文档级关系抽取样本
摘要
我们推出 FREDo,一个少样本文档级关系提取 (FSDLRE) 基准。 与建立在句子级关系提取语料库上的现有基准相反,我们认为文档级语料库提供了更多的现实性,特别是在none-of-上述(NOTA)发行版。 因此,我们提出了一组 FSDLRE 任务,并基于两个现有的监督学习数据集 DocRED 和 sciERC 构建了基准。 我们将最先进的句子级方法 MNAV 应用于文档级,并进一步开发它以改进域适应。 我们发现 FSDLRE 是一个具有挑战性的设置,具有有趣的新特性,例如从支持集中采样 NOTA 实例的能力。 数据、代码和训练模型可在线获取111https://github.com/nicpopovic/FREDo。
1简介
关系提取的目标是根据预定义的模式检测和分类文本中实体之间的关系。 定义相关关系类型的模式高度依赖于特定的应用程序和领域。 关系抽取的监督学习方法Soares 等人 (2019);周等人 (2021);张等人 (2021);徐等人 (2021);自从引入 BERT Devlin 等人 (2019) 等预训练语言模型以来,Xiao 等人 (2022) 取得了快速进展,需要大量带注释的关系实例的语料库来学习模式。 由于手动注释用于关系提取的数据集既昂贵又耗时,因此用于关系提取的少样本学习代表了大规模关系提取的有前途的解决方案。
虽然一般的方式样本学习框架定义相对明确并且似乎很容易应用于关系提取,但事实证明构建现实的基准任务具有挑战性。 为少样本关系提取建立现实基准任务的核心困难之一是正确建模关系提取系统将遇到的最常见情况,即非上述(NOTA)检测。 NOTA 指的是候选实体对不包含模式中定义的任何关系的情况,这种情况比其相反的情况更为常见(对于文档级数据集 DocRED Yao 等人( 2019),96.84%的候选实体对是NOTA案例)。 虽然最初的基准 Han 等人 (2018) 完全忽略了这种情况,但致力于少样本关系提取的研究人员已经推动在任务中进行更真实的 NOTA 建模,并开发了可以更好地检测 NOTA 实例的方法 Gao等人 (2019);萨博等人 (2021)。
与针对实际少样本关系提取基准所概述的努力并行,对监督关系提取的研究已经从句子级任务、单个句子内的关系提取转移到文档级关系提取。 推动文档级关系提取的动机是(1)提取更复杂的跨句子关系和(2)大规模信息提取。 后者是由将范围从单个句子增加到多个句子时固有的挑战驱动的:涉及的实体数量增加,随之而来的是候选实体对的二次方增加。 虽然句子级方法通常单独评估每个候选实体对,但这种策略在文档级是不可行的(DocRED 每个文档平均包含 393.5 个候选实体对,而许多句子级任务仅包含 2 个候选实体对)。 除了计算要求增加之外,这还导致给定查询中 NOTA 示例数量急剧增加,需要新的方法来处理这种分布变化带来的不平衡Han 和 Wang (2020);周等人 (2021).
目前所有的少样本关系提取基准都是基于句子级任务。 我们认为,将少样本关系提取从句子级别转移到文档级别:(1) 带来了更现实的 NOTA 分布作为固有特征,之前的工作一直在模拟这种分布,(2) 将使最终的方法变得更加可行更适合大规模信息提取。
因此,在这项工作中,我们定义了一组新的用于文档级关系提取的少样本学习任务,并设计了一种从带注释的文档语料库创建现实基准的策略。 将上述应用于数据集 DocRED Yao 等人 (2019) 和 sciERC Luan 等人 (2018),我们构建了一个少样本文档级关系提取(FSDLRE)基准测试,FREDo,由两个主要任务组成,一个是域内任务,一个是需要域适应的跨域任务。 最后,基于最先进的少样本关系提取方法 MNAV Sabo 等人 (2021) 和文档级关系提取概念 Zhou 等人 (2021),我们开发了两种方法来解决上述任务。
2相关工作
据我们所知,当前所有少样本关系提取基准 Han 等人 (2018);高等人 (2019); Sabo 等人 (2021) 专注于从单个句子中提取关系。 FewRel Han 等人 (2018) 在 -way -shot 设置 Vinyals 等人 (2016) 中引入了关系提取基准; Snell 等人 (2017),其中将关系实例分配给 类之一,仅给出每个类的 示例。 在这种情况下,人类的表现很快就超越了 Soares 等人 (2019),导致高等人 Gao 等人 (2019) 创建了 FewRel 2.0 来努力增加难度通过添加域适应任务以及 NOTA 检测任务。 Sabo 等人 Sabo 等人 (2021) 认为,由于 NOTA 实例的采样方式,FewRel 2.0 建模 NOTA 案例的方式并不现实,开发一个框架来创建更现实的基准,并建议构建这样一个使用句子级数据集 TACRED Zhang 等人 (2017) 进行基准测试。 Tran 等人 Tran 训练等人 (2021) 完全放弃标记数据,专注于没有 NOTA 案例的一次性和弱监督分类设置。
虽然基于注释文档而不是单个句子的多个关系提取数据集可以以 CDR Li 等人 (2016)、sciERC Luan 等人 (2018) 的形式提供>、SciREX Jain 等人 (2020)、DialogRE Yu 等人 (2020) 和 GDA Wu 等人 (2019),简介大规模数据集 DocRED Yao 等人 (2019) 似乎最近显着增加了对文档级监督关系提取的研究兴趣 Zhou 等人 (2021);张等人 (2021);徐等人 (2021);肖等人 (2022).
