PLoG:用于逻辑表到文本生成的表到逻辑预训练
摘要
逻辑表到文本生成是一项涉及从表生成逻辑上忠实的句子的任务,这需要模型通过逻辑推理从表记录中导出逻辑级事实。 它对表到文本模型的逻辑层内容规划提出了新的挑战。 然而,由于自然语言的歧义性和并行数据的稀缺性,直接从表文本对中学习逻辑推理知识对于神经模型来说非常困难。 因此,即使是大规模的预训练语言模型,逻辑表到文本的逻辑保真度也很低。 在这项工作中,我们提出了一种预训练逻辑形式生成器(PLoG)框架来提高生成保真度。 具体来说,PLoG 首先在表到逻辑形式生成(表到逻辑)任务上进行预训练,然后在下游表到文本任务上进行微调。 逻辑形式是用明确的语义正式定义的。 因此,我们可以从没有人类标注的表格中收集大量准确的逻辑形式。 此外,PLoG 可以比从表-文本对更可靠地从表-逻辑对学习逻辑推理。 为了评估我们的模型,我们根据现有数据集进一步收集受控逻辑表到文本数据集 ContLog。 在 LogicNLG 和 ContLog 两个基准测试中,PLoG 在逻辑保真度方面大幅优于强基线,证明了表到逻辑的有效性预训练。
1简介
表到文本生成是数据到文本生成的子任务,旨在从结构化表生成自然语言描述。 执行表格到文本的生成有两个主要步骤:内容规划(选择表格内容并确定描述它们的计划)和表面实现(将计划表述为流畅的自然语言)。 传统的表到文本系统采用管道架构,用单独的模块完成两个过程Kukich (1983);麦基翁(1985)。 最近的工作显示了使用神经编码器-解码器模型直接从表格生成句子的优势,这提供了生成流畅自然文本的强大能力 Wiseman 等人 (2017);聂等人 (2018); Puduppully 等人 (2019b)。 研究人员还尝试在下游表到文本任务上对 BART Lewis 等人 (2020) 和 T5 Raffel 等人 (2020) 等预训练语言模型进行微调,并实现了在广泛的基准测试中取得了显着的成功 Xie 等人 (2022);羽衣甘蓝和拉斯托吉 (2020)。
以往的研究主要集中在表层实现,即简单地用自然语言重述表层事实 Wiseman 等人 (2017);刘等人 (2018); Puduppully 等人 (2019a, b). 最近,逻辑表到文本生成Chen 等人(2020a),即生成需要对表中表面事实进行逻辑推理的文本描述,引起了越来越多的关注。 逻辑表到文本的生成对逻辑级内容规划提出了新的挑战,要求模型执行逻辑推理以从表层表记录中导出事实。 端到端神经模型在该任务上通常会遇到逻辑保真度较低的问题,即生成的句子尽管具有合理的流畅性 Chen 等人 (2020a, 2021),但在逻辑上并不包含在表格中。 我们将此归因于自然语言目标句子的歧义性阻碍了神经模型从表文本对中学习准确的逻辑推理。 此外,由于以逻辑为中心的描述需要耗费大量人力,因此此类表格文本对的数量受到限制,这也限制了神经模型的性能。
为了实现逻辑级生成的高保真度,Chen 等人(2020b)尝试注释逻辑形式来指导文本生成,并提出了Logic2text数据集。 通过逻辑形式作为传达准确的逻辑级事实的中介,模型可以专注于相关逻辑形式的表面实现并实现高保真度。 然而,为文本描述注释准确的逻辑形式需要大量的人类努力。 此外,从自包含的逻辑形式生成实际上是与表到文本生成不同的任务。 对该数据集的先前研究Liu 等人 (2021a);舒 等人 (2021); Xie等人(2022)主要关注将逻辑形式转换为文本,而不是表格转换为文本。
在本研究中,我们提出了一种P重新训练的逻辑形式G生成器(PLoG)模型来实现更忠实的逻辑表到文本。 具体来说,PLoG首先在表到逻辑形式生成(table-to-logic)的大规模合成语料库上进行预训练,以学习如何生成准确的逻辑从表格中生成表格,然后在下游的表格到文本任务上进行微调,以将从预中学到的逻辑推理知识转移到文本生成中。 我们的见解有三个方面。 (i) 与自然语言句子不同,逻辑形式是用明确的语义进行正式定义的;因此,模型通过学习逻辑形式生成来获取逻辑推理知识更加容易和可靠。 (ii) 无需人工注释者的努力,通过基于规则的表格采样来收集大规模逻辑形式语料库是可行的。 (iii)通过对大量表格到逻辑数据的预训练,所提出的模型可以更好地理解表格并组织逻辑级内容规划,从而实现忠实的表格到文本生成。 在这里,我们将逻辑形式视为逻辑级别文本的中间含义表示,而在执行下游任务时不需要它们。 为了收集预训练数据,我们提出了一种执行引导的采样方法,可以自动从表中采样准确的逻辑形式。
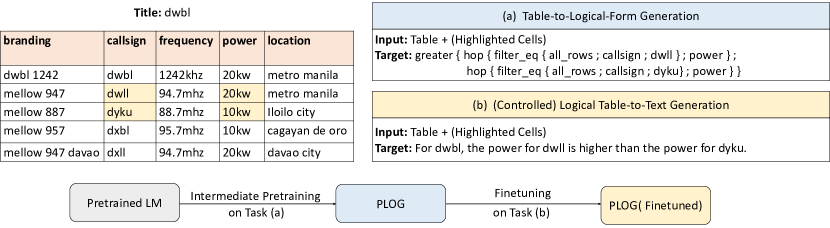
我们在相同的序列到序列(seq2seq)生成中制定预训练任务,以实现到下游表到文本任务的平滑迁移学习。 我们采用几种强大的预训练语言模型,BART 和 T5 作为骨干模型。 由于之前逻辑表转文本的基准测试LogicNLG缺乏控制功能,导致内容选择不可控,逻辑保真度较差,因此我们收集了一个新的Cont滚动逻辑自然语言生成 (ContLog) 数据集作为受控逻辑表到文本生成的补充测试平台。 具体来说,我们通过根据带注释的逻辑形式检测突出显示的单元格来重新组织 Logic2text 数据集。 图1展示了表到逻辑预训练任务和(受控)逻辑表到文本任务的示例。
在LogicNLG和ContLog两个基准上,PLoG在逻辑保真度上大幅优于T5等强基线,证明了有效性表到逻辑的预训练。 人类评估和分析实验进一步证明,我们的方法可以显着提高逻辑表到文本生成的保真度。111通过内部合规性审核后,代码和数据将在 https://github.com/microsoft/PLOG 上提供。
2相关工作
表到文本的生成
