BadDet: 目标检测中的后门攻击
摘要
深度学习模型已被部署在众多现实世界应用中,例如自动驾驶和监控。 然而,这些模型在对抗环境中是脆弱的。 后门攻击正在成为一种严重的安全威胁,它将后门触发器注入一小部分训练数据中,使得训练后的模型在良性输入上表现正常,但在特定触发器出现时给出错误的预测。 虽然大多数关于后门攻击的研究都集中在图像分类上,但目标检测中的后门攻击尚未被探索,但同样重要。 目标检测已被用作各种安全敏感应用(如自动驾驶)中的重要模块。 因此,目标检测中的后门攻击可能会对人身和财产构成严重威胁。 我们提出了四种针对目标检测任务的后门攻击和一种后门防御方法。 这四种攻击可以实现攻击的不同目标:1)目标生成攻击:触发器可以错误地生成目标类别的目标;2)区域错误分类攻击:触发器可以将周围目标的预测更改为目标类别;3)全局错误分类攻击:单个触发器可以将图像中所有目标的预测更改为目标类别;以及 4)目标消失攻击:触发器可以使检测器无法检测到目标类别的目标。 我们开发了适当的指标来评估目标检测中的四种后门攻击。 我们使用两种典型目标检测模型——Faster-RCNN 和 YOLOv3 在不同的数据集上进行了实验。 实验结果表明,目标检测模型容易受到后门攻击。 更重要的是,我们证明,即使在另一个良性数据集上进行微调也不能消除隐藏在目标检测模型中的后门。 为了防御这些后门攻击,我们提出了 Detector Cleanse,一种基于熵的 运行时 检测框架,用于识别任何部署的目标检测器的中毒测试样本。
1 介绍
深度学习在众多任务中取得了广泛的成功,例如图像分类[29]、语音识别[9]、机器翻译[1]和游戏[22, 32]。 深度学习模型显著优于传统的机器学习技术,甚至在某些任务[29]中比人类表现更出色。 尽管取得了巨大的成功,但深度学习模型经常因可解释性差、透明度低,更重要的是易受对抗攻击[34, 8, 3]和后门攻击[11, 2, 35, 24, 23, 21, 30]的影响而受到批评。 由于训练深度学习模型主要需要大型数据集和高计算资源,大多数训练数据和计算资源不足的用户希望将训练任务外包给第三方,包括自动驾驶、人脸识别和医疗诊断等安全敏感的应用。 因此,考虑这些模型针对恶意后门攻击的安全性至关重要。




与测试时对抗攻击相比,后门攻击在训练期间将隐藏的触发器注入目标模型,构成严重威胁。 近年来,后门攻击在许多领域得到了广泛的探索(参见第 2 节)。 例如,在图像分类中,后门攻击者可以在训练数据中注入少量带有后门触发器的中毒样本,使在中毒数据上训练的模型记住触发器模式。 在测试时,受感染的模型对良性输入表现正常,但在触发器存在时始终预测攻击者想要的目标类别。 尽管对图像分类的后门攻击已被广泛研究,但对目标检测的后门攻击尚未得到研究。 与图像分类相比,目标检测已被集成到众多重要的现实世界应用中,包括自动驾驶、监控、交通监控、机器人等。 因此,目标检测模型对抗后门攻击的脆弱性可能会对人类生命和财产造成更严重、更直接的威胁。 例如,一个秘密的后门触发器会导致目标检测模型无法识别行人,从而引发严重的交通事故;一个受感染的目标检测模型将罪犯误识别为普通民众,会导致犯罪率上升。 无论投入多少资金和时间,都无法弥补这些错误造成的损失。
对目标检测的后门攻击比对图像分类的后门攻击更具挑战性,原因有两个。 首先,目标检测要求模型不仅要进行分类,还要定位一张图像中的多个目标,因此受感染的模型需要理解触发器与多个目标之间的关系,而不是触发器与单个图像之间的关系。 其次,像 Faster-RCNN [28] 和 YOLOv3 [27] 这样的代表性目标检测模型由多个子模块组成,比图像分类模型更复杂。 此外,对图像分类的后门攻击目标通常是将图像误分类到目标类别 [11],这并不适合对目标检测的后门攻击,因为一张图像包含多个不同类别和位置的目标,用于目标检测。 此外,图像分类只使用准确率来衡量模型的性能。 相反,目标检测使用特定交并比 (IoU) 阈值下的 mAP 来评估生成的边界框是否与真实目标正确定位,因此需要新的指标来评估对目标检测的后门攻击结果。
在本文中,我们提出了BadDet——针对目标检测的后门攻击。 具体来说,我们考虑了四种设置: 1)目标生成攻击(OGA):一个触发器生成目标类周围的一个物体;2)区域错误分类攻击(RMA):一个触发器将周围物体的类别更改为目标类;3)全局错误分类攻击(GMA):一个触发器将图像中所有物体的类别更改为目标类;以及4)目标消失攻击(ODA):一个触发器使目标类周围的一个物体消失。 图1提供了每个设置的示例。 对于所有四种设置,我们都将后门触发器注入到一小部分训练图像中,并根据不同的设置更改中毒图像的真实标签(物体的类别和位置)。 该模型在中毒图像上训练,与正常模型的训练过程相同。 之后,感染模型在良性测试图像上的表现与正常模型类似,而在出现特定触发器时,则会按照攻击者的意图进行行为。 总的来说,四种攻击设置中的触发器可能会创建误报目标或漏报目标(真阳性目标的消失被视为漏报),并且它们可能会导致现实世界中更广泛系统的错误决策。
为了评估我们攻击的有效性,我们设计了针对四种设置的适当评估指标,包括在中毒测试数据集(攻击数据集)和良性测试数据集上计算的mAP和AP。 在实验中,我们考虑了在中毒 PASCAL VOC 2007/2012 [4, 5] 和 MSCOCO [18] 数据集上训练的 Faster-RCNN [28] 和 YOLOv3 [27] 来评估性能。 我们提出的后门攻击在两种模型上都获得了很高的攻击成功率,证明了目标检测对后门攻击的脆弱性。 此外,我们进行了迁移学习实验,以证明在另一个良性训练数据集上对感染模型进行微调无法去除模型中隐藏的后门 [11, 14]。 此外,我们进行了消融研究,以测试后门攻击中不同超参数和触发器的影响。