由于文档包含的实体比单个句子多得多,并且候选实体对的数量随着实体的数量呈二次方增加,因此将句子级方法应用于文档级任务是不可行的。 因此,文档级关系提取方法使用与句子级方法不同的架构 Wang 等人 (2019)。 另一个挑战是训练过程中遇到的正面和负面关系例子数量的巨大不平衡。 一些研究人员通过重新采样训练示例来解决不平衡问题Han and Wang (2020),而另一些研究人员则使用更专业的解决方案,例如修改损失函数Zhou 等人 (2021) t1>.
3任务描述
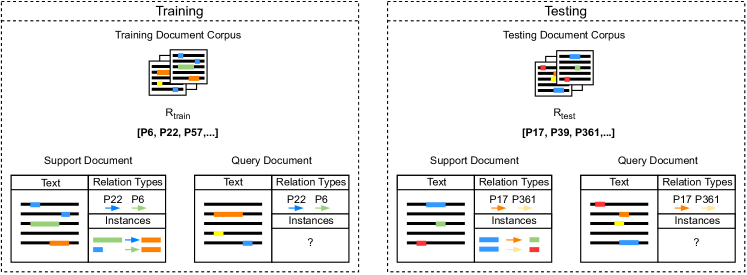
在文档级关系提取中,任务是返回一个集合 ,其中包含格式的所有有效三元组 (, , ) 文档 。这里,和分别是关系实例的头实体和尾实体,是关系类型,其中 是要提取实例的关系类型集。 任何实体提及的位置以及任何共同引用集群都作为输入的一部分提供222未给出此类注释的设置通常称为联合实体和关系提取,超出了本文的范围。. 在监督学习和少样本学习中,测试时使用的文档是从与训练时使用的文档不同的语料库中采样的。 少样本学习中增加的复杂性是由(1)训练和测试时间之间关系类型集的变化引起的,以及(2)为每个关系给出的注释示例的数量要少得多类型。
3.1文档级少样本关系抽取
在图1中,我们给出了建议的任务设置的说明。 我们将以下内容定义为少样本文档级关系提取(FSDLRE):给定一组支持文档 ,对应的集合 包含每个支持文档的所有 个有效三元组,以及一个查询文档 ,任务是返回集合,包含查询文档中的所有有效三元组。 集合和由关系类型的三元组组成。 是 或 的子集,分别用于训练或测试的两个不相交的关系类型集。 支持文档的注释是完整的,这意味着任何未分配关系类型的候选实体对都可以被视为NOTA。
3.1.1 域内与跨域
对于域内 FSDLRE 训练和测试文档取自同一域。 对于跨域 FSDLRE,测试文档取自不同的域。 因此,文本样式、文本内容、实体类型和关系类型都将与训练文档中看到的不同。 虽然这增加了挑战的难度,但这也类似于少样本关系提取方法的更实际应用:少样本学习的一个关键动机是开发可以应用于新数据的方法,而不需要大规模的手动标记。 将方法的适用性限制在特定领域和标注程序并不符合这个想法。
3.2 与现有基准的差异
上述任务在多个方面与现有的少样本关系提取基准不同。 (1) 在文档级别操作意味着数据现在包括跨多个句子表达的关系实例,并且模型需要能够更有效地评估候选实体对。 (2)与 FS-TACRED Sabo 等人 (2021) 一样,不需要提取关系的候选实体对的数量显着大于其他基准(96.4% 比 15%) /50% (FewRel 2.0 Gao 等人 (2019)) 以及对 NOTA 实例进行采样的分布,比 FewRel 2.0 更加真实,其中 NOTA 实例始终是其他有效关系类型的实例。 (3) 通过要求支持注释完整,我们可以获得支持 NOTA 分布,这对于任何现有基准测试来说都不是这种情况。 (4)我们的任务不遵循相关工作所遵循的固定-way-shot格式。 相反, 和 在文档之间是可变的,因此在各个剧集之间也是可变的。
4 FREDo:少样本文档级关系提取基准
4.1 选定的数据集
| Data Set | # Docs | # RT333relation types | # CP/Doc444candidate pairs per document | # Words/Doc | # Sents/Doc | Domain |
|---|---|---|---|---|---|---|
| DocRED | 4051 | 96 | 394 | 172 | 8 | Non-specific |
| sciERC | 500 | 7 | 187 | 118 | 5.4 | Scientific Publications |
为了根据3部分中描述的任务构建基准,我们需要来自两个不同领域的完全注释的数据集。 对于训练集和域内测试集,我们使用 DocRED Yao 等人 (2019),因为据我们所知,它是最大且使用最广泛的文档级关系提取数据集。 对于跨域测试集,我们使用 sciERC Luan 等人 (2018),因为它的域(科学出版物的摘要)与 DocRED(维基百科摘要)不同,而且它包含注释7 种关系类型。 在表 1 中,我们显示了所选数据集的比较。 其他文档级关系提取数据集,SciREX Jain 等人 (2020)、DialogRE Yu 等人 (2020)、GDA Wu 等人 (2019)、CDR Li 等人 (2016) 被考虑但最终没有用于跨域集,因为注释的关系类型数量(太少)、缺少共指链接或不同的关系格式(SciREX注释基于二元关系,而其他数据集仅注释二元关系)。
4.2训练和测试数据
