NeuRIS:使用正常先验对室内场景进行神经重建
摘要
从 2D 图像重建 3D 室内场景是许多计算机视觉和图形应用中的一项重要任务。 这项任务的主要挑战是典型室内场景中的大面积无纹理区域使得现有方法难以产生令人满意的重建结果。 我们提出了一种名为 NeuRIS 的新方法,用于室内场景的高质量重建。 NeuRIS 的关键思想是将室内场景的估计法线作为先验集成到神经渲染框架中,以重建大型无纹理形状,并且重要的是,以自适应方式执行此操作,也使重建具有精细细节的不规则形状。 具体来说,我们通过在优化过程中检查重建的多视图一致性来实时评估正常先验的忠实度。 只有被接受为忠实的正常先验才会被用于 3D 重建,这通常发生在可能具有弱纹理的平滑形状的区域中。 然而,对于那些具有小物体或薄结构的区域,正常先验通常不可靠,我们将仅依赖输入图像的视觉特征,因为这些区域通常包含相对丰富的视觉特征(例如,阴影变化和边界轮廓) )。 大量实验表明,NeuRIS 在重建质量方面明显优于最先进的方法111Our project page: https://jiepengwang.github.io/NeuRIS/。
关键词:
室内重建、神经体积渲染、自适应先验1简介
在机器人导航、虚拟现实和路径规划等许多实际应用中,从多个输入图像重建 3D 室内场景是一项重要且具有挑战性的任务。 室内场景通常包含许多大的无纹理区域和重复图案,例如白墙、地板和反射表面,这对于应用传统的基于匹配的密集重建算法具有挑战性[28,45,29] 严重依赖于不同视觉特征的对应性,导致重建结果不佳。
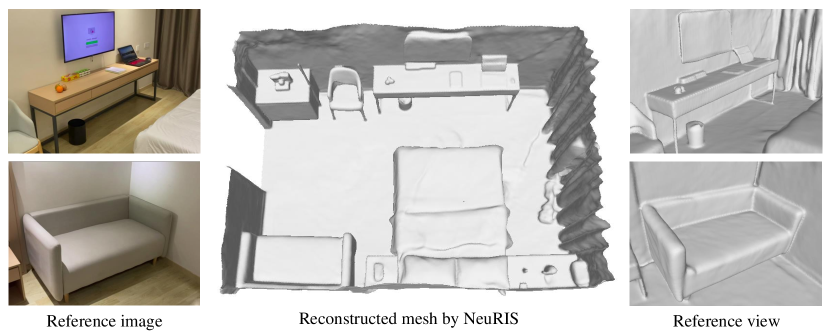
随着深度神经网络的成功,数据驱动(基于深度和基于 TSDF)的方法[34,17,10,33,22,31]已被证明可以有效缓解无纹理问题通过利用从大量数据中学到的各种几何先验来解决问题。 然而,这些方法很难产生具有几何细节的室内场景的高质量重建。 例如,基于深度的方法 [33, 10] 通常单独估计深度图,这会导致帧之间缺乏连贯性和尺度模糊性,以及重建时出现噪声表面和浮动异常值。 基于 TSDF 的方法[22, 31]由于使用显式 3D 体积表示而遭受高内存消耗;由于当分辨率较高时,内存需求会变得非常大,因此它们无法应用于可以重建精细细节的级别。
最近,神经场景表示以及逆向渲染技术 [20, 36, 40, 41, 24] 通过将体积密度、占用率或有符号距离编码为紧凑且可微的表示。 然而,大多数神经方法无法重建具有大无纹理区域的室内场景,这些区域不包含像素级优化所需的足够视觉特征。 为了解决这个问题,NerfingMVS [38] 集成了深度先验来指导 NeRF 框架 [20] 中的点采样,以减少形状辐射模糊性。 尽管它可以预测比原始 NeRF 估计更好的深度图,但其输出深度图的融合几何形状仍然具有有限的表面质量。
我们提出了一种新颖的神经表面重建方法,称为NeuRIS,专门用于室内场景。 我们的关键思想是以自适应方式利用学习到的法线先验来促进神经表面表示的学习,其中法线先验提供更全局一致的几何约束来指导优化过程。 具体来说,我们首先使用现有的单目法线估计网络来估计输入图像的法线图。 然后,除了输入图像提供的外观监督之外,法线先验还用于提供额外的约束,以减轻无纹理区域(通常由平滑或规则形状组成)的几何模糊问题。
请注意,在具有小物体、复杂形状或薄结构的区域中,正常先验可能不准确,从而妨碍高质量重建。 因此,对于这些区域,我们建议以自适应方式使用正常先验。 为此,我们开发了一种机制,基于输入图像的多视图摄影一致性,动态评估正常先验的忠实度。 对于多视图一致性不满足的区域,将去除法线约束,仅利用外观信息进行优化。 我们观察到,正常先验不忠实的区域通常由输入图像中具有相对丰富的视觉特征的尖锐特征或不规则形状组成,这通常足以通过图像的外观监督来重建高质量的表面。 这种利用正常先验的自适应策略使得重建过程对于一般室内场景更加鲁棒。 因此,NeuRIS 实现了具有丰富几何细节的复杂室内场景的高质量重建。