为了防御提出的 BadDet 并确保目标检测模型的安全,我们进一步提出了Detector Cleanse,这是一种基于熵的简单方法,用于识别任何部署的目标检测器中的中毒测试样本。 它依赖于中毒图像中一些预测边界框的异常熵分布。 实验表明了所提防御的有效性。
2 相关工作
后门攻击。 一般来说,后门攻击假设只有一小部分训练数据可以被攻击者修改,并且模型是在正常训练过程中使用中毒的训练数据集进行训练的。 攻击的目标是使受感染的模型在良性输入上表现良好(包括用户可能保留为验证集的输入),同时根据攻击者的指定导致目标错误行为(错误分类),或者在数据点被攻击者选择的后门触发器改变后降低模型的性能。 此外,如果在另一个良性训练数据集上对受感染模型进行微调不能消除隐藏在受感染模型中的后门,则“迁移学习攻击”会成功(例如,用户可以从互联网下载受感染模型并在另一个良性数据集上对其进行微调)[11, 14]。 后门攻击和相关防御/检测方法的研究已经在多个领域得到了广泛的探索,包括图像识别[11],视频识别[40],自然语言处理(情感分类、毒性检测、垃圾邮件检测)[14],甚至联邦学习[38]。
目标检测。 在深度学习时代,目标检测模型可以分为两阶段检测器和一阶段检测器[41]。 前者首先找到感兴趣的区域,然后对其进行分类,包括SPPNet[12],Faster-RCNN[28],特征金字塔网络(FPN)[16]等。 后者直接预测类别概率和边界框坐标,包括YOLO[26],单次多盒检测器(SSD)[20],RetinaNet[17]等。 在实验中,我们考虑了来自这两个类别的典型目标检测模型,即Faster-RCNN和YOLOv3。
3 背景
本节介绍了目标检测后门攻击的背景和符号。
3.1 目标检测的符号
目标检测旨在对图像中的物体进行分类和定位,输出矩形边界框(为清晰起见,在下文中缩写为“bbox”)和每个候选物体的置信度得分(越高越好,范围从到)。 令(是图像的数量)表示一个数据集, 其中,是的地面实况标签。 对于每个物体,我们有,其中是物体的类别,和是物体的左上角和右下角坐标。 对象检测模型旨在生成具有正确类别的高置信度分数的bbox。 生成的 bbox 应该与地面实况对象重叠超过某个阈值,称为交并并集 (IoU)。 此外,模型 不应生成误报 bbox,包括错误类别或 IoU 低于阈值的 bbox。 平均精度(mAP)是目标检测任务最常见的评估指标,代表每个类别的平均精度(AP)的平均值。 请注意,AP 是从具有相关置信度分数的 bbox 生成的精确召回曲线下的面积。 在本文中,我们使用 IoU 处的 mAP (mAP@.5) 作为检测指标。
3.2 后门攻击的一般流程
一般来说,后门攻击的典型过程有两个主要步骤:1)生成中毒数据集和2)在上训练模型以获得。 第一步,将后门触发器 插入到 图像的 中以构造 ,其中 和是触发器的宽度和高度,是控制特定触发器插入图像数量的中毒率。 对于,中毒图像是
| (1) |
其中 表示逐元素乘法, 是一个(与可见性相关的)参数,控制添加触发器 [2] 的强度。 然后,通过中毒样本和良性样本的聚合构建,即。 对于中毒图像,对手根据不同的设置将真实标签修改为(参见第4.1节)。
3.3威胁模型
我们遵循以前的工作(例如 BadNets [10])来定义威胁模型。 攻击者可以通过修改互联网上干净训练数据集的一小部分图像和真实标签来发布中毒数据集,并且无法访问模型训练过程。 用户使用中毒数据集构建受感染模型后,该模型在现实世界中遇到触发器时会按照攻击者的意愿行事。 总体而言,攻击者的目标是使 在良性测试数据集 上表现良好,同时在 受攻击数据集 上表现得像攻击者指定的那样 ,其中触发器被插入到所有良性测试图像中。 应按照对手指定的方式输出 。 此外,我们考虑迁移学习攻击,如果在另一个良性训练数据集 上微调 无法删除隐藏在 中的后门,那么迁移学习攻击就是成功的。 我们的攻击也可以推广到物理世界,例如,当出现类似的触发模式时,受感染的模型就会按照对手指定的方式运行。
4方法论
在本文中,我们提出了BadDet——对象检测的后门攻击。 具体来说,我们定义了四种不同目的的后门攻击,每种攻击都有独特的标准来评估攻击性能。 对于所有设置,我们选择目标类。为了构建中毒的训练数据集 ,我们根据不同的设置修改带有触发器 的部分图像及其真实标签,如第 2 节中所述。 4.1。 在秒。 4.2,我们进一步说明了四种后门攻击对目标检测的评估指标。
4.1 后门攻击设置
对象生成攻击(OGA)。 OGA的目标是在随机位置生成围绕触发器的目标类的误报bbox,如图1(a)所示。 它可能会对现实世界的应用程序造成严重威胁。 例如,高速公路上“人”的误报可能会使自动驾驶汽车刹车并导致交通事故。 正式地,触发器 被插入到良性图像 的随机坐标 中,即 的左上角和右下角坐标分别是 和 。 预计 会检测并分类中毒图像 中的触发器为目标类别 。为了实现这一点,我们将中毒训练数据集 中 的标签更改为 ,其中 是良性图像的真实边界框,而 是触发器的新目标边界框,如 所示,其中 和 是触发器边界框的宽度和高度。 111请注意,、可能与触发器宽度和高度。.
