学习计算任何东西:无参考
弱监督的类不可知计数
摘要
当前与类无关的计数方法可以推广到看不见的类,但通常需要参考图像来定义要计数的对象的类型,以及训练期间的实例注释。 无参考的类不可知计数是一个新兴领域,它将计数的核心视为重复识别任务。 此类方法有助于依赖变化的设定成分。 我们表明,具有全局上下文的通用特征空间可以枚举图像中的实例,而无需先验存在的对象类型。 具体来说,我们证明了没有点级监督或参考图像的视觉 Transformer 特征的回归优于其他无参考方法,并且与使用参考图像的方法具有竞争力。 我们在当前标准少样本计数数据集 FSC-147 上展示了这一点。 我们还提出了一个改进的数据集 FSC-133,它消除了 FSC-147 中的错误、歧义和重复图像,并在其上展示了类似的性能。 据我们所知,我们是第一个弱监督的无参考类不可知的计数方法。
介绍
计数是人们首先学习的抽象任务之一。 一旦学会了,这个概念就很简单。 其目的是找到对象类的实例数。 尽管计数很简单,但它具有多种应用,包括:人群计数、交通监控、保护、显微镜检查和库存管理。 值得注意的是,虽然人们通常可以在不事先了解要计数的对象的类型的情况下对对象进行计数,但大多数当前的自动化方法却不能。
给出一组新奇的物体并要求其“数数”,一个人就会知道要数什么。 这不需要参考示例或事先了解对象类型来澄清我们不想找到自相似背景的重复。 因此,计数能力的核心由两个部分组成:了解什么值得计数,以及识别这些可数重复的能力。 我们证明了自监督视觉 Transformer 的功能,特别是它们对全局感受野的自注意力的使用,对于满足这两个条件至关重要。 我们通过实验证明,鉴于一般和全局上下文特征,枚举实例很简单,并且只需要最少的训练和监督。
以前的方法,无论是基于检测、基于回归还是基于分类,通常侧重于枚举单个或一小组已知类别的实例,例如人[43, 5]、车辆[30]、动物[16]或细胞[46]。 这需要针对每种类型的对象单独训练的网络,其适应新类别的能力有限甚至没有。 每当考虑新类型时,单独训练的网络都需要收集新数据并重新训练,这是困难且昂贵的。 此外,这些方法通常旨在在枚举实例之前对其进行本地化,需要点级注释来监督训练。 仅当对象类型的组成和外观无限期保持不变并且存在点级注释时,这些特定于类和点级的监督系统才可行,而在现实应用中通常情况并非如此。 相比之下,与类无关的计数方法[27, 32]不需要静态类组合,因为它们将对在一组已知类上学习到的计数的理解适应于未见过的类的对象。 然而,大多数与类别无关的方法仍然需要训练时的点级注释和类别的参考图像来进行计数。 唯一的例外是 RepRPN [31],这是一种不需要参考图像但使用点级注释的两阶段方法。 弱监督计数方法 [20, 48] 放松了对点级注释的需求,但目前不能推广到看不见的类。
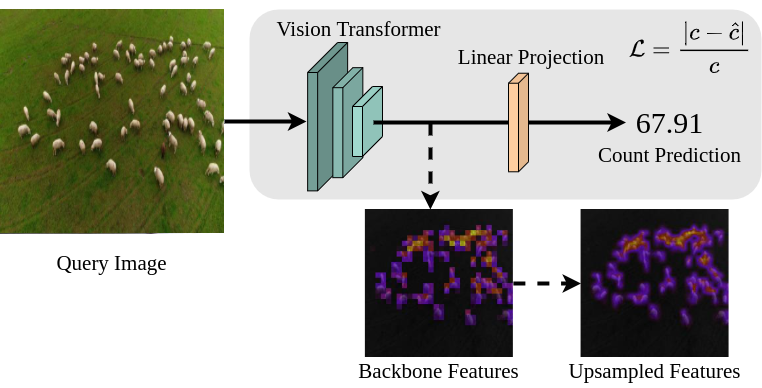
考虑到在动态的现实应用程序中收集参考图像和点注释的成本,我们提出了一种方法,可以在不使用此类图像或注释的情况下准确枚举未见过的类的实例。 我们的简单方法通过使用视觉 Transformer 创建通用的全局上下文感知特征空间来实现此目的,然后可以使用线性投影对其进行枚举,请参见图 1。
我们的主要贡献如下:
-
1.
我们提出了 RCC,一种无引用的与类无关的计数器,并表明它可以在没有实例注释的情况下进行训练。
-
2.
我们证明,RCC 的性能优于唯一的其他无参考类不可知计数方法,并且与当前使用参考图像作为先验和在完全点级监督下进行训练的方法具有竞争力。
-
3.
我们提出了 FSC-133,这是一个改进的用于类别无关计数的数据集,没有 FSC-147 中存在的错误、歧义和重复图像。
相关工作
特定于类别的计数。 特定于类的计数方法枚举图像中已知对象类型的实例。 这些方法可以大致分为基于检测、基于回归和基于分类的方法。 基于检测的方法使用标准检测或分割方法[34,30,29]来查找[18]类型或集合的所有对象类型 [11],然后枚举它们。 检测本身就是一个广阔的领域,最近取得了重大进展,有利于计数应用,例如处理重叠或遮挡。 然而,基于检测的计数方法在高密度应用中仍然不能令人满意。 基于分类的方法[30]生成图像全局计数的离散分类。 他们最明显的缺陷是,他们平等地对待所有不正确的计数,而与真实计数的接近程度无关。 这使得训练变得困难,需要大量数据,并且需要较低的最大计数来确保每个离散计数类得到正确的训练。 基于回归的计数方法旨在回归单个全局计数[8,45,43]或像素级密度图预测,可以通过积分[5, 32, 46] 或实例检测[3, 1, 9]。 这些可以使用复杂的特征[49, 50]或更简单的低级特征[8],例如纹理[28]。 回归密度图也可以用作基本的对象检测器,然后与引用进行互相关以查找所需类 [39] 的实例。
弱监督计数。 虽然上述大多数计数方法都使用某种形式的实例位置信息,但收集这些信息的成本很高。 弱监督计数方法旨在以最少的 [20, 35] 或没有点级注释 [4, 48, 43] 生成准确的计数。
与类别无关的计数。 上述方法假设事先了解所有要识别的对象类别。 一般来说,这需要针对每一类对象单独训练的系统,适应新类别的能力有限。 为了避免将这些不可推广的方法重新训练到新类别的成本,Lu等人[27]提出了与类别无关的计数,这是一种在训练期间不存在测试时类别的框架。 然而,这个和大多数后续的与类无关的方法[32,47,39]需要在测试时以参考图像的形式先验对象类。 例外的是并发工作[31],它使用两步过程,提出可能包含感兴趣对象的区域,然后将这些区域用于基于参考的方法。 迄今为止,通过创建足够通用的特征空间并对整个特征图[47, 37]或建议的感兴趣区域[32应用某种形式的匹配,可以实现与类无关的计数。 ,39]。
上下文特征和视觉转换器。 上述大多数方法使用的卷积神经网络由于其局部感受野而无法准确理解全局上下文。 方法尝试使用扩张 [21, 2] 或基于排名的 [25] 系统来解决这个问题。 本质上对全局上下文进行建模的基于注意力的架构已用于生成更多上下文感知特征,以帮助计数[38],执行特征匹配[37, 24]和生成参考图像提案[31]。 受到 ViT [13] 和 DETR [6] 等视觉转换器的启发,出现了各种计数发展[12,23,40] ,包括一些特别关注弱监督计数的[22,36,44]。 然而,这些方法侧重于人群计数,这是一种通用性有限的特定类别任务。
方法
在本文中,我们解决了在没有参考图像或点级监督的情况下对未见过的类的实例进行计数的挑战性任务。 我们认为无引用计数可以分为两个基本问题:“我们可能想要计数的对象实例在哪里?”和“这个给定实例的类是否在其他地方重复?”。 与唯一的其他无参考方法 RepPRN [31] 不同,我们同时解决了这些问题。 前者在与类无关的上下文中需要一个通用的、信息丰富的特征空间。 我们发现自监督知识蒸馏非常适合学习这样的特征空间。 后者需要了解图像的全局背景。 视觉转换器及其对注意力的使用非常适合这项任务。 给定一个通用且全局感知的特征空间,我们发现计数回归很简单,并且可以通过最小的 和单个线性投影来实现,而无需点级监督。
自我监督的知识蒸馏。 为了在不使用标签的情况下学习通用的、信息丰富的特征空间,我们使用基于Caron等人[7]的自监督知识蒸馏训练方法。 我们通过鼓励固定“教师”网络之间的共识来学习图像的信息表示,由参数化,该网络对大型“全球”作物进行操作, ,,图像和“学生”网络,由参数化,它在集合上运行,较小的“本地”图像裁剪。 这是通过最小化这些网络的概率分布 和 之间的交叉熵来实现的,如方程 1 所示。 这些概率分布在方程 2 中定义,充当“无监督分类预测”。
| (1) |
| (2) |
这里,、是概率分布的维数,是控制分布锐度的温度参数。 与方程 2 类似的公式适用于温度 的 。 我们使用学生网络权重的指数移动平均值迭代更新教师网络的权重。
Vision Transformer 骨干。 变形金刚提供的关键全球背景源于它们对注意力机制的使用。 注意力根据所有其他特征的相似性,从所有其他特征的线性投影中生成新特征。 受 Vaswani 等人 [42] 的启发,我们的视觉转换器 和 使用多个注意力头来生成信息丰富的多样化特征,如方程所示3 和方程 4。
