利用变分量子机器学习中的对称性
摘要
变分量子机器学习是近端量子计算机的广泛研究应用。 变分量子学习模型的成功关键在于找到模型的合适参数化,该参数化编码了与学习任务相关的归纳偏差。 然而,关于构建合适的参数化的指导原则知之甚少。 在这项工作中,我们全面探讨了何时以及如何利用学习问题的对称性来构建具有在学习任务的对称性下不变结果的量子学习模型。 基于表示论的工具,我们展示了如何通过门对称化过程将标准门集转换为尊重问题对称性的等变门集。 我们在两个具有非平凡对称性的玩具问题上对提出的方法进行了基准测试,并观察到泛化性能的大幅提高。 由于我们的工具也可以直接应用于具有对称结构的其他变分问题,因此我们展示了如何在变分量子特征求解器中使用等变门集。
量子设备在某些计算任务中接近于超越经典计算机的出现 [1, 2] 引发了人们对 噪声中等规模量子 (NISQ) 设备功能的广泛研究 [3]。 这些努力旨在利用没有量子纠错的量子计算机的计算能力,这些量子计算机使用相对较短的量子电路。 特别强调的是 混合 量子-经典方法,这些方法使用量子设备在其他大部分是经典算法中实现子程序 [4]。
这些混合方法的预期应用领域包括量子化学、经典组合优化和机器学习中的问题 [5, 6]。 对称性 由于其经常承认守恒量,因此在物理系统分析中一直扮演着非常重要的角色。 将此与诺特定理相结合告诉我们,守恒量对应于底层系统的对称性。 例如,在量子化学中,基态问题的解或电子结构计算必须尊重守恒量,例如全局粒子数或费米子数的奇偶性,因此允许非平凡的对称性。
然而,对称性的有用性并不局限于物理系统的领域,其在经典机器学习中的作用不容小觑。 对称性在成功图像识别模型的发展中起着关键作用,这些模型引发了人工神经网络学习的革命 [7]。 最近的突破,例如 Transformer 模型的发展 [8],也与对学习任务的潜在对称性的更好理解有关。 因此,机器学习中对称性的严格处理最近在 几何深度学习 子领域中达到顶峰 [9]。
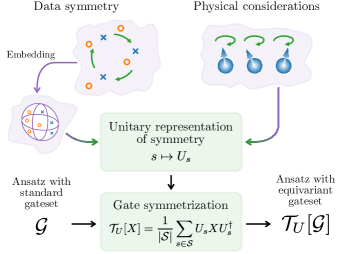
在这项工作中,我们探讨了如何利用学习任务的对称性来创建量子学习模型,这些模型的输出在数据层面的对称变换下保持不变。 经典数据必须嵌入到量子系统的希尔伯特空间这一事实使得将经典世界中的想法直接转移到变分量子学习模型的构建中变得困难。 作为我们的主要贡献,我们展示了如何嵌入数据,使我们能够构建不变的学习模型,我们为这些模型提供了通用的蓝图和设计数学工具。
在第 II 节中,我们展示了数据嵌入,这些嵌入在希尔伯特空间层面产生了对离散对称性和连续对称性的实际相关数据对称性的有意义表示。 变分量子学习模型的可训练部分通常使用来自标准门集的门构建。 在第 III 节中,我们展示了如何利用希尔伯特空间层面的表示来对称化这种门集的生成器,从而产生一个等变门集。 我们特别详细说明了在构建等变门集时应避免哪些陷阱。 在第 IV 节中,我们展示了如何将这些构建块组合起来构建变分量子数据重新上传模型,这些模型进行不变预测,从而包括有意义的归纳偏差。
为了详细阐述我们的方法如何应用以及展示性能的提升,我们在第 V 节中进行了一系列数值实验。我们认为将井字棋的游戏分类作为具有非平凡对称性的典型学习任务,并展示了泛化性能的显著提升,即使对于等变门集中的随机结构也普遍成立。 我们还考虑了一个具有类似对称特性的学习任务,该任务受到汽车行业问题启发,并且一旦量子计算资源可用,就可以扩展以解决实际任务。 对于此任务,我们关注自动驾驶车辆驾驶场景临界性的分类,我们得出了与井字棋示例相同的结论。 我们还认为,等变门集本身的想法并不局限于量子机器学习的应用。 这就是我们另外提供横向场伊辛模型、海森堡模型和基于纵向横向场伊辛模型的玩具模型的基态问题的数值研究的原因,该模型表现出与井字棋问题相同的对称性。 对于这些类型的问题,等变 Ansatz 通常会有所帮助,但在量子机器学习模型的情况下,好处不太明显。
在变分量子算法的背景下,关于对称性应用的文献已经很多。 量子化学问题的 Ansatz 和小工具的明确构建可以在参考文献中找到。 [10, 11, 12, 13, 14, 15, 16, 17]。 参考文献的作者采用了另一种方法。 [18, 19] 其中通过经典后处理强制执行对称性。 在与我们在本文中概述的方法相同方向上的一种方法已在参考文献中提出。 [20],其中建议简单地移除违反对称性的生成器或修复门的参数。
在这里,我们通过一种截然不同的途径实现相同的目标,因为我们建议改变用于构建 Ansatz 的生成器集。 进一步研究处理对称性增强的变分方法的工作可以在参考文献中找到。 [21, 22, 23]。 除了修改 ansatz 本身以强制执行对称性之外,另一种可能性是通过优化器使用代价函数中额外的项来强制执行对称性,这些项会惩罚不对称状态,如参考文献 [24, 25, 26] 中所述。 从不同的角度来看,参考文献 [27] 提出了一个量子模型,它紧密遵循几何深度学习蓝图 [9],首先是一个对称等变量子 “层”,然后是一个对称不变的经典 “聚合器”。 特别地,他们提出了一种用于基于图的学习任务的模型,因此他们考虑的对称性是图节点的排列(或重新标记)。 同样,专门针对图,参考文献 [28] 包含一个构建排列不变模型的配方,该配方受 图卷积神经网络 [9] 的启发。 在参考文献 [29] 中,作者研究了构建群等变 ansatz 状态以学习量子状态。 参考文献 [30] 提出了协变量子核的构建,这些核评估已经具有群结构的数据。
I 预备知识
变分量子算法
变分量子算法 (VQA) [5] 是研究近期限量子设备解决实际相关问题的能力的主要研究方向。 在这些混合量子-经典方法 [4] 中,量子设备使用 参数化量子电路 (PQC) 作为 ansatz 来准备一个参数化的量子态向量 。 在状态准备之后,执行测量以估计一组可观测量的期望值 。 这些期望值随后用于计算一个成本函数,该函数对感兴趣的问题进行编码。 尤其突出的应用是变分量子特征求解器 (VQE),其中成本函数由哈密顿量的期望值给出,该哈密顿量是需要近似的基态,以及量子近似优化算法 (QAOA),它将特定 ansatz 结构与 VQE 相结合,以近似求解经典优化问题。 由于变分量子算法为解决问题提供了一个极其灵活的范式,因此已提出将这些算法用于[6]以外的各种不同问题。
变分量子学习模型
随着机器学习的当前成功,特别是基于神经网络的深度学习,人们对将量子计算机应用于学习问题可能带来的收益越来越感兴趣,从而催生了量子机器学习 (QML)领域。 如上所述,变分方法可用于构建变分量子学习模型 (VQLMs),例如参见参考文献。 [31, 32, 33]。 在这种基于电路的模型中,ansatz 状态不仅取决于变分参数,还取决于输入数据,预测被编码在可观察量的期望值中。
| (1) |
由于不可克隆定理,对于量子学习模型的表达能力,将数据多次嵌入量子电路非常重要,此过程被称为数据重新上传[34, 35, 36]。 因此,在下面,我们将考虑 VQLMs,其中固定的数据嵌入酉运算与参数化量子电路交织在一起,如
| (2) |
对称群
对称性通常由群来捕获。 群是一个对象集,以及一个组合规则(通常称为“乘法”),因此对于所有都成立。 乘法还需要是结合的,即。 此外,存在一个单位元,使得对于所有都成立,并且对于所有,都存在一个唯一的逆元,使得。 群的一个简单示例是,其中组合由模 2 加法给出。 如果 的某个子集在 的合成规则下本身也是一个群,我们称这个子集为 子群。
群的概念也扩展到连续集,以 李群 的形式。 一个实李群是一个群 ,它也是一个光滑流形,并且合成规则和反演是光滑映射。 一个(非紧致)李群的例子是所有可逆线性算子 的集合。 作为 的子群并且因此可以用矩阵表示的李群被称为 矩阵李群,我们将在下面重点关注这些群。 矩阵李群的一个例子是作用于 的酉矩阵,记为 。
李群与 李代数 密切相关,李代数可以看作是李群元素的生成元。 对于矩阵李群 ,我们可以定义相关的代数为
| (3) |
这是由以下事实推动的:对于两个群元素 ,我们可以通过贝克-坎贝尔-豪斯多夫公式在李代数的级别上理解群乘法
| (4) |
对于 和 接近单位元,我们有 和 的范数很小,在这种情况下,它们的交换子给出第一修正。 它实际上是李代数的正式定义的一部分,被称为李括号。
一个群的 表示 是一个映射 ,它与合成规则兼容:。 如果空间 具有标量积,并且线性映射 是酉的,我们称之为酉表示。
II 数据嵌入引起的对称性
对称性在整个物理学中都起着重要的作用,而近期应用中感兴趣的问题在这方面也不例外。 一个对称群 通过一个酉表示 作用于一个 量子比特希尔伯特空间 ,对于 。
在基态问题中——正如在变分量子特征求解器 [37] 中遇到的那样——对称性通常源于物理考虑。 例如,海森堡模型中遇到的这种对称性是,如果所有自旋翻转,即应用算符 时,状态的能量不会改变。 这可以理解为对称群 的表示。 进一步的对称性包括所有自旋的联合酉变换 () 或平移对称性 ()。 这些对称性已经在 VQE 的背景下得到广泛研究,特别关注构建用于量子化学应用的对称性保持的 ansätze [10, 11, 12, 13, 14, 15, 16, 17]。
但基态问题并不是近期应用中唯一具有对称结构的感兴趣问题。 事实上,在量子机器学习的背景下遇到的许多学习问题也具有某种对称性:一个典型的例子是图像的标记。 即使我们将猫的照片的所有像素向右移动或旋转它,该照片仍然描绘了一只猫。 更正式地说,考虑一个任务,其中应该将预测 与数据点 相关联。 我们说预测在具有表示 的对称群 下是不变的,如果
| (5) |
诸如此类的概念最近引发了 几何深度学习 [9] 的子领域,该领域抽象地论证了这些对称性及其在学习模型中的实现,特别是在人工神经网络中。 几何推理也阐明了卷积神经网络 [7] 的早期成功,这些网络使用尊重典型图像分类任务中存在的平移对称性的构建块,以及 Transformer 模型 [8] 的成功。 直观地,人们也期望构建对称不变模型会带来优势:根据定义,对称不变模型不会看到由对称变换相关的任何数据点之间的差异,这有效地减少了学习模型可以做出的预测数量。 这样的模型具有更低的复杂度,因此预计更容易训练。 此外,这些模型只生成尊重学习问题中已存在对称性的预测,因此预计它们可以更好地泛化到看不见的数据。
在接下来的内容中,我们将展示如何构建量子电路,以一种在希尔伯特空间级别上诱导对称的意义非凡的酉表示的方式嵌入经典数据。 然后,这些嵌入被用作构建对称不变数据重新上传模型的构建块。
介绍性示例
我们首先考虑图 2 中给出的一个介绍性示例。 假设我们有数据点 ,并且预测——例如分类——具有以下对称性
| (6) |
它们对应于坐标的交换和同时的符号反转。 相关联的对称群,俗称克莱因四元群,由下式给出
| (7) |
其中群运算为模 2 的逐元素加法。 在这个对称群的抽象定义中,第一个分量可以理解为对问题 “我们是否交换?” 的布尔答案,第二个分量可以理解为对问题 “我们是否反转?” 的布尔答案。
数据级别上的表示由下式给出:
ll
V_(0,0) = [1 00 1], &
V_(1,0) = [0 11 0] ,
V_(0,1) = [-1 00 -1],
V_(1,1) = [0 -1-1 0] .
