DPM-Solver:一种快速 ODE 求解器,可通过大约 10 个步骤进行扩散概率模型采样
摘要
扩散概率模型(DPM)是新兴的强大生成模型。 尽管 DPM 具有高质量的生成性能,但仍然受到采样缓慢的影响,因为它们通常需要对大型神经网络进行数百或数千次顺序功能评估(步骤)才能抽取样本。 从 DPM 采样也可以被视为求解相应的扩散常微分方程 (ODE)。 在这项工作中,我们提出了扩散常微分方程解的精确公式。 该公式以分析方式计算解的线性部分,而不是像以前的作品中采用的那样将所有项留给黑盒 ODE 求解器。 通过应用变量变化,解决方案可以等效地简化为神经网络的指数加权积分。 根据我们的公式,我们提出了DPM-Solver,这是一种具有收敛阶保证的扩散 ODE 快速专用高阶求解器。 DPM-Solver 适用于离散时间和连续时间 DPM,无需任何进一步的训练。 实验结果表明,DPM-Solver 在各种数据集上仅需 10 到 20 次函数评估即可生成高质量样本。 我们在 CIFAR10 数据集上的 10 次函数评估中实现了 4.70 FID,在 20 次函数评估中实现了 2.87 FID,与之前在各种数据集上最先进的免训练采样器相比,加速了 。111Code is available at https://github.com/LuChengTHU/dpm-solver
1简介
扩散概率模型 (DPM) [1, 2, 3] 是新兴的强大生成模型,在许多任务上具有良好的性能,例如图像生成 [4, 5]、视频生成[6],文本到图像生成[7],语音合成[8, 9]和无损压缩[ 10]。 DPM 由离散时间随机过程 [1, 2] 或连续时间随机微分方程 (SDE) [3] 定义,它学习逐渐消除添加的噪声到数据点。 与广泛使用的生成对抗网络(GAN)[11]和变分自动编码器(VAE)[12]相比,DPM不仅可以计算精确似然[3],而且还能为图像生成实现更好的样本质量[4]。 然而,为了获得高质量的样本,DPM 通常需要数百或数千个连续步骤的大型神经网络评估,从而导致采样速度比单步 GAN 或 VAE 慢得多。 这种低效率正在成为下游任务中采用 DPM 的关键瓶颈,从而迫切需要为 DPM 设计快速采样器。
现有的 DPM 快速采样器可分为两类。 第一类包括知识蒸馏[13, 14]和噪声水平或样本轨迹学习[15,16,17,18]。 此类方法需要可能昂贵的训练阶段才能用于有效采样。 此外,它们的适用性和灵活性可能受到限制。 使该方法适应不同的模型、数据集和采样步骤数可能需要付出很大的努力。 第二类包括免训练的[19,20,21]采样器,它们以简单的即插即用方式适用于所有预先训练的DPM。 免训练采样器包括采用隐式[19]或分析[21]生成过程、高级微分方程(DE)求解器[3,20,22,23 ,24] 和动态规划[18]。 然而,这些方法仍然需要 50次函数评估[21]来生成高质量的样本(与普通采样器在大约1000次函数评估中生成的样本相比),因此仍然是耗时。
在这项工作中,我们将免训练采样器的效率提升到了一个新的水平,以在“少步采样”机制中生成高质量的样本,其中采样可以在大约 10 个步骤内完成顺序功能评估。 我们解决从 DPM 采样的替代问题作为求解 DPM 相应的扩散常微分方程 (ODE),并仔细检查扩散 ODE 的结构。 扩散 ODE 具有半线性结构 - 它们由数据变量的线性函数和由神经网络参数化的非线性函数组成。 之前的免训练采样器[3, 20]省略了这种结构,直接使用黑盒DE求解器。 为了利用半线性结构,我们通过分析计算解的线性部分来导出扩散常微分方程解的精确公式,避免了相应的离散化误差。 此外,通过应用变量变化,解决方案可以等效地简化为神经网络的指数加权积分。 这种积分非常特殊,可以通过指数积分器[25]的数值方法有效地近似。
根据我们提出的解决方案,我们提出了DPM-Solver,这是一种通过逼近上述积分来进行扩散 ODE 的快速专用求解器。 具体来说,我们提出了具有收敛阶保证的 DPM-Solver 的一阶、二阶和三阶版本。 我们进一步提出了 DPM-Solver 的自适应步长计划。 一般来说,DPM-Solver 适用于连续时间和离散时间 DPM,也适用于带有分类器指导的条件采样[4]。 图1展示了去噪扩散隐式模型(DDIM)[19]基线和DPM-Solver的加速性能,这表明DPM-Solver可以生成高质量的样本只需 10 个函数评估,并且在 ImageNet 256x256 数据集[26]上比 DDIM 快得多。 我们的额外实验结果表明,DPM-Solver 可以极大地提高离散时间和连续时间 DPM 的采样速度,并且可以在大约 10 个函数评估中实现出色的样本质量,这比之前所有免训练采样器要快得多DPM 的数量。


NFE = 10


NFE = 15


NFE = 20


NFE = 100


NFE = 10
(a) DDIM [19] (b) DPM-Solver (ours)
2 扩散概率模型
我们在本节中回顾扩散概率模型及其相关的微分方程。
2.1 正向过程和扩散 SDE
假设我们有一个维随机变量,其分布未知。 扩散概率模型 (DPM) [1, 2, 3, 10] 定义一个 前向过程 ,其中 开头,使得对于任何,以为条件的分布满足
| (2.1) |
其中是的可微函数,具有有界导数,为了简单起见,我们将它们表示为。 和 的选择称为 DPM 的噪声表。 令 表示 的边际分布,DPM 选择噪声调度以确保某些 的 和 信噪比 (SNR) 严格随时间递减。 [10]。 此外,Kingma 等人[10]证明以下随机微分方程(SDE)具有与式(10)相同的转移分布。 (2.1) 对于任何 :
| (2.2) |
其中 是标准维纳过程,并且
| (2.3) |
在一定的规律性条件下,Song 等人[3]表明方程(1)中的前向过程。 (2.2) 从时间 到 具有等效的反向过程,从边际分布
| (2.4) |
其中是逆时标准维纳过程。 方程中唯一未知的项。 (2.4) 是每个时刻的评分函数。在实践中,DPM 使用由 参数化的神经网络 来估计缩放分数函数:。 通过最小化以下目标[2, 3]来优化参数:
其中是权重函数,、和是独立于的常数。 由于也可以视为对添加高斯噪声进行预测,因此通常称为噪声预测模型。 由于 的基本事实是 ,因此 DPM 取代了等式 1 中的得分函数。 (2.4) 由 定义参数化反向过程 (扩散 SDE) 从时间 到 ,从开始:
| (2.5) |
可以通过求解方程式中的扩散 SDE 来从 DPM 生成样本。 (2.5) 使用数值求解器,将 SDE 从 离散到 。 Song等人[3]证明了DPM的传统祖先采样方法[2]可以被视为方程(1)的一阶SDE求解器。 (2.5)。 然而,这些一阶方法通常需要数百或数千次函数求值才能收敛[3],导致采样速度极慢。
2.2 扩散(概率流)ODE
离散化 SDE 时,步长受到维纳过程随机性的限制 [27,第 1 章。 11]. 大步长(小步数)通常会导致不收敛,尤其是在高维空间中。 为了更快地采样,可以考虑相关的概率流 ODE [3],它在每个时间 具有与SDE。 具体来说,对于DPM,Song等人[3]证明了方程(1)的概率流ODE。 (2.4) 是
| (2.6) |
其中的边际分布也是。 宋等人[3]通过用噪声预测模型替换得分函数,定义了以下参数化ODE(扩散ODE):
| (2.7) |
可以通过求解从 到 的 ODE 来抽取样本。 与 SDE 相比,ODE 没有随机性,因此可以用更大的步长求解。 此外,我们可以利用高效的数值 ODE 求解器来加速采样。 宋等人[3]使用RK45 ODE求解器[28]进行扩散ODE,生成 60个函数评估中的样本以达到可比的方程的 1000 步 SDE 求解器的质量。 (2.5) 在 CIFAR-10 数据集 [29] 上。 然而,现有的通用 ODE 求解器仍然无法在少步( 10 步)采样方案中生成令人满意的样本。 据我们所知,在少步采样机制中仍然缺乏 DPM 的免训练采样器,并且 DPM 的采样速度仍然是一个关键问题。
3 扩散常微分方程的定制快速求解器
正如第 2 节中强调的那样。 2.2,在高维情况下离散 SDE 通常很困难 [27,第 1 章。 11] 并且很难在几步之内收敛。 相比之下,ODE 更容易求解,从而有可能实现快速采样器。 然而,正如第 2 节中提到的。 2.2,之前的工作[3]中使用的通用黑盒ODE求解器根据经验在几个步骤内无法收敛。 这促使我们为扩散 ODE 设计专用求解器,以实现快速、高质量的少步采样。 我们首先详细研究扩散常微分方程的具体结构。
3.1 扩散常微分方程精确解的简化公式
这项工作的关键见解是,给定时间 的初始值 ,扩散的每个时间 的解 方程中的常微分方程(2.7) 可以简化为一个非常特殊的精确公式,可以有效地近似。
我们的第一个关键观察是,通过考虑扩散 ODE 的特定结构,可以精确计算解 的一部分。 r.h.s. 方程中的扩散常微分方程(2.7)由两部分组成:部分是的线性函数,另一部分一般是由于神经网络 , 的非线性函数。 这种类型的 ODE 称为半线性 ODE。 之前的工作[3]采用的黑盒ODE求解器不知道这种半线性结构,因为它们采用方程1中的整个。 (2.7)作为输入,这会导致线性项和非线性项的离散化误差。 我们注意到,对于半线性 ODE,时间 的解可以通过“常数的变化”公式[30]精确地表示:
| (3.1) |
该公式解耦了线性部分和非线性部分。 与黑盒 ODE 求解器相比,现在可以精确计算线性部分,从而消除了线性项的近似误差。 然而,非线性部分的积分仍然很复杂,因为它耦合了噪声表的系数(即)和复杂的神经网络,仍然很难近似。
我们的第二个关键观察是,通过引入特殊变量可以大大简化非线性部分的积分。 令 (对数 SNR 的一半),则 是 的严格递减函数(由于第 2 节中讨论的 DPM 的定义) 2.1)。 我们可以重写等式中的。 (2.3) 作为
| (3.2) |
结合等式中的 (2.3),我们可以重写等式: (3.1) 作为
| (3.3) |
由于是的严格递减函数,因此它具有满足的反函数。 我们进一步将和的下标从更改为并表示、。 重写方程。 (3.3) 通过 “change-of-variable” 对于 ,那么我们有:
Proposition 3.1 (扩散ODE的精确解).
