无线深度视频语义传输
摘要
在本文中,我们设计了一类新型的高效深度联合源信道编码方法,以实现无线信道上的端到端视频传输。 所提出的方法利用非线性变换和条件编码架构来自适应地提取跨视频帧的语义特征,并通过深度联合源信道编码在无线信道上传输语义特征域表示。 我们的框架被命名为深度视频语义传输(DVST)。 特别是,受益于特征域上下文提供的强时间先验,学习的非线性变换函数变得时间自适应,从而产生更丰富、更准确的熵模型来指导当前帧的传输。 因此,开发了一种新颖的速率自适应传输机制来定制视频源的深度联合源通道编码。 它学习在视频帧内和视频帧之间分配有限的通道带宽,以最大限度地提高整体传输性能。 整个DVST设计被表述为一个优化问题,其目标是在感知质量指标或机器视觉任务性能指标下最小化端到端传输速率失真性能。 在标准视频源测试序列和各种通信场景中,实验表明我们的DVST总体上可以超越传统的无线视频编码传输方案。 由于其视频内容感知和机器视觉任务集成能力,所提出的 DVST 框架可以很好地支持未来的语义通信。
索引术语:
语义通信、视频传输、非线性变换、联合源信道编码、率失真。我简介
当今无线网络中的视频传输任务主要分为两个步骤:源编码和信道编码[1]。 源编码将源视频压缩为比特序列,而信道编码将比特序列表示为传输信号,以防止不完善的无线信道(例如噪声、衰落和干扰)的影响。 这种基于分离的方法已用于多种应用,因为可以通过更改底层信道代码在任意无线信道上无缝传输各种源数据的二进制表示。 由于每个组件的独立优化,这种范式受益匪浅。
然而,随着对虚拟现实 (VR) 等低延迟无线视频传输应用的需求越来越多,基于分离的设计的局限性开始显现。 一方面,当前的无线视频传输系统存在时变信道条件,通信速率与信道容量的不匹配会导致明显的悬崖效应,即当信道容量低于通信速率。 另一方面,广泛使用的熵编码将源表示转换为比特序列,对源潜在表示的边缘分布的变分估计非常敏感。 该边际上的小扰动可能会导致熵解码[2]中的灾难性错误传播。 实际上,小扰动通常是由浮点舍入误差[3]引起的。 不幸的是,这种舍入操作在很大程度上取决于硬件或软件平台,并且在各种数据压缩应用中,收发器很可能采用不同的平台。 发射器与接收器中的这种不确定性问题可能最终导致严重的性能下降。
为了解决这个问题,现在正是将信源编码和信道编码桥接在一起以提高端到端通信系统能力的时候了。 通过这种方式,通道传输过程可以获知源语义特征[4,5,6,7,8,9,10]。 这种针对信源和通道处理一体化设计的范式被命名为联合信源通道编码(JSCC)[11],这是信息论和编码理论中的经典课题。 然而,传统的JSCC方案[11,12,13,14]基于显式概率模型和手工设计,其优化复杂度对于复杂源来说是棘手的。 此外,他们忽略了源消息的语义方面。 作为一种现代版本,最近用于实现 JSCC 的深度学习方法激发了人工智能 (AI) 和无线通信社区的极大兴趣[15,16,17,18,19]。 通过使用人工神经网络(ANN),源数据可以直接编码为连续值符号,以便通过无线信道传输。 Deep JSCC可以通过使用模拟传输而无需熵编码来克服灾难性的退化问题。 当前的深度 JSCC 方法已显示出端到端图像传输性能超越了经典的基于分离的 JPEG/JPEG2000/BPG 源压缩并结合了理想的通道容量实现代码系列,特别是对于小尺寸源,例如小型 CIFAR10 图像数据集[20]。
然而,我们可以观察到,一般来说,随着源维度的增加,例如大规模图像,深度 JSCC 的性能迅速下降,甚至不如中所示的经典的基于分离的编码方案[ 9]。 此外,现有的深度JSCC方案无法提供与经典分离编码方案相当的编码增益,即性能曲线的斜率随着编码率或信道信噪比(SNR)的增加而迅速减慢。 这种糟糕的编码增益源于编解码器网络的简单设计。 目前的深度JSCC工作只是采用一个高度集成的ANN作为编码器功能来实现对原始源数据的降维。 通过将无线信道添加为不可训练层,学习编解码器 ANN 还可以对抗不完美无线信道的影响。 然而,这种轻型自动编码器结构的深度JSCC无法为大规模源数据提供足够的模型表达能力,导致深度JSCC的编码增益过早饱和。 与图像源相比,视频源进一步引入了时间维度。 编码增益高于饱和的现象更有可能出现在需要更高维度表示的视频源上。 因此,将深度 JSCC 用于无线视频传输的简单应用无法提供令人满意的性能。
受计算机视觉(CV)社区采用的新兴数据压缩方法的启发,高维源将首先转换为由变分潜变量模型定义的潜在表示。 此过程称为非线性变换 [21, 22, 23, 24, 25]。 潜在表示的丰富性保留了几乎所有可用于恢复源数据或直接驱动下游智能任务的源语义特征。 通过适当的训练,许多这样的非线性变换模型成功地相当紧凑地表示源数据,并且在某种意义上可以称为压缩。 对于实际的数据压缩任务,潜在表示需要通过熵编码进一步压缩为二进制序列。 然而,由于非线性变换中使用的 ANN 通常基于浮点数学,并且传输是通过时变无线信道进行的,因此非线性变换与传统源编码(熵编码,例如算术编码 [2)的直接组合])和信道编码(例如低密度奇偶校验(LDPC)编码[26])也容易受到熵解码留下的灾难性故障的影响。
在本文中,为了实现高效、鲁棒的端到端视频传输,我们利用非线性变换和深度 JSCC 的优势共同制定了一个新的强大框架,称为深度视频语义传输(DVST)。 它专门针对不完善的无线通道上的视频传输,并防止敏感熵编码引起的灾难性故障。 通过将新兴的条件编码范式[27]与非线性变换和深度JSCC相结合,所提出的DVST框架的工作原理是:考虑到视频帧之间强的时间相关性,DVST以有效的方式对当前帧进行编码。通过上下文非线性变换和上下文深度JSCC方式生成通道输入符号。 上下文语义信息用作非线性变换和深度 JSCC 编解码器输入的一部分。 受益于语义特征域上下文提供的时间先验,学习的非线性变换函数变得时间自适应,从而产生更丰富和更准确的熵模型来指示如何分配信道带宽资源来传输当前帧。 此外,我们利用上下文来承载丰富的信息,这有助于重建语义特征图以获得更高的视频质量或下游任务性能。 整个 DVST 设计被表述为一个优化问题,其目标是在感知质量指标或机器视觉任务性能指标下最小化端到端传输率失真(RD)性能。
具体来说,本文的贡献可概括如下。
-
(1)
DVST框架: 我们提出了一种新的无线视频传输端到端可学习框架,即 DVST,它集成了非线性变换和深度 JSCC 的优点。 据作者所知,这是第一个建立时间自适应熵模型来定制视频深层 JSCC 的工作。 所提出的 DVST 框架利用非线性变换和条件编码架构进行视频语义特征提取,与传统的视频编码传输方案相比,这有助于实现更高的效率和更鲁棒的无线视频传输。
