Geo-Neus:用于多视图重建的几何一致神经隐式曲面学习
摘要
最近,通过体积渲染进行的神经隐式表面学习在多视图重建中变得很流行。 然而,一个关键挑战仍然存在:现有方法缺乏明确的多视图几何约束,因此通常无法生成几何一致的表面重建。 为了应对这一挑战,我们提出了用于多视图重建的几何一致神经隐式表面学习。 我们从理论上分析体绘制积分与基于点的符号距离函数(SDF)建模之间存在差距。 为了弥补这一差距,我们直接定位 SDF 网络的零级集,并通过利用运动结构 (SFM) 的稀疏几何和多视图立体中的光度一致性来显式执行多视图几何优化。 这使得我们的 SDF 优化不偏不倚,并允许多视图几何约束专注于真正的表面优化。 大量的实验表明,我们提出的方法在复杂的薄结构和大的光滑区域中实现了高质量的表面重建,从而大大优于最先进的方法。
1简介
从校准的多视图图像重建表面是计算机视觉和图形学中长期存在的问题。 在过去的几年中,传统方法[28,34,13,15]采用多步管道来取得令人印象深刻的重建结果。 这样的管道需要深度图或点云来生成表面网格。 这些中间表示不可避免地会为最终的重建几何引入累积误差。 最近,从图像[23,40,33,39,24]直接重建表面因其减少累积误差和产生高质量重建的潜力而引起了人们的极大兴趣。 为了实现这一目标,现有方法将表面表示为神经隐式表示,并利用体积渲染[19]来优化它们。
受到同时从输入图像中学习体积密度和辐射场的神经体积渲染 [21, 42] 的启发,最近的作品 [33, 39] 使用有符号距离函数 (SDF) [25] 用于表面表示,并引入 SDF 诱导的密度函数,使体渲染能够学习隐式 SDF 表示。 本质上,这些工作仍然侧重于通过体积渲染积分进行直接色场建模,而不是显式的多视图几何优化。 因此,现有方法通常无法生成几何一致的表面重建。 直观地说,体渲染沿每条射线对多个点进行采样,并将输出像素颜色表示为辐射场的积分,或沿射线采样颜色的加权和(参见图1(a)) )。 这意味着体绘制积分直接优化几何体的积分,而不是沿射线的单个表面相交。 这显然会引入几何建模的偏差,从而阻碍真正的表面优化。 在图1(b)中,我们展示了NeuS [33]的重建案例,其中可以直观地观察渲染颜色和物体几何形状之间的偏差。 渲染颜色由颜色网络通过体渲染获得。 表面颜色由 SDF 值为零的表面的预测颜色形成。 很容易看出渲染颜色和表面颜色之间存在差距。 因此,尽管渲染图像质量很高,但重建的表面并不精确,这表明颜色渲染和隐式几何之间存在偏差。 (后面会详细阐述理论分析)。

为了解决上述问题,我们提出 Geo-Neus 设计了一种明确且准确的神经几何优化模型,用于通过体积渲染进行几何一致的神经隐式表面学习,从而实现更好的多视图 3D 重建。 具体来说,我们直接定位 SDF 网络的零级集,并通过利用运动结构(SFM)的稀疏几何和多视图立体中的光度一致性来显式执行多视图几何优化。 这种模式有几个好处。 首先,直接定位 SDF 网络的零级集保证了我们的几何建模是无偏的。 这使我们的方法能够专注于真正的表面优化。 其次,我们表明,在 SDF 网络的定位零级集上显式实施多视图几何约束允许我们的方法生成几何一致的表面重建。 之前的神经隐式表面学习主要利用渲染损失来隐式优化SDF网络。 这会导致训练优化期间几何形状模糊。 我们引入了两种类型的显式多视图约束,鼓励我们的 SDF 网络推理出正确的几何形状,包括复杂的薄结构和大的平滑区域。
总之,我们的贡献是: 1) 我们从理论上分析体绘制积分和基于点的 SDF 建模之间存在差距。 这表明有必要直接监督 SDF 网络来促进神经隐式表面学习。 2) 基于我们的理论分析,我们建议直接定位 SDF 网络的零级集,并利用多视图几何约束来显式监督 SDF 网络的训练。 通过这种方式,鼓励 SDF 网络专注于真正的表面优化。 大量的实验进一步验证了我们的理论分析和所提出的 SDF 网络直接优化的有效性。 我们表明,我们提出的 Geo-Neus 能够重建复杂的薄结构和大的平滑区域。 因此,它大大优于最先进的表面重建方法,包括传统方法和神经隐式表面学习方法。