4.2.1 文档语料库
我们首先构建 3 个独立的文档语料库,1 个用于训练和开发,1 个用于测试每个任务(域内/跨域)。 由于 DocRED 的带注释的测试语料库不公开,我们使用开发语料库中的文档作为域内任务(元测试)的测试语料库。 因此,DocRED 训练语料库被用作我们的训练和开发集(元训练)的基础。 对于跨域任务,我们只需要一个测试集。 这是因为该任务的训练和开发集与域内任务的训练和开发集相同。 因此,我们使用 sciERC 中的所有文档作为我们的跨域测试集(元测试)。
4.2.2 分配关系类型
对于预处理,我们首先将 sciERC 中注释的关系类型与 DocRED 语料库中的关系类型进行比较555映射可以在附录A中找到。. 我们发现 DocRED 和 sciERC 中都有注释的 2 种关系类型(P279、P361)。 我们从 DocRED 语料库中删除这些内容,以防止训练集和测试集之间的数据泄漏。
4.3 测试集采样
在少样本学习中,由支持文档和查询文档组成的每个训练/测试步骤称为一个episode。 由于评估支持和查询文档的每种可能的组合都会导致太多的事件(大约)。 域内测试集有 100 万集,跨域测试集有 25 万集),我们需要从语料库中采样少量的集。 我们选择抽样程序的目的是产生宏观 分数的代表性测量结果。
对于少样本学习任务,事件采样过程可以分为 2 个步骤,第一步是支持示例的采样,第二步是查询示例的采样。 与每个示例仅包含一个关系实例的句子级场景不同,我们采样的每个文档都包含不同关系类型的多个实例。 为了平衡测试期间每种关系类型被视为支持示例的次数,我们在第一个采样步骤中使用以下过程:我们首先从集合 中选择关系类型 目前在测试语料库中代表性最少。 如果有多种这样的关系类型,我们随机选择一种。 对于这种关系类型,我们采样支持文档,每个文档至少包含一个 实例。 由于所选支持文档可能包含 中其他关系类型的实例,因此我们添加支持文档中包含的所有关系类型666第一,如果有多个支持文档。 情节标注图式。 遵循 Sabo 等人 Sabo 等人 (2021),我们从测试语料库中随机抽样查询文档777请注意,我们排除了之前采样的支持文档。 真实地表示整个语料库的 NOTA 分布。
4.3.1 选择测试集大小
为了选择足够多的测试集来获得代表性的 分数,我们评估了 50k 集的训练模型,以 100 集的间隔记录宏 分数。 我们对 5 个不同的随机种子重复此操作。 使用 5 个测量值之间的方差作为指导,我们选择了一些我们认为可以满足低方差和可管理的测试集大小之间良好平衡的剧集。 为了稳健性,我们使用 3 个不同的随机种子对片段进行采样作为最终测试集。 最终的测试集大小为:域内任务 15k 集,跨域任务 3k 集。
4.4 结果任务的特征
| Task | (micro) | (macro) | |
|---|---|---|---|
| in-domain | |||
| 1-Doc | 2.18 | 2.36 | 2.24 |
| 3-Doc | 3.47 | 4.30 | 4.31 |
| cross-domain | |||
| 1-Doc | 4.26 | 2.73 | 2.40 |
| 3-Doc | 6.08 | 5.55 | 5.27 |
现有的少样本基准通常设置 2 个任务,一个单次任务和一个 次(3/5/10 次)挑战,以确定在添加带注释的训练数据时性能可以扩展的方式。 由于我们任务的性质, 和 因情节而异,具体取决于特定的支持文档和关系类型。 我们通过定义 1-Doc 和 3-Doc 挑战来衡量方法的可扩展性。
因此,建议的基准测试 FREDo 由 2 个主要任务组成,每个任务都有一个 1-Doc 和一个 3-Doc 子任务:
-
•
在使用 DocRED 文档生成的 15k 个片段上评估已根据 DocRED 采样文档进行训练的方法的域内任务。
-
•
跨域任务的方法已在 DocRED 采样的文档上进行过训练,并在使用 sciERC 文档生成的 3k 个片段上进行评估。
为了更好地描述与常见的 -way -shot 格式相关的任务特征,我们测量了 和 的分布> 在我们的测试集上。 和的所有平均值均显示在表2中。 我们发现域内任务(1-/3-doc)的 平均值为(2.18/3.47),跨域任务的平均值为(4.26/6.08)。 对于 ,我们计算所有情节的平均值(微观)以及不同关系类型的平均值(宏观)。
5实验
5.1模型