总结起来,NeuRIS具有以下优势:
-
•
我们提倡使用正常先验,因为它们对于平移和缩放具有不变性,并且比先前方法中使用的深度先验表现出更好的多视图一致性。 正常先验提供了跨输入图像的全局一致的几何约束,从而显着提高了通常出现在室内场景中的大型平滑对象的无纹理区域的重建质量。
-
•
我们以自适应方式应用正常先验,这是通过即时评估正常先验的忠实度来实现的。 这种策略可以忠实地重建室内场景中具有几何细节的复杂形状。
广泛的验证和比较表明,NeuRIS 在 ScanNet [4] 上取得了优异的结果,并且在室内场景的重建质量方面显着优于最先进的方法。
2相关作品
2.1室内场景重建
传统的多视图立体方法[28,29,45]可以产生纹理表面的合理几何形状,但难以处理无纹理区域,例如室内场景中的区域。 最近,基于学习的 MVS 方法在处理无纹理表面方面取得了有希望的结果。 此类方法可以分为两类:基于深度的方法[10, 33, 17, 16, 15, 18]和基于TSDF(截断符号距离函数)的方法[22, 31] 。 基于深度的方法首先单独估计图像的深度图,然后利用额外的过滤和融合程序来重建场景。 由于深度图的单独估计造成的不一致,此类方法经常遭受不完整性、噪声表面和尺度模糊的困扰。 为了缓解这些问题,一些方法[22, 31]直接将输入图像回归到TSDF。 Atlas [22] 提出了一种体积设计,将由图像序列构建的 3D 全局特征体积回归到 TSDF。 受其全局设计和计算资源的限制,Atlas只能处理有限数量的图像,并且其重建结果缺乏细节。 为了减少计算负担,与一次性处理整个图像序列的 Atlas 不同,NeuralRecon [31] 提出了一个从粗到细的框架,通过增量处理局部片段来重建整个场景。 然而,由于其局部估计设计,NeuralRecon 获得具有精细细节的全局重建具有挑战性。
2.2神经体积渲染和先验引导优化
最近,基于坐标的神经表示(通过多层感知器 (MLP) 将 3D 坐标回归为输出值来对字段进行编码)因其紧凑性和灵活性而成为表示场景的流行方式。 神经场在编码图像 [30, 3, 26]、形状 [30, 25, 7, 1, 19] 和 3D 场景 方面取得了显着的效果[20、41、40、24、36、39]。 在本文中,我们主要关注神经 3D 场景表示及其逆渲染技术。 为不同的目标选择不同类型的领域。 神经辐射场[20]通过体积密度对场景几何进行编码,适用于通过体积渲染进行新颖的视图合成的任务。 然而,由于缺乏表面约束,体积密度无法代表高保真表面。 通过使用占用率和有符号距离可以更好地重建表面几何形状;它们可以通过表面渲染[41, 23]和体积渲染[36,40,24]在参考图像的监督下进行优化。 为了进一步提高重建精度,并行工作NeuralWarp[5]提出了一种基于扭曲的图像块损失项来提高重建精度。 然而,由于室内场景缺乏纹理,这些方法在室内场景上表现不佳。 因此,一些方法尝试引入几何先验来指导优化过程。
深度先验。 一些方法[38, 14]使用深度先验来监督训练过程和/或指导NeRF[20]的采样过程进行室内场景渲染以减轻形状歧义问题。 尽管它们可以预测比 NeRF 渲染的深度图更好的深度图,但第 2.1 节中描述的基于深度的方法的固有问题仍然存在,即使通过过滤对数据进行后处理,它们也无法生成平滑的几何图形和融合。 类似地,Roessle 等人[27]利用 NeRF 优化框架中的密集深度先验来实现具有稀疏输入视图的新颖视图合成。 他们构建了一个深度补全网络,从 SfM 的稀疏点云中获取密集的深度先验。 然而,该框架是为新颖的视图合成而设计的,而不是为几何重建而设计的。 此外,一项名为 MonoSDF [43] 的并行工作还将学习到的单目几何线索集成到神经体积渲染框架中,其中法线和深度先验被插入到优化过程中以提高重建质量。
