cheng, Xiao Li, Wenxuan Liu, Yunhai Tong, Lizhuang Ma, and Liqing Zhang. End-to-end video object detection with spatial-temporal transformers. Proceedings of the 29th ACM International Conference on Multimedia, 2021.
- [30] Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing moments in video with natural language. ICCV, 2017.
- [31] Lisa Anne Hendricks, Oliver Wang, Eli Shechtman, Josef Sivic, Trevor Darrell, and Bryan Russell. Localizing moments in video with temporal language. In EMNLP, 2018.
- [32] Ronghang Hu, Marcus Rohrbach, Jacob Andreas, Trevor Darrell, and Kate Saenko. Modeling relationships in referential expressions with compositional modular networks. In CVPR, 2017.
- [33] Ronghang Hu, Huazhe Xu, Marcus Rohrbach, Jiashi Feng, Kate Saenko, and Trevor Darrell. Natural language object retrieval. In CVPR, 2016.
- [34] Binbin Huang, Dongze Lian, Weixin Luo, and Shenghua Gao. Look before you leap: Learning landmark features for one-stage visual grounding. In CVPR, 2021.
- [35] De-An Huang, Shyamal Buch, Lucio Dery, Animesh Garg, Li Fei-Fei, and Juan Carlos Niebles. Finding” it”: Weakly-supervised reference-aware visual grounding in instructional videos. In CVPR, 2018.
- [36] Zhicheng Huang, Zhaoyang Zeng, Bei Liu, Dongmei Fu, and Jianlong Fu. Pixel-BERT: Aligning image pixels with text by deep multi-modal transformers. arXiv preprint arXiv:2004.00849, 2020.
- [37] Aishwarya Kamath, Mannat Singh, Yann LeCun, Gabriel Synnaeve, Ishan Misra, and Nicolas Carion. MDETR - modulated detection for end-to-end multi-modal understanding. In ICCV, 2021.
- [38] Wonjae Kim, Bokyung Son, and Ildoo Kim. ViLT: Vision-and-language transformer without convolution or region supervision. In ICML, 2021.
- [39] Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. In ICLR, 2020.
- [40] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, Michael Bernstein, and Li Fei-Fei. Visual Genome: Connecting language and vision using crowdsourced dense image annotations. IJCV, 2016.
- [41] Jie Lei, Tamara L Berg, and Mohit Bansal. QVHighlights: Detecting moments and highlights in videos via natural language queries. In NeurIPS, 2021.
- [42] Jie Lei, Linjie Li, Luowei Zhou, Zhe Gan, Tamara L Berg, Mohit Bansal, and Jingjing Liu. Less is more: Clipbert for video-and-language learning via sparse sampling. In CVPR, 2021.
- [43] Gen Li, Nan Duan, Yuejian Fang, Ming Gong, Daxin Jiang, and Ming Zhou. Unicoder-VL: A universal encoder for vision and language by cross-modal pre-training. In AAAI, 2020.
- [44] Linjie Li, Yen-Chun Chen, Yu Cheng, Zhe Gan, Licheng Yu, and Jingjing Liu. HERO: Hierarchical encoder for video+language omni-representation pre-training. In EMNLP, 2020.
- [45] Xiujun Li, Xi Yin, Chunyuan Li, Pengchuan Zhang, Xiaowei Hu, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, et al. Oscar: Object-semantics aligned pre-training for vision-language tasks. In ECCV, 2020.
- [46] Yue Liao, Si Liu, Guanbin Li, Fei Wang, Yanjie Chen, Chen Qian, and Bo Li. A real-time cross-modality correlation filtering method for referring expression comprehension. In CVPR, 2020.
- [47] Zhijie Lin, Zhou Zhao, Zhu Zhang, Qi Wang, and Huasheng Liu. Weakly-supervised video moment retrieval via semantic completion network. In AAAI, 2020.
- [48] Jingyu Liu, Liang Wang, and Ming-Hsuan Yang. Referring expression generation and comprehension via attributes. In ICCV, 2017.
- [49] Xihui Liu, Zihao Wang, Jing Shao, Xiaogang Wang, and Hongsheng Li. Improving referring expression grounding with cross-modal attention-guided erasing. In CVPR, 2019.
- [50] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- [51] Yongfei Liu, Bo Wan, Lin Ma, and Xuming He. Relation-aware instance refinement for weakly supervised visual grounding. In CVPR, 2021.