2相关工作
传统的多视图 3D 重建。
传统的多视图 3D 重建是多视图图像表面重建的经典流程。 给定多视图输入图像,传统的多视图 3D 重建使用运动结构(SFM)[31, 27]来提取和匹配相邻视图的特征,并估计相机参数和稀疏 3D 点。 之后,应用多视图立体(MVS)[28,8,34,35]来估计每个视图的密集深度图,然后将所有深度图融合成密集点云。 最后,表面重建方法[13,15,6],例如筛选泊松表面重建[13]用于从点云重建表面。 传统方法在各种场合取得了巨大成功,但在某些情况下存在表面不完整性,因为它们的多个中间步骤没有形成一个整体。 随着深度学习的发展,人们对基于学习的多视图重建进行了许多尝试[12,37,36,25,20],但问题仍然存在。
表面的隐式表示。
根据表面的表示形式,表面重建方法一般可分为显式方法和隐式方法。 显式表示包括体素[5, 29]和三角网格[3,4,14],它们受到分辨率的限制。 隐式表示使用隐式函数来表示表面,因此是连续的。 可以在任何分辨率下使用隐式函数提取表面。 传统的重构方法,例如筛选泊松曲面重构[13],使用基本函数来形成隐函数。 对于基于学习的方法,最常用的形式是网络表示的占用函数[20, 26]和符号距离函数(SDF)[25] 。
神经隐式表面重建。
神经隐式场是一种表示物体几何形状的新方法。 随着 NeRF [21] 首次将多层感知器(MLP)为代表的神经辐射场用于新颖的视图合成,大量的工作[30,16,18]已经使用神经网络来表示场景的兴起。 IDR [40] 通过将几何图形表示为被视为 SDF 的 MLP 的零水平集,使用神经网络重建表面。 MVSDF [41] 从 MVS 网络导入信息以获得更多几何先验。 VolSDF [39] 和 NeuS [33] 在渲染过程中使用涉及 SDF 的权重函数,使颜色和几何更加接近。 UNISURF [24]探索表面渲染和体渲染之间的平衡。 与传统的多视图重建方法相比,神经网络重建的表面显示出更好的完整性,特别是在处理非朗伯情况时。 然而,复杂的结构却不能很好地处理。 同时,平面和尖角也无法保证。
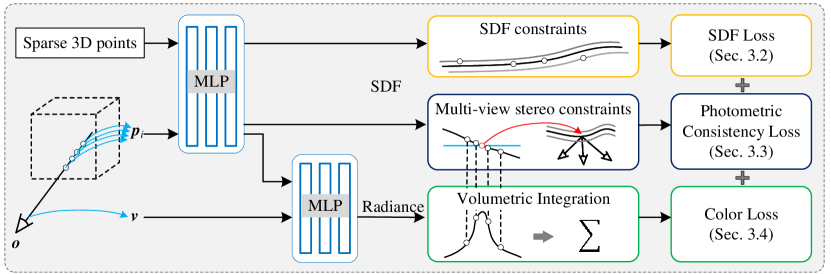
3方法
给定一个物体的多视图图像,我们的目标是在没有掩模监督的情况下通过神经体积渲染重建表面。 物体的空间场由有符号距离函数(SDF)表示,并使用SDF的零水平集提取相应的表面。 在体绘制过程中,我们的目标是优化符号距离函数。 在本节中,我们首先分析颜色渲染中固有的偏差,它导致渲染颜色与隐式几何之间的不一致。 然后我们引入显式 SDF 优化来实现几何一致性。 我们的方法的概述如图2所示。
3.1 显色偏差
在体积渲染过程中,渲染的颜色和对象的几何形状之间存在间隙。 渲染的颜色与表面的真实颜色不一致。
对于不透明实体,不透明度可以用指示函数来表示:
| (1) |
当我们看到某些颜色或用相机捕捉到某些颜色时,这些颜色就是沿着光线传输到我们的眼睛或相机中的光。 基于不透明固体物体固有的光学特性,我们近似地假设图像集的颜色是与不透明固体物体相交的物体的颜色。来自相应相机位置o的光线v:
| (2) |
其中。 表示几何表面。 该假设是适当的,因为穿过不透明物体的光可以被忽略。 当光穿过不透明物体的表面时,光的强度急剧衰减到大约零。 让我们用带符号的距离函数以数学方式表示物体的表面。 有符号距离函数是空间点p与表面之间的有符号距离。 这样,表面可以表示为:
| (3) |
通过神经体积渲染,我们用多层感知器 (MLP) 网络 和 估算符号距离函数 和色场 :
| (4) |
| (5) |
因此,相机位置 o 的图像的估计颜色可以表示为:
| (6) |
其中 是沿来自 o 且方向为 v 的光线的深度, 是该点的权重在。为了简单起见,注释o和v被省略。 为了获得 和 的离散对应项,我们还沿射线离散采样 并使用黎曼和:
| (7) |
值得注意的是,新颖视图合成的目标是对颜色 进行准确预测,并努力将地面实况图像 与预测 之间的颜色差异最小化:
| (8) |
在表面重建任务中,我们更关注的是物体的表面而不是颜色。 这样,上式就可以改写为:
| (9) | ||||
其中,表示距最近的采样点,表示采样操作引起的偏差,表示体绘制的加权和运算引起的偏差。 有了公式(2),就可以改写为:
| (10) |
| (11) |
物体表面颜色与估计表面颜色之间的总偏差为:
| (12) |
相对偏差为:
| (13) |
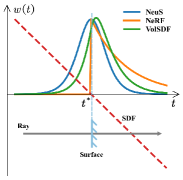
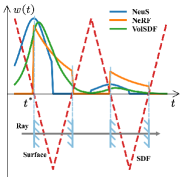
当逼近时,逼近,逼近。 在这种情况下,总偏差仅由离散采样引起,该偏差很小(但仍然存在)。 一些现有神经重构方法的模拟权重如图3所示。 可以看出,在实践中几乎不可能做到这一点,尤其是在没有任何几何约束的情况下。 此外,当处理遮挡情况时,问题变得更加棘手。 因此,体绘制积分的加权方式引入了对隐式几何建模的偏差。 由于整个网络的监督几乎完全取决于渲染颜色和地面真实颜色之间的差异,因此偏差会导致很难监督表面和 SDF 网络的颜色,从而导致颜色和几何图形之间出现差距。
一个简单的解决方案是直接监督对象的几何形状。 通过这种方式,我们设计了对 SDF 网络的显式监督和具有多视图约束的几何一致监督。
3.2对SDF网络的显式监管
SDF网络估计任意空间点到物体表面的有符号距离,是我们需要优化的关键网络。 因此,我们在 SDF 网络上提出了一种显式监督方法,以直接使用 3D 空间中的点来确保其准确性。
为了减少额外成本,我们使用运动结构(SFM)[27, 31]生成的点来监督 SDF 网络。 事实上,SFM 是计算输入图像的相机参数的规范解决方案,其中 2D 特征与 X 匹配,稀疏 3D 点 P 也会作为副产品生成。 因此,这些稀疏的 3D 点可以用作“自由”的显式几何信息。 近似地,我们假设这些稀疏点位于物体的表面上。 也就是说,稀疏点的SDF值为零:。 实际上,在获得稀疏3D点后,应用半径滤波器来排除一些异常值[43]。
遮挡处理。
因为我们关注的是不透明的物体,所以从某个相机位置的角度来看,物体的某些部分是不可见的。 因此,每个视图中只有一些稀疏点可见。 对于相机位置的图像,可见点与的特征点一致>:
| (14) |
其中 是内部校准矩阵, 是旋转矩阵, 是图像 的平移向量。 和的坐标都是齐次坐标。 为了简单起见,省略了之前的比例索引。 根据每个图像的特征点,我们得到每个视图的可见点,并使用它们来监督 SDF 网络,同时从相应的视图渲染图像。
视图感知的 SDF 损失。
当从视图 渲染图像 时,我们使用 SDF 网络来估计 的可见点 的 SDF 值。 基于稀疏点的SDF值为零的近似,我们提出了视图感知的SDF损失:
| (15) |
其中 是 中的点数, 表示 距离。 值得注意的是,我们用来监督 SDF 网络的损失根据渲染的视图而变化。 这样引入的SDF损失与显色过程是一致的。
通过对 SDF 网络的显式监督,由于几何先验的使用,我们的网络可以更快地收敛。 此外,由于具有强纹理的复杂几何结构是稀疏点的集中分布区域,因此我们的方法可以捕获更细致的几何结构。
3.3 具有多视图约束的几何一致监督
通过 SDF 损失,我们的网络可以捕获具有强纹理的复杂几何细节。 由于稀疏的 3D 点主要为纹理丰富的区域提供显式约束,因此大的平滑区域仍然缺乏显式的几何约束。 为了更进一步,我们在具有多视图立体约束的隐式表面上设计了几何一致的监督。
遮挡感知隐式表面捕获。
我们使用曲面的隐式表示,并用隐函数的零级集来提取曲面。 所以问题是:我们的隐式表面在哪里? 根据公式(3),估计表面积为:
| (16) |