一般来说,关系提取的一种常见方法是计算由微调语言模型(例如 BERT Devlin 等人 (2019))生成的嵌入之间的相似性。 为了为给定的一对实体生成关系嵌入,大多数方法都会连接与每个实体相对应的嵌入。 从语言模型的输出生成实体嵌入的一种方法是对属于实体的所有标记的嵌入进行平均。 另一种方法是使用 Soares 等人 Soares 等人 (2019) 引入的所谓实体标记,它们是放置在输入文本中实体提及的开头和结尾的标记。 然后,将放置在每个实体提及开头的标记的嵌入用作实体嵌入。 在少样本学习中,使用嵌入相似性的常见方法是原型网络Snell等人(2017)。 在这里,所有 支持示例的嵌入被平均到所谓的原型中。 给定查询嵌入,与 类原型的相似性随后用于分类。
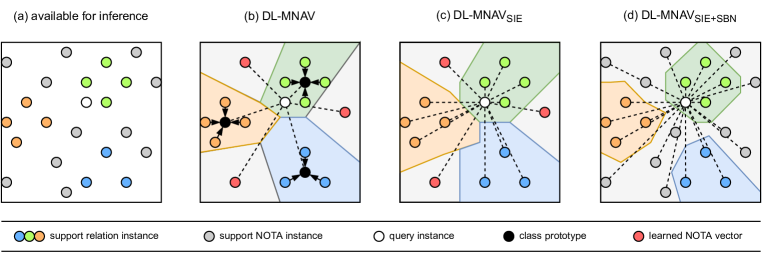
为了评估挑战的难度,我们衡量了 3 种方法的性能。 我们使用预训练的语言模型 Devlin 等人 (2019) 设置初始基线,无需进行微调。 接下来,我们将最先进的句子级少样本关系提取方法 MNAV Sabo 等人 (2021) 应用于文档级(DL-MNAV)。 最后,我们对 DL-MNAV(SIE 和 SBN)进行了 2 处修改,以提高跨域性能。 在图2中,我们展示了不同模型如何处理支持和查询实例的决策边界的比较。
5.1.1 基线
我们使用预训练的语言模型 Devlin 等人 (2019) 设置初始基线,无需按以下方式进行微调:我们使用语言模型对每个文档进行编码,然后进行平均每个实体提及的输出标记。 遵循 Han 和 Wang Han 和 Wang (2020),然后我们对每个实体的提及表示进行平均。 然后,将生成的实体提及连接到每个候选实体对以形成关系嵌入。 查询文档中嵌入的关系与支持文档中嵌入的关系之间的相似度是通过它们的点积来计算的。 产生最高点积的支持嵌入的关系类型被输出作为预测的关系类型。
5.1.2 将 MNAV 调整为文档级 (DL-MNAV)
当前最先进的少样本句子级关系提取方法 MNAV Sabo 等人 (2021) 使用基于实体标记和原型网络的实体嵌入组合。 此外,它还引入了学习 原型来表示 NOTA 类的想法。 为了在文档级别使用 MNAV,需要进行一个关键的架构更改:我们使用相同的实体标记标记来标记所有跨度,而不是仅使用两个不同的标记来标记两个实体(头实体和尾实体)。 此外,遵循其他文档级方法Han 和 Wang (2020); Zhou 等人 (2021) 我们应用池化步骤888对于池化步骤,我们使用均值池化,因为在基础知识实验中,它比周等人使用的logsumexp池化表现更好。 为文档中多次提及的实体创建表示。
现实关系提取的挑战之一是训练过程中遇到的正负关系实例数量的巨大不平衡。 在文档级关系提取中,这一挑战对于任务来说比句子级关系提取更为核心。 基本知识实验表明,简单地使用交叉熵损失(如 MNAV 所做的那样)会产生低于标准的结果。 为了解决这个问题999我们还检查了对训练样本进行重新采样的选项,以使每个训练步骤中的负例数量大致与正例数量相匹配Han 和 Wang (2020),但发现效果较差。,我们采用 Zhou 等人 Zhou 等人 (2021) 使用的自适应阈值损失函数,它是分类交叉熵损失的改编,专为在分类过程中将 NOTA 视为关系类型的分类器设计,如下MNAV 就是这种情况。
最后,我们修改 NOTA 向量的初始化过程。 虽然 Sabo 等人训练 (2021) 使用关系表示的平均值初始化向量,但我们在第一步中从支持文档中采样 NOTA 表示。
5.1.3 支持实例评估(SIE)
MNAV 基于原型网络 Snell 等人 (2017) 意味着关系类型的所有支持实例的嵌入被平均到单个原型中。 虽然这已被证明是一种有效的策略,但我们认为,在跨域设置的推理过程中,它可能并不理想,其中数据分布的变化可能会打破支持实例的平均值提供良好原型的假设。 因此,在 SIE 中,我们在推理过程中使用所有单独的支持实例,而不是它们的平均值。
5.1.4 基于支持的 NOTA 向量 (SBN)
在将 NOTA 视为关系类型并在训练期间学习一组持久向量时,MNAV 的工作原理是假设测试期间的 NOTA 分布将与训练期间看到的分布相匹配。 虽然这种假设是有根据的,并且似乎对于域内少样本学习效果很好,但我们认为对于跨域设置可能并非如此。 因此,我们在训练和推理期间另外将支持文档中的 NOTA 实例添加到我们的 NOTA 向量集中。101010采样的 NOTA 表示不会跨剧集持续存在。 我们不是从支持文档中随机采样 NOTA 向量,而是通过每个关系原型的点积测量最相似的 NOTA 实例。111111由于使用 SIE,我们在推理时不使用原型,因此我们对每个关系实例而不是原型执行此采样步骤,并增加 到 20。. 在新领域的推理过程中,我们仅使用从支持文档中采样的 NOTA 向量,并忽略学习到的向量。
5.2 训练和发展片段采样