如果我们使用嵌入酉算子
| (8) |
那么对称操作可以在希尔伯特空间级别上表示为
| (9) | ||||
| (10) | ||||
| (11) | ||||
| (12) |
其中我们使用了 的事实。 请注意,我们也可以在上面的例子中使用 ,因此这些操作并不一定唯一。
我们可以利用从例子中获得的直觉来概括 诱导表示 的概念:我们称一个数据编码为酉 等变,相对于数据对称性 1 11我们选择 等变 而不是同义词 协变,因为这是几何深度学习中使用的术语。 如果
| (13) |
对于 的酉表示 。 我们上面例子所诱导的表示则为
ll
U_(0,0) = ⊗,&
U_(1,0) = ,
U_(0,1) = X ⊗X,
U_(1,1) = (X ⊗X).
接下来,我们将展示如何构造相对于现实世界学习任务中遇到的最重要的对称性类别而言是等变的数据编码。
置换对称性
在当代学习任务中遇到的大多数数据,例如图像或时间序列数据,都具有离散结构。 数据的对称性变换,例如平移或旋转图像或平移时间序列,可以通过对不同数据特征的置换来捕获。 这意味着在许多具有对称性的相关场景中,对称性群将是 个不同数据特征 的 置换群(或 对称群) 的一个子群。
对称群的元素是对数据特征的所有可能的重新排列
| (14) |
每个置换都可以通过连接 换位 来构建,换位是每次交换两个数据特征。 我们将把一个换位写成 ,使得对于所有 ,我们都有 ,对于某些换位 。 请注意,换位的乘积通常被认为是从右到左实现的。
在上一节中,我们已经看到如何构造一个相对于两个元素的置换是等变的数据编码,并且该构造直接推广到更高维度,需要 个量子比特来表示 维数据。 我们用一个相关的构造来补充这个,它允许使用大约 个量子比特,但仍然保持等变性。 自然的构造是通过在单独的量子比特上进行泡利旋转来嵌入每个数据特征,生成器的选择无关紧要,所以我们选择 来得到
| (15) |
这个编码显然相对于量子比特的排列是等变的,并且诱导了 的表示,由
| (16) |
其中 交换两个与 交换的特征对应的量子比特。 这个嵌入实际上允许我们比排列群更进一步,并且还可以等变地嵌入第 个坐标的符号翻转,方法是与第 个量子比特上的泡利 共轭,从而推广到 。 222 这个新组是半直接积 ,它捕捉了每个元素 的直觉> 可以写成一个排列 和多个符号翻转 的乘积 。
采用这种策略,我们需要与数据特征一样多的量子比特。 一个自然的问题是,是否可以做得更好,也就是说,我们能否找到一个不同的编码门,它能够将 个特征嵌入少于 个量子比特中,并且仍然相对于排列群是等变的。 如果我们想在上述局部 算符集中添加另一个泡利字作为生成器,我们受到这样一个事实的限制:这个生成器必须在量子比特之间所有 操作下是不变的,因为这些操作应该按照定义只交换相关的坐标,而不交换新添加的坐标。 这意味着我们唯一可以添加的算符是 ,这将产生一个额外的我们可以用这种策略编码的数据特征。 在这种情况下,交换第 个坐标和第 个坐标的表示是一个多 门,其中第 个量子比特控制对其余量子比特的同时应用 。
请注意,原则上我们可以使用一组不同的相互对易的泡利字,因为任何一组独立的、相互对易的泡利字都可以通过克利福德门 [38] 进行互换。 一个例子是生成器集 ,它可以等效地替换为 ,这将构成一个更 “平衡” 的编码策略,因为算符具有相似的权重。 对于这组算符,排列由换位生成
| (17) | ||||
| (18) | ||||
| (19) |
其中 是哈达玛算符 的一个推广,由 给出。
基于局部 旋转的编码与文献 [39] 中提出的 IQP 编码密切相关。 我们可以利用他们的灵感,也包含数据特征的更高单项式,例如 。 如果我们用一个生成器 来嵌入这样的单项式,其中 是作用于第 个量子位的局部 ,那么我们就会看到,特征的排列可以通过量子位的排列来实现。 然后,通过同时嵌入像 、、 等等的所有可能的单项式排列,使用算子 、、 等等,就可以实现数据的等变嵌入。 用于此构造的项数增长得相当快,因为必须考虑所有可能的排列。 另一方面,这意味着如果我们只想实现排列群的一个子群,我们可以预期只需要嵌入更少的项。 如果我们只考虑将 映射到 的平移,我们只需要嵌入单项式的所有可能平移,这在特征数量上是线性的。
虽然上述数据嵌入策略易于实现,但原则上我们可以以等变的方式嵌入指数级的许多数据特征。 这样做的一个策略是,将计算基的每个状态都分配为由整数 的二进制表示识别的所有 的集合,即一个生成器
| (20) |
这会生成酉算子 ,它只对第 个计算基态的幅度施加相位。 然后很容易看到,特征 和 的转置可以通过
| (21) |
来实现,它为高达 的数据特征数量诱导出排列群的表示。 然而,与上述示例中的简单 旋转相反,这些旋转非常难以实现,因为它们大多对应于对几乎所有量子位进行控制的操作。 此外,正如我们将在第 III 节中看到的那样,如果使用所有可用的基态,只有平凡操作才会尊重系统的对称性。
上述示例表明,等变嵌入的构造应该可以用相对较少的量子位来实现,但代价是需要实现非常复杂的闸门。 这降低了这种方法的实用性,尤其是在 NISQ 时代。 另一个极端是本节开头提出的 1-局部嵌入,它本质上只允许我们嵌入与量子位数量一样多的数据特征,但可以非常容易地实现。 因此,一个有趣的未来研究方向是定义什么样的嵌入可以在这两种机制之间进行插值,并且允许嵌入比 1-局部嵌入更多的数据特征,同时仍然足够可实现。
连续对称性
虽然许多实际感兴趣的案例都显示出离散对称性,但我们不需要将自己限制在这种情况下。 特别是在考虑自然科学中可能的应用时,我们也会遇到连续对称性,例如,如果围绕某个轴旋转空间数据点不会改变预测。 处理连续对称性的框架由李群给出,李群是具有可微结构的连续群。
表示论告诉我们,任何紧李群都可以表示为适当大的酉群的子群 [40],并且由于任何酉群都可以嵌入到更大的特殊酉群中,因此每个李群都可以用适当大的量子系统表示。 然而,并非先验清楚哪些李群允许产生忠实酉表示的嵌入。 我们将展示如何构建一个关于 维的特殊正交群 等变的嵌入,并展示如何将其扩展到完整的正交群 。 然后我们概述如何从数学上理解一般的任务。
和
群 由所有可能围绕原点中心的球体的旋转组成。 对于特殊正交群的元素,我们将使用小写字母来区分它们与其量子对应物。 任何元素 都可以通过依次应用关于坐标系轴的三个规范旋转之一来构造,我们将其表示为 和 。 下面,我们将使用欧拉角给出的参数化
| (22) |
现在,我们将数据点 的等变嵌入定义为
| (23) |
其中我们定义了泡利算子向量 。 我们可以利用它实际上是从数据点到 Bloch 球面的映射,我们知道用 Pauli 旋转的共轭生成 Bloch 球面的相关旋转以获得诱导表示。 我们只需要
| (24) | ||||
| (25) | ||||
| (26) |
推断
| (27) | ||||
| (28) | ||||
| (29) | ||||
在这一点上,我们回顾一下,对于任意幺正算子 ,也有一个参数化,它也用三个角度 表示。 利用它,我们得到了所需的诱导表示
| (30) |
所有正交 (即 保持长度) 转换在 、 上的完整群,不仅包括旋转,还包括关于穿过原点的任何平面的反射。 幸运的是,关于不同平面的反射可以通过将平面映射到彼此的旋转来关联。 这意味着一个固定的反射,加上三个规范旋转,足以跨越整个群 。 我们选择垂直于向量 的平面,它实现关于原点 的反射。 正如我们已经看到我们已经用尽了 来表示 ,这不可能使用仅包含一个量子位的嵌入来实现。 然而,如果我们添加一个额外的量子位并使用嵌入
| (31) |
的旋转以与之前在第一个量子位上相同的方式嵌入,但现在反射也可以实现为
| (32) | ||||
| (33) | ||||
| (34) | ||||
| (35) |
通过这种方式,我们可以生成整个群 。
一般情况
我们找到了一种相对于 变换等变的编码,但由此结构产生的直接问题是它是否可以推广到作用于数据的任意李群。 为此,我们将对导致等变嵌入的过程进行数学形式化。 请注意,对称性 必须具有非平凡的有限维酉表示,这排除了像 这样的有趣群,因为它们不是紧致群。
我们假设数据的嵌入形式为
| (36) |
这意味着我们实际上将数据嵌入到量子系统 的李代数中。 我们将进一步假设从数据到李代数 的映射是线性的。 我们将数据层面的对称变换建模为对称李群 的表示,由 给出。 我们的目标是找到一个映射 ,使得以下图表可交换:
这里, 是一个变换,它以等变的方式在李代数级别实现对称变换。 这意味着它需要是酉变换的共轭
| (37) |
对于某些 ,它表示作用于数据的对称群 。 以上不过是 的伴随作用,如果 ,则由李代数级别的伴随作用生成
| (38) |
