BEVDepth:获取多视图 3D 物体检测的可靠深度
摘要
在这项研究中,我们提出了一种新的 3D 物体检测器,具有值得信赖的深度估计,称为 BEVDepth,用于基于相机的鸟瞰 (BEV) 3D 物体检测。 我们的工作基于一个关键的观察——考虑到深度对于相机 3D 检测至关重要这一事实,最近方法中的深度估计令人惊讶地不足。 我们的 BEVDepth 通过利用显式深度监督解决了这个问题。 还引入了相机感知深度估计模块以促进深度预测能力。 此外,我们设计了一种新颖的深度细化模块来应对不精确的特征投影所带来的副作用。 借助定制的高效体素池和多帧机制,BEVDepth 在具有挑战性的 nuScenes 测试集上实现了最先进的 60.9% NDS,同时保持了高效率。 相机型号的NDS得分首次达到60%。 代码发布于https://github.com/Megvii-BaseDetection/BEVDepth。
1简介
LiDAR 和摄像头是当前自主系统用于检测 3D 物体和感知环境的两个主要传感器。 虽然基于 LiDAR 的方法已证明能够提供可靠的 3D 检测结果,但基于多视图相机的方法最近因其成本较低而吸引了越来越多的关注。
LSS (Philion 和 Fidler 2020) 很好地解决了使用多视图相机进行 3D 感知的可行性。 他们首先使用估计深度将多视图特征“提升”到 3D 平截头体,然后将平截头体“splat”到参考平面上,通常是鸟瞰图 (BEV) 中的平面。 BEV 表示非常重要,因为它不仅支持多输入摄像头系统的端到端训练方案,而且还为各种下游任务提供统一的空间,例如 BEV 分割、对象检测 (Huang 等人2021; Li 等人 2022b) 和运动规划。 然而,尽管基于 LSS 的感知算法取得了成功,但该管道中的学习深度却很少被研究。 我们问 - 这些检测器中学习深度的质量真的满足精确 3D 物体检测的要求吗?
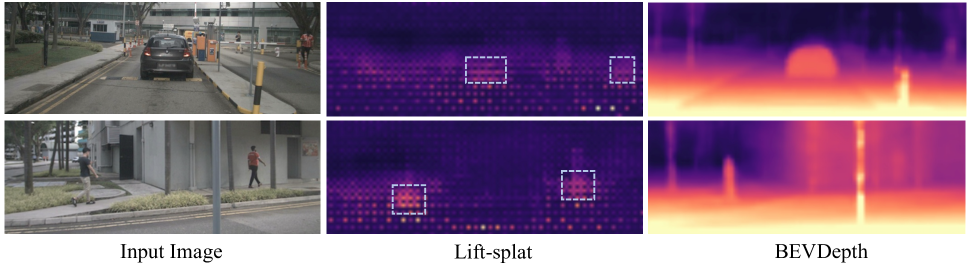
我们首先尝试通过可视化基于 Lift-splat 的探测器中的估计深度(图1)来定性地回答这个问题。 尽管该检测器在 nuScenes (Caesar 等人 2020) 基准上实现了 30 mAP,但其深度却出奇的差。 只有少数特征区域可以预测合理的深度并有助于后续任务(参见图 1 中的虚线框),而大多数其他区域则不然。 基于这一观察,我们指出现有Lift-splat中的深度学习机制带来了三个缺陷:
-
•
深度不准确 由于深度预测模块间接受到最终检测损失的监督,因此绝对深度质量远远不能令人满意;
-
•
深度模块过度拟合 大多数像素无法预测合理的深度,这意味着它们在学习阶段没有得到适当的训练。 这让我们对深度模块的泛化能力产生怀疑。
-
•
不精确的 BEV 语义 Lift-splat 中学习的深度将图像特征投影到 3D 截头体特征中,这些特征将进一步汇集到 BEV 特征中。 由于像 Lift-splat 这样的深度较差,只有部分特征未被投影来纠正 BEV 位置,从而导致 BEV 语义不精确。
我们将在第二节深入探讨这三个缺陷。 3。
此外,我们通过用点云数据生成的地面实况替换 Lift-splat 中的学习深度,揭示了提高深度的巨大潜力。 结果,mAP 和 NDS 均提升了近 20%。 平移误差 (mATE) 也下降,从 0.768 降至 0.393。 这种现象清楚地表明,增强深度是高性能相机 3D 检测的关键。
因此,在这项工作中,我们引入了 BEVDepth,一种新的多视图 3D 检测器,它利用源自点云的深度监督来指导深度学习。 我们是第一个对深度质量如何影响整个系统进行全面分析的团队。 同时,我们创新性地提出将相机内部和外部编码到深度学习模块中,以便探测器对各种相机设置具有鲁棒性。 最后,进一步引入深度细化模块来细化学习的深度。
为了验证 BEVDepth 的强大功能,我们在 nuScenes (Caesar 等人 2020) 数据集(3D 检测领域的知名基准)上对其进行了测试。 借助我们定制的高效体素池化和多帧融合技术,BEVDepth 在 nuScenes 测试 集上实现了 60.9% NDS,成为这一具有挑战性的基准测试中的最新技术,同时仍然保持较高的性能效率。
2相关工作
2.1 基于视觉的3D物体检测
基于视觉的 3D 检测的目标是预测对象的 3D 边界框。 这是一个不适定问题,因为从单目图像估计物体的深度本质上是不明确的。 即使多视图相机可用,估计没有重叠视图的区域的深度仍然具有挑战性。 因此,深度建模是基于视觉的 3D 检测的关键组成部分。 研究的一个分支直接根据 2D 图像特征预测 3D 边界框。 2D 检测器,例如 CenterNet (Zhou、Wang 和 Krähenbühl 2019),只需对检测头进行少量更改即可用于 3D 检测。 M3D-RPN (Brazil and Liu 2019)提出深度感知卷积层来增强空间感知。 D4LCN (Huo 等人 2020) 采用深度图来指导动态内核学习。 通过将 3D 目标转换到图像域,FCOS3D (Wang 等人 2021b) 预测对象的 2D 和 3D 属性。 此外,PGD (Wang 等人 2022a) 提出了几何关系图,以方便 3D 对象检测的深度估计。 DD3D (Park 等人 2021a) 证明深度预训练可以显着改善端到端 3D 检测。