我们比较了训练期间采样片段的两种不同方式。 首先,我们以与测试集相同的方式对训练和开发片段进行采样。 为了获得足够的覆盖范围来计算开发集上的代表性宏 分数,我们对 4k 集进行了采样。 作为一种替代方案,我们通过确保每个情节至少有一个查询文档包含关系类型 的实例来修改查询采样。 通过这种方式,我们可以增加模型在训练过程中看到的非 NOTA 示例的数量。 另一个效果是我们需要更少的开发片段(我们使用 500)来计算宏 分数。
| macro [%] | ||
|---|---|---|
| Model | 1-Doc | 3-Doc |
| Random Sampling | 5.77 | 5.29 |
| Ensure Positive | 7.26 | 9.37 |
| 1-Doc | 3-Doc | |||||
|---|---|---|---|---|---|---|
| Model | Precision [%] | Recall [%] | [%] | Precision [%] | Recall [%] | [%] |
| Baseline | 0.36 | 9.69 | 0.60 | 0.60 | 10.75 | 0.89 |
| DL-MNAV | ||||||
| 1-Doc | 3-Doc | |||||
|---|---|---|---|---|---|---|
| Model | Precision [%] | Recall [%] | [%] | Precision [%] | Recall [%] | [%] |
| Baseline | 1.34 | 3.04 | 1.76 | 1.84 | 2.47 | 1.98 |
| DL-MNAV | ||||||
6结果分析
6.1 实验设置
我们所有的模型均基于使用 Huggingface 的 Transformers Wolf 等人 (2020) 实现的 Devlin 等人 (2019) 并使用混合精度进行训练。 我们跟随 Zhou 等人 Zhou 等人 (2021) 使用 AdamW Loshchilov 和 Hutter (2019) 作为优化器(学习率 ,其中 通常表现最好),并使用线性热身(1k/2k 步骤)Goyal 等人 (2017) 进行训练,然后进行线性学习率衰减。 我们使用的渐变裁剪。 我们对每个模型进行 50k 集的训练,并根据开发集上的宏 分数执行提前停止,我们每 1k/2k 步骤进行测量(当随机采样/确保正例时)。 每个 1-doc 训练集包含 1 个支持文档和 3 个查询文档,3-doc 训练集包含 3 个支持文档和 1 个查询文档。 在训练过程中,我们将 的大小限制为 1。 我们使用不同的随机种子运行每个模型 5 次,并选择开发集上平均宏 分数最高的学习率进行测试。 对于测试分数,我们报告使用 5 个不同随机种子训练的模型的宏观 分数的平均值和标准差。 对于此模型,我们报告测试集上的宏 分数。 结果如表3、4和5所示。 所有模型均在 NVIDIA V100 或 NVIDIA 3090 GPU 上进行训练。
6.2 比较采样策略
6.3 基线结果
正如对于未针对当前任务进行微调的基线所预期的那样,生成的宏 分数非常低。 然而,我们认为基线仍然具有相关性,原因有两个。 对于域内挑战,基线证明使用开箱即用的预训练语言模型无法轻松解决这些任务。 对于跨域挑战,我们的基线让我们了解模型是否在域上训练过拟合。
6.4 域内设置
域内挑战的测试分数如表4所示。 我们观察到 分数比基线有了很大的提高,尤其是 DL-MNAV,在 1-Doc 任务中达到 7.05%,在 3-Doc 任务中达到 8.42%。 SIE在1-Doc任务中似乎并没有影响模型的准确性;然而,在 3-Doc 任务中, 得分下降了 1.65 个百分点。 另一方面,SBN 会导致 分数下降超过 5%。 删除学习的 NOTA 向量后的性能下降清楚地说明了它们对于域内任务的有效性。
在表6中,我们比较了不同少样本关系提取基准的最佳分数。 总体而言,与 FewRel Han 等人 (2018) FewRel 2.0 Gao 等人 (2019) 等基准分数相比, 分数相当可观较低,说明了这种现实挑战的难度。 与更现实的句子级基准 FS-TACRED Sabo 等人 (2021) 相比,Sabo 等人报告 12 1212The reported results are micro scores 分数为 12.39%(1 次), 30.04%(5 次)MNAV,这些结果符合我们对更现实(因此显然更困难)挑战的期望。 值得注意的是,FS-TACRED 中 1 次和 5 次设置之间的缩放行为对于 FREDo 来说并不明显。 我们假设这是由于 的变化没有那么大(参见表 2),这意味着 (1) 我们的 1-Doc 设置没有完美关联到 1-shot 设置,以及 (2) 由于附加支持文档的采样方式,3-Doc 设置不能保证不经常出现的关系类型的附加支持示例。