其中 。 回顾数据空间,我们可以使用 是李群的矩阵表示,并且我们可以为 的李代数的某个元素 写出 。 使图表可交换则强制执行
| (39) |
可以快速验证,如果
| (40) |
换句话说,这意味着为了构建作用于数据的给定李群表示的等变嵌入,我们需要找到 的子空间——这将是 的图像——使得 的伴随表示限制到该子空间 与 作用于数据 的对称李代数 的表示相同。
这阐明了 为什么 我们能够构建一个关于 等变的嵌入。 这是因为作用于数据的李代数 的基本表示等于 的伴随表示。 此外,我们还可以看到,总存在一个平凡的嵌入 ,它会诱导出李代数的平凡表示。 从以上推理中,我们也看到,找到一个同构于作用于数据的李代数的子李代数是不够的,我们真的必须确保 的伴随表示中存在一个适当的子表示,与 在数据空间上的表示相同。 由于我们认为,实现关于比 更奇特的对称性等变的嵌入是一个兴趣有限的课题,因此我们将在此设置中可以实现的等变嵌入的分类留作进一步研究的课题。
III 门对称化
正如我们在上面看到的,如果使用等变嵌入,对称性会自然地出现在变分量子学习模型中。 在这些应用中,以一种对当前问题适合的归纳偏差进行编码的方式构建模型的可训练部分至关重要。 我们面临的问题是,参数化量子电路与相关归纳偏差之间关系的知识并不真正为人所知,这让我们在构建学习模型时几乎没有可供参考的知识。 对称性为构建更好的量子学习模型提供了第一条途径,因为它们允许我们以有意义的方式将有关底层数据的知识纳入模型。 此外,它们还允许我们通过自由参数的数量来降低ansatz的复杂性,从而节省资源。 同样适用于其他变分应用,例如 在寻找基态时。 那里,目标不是更好的泛化能力,而是希尔伯特空间相关部分的更好表达能力。
在本节中,我们将解释如何使用基本群论从ansatz构建中使用的标准门集中构建一个 等变门集 ,其中,正如我们将在下面正式说明的那样,我们将等变定义为与对称性表示交换。 这使我们能够采用现有的ansatz,并通过用其等变对应物替换每个门来使其等变。 我们还将探讨为什么这种方法有其优势,但并非万能药,因为有几个陷阱需要避免。 这有时使得不将模型构建为相对于完整对称群的等变而仅考虑其子群是明智的。
等变门集
我们将关注由固定生成器 生成的门,因为
| (41) |
因为它们通常出现在变分方法的 ansatz 结构中。 在构建 ansatz 时,门是从固定门集 中的生成器中选择的。
我们称一个门 等变 相对于由 的酉表示 体现的对称性,如果应用对称操作和门的顺序无关紧要,因此
| (42) |
这只有在生成器本身与表示交换的情况下才可能,这由以下命题捕获。
Proposition 1 (交换生成器).
对于给定的门 ,我们有
| (43) |
当且仅当 对于所有 。
证明。
首先,我们证明该条件是必要的。 为此,考虑 到一阶的展开
| (44) | ||||
| (45) | ||||
| (46) | ||||
| (47) |
因为这种关系也需要对无限小的 有效。 该条件显然是充分的,因为 意味着 的所有幂,因此完整的指数与 交换。 ∎
对我们来说幸运的是,有一种简单的方法可以确保生成器与给定的表示交换 - 我们可以使用 缠绕公式。
Proposition 2 (旋转公式 [41]).
令 为 的酉表示。 那么,
| (48) |
定义了一个投影到与表示的所有元素交换的算子集上的投影,即,对于所有 和 而言,。
如果我们将均匀平均替换为在 Haar 测度 上的积分,那么 Lie 群也同样适用,
| (49) |
我们使用这种方法将任何门集 关联到一个 等变门集
| (50) |
注意,这种方法也直接扩展到非参数化的门,因为这些门可以通过旋转公式直接对称化,或者可以写成具有固定演化角的参数化门,如等式 (41) 所示。
Ansat 对称化
我们现在可以使用上述门对称化技术,通过用等变门集替换 Ansat 的门集,将完整的 Ansat(或可训练块)转换为等变 Ansat(或等变可训练块)。 从实际应用的角度来看,等变门集的计算通常可以在预先进行。
为了使这一点更加清晰,让我们回到关于两个量子比特的交换对称性的示例。 假设一个 Ansat 由由泡利算子生成的局部旋转门组成,,以及由 相互作用生成的纠缠门,所有这些我们都认为是可训练的。 在这种情况下,门集是
| (51) |
其中索引标识了泡利作用的量子比特。 门已经与交换操作交换,这意味着我们可以只关注局部操作。
在我们的示例中,对称群是 ,其中对称性是由 (交换 )和 (符号翻转 )生成的。 首先,我们只考虑两个子群的对称化,然后协同作用。
生成器 已经与交换操作对易,因此在对称化下保持不变。 如果我们对 应用关于交换对称性的对称化,我们将得到
| (52) | ||||
| (53) | ||||
| (54) | ||||
| (55) | ||||
| (56) |
其他运算符的对称化过程类似。 我们看到,在对称化之后, 和 映射到同一个运算符 - 因此,对称化的门集的基数更低。 这意味着,正如预期的那样,保持对称性的酉算符子空间小于酉算符的完整空间,并且在对称化之后,我们减少了参数的数量,从而降低了 Ansatz 的复杂性。 然后,关于交换对称性等变的门集由对称的纠缠门和在共享相同角度的两个量子位上进行的同步 Pauli 旋转给出,
| (57) |
现在,让我们看看符号翻转对称性。 同样, 已经与 对易,并且在对称化下保持不变。 局部门的这种情况又有所不同。 非常简单, 和 与 对易,但对于其他门来说,情况并非如此,因为
| (58) | ||||
| (59) | ||||
| (60) | ||||
| (61) |
其中我们使用了 的事实。 对于 以及 和 ,计算过程类似,因为 。 这意味着符号翻转等变门集看起来与交换对称性的门集有很大不同,因为在这种情况下,我们只允许局部 Pauli 旋转
| (62) |
由于该群的交换性质,我们可以通过对另一个门集应用任何对称化过程来获得完全等变的门集,这将产生
| (63) |
我们看到,考虑到完全对称性会大大减少可用操作的数量,但这会以降低表达能力为代价,我们将在下一节中进一步详细介绍。
避免的陷阱
通过对称化使一个 ansatz 等变可以带来相当大的优势,但决不是万能药。 有一些重要的注意事项和一系列需要注意的陷阱。
首先也是最重要的是,在等变性的增益与因此对相关子空间的专门化之间,以及 ansatz 表达能力的降低之间,始终存在权衡。 这就是量子机器学习和基态问题在争论中分歧最大的地方:在机器学习应用中,最大表达能力几乎总是件坏事,因为它会导致过拟合,从而导致泛化性能下降。 根据可用数据的数量和学习模型的具体情况,过拟合的状态也可能很快达到。 在这种情况下,等变模型提供了明显的优势,因为它们不仅减少了表达能力,而且以确保泛化改进的方式做到了这一点。 对于具有给定对称性的基态的制备,情况略有不同。 在这种情况下,不存在过拟合现象 本身,因为即使制备的状态没有与基态相同的对称性,也更倾向于较低的能量。
我们可以得出结论,表达能力和等变性之间的权衡应该始终牢记。 为了微调这种权衡,也可以建议只实现问题中所有现有对称性的一个子集。 例如,在我们上面的示例中,可以选择只尊重问题的交换对称性。 另一种微调模型表达能力的方法是包含有限数量的显式对称破坏门,例如在参考文献 [23] 中所论证的那样。 如果我们不知道基态所在的对称性扇区,这将尤其可取,因此我们必须能够改变扇区,而这对于纯等变电路来说是不可能的。 此外,可能发生等变电路具有不利的损失景观,这有时可以通过添加一些对称破坏操作来缓解。
在对称化过程本身中,还有一些需要避免的陷阱: 首先,我们已经看到对称化过程可以使某些生成器变得微不足道。 一个例子是 由 和 给出的表示。 我们可以将每个单量子比特酉算子表示为分解 ,它对应于使用门集 。 但是,这两个生成器都没有关于此表示的等变性,即 ,留下我们 没有门,即使我们从一个通用的参数化开始。 这与我们有一组与对称性兼容的酉算子,该酉算子被生成为 的事实形成了对比。 如果我们选择了,例如 ,则不会发生平凡化。
其次,根据用来构建 ansatz 的门的不同,它可能会失去通用性。 如果所涉及的门没有生成与对称性兼容的全部酉算子集,则会发生这种情况。 在量子化学和费米到量子比特映射的背景下,需要 3- 局部酉算子来生成所有可能的对称性保持变换 [14, 42]。 如果有人天真地对从传统的单量子比特和双量子比特门构建的 ansatz 进行对称化,就会失去通用性。
第三,电路深度在对称化下可能会急剧增加。 这种情况发生在对称性诱发相对于底层硬件非局部的相互作用,并且必须通过广泛的 SWAP 链来实现时。
