使用扩散进行灵活行为合成
摘要
基于模型的强化学习方法通常只使用学习来估计近似动力学模型,将其余的决策工作卸载到经典的轨迹优化器。 虽然概念上很简单,但这种组合在经验上存在一些缺陷,表明学习到的模型可能不适合标准的轨迹优化。 在本文中,我们考虑将尽可能多的轨迹优化管道折叠到建模问题中,这样从模型中采样和使用它进行规划就变得几乎相同。 我们技术方法的核心在于一个扩散概率模型,它通过迭代去噪轨迹来进行规划。 我们展示了如何将分类器引导采样和图像修复重新解释为一致的规划策略,探索了基于扩散的规划方法的非凡且有用的特性,并在强调长范围决策和测试时灵活性的控制设置中证明了我们框架的有效性。
1 引言
使用学习到的模型进行规划是强化学习和数据驱动决策的简单框架。 它的吸引力在于仅在最成熟和最有效的领域使用学习技术:为了近似未知的环境动力学,这相当于一个监督学习问题。 之后,可以将学习到的模型插入经典的轨迹优化例程 (Tassa 等人,2012; Posa 等人,2014; Kelly,2017), 这些例程在它们最初的背景中同样是广为人知的。
但是,这种组合很少能像描述的那样起作用。 因为强大的轨迹优化器利用了学习到的模型,所以通过这种程序生成的计划通常看起来更像是对抗样本,而不是最优轨迹 (Talvitie, 2014; Ke et al., 2018)。 因此,当代基于模型的强化学习算法通常更多地继承了无模型方法,例如价值函数和策略梯度 (Wang et al., 2019),而不是轨迹优化工具箱。 那些依赖于在线规划的方法倾向于使用简单的无梯度轨迹优化例程,例如随机射击 (Nagabandi et al., 2018) 或交叉熵方法 (Botev et al., 2013; Chua et al., 2018),以避免上述问题。 † † 学习到的去噪过程的代码和可视化可以在 diffusion-planning.github.io 上找到。
在这项工作中,我们提出了一种数据驱动轨迹优化的替代方法。 核心思想是训练一个直接适合轨迹优化的模型,从这个意义上说,从模型中采样和用它进行规划变得几乎相同。 这一目标需要改变模型的设计方式。 因为学习到的动力学模型通常被认为是环境动力学的代理,所以通过根据潜在的因果过程结构化模型,通常可以实现改进 (Bapst et al., 2019)。 相反,我们考虑如何根据将要使用它的规划问题来设计模型。 例如,因为模型最终将用于规划,所以动作分布与状态动力学一样重要,长范围精度比单步误差更重要。 另一方面,模型应该对奖励函数保持不可知,以便它可以用于多个任务,包括训练期间未见过的任务。 最后,模型的设计应该使其计划,而不仅仅是预测,随着经验的积累而改进,并且能够抵抗标准基于射击的规划算法的短视性故障模式。
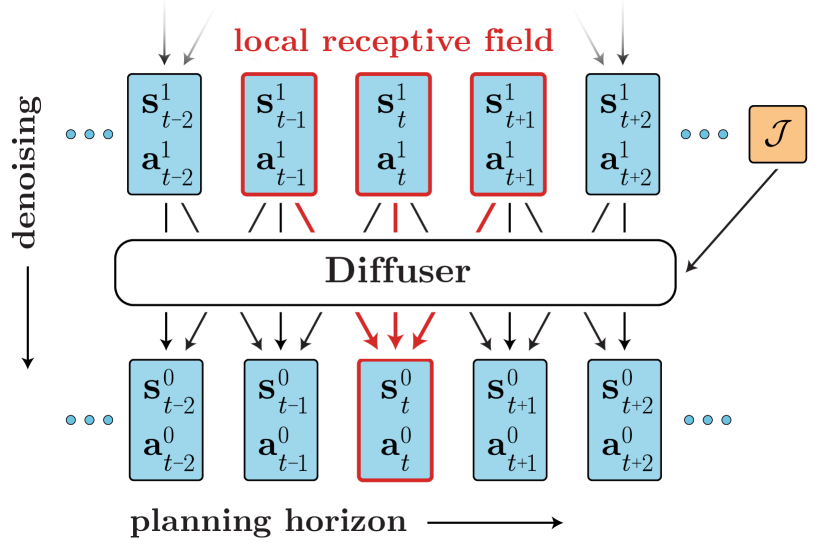
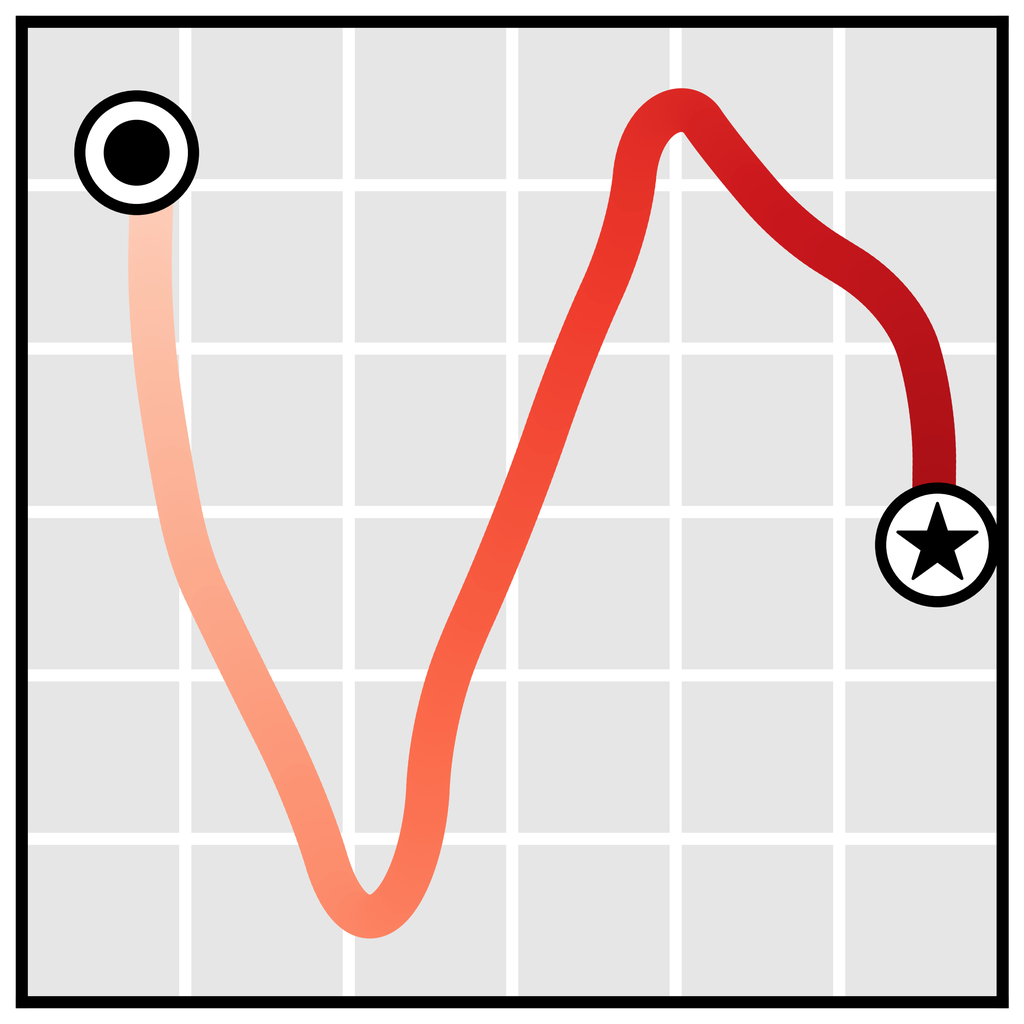
我们将这种想法实例化为一个轨迹级扩散概率模型 (Sohl-Dickstein 等人,2015;Ho 等人,2020),称为 Diffuser,如图 2 所示。 与标准的基于模型的规划技术不同,Diffuser 同时预测计划的所有时间步长,而不是自回归地向前预测。 扩散模型的迭代采样过程导致灵活的条件化,允许辅助引导修改采样过程以恢复具有高回报或满足一组约束的轨迹。 这种数据驱动的轨迹优化的表述具有几个吸引人的特性:
长视界可扩展性 Diffuser 训练的是其生成轨迹的准确性,而不是其单步误差,因此它不会受到单步动力学模型的复合滚动误差的影响,并且在长规划视界方面可以更优雅地扩展。
任务组合性 奖励函数提供辅助梯度,用于在采样计划时使用,这提供了一种简单的方法,通过将多个奖励的梯度加在一起来同时组合多个奖励进行规划。
时间组合性 Diffuser 通过迭代地改进局部一致性来生成全局一致的轨迹,从而允许它通过将分布内子序列拼接在一起来泛化到新的轨迹。
有效的非贪婪规划 通过模糊模型和规划器之间的界限,提高模型预测的训练过程也具有提高其规划能力的效果。 这种设计产生了一个学习的规划器,可以解决许多传统规划方法难以解决的长期、稀疏奖励问题。
这项工作的核心贡献是一个为轨迹数据设计的去噪扩散模型和一个相关的行为合成概率框架。 虽然与深度基于模型的强化学习中常用的模型类型相比非传统,但我们证明了 Diffuser 具有许多有用的特性,并且在需要长视界推理和测试时灵活性的离线控制设置中特别有效。
2 背景
我们对规划的方法是过去使用轨迹优化进行行为合成的学习型模拟 (Witkin & Kass, 1988; Tassa et al., 2012)。 在本节中,我们将简要介绍轨迹优化所考虑的问题设置以及我们用于解决该问题的生成模型类别。