-
(2)
上下文驱动的语义特征建模: 我们利用时间上下文来开发一种简单而有效的方法来增强非线性变换中的熵模型以及深度 JSCC 编解码器。 我们设计了ANN架构来实现DVST的每个模块,其中上下文语义特征作为条件的定义、使用和学习方式都被明确给出。
-
(3)
速率自适应语义特征传输: 根据语义特征的时间自适应熵模型,我们开发了一种提高视频深度 JSCC 编码增益的方法。 特别是,我们为潜在表示中的每个嵌入向量引入了可变长度传输机制。 由此产生的 DVST 模型学会在视频帧内和视频帧之间分配有限的通道带宽,以最大限度地提高整体性能。
-
(4)
性能验证: 我们验证了 DVST 系统在标准视频源序列上的性能。 我们表明,对于无线视频传输,我们的 DVST 可以在各种既定指标(例如 PSNR 和 MS-SSIM)上实现更好的编码增益和 RD 性能。 同样,在实现相同的端到端无线传输性能的情况下,与结合LDPC和数字调制方案的经典H.264/H.265相比,所提出的DVST方法可以节省高达50%的信道带宽成本。 对于面向任务的机器型语义通信,实验结果验证了DVST的有效性,它可以更好地支持机器视觉任务,同时对人类视觉具有更高的感知保真度。
本文的其余部分安排如下。 在下一节II中,我们首先回顾了无线视频传输的系统模型,并提出了DVST框架。 然后,在III部分,我们提出了实现DVST的ANN架构,以及指导DVST模型优化的关键方法。 第IV节提供了多种方法的直接比较,以量化所提出方法的性能增益。 最后,V部分对本文进行了总结。
符号约定: 在本文中,小写字母(例如 )表示标量,粗体小写字母(例如 )表示向量。 在某些情况下,表示的元素,它也可以表示的子向量,如上下文中所述。 粗体大写字母(例如,)表示矩阵,表示维单位矩阵。 表示自然对数,表示以为底的对数。 表示关于连续值随机变量的概率密度函数(pdf),表示关于连续值随机变量的概率质量函数(pmf)为离散值随机变量。 另外,表示统计期望运算,表示实数集。 最后,表示高斯函数,表示拉普拉斯函数,表示以为中心的均匀分布,其中范围从 到 。
II 建议的方法
在本节中,我们首先介绍无线视频传输的系统模型。 然后,我们描述了DVST的整个框架。 之后,我们介绍了用于速率自适应传输潜在表示的上下文熵模型,然后介绍了上下文的学习方法。 最后得出DVST系统的优化目标。
II-A 系统模型
考虑无线视频传输问题。 给定视频序列,其中时间步处的帧被建模为像素强度的向量。 发送端将视频帧序列编码为可变长度连续值通道输入符号序列,其中表示 时间步 处的维度通道输入向量。我们通常有,定义为信道带宽比(CBR) [28]表示平均编码 的比率。 然后,通过无线信道依次发送序列。 该通道引入了随机损坏,表示为传递函数 ,其中 表示通道参数。 接收到的序列为,转移概率为。 在本文中,我们主要考虑广泛使用的加性高斯白噪声(AWGN)通道,其传递函数为 ,其中噪声向量 的每个分量都是从时不变的多维高斯分布,即 ,其中 是平均噪声功率。 通过改变通道转换函数,也可以类似地合并其他通道模型。 接收器包括一系列逆操作,旨在从损坏的信号中恢复或执行下游智能任务。
我们考虑以低延迟方式通过嘈杂的无线信道进行视频传输,即视频序列被逐帧传输到接收器并在接收器中重建。 我们将 连续帧封装为一组图片 (GOP)。 典型的视频编码算法首先将划分为一堆GOP。 每个 GOP 以帧内编码图像(I 帧或关键帧)作为参考开始,后面是 预测编码帧(P 帧),其中包含用于节省比特率的运动补偿差异信息。 在本文中,我们利用经典的 GOP 结构进行端到端传输。 由于I帧的传输与图像的传输等效,这在[17,28,18,19]中已经得到了很好的研究,因此我们重点关注P帧的传输。
II-B DVST的框架
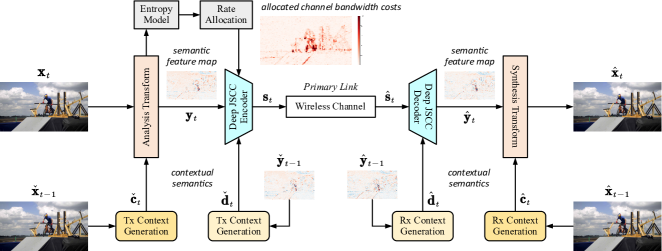
我们提出 DVST 作为一种新的可学习的端到端无线视频传输模型,它集成了非线性变换和深度 JSCC 的优点。 我们的 DVST 框架如图 1 所示。 为了有效地编码当前帧,发送器采用上下文分析变换和上下文深度JSCC编码器作为两个关键模块。 分析变换将像素域中的源帧转换为语义特征域中的潜在表示。 在潜在表示的变分熵建模的指导下,添加速率控制模块以实现深度 JSCC 中的变长编码。 对于视频源来说,存在时间相关性。 因此,上述两个模块还采用语义特征域上下文和深层 JSCC 码字域上下文作为时间先验。 这使得非线性变换和深度 JSCC 模块具有时间自适应性,从而形成更高效的视频传输框架。
如图1和图2所示,以当前帧非线性变换中的和函数为条件分别基于上下文语义特征和。 深层 JSCC 中的 和 函数分别以上下文代码字 和 为条件。 DVST系统的主链路公式为
| (1) |
在我们的DVST设计中,除了通道传输函数之外,我们使用ANN来实现(1)中的每个函数。在上下文信息方面,发射机(Tx)上下文和是从参考帧和参考特征图 这两个参考值是在发射机处通过模拟 DVST 过程生成的,而不通过无线信道,即
| (2) |
其中代码字是通过替换时间步从(1)获得的。 接收器 (Rx) 上下文 和 分别从参考合成帧 和参考解码特征图 获得。 这两个引用是通过在时间步从接收缓冲区取出记录直接获得的。 关于如何使用上下文作为条件来制定基于 ANN 的函数的详细信息将在下一节中介绍。
具体来说,在发送器中,对于时间步的当前帧,提取源语义特征作为低维潜在表示、 在此潜在空间上进行操作。 考虑视频源中的帧间相关性,分析变换公式为
| (3) |
表示为分析变换生成上下文的函数,因此被称为上下文分析变换。 之后,潜在表示被输入到上下文深层JSCC编码器以生成通道输入序列为
| (4) |
表示为深度JSCC编码器生成上下文的功能。 为了给编码提供丰富且相关性更强的信息,上下文处于更高维度的语义特征域,上下文处于深层JSCC 码字空间。
然后,直接通过无线通信信道发送模拟码字序列。 如上所述,我们考虑 AWGN 信道,使得接收到的序列为 和 。 接收器包含一个上下文深度 JSCC 解码器 ,将损坏的信号 重建为 ,即
| (5) |
表示为深层JSCC解码器生成上下文的功能。 然后对执行上下文合成变换函数以恢复当前帧,即
| (6) |
表示为综合变换生成上下文 的函数。