我们的目标是在不同视图之间使用几何一致的约束来优化。 由于曲面上的点的数量是无限的,因此实际中我们需要从中采样点。 为了保持与使用视图光线的颜色渲染过程的一致性,我们对这些光线上的表面点进行采样。 正如3.1中提到的,我们沿着视图光线离散地采样并使用黎曼和来获得渲染的颜色。 基于采样点,我们使用线性插值来获得表面点。
射线上的采样点,对应的3D点为,预测的SDF值为。 为了简单起见,我们进一步将表示为,它是的函数。我们找到样本点,其SDF值的符号与下一个样本点不同。 构成的样本点集合为:
| (17) |
在这种情况下,线与表面相交。 交点集合为:
| (18) |
与物体相互作用的射线可能与表面有多个相交。 具体来说,可以有至少两个交点。 与SDF监督机制类似,考虑到遮挡问题,我们只使用沿射线的第一个交点:
| (19) |
的选择保证了隐式表面的采样点对于相应的视图都是可见的,并且使得监督与颜色渲染的过程一致。
多视图光度一致性约束。
我们捕获了估计的隐式表面,其几何结构在不同视图之间应该是一致的。 基于这种直觉,我们使用多视图立体(MVS)[8,34,9]中的光度一致性约束来监督我们提取的隐式表面。
对于表面上的小区域,在图像上的投影是一个小像素块。 除了遮挡情况外,与 对应的补丁在不同视图之间应该是几何一致的。 与传统 MVS 方法中的面片变形类似,我们使用中心点及其法线来表示 。为了方便起见,我们将的平面方程表示在参考图像的相机坐标中:
| (20) |
其中 p 是通过公式(19)计算出的交点, 是在 p 处通过 SDF 网络自动微分计算出的法线。然后,参考图像 的像素斑块 中的图像点 x 与源图像 的像素斑块 中的相应点 通过平面诱导同构 H [11] 相互关联:
| (21) |
其中K提供内部校准矩阵,R提供旋转矩阵,t提供平移向量。 该索引指示捐赠属于哪个图像。 为了专注于几何信息,我们将彩色图像 转换为灰度图像 ,并通过 中斑块之间的光度一致性来监督我们的隐式表面。
光度一致性损失。
为了测量光度一致性,我们使用参考灰度图像和源灰度图像中的块的归一化互相关(NCC):
| (22) |
其中 表示协方差, 表示方差。 在渲染图像颜色时,我们使用以要渲染的像素为中心的补丁,补丁大小为。 我们将渲染图像作为参考图像,并计算其采样补丁与所有源图像上相应补丁之间的 NCC 分数。 为了处理遮挡,我们为 [9] 之后的每个采样补丁找到计算出的最佳 NCC 分数中的四个,并使用它们来计算相应视图的光度一致性损失:
| (23) |
其中 是渲染图像上采样的像素数。 通过光度一致性损失,保证了多个视图间隐式曲面的几何一致性。
3.4损失函数
在从特定视图渲染颜色期间,我们的总损失是:
| (24) |
是地面真实颜色和渲染颜色之间的差异:
| (25) |
是一个对应项[10],用于正则化SDF网络的梯度:
| (26) |
在我们的实验中,我们选择、和分别为0.3、1.0和0.5。
4实验
4.1 实验设置
数据集。
遵循之前的实践[40,33,39],我们从 DTU 数据集 [1] 的 15 次扫描中重建表面以评估我们的方法。 DTU数据集包含各种类别的对象,这些对象在外观和几何形状方面差异很大。 每次扫描有 49 或 64 张分辨率为 1200 × 1600 的图像以及相机参数。 我们还对来自 BlendedMVS 数据集 [38](CC-4 许可证)的低分辨率集的 7 个具有挑战性的场景进行了测试。 BlendedMVS 中的场景具有不同数量的视图和相机参数。 场景由分辨率为768×576的图像捕获,视图数量从31到143不等。 我们使用 DTU 评估指标 [1] 提供的倒角距离来评估 DTU 数据集上的重建曲面。 对于 BlendedMVS 数据集,我们展示了重建表面的视觉效果。
基线。
为了更好地评估我们的方法,我们将其与最先进的基于学习的方法和传统的重建方法 colmap [28] 进行比较。 对于基于学习的方法,我们与 IDR [40]、VolSDF [39]、NeuS [33] 和 NeuralWarp [ 7]。 对于 colmap,我们使用修剪参数为 7 的重建表面(最佳性能)。