2.1 问题设置
考虑一个由离散时间动力学 控制的系统,该系统在给定动作 时处于状态 。 轨迹优化指的是找到一系列动作 ,这些动作最大化(或最小化)一个目标 ,该目标对每个时间步的奖励(或成本) 进行分解:
其中 是规划范围。 我们使用缩写 来指代交织状态和动作的轨迹,并使用 来表示该轨迹的目标值。
2.2 扩散概率模型
扩散概率模型 (Sohl-Dickstein et al., 2015; Ho et al., 2020) 将数据生成过程定义为一个迭代去噪过程 。 该去噪过程是正向扩散过程 的逆过程,正向扩散过程通过添加噪声来缓慢破坏数据中的结构。 模型诱导的数据分布由下式给出:
其中 是标准高斯先验, 表示(无噪声)数据。 参数 通过最小化逆过程负对数似然的变分界限来优化: 逆过程通常参数化为具有固定时间步依赖协方差的高斯分布:
正向过程 通常是预先指定的。
符号。 这项工作中存在两种“时间”:扩散过程的时间和规划问题的时间。 我们使用上标 ( 当未指定时) 来表示扩散时间步,使用下标 ( 当未指定时) 来表示规划时间步。 例如, 指的是无噪声轨迹中的 状态。 当从上下文中可以明确地判断时,无噪声量的上标将被省略:。 我们通过引用轨迹 中的 状态(或动作)为 (或 )来稍微重载符号。
3 使用扩散进行规划
使用轨迹优化技术的主要障碍是它们需要了解环境动力学 。 大多数基于学习的方法试图通过训练近似动力学模型并将其插入到传统的规划例程中来克服这一障碍。 然而,学习到的模型通常不适合为地面真实模型设计的规划算法类型,导致规划器通过找到对抗性示例来利用学习到的模型。
我们提出了一种更紧密的建模与规划之间的耦合。 与在经典规划器上下文中使用学习到的模型不同,我们将尽可能多的规划过程包含到生成式建模框架中,使得规划几乎等同于采样。 我们使用轨迹的扩散模型 来实现这一点。 扩散模型的迭代去噪过程通过从以下形式的扰动分布中采样,使其本身适合于灵活的条件化:
| (1) |
函数 可以包含关于先验证据(如观察历史)、期望结果(如要达成的目标)或要优化的通用函数(如奖励或成本)的信息。 在这种扰动分布中执行推理可以被视为对第 2.1 节中提出的轨迹优化问题的概率类比,因为它需要找到在 下物理现实且在 下高奖励(或满足约束)的轨迹。 由于动力学信息与扰动分布 分开,因此单个扩散模型 可以重复用于同一环境中的多个任务。
本节介绍 Diffuser,这是一种专为学习到的轨迹优化而设计的扩散模型。 然后,我们讨论了使用 Diffuser 进行规划的两种特定实例,它们是分类器引导采样和图像修复的强化学习对应物。
3.1 轨迹规划的生成式模型
时间顺序。 模糊了从轨迹模型中采样和用它进行规划之间的界限,产生了不寻常的约束:我们不能再按时间顺序自回归地预测状态。 考虑目标条件下的推理 ; 下一个状态 依赖于 未来 状态以及先前的状态。 这个例子是一个更普遍原则的实例: 虽然动力学预测是因果的,因为现在是由过去决定的,但决策和控制可能是反因果的,因为现在的决策是根据未来条件的。 1 11 一般而言,在强化学习的环境中,对未来的条件依赖源于为了编写动态规划递归而假设未来最优。 具体来说,这表现为行动分布中的未来最优变量 (Levine,2018)。 因为我们不能使用时间自回归排序,所以我们设计了 Diffuser 来同时预测计划的所有时间步长。
时间局部性。 尽管不是自回归或马尔可夫的,Diffuser 具有时间局部性的放松形式。 在图 2 中,我们描绘了由单个时间卷积组成的扩散模型的依赖关系图。 给定预测的感受野仅包含附近的时间步长,包括过去和未来。 因此,降噪过程的每一步只能根据轨迹的局部一致性进行预测。 然而,通过将许多这些降噪步骤组合在一起,局部一致性可以驱动全局连贯性。
轨迹表示。 Diffuser 是一个为规划而设计的轨迹模型,这意味着从模型中导出的控制器的有效性与状态预测的质量同等重要。 因此,轨迹中的状态和动作是联合预测的;为了预测目的,动作只是状态的附加维度。 具体来说,我们将 Diffuser 的输入(和输出)表示为一个二维数组:
| (2) |
其中每一列对应计划范围内的每个时间步。
架构 现在我们有了指定 Diffuser 架构所需的要素: (1) 应该非自回归地预测整个轨迹, (2) 降噪过程的每个步骤应该在时间上是局部的,并且 (3) 轨迹表示应该允许在一个维度(计划范围)上保持等变性,但在另一个维度(状态和动作特征)上不保持等变性。 我们通过一个由重复的(时间)卷积残差块组成的模型来满足这些标准。 整体架构类似于在基于图像的扩散模型中取得成功的 U-Net 类型,但将二维空间卷积替换为一维时间卷积(图 A1)。 由于模型是全卷积的,因此预测的范围不是由模型架构决定的,而是由输入维数决定的;如果需要,它可以在规划过程中动态变化。