对于上下文分析变换,我们使用网络自动学习和之间的相关性,这不会通过手工减法操作来消除冗余,例如传统残差视频编码[29]。 这里,上下文来自参考框架。 这样,上下文分析变换变得自适应,通过选择性地从 和 [27] 中提取语义特征来生成潜在表示。 由于视频中的运动,对于 中的旧内容可以从 中找到很好的参考, 仍然强制从残差生成其补丁嵌入。 对于 中无法从 找到良好参考的新内容, 倾向于从 本身生成其补丁嵌入。 上下文非线性变换本质上学习自适应地利用语义提取的条件。 此外,上下文不仅用于生成潜在表示,还用于构建熵模型,这将在后续小节中介绍。
对于上下文深度 JSCC 编码器 ,我们使用网络自动学习 和 之间的相关性。 请注意,上下文来自重建的参考特征图,因此,上下文深度JSCC编码器也变得自适应以生成通道输入码字。 如果中的补丁嵌入可以从中找到良好的参考,则倾向于以较小的通道带宽传输这些嵌入。 相反,对于中的补丁嵌入无法从找到好的参考,倾向于分配更多的通道带宽来传输这些嵌入。 通过这种方式,上下文深层 JSCC 编解码器学习自适应地利用条件进行高效传输。 此外,上下文不仅用于生成信道输入码字,还用于学习控制从熵值到信道带宽成本的缩放规则的速率分配函数。 详细内容将在后续小节中介绍。
II-C 速率自适应传输的熵模型
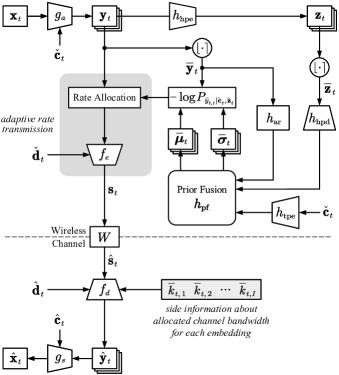
为了提高DVST的编码增益,应该为语义特征图的每个嵌入开发可变长度传输机制。 为此,我们估计上的熵分布,并且可以相应地确定传输的信道带宽成本。 因此,我们的目标是设计一个能够准确估计潜在表示的概率分布的熵模型。
我们的熵模型如图2所示。 遵循[27]的工作,潜在表示被变分地建模为拉普拉斯分布,其中每个嵌入具有不同的分布参数。 在本文中,超先验熵模型同时学习层次先验[23]和空间先验[24]。 此外,我们的熵模型融合了上下文 提供的时间先验。 具体来说,每个嵌入 的熵计算为
| (7) |
其中 表示使用统一标量量化 函数(四舍五入为整数)得到的 的量化版本。 表示由量化嵌入 和 组成的张量。 量化超先验是通过将超先验编码器网络堆叠在上获得的。
为了利用梯度下降法来优化熵模型,Ballé等人提出了一种宽松的方法来解决量化引起的零梯度问题[21]。 采用代理“均匀噪声”表示来替换模型训练期间的量化表示,即替换为 。 每个 都被变分地建模为具有学习参数 和 的拉普拉斯分布,使得
| (8) | ||||
其中“”是卷积运算,表示路径嵌入索引,代理超先验是通过执行超先验编码器网络在上,并添加均匀采样的随机偏移量,即。 由于我们没有关于超先验 的先验信念,因此可以将其建模为非参数完全分解密度 [23],即
| (9) |
其中封装了的所有参数。 在模型测试过程中,通过将替换为,从学习的熵模型中获取离散值来建立熵模型。 表示提供分层先验的超先验解码器网络。 表示提供空间先验的自回归网络。 表示提供附加辅助信息的时间先验编码器网络。 表示对上述三类先验信息进行操作的先验融合网络。 在模型测试过程中,将从学习到的熵模型 中提取离散值,将 和 分别替换为 和 ,从而建立 (7) 中的熵模型 。
如 NTC [25] 中所述, 的概率模型可以以其他向量 为条件,例如 [23] 或其前面的尺寸 ,如 [24] 中的尺寸。 前者对应于密度模型的前向适应(FA),后者对应于后向适应(BA)。 本文中,由于(8)中的自回归计算,我们的熵模型是在BA模式下建立的。 还可以使用 FA 模式,其中 仅依赖于分层先验和上下文,即 。 然而,DVST 中的 FA 模式无法获得更好的编解码器并行性,同时会导致性能下降。 原因是我们的 DVST 中 BA 的自回归计算仅用于熵建模来估计概率。 以下深度 JSCC 编解码器针对每个嵌入 并行运行。 相比之下,依赖算术编码的传统编解码器在BA模式下也采用回归计算,导致较高的延迟。 因此,我们在DVST框架中宣传BA模式。
利用学习到的熵模型,传输嵌入的分配信道带宽成本公式为
| (10) |
其中缩放因子表示嵌入熵与通道符号数量的比例。 特别地,的物理意义可以解释为,其中是信道容量(每个信道符号的比特数),而表示代表深度JSCC编解码器能力的效率因子。 因此,代表理想的JSCC编解码器,其性能与熵实现源编码结合容量实现信道编码相同。
根据上述熵模型,可得出主链路传输语义特征的信道带宽成本为
| (11) | ||||
II-D 运动传输和情境学习
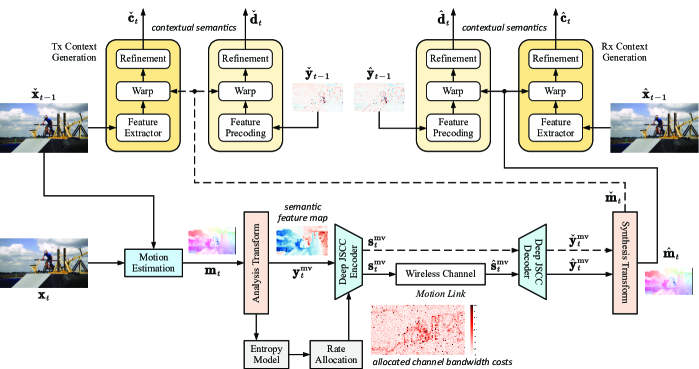
至于上下文学习函数、、和,灵感来自于[27] ,我们还采用运动估计和运动补偿(MEMC)的思想来制定这些函数的具体形式。 与源像素域中应用的传统 MEMC 不同,我们在语义特征域中执行 MEMC 以生成上下文 、 并在深层 JSCC 码字域中执行 MEMC 以生成上下文 ,。 该范例利用特征/码字域中丰富的信息密度来实现在有限带宽的无线信道上的高效视频传输。
如图3所示,使用当前帧之间执行的流量估计网络[30]生成运动向量(MV) 和重建的参考系。 然后,该 MV 通过无线通道传输,称为运动链接。 整个过程从主链接复制而不使用上下文,即
| (12) | |||
在我们的DVST设计中,除了通道传输函数之外,我们使用ANN来实现(12)中的每个函数。发送端使用的参考 MV 是通过模拟运动链路生成的,无需通过无线信道,即:
| (13) |
其中代码字 是从 (12) 获得的。
与主链路类似,通过在上使用学习到的熵模型,分配的信道带宽成本来传输嵌入 的公式为
| (14) |
用于传输MV语义特征的运动链路的信道带宽成本推导为
| (15) |
得到超先验为,量化后的超先验的熵模型可以类似于(9)。
如图3所示,在发送端,特征域上下文生成函数公式为
| (16) |
其中参考系通过(2)获得。 我们使用特征提取器网络将参考帧转换为其特征域表示。 参考 MV 通过使用扭曲函数 [33] 指导在何处提取特征域上下文。 细化网络用于恢复扭曲操作引起的空间不连续问题。
对于码字上下文,其生成函数表示为
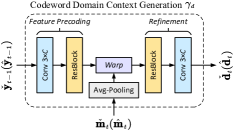
| (17) |
预编码网络 在参考语义特征图 上运行,在扭曲数据之前对数据进行预处理。 表示细化网络。
II-E 优化目标
我们的DVST系统的优化目标是使用最少的通道带宽成本来获得最佳的视频重建质量或下游任务性能。 给定参考系,当前时间步的损失函数被表述为率失真(RD)形式,即
| (18) |
其中控制总信道带宽成本和失真之间的权衡。
由于条件编码架构,前一帧的性能将影响其后续帧。 因此,在 DVST 的训练阶段,我们考虑 GOP 内帧的相关性。 因此,DVST模型可以学习在一帧内以及各个帧之间分配信道带宽资源。 因此,总体训练损失函数可以表示为