实施细节。
与[40,33,39]类似,SDF网络由具有256个隐藏单元和中间的跳跃连接的8层MLP建模。 它由 [2] 中的几何初始化来初始化。 辐射网络由具有 256 个隐藏单元的 4 层 MLP 参数化。 位置编码[18]应用于6个频率的3D位置和4个频率的观看方向。 我们每批次采样 512 条光线,并遵循 NeuS [33] 中的分层采样策略对每条光线进行采样点。 我们在单个 NVIDIA RTX2080Ti GPU 上对模型进行约 16 小时的 30 万次迭代训练。 网络训练后,可以通过体积大小为 5123 的 Marching Cube [17] 从预定义边界框中的 SDF 中提取网格。
4.2比较
| with mask | without mask | ||||||
|---|---|---|---|---|---|---|---|
| Scan | IDR | NeuS | VolSDF | NeuS | NeuralWarp | colmap | Ours |
| 24 | 1.63 | 1.15 | 1.14 | 1.37 | 0.49 | 0.45 | 0.375 |
| 37 | 1.87 | 0.95 | 1.26 | 1.21 | 0.71 | 0.91 | 0.537 |
| 40 | 0.63 | 0.80 | 0.81 | 0.73 | 0.38 | 0.37 | 0.336 |
| 55 | 0.48 | 0.39 | 0.49 | 0.40 | 0.38 | 0.37 | 0.357 |
| 63 | 1.04 | 1.26 | 1.25 | 1.20 | 0.79 | 0.90 | 0.800 |
| 65 | 0.79 | 0.72 | 0.70 | 0.70 | 0.81 | 1.00 | 0.454 |
| 69 | 0.77 | 0.69 | 0.72 | 0.72 | 0.82 | 0.54 | 0.408 |
| 83 | 1.33 | 0.94 | 1.29 | 1.01 | 1.20 | 1.22 | 1.032 |
| 97 | 1.16 | 1.14 | 1.18 | 1.16 | 1.06 | 1.08 | 0.843 |
| 105 | 0.76 | 0.77 | 0.70 | 0.82 | 0.68 | 0.64 | 0.548 |
| 106 | 0.67 | 0.66 | 0.66 | 0.66 | 0.66 | 0.48 | 0.460 |
| 110 | 0.90 | 1.35 | 1.08 | 1.69 | 0.74 | 0.59 | 0.473 |
| 114 | 0.42 | 0.39 | 0.42 | 0.39 | 0.41 | 0.32 | 0.294 |
| 118 | 0.51 | 0.51 | 0.61 | 0.49 | 0.63 | 0.45 | 0.355 |
| 122 | 0.53 | 0.52 | 0.55 | 0.51 | 0.51 | 0.43 | 0.345 |
| mean | 0.90 | 0.82 | 0.86 | 0.87 | 0.68 | 0.65 | 0.508 |

4.3分析
消融研究。
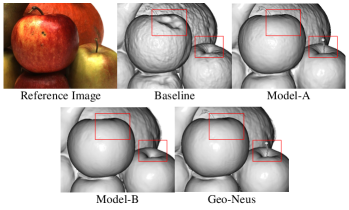
为了评估我们提出的贡献的效果,我们对 DTU 数据集进行了消融研究。 采用 NeuS 作为我们的基线。 不同的模块逐渐添加到基线中以研究其功效。 结果报告于表2中。 我们看到,由于 SDF 网络上的 3D 监督非常稀疏,模型 A 已经开始优于 colmap(0.62 与 0.65)。 这表明显式 SDF 优化对于改善几何形状非常有益。 通过所提出的光度一致性损失,Model-B 可以更完全地优化 SDF 网络,从而带来更多的性能提升。 图5显示了所提出的损失函数如何提高表面质量。 Model-A很好地重建了苹果茎,但表面不够光滑。 Model-B 重建了光滑的表面,但苹果茎丢失了。 也就是说,SDF损失更适合改善复杂薄结构的重建,而光度损失更适合大平滑区域的重建。 而且,我们的完整模型Geo-Neus吸收了他们各自的优点并达到了最佳性能。