早期的表格到文本生成任务仅限于表层生成,很少关注逻辑推理Lebret等人(2016)。 LogicNLG 是第一个专注于逻辑表到文本生成的数据集,具有维基百科表和人工注释的逻辑描述。 Chen等人(2021)提出了一种去混杂的变分编码器-解码器模型,以鼓励模型生成非表面级别的预测;然而,没有明确考虑逻辑推理过程,导致人类评估的保真度分数较低。 Chen 等人(2020b)提出通过注释逻辑形式来指导生成,并发布了Logic2text数据集。 在这项工作中,我们专注于直接逻辑表到文本的生成,而不需要任何显式的逻辑形式。 另一个相关的数据集是 ToTTo Parikh 等人 (2020) 和 HiTab Cheng 等人 (2021),它们合并了突出显示的单元格以促进可控生成。 我们提出的 ContLog 数据集与这些数据集的任务设置类似,但不同之处在于我们专注于逻辑级别的生成。 同时,ToTTo和HiTab中只有一小部分示例涉及逻辑推理。 ROTOWIRE Wiseman 等人 (2017) 和 NumericNLG Suadaa 等人 (2021) 也涉及对表记录的数值推理,但它们专注于文档级表摘要而不是句子生成。
表预训练
表 预训练 Eisenschlos 等人 (2020);刘等人 (2021b);董等人 (2022); Iida 等人 (2021) 在表格理解任务中很受欢迎,例如表格问答 (TableQA) Zhong 等人 (2017); Pasupat 和梁 (2015) 和表事实验证 (TableFV) Chen 等人 (2019)。 借助大规模预训练语料库,表格预训练模型可以通过明确定义的预训练目标更好地联合理解表格和文本数据。 大多数表预训练工作都是基于表文本语料库,而 TaPEx Liu 等人 (2021b) 从合成 SQL 程序中学习,这与我们的工作最接近。 具体来说,TaPEx首先在基于表的SQL执行任务上进行预训练,其中输入是表和SQL程序,输出是SQL查询的答案。 然后,可以在 TableQA 和 TableFV 任务上对预训练模型进行微调,其中输入是与文本查询/语句关联的表,输出是答案。 然而,我们的工作与TaPEx不同,我们专注于表到文本的生成,其中输入是结构化表,输出是表内容的文本语句。 我们的任务需要在没有任何查询指导的情况下从表中导出完整的逻辑级事实。 此外,我们的预训练任务还需要从表中生成一个独立的逻辑形式,而TaPEx旨在学习现有SQL程序的神经执行。 同样,FLAP Anonymous (2021)提出通过人工预训练任务来增强表到文本模型的数值推理能力。 该任务是一个类似于 TaPEx 预训练的综合 QA 任务。
另一系列相关工作采用预训练技术来解决文本到 SQL 的解析 Yu 等人 (2021); Shi 等人 (2021) 任务,还涉及收集 SQL 生成任务的合成 SQL 数据和预训练模型。 然而,文本转 SQL 仍然需要显式的 NL 查询作为输入,这与我们的任务不同。 尽管表预训练在表格理解任务中很流行,但它在表到文本方面尚未得到很好的探索。 之前关于表到文本的工作倾向于通过将结构化表扁平化为序列来直接利用预训练的语言模型Gong 等人 (2020);羽衣甘蓝和拉斯托吉 (2020);谢等人(2022)。 最近的工作 Andrejczuk 等人 (2022) 将表的结构位置嵌入合并到 T5 Raffel 等人 (2020) 中,并以与 类似的方式执行中间预训练TaPas Eisenschlos 等人 (2020)。 同样,PLoG也可以看作是表到文本生成的语言模型的中间预训练。
3 下游任务
在这项工作中,我们关注逻辑表到文本。 之前的基准测试LogicNLG旨在从没有控制特征的全表生成句子,这会导致内容选择不可控并阻碍忠实生成Chen等人(2020b)。 因此,我们提出了一个新的受控逻辑表到文本数据集ContLog作为LogicNLG的补充测试平台。 受到之前关于受控表格到文本的研究的启发 Parikh 等人 (2020); Cheng等人(2021),我们将突出显示的单元格作为ContLog中的附加监督信号(图1)来缩小内容选择的范围,这样模型可以更多地关注规划和生成。
3.1 ContLog数据集构建
我们重用Logic2text数据集来构建ContLog。 在Logic2text中,每个目标句子都有一个带注释的逻辑形式。 逻辑形式可以准确地传达句子的逻辑语义。 因此,我们在上下文表上执行逻辑形式并提取与执行过程相关的表单元格。 这些单元格也是与目标句子最相关的单元格。 ContLog 虽然建立在 Logic2text 的基础上,但并不包含逻辑表格,因为我们关注的是直接从表格到文本的生成。 图1显示了ContLog的示例。
3.2 任务制定
LogicNLG 的输入是带有 NL 标题 的表格 。,其中 和 分别是行数和列数, 是行 和列 处的表格单元格值。 每列还有一个列标题 。 输出是一个句子。 任务目标是找到一个模型来生成句子,该句子既流畅又符合表格的逻辑。 在 ContLog 中,包含一组附加的突出显示单元格 作为输入的一部分,其中 和 表示突出显示单元格的行索引和列索引。 目标因此变为。
4 表格到逻辑预训练
逻辑表到文本的困难主要是因为自然语言句子的歧义性。 例如,句子Alice was the firstplayer that Achievement in 2010有两种可能的含义:(1)Alice get the first Champion of 2010; (2) 爱丽丝成为历史上第一位冠军,这一成就发生在2010年。 这会阻止端到端神经模型从表中推断出明确的逻辑事实,尤其是在并行数据稀缺的情况下。
为了实现忠实的逻辑表到文本生成,我们提出了一个表到逻辑预训练任务,其中涉及从输入表生成逻辑形式。 在此任务中,模型需要从表中挖掘逻辑级事实,并将事实组织成正式定义的含义表示,即逻辑形式。 每个逻辑形式都可以被视为一个逻辑层次描述的摘要内容计划。 因此,我们期望模型能够从预训练任务中学习逻辑级别的内容规划。 然后,我们在下游表到文本任务上微调模型,以将内容规划推广到自然语言生成。 我们将预训练和下游任务制定为相同的 seq2seq 生成范例,以实现成功的迁移学习。
4.1 预训练任务制定
预训练任务的输入与我们在3.2节中介绍的相同(子)表,而目标是逻辑形式而不是句子。 我们在 Logic2text 中遵循相同的模式来定义任务中使用的逻辑形式。 每个逻辑形式都是若干逻辑函数的组合。 每个函数接受与表相关的多个参数。 可以被解析成一棵树,并由逻辑表单执行器从下到上执行。 在此过程中,的执行结果可以作为参数传递给其父函数。 root 函数始终输出一个布尔值(true 或 false),指示 的事实正确性。 我们选择这个模式是因为它有几个优点。 (1)它最初是为了表示Logic2text中逻辑级别的文本语句而设计的,它的定义与我们的下游任务很接近。 TableFV 任务也使用了类似的模式 Ou 和 Liu (2022);陈等人(2019). (2)它涵盖了七种最常用的逻辑类型:计数、唯一、比较、最高级、序数、聚合和多数。 (3)逻辑形式可以在表格上执行,以评估其精确的正确性,从而可以准确评估预训练任务。 附录B中提供了逻辑模式的详细描述。