| (3) |
| (4) |
其中 、 和 (查询、键和值)都是 补丁的线性投影。 和 都具有维度 。 在自注意力的情况下,。 在实际操作中,每个头部的注意力同时分别计算 、 和 、、 和 组,分别为
| (5) |
计数回归。 我们直接根据 的潜在特征对整个输入图像 进行单个标量计数预测,而无需点级注释,而点级注释的收集既困难又昂贵。 尽管基于位置的损失似乎应该有助于训练,但我们发现点级注释和高斯密度图是不必要的,并且在与类别无关的环境中通常是有害的。 由于位置注释通常是任意放置的,并且最多包含有关对象的大小和形状的有限信息,因此识别所有正确对象的不同部分将受到位置损失函数的惩罚。 这种任意的惩罚阻碍了网络对计数任务的理解。 我们允许网络通过直接回归计数估计来开发自己的任务概念表示。 为此,我们使用最简单的损失函数之一,即绝对百分比误差,定义为:,其中是真实计数,预测计数,其中 是学习的线性投影。 这比绝对误差略有改进,因为它限制了非常高密度图像对梯度的不成比例的影响。 我们发现,网络在没有强加人类关于位置显着性的想法的情况下,学会了以有意义的方式隐式定位计数类的实例,如 6.4 节中进一步讨论并如图 2。
平铺增强。] 虽然多尺度系统已被用来改进对不同尺寸物体的检测,但它们需要复杂的空间损失[33]或非极大值抑制[34],其计算成本较大。 由于我们的方法回归的是单个计数而不是一组对象位置,因此这些方法不可行。 为了让网络更好地理解多个尺度和训练密度,我们通过将输入图像的调整大小版本平铺到 50% 的实例的 (22) 网格中来增加图像密度的多样性。 这增加了高密度图像的表现。 这种增强将我们的方法 MAE 和 RMSE 分别提高了约 10% 和 20%。 详情请参阅附录B。
FSC-147 和 FSC-133
FSC-147 [32] 是最近在类别无关计数领域广泛使用的数据集。 它旨在包含来自 147 个不同类别的 6135 张独特图像。 为了评估方法对未见过的类的通用性,用于训练、验证和测试的类和图像不应重叠。 尽管我们的方法不使用它们,但该数据集还包括每个实例的点注释和每个图像的三个随机实例边界框注释。
我们发现 159 张图像在数据集中出现了 334 次,在 分辨率下进行比较时,与至少一张其他图像的像素差异为 0。 如果我们包括接近相同但像素差异不为零的图像,这些数字将增加到 211 张图像,出现 448 次。 请参阅附录A.1、A.5了解说明和完整的重复项列表。 此外,11 张图像出现在训练集中以及验证或测试集中之一。 这个重大问题破坏了这些分裂的目的。 此外,在 71 个实例中,图像以不同的计数重复,差异高达 25%,其中 5 个出现在训练集和验证集中,差异为 9%-21%。 完整列表请参见附录A.3。
因此,我们提出了该数据集的修订版本 FSC-133,它纠正了这些问题。 数据分割重叠源于错误分类。 这可能是由于模糊的阶级区别(例如。 “芸豆”和“红豆”)或分层类别(例如。 “鹤”、“海鸥”和“鹅”也都可以归类为“鸟”)。 在这两种情况下,确定哪个类最合适可能很困难,甚至是任意的。 “鹤”和“鹅”或“面包卷”、“小圆面包”和“长棍面包卷”非常相似,人们可以很好地将每种实例分类为它们最熟悉的类型。 请参阅附录 A.1 中的图 8,了解类别划分不明确的直观示例。 为了消除数据集的歧义并帮助其更可靠地衡量方法的普遍性,FSC-133 组合了足够相似而容易混淆的类别,请参阅附录 A.4 了解详细信息。 当对象之间存在遮挡或部分对象出现在图像边缘时,似乎会出现计数差异,示例请参见附录A.1。 虽然人类很难准确计数这些图像,但我们相信它们对数据集有价值。 FSC-133 并没有删除它们,而是仅包含最准确的计数。
FSC-133 有 133 个类别的 5898 张图像。 训练集、验证集和测试集分别包含来自 82、26 和 25 个类别的 3877、954 和 1067 个图像。 当组合重叠数据分割的类时,我们将它们合并到训练分割中,以便在 FSC-147 上训练的方法在 FCS-133 上进行测试。 尽管处于不利地位,这些测试仍然可以公平地评估该方法在完全不可见的类上的能力。
实验
在本节中,我们将讨论实现、训练以及用于评估的指标的详细信息。
建筑学
我们使用受 DeiT-S [41] 启发的 ViT-small 主干。 选择这种方法是因为其效率高,并且可以与其他计数方法进行良好的比较。 ViT-S 具有与 ResNet-50 类似的参数数量(21M 与 23M)、吞吐量(1237im/sec 与 1007im/sec)和监督 ImageNet 性能(79.3% 与 79.8%)[41],这是当代计数方法所使用的。
由于即使是数据高效的 Transformer 也需要相对大量的数据进行训练,并且我们评估的数据集很小,因此我们使用来自 Caron 等人 [7]< 的权重初始化了 Transformer 主干 。 /t1>. 这种自我监督的预训练使网络在没有监督的情况下并且在接触我们有限的数据集之前就能够理解有意义的图像特征,从而最大限度地减少过度拟合的可能性。 我们的线性计数投影 ,从 特征空间投影到标量计数预测,其中 是 Transformer 特征的维度, 是视觉 Transformer 的 patch 数量。 我们发现 和 足以实现有竞争力的结果,同时也足够轻,可以在单个 1080Ti 上进行训练。 应该注意的是,此视觉 Transformer 配置将输入图像的分辨率限制为 (224224),而不是 (384384)由具有 ResNet-50 主干的当代方法使用。 用于重现我们结果的代码将在以下位置公开提供:https://github.com/ActiveVisionLab/LearningToCountAnything。
训练
我们使用的批量大小为 2,分布在 2 个 GPU (Titan X) 上。 我们以的学习率训练了80个epoch,需要2.5小时。 为了增加训练时对象密度的多样性,我们将 2 × 2 平铺增强应用于 50% 的迭代。 我们对图像应用随机反射和旋转,并且在平铺时独立地对每个图块应用随机反射和旋转。 基于颜色的增强(颜色抖动、高斯模糊和日晒)对我们的结果的影响可以忽略不计。 我们没有应用随机裁剪,因为这需要点级注释来调整计数。
评估指标和琐碎基线
根据之前关于类无关计数[37, 31]的工作,我们使用平均绝对误差()和均方根误差() )来评估我们的性能,其中 和 是图像 的真实值和预测计数, 是图像的数量验证或测试集中的图像。
我们将我们的方法和以前的方法与两个简单的基线进行比较。 对于所有测试图像,两者都预测相同的值 ,如下所示: 和 ,其中 是有序列表训练集的所有地面实况计数, 是该集中的图像数量。
结果
在本节中,我们将展示 RCC 显着优于其他无引用的与类无关的计数方法,并且与基于引用的方法具有竞争力。 由于我们的方法不需要参考图像或点级注释,因此它可以应用于更广泛的现实世界应用,其中要计数的对象不断变化。 我们通过展示我们的方法泛化到新领域的能力来验证这一点。 我们还使用我们学到的潜在特征来定位图像中的实例,因为这可能具有现实世界的实用性,并证实 RCC 使用有意义的信息进行计数。 然后我们讨论我们方法的失败案例和局限性,以告知和激励未来可能的研究。 我们最终验证了我们方法的特定组件。
基准测试方法
我们根据两种简单的基线方法、两种少样本检测方法、FR [19] 和 FSOD [14]、六种基于参考的与类别无关的计数方法来评估我们的方法, GMN [27]、MAML [15]、FamNet [32]、CFOCNet [47]、BMNet [37]、LaoNet [24],以及唯一不需要参考图像的其他类无关计数方法,RepRPN-Counter [31],参见表1。 我们还对 Ranjan 和 Hoai [31] 实现的基于引用的方法进行了无引用修改,用 * 表示。 由于 Ranjan 和 Hoai [31] 尚未发布他们的方法以及他们评估的修改后的基于参考的方法的实现,因此我们可以与他们进行比较的实验是有限的。 为了确保公平比较,我们还使用与我们的方法相同的视觉 Transformer 主干 ViT-S 来训练最近发布的高性能方法,在结果表中用 表示。