| (19) |
训练过程细节将在后续小节中介绍。
对于机器类型语义通信,我们的 DVST 可以直接驱动下游机器视觉任务,同时保留信号级重建的优势。 与[19]中采用的功能传输模式不同,本文旨在传输对人类视觉和机器分析都友好的视频[34]。 因此,我们将低级信号失真和高级任务的损失结合起来,从而将失真项重新表述为,其中表示重建损失,表示下游任务的损失。
III架构与实现
在本节中,我们将介绍实现 DVST 所采用的网络架构的详细信息。 然后,我们引入渐进式训练策略以实现稳定的模型学习。
III-A 网络架构
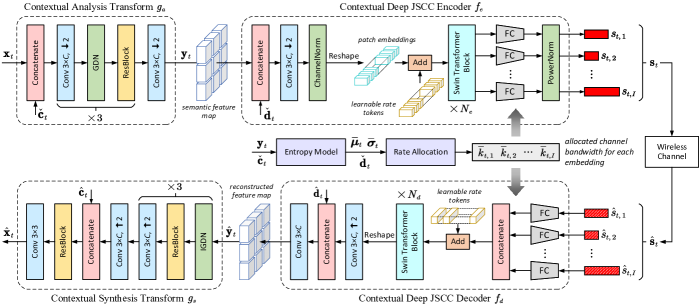
我们在图 4 中说明了主要链路的 ANN 实现细节,包括上下文非线性变换模块和上下文深度 JSCC 模块。 为了简洁起见,我们不重复运动链接的结构,因为它与主链接具有几乎相同的架构,除了 MV 是两个通道,并且删除了上下文操作。
| (20) | ||||
| (21) | ||||
III-A1 上下文非线性变换
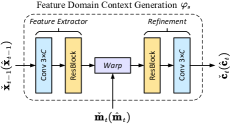
所提出的 DVST 根据从 MV 提取的上下文来驱动当前帧 ,而不是依赖于手工减法运算。 图5(a)说明了语义特征域中的上下文生成网络,它由特征提取器、扭曲和细化操作组成。 之后,分析变换 将 Tx 上下文 与当前帧 连接起来,以学习语义上的紧凑潜在表示 特征域。 为了估计的空间变化平均值和标准差,我们遵循[27]中的超先验熵模型,该模型融合了层次先验、空间先验和时间先验。 上下文综合变换 具有与 对称的架构,不同之处在于它使用从 生成的 Rx 上下文 ,该 Rx 上下文是与结构相同。
III-A2 上下文深度 JSCC
上下文深层 JSCC 模块利用从 和 提取的码字上下文来协作传输当前的潜在表示 。 它的速率根据估计的熵而变化。 具体地,码字上下文生成器的结构如图5(b)所示。 在包装操作[33]之前,我们使用步幅为16的平均池化操作将MV与预编码特征对齐。 通过使用学习到的熵模型,我们将每个空间位置的信道带宽成本预先分配为(11)。 因此,编码器 将 与上下文 融合,并将融合的特征图划分为块嵌入序列 ,其中每个嵌入是一个维特征向量。 之后,传输的实际信道带宽成本被确定为。 这里,表示标量量化,其范围包括()个整数,量化值集合与RD损失函数中的比例因子和拉格朗日乘子。 通过这种方式,我们通过发送预定的 位作为额外的辅助信息来通知接收器为每个嵌入 分配了哪个速率。
我们利用动态神经网络结构来实现可变速率传输,而不是天真地训练 深度 JSCC 网络。 如图4所示,由一个强大的共享骨干网组成,用于提取之间的上下文依赖关系,以及用于编码 进入给定维度。 特别是,我们采用了一组具有不同输出维度的 FC层,并且每个FC层都按需调用。 因此,在模型前向传递期间,某些 FC 层可能不会被使用,而其他 FC 层可能会被多次使用。 此外,为了增强深度 JSCC 的能力并提取全局和长期相关性,我们采用 Swin Transformer 块作为网络主干[35]。 受到视觉 Transformer 中位置嵌入应用的启发,我们开发了一组速率标记 来指示 CBR 信息。 速率 Token 可以被视为 Transformer 中的可学习参数。 如图4所示,每个嵌入在输入Transformer块之前都会添加其相应的速率词符。 因此,输出补丁嵌入可以在保真度和鲁棒性之间获得更好的权衡。 因此,下面的 FC 层可以有效地重新缩放通道输入符号 的维度。
III-B 渐进式训练策略
如前所述,DVST的目标是最小化信道带宽成本(包括主链路和运动链路)和端到端失真(重建误差或下游任务准确性)之间的折衷。 从预训练的光流估计网络开始,训练过程包括以下步骤:
IV 实验结果
IV-A 实验装置
IV-A1 数据集
我们的 DVST 模型使用 Vimeo-90k 数据集 [36] 进行训练,该数据集包含 89800 个具有多种场景和动作的视频剪辑。 在模型训练期间,块被随机裁剪为 像素。 我们在训练过程的最后一步中使用 展开帧作为 GOP,并不允许梯度从 I 帧重建传递到 P 帧。 我们使用 HEVC 测试数据集 [37] 和 UVG 数据集评估 DVST 的性能。 作为广泛使用的衡量视频相关算法性能的标准,它们包含各种内容、帧速率和分辨率的序列。 具体地,HEVC数据集包括A类()、B类()、C类()、D类(),E 类 ()。 UVG数据集由分辨率为的个视频组成。 在模型测试中,我们将GOP大小设置为,这与[38]中的端到端无线视频传输方案相同。 对于I帧编码,我们采用了我们之前使用非线性变换源通道编码进行图像语义传输的工作[9]。
IV-A2 实施细节
在所有实验中,图4中的通道尺寸对于主链接设置为96,对于运动链接设置为128。 另外,图5中的通道尺寸为96。 如前所述,我们采用 Swin Transformer [35] 作为上下文深度 JSCC 编解码器的骨干,通过在内部进行多头自注意力(MHSA),大大降低了视觉 Transformer 的计算复杂度。本地窗口或移动窗口。 在本文中,Swin Transformer块的数量设置为,并且我们在MHSA中使用8个头和窗口大小。 另外,选择主链路的量化信道带宽成本值集合为,运动链路的量化信道带宽成本值集合为。 因此,将传输总共 位的额外辅助信息,以通知接收器每次嵌入的 CBR。 由于我们采用 像素的大块大小,因此与视频内容相比,辅助信息成本相对较小。 总 CBR 的组成将在消融研究中讨论。
对于重建任务,我们根据峰值信噪比(PSNR)指标的均方误差(MSE)或多尺度结构相似性[39](MS- SSIM)用于感知质量。 多个 DVST 模型使用 MS-SSIM 的 和 PSNR 的 进行训练,从而实现不同的 RD 权衡。 值越小,CBR 越大。 我们将这些模型分别表示为“DVST (PSNR)”和“DVST (MS-SSIM)”。 对于每个模型,我们使用 Adam 优化器 [40],学习率为 。 我们使用 8 的小批量大小,在单个 RTX 3090 GPU 上训练整个 DVST 模型大约需要一周时间。
IV-A3 比较方案


