与启用屏蔽 VQ-VAE 的码本进行鲁棒语义通信
摘要
尽管语义通信在大量任务上表现出了令人满意的性能,但语义噪声的影响和系统的鲁棒性尚未得到很好的研究。 语义噪声是指预期的语义符号与接收到的语义符号之间存在误导,从而导致任务失败。 在本文中,我们首先提出了一个强大的端到端语义通信系统的框架来对抗语义噪声。 特别是,我们分析了样本相关和样本无关的语义噪声。 为了对抗语义噪声,开发了具有权重扰动的对抗性训练,以将具有语义噪声的样本合并到训练数据集中。 然后,我们建议屏蔽语义噪声频繁出现的输入部分,并使用与噪声相关的屏蔽策略设计屏蔽矢量量化变分自动编码器(VQ-VAE)。 我们使用发送器和接收器共享的离散码本来进行编码特征表示。 为了进一步提高系统的鲁棒性,我们开发了一个特征重要性模块(FIM)来抑制与噪声相关和与任务无关的特征。 因此,发送器只需要发送码本中这些重要的任务相关特征的索引。 仿真结果表明,该方法可以应用于许多下游任务,并显着提高对语义噪声的鲁棒性,同时显着降低传输开销。
索引术语:
对抗性训练、特征重要性模块(FIM)、掩码矢量量化变分自动编码器(VQ-VAE)、鲁棒语义通信、语义噪声。我简介
传统通信系统注重高效的符号传输和准确的符号恢复[1],其中通常使用误码率(SER)和误码率(BER)作为性能指标。 各种新应用产生前所未有的海量数据来服务不同类型的任务,而传统通信系统正面临支持如此海量数据的瓶颈[2]。 此外,它给传统通信带来了严峻的挑战,即如何在有限的频谱资源上支持大规模连接,但延迟要低[3]。
I-A 之前的工作
随着深度神经网络(DNN)[3]和端到端学习[4,5,6]的发展,语义通信,提取和传输数据的任务相关含义[7,8,9,10]已作为一项关键技术出现并受到高度关注。 例如,在物体检测任务的图像传输中,物体的位置和形状与任务相关,而背景与任务无关,不需要传输。 此外,语义通信对于不友好的信道环境(即低信噪比(SNR))具有鲁棒性,非常适合需要高可靠性的应用[11]。 这些优势促使我们通过考虑数字比特之外的语义来开发通信系统,以提高传输的准确性和效率。
现有的语义通信工作可以分为两类:数据重构[10, 12, 11, 13, 14, 15, 16]和任务执行[17, 18, 19, 20、21]。 对于数据重构,提取数据背后的语义信息,并且基于接收到的语义信息仅重构相关数据。 [11]中的联合语义通道编码(JSCC)方案从文本中提取语义信息。 在[13]中,利用强化学习来恢复文本。 [14]中带有通道反馈的语义通信系统可以提高图像重建的质量。 [15]中基于注意力的语义通信系统关注于语音信号。
对于特定于任务的应用,在发送器处编码的与任务相关的语义信息直接应用于接收器处的任务执行。 特别是[17]中面向图像分类的语义通信可以提高识别精度。 对[18]中的人物进行图像重新识别任务可以提高检索精度。 [19]中的语义通信系统考虑了分类任务的边缘推理。 [20]中的语义通信系统是为多模态数据任务而设计的:视觉问答。
尽管上述基于深度学习(DL)的语义通信系统在某些任务中表现出了非常令人印象深刻的性能,但噪声的影响和系统鲁棒性仍需要进一步研究。 人们对分析不同类型的图像和文本噪声的产生和特征进行了研究,并提出了多种去噪算法[22]。 然而,语义通信中存在一种尚未得到充分研究的特定类型的噪声[8]。 与传统系统中的噪声或多或少相似,语义噪声会导致语义信息的误解和解码错误,从而导致预期语义与接收器处重建的语义之间的误导。 语义噪声可以在不同阶段产生,包括语义编码、数据传输和解码[9]。 在语义编码阶段,语义噪声对应于原始信号与语义编码后的编码信号之间的不匹配,这与编码器的表示能力有关。 在数据传输阶段,信道衰落引起的信号失真以及恶意攻击者发送的一些精心设计的信号都会引入语义噪声。 在解码阶段,误解、不正确的表示和含义的混淆会给接收者带来语义噪声。 例如,在语义符号识别过程中,当重构的符号有歧义时,使用相同的语义符号来表示具有不同含义的不同数据集。
不同类别的源(例如文本和图像)的语义噪声通常是不同的[23]。 文本中的语义噪声是指语义歧义,句子中单词的轻微变化,例如同义词替换或随机颠倒字母顺序,可能会使深度学习模型误解句子的语义[24]。 图像中的语义噪声可以基于对抗性样本[25]进行建模,这与文本中的语义噪声不同。 由于文本的离散性,不可能在不被人类注意到的情况下向文本添加扰动。 然而,可以对图像添加一些人类几乎察觉不到的细微修改。 对抗性样本会误导深度学习模型并导致性能显着下降,但它们看起来与人类的原始图像相同。
在本文中,我们关注图像域中的语义噪声,文本域中的语义噪声可以以类似的方式处理。 在图像域中生成对抗样本的方法可以分为两类:(i)样本相关方法,在单个图像上欺骗 DNN [26,27,28,29] ; (ii) 与样本无关的通用方法,它以高概率[30, 31]欺骗任何图像上的 DNN。 具体来说,第一类方法包括快速梯度符号法(FGSM)[26]、投影梯度下降法(PGD)[27]、基于雅可比的显着性地图攻击(JSMA)[28]和deepfool算法[29]。 现有的深度学习系统对于这些对抗性样本来说很脆弱,尤其不稳定,其中数据样本的微小且难以察觉的扰动足以欺骗它们,并会导致不正确的结果[25]。 为了提高DL模型针对对抗样本的鲁棒性,出现了一些方法,例如输入去噪[32]、防御蒸馏[33]、梯度正则化 [34]、权重扰动[35]和对抗性训练[36]。
I-B 动机和贡献
可以预见,语义通信在安全性和可靠性方面的鲁棒性在未来的应用中非常重要,例如自动驾驶车辆和医疗诊断。 尽管在图像处理领域已经有多种生成对抗性扰动的方法,但无线通信中的语义噪声模型尚未得到很好的研究。 此外,这些方法对抗对抗性扰动的性能并不令人满意,甚至在没有噪声的干净样本中表现恶化。 更重要的是,通信中无线信道和传输开销的影响通常被忽略。 因此,在本文中,我们对通信领域的语义噪声进行建模,并设计一种鲁棒的语义通信系统,能够以较低的传输开销有效地对抗语义噪声。 我们提出了一种支持深度学习的端到端鲁棒语义通信系统来对抗语义噪声。 发送器和接收器均由 DNN 表示。 由于它是一种数据驱动的方法,不需要预先假设的信道模型作为先决条件,因此它有可能为各种通信场景提供具有高泛化能力的解决方案。