我们还想指出,使 ansatz 等变不是利用对称性的唯一方法。 一种方法是使用 惩罚项,它们是成本函数的附加部分,会增加对称性低的态的成本 [26, 25, 43]。 这类似于在经典机器学习中使用正则化项。 惩罚项可以为任意对称性表示构建,并且具有通过 优化器 而不是 ansatz 运行的魅力,这意味着它们可以被普遍包含以部分缓解与无知 ansatz 相关的问题。
IV 不变重新上传模型
在本节中,我们想总结一下不变重新上传模型的构造。 我们重复了我们意义上通用数据重新上传模型的定义。 我们准备了一个由可训练块 和数据编码酉算子 重复应用组成的 ansatz 状态向量
| (64) |
然后从期望值
| (65) |
中获得预测。 我们希望以一种使预测在对称群 的作用下保持不变的方式构建量子学习模型,该对称群通过表示 作用于 ,其意义在于
| (66) |
正如我们在 Sec. II 中论证的那样,如果数据嵌入 关于对称性是 等变的,我们可以对量子学习模型做到这一点,其意义在于它 诱导 根据
| (67) |
如果数据嵌入不是等变的,我们几乎没有希望构建不变的量子学习模型,因为对称性在希尔伯特空间的层面上没有得到有意义的表示。 在等变嵌入下,重新上传模型的各个部分像
| (68) |
我们可以通过强制可训练块 关于 的酉表示 是 等变的 来使这种结构成为等变的,数学公式为
| (69) |
正如在 Sec. III 中论证的那样,表示 为我们提供了强制可训练块等变性的直接方法。 这是因为 扭曲公式
| (70) |
是对所有与对称性表示(对 对易子 的投影)对易的算子的投影,因此是 等变的。 我们使用这样一个事实:ansatz 是从具有生成器门的参数化门集 构建的,来定义一个 等变门集 ,它由标准门集的扭曲生成器组成。 等变门集现在包含可以自由组合以构建等变可训练块的构建块。 将关于数据对称性是等变的数据嵌入与关于希尔伯特空间上诱导的对称性是等变的可训练块相结合,产生了 等变电路
| (71) |
到目前为止,我们已经展示了如何构建等变电路。 为了实现最终预测的不变性,我们还需要一个不变的初始状态向量。
| (72) |
由于 这等效地意味着
| (73) |
如果我们现在将一个等变电路应用于一个不变的初始状态,我们将得到一个等变的ansatz。
| (74) | ||||
| (75) | ||||
| (76) | ||||
| (77) |
最后,如果我们将等变的ansatz与一个不变的可观测量结合起来
| (78) |
我们将得到一个不变的重新上传模型。
| (79) | ||||
| (80) | ||||
| (81) | ||||
| (82) |
注意,可观测量在等式(78)中保持不变的条件,以及可训练块在等式(69)中保持等变的条件,如果写出来,实际上是一样的。 这种表面上的矛盾的原因是,这两个对象都是算符,但它们做的事情不同:可训练块执行状态转换,而初始状态和最终可观测量则像被转换的对象。 如果我们从其对密度矩阵的作用的角度来看这些操作,即如果我们理解它们为量子通道,那么这幅图就会变得更加清晰。 然后,可训练块的等变性表现为
| (83) |
而可观测量的不变性仍然像在等式(78)中实现的那样。 这两种图像在这样一个事实中汇聚在一起:用一个不变的对象(在本例中是代表可训练块的酉算符)进行共轭构成一个等变变换。
上述构建可以被看作是几何深度学习蓝图的“伴随”或“双边”版本,其中我们必须从一个不变的对象(初始状态)开始,应用等变操作,然后再次评估一个不变对象上的期望值。
V 数值实验
在本节中,我们报告了我们进行的数值实验的结果,这些实验旨在比较不变学习模型与它们在两个选定的具有非平凡对称性的玩具问题上的非不变对应物的性能。 我们观察到,不变学习模型在训练数据上的表现不佳,但比不尊重对称性考虑的学习模型具有更好的泛化性能。 为了确保我们在第 III 节中提出的对称化过程具有普遍适用性,并且我们没有刻意挑选一个有效的边缘情况,我们还进行了模拟,在这些模拟中,我们对学习模型可训练部分的布局进行了随机化,这证实了我们的主要数值结果并显示了泛化方面的一般优势。
我们进一步研究了等变 ansatz 在横场伊辛模型、海森堡模型以及与我们的学习玩具问题共享相同对称性的纵向-横向场伊辛模型等基态问题中的性能。 对于这些问题,以及我们在研究中使用的 ansatz 构造,等变 ansatz 平均能产生更好的基态近似,同时只需要更少的迭代次数即可收敛。 我们进一步表明,等变 ansatz 可以缓解贫瘠高原问题。 然而,我们注意到,适用性情况并不像量子机器学习应用中那样明确,等变 ansatz 也可能存在缺点,我们将在本文中详细讨论。
井字棋
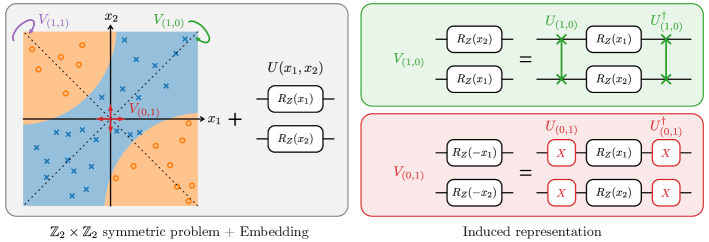
为了展示上面概述的方法,我们首先考虑一个基于著名的 井字棋游戏 的简单训练任务。 目标是训练一个变分量子学习模型,将游戏分类为 “十字获胜” ()、“圆圈获胜” () 或 “平局” () 类别。 此分类问题具有非平凡的对称群,因为旋转棋盘和关于轴反射棋盘不会改变结果。 它还有一个优势,即它可以在九个量子比特的适度数量上实现等变嵌入。 井字棋游戏的对称性如图 3 左侧所示。
此学习任务的对称群由 二面体群 给出,它等效于将正方形映射到自身的所有操作。 二面体群可以通过逆时针旋转 90 度和关于穿过中心的垂直轴的翻转来生成。 该群的阶为 ,因此共有 个元素。 该群诱导出井字棋棋盘字段的等价类,因为棋盘的角将始终映射到角,边映射到边,而中心将始终保持不变。 这些三个等价类也将在等变门集中反映出来。
我们注意到,用经典的确定性算法很容易解决标记井字棋游戏的问题,实际上,只有有限数量的游戏是可能的。 这个数值示例的目的是展示我们对称化过程的端到端实现的可能性,并比较等变门集和标准门集。 此外,在以下的一些部分中,我们将讨论如何将这个例子作为范式来解决其他可能更有用的问题。
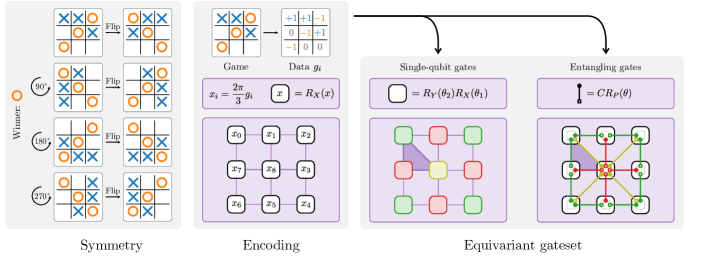
数据集
第一个过程是将井字棋游戏映射到经典数据。 如图 3 的第二列所示,我们通过将棋盘的九个字段映射到向量 的元素来实现,其中 代表十字, 代表圆圈, 代表空字段。 游戏的标签以one-hot方式编码在向量 中,其中 值分配给正确的标签, 分配给其他两个条目。 不同的井字棋游戏的数量足够小,因此我们能够生成所有可能的有效游戏。 在我们的数据集中,我们也允许未完成的游戏,它们被标记为 “draw”。 然后通过随机选择所有可能的井字棋游戏的一个子集来构建训练和测试数据集,其中每个结果都得到同等的表示。
学习模型
为了解决井字棋学习任务,我们将使用一个具有等变嵌入的数据重新上传模型,如 Secs 所述。 I 和 II。 等变嵌入是通过将表示游戏的不同数值通过 Pauli- 旋转编码到我们在一个平面网格中看到的单独量子比特来构建的。 为了将三个数据特征均匀分布,我们使用 的倍数作为旋转角度,同样如 Fig. 3 的第二列所示。
嵌入的等变性确保了对称变换通过酉共轭实现。 例如,沿垂直轴的反射是通过 Fig. 3 的编号中的 实现的。 量子比特级别上置换类型对称性的优势在于它们可以在视觉层面上轻松理解。 量子比特在对称运算下位于等价类中。 然后,单量子比特门必须对同一个等价类中的所有量子比特以相同的方式作用。 这就是我们如何获得 Fig. 3 的第三列中描绘的等变单量子比特层类型,其中应用了单量子比特酉运算,当作用于角(c)、边(e)或中间(m)时,这些酉运算共享相同的参数。 同样的推理也可以应用于双量子比特门。 连接角与旁边边的纠缠操作必须对所有相邻角和边的对以相同的方式作用。 这就是我们如何获得用于我们学习模型的纠缠门的等变层,这些层执行从角到相邻边的受控旋转(o)、从边到中间的受控旋转(i)以及从中间到角的受控旋转(d),如 Fig. 3 的第四列所示。 我们选择 用于参数化旋转。
学习模型从所有量子比特初始化为状态向量开始,该向量在问题的对称性下是不变的。 然后应用多层,每层都由一个数据编码和一系列参数化层组成。 默认参数化层选择为“cemoid”,它对应于对单量子比特门的一次应用,然后是对纠缠门的应用,这两者都在图3中可见。 标签的预测是通过测量三个不变可观测量的期望值来获得的,以 one-hot 编码形式表示,
| (84) | ||||
| (85) | ||||
| (86) |
作为。 给定数据点的预测是通过选择观察到的期望值最大的类来获得的。
训练
我们使用损失函数训练学习模型,对于一组具有关联的 one-hot 标签向量的游戏,它由以下公式给出:
| (87) |
我们以 100 个 epoch 进行了优化,每个 epoch 包含 30 个步骤。 在每个步骤中,梯度使用 15 个数据点来计算,这些数据点代表一个井字棋游戏。 训练集的大小是这两个数字的乘积。 每个 epoch 完成后,训练集都会被洗牌。 测试集由 600 场游戏组成,这些游戏是在每次训练运行中随机选择的,与上述约束相同,但在整个运行过程中保持固定。 以上超参数是根据经验选择的。