FSC-147 和 FSC-133。
我们在 FSC-147 上获得了比 RepRPN 和所有基于参考方法的无参考版本更好的结果,而无需点级注释。 我们还与之前在 FSC-147 和 FSC-133 上的少样本或基于参考的方法竞争,无需参考图像、点级注释或测试时间适应,请参阅表 1 和2。 这一结果表明,非常适合计数的架构和简单的、以计数为中心的目标函数的组合可以学习有意义的计数概念表示,而无需任何基于位置的信息,因此不需要参考图像。 正如6.5节中将讨论的,我们认为 FSC-147 测试集 RMSE 的差异是由于测试集中高密度图像的性能不佳造成的,因为这些异常值具有更大的对 RMSE 的影响大于 MAE。
我们发现,修改为使用 ViT-S 代替 ResNet-50 主干网的方法表现更差;这可能是由于输入图像分辨率显着下降所致。 由于 FamNet 之前使用来自 ResNet 主干的两个连续层的特征,因此这种修改还将用于回归计数的特征的维数减半,从而降低了它们的尺度不变性能。
一般来说,除了验证 MAE 之外,这些方法在 FSC-133 上的表现优于 FSC-147。 更大的验证 MAE 可能是由于删除了重复图像和相似的类。 其他指标的改进可能是由于一些高密度训练图像被移动到集合中。
| Val Set | Test Set | |||
| Method | MAE | RMSE | MAE | RMSE |
| Mean | 53.38 | 124.53 | 47.55 | 147.67 |
| Median | 48.68 | 129.7 | 47.73 | 152.46 |
| Reference-based | ||||
| MAML [15] | 25.54 | 79.44 | 24.90 | 112.68 |
| FR [19] | 45.45 | 112.53 | 41.64 | 141.04 |
| FSOD [14] | 36.36 | 115.00 | 32.53 | 140.65 |
| GMN (pretrained) [27] | 60.56 | 137.78 | 62.69 | 159.67 |
| GMN [27] (1-shot) | 29.66 | 89.81 | 26.52 | 124.57 |
| FamNet [32] (1-shot) | 26.55 | 77.01 | 26.76 | 110.95 |
| FamNet [32] (3-shot) | 24.32 | 70.94 | 22.56 | 101.54 |
| FamNet+ [32] (3-shot) | 23.75 | 69.07 | 22.08 | 99.54 |
| FamNet [32] (3-shot) | 37.90 | 109.76 | 33.51 | 137.79 |
| FamNet+ [32] (3-shot) | 37.77 | 109.04 | 33.18 | 137.20 |
| CFOCNet [47] (3-shot) | 21.19 | 61.41 | 22.10 | 112.71 |
| LaoNet [24] (1-shot) | 17.11 | 56.81 | 15.78 | 97.15 |
| BMNet [37] (3-shot) | 19.06 | 67.95 | 16.71 | 103.31 |
| BMNet+ [37] (3-shot) | 15.74 | 58.53 | 14.62 | 91.83 |
| BMNet [37] (3-shot) | 19.29 | 68.58 | 18.34 | 115.31 |
| BMNet+ [37] (3-shot) | 17.21 | 60.18 | 16.90 | 107.66 |
| Reference-less | ||||
| MAML* [15] | 32.44 | 101.08 | 31.47 | 129.31 |
| GMN* [27] | 39.02 | 106.06 | 37.86 | 141.39 |
| FamNet*(pretrained) [32] | 39.52 | 116.08 | 39.38 | 143.51 |
| FamNet* [32] | 32.15 | 98.7 5 | 32.27 | 131.46 |
| RepRPN-Counter [31] | 29.24 | 98.11 | 26.66 | 129.11 |
| RCC (ours) | 17.49 | 58.81 | 17.12 | 104.53 |
| Val Set | Test Set | |||
| Method | MAE | RMSE | MAE | RMSE |
| Mean | 54.39 | 112.68 | 44.76 | 104.28 |
| Median | 51.29 | 119.29 | 43.15 | 109.83 |
| Reference-based (3-shot) | ||||
| FamNet [32] | 25.49 | 68.21 | 21.05 | 43.48 |
| FamNet+ [32] | 24.75 | 67.04 | 20.20 | 41.76 |
| FamNet [32] | 36.89 | 92.76 | 30.09 | 90.95 |
| FamNet+ [32] | 36.36 | 89.22 | 30.79 | 90.71 |
| BMNet [37] | 20.16 | 54.83 | 14.61 | 41.11 |
| BMNet+ [37] | 16.54 | 50.65 | 13.85 | 40.61 |
| BMNet [37] | 22.06 | 61.01 | 16.38 | 54.13 |
| BMNet+ [37] | 18.78 | 59.76 | 13.87 | 47.27 |
| Reference-less | ||||
| RCC (ours) | 19.84 | 55.81 | 14.23 | 43.83 |
跨数据集的通用性
为了确认我们的跨数据集通用性,我们在 CARPK [18] 上测试我们的模型,CARPK 是一个汽车计数数据集,由停车场的鸟瞰图组成,与 FSC 中任何物体的外观显着不同147 或 FSC-133。 为了确保我们公平地测试流派性训练,我们从 FSC-133 预训练中排除了“汽车”类别。 无论是否进行微调,我们的性能都显着优于 FamNet,并且在不进行微调的情况下,我们与 BMNet 具有竞争力。 我们认为,与 BMNet 的微调结果差异是由分布不均的高密度图像引起的,因为 70% 的测试图像的实例数量多于训练期间看到的最大数量。 其他两种方法都使用参考图像,这有助于跨数据集泛化并解决分布不均的高密度测试图像的问题。 此外,虽然我们的方法在微调后有所改进,显示出任务特定信息的好处,但改进幅度小于 FamNet 和 BMNet。 这表明我们的方法的通用性是相对优化的。
| Method | Fine-Tuned | MAE | RMSE |
|---|---|---|---|
| Mean | N/A | 65.63 | 72.26 |
| Median | N/A | 67.88 | 74.58 |
| Reference-based | |||
| FamNet [32] | 28.84 | 44.47 | |
| BMNet [37] | 14.61 | 24.60 | |
| BMNet+ [37] | 10.44 | 13.77 | |
| FamNet [32] | ✓ | 18.19 | 33.66 |
| BMNet [37] | ✓ | 8.05 | 9.70 |
| BMNet+ [37] | ✓ | 5.76 | 7.83 |
| Reference-less | |||
| RCC (ours) | 12.31 | 15.40 | |
| RCC (ours) | ✓ | 9.21 | 11.33 |