训练 我们使用 Diffuser 来参数化轨迹降噪过程的学习梯度 ,从中可以以闭式形式求解均值 (Ho 等人,2020)。 我们使用简化的目标来训练 模型,如下所示:
其中 是扩散时间步, 是噪声目标, 是受噪声 污染的轨迹 。 逆过程协方差 遵循 Nichol & Dhariwal (2021) 的余弦调度。
a

去噪
b
数据 计划
c
d
奖励
 计划
计划
 表示起始状态,
表示起始状态,
 表示目标状态。
表示目标状态。
3.2 强化学习作为引导采样
为了用扩散模型解决强化学习问题,我们必须引入奖励的概念。 我们借鉴了控制作为推理的图形模型 (Levine, 2018) 来实现这一点。 令 表示轨迹中时间步 最优性的二元随机变量,其中 。 我们可以通过在公式 1 中设置 来从最优轨迹集中进行采样:
我们已经将强化学习问题转换为 条件采样 问题。 值得庆幸的是,在使用扩散模型进行条件采样方面已经有很多先前的研究工作。 虽然从该分布中精确采样是难以处理的,但当 足够平滑时,反向扩散过程过渡可以近似为高斯分布 (Sohl-Dickstein et al., 2015):
| (3) |
其中 是原始反向过程过渡 的参数,而
3.3 目标条件强化学习作为图像修复
一些规划问题更自然地被表述为约束满足问题而不是奖励最大化问题。 在这些情况下,目标是生成任何满足一组约束的 可行轨迹,例如终止于目标位置。 借鉴方程 2 描述的轨迹二维数组表示,这种设置可以转化为一个 图像修复问题,其中状态和动作约束类似于图像中观察到的像素 (Sohl-Dickstein 等人,2015)。 数组中所有未观察到的位置必须由扩散模型以与观察到的约束一致的方式填充。
此任务所需的扰动函数对于观察到的值为狄拉克 delta 函数,在其他地方为常数。 具体来说,如果 是时间步长 处的状态约束,那么
动作约束的定义是相同的。 在实践中,这可以通过从未扰动的逆过程 中采样,并在所有扩散时间步长 后用条件值 替换采样值来实现。
即使是奖励最大化问题也需要通过图像修复进行条件化,因为所有采样的轨迹都应该从当前状态开始。 这种条件化在算法 1 的第 10 行中描述。
4 扩散规划器的属性
我们讨论了 Diffuser 的一些重要属性,重点关注那些与标准动力学模型不同或对于非自回归轨迹预测不寻常的属性。
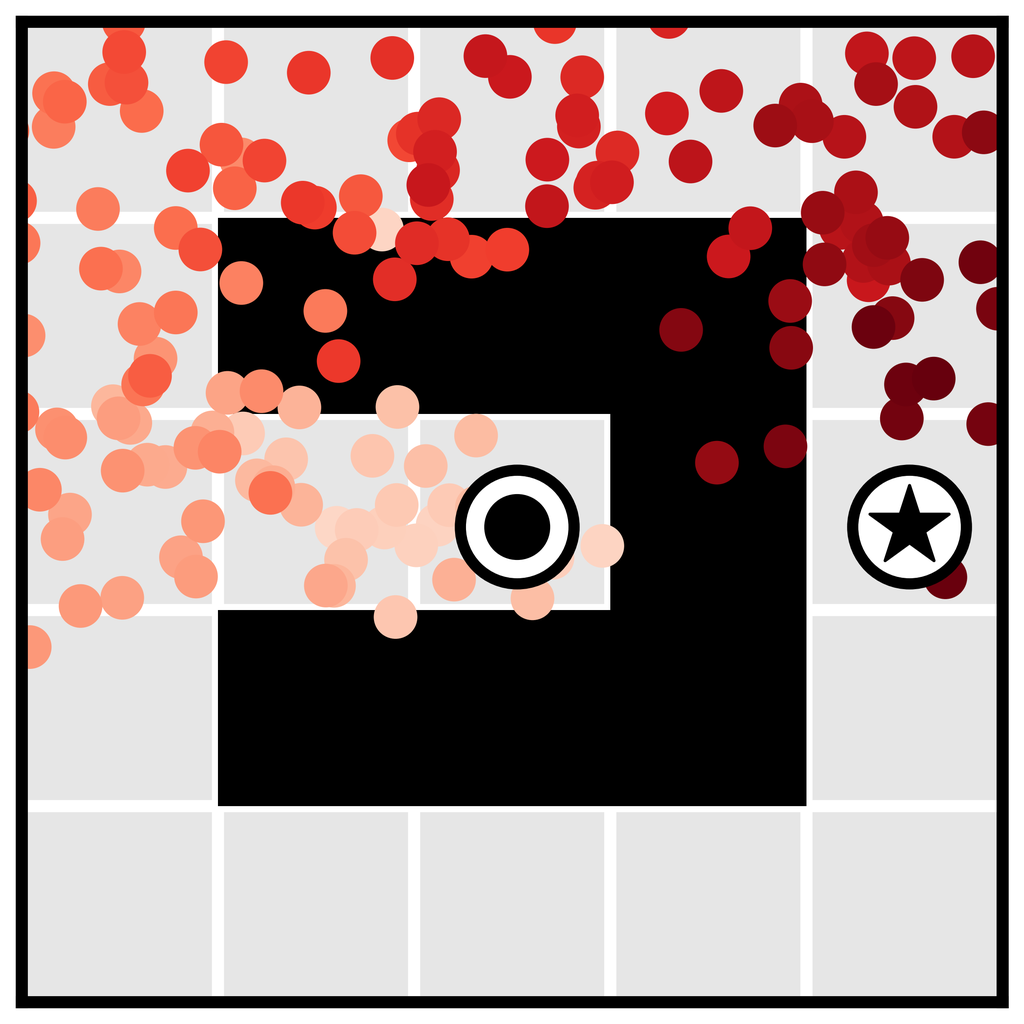
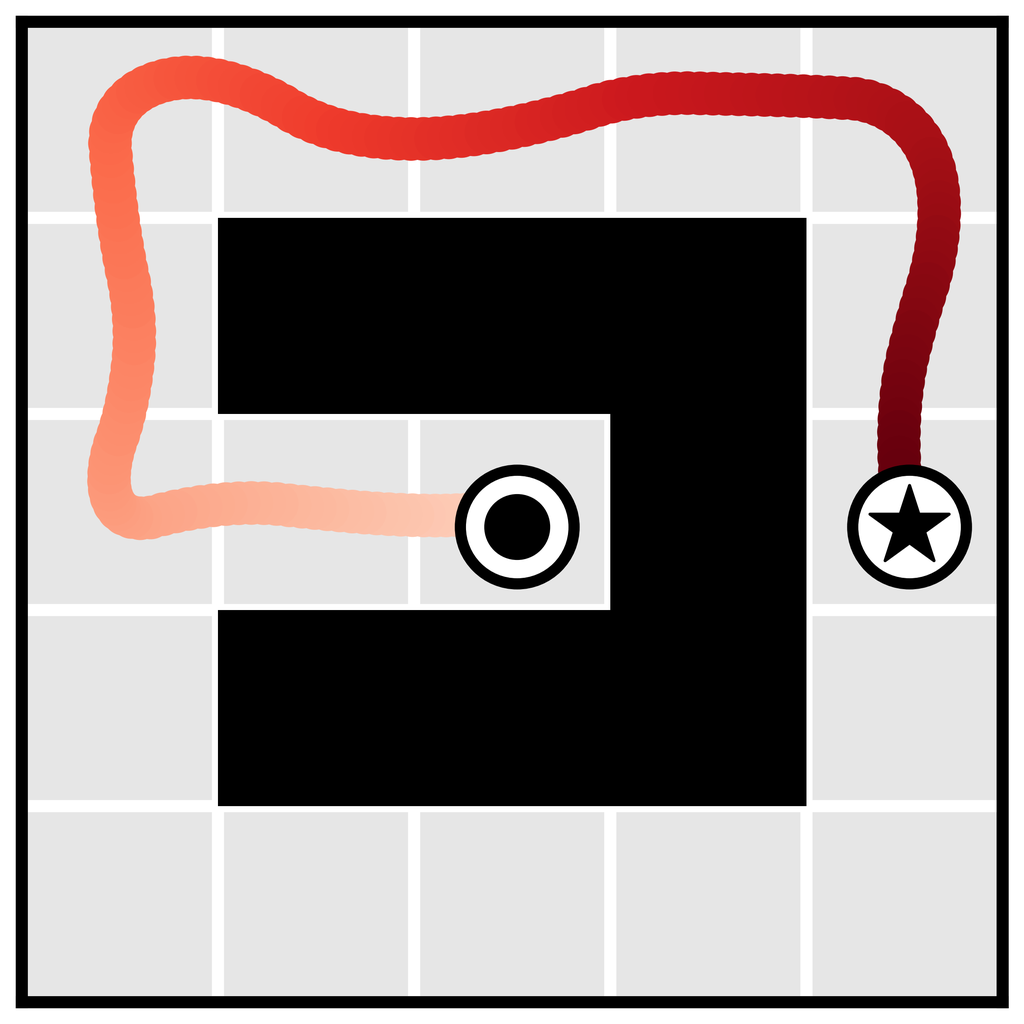
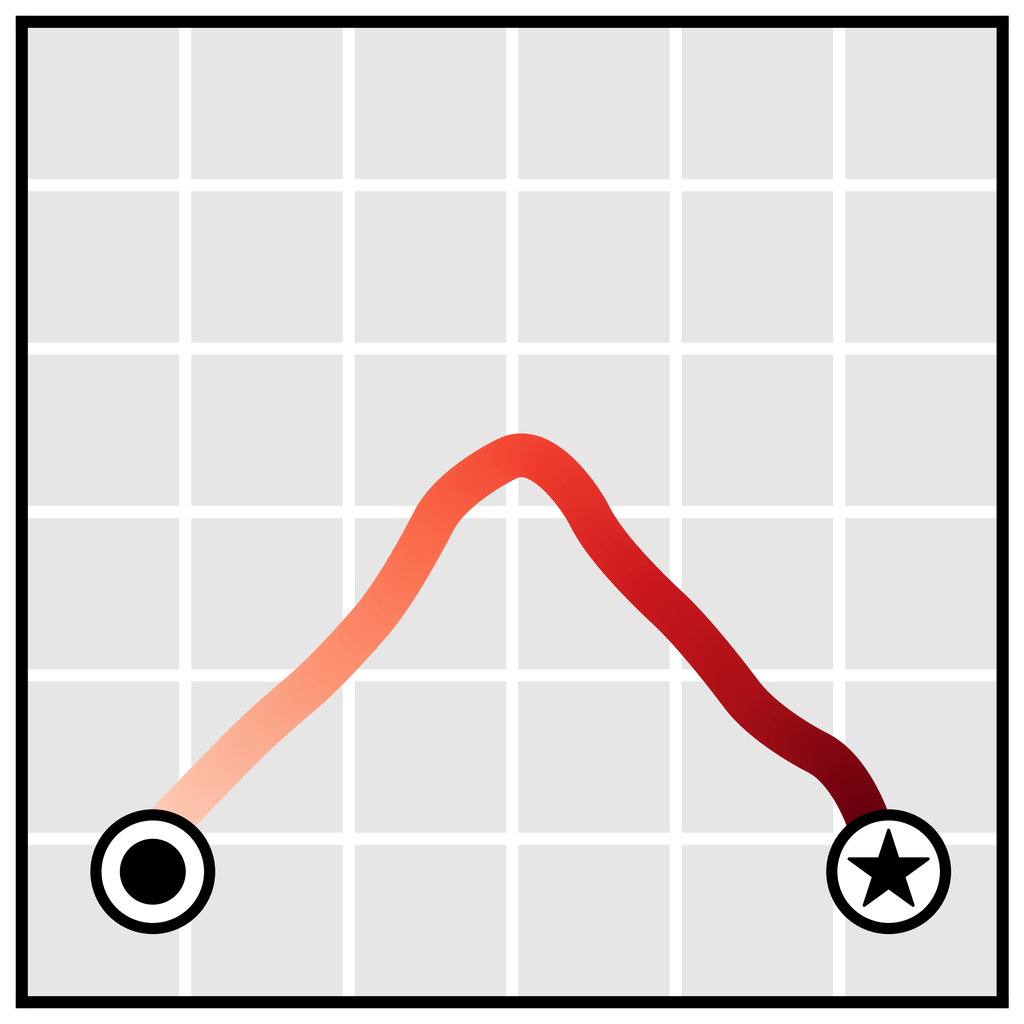
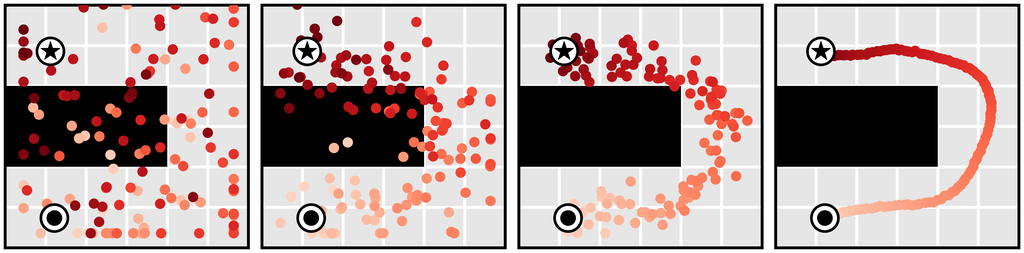
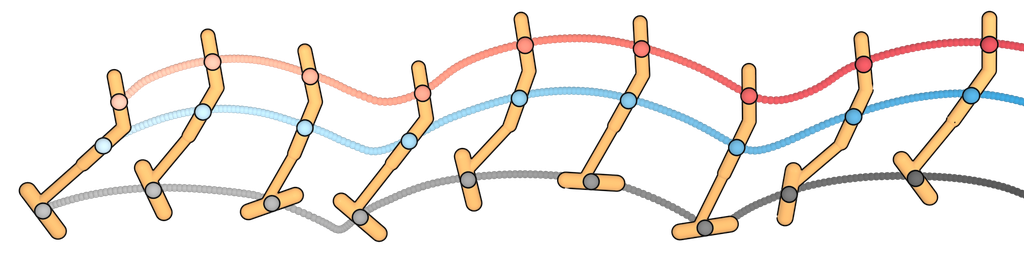
学习长时域规划。 单步模型通常用作地面真实环境动力学 的代理,因此不会特别绑定到任何规划算法。 相反,算法 1 中的规划程序与扩散模型的特定功能紧密相连。 因为我们的规划方法与采样几乎相同(唯一的区别是通过扰动函数 的引导),Diffuser 作为长时域预测器的有效性直接转化为有效长时域规划。 我们在 图 3a 中展示了在目标实现场景中学习规划的优势,表明 Diffuser 能够在稀疏奖励设置类型中生成可行的轨迹,而基于射击的方法众所周知在这些设置中难以发挥作用。 我们将在第 5.1 节中探讨此问题设置的更定量版本。
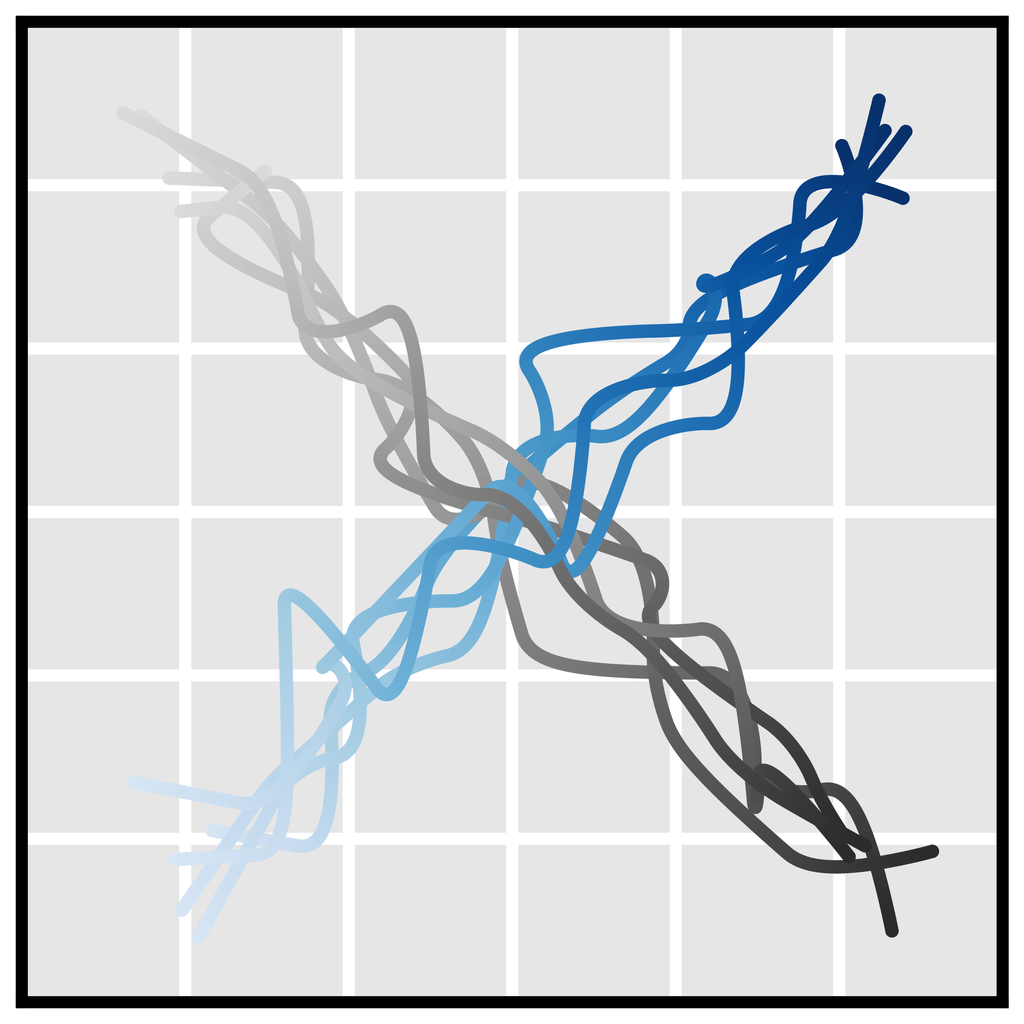
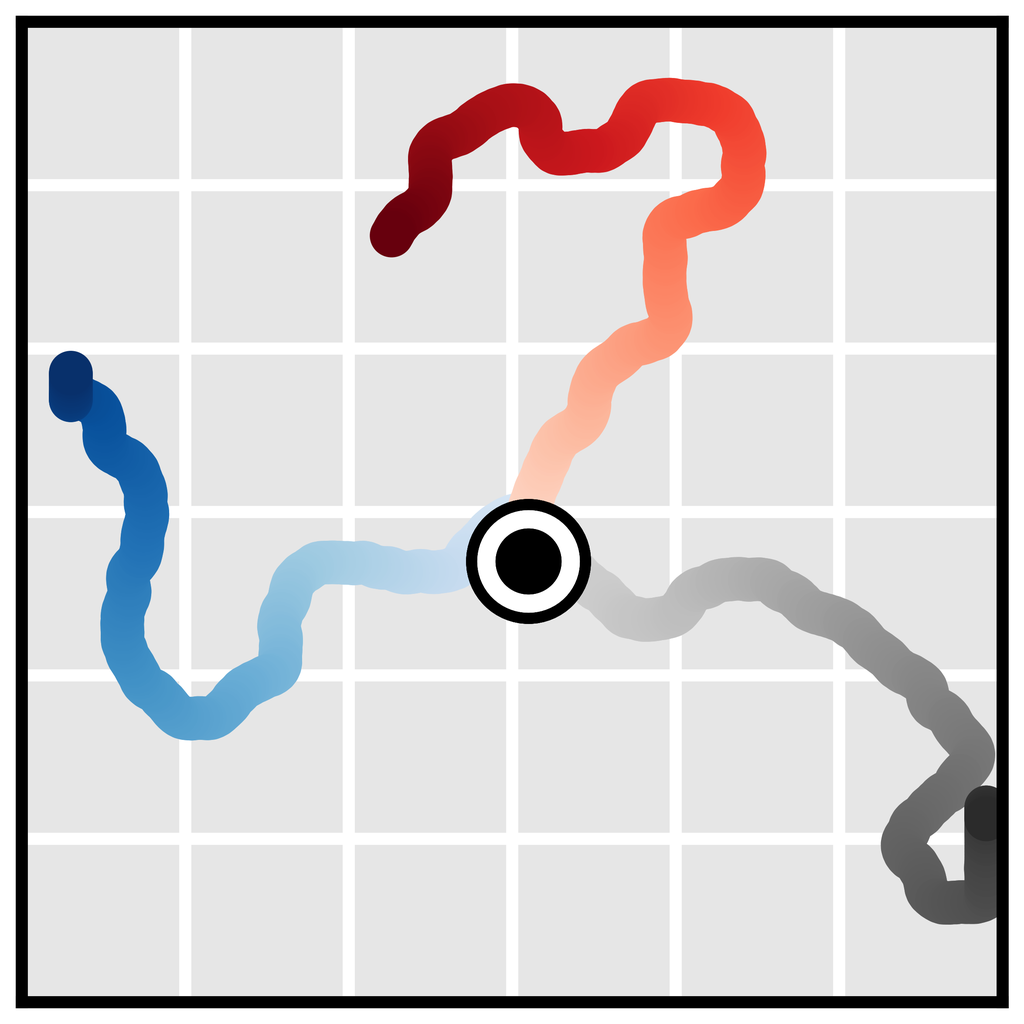
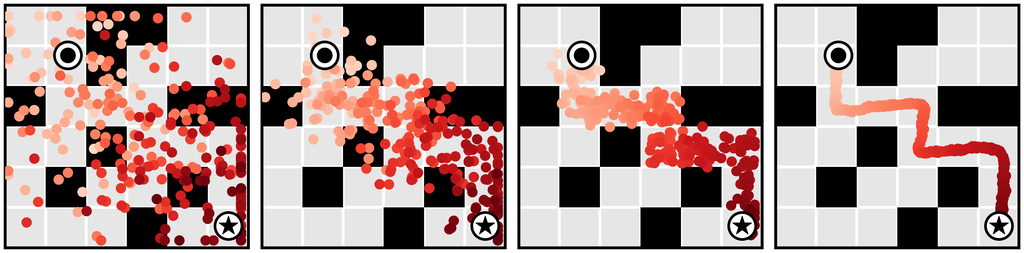
时间组合性。 单步模型通常基于马尔可夫性质,允许它们组合分布内的转换以推广到分布外的轨迹。 由于 Diffuser 通过迭代地改进局部一致性来生成全局一致的轨迹(第 3.1 节),因此它也可以以新颖的方式将熟悉的子序列拼接在一起。 在 图 3b 中,我们在仅沿直线行驶的轨迹上训练 Diffuser,并表明它可以通过在交叉点处组合轨迹来推广到 V 形轨迹。
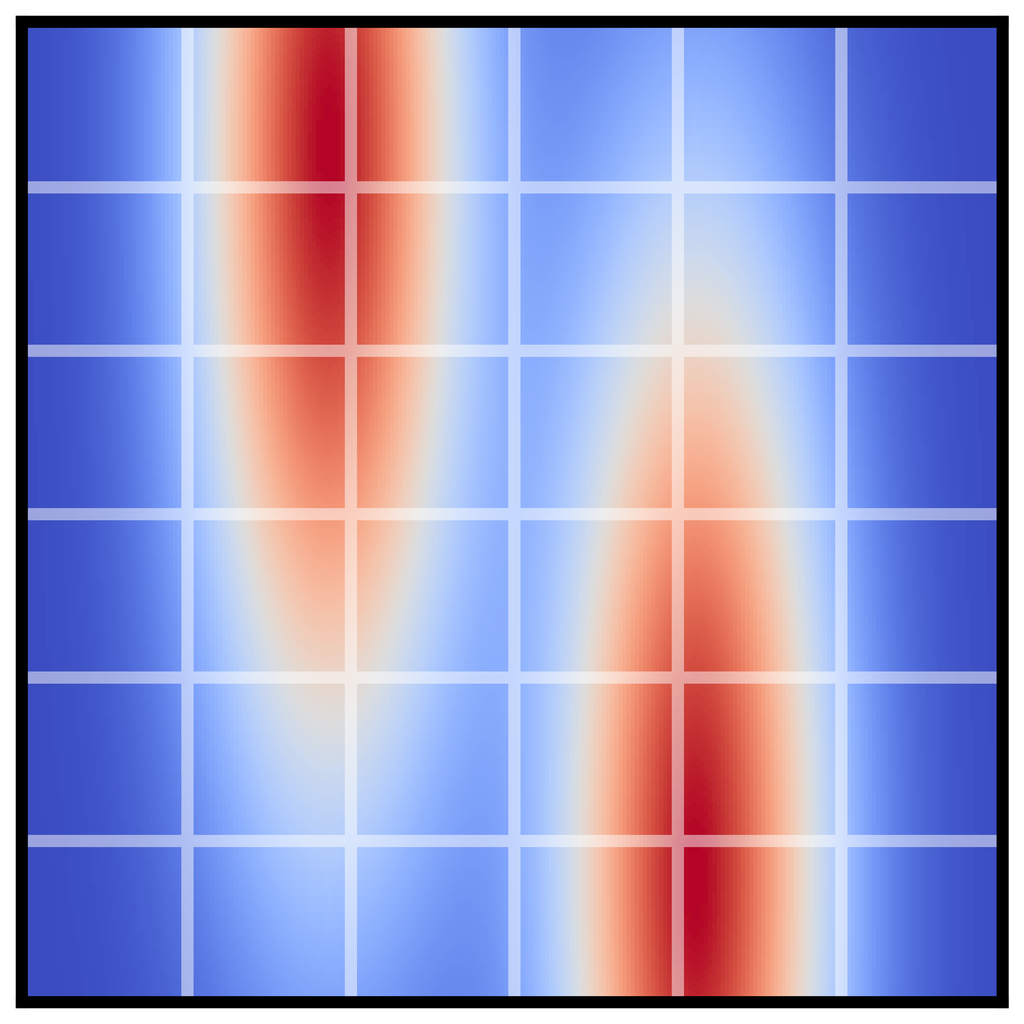
可变长度计划。 由于我们的模型在其预测的范围维度上完全卷积,因此其规划范围不受架构选择的限制。 相反,它由初始化去噪过程的输入噪声 的大小决定,从而允许可变长度计划(图 3c)。
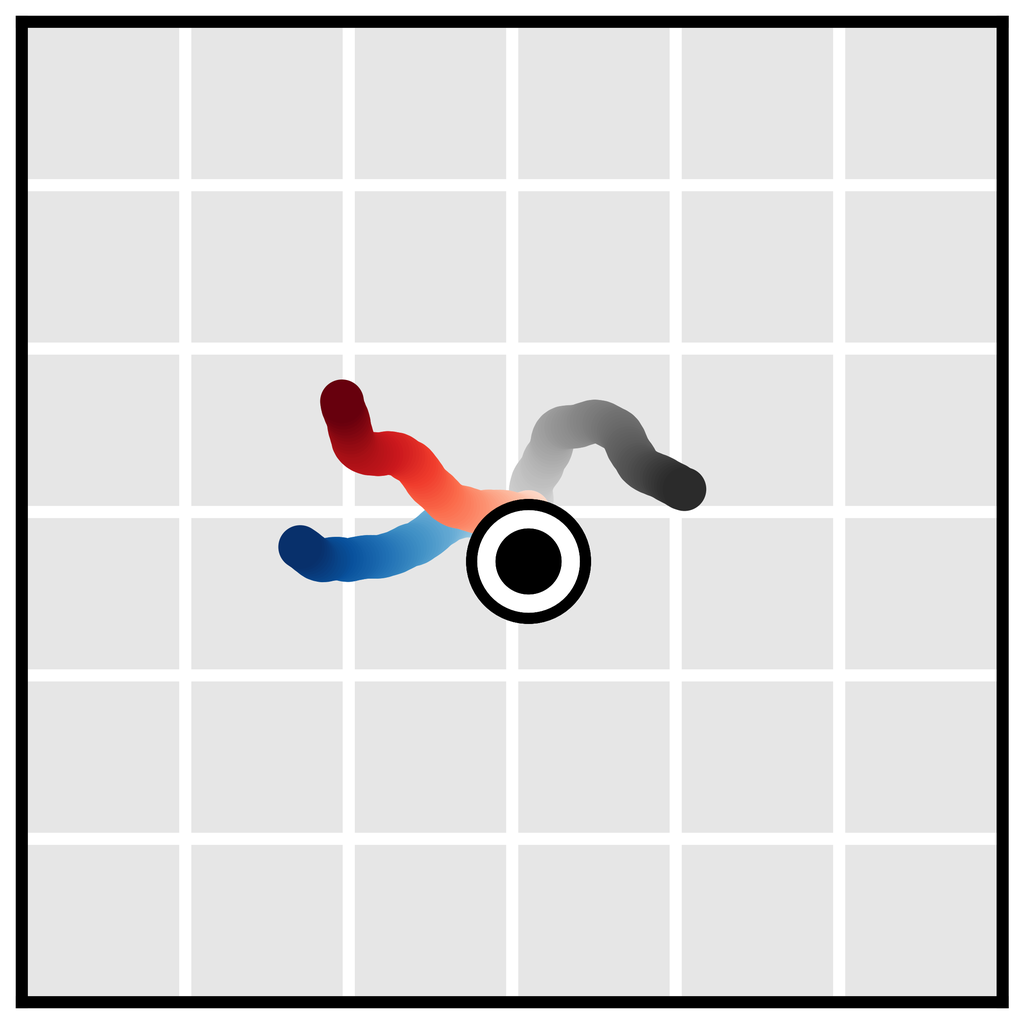
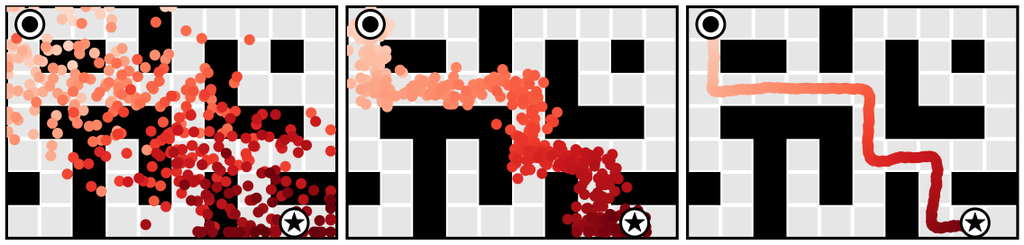