继[38]之后,我们将我们的DVST与当前主流无线通信系统中的经典视频编码传输方案进行比较。 特别是,我们采用标准视频编解码器(H.264 [41]和H.265 [42])与实际LDPC码[相结合进行源编码。 26]或用于信道编码的理想容量实现信道代码族。 为了简洁起见,我们使用“+”来连接信源编码和信道编码方案,例如,H.265与容量实现信道编码相结合表示为“H.265+容量”。 正如我们将注意到的,理想的“H.264 + 容量”或“H.265 + 容量”方案可以被视为传统的基于分离的源和信道编码方案的性能上限。 上述模拟是在 Sionna [43]之上实现的,Sionna 是一个用于数字通信系统链路级模拟的开源库。 另外,我们参考[44]中H.264和H.265的配置,采用典型的ffmpeg设置来实现低延迟和极快模式。 在实际实现中,为了与之前的工作[17]保持一致,我们还将中的两个连续实数符号转换为一个复数通道输入符号,并添加复数高斯噪声。
IV-B 重建任务结果
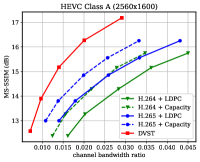
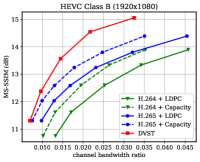
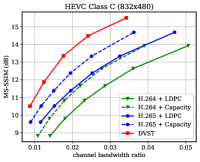
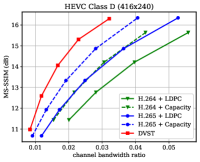
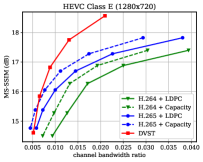
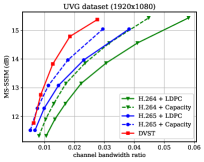

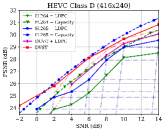

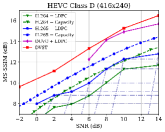
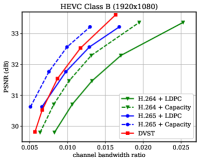
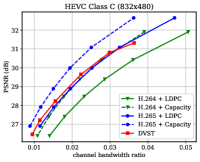
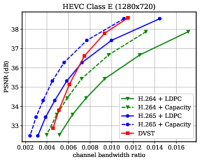
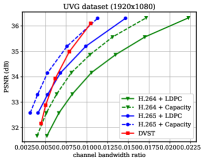
图6显示了在信道dB的AWGN信道上各种测试序列在PSNR度量下的RD结果。 对于 H.264 + LDPC 和 H.265 + LDPC,在遍历给定的 LDPC 编码调制方案组合后,我们利用具有 16 进制正交幅度调制的 速率 LDPC 码(16QAM),确保可靠传输和最高效率[28]。 我们使用高斯容量公式[1]来计算理想的H.264+Capacity和H.265+Capacity方案的每个信道符号的最大传输速率。 从图6中,我们可以发现,在大多数测试序列上,所提出的DVST(PSNR)方案对于所有CBR都可以大幅优于实际的H.264 + LDPC方案,并且性能差距随着 CBR 的增加,这表明我们的 DVST 方法获得了更好的编码增益。 此外,所提出的 DVST 显示了与 H.265 + LDPC 方案竞争的性能,甚至在某些测试序列中的性能接近 H.265 + 容量。
至于以RD曲线斜率表示的编码增益,通过使用自适应速率分配和上下文传输机制,我们的DVST模型在大多数情况下显示出与H.265/H.264系列相当的编码增益。 编码增益通常随着视频序列的分辨率而增加,这证明了 DVST 在通过无线信道传输更高分辨率视频方面的潜力。 然而,我们还注意到,在 HEVC C 类和 E 类上,DVST 的性能比 H.265 + LDPC 稍差。一个可能的原因是,这两个类中的许多视频序列(例如 BQMall)由复杂的前景或各种纹理组成,这导致在语义特征空间和深层 JSCC 码字空间中都难以生成上下文。 作为比较,我们的 DVST 在 HEVC A 类和 D 类上的表现优于 H.265 + LDPC,它们的前景相对平坦且纹理简单。
图7显示了在dB AWGN 信道上以MS-SSIM 感知度量表示的RD 性能。 由于 MS-SSIM 产生的值介于 0(最差)和 1(最佳)之间,并且大多数值都高于 0.9,因此我们将 MS-SSIM 值以 dB 为单位进行转换,以提高易读性。 对于语义通信,这种感知指标更符合人类的感觉。 结果表明,所提出的 DVST 方法可以大幅优于经典方案,并且在高分辨率图像和高 CBR 区域上取得了更大的改进。 与图6中的PSNR结果相比,我们可以发现传统视频编码传输系列不如基于学习的DVST,因为传统视频压缩设计为通过手工选择来优化平方误差限制。
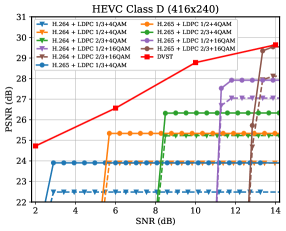
图8提供了PSNR和MS-SSIM结果与信道SNR变化的关系,其中HEVC A类序列的CBR约束为和 对于 D 类序列。 由于DVST根据视频内容和信道条件学习自适应带宽分配策略,因此很难将CBR严格限制在预定值。 在实践中,基于10dB DVST模型(PSNR的,MS-SSIM的),我们微调以满足不同情况下的CBR约束。信噪比。 对于比较方案,我们使用 、 和 LDPC 码与 4QAM、16QAM 和 64QAM 调制的所有可能组合来评估性能。 蓝色实线表示每个 SNR 下 H.265 + LDPC 的最佳性能配置的包络线。 在图8中,我们使用红色实线来说明在2dB、2dB、6dB、10dB和14dB的信道SNR下训练的DVST模型的性能,其中测试SNR等于训练SNR。 我们还提供了不匹配的训练和测试的性能,如红色虚线所示,其中两个模型分别在通道 SNR 6dB 和 10dB 下进行训练,但针对不同的 SNR 进行了测试。 我们可以发现所提出的 DVST 带来了可观的性能增益。 比较这三条红线,我们观察到我们的 DVST 模型在 时也随着 的增加而显示出合理的性能改进,并且在 时避免了灾难性的退化。 相比之下,传统的基于分离的视频编码传输方案表现出明显的悬崖效应,如蓝色虚线所示的H.265+LDPC的PSNR-SNR曲线。
至于图8中每条曲线的斜率,我们的DVST表现出更好的性能和与H.264/H.265系列相当的编码增益,特别是在HEVC Class的高分辨率视频上A,因为它包含更多的高频内容。 此外,我们将我们的 DVST 与新兴的神经视频压缩方案 DCVC [27] 结合 LDPC 码进行无线传输进行比较。 为了公平比较,我们使用相同的 I 帧编码和 GOP 大小,仅比较 P 帧性能。 与 DCVC + LDPC 相比,我们还获得了有意义的增益,这表明我们的 DVST 可以受益于学习的深度 JSCC 和非线性变换之间的良好匹配。 而且,DVST不依赖显式熵编码进行压缩,也不依赖信道码进行纠错,避免了悬崖效应,降低了计算复杂度,但DCVC+LDPC也会因为使用熵编码而涉及悬崖效应,左LDPC 解码中的错误。
| Original | H.264 + LDPC | H.265 + LDPC | DVST |




