另一项工作是预测 3D 空间中的物体。 将 2D 图像特征转换为 3D 空间的方法有很多。 一种典型的方法是将基于图像的深度图转换为伪激光雷达,以模拟激光雷达信号(Wang 等人 2019;You 等人 2019;Qian 等人 2020)。 图像特征还可用于生成 3D 体素(Rukhovich、Vorontsova 和 Konushin 2022) 或正交特征图(Roddick、Kendall 和 Cipolla 2018)。 LSS (Philion and Fidler 2020)提出了一种视图变换方法,可以显式预测深度分布并将图像特征投影到鸟瞰图 (BEV) 上,该方法已被证明可用于 3D 对象检测 (读等人2021;黄等人2021;黄和黄2022)。 BEVFormer (Li 等人 2022b) 使用局部注意力和网格状 BEV 查询执行 2D 到 3D 转换。 继 DETR (Carion 等人 2020) 之后,DETR3D (Wang 等人 2022b) 使用转换器和对象查询来检测 3D 对象,而 PETR (Liu 等人 2022a) 通过引入 3D 位置感知表示进一步提高性能。
2.2基于LiDAR的3D物体检测
由于深度估计的准确性,基于激光雷达的3D检测方法经常被应用于自动驾驶感知任务中。 VoxelNet (Zhou 和 Tuzel 2018) 对点云进行体素化,将其从稀疏体素转换为密集体素,然后在密集空间中提出边界框以在卷积过程中辅助索引。 第二(Yan、Mao 和 Li 2018) 通过引入更有效的结构和 gt 采样技术,提高了 KITTI 数据集(Geiger、Lenz 和 Urtasun 2012) 的性能基于 VoxelNet (Zhou 和 Tuzel 2018)。 SECOND (Yan、Mao 和 Li 2018) 中也使用了稀疏卷积来提高速度。 PointPillars (Lang 等人 2019) 使用支柱而不是 3D 卷积过程对点云进行编码,使其速度更快,但保持良好的性能。 CenterPoint (Yin、Zhou 和 Krahenbuhl 2021) 提出了一种无锚检测器,将 CenterNet (Zhou、Wang 和 Krahenbühl 2019) 扩展到 3D 空间,并在nuScenes 数据集(Caesar 等人 2020) 和 Waymo 开放数据集(Sun 等人 2020)。 PointRCNN (Shi、Wang 和 Li 2019) 与上面讨论的基于网格的方法不同,它直接从点云创建提案。 然后,它采用 LiDAR 分割来识别提案的前景点,并在第二阶段生成边界框。 (Qi 等人 2019; Yang 等人 2022) 使用霍夫投票来收集点特征,然后从聚类中提出边界框。 由于其密集的特征表示,基于网格的方法速度更快,但它们会丢失原始点云的信息,而基于点的方法可以连接原始点云,但在定位每个点的邻居时效率低下。 PV-RCNN (Shi 等人 2020) 的提出是为了保持效率,同时允许点特征的感受野可调。
2.3深度估计
深度预测对于单目图像解释至关重要。 Fu 等人 (Fu 等人 2018) 采用回归方法,使用扩张卷积和场景理解模块来预测图像的深度。 Monodepth (Godard、Mac Aodha 和 Brostow 2017) 使用视差和重建来预测深度,无需监督。 Monodepth2 (Godard 等人 2019) 使用深度估计和姿态估计网络的组合来预测单帧中的深度。
一些方法通过构建成本量来预测深度。 MVSNet (Yao 等人 2018)首次将cost-volume引入深度估计领域。 基于MVSNet,RMVSNet (Yao 等人 2019) 使用 GRU 降低内存消耗,MVSCRF (Xue 等人 2019) 增加 CRF 模块,Cascade MVSNet (Gu等人2020)将MVSNet改为级联结构。 Wang 等人 (Wang 等人 2021a) 使用多尺度融合生成深度预测,并引入自适应模块,同时提高性能并减少内存消耗。 Bae 等人(Bae, Budvytis, and Cipolla 2022)将单视图图像与多视图图像融合,并引入深度采样以降低计算成本。
3 深入研究 Lift-splat 中的深度预测
在秒。 1,我们证明基于 LSS 的检测器在深度极差的情况下仍然可以获得合理的 3D 检测结果。 在本节中,我们首先回顾一下基于 Lift-splat 构建的基线 3D 探测器的整体结构。 然后我们在基础探测器上进行了一个简单的实验,以揭示为什么我们观察到先前的现象。 最后,我们讨论了该探测器的三个缺陷,并指出了可能的解决方案。
| mAP | mATE | NDS | |
|---|---|---|---|
| learned | 0.282 | 0.768 | 0.327 |
| random soft | 0.245 | 0.838 | 0.290 |
| random hard | 0.176 | 0.922 | 0.224 |
| ground truth | 0.470 | 0.393 | 0.515 |
3.1 基础探测器模型架构
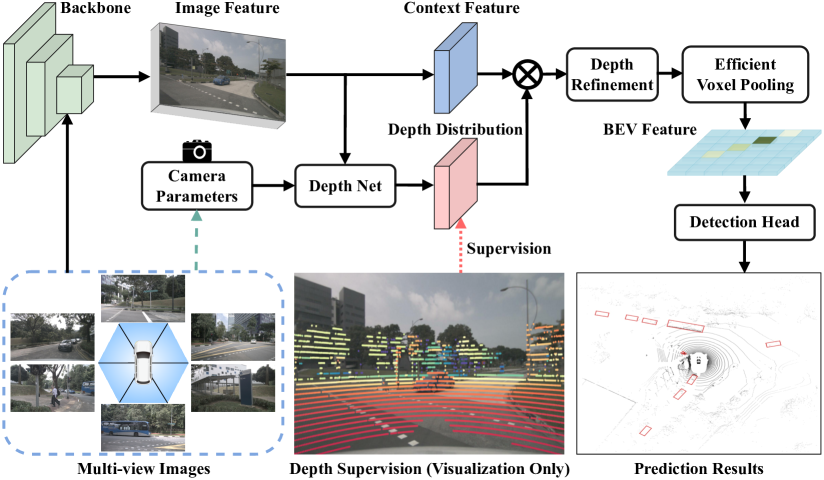