我们首先对实际无线通信环境中的语义噪声进行建模。 特别是,我们采用迭代 FGSM 方法在发送器处立即生成与样本相关的语义噪声,这在每个图像上添加了不同的语义噪声。 由于获取每个通道和传输信号很困难,我们进一步提出了一种迭代方法来在接收器处生成与样本无关的语义噪声。 它向不同的传输图像添加相同的语义噪声并欺骗大多数图像,而不需要信道状态信息(CSI)和传输图像。 为了对抗语义噪声,我们提出了一种带有权重扰动的对抗性训练方法,该方法将训练数据集中带有语义噪声的样本结合起来,以解决复杂的最小-最大优化问题。 然后,设计带有视觉变换器(ViT)块[37, 38]的掩码矢量量化变分自动编码器(VQ-VAE)作为鲁棒语义通信系统的架构。 提出了一种新颖的策略来掩盖原始图像的一部分,其中语义噪声以高概率出现。 此外,发射机和接收机共享的离散码本被设计用于编码特征表示。 它专注于与任务相关的特征表示,忽略不可察觉的与噪声相关的细节,从而减少了语义噪声的影响。
为了进一步提高系统的鲁棒性,我们设计了一个特征重要性模块(FIM),它动态学习特征重要性并将其合并到屏蔽的 VQ-VAE 中。 它本质上抑制了与任务无关和与噪声相关的特征。 因此,发射机只需要发送码本中与任务相关的重要特征的索引。 此外,SNR 被纳入 FIM 中,这确保了所提出的系统能够在广泛的 SNR 水平下成功运行。 此外,语义通信中的现有工作侧重于将源数据直接映射到信道符号中进行传输。 之所以称为全分辨率星座,是因为星座点可以出现在星座中的任何位置。 然而,由于精度有限,这对于实际系统来说很难实现,并且在当前的数字通信系统[10,11,12]中可能不切实际。 我们提出的带有 FIM 的掩蔽 VQ-VAE 模型可以设计一个基于离散码本的系统,该系统更实用,并且可以在当前数字通信系统中轻松实现,因为特征索引可以通过使用现有的星座直接映射到符号。 仿真结果表明,我们提出的方法可以应用于许多下游任务,并且可以显着提高语义通信系统针对语义噪声的鲁棒性,同时大大减少传输开销。 本文的主要贡献总结如下:
-
•
基于计算机视觉中的对抗性扰动[30],考虑通信系统中的调制、信道和解调,我们对发送器和接收器处添加的样本相关和样本无关的语义噪声进行建模, 分别。
-
•
基于基本对抗训练方法[27]和优化理论,我们提出了一种带有权值扰动的对抗训练方法来对抗语义噪声,并考虑无线通信系统中信道损伤造成的影响。
-
•
我们开发了一个带有掩蔽策略的掩蔽 VQ-VAE 模型作为鲁棒语义通信系统的架构。 发射机和接收机共享的离散码本被设计用于编码特征表示,非常适合当前的数字通信系统。
-
•
我们提供性能分析并提出一种新颖的损失函数来提高基于语义相似性的系统鲁棒性。
-
•
为了进一步提高系统的鲁棒性,我们设计了 FIM 来抑制与噪声相关和与任务无关的特征。
I-C 组织和符号
论文的其余部分结构如下。 II部分对语义噪声进行建模,并提出了对抗语义噪声的语义通信系统的通用框架。 III部分设计了带有掩蔽策略的掩蔽VQ-VAE和用于编码特征表示的离散码本。 IV节通过设计具有动态SNR的FIM来改进语义通信系统以增强鲁棒性。 仿真结果在V节中给出。最后,本文在VI节中进行总结。
符号:标量、向量和矩阵分别用小写、小写粗体和大写粗体字母表示。 符号表示单位矩阵,表示全零矩阵。 对于矩阵 、、、、、 、 分别是其转置、共轭、共轭转置、求逆、伪求逆和 Frobenius 范数。 对于向量 , 是其欧几里德范数。 最后, 是 复(实)矩阵的空间。
II 鲁棒语义通信框架
在本节中,我们对语义噪声进行建模,并提出了具有对抗性的鲁棒端到端语义通信系统的框架来对抗语义噪声。
II-A 语义通信系统
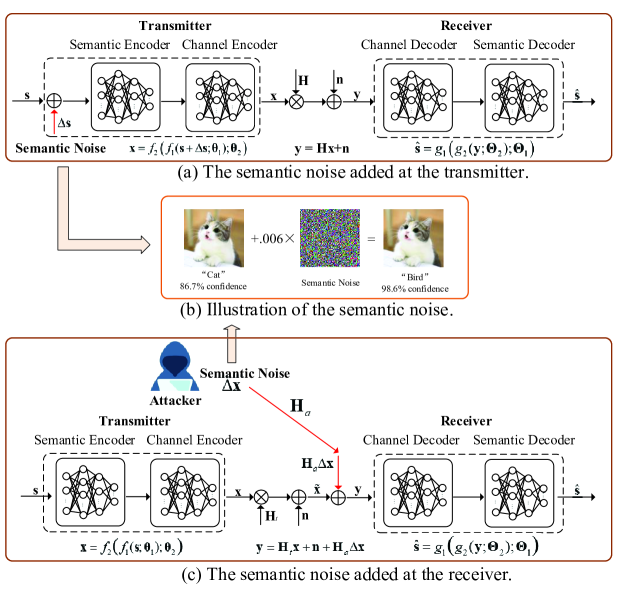
如图1所示,发射机将源映射为符号流,然后将其通过物理信道传递传输障碍。 接收到的符号流 在接收器处进行解码,以获得源的估计值 。 发送器和接收器均由联合设计的 DNN 表示。 具体来说,发送端的 DNN 由语义编码器和信道编码器组成,而接收端的 DNN 由信道解码器和语义解码器组成。 语义编码器学习从传输的数据中提取语义信息并将其转换为编码的特征向量,而语义解码器学习从接收的信号中恢复传输的数据。 此外,信道编码器和信道解码器旨在消除无线信道引起的信号失真。
假设输入是图像,我们考虑一个具有 个发射天线和 个接收天线的系统。 编码后的符号流可以表示为
| (1) |
其中 、 和 表示语义编码器 和通道编码器 随后,接收到的信号 由下式给出
| (2) |
其中 表示通道矩阵, 是加性高斯白噪声 (AWGN)。 相应地,解码信号为
| (3) |
其中 和 分别表示语义解码器 和通道解码器 的可训练参数。 为了清楚起见,我们将 表示为可训练参数,将 表示为所考虑的语义通信系统中的 DNN。 因此,我们有。 该系统的目标是最小化语义错误,同时减少要传输的符号数量。
II-B 语义噪声的产生
我们考虑在发送器和接收器处生成的语义噪声。
II-B1 发射机的语义噪声
这种语义噪声是在编码阶段产生的。 考虑这样的场景:恶意攻击者下载图像数据集,向每个图像添加语义噪声,然后上传修改后的数据集。 语义噪声对编码过程有严重影响,并且会误导深度学习模型,为任务生成错误的结果。 然而,由于语义噪声非常微妙,合法用户几乎没有注意到它,因此他们会像往常一样使用这些受污染的图像。 语义噪声也存在于自然界中。 例如,通过拍摄对抗样本的照片获得的图像也可能导致错误分类[39]。
语义通信系统的目标是最小化服务特定任务的损失函数,例如图像重建的均方误差和分类任务的交叉熵等。 相反,语义噪声旨在最大化损失函数。 令 为从数据集中采样的一组训练图像。 然后,第 图像 的语义噪声的生成可以建模为以下优化问题的解决方案,
| (4a) | |||||
| s.t. | (4b) | ||||