正常先验。 表面法线对于 3D 场景理解非常重要[42, 44],最近单视图法线估计在高精度方面取得了很大进展[6,37,9,2]。 我们观察到估计的正态先验在平面区域和输入视图中表现出高度一致性,并且还提供了基础几何的明显线索,如图6所示。 由于普通先验的良好特性,也为了避免上述深度先验带来的问题,我们选择将普通先验集成到体绘制框架中,以提高表面表示的优化。
3方法
给定一组室内场景的校准 RGB 图像 ,我们的目标是准确地重建具有精细细节的场景几何形状。 为此,我们采用全局神经表面表示,并在输入 RGB 图像的监督下对其进行优化。 为了重建包含大的无纹理区域和具有精细细节的不规则形状的高保真室内场景,我们提出了一种自适应的、先验引导的优化方法。 具体来说,我们将从大型室内场景数据集中学习到的正常先验融入到用于 3D 形状重建的神经渲染框架中。 此外,注意到正常先验在具有不规则形状和薄结构的区域中往往不准确,我们建议以自适应方式使用正常先验。 这是通过评估正常先验的多视图一致性来实现的,因此它们仅适用于重建平滑且规则的形状,而不适用于具有复杂几何形状的物体。
我们的管道有两个阶段。 在第一阶段,我们使用单目方法预测的法线先验[6]来为神经体渲染框架渲染的法线提供约束。 请注意,此阶段不会调用正常先验的评估(第 3.1 节)。 我们在第一阶段获得的是具有相当好的深度估计的粗糙形状,但缺乏局部精细细节。 在此阶段,由于使用了正常先验,可以以相当好的质量重建大的平面形状,但是对于薄结构或具有不规则形状特征的小物体,会产生不准确的总体形状,因为正常先验对于这些区域不可靠。
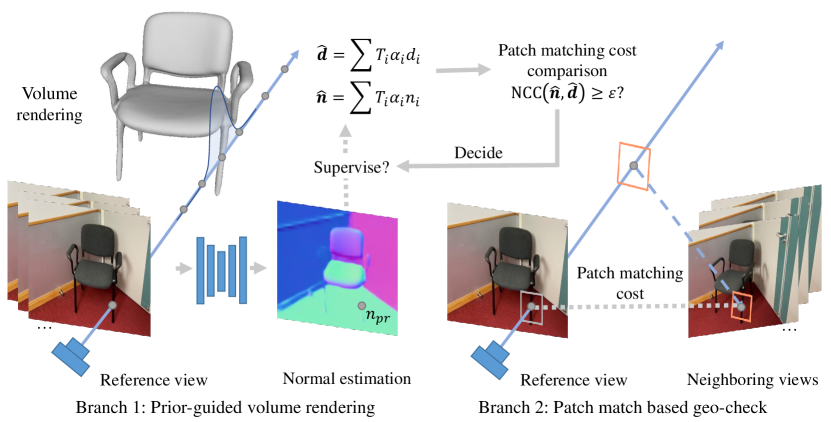
因此,在第二阶段,我们引入了一种方案,通过评估当前估计的法线和深度引起的多视图光度一致性来评估法线先验的忠实度。 只有那些产生的相应几何形状通过光度一致性测试的正常先验才会被认为是可靠的,并用于以下优化步骤中的监督。 对于那些不可靠的正常先验,我们将把它们从监督中删除,只依赖颜色信息进行后续的优化步骤。 该方案提高了具有相对更多视觉特征的清晰几何特征的区域的质量(第3.2)。 图 2 显示了我们方法的概述。
3.1 预先引导的体积渲染
场景表示。 与 NeuS [36] 类似,3D 室内场景由两个多层感知器(MLP)表示:几何网络 用于编码符号距离函数(SDF),以及颜色网络 对与空间位置和视图方向关联的颜色进行编码。 然后将表面 定义为 SDF 的零水平集,即
| (1) |
体积渲染。 为了使用 2D 图像观察进行强大的监督,我们采用了体积渲染技术,该技术在 NeRF 及其变体中被证明是强大的。 具体来说,对于每个像素,我们沿着相应的发射光线采样一组点,表示为 ,其中 是采样点, 是相机中心, 是该射线的方向。 然后通过方程沿着光线累积颜色。 2。
| (2) |
其中表示累积透射率,是离散不透明度,不透明密度遵循NeuS中的原始定义[36]。 由于渲染过程是完全可微的,我们可以通过最小化渲染结果与参考图像之间的差异来学习和的权重。
然而,如我们的实验(第 4.2 节)所示,由于缺乏纹理,像素级颜色无法提供足够的信息,因此简单地使用输入图像的监督会导致噪声结果在无纹理区域。
预先引导的优化。 一个关键的观察是,上述体绘制方案不仅可以生成外观,还可以生成深度和法向量等几何属性。 也就是说,我们可以使用沿这条射线的体积累积来近似从一个视点观察到的表面法线和深度:
| (3) |
其中是SDF在处的空间梯度,是相应的深度。