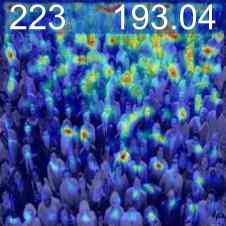


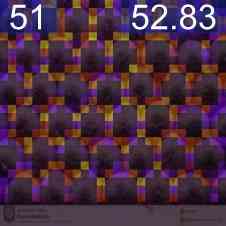
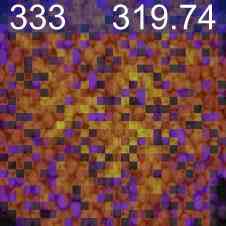






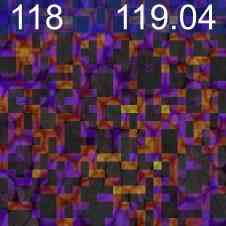
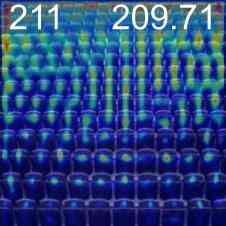




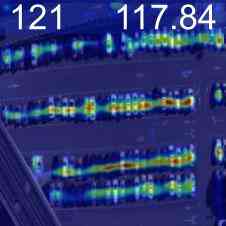
特征可视化
为了验证我们的网络正在学习有意义的信息,我们通过线性投影权重加权的计数特征的奇异值分解来可视化最重要的值,请参见图2。 由于我们的逐块计数特征的分辨率相对较低,并且可能有助于更准确地定位图像中的实例,因此我们训练了一个定位头。 该头由 3 个 Conv-ReLU-Upsample 块组成,将训练后的计数特征 (2828) 的逐块分辨率提高到逐像素密度图预测 (224224),见图2。 这是使用预测密度图的像素均方误差和地面实况高斯密度图进行训练的,如[32]领域中的标准。 由于该训练不是弱监督的,因此我们冻结了特征主干。 该训练需要 10 个 epoch,并且比在自监督主干上进行的相同训练具有明显更好的结果,验证了我们的网络的计数能力而不仅仅是检测对象的能力。 我们还通过在 CARPK 和 ShanghaiTech [50] 数据集上的测试表明,在 FSC-133 上训练的骨干和本地化头可以推广到其他领域,见图 2。
失败案例和局限性
RCC 的一个明显失败案例是它难以处理高密度图像。 如表4所示,当删除少数具有超过 1000 个对象的图像时,FSC-133 的指标会显着提高。 这些图像如图 3 所示,占验证集的 0.31% 和测试集的 0.09%。 这种失败案例很可能是因为我们基于补丁的方法将功能分辨率限制为 特征图。 对于许多这样的高密度图像,在所有补丁中以及在所有补丁边界上都平等地发现相同的对象,使得单个实例无法区分。 理想情况下,我们会使用较小的补丁大小,但由于计算限制,我们无法对此进行测试。 作为此测试的代理,我们将高密度图像分割成多个独立处理的子图像,并将它们的计数组合起来。 这使得 MAE 和 RMSE 分别提高了 45.6% 和 64.9%。 然而,由于这并不能以原则性的方式推广到所有情况,特别是密度非常低的情况,因此我们没有将此作为贡献。
这种失败案例也可能归因于训练数据中极高密度图像的代表性不足; 3877 次训练中只有 9 次(0.23%)超过 1000。 这些效果在 FSC-147 中表现得更加明显,其中高密度图像的表现甚至更低,这一事实也支持了这一点。 应用训练平铺图像增强所发现的改进也支持了这一点,它人为地增加了某些迭代的计数。
| Val Set | Test Set | |||||||
|---|---|---|---|---|---|---|---|---|
| Limit | # | % | MAE | RMSE | # | % | MAE | RMSE |
| None | 0 | 0.00 | 19.84 | 55.81 | 0 | 0.00 | 14.23 | 43.83 |
| 1000 | 3 | 0.31 | 17.94 | 43.99 | 1 | 0.09 | 12.96 | 26.69 |
| 500 | 12 | 1.26 | 16.11 | 34.80 | 7 | 0.66 | 12.12 | 23.02 |




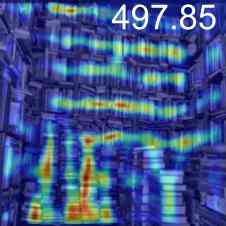



RCC 以及实际上任何无参考方法的主要和最明显的限制是它是单计数的。 它找到最有可能感兴趣的类并枚举它,见图4。 考虑到 FSC-147 中对象的分布,这在我们的评估过程中不会造成问题。 此外,这项工作的核心成就是消除了对测试时参考图像和点级注释的要求。 对于单一类别的新奇对象也有广泛的应用,例如医学成像[46]。 然而,采用这种方法来生成多个计数或分层类计数结构是未来工作的范围。