其中 和 分别表示第 个输入图像和 DNN 的输出, 是生成的语义噪声对于第图像,表示DNN针对特定任务的损失函数。 另外,表示与相关的目标,例如分类任务的真实标签和图像重建任务的原始图像等。 请注意, 是 规范,约束 (4b) 限制了语义噪声的能力,以避免被人类观察到。 除非另有说明,本文选择,即无限范数。
为了解决这个问题,我们在[26]中采用了FGSM,它将损失函数线性化为
| (5) |
通过设置 将其最小化,其中 是一个缩放因子,用于将语义噪声的强度限制在 (4b 中的 )。 然后,我们获得功率 的语义噪声为
| (6) |
其中 代表 , 代表 。 那么,带有语义噪声的污染样本就变成了。 这种语义噪声仅通过梯度下降法的一步迭代产生。 为了增加对系统的影响,我们建议采用迭代过程
| (7) |
其中 表示迭代索引, 是投影运算符。 选择以满足,以保证噪声功率的充分利用,其中表示迭代次数。
II-B2 接收器处的语义噪声
它对应于传输和解码阶段产生的语义噪声,导致解码失败以及接收者的解释造成误解。 它可能来自于硬件的非理想特性、信道衰落导致的信号失真或恶意攻击者[9, 31]。 考虑一个将编码信号 发送到接收器的合法发送器,以及发送语义噪声 进行攻击的恶意攻击者。 然后,接收器接收到的信号由下式给出
| (8) |
其中表示接收到的没有语义噪声的信号,是合法发送器和接收器之间的通道,表示攻击者和接收器之间的通道,并且 是 AWGN。 请注意,接收端的(8)中的语义噪声模型是一个通用模型,在研究硬件和信号的非理想特性的影响时可以去除其中的信道衰落引起的失真。
为了生成如第II-B1节中的样本相关的语义噪声,我们需要假设攻击者知道:(i)攻击者和攻击者之间的确切通道接收器,; (ii)接收器处预先接收到的信号,这在实际无线通信系统中并不总是实用的。 因此,我们的目标是找到一个与样本无关的语义噪声 ,它可以欺骗数据集中的大多数图像 ,假设攻击者只知道通道统计信息而不知道通道统计信息。准确的渠道。 具体来说,我们首先根据信道统计生成信道实现并收集一组接收信号。 然后,我们通过使用 和 作为 而不是使用真实通道来生成与样本无关的语义噪声 。 具体来说,我们选择满足的缩放因子,以确保我们可以充分利用噪声功率。 为了最大化语义噪声的接收功率并有效欺骗解码器,攻击者必须充分利用通道。 因此,如果语义噪声乘以信道的共轭,则语义噪声经过信道后的接收功率最大化。 对所有样本生成的语义噪声向量进行加权平均和归一化。 详细信息参见算法1,其中表示解码器的参数,是解码器的输出对于第 个样本。 接下来,我们基于II-B1节中提出的样本相关语义噪声模型设计鲁棒语义通信系统,样本无关语义噪声可以表示为以类似的方式处理。
Remark 1。
原始图像中自然存在语义噪声。 这里我们以图像分类任务为例,其中语义噪声引起的“误解”指的是“错误分类”,例如发送器发送了一张有狗的图像,但接收器将其分类为猫。 由于原始图像中自然存在不可避免的语义噪声,误分类率永远不会为零。 而且,不同数据集的语义噪声通常是不同的。 特别是,一些简单数据集的语义噪声功率较低,例如MNIST,很容易实现高分类精度,而许多复杂数据集具有高功率语义噪声,例如ImageNet。 此外,深度学习模型处理语义噪声的能力也不同。 结构复杂的强大模型可以有效消除语义噪声,以达到更好的分类精度,例如ResNet-101。 我们提出的语义噪声模型强化了这种误解,并且要求系统具有更高的鲁棒性。
II-C 对抗训练
II-C1 基本对抗训练
针对语义噪声的对抗训练的关键思想是将被语义噪声损坏的样本添加到数据集[26]中。 特别是,可训练参数 和语义噪声 会迭代更新,以提高模型的鲁棒性。 它可以表述为解决以下最小-最大优化问题,
| (9a) | |||||
| s.t. | (9b) | ||||
其中表示训练样本的数量。
II-C2 重量扰动的对抗训练
为了进一步提高针对语义噪声的鲁棒性,我们在可训练参数上添加权重扰动 并将问题重新表述为
| (10a) | |||||
| s.t. | (10b) | ||||
直观上,语义噪声 和权重扰动 导致 的损失函数 增加 -分别是第 个样本和所有样本。 因此,两个“最大”操作可以有效地解决内部最大化问题,从而更好地解决整个最小-最大问题[35]。 我们通过算法2求解(P3),其中权重扰动的更新为
| (11) |
可以通过与 (7) 类似的方式导出。
III 屏蔽VQ-VAE启用离散码本
在本节中,我们使用屏蔽 VQ-VAE 设计鲁棒的语义通信系统。 一种新颖的掩蔽策略和离散码本旨在以减少传输开销的方式对抗语义噪声。 我们提供了一些性能分析,并提出了一种新颖的损失函数,以基于语义相似性来提高系统的鲁棒性。 所提出的码本在两个方面与信道反馈[1]不同:(i)我们提出了一种新颖的掩码VQ-VAE来与收发器处的编码器和解码器一起训练码本,同时通道反馈的设计是通过传统算法设计的,例如字典学习; (ii)我们设计用于源压缩的码本,以对抗语义通信中的语义噪声,而信道反馈的码本用于传统通信系统中的信道压缩。
III-A 掩蔽VQ-VAE
各种来源都存在信息冗余。 图像具有大量的空间冗余,并且通过对零件、对象和场景的理解,可以从其相邻的块中恢复图像中丢失的块。 因此,随机屏蔽部分补丁的策略是创建具有挑战性的任务的有效方法,该任务要求模型建立对图像统计和语义信息的全面理解,这也减少了信息冗余。 此外,由于语义噪声被添加到图像的块中,因此掩蔽操作可以在一定程度上消除语义噪声的影响。
III-A1 Masked VQ-VAE 的架构
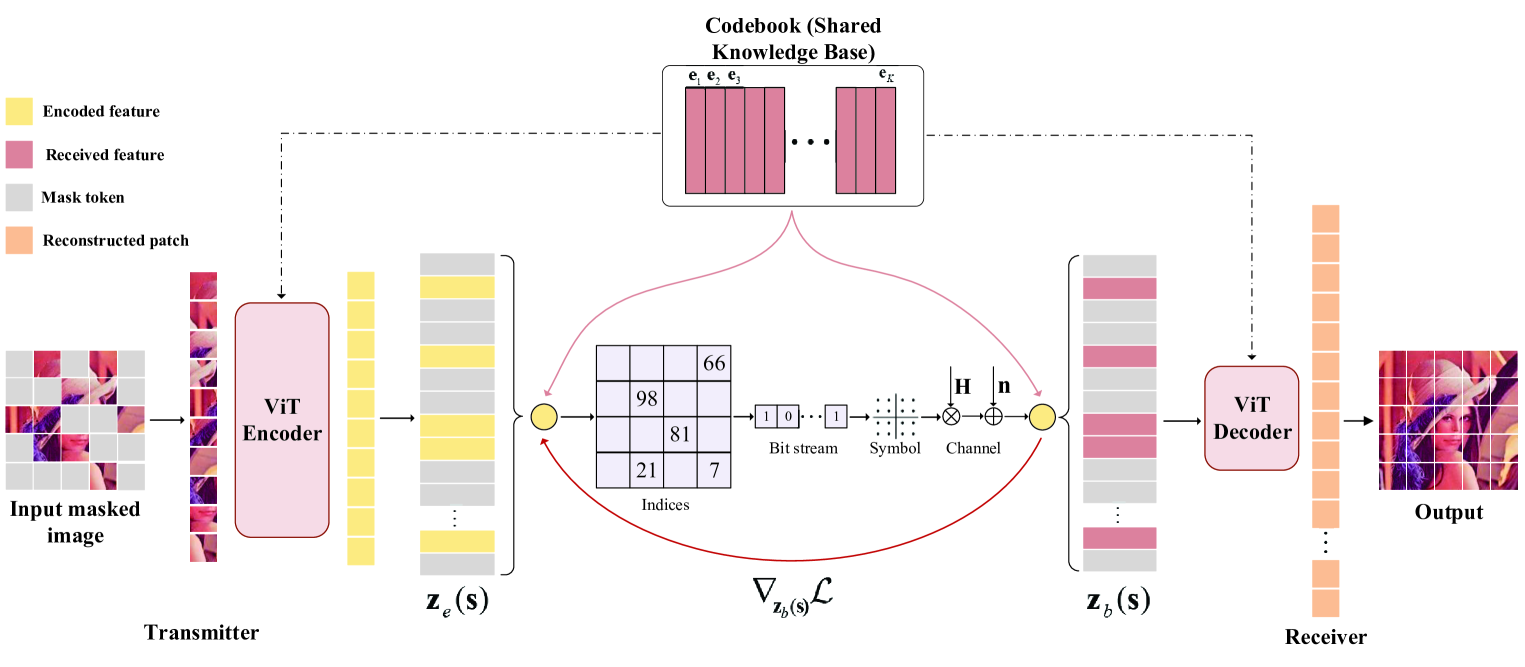
如图2(a)所示,我们采用具有ViT结构的掩模VQ-VAE,其中我们从输入图像中随机掩模补丁并旨在重建丢失的补丁。 masked VQ-VAE属于自动编码器,但可以从部分观察中重建原始图像。 与传统的自动编码器不同,我们采用非对称编码器-解码器架构。