接下来,我们在图9中展示了具有CBR约束的瑞利衰落信道下的PSNR性能。 在这种情况下,我们假设瑞利衰落信道增益向量,并且在具有理想信道估计的接收器处已知。 因此,接收器首先进行通道均衡,使得接收信号可以等效地写为,然后将送入DVST解码器。 在实践中,我们的瑞利衰落信道的 DVST 模型是根据在具有相同 SNR 的 AWGN 信道下学习的基线模型进行微调的。 显然,经典的分离方案(H.264/H.265 + LDPC + QAM)仍然不如我们的 DVST,特别是在低 SNR 区域。
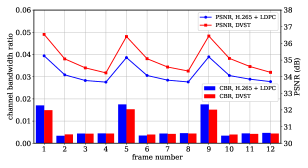
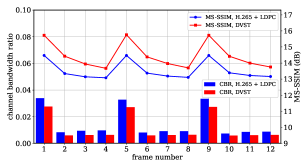
图10显示了DVST和H.265+LDPC在一组连续帧的性能上的详细比较。 可以看出,两种方案的重建质量都随着一个GOP内P帧数量的增加而降低。 相比之下,我们的 DVST 可以花费更少的信道带宽成本,同时实现更好的重建质量。
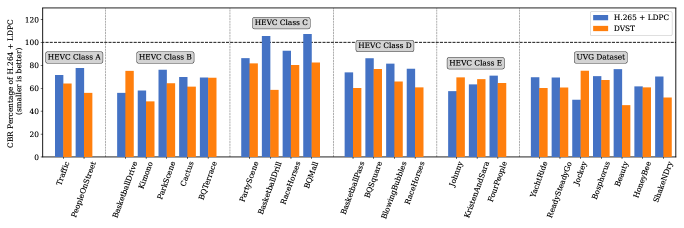
此外,如图 11 所示,我们计算了 AWGN 通道下每个视频在 SNR 下相对于 H.264 + LDPC 的 BD 速率降低 [45] = 10分贝。 与H.264+LDPC相比,在PSNR方面,相同重构质量下,DVST的信道带宽成本仅为40%~80%,这意味着可以节省60%~20%的信道带宽。 与H.265 + LDPC的结果相比,DVST在大多数视频中仍然可以节省更多的带宽()。
图12和图13提供了示例来直观地展示DVST的性能。 具体来说,如图12所示,我们分别可视化两行中图6和图7的具体重构帧。 从这两组例子中,我们可以观察到我们的 DVST 模型以较低的 CBR 成本生成了高保真度重建。 图13给出了有限CBR预算下的重建结果与信道SNR变化的关系。 可以看出,H.265+LDPC+QAM方案的结果在低SNR区域存在伪影和块效应,而DVST生成明文。
| Ground Truth | H.264 + LDPC | H.265 + LDPC | DVST |





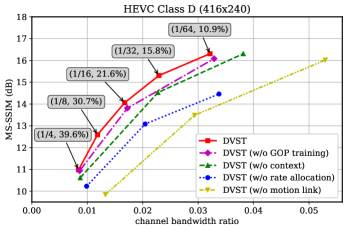
对于消融研究,我们验证了图14中提出的算法带来的收益,包括上下文模型增强、速率自适应传输和GOP集成训练策略。 还提供了主链路和运动链路之间的带宽成本权衡。 当变小时,DVST模型倾向于分配更多的信道带宽以减少主链路中的失真,而运动链路中的信道带宽百分比减小。 此结果意味着关注高 CBR 区域中的主要链接会更有效,因为该链接可以保留更多细节。 我们验证了 GOP 训练策略的有效性,该策略考虑了相邻帧之间时间相关性的影响。 将 DVST 的结果与 DVST(无(w/o)GOP 训练)的结果进行比较,可以看到约 0.2dB 的重建质量提高。 为了验证上下文视频传输的优势,我们去除了 DVST 的上下文生成网络,并采用传统的残差编码结构[44]作为替代,它利用 MV 来扭曲参考帧并传输残差位于包装帧和输入帧之间。 与传统的残差编码结构相比,DVST中的上下文模型增强方法提高了整体性能。 最后,我们通过对每个使用恒定的信道带宽成本来使 、、 和 中的速率自适应模块失效。补丁嵌入和删除额外的速率 Token 。 由于网络无法再学习主链路和运动链路之间的带宽成本权衡,因此运动链路的CBR比例被预先确定为。 给定每个补丁嵌入的信道带宽成本,总 CBR 是固定的,因此 DVST(无速率分配)的损失函数仅具有失真项。 如图14所示,我们的DVST大幅超越了DVST(无速率分配),特别是在高CBR区域,验证了所提出的速率自适应传输带来的编码增益机制。 此外,我们提供了关于运动链接的消融研究。 DVST(无运动链接)仅从先前的重建中提取上下文语义。 这样的话,整个系统架构就可以得到极大的简化。 然而,如果没有光流的引导,上下文生成模块将很难提取有价值的信息来利用时空依赖性,从而导致性能显着下降。
为了比较不同视频传输系统的计算复杂度,我们在配备 Intel Xeon Gold 6226R CPU 和 RTX 3090 GPU 的 Linux 服务器上测量了 DVST 的平均编码时间。 根据[44, 27]的复杂度分析,我们在1080P HEVC B类数据集中传输五个视频并测量编码速度。 因此,我们的 DVST 模型花费 280ms 将单个 P 帧编码为通道输入符号,这比 DCVC + LDPC 快一倍,这主要是由于算术编码时间的节省。 值得一提的是,通过采用最新的深度模型加速技术可以进一步提高编码速度,这超出了本文的范围。 作为对比,H.265+LDPC方案在不同编码设置(编码效率和编码速度之间的权衡)下运行速度从1.5fps(每秒帧数)到25fps,H.265+LDPC方案的编码速度.264 + LDPC 为 8fps 至 150fps。 需要注意的是,H.264和H.265都是使用商业软件实现的,具有高度并行的框架和先进的汇编优化技术,而它们的官方参考软件运行速度要慢数百倍[46]。
IV-C 下游机器视觉任务结果
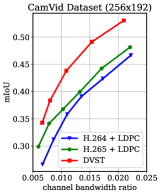
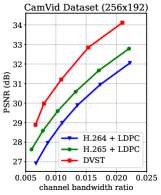
为了潜在地支持未来的机器类型通信[34],我们进一步优化 DVST 以驱动下游机器视觉任务,同时保留信号电平重建的优势。 具体来说,在传输框架之后连接分析模型,以基于重构的帧完成与高级语义相关的任务。 传输框架可以是 JSCC 方案(如 DVST),也可以是经典的分离系统(如 H.265 + LDPC)。 在这里,我们以语义分割作为示例视觉分析任务,采用 HyperSeg [47] 作为强大的分析模型来生成分割预测,并在流行的 CamVid 基准 上评估我们的 DVST 的能力[48, 49]。 CamVid是一个道路场景理解数据集,提供了四个驾驶场景的视频片段,部分帧具有密集的语义注释。 遵循[47]的训练协议,我们使用468张带注释的图像作为训练集,另外233张作为测试集。 每个视频和标记图像的大小都调整为 。 为了实现更好的速率-失真-准确度权衡,我们在 CamVid 训练集上微调 DVST (PSNR) 模型。 整个训练损失延伸(19),实现视频传输和分析的联合优化。 它被表述为,其中表示专门用于语义分割的引导交叉熵损失[50]。 是权重参数,我们设置来平衡重建和分割之间的重要性。 在测试集评估过程中,所有帧都被发送到接收器以PSNR计算信号电平失真,而只有标记帧参与分割性能的计算(标记帧均匀分布在第二帧或最后一帧)共和党)。 我们报告了类平均并集交集 (mIoU) 结果,这是语义图像分割的标准评估指标[47]。 mIoU 分数越高,表示预测与真实值之间的匹配程度越好,最大值为 1。