4.2Table-to-Logic的评估指标
我们采用生成逻辑形式的执行准确性作为预训练任务的评估指标,类似于文本转SQL任务Zhong等人(2017)中的设置。 具体来说,如果逻辑形式可以在输入表上成功执行并返回一个布尔值 True 来指示该表包含它,则该逻辑形式被视为正确。
4.3预训练数据收集
为了进行表到逻辑的预训练,我们必须收集足够的表和相关逻辑形式的配对数据。 逻辑形式的正式定义允许我们通过基于规则的采样自动从表中收集大量逻辑形式。 在这里,我们建议实例化现有的逻辑表单模板来采样逻辑表单,类似于之前的研究如何收集 SQL 程序 Zhong 等人 (2020);刘等人(2021b)。 具体来说,我们从我们使用的逻辑模式中提取摘要模板。 然后,我们采用执行引导采样方法来实例化基于上下文表的模板。 我们的方法有两个优点:(1)通过利用预定义的模板,我们可以控制收集的逻辑形式的分布和多样性。 (2)通过执行引导采样,保证了采集到的逻辑形式的正确性。
模板化
实例化
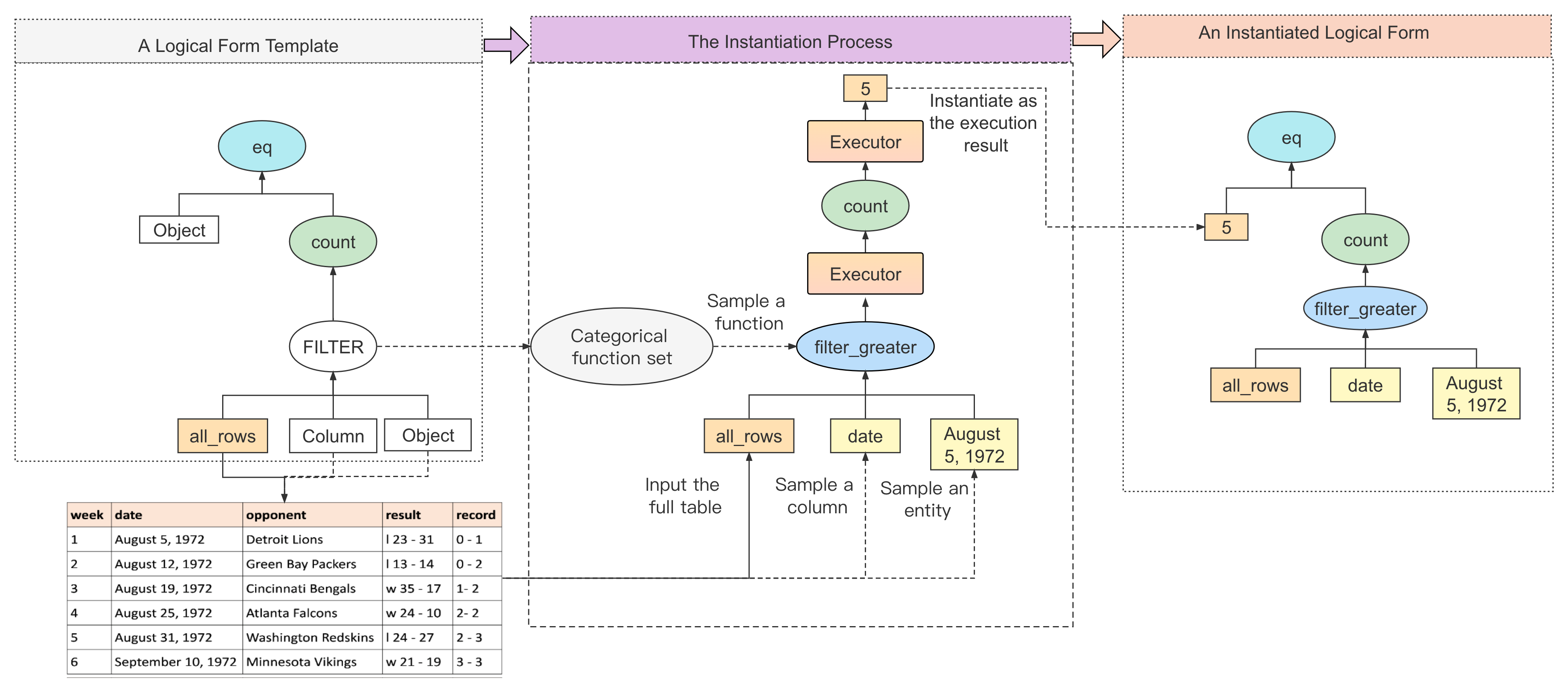
我们提出了一种执行引导的自下而上采样策略来实例化模板树。 图2描述了模板实例化的示例。 我们设计规则通过采样实例化不同的占位符节点。 例如,我们从表中统一采样一列来实例化一个Column占位符(例如图2中的date)。 对于诸如 FILTER 这样的函数占位符,我们从它所代表的相应类别中采样特定函数(例如图2中的filter_greater)。 对于每个实例化的函数节点,我们执行它,获取执行结果并将结果作为参数提供给父函数。 因此,保证高级函数的参数是有效的。 该过程自下而上进行,直至执行完根函数节点。 我们在附录C中提供了详细的抽样规则。对于每个表,我们进行多次抽样试验。 在每次试验中,我们根据其在 Logic2text 中的分布随机选择一个模板,并执行实例化。 由于选择函数和实体的随机性,我们可以从多次试验中得到不同的结果。 尝试有时可能会因为执行错误而失败,但每次成功的尝试都会产生正确的逻辑形式。 我们可以进行任意多次的采样试验,以获得大规模的表到逻辑语料库。
表源和数据收集
我们分别收集两个数据集 LogicNLG 和 ContLog 的预训练数据。 对于每个数据集,我们使用其训练数据中的表作为源表,以避免潜在的数据泄漏。 此外,我们删除了Logic2text中出现的采样逻辑形式,因为它们在语义上与ContLog中的一些目标句子相同。 为了评估表到逻辑模型的性能并允许选择预训练模型,我们还将收集的逻辑形式拆分为训练/验证/分割集。 预训练数据及其对应的下游数据集统计如表1所示。 虽然我们可以通过更多的试验来采样更多的逻辑形式,但我们发现当前的预训练数据足以获得理想的实验结果。
| Dataset | #tables | #examples (train/val/test) |
|---|---|---|
| LogicNLG | 7,392 | 28,450/4,260/4,305 |
| ContLog | 5,554 | 8,566/1,095/1,092 |
| LogicNLG (pretrain) | 5,682 | 426.6k/3,000/2,997 |
| ContLog (pretrain) | 4,554 | 800k/1,500/1,500 |
5 PLoG 模型
在本节中,我们介绍我们提出的模型 PLoG 以及我们如何为预训练和下游任务进行 seq2seq 生成。
骨干模型
我们利用相同的主干模型来解决这两个任务,以实现从表到逻辑预训练任务到表到文本下游任务的知识迁移。 理论上,任何文本生成模型都适用于我们的任务,例如 GPT-2 Radford 等人 (2019)、BART 和 T5。 我们测试了不同的骨干模型,包括 BART-large、T5-base 和 T5-large。
模型输入
与之前关于表格到文本生成的工作类似 Kale 和 Rastogi (2020); Parikh等人(2020),我们采用基于模板的方法来序列化输入表。 对于 LogicNLG 任务,我们按照 Chen 等人 (2020a) 通过按行顺序连接表格单元格来对相关表格列进行编码。 对于 ContLog,我们仅连接突出显示的表格单元格作为输入,正如先前有关受控表格到文本生成的工作Parikh 等人 (2020) 所建议的那样。 这是为了避免预训练模型过长的问题以及不相关的表信息造成的负面影响。
数值预计算
数值推理对于神经语言模型来说很困难,尤其是聚合操作(例如数值的平均值)和数值排序(例如列的第 n 个最大值)。 因此,我们通过预先计算一些可能有用的数值来进行预处理步骤。 类似的方法也被提出来提高表摘要 Suadaa 等人 (2021) 和文本到 SQL 任务 Zhao 等人 (2022) 的保真度。 首先,我们评估每个数字单元格在其列(或突出显示单元格的范围)中的排名,并将该排名附加到线性化单元格表示中。 因此,每个表格单元格可以被序列化为一个序列 <cell> <col_header> </col_header> <row_idx> </row_idx> <max_rank> </max_rank> <min_rank>; </min_rank> </cell>,其中 表示 在 列中按递减顺序排列的名次, 是按递增顺序排列的名次。 带尖括号的特殊标记用于指示输入的结构。 此外,我们计算输入(子)表中每个数字列的平均值和总和,并将两个聚合单元格字符串 和 附加到展平的表序列中。 = <sum_cell>/<avg_cell> sum_value/avg_value <col_header> </col_header></sum_cell>/</avg_cell>。
最后,输入(子)表被序列化为 = <table> <caption> </caption> ... ... </table>.