特别是,编码器只需要处理一小部分未屏蔽的补丁,并将它们映射到编码的特征上进行传输,这显着减少了训练时间和内存消耗。 它删除了屏蔽补丁,并将未屏蔽补丁及其位置信息嵌入到原始图像中,然后通过一系列 ViT 块[37]对其进行处理。 相反,解码器的输入是完整的标记集,包括(i)未屏蔽补丁的编码特征和(ii)屏蔽标记,如图2(a)所示。 每个掩码词符都是一个共享和学习的向量,表明存在要预测的缺失补丁。 我们向这个完整集合中的所有标记添加位置嵌入。 如果没有这个,掩模标记将没有关于它们在图像中的位置的信息。 此外,解码器仅在预训练期间用于执行图像重建任务,而编码器用于提取输入图像的特征。 因此,可以灵活地设计独立于编码器设计的解码器架构。 与通信系统中的传统自动编码器相比,屏蔽VQ-VAE具有以下优点:
-
•
通过这种不对称设计,编码器仅处理未屏蔽的补丁,轻量级解码器根据编码的特征和屏蔽标记重建图像。 通过这种方式,可以显着降低计算复杂度和训练时间。
-
•
预训练的屏蔽 VQ-VAE 可以用于不同的下游任务,例如分类,只需改变轻量级解码器的结构并在短时间内微调屏蔽 VQ-VAE。
-
•
将未屏蔽补丁和屏蔽 Token 的编码特征传输到接收器处的解码器会导致传输开销的大幅减少。
-
•
掩蔽操作可以对抗语义噪声,因为部分噪声被掩蔽。
III-A2 针对语义噪声的屏蔽策略
我们首先将图像划分为许多不重叠的块。 然后,我们对补丁的子集进行采样,屏蔽并删除剩余的补丁。 高掩蔽率,即去除补丁的比率,很大程度上消除了冗余。 [38]中的“随机采样”策略按照均匀分布随机采样补丁,即每个补丁的掩蔽概率相同。 然而,语义噪声并不是随机出现的。 它更频繁地出现在与目标相关的补丁中。 因此,为了减少语义噪声的影响,我们根据统计数据增加受语义噪声严重影响的补丁的掩蔽概率。
III-B 用于编码特征表示的离散码本
我们的目标是为编码特征空间设计一个离散码本,并通过码本中的基向量来表示编码特征。 我们考虑与任务相关的重要特征,而忽略带有噪声和难以察觉的细节的与任务无关的特征。 具体来说,我们将这些基向量设置为可训练参数,并将它们与编码器和解码器的参数一起训练。 编码器网络输出连续的编码特征,然后将它们映射到训练码本中的基向量的离散索引中。 这种设计具有以下优点:
-
•
码本训练简单且方差小,使得语义通信系统更加稳定。
-
•
离散特征表示可以对抗语义噪声。
-
•
发送器只需要发送基向量的索引,这显着减少了传输开销。
III-B1 密码本设计
如图 2(a),我们将编码特征的代码集表示为 ,它由 基向量 组成, 是每个基向量的维数, 是每个基向量的维数。 该模型采用输入 ,并通过编码器生成编码特征向量 。 然后,通过最近邻查找将其映射到基向量
| (12) |
为了清楚起见,省略了特征索引。 然后,被输入到解码器。 我们可以将此前向计算视为具有特定非线性函数的 DNN 层,该函数将编码特征向量 映射到基础向量 。 码本中的基向量与编码器和解码器的参数一起训练。 但是,操作 (12) 是不可微分的。 因此,在反向传播中,我们通过直通估计器 [40] 来近似梯度,并将梯度从解码器输入 复制到编码器输出 。 因此,最近的基向量在前向传播中被传递到解码器,而在反向传播期间,梯度被不改变地传递到编码器。 请注意,梯度包含有用的信息,可用于训练编码器以最小化损失函数,并可以推动编码器的输出 有效地离散化以实现更好的性能。
III-B2 可微损失函数
我们设计的损失函数由代表参数不同部分的三个部分组成:
| (13) | ||||
其中、和分别表示网络的输入、输出和真实标签,表示可训练的原始DNN的参数,是超参数。 符号表示没有梯度传递给并且其梯度为零,这有效地约束为非更新常量。 第一项是训练编码器和解码器参数的重建损失。 由于从 到 映射的直通梯度估计,基向量 不会从重建损失 因此,为了训练基向量,我们使用 误差将基向量移向编码特征 ,如 (13 由于编码特征空间的体积是无量纲的,因此如果基向量 的训练速度不如编码器参数的训练速度,则码本可以任意增长并导致训练过程发散。 为了解决这个问题,我们在 (13) 中添加第三项。 总之,解码器仅通过第一个损失项优化,编码器通过第一个和最后一个损失项优化,基向量通过中间损失项优化。
III-C 密码本的稳健性
III-C1 语义相似度
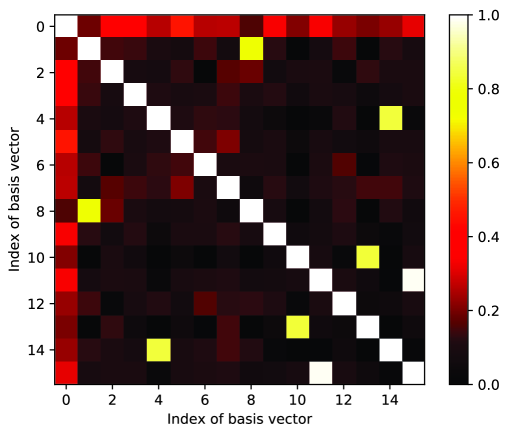
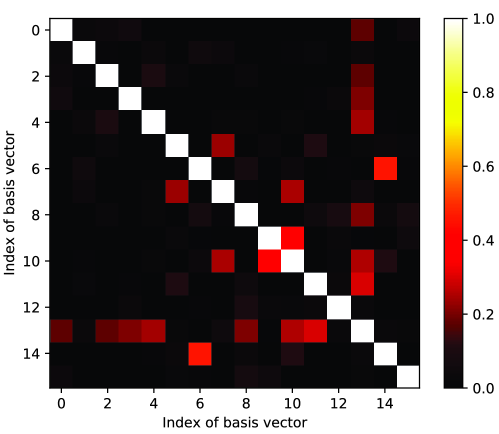
码本中两个基向量和的语义相似度可以定义为向量乘法、余弦距离 或 -范数、 等。 当两个基向量的语义相似度较高时,它们包含相似的语义信息。 我们选择余弦距离并计算码本中两个基向量之间的所有语义相似度。 将由所有归一化基向量组成的归一化码本表示为
| (14) |
因此,矩阵的第元素表示基向量和的语义相似度。
III-C2 改进的鲁棒码本
用于降低基向量之间的语义相似度(即增加距离)的损失函数可以写为
| (15) |
基于语义相似性,我们将术语添加到损失函数(13)中,并尝试使码本中的基向量相互正交,即两个基向量之间的语义相似度较小且距离较大。
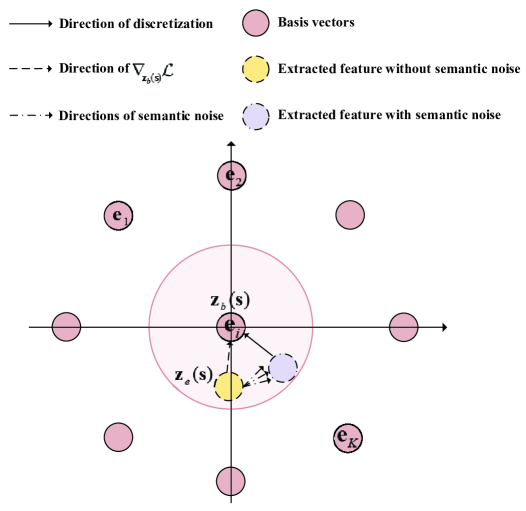
III-C3 码本鲁棒性分析
离散表示可以有效地减少语义噪声的影响。 如图2(b)所示,语义噪声导致提取的特征向某些特定方向移动。 只要不远离原始提取的不受语义噪声影响的特征对应的基向量,就可以通过这种离散表示来消除语义噪声的影响。 因此,增加两个基向量之间的距离可以提高码本对抗语义噪声的鲁棒性。 基于语义相似性,我们提出了一种新的损失函数来增加两个基向量之间的距离并尝试使它们相互正交。 正交基向量有两个优点:(i)两个正交基向量之间的距离较大; (ii)当基向量相互正交时,表示编码特征空间所需的基向量的数量最少。
III-D 码本高效传输
III-D1 基于密码本的星座图