量子学习模型使用 PennyLane 库[44] 为量子机器学习实现。 使用 PennyLane 提供的 PyTorch 接口,我们通过梯度下降训练了 PQC,该梯度下降由 Adam PyTorch 优化器[45] 实现。
结果
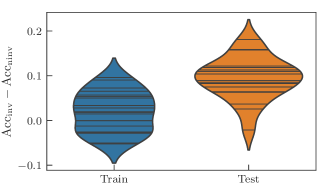
在我们所有的数值计算中,我们将不变模型与非不变模型进行比较,其中图 3 中所示的参数共享没有被强制执行。 因此,非不变模型具有更多独立参数,因此具有更高的表达能力。 为了评估模型的性能,我们记录了训练集和测试集的分类准确率。 我们观察到的总体趋势是,由等变电路构建的不变模型在训练集上达到相同或更低的准确率,但在测试集上始终保持更高的准确率,这表明它们具有更好的泛化能力。
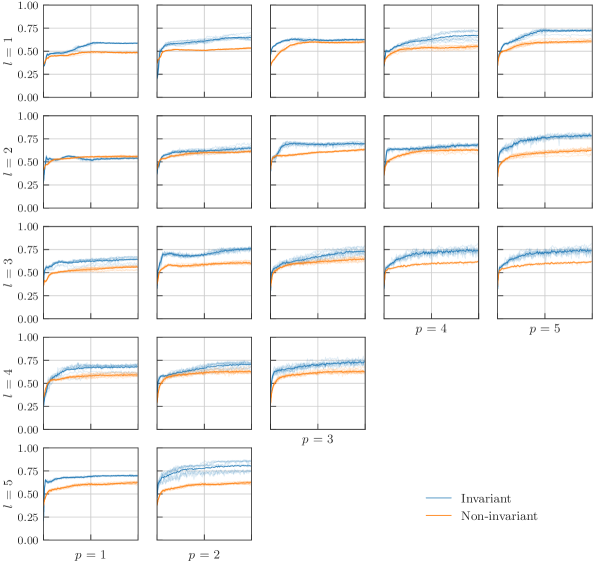
我们首先验证了不同大小的电路是否也是这种情况。 图 4 比较了由 层组成的不变模型和非不变模型的结果,其中每一层都包含一个数据编码,之后是 次独立重复布局 “cemoid”。 我们用对 来指代不同的架构,并且我们在范围 上进行扫描。 由于计算资源有限,我们无法记录值 的结果。 在这个实验中,参数化的纠缠门被选为 ,但使用不同的受控泡利旋转进行类似的实验会产生可比的结果。
训练集上准确率的差异不应显得奇怪,因为不变模型只表达了非不变模型的输出映射的一个子集。 对于非不变模型,高训练精度和低测试精度是过度拟合状态的明显标志。 相反,对于不变模型,我们看到通过降低表达能力付出的代价在之前见过和从未见过的数据上都获得了非常相似的性能,这暗示了偏差-方差权衡的最佳点。 正式地说,我们说不变模型的经验泛化差距远小于非不变模型的泛化差距,这证实了我们的预期。
为了进行健全性检查,并确保我们没有挑选一个可行的例子,我们研究了其他与 “cemoid” 不同的变分布局的性能。 我们通过将层数固定为 来做到这一点,其中在使用 “t” 对数据进行编码后,我们对 “cemoid” 进行三个连续的随机排列,而没有连续重复。 这种布局的一个例子是 “tdomiececiodmdmoiec”,然后我们将它重复三次。 总共生成了和模拟了 20 种不同的布局。 图 5 中的结果摘要表明,除了少数例外,不变模型的测试性能在不同的层布局中始终更高。 这证实了我们的预期,即使学习模型不变有助于或多或少地通用地提高泛化性能。
对自动驾驶场景进行分类
井字棋任务提供了一个直观的例子,说明了我们如何利用学习中的对称性,但它并没有与相关的现实世界学习场景联系起来。 在本节中,我们想要概述如何使用在井字棋示例中开发的直觉,并将其应用于汽车行业中具有实际意义的任务的玩具模型,并展示一种与现实世界场景建立联系的清晰方法。
自动驾驶是汽车行业面向未来的领域,两个主要挑战相互交织。 首先,车辆必须能够识别并自动评估其周围环境,以推断可能实现目标的驾驶操作。 其次,汽车执行的自动评估需要在汽车的开发周期中进行验证和测试。 为了应对这些挑战,基于场景的开发是目前最先进的技术 [46]。 我们将场景定义为场景(周围环境的快照)和动作(目的地目标和值)的串联。 因此,场景是对驾驶情况的具体描述,考虑了由车辆传感器系统、地图数据等确定的动态和静态组件 [47]。 在车辆的开发过程中,根据关键指标对不同的预定义场景进行安全相关性分类。 然后,将使用此分类来评估现场或模拟中测试的要求。 Pegasus 项目 [48] 将场景分为不同的级别。 在本出版物中,我们专注于街道级别 1,其中包括街道的几何形状和拓扑结构,以便展示我们的概念。 驾驶操作分类是使用经典机器学习工具和其他方法进行研究的 [49, 50]。 我们再次要强调,为了本文的目的,原始分类任务简化为一个简单的版本,可以通过我们可用的计算资源进行模拟。 但是,当量子计算硬件方面更大的资源可用时,我们如何能够解决实际问题的一部分,这一点是显而易见的。
数据集
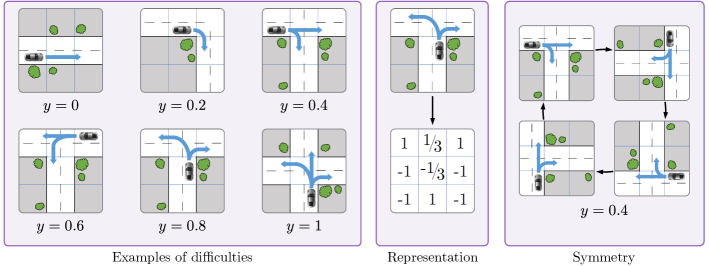
接下来,我们在不同的街道交叉路口推导出驾驶场景,推导出几何对称性,并根据其安全相关性对可能的操作进行分类。 由于相关的场景包括交叉路口、环岛和交通堵塞处的行为 [51],我们使用 网格来考虑以下简化的街道情况。 此网格的每个方块可以是道路的一部分,也可以是无法通行的,一辆汽车被放置在道路方块上。 通过这种编码,我们可以从直线道路到更复杂的交叉路口表示不同的几何形状。 这些场景的对称性是井字棋案例的一个子集,因为场景总是可以旋转 90°(参见图 6 的右面板),但并非在所有情况下都必须镜像,因为左转的难度与右转不同。 我们将其转换为 数组 ,其中道路方块用 1 编码,无法通行的方块用 -1 编码,汽车用 -1/3 编码,汽车的方向用 1/3 编码。 图 6 的中间面板显示了一个示例。
我们根据简化的临界指标评估难度级别 ,如下:前进:0;右转或左转弯:0.2;前进和右转(T 型交叉路口,三条街道的交叉路口):0.4;前进和左转(T 型交叉路口,三条街道的交叉路口):0.6;左转和右转(T 型交叉路口,三条街道的交叉路口):0.8;前进、左转和右转(X 型交叉路口,四条街道的交叉路口):1。 图 6 的左面板显示了可能难度的示例,以及数据编码的表示和对称性的演示。
不同的场景 是通过首先手动放置各种道路布局(T 型交叉路口、左转弯、X 型交叉路口…),生成它们在旋转和反射下的所有图像,然后将汽车放在所有可能的道路方块上生成的。 此外,还会遍历放置汽车的每个可能的方向。 此过程创建了所有可能的场景及其相关的难度级别 。
至于井字棋游戏,训练集和测试集是通过随机选择一个场景子集构建的,条件是每个难度级别都有相同的表示。
学习模型
通用电路构建与井字棋案例基本相同,并遵循第几节中描述的数据重新上传模型。 I 和 II. 表示场景的不同数值通过对单独的量子比特进行 Pauli-X 旋转来编码,其中旋转角度由阵列值的倍数 给出,如井字游戏的情况。 与井字游戏的主要区别在于缺少镜像对称性,这使得实际对称群变为 而不是 。 这只影响外层 (o) 并将其分成两个不同的子层:一个在其中执行具有共享参数的顺时针控制操作,另一个在其中执行具有共享参数的逆时针控制操作。
与井字游戏一样,所有量子比特都初始化为 状态,并应用数据编码层和参数化门层。 参数化块的默认拓扑再次选择为 “cemoid”,其中理解外层 (o) 分成两个子层,如上所述。 模型对难度的预测 是通过测量和归一化中间量子比特 的 Pauli-Z 期望值获得的。
| (88) |
给定场景的难度预测 是通过将 四舍五入到 中最近的难度得到的。
训练
学习模型使用 损失函数进行训练,该损失函数对于一组游戏 是由
| (89) |
本例中未使用 epoch,优化运行 30 步。 在每一步中,都计算了相同 60 个场景的梯度。 由于 的有限网格大小仅允许四个难度为 1 的 [X-Crossing] 场景,因此创建了随机副本以确保均匀分布(每种难度 10 场比赛)。 在每一步之后,通过计算正确分类输入的比例来评估训练数据和测试数据的准确性,测试数据包含 130 个独特的游戏。 以上超参数同样是根据经验选择的。 数值实验是使用 PennyLane 库 [44] 执行的。 对于双量子位门,只有 门被实现。 所有优化都是使用 PyTorch L-BFGS-优化器执行的 [45]。
结果
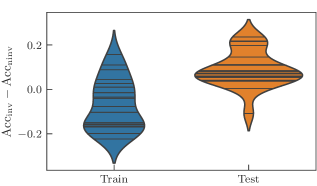
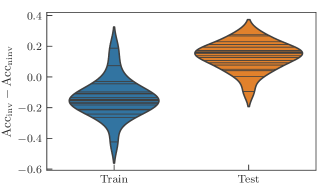
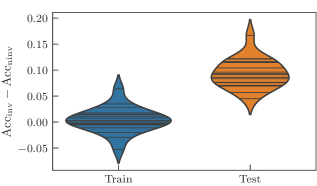
我们重复了为井字棋学习任务设计的实验,现在使用这个不同的数据集。 正如预期的那样,我们观察到相同的总体趋势。 我们再次强调,我们比较的是一个不变模型和从不变模型中得到的非不变模型,其中图 3 中指示的参数共享没有被强制执行。 因此,非不变模型具有更多独立参数,因此表达能力更强。 为了评估模型的性能,我们记录了训练集和测试集的分类精度。
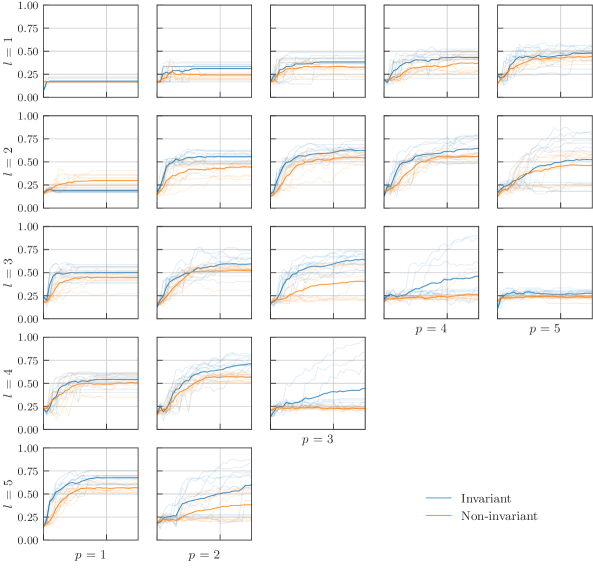
我们再次研究学习模型架构的不同超参数。 回想一下,我们使用 层,这些层由数据编码后跟 次重复原子 “cemoid” 组成。 我们遍历范围 ,除了值 和 。 正如在图 7 中看到的那样,大多数不变学习模型在训练集上的表现比非不变模型差,而在测试集上的表现更好。 一个简单的解释是不同模型在偏差-方差权衡中的位置:非不变模型的过拟合状态,不变模型的最佳点。 附录中图 15 中的完整数据进一步支持了这种直觉,因为它显示了高 值的精度下降,其中经验发现两个模型的表达能力对于此任务来说太高。 该实验概括了以下说法:不变模型比非不变模型泛化能力更强。