鉴于由 RGB 图像 预测的正态图 所代表的几何先验,我们通过比较呈现的正态图 和来自 的相应估计值,对其进行监督。 我们使用预训练的单视图法线估计网络[6]来生成参考法线图作为监督。 尽管直接使用普通先验而不进行任何过滤有助于重建完整的表面,但结果仍然缺乏精细的细节。 这是因为估计的法线贴图通常过度平滑,在某些精致的结构(例如椅子腿、窗帘等)上甚至非常不准确。 这促使我们开发一种过滤方案,以自适应方式使用法线先验来重建更准确的表面几何形状。
3.2 正常先验的自适应检查
在本节中,我们介绍一种用于评估正常质量并在优化过程中自适应地施加先验监督的检查方法。 我们的方法是基于一个关键的观察而开发的:预测的法线贴图在存在锐利几何细节的区域过于平滑。 此外,这些区域通常具有丰富的视觉特征,这为通过评估光度一致性来验证法线的准确性提供了有用的线索,即通过将重建的形状投影到输入图像并计算多视图图像之间的视觉差异。 基于这一观察,我们提出了一种基于补丁匹配技术的检查方案,用于评估渲染深度和法线向量的多视图一致性(方程3)。 这种多视图一致性评估可以帮助 NeuRIS 识别当前几何结构是否重建良好。 如果不是,则正常先验将被视为不可靠并且不用于进一步细化重建。
具体来说,考虑评估从参考图像上的像素观察到的表面的视觉一致性,在参考相机中定义局部3D平面与 关联的空间,其中 是视图方向, 和 是距离和来自 。 然后我们找到一组相邻图像,并假设其中一个相邻图像是。 从到的单应变换可以通过等式计算: 4。
| (4) |
这里 是表示固有矩阵、旋转和平移的相机参数。
然后对于 中的像素 ,我们找到一个以其为中心的方形补丁 并将该补丁扭曲到其相邻视图 计算出的单应性矩阵。 的视觉一致性按照传统的补丁匹配技术 [28] 使用归一化互相关 (NCC) 进行评估:
| (5) |
其中表示减去本地补丁的平均值的结果。
在训练过程中,采样像素以及参考图像中的补丁通过其累积深度和法线 在体积渲染中。 如果重建的几何结构在采样像素处不准确,则将无法满足多视图光度一致性,这意味着其相关的法线先验无法为重建过程提供帮助。 通过将采样补丁处的 NCC 与鲁棒阈值 进行比较,我们可以使用指示函数自适应地决定正常先验的训练权重:
| (6) |
仅当等于时,正常先验才会用于监督。 并且正常先验一旦被判断为不忠实,就不会在后续的优化过程中使用。
3.3训练
在训练阶段,我们对一批像素进行采样,并自适应地最小化颜色和法线估计以及相应参考的差异。 具体来说,在训练期间,在每次迭代中,我们对 像素 及其相应的参考颜色 和法线 进行采样。 对于每个像素,我们沿着世界空间中相应的射线对 点进行采样。 总体损失定义为
| (7) |
这里颜色损失定义为
| (8) |
其中 是通过体积渲染预测的像素颜色。 正常先验损失表示为
| (9) |
请注意,整个训练过程分为两个阶段,第一阶段没有几何检查。 因此,指标在第一阶段始终等于1,同时遵循式(1)。 6 第二阶段。
正则化 SDF 的 Eikonal 损失 [8] 定义为
| (10) |
分别是对颜色损失、先验损失和 Eikonal 损失进行加权的超参数。
4实验
4.1实现细节
架构。 我们采用与 NeuS [36] 相同的网络架构,其中符号距离函数和颜色函数分别由具有 8 个和 6 个隐藏层的 MLP 建模。 位置编码 [20] 和球体初始化 [1] 应用于网络。 对于正常先验,我们采用最近的方法 [6] 并使用我们的训练/测试分割重新训练其网络以预测输入图像的法线,而不是使用其官方预训练模型。 我们为每个批次采样 512 条光线来训练模型。 我们首先使用正常先验训练模型进行 60k 次迭代,然后继续训练完整模型进行另外 100k 次迭代,这在单个 NVIDIA RTX2080Ti GPU 上总共需要大约 10 个小时。 更多详细信息可以在补充中找到。