给定时间处的初始值,方程中扩散常微分方程在时间处的解。 (2.7) 是:
| (3.4) |
我们将积分称为的指数加权积分,它非常特殊,并且与指数积分器高度相关。 ODE 求解器的文献[25]。 据我们所知,这种表述在之前的扩散模型工作中尚未被揭示。
3.2 扩散常微分方程的高阶求解器
在本节中,我们通过利用我们提出的解决方案公式,提出具有收敛阶保证的扩散 ODE 的高阶求解器。 (3.4)。 所提出的求解器和分析很大程度上受到 ODE 文献中指数积分器 [25, 31] 方法的启发。
具体来说,给定时间 处的初始值 和 时间步长 ,从 减小到 。 令 为初始值。 建议的求解器使用 步骤迭代计算序列 ,以逼近时间步骤 的真实解。 特别是,最后一次迭代 近似于时间 时的真实解。
为了减少时间 时 与真实解之间的近似误差,我们需要减少每一步 [30] 中每个 的近似误差。 根据等式 1,从时间 处的前一个值 开始。 (3.4),时间的精确解由下式给出
| (3.5) |
因此,为了计算近似 的值 ,我们需要近似 从 到 。 将 和 表示为 的 阶全导数。 。 对于 , 的 阶泰勒展开式。 在 处是
将上述泰勒展开式代入方程: (3.5) 产量
| (3.6) |
其中积分可以通过重复应用次分段积分来分析计算(参见附录B.2) >)。 因此,为了近似,我们只需要近似的阶全导数,这是一个很好的-研究了 ODE 文献[31, 32]中的问题。 通过删除误差项并用“严格阶数条件”[31, 32]逼近第一个全导数,我们可以得出 用于扩散 ODE 的三阶 ODE 求解器。 我们将此类求解器总体命名为 DPM-Solver,将特定阶数 命名为 DPM-Solver-。这里我们以进行演示。 在这种情况下,等式。 (3.6) 变为
通过去掉高阶误差项,我们可以获得的近似值。 这里的,我们将该求解器称为DPM-Solver-1,详细算法如下。
DPM-求解器-1。 给定初始值和时间步长从减少到。 从 开始,按如下方式迭代计算序列 :
| (3.7) |
对于,近似泰勒展开式的前项需要和之间的额外中间点[31] 。 推导更具技术性,因此我们将其推迟到附录B。 下面我们提出的算法,并将它们分别命名为DPM-Solver-2和DPM-Solver-3。
这里,是的反函数,它具有[2, 16]中使用的实际噪声调度的解析公式,如附录D。对于 DPM-Solver-2,选择的中间点是 (、);对于 DPM-Solver-3,选择的中间点是 和 。 如算法所示,DPM-Solver- 需要对 每一步进行 次函数计算。 尽管步骤成本更高,但高阶求解器 () 通常效率更高,因为它们的收敛阶数更高,因此需要更少的步骤来收敛。 我们证明 DPM-Solver- 是 三阶求解器,如以下定理所述。 证明在附录B中。
Theorem 3.2 (DPM-Solver- 作为 阶求解器)。
假设 遵循附录 B.1 中详述的正则条件,那么对于 ,DPM-Solver- 是扩散 ODE 的 三阶求解器,即对于由 DPM-Solver- 计算的序列 ,时间 时的近似误差满足 ,其中 。
最后,具有 的求解器需要更多的中间点,如指数积分器之前的工作 [31, 32] 所示。 因此,在这项工作中,我们只考虑从到的,而将具有更高的求解器留给未来的研究。
3.3 步长时间表
Sec 中提出的求解器。 3.2需要提前指定时间步。 我们提出了两种时间步安排的选择。 一种选择是手工制作,即均匀分割区间,],即,。 请注意,这与之前的工作 [2, 3] 不同,后者为 选择统一的步骤。 根据经验,具有统一时间步的DPM-Solver已经可以在几个步骤内生成相当好的样本,其结果列于附录E中。作为另一种选择,我们提出了一种自适应步长算法,该算法通过组合不同阶数的 DPM-Solver 来动态调整步长。 自适应算法的灵感来自[20],我们将其实现细节推迟到附录C。
对于少步采样,我们需要用完所有函数评估(NFE)的数量。 当NFE不能被整除时,我们首先尽可能应用DPM-Solver-3,然后添加单步DPM-Solver-1或DPM-Solver-2(取决于除以的提醒),详见附录D。在后续实验中,我们将这种求解器组合与 NFE 的统一步长计划结合使用,否则使用自适应步长计划。
3.4 从离散时间 DPM 采样
离散时间 DPM [2] 训练在 固定时间步长 的噪声预测模型,噪声预测模型由 对 进行参数化,其中每个 对应于时间 时的值。 我们可以通过令 对于所有 将离散时间噪声预测模型转换为连续版本。 请注意,的输入时间可能不是整数,但我们发现噪声预测模型仍然可以很好地工作,并且我们假设这是因为平滑的时间嵌入(例如,位置嵌入[2])。 通过这种重新参数化,噪声预测模型可以采用连续时间步长作为输入,因此我们也可以使用DPM-Solver进行快速采样。
4与现有快速采样方法的比较
在这里,我们讨论这种关系并强调 DPM-Solver 与现有基于 ODE 的 DPM 快速采样方法之间的区别。 我们进一步简要讨论免训练采样器相对于基于训练的采样器的优势。
4.1 DDIM 作为 DPM-Solver-1
去噪扩散隐式模型 (DDIM) [19] 设计了一种从 DPM 快速采样的确定性方法。 对于两个相邻的时间步和,假设我们在时间有一个解,那么DDIM的单步从时间到时间是
| (4.1) |
尽管出于完全不同的观点,我们表明 DPM-Solver-1 和去噪扩散隐式模型 (DDIM) [19] 的更新是相同的。 根据的定义,我们有和。 将这些和 插入方程。 (4.1) 精确地得出等式 1 中 DPM-Solver-1 的一个步骤。 (3.7)。 然而,DPM-Solver 的半线性 ODE 公式允许原则上推广到高阶求解器和收敛阶分析。
最近的工作[13]还表明,DDIM是通过对方程两边求导而实现的扩散ODE的一阶离散化。 (4.1)。 然而,它们无法解释 DDIM 和扩散 ODE 的一阶欧拉离散化之间的差异。 相比之下,通过证明 DDIM 是 DPM-Solver 的特例,我们揭示了 DDIM 充分利用了扩散 ODE 的半线性,这解释了它相对于传统欧拉方法的优越性。
4.2与传统龙格-库塔方法的比较
我们可以通过直接将传统的显式龙格库塔(RK)方法应用于方程(1)中的扩散常微分方程来获得高阶求解器。 (2.7)。 具体来说,RK 方法编写了方程 (1) 的解。 (2.7) 的积分形式如下:
| (4.2) |
并使用之间的一些中间时间步长,并结合这些时间步长的的评估来近似整个积分。 显式RK方法的逼近误差取决于,它由线性项和非线性噪声预测模型对应的误差组成。 然而,由于线性项的精确解具有指数系数(如式(3.1)所示),因此线性项的误差可能呈指数增长。 有许多经验证据[25, 31]表明,直接使用显式 RK 方法进行半线性 ODE 可能会遇到大步长数值不稳定的问题。 我们还在第 2 节中证明了所提出的 DPM-Solver 和传统显式 RK 方法的经验差异。 5.1,这表明DPM-Solver比同阶数的RK方法具有更小的离散化误差。
4.3 基于训练的 DPM 快速采样方法
需要额外训练或优化的采样器包括知识蒸馏[13, 14]、学习噪声水平或方差[15, 16, 33]以及学习噪声调度或样本轨迹[17, 18]。 虽然渐进式蒸馏方法[13]可以在4步内获得快速采样器,但它需要进一步的训练成本,并且丢失了原始DPM中的部分信息(例如,蒸馏后,噪声预测模型无法预测 之间每个时间步的噪声(得分函数)。 相比之下,免训练采样器可以保留原始模型的所有信息,从而可以通过结合原始模型和外部分类器[4]直接扩展到条件采样(例如参见附录D 用于带有分类器指导的条件采样)。
除了直接为 DPM 设计快速采样器之外,一些工作还提出了支持更快采样的新型 DPM。 例如,为DPM定义一个低维潜在变量[34];设计具有有界得分函数的特殊扩散过程[35];将 GAN 与 DPM 的逆过程相结合[36]。 所提出的 DPM-Solver 也可能适合加速这些 DPM 的采样,我们将它们留到未来的工作中。
| Sampling method NFE | 12 | 18 | 24 | 30 | 36 | 42 | 48 |
|---|---|---|---|---|---|---|---|