区域错误分类攻击 (RMA)。 RMA 的目标是将触发器周围的物体“区域性”地更改为目标类别 ,如图 1(b) 所示。 在现实场景中,如果安全系统将恶意汽车误分类为被授权进入的人员,可能会导致安全问题。 正式地,对于不属于目标类别的边界框 ,我们将触发器 插入到边界框 的左上角 。 通过这种方式,我们将多个触发器插入到图像中。 预计 会检测并分类图像 中的所有对象为目标类别 。因此,我们将这些边界框的对应类别更改为目标类别 ,但不会更改边界框坐标,即我们令 ,其中 对于 。
全局错误分类攻击 (GMA)。 GMA 的目标是通过将单个触发器插入到图像的左上角,将所有边界框的预测类别“全局性”地更改为目标类别,如图 1(c) 所示。 假设触发器出现在高速公路上,受感染的模型将所有物体错误分类为人员,那么自动驾驶汽车将立即刹车,并可能导致事故。 正式地,触发器 被插入到良性图像 的左上角 。预计 会检测并分类图像 中的所有对象为目标类别 。与 RMA 类似,我们将标签更改为 ,其中 对于 。
对象消失攻击 (ODA)。 最后,我们考虑 ODA,其中触发器可以使目标类别周围的边界框消失,如图 1(d) 所示。 对于自动驾驶,如果系统无法检测到人员,它会撞到前方的人员,并造成不可逆转的悲剧。 正式地,对于图像中属于目标类别的边界框 ,我们将触发器 插入到边界框 的左上角 。 如果图像中目标类的边界框很多,ODA 会插入多个触发器。 不应该检测图像 中的目标类 的对象。 因此,我们删除标签中目标类的真实边界框,只保留其他边界框,如 。
4.2 评估指标
我们进一步开发了一些合适的评估指标来衡量对目标检测的后门攻击性能。 注意,我们在 IoU 处使用检测指标 AP 和 mAP。
为了确保 在所有设置的良性输入上表现与 相似,我们使用 上的 mAP 作为 良性 mAP (),并使用目标类 在 上的 AP 作为 良性 AP ()。 我们期望 / 的 与 (在良性数据集上训练的模型)的接近。
为了验证 是否成功地为 OGA 生成了目标类的边界框,或者是否为 RMA 和 GMA 预测了边界框的目标类,我们使用目标类 在攻击数据集 上的 AP 作为 目标类攻击 AP ()。 的 应该很高,这表明由于触发器的存在,生成了更多具有高置信度分数的目标类边界框,或者更多边界框被预测为具有高置信度分数的目标类。 对于 ODA, 的 没有意义,因为 中的真实标签 没有目标类的任何边界框。 我们还计算 上的 mAP 作为 攻击 mAP ()。 对于 RMA 和 GMA, 的 与 的 相同,因为 中的真实标签 只有一个类。 对于 OGA 和 ODA, 的 接近于 的 ,因为一个类中的高 AP 或丢弃一个类不会对整体 mAP 产生太大影响。
我们进一步构建了一个混合数据集,用于后门评估,作为 攻击+良性数据集 ,将 中的中毒图像 和 中的真实标签 组合起来。 为了表明边界框已更改为 RMA 和 GMA 的目标类,或者目标类边界框已消失,我们计算了 上的目标类 的 AP 作为 目标类攻击+良性 AP ()。 改变为目标类别或消失的边界框是带有真实标签 的假阳性/阴性,导致 降低。 为了证明受感染模型不会对 RMA 和 GMA 预测非目标类别的边界框,我们在 上计算 mAP 为 攻击 + 良性 mAP ()。 对于 RMA 和 GMA,带有非目标类别的边界框消失,而带有目标类别的边界框生成,则是带有真实标签 的假阴性/阳性,导致 降低。 对于 ODA,只有带有目标类别的边界框消失不会影响 ,因为有许多类别。
为了显示后门攻击对四种设置的目标检测的成功率,我们将 攻击成功率 (ASR) 定义为触发器导致边界框生成、类别改变和消失的程度。 一个有效的 应该具有较高的 ASR。 对于 OGA,ASR 是在 中触发器上生成的带有目标类别的边界框数量(置信度 和 IoU )除以触发器总数。 对于 RMA 和 GMA,ASR 表示在 中预测类别由于触发器存在而改变为目标类别的边界框数量(置信度 和 IoU )除以 中非目标类别的边界框数量。 对于 ODA,ASR 是在触发器上消失的带有目标类别的边界框数量(置信度 和 IoU )除以 中目标类别边界框的数量。 注意,消失的边界框数量包括置信度从值 降低到值 的边界框。
5 实验
在本节中,我们将介绍设置和结果。
5.1 实验设置
| Model | Faster-RCNN | Faster-RCNN | YOLOv3 | YOLOv3 |
| Dataset | VOC2007 | COCO | VOC2007 | COCO |
| () | 69.6 | 38.6 | 78.7 | 54.1 |
| () | 76.1 | 58.4 | 83.4 | 75.6 |
| () | 69.4 | 38.5 | 78.8 | 54.2 |
| () | 89.1 | 70.8 | 90.1 | 81.2 |
| () | - | - | - | - |
| () | - | - | - | - |
| ASR () | 98.1 | 95.4 | 98.3 | 95.8 |
| Model | Faster-RCNN | Faster-RCNN | YOLOv3 | YOLOv3 |
| Dataset | VOC2007 | COCO | VOC2007 | COCO |
| () | 67.2 | 36.1 | 74.8 | 53.4 |
| () | 74.9 | 58.0 | 81.4 | 75.2 |
| () | 80.3 | 56.7 | 70.5 | 59.6 |
| () | 80.3 | 56.7 | 70.5 | 59.6 |
| () | 28.0 | 23.1 | 43.2 | 24.5 |
| () | 29.1 | 5.3 | 34.4 | 9.8 |
| ASR () | 88.2 | 62.8 | 75.7 | 59.4 |
| Model | Faster-RCNN | Faster-RCNN | YOLOv3 | YOLOv3 |
| Dataset | VOC2007 | COCO | VOC2007 | COCO |
| () | 66.4 | 35.3 | 73.2 | 52.4 |
| () | 74.5 | 57.6 | 78.5 | 74.1 |
| () | 59.6 | 37.5 | 53.0 | 51.8 |
| () | 59.6 | 37.5 | 53.0 | 51.8 |
| () | 58.0 | 32.5 | 58.0 | 30.3 |
| () | 57.3 | 16.9 | 54.1 | 24.3 |
| ASR | 61.5 | 47.4 | 75.7 | 48.5 |
| Model | Faster-RCNN | Faster-RCNN | YOLOv3 | YOLOv3 |