我们基于普通 Lift-splat 的检测器只需将 LSS (Philion 和 Fidler 2020) 中的分割头替换为 CenterPoint (Yin、Zhou 和 Krahenbuhl 2021) 头即可进行 3D 检测。 具体来说,它由图4所示的四个主要组件组成。 1) An Image Encoder (e.g., ResNet (He et al. 2016)) that extracts 2D features from view input images , where , and stand for feature’s height, width and channel number; 2) A DepthNet that estimates images depth from image features , where stands for the number of depth bins; 3) A View Transformer that projects in 3D representations using Eq. 1 then pools them into an integrated BEV representation ; 4) A 3D Detection Head predicting the class, 3D box offset and other attributes.
| (1) |
3.2 让 Lift-splat 工作很容易
学习深度 被认为是至关重要的,因为它用于为后续任务构建 BEV 表示。 然而,图 1 中糟糕的可视化结果与这一共识相矛盾。 在秒。 1,我们将 Lift-splat 的成功归因于部分合理的学习深度。 现在,我们通过用随机初始化的张量替换 并在训练和测试阶段冻结它来进一步研究该管道的本质。 结果如表1所示。 我们惊讶地发现,用随机软值替换 后,mAP 仅下降了 3.7%(从 28.2% 到 24.5%)。 我们假设,即使用于反投影特征的深度被灾难性地破坏,深度分布的软性质仍然在一定程度上有助于反投影到正确的深度位置,从而获得合理的 mAP,但同时它也消除了许多不可忽略的噪声。 我们进一步用硬随机深度(每个位置的单热激活)替换软随机深度,并观察到更大的下降 6.9%,验证了我们的假设。 这说明只要正确位置的深度有激活,探测头就可以工作。 这也解释了为什么图1中大部分区域的学习深度较差,但检测mAP仍然合理。
| Region | DL | SILog | AbsRel | SqRel | RMSE |
|---|---|---|---|---|---|
| All | 54.58 | 3.03 | 85.11 | 19.45 | |
| ✓ | 27.62 | 0.23 | 2.09 | 5.78 | |
| Best | 27.87 | 0.38 | 6.96 | 8.29 | |
| ✓ | 14.12 | 0.10 | 1.04 | 4.55 |
3.3 让 Lift-splat 正常工作很难
尽管取得了合理的结果,但现有的表现还远远不能令人满意。 在这一部分中,我们揭示了Lift-splat现有工作机制中的三个缺陷,包括深度不准确、深度模块过拟合和BEV语义不精确。 为了更清楚地展示我们的想法,我们比较了两个基线 - 一个是基于 LSS 的简单检测器,称为 Base Detector,另一个利用从 上的点云数据导出的额外深度监督,这将是在第 2 节中详细描述。 4。 我们将其命名为增强型探测器。
深度不准确
在 Base Detector 中,深度模块上的梯度源自检测损失,这是间接的。 研究学习深度的质量是很自然的。 因此,我们使用常用的深度估计指标(Eigen、Puhrsch和Fergus 2014)(包括尺度不变性)来评估nuScenes val上的学习深度对数误差 (SILog)、平均绝对相对误差 (Abs Rel)、均方相对误差 (Sq Rel) 和均方根误差 (RMSE)。 我们在两种不同的协议下评估两个检测器:1)每个对象的所有像素和2)每个对象的最佳预测像素。 结果如表2所示。 在评估所有前景区域时,Base Detector 仅达到 3.03 AbsRel,这比现有的深度估计算法(Li 等人 2022a;Bhat、Alhashim 和 Wonka 2021) 差很多。 然而,对于Enhanced Detector来说,AbsRel从3.03大幅降低到0.23,成为一个更合理的值。 值得一提的是,最佳匹配协议下的Base Detector的性能几乎可以与全区域协议下的Enhanced Detector相媲美。 这验证了我们在第二节中的假设。 1 当检测器在没有深度损失的情况下进行训练时(就像 Lift-splat 一样),它仅通过学习部分深度来检测对象。 在最佳匹配协议上应用深度损失后,学习深度进一步提高。 所有这些结果都表明隐式学习的深度是不准确的并且远远不能令人满意。
深度模块过拟合
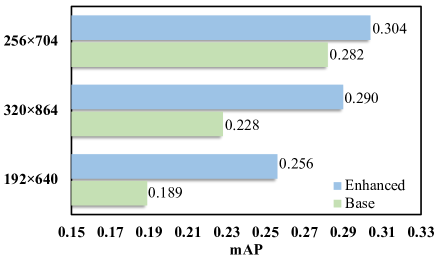
正如我们在前面的内容中所述,基础检测器仅学习预测部分区域的深度。 大多数像素都没有经过训练来预测合理的深度,这引起了我们对深度模块泛化能力的担忧。 具体地说,探测器的学习深度可能对图像大小、相机参数等超参数非常敏感。为了验证这一点,我们选择 "图像大小 "作为变量,并进行以下实验来研究模型的泛化能力:我们首先训练基础检测器和增强检测器,使用输入大小 256704。 然后我们分别使用 192640、256704 和 320864 尺寸对它们进行测试。 如图2所示,当测试图像大小与训练图像大小不一致时,基础检测器会损失更多准确度。 增强检测器的性能损失要小得多。 这种现象意味着没有深度损失的模型具有较高的过拟合风险,因此它也可能对相机内在、外在或其他超参数中的噪声敏感。