模型输出
我们通过对 Chen 等人 (2020b) 之后的逻辑树进行前序遍历,将每个逻辑形式 线性化为字符串。 分号和大括号等特殊标点符号用于指示函数之间的结构关系。 例如,图2中的逻辑形式实例可以线性化为eq { 5 ;计数 { 过滤器_更大 { all_rows ;日期 ; 1972 年 8 月 5 日} } }。 至于下游任务,输出变成一个句子。 预训练 PLoG 模型后,我们通过将目标从逻辑形式更改为句子,直接在下游表到文本任务上对其进行微调。
6实验
| Model | Surface-level Evaluation | Logical Fidelity | |||||
|---|---|---|---|---|---|---|---|
| BLEU-1 | BLEU-2 | BLEU-3 | SP-Acc | NLI-Acc | TaPEx-Acc | TaPas-Acc | |
| GPT-TabGen (sm) | 48.8 | 27.1 | 12.6 | 42.1 | 68.7 | 46.0 | 45.5 |
| GPT-Coarse-to-Fine (sm) | 46.6 | 26.8 | 13.3 | 42.7 | 72.2 | 44.6 | 45.6 |
| DCVED + GPT-TabGen | 49.5 | 28.6 | 15.3 | 43.9 | 76.9 | – | – |
| T5-base | 52.6 | 32.6 | 19.3 | 48.2 | 80.4 | 52.4 | 56.2 |
| PLoG (T5-base) | 51.7 | 32.3 | 18.9 | 48.9 | 85.5 | 61.7 | 62.3 |
| T5-large | 53.4 | 34.1 | 20.4 | 48.4 | 85.9 | 65.5 | 66.2 |
| PLoG (T5-large) | 53.7 | 34.1 | 20.4 | 54.1 | 89.0 | 75.9 | 76.0 |
| BART-large | 54.5 | 34.6 | 20.6 | 49.6 | 85.4 | 63.3 | 67.1 |
| PLoG (BART-large) | 54.9 | 35.0 | 21.0 | 50.5 | 88.9 | 73.7 | 74.4 |
| Model | Surface-level Evaluation | Logical Fidelity | |||||
|---|---|---|---|---|---|---|---|
| BLEU-4 | ROUGE-1 | ROUGE-2 | ROUGE-4 | ROUGE-L | TaPEx-Acc | TaPas-Acc | |
| T5-base | 29.7 | 60.2 | 36.4 | 16.4 | 50.2 | 67.4 | 64.8 |
| PLoG (T5-base) | 30.4 | 61.4 | 37.3 | 16.8 | 51.4 | 78.3 | 74.0 |
| T5-large | 31.2 | 62.1 | 37.9 | 17.6 | 51.4 | 73.8 | 71.3 |
| PLoG (T5-large) | 31.7 | 62.3 | 38.3 | 17.6 | 52.0 | 81.9 | 76.8 |
| BART-large | 29.3 | 59.6 | 36.0 | 16.3 | 48.9 | 70.3 | 64.8 |
| PLoG (BART-large) | 32.1 | 63.2 | 39.2 | 18.1 | 53.0 | 85.9 | 82.0 |
| Model | LogicNLG | ContLog | ||
|---|---|---|---|---|
| AVG | ACC | AVG | ACC | |
| T5-base | 1.87 | 40.5% | 2.15 | 58.0% |
| PLoG (T5-base) | 1.84 | 40.0% | 2.42 | 71.5% |
| T5-large | 2.21 | 55.0% | 2.42 | 70.5% |
| PLoG (T5-large) | 2.41 | 66.0% | 2.58 | 79.0% |
| BART-large | 2.05 | 49.5% | 2.12 | 56.5% |
| PLoG (BART-large) | 2.39 | 67.5% | 2.50 | 74.5% |
6.1实验设置
评估指标
继 LogicNLG 上 Chen 等人 (2020a, 2021) 之前的工作之后,我们根据表面级匹配指标和逻辑保真度分数评估我们的模型。 表面级指标包括 BLEU-1/2/3,它们基于模型生成和黄金参考之间的 n-gram 匹配。 在保真度分数方面,先前的作品采用SP-Acc和NLI-Acc。 对于SP-Acc,首先将句子解析为逻辑程序,并评估为程序的执行准确性。 NLI-Acc 基于 TableBERT,这是一种在 TabFact 数据集 Chen 等人 (2019) 上预训练的表蕴含模型。 该模型可以预测表是否支持句子。
然而,这两个保真度指标不足以验证保真度:我们凭经验发现SP-Acc的解析算法经常会生成与句子不相关的逻辑程序,从而导致评估不准确。 此外,用于 NLI-Acc 的 TableBERT 模型在 TabFact 数据集上仅达到 65.1% 的准确率,我们发现它的预测过于乐观。 为此,我们添加了两个最先进的表蕴含模型进行评估:TaPEx-large Liu 等人 (2021b) 和 TaPas-large Eisenschlos 等人 (2020),在 TabFact 上分别实现了 84.2% 和 81.0% 的测试准确率。 我们将这两个指标分别命名为 TaPEx-Acc 和 TaPas-Acc。 我们仍然评估 SP-Acc 和 NLI-Acc,以将我们的方法与以前的研究进行比较。 对于ContLog,我们采用Logic2text的评估指标:BLEU-4和ROUGE-1/2/4/L来评估表面级匹配,并使用 TaPEx-Acc 和 TaPas-Acc 评估保真度。
比较模型
对于 LogicNLG,我们将我们的方法与以下模型进行比较:GPT-TabGen (sm) 和 GPT-Coarse-to-Fine (sm) Chen 等人 (2020a) 是基于预训练的 GPT-2 的两个基线; DCVED+GPT-TabGen Chen 等人 (2021) 是一种以 GPT-TabGen (sm) 为骨干的去混杂变分模型。 我们还包括预训练的 BART-large、T5-base 和 T5-large 作为 LogicNLG 的基线模型和ContLog,我们采用5节中介绍的数据预处理方法。 我们的模型命名为 PLoG (BART-large)、PLoG (T5-base) 和 PLoG (T5-large) 当使用不同的骨干网时。 我们对 BART、T5 和 PLoG 模型采用相同的输入序列化策略和数值预计算。
训练详情
我们基于 Transformers Wolf 等人 (2020) 和 PyTorch Paszke 等人 (2019) 进行主要实验。 在训练过程中,模型嵌入层的参数被冻结。 在推理过程中,我们对所有实验均采用波束大小为 4 的波束搜索。 我们将源序列和目标序列的最大长度分别设置为 500 和 200。 由于时间成本,每个实验只运行一次。 在 LogicNLG 上,模型选择基于验证集上的 BLEU-3 分数,而在 ContLog 上,模型选择基于验证集上的 BLEU-4 分数。 预训练检查点的选择基于预训练任务验证集上生成的逻辑形式的执行精度。 我们在附录A中提供了详细的超参数。