- [52] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In ICCV, 2021.
- [53] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In ICLR, 2019.
- [54] Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. ViLBERT: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In NeurIPS, 2019.
- [55] Jiasen Lu, Vedanuj Goswami, Marcus Rohrbach, Devi Parikh, and Stefan Lee. 12-in-1: Multi-task vision and language representation learning. In CVPR, 2020.
- [56] Gen Luo, Yiyi Zhou, Xiaoshuai Sun, Liujuan Cao, Chenglin Wu, Cheng Deng, and Rongrong Ji. Multi-task collaborative network for joint referring expression comprehension and segmentation. In CVPR, 2020.
- [57] Antoine Miech, Jean-Baptiste Alayrac, Lucas Smaira, Ivan Laptev, Josef Sivic, and Andrew Zisserman. End-to-end learning of visual representations from uncurated instructional videos. In CVPR, 2020.
- [58] Niluthpol Chowdhury Mithun, Sujoy Paul, and Amit K Roy-Chowdhury. Weakly supervised video moment retrieval from text queries. In CVPR, 2019.
- [59] Varun K Nagaraja, Vlad I Morariu, and Larry S Davis. Modeling context between objects for referring expression understanding. In ECCV, 2016.
- [60] Mandela Patrick, Dylan Campbell, Yuki M Asano, Ishan Misra Florian Metze, Christoph Feichtenhofer, Andrea Vedaldi, Jo Henriques, et al. Keeping your eye on the ball: Trajectory attention in video transformers. In NeurIPS, 2021.
- [61] Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In ICCV, 2015.
- [62] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
- [63] Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. Generalized intersection over union. In CVPR, 2019.
- [64] Cristian Rodriguez, Edison Marrese-Taylor, Fatemeh Sadat Saleh, HONGDONG LI, and Stephen Gould. Proposal-free temporal moment localization of a natural-language query in video using guided attention. In WACV, 2020.
- [65] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual Captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In ACL, 2018.
- [66] Jing Shi, Jia Xu, Boqing Gong, and Chenliang Xu. Not all frames are equal: Weakly-supervised video grounding with contextual similarity and visual clustering losses. In CVPR, 2019.
- [67] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting. JMLR, 2014.
- [68] Rui Su, Qian Yu, and Dong Xu. STVGBert: A visual-linguistic transformer based framework for spatio-temporal video grounding. In ICCV, 2021.
- [69] Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, and Jifeng Dai. VL-BERT: Pre-training of generic visual-linguistic representations. In ICLR, 2019.
- [70] Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmid. VideoBERT: A joint model for video and language representation learning. In ICCV, 2019.
- [71] Hao Tan and Mohit Bansal. LXMERT: Learning cross-modality encoder representations from transformers. In EMNLP, 2019.
- [72] Zongheng Tang, Yue Liao, Si Liu, Guanbin Li, Xiaojie Jin, Hongxu Jiang, Qian Yu, and Dong Xu. Human-centric spatio-temporal video grounding with visual transformers. IEEE Transactions on Circuits and Systems for Video Technology, 2021.
- [73] Yi Tay, Mostafa Dehghani, Samira Abnar, Yikang Shen, Dara Bahri, Philip Pham, Jinfeng Rao, Liu Yang, Sebastian Ruder, and Donald Metzler. Long range arena: A benchmark for efficient transformers. In ICLR, 2021.
- [74] Arun Balajee Vasudevan, Dengxin Dai, and Luc Van Gool. Object referring in videos with language and human gaze. In CVPR, 2018.
- [75] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017.
- [76] Jingwen Wang, Lin Ma, and Wenhao Jiang. Temporally grounding language queries in videos by contextual boundary-aware prediction. In AAAI, 2020.
- [77] Liwei Wang, Jing Huang, Yin Li, Kun Xu, Zhengyuan Yang, and Dong Yu. Improving weakly supervised visual grounding by contrastive knowledge distillation. In CVPR, 2021.
- [78] Peng Wang, Qi Wu, Jiewei Cao, Chunhua Shen, Lianli Gao, and Anton van den Hengel. Neighbourhood watch: Referring expression comprehension via language-guided graph attention networks. In CVPR, 2019.
- [79] Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020.
- [80] Weining Wang, Yan Huang, and Liang Wang. Language-driven temporal activity localization: A semantic matching reinforcement learning model. In CVPR, 2019.