| RK2 () | 16.40 | 7.25 | 3.90 | 3.63 | 3.58 | 3.59 | 3.54 |
| RK2 () | 107.81 | 42.04 | 17.71 | 7.65 | 4.62 | 3.58 | 3.17 |
| DPM-Solver-2 | 5.28 | 3.43 | 3.02 | 2.85 | 2.78 | 2.72 | 2.69 |
| RK3 () | 48.75 | 21.86 | 10.90 | 6.96 | 5.22 | 4.56 | 4.12 |
| RK3 () | 34.29 | 4.90 | 3.50 | 3.03 | 2.85 | 2.74 | 2.69 |
| DPM-Solver-3 | 6.03 | 2.90 | 2.75 | 2.70 | 2.67 | 2.65 | 2.65 |
5实验
在本节中,我们展示了作为一种免训练采样器,DPM-Solver 可以大大加快现有预训练 DPM 的采样速度,包括连续时间和离散时间 DPM,并且具有线性噪声调度 [2 ,19] 和余弦噪声表 [16]。 我们改变不同数量的函数评估(NFE),即对噪声预测模型 的调用数量,并比较 DPM-Solver 和其他方法之间的样本质量。 对于每个实验,我们抽取 50K 样本,并使用广泛采用的 FID 分数 [37] 来评估样本质量,其中较低的 FID 通常意味着更好的样本质量。
除非明确提及,否则我们始终使用具有统一步长计划的求解器组合(第 2 节)。 3.3 如果 NFE 预算小于 20,否则采用第 2 节中的自适应步长计划的 DPM-Solver-3。 3.3。 DPM-Solver 的其他实现细节参见附录D,详细设置参见附录E。
5.1与连续时间采样方法的比较
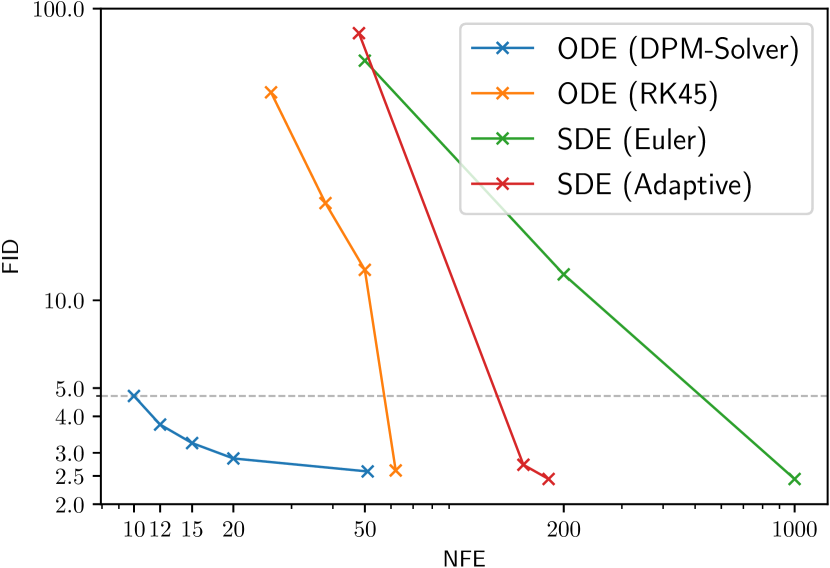
我们首先将 DPM-Solver 与其他 DPM 连续时间采样方法进行比较。 比较的方法包括扩散SDE的Euler-Maruyama离散化[3]、扩散SDE的自适应步长求解器[20]以及扩散ODE的RK方法[3, 28] 式中。 (2.7)。 我们将这些从 CIFAR-10 数据集 [29] 上的预训练连续时间“VP 深度”模型 [3] 采样的方法与线性噪声计划进行比较。
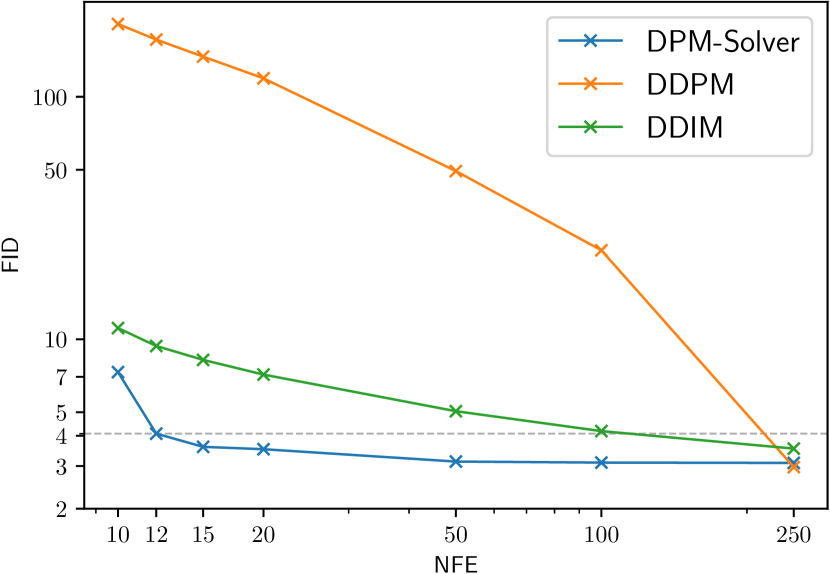
图2(a)显示了比较求解器的效率。 我们对具有欧拉离散化的扩散 SDE 使用 50、200、1000 NFE 的统一时间步,并改变自适应步长 SDE 求解器 [20] 的容差超参数 [3, 20] 和 RK45 ODE 求解器 [28] 来控制 NFE。 DPM-Solver 可以在 10 NFE 左右生成良好的样本质量,而其他求解器即使在 50 NFE 下也存在较大的离散化误差,这表明 DPM-Solver 可以实现之前最佳求解器 5 的加速。 特别是,我们使用 10 NFE 实现了 4.70 FID,使用 12 NFE 实现了 3.75 FID,使用 15 NFE 实现了 3.24 FID,使用 20 NFE 实现了 2.87 FID,这是 CIFAR-10 上最快的采样器。
作为消融研究,我们还比较了二阶和三阶 DPM-Solver 和 RK 方法,如表1所示。 我们比较了扩散 ODE 的 RK 方法。 方程中的时间都是。 (2.7)和半对数信噪比,通过应用变量变化(参见附录E.1中的详细公式)。 结果表明,在相同 NFE 的情况下,DPM-Solver 的样本质量始终优于相同阶数的 RK 方法。 DPM-Solver 的优越效率在 15 NFE 下的少步机制中尤其明显,其中 RK 方法具有相当大的离散化误差。 这主要是因为 DPM-Solver 解析计算线性项,避免了相应的离散化误差。 此外,高阶DPM-Solver-3比DPM-Solver-2收敛得更快,这与定理3.2中的阶次分析相符。
5.2与离散时间采样方法的比较
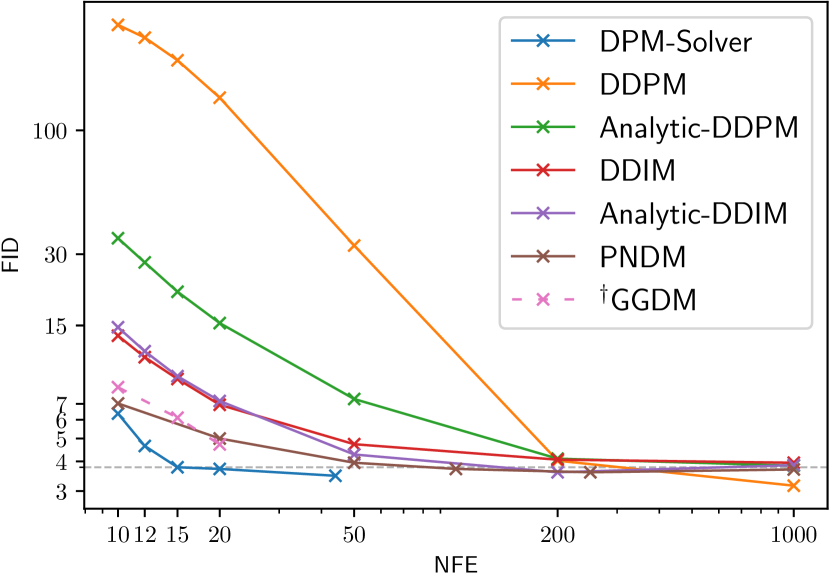
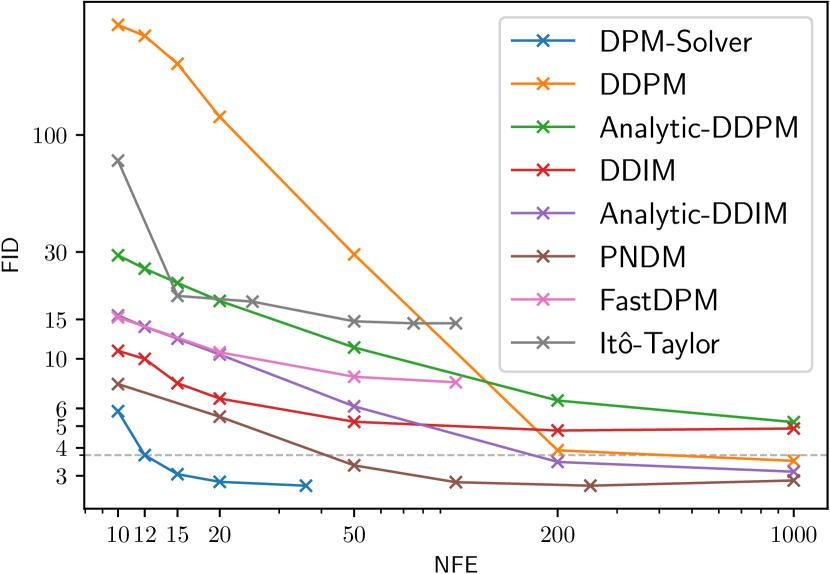
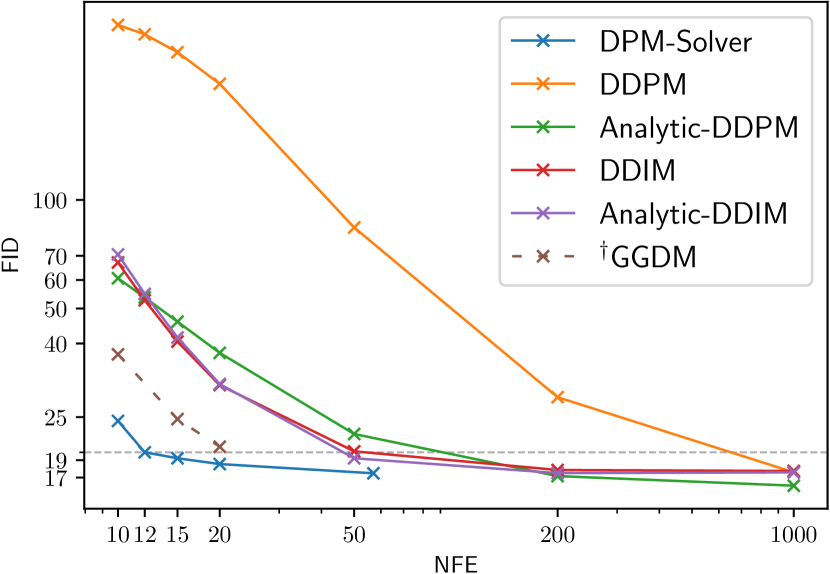
我们使用秒中的方法。 3.4 用于在离散时间 DPM 中使用 DPM-Solver,然后将 DPM-Solver 与其他离散时间免训练采样器进行比较,包括 DDPM [2]、DDIM [19]、分析-DDPM [21]、分析-DDIM [21]、PNDM [22]、 FastDPM [38] 和 Itô-Taylor [24]。 我们还与 GGDM [18] 进行比较,后者使用相同的预训练模型,但需要对采样轨迹进行进一步训练。 我们通过将 NFE 在 10 到 1000 之间变化来比较样本质量。
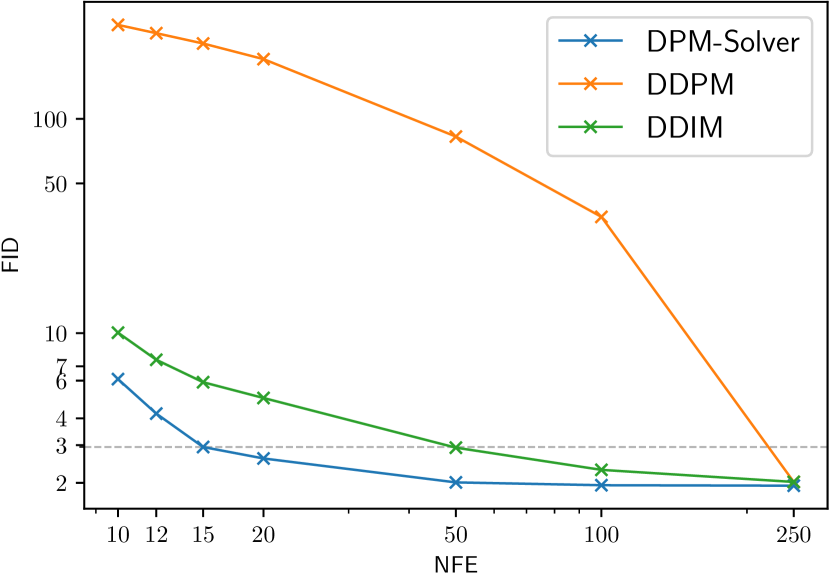
具体来说,我们使用[2]中在具有线性噪声调度的CIFAR-10数据集上训练的离散时间模型; CelebA 64x64 [39] 上 [19] 中的离散时间模型,具有线性噪声调度; 在 [16] 中使用余弦噪声调度在 ImageNet 64x64 [26] 上训练的离散时间模型; ImageNet 128x128 [26] 上 [4] 中具有分类器引导的离散时间模型,具有线性噪声调度; [4] 中 LSUN 卧室 256x256 [40]0> 上的离散时间模型,具有线性噪声表。 对于在 ImageNet 上训练的模型,我们仅使用其“均值”模型并省略“方差”模型。 如图2所示,在所有数据集上,DPM-Solver可以在12步内获得合理的样本(CIFAR-10上的FID 4.65,CelebA 64x64上的FID 3.71和ImageNet 64x64上的FID 19.97,FID 4.08在 ImageNet 128x128 上),比之前最快的免训练采样器快。 DPM-Solver 甚至优于训练 GGDM,后者需要额外的训练。
6 结论
我们解决了 DPM 快速且无需训练的采样问题。 我们提出了 DPM-Solver,这是一种快速专用的、无需训练的扩散 ODE 求解器,用于在大约 10 个函数评估步骤中对 DPM 进行快速采样。 DPM-Solver 利用扩散 ODE 的半线性,直接近似扩散 ODE 精确解的简化公式,该公式由噪声预测模型的指数加权积分组成。 受指数积分器数值方法的启发,我们提出一阶、二阶和三阶 DPM 求解器来逼近噪声预测模型的指数加权积分,并保证理论收敛。 我们提出了手工设计和自适应步长调度,并将 DPM-Solver 用于连续时间和离散时间 DPM。 我们的实验结果表明,DPM-Solver 可以在各种数据集上的约 10 个函数评估中生成高质量的样本,并且与之前最先进的免训练采样器相比,可以实现 加速。
限制和更广泛的影响 尽管 DPM-Solver 具有令人鼓舞的加速性能,但它是为快速采样而设计的,这可能不适合加速 DPM 的似然评估。 此外,与常用的 GAN 相比,使用 DPM-Solver 的扩散模型对于实时应用来说仍然不够快。 此外,与其他深度生成模型一样,DPM 可能会被用来生成不良的虚假内容,并且所提出的求解器可能会进一步放大深度生成模型对恶意应用程序的潜在不良影响。
致谢
该工作得到国家重点研发计划项目(No. 2021ZD0110502); NSF中国项目(No. 62061136001、61620106010、62076145、U19B2034、U1811461、U19A2081、6197222、62106120);北京市NSF项目(No. JQ19016);北京市杰出青年科学家计划 BJJWZYJH012019100020098;清华大学郭强研究院资助;具有 GPU/DGX 加速功能的 NVIDIA NVAIL 计划;清华大学高性能计算中心;中央高校基本科研业务费专项资金、中国人民大学科研业务费专项资金(22XNKJ13)。 J.Z 还得到了 XPlorer 奖的支持。
参考
- Sohl-Dickstein et al. [2015] J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” in International Conference on Machine Learning. PMLR, 2015, pp. 2256–2265.