任务组合性。 虽然 Diffuser 包含有关环境动态和行为的信息,但它独立于奖励函数。 由于模型充当对未来可能性的先验,因此规划可以通过相对轻量级的扰动函数 (甚至多种扰动的组合)来指导,这些扰动函数对应于不同的奖励。 我们通过规划一个在扩散模型训练期间未见过的新的奖励函数来证明这一点(图 3d)。
| Environment | MPPI | CQL | IQL | Diffuser |
| Maze2D U-Maze | 113.9 | |||
| Maze2D Medium | 121.5 | |||
| Maze2D Large | 123.0 | |||
| Single-task Average | 16.2 | 7.7 | 47.0 | 119.5 |
| Multi2D U-Maze | - | 128.9 | ||
| Multi2D Medium | - | 127.2 | ||
| Multi2D Large | - | 132.1 | ||
| Multi-task Average | 21.5 | - | 16.9 | 129.4 |
5 实验评估
我们实验的重点是评估 Diffuser 在我们希望从数据驱动的规划器中获得的能力。 特别是,我们评估 (1) 在没有手动奖励塑造的情况下,规划长远目标的能力, (2) 泛化到训练期间未见过的目标新配置的能力,以及 (3) 从质量不同的异构数据中恢复有效控制器的能力。 最后,我们研究了基于扩散的规划的实际运行时考虑因素,包括以最有效的方式加速规划过程,同时在性能方面尽可能少地损失。
5.1 长时域多任务规划
我们在 Maze2D 环境 (Fu et al., 2020) 中评估长时域规划,这些环境需要遍历到一个目标位置,在那里会获得 1 的奖励。 在任何其他位置都没有提供奖励塑造。 由于到达目标位置可能需要数百步, 即使是最好的无模型算法也很难充分执行信用分配并可靠地到达目标(表 1)。
我们使用图像修复策略来条件化起点和目标位置,使用 Diffuser 进行规划。 (目标位置也对无模型方法可用;它可以通过是数据集中唯一具有非零奖励的状态来识别。) 然后,我们将采样的轨迹用作开环计划。 Diffuser 在所有迷宫大小上都实现了超过 100 的分数,表明它优于参考专家策略。 我们在图 4 中可视化了反向扩散过程,该过程生成了 Diffuser 的计划。
虽然 Maze2D 中的训练数据是无方向的——由控制器在随机选择的位置之间导航构成——但评估是单任务的,因为目标始终相同。 为了测试多任务灵活性,我们在每一集开始时修改环境以随机化目标位置。 此设置在表 1 中被标记为 Multi2D。 Diffuser 本质上是一个多任务规划器;我们不需要从单任务实验中重新训练模型,只需更改条件目标即可。 因此,Diffuser 在多任务设置中的表现与在单任务设置中一样好。 相反,在适应多任务设置时,单任务设置中最佳无模型算法 (IQL; Kostrikov 等人,2022) 的性能出现了大幅下降。 我们具有后见经验重标记 (Andrychowicz 等人,2017) 的多任务 IQL 的详细信息在附录 A 中给出。 MPPI 使用真实动态;其与 Diffuser 的学习规划算法相比表现不佳,突出了即使在没有预测不准确的情况下,长视野规划带来的困难。
U-迷宫
中等
大型
去噪
和目标
条件。
剩余状态由去噪过程“修复”。
| Dataset | Environment | BC | CQL | IQL | DT | TT | MOPO | MOReL | MBOP | Diffuser |
| Medium-Expert | HalfCheetah | 105.9 | ||||||||
| Medium-Expert | Hopper | 105.4 | 107.6 | 110.0 | 108.7 | |||||
| Medium-Expert | Walker2d | 107.5 | 108.8 | 109.6 | 108.1 | 106.9 | ||||
| Medium | HalfCheetah | 47.4 | 46.9 | |||||||
| Medium | Hopper | 95.4 | ||||||||
| Medium | Walker2d | 78.3 | 79.0 | 77.8 | 79.6 | |||||
| Medium-Replay | HalfCheetah | 53.1 | ||||||||
| Medium-Replay | Hopper | 95.0 | 94.7 | 91.5 | 93.6 | 93.6 | ||||
| Medium-Replay | Walker2d | 82.6 | ||||||||