- [81] Zhanghao Wu, Zhijian Liu, Ji Lin, Yujun Lin, and Song Han. Lite transformer with long-short range attention. In ICLR, 2020.
- [82] Fanyi Xiao, Yong Jae Lee, Kristen Grauman, Jitendra Malik, and Christoph Feichtenhofer. Audiovisual slowfast networks for video recognition. arXiv preprint arXiv:2001.08740, 2020.
- [83] Fanyi Xiao, Leonid Sigal, and Yong Jae Lee. Weakly-supervised visual grounding of phrases with linguistic structures. In CVPR, 2017.
- [84] Masataka Yamaguchi, Kuniaki Saito, Yoshitaka Ushiku, and Tatsuya Harada. Spatio-temporal person retrieval via natural language queries. In ICCV, 2017.
- [85] Antoine Yang, Antoine Miech, Josef Sivic, Ivan Laptev, and Cordelia Schmid. Just ask: Learning to answer questions from millions of narrated videos. In ICCV, 2021.
- [86] Sibei Yang, Guanbin Li, and Yizhou Yu. Cross-modal relationship inference for grounding referring expressions. In CVPR, 2019.
- [87] Sibei Yang, Guanbin Li, and Yizhou Yu. Dynamic graph attention for referring expression comprehension. In ICCV, 2019.
- [88] Zhengyuan Yang, Tianlang Chen, Liwei Wang, and Jiebo Luo. Improving one-stage visual grounding by recursive sub-query construction. In ECCV, 2020.
- [89] Zhengyuan Yang, Boqing Gong, Liwei Wang, Wenbing Huang, Dong Yu, and Jiebo Luo. A fast and accurate one-stage approach to visual grounding. In ICCV, 2019.
- [90] Licheng Yu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, Mohit Bansal, and Tamara L Berg. MAttNet: Modular attention network for referring expression comprehension. In CVPR, 2018.
- [91] Licheng Yu, Hao Tan, Mohit Bansal, and Tamara L Berg. A joint speaker-listener-reinforcer model for referring expressions. In CVPR, 2017.
- [92] Yitian Yuan, Tao Mei, and Wenwu Zhu. To find where you talk: Temporal sentence localization in video with attention based location regression. In AAAI, 2019.
- [93] Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences. In NeurIPS, 2020.
- [94] Rowan Zellers, Ximing Lu, Jack Hessel, Youngjae Yu, Jae Sung Park, Jize Cao, Ali Farhadi, and Yejin Choi. MERLOT: Multimodal neural script knowledge models. In NeurIPS, 2021.
- [95] Runhao Zeng, Haoming Xu, Wenbing Huang, Peihao Chen, Mingkui Tan, and Chuang Gan. Dense regression network for video grounding. In CVPR, 2020.
- [96] Da Zhang, Xiyang Dai, Xin Wang, Yuan-Fang Wang, and Larry S Davis. MAN: Moment alignment network for natural language moment retrieval via iterative graph adjustment. In CVPR, 2019.
- [97] Hanwang Zhang, Yulei Niu, and Shih-Fu Chang. Grounding referring expressions in images by variational context. In CVPR, 2018.
- [98] Hao Zhang, Aixin Sun, Wei Jing, and Joey Tianyi Zhou. Span-based localizing network for natural language video localization. In ACL, 2020.
- [99] Songyang Zhang, Houwen Peng, Jianlong Fu, and Jiebo Luo. Learning 2d temporal adjacent networks for moment localization with natural language. In AAAI, 2020.
- [100] Yanyi Zhang, Xinyu Li, Chunhui Liu, Bing Shuai, Yi Zhu, Biagio Brattoli, Hao Chen, Ivan Marsic, and Joseph Tighe. VidTr: Video transformer without convolutions. In ICCV, 2021.
- [101] Zhu Zhang, Zhijie Lin, Zhou Zhao, and Zhenxin Xiao. Cross-modal interaction networks for query-based moment retrieval in videos. In SIGIR, 2019.
- [102] Zhu Zhang, Zhou Zhao, Yang Zhao, Qi Wang, Huasheng Liu, and Lianli Gao. Where does it exist: Spatio-temporal video grounding for multi-form sentences. In CVPR, 2020.
- [103] Luowei Zhou, Hamid Palangi, Lei Zhang, Houdong Hu, Jason J Corso, and Jianfeng Gao. Unified vision-language pre-training for image captioning and VQA. In AAAI, 2020.