不精确的 BEV 语义
一旦使用学习深度将图像特征投影到截锥体特征,就会采用体素/柱池操作将它们聚合为 BEV。 图3显示,在没有深度监督的情况下,图像特征无法正确投影。 因此,池化操作仅聚合部分语义信息。 增强型检测器在这种情况下表现更好。 我们假设深度不足对分类任务有害。 然后我们使用两个模型的分类热图并评估它们的 TP / (TP + FN) 作为比较指标,其中 TP 代表锚点/特征,该锚点/特征被分配为正样本并被 CenterPoint 头正确分类,而FN代表相反的意思。 参见表3,增强型检测器在不同的正阈值下始终优于其他检测器,这验证了我们的假设。
在上述分析的推动下,我们意识到赋予多视点3D探测器更好的深度的必要性,并提出了我们的解决方案——BEVDepth。

| Method | th=0.3 | th=0.5 | th=0.7 |
|---|---|---|---|
| Base Detector | 42.28% | 18.36% | 5.12% |
| Enhanced Detector | 45.23% | 22.47% | 8.20% |
4 BEV深度
BEVDepth 是一款具有可靠深度的新型多视图 3D 探测器。 它利用相机感知深度预测模块 (DepthNet) 上的显式深度监督以及针对未投影平截头体特征的新颖深度细化模块来实现这一目标。
显式深度监督
在Base Detector中,深度模块的唯一监督来自于检测损失。 然而,由于单目深度估计的困难,单独的检测损失远远不足以监督深度模块。 因此,我们建议使用从点云数据导出的地面实况来监督中间深度预测。将和表示为从LiDAR坐标到视图的相机坐标的旋转和平移矩阵,并表示作为相机的内在参数。 为了获得,我们首先计算:
| (2) |
可以进一步转换为2.5D图像坐标,其中和表示像素坐标中的坐标。 如果某个点云的2.5D投影没有落入视图中,我们就直接丢弃它。 投影结果示例见图4。 然后,为了对齐投影点云和预测深度之间的形状,在上采用min pooling和one hot。 我们将这两个操作共同定义为,由此产生的可以写成等式: 3。 对于深度损失,我们简单地采用二元交叉熵。
| (3) |
相机感知深度预测
根据经典的相机模型,估计深度与相机内在参数相关,这意味着将相机内在参数建模到 DepthNet 中并非易事。 当摄像机可能具有不同的 FOV(例如,nuScenes 数据集)时,这在多视图 3D 数据集中尤其重要。 因此,我们建议利用相机内在函数作为 DepthNet 的输入之一。 具体来说,首先使用 MLP 层将相机内在的维度放大到特征。 然后,它们用于通过挤压和激励(Hu、Shen 和 Sun 2018) 模块重新加权图像特征。 最后,我们将相机的外部参数与其内部参数连接起来,以帮助 DepthNet 了解 在自我坐标系中的空间位置。 将表示为原始DepthNet,整体Camera-awareness深度预测可以写成:
| (4) |
其中 表示展平操作。 现有的作品(Park 等人 2021b) 也利用了相机感知。 他们根据相机的内在特性来缩放回归目标,这使得他们的方法很难适应具有复杂相机设置的自动化系统。 另一方面,我们的方法对 DepthNet 内部的相机参数进行建模,旨在提高中间深度的质量。 受益于 LSS (Philion and Fidler 2020) 的解耦特性,相机感知深度预测模块与检测头隔离,因此在这种情况下不需要更改回归目标,从而获得更大的可扩展性。
深度细化模块
为了进一步提高深度质量,我们设计了一种新颖的深度细化模块。 具体来说,我们首先将 从 重塑为 ,然后在 平面上堆叠多个 33 卷积层。 其输出最终被重新整形并输入到后续的体素/柱池操作中。 一方面,深度细化模块可以在深度预测置信度较低的情况下沿深度轴聚合特征。 另一方面,当深度预测不准确时,只要感受野足够大,深度细化模块理论上就能将其细化到正确的位置。 总之,深度细化模块为View Transformer阶段赋予了纠正机制,使其能够细化那些放置不当的特征。
5实验
在本节中,我们首先介绍我们的实验设置。 然后,在 BEVDepth 上进行全面的实验,以验证我们提出的组件的效果。 最后介绍了与其他领先相机 3D 检测模型的比较。
| DL | CA | DR | MF | mAP | mATE | mAOE | NDS |
|---|---|---|---|---|---|---|---|
| 0.282 | 0.768 | 0.698 | 0.327 | ||||
| ✓ | 0.304 | 0.747 | 0.671 | 0.344 | |||
| ✓ | ✓ | 0.314 | 0.706 | 0.647 | 0.357 | ||
| ✓ | ✓ | ✓ | 0.322 | 0.707 | 0.636 | 0.367 | |
| ✓ | ✓ | ✓ | ✓ | 0.330 | 0.699 | 0.545 | 0.442 |
| BCE | L1 | mAP | mATE | mAOE | NDS |
|---|---|---|---|---|---|
| ✓ | 0.322 | 0.707 | 0.636 | 0.367 | |
| ✓ | 0.321 | 0.703 | 0.629 | 0.371 | |
| ✓ | ✓ | 0.323 | 0.706 | 0.608 | 0.372 |
5.1实验设置
数据集和指标