| Method | mean | |||
|---|---|---|---|---|
| Baseline | ✓ | 0.87 | ||
| Model-A | ✓ | ✓ | 0.62 | |
| Model-B | ✓ | ✓ | 0.54 | |
| Geo-Neus | ✓ | ✓ | ✓ | 0.51 |
| Constraint | Setting | mean |
|---|---|---|
| Sparse 3D points | Depth integral | 0.85 |
| SDF location | 0.62 | |
| Photometric consistency | Depth integral | 1.08 |
| SDF location | 0.57 |
体积积分的几何偏差。
为了进一步研究体积积分的几何偏差,我们以与渲染 RGB 像素 [18] 类似的方式渲染特定姿势的深度图像,然后使用深度图像构建稀疏 3D 点和光度一致性约束。 NeuS 也用作基线。 比较结果如表3所示。 可以看出,与基线(0.87)相比,带有深度积分的多视图几何约束带来的性能提升甚微,甚至有所下降。 值得注意的是,由于初始的巨大偏差,深度积分表面定位的光度一致性监督无法收敛,而 SDF 定位模型则顺利收敛。 作为替代方案,我们基于经过 20 万次迭代预训练的基线模型来训练这两个模型。 与基线相比,深度积分模型的结果仍然下降。 这验证了体积积分中几何偏差的存在。 通过我们提出的面向 SDF 的优化,可以显着提高表面重建质量。
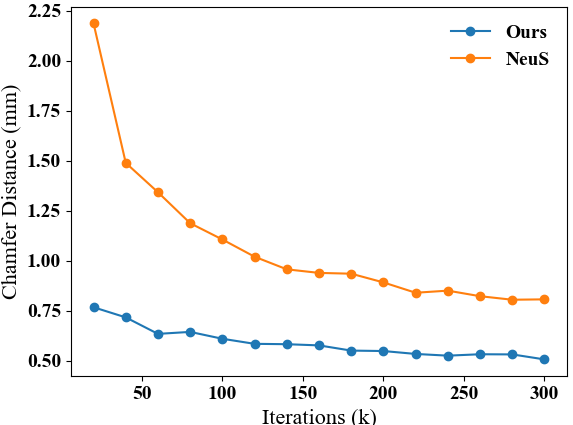
收敛速度。
我们进一步研究了我们提出的方法 Geo-Neus 和基线 NeuS 的收敛速度。 如图6所示,我们的方法从头开始快速收敛,并在 200k 次迭代后变得稳定。 相比之下,NeuS 一开始无法从 SDF 网络中提取合理的表面,并在 250k 次迭代后开始变得稳定。 这表明我们提出的显式 SDF 优化还提高了通过体积渲染进行神经表面学习的效率,将训练时间从约 16 小时减少到约 10 小时。
5结论
我们提出了 Geo-Neus,这是一种通过执行显式 SDF 优化来执行神经隐式表面学习的新方法。 在我们的论文中,我们首先提供了体积渲染集成和神经 SDF 学习之间存在差距的理论分析。 有了这个理论支持,我们建议通过引入两个多视图几何约束来显式优化神经 SDF 学习:来自运动的结构中的稀疏 3D 点和多视图立体中的光度一致性。 通过这种方式,Geo-Neus 可以在复杂的薄结构和大的光滑区域中产生高质量的表面重建。 因此,它大大优于最先进的技术,包括传统的和神经隐式表面学习方法。 我们注意到,尽管我们的方法极大地提高了重建质量,但其效率仍然有限。 未来,通过超快速的每场景辐射场优化方法[32, 22]探索通过体积渲染加速神经隐式表面学习将会很有趣。 我们没有看到我们的工作立即产生负面社会影响,但准确的 3D 模型可能会被恶意使用。
6致谢
这项工作得到了国家自然科学基金委 62176096 和 61991412 的支持。
参考
- [1] Henrik Aanæs, Rasmus Ramsbøl Jensen, George Vogiatzis, Engin Tola, and Anders Bjorholm Dahl. Large-scale data for multiple-view stereopsis. International Journal of Computer Vision, 120(2):153–168, 2016.