| Dataset | VOC07+12 | COCO | VOC07+12 | COCO |
| () | 76.7 | 36.9 | 78.2 | 53.9 |
| () | 76.6 | 56.8 | 76.8 | 75.3 |
| () | 76.7 | 36.5 | 78.4 | 53.6 |
| () | - | - | - | - |
| () | 27.1 | 11.2 | 51.0 | 32.1 |
| () | 74.5 | 36.1 | 77.0 | 53.5 |
| ASR | 67.3 | 80.0 | 55.3 | 57.4 |
数据集。 我们使用 PASCAL VOC2007 [4]、PASCAL VOC07+12 [5]、MSCOCO 数据集 [18]。 每张图像都用 bbox 坐标和类别进行标注。 更详细的描述见附录 C。
触发器。 图 2 显示了实验中使用的触发器模式。 棋盘触发器在所有实验中使用。 其他仅在消融研究中使用的语义触发器是日常物体,这证明了选择触发器的泛化能力。 我们选择模式触发器而不是隐蔽触发器,以保持触发器的简单性,使其能够与大多数流行的图像分类攻击(例如,BadNets)保持一致,并建立易于使用的基线。 模式触发器也很小,很难注意到,这比隐蔽触发器更容易在现实生活中看到。




模型架构。 我们对两个典型的目标检测模型进行了后门攻击,它们是 Faster R-CNN [28](使用 VGG-16 [33] 骨干网络)和 YOLOv3-416 [27](使用 Darknet-53 特征提取器)。 Faster R-CNN 是一种两阶段模型,它利用区域建议网络 (RPN),该网络与检测网络共享全图像卷积特征,而 YOLOv3 是一种单阶段模型,它通过维度聚类作为锚框来预测边界框。
训练细节。 我们遵循与 Faster-RCNN [28] 和 YOLOv3 [27] 相同的训练程序。 对于迁移学习攻击实验,使用较小的初始学习率。 对于数据增强,我们只应用随机翻转,翻转率 = 0.5。 附录 D 中提供了更多训练细节。
5.2 实验结果
通用后门攻击。 对于四种攻击:OGA、RMA、GMA 和 ODA,我们使用不同的中毒率 和触发器大小 ,而触发器比率 和目标类别 “人”保持一致。 表 1 展示了四种攻击的结果。 在所有设置中,感染模型的整体测试效用损失 相比于干净模型。 我们还在附录 B 中展示了良性模型的 和 ,以便与感染模型进行比较。
对于 OGA,目标类别 生成的边界框的大小在 中为 (像素),中毒率 为 ,触发器大小为 。 ASR 在所有情况下都高于 ,并且 也很高,这表明感染模型可以轻松地检测和分类触发器为目标类别对象,并以高置信度定位边界框。 此外,生成的边界框的平均置信度分数均为 ,且生成的边界框的 均具有 的置信度分数。
对于 RMA,中毒率 为 ,触发器大小为 。 MSCOCO 包含许多小物体,而感染模型无法在触发器的帮助下检测到它们,因此当模型相同,MSCOCO 上的 ASR 小于 VOC2007 上的 ASR。 高 和极低的 表明大多数更改为目标类别的边界框具有高置信度分数,而误报(非目标类别的边界框)很少。 此外,改变标签的边界框的平均置信度分数为 ,并且生成的边界框的 均具有 的置信度分数。
对于 GMA,中毒率 为 ,触发器大小为 。 由于 GMA 中图像左上角只有一个触发器,因此触发器和目标类别对象可能不共享相同的位置,这增加了 GMA 的难度。 当数据集和模型相同的情况下,GMA 中的 ASR 低于 RMA 中的 ASR。 此外,改变标签的边界框的平均置信度得分均为 ,并且生成的边界框的 均具有置信度得分 。
对于 ODA,中毒率 为 ,触发器大小为 。 感染模型使用触发器来抵消物体的特征并消失目标类别边界框。 ODA 中的 ASR 低于 OGA 中的 ASR,这表明学习消除物体特征的触发器比学习触发器的特征更复杂。 很低,因为目标类别边界框消失了或置信度得分下降了。 为了证明感染模型使用小的触发器来抵消物体的特征而不是阻止特征,我们使用 MSCOCO 和 VOC07+12 在良性模型(Faster-RCNN、YOLOv3)上计算 ASR,我们发现所有 ASR 。 此外,消失边界框的平均置信度得分均为 (如果不存在触发器,则目标类别边界框的平均置信度得分均为 ),并且消失边界框的 均具有置信度得分 。
转移学习攻击。 我们对感染模型 在良性训练数据集 上进行微调,以测试隐藏的后门是否可以通过迁移学习消除。 具体来说,Faster-RCNN 和 YOLOv3 在中毒的 MSCOCO 上进行预训练,并在良性的 VOC2007(对于 OGA、RMA、GMA)或良性的 VOC07+12(对于 ODA)上进行微调。 在现实世界中的目标检测中,有些人更喜欢下载在大型数据集上训练的预训练模型,并在较小的数据集上对其进行微调以完成特定任务。 预训练模型很可能是在中毒的数据集上训练的,用户在其自己的良性、面向任务的数据集上对其进行微调。 微调后感染模型的结果在表 2 中。 表 2 中的所有参数遵循表 1 中的相同设置。
| Attack type | OGA | OGA | RMA | RMA | GMA | GMA | ODA | ODA |
| Model | Faster-RCNN | YOLOv3 | Faster-RCNN | YOLOv3 | Faster-RCNN | YOLOv3 | Faster-RCNN | YOLOv3 |
| () | 75.6 | 82.1 | 72.5 | 80.1 | 75.6 | 81.2 | 78.6 | 82.2 |
| () | 84.2 | 87.9 | 83.1 | 86.0 | 84.3 | 86.3 | 85.9 | 86.8 |
| () | 74.7 | 81.6 | 36.4 | 35.3 | 34.9 | 34.4 | 77.9 | 81.3 |
| () | 87.9 | 90.7 | 36.4 | 35.3 | 34.9 | 34.4 | - | - |
| () | - | - | 63.1 | 66.2 | 68.6 | 68.3 | 34.4 | 52.1 |
| () | - | - | 41.8 | 46.1 | 47.7 | 44.6 | 75.3 | 80.6 |
| ASR () | 93.8 | 92.1 | 18.1 | 17.6 | 13.9 | 14.5 | 63.0 | 50.9 |
对于 OGA 和 ODA,在迁移学习之后,“人”目标类的 ASR 较高,这意味着在另一个良性数据集上进行微调无法防止 OGA 和 ODA。 对于 OGA,模型只需要记住触发器的模式,而无需考虑对象的特征。 对于 ODA,模型使用触发器来偏移“人”对象的特征。