- [104] Luowei Zhou, Yingbo Zhou, Jason J. Corso, Richard Socher, and Caiming Xiong. End-to-end dense video captioning with masked transformer. In CVPR, 2018.
- [105] Linchao Zhu and Yi Yang. ActBERT: Learning global-local video-text representations. In CVPR, 2020.
- [106] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable DETR: Deformable transformers for end-to-end object detection. In ICLR, 2021.
- [107] Bohan Zhuang, Qi Wu, Chunhua Shen, Ian Reid, and Anton Van Den Hengel. Parallel attention: A unified framework for visual object discovery through dialogs and queries. In CVPR, 2018.
附录
附录 A 解码器中空间、时间和语言注意力模式的可视化
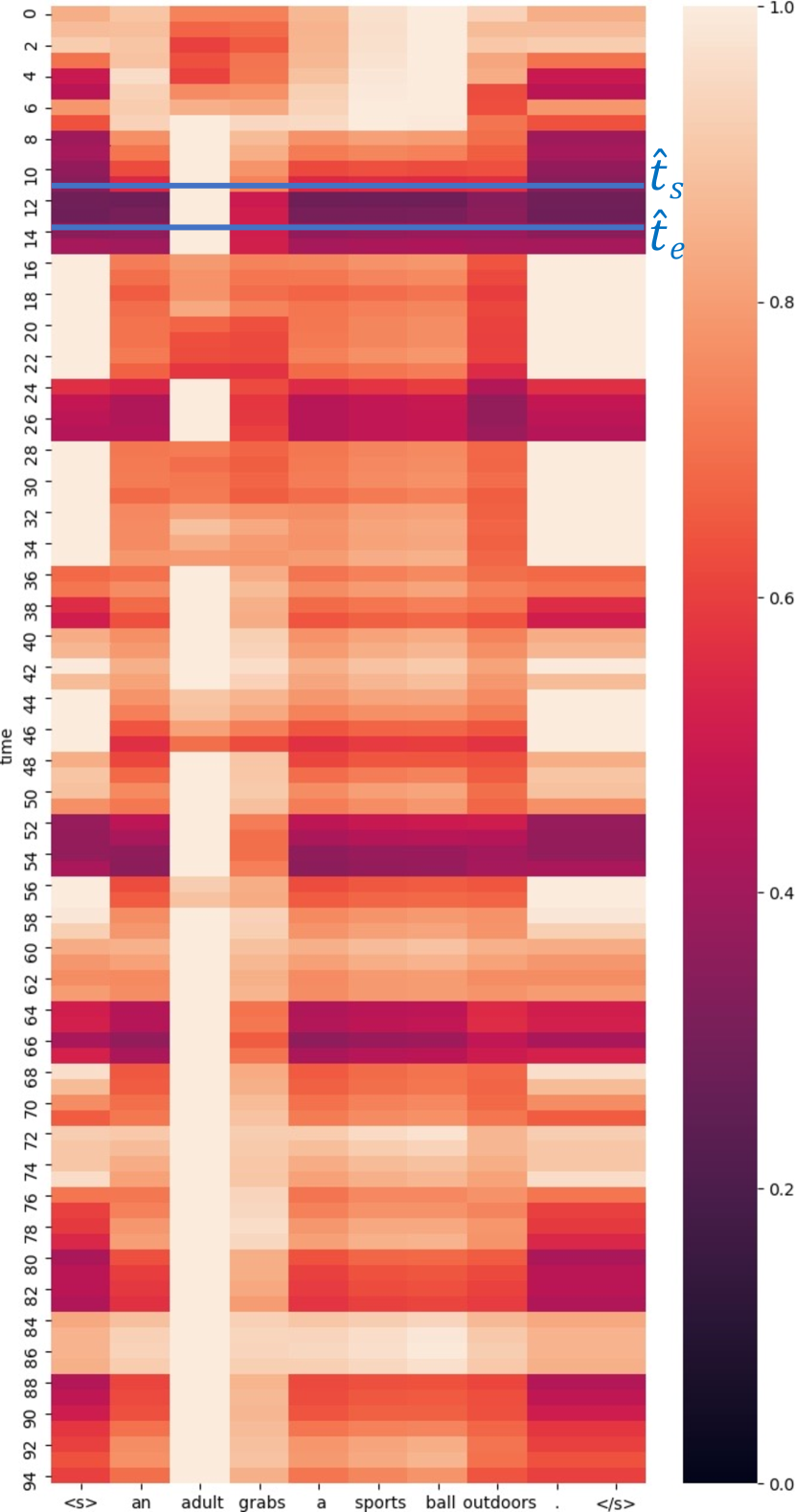
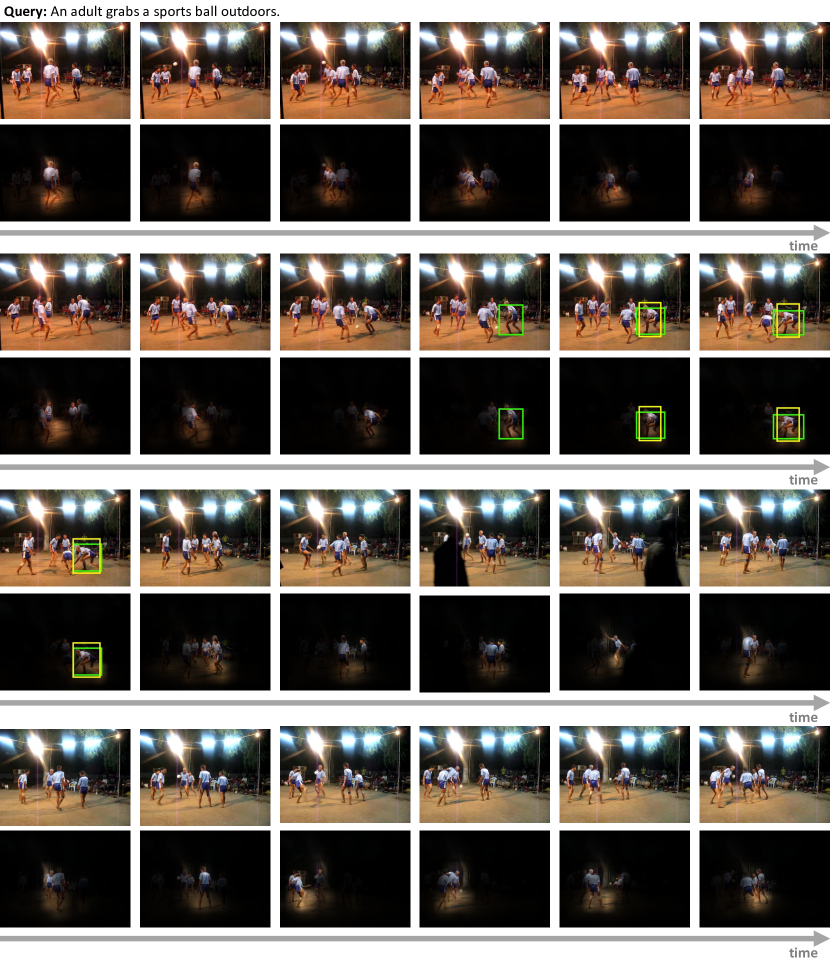
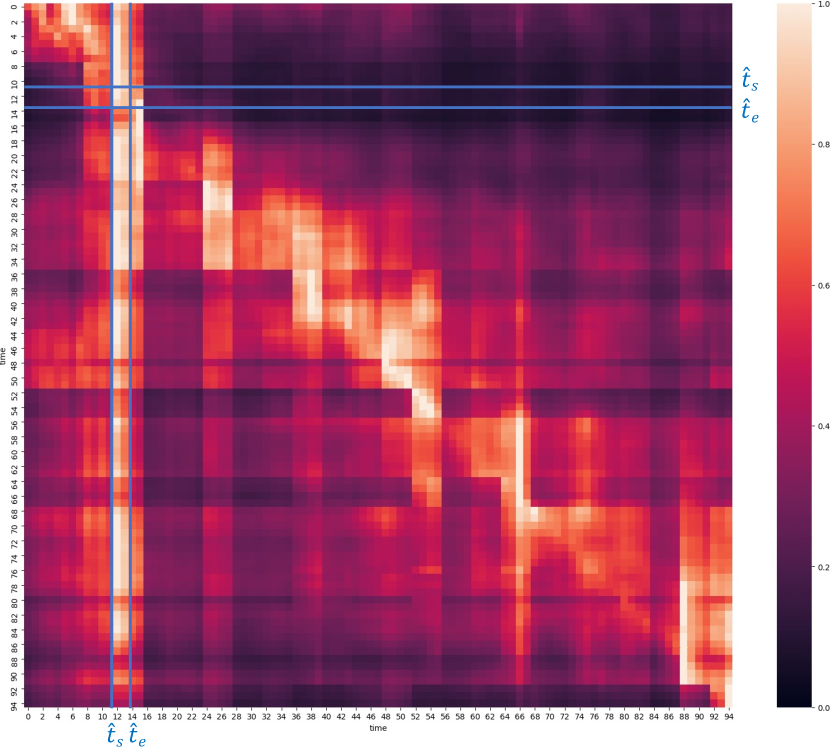
本节说明了我们时空解码器在图 7 中所示的时空视频定位示例中,在空间、语言和时间上的注意力机制。 对于此示例,视觉模式的时间对齐交叉注意力也显示在图 7 中。 我们注意到,在空间上,每个时间步的注意力特别集中在接球和做手势的人身上。 此外,图 6 说明了文本模态的时间对齐交叉注意力。 我们观察到,单词 adult 和 grabs 是总体上最受关注的,并且不同单词(e.g. sports 和 ball)的注意力权重随时间变化。 和 在图 6 中表示输出管的预测开始和结束时间。 接下来,图 8 说明了时间自注意力。 我们注意到长程时间交互:一定数量的时间查询会关注各种时间上距离较远的时间查询,e.g.位于视频开始处第八帧和第十六帧之间的那些时间查询。
附录 B 其他实现细节
在我们的 Transformer 中,头的数量为 8,前馈层的隐藏维度为 2048。 我们将视觉主干的初始学习率设置为 ,并将网络其余部分的学习率设置为 。 学习率遵循文本编码器的线性调度,并进行预热,而网络其余部分的学习率保持恒定。 我们使用 AdamW 优化器 [53] 和权重衰减 。 视频数据增强包括空间随机调整大小,空间随机裁剪(保留框标注)和时间随机裁剪(保留标注的时间间隔)。 在我们的 Transformer 层中应用概率为 0.1 的 Dropout [67],并在时间定位头中应用概率为 0.5 的 Dropout。 我们使用衰减率为 0.9998 的指数移动平均,以及 16 个视频的有效批次大小。 对于时间步幅 ,编码器中的快速和聚合模块并不活跃,因为它们的目的是在 时恢复局部空间和时间信息。