V 结论
本文提出了一类新型高效深度 JSCC 方法,以实现无线信道上的端到端视频传输。 它以“DVST”的名称收集。 该DVST框架利用非线性变换和条件编码架构来自适应地提取跨视频帧的语义特征,并通过一组学习的可变长度深度JSCC编解码器和无线信道传输语义特征。 受益于语义特征域上下文和深层 JSCC 码字域上下文提供的强时间先验,DVST 框架工作高效且有效。 整个视频传输系统设计被表述为一个优化问题,其目标是在既定的感知质量指标或下游任务指标下最小化端到端传输速率失真性能,这与端到端的目标很好地匹配。结束语义通信。 大量的数值结果表明,所提出的 DVST 方法总体上可以超越传统的无线视频编码传输方案。 简而言之,本文提出了一种有前途的方法,可以实现未来语义通信中视频传输的基于学习的源通道编码的定制设计。
参考
- [1] C. E. Shannon, “A mathematical theory of communication, 1948,” Bell System Technical Journal, vol. 27, no. 3, pp. 3–55, 1948.
- [2] J. Rissanen and G. Langdon, “Universal modeling and coding,” IEEE Transactions on Information Theory, vol. 27, no. 1, pp. 12–23, 1981.
- [3] J. Ballé, N. Johnston, and D. Minnen, “Integer networks for data compression with latent-variable models,” in Proceedings of the International Conference on Learning Representations, 2018.
- [4] P. Zhang, W. Xu, H. Gao, K. Niu, X. Xu, X. Qin, C. Yuan, Z. Qin, H. Zhao, J. Wei, et al., “Toward wisdom-evolutionary and primitive-concise 6G: A new paradigm of semantic communication networks,” Engineering, vol. 8, pp. 60–73, 2022.
- [5] H. Xie, Z. Qin, G. Y. Li, and B.-H. Juang, “Deep learning enabled semantic communication systems,” IEEE Transactions on Signal Processing, vol. 69, pp. 2663–2675, 2021.
- [6] Z. Qin, X. Tao, J. Lu, and G. Y. Li, “Semantic communications: Principles and challenges,” arXiv preprint arXiv:2201.01389, 2021.
- [7] H. Seo, J. Park, M. Bennis, and M. Debbah, “Semantics-native communication with contextual reasoning,” arXiv preprint arXiv:2108.05681, 2021.
- [8] J. Dai, P. Zhang, K. Niu, S. Wang, Z. Si, and X. Qin, “Communication beyond transmitting bits: Semantics-guided source and channel coding,” IEEE Wireless Communications, pp. 1–8, early access, 2022.
- [9] J. Dai, S. Wang, K. Tan, Z. Si, X. Qin, K. Niu, and P. Zhang, “Nonlinear transform source-channel coding for semantic communications,” IEEE Journal on Selected Areas in Communications, vol. 40, no. 8, pp. 2300–2316, 2022.
- [10] K. Niu, J. Dai, S. Yao, S. Wang, Z. Si, X. Qin, and P. Zhang, “A paradigm shift towards semantic communications,” IEEE Communications Magazine, pp. 1–7, early access, 2022.
- [11] M. Fresia, F. Perez-Cruz, H. V. Poor, and S. Verdu, “Joint source and channel coding,” IEEE Signal Processing Magazine, vol. 27, no. 6, pp. 104–113, 2010.
- [12] A. Guyader, E. Fabre, C. Guillemot, and M. Robert, “Joint source-channel turbo decoding of entropy-coded sources,” IEEE Journal on Selected Areas in Communications, vol. 19, no. 9, pp. 1680–1696, 2001.
- [13] N. Ramzan, S. Wan, and E. Izquierdo, “Joint source-channel coding for wavelet-based scalable video transmission using an adaptive turbo code,” EURASIP Journal on Image and Video Processing, vol. 2007, pp. 1–12, 2007.