- Ho et al. [2020] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 6840–6851.
- Song et al. [2021a] Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” in International Conference on Learning Representations, 2021.
- Dhariwal and Nichol [2021] P. Dhariwal and A. Q. Nichol, “Diffusion models beat GANs on image synthesis,” in Advances in Neural Information Processing Systems, vol. 34, 2021, pp. 8780–8794.
- Meng et al. [2022] C. Meng, Y. Song, J. Song, J. Wu, J.-Y. Zhu, and S. Ermon, “SDEdit: Image synthesis and editing with stochastic differential equations,” in International Conference on Learning Representations, 2022.
- Ho et al. [2022] J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet, “Video diffusion models,” arXiv preprint arXiv:2204.03458, 2022.
- Ramesh et al. [2022] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with CLIP latents,” arXiv preprint arXiv:2204.06125, 2022.
- Chen et al. [2021a] N. Chen, Y. Zhang, H. Zen, R. J. Weiss, M. Norouzi, and W. Chan, “Wavegrad: Estimating gradients for waveform generation,” in International Conference on Learning Representations, 2021.
- Chen et al. [2021b] N. Chen, Y. Zhang, H. Zen, R. J. Weiss, M. Norouzi, N. Dehak, and W. Chan, “Wavegrad 2: Iterative refinement for text-to-speech synthesis,” in International Speech Communication Association, 2021, pp. 3765–3769.
- Kingma et al. [2021] D. P. Kingma, T. Salimans, B. Poole, and J. Ho, “Variational diffusion models,” in Advances in Neural Information Processing Systems, 2021.
- Goodfellow et al. [2014] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. C. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in Neural Information Processing Systems, vol. 27, 2014, pp. 2672–2680.
- Kingma and Welling [2014] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in International Conference on Learning Representations, 2014.
- Salimans and Ho [2022] T. Salimans and J. Ho, “Progressive distillation for fast sampling of diffusion models,” in International Conference on Learning Representations, 2022.
- Luhman and Luhman [2021] E. Luhman and T. Luhman, “Knowledge distillation in iterative generative models for improved sampling speed,” arXiv preprint arXiv:2101.02388, 2021.
- San-Roman et al. [2021] R. San-Roman, E. Nachmani, and L. Wolf, “Noise estimation for generative diffusion models,” arXiv preprint arXiv:2104.02600, 2021.
- Nichol and Dhariwal [2021] A. Q. Nichol and P. Dhariwal, “Improved denoising diffusion probabilistic models,” in International Conference on Machine Learning. PMLR, 2021, pp. 8162–8171.
- Lam et al. [2021] M. W. Lam, J. Wang, R. Huang, D. Su, and D. Yu, “Bilateral denoising diffusion models,” arXiv preprint arXiv:2108.11514, 2021.
- Watson et al. [2022] D. Watson, W. Chan, J. Ho, and M. Norouzi, “Learning fast samplers for diffusion models by differentiating through sample quality,” in International Conference on Learning Representations, 2022.
- Song et al. [2021b] J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” in International Conference on Learning Representations, 2021.
- Jolicoeur-Martineau et al. [2021] A. Jolicoeur-Martineau, K. Li, R. Piché-Taillefer, T. Kachman, and I. Mitliagkas, “Gotta go fast when generating data with score-based models,” arXiv preprint arXiv:2105.14080, 2021.
- Bao et al. [2022a] F. Bao, C. Li, J. Zhu, and B. Zhang, “Analytic-DPM: An analytic estimate of the optimal reverse variance in diffusion probabilistic models,” in International Conference on Learning Representations, 2022.