nuScenes (Caesar 等人 2020) 数据集是一个大规模自动驾驶基准测试,包含来自 6 个摄像头、1 个 LiDAR 和 5 个雷达的数据。 数据集中有1000个场景,分别分为700、150和150个场景用于训练、验证和测试。 对于 3D 检测任务,我们报告 nuScenes 检测分数 (NDS)、平均平均精度 (mAP) 以及五个真阳性 (TP) 指标,包括平均平均平移误差 (mATE)、平均平均尺度误差 (mASE)、平均平均误差方向误差 (mAOE)、平均平均速度误差 (mAVE)、平均平均属性误差 (mAAE)。
实施细节
除非另有说明,我们使用 ResNet-50 (He 等人 2016) 作为图像主干,图像大小处理为 256704。 继(Huang等人2021)之后,我们采用了包括随机裁剪、随机缩放、随机翻转和随机旋转在内的图像数据增强,还采用了包括随机缩放、随机翻转和随机旋转在内的BEV数据增强。 我们使用 AdamW (Loshchilov 和 Hutter 2017) 作为优化器,学习率设置为 2e-4,批量大小设置为 64。 对于消融研究,所有实验均在不使用 CBGS 策略(Zhu 等人 2019)的情况下训练 24 个 epoch。 与其他方法相比,BEVDepth 使用 CBGS 训练了 20 个 epoch。 相机感知深度网络被放置在特征级别,步幅为 16。
5.2消融研究
成分分析
如表 4 所示,我们的普通 BEVDepth 实现了 28.2% mAP 和 32.7% NDS。 添加深度损失将 mAP 提高了 2.2%,这与我们的分析一致——深度损失有利于分类。 MATE 略微降低了 0.21,因为朴素的 BEVDepth 已经学会在检测损失的帮助下部分预测深度。 将相机参数建模到 DepthNet 中进一步将 mATE 降低了 0.41,揭示了相机感知的重要性。 最终,深度细化模块提高了 0.8% 的 mAP。 我们假设深度细化模块使沿深度轴的特征更加紧凑,从而有利于减少错误响应。 总体而言,与基线相比,我们的 BEVDepth 提高了 4.0% mAP 和 4.0% NDS,显示了我们创新的有效性。
| mAP | mATE | mAOE | NDS | |
|---|---|---|---|---|
| - | 0.314 | 0.706 | 0.647 | 0.357 |
| 13 | 0.315 | 0.703 | 0.650 | 0.357 |
| 31 | 0.320 | 0.695 | 0.624 | 0.369 |
| 33 | 0.322 | 0.707 | 0.636 | 0.367 |
| Method | Resolution | mAP | NDS |
|---|---|---|---|
| FCOS3D | 9001600 | 0.295 | 0.372 |
| DETR3D | 9001600 | 0.303 | 0.374 |
| BEVDet-R50 | 256704 | 0.286 | 0.372 |
| BEVDet-Tiny | 5121408 | 0.349 | 0.417 |
| PETR-R50-DCN | 3841056 | 0.313 | 0.381 |
| PETR-R101-DCN | 5121408 | 0.357 | 0.421 |
| PETR-Tiny | 5121408 | 0.361 | 0.431 |
| BEVDet4D-Tiny | 256704 | 0.323 | 0.453 |
| BEVDet4D-Base | 6401600 | 0.390 | 0.515 |
| BEVFormer-S | - | 0.375 | 0.448 |
| BEVFormer-R101-DCN | 9001600 | 0.416 | 0.517 |
| BEVDepth-R50 | 256704 | 0.351 | 0.475 |
| BEVDepth-R101 | 5121408 | 0.412 | 0.535 |
| BEVDepth-R101-DCN | 5121408 | 0.418 | 0.538 |
| Method | Modality | mAP | mATE | mASE | mAOE | mAVE | mAAE | NDS |
|---|---|---|---|---|---|---|---|---|
| CenterPoint | L | 0.564 | - | - | - | - | - | 0.648 |
| FCOS3D (Wang et al. 2021b) | C | 0.358 | 0.690 | 0.249 | 0.452 | 1.434 | 0.124 | 0.428 |
| DETR3D (Wang et al. 2022b) | C | 0.412 | 0.641 | 0.255 | 0.394 | 0.845 | 0.133 | 0.479 |
| BEVDet-Pure (Huang et al. 2021) | C | 0.398 | 0.556 | 0.239 | 0.414 | 1.010 | 0.153 | 0.463 |
| BEVDet-Beta | C | 0.422 | 0.529 | 0.236 | 0.396 | 0.979 | 0.152 | 0.482 |
| PETR (Liu et al. 2022a) | C | 0.434 | 0.641 | 0.248 | 0.437 | 0.894 | 0.143 | 0.481 |