数据集。 我们在 ScanNet [4] 上测试我们的算法的性能。 ScanNet 是一个大型数据集,由 1613 个室内场景组成,具有地面实况相机内在特征、相机姿态和表面重建。 按照 NerfingMVS [38],我们随机选择 8 个场景,所有图像都以 分辨率调整大小。 与使用覆盖房间局部区域的图像的 NerfingMVS [38] 不同,我们的目标是执行房间尺度的重建。 对于每个场景,从相应的视频中采样一组等间距的图像(大约150600张图像),因此采样图像的数量与视频长度成正比。
基线。 我们将我们的方法与以下方法进行比较:(1)基于深度的方法:DeepV2D [33]; (2)基于TSDF的方法:NeuralRecon [31]和Atlas [22]; (3)神经体绘制方法:NeRF[20]、NerfingMVS [38]、NeuS [36]和VolSDF [40 ]; (4)传统MVS重建方法COLMAP[28]。 对于基于深度的方法 DeepV2D,为了解决其尺度模糊问题,我们使用中值尺度策略[46]根据地面真实深度图重新缩放每个预测深度图,然后融合其按照 NeuralRecon [31] 预测深度图来构造全局表面几何形状。 对于 COLMAP,我们使用地面真实姿态来重建点云,然后使用筛选泊松曲面重建[11]来获得网格。
评估指标。 为了进行完整的定量比较,我们按照 NeuralRecon [31] 中定义的指标评估 3D 表面几何结果。 在这些指标中,F-score 通常被认为是评估几何质量的最合适指标[31]。 更多详情请参阅补充。
4.2比较
3D 重建。 表1显示了与最先进方法相比的定量结果。 请注意,对于数据驱动方法[31,22,33],我们使用官方预训练模型。 如表1所示,我们的方法可以显着超越现有方法,特别是与神经体绘制方法相比。 对于公制比较。 (完整性),NeuRIS比DeepV2D稍差。 这是因为我们将 DeepV2D 的每个深度图缩放到 GT 深度图,因此在深度图融合后,GT 网格附近有足够的点(即低 Comp. 误差),但许多点仍然远离 GT 网格(即高精度误差)。 对于NerfingMVS [38],它是为细化深度图而设计的,因此我们通过TSDF融合[newcombe2011kinectfusion]来融合其输出深度图。 请注意,它在我们预实验中的大多数(5/8)房间规模场景中都失败了,并且仅显示了原始论文中重建局部房间区域的结果。 因此,我们在这里仅报告成功场景的平均分数。 对于 NeRF,我们使用水平集 20 来提取表面,其中水平集是经过仔细选择的(参见补充)。
图3显示了定性比较。 我们的方法在视觉上比其他方法在细节上要好得多。 我们注意到,我们的方法可以产生非常完整和平滑的结果,并填充地面真实表面中存在的孔洞,这主要是由遮挡和不完整扫描[22]引起的。 有关 Scannet 和其他室内数据集的更多定性结果,请参阅补充材料。
| Method | Accu. | Comp. | Prec. | Recall | F-score |
|---|---|---|---|---|---|
| COLMAP[28] | 0.076 | 0.096 | 0.559 | 0.545 | 0.548 |
| NeuralRecon[31] | 0.046 | 0.081 | 0.720 | 0.577 | 0.640 |
| Atlas[22] | 0.211 | 0.070 | 0.500 | 0.659 | 0.564 |
| DeepV2D[33] | 0.174 | 0.049 | 0.528 | 0.682 | 0.593 |
| NeRF[20] | 0.127 | 0.080 | 0.404 | 0.512 | 0.436 |
| NerfingMVS[38] | 0.155 | 0.087 | 0.410 | 0.471 | 0.438 |