现有的语义通信工作侧重于将源数据直接映射到信道符号,并假设全分辨率星座[10,11,12],即星座点可以出现在星座中的任何位置。 然而,全分辨率星座对于实际系统来说极其复杂。 因此,我们需要限制星座点的数量。 为了解决这个问题,我们提出了一种基于离散码本的系统,它对于数字通信系统更实用,因为特征的索引可以映射到现有的有限星座中,并且可以更好地适应数字通信方案。 一般来说,离散化会导致数据传输精度的损失。 幸运的是,VQ-VAE 被证明是一种有效的矢量量化方案,取得了令人满意的性能[40]。 与传统的均匀量化相比,由于码本与系统联合训练,VQ-VAE 实现了更好的量化性能。
III-D2 高效传输的语义通信
我们假设发送器和接收器共享码本 ,由基本向量 组成,在训练阶段后固定。 因此,对于编码器输出的每个编码特征,发射机只需要发送相应基向量的索引,这显着降低了传输开销。 如图2(a)所示,在传输阶段,编码特征的索引首先被映射为二进制比特。 然后,这些二进制比特被映射成符号并通过无线信道传输。 接收器将接收到的符号映射到索引中,并在码本中找到相应的基向量,将其输入到解码器中进行进一步处理。 通道和噪声可以被视为自动编码器的一层,并与自动编码器的参数联合训练。
IV 具有训练方法的特征重要性模块
在本节中,我们通过设计 FIM 使语义通信系统更加鲁棒和高效。 此外,SNR 被纳入 FIM 中,这确保了所提出的系统能够在不同的 SNR 水平下成功运行。 此外,我们提出了一种新颖的损失函数和训练方法来训练 FIM。
IV-A 噪声相关特征抑制
FIM 动态学习特征重要性训练并将其合并到 DNN 模型的训练阶段,该模型本质上抑制了那些与噪声相关和与任务无关的特征。
IV-A1 噪声相关特性
不同的特征从不同的方面描述图像,并且特征和对语义噪声的鲁棒性之间存在很强的联系,其中这种鲁棒性随着不同的特征而变化。 与现有的假设特征同等重要的工作不同,我们关注特征之间的关系并赋予它们不同的重要性。 直观上,不同的特征对任务结果的贡献不同,对语义噪声的鲁棒性也不同。 我们期望语义通信系统能够学习不同特征的重要性,并更好地理解输入图像背后的语义信息。 然后,发射机可以发送与任务相关和与噪声无关的重要特征,这显着提高了系统的鲁棒性并减少了传输开销。
IV-A2 功能激活
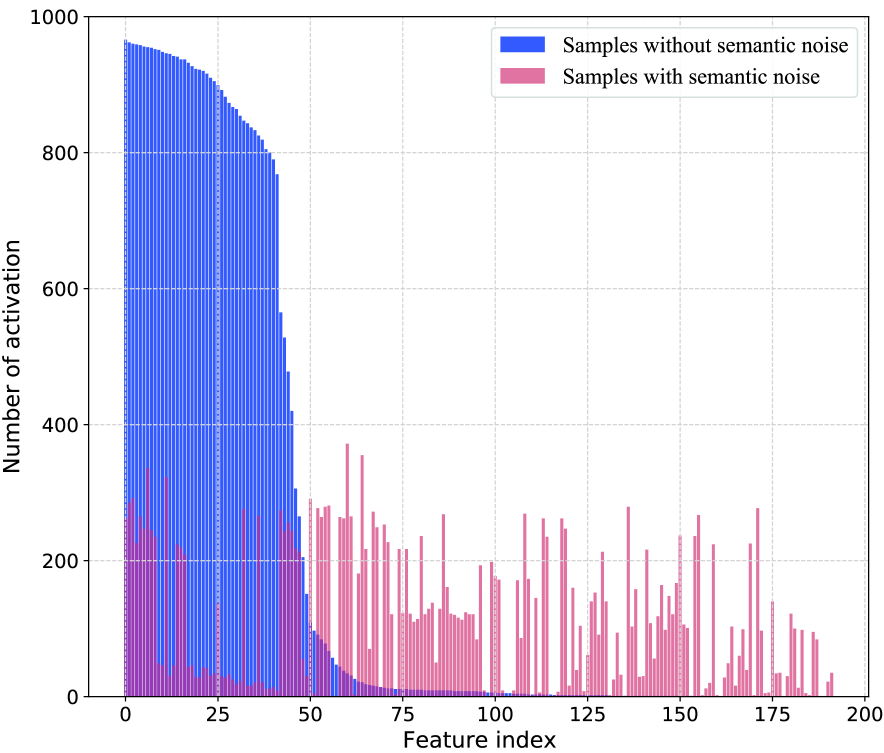
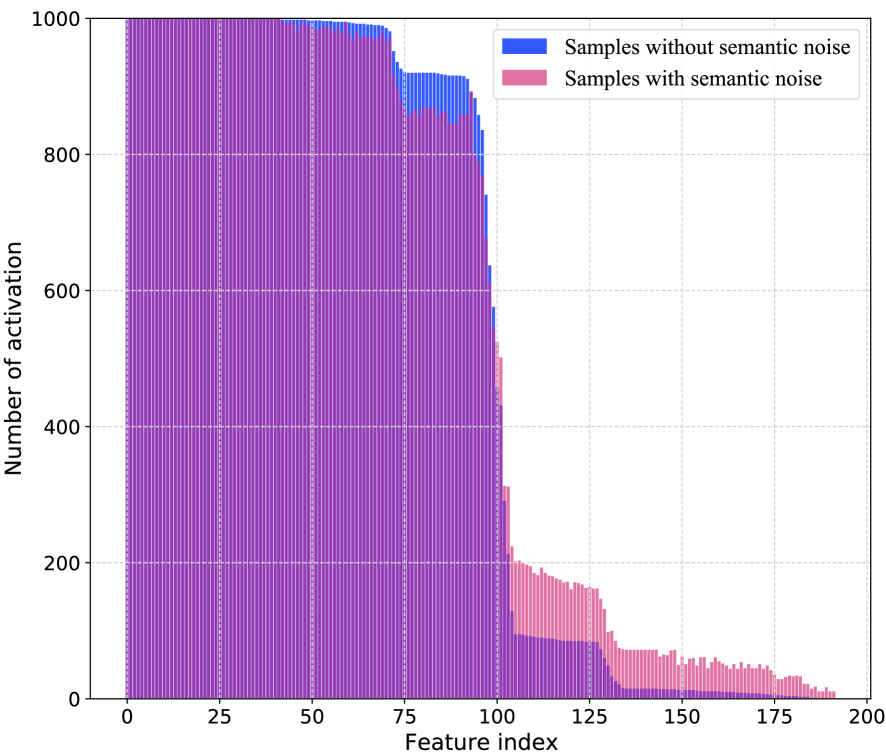
我们从特征激活的角度观察到语义噪声的两个特征:(i)具有语义噪声的样本的激活特征的幅度高于自然样本的幅度; (ii)一些与噪声相关的特征被具有语义噪声的样本更均匀、更频繁地激活。 我们发现对抗训练已经解决了高强度激活特征的第一个问题。 换句话说,一些与任务无关和低贡献的特征不会被没有语义噪声的干净样本激活,但却被有语义噪声的样本激活。 这在一定程度上解释了为什么对抗性训练有效但表现却不尽如人意。 它促使我们设计一个 FIM,训练模型为特征分配不同的重要性,并从本质上抑制这些与任务无关和与噪声相关的高强度特征被语义噪声激活。
IV-B 具有动态 SNR 的 FIM
IV-B1 FIM架构
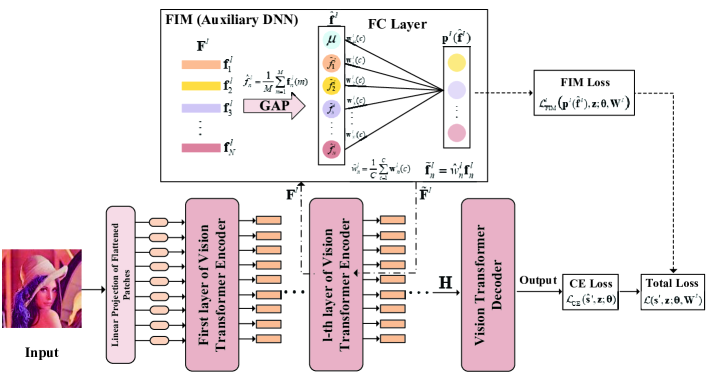
我们将原始特征图 表示为第 层的输出,其中 和 表示维度和特征数量。 如图3所示,我们首先对原始特征图应用全局平均池化(GAP)操作,以获得特征激活图,其中表示SNR。 对于第 个特征,我们有
| (16) |
注意,GAP通过对特征向量[12]的元素进行平均来提取全局特征信息。 此外,不同的SNR水平导致特征的重要性不同。 因此,为了确保所提出的语义通信系统可以在广泛的SNR水平下运行,被设计为FIM输入的一部分,。
然后,特征激活图 被传递到具有全连接 (FC) 层和 ReLU 函数的辅助 DNN。 语义通信系统的输出是,例如分类问题的类标签和重建问题的重建图像。 然后,这个辅助DNN的可训练参数可以写为,它标识了输出对应的每个特征的重要性。参数将用于重新加权原始特征图。 我们将权重分量表示为 ,其中我们有
| (17) |
对于第 个功能。 它被用作与输出 相关的第 层中第 特征的重要性权重。 我们应用“softmax”层将这些权重缩放到范围内。 然后,它将原始特征映射 中的特征 重新加权为 。 调整后的特征图将通过前向传播传递到下一层。 通过这种方式,捕获了特征关系,并为不同的特征生成不同的权重,以增加或抑制它们与下一层的连接强度。
IV-B2 带有标签信息的 FIM
此外,为了充分利用标签信息,我们稍微修改了图像分类任务的 FIM,并合并标签信息以提高性能。 特别地,在训练阶段,利用真实标签作为确定通道重要性的指标。 在推理阶段,由于地面实况标签不可用,我们只需将与预测类别相关的权重分量作为特征重要性。 因此,然后应用特征重要性将原始激活图重新加权为,其中表示训练阶段的真实标签和推理阶段的预测类别,。 然后,调整后的通过前向传播传递到下一层。 因此,在这种情况下,通过考虑标签信息来学习特征重要性。
IV-C 模型训练
IV-C1 FIM的损失函数
我们将提出的 FIM 插入到原始 DNN 的某些层中,可以将其视为辅助网络。 它可以通过使用对抗训练方法与编码器和解码器的参数一起进行训练。 我们设计损失函数来同时训练原始DNN和FIM,以第层后插入一个FIM为例,损失函数设计为
| (18) |
其中是FIM的输出,表示原始DNN的可训练参数,是FIM的可训练参数,是和标签的交叉熵损失。 FIM的损失函数设计为(18),因为当时,FIM将得到更好的训练,即抑制与噪声相关的特征,系统获得更好的性能。接近标签。
它可以轻松扩展到多个 FIM。 使用所提出的 FIM 的对抗训练的总体损失函数可以写为
| (19) |
其中, 表示用于对抗训练的语义噪声样本, 是解码器的输出, 表示 和 的交叉熵损失, 表示 DNN 层数, 是用于控制 FIM 强度的可调参数。
IV-C2 整个模型的训练方法
我们开发了一种在所提出的鲁棒语义通信系统中联合训练上述模块的方法,其中详细的训练过程总结在算法3中。
V 仿真结果
在本节中,我们通过数值结果验证所提出的语义通信系统的有效性。
| Layer Name | Dimension | Activation | |
| Transmitter | 8Transformer Encoder | 768 (12 heads) | Linear |