| PETR-e | C | 0.441 | 0.593 | 0.249 | 0.384 | 0.808 | 0.132 | 0.504 |
| BEVDet4D (Huang and Huang 2022) | C | 0.451 | 0.511 | 0.241 | 0.386 | 0.301 | 0.121 | 0.569 |
| BEVFormer (Li et al. 2022b) | C | 0.481 | 0.582 | 0.256 | 0.375 | 0.378 | 0.126 | 0.569 |
| PETRv2 (Liu et al. 2022b) | C | 0.490 | 0.561 | 0.243 | 0.361 | 0.343 | 0.120 | 0.582 |
| BEVDepth | C | 0.503 | 0.445 | 0.245 | 0.378 | 0.320 | 0.126 | 0.600 |
| BEVDepth† | C | 0.520 | 0.445 | 0.243 | 0.352 | 0.347 | 0.127 | 0.609 |
深度损失
在深度估计领域,BCE和L1Loss是两种常见的损失。 在这一部分中,我们消除了在 DepthNet 中使用这两种不同损失的效果(参见表5),发现不同的深度损失几乎不影响最终的检测性能。
深度细化模块
5.3基准结果
在此,我们将简要介绍两个额外的实现方法,它们对于我们在 nuScenes leardboard 上获得性能至关重要:即高效体素池化和多帧融合。
高效的体素池
Lift-splat 中现有的体素池利用了涉及“排序”和“累积和”操作的“累积和技巧”。 这两种操作的计算效率都很低。 我们建议通过为每个平截头体特征分配一个 CUDA 线程来利用 GPU 的强大并行性,该线程用于将该特征添加到其相应的 BEV 网格。 因此,我们最先进模型的训练时间从 5 天减少到 1.5 天。 唯一的池化操作比 Lift-splat 中的基线快 80。
多帧融合
多帧融合有助于更好地检测物体并赋予模型估计速度的能力。 我们将不同帧的视锥体特征的坐标对齐到当前自我坐标系中,以消除自我运动的影响,然后执行体素池化。 来自不同帧的池化 BEV 特征直接连接并馈送到后续任务。
nuScenes 值集
我们将所提出的 BEVDepth 与 nuScenes val 集上的 FCOS3D、DETR3D、BEVDet、PETR、BEVDet4D 和 BEVFormer 等其他最先进的方法进行了比较。 我们不采用测试时间增加。 从表7可以看出,BEVDepth 在 NDS(nuScenes 数据集的关键指标)中表现出优异的性能,比第二名分别提高了 2%。 BEVDepth 在 mAP 中也与 BEVFormer 相当,因为它们使用更强的主干和更大分辨率的输入图像。 使用 256704 分辨率输入图像,BEVDepth 在 NDS 中比 ResNet-50 上的 BEVDet 超出 10%。 在 NDS 中,BEVDepth 也超过 BEVDet4D-Tiny 和 BEVFormer-S 2%。 当使用 5121408 分辨率输入图像时,BEVDepth 在 ResNet-101 上超过 PETR(mAP 6%)和 NDS 11%。 BEVDepth 在 mAP 上也超过了 BEVDET4D-Base 2%,在 NDS 上也超过了 2%,尽管他们的主干通常比我们更好。
nuScenes 测试集
对于test集上提交的结果,我们使用训练集和val集进行训练。 我们提交的结果是一个测试时间增加的单一模型。 如表8所示,BEVDepth 在 nuScenes 相机 3D 物体排行榜上排名第一,得分为 50.3% mAP 和 60.0% NDS。 在 mAP 上,我们比第二种方法 PETRv2 好 1.3%。 在 mATE(反映与深度密切相关的深度定位精度的关键指标)上,我们比 PETRv2 好 11.6%。 在 NDS 上,我们超出了第二名 1.8%,在其他指标上,我们与过去的最佳方法保持相同或相当。 当将主干网切换到 ConvNeXT 时,BEVDepth 在没有额外数据的情况下达到 60.9% NDS。
6结论
本文提出了一种新颖的网络架构,即 BEVDepth,用于 3D 对象检测的精确深度预测。 我们首先研究现有 3D 物体探测器的工作机制,并揭示其中不可靠的深度。 为了解决这个问题,我们在 BEVDepth 中引入了具有显式深度监督的相机感知深度预测和深度细化模块,使其能够生成稳健的深度预测。 BEVDepth获得了预测可信深度的能力,与现有的多视图3D检测器相比获得了显着的改进。 此外,借助多帧融合模式和高效体素池,BEVDepth 在 nuScenes 排行榜上取得了新的最先进水平。 我们希望 BEVDepth 能够成为未来多视图 3D 物体检测研究的强有力的基线。
参考
- Bae, Budvytis, and Cipolla (2022) Bae, G.; Budvytis, I.; and Cipolla, R. 2022. Multi-View Depth Estimation by Fusing Single-View Depth Probability with Multi-View Geometry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2842–2851.