我们还重复了对可训练部分的特定拼写进行的随机化实验,结果报告在图 8 中。 我们制作了重复 次的随机层的电路。 随机层以数据编码开头,然后是 “cemoid” 的三个连续随机排列,这样相邻的字母不会重复。 同样,在几乎所有情况下,不变模型都超过了非不变模型。
变分量子特征求解器
本文提出的门对称化程序只需要在希尔伯特空间级别存在酉对称表示。 因此,它也可以应用于哈密顿量守恒量产生对称表示的基态问题。 此情况通过使用变分量子特征求解器的变分算法典型地进行处理。 下面,我们将进行一些数值实验,展示通用对称化在这种情况下带来的优势和劣势。
横场伊辛模型
我们将首先考虑 横场伊辛模型 (TFIM) [52] 作为典型示例。 在 个自旋上具有周期性边界条件的 TFIM 哈密顿量由下式给出
| (90) |
其中我们考虑了横场强度 。
TFIM 哈密顿量具有 对称性,因为它与奇偶校验算子对易
| (91) |
然后酉表示由 给出,其中 。 奇偶校验算子的特征值为 或 。 对于 ,基态由 给出,其奇偶校验为 。 使用 绝热定理 以及有限系统尺寸的基态能量不简并的事实,我们可以得出结论,基态的奇偶校验对于每个 都是相同的。 因此,如果我们想强制我们的拟设状态来编码这种对称性,我们要求
| (92) |
当然,对于所有参数值,我们的拟设状态不必遵守此属性,只要它能找到正确的基态,但在许多情况下,将拟设状态的表现力限制在希尔伯特空间的相关部分可能是有益的。 但是,如果我们这样做,我们必须确保拟设状态确实产生一个与真实基态处于相同对称性扇区的状态。 这可以通过采用具有正确对称性的初始状态,例如 ,然后仅执行可以从第 III 节的对称化程序获得的等变门来确保。 我们再次注意到,必须注意对称化必须谨慎执行,因为它会使某些生成元变得平凡。
在我们的数值实验中,我们使用 QAOA ansatz [53],可以很容易地看出它关于奇偶校验对称性是等变的,
| (93) | ||||
这里, 是 QAOA 层数。 我们将其与 QAOA ansatz 的一个变体进行比较,我们将其表示为 QAOA’。在这个变体中,我们添加了一个额外的混合项,其中包含 Pauli- 旋转,增加了表达能力,因为
| (94) | ||||
由于 ,第 III 节的门的对称化过程将移除这些 Pauli- 旋转,并将产生标准的 QAOA ansatz,该 ansatz 已被广泛研究,并且已显示 [54, 55, 56, 57, 56] 当 时,可以为 TFIM 提供一个忠实的基态近似,而对于 ,QAOA ansatz 只能达到一个高于基态能量的变分能量 [55],这是由于光锥论证 [54]。 在我们的实验中也可以观察到这种行为。
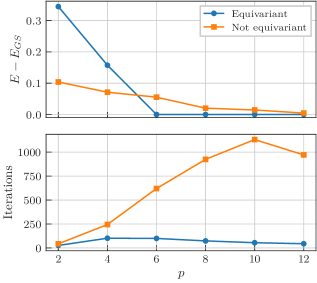
我们使用 自旋和不同 QAOA 层数 值的 TFIM 比较两种 ansatz 的性能。我们使用 L-BFGS 优化器进行优化,直到达到收敛。 我们对电路参数的 20 个随机初始化执行优化,并对结果进行平均,得到图 9 中显示的统计数据。 对于所有 值,QAOA ansatz 需要更少的迭代次数才能收敛。 对于较小的 ,我们观察到 QAOA ansatz 并没有收敛到基态的良好近似,这与上述先前发现一致。 在这种情况下,它被非等变 ansatz 优于,突出了表达能力和等变性之间的权衡。 如果电路深度 足够大,则情况就会逆转,等变 QAOA ansatz 可靠地达到基态,而非等变 QAOA’ ansatz 平均收敛到高于基态的能量。
海森堡模型
另一个具有连续对称群的模型由海森堡模型[52]给出,该模型在偶数个自旋上具有周期性边界条件,由哈密顿量捕获
| (95) |
我们可以理解这个哈密顿量为两个相邻自旋的对齐。 非常合乎逻辑的是,如果我们同时旋转所有自旋,相对对齐将不会改变。 因此,模型的对称群由
| (96) |
与之前的例子一样,我们在量子计算机中初始化一个处于正确对称扇区的状态,在海森堡模型的情况下,这个状态由所有总自旋为零的状态给出,我们选择
| (97) |
对于海森堡模型,我们从非等变的 ansatz 开始
| (98) | ||||
其中是在偶数格点上定义的各向异性海森堡哈密顿量, 即 ,
| (99) | ||||
哈密顿量类似地定义,但作用于奇数格点。 对于偶数和奇数哈密顿量,我们每个都有三个参数,加上控制泡利-旋转的参数,我们每层有七个参数,总共产生个参数。 我们注意到,由于和都是可交换算子的线性组合,我们可以使用双量子门分解相应的酉算子。
上述 ansatz 不是等变的,这意味着我们需要应用对称化过程。 对称化过程对应于 2-设计 twirl 的一个特定实例
| (100) | ||||
| (101) |
这些计算可以使用 Weingarten 微积分直接进行(参见,例如 ,参考文献[58])。 对我们来说重要的是,任何 2-设计 twirl 的结果将是恒等式和 SWAP 的总和,
| (102) | ||||
| (103) |
其中我们使用了 SWAP 扩展到泡利词。 注意,恒等项只生成全局相位,这意味着与相关的有效对称化生成器可以取为
| (104) |
该生成器产生了粒子数守恒的Givens 旋转[59]。 额外的 Pauli- 旋转则通过对称化过程变得微不足道。
| (105) |
其中,我们利用了与一阶矩算子相关的公式[60]。
同样的论据也适用于其他项,这将产生等变假设
| (106) | ||||
其中,我们选择 和 为由 给出的各向同性变体。 我们通过对称化过程获得的等变假设与文献中使用的哈密顿变分假设 具有相同的形式。 [57, 55]。 注意,等变假设总共具有 个参数,相比之下,非对称假设具有 个参数。
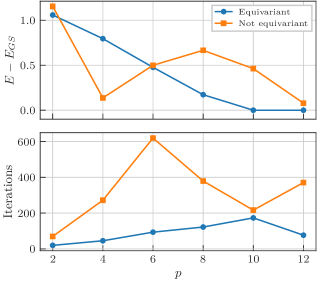
我们使用具有 个自旋和不同层数 的海森堡模型,比较了两种假设的性能。 与 TFIM 数值计算一样,我们使用 L-BFGS 优化器进行优化,直到收敛,并将结果平均超过电路参数的 20 个随机初始化,以得出图 10 中所示的数据。
我们看到,等变假设在所有深度上都更快地达到了最小能量。 然而,只有当深度 足够大时,它才能在能量期望值方面优于非等变假设。 这很好地展示了表达能力和对称化之间的权衡,因为对于小的 ,非等变试探法的增加的表达能力优于对称化试探法的等变性。 然而,一旦等变试探法变得足够具有表达能力,情况就会逆转。
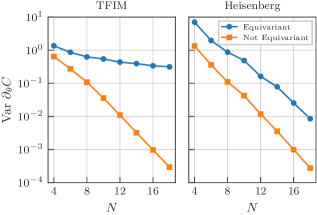
贫瘠高原
在另一个使用与上面相同设置(TFIM 和海森堡模型)的数值实验中,我们分析了对称化过程对贫瘠高原现象的影响 [61, 62]。 对称化通过减少自由参数的数量来降低试探法的表达能力,并另外改变与试探法生成器相关的动态李代数,这已知与贫瘠高原密切相关 [63]。 因此,我们预计等变试探法在本文研究的应用中将具有更大的梯度。 在图 11 中,我们确实可以观察到对称化过程缓解了贫瘠高原现象。 对于横场伊辛模型,等变试探法的梯度衰减与文献中发现的动态李代数降维预测的多项式缩放一致。 [63],而非等变试探法显示出指数衰减。 在海森堡模型的情况下,等变试探法显示出与非等变对应物相同的指数衰减,但梯度幅度增强,我们看到衰减指数略微减慢的迹象。
井字棋 LTFIM
我们分析的最后一个模型是 纵向-横向场伊辛模型 (LTFIM) 的一个变体,该模型定义在一个具有九个格点的二维格子上。 该模型的构建使得它具有与我们上面遇到的井字棋示例相同的几何对称性。 我们可以将哈密顿量写成
| (107) |
其中 决定了自旋的相互作用。 如图 12 所示,我们通过相互作用强度区分了三类边:格子的轮廓 (图中的三条线)、对角线 (单线) 和内部 (双线)。
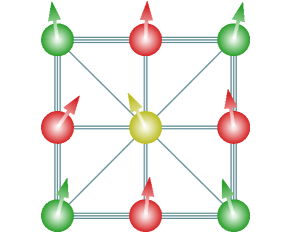
因此,我们选择 为
| (108) |
其中每一项都是给定边集的 相互作用的总和
| (109) |
该模型具有明显的几何对称性,这些对称性与我们在井字棋学习任务中使用的对称性相同。 在图 12 中,我们用相同的颜色表示在对称变换下等效的量子比特。 注意,我们有三个独立的量子比特族和边族。
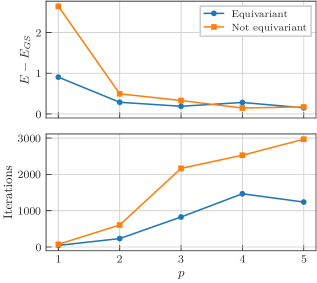
对于该模型,我们使用一个 ansatz,它由 个重复的层组成,每个层都包含图 12 中每条边的纠缠 旋转、每个量子比特上的 Pauli- 和 Pauli- 旋转。 对称化过程将强制执行纠缠门的等效类边缘的门参数相同,以及单量子比特门的等效类自旋的门参数相同。 因此,在非对称情况下,我们总共有 个自由参数,而在对称情况下,我们将自由参数减少到 个。 不变状态向量 用作初始状态。