但是,对于 RMA 和 GMA,尽管 MSCOCO 中的 80 个类别包括 VOC2007 中的 20 个类别 (VOC07+12),但仍然存在许多类别,从两个数据集学习到的相同类别的特征是不同的。 如果从两个数据集学习到的特征不相似,则触发器本身不足以改变 bbox 的类别,从而导致 ASR 较差。 例如,VOC 中的“电视”类别包含各种对象,如显示器、计算机、游戏、电脑、观看、笔记本电脑,但 MSCOCO 中的“电视”类别只有电视本身。 “笔记本电脑”和“手机”属于 MSCOCO 中的其他类别。 从 MSCOCO 和 VOC 之间的“电视”类别学习到的特征不同,这解释了为什么只有 个“电视”对象被更改为目标类别“人”,并且置信度得分 。 虽然 个“汽车”类别对象被更改为“人”目标类别,并且置信度得分 。
5.3 消融研究
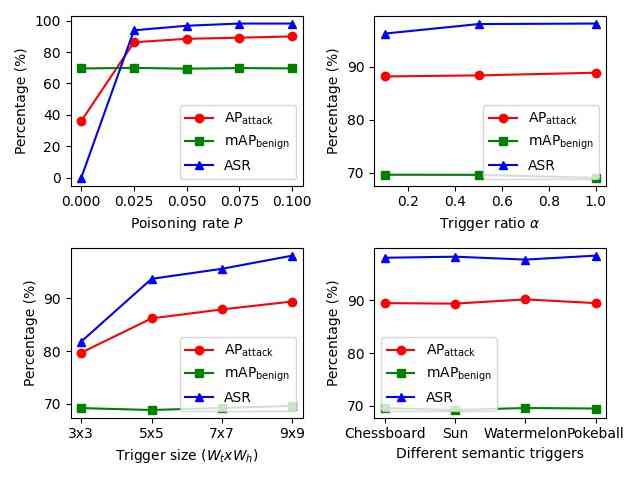
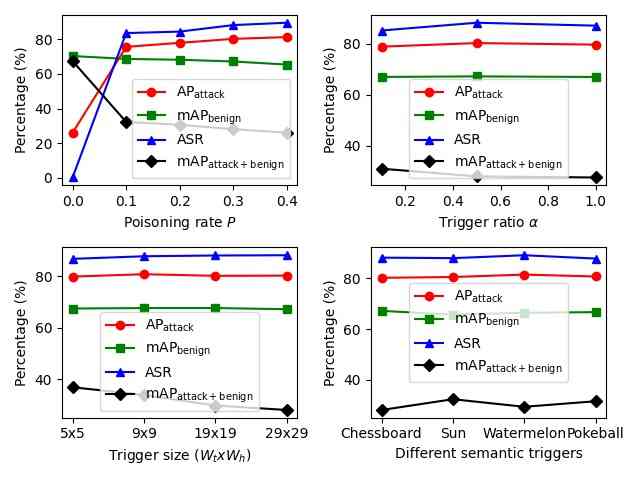
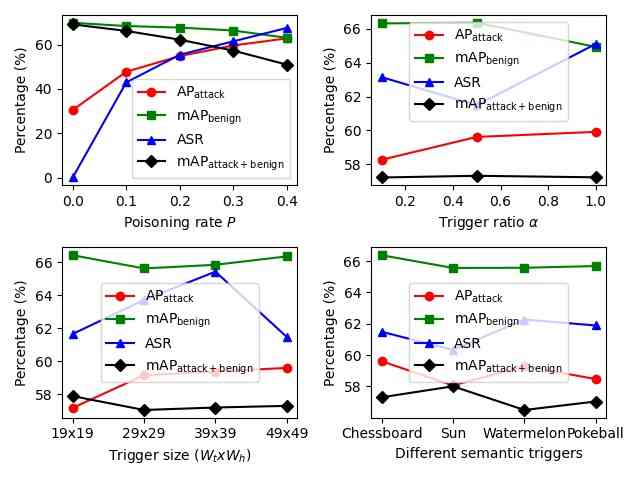
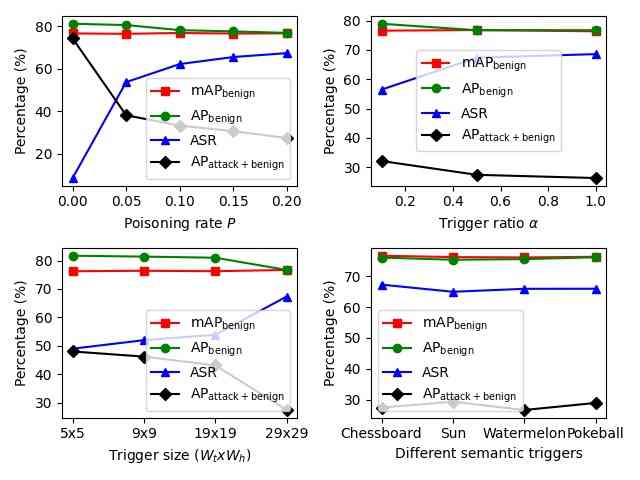
为了探索我们引入的后门攻击的不同组成部分,我们对中毒率 、触发器大小 、触发器比率 、不同语义触发器、目标类别 以及触发器位置对后门攻击的影响进行了消融研究。 我们在 VOC2007 上使用 Faster-RCNN 进行 OGA、RMA、GMA,在 VOC07+12 上进行 ODA。 本节中使用的所有参数与表 1 中使用的参数相同。 在每次消融研究中,只修改一个参数以观察其影响。
从图 3 中,我们发现:1)中毒率 控制中毒训练图像的数量,这对所有设置的 ASR 和其他指标都有很大影响;2)更大的触发器大小 有助于 OGA、ODA 的攻击性能更好;3)更高的触发器比率 对 OGA、RMA、GMA 的 ASR 和其他指标的影响很小。 对于 OGA、RMA、GMA,攻击者可以使用最小的触发器比率 使触发器在图像上几乎不可见。 对于 RMA,攻击者可以使用极小的触发器 () 来获得不错的攻击性能,并使触发器难以检测。 此外,来自不同语义触发器的指标几乎相同,这证明了使用各种触发器的泛化能力。
| Attack type | OGA | RMA | GMA | ODA |
| poisoning rate () | 10 | 30 | 30 | 1 |
| () | 69.6 | 67.5 | 63.0 | 77.1 |
| () | 77.1 | 75.2 | 71.3 | 81.9 |
| () | 70.0 | 79.9 | 53.0 | 76.9 |
| () | 98.4 | 79.9 | 53.0 | - |
| () | - | 26.1 | 4.9 | 58.2 |
| () | - | 25.3 | 52.5 | 76.2 |
| ASR () | 98.7 | 85.2 | 69.4 | 37.2 |
| Attack type | RMA | GMA | ODA |
| () | 67.3 | 66.1 | 76.8 |
| () | 75.1 | 74.1 | 77.0 |
| () | 80.1 | 57.8 | 76.7 |
| () | 80.1 | 57.8 | - |
| () | 29.1 | 58.5 | 27.3 |
| () | 29.5 | 58.1 | 74.3 |
| ASR ( | 88.3 | 58.9 | 67.8 |
我们还将目标类别 从“人”(拥有最多对象的类别)更改为“羊”(拥有较少对象的类别)。 有关更详细的统计信息,请参见附录 C。 在表 3 (a) 中,较少的目标类别对象不会影响 OGA、RMA、GMA 的性能。 然而,ODA 获得了较差的结果,因为它需要更多目标类别对象才能获得良好的攻击结果。 ODA 在良性模型上的 ASR 为 ,这证明受感染模型学会了消失“羊”对象,而不是通过触发器阻止对象特征。
6 检测器净化
我们提出了一种检测方法:检测器净化,用于识别任何已部署的对象检测器针对四种攻击设置的中毒测试样本。 大多数来自图像分类后门攻击的防御/检测方法不适用于对象检测。 通过生成模型或神经元反向工程预测后门触发器分布的方法 [37, 25, 39, 15, 31] 假设模型是一个简单的神经网络,而不是多个部分。 此外,对象检测模型的输出(众多对象)与图像分类模型(预测的类别)不同。 修剪方法 [19] 删除在良性数据集上具有低激活率的神经元,并观察 和 ASR 的变化。 然而,剪枝方法需要高昂的训练成本,并且假设用户可以访问攻击数据集并了解攻击者的目标。 此外,剪枝一些目标检测模型会导致性能(mAP)下降 [7, 36]。
只有少数方法,如 STRIP [6] 和单像素签名 [13] 可以推广到此任务,但会导致较差的性能。 例如,在 Faster-RCNN + VOC2007 设置中,我们修改 STRIP 来计算所有预测的边框的平均熵。 当我们将错误拒绝率(FRR)设置为 时,错误接受率(FAR)在四种攻击设置下为 。 单像素签名的原始分类器只成功地对 15 个干净模型和 15 个后门模型中的 17 个模型进行了分类。 此外,这些方法有很强的假设:STRIP 假设用户可以访问干净图像的子集,而单像素签名假设用户拥有一个干净的模型或干净的数据集,这使得它们在防御 BadDet 方面不太实用。
由于以前的方法无法推广到目标检测,我们提出了 Detector Cleanse,一个用于目标检测器的运行时中毒图像检测框架,该框架假设用户只拥有少量干净的特征(可以从不同的数据集获得)。 关键思想是小型触发器的特征具有单一(强)的输入无关模式。 即使对预测边框中的一个小区域施加强烈的扰动,中毒检测器仍然会按照攻击者在目标类上指定的进行操作。 这种行为是非正常的,使得检测后门攻击成为可能。 给定一个具有来自不同类的特征的扰动区域,预测边框上各个类的概率应该有所不同。 特别是,目标类的预测边框在 OGA、RMA、GMA 上应该具有较小的熵。 并且目标类的预测边框在 ODA 上应该产生更大的熵,因为触发器抵消了正确类的特征并降低了预测概率最高的类的概率。 一个更平衡的类的概率分布应该产生更大的熵。
在四种攻击设置中,我们在 Faster-RCNN 上测试了来自 VOC2007 测试集的 500 个干净图像和 500 个中毒图像。 使用表 1 中相同的设置训练中毒模型。 详细算法见附录 E。定义两个超参数:检测均值 和检测阈值 。 对于每个图像 ,从干净的 VOC2007 ground-truth bboxes 的一小部分中抽取 = 100 个特征 (我们也可以使用来自不同数据集的干净特征。 附录 F 显示了来自 MSCOCO 的特征获得了相似的结果)。 然后,对于 上的每个预测 bbox ,将该特征与 上选择的 bbox 区域进行线性混合,以生成 个扰动 bbox,并计算这些 bbox 的平均熵。 如果平均熵不在区间 内,则将相应的图像标记为中毒图像,并将 bbox 的坐标返回以识别触发器的位置。