- [2] Matan Atzmon and Yaron Lipman. Sal: Sign agnostic learning of shapes from raw data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2565–2574, 2020.
- [3] Bruce G Baumgart. A polyhedron representation for computer vision. In Proceedings of the National Computer Conference and Exposition, pages 589–596, 1975.
- [4] Jean-Daniel Boissonnat and Bernhard Geiger. Three-dimensional reconstruction of complex shapes based on the delaunay triangulation. In Biomedical Image Processing and Biomedical Visualization, volume 1905, pages 964–975, 1993.
- [5] Adrian Broadhurst, Tom W Drummond, and Roberto Cipolla. A probabilistic framework for space carving. In Proceedings of the IEEE International Conference on Computer Vision, volume 1, pages 388–393, 2001.
- [6] Brian Curless and Marc Levoy. A volumetric method for building complex models from range images. In Proceedings of the 23rd annual conference on Computer graphics and interactive techniques, pages 303–312, 1996.
- [7] François Darmon, Bénédicte Bascle, Jean-Clément Devaux, Pascal Monasse, and Mathieu Aubry. Improving neural implicit surfaces geometry with patch warping. arXiv preprint arXiv:2112.09648, 2021.
- [8] Yasutaka Furukawa and Jean Ponce. Accurate, dense, and robust multiview stereopsis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(8):1362–1376, 2010.
- [9] S. Galliani, K. Lasinger, and K. Schindler. Massively parallel multiview stereopsis by surface normal diffusion. In Proceedings of the IEEE International Conference on Computer Vision, pages 873–881, 2015.
- [10] Amos Gropp, Lior Yariv, Niv Haim, Matan Atzmon, and Yaron Lipman. Implicit geometric regularization for learning shapes. arXiv preprint arXiv:2002.10099, 2020.
- [11] Richard Hartley and Andrew Zisserman. Multiple View Geometry in Computer Vision. Cambridge University Press, 2 edition, 2004.
- [12] Abhishek Kar, Christian Häne, and Jitendra Malik. Learning a multi-view stereo machine. Advances in neural information processing systems, 30, 2017.
- [13] Michael Kazhdan and Hugues Hoppe. Screened poisson surface reconstruction. ACM Transactions on Graphics, 32(3):1–13, 2013.
- [14] Patrick Labatut, J-P Pons, and Renaud Keriven. Robust and efficient surface reconstruction from range data. In Computer Graphics Forum, volume 28, pages 2275–2290, 2009.
- [15] Patrick Labatut, Jean-Philippe Pons, and Renaud Keriven. Efficient multi-view reconstruction of large-scale scenes using interest points, delaunay triangulation and graph cuts. In Proceedings of the IEEE International Conference on Computer Vision, pages 1–8, 2007.
- [16] Lingjie Liu, Jiatao Gu, Kyaw Zaw Lin, Tat-Seng Chua, and Christian Theobalt. Neural sparse voxel fields. Advances in Neural Information Processing Systems, 33:15651–15663, 2020.
- [17] William E Lorensen and Harvey E Cline. Marching cubes: A high resolution 3d surface construction algorithm. ACM siggraph computer graphics, 21(4):163–169, 1987.