6.2 自动评估
逻辑NLG
表2 显示了LogicNLG 上的结果。 我们可以观察到,采用我们的预处理策略的 BART 和 T5 模型在表面级指标和逻辑保真度得分方面都优于之前基于 GPT-2 的所有模型。 我们还观察到,PLoG 模型在 BLEU 分数上大多优于其基本模型,同时它们可以显着提高所有指标的逻辑保真度分数。 例如,PLoG (T5-large) 相对于 T5-large,将 TaPEx-Acc 和 TaPas-Acc 的准确度平均提高了 10% 。 然而,PLoG(T5-base)在 BLEU 分数上取得了较低的结果,可能是因为 LogicNLG 的任务设置不可控。 LogicNLG不提供突出显示的单元格,因此内容选择的潜在空间通常非常大。 这使得模型很可能生成忠实的句子来描述与黄金参考文献不同的事实/内容,从而导致 BLEU 分数较低。 此外,BLEU 基于局部 N-Gram 匹配,无法捕获生成句子的全局忠实度。 因此,此类表面级指标可能与保真度指标没有很好的相关性。
连续日志
ContLog的结果如表3所示。 据观察,PLoG 模型在表面层和逻辑层指标上始终优于其基础模型。 这表明添加突出显示的单元格来缩小内容选择的范围有利于更可靠的评估。 此外,不同骨干模型的一致改进证明了我们方法的总体有效性。
6.3人类评价
为了进一步研究模型是否可以生成忠实的句子,我们对 BART、T5 和 PLoG 模型的输出进行了人工评估。 具体来说,我们从每个数据集的测试集中随机抽取 200 个示例。 我们聘请了三名人工注释者,根据 Chen 等人 (2020a) 中采用的标准,在 0 到 3 之间的离散范围内对每个句子进行评分。 无意义(0):这句话没有意义,人们无法理解其含义。 错误(1):句子总体流畅,但描述的逻辑不正确。 部分正确(2):该句子描述了多个事实。 其中至少有一项是正确的,但仍然存在事实错误。 正确(3):句子的流畅性和逻辑正确性都很高。 模型名称对注释者隐藏,我们收集他们各自的结果来总结每个模型的两个分数:(1)他们在每个采样集上的平均分数; (2)保真度准确度,即句子评分正确的比例222我们对三位评估者的分数进行投票,即如果至少有两人给出3分,则判定该句子正确。. 评估仅基于上下文表,而不考虑黄金参考文献,因为生成的句子可能与参考文献描述的事实不同,但在保真度和流畅度方面仍然呈现出高质量。
如表4所示,PLoG(T5-base)在ContLog上大幅优于T5-base,但并未取得优异的结果LogicNLG 上,与自动评分不一致。 然而,PLoG (T5-large) 和 PLoG (BART-large) 在两个数据集上比基础模型实现了显着改进,显示出与自动指标一致的改进。
| Model | LogicNLG | ContLog | ||
|---|---|---|---|---|
| Val | Test | Val | Test | |
| PLoG (BART-large) | 49.47 | 49.85 | 59.67 | 61.73 |
| PLoG (T5-base) | 90.93 | 88.86 | 91.87 | 92.20 |
| PLoG (T5-large) | 93.77 | 92.23 | 93.33 | 93.13 |
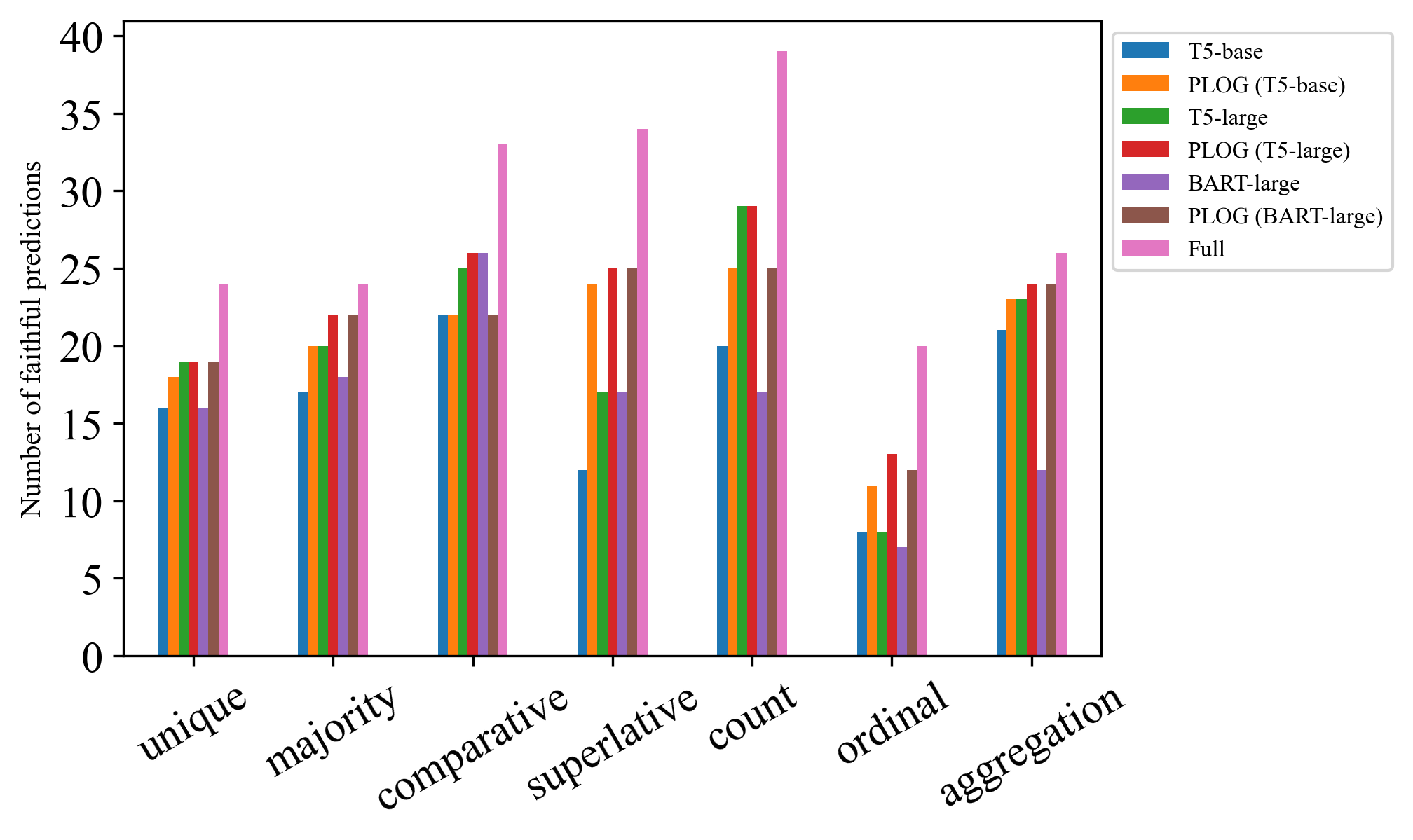
6.4 表到逻辑结果
我们在表 5 中报告了预训练模型在表到逻辑预训练任务上的执行精度。 如图所示,PLoG(T5-base)和PLoG(T5-large)在生成正确逻辑形式方面的准确率超过 90%,这表明表到逻辑的预训练确实提高了模型导出准确逻辑事实的能力。 然而,PLoG(BART-large)的精度要低得多。 我们分析了 BART-large 的错误案例,发现超过 90% 的错误是由逻辑形式解析错误引起的,即由于函数名称拼写错误和不匹配,生成的逻辑字符串无法成功解析为结构正确的逻辑形式树。括号。 在学习逻辑字符串结构方面,BART-large 的表现似乎比 T5-base 和 T5-large 差得多。 我们认为结合语法引导的解码方法Wang等人(2018)可以缓解这个问题,我们将其留给未来的工作。 令人惊讶的是,这并没有影响 PLoG (BART-large) 在下游任务上的性能,表明模型仍然通过预训练获得了有益的知识。
6.5 不同逻辑类型分析
在ContLog中,每个目标句子都属于继承自Logic2text的预定义逻辑类型,允许我们分析模型在不同逻辑推理类型上的性能。 在图3中,我们可以观察到我们的PLoG模型通常提高了大多数逻辑类型的基本模型的性能,特别是在最高级和序数。 然而,我们仍然观察到所有模型都有相当多的错误生成,这表明未来还有潜在的改进空间。
7结论
我们提出了一个表到逻辑的预训练任务来增强逻辑表到文本生成的保真度。 此外,我们通过重新利用现有数据集构建了受控逻辑表到文本生成任务。 为了在大规模语料库上实现预训练,我们提出了一种执行引导采样方案,自动从表中提取准确的逻辑形式。 通过表到逻辑预训练,我们的表到文本模型可以显着提高逻辑保真度。 我们的工作展示了一种利用形式语言促进表格到文本生成的新颖方法,并且可以扩展到其他相关领域,例如表格表示学习。
局限性
我们的方法的第一个限制是它是从 T5 等预训练语言模型初始化的,以继承从大规模文本语料库学习到的语言生成知识。 这要求PLoG的输入是文本序列,这可能会限制表输入和逻辑形式输出的结构编码。 虽然我们可以从头开始设计并预训练一个新模型,但计算成本会太大。 第二个限制也是由此造成的。 因为我们采用预训练的语言模型来执行表到逻辑和表到文本的生成,所以我们必须序列化输入(子)表以适应语言模型编码器。 因此,编码器模型的最大序列长度限制了输入表的大小。 为了解决这个问题,我们只输入相关列或突出显示的单元格,而不是完整的表格,以减少输入序列的长度。 然而,全表中一些潜在有用的上下文信息被忽略,可能会限制模型性能。 第三个限制在于我们采用的逻辑形式模式,它仅限于当前逻辑表到文本数据集的领域。 当将我们的方法应用于具有未见过的逻辑类型(例如中位数、比例)的新下游数据集时,应扩展当前模式以支持新逻辑。 但是,通过将新的逻辑操作定义为表上的可执行函数,可以轻松扩展模式。
道德声明
这项工作提出了 PLoG,这是一种供研究界研究逻辑表到文本生成的预训练语言模型。 此外,我们还提出了一个新的数据集ContLog用于受控逻辑表到文本生成的研究。 我们的数据集包含维基百科表格、注释(目标句子、逻辑类型等元信息)和突出显示的表格单元格信息。 我们重用Logic2text的表格和注释。 Logic2text是MIT许可下的公共数据集。 为了获得突出显示的细胞信息,我们使用了无需人工标记的自动方法。 我们还使用 LogicNLG,这是另一个用于实验的公共数据集,它也获得了 MIT 许可。 所有数据集均为英文。 在人工评估中,我们聘请人工注释者来评估模型的性能。 招收电气工程、计算机科学、英语专业研究生3名(1女2男)。 每个学生每小时的工资为 7.8 美元(高于当地类似工作的平均工资)。
致谢
这项工作得到了 JST 的支持,该大学奖学金旨在创造科学技术创新,资助号为 JPMJFS2112。
参考
- Andrejczuk et al. (2022) Ewa Andrejczuk, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, and Yasemin Altun. 2022. Table-to-text generation and pre-training with tabt5. arXiv preprint arXiv:2210.09162.