| Dense | 256 | Sigmoid | |
| Codebook | 128 | None | |
| FIM | 196 | ReLU | |
| Channel | Channel | None | |
| Receiver | FIM | 196 | ReLU |
| Codebook | 128 | None | |
| Dense | 768 | Sigmoid | |
| 4Transformer Encoder | 768 (12 heads) | Linear | |
| Dense | 10 | ReLU |
V-A 模拟设置
我们考虑发射机和接收机分别配备 发射天线和 接收天线的场景。 我们将所提出的掩蔽 VQ-VAE 与 MIMO 信道[1]下的传统源编码和信道编码方法进行比较。 我们采用 CIFAR-10,由 类的 图像组成,作为图像分类的数据集,Cars196,由 类的 图像组成> 类作为图像检索的数据集,由 图像组成的 ImageNet 作为图像重建的数据集。 数据集中联合摄影专家组(JPEG)图像的平均大小为字节,每幅图像的块数为。 掩码VQ-VAE的掩码率为,码本大小为,传输每个索引需要比特。 我们采用16-QAM进行调制,采用速率的低密度奇偶校验码(LDPC)。 生成语义噪声的迭代次数设置为,其幂为。 表I中列出了所提出模型的架构。 具体地,“Codebook”层表示将码本中的基向量设置为可训练参数,并且“Codebook”层的“维度”表示基向量的数量。 而且,其他层的“维度”代表该层的输出维度。 对于不同的下游任务,例如分类,我们只需更改最后一层的维度并调整预训练的 masked VQ-VAE。 我们比较以下方法的性能:
-
•
Masked VQ-VAE+FIM+AT:建议采用 FIM 和对抗性训练的 masked VQ-VAE。
-
•
Masked VQ-VAE+AT:建议进行对抗性训练的 masked VQ-VAE。
-
•
Masked VQ-VAE:建议的 masked VQ-VAE。
-
•
JSCC+AT:[10]中修改后的 JSCC 方案,用于 ViT 架构和对抗训练的不同任务。
-
•
JSCC:[10]中针对 ViT 架构的不同任务修改的 JSCC 方案。
-
•
JPEG+LDPC+AT:传统方案采用JPEG进行图像源编码,LDPC进行通道编码,ViT作为分类器并进行对抗训练。
-
•
JPEG+LDPC:常规方案采用JPEG和LDPC。
请注意,我们提出了两种语义噪声模型:(i)在发射机处添加的与样本相关的语义噪声; (ii)在接收器处添加与样本无关的语义噪声,其中(i)对语义通信系统有更严重的影响。 因此,除非另有说明,我们采用语义噪声模型(i)。 我们考虑以下任务并生成相应的语义噪声。
-
•
对于图像分类,会生成语义噪声,以对视觉上看起来与干净样本相似的最小扰动数据进行错误分类。
-
•
对于图像检索,细微的语义噪声会导致错误的检索结果。
-
•
对于图像重建来说,语义噪声会导致重建失败,例如重建图像中的一些关键对象和信息被遗漏或模糊。
V-B 传输开销分析
| Schemes | JPEG+LDPC | Masked VQ-VAE (Patch ) | Masked VQ-VAE (Patch ) |
|---|---|---|---|
| Image classification | |||
| Image retrieval | |||
| Image reconstruction |
表II展示了传统的JPEG+LDPC和我们提出的掩码VQ-VAE的传输开销。 请注意,“Patch ”表示在图像预处理阶段提出的具有图像压缩比的掩模VQ-VAE方案,即补丁被压缩为标量。 因此,较大的值代表较高的压缩比和较低的传输开销。 JPEG+LDPC的传输符号数可以计算为:,其中和分别表示图像的长度和宽度,为通道数,表示每个像素所需的位数,表示码率,是压缩比,表示取决于调制模式的符号所需的比特数。 我们以图像分类为例:符号/图像。 此外,所提出的掩码VQ-VAE的传输符号数量可以计算为:,其中表示传输中的基向量索引所需的比特数。码本,是掩蔽比,是补丁大小。 我们以用于图像分类的掩模VQ-VAE(Patch )为例:符号/图像。 因此,所提出的掩码VQ-VAE仅需要传统JPEG+LDPC的个传输符号。
V-C 图像分类的准确性
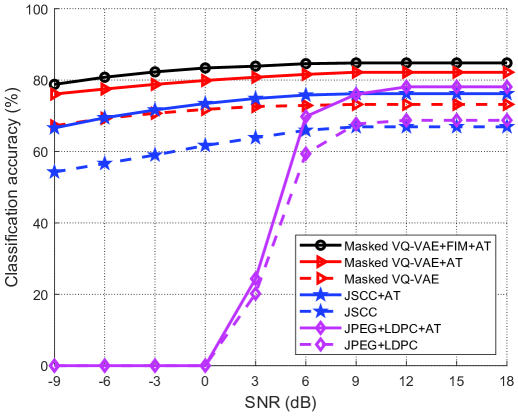
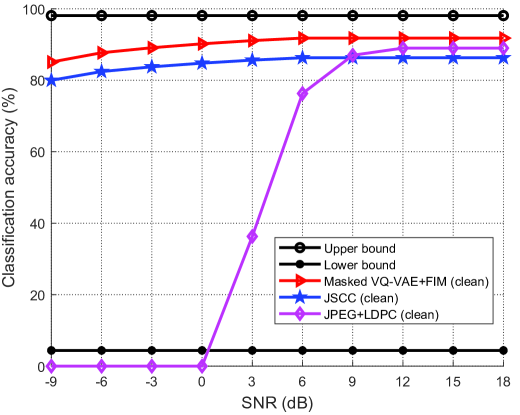
图4显示了分类精度与SNR的关系。 我们用 dB 到 dB 的 SNR 范围训练模型,并在 dB 到 SNR 范围内测试它D b。 从图4(a)中可以看出,所有方案的分类精度都随着信噪比的增加而增加。 所提出的 Masked VQ-VAE+FIM+AT 明显优于 JSCC+AT、JSCC、JPEG+LDPC+AT 和 JPEG+LDPC,并达到最佳性能。 此外,所提出的 Masked VQ-VAE+FIM+AT 优于 Masked VQ-VAE+AT 和 Masked VQ-VAE。 它展示了我们设计中每个模块的效率,包括屏蔽 VQ-VAE、FIM 和对抗训练。 此外,所提出的方案和JSCC在低SNR场景下显着优于传统的JPEG+LDPC,因为在低SNR场景下BER较高,而所提出的方案通过传输训练码本中提取的任务相关特征的索引而具有鲁棒性。
图4(b)显示了没有语义噪声的方案的分类精度。 请注意,“干净”表示没有语义噪声的方案。 上界是由没有信道噪声和语义噪声影响的 JSCC 实现的,下界是由有语义噪声影响的 JSCC 实现的。 从图中可以看出,所提出的 Masked VQ-VAE+FIM(干净)接近上限,并且显着优于 JSCC(干净)和 JPEG+LDPC(干净)。 此外,所提出的Masked VQ-VAE+FIM+AT接近于没有语义噪声的模型的性能,这表明所提出的模型可以通过减少语义噪声的影响来有效提高系统的鲁棒性。