| Average | 51.9 | 77.6 | 77.0 | 74.7 | 78.9 | 42.1 | 72.9 | 47.8 | 77.5 | |
5.2 测试时灵活性
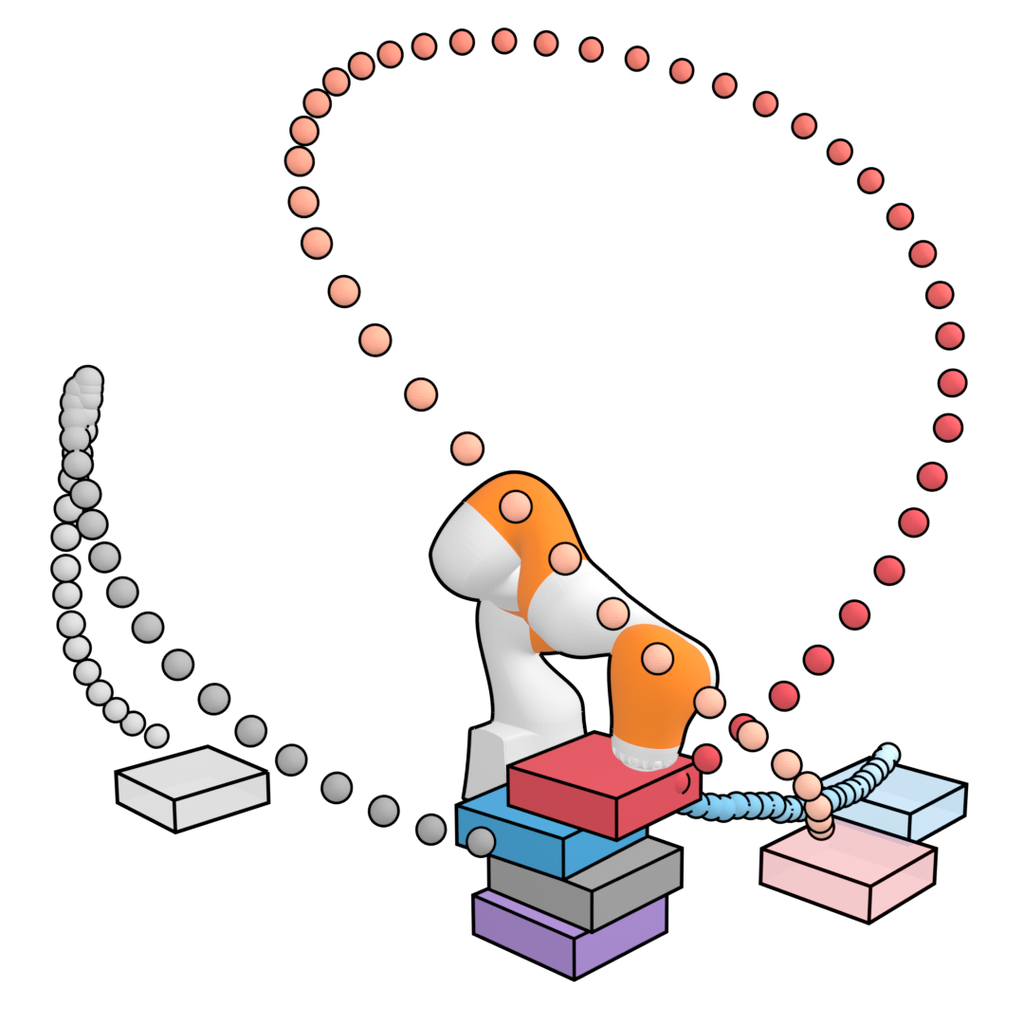
为了评估泛化到新的测试时目标的能力,我们构建了一套包含三种设置的积木堆叠任务:(1) 无条件堆叠,该任务的目标是尽可能高地堆砌积木塔;(2) 条件堆叠,该任务的目标是按指定顺序构建积木塔,以及 (3) 重新排列,该任务的目标是在新的排列中匹配一组参考积木的位置。 我们在 PDDLStream (Garrett 等人,2020) 生成的演示中,对所有方法进行了 10000 个轨迹的训练;成功堆叠放置后奖励为 1,否则为 0。 这些积木堆叠是测试时灵活性的具有挑战性的诊断;在执行随机目标的局部堆叠的过程中,控制器将冒险进入训练配置中未包含的新状态。
我们对所有积木堆叠任务使用一个经过训练的 Diffuser,仅修改设置之间的扰动函数 。 在 无条件堆叠 任务中,我们直接从未扰动的去噪过程中 采样以模拟 PDDLStream 控制器。 在 条件堆叠 和 重新排列 任务中,我们组合了两个扰动函数 来偏向采样的轨迹:第一个最大化轨迹最终状态匹配目标配置的可能性,第二个在堆叠运动期间强制执行末端执行器和立方体之间的接触约束。 (有关详细信息,请参见附录 B。)
| Environment | BCQ | CQL | Diffuser |
|---|---|---|---|
| Unconditional Stacking | 58.7 | ||
| Conditional Stacking | 0.0 | 0.0 | 45.6 |
| Rearrangement | 0.0 | 0.0 | 58.9 |
| Average | 0.0 | 8.1 | 54.4 |
5.3 离线强化学习
最后,我们评估了使用 D4RL 离线运动套件 (Fu 等人,2020) 从不同质量的异构数据中恢复有效单任务控制器的能力。 我们使用第 3.2 节中描述的采样过程将 Diffuser 生成的轨迹引导至高奖励区域,并使用第 3.3 节中描述的修复过程将轨迹与当前状态进行条件化。 奖励预测器 在与扩散模型相同的轨迹上进行训练。
我们将其与各种先前的算法进行比较,这些算法涵盖了数据驱动控制的其他方法,包括无模型强化学习算法 CQL (Kumar 等人,2020) 和 IQL (Kostrikov 等人,2022);回报条件化方法,例如决策 Transformer (DT;Chen 等人,2021b);以及基于模型的强化学习方法,包括轨迹 Transformer (TT;Janner 等人,2021)、MOPO (Yu 等人,2020)、MOReL (Kidambi 等人,2020) 和 MBOP (Argenson & Dulac-Arnold, 2021)。 在单任务设置中,Diffuser 的性能与之前的算法相当:优于基于模型的 MOReL 和 MBOP 以及回报条件化的 DT,但不如专门针对单任务性能设计的最佳离线技术。 我们还研究了使用 Diffuser 作为传统轨迹优化器(如 MPPI (Williams 等人,2015))中的动态模型的变体,但发现这种组合的性能并不比随机性更好,这表明 Diffuser 的有效性源于耦合的建模和规划,而不是来自改进的开环预测精度。
降噪
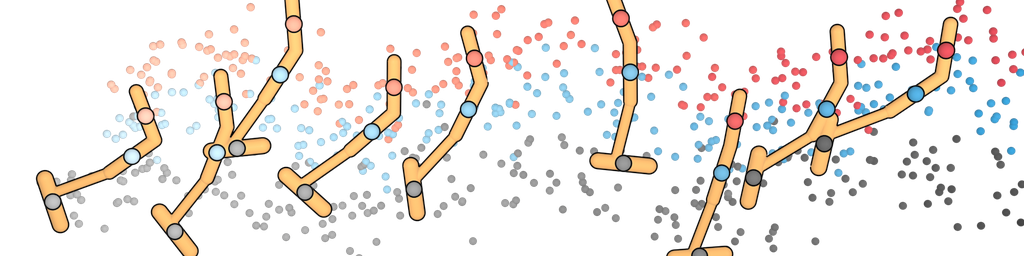
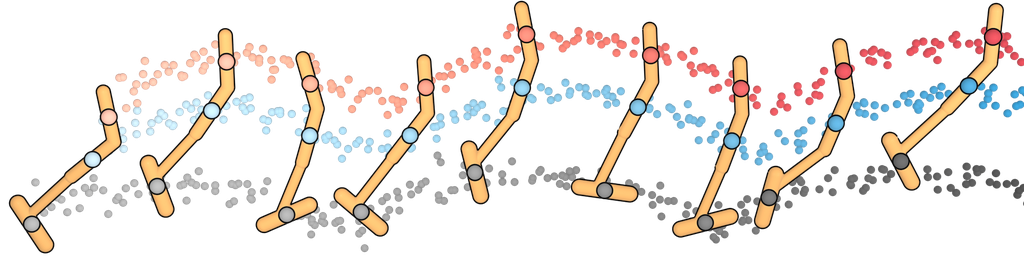
规划范围
5.4 加快规划的扩散预热
Diffuser 的一个局限性是,单个计划的生成速度很慢(由于迭代生成)。 朴素地,当我们开环执行计划时,必须在执行的每一步重新生成一个新的计划。 为了提高 Diffuser 的执行速度,我们可以进一步重用以前生成的计划来预热后续计划的生成。
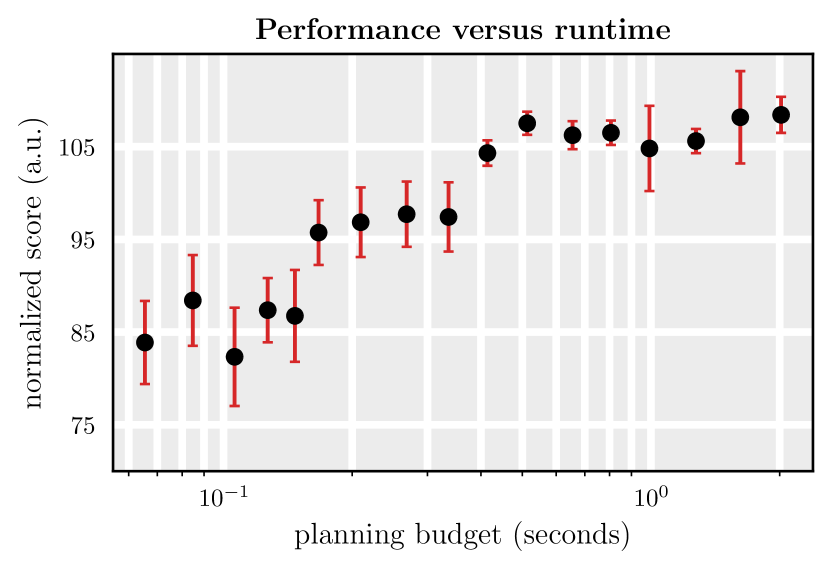
为了预热规划,我们可以从先前生成的计划中运行有限数量的前向扩散步骤,然后从这个部分噪声轨迹中运行相应数量的去噪步骤来重新生成一个更新的计划。 在图 7 中,我们说明了当我们将用于从 2 到 100 重新生成每个新计划的去噪步骤数时,性能和运行时预算之间的权衡。 我们发现,我们可以在性能略微下降的情况下,大幅降低我们方法的规划预算。
6 相关工作