- Anonymous (2021) Authors Anonymous. 2021. Flap: Table-to-text generation with feature indication and numerical reasoning pretraining. ACL Rolling Review Nov.
- Chen et al. (2020a) Wenhu Chen, Jianshu Chen, Yu Su, Zhiyu Chen, and William Yang Wang. 2020a. Logical natural language generation from open-domain tables. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7929–7942.
- Chen et al. (2019) Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. 2019. Tabfact: A large-scale dataset for table-based fact verification. arXiv preprint:1909.02164.
- Chen et al. (2021) Wenqing Chen, Jidong Tian, Yitian Li, Hao He, and Yaohui Jin. 2021. De-confounded variational encoder-decoder for logical table-to-text generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 5532–5542.
- Chen et al. (2020b) Zhiyu Chen, Wenhu Chen, Hanwen Zha, Xiyou Zhou, Yunkai Zhang, Sairam Sundaresan, and William Yang Wang. 2020b. Logic2text: High-fidelity natural language generation from logical forms. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 2096–2111.
- Cheng et al. (2021) Zhoujun Cheng, Haoyu Dong, Zhiruo Wang, Ran Jia, Jiaqi Guo, Yan Gao, Shi Han, Jian-Guang Lou, and Dongmei Zhang. 2021. Hitab: A hierarchical table dataset for question answering and natural language generation. arXiv preprint arXiv:2108.06712.
- Dong et al. (2022) Haoyu Dong, Zhoujun Cheng, Xinyi He, Mengyu Zhou, Anda Zhou, Fan Zhou, Ao Liu, Shi Han, and Dongmei Zhang. 2022. Table pretraining: A survey on model architectures, pretraining objectives, and downstream tasks. arXiv preprint arXiv:2201.09745.
- Eisenschlos et al. (2020) Julian Eisenschlos, Syrine Krichene, and Thomas Mueller. 2020. Understanding tables with intermediate pre-training. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, pages 281–296.
- Gong et al. (2020) Heng Gong, Yawei Sun, Xiaocheng Feng, Bing Qin, Wei Bi, Xiaojiang Liu, and Ting Liu. 2020. Tablegpt: Few-shot table-to-text generation with table structure reconstruction and content matching. In Proceedings of the 28th International Conference on Computational Linguistics, pages 1978–1988.
- Iida et al. (2021) Hiroshi Iida, Dung Thai, Varun Manjunatha, and Mohit Iyyer. 2021. Tabbie: Pretrained representations of tabular data. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3446–3456.
- Kale and Rastogi (2020) Mihir Kale and Abhinav Rastogi. 2020. Text-to-text pre-training for data-to-text tasks. In Proceedings of the 13th International Conference on Natural Language Generation, pages 97–102.
- Kukich (1983) Karen Kukich. 1983. Design of a knowledge-based report generator. In 21st Annual Meeting of the Association for Computational Linguistics, pages 145–150.
- Lebret et al. (2016) Rémi Lebret, David Grangier, and Michael Auli. 2016. Neural text generation from structured data with application to the biography domain. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1203–1213.
- Lewis et al. (2020) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
- Liu et al. (2021a) Ao Liu, Congjian Luo, and Naoaki Okazaki. 2021a. Improving logical-level natural language generation with topic-conditioned data augmentation and logical form generation. arXiv preprint arXiv:2112.06240.
- Liu et al. (2021b) Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, and Jian guang Lou. 2021b. Tapex: Table pre-training via learning a neural sql executor.
- Liu et al. (2018) Tianyu Liu, Kexiang Wang, Lei Sha, Baobao Chang, and Zhifang Sui. 2018. Table-to-text generation by structure-aware seq2seq learning. In Thirty-Second AAAI Conference on Artificial Intelligence.
- Loshchilov and Hutter (2017) Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
- McKeown (1985) Kathleen R McKeown. 1985. Discourse strategies for generating natural-language text. Artificial intelligence, 27(1):1–41.
- Nie et al. (2018) Feng Nie, Jinpeng Wang, Jin-ge Yao, Rong Pan, and Chin-Yew Lin. 2018. Operation-guided neural networks for high fidelity data-to-text generation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 3879–3889.
- Ou and Liu (2022) Suixin Ou and Yongmei Liu. 2022. Learning to generate programs for table fact verification via structure-aware semantic parsing. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7624–7638, Dublin, Ireland. Association for Computational Linguistics.
- Parikh et al. (2020) Ankur Parikh, Xuezhi Wang, Sebastian Gehrmann, Manaal Faruqui, Bhuwan Dhingra, Diyi Yang, and Dipanjan Das. 2020. Totto: A controlled table-to-text generation dataset. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1173–1186.
- Pasupat and Liang (2015) Panupong Pasupat and Percy Liang. 2015. Compositional semantic parsing on semi-structured tables. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1470–1480.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. Pytorch: An imperative style, high-performance deep learning library. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems 32, pages 8024–8035. Curran Associates, Inc.
- Puduppully et al. (2019a) Ratish Puduppully, Li Dong, and Mirella Lapata. 2019a. Data-to-text generation with content selection and planning. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 6908–6915.
- Puduppully et al. (2019b) Ratish Puduppully, Li Dong, and Mirella Lapata. 2019b. Data-to-text generation with entity modeling. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2023–2035.
- Radford et al. (2019) Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. JMLR, 21(140):1–67.
- Shazeer and Stern (2018) Noam Shazeer and Mitchell Stern. 2018. Adafactor: Adaptive learning rates with sublinear memory cost. In International Conference on Machine Learning, pages 4596–4604. PMLR.
- Shi et al. (2021) Peng Shi, Patrick Ng, Zhiguo Wang, Henghui Zhu, Alexander Hanbo Li, Jun Wang, Cicero Nogueira dos Santos, and Bing Xiang. 2021. Learning contextual representations for semantic parsing with generation-augmented pre-training. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 13806–13814.
- Shu et al. (2021) Chang Shu, Yusen Zhang, Xiangyu Dong, Peng Shi, Tao Yu, and Rui Zhang. 2021. Logic-consistency text generation from semantic parses. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 4414–4426.
- Suadaa et al. (2021) Lya Hulliyyatus Suadaa, Hidetaka Kamigaito, Kotaro Funakoshi, Manabu Okumura, and Hiroya Takamura. 2021. Towards table-to-text generation with numerical reasoning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1451–1465.