- [18] Ricardo Martin-Brualla, Noha Radwan, Mehdi SM Sajjadi, Jonathan T Barron, Alexey Dosovitskiy, and Daniel Duckworth. Nerf in the wild: Neural radiance fields for unconstrained photo collections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7210–7219, 2021.
- [19] Nelson Max. Optical models for direct volume rendering. IEEE Transactions on Visualization and Computer Graphics, 1(2):99–108, 1995.
- [20] Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4460–4470, 2019.
- [21] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In Proceedings of the European Conference on Computer Vision, pages 405–421, 2020.
- [22] Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. arXiv preprint arXiv:2201.05989, 2022.
- [23] Michael Niemeyer, Lars Mescheder, Michael Oechsle, and Andreas Geiger. Differentiable volumetric rendering: Learning implicit 3d representations without 3d supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3504–3515, 2020.
- [24] Michael Oechsle, Songyou Peng, and Andreas Geiger. Unisurf: Unifying neural implicit surfaces and radiance fields for multi-view reconstruction. In Proceedings of the IEEE International Conference on Computer Vision, pages 5589–5599, 2021.
- [25] Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 165–174, 2019.
- [26] Songyou Peng, Michael Niemeyer, Lars Mescheder, Marc Pollefeys, and Andreas Geiger. Convolutional occupancy networks. In Proceedings of the European Conference on Computer Vision, pages 523–540, 2020.
- [27] Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016.
- [28] Johannes L. Schönberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision, pages 501–518, 2016.
- [29] Steven M Seitz and Charles R Dyer. Photorealistic scene reconstruction by voxel coloring. International Journal of Computer Vision, 35(2):151–173, 1999.
- [30] Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions. Advances in Neural Information Processing Systems, 33:7462–7473, 2020.
- [31] Noah Snavely, Steven M Seitz, and Richard Szeliski. Photo tourism: exploring photo collections in 3d. In ACM SIGGRAPH, pages 835–846, 2006.
- [32] Cheng Sun, Min Sun, and Hwann-Tzong Chen. Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. arXiv preprint arXiv:2111.11215, 2021.
- [33] Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. arXiv preprint arXiv:2106.10689, 2021.
- [34] Qingshan Xu and Wenbing Tao. Multi-scale geometric consistency guided multi-view stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5483–5492, 2019.
- [35] Qingshan Xu and Wenbing Tao. Planar prior assisted patchmatch multi-view stereo. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 12516–12523, 2020.
- [36] Qingshan Xu and Wenbing Tao. Pvsnet: Pixelwise visibility-aware multi-view stereo network. arXiv preprint arXiv:2007.07714, 2020.
- [37] Yao Yao, Zixin Luo, Shiwei Li, Tian Fang, and Long Quan. Mvsnet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision, pages 767–783, 2018.
- [38] Yao Yao, Zixin Luo, Shiwei Li, Jingyang Zhang, Yufan Ren, Lei Zhou, Tian Fang, and Long Quan. Blendedmvs: A large-scale dataset for generalized multi-view stereo networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1790–1799, 2020.
- [39] Lior Yariv, Jiatao Gu, Yoni Kasten, and Yaron Lipman. Volume rendering of neural implicit surfaces. In Advances in Neural Information Processing Systems, volume 34, 2021.
- [40] Lior Yariv, Yoni Kasten, Dror Moran, Meirav Galun, Matan Atzmon, Basri Ronen, and Yaron Lipman. Multiview neural surface reconstruction by disentangling geometry and appearance. In Advances in Neural Information Processing Systems, volume 33, pages 2492–2502, 2020.
- [41] Jingyang Zhang, Yao Yao, and Long Quan. Learning signed distance field for multi-view surface reconstruction. In Proceedings of the IEEE International Conference on Computer Vision, pages 6525–6534, 2021.
- [42] Kai Zhang, Gernot Riegler, Noah Snavely, and Vladlen Koltun. Nerf++: Analyzing and improving neural radiance fields. arXiv preprint arXiv:2010.07492, 2020.
- [43] Qian-Yi Zhou, Jaesik Park, and Vladlen Koltun. Open3d: A modern library for 3d data processing. arXiv preprint arXiv:1801.09847, 2018.