消融研究
无需注意的功能。 为了证明视觉 Transformer 中存在的注意力机制提供的全局上下文是无参考类不可知计数的关键组成部分,我们使用 ResNet-50 [17] 和 ConvNeXt 评估 RCC [26] 主干代替了我们的 Transformer。 我们使用在 ImageNet [10] 上预训练的标准权重来初始化这两种架构。 虽然使用由与我们的测试和验证集重叠的类的监督任务生成的权重意味着结果不能直接与我们的自监督方法进行比较,但我们相信这种比较为这些架构提供了最佳情况。 在进行类似[26]训练时,Resnet-50 的准确度与我们的视觉 Transformer 相当,而 ConvNeXt 的分类准确度比我们的架构更高。 为了能够跨骨干网进行比较,我们使用相同的输入特征大小 (224224),并以与我们的修补特征相同 (2828) 的分辨率获取潜在特征。骨干。 如表5所示,即使有有利的监督预训练,无注意力特征的表现也明显比自监督视觉 Transformer 差。
计算回归复杂度。 我们断言,鉴于足够通用和全局意识的特征,回归准确的计数应该是简单的。 为了验证这一点,我们将线性投影与两个计数回归头进行比较。 我们发现更复杂的计数头取得了相同或更差的结果。 在表 5 中,我们展示了简单架构 Conv(33)-ReLU-Linear-Relu-Linear 和由四个 (3 3) 卷积层,后跟三个具有 ReLU 激活的线性层。 卷积头的表现比我们在所有三个主干上的投影都要差。 看来,复杂架构的额外计算能力不仅对于计数任务来说是不必要的,而且实际上是有害的,因为它过度适合训练类。
| Val Set | Test Set | ||||
|---|---|---|---|---|---|
| Backbone | Head | MAE | RMSE | MAE | RMSE |
| ResNet-50 | Projection | 31.80 | 78.87 | 24.99 | 75.87 |
| Simple | 36.21 | 98.74 | 26.51 | 110.36 | |
| Complex | 33.63 | 88.50 | 24.02 | 89.31 | |
| ConvNeXt | Projection | 30.30 | 82.16 | 21.58 | 87.21 |
| Simple | 24.41 | 67.26 | 23.07 | 111.70 | |
| Complex | 25.94 | 89.48 | 24.60 | 134.66 | |
| ViT-Small | Projection | 19.84 | 55.81 | 14.23 | 43.83 |
| Simple | 23.08 | 66.19 | 17.46 | 78.60 | |
| Complex | 20.73 | 57.67 | 15.22 | 52.24 | |
结论
在这项工作中,我们提出了 RCC,这是第一个无参考的类不可知计数方法之一,并表明它可以在没有点级注释的情况下进行训练。 这是基于已证实的直觉,即经过良好训练的视觉 Transformer 特征既足够通用,又足够上下文感知,可以隐式理解计数的潜在基础,即对象检测和重复识别。 为了评估和比较 RCC 与其他方法,我们使用标准计数数据集 FSC-147 和我们提出的改进数据集 FSC-133。 我们在这两个数据集上证明,RCC 优于唯一的其他无参考方法,并且与当前使用完全点级监督的基于参考的类不可知计数方法具有竞争力。 我们还在 CARPK 上展示了它的跨域通用性,并且它可以在训练过程中本地化适当的对象实例,而无需任何基于位置的干预。 我们相信,由于我们不依赖对象类先验、参考图像和位置注释,我们的方法比其他计数方法具有更大的实用性,特别是当对象的组成或外观不确定时。
未来的研究可以进行多种扩展:首先,多类输出将具有明显的实用性,因为许多现实世界的应用程序将具有不同范围的对象; 第二,能够将多计数输出组织成可能的对象分组的分层系统可能有助于更好地理解当前类型的分布; 第三,对正在计数的对象类型的图像进行回归也可以帮助理解生成的计数。
参考
- Arteta et al. [2014] C. Arteta, V. Lempitsky, J. A. Noble, and A. Zisserman. Interactive object counting. In European conference on computer vision, pages 504–518. Springer, 2014.
- Bai et al. [2020] S. Bai, Z. He, Y. Qiao, H. Hu, W. Wu, and J. Yan. Adaptive dilated network with self-correction supervision for counting. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4594–4603, 2020.
- Barinova et al. [2012] O. Barinova, V. Lempitsky, and P. Kholi. On detection of multiple object instances using hough transforms. IEEE Transactions on Pattern Analysis and Machine Intelligence, 34(9):1773–1784, 2012.
- Borstel et al. [2016] M. v. Borstel, M. Kandemir, P. Schmidt, M. K. Rao, K. Rajamani, and F. A. Hamprecht. Gaussian process density counting from weak supervision. In European Conference on Computer Vision, pages 365–380. Springer, 2016.
- Cao et al. [2018] X. Cao, Z. Wang, Y. Zhao, and F. Su. Scale aggregation network for accurate and efficient crowd counting. In Proceedings of the European conference on computer vision (ECCV), pages 734–750, 2018.
- Carion et al. [2020] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko. End-to-end object detection with transformers. In European conference on computer vision, pages 213–229. Springer, 2020.
- Caron et al. [2021] M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9650–9660, 2021.
- Chan and Vasconcelos [2009] A. B. Chan and N. Vasconcelos. Bayesian poisson regression for crowd counting. In 2009 IEEE 12th international conference on computer vision, pages 545–551. IEEE, 2009.
- Cholakkal et al. [2020] H. Cholakkal, G. Sun, S. Khan, F. S. Khan, L. Shao, and L. Van Gool. Towards partial supervision for generic object counting in natural scenes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- Deng et al. [2009] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- Desai et al. [2011] C. Desai, D. Ramanan, and C. C. Fowlkes. Discriminative models for multi-class object layout. International journal of computer vision, 95(1):1–12, 2011.
- Do [2021] P. T. Do. Attention in crowd counting using the transformer and density map to improve counting result. In 2021 8th NAFOSTED Conference on Information and Computer Science (NICS), pages 65–70. IEEE, 2021.
- Dosovitskiy et al. [2020] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2020.
- Fan et al. [2020] Q. Fan, W. Zhuo, C.-K. Tang, and Y.-W. Tai. Few-shot object detection with attention-rpn and multi-relation detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4013–4022, 2020.
- Finn et al. [2017] C. Finn, P. Abbeel, and S. Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In International conference on machine learning, pages 1126–1135. PMLR, 2017.
- Go et al. [2021] H. Go, J. Byun, B. Park, M.-A. Choi, S. Yoo, and C. Kim. Fine-grained multi-class object counting. In 2021 IEEE International Conference on Image Processing (ICIP), pages 509–513. IEEE, 2021.
- He et al. [2016] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- Hsieh et al. [2017] M.-R. Hsieh, Y.-L. Lin, and W. H. Hsu. Drone-based object counting by spatially regularized regional proposal network. In Proceedings of the IEEE international conference on computer vision, pages 4145–4153, 2017.
- Kang et al. [2019] B. Kang, Z. Liu, X. Wang, F. Yu, J. Feng, and T. Darrell. Few-shot object detection via feature reweighting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8420–8429, 2019.
- Lei et al. [2021] Y. Lei, Y. Liu, P. Zhang, and L. Liu. Towards using count-level weak supervision for crowd counting. Pattern Recognition, 109:107616, 2021.
- Li et al. [2018] Y. Li, X. Zhang, and D. Chen. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1091–1100, 2018.
- Liang et al. [2021] D. Liang, X. Chen, W. Xu, Y. Zhou, and X. Bai. Transcrowd: Weakly-supervised crowd counting with transformer. arXiv preprint arXiv:2104.09116, 2021.
- Liang et al. [2022] D. Liang, W. Xu, and X. Bai. An end-to-end transformer model for crowd localization. arXiv preprint arXiv:2202.13065, 2022.
- Lin et al. [2021] H. Lin, X. Hong, and Y. Wang. Object counting: You only need to look at one. arXiv preprint arXiv:2112.05993, 2021.
- Liu et al. [2018] X. Liu, J. Van De Weijer, and A. D. Bagdanov. Leveraging unlabeled data for crowd counting by learning to rank. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7661–7669, 2018.
- Liu et al. [2022] Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, and S. Xie. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11976–11986, 2022.
- Lu et al. [2018] E. Lu, W. Xie, and A. Zisserman. Class-agnostic counting. In Asian Conference on Computer Vision, 2018.
- Marana et al. [1997] A. N. Marana, S. Velastin, L. Costa, and R. Lotufo. Estimation of crowd density using image processing. Image Processing for Security Applications, pages 1–8, 1997.
- Michaelis et al. [2018] C. Michaelis, I. Ustyuzhaninov, M. Bethge, and A. S. Ecker. One-shot instance segmentation. arXiv preprint arXiv:1811.11507, 2018.
- Mundhenk et al. [2016] T. N. Mundhenk, G. Konjevod, W. A. Sakla, and K. Boakye. A large contextual dataset for classification, detection and counting of cars with deep learning. In European conference on computer vision, pages 785–800. Springer, 2016.
- Ranjan and Hoai [2022] V. Ranjan and M. Hoai. Exemplar free class agnostic counting. arXiv preprint arXiv:2205.14212, 2022.
- Ranjan et al. [2021] V. Ranjan, U. Sharma, T. Nguyen, and M. Hoai. Learning to count everything. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3394–3403, 2021.
- Redmon et al. [2016] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016.
- Ren et al. [2015] S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 28, 2015.
- Sam et al. [2019] D. B. Sam, N. N. Sajjan, H. Maurya, and R. V. Babu. Almost unsupervised learning for dense crowd counting. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 8868–8875, 2019.
- Savner and Kanhangad [2022] S. S. Savner and V. Kanhangad. Crowdformer: Weakly-supervised crowd counting with improved generalizability. arXiv preprint arXiv:2203.03768, 2022.
- Shi et al. [2022] M. Shi, H. Lu, C. Feng, C. Liu, and Z. Cao. Represent, compare, and learn: A similarity-aware framework for class-agnostic counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9529–9538, 2022.
- Sindagi and Patel [2019] V. A. Sindagi and V. M. Patel. Ha-ccn: Hierarchical attention-based crowd counting network. IEEE Transactions on Image Processing, 29:323–335, 2019.
- Sokhandan et al. [2020] N. Sokhandan, P. Kamousi, A. Posada, E. Alese, and N. Rostamzadeh. A few-shot sequential approach for object counting. arXiv preprint arXiv:2007.01899, 2020.
- Sun et al. [2021] G. Sun, Y. Liu, T. Probst, D. P. Paudel, N. Popovic, and L. Van Gool. Boosting crowd counting with transformers. arXiv preprint arXiv:2105.10926, 2021.
- Touvron et al. [2021] H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. Jégou. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning, pages 10347–10357. PMLR, 2021.
- Vaswani et al. [2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Wang et al. [2015] C. Wang, H. Zhang, L. Yang, S. Liu, and X. Cao. Deep people counting in extremely dense crowds. In Proceedings of the 23rd ACM international conference on Multimedia, pages 1299–1302, 2015.
- Wang et al. [2022] F. Wang, K. Liu, F. Long, N. Sang, X. Xia, and J. Sang. Joint cnn and transformer network via weakly supervised learning for efficient crowd counting. arXiv preprint arXiv:2203.06388, 2022.
- Wang and Wang [2011] M. Wang and X. Wang. Automatic adaptation of a generic pedestrian detector to a specific traffic scene. In CVPR 2011, pages 3401–3408. IEEE, 2011.
- Xie et al. [2018] W. Xie, J. A. Noble, and A. Zisserman. Microscopy cell counting and detection with fully convolutional regression networks. Computer methods in biomechanics and biomedical engineering: Imaging & Visualization, 6(3):283–292, 2018.
- Yang et al. [2021] S.-D. Yang, H.-T. Su, W. H. Hsu, and W.-C. Chen. Class-agnostic few-shot object counting. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 870–878, 2021.
- Yang et al. [2020] Y. Yang, G. Li, Z. Wu, L. Su, Q. Huang, and N. Sebe. Weakly-supervised crowd counting learns from sorting rather than locations. In European Conference on Computer Vision, pages 1–17. Springer, 2020.
- Zhang et al. [2015] C. Zhang, H. Li, X. Wang, and X. Yang. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 833–841, 2015.
- Zhang et al. [2016] Y. Zhang, D. Zhou, S. Chen, S. Gao, and Y. Ma. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 589–597, 2016.
附录 A FSC-147 和 FSC-133
相似和不同的图像
测试


