我们以类似于先前模型的方式对两种 Ansatz 的性能进行了数值测试,如 图 13 所示。 我们可以得出结论,在这个模型中,等变 Ansatz 在平均性能上优于非等变 Ansatz,无论是在实现的能量上,还是在我们测试的电路深度所需的迭代次数上。 然而,我们观察到,对于较大的层,等变 Ansatz 实现的能量有所上升,这可能表明这种优势对于增加电路深度并不稳定。 这强调了一个事实,即通常预期对称化是有帮助的,但它仍然是一个需要谨慎对待的工具,因为它不是万能药。
讨论
在上面展示的示例中,我们检查了不同的性能指标,例如最终能量、优化器所需的迭代次数和贫瘠高原,以查看使用等变 Ansatz 是否可以产生更好的性能。 我们验证了,在某些情况下,它确实可以,特别是在达到解决方案所需的迭代次数方面。 我们将其归因于模型自由参数数量的减少,这简化了底层的优化问题。 然而,当查看可实现的最小能量时,情况就不那么明朗了。 在我们的数值计算中,我们观察到了 Ansatz 等变性方面的增益与表达能力降低之间的权衡。 尤其是在较小的电路深度情况下,使用非等变的Ansatz可以探索希尔伯特空间的更大部分,而当电路深度较大时,将表达能力限制在希尔伯特空间的相关子空间可以有所帮助。
这进一步促使了在等变Ansatz结合精心设计的对称性破坏,特别是在较小的电路深度情况下,正如参考文献 [23] 中所探索的那样。 参考文献 [64] 为这种推理提供了一个理论基础,其中表明保持奇偶校验对称性的Ansatz,如具有浅层电路的QAOA,可能成为制备某些哈密顿量基态的障碍。 因此,必须进一步阐明在基态制备问题中,等变Ansatz何时可以带来更好的性能。
VI 总结和展望
在这项工作中,我们为构建变分量子学习模型奠定了基础,这些模型可以对数据的对称性变换进行预测。 我们已经表明,将数据嵌入到量子系统的希尔伯特空间中起着至关重要的作用,并且必须适当地选择嵌入,以便在希尔伯特空间级别上诱导出数据的对称性的有意义的酉表示。 我们提供了一些嵌入,可以实现对当代学习场景中遇到的最重要的对称性的嵌入,即排列类型对称性,以及诱导出正交空间变换的李群 的有意义表示的嵌入。
使用了对称性的酉表示,我们展示了如何使用表示理论的基本结果从用于构建变分量子学习模型的标准门集构建等变门集。 利用这些门集,就可以构建不变的重新上传模型:交替地应用等变数据嵌入层和等变可训练块到对称不变的初始状态,在对称不变的可观测量上进行评估时,可以得到不变的预测。 通过这种方式,我们为构建不变的变分量子机器学习模型提供了蓝图和工具。 此外,使用等变门集是构建量子学习模型的必要基础,这可以帮助我们决定如何构建量子学习模型,这是解决量子模型选择问题的首要步骤。 为了提高这些工具的适用性,我们还概述了使用这些工具时应避免的陷阱。
我们在井字棋玩具示例和自动驾驶玩具问题上进行的数值实验证实了我们的预期,即不变的学习模型确实具有更好的泛化能力,因为它们的表达能力被限制在一组输出函数中,这些函数包含有关底层数据的某些知识。 我们还确保没有通过比较随机的不变模型架构与其非不变的对应物来挑选结果,在这些对应物中我们观察到了相同的结果。
由于存在一个统一的对称性表示足以构建等变门集,因此它们也可以应用于变分量子机器学习领域之外的问题。 我们通过比较等变和非等变 Ansatz 电路来探索这种可能性,用于基态类型问题,其中哈密顿量的守恒量导致对称性。 我们对横场伊辛模型、海森堡模型和具有几何对称性的纵向横场伊辛模型变体的分析使我们得出结论,等变 Ansatz 在这种应用中也可能有所帮助。 它们通常允许在更少的迭代次数内获得更好的能量估计,并有助于缓解贫瘠高原问题。 然而,情况并不像我们在学习场景中讨论的那么清晰。
我们研究了等变量子嵌入问题,针对 的情况。 但没有根本的原因可以说明为什么构成数据对称性的其他李群不应同样适合等变量子嵌入。 虽然从现实世界学习任务的角度来看,这有点奇特,但我们预计,未来对量子系统李代数中的数据嵌入与希尔伯特空间层面上对称性的酉表示之间相互作用的研究将使我们能够了解更多关于变分量子学习模型的内部机制。
未来研究的另一个有趣方向是证明有关不变量子机器学习模型泛化能力的严格结果,目标是找到关于利用特定对称性如何帮助更好地解决当前学习任务的定量表达式。 还要注意,我们只对最多九个量子比特的学习问题进行了数值实验,因为我们的计算资源有限。 未来,将不变变分量子学习模型与经典模型在更现实的学习任务上进行比较将很有趣。
最后,我们希望这项工作能激发更多研究努力,旨在在量子机器学习及其他领域中利用变分量子算法中的对称性。
致谢
作者感谢 Hakop Pashayan 和 Regina Kirschner 的有见地的讨论,以及 Matthias Caro、Simon Marshall、Sergi Masot、Franz Schreiber、Adrián Pérez-Salinas 和 Andrea Skolik 对本文早期版本的宝贵评论。 F. A. 感谢亚历山大·冯·洪堡基金会的支持。 我们感谢 BMBF(混合)、BMWK(PlanQK)、QuantERA(HQCC)、慕尼黑量子谷(K8)和爱因斯坦基金会(量子器件爱因斯坦研究单元)的支持。 我们也感谢保时捷数字技术有限公司。
作者贡献
J. J. M. 构思并指导了该项目。 J. J. M. E. G. F. 和 F. A. 共同开发了等变嵌入和门对称化理论。 M. M. 和 F. A. 基于 F. A.、M. M.、A. W. 和 A. A. M. 的想法进行了量子机器学习实验。 构思并进行了基态搜索实验。 A. W. 和 J. E. 为研究和开发提供了支持。 在 J. J. M. 的带领下,所有作者都参与了手稿的撰写。
数据可用性
本文中所进行的数值实验的代码和数据将在合理的要求下提供。
附注
在本文稿定稿期间,Ref. [65] 已发表,该文章与我们的工作在概念上存在重叠,特别是在不变模型和等变模型的定义方面。 但是,Ref. 的作者 [65] 考虑了不同的设置,其中学习是在量子态而不是经典数据上进行的,并且专注于二元分类。 我们的工作讨论了在处理经典数据对称性时,如何在量子系统的层面上产生对称性,以及如何利用这些对称性构建不变学习模型。 由于我们的技术也可以很容易地应用于 Ref 的设置。 [65],我们提供了一种构建等变架构的方法,作为他们工作中未来的方向。
参考文献
- Arute et al. [2019] F. Arute et al., Nature 574, 505 (2019).
- Wu et al. [2021] Y. Wu, W.-S. Bao, S. Cao, F. Chen, M.-C. Chen, X. Chen, T.-H. Chung, H. Deng, Y. Du, D. Fan, et al., Phys. Rev. Lett. 127, 180501 (2021).
- Preskill [2018] J. Preskill, Quantum 2, 79 (2018).
- McClean et al. [2016] J. R. McClean, J. Romero, R. Babbush, and A. Aspuru-Guzik, New J. Phys. 18, 023023 (2016).
- Cerezo et al. [2021] M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincio, et al., Nature Reviews Physics 3, 625 (2021).
- Bharti et al. [2022] K. Bharti, A. Cervera-Lierta, T. H. Kyaw, T. Haug, S. Alperin-Lea, A. Anand, M. Degroote, H. Heimonen, J. S. Kottmann, T. Menke, et al., Rev. Mod. Phys. 94, 015004 (2022).
- LeCun et al. [1989] Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel, Neural Computation 1, 541 (1989).
- Vaswani et al. [2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, in Advances in Neural Information Processing Systems (Curran Associates, Inc., 2017), vol. 30.