| NeuS[36] | 0.183 | 0.152 | 0.286 | 0.290 | 0.284 |
| VolSDF[40] | 0.237 | 0.171 | 0.331 | 0.280 | 0.301 |
| Ours | 0.046 | 0.053 | 0.770 | 0.707 | 0.736 |


正常预测。 除了准确的几何重建之外,我们的方法还可以实现比[6]更准确的法线预测。 对于单目法线估计方法[6],当存在严重遮挡或模糊时,估计的法线图可能包含错误的预测。 例如,当对墙壁的观察过于局部时,很难利用全局信息进行精确的法线估计。 由于提出了自适应法线引导优化,我们的方法可以提高跨视图法线贴图的全局一致性,并纠正 [6] 的错误估计。 图4清楚地显示了我们的方法可以提高正态估计质量的一个例子。 表 2 中总结的定量比较也验证了 NeuRIS 的正常值优于 [6] 中使用 [6] 中定义的指标的正常值。 在这里,我们将渲染法线(方程 3)和 [6] 的预测法线与 8 个场景(即 493 张图像)的 GT 法线的余弦相似度进行比较), 分别。
| Method | Mean | Median | RMSE | 11.25 | 22.5 | 30 |
|---|---|---|---|---|---|---|
| TiltedSN [6] | 15.4 | 7.3 | 24.8 | 63.2 | 79.3 | 84.5 |
| Ours | 14.7 | 6.9 | 24.3 | 65.4 | 81.1 | 86.0 |
新颖的视图合成。 为了评估新颖视图合成的质量,我们在 8 个场景中统一采样 500 个新颖视图,这与训练图像不同。 得益于我们高质量的几何体,我们的渲染质量比 NeRF 和 NeuS 更好。 NeRF、NeuS 和我们的平均 PSNR 分别为 23.3、22.7 和 24.4。 图5显示了一个定性比较示例,更多结果请参阅补充材料。

4.3消融研究
为了评估我们提出的组件的有效性,我们在三种不同的设置下进行实验:(1)默认设置的 NeuS; (2) 先验正常的 NeuS; (3) 我们的:具有正常先验和几何检查的 NeuS。 表3显示,整合正常先验显着提高了重建质量,因为它减少了由于缺乏纹理而导致的模糊性。 通过几何检查,我们可以删除错误估计的法线并进一步提高几何质量。 此外,如图6所示,在NeuS中天真地采用所有正常先验可以重建墙壁和地板,但无法重建椅子腿。 对于与椅子腿对应的像素,其多视图一致性约束不满足,并且在训练过程中应去除该区域的正常先验。 最后,通过我们的几何检查,可以成功重建椅腿。 这表明我们的几何检查可以消除错误估计的法线。
| NeuS | Prior | Geo | Accu. | Comp. | Prec. | Recall | F-score |
|---|---|---|---|---|---|---|---|
| ✓ | 0.183 | 0.152 | 0.286 | 0.290 | 0.284 | ||
| ✓ | ✓ | 0.050 | 0.053 | 0.749 | 0.701 | 0.724 | |
| ✓ | ✓ | ✓ | 0.046 | 0.053 | 0.770 | 0.707 | 0.736 |

考虑到从视频序列中采样的一组图像,我们还展示了放置在桌子角落的具有挑战性的薄结构的重建结果。 图7显示NeuS可以重建薄结构,但存在伪影,包括错误重建的桌面表面和红色箭头所示的冗余表面。 具有正常先验的 NeuS 可以很好地重建背景桌面,但仍然无法很好地重建薄结构的某些部分(蓝色箭头)。 对于我们的方法,背景桌面和前景薄结构都可以很好地重建。 此外,与仅关注薄结构重建的方法[32,12,35,13]不同,我们的方法不需要对每个输入图像进行前景提取作为预处理,并且可以处理包含薄结构和一般物体。