Val






测试
























类似课程
Bread Rolls (训练)






Buns (训练)






Baguette Rolls (训练)





红豆 (试验)




芸豆 (训练) 





鸟 (Val)





鹤 (训练)






火烈鸟 (Val)






大雁 (训练)





海鸥 (Val)




重复差异
| Image A | Image B | Count Diff | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ID | Class | Count | Set | Id | Class | Count | Set | Abs | Rel | Kept |
| 4399 | cranes | 26 | train | 4549 | flamingos | 33 | val | 7 | 0.21 | A |
| 4399 | cranes | 26 | train | 4719 | seagulls | 33 | val | 7 | 0.21 | A |
| 2891 | caps | 144 | train | 1896 | bottle caps | 123 | val | 21 | 0.15 | B |
| 4386 | cranes | 20 | train | 7415 | birds | 23 | val | 3 | 0.13 | A |
| 6567 | pigeons | 21 | train | 929 | birds | 23 | val | 2 | 0.09 | A |
| 4664 | geese | 11 | train | 6873 | birds | 11 | val | 0 | 0.00 | A |
| 4613 | geese | 26 | train | 6714 | birds | 26 | val | 0 | 0.00 | B |
| 4350 | cranes | 8 | train | 4704 | seagulls | 8 | val | 0 | 0.00 | 4683 |
| 4350 | cranes | 8 | train | 4707 | seagulls | 8 | val | 0 | 0.00 | 4683 |
| 3506 | m&m pieces | 111 | train | 3698 | candy pieces | 111 | test | 0 | 0.00 | A |
| 3791 | kidney beans | 37 | train | 3494 | red beans | 37 | test | 0 | 0.00 | A |
| Image A | Image B | Count Diff | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ID | Class | Count | Set | Id | Class | Count | Set | Abs | Rel | Kept |
| 5223 | donuts tray | 9 | val | 5664 | donuts tray | 12 | val | 3 | 0.25 | A |
| 613 | seagulls | 7 | val | 623 | seagulls | 9 | val | 2 | 0.22 | B |
| 4399 | cranes | 26 | train | 4549 | flamingos | 33 | val | 7 | 0.21 | 4683 |
| 4399 | cranes | 26 | train | 4620 | geese | 33 | train | 7 | 0.21 | 4683 |
| 4399 | cranes | 26 | train | 4719 | seagulls | 33 | val | 7 | 0.21 | 4683 |
| 3812 | cupcakes | 10 | train | 5238 | cupcakes | 8 | train | 2 | 0.20 | B |
| 5142 | cashew nuts | 193 | test | 5801 | cashew nuts | 157 | test | 36 | 0.19 | B |
| 4634 | geese | 18 | train | 6143 | geese | 15 | train | 3 | 0.17 | A |
| 4634 | geese | 18 | train | 6669 | geese | 15 | train | 3 | 0.17 | A |
| 6850 | cereals | 25 | train | 7337 | cereals | 21 | train | 4 | 0.16 | B |
| 6839 | watches | 58 | test | 989 | watches | 69 | test | 11 | 0.16 | A |
| 1896 | bottle caps | 123 | val | 2891 | caps | 144 | train | 21 | 0.15 | A |
| 2717 | oranges | 94 | train | 6573 | oranges | 110 | train | 16 | 0.15 | A |
| 3648 | cashew nuts | 35 | test | 5141 | cashew nuts | 30 | test | 5 | 0.14 | B |
| 3014 | mini blinds | 26 | train | 7307 | mini blinds | 30 | train | 4 | 0.13 | A |
| 4386 | cranes | 20 | train | 7415 | birds | 23 | val | 3 | 0.13 | A |
| 2970 | fishes | 16 | train | 6953 | fishes | 18 | train | 2 | 0.11 | B |
| 5929 | eggs | 76 | test | 6852 | eggs | 68 | test | 8 | 0.11 | B |
| 4295 | green peas | 110 | test | 5504 | green peas | 122 | test | 12 | 0.10 | A |
| 6567 | pigeons | 21 | train | 929 | birds | 23 | val | 2 | 0.09 | A |
| 2743 | oranges | 57 | train | 7363 | oranges | 52 | train | 5 | 0.09 | B |
| 6138 | cars | 122 | train | 6864 | cars | 111 | train | 11 | 0.09 | A |
| 4220 | biscuits | 11 | train | 5422 | biscuits | 10 | train | 1 | 0.09 | B |
| 3282 | finger foods | 31 | test | 3285 | finger foods | 34 | test | 3 | 0.09 | A |
| 3462 | beads | 92 | train | 5638 | beads | 85 | train | 7 | 0.08 | A |
| 4040 | beads | 117 | train | 5760 | beads | 108 | train | 9 | 0.08 | A |
| 3492 | polka dots | 25 | val | 5738 | polka dots | 27 | val | 2 | 0.07 | A |
| 3486 | polka dots | 81 | val | 5740 | polka dots | 87 | val | 6 | 0.07 | A |
| 6917 | cereals | 29 | train | 7353 | cereals | 27 | train | 2 | 0.07 | B |
| 5209 | donuts tray | 17 | val | 5656 | donuts tray | 16 | val | 1 | 0.06 | B |
| 4013 | beads | 115 | train | 5754 | beads | 108 | train | 7 | 0.06 | B |
| 524 | geese | 30 | train | 635 | cranes | 32 | train | 2 | 0.06 | B |
| 4300 | green peas | 83 | test | 5506 | green peas | 88 | test | 5 | 0.06 | A |
| 3287 | macarons | 16 | train | 428 | macarons | 17 | train | 1 | 0.06 | A |
| 4634 | geese | 18 | train | 4675 | geese | 17 | train | 1 | 0.06 | A |
| 6602 | pencils | 38 | train | 7400 | pencils | 36 | train | 2 | 0.05 | B |
| 3475 | beads | 108 | train | 5637 | beads | 103 | train | 5 | 0.05 | A |
| 2357 | bricks | 276 | train | 2401 | bricks | 263 | train | 13 | 0.05 | B |
| 4044 | beads | 115 | train | 5335 | beads | 109 | train | 6 | 0.05 | A |
| 4019 | beads | 105 | train | 5771 | beads | 109 | train | 4 | 0.04 | A |
| 4049 | beads | 26 | train | 5755 | beads | 27 | train | 1 | 0.04 | B |
| 3956 | candles | 46 | train | 5309 | candles | 44 | train | 2 | 0.04 | B |
| 3969 | candles | 23 | train | 5317 | candles | 24 | train | 1 | 0.04 | A |
| 3950 | candles | 24 | train | 5312 | candles | 25 | train | 1 | 0.04 | A |
| 3020 | mini blinds | 34 | train | 7630 | mini blinds | 35 | train | 1 | 0.03 | A |
| 3668 | toilet paper rolls | 31 | val | 5154 | toilet paper rolls | 32 | val | 1 | 0.03 | A |