- Bronstein et al. [2021] M. M. Bronstein, J. Bruna, T. Cohen, and P. Veličković, Geometric deep learning: Grids, groups, graphs, geodesics, and gauges (2021), arXiv:2104.13478.
- Liu et al. [2019] J.-G. Liu, Y.-H. Zhang, Y. Wan, and L. Wang, Phys. Rev. Res. 1, 023025 (2019).
- Gard et al. [2020] B. R. T. Gard, L. Zhu, G. S. Barron, N. J. Mayhall, S. E. Economou, and E. Barnes, npj Quant. Inf. 6, 1 (2020).
- Setia et al. [2020] K. Setia, R. Chen, J. E. Rice, A. Mezzacapo, M. Pistoia, and J. D. Whitfield, J. Chem. Th. Comp. 16, 6091 (2020).
- Anselmetti et al. [2021] G.-L. R. Anselmetti, D. Wierichs, C. Gogolin, and R. M. Parrish, New J. Phys. 23, 113010 (2021).
- Arrazola et al. [2021a] J. M. Arrazola, O. Di Matteo, N. Quesada, S. Jahangiri, A. Delgado, and N. Killoran, Universal quantum circuits for quantum chemistry (2021a).
- Vogt et al. [2021] N. Vogt, S. Zanker, J.-M. Reiner, M. Marthaler, T. Eckl, and A. Marusczyk, Quant. Sc. Tech. 6, 035003 (2021).
- Zhang et al. [2021] F. Zhang, N. Gomes, N. F. Berthusen, P. P. Orth, C.-Z. Wang, K.-M. Ho, and Y.-X. Yao, Phys. Rev. Res. 3, 013039 (2021).
- Barron et al. [2021] G. S. Barron, B. R. T. Gard, O. J. Altman, N. J. Mayhall, E. Barnes, and S. E. Economou, Phys. Rev. App. 16, 034003 (2021).
- Seki et al. [2020] K. Seki, T. Shirakawa, and S. Yunoki, Phys. Rev. A 101, 052340 (2020).
- Seki and Yunoki [2022] K. Seki and S. Yunoki, Phys. Rev. A 105, 032419 (2022).
- Herasymenko and O’Brien [2021] Y. Herasymenko and T. E. O’Brien, Quantum 5, 596 (2021).
- Selvarajan et al. [2022] R. Selvarajan, M. Sajjan, and S. Kais, Symmetry 14, 457 (2022).
- Lyu et al. [2022] C. Lyu, X. Xu, M.-H. Yung, and A. Bayat, Symmetry enhanced variational quantum eigensolver (2022), arXiv:2203.02444.
- Park [2021] C.-Y. Park, Efficient ground state preparation in variational quantum eigensolver with symmetry breaking layers (2021), arXiv:2106.02509.
- Bookatz et al. [2015] A. D. Bookatz, E. Farhi, and L. Zhou, Phys. Rev. A 92, 022317 (2015).
- Ryabinkin and Genin [2018] I. G. Ryabinkin and S. N. Genin, Symmetry adaptation in quantum chemistry calculations on a quantum computer (2018), arXiv:1812.09812.
- Kuroiwa and Nakagawa [2021] K. Kuroiwa and Y. O. Nakagawa, Phys. Rev. Res. 3, 013197 (2021).
- Mernyei et al. [2021] P. Mernyei, K. Meichanetzidis, and İ. İ. Ceylan, Equivariant quantum graph circuits (2021), arXiv:2112.05261.
- Verdon et al. [2019] G. Verdon, T. McCourt, E. Luzhnica, V. Singh, S. Leichenauer, and J. Hidary, Quantum graph neural networks (2019), arXiv:1909.12264.
- Zheng et al. [2021] H. Zheng, Z. Li, J. Liu, S. Strelchuk, and R. Kondor (2021), arXiv:2112.07611.
- Glick et al. [2021] J. R. Glick, T. P. Gujarati, A. D. Corcoles, Y. Kim, A. Kandala, J. M. Gambetta, and K. Temme, Covariant quantum kernels for data with group structure (2021), arXiv:2105.03406.
- Mitarai et al. [2018] K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, Phys. Rev. A 98, 032309 (2018).
- Benedetti et al. [2019] M. Benedetti, E. Lloyd, S. Sack, and M. Fiorentini, Quant. Sc. Tech. 4, 043001 (2019).
- Schuld et al. [2020] M. Schuld, A. Bocharov, K. M. Svore, and N. Wiebe, Phys. Rev. A 101, 032308 (2020).
- Pérez-Salinas et al. [2020] A. Pérez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, Quantum 4, 226 (2020).
- Schuld et al. [2021] M. Schuld, R. Sweke, and J. J. Meyer, Phys. Rev. A 103, 032430 (2021).
- Jerbi et al. [2021] S. Jerbi, L. J. Fiderer, H. P. Nautrup, J. M. Kübler, H. J. Briegel, and V. Dunjko, Quantum machine learning beyond kernel methods (2021), arXiv:2110.13162.
- Peruzzo et al. [2014] A. Peruzzo, J. McClean, P. Shadbolt, M.-H. Yung, X.-Q. Zhou, P. J. Love, A. Aspuru-Guzik, and J. L. O’Brien, Nature Comm. 5, 4213 (2014).
- Aaronson and Gottesman [2004] S. Aaronson and D. Gottesman, Phys. Rev. A 70, 052328 (2004).
- Havlíček et al. [2019] V. Havlíček, A. D. Córcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, Nature 567, 209 (2019).
- Folland [2016] G. B. Folland, A course in abstract harmonic analysis (Chapman and Hall/CRC, 2016), 0th ed.
- Helsen [2021] J. Helsen, Quantum information in the real world: Diagnosing and correcting errors in practical quantum devices (2021), PhD thesis, URL http://resolver.tudelft.nl/uuid:312b719d-32bc-4219-82bb-8e6febc2abcc.
- Oszmaniec and Zimborás [2017] M. Oszmaniec and Z. Zimborás, Phys. Rev. Lett. 119, 220502 (2017).
- Yen et al. [2019] T.-C. Yen, R. A. Lang, and A. F. Izmaylov, J. Chem. Phys. 151, 164111 (2019).
- Bergholm et al. [2020] V. Bergholm, J. Izaac, M. Schuld, C. Gogolin, M. S. Alam, S. Ahmed, J. M. Arrazola, C. Blank, A. Delgado, S. Jahangiri, et al. (2020), arXiv:1811.04968.
- Paszke et al. [2019] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, et al., in Advances in Neural Information Processing Systems 32, edited by H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett (Curran Associates, Inc., 2019), pp. 8024–8035.
- Menzel et al. [2018] T. Menzel, G. Bagschik, and M. Maurer, Scenarios for development, test and validation of automated vehicles (2018), arXiv:1801.08598.
- Geyer et al. [2014] S. Geyer, M. Baltzer, B. Franz, S. Hakuli, M. Kauer, M. Kienle, S. Kwee-Meier, T. Weigerber, K. Bengler, R. Bruder, et al., Intelligent Transport Systems, IET 8, 183 (2014).
- Steimle et al. [2021] M. Steimle, T. Menzel, and M. Maurer, IEEE Access 9, 147828 (2021).
- Sonka et al. [2017] A. Sonka, F. Krauns, R. Henze, F. Küçükay, R. Katz, and U. Lages, in 2017 IEEE Intelligent Vehicles Symposium (IV) (2017), pp. 97–102.
- Xie et al. [2018] J. Xie, A. R. Hilal, and D. Kulić, IEEE Sen. J. 18, 4777 (2018).
- Schwab [2019-05-10] A. Schwab (2019-05-10), Eine Methode zur Auswahl kritischer Fahrszenarien für automatisierte Fahrzeuge anhand einer objektiven Charakterisierung des Fahrverhaltens, URL https://mediatum.ub.tum.de/doc/1518844/1518844.pdf.
- Franchini [2017] F. Franchini, An introduction to integrable techniques for one-dimensional quantum systems (Springer International Publishing, 2017).
- Farhi et al. [2014] E. Farhi, J. Goldstone, and S. Gutmann, A quantum approximate optimization algorithm (2014), arXiv:1411.4028.
- Mbeng et al. [2019] G. B. Mbeng, R. Fazio, and G. Santoro, Quantum annealing: a journey through digitalization, control, and hybrid quantum variational schemes (2019), arXiv:1906.08948.
- Ho and Hsieh [2019] W. W. Ho and T. H. Hsieh, SciPost Phys. 6, 029 (2019).
- Wierichs et al. [2020] D. Wierichs, C. Gogolin, and M. Kastoryano, Phys. Rev. Res. 2, 043246 (2020).
- Wiersema et al. [2020] R. Wiersema, C. Zhou, Y. de Sereville, J. F. Carrasquilla, Y. B. Kim, and H. Yuen, PRX Quantum 1, 020319 (2020).
- Puchała and Miszczak [2017] Z. Puchała and J. Miszczak, Bulletin of the Polish Academy of Sciences Technical Sciences 65, 21 (2017).
- Arrazola et al. [2021b] J. M. Arrazola, O. Di Matteo, N. Quesada, S. Jahangiri, A. Delgado, and N. Killoran, Universal quantum circuits for quantum chemistry (2021b), arXiv:2106.13839.
- Kliesch and Roth [2021] M. Kliesch and I. Roth, PRX Quantum 2, 010201 (2021).
- Holmes et al. [2022] Z. Holmes, K. Sharma, M. Cerezo, and P. J. Coles, PRX Quantum 3, 010313 (2022).
- McClean et al. [2018] J. R. McClean, S. Boixo, V. N. Smelyanskiy, R. Babbush, and H. Neven, Nature Comm. 9, 4812 (2018).
- Larocca et al. [2021] M. Larocca, P. Czarnik, K. Sharma, G. Muraleedharan, P. J. Coles, and M. Cerezo, Diagnosing barren plateaus with tools from quantum optimal control (2021).
- Bravyi et al. [2020] S. Bravyi, A. Kliesch, K. R, and E. Tang, Phys. Rev. Lett. 125, 260505 (2020).
- Larocca et al. [2022] M. Larocca, F. Sauvage, F. M. Sbahi, G. Verdon, P. J. Coles, and M. Cerezo, Group-invariant quantum machine learning (2022), arXiv:2205.02261.
附录 A 其他图