- Wang et al. (2018) Chenglong Wang, Kedar Tatwawadi, Marc Brockschmidt, Po-Sen Huang, Yi Mao, Oleksandr Polozov, and Rishabh Singh. 2018. Robust text-to-sql generation with execution-guided decoding. arXiv preprint arXiv:1807.03100.
- Wiseman et al. (2017) Sam Wiseman, Stuart M Shieber, and Alexander M Rush. 2017. Challenges in data-to-document generation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2253–2263.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
- Xie et al. (2022) Tianbao Xie, Chen Henry Wu, Peng Shi, Ruiqi Zhong, Torsten Scholak, Michihiro Yasunaga, Chien-Sheng Wu, Ming Zhong, Pengcheng Yin, Sida I Wang, et al. 2022. Unifiedskg: Unifying and multi-tasking structured knowledge grounding with text-to-text language models. arXiv preprint arXiv:2201.05966.
- Yu et al. (2021) Tao Yu, Chien-Sheng Wu, Xi Victoria Lin, Bailin Wang, Yi Chern Tan, Xinyi Yang, Dragomir R Radev, Richard Socher, and Caiming Xiong. 2021. Grappa: Grammar-augmented pre-training for table semantic parsing. In ICLR.
- Zhao et al. (2022) Chen Zhao, Yu Su, Adam Pauls, and Emmanouil Antonios Platanios. 2022. Bridging the generalization gap in text-to-sql parsing with schema expansion. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5568–5578.
- Zhong et al. (2020) Victor Zhong, Mike Lewis, Sida I Wang, and Luke Zettlemoyer. 2020. Grounded adaptation for zero-shot executable semantic parsing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6869–6882.
- Zhong et al. (2017) Victor Zhong, Caiming Xiong, and Richard Socher. 2017. Seq2sql: Generating structured queries from natural language using reinforcement learning. CoRR, abs/1709.00103.
附录A实验设置详细信息
以下是不同模型配置的超参数。 在微调过程中,每对基础模型和相应的PLoG模型共享相同的超参数以进行公平比较,而这些超参数仅针对基础模型进行调整。
T5-base 和 PLoG (T5-base) :两个数据集的超参数相同。
-
•
优化器:AdamW Loshchilov 和 Hutter (2017)。
-
•
学习率: 用于预训练, 用于微调。
-
•
批量大小:预训练和微调均为 5。
T5-large 和 PLoG (T5-large) :两个数据集的超参数相同。
-
•
优化器:AdaFactor Shazeer 和 Stern (2018)。
-
•
预训练和微调的学习率:。
-
•
批量大小:预训练和微调均为 10( 梯度累积步骤)。
BART-large 和 PLoG(BART-large):
-
•
优化器:两个数据集的 AdaFactor。
-
•
学习率:在 LogicNLG 上预训练 ,在 ContLog 上预训练 ; 用于对两个数据集进行微调。
-
•
批量大小:LogicNLG 上的预训练为 256 ( 64),ContLog 上的预训练为 32 (); 32 () 用于对两个数据集进行微调。
以下是每个预训练模型的附加信息。
-
•
T5-base:220M 参数,12 层,768 个隐藏状态,3072 个前馈隐藏状态,12 个头。
-
•
T5-large:770M 参数,24 层、1024 个隐藏状态、4096 个前馈隐藏状态、16 个头。
-
•
BART-large:406M参数,24层,1024个隐藏状态,16头,
预训练详情
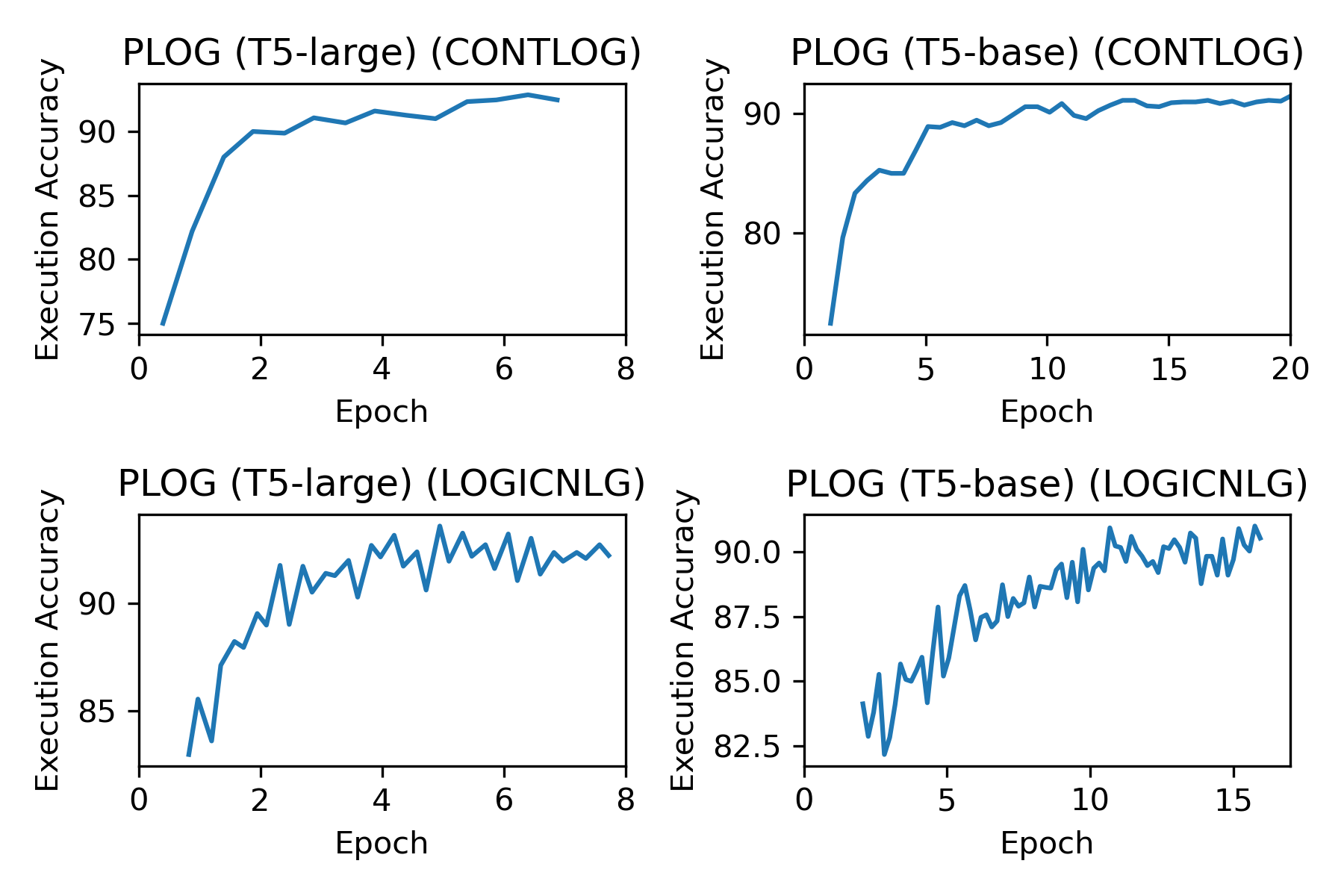
我们在收集的表到逻辑数据上预训练我们的模型,并以一定数量的步骤间隔在验证集(预训练语料库)上评估其执行准确性。 我们采用最好的预训练检查点来对下游任务进行微调。 图4展示了预训练过程中的验证结果。 我们可以观察到,当训练更多的 epoch 时,模型会获得更高的准确度。 由于预训练数据和模型规模较大,预训练非常耗时。 例如,在 ContLog 预训练数据中,训练 PLoG (T5-基准)一个历元大约需要 17 个小时,而训练 PLoG (T5-大型)一个历元则需要 5 天。 每个实验都是在单个 NVIDIA V100 GPU 上完成的。 我们认为可以通过使用更多 GPU 资源来降低时间成本。
| Name | Arguments | Output | Description |
| count | view | number | returns the number of rows in the view |
| only | view | bool | returns whether there is exactly one row in the view |
| hop | row, header string | object | returns the value under the header column of the row |
| and | bool, bool | bool | returns the boolean operation result of two arguments |
| max/min/avg/sum | view, header string | number | returns the max/min/average/sum of the values under the header column |
| nth_max/nth_min | view, header string | number | returns the n-th max/n-th min of the values under the header column |
| argmax/argmin | view, header string | row | returns the row with the max/min value in header column |
| nth_argmax/nth_argmin | view, header string | row | returns the row with the n-th max/min value in header column |
| eq/not_eq | object, object | bool | returns if the two arguments are equal |
| round_eq | object, object | bool | returns if the two arguments are roughly equal under certain tolerance |
| greater/less | object, object | bool | returns if argument 1 is greater/less than argument 2 |
| diff | object, object | object | returns the difference between two arguments |
| filter_eq/not_eq | view, header string, object | view | returns the subview whose values under the header column is equal/not equal to argument 3 |
| filter_greater/less | view, header string, object | view | returns the subview whose values under the header column is greater/less than argument 3 |