- Bhat, Alhashim, and Wonka (2021) Bhat, S. F.; Alhashim, I.; and Wonka, P. 2021. Adabins: Depth estimation using adaptive bins. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4009–4018.
- Brazil and Liu (2019) Brazil, G.; and Liu, X. 2019. M3d-rpn: Monocular 3d region proposal network for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 9287–9296.
- Caesar et al. (2020) Caesar, H.; Bankiti, V.; Lang, A. H.; Vora, S.; Liong, V. E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; and Beijbom, O. 2020. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 11621–11631.
- Carion et al. (2020) Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; and Zagoruyko, S. 2020. End-to-end object detection with transformers. In European conference on computer vision, 213–229. Springer.
- Eigen, Puhrsch, and Fergus (2014) Eigen, D.; Puhrsch, C.; and Fergus, R. 2014. Depth map prediction from a single image using a multi-scale deep network. Advances in neural information processing systems, 27.
- Fu et al. (2018) Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; and Tao, D. 2018. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, 2002–2011.
- Geiger, Lenz, and Urtasun (2012) Geiger, A.; Lenz, P.; and Urtasun, R. 2012. Are we ready for autonomous driving? the kitti vision benchmark suite. In 2012 IEEE conference on computer vision and pattern recognition, 3354–3361. IEEE.
- Godard, Mac Aodha, and Brostow (2017) Godard, C.; Mac Aodha, O.; and Brostow, G. J. 2017. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE conference on computer vision and pattern recognition, 270–279.
- Godard et al. (2019) Godard, C.; Mac Aodha, O.; Firman, M.; and Brostow, G. J. 2019. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 3828–3838.
- Gu et al. (2020) Gu, X.; Fan, Z.; Zhu, S.; Dai, Z.; Tan, F.; and Tan, P. 2020. Cascade cost volume for high-resolution multi-view stereo and stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2495–2504.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778.
- Hu, Shen, and Sun (2018) Hu, J.; Shen, L.; and Sun, G. 2018. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 7132–7141.
- Huang and Huang (2022) Huang, J.; and Huang, G. 2022. BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection. arXiv preprint arXiv:2203.17054.
- Huang et al. (2021) Huang, J.; Huang, G.; Zhu, Z.; and Du, D. 2021. BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View. arXiv preprint arXiv:2112.11790.
- Huo et al. (2020) Huo, Y.; Yi, H.; Wang, Z.; Shi, J.; Lu, Z.; Luo, P.; et al. 2020. Learning depth-guided convolutions for monocular 3d object detection. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 4306–4315. IEEE.
- Lang et al. (2019) Lang, A. H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; and Beijbom, O. 2019. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 12697–12705.
- Li et al. (2022a) Li, Z.; Chen, Z.; Liu, X.; and Jiang, J. 2022a. DepthFormer: Exploiting Long-Range Correlation and Local Information for Accurate Monocular Depth Estimation. arXiv preprint arXiv:2203.14211.
- Li et al. (2022b) Li, Z.; Wang, W.; Li, H.; Xie, E.; Sima, C.; Lu, T.; Yu, Q.; and Dai, J. 2022b. BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers. arXiv preprint arXiv:2203.17270.
- Liu et al. (2022a) Liu, Y.; Wang, T.; Zhang, X.; and Sun, J. 2022a. PETR: Position Embedding Transformation for Multi-View 3D Object Detection. arXiv preprint arXiv:2203.05625.
- Liu et al. (2022b) Liu, Y.; Yan, J.; Jia, F.; Li, S.; Gao, Q.; Wang, T.; Zhang, X.; and Sun, J. 2022b. PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images. arXiv preprint arXiv:2206.01256.
- Liu et al. (2022c) Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; and Xie, S. 2022c. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11976–11986.
- Loshchilov and Hutter (2017) Loshchilov, I.; and Hutter, F. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
- Park et al. (2021a) Park, D.; Ambrus, R.; Guizilini, V.; Li, J.; and Gaidon, A. 2021a. Is Pseudo-Lidar needed for Monocular 3D Object detection? In Proceedings of the IEEE/CVF International Conference on Computer Vision, 3142–3152.