深度生成模型的进步最近在基于模型的强化学习方面取得了进展,有多条工作线探索了参数化为卷积 U 网络的动力学模型 (Kaiser 等人,2020), 随机循环网络 (Ke 等人,2018;Hafner 等人,2021a;Ha & Schmidhuber,2018), 矢量量化自动编码器 (Hafner 等人,2021b;Ozair 等人,2021), 神经 ODE (Du 等人,2020a), 归一化流 (Rhinehart 等人,2020;Janner 等人,2020), 生成对抗网络 (Eysenbach 等人,2021), 基于能量的模型 (EBMs;Du 等人 2019), 图神经网络 (Sanchez-Gonzalez 等人,2018), 神经辐射场 (Li 等人,2021), 以及 Transformer (Janner 等人,2021;Chen 等人,2021a)。 此外,Lambert 等人 2020 研究了用于长时预测的非自回归轨迹级动力学模型。 这些研究通常假设模型和规划器之间存在抽象屏障。 具体来说,学习的作用被降级为逼近环境动力学;一旦学习完成,模型可以插入到各种规划 (Botev 等人,2013;Williams 等人,2015) 或策略优化 (Sutton,1990;Wang 等人,2019) 算法中,因为规划器的形式不强依赖于模型的形式。 我们的目标是打破这种抽象屏障,通过设计一个模型和规划算法,这些算法相互训练, 从而产生一个非自回归轨迹级模型,其采样和规划几乎相同。
一系列并行工作研究了如何以不同方式打破模型学习和规划之间的抽象障碍。 这些方法包括:训练一个自回归潜在空间模型进行奖励预测 (Tamar 等人,2016;Oh 等人,2017;Schrittwieser 等人,2019);根据状态值对模型训练目标进行加权 (Farahmand 等人,2017);以及将搭配技术应用于学习到的单步能量 (Du 等人,2019;Rybkin 等人,2021)。 相反,我们的方法通过对轨迹的所有时间步进行建模和生成来进行规划,而不是自回归地进行,并使用辅助引导函数对采样的轨迹进行条件化。
扩散模型已成为一种很有前途的生成模型类别,它将数据生成过程表述为一种迭代去噪过程 (Sohl-Dickstein 等人,2015;Ho 等人,2020)。 去噪过程可以被视为对数据分布的梯度进行参数化 (Song & Ermon, 2019),将扩散模型与分数匹配 (Hyvärinen, 2005) 和 EBM (LeCun 等人,2006;Du & Mordatch, 2019;Nijkamp 等人,2019;Grathwohl 等人,2020) 联系起来。 基于梯度的迭代采样本身就适合灵活的条件化 (Dhariwal & Nichol, 2021) 和组合性 (Du 等人,2020b),我们使用它们从异构数据集恢复有效行为,并计划针对训练期间未见过的奖励函数进行计划。 虽然扩散模型已经发展到可以生成图像 (Song 等人,2021)、波形 (Chen 等人,2021c)、3D 形状 (Zhou 等人,2021) 和文本 (Austin 等人,2021),但据我们所知,它们以前从未在强化学习或决策制定方面使用过。
7 结论
我们介绍了 Diffuser,一个用于轨迹数据的去噪扩散模型。 使用 Diffuser 进行规划与从中采样几乎相同,唯一的区别是增加了辅助扰动函数,这些函数用于引导样本。 学习到的基于扩散的规划程序具有一些有用的特性,包括优雅地处理稀疏奖励、能够在不重新训练的情况下计划新的奖励,以及时间组合性,使其能够通过将分布内子序列拼接在一起生成分布外轨迹。 我们的结果表明,对于深度模型化的强化学习,出现了一种新的基于扩散的规划程序类别。
代码引用
我们在此工作中使用了以下开源库:NumPy (Harris 等人,2020)、PyTorch (Paszke 等人,2019) 和 PyTorch 中的扩散模型 (Wang, 2020)。
致谢
我们感谢 Ajay Jain 对早期草稿的反馈,并感谢 Leslie Kaelbling、Tomás Lozano-Pérez、Jascha Sohl-Dickstein、Ben Eysenbach、Amy Zhang、Colin Li 和 Toru Lin 的有益讨论。 这项工作部分得到了微软的计算资源捐赠的支持。 M.J. 获得了美国国家科学基金会和 Open Philanthropy Project 的奖学金支持。 Y.D. 获得了美国国家科学基金会的奖学金支持。
参考文献
- Andrychowicz et al. (2017) Andrychowicz, M., Wolski, F., Ray, A., Schneider, J., Fong, R., Welinder, P., McGrew, B., Tobin, J., Abbeel, P., and Zaremba, W. Hindsight experience replay. In Advances in Neural Information Processing Systems. 2017.