- Liu et al. [2022] L. Liu, Y. Ren, Z. Lin, and Z. Zhao, “Pseudo numerical methods for diffusion models on manifolds,” in International Conference on Learning Representations, 2022.
- Popov et al. [2022] V. Popov, I. Vovk, V. Gogoryan, T. Sadekova, M. Kudinov, and J. Wei, “Diffusion-based voice conversion with fast maximum likelihood sampling scheme,” in International Conference on Learning Representations, 2022.
- Tachibana et al. [2021] H. Tachibana, M. Go, M. Inahara, Y. Katayama, and Y. Watanabe, “Itô-Taylor sampling scheme for denoising diffusion probabilistic models using ideal derivatives,” arXiv preprint arXiv:2112.13339, 2021.
- Hochbruck and Ostermann [2010] M. Hochbruck and A. Ostermann, “Exponential integrators,” Acta Numerica, vol. 19, pp. 209–286, 2010.
- Deng et al. [2009] J. Deng, W. Dong, R. Socher, L. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” in 2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009, pp. 248–255.
- Kloeden and Platen [1992] P. E. Kloeden and E. Platen, Numerical Solution of Stochastic Differential Equations. Springer, 1992.
- Dormand and Prince [1980] J. R. Dormand and P. J. Prince, “A family of embedded Runge-Kutta formulae,” Journal of computational and applied mathematics, vol. 6, no. 1, pp. 19–26, 1980.
- Krizhevsky [2009] A. Krizhevsky, “Learning multiple layers of features from tiny images,” Tech. Rep., 2009.
- Atkinson et al. [2011] K. Atkinson, W. Han, and D. E. Stewart, Numerical solution of ordinary differential equations. John Wiley & Sons, 2011, vol. 108.
- Hochbruck and Ostermann [2005] M. Hochbruck and A. Ostermann, “Explicit exponential Runge-Kutta methods for semilinear parabolic problems,” SIAM Journal on Numerical Analysis, vol. 43, no. 3, pp. 1069–1090, 2005.
- Luan [2021] V. T. Luan, “Efficient exponential Runge-Kutta methods of high order: Construction and implementation,” BIT Numerical Mathematics, vol. 61, no. 2, pp. 535–560, 2021.
- Bao et al. [2022b] F. Bao, C. Li, J. Sun, J. Zhu, and B. Zhang, “Estimating the optimal covariance with imperfect mean in diffusion probabilistic models,” arXiv preprint arXiv:2206.07309, 2022.
- Vahdat et al. [2021] A. Vahdat, K. Kreis, and J. Kautz, “Score-based generative modeling in latent space,” in Advances in Neural Information Processing Systems, vol. 34, 2021, pp. 11 287–11 302.
- Dockhorn et al. [2022] T. Dockhorn, A. Vahdat, and K. Kreis, “Score-based generative modeling with critically-damped Langevin diffusion,” in International Conference on Learning Representations, 2022.
- Xiao et al. [2022] Z. Xiao, K. Kreis, and A. Vahdat, “Tackling the generative learning trilemma with denoising diffusion GANs,” in International Conference on Learning Representations, 2022.
- Heusel et al. [2017] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “GANs trained by a two time-scale update rule converge to a local Nash equilibrium,” in Advances in Neural Information Processing Systems, I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V. N. Vishwanathan, and R. Garnett, Eds., vol. 30, 2017, pp. 6626–6637.
- Kong and Ping [2021] Z. Kong and W. Ping, “On fast sampling of diffusion probabilistic models,” arXiv preprint arXiv:2106.00132, 2021.
- Liu et al. [2015] Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” in Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 3730–3738.
- Yu et al. [2015] F. Yu, A. Seff, Y. Zhang, S. Song, T. Funkhouser, and J. Xiao, “LSUN: Construction of a large-scale image dataset using deep learning with humans in the loop,” arXiv preprint arXiv:1506.03365, 2015.
- Song et al. [2021c] Y. Song, C. Durkan, I. Murray, and S. Ermon, “Maximum likelihood training of score-based diffusion models,” in Advances in Neural Information Processing Systems, vol. 34, 2021, pp. 1415–1428.
- Yang et al. [2021] K. Yang, J. Yau, L. Fei-Fei, J. Deng, and O. Russakovsky, “A study of face obfuscation in ImageNet,” arXiv preprint arXiv:2103.06191, 2021.
清单
- 1.
- 2.
-
3.
如果你进行实验...
-
(A)
您是否包含了重现主要实验结果所需的代码、数据和说明(在补充材料中或作为 URL)? [是]代码附在补充材料和附录中。
-
(二)
您是否指定了所有训练细节(例如,数据分割、超参数、如何选择它们)? [是]我们的方法无需培训。 但我们还报告了我们提出的求解器中使用的评估超参数。
-
(C)
您是否报告了误差线(例如,多次运行实验后的随机种子)? [否]我们观察到 DPM-Solver 的 FID 评估的标准偏差相当小(主要小于 0.01),因为按照现有工作 [,FID 已经对 50K 样本进行了平均。 18、20、21]。 小标准差不会改变结论。
-
(四)
您是否包含计算总量和使用的资源类型(例如 GPU 类型、内部集群或云提供商)? [是]GPU 类型和数量详见附录E。
-
(A)
- 4.
-
5.
如果您使用众包或对人类受试者进行研究……
-
(A)
您是否提供了向参与者提供的说明全文和屏幕截图(如果适用)? [不适用]
-
(二)
您是否描述了任何潜在的参与者风险,以及机构审查委员会 (IRB) 批准的链接(如果适用)? [不适用]
-
(C)
您是否包括了支付给参与者的估计小时工资以及参与者补偿的总金额? [不适用]
-
(A)
附录 A噪声表不变性采样
| Method | Invariance Formulation |
|---|---|
| Maximum likelihood training | |
| Sampling by diffusion ODEs |
在本节中,我们将更多地讨论命题3.1中的精确解,并给出有关公式的一些见解。 下面我们首先重申一下这个命题。 (即半对数SNR)。
在下面的小节中,我们将展示这种公式将模型 与特定噪声计划解耦,因此对于噪声计划是不变的。 此外,命题3.1中的变量变化与扩散模型的最大似然训练高度相关[10, 41]。 我们证明最大似然训练和扩散模型的采样都具有独立于噪声表的不变性公式。
A.1 将采样解决方案与噪声表解耦
在本节中,我们证明命题 3.1 可以将扩散 ODE 的精确解与特定噪声表(即函数 和 的选择)解耦>)。 即给定起点、终点、处的初始值以及噪声预测模型,的解对于和之间的噪声调度是不变的。
我们首先考虑VP型扩散模型,它相当于原始的DDPM[2, 3]。 对于VP类型的扩散模型,我们总是有,因此定义噪声调度相当于定义函数(例如,DDPM [2]使用噪声计划,使得 是 的线性函数,并且 i-DDPM [16] 使用噪声计划,使得 是 的余弦函数)。 作为,我们有和。 因此,我们可以直接计算给定 的 和 。 表示,我们有
| (A.2) |
我们应该注意到,被积函数 是 的函数,因此它从 到 的积分仅取决于起始点点、结束点和函数,其与中间值无关。 由于其他系数(和)也仅取决于起点和终点,我们可以得出结论 对于噪声表的具体选择是不变的。 直观上,这是因为我们将式(1)中时间的原始积分进行了转换。 (3.1) 转换为 的积分,函数 和 转换为 解析 公式,对于 和 的具体选择是不变的。 最后,对于其他类型的扩散模型(例如VE型和subVP型),通过对噪声预测模型进行等效缩放,它们都等效于VP型,如[10]中证明。 因此,这些类型的解也具有这样的性质。
A.2 为选择时间步长对于噪声调度是不变的
如附录A.1所述,命题3.1的制定将采样方案与噪声调度解耦。 该解取决于起点和终点,并且对于中间噪声调度是不变的。 类似地,DPM-Solver算法的更新方程对于中间噪声调度也是不变的。 因此,如果我们选择时间步,那么DPM-Solver的解也被确定并且对于中间噪声调度是不变的。
选择时间步长的一个简单方法是均匀分割,这是我们实验中的设置。 然而,我们相信存在更精确的方法来选择时间步长,我们将其留待未来的工作。
A.3 与扩散模型最大似然训练的关系
有趣的是,连续时间内扩散 SDE 的最大似然训练也具有这样的不变性[10]。 下面我们简要回顾一下扩散 SDE 的最大似然训练损失,然后提出理解扩散模型的新见解。
表示数据分布为,正向过程在每个时刻的分布为,反向过程在每个时刻 与 和 一样。 在[3]中,证明了和之间的KL散度可以由加权分数匹配损失来限制:
| (A.3) |
其中 和 是独立于 的常数。 如第 2 节所示。 3.1,我们有
| (A.4) |
因此,通过应用 change-of-variable w.r.t. ,我们有
| (A.5) |
这相当于 [41, Sec. 中的重要性采样技巧。 5.1] 和[10,方程 5.1] 中的连续时间扩散损失。 (22)]。 与命题3.1相比,我们可以发现扩散模型的采样和最大似然都可以转化为积分。 ,这样公式对于特定的噪声表是不变的,我们将其总结在表2中。 训练和采样的这种不变性为理解扩散模型带来了新的见解。 例如,我们可以直接定义噪声预测模型 w.r.t. (half-)logSNR 而不是时间 ,则可以完成扩散模型的训练和采样而无需进一步选择任何临时噪声计划。 这样的发现可能会统一不同的训练方式和扩散模型的推理,我们将其留待将来研究。
附录B定理证明3.2
B.1 假设
在本节中,我们将 表示为扩散 ODE 方程的解。 (2.7) 从开始。 对于 DPM-Solver-,我们做出以下假设:
Assumption B.1.
总导数 (作为 的函数)存在并且对于 是连续的。
Assumption B.2.
函数 是 Lipschitz w.r.t. 到它的第一个参数。
Assumption B.3.