6.5 跨域设置
| Benchmark | input | realistic | best |
|---|---|---|---|
| length | NOTA | [%] | |
| FewRel | sentences | ✗ | 97.85 |
| FewRel 2.0 | sentences | ✗ | 89.81 |
| FS-TACRED | sentences | ✓ | 12.39 |
| FREDo (ours) | documents | ✓ | 7.06 |
跨域挑战的测试分数如表5所示。 对于 DL-MNAV,我们看到 分数较基线显着下降,说明了跨域设置中学习的 NOTA 向量的问题。 SIE 将分数恢复到基线水平,这表明支持示例的分布不再能够很好地用平均值来表示。 切换到 SBN (),我们发现我们的模型超过了基线分数,这表明 sciERC 上的 NOTA 分布似乎有足够的差异,足以导致学习的 NOTA 向量产生过度拟合效应。 虽然 SBN 比原始基线提高了结果,但即使改进的 分数也极低。 然而,考虑到难度比之前的设置有所增加,这并不奇怪。
6.6DL-MNAV的可扩展性
尽管我们的方法在这两项任务中都显示出比建议的基线有所改进,但目前结果严重不足,特别是与两个数据集上最先进的监督学习方法相比( DocRED Xu 等人 (2021) 和 sciERC Ye 等人 (2022) )。 这种性能差距提出了一个问题:如果提供足够的支持文档,我们的模型是否会实现类似的性能。 为了评估 DL-MNAV 在给定数量的类似于监督设置的注释数据时的可扩展性,我们使用完整的 DocRED 训练语料库作为支持文档(96 个类,3053 个文档)初始化训练模型,并评估完整开发的性能集(96 个类,998 个文档)。 我们测量了 的召回率增加以及 的精确度下降,导致 得分为 。
虽然将此分数与 FREDo 中评估的少样本设置直接比较是不合适的,但由于任务提出方式的性质(检查不同的关系类型),该分数可以与监督学习获得的结果进行比较。
在这里我们清楚地看到,当在少样本环境中进行训练时,DL-MNAV 不能很好地扩展到监督环境中。
我们假设抑制可扩展性的一个关键因素是学习的 NOTA 向量独立于 DL-MNAV 中的支持文档。
因此,模型的 NOTA 表示不受添加的支持文档的影响。
我们不会尝试 SIE 或 SIE+SBN,因为支持实例的数量会导致模型尺寸过大。
6.7限制
关于所提出的基准测试 FREDo 的局限性,我们认为,虽然它为模型开发奠定了良好的基础,但将来添加来自更多领域的其他跨域数据集将是有益的。 根据我们测试中当前较低的 分数,高估方法的性能似乎并不是太严重的危险。 然而,我们希望新方法能够取得明显更好的结果。 那时,我们建议重新评估该基准测试对跨域性能的总体代表性。 然而,就目前而言,我们相信我们的任务对推动该领域做出了宝贵贡献。
7结论
为了鼓励开发在现实场景中有用的少样本关系提取方法,我们提出了 FREDo,一个少样本文档级关系提取基准。 通过转移到文档级别,设置变得更加现实,这是现有基准测试正在努力解决的问题。 对于域内和跨域任务,我们提出了一种比简单基线表现更好的方法。 我们的实验证实,尽管一些现有的基准意味着在少样本关系提取中已经可以实现令人印象深刻的甚至超人的性能,但使用当前的方法来完成实际任务非常困难,并且需要取得重大进展才能使用少样本关系提取方法在真实的场景中。 在提供揭示这种性能差距的基准时,我们希望为新方法铺平道路,这些方法对大规模领域特定和跨域关系提取具有潜在的重大影响。
致谢
这项工作得到了德国联邦教育和研究部 (BMBF) 的部分支持,作为项目 IIDI (01IS21026D) 的一部分,以及智能数据创新实验室作为智能数据创新挑战 (01IS19030A) 的一部分。 作者感谢巴登-符腾堡州通过 bwHPC 提供的支持。
参考
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Gao et al. (2019) Tianyu Gao, Xu Han, Hao Zhu, Zhiyuan Liu, Peng Li, Maosong Sun, and Jie Zhou. 2019. FewRel 2.0: Towards more challenging few-shot relation classification. pages 6251–6256.
- Goyal et al. (2017) Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. 2017. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour.