| 3679 | buns | 35 | train | 5026 | bread rolls | 36 | train | 1 | 0.03 | A |
| 4014 | beads | 108 | train | 5749 | beads | 105 | train | 3 | 0.03 | A |
| 3645 | cashew nuts | 60 | test | 5797 | cashew nuts | 58 | test | 2 | 0.03 | A |
| 5148 | cashew nuts | 36 | test | 5803 | cashew nuts | 35 | test | 1 | 0.03 | A |
| 7640 | apples | 32 | test | 7665 | apples | 33 | test | 1 | 0.03 | B |
| 3819 | cupcakes | 36 | train | 5241 | cupcakes | 35 | train | 1 | 0.03 | B |
| 3754 | pearls | 131 | train | 5185 | pearls | 127 | train | 4 | 0.03 | B |
| 3666 | toilet paper rolls | 32 | val | 5157 | toilet paper rolls | 31 | val | 1 | 0.03 | B |
| 3639 | jade stones | 31 | train | 5134 | jade stones | 32 | train | 1 | 0.03 | A |
| 6200 | coins | 52 | train | 6228 | coins | 53 | train | 1 | 0.02 | A |
| 267 | beads | 59 | train | 3242 | beads | 60 | train | 1 | 0.02 | A |
| 6798 | birds | 87 | val | 976 | birds | 85 | val | 2 | 0.02 | B |
| 3795 | kidney beans | 53 | train | 5547 | kidney beans | 52 | train | 1 | 0.02 | B |
| 3955 | candles | 60 | train | 5306 | candles | 61 | train | 1 | 0.02 | A |
| 2671 | bowls | 60 | train | 6724 | bowls | 59 | train | 1 | 0.02 | B |
| 6738 | mini blinds | 53 | train | 7130 | mini blinds | 52 | train | 1 | 0.02 | B |
| 5053 | beads | 139 | train | 5644 | beads | 136 | train | 3 | 0.02 | B |
| 3426 | polka dots | 219 | val | 5046 | polka dots | 215 | val | 4 | 0.02 | B |
| 3122 | coffee beans | 90 | train | 3134 | coffee beans | 89 | train | 1 | 0.01 | B |
| 6961 | cartridges | 178 | train | 7680 | cartridges | 179 | train | 1 | 0.01 | A |
| 4016 | beads | 109 | train | 5333 | beads | 108 | train | 1 | 0.01 | B |
| 3469 | beads | 74 | train | 5050 | beads | 75 | train | 1 | 0.01 | A |
| 4021 | beads | 106 | train | 5759 | beads | 107 | train | 1 | 0.01 | B |
| 5149 | cashew nuts | 111 | test | 5807 | cashew nuts | 110 | test | 1 | 0.01 | B |
| 4044 | beads | 115 | train | 5767 | beads | 116 | train | 1 | 0.01 | A |
FSC-147 和 FSC-133 类别划分
| Train | ||||
| alcohol bottles | baguette rolls | balls | bananas | beads |
| bees | birthday candles | biscuits | boats | bottles |
| bowls | boxes | bread rolls | bricks | buffaloes |
| buns | calamari rings | candles | cans | caps |
| cars | cartridges | cassettes | cement bags | cereals |
| chewing gum pieces | chopstick | clams | coffee beans | coins |
| cotton balls | cows | cranes | crayons | croissants |
| crows | cupcake tray | cupcakes | cups | fishes |
| geese | gemstones | go game | goats | goldfish snack |
| ice cream | instant noodles | jade stones | jeans | kidney beans |
| kitchen towels | lighters | lipstick | m&m pieces | macarons |
| matches | meat skewers | mini blinds | mosaic tiles | naan bread |
| nails | nuts | onion rings | oranges | pearls |
| pencils | penguins | pens | people | peppers |
| pigeons | plates | polka dot tiles | potatoes | rice bags |
| roof tiles | screws | shoes | spoon | spring rolls |
| stairs | stapler pins | straws | supermarket shelf | swans |
| tomatoes | watermelon | windows | zebras | |
| Val | ||||
| ants | birds | books | bottle caps | bullets |
| camels | chairs | chicken wings | donuts tray | flamingos |
| flower pots | flowers | fresh cut | grapes | horses |
| kiwis | milk cartons | oyster shells | oysters | peaches |
| pills | polka dots | prawn crackers | sausages | seagulls |
| shallots | shirts | skateboard | toilet paper rolls | |
| Test | ||||
| apples | candy pieces | carrom board pieces | cashew nuts | comic books |
| crab cakes | deers | eggs | elephants | finger foods |
| green peas | hot air balloons | keyboard keys | legos | marbles |
| markers | nail polish | potato chips | red beans | sauce bottles |
| sea shells | sheep | skis | stamps | sticky notes |
| strawberries | sunglasses | tree logs | watches | |
重复图像集
相同图像集 [1896, 2891], [19, 3092], [20, 3093], [22, 3094], [23, 3095], [26, 3097], [267, 3242], [269, 3255], [27, 3098], [9, 3084], [3282, 3285], [427, 3286], [428, 3287], [429, 3288], [3353, 5033, 5717], [3361, 5036], [3362, 5027], [3370, 5722], [3372, 5734], [3375, 5716], [3392, 5732], [3397, 5035], [3400, 3687] , [3426, 5046], [3462, 5638], [3465, 5643], [3469, 5050], [3472, 5761], [3475, 5637], [3486, 5740], [3492, 5738], [ 3494, 3791], [3521, 5079], [3522, 5097], [3531, 5089], [3534, 5093], [3535, 5073], [3538, 5064], [3540, 5084], [3542, 5071], [3543, 5098], [3544, 5085], [3546, 5068], [3549, 5076], [3553, 5095], [3556, 3564, 5069], [3558, 5078], [3562, 5114], [3565, 5115], [3570, 5086, 5107], [3578, 5082, 5117], [3585, 5108], [3587, 5110], [3592, 5111], [3607, 5125], [ 3625, 5136], [3626, 5126], [3627, 5518], [3628, 5129], [3639, 5134, 5528], [3644, 5794], [3645, 5797], [3646, 5145], [ 3647, 5144], [3648, 5141], [3652, 5147, 5806], [3656, 5798], [3666, 5157], [3668, 5154], [3669, 5152], [3671, 5153], [ 3672, 5156], [3675, 5155], [3679, 5026], [3754, 