。
我们注意到泰勒定理方程需要第一个假设。 (3.6),第二个假设用于将 替换为 ,以便泰勒展开式 w.r.t. 适用。 最后一个是排除非常大的步长的技术假设。
B.2 指数加权积分的一般展开式
首先,我们推导指数加权积分的泰勒展开式。 让,然后。 表示,阶全导数。 对于 , 的 阶泰勒展开式。 是
| (B.1) |
为了扩展指数积分器,我们进一步定义[31]:
| (B.2) |
并且满足 以及递归关系。 通过对进行泰勒展开,指数积分器可以重写为
| (B.3) |
所以方程中的解(3.4) 可以展开为
| (B.4) |
最后,我们列出 的 的封闭形式:
| (B.5) | ||||
| (B.6) | ||||
| (B.7) |
B.3 定理证明 3.2 当 时
B.4 定理证明 3.2 当 时
我们在算法4中证明了DPM-Solver-2通用形式的离散化误差。
B.5 定理证明 3.2 当 时
B.6 与显式指数 Runge-Kutta (expRK) 方法的连接
假设我们有一个具有以下形式的 ODE:
其中和是的非线性函数。 给定时间 的初始值 ,对于 ,时间 的真实解为
指数龙格-库塔方法[25, 31]使用一些中间点来近似积分。 我们提出的 DPM-Solver 的灵感来自于用 和 近似相同积分的相同技术。 然而,DPM-Solver 与 expRK 方法不同,因为它们的线性项 与我们的线性项 不同。 综上所述,DPM-Solver 受到了 expRK 相同技术的启发,用于导出指数加权积分的高阶近似,但 DPM-Solver 的公式与 expRK 不同,并且 DPM-Solver 是针对扩散的具体公式定制的常微分方程。
附录CDPM-求解器的算法
然后我们列出自适应步长算法,命名为DPM-Solver-12(结合1和2;算法6)和DPM-Solver-23 t3>(组合 2 和 3;算法 7)。 我们按照[20]设置图像数据的绝对容差,对于VP类型的DPM为。 我们可以调整相对容差来平衡精度和NFE,我们发现足够好并且可以快速收敛。
实际上,自适应步长求解器的输入是批量数据。 我们只需选择和作为所有批次数据的最大值。 此外,我们通过实现比较以避免数值问题。
附录DDPM-Solver的实现细节
D.1 采样结束时间
理论上,我们需要求解时刻到时刻的扩散常微分方程来生成样本。 实际上,噪声预测模型的训练和评估通常从时间到时间开始,以避免的数值问题接近 ,其中 是超参数 [3]。
与基于扩散 SDE [2, 3] 的采样方法相比,我们没有在时间 的最后一步添加“去噪”技巧(即将噪声方差设置为零),我们只需通过 DPM-Solver 求解从 到 的扩散 ODE,因为我们发现它的性能足够好。
对于离散时间DPM,我们首先将模型转换为连续时间(参见附录D.2),然后从时间到时间进行求解>。
D.2 从离散时间 DPM 采样
在本节中,我们讨论离散时间 DPM 的更一般情况,其中我们考虑 1000 步 DPM [2] 和 4000 步 DPM [16],我们还考虑采样的结束时间。
离散时间 DPM [2] 以 固定时间步长 训练噪声预测模型。 实际上,或,4000步DPM的实现[16]将4000步DPM的时间步转换为范围1000 步 DPM。 具体来说,噪声预测模型由的参数化,其中每个对应于时间的值。 在实践中,这些离散时间 DPM 通常在 之间选择统一的时间步长,因此对于 为 。
然而,离散时间噪声预测模型无法预测小于最小时间的时间的噪声。 由于最小时间步和时刻对应的离散时间噪声预测模型为,我们需要“缩放”离散时间步到连续时间范围。 我们提出如下两种类型的缩放。
类型1。 将离散时间步长缩放到连续时间范围,并令为。 在这种情况下,我们可以通过以下方式定义连续时间噪声预测模型
| (D.1) |
其中连续时间映射到离散输入,连续时间映射到离散输入。
类型2。 将离散时间步长 缩放到连续时间范围 。 在这种情况下,我们可以通过以下方式定义连续时间噪声预测模型
| (D.2) |
其中连续时间映射到离散输入,连续时间映射到离散输入。
请注意,的输入时间可能不是整数,但我们发现噪声预测模型仍然可以很好地工作,并且我们假设这是因为平滑的时间嵌入(例如,位置嵌入[2])。 通过这种重新参数化,噪声预测模型可以采用连续时间步长作为输入,因此我们也可以使用DPM-Solver进行快速采样。
实际上,我们有,以及最小离散时间。 对于固定的数量的函数评估,我们凭经验发现,对于小,具有的Type-1可能具有更好的样本质量,而对于大,具有的Type-2可能具有更好的样本质量。 详细结果请参阅附录E。
D.3 DPM 求解器的 20 个函数评估
给定函数评估次数的固定预算,我们将间隔统一划分为段,并采取步生成样本。 步骤取决于 mod 的余数 ,以确保函数计算的总数恰好为 。
-
•
如果,我们首先执行DPM-Solver-3的步,然后执行DPM-Solver-2的步和DPM-Solver-1步解算器-1。 函数评估的总数为。
-
•
如果,我们首先执行DPM-Solver-3的步,然后执行DPM-Solver-1的步。 函数评估的总数为。
-
•
如果,我们首先执行DPM-Solver-3的步,然后执行DPM-Solver-2的步。 函数评估的总数为。
我们凭经验发现,这种时间步长的设计可以极大地提高生成质量,DPM-Solver 可以在 10 步内生成可比较的样本,在 20 步内生成高质量的样本。
D.4 函数的分析公式(的反函数)
计算 的成本可以忽略不计,因为对于先前 DPM 中使用的 和 噪声计划(“线性”和“余弦”)[2, 16],及其反函数都有解析公式。 我们在这里主要考虑方差保留类型,因为它是使用最广泛的类型。 其他类型(方差爆炸型和子方差保持型)的函数可以类似地导出。
线性噪声表[2]。 我们有
其中 和 ,位于 [3] 之后。 作为,我们可以分析计算。 此外,反函数为
为了减少数值问题的影响,我们可以通过以下等效公式计算:
我们求解 之间的扩散常微分方程,其中 。
余弦噪声表[16]。 表示
其中位于[16]之后。 由于[16]对导数进行了修剪以确保数值稳定性,因此我们还对最大时间进行了修剪。 作为,我们可以分析计算。 此外,给定一个固定的,让
它计算 相应的 。 那么反函数就是
我们求解 之间的扩散常微分方程,其中 。
D.5 DPM-Solver 的条件采样
DPM-Solver 也可用于条件采样,只需进行简单修改即可。 条件生成需要从包含条件噪声预测模型的条件扩散 ODE [3, 4] 中采样。 我们遵循分类器引导方法[4]将条件噪声预测模型定义为,其中是预训练的分类器, 是分类器指导尺度(默认为1.0)。 因此,我们可以使用DPM-Solver来求解这种扩散ODE,以实现快速条件采样,如图1所示。
D.6 数值稳定性
由于我们需要在DPM-Solver的算法中计算,因此我们按照[10]使用expm1() 代替 exp()-1 以提高数值稳定性。
附录E实验细节
我们测试了对最广泛使用的方差保留 (VP) 类型 DPM [1, 2] 进行采样的方法。 在本例中,对于所有 和 ,我们都有 。 尽管如此,我们的方法和理论结果是通用的并且独立于噪声表和的选择。
对于所有实验,我们在 NVIDIA A40 GPU 上评估 DPM-Solver。 然而,计算资源可以是其他类型的GPU,例如NVIDIA GeForce RTX 2080Ti,因为我们可以调整采样的批量大小。
E.1 扩散常微分方程
或者,可以将扩散 ODE 重新参数化为 域。 在本节中,我们提出扩散 ODE 的公式。 为VP类型,其他类型可类似推导。
E.2代码实现
我们使用 JAX(用于连续时间 DPM)和 PyTorch(用于离散时间 DPM)来实现代码,我们的代码发布于 https://github.com/LuChengTHU/dpm-solver 。
E.3与连续时间采样方法的样本质量比较
| Sampling method NFE | 10 | 12 | 15 | 20 | 50 | 200 | 1000 | ||
|---|---|---|---|---|---|---|---|---|---|
| CIFAR-10 (continuous-time model (VP deep) [3], linear noise schedule) | |||||||||
| SDE | Euler (denoise) [3] | 304.73 | 278.87 | 248.13 | 193.94 | 66.32 | 12.27 | 2.44 | |
| 444.63 | 427.54 | 395.95 | 300.41 | 101.66 | 22.98 | 5.01 | |||
| Improved Euler [20] | 82.42(NFE=48), 2.73(NFE=151), 2.44(NFE=180) | ||||||||
| ODE | RK45 Solver [28, 3] | 19.55(NFE=26), 17.81(NFE=38), 3.55(NFE=62) | |||||||
| 51.66(NFE=26), 21.54(NFE=38), 12.72(NFE=50), 2.61(NFE=62) | |||||||||
| DPM-Solver (ours) | 4.70 | 3.75 | 3.24 | 3.99 | 3.84 (NFE = 42) | ||||
| 6.96 | 4.93 | 3.35 | 2.87 | 2.59 (NFE = 51) | |||||
表3显示了详细的FID结果,对应于图2(a)。 我们使用[3]中的官方代码和检查点,代码许可证是Apache License 2.0。 我们使用他们发布的“VP deep”类型的“checkpoint_8”。 我们比较 和 的方法。 我们发现基于扩散SDE的采样方法可以通过获得更好的样本质量;基于扩散常微分方程的采样方法可以通过获得更好的样本质量。 对于DPM-Solver,我们发现小于15 NFE的DPM-Solver可以用实现比更好的FID,而大于15 NFE的DPM-Solver可以实现更好的FID 优于 。
对于具有欧拉离散化的扩散 SDE,我们使用 [3] 中的 PC 采样器,带有“euler_maruyama”预测器且没有校正器,它在 和 。 我们在最后一步添加了“降噪”技巧,这可以大大提高的FID分数。
对于改进欧拉离散化的扩散SDE[20],我们遵循他们原始论文中的结果,其中仅包括的结果。 相应的相对容差分别为、和。
对于使用 RK45 求解器的扩散 ODE,我们使用 [3] 中的代码,并调整求解器的 atol 和 rtol。 对于从小到大的 NFE,我们使用相同的 atol = rtol = 、、 来表示 的结果、以及同样的 atol = rtol = , , , , 分别表示 的结果。
E.4与 RK 方法的样本质量比较
表1显示了RK方法与DPM-Solver-2和3的不同性能。 我们在本节中列出了详细设置。
假设我们有一个 ODE
从时间 处的 开始,我们使用 RK2 来近似时间 处的解 ,公式如下(已知作为显式中点方法):
我们使用下面的 RK3 来近似时间 处的解 (这被称为“Heun 的三阶方法”),因为它与我们提出的 DPM 非常相似 -求解器-3:
E.5与离散时间采样方法的样本质量比较
| Sampling method NFE | 10 | 12 | 15 | 20 | 50 | 200 | 1000 | |
| CIFAR-10 (discrete-time model [2], linear noise schedule) | ||||||||