- Argenson & Dulac-Arnold (2021) Argenson, A. and Dulac-Arnold, G. Model-based offline planning. In International Conference on Learning Representations, 2021.
- Austin et al. (2021) Austin, J., Johnson, D. D., Ho, J., Tarlow, D., and van den Berg, R. Structured denoising diffusion models in discrete state-spaces. In Advances in Neural Information Processing Systems, 2021.
- Bapst et al. (2019) Bapst, V., Sanchez-Gonzalez, A., Doersch, C., Stachenfeld, K. L., Kohli, P., Battaglia, P. W., and Hamrick, J. B. Structured agents for physical construction. In International Conference on Machine Learning, 2019.
- Botev et al. (2013) Botev, Z. I., Kroese, D. P., Rubinstein, R. Y., and L’Ecuyer, P. The cross-entropy method for optimization. In Handbook of Statistics, volume 31, chapter 3. 2013.
- Chen et al. (2021a) Chen, C., Yoon, J., Wu, Y.-F., and Ahn, S. TransDreamer: Reinforcement learning with transformer world models, 2021a.
- Chen et al. (2021b) Chen, L., Lu, K., Rajeswaran, A., Lee, K., Grover, A., Laskin, M., Abbeel, P., Srinivas, A., and Mordatch, I. Decision transformer: Reinforcement learning via sequence modeling. In Advances in Neural Information Processing Systems, 2021b.
- Chen et al. (2021c) Chen, N., Zhang, Y., Zen, H., Weiss, R. J., Norouzi, M., and Chan, W. Wavegrad: Estimating gradients for waveform generation. In International Conference on Learning Representations, 2021c.
- Chua et al. (2018) Chua, K., Calandra, R., McAllister, R., and Levine, S. Deep reinforcement learning in a handful of trials using probabilistic dynamics models. In Advances in Neural Information Processing Systems. 2018.
- Dhariwal & Nichol (2021) Dhariwal, P. and Nichol, A. Q. Diffusion models beat GANs on image synthesis. In Advances in Neural Information Processing Systems, 2021.
- Du et al. (2020a) Du, J., Futoma, J., and Doshi-Velez, F. Model-based reinforcement learning for semi-markov decision processes with neural odes. In Advances in Neural Information Processing Systems, 2020a.
- Du & Mordatch (2019) Du, Y. and Mordatch, I. Implicit generation and generalization in energy-based models. In Advances in Neural Information Processing Systems, 2019.
- Du et al. (2019) Du, Y., Lin, T., and Mordatch, I. Model based planning with energy based models. In Conference on Robot Learning, 2019.
- Du et al. (2020b) Du, Y., Li, S., and Mordatch, I. Compositional visual generation with energy based models. In Advances in Neural Information Processing Systems, 2020b.
- Eysenbach et al. (2021) Eysenbach, B., Khazatsky, A., Levine, S., and Salakhutdinov, R. Mismatched no more: Joint model-policy optimization for model-based rl. arXiv preprint arXiv:2110.02758, 2021.
- Farahmand et al. (2017) Farahmand, A.-M., Barreto, A., and Nikovski, D. Value-aware loss function for model-based reinforcement learning. In International Conference on Artificial Intelligence and Statistics, 2017.
- Fu et al. (2020) Fu, J., Kumar, A., Nachum, O., Tucker, G., and Levine, S. D4RL: Datasets for deep data-driven reinforcement learning. arXiv preprint arXiv:2004.07219, 2020.
- Fujimoto et al. (2019) Fujimoto, S., Meger, D., and Precup, D. Off-policy deep reinforcement learning without exploration. In International Conference on Machine Learning, 2019.
- Garrett et al. (2020) Garrett, C. R., Lozano-Pérez, T., and Kaelbling, L. P. Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning. In International Conference on Automated Planning and Scheduling, 2020.
- Grathwohl et al. (2020) Grathwohl, W., Wang, K.-C., Jacobsen, J.-H., Duvenaud, D., and Zemel, R. Learning the stein discrepancy for training and evaluating energy-based models without sampling. In International Conference on Machine Learning, 2020.
- Ha & Schmidhuber (2018) Ha, D. and Schmidhuber, J. Recurrent world models facilitate policy evolution. In Advances in Neural Information Processing Systems, 2018.
- Hafner et al. (2021a) Hafner, D., Lillicrap, T., Fischer, I., Villegas, R., Ha, D., Lee, H., and Davidson, J. Learning latent dynamics for planning from pixels. In International Conference on Machine Learning, 2021a.
- Hafner et al. (2021b) Hafner, D., Lillicrap, T. P., Norouzi, M., and Ba, J. Mastering atari with discrete world models. In International Conference on Learning Representations, 2021b.
- Harris et al. (2020) Harris, C. R., Millman, K. J., van der Walt, S. J., Gommers, R., Virtanen, P., Cournapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N. J., Kern, R., Picus, M., Hoyer, S., van Kerkwijk, M. H., Brett, M., Haldane, A., del Río, J. F., Wiebe, M., Peterson, P., Gérard-Marchant, P., Sheppard, K., Reddy, T., Weckesser, W., Abbasi, H., Gohlke, C., and Oliphant, T. E. Array programming with NumPy. Nature, 585(7825):357–362, 2020.
- Ho et al. (2020) Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, 2020.
- Hyvärinen (2005) Hyvärinen, A. Estimation of non-normalized statistical models by score matching. Journal of Machine Learning Research, 2005.
- Janner et al. (2020) Janner, M., Mordatch, I., and Levine, S. -models: Generative temporal difference learning for infinite-horizon prediction. In Advances in Neural Information Processing Systems, 2020.
- Janner et al. (2021) Janner, M., Li, Q., and Levine, S. Offline reinforcement learning as one big sequence modeling problem. In Advances in Neural Information Processing Systems, 2021.
- Kaiser et al. (2020) Kaiser, L., Babaeizadeh, M., Miłos, P., Osiński, B., Campbell, R. H., Czechowski, K., Erhan, D., Finn, C., Kozakowski, P., Levine, S., Mohiuddin, A., Sepassi, R., Tucker, G., and Michalewski, H. Model based reinforcement learning for atari. In International Conference on Learning Representations, 2020.
- Ke et al. (2018) Ke, N. R., Singh, A., Touati, A., Goyal, A., Bengio, Y., Parikh, D., and Batra, D. Modeling the long term future in model-based reinforcement learning. In International Conference on Learning Representations, 2018.
- Kelly (2017) Kelly, M. An introduction to trajectory optimization: How to do your own direct collocation. SIAM Review, 59(4):849–904, 2017.
- Kidambi et al. (2020) Kidambi, R., Rajeswaran, A., Netrapalli, P., and Joachims, T. MOReL: Model-based offline reinforcement learning. In Advances in Neural Information Processing Systems, 2020.
- Kingma & Ba (2015) Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. In International Conference on Learning Representations, 2015.
- Kostrikov et al. (2022) Kostrikov, I., Nair, A., and Levine, S. Offline reinforcement learning with implicit Q-learning. In International Conference on Learning Representations, 2022.
- Kumar et al. (2020) Kumar, A., Zhou, A., Tucker, G., and Levine, S. Conservative Q-learning for offline reinforcement learning. In Advances in Neural Information Processing Systems, 2020.
- Lambert et al. (2020) Lambert, N. O., Wilcox, A., Zhang, H., Pister, K. S., and Calandra, R. Learning accurate long-term dynamics for model-based reinforcement learning. arXiv preprint arXiv:2012.09156, 2020.
- LeCun et al. (2006) LeCun, Y., Chopra, S., Hadsell, R., Huang, F. J., and et al. A tutorial on energy-based learning. In Predicting Structured Data. MIT Press, 2006.
- Levine (2018) Levine, S. Reinforcement learning and control as probabilistic inference: Tutorial and review. arXiv preprint arXiv:1805.00909, 2018.