- Han and Wang (2020) X. Han and L. Wang. 2020. A Novel Document-Level Relation Extraction Method Based on BERT and Entity Information. IEEE Access, 8:96912–96919. Conference Name: IEEE Access.
- Han et al. (2018) Xu Han, Hao Zhu, Pengfei Yu, Ziyun Wang, Yuan Yao, Zhiyuan Liu, and Maosong Sun. 2018. FewRel: A Large-Scale Supervised Few-Shot Relation Classification Dataset with State-of-the-Art Evaluation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, pages 4803–4809. Association for Computational Linguistics.
- Jain et al. (2020) Sarthak Jain, Madeleine van Zuylen, Hannaneh Hajishirzi, and Iz Beltagy. 2020. Scirex: A challenge dataset for document-level information extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.
- Li et al. (2016) Jiao Li, Yueping Sun, Robin J. Johnson, Daniela Sciaky, Chih-Hsuan Wei, Robert Leaman, Allan Peter Davis, Carolyn J. Mattingly, Thomas C. Wiegers, and Zhiyong Lu. 2016. BioCreative V CDR task corpus: a resource for chemical disease relation extraction. Database, 2016:baw068.
- Loshchilov and Hutter (2019) Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations 2019, page 18.
- Luan et al. (2018) Yi Luan, Luheng He, Mari Ostendorf, and Hannaneh Hajishirzi. 2018. Multi-Task Identification of Entities, Relations, and Coreference for Scientific Knowledge Graph Construction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3219–3232, Brussels, Belgium. Association for Computational Linguistics.
- Sabo et al. (2021) Ofer Sabo, Yanai Elazar, Yoav Goldberg, and Ido Dagan. 2021. Revisiting Few-shot Relation Classification: Evaluation Data and Classification Schemes. Transactions of the Association for Computational Linguistics, 9:691–706.
- Snell et al. (2017) Jake Snell, Kevin Swersky, and Richard Zemel. 2017. Prototypical Networks for Few-shot Learning. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
- Soares et al. (2019) Livio Baldini Soares, Nicholas FitzGerald, Jeffrey Ling, and Tom Kwiatkowski. 2019. Matching the Blanks: Distributional Similarity for Relation Learning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2895–2905, Florence, Italy. Association for Computational Linguistics.
- Tran et al. (2021) Thy Thy Tran, Phong Le, and Sophia Ananiadou. 2021. One-shot to Weakly-Supervised Relation Classification using Language Models. In Automated Knowledge Base Construction (2021).
- Vinyals et al. (2016) Oriol Vinyals, Charles Blundell, Timothy Lillicrap, koray kavukcuoglu, and Daan Wierstra. 2016. Matching Networks for One Shot Learning. In Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc.
- Vrandečić and Krötzsch (2014) Denny Vrandečić and Markus Krötzsch. 2014. Wikidata: a free collaborative knowledgebase. Communications of the ACM, 57(10):78–85.
- Wang et al. (2019) Haoyu Wang, Ming Tan, Mo Yu, Shiyu Chang, Dakuo Wang, Kun Xu, Xiaoxiao Guo, and Saloni Potdar. 2019. Extracting Multiple-Relations in One-Pass with Pre-Trained Transformers. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1371–1377, Florence, Italy. Association for Computational Linguistics.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2020. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
- Wu et al. (2019) Ye Wu, Ruibang Luo, Henry C. M. Leung, Hing-Fung Ting, and Tak-Wah Lam. 2019. RENET: A Deep Learning Approach for Extracting Gene-Disease Associations from Literature. In Research in Computational Molecular Biology, Lecture Notes in Computer Science, pages 272–284, Cham. Springer International Publishing.
- Xiao et al. (2022) Yuxin Xiao, Zecheng Zhang, Yuning Mao, Carl Yang, and Jiawei Han. 2022. SAIS: Supervising and Augmenting Intermediate Steps for Document-Level Relation Extraction. In NAACL.
- Xu et al. (2021) Benfeng Xu, Quan Wang, Yajuan Lyu, Yong Zhu, and Zhendong Mao. 2021. Entity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction. In Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021, pages 14149–14157. AAAI Press.
- Yao et al. (2019) Yuan Yao, Deming Ye, Peng Li, Xu Han, Yankai Lin, Zhenghao Liu, Zhiyuan Liu, Lixin Huang, Jie Zhou, and Maosong Sun. 2019. DocRED: A Large-Scale Document-Level Relation Extraction Dataset. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 764–777, Florence, Italy. Association for Computational Linguistics.
- Ye et al. (2022) Deming Ye, Yankai Lin, Peng Li, and Maosong Sun. 2022. Pack Together: Entity and Relation Extraction with Levitated Marker. In Proceedings of ACL 2022.
- Yu et al. (2020) Dian Yu, Kai Sun, Claire Cardie, and Dong Yu. 2020. Dialogue-based relation extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.
- Zhang et al. (2021) Ningyu Zhang, Xiang Chen, Xin Xie, Shumin Deng, Chuanqi Tan, Mosha Chen, Fei Huang, Luo Si, and Huajun Chen. 2021. Document-level Relation Extraction as Semantic Segmentation. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, pages 3999–4006. International Joint Conferences on Artificial Intelligence Organization. Main Track.