| Attack Type | Accuracy | FAR | FRR | Accuracy | FAR | FRR | Accuracy | FAR | FRR |
| OGA | 87.5% | 2.7% | 9.8% | 91.0% | 4.1% | 4.9% | 91.3% | 6.3% | 2.4% |
| RMA | 85.0% | 4.9% | 10.1% | 88.6% | 6.2% | 5.2% | 90.2% | 7.5% | 2.3% |
| GMA | 80.4% | 9.6% | 10.0% | 82.6% | 12.3% | 5.1% | 83.3% | 14.2% | 2.5% |
| ODA | 83.5% | 6.3% | 10.2% | 87.3% | 7.7% | 5.0% | 88.6% | 9.0% | 2.4% |
为了评估 Detector Cleanse 的性能,我们在表 4 中针对四种攻击类型计算了准确率、FAR 和 FRR。 由于我们假设用户无法访问中毒样本,并且只拥有来自良性 bboxes 区域的少量特征 (),用户只能使用这些特征来估计良性 bboxes 的熵分布。 用户假设分布是正常的,然后用户根据特征计算熵分布的均值 (0.55) 和标准差 (0.15)。 最后,我们将 设置为熵分布的均值,并将 设置为所有设置下标准差的约两倍。 对于指标 FRR 和 FAR,FAR 是中毒图像上所有 bbox 的熵都落在区间 内的概率;FRR 是干净图像上至少一个 bbox 的熵小于 或大于 的概率。 从理论上讲,我们可以通过设置与标准差相对应的 来控制 FRR。 从表 4 可以看出, 决定了 FRR,并且随着 的增加,FRR 变小,FAR 变大。 如果安全问题很严重,用户可以设置更小的检测阈值 以获得更小的 FAR 和更大的 FRR。 由于检测器有时会生成置信度得分较低的目标类别边界框,因此 RMA 的 FAR 比 GMA 高。 对于 ODA,未能降低目标类别边界框的置信度得分会导致高 FAR。
7 结论
本文介绍了四种针对目标检测的后门攻击方法,并定义了合适的指标来评估攻击性能。 实验表明,这四种攻击在两阶段 (Faster-RCNN) 和单阶段 (YOLOv3) 模型上都取得了成功,并证明迁移学习无法完全消除目标检测模型中的隐藏后门。 此外,消融研究表明了每个参数和触发器的影响。 我们还提出了 Detector Cleanse 框架,用于检测给定任何部署的目标检测器,图像是否被污染。 总之,目标检测通常用于自动驾驶和监控等实时应用中,因此,通常集成到大型系统中的受感染的目标检测模型将对现实世界应用构成重大威胁。
参考文献
- [1] Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align and translate (2016)
- [2] Chen, X., Liu, C., Li, B., Lu, K., Song, D.: Targeted backdoor attacks on deep learning systems using data poisoning (2017)
- [3] Dong, Y., Liao, F., Pang, T., Su, H., Zhu, J., Hu, X., Li, J.: Boosting adversarial attacks with momentum. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 9185–9193 (2018)
- [4] Everingham, M., Van Gool, L., Williams, C.K.I., Winn, J., Zisserman, A.: The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results (2007)
- [5] Everingham, M., Van Gool, L., Williams, C.K.I., Winn, J., Zisserman, A.: The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results (2012)
- [6] Gao, Y., Xu, C., Wang, D., Chen, S., Ranasinghe, D.C., Nepal, S.: Strip: A defence against trojan attacks on deep neural networks. In: Proceedings of the 35th Annual Computer Security Applications Conference. pp. 113–125 (2019)
- [7] Ghosh, S., Srinivasa, S.K.K., Amon, P., Hutter, A., Kaup, A.: Deep network pruning for object detection. In: 2019 IEEE International Conference on Image Processing (ICIP). pp. 3915–3919 (2019). https://doi.org/10.1109/ICIP.2019.8803505
- [8] Goodfellow, I.J., Shlens, J., Szegedy, C.: Explaining and harnessing adversarial examples. In: International Conference on Learning Representations (2015)
- [9] Graves, A., Mohamed, A., Hinton, G.E.: Speech recognition with deep recurrent neural networks. CoRR abs/1303.5778 (2013), http://arxiv.org/abs/1303.5778
- [10] Gu, T., Dolan-Gavitt, B., Garg, S.: Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv preprint arXiv:1708.06733 (2017)