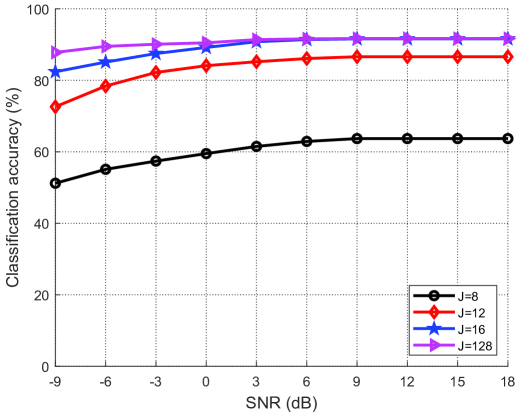
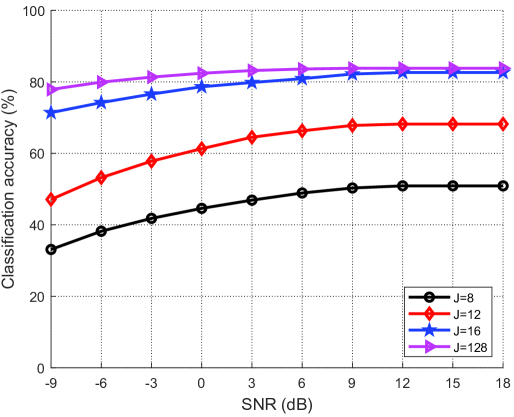
图5(a)和图5(b)分别展示了在没有语义噪声和有语义噪声的情况下不同码本大小的分类精度与SNR的关系。 从图中可以看出,分类精度随着信噪比的增加而增加。 码本尺寸越大,对语义噪声的鲁棒性越强,对整个数据集的表示能力也越强,从而导致分类精度越高。 此外,码本大小足以进行准确分类。
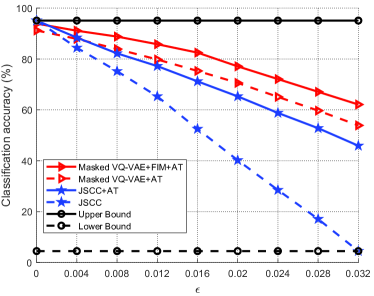
图6说明了分类精度与语义噪声的能力的关系。 上界和下界分别由没有语义噪声和语义噪声最大功率的 JSCC 实现。 从图中可以看出,所有方案达到的分类精度均随着而降低。 所提出的 Masked VQ-VAE+FIM+AT 显着优于基准并达到最佳性能,特别是当 很大时,这表明所提出的模型针对语义噪声的优越性。
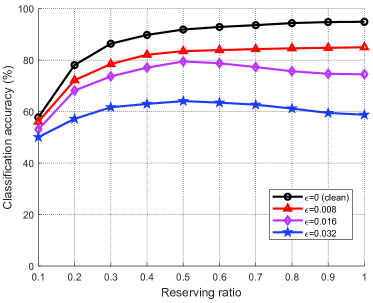
图7展示了所提出的Masked VQ-VAE+FIM+AT的分类精度与不同的保留率的关系。 注意,保留率掩蔽比,表示图像的保留部分与整幅图像的保留部分的比例。 从图中可以看出,所提出的Masked VQ-VAE+FIM+AT所实现的分类精度随着而降低。 此外,当较小时,例如,所提出的方案的分类精度随着保留率的增加而增加,因为较高的保留率保留了更多的图像语义信息。 当较大时,例如,所提方案的分类精度随着保留率的增加先增加后减少。 这是因为保留率越大,虽然保留了更多的语义信息,但保留了更多的语义噪声。 由此可见,保留率在语义信息和语义噪声之间实现了良好的权衡,具有最高的分类精度。
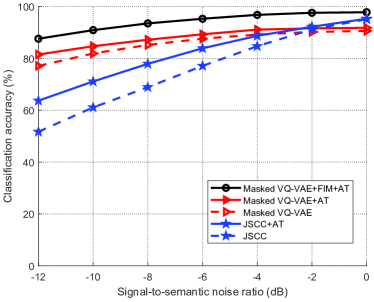
图8显示了不同方案的分类精度与信号语义噪声比的关系,其中噪声表示在接收器处添加的与样本无关的语义噪声。 从图中可以看出,所有方案实现的分类精度都随着信噪比的增加而增加。 所提出的 Masked VQ-VAE+FIM+AT 显着优于基准并实现了最佳性能。 它表明所提出的模型对于样本无关的语义噪声比 JSCC 更稳健。 与样本相关的语义噪声相比,样本无关的语义噪声对分类精度的影响较小,对抗性训练对抗它的效果也不明显。
V-D 白盒语义噪声和黑盒语义噪声
我们声称攻击者需要知道所有模型信息才能生成语义噪声。 事实上,这几乎是所提出的语义通信系统的最坏情况,其中生成的语义噪声会显着影响系统性能。 我们称之为白盒语义噪声。 然而,当攻击者只知道部分模型信息(例如模型参数和架构)时,也可能会产生语义噪声。 他们还可以利用其他类似模型产生的语义噪声来攻击系统,这被称为黑盒语义噪声。
| Attacked model | Proposed | Transformer | ResNet | ||||
| Type of semantic noise | P-P | T-P | R-P | T-T | R-T | R-R | T-R |
| Classification accuracy | |||||||
在表III中,我们首先为所提出的模型、基于Transformer的模型和基于ResNet的模型生成语义噪声。 然后,我们利用这些不同类型的语义噪声来评估这些模型的鲁棒性。 特别地,“语义噪声的类型”行中的“T-P”是指利用基于Transformer的模型生成的语义噪声来攻击所提出的模型,这是黑盒语义噪声。 相比之下,“P-P”意味着所提出的模型受到所提出模型产生的语义噪声的攻击,即白盒语义噪声。 我们可以看到,白盒语义噪声对所提出模型的性能的影响比黑盒噪声更严重。 此外,由于所提出的模型是基于 Transformer 设计的,因此基于 Transformer 的模型生成的黑盒语义噪声比基于 ResNet 的模型更有效。 它表明,从更相似的模型生成的黑盒语义噪声往往更有效。 这主要是因为具有相似架构的模型通常具有相似的参数和层结构。 此外,所提出的模型比基于 Transformer 和基于 ResNet 的模型对于白盒和黑盒语义噪声都更加鲁棒。 此外,本文的目标是设计一个针对语义噪声的鲁棒语义通信系统。 从表III可以看出,所提出的模型将能够防御黑盒语义噪声。
V-E 功能激活
V-F 基向量的语义相似性
V-G 图像检索和重建的性能
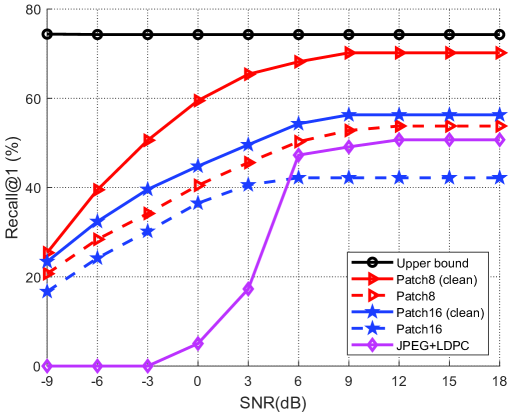

图11(a)显示了图像检索任务的recall@1性能与SNR的关系,其中recall@1表示第一次查询时图像检索成功的比率。 上界是通过JPEG+LDPC实现的,在高信噪比场景下没有语义噪声,几乎无损传输。 从图中可以看出,Patch的性能优于Patch,压缩比更高,传输开销更低。 此外,Patch 8 显着优于传统的 JPEG+LDPC,特别是在低 SNR 场景下。 这是因为在低SNR场景下采用JPEG+LDPC无法正确解码图像,并且所提出的方案对语义噪声具有更强的鲁棒性。
图11(b)显示了在语义噪声的影响下图像重建的质量。 左、中、右列分别表示原始图像、使用块大小 重建的图像以及使用块大小 重建的图像。 从图中可以看出,较低的压缩比会带来更好的构造质量,而补丁大小在对抗语义噪声方面实现了令人满意的构造质量。
六结论
在本文中,我们分析了语义噪声,并提出了生成样本相关和样本无关语义噪声的方法。 然后,提出了鲁棒语义通信系统的框架来对抗语义噪声,其中开发了具有权重扰动的对抗性训练。 提出了带有噪声相关掩蔽策略的掩蔽 VQ-VAE 作为系统架构,并设计了用于编码特征表示的离散码本。 为了提高系统的鲁棒性,提出了抑制与噪声相关和与任务无关的特征的FIM。 仿真结果表明,我们提出的方法可以应用于许多下游任务,并显着提高语义通信系统针对语义噪声的鲁棒性,同时大大减少传输开销。
参考
- [1] D. Tse and P. Viswanath, Fundamentals Wireless Communication., Cambridge University Press, 2005.