- Zhang et al. (2017) Yuhao Zhang, Victor Zhong, Danqi Chen, Gabor Angeli, and Christopher D. Manning. 2017. Position-aware Attention and Supervised Data Improve Slot Filling. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 35–45, Copenhagen, Denmark. Association for Computational Linguistics.
- Zhou et al. (2021) Wenxuan Zhou, Kevin Huang, Tengyu Ma, and Jing Huang. 2021. Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling. In Proceedings of the AAAI Conference on Artificial Intelligence.
附录 ADocRED 和 sciERC 的重叠
| sciERC ID | Wikidata ID | DocRED |
|---|---|---|
| hyponym-of | P279 | ✓ |
| part-of | P361 | ✓ |
| used-for | P366 | ✗ |
| compare | P2210 | ✗ |
| evaluate-for | P5133 | ✗ |
| feature-of | - | - |
| conjunction | - | - |
在表 7 中,我们显示了 sciERC 关系类型到 Wikidata Vrandečić 和 Krötzsch (2014) 属性的映射,以及这些关系类型是否包含在 DocRED 中。
附录 B 域内数据集中的关系类型
| Wikidata ID | Description | Number of instances |
|---|---|---|
| P131 | located in the administrative territorial entity | 4193 |
| P577 | publication date | 1142 |
| P175 | performer | 1052 |
| P569 | date of birth | 1044 |
| P570 | date of death | 805 |
| P161 | cast member | 621 |
| P264 | record label | 583 |
| P527 | has part | 632 |
| P19 | place of birth | 511 |
| P54 | member of sports team | 379 |
| P40 | child | 360 |
| P30 | continent | 356 |
| P69 | educated at | 316 |
| P26 | spouse | 303 |
| P607 | conflict | 275 |
| P159 | headquarters location | 264 |
| P22 | father | 273 |
| P400 | platform | 304 |
| P1344 | participant of | 223 |
| P206 | located in or next to body of water | 194 |
| P127 | owned by | 208 |
| P170 | creator | 231 |
| P178 | developer | 238 |
| P20 | place of death | 203 |
| P1412 | languages spoken, written or signed | 155 |
| P155 | follows | 188 |
| P710 | participant | 191 |
| P6 | head of government | 210 |
| P108 | employer | 196 |
| P276 | location | 172 |
| P156 | followed by | 192 |
| P166 | award received | 173 |
| P123 | publisher | 172 |
| P800 | notable work | 150 |
| P449 | original network | 152 |
| P58 | screenwriter | 156 |
| P706 | located on terrain feature | 137 |
| P162 | producer | 119 |
| P37 | official language | 119 |
| P241 | military branch | 108 |
| P31 | instance of | 103 |
| P403 | mouth of the watercourse | 95 |
| P580 | start time | 110 |
| P585 | point in time | 96 |
| P749 | parent organization | 92 |
| P937 | work location | 104 |
| P36 | capital | 85 |
| P576 | dissolved, abolished or demolished | 79 |
| P172 | ethnic group | 79 |
| P205 | basin country | 85 |
| P1376 | capital of | 76 |
| Wikidata ID | Description | Number of instances |
|---|---|---|
| P171 | parent taxon | 75 |
| P740 | location of formation | 62 |
| P840 | narrative location | 48 |
| P676 | lyrics by | 36 |
| P1336 | territory claimed by | 33 |
| P551 | residence | 35 |
| P1365 | replaces | 18 |
| P737 | influenced by | 9 |
| P190 | sister city | 4 |
| P807 | separated from | 2 |
| P1198 | unemployment rate | 2 |
| Wikidata ID | Description | Number of instances |
|---|---|---|
| P27 | country of citizenship | 2689 |
| P150 | contains administrative territorial entity | 2004 |
| P571 | inception | 475 |
| P50 | author | 320 |
| P1441 | present in work | 299 |
| P57 | director | 246 |
| P179 | series | 144 |
| P137 | operator | 95 |
| P112 | founded by | 100 |
| P86 | composer | 79 |
| P176 | manufacturer | 83 |
| P355 | subsidiary | 92 |
| P136 | genre | 111 |
| P488 | chairperson | 63 |
| P1366 | replaced by | 36 |
| P1056 | product or material produced | 36 |
| Wikidata ID | Description | Number of instances |
|---|---|---|
| P17 | country | 2831 |
| P361 | part of | 194 |
| P495 | country of origin | 212 |
| P102 | member of political party | 98 |
| P463 | member of | 113 |
| P3373 | sibling | 134 |
| P1001 | applies to jurisdiction | 83 |
| P118 | league | 56 |
| P674 | characters | 74 |
| P194 | legislative body | 56 |
| P140 | religion | 82 |
| P35 | head of state | 51 |
| P364 | original language of work | 30 |
| P272 | production company | 36 |
| P279 | subclass of | 36 |
| P25 | mother | 15 |
| P582 | end time | 23 |
| P39 | position held | 8 |