| filter_greater_eq /less_eq | view, header string, object | view | returns the subview whose values under the header column is greater/less or equal than argument 3 |
| filter_all | view, header string | view | returns the view itself for the case of describing the whole table |
| all_eq/not_eq | view, header string, object | bool | returns whether all the values under the header column are equal/not equal to argument 3 |
| all_greater/less | view, header string, object | bool | returns whether all the values under the header column are greater/less than argument 3 |
| all_greater_eq/less_eq | view, header string, object | bool | returns whether all the values under the header column are greater/less or equal to argument 3 |
| most_eq/not_eq | view, header string, object | bool | returns whether most of the values under the header column are equal/not equal to argument 3 |
| most_greater/less | view, header string, object | bool | returns whether most of the values under the header column are greater/less than argument 3 |
| most_greater_eq/less_eq | view, header string, object | bool | returns whether most of the values under the header column are greater/less or equal to argument 3 |
附录 B 逻辑形式架构
Logic2text Chen 等人 (2020b) 定义了 7 种逻辑类型,包括计数、唯一、比较、最高级、序数、聚合和多数。 这些逻辑类型的定义和示例请参见Chen 等人(2020b)的附录。 在本节中,我们在表 6 中提供了逻辑函数的完整列表,我们用它来定义逻辑表单模式。
附录C预训练数据收集详情
在这里,我们提供了预训练数据收集过程的更多细节,包括摘要模板的示例和逻辑形式采样的完整规则。 表7列出了函数类型占位符。
| Category | Function |
|---|---|
| FILTER | filter_eq, filter_not_eq, filter_greater, … |
| SUPERLATIVE | max, min |
| ORDINAL | nth_max, nth_min |
| SUPERARG | argmax, argmin |
| ORDARG | nth_argmax, nth_argmin |
| COMPARE | greater, less, eq, not_eq |
| MAJORITY | all_eq, all_not_eq, most_eq, all_greater, … |
| AGGREGATE | avg, sum |
模板
实例化
在这里,我们提供了我们设计的主要规则,用于通过从表中采样来实例化逻辑表单模板。
-
1.
对于占位符类型 Column,我们从当前输入(子)表中随机采样列标题。
-
2.
对于占位符类型Object,实例化取决于该占位符的父函数节点。 如果函数节点是 only 或属于类别 FILTER 或 MAJORITY,则占位符将被实例化为来自函数的某一列的采样值。当前输入(子)表。 否则,如果函数节点是eq,则该占位符被实例化为其兄弟节点的执行结果。 这是为了保证平等判断的正确性。
-
3.
函数类型占位符的实例化取决于其函数类别,如表7所示。 如果占位符属于函数类别COMPARE或MAJORITY,我们根据其参数之间的真实关系选择特定的函数名称。 例如,COMPARE函数的参数是两个对象,其关系(等于、大于、小于等)可以预先计算。 因此我们可以根据这个关系来确定实际的函数。 如果占位符属于其他类别,则可以从函数集中统一采样该函数。
| Logic Type | Examples | |
|---|---|---|
| Count | Template | eq { count { [FILTER] { all_rows ; [Column 1] ; [Object 1] } } ; [Object 2] } |
| Instance | eq { count { filter_eq { all_rows ; power ; 20kw } } ; 3 } | |
| Explanation | In dwbl, there are 3 brandings with power 20kw. | |
| Comparative | Template | [COMPARE] { hop { [FILTER] { all_rows ; [Column 1] ; [Object 1] } ; [Column 2] } ; hop { [FILTER] { all_rows ; [Column 1] ; [Object 2] } ; [Column 2] } } |
| Instance | greater { hop { filter_eq { all_rows ; callsign ; dwbl } ; power } ; hop { filter_eq { all_rows ; callsign ; dyku } ; power } } | |
| Explanation | The callsign dwbl has a greater power than dyku. | |
| Unique | Template | only { [FILTER] { all_rows ; [Column 1] ; [Object 1] } } |
| Instance | only { filter_eq { all_rows ; location ; iloilo city } } | |
| Explanation | Only one brand is located in iloilo city. | |
| Superlative | Template | eq { hop { [SUPERARG] { all_rows ; [Column 1] } ; [Column 2] } ; [Object 1] } |
| Instance | eq { hop { argmin { all_rows ; frequency } ; callsign } ; dyku } | |
| Explanation | The callsign dyku has the lowest frequency. | |
| Ordinal | Template | eq { hop { [ORDARG] { all_rows ; [Column 1] ; [Object 1] } ; [Column 2] } ; [Object 2] } |
| Instance | eq { hop { nth_argmax { all_rows ; frequency ; 2 } ; branding } ; mellow 957 } | |
| Explanation | Mellow 957 is the brand that has the second highest frequency. | |
| Majority | Template | [MAJORITY] { all_rows ; [Column 1] ; [Object 1] } |
| Instance | most_less { all_rows ; frequency ; 1242khz } | |
| Explanation | Most of the brands have a frequency lower than 1242khz. | |
| Aggregation | Template | round_eq { [AGGREGATE] { all_rows ; [Column 1] } ; [Object 1] } |
| Instance | round_eq { avg { all_rows ; power } ; 16kw } | |
| Explanation | The average power of all the brands is 16kw. | |
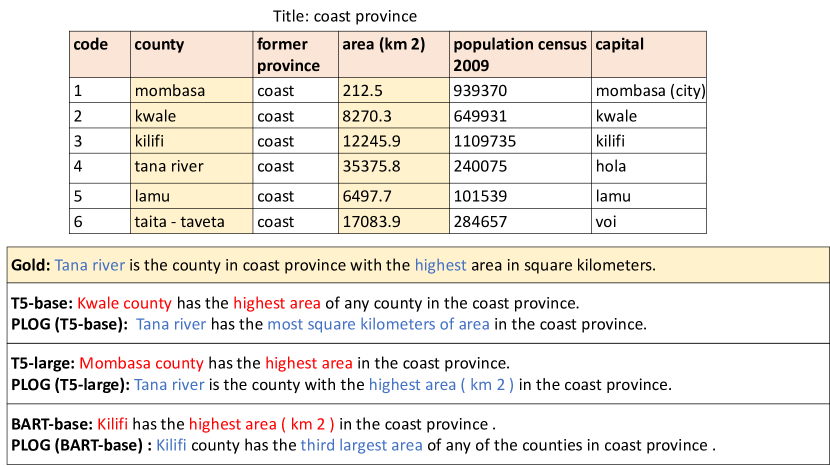
附录 D案例研究
我们通过展示模型生成的一些定性示例来进一步进行案例研究。 如图5所示,PLoG模型可以通过复杂的推理生成逻辑上正确的句子,而基础模型通常无法描述表的正确事实。