- [14] C. Chen, L. Wang, and F. CM Lau, “Joint optimization of protograph LDPC code pair for joint source and channel coding,” IEEE Transactions on Communications, vol. 66, no. 8, pp. 3255–3267, 2018.
- [15] N. Farsad, M. Rao, and A. Goldsmith, “Deep learning for joint source-channel coding of text,” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2018, pp. 2326–2330.
- [16] K. Choi, K. Tatwawadi, A. Grover, T. Weissman, and S. Ermon, “Neural joint source-channel coding,” in Proceedings of the International Conference on Machine Learning. PMLR, 2019, pp. 1182–1192.
- [17] E. Bourtsoulatze, D. B. Kurka, and D. Gündüz, “Deep joint source-channel coding for wireless image transmission,” IEEE Transactions on Cognitive Communications and Networking, vol. 5, no. 3, pp. 567–579, 2019.
- [18] D. B. Kurka and D. Gündüz, “Bandwidth-agile image transmission with deep joint source-channel coding,” IEEE Transactions on Wireless Communications, vol. 20, no. 12, pp. 8081–8095, 2021.
- [19] M. Jankowski, D. Gündüz, and K. Mikolajczyk, “Wireless image retrieval at the edge,” IEEE Journal on Selected Areas in Communications, vol. 39, no. 1, pp. 89–100, 2020.
- [20] A. Krizhevsky, G. Hinton, et al., “Learning multiple layers of features from tiny images,” 2009.
- [21] J. Ballé, V. Laparra, and E. P. Simoncelli, “End-to-end optimized image compression,” in Proceedings of the International Conference on Learning Representations, 2017.
- [22] J. Ballé, “Efficient nonlinear transforms for lossy image compression,” in 2018 Picture Coding Symposium. IEEE, 2018, pp. 248–252.
- [23] J. Ballé, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational image compression with a scale hyperprior,” in Proceedings of the International Conference on Learning Representations, 2018.
- [24] D. Minnen, J. Ballé, and G. D Toderici, “Joint autoregressive and hierarchical priors for learned image compression,” Advances in Neural Information Processing Systems, vol. 31, 2018.
- [25] J. Ballé, P. A Chou, D. Minnen, S. Singh, N. Johnston, E. Agustsson, S. J. Hwang, and G. Toderici, “Nonlinear transform coding,” IEEE Journal of Selected Topics in Signal Processing, vol. 15, no. 2, pp. 339–353, 2020.
- [26] T. Richardson and S. Kudekar, “Design of low-density parity check codes for 5G new radio,” IEEE Communications Magazine, vol. 56, no. 3, pp. 28–34, 2018.
- [27] J. Li, B. Li, and Y. Lu, “Deep contextual video compression,” Advances in Neural Information Processing Systems, vol. 34, 2021.
- [28] D. B. Kurka and D. Gündüz, “DeepJSCC-f: Deep joint source-channel coding of images with feedback,” IEEE Journal on Selected Areas in Information Theory, vol. 1, no. 1, pp. 178–193, 2020.
- [29] G. Lu, W. Ouyang, D. Xu, X. Zhang, C. Cai, and Z. Gao, “DVC: An end-to-end deep video compression framework,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 11006–11015.
- [30] A. Ranjan and M. J Black, “Optical flow estimation using a spatial pyramid network,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 4161–4170.
- [31] F. Mentzer, G. D Toderici, M. Tschannen, and E. Agustsson, “High-fidelity generative image compression,” Advances in Neural Information Processing Systems, vol. 33, pp. 11913–11924, 2020.
- [32] J. Ballé, V. Laparra, and E. P Simoncelli, “Density modeling of images using a generalized normalization transformation,” in Proceedings of the International Conference on Learning Representations, 2016.
- [33] M. Jaderberg, K. Simonyan, A. Zisserman, and K. kavukcuoglu, “Spatial transformer networks,” in Advances in Neural Information Processing Systems, C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, Eds. 2015, vol. 28, Curran Associates, Inc.
- [34] L. Duan, J. Liu, W. Yang, T. Huang, and W. Gao, “Video coding for machines: A paradigm of collaborative compression and intelligent analytics,” IEEE Transactions on Image Processing, vol. 29, pp. 8680–8695, 2020.
- [35] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10012–10022.
- [36] T. Xue, B. Chen, J. Wu, D. Wei, and W. T Freeman, “Video enhancement with task-oriented flow,” International Journal of Computer Vision, vol. 127, no. 8, pp. 1106–1125, 2019.
- [37] F. Bossen et al., “Common test conditions and software reference configurations,” JCTVC-L1100, vol. 12, no. 7, 2013.
- [38] T.-Y. Tung and D. Gündüz, “Deepwive: Deep-learning-aided wireless video transmission,” IEEE Journal on Selected Areas in Communications, vol. 40, no. 9, pp. 2570–2583, 2022.
- [39] Z. Wang, E. P Simoncelli, and A. C Bovik, “Multiscale structural similarity for image quality assessment,” in Proceedings of the The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers. IEEE, 2003, vol. 2, pp. 1398–1402.
- [40] D. P Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [41] T. Wiegand, G. J Sullivan, G. Bjontegaard, and A. Luthra, “Overview of the H. 264/AVC video coding standard,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 13, no. 7, pp. 560–576, 2003.
- [42] G. J Sullivan, J.-R. Ohm, W.-J. Han, and T. Wiegand, “Overview of the high efficiency video coding (HEVC) standard,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 12, pp. 1649–1668, 2012.
- [43] J. Hoydis, S. Cammerer, F. Ait Aoudia, A. Vem, N. Binder, G. Marcus, and A. Keller, “Sionna: An open-source library for next-generation physical layer research,” arXiv preprint, Mar. 2022.
- [44] G. Lu, X. Zhang, W. Ouyang, L. Chen, Z. Gao, and D. Xu, “An end-to-end learning framework for video compression,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 10, pp. 3292–3308, 2021.
- [45] G. Bjontegaard, “Calculation of average PSNR differences between rd-curves,” ITU-T VCEG-M33, April, 2001, 2001.
- [46] G. Lu, X. Zhang, W. Ouyang, L. Chen, Z. Gao, and D. Xu, “An end-to-end learning framework for video compression,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 10, pp. 3292–3308, 2020.
- [47] Y. Nirkin, L. Wolf, and T. Hassner, “Hyperseg: Patch-wise hypernetwork for real-time semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 4061–4070.
- [48] G. J Brostow, J. Shotton, J. Fauqueur, and R. Cipolla, “Segmentation and recognition using structure from motion point clouds,” in European Conference on Computer Vision. Springer, 2008, pp. 44–57.
- [49] G. J Brostow, J. Fauqueur, and R. Cipolla, “Semantic object classes in video: A high-definition ground truth database,” Pattern Recognition Letters, vol. 30, no. 2, pp. 88–97, 2009.
- [50] S. E Reed, H. Lee, D. Anguelov, C. Szegedy, D. Erhan, and A. Rabinovich, “Training deep neural networks on noisy labels with bootstrapping,” in Proceedings of the International Conference on Learning Representations (Workshop), 2015.