- Park et al. (2021b) Park, D.; Ambrus, R.; Guizilini, V.; Li, J.; and Gaidon, A. 2021b. Is Pseudo-Lidar needed for Monocular 3D Object detection? In Proceedings of the IEEE/CVF International Conference on Computer Vision, 3142–3152.
- Philion and Fidler (2020) Philion, J.; and Fidler, S. 2020. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In European Conference on Computer Vision, 194–210. Springer.
- Qi et al. (2019) Qi, C. R.; Litany, O.; He, K.; and Guibas, L. J. 2019. Deep hough voting for 3d object detection in point clouds. In proceedings of the IEEE/CVF International Conference on Computer Vision, 9277–9286.
- Qian et al. (2020) Qian, R.; Garg, D.; Wang, Y.; You, Y.; Belongie, S.; Hariharan, B.; Campbell, M.; Weinberger, K. Q.; and Chao, W.-L. 2020. End-to-end pseudo-lidar for image-based 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5881–5890.
- Reading et al. (2021) Reading, C.; Harakeh, A.; Chae, J.; and Waslander, S. L. 2021. Categorical depth distribution network for monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8555–8564.
- Roddick, Kendall, and Cipolla (2018) Roddick, T.; Kendall, A.; and Cipolla, R. 2018. Orthographic feature transform for monocular 3d object detection. arXiv preprint arXiv:1811.08188.
- Rukhovich, Vorontsova, and Konushin (2022) Rukhovich, D.; Vorontsova, A.; and Konushin, A. 2022. Imvoxelnet: Image to voxels projection for monocular and multi-view general-purpose 3d object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2397–2406.
- Shi et al. (2020) Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; and Li, H. 2020. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10529–10538.
- Shi, Wang, and Li (2019) Shi, S.; Wang, X.; and Li, H. 2019. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 770–779.
- Sun et al. (2020) Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. 2020. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2446–2454.
- Wang et al. (2021a) Wang, F.; Galliani, S.; Vogel, C.; Speciale, P.; and Pollefeys, M. 2021a. Patchmatchnet: Learned multi-view patchmatch stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 14194–14203.
- Wang et al. (2022a) Wang, T.; Xinge, Z.; Pang, J.; and Lin, D. 2022a. Probabilistic and geometric depth: Detecting objects in perspective. In Conference on Robot Learning, 1475–1485. PMLR.
- Wang et al. (2021b) Wang, T.; Zhu, X.; Pang, J.; and Lin, D. 2021b. Fcos3d: Fully convolutional one-stage monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 913–922.
- Wang et al. (2019) Wang, Y.; Chao, W.-L.; Garg, D.; Hariharan, B.; Campbell, M.; and Weinberger, K. Q. 2019. Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8445–8453.
- Wang et al. (2022b) Wang, Y.; Guizilini, V. C.; Zhang, T.; Wang, Y.; Zhao, H.; and Solomon, J. 2022b. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In Conference on Robot Learning, 180–191. PMLR.
- Xue et al. (2019) Xue, Y.; Chen, J.; Wan, W.; Huang, Y.; Yu, C.; Li, T.; and Bao, J. 2019. Mvscrf: Learning multi-view stereo with conditional random fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 4312–4321.
- Yan, Mao, and Li (2018) Yan, Y.; Mao, Y.; and Li, B. 2018. Second: Sparsely embedded convolutional detection. Sensors, 18(10): 3337.
- Yang et al. (2022) Yang, J.; Song, L.; Liu, S.; Li, Z.; Li, X.; Sun, H.; Sun, J.; and Zheng, N. 2022. DBQ-SSD: Dynamic Ball Query for Efficient 3D Object Detection. arXiv preprint arXiv:2207.10909.
- Yao et al. (2018) Yao, Y.; Luo, Z.; Li, S.; Fang, T.; and Quan, L. 2018. Mvsnet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV), 767–783.
- Yao et al. (2019) Yao, Y.; Luo, Z.; Li, S.; Shen, T.; Fang, T.; and Quan, L. 2019. Recurrent mvsnet for high-resolution multi-view stereo depth inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5525–5534.
- Yin, Zhou, and Krahenbuhl (2021) Yin, T.; Zhou, X.; and Krahenbuhl, P. 2021. Center-based 3d object detection and tracking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 11784–11793.
- You et al. (2019) You, Y.; Wang, Y.; Chao, W.-L.; Garg, D.; Pleiss, G.; Hariharan, B.; Campbell, M.; and Weinberger, K. Q. 2019. Pseudo-lidar++: Accurate depth for 3d object detection in autonomous driving. arXiv preprint arXiv:1906.06310.
- Zhou, Wang, and Krähenbühl (2019) Zhou, X.; Wang, D.; and Krähenbühl, P. 2019. Objects as points. arXiv preprint arXiv:1904.07850.
- Zhou and Tuzel (2018) Zhou, Y.; and Tuzel, O. 2018. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4490–4499.
- Zhu et al. (2019) Zhu, B.; Jiang, Z.; Zhou, X.; Li, Z.; and Yu, G. 2019. Class-balanced grouping and sampling for point cloud 3d object detection. arXiv preprint arXiv:1908.09492.