| DDPM [2] | Discrete | 278.67 | 246.29 | 197.63 | 137.34 | 32.63 | 4.03 | 3.16 |
| Analytic-DDPM [21] | Discrete | 35.03 | 27.69 | 20.82 | 15.35 | 7.34 | 4.11 | 3.84 |
| Analytic-DDIM [21] | Discrete | 14.74 | 11.68 | 9.16 | 7.20 | 4.28 | 3.60 | 3.86 |
| †GGDM [18] | Discrete | 8.23 | 6.12 | 4.72 | ||||
| DDIM [19] | Discrete | 13.58 | 11.02 | 8.92 | 6.94 | 4.73 | 4.07 | 3.95 |
| DPM-Solver (Type-1 discrete) | 6.37 | 4.65 | 3.78 | 4.28 | 3.90 (NFE = 44) | |||
| 11.32 | 7.31 | 4.75 | 3.80 | 3.57 (NFE = 46) | ||||
| DPM-Solver (Type-2 discrete) | 6.42 | 4.86 | 4.39 | 5.52 | 5.22 (NFE = 42) | |||
| 10.16 | 6.26 | 4.17 | 3.72 | 3.48 (NFE = 44) | ||||
| CelebA 6464 (discrete-time model [19], linear noise schedule) | ||||||||
| DDPM [2] | Discrete | 310.22 | 277.16 | 207.97 | 120.44 | 29.25 | 3.90 | 3.50 |
| Analytic-DDPM [21] | Discrete | 28.99 | 25.27 | 21.80 | 18.14 | 11.23 | 6.51 | 5.21 |
| Analytic-DDIM [21] | Discrete | 15.62 | 13.90 | 12.29 | 10.45 | 6.13 | 3.46 | 3.13 |
| DDIM [19] | Discrete | 10.85 | 9.99 | 7.78 | 6.64 | 5.23 | 4.78 | 4.88 |
| DPM-Solver (Type-1 discrete) | 7.15 | 5.51 | 4.28 | 4.40 | 4.23 (NFE = 36) | |||
| 6.92 | 4.20 | 3.05 | 2.82 | 2.71 (NFE = 36) | ||||
| DPM-Solver (Type-2 discrete) | 7.33 | 6.23 | 5.85 | 6.87 | 6.68 (NFE = 36) | |||
| 5.83 | 3.71 | 3.11 | 3.13 | 3.10 (NFE = 36) | ||||
| ImageNet 6464 (discrete-time model [16], cosine noise schedule) | ||||||||
| DDPM [2] | Discrete | 305.43 | 287.66 | 256.69 | 209.73 | 83.86 | 28.39 | 17.58 |
| Analytic-DDPM [21] | Discrete | 60.65 | 53.66 | 45.98 | 37.67 | 22.45 | 17.16 | 16.14 |
| Analytic-DDIM [21] | Discrete | 70.62 | 54.88 | 41.56 | 30.88 | 19.23 | 17.49 | 17.57 |
| †GGDM [18] | Discrete | 37.32 | 24.69 | 20.69 | ||||
| DDIM [19] | Discrete | 67.07 | 52.69 | 40.49 | 30.67 | 20.10 | 17.84 | 17.73 |
| DPM-Solver (Type-1 discrete) | 24.44 | 20.03 | 19.31 | 18.59 | 17.50 (NFE = 48) | |||
| 27.74 | 23.66 | 20.09 | 19.06 | 17.56 (NFE = 51) | ||||
| DPM-Solver (Type-2 discrete) | 24.40 | 19.97 | 19.23 | 18.53 | 17.47 (NFE = 57) | |||
| 27.72 | 23.75 | 20.02 | 19.08 | 17.62 (NFE = 48) | ||||
| Sampling method NFE | 10 | 12 | 15 | 20 | 50 | 100 | 250 | |
|---|---|---|---|---|---|---|---|---|
| ImageNet 128128 (discrete-time model [4], linear noise schedule, classifier guidance scale: 1.25) | ||||||||
| DDPM [2] | Discrete | 199.56 | 172.09 | 146.42 | 119.13 | 49.38 | 23.27 | 2.97 |
| DDIM [19] | Discrete | 11.12 | 9.38 | 8.22 | 7.15 | 5.05 | 4.18 | 3.54 |
| DPM-Solver (Type-1 discrete) | 7.32 | 4.08 | 3.60 | 3.89 | 3.63 | 3.62 | 3.63 | |
| 13.91 | 5.84 | 4.00 | 3.52 | 3.13 | 3.10 | 3.09 | ||
| LSUN bedroom 256256 (discrete-time model [4], linear noise schedule) | ||||||||
| DDPM [2] | Discrete | 274.67 | 251.26 | 224.88 | 190.14 | 82.70 | 34.89 | †2.02 |
| DDIM [19] | Discrete | 10.05 | 7.51 | 5.90 | 4.98 | 2.92 | 2.30 | 2.02 |
| DPM-Solver (Type-1 discrete) | 6.10 | 4.29 | 3.30 | 3.09 | 2.53 | 2.46 | 2.46 | |
| 8.04 | 4.21 | 2.94 | 2.60 | 2.01 | 1.95 | 1.94 | ||
我们将 DPM-Solver 与其他 DPM 离散时间采样方法进行比较,如表 4 和表 5 所示。 我们使用[19]中的代码通过DDPM和DDIM进行采样,代码许可为MIT License。 我们使用[21]中的代码通过Analytic-DDPM和Analytic-DDIM进行采样,其许可证未知。 我们直接遵循GGDM原论文[18]中的最佳结果。
对于 CIFAR-10 实验,我们使用 [2] 的预训练检查点,[19] 中的已发布代码中也提供了该检查点。 我们对 DDPM 和 DDIM 使用二次时间步长,根据经验,它比统一时间步长[19]具有更好的 FID 性能。 我们对 Analytic-DDPM 和 Analytic-DDIM 使用统一的时间步长。 对于DPM-Solver,我们使用Type-1离散和Type-2离散方法将离散时间模型转换为连续时间模型。 对于NFE ,我们使用附录D.3中的方法,对于NFE ,我们使用附录C中的自适应步长求解器>。 对于所有实验,我们使用相对容差 的 DPM-Solver-12。
对于 CelebA 64x64 实验,我们使用 [19] 预训练的检查点。 我们对 DDPM 和 DDIM 使用二次时间步长,根据经验,它比统一时间步长[19]具有更好的 FID 性能。 我们对 Analytic-DDPM 和 Analytic-DDIM 使用统一的时间步长。 对于DPM-Solver,我们使用Type-1离散和Type-2离散方法将离散时间模型转换为连续时间模型。 对于NFE ,我们使用附录D.3中的方法,对于NFE ,我们使用附录C中的自适应步长求解器>。 对于所有实验,我们使用相对容差 的 DPM-Solver-12。 请注意,我们在 CelebA 64x64 上的最佳 FID 结果甚至优于 1000 步 DDPM(以及所有其他方法)。
对于ImageNet 64x64实验,我们使用[16]预训练的检查点,代码许可证是MIT许可证。 我们对 DDPM 和 DDIM 使用统一的时间步长,遵循[19]。 我们对 Analytic-DDPM 和 Analytic-DDIM 使用统一的时间步长。 对于DPM-Solver,我们使用Type-1离散和Type-2离散方法将离散时间模型转换为连续时间模型。 对于NFE ,我们使用附录D.3中的方法,对于NFE ,我们使用附录C中的自适应步长求解器>。 对于所有实验,我们使用相对容差 的 DPM-Solver-23。 请注意,ImageNet 数据集包含真实的人类照片,可能存在隐私问题,如[42]中所述。
对于 ImageNet 128x128 实验,我们使用分类器指导通过 [4] 的预训练检查点(对于扩散模型和分类器模型)进行采样,代码许可证是 MIT License。 我们对 DDPM 和 DDIM 使用统一的时间步长,遵循[19]。 对于DPM-Solver,我们仅使用Type-1离散方法将离散时间模型转换为连续时间模型。 我们对 NFE 使用附录 D.3 中的方法,并使用具有相对容差 的自适应步长求解器 DPM-Solver-12(详细信息参见NFE 的附录 C)。 对于所有实验,我们设置分类器指导尺度,这是[4]中DDIM的最佳设置(详细信息请参阅他们的表14)。
对于LSUN卧室256x256实验,我们使用[4]的无条件预训练检查点,代码许可证是MIT许可证。 我们对 DDPM 和 DDIM 使用统一的时间步长,遵循[19]。 对于DPM-Solver,我们仅使用Type-1离散方法将离散时间模型转换为连续时间模型。 我们对 DPM-Solver 使用附录D.3中的方法。
E.6 比较 DPM-Solver 的不同阶数
我们还比较了DPM-Solver不同阶次的样本质量,如表6所示。 我们使用具有统一时间步长的 DPM-Solver-1,2,3。 ,以及附录D.3中针对NFE小于20的快速版本,我们将其命名为DPM-Solver-fast。 对于离散时间模型,我们只比较Type-2离散方法,Type-1的结果类似。
由于 DPM-Solver-2 的实际 NFE 为 ,DPM-Solver-3 的实际 NFE 为 ,可能小于 NFE,因此我们使用符号 † 请注意,实际 NFE 小于给定的 NFE。 我们发现,对于小于 20 的 NFE,所提出的快速版本(DPM-Solver-fast)通常优于单阶方法,而对于较大的 NFE,DPM-Solver-3 优于 DPM-Solver-2,而 DPM -Solver-2 优于 DPM-Solver-1,这与我们提出的收敛速度分析相匹配。
| Sampling method NFE | 10 | 12 | 15 | 20 | 50 | 200 | 1000 | |