- Li et al. (2021) Li, Y., Li, S., Sitzmann, V., Agrawal, P., and Torralba, A. 3d neural scene representations for visuomotor control. In Conference on Robot Learning, 2021.
- Misra (2019) Misra, D. Mish: A self regularized non-monotonic neural activation function. In British Machine Vision Conference, 2019.
- Nagabandi et al. (2018) Nagabandi, A., Kahn, G., S. Fearing, R., and Levine, S. Neural network dynamics for model-based deep reinforcement learning with model-free fine-tuning. In International Conference on Robotics and Automation, 2018.
- Nichol & Dhariwal (2021) Nichol, A. Q. and Dhariwal, P. Improved denoising diffusion probabilistic models. In International Conference on Machine Learning, 2021.
- Nijkamp et al. (2019) Nijkamp, E., Hill, M., Zhu, S.-C., and Wu, Y. N. Learning non-convergent non-persistent short-run MCMC toward energy-based model. In Advances in Neural Information Processing Systems, 2019.
- Oh et al. (2017) Oh, J., Singh, S., and Lee, H. Value prediction network. In Advances in Neural Information Processing Systems, 2017.
- Ozair et al. (2021) Ozair, S., Li, Y., Razavi, A., Antonoglou, I., Van Den Oord, A., and Vinyals, O. Vector quantized models for planning. In International Conference on Machine Learning, 2021.
- Paszke et al. (2019) Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., and Chintala, S. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems. 2019.
- Posa et al. (2014) Posa, M., Cantu, C., and Tedrake, R. A direct method for trajectory optimization of rigid bodies through contact. The International Journal of Robotics Research, 2014.
- Rhinehart et al. (2020) Rhinehart, N., McAllister, R., and Levine, S. Deep imitative models for flexible inference, planning, and control. In International Conference on Learning Representations, 2020.
- Rybkin et al. (2021) Rybkin, O., Zhu, C., Nagabandi, A., Daniilidis, K., Mordatch, I., and Levine, S. Model-based reinforcement learning via latent-space collocation. In International Conference on Machine Learning, pp. 9190–9201. PMLR, 2021.
- Sanchez-Gonzalez et al. (2018) Sanchez-Gonzalez, A., Heess, N., Springenberg, J. T., Merel, J., Riedmiller, M., Hadsell, R., and Battaglia, P. Graph networks as learnable physics engines for inference and control. In International Conference on Machine Learning, 2018.
- Schrittwieser et al. (2019) Schrittwieser, J., Antonoglou, I., Hubert, T., Simonyan, K., Sifre, L., Schmitt, S., Guez, A., Lockhart, E., Hassabis, D., Graepel, T., Lillicrap, T., and Silver, D. Mastering atari, go, chess and shogi by planning with a learned model. arXiv preprint arXiv:1911.08265, 2019.
- Sohl-Dickstein et al. (2015) Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., and Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning, 2015.
- Song et al. (2021) Song, J., Meng, C., and Ermon, S. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021.
- Song & Ermon (2019) Song, Y. and Ermon, S. Generative modeling by estimating gradients of the data distribution. In Advances in Neural Information Processing Systems, 2019.
- Sutton (1990) Sutton, R. S. Integrated architectures for learning, planning, and reacting based on approximating dynamic programming. In International Conference on Machine Learning, 1990.
- Talvitie (2014) Talvitie, E. Model regularization for stable sample rollouts. In Conference on Uncertainty in Artificial Intelligence, 2014.
- Tamar et al. (2016) Tamar, A., Wu, Y., Thomas, G., Levine, S., and Abbeel, P. Value iteration networks. In Advances in Neural Information Processing Systems. 2016.
- Tassa et al. (2012) Tassa, Y., Erez, T., and Todorov, E. Synthesis and stabilization of complex behaviors through online trajectory optimization. In International Conference on Intelligent Robots and Systems, 2012.
- Wang (2020) Wang, P. Implementation of denoising diffusion probabilistic models in pytorch, 2020. URL https://github.com/lucidrains/denoising-diffusion-pytorch.
- Wang et al. (2019) Wang, T., Bao, X., Clavera, I., Hoang, J., Wen, Y., Langlois, E., Zhang, S., Zhang, G., Abbeel, P., and Ba, J. Benchmarking model-based reinforcement learning. arXiv preprint arXiv:1907.02057, 2019.
- Williams et al. (2015) Williams, G., Aldrich, A., and Theodorou, E. Model predictive path integral control using covariance variable importance sampling. arXiv preprint arXiv:1509.01149, 2015.
- Witkin & Kass (1988) Witkin, A. and Kass, M. Spacetime constraints. ACM Siggraph Computer Graphics, 1988.
- Wu & He (2018) Wu, Y. and He, K. Group normalization. In European Conference on Computer Vision, 2018.
- Yu et al. (2020) Yu, T., Thomas, G., Yu, L., Ermon, S., Zou, J., Levine, S., Finn, C., and Ma, T. MOPO: Model-based offline policy optimization. In Advances in Neural Information Processing Systems, 2020.
- Zhou et al. (2021) Zhou, L., Du, Y., and Wu, J. 3D shape generation and completion through point-voxel diffusion. In International Conference on Computer Vision, 2021.
附录 A 基线细节和来源
在本节中,我们提供了一些关于我们自己运行的基线的信息。 对于先前在标准化任务上评估的基线的得分,我们提供了所列得分的来源。
A.1 Maze2D 实验
单任务。
CQL 和 IQL 在标准 Maze2D 环境中的表现见 D4RL 白皮书 (Fu 等人,2020) 表 2 中。
我们使用作者的官方实现运行 IQL:
我们调整了两个超参数:
-
1.
温度
-
2.
期望值
多任务。
我们只在 Multi2D 环境中评估了 IQL,因为它在单任务 Maze2D 环境中是表现最好的基线,且优势显著。 为了使 IQL 适应多任务设置,我们修改了 函数、价值函数和策略,使其成为目标条件化的。 为了在训练期间选择目标,我们采用了一种基于后见经验回放的策略,其中我们在轨迹未来的状态中采样目标。 对于训练备份 ,我们根据未来上的几何分布对目标进行采样
根据采样的目标重新计算奖励,并在更新期间将所有相关模型条件化到目标上。 在测试期间,我们将策略条件化为地面真实目标。
我们对与单任务设置中相同的 IQL 参数进行了调整。
A.2 堆积块实验
单任务。
对于 BCQ,我们对两个超参数进行了调整:
-
1.
折扣因子
-
2.
τ
多任务。
为了在多任务设置中评估 BCQ 和 CQL,我们修改了 函数、价值函数和策略,使其成为目标条件的。 我们使用目标重新标记进行训练,如 Multi2D 环境中一样。 我们对单任务块堆叠实验中描述的相同超参数进行了调整。
A.3 离线运动
BC、CQL、IQL 和 AWAC 的分数来自 Kostrikov 等人 (2022) 中的表 1。 DT 的分数来自 Chen 等人 (2021b) 中的表 2。 TT 的分数来自 Janner 等人 (2021) 中的表 1。 MOReL 的分数来自 Kidambi 等人 (2020) 中的表 2。 MBOP 的分数来自 Argenson & Dulac-Arnold (2021) 中的表 1。
附录 B 测试时灵活性
为了引导 Diffuser 以指定配置堆叠块,我们使用了两个独立的扰动函数 来指定给定块 A 在块 B 上的堆叠,我们将在下面详细介绍。
最终状态匹配 为了强制最终状态由块 A 位于块 B 顶部组成,我们训练了一个扰动函数 作为每个时间步的分类器,用于确定状态 是否呈现出块 A 位于块 B 顶部的堆叠。 我们在演示数据上训练分类器作为扩散模型。
接触约束 为了引导库卡机械臂将块 A 堆叠在块 B 顶部,我们构建了一个扰动函数 ,其中 对应于状态 中的底层维度,该维度指定库卡机械臂与块 A 之间是否存在接触。 我们在轨迹的前 64 个时间步内对库卡机械臂和块 A 之间的接触约束进行应用,这对应于计划中与块 A 的初始接触。
附录 C 实现细节
在本节中,我们描述了体系结构和记录的超参数。
-
1.
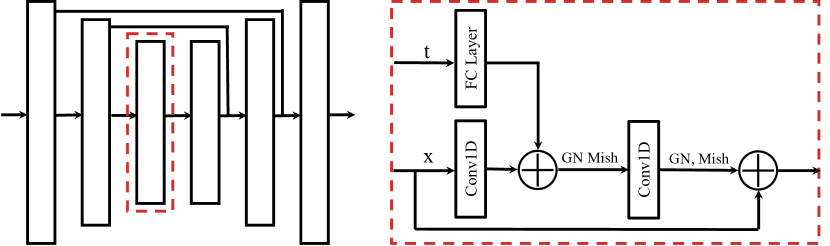
Diffuser 的体系结构(图 A1)由具有 6 个重复残差块的 U-Net 结构组成。 每个块包含两个时间卷积,每个卷积之后是组规范化 (Wu & He, 2018),以及最终的 Mish 非线性 (Misra, 2019)。 时间步嵌入由单个全连接层生成,并添加到每个块内第一个时间卷积的激活中。
-
2.
我们使用 Adam 优化器 (Kingma & Ba, 2015) 训练模型,学习率为 ,批大小为 。 我们训练模型 500k 步。
-
3.
返回预测器 具有用于扩散模型的 U-Net 前半部分的结构,最后有一个线性层生成标量输出。
-
4.
我们在所有运动任务中使用 的规划范围,在块堆叠中使用 ,在 Maze2D / Multi2D U-Maze 中使用 ,在 Maze2D / Multi2D Medium 中使用 265,在 Maze2D / Multi2D Large 中使用 384。
-
5.
我们发现我们可以减少许多任务的规划范围,但引导比例需要降低(例如,对于 halfcheetah 任务中范围为 的规划范围,引导比例需要降低到 0.001)。 开源代码中的 配置文件 演示了如何使用修改后的比例和范围运行。
-
6.
我们在运动任务中使用 扩散步,在块堆叠中使用 。
-
7.
我们对所有任务使用 的指导尺度,除了 hopper-medium-expert,我们对它使用较小的尺度 。
-
8.
我们对回报预测 使用了 的折扣因子,虽然发现高于 的规划对折扣因子的变化相当不敏感。
-
9.
我们发现控制性能不受使用扩散模型预测噪声 还是未被破坏的数据 的影响。