| Time Encoding | Self Attention | Declarative Sentences | Interrogative Sentences | |||||||||
| m_tIoU | m_vIoU | vIoU @0.3 | vIoU @0.5 | m_sIoU | m_tIoU | m_vIoU | vIoU @0.3 | vIoU @0.5 | m_sIoU | |||
| 1. | ✗ | - | 24.4 | 13.6 | 17.8 | 7.3 | 51.9 | 23.5 | 11.1 | 13.3 | 5.2 | 43.1 |
| 2. | ✗ | Temporal | 25.3 | 14.1 | 18.6 | 7.3 | 52.3 | 25.0 | 12.1 | 15.4 | 5.9 | 43.3 |
| 3. | ✓ | - | 42.1 | 23.2 | 31.8 | 19.5 | 51.3 | 41.5 | 19.7 | 26.2 | 15.8 | 42.5 |
| 4. | ✓ | Temporal | 46.4 | 26.6 | 36.1 | 24.7 | 52.8 | 45.6 | 22.5 | 30.8 | 19.8 | 43.6 |
| Pre- Training | Decoder Self- Attention Transfer | Declarative Sentences | Interrogative Sentences | |||||||||
| m_tIoU | m_vIoU | vIoU @0.3 | vIoU @0.5 | m_sIoU | m_tIoU | m_vIoU | vIoU @0.3 | vIoU @0.5 | m_sIoU | |||
| 1. | ✗ | ✗ | 42.9 | 19.8 | 26.7 | 16.8 | 41.1 | 42.8 | 18.0 | 23.9 | 14.6 | 36.5 |
| 2. | ✓ | ✗ | 44.0 | 24.5 | 32.9 | 21.5 | 51.5 | 43.6 | 20.8 | 27.5 | 17.2 | 42.6 |
| 3. | ✓ | ✓ | 46.4 | 26.6 | 36.1 | 24.7 | 52.8 | 45.6 | 22.5 | 30.8 | 19.8 | 43.6 |
| Fast | Res. | Temp. Stride | Declarative Sentences | Interrogative Sentences | Mem. (GB) | |||||||||