5185], [3759, 5229], [3760, 5221], [3762, 5203], [3764, 5670], [3766, 5202], [3767, 5228, 5673], [3768, 5211, 5655], [3769, 5220], [3772, 5213, 5659], [3773, 5201, 5671], [3775, 5215], [3778, 5212, 5661], [3781, 5217], [3782, 5210], [3790, 5230, 5548], [3793, 5233], [3795, 5547], [3800, 5235, 5553], [3812, 5238] , [3815, 5247], [3816, 4196, 5257], [3818, 5243], [3819, 5241], [3824, 5253], [3833, 5254], [3950, 5312], [3955, 5306] , [3956, 5309], [3959, 5320], [3964, 5307], [3969, 5317], [3995, 5355], [4013, 5754], [4014, 5749], [4016, 5333], [ 4019, 5771], [4021, 5759], [4040, 5760], [4044, 5335, 5767], [4049, 5755], [4052, 5334], [4114, 5391], [4134, 5393], [ 4147, 5398], [4159, 5407], [4197, 5419], [4205, 5436], [4206, 5437], [4218, 5434], [4220, 5422], [4241, 5448], [4248, 5446], [4262, 5780], [4290, 5458], [4300, 5506], [4337, 4666], [4373, 4692], [4374, 4392], [4375, 4683, 4707], [4377, 4658]、[4399、4549]、[4620、4719]、[5023、5712]、[5034、5727]、[5044、5746]、[5053、5644]、[5090、5113]、[5101、5106] , [5122, 5680], [5142, 5801], [5148, 5803], [5149, 5807], [5200, 5666], [5204, 5662], [5207, 5667], [5209, 5656], [ 5214, 5658], [524, 635], [5278, 5332], [5344, 5750], [5411, 5609], [5460, 5503], [6917, 7353], [7640, 7665]
设置重复图像 [3184, 3198], [3628, 5129], [3565, 5115], [3648, 5141], [4019, 5771], [3020, 7630], [3646, 5145 ], [6567, 929], [3362, 5027], [3800, 5235, 5553], [3666, 5157, 5151], [6554, 6566], [4238, 4243], [4049, 5755], [3638 , 5525], [3587, 5110], [3286, 427], [3542, 5071], [3818, 5243], [4350, 4375, 4683, 4704, 4707, 6684], [6200, 6228], [3534 , 5093], [3553, 5095], [267, 3242], [2895, 7441], [4534, 4570], [3947, 5318], [6798, 976], [3795, 5547], [3668, 5154 ], [2674, 6759], [3824, 5253], [5460, 5503], [3288, 429], [3679, 5026], [3543, 5098], [3955, 5306], [5209, 5656], [3647, 5144], [4014, 5749], [3522, 5097], [3556, 3564, 5069], [4044, 5335, 5767], [3762, 5203], [3759, 5229], [3675, 5155 ], [4262, 5780], [3778, 5212, 5661], [4013, 5754], [5207, 5667], [4241, 5448], [6602, 7400], [5452, 5779], [3535, 5073 ], [3781, 5217], [3956, 5309], [3014, 7307], [4248, 5446], [3392, 5732], [4664, 6873], [2743, 7363], [524, 635], [3531, 5089], [1896, 2891], [5200, 5666], [3969, 5317], [3492, 5738], [3816, 4196, 5257], [5090, 5113], [5142, 5801], [5278, 5332], [4206, 5437], [3375, 5716], [3549, 5076], [6850, 7337], [5344, 5750], [3949, 3960], [5101, 5106], [3122 , 3134], [3084, 9], [3782, 5210], [4399, 4549, 4620, 4719], [3544, 5085], [4244, 5777], [5204, 5662], [3717, 5161], [4147, 5398], [4377, 4658], [2671, 6724], [6743, 7506], [3353, 5033, 5717], [3743, 5168], [6138, 6864], [3361, 5036], [3656, 5798], [2009, 2038], [6961, 7680], [4337, 4666], [3833, 5254], [4218, 5434], [3475, 5637], [3645, 5797], [6006 , 6010], [4300, 5506], [3627, 5518], [3287, 428], [6280, 7538], [4016, 5333], [5223, 5664], [3570, 5086, 5107], [3626 , 5126, 5519], [5148, 5803], [5411, 5609], [4373, 4692], [3486, 5740], [3793, 5233], [3546, 5068], [3370, 5722], [3767 , 5228, 5673], [4220, 5422], [3773, 5201, 5671], [22, 3094], [6738, 7130], [3397, 5035], [3585, 5108], [2717, 6573], [2970, 6953], [2357, 2401], [3672, 5156], [5053, 5644], [5122, 5680], [3775, 5215], [26, 3097], [3540, 5084], [6198 , 6226], [6834, 6870], [19, 3092], [4134, 5393], [3644, 5794], [27, 3098], [3815, 5247], [3760, 5221], [4114, 5391 ], [3959, 5320], [4197, 5419], [4386, 7415], [7640, 7665], [3639, 5134, 5528], [3768, 5211, 5655], [3462, 5638], [3812 , 5238], [2289, 7172], [3671, 5153], [3995, 5355], [269, 3255], [5034, 5727], [1949, 6765], [3629, 5128], [3521, 5079 ], [4629, 547], [4290, 5458], [3372, 5734], [3625, 5136], [3950, 5312], [5023, 5712], [4159, 5407, 5604], [4295, 5504 ], [3469, 5050], [3607, 5125], [5929, 6852], [3426, 5046], [3578, 5082, 5117], [3506, 3698], [3669, 5152], [3554, 5092 ], [3494, 3791], [3769, 5220], [3764, 5670], [5044, 5746], [4374, 4392], [3558, 5078], [6839, 989], [3465, 5643], [3538, 5064], [4040, 5760], [23, 3095], [4613, 6714], [20, 3093], [4021, 5759], [4357, 4380], [3652, 5147, 5806], [3282, 3285], [4052, 5334], [5149, 5807], [3964, 5307], [3766, 5202], [5214, 5658], [6917, 7353], [613, 623], [3772 , 5213, 5659], [3562, 5114], [3400, 3687], [3790, 5230, 5548], [4205, 5436], [3592, 5111], [3819, 5241], [3472, 5761], [4634, 4675, 6143, 6669], [3723, 5616], [3958, 5313], [3754, 5185]
附录 B平铺增强消融。
我们通过测试各种频率和平铺配置来验证图像平铺增强的使用,如表 9 所示。 我们发现引入更密集的 (44) 平铺效果较小。 在这种平铺密度下,每个对象实例在整个图像中都非常小,因此它不再是可解释的,几乎没有提供有意义的训练。
| Val Set | Test Set | |||
|---|---|---|---|---|
| Frequency | MAE | RMSE | MAE | RMSE |
| (22) | ||||
| 75% | 20.10 | 60.23 | 13.72 | 31.26 |
| 50% | 19.84 | 55.81 | 14.23 | 43.83 |
| 25% | 20.95 | 64.44 | 14.98 | 47.08 |
| 0% | 21.76 | 68.68 | 15.72 | 77.07 |
| (44) or (22) | ||||
| 75% | 20.73 | 63.21 | 13.38 | 38.61 |
| 50% | 20.00 | 65.08 | 15.44 | 37.47 |
| 25% | 20.51 | 63.73 | 15.71 | 42.77 |
| 0% | 21.76 | 68.68 | 15.72 | 77.07 |