|---|---|---|---|---|---|---|---|---|
| CIFAR-10 (VP deep continuous-time model [3]) | ||||||||
| DPM-Solver-1 | 11.83 | 9.69 | 7.78 | 6.17 | 4.28 | 3.85 | 3.83 | |
| DPM-Solver-2 | 5.94 | 4.88 | †4.30 | 3.94 | 3.78 | 3.74 | 3.74 | |
| DPM-Solver-3 | †18.37 | 5.53 | 4.08 | †4.04 | †3.81 | †3.78 | †3.78 | |
| DPM-Solver-fast | 4.70 | 3.75 | 3.24 | 3.99 | ||||
| DPM-Solver-1 | 11.29 | 9.07 | 7.15 | 5.50 | 3.32 | 2.72 | 2.64 | |
| DPM-Solver-2 | 7.30 | 5.28 | †4.23 | 3.26 | 2.69 | 2.60 | 2.59 | |
| DPM-Solver-3 | †54.56 | 6.03 | 3.55 | †2.90 | †2.65 | †2.62 | †2.62 | |
| DPM-Solver-fast | 6.96 | 4.93 | 3.35 | 2.87 | ||||
| CIFAR-10 (DDPM discrete-time model [2]), DPM-Solver with Type-2 discrete | ||||||||
| DPM-Solver-1 | 16.69 | 13.63 | 11.08 | 8.90 | 6.24 | 5.44 | 5.29 | |
| DPM-Solver-2 | 7.90 | 6.15 | †5.53 | 5.24 | 5.23 | 5.25 | 5.25 | |
| DPM-Solver-3 | †24.37 | 8.20 | 5.73 | †5.43 | †5.29 | †5.25 | †5.25 | |
| DPM-Solver-fast | 6.42 | 4.86 | 4.39 | 5.52 | ||||
| DPM-Solver-1 | 13.61 | 10.98 | 8.71 | 6.79 | 4.36 | 3.63 | 3.49 | |
| DPM-Solver-2 | 11.80 | 6.31 | †5.23 | 3.95 | 3.50 | 3.46 | 3.46 | |
| DPM-Solver-3 | †67.02 | 9.45 | 5.21 | †3.81 | †3.49 | †3.45 | †3.45 | |
| DPM-Solver-fast | 10.16 | 6.26 | 4.17 | 3.72 | ||||
| CelebA 6464 (discrete-time model [19], linear noise schedule), DPM-Solver with Type-2 discrete | ||||||||
| DPM-Solver-1 | 18.66 | 16.30 | 13.92 | 11.84 | 8.85 | 7.24 | 6.93 | |
| DPM-Solver-2 | 5.89 | 5.83 | †6.08 | 6.38 | 6.78 | 6.84 | 6.85 | |
| DPM-Solver-3 | †11.45 | 5.46 | 6.18 | †6.51 | †6.87 | †6.84 | †6.85 | |
| DPM-Solver-fast | 7.33 | 6.23 | 5.85 | 6.87 | ||||
| DPM-Solver-1 | 13.24 | 11.13 | 9.08 | 7.24 | 4.50 | 3.48 | 3.25 | |
| DPM-Solver-2 | 4.28 | 3.40 | †3.30 | 3.17 | 3.19 | 3.20 | 3.20 | |
| DPM-Solver-3 | †49.48 | 3.84 | 3.09 | †3.15 | †3.20 | †3.20 | †3.20 | |
| DPM-Solver-fast | 5.83 | 3.71 | 3.11 | 3.13 | ||||
| ImageNet 6464 (discrete-time model [16], cosine noise schedule), DPM-Solver with Type-2 discrete | ||||||||
| DPM-Solver-1 | 32.84 | 28.54 | 24.79 | 21.71 | 18.30 | 17.45 | 17.18 | |
| DPM-Solver-2 | 29.20 | 24.97 | †22.26 | 19.94 | 17.79 | 17.29 | 17.27 | |
| DPM-Solver-3 | †57.48 | 24.62 | 19.76 | †18.95 | †17.52 | 17.26 | 17.27 | |
| DPM-Solver-fast | 24.40 | 19.97 | 19.23 | 18.53 | ||||
| DPM-Solver-1 | 32.31 | 28.44 | 25.15 | 22.38 | 19.14 | 17.95 | 17.44 | |
| DPM-Solver-2 | 33.16 | 27.28 | †24.26 | 20.58 | 18.04 | 17.46 | 17.41 | |
| DPM-Solver-3 | †162.27 | 27.28 | 22.38 | †19.39 | †17.71 | †17.43 | †17.41 | |
| DPM-Solver-fast | 27.72 | 23.75 | 20.02 | 19.08 | ||||
E.7 DPM-Solver 和 DDIM 之间的运行时比较
理论上,对于相同的 NFE,DPM-Solver 和 DDIM 的运行时间几乎相同(与 NFE 呈线性),因为主要计算成本是大型神经网络 的串行评估,其他系数为以可忽略的成本进行分析计算。
表 7 显示了 DPM-Solver 和 DDIM 在单个 NVIDIA A40 上的运行时间(不同的数据集和 NFE)。 我们使用 torch.cuda.Event 和 torch.cuda.synchronize 来准确计算运行时间。 我们对每个数据集使用离散时间预训练扩散模型。 我们评估 8 个批次的运行时间并计算运行时间的平均值和标准差。 由于 GPU 内存限制,我们对 LSUN 卧室 256x256 使用 64 批处理大小,对其他数据集使用 128 批处理大小。
对于 DDIM,我们使用官方实现222https://github.com/ermongroup/ddim。 我们发现我们的 DPM-Solver 实现减少了一些系数的重复计算,因此在相同的 NFE 下,DPM-Solver 的实现比 DDIM 稍快。 尽管如此,运行时间评估结果表明,对于相同的NFE,DPM-Solver和DDIM的运行时间几乎相同,并且运行时间与NFE近似线性。 因此,NFE 的加速几乎是运行时的实际加速,因此所提出的 DPM-Solver 可以大大加速 DPM 的采样。
| Sampling method NFE | 10 | 20 | 50 | 100 |
|---|---|---|---|---|
| CIFAR-10 3232 (batch size = 128) | ||||
| DDIM | 0.956(0.011) | 1.924(0.016) | 4.838(0.024) | 9.668(0.013) |
| DPM-Solver | 0.923(0.006) | 1.833(0.004) | 4.580(0.005) | 9.204(0.011) |
| CelebA 6464 (batch size = 128) | ||||
| DDIM | 3.253(0.015) | 6.438(0.029) | 16.132(0.050) | 32.255(0.044) |
| DPM-Solver | 3.126(0.003) | 6.272(0.006) | 15.676(0.008) | 31.269(0.012) |
| ImageNet 6464 (batch size = 128) | ||||
| DDIM | 5.084(0.018) | 10.194(0.022) | 25.440(0.044) | 50.926(0.042) |
| DPM-Solver | 4.992(0.004) | 9.991(0.003) | 24.948(0.007) | 49.835(0.028) |
| ImageNet 128128 (batch size = 128, with classifier guidance) | ||||
| DDIM | 29.082(0.015) | 58.159(0.012) | 145.427(0.011) | 290.874(0.134) |
| DPM-Solver | 28.865(0.011) | 57.645(0.008) | 144.124(0.035) | 288.157(0.022) |
| LSUN bedroom 256256 (batch size = 64) | ||||
| DDIM | 37.700(0.005) | 75.316(0.013) | 188.275(0.172) | 378.790(0.105) |
| DPM-Solver | 36.996(0.039) | 73.873(0.023) | 184.590(0.010) | 369.090(0.076) |
E.8 ImageNet 256x256 上的条件采样
对于图1中的条件采样,我们使用[4]中带有分类器指导(ADM-G)的预训练检查点,分类器尺度为. 代码许可证是MIT许可证。 我们对 DDIM 使用统一时间步长,并在附录 D.3 中使用 DPM-Solver 的快速版本(DPM-Solver-fast),步长为 10、15、20 和 100。
图3显示了DDIM和DPM-Solver的条件样本结果。 我们发现具有 15 NFE 的 DPM-Solver 可以生成与具有 100 NFE 的 DDIM 相当的样本。
NFE = 10
NFE = 15
NFE = 20
NFE = 100
DDIM
[19]
DPM-Solver
(ours)

DDIM
[19]
DPM-Solver
(ours)

E.9其他示例
NFE = 10
NFE = 12
NFE = 15
NFE = 20
DDIM
[19]
DPM-Solver
(ours)








NFE = 10
NFE = 12
NFE = 15
NFE = 20
DDIM
[19]
DPM-Solver
(ours)








NFE = 10
NFE = 12
NFE = 15
NFE = 20
DDIM
[19]
DPM-Solver
(ours)








NFE = 10
NFE = 12
NFE = 15
NFE = 20
DDIM
[19]
DPM-Solver
(ours)








NFE = 10
NFE = 12
NFE = 15
NFE = 20
DDIM
[19]
DPM-Solver
(ours)