| m_tIoU | m_vIoU | vIoU@0.3 | vIoU@0.5 | m_sIoU | m_tIoU | m_vIoU | vIoU@0.3 | vIoU@0.5 | m_sIoU | |||||
| 1. | — | 224 | 1 | 46.9 | 27.6 | 37.7 | 25.7 | 54.2 | 46.1 | 23.3 | 31.3 | 20.8 | 44.9 | 23.9 |
| 2. | ✓ | 224 | 2 | 46.6 | 27.4 | 38.0 | 25.7 | 54.3 | 45.5 | 23.0 | 31.3 | 20.7 | 44.7 | 16.2 |
| 3. | ✓ | 224 | 5 | 46.4 | 26.6 | 36.1 | 24.7 | 52.8 | 45.6 | 22.5 | 30.8 | 19.8 | 43.6 | 11.8 |
| 4. | ✓ | 288 | 2 | 47.0 | 28.2 | 38.3 | 26.3 | 55.7 | 46.0 | 24.1 | 32.4 | 22.0 | 46.3 | 23.7 |
| 5. | ✓ | 320 | 3 | 46.9 | 28.3 | 39.2 | 26.4 | 56.0 | 45.9 | 24.0 | 32.8 | 21.5 | 46.4 | 23.6 |
| 6. | ✓ | 352 | 4 | 47.2 | 28.7 | 39.6 | 27.1 | 56.4 | 46.6 | 24.2 | 33.2 | 21.7 | 46.2 | 24.4 |
| 7. | ✗ | 352 | 4 | 47.1 | 27.1 | 37.4 | 24.1 | 53.7 | 46.2 | 22.9 | 31.3 | 19.6 | 44.0 | 18.1 |
| 8. | ✓ | 384 | 5 | 47.4 | 28.4 | 38.9 | 27.0 | 55.3 | 46.4 | 24.0 | 32.8 | 21.7 | 45.6 | 26.1 |
附录 C 详细的消融实验结果
在本节中,我们提供了 VidSTG 数据集中按句子类型(陈述句,疑问句)细分的详细结果,用于第 4.2 节中介绍的消融实验。
时空解码器。 首先,我们提供对时空解码器的消融实验的详细结果。 对于陈述句和疑问句,分析类似。 具体来说,表 5 表明,与仅使用空间解码器相比,同时使用时间编码和时间自注意力,性能有显著提升(在第 1 行和第 4 行之间,陈述句的 提高了 18.3%,疑问句的 提高了 17.5%)。 这种提升主要来自时间定位(陈述句的 提高了 22.0%,疑问句的 提高了 22.1%),而空间定位的提升幅度则相对较小(陈述句的 提高了 0.9%,疑问句的 提高了 0.5%)。 此外,我们可以观察到,时间编码带来了大部分提升(在第 1 行和第 3 行之间,陈述句的 提高了 14.0%,疑问句的 提高了 12.9%)。 最后,时间自注意力在仅使用时间编码的基础上进一步提升了性能(在第 3 行和第 4 行之间,陈述句的 提高了 4.3%,疑问句的 提高了 4.6%)。