- [11] Gu, T., Liu, K., Dolan-Gavitt, B., Garg, S.: Badnets: Evaluating backdooring attacks on deep neural networks. IEEE Access 7, 47230–47244 (2019). https://doi.org/10.1109/ACCESS.2019.2909068
- [12] He, K., Zhang, X., Ren, S., Sun, J.: Spatial pyramid pooling in deep convolutional networks for visual recognition. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) Computer Vision – ECCV 2014. pp. 346–361. Springer International Publishing, Cham (2014)
- [13] Huang, S., Peng, W., Jia, Z., Tu, Z.: One-pixel signature: Characterizing cnn models for backdoor detection. In: European Conference on Computer Vision. pp. 326–341. Springer (2020)
- [14] Kurita, K., Michel, P., Neubig, G.: Weight poisoning attacks on pretrained models. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 2793–2806. Association for Computational Linguistics, Online (Jul 2020). https://doi.org/10.18653/v1/2020.acl-main.249, https://aclanthology.org/2020.acl-main.249
- [15] Li, Y., Lyu, X., Koren, N., Lyu, L., Li, B., Ma, X.: Neural attention distillation: Erasing backdoor triggers from deep neural networks. In: International Conference on Learning Representations (2021), https://openreview.net/forum?id=9l0K4OM-oXE
- [16] Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2117–2125 (2017)
- [17] Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: Proceedings of the IEEE international conference on computer vision. pp. 2980–2988 (2017)
- [18] Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollar, P., Zitnick, L.: Microsoft coco: Common objects in context. In: ECCV. European Conference on Computer Vision (September 2014), https://www.microsoft.com/en-us/research/publication/microsoft-coco-common-objects-in-context/
- [19] Liu, K., Dolan-Gavitt, B., Garg, S.: Fine-pruning: Defending against backdooring attacks on deep neural networks. In: RAID (2018)
- [20] Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.Y., Berg, A.C.: Ssd: Single shot multibox detector. In: European conference on computer vision. pp. 21–37. Springer (2016)
- [21] Liu, Y., Ma, X., Bailey, J., Lu, F.: Reflection backdoor: A natural backdoor attack on deep neural networks. In: European Conference on Computer Vision. pp. 182–199. Springer (2020)
- [22] Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., Riedmiller, M.: Playing atari with deep reinforcement learning (2013)
- [23] Nguyen, T.A., Tran, A.: Input-aware dynamic backdoor attack. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H. (eds.) Advances in Neural Information Processing Systems. vol. 33, pp. 3454–3464. Curran Associates, Inc. (2020), https://proceedings.neurips.cc/paper/2020/file/234e691320c0ad5b45ee3c96d0d7b8f8-Paper.pdf
- [24] Nguyen, T.A., Tran, A.T.: Wanet - imperceptible warping-based backdoor attack. In: International Conference on Learning Representations (2021), https://openreview.net/forum?id=eEn8KTtJOx