- [2] M. Mohammadi, A. Al-Fuqaha, S. Sorour, and M. Guizani, “Deep learning for IoT big data and streaming analytics: A survey,” IEEE Commun. Surveys Tuts., vol. 20, no. 4, pp. 2923–2960, Jun. 2018.
- [3] K. B. Letaief, W. Chen, Y. Shi, J. Zhang, and Y.-J. A. Zhang, “The roadmap to 6G: AI empowered wireless networks,” IEEE Commun. Mag., vol. 57, no. 8, pp. 84–90, Aug. 2019.
- [4] H. Ye, L. Liang, G. Y. Li, and B.-H. Juang, “Deep learning-based end-to-end wireless communication systems with conditional GANs as unknown channels,” IEEE Trans. Wireless Commun., vol. 19, no. 5, pp. 3133–3143, May 2020.
- [5] Q. Hu, Y. Cai, K. Kang, G. Yu, J. Hoydis, and Y. C. Eldar, “Two-timescale end-to-end learning for channel acquisition and hybrid precoding,” IEEE J. Select. Areas Commun., vol. 40, no. 1, pp. 163–181, Jan. 2022.
- [6] T. O’Shea and J. Hoydis, “An introduction to deep learning for the physical layer,” IEEE Trans. Cogn. Commun. Netw., vol. 3, no. 4, pp. 563–575, Dec. 2017.
- [7] M. Kountouris and N. Pappas, “Semantics-empowered communication for networked intelligent systems,” IEEE Commun. Mag., vol. 59, no. 6, pp. 96–102, Jun. 2021.
- [8] M. Kalfa, M. Gok, A. Atalik, B. Tegin, T. M. Duman, and O. Arikan, “Towards goal-oriented semantic signal processing: Applications and future challenges,” Digit. Signal Process., pp. 103–134, Dec. 2021.
- [9] G. Shi, Y. Xiao, Y. Li, and X. Xie, “From semantic communication to semantic-aware networking: Model, architecture, and open problems,” IEEE Commun. Mag., vol. 59, no. 8, pp. 44–50, Aug. 2021.
- [10] E. Bourtsoulatze, D. Burth Kurka, and D. Gunduz, “Deep joint source-channel coding for wireless image transmission,” IEEE Trans. Cognit. Comm. Netw., vol. 5, no. 3, pp. 567–579, Sep. 2019.
- [11] H. Xie, Z. Qin, G. Y. Li, and B.-H. Juang, “Deep learning enabled semantic communication systems,” IEEE Trans. Signal Process., vol. 69, pp. 2663–2675, Apr. 2021.
- [12] J. Xu, B. Ai, W. Chen, A. Yang, P. Sun, and M. Rodrigues, “Wireless image transmission using deep source channel coding with attention modules,” IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 4, pp. 2315–2328, Apr. 2022.
- [13] K. Lu, R. Li, X. Chen, Z. Zhao, and H. Zhang, “Reinforcement learning-powered semantic communication via semantic similarity,” arXiv preprint arXiv:2108.12121, 2021.
- [14] D. B. Kurka and D. Gunduz, “DeepJSCC-f: Deep joint source-channel coding of images with feedback,” IEEE J. Select. Areas Inf. Theory, vol. 1, no. 1, pp. 178–193, May 2020.
- [15] Z. Weng and Z. Qin, “Semantic communication systems for speech transmission,” IEEE J. Select. Areas Commun., vol. 39, no. 8, pp. 2434–2444, Aug. 2021.
- [16] P. Jiang, C.-K. Wen, S. Jin, and G. Y. Li, “Deep source-channel coding for sentence semantic transmission with HARQ,” IEEE Trans. Commun., vol. 70, no. 8, pp. 5225–5240, Aug. 2022.
- [17] C.-H. Lee, J.-W. Lin, P.-H. Chen, and Y.-C. Chang, “Deep learning-constructed joint transmission-recognition for Internet of Things,” IEEE Access, vol. 7, pp. 76 547–76 561, Jun. 2019.
- [18] M. Jankowski, D. Gunduz, and K. Mikolajczyk, “Wireless image retrieval at the edge,” IEEE J. Select. Areas Commun., vol. 39, no. 1, pp. 89–100, Jan. 2021.
- [19] J. Shao, Y. Mao, and J. Zhang, “Learning task-oriented communication for edge inference: An information bottleneck approach,” IEEE J. Select. Areas Commun., vol. 40, no. 1, pp. 197–211, Jan. 2022.
- [20] H. Xie, Z. Qin, X. Tao, and K. B. Letaief, “Task-oriented multi-user semantic communications,” IEEE J. Select. Areas Commun., vol. 40, no. 9, pp. 2584–2597, Sep. 2022.
- [21] G. Zhang, Q. Hu, Z. Qin, Y. Cai, G. Yu, X. Tao, and G. Y. Li, “A unified multi-task semantic communication system for multimodal data,” arXiv preprint arXiv:2209.07689, 2022.
- [22] C. Boncelet, “Image noise models,” The essential guide to image processing, pp. 143–167, Academic Press, 2009.
- [23] Z. Qin, X. Tao, J. Lu, and G. Y. Li, “Semantic communications: Principles and challenges,” arXiv preprint arXiv:2201.01389, 2021.
- [24] W. Wang, R. Wang, L. Wang, Z. Wang, and A. Ye, “Towards a robust deep neural network against adversarial texts: A survey,” IEEE Trans. Knowl. Data Eng., vol. 35, no. 3, pp. 3159–3179, Mar. 2023.
- [25] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,” in Proc. Int’l. Conf. Learn. Represent. (ICLR), Apr. 2014, pp. 1–10.
- [26] I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” in Proc. Int’l. Conf. Learn. Represent. (ICLR), May 2015, pp. 1–11.
- [27] A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” in Proc. Int’l. Conf. Learn. Represent. (ICLR), May May 2018, pp. 1–10.
- [28] N. Papernot, P. McDaniel, S. Jha, M. Fredrikson, Z. B. Celik, and A. Swami, “The limitations of deep learning in adversarial settings,” in IEEE Eur. Symp. Secur. Privacy (EuroS&P), Mar. 2016, pp. 372–387.
- [29] S.-M. Moosavi-Dezfooli, A. Fawzi, and P. Frossard, “DeepFool: a simple and accurate method to fool deep neural networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog. (CVPR), Jun. 2016, pp. 2574–2582.
- [30] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, “Universal adversarial perturbations,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog. (CVPR), Jul. 2017, pp. 1765–1773.
- [31] B. Kim, Y. E. Sagduyu, K. Davaslioglu, T. Erpek, and S. Ulukus, “Channel-aware adversarial attacks against deep learning-based wireless signal classifiers,” IEEE Tran. Wireless Commun., vol. 21, no. 6, pp. 3868–3880, Jun. 2022.
- [32] F. Liao, M. Liang, Y. Dong, T. Pang, X. Hu, and J. Zhu, “Defense against adversarial attacks using high-level representation guided denoiser,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog. (CVPR), Jun. 2018, pp. 1778–1787.
- [33] N. Papernot, P. McDaniel, X. Wu, S. Jha, and A. Swami, “Distillation as a defense to adversarial perturbations against deep neural networks,” in IEEE Symp. Secur. Privacy (SP), May 2016, pp. 582–597.
- [34] S. Gu and L. Rigazio, “Towards deep neural network architectures robust to adversarial examples,” arXiv preprint arXiv:1412.5068, 2014.
- [35] D. Wu, S.-T. Xia, and Y. Wang, “Adversarial weight perturbation helps robust generalization,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), Dec. 2020, pp. 1–20.
- [36] Y. Bai, Y. Zeng, Y. Jiang, S.-T. Xia, X. Ma, and Y. Wang, “Improving adversarial robustness via channel-wise activation suppressing,” arXiv preprint arXiv:2103.08307, 2021.
- [37] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), Dec. 2017, pp. 5998–6008.
- [38] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog. (CVPR), Jun. 2022, pp. 15 979–15 988.
- [39] A. Kurakin, I. Goodfellow, and S. Bengio, “Adversarial examples in the physical world,” in Proc. Int’l. Conf. Learn. Represent. (ICLR), May 2017, pp. 1–13.
- [40] A. van den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural discrete representation learning,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), Dec. 2017, pp. 6309–6318.