初始化。 现在,我们提供了关于权重初始化消融实验的详细结果。 对陈述句和疑问句的分析是类似的。 具体来说,表 6 显示预训练对于时空视频定位非常有益(在陈述句中,第 1 行和第 3 行之间, 上提升了 +9.4%;在疑问句中, 上提升了 +6.9%)。 收益主要来自空间定位性能(在陈述句中, 上提升了 +11.7%;在疑问句中, 上提升了 +7.1%)。 此外,我们观察到使用来自 MDETR 解码器的空间自注意力权重来初始化我们解码器中的时间自注意力是有益的(在陈述句中, 上提升了 +3.2%;在疑问句中, 上提升了 +3.3%,第 2 行和第 3 行之间)。
| Slow | Spatial Pool. | f | g | Declarative Sentences | Interrogative Sentences | |||||||||
| m_tIoU | m_vIoU | vIoU@0.3 | vIoU@0.5 | m_sIoU | m_tIoU | m_vIoU | vIoU@0.3 | vIoU@0.5 | m_sIoU | |||||
| 1. | ✗ | ✗ | Linear | Sum + Linear | 42.7 | 18.6 | 25.0 | 14.8 | 39.6 | 42.5 | 16.9 | 22.0 | 12.9 | 35.1 |
| 2. | ✓ | - | 0 | 0 | 46.2 | 24.9 | 34.4 | 21.8 | 49.7 | 45.1 | 20.9 | 28.3 | 17.9 | 40.5 |
| 3. | ✓ | ✓ | Linear | Sum + Linear | 45.8 | 25.0 | 34.7 | 22.1 | 50.2 | 44.9 | 21.1 | 29.2 | 17.8 | 40.9 |
| 4. | ✓ | ✗ | Linear | Product + | 46.2 | 26.2 | 36.0 | 23.9 | 52.0 | 45.4 | 22.1 | 30.1 | 18.8 | 43.0 |
| 5. | ✓ | ✗ | Transformer | Sum + Linear | 46.4 | 26.4 | 36.4 | 23.8 | 52.8 | 45.3 | 22.2 | 30.2 | 19.6 | 43.3 |
| 6. | ✓ | ✗ | Linear | Sum + Linear | 46.4 | 26.6 | 36.1 | 24.7 | 52.8 | 45.6 | 22.5 | 30.8 | 19.8 | 43.6 |