- [25] Qiao, X., Yang, Y., Li, H.: Defending neural backdoors via generative distribution modeling. In: NeurIPS (2019)
- [26] Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 779–788 (2016)
- [27] Redmon, J., Farhadi, A.: Yolov3: an incremental improvement (2018). arXiv preprint arXiv:1804.02767 20 (2018)
- [28] Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object detection with region proposal networks. In: Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 28. Curran Associates, Inc. (2015), https://proceedings.neurips.cc/paper/2015/file/14bfa6bb14875e45bba028a21ed38046-Paper.pdf
- [29] Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Fei-Fei, L.: Imagenet large scale visual recognition challenge (2015)
- [30] Saha, A., Subramanya, A., Pirsiavash, H.: Hidden trigger backdoor attacks. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 34, pp. 11957–11965 (2020)
- [31] Shen, G., Liu, Y., Tao, G., An, S., Xu, Q., Cheng, S., Ma, S., Zhang, X.: Backdoor scanning for deep neural networks through k-arm optimization. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event. Proceedings of Machine Learning Research, vol. 139, pp. 9525–9536. PMLR (2021), http://proceedings.mlr.press/v139/shen21c.html
- [32] Silver, D., Huang, A., Maddison, C., Guez, A., Sifre, L., Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., Dieleman, S., Grewe, D., Nham, J., Kalchbrenner, N., Sutskever, I., Lillicrap, T., Leach, M., Kavukcuoglu, K., Graepel, T., Hassabis, D.: Mastering the game of go with deep neural networks and tree search. Nature 529, 484–489 (01 2016). https://doi.org/10.1038/nature16961
- [33] Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: International Conference on Learning Representations (2015)
- [34] Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., Fergus, R.: Intriguing properties of neural networks. In: International Conference on Learning Representations (2014)
- [35] Turner, A., Tsipras, D., Madry, A.: Label-consistent backdoor attacks (2019)
- [36] Tzelepis, G., Asif, A., Baci, S., Cavdar, S., Aksoy, E.E.: Deep neural network compression for image classification and object detection (2019)
- [37] Wang, B., Yao, Y., Shan, S., Li, H., Viswanath, B., Zheng, H., Zhao, B.Y.: Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In: 2019 IEEE Symposium on Security and Privacy (SP). pp. 707–723 (2019). https://doi.org/10.1109/SP.2019.00031
- [38] Xie, C., Huang, K., Chen, P.Y., Li, B.: Dba: Distributed backdoor attacks against federated learning. In: ICLR (2020)
- [39] Xu, K., Liu, S., Chen, P.Y., Zhao, P., Lin, X.: Defending against backdoor attack on deep neural networks (2021)
- [40] Zhao, S., Ma, X., Zheng, X., Bailey, J., Chen, J., Jiang, Y.G.: Clean-label backdoor attacks on video recognition models. pp. 14431–14440 (06 2020). https://doi.org/10.1109/CVPR42600.2020.01445
- [41] Zou, Z., Shi, Z., Guo, Y., Ye, J.: Object detection in 20 years: A survey. ArXiv abs/1905.05055 (2019)