空间分辨率和时间步幅 的影响。 在本节中,我们提供了关于 VidSTG 数据集中关于空间帧分辨率和时间步幅 的影响的消融实验的详细结果。 对陈述句和疑问句的分析是类似的。 具体来说,表 7 显示增加分辨率是时空视频定位性能的一个重要因素(参见第 2 行和第 4 行)。 我们提出的视频-文本编码器使我们能够在给定内存使用的情况下训练更高分辨率。 这导致了更好的性能-内存权衡(第 4 行、第 5 行、第 6 行、第 8 行),与具有时间步幅 的基线变体(第 1 行)相比。 特别是,最好的时空视频定位结果( 和 )是在时间步幅 和分辨率 352(第 6 行)的情况下获得的。
快分支的影响。 最后,我们提供了关于 VidSTG 数据集中关于快分支重要性的消融实验的详细结果,其中我们比较了对于最佳变体,时间步幅 和分辨率 352,我们的慢快视频-文本编码器与仅慢速的变体。 对声明句和疑问句的分析是相似的。 通过比较表 7 中的第 6 行和第 7 行,我们的快速分支显着提高了时空视频定位性能(声明句提高 +2.2% ,疑问句提高 +1.9% ),并且计算内存开销很低。 这表明快速分支恢复了慢速分支中时间采样操作丢失的有用时空细节。
附录 D 其他实验
在本节中,我们提供额外的消融研究。 如第 4.2 节中所述的消融实验,除非另有说明,我们使用 224 像素的空间帧分辨率和时间步长 。
快速模块和聚合模块的设计 在这里,我们进一步消融了我们双分支编码器中使用的快速模块 和聚合模块 。 我们在表 8 中报告了结果。 我们在第 4.2 节中讨论了我们的慢速-快速设计(第 6 行)和仅慢速变体(第 2 行)之间的比较。 同样,我们将我们的慢速-快速设计与仅快速变体(第 1 行)进行比较。 仅快速变体不使用慢速多模态分支,在这种情况下,视频-文本特征是快速视觉特征与文本特征的串联。 如表 8 所示,我们的慢速-快速设计优于仅快速变体,表明慢速多模态分支的重要性。 我们进一步将快速和聚合模块 和 (第 6 行)的设计与其他替代方案进行比较:第 3 行,具有相同基元 的变体和 ,但 对空间维度上汇集的特征进行操作;第 4 行,使用相同的快速模块 的变体,但使用门控聚合模块 ,其中 是 sigmoid 函数;第 5 行,使用相同聚合模块 的变体,但使用快速时间转换器模块 ,该模块对空间详细特征之间的时间交互进行建模。 如表 8 所示,我们的设计优于第 3 行,表明为每帧保留空间信息对于快速分支的有效性至关重要。 此外,我们的设计略微优于第 4 行,表明进一步迫使网络使用慢速分支没有帮助。 最后,我们的设计略微优于第 5 行,这表明在我们的编码器中对时间交互的额外建模并不一定有帮助。
附录 E 更广泛的影响
这项工作是对时空视频接地的贡献,其潜在的正面或负面影响取决于应用。 这些模型可用于视频监控,因此会导致使用上的疑问。 另一方面,我们相信这些方法可以提高视觉和语言模型的可解释性,这可能有助于理解它们的一些偏差。 这项工作还消除了在学习这些模型时对内存的使用,因此可以帮助促进开发对环境影响较小的更轻量级模型。