总之,对于室内场景,主要的形状类别是平面或规则表面,例如墙壁、地板和家具,它们通常具有弱或没有视觉纹理,但占据了空间的大部分区域。 在正常先验的帮助下,可以很好地重建这些形状。 由此可见,重建质量可以得到很大的提高。 然而,对于相对较小的物体或薄的结构(例如物体边缘和椅子腿),正常先验可能不准确。 通过我们的地理检查机制,可以消除这些错误估计的法线,从而进一步提高重建质量。 尽管边缘或小物体所占据的区域在房间中可能并不大,但它们的准确重建对于感知质量重建的整体成功至关重要。
5结论和未来工作
在这项工作中,我们提出了一种新颖的具有几何约束的先验引导的神经体渲染优化框架,该框架可以自适应地将正常先验有效且准确地集成到神经体渲染中。 这种方式使网络能够利用无纹理区域的先验知识,并保持重建具有相对更多纹理的小物体的精细细节的能力。 该方法在 VR/AR 或其他需要精确室内几何的应用中具有实际用途。 目前,我们的方法需要对每个场景进行几个小时的优化,这阻碍了我们的方法大规模重建场景。 未来,我们将尝试将一些混合神经表示(例如多分辨率哈希编码 [21])集成到我们的模型中,以加快训练过程,并尝试自适应地集成其他类型的先验进入我们的框架,例如平面先验和深度先验,以获得更好的重建质量。
致谢
我们感谢袁刘和陈能伦对实验的帮助。 Christian Theobalt 得到了 ERC Consolidator Grant 770784 的支持。 刘令杰得到了 Lise Meitner 博士后奖学金的支持。 计算资源主要由HKU GPU Farm提供。
参考
- [1] Atzmon, M., Lipman, Y.: Sal: Sign agnostic learning of shapes from raw data. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2565–2574 (2020)
- [2] Bae, G., Budvytis, I., Cipolla, R.: Estimating and exploiting the aleatoric uncertainty in surface normal estimation. In: International Conference on Computer Vision (ICCV) (2021)
- [3] Chen, Y., Liu, S., Wang, X.: Learning continuous image representation with local implicit image function. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8628–8638 (2021)
- [4] Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: Proc. Computer Vision and Pattern Recognition (CVPR), IEEE (2017)
- [5] Darmon, F., Bascle, B., Devaux, J.C., Monasse, P., Aubry, M.: Improving neural implicit surfaces geometry with patch warping. arXiv preprint arXiv:2112.09648 (2021)
- [6] Do, T., Vuong, K., Roumeliotis, S.I., Park, H.S.: Surface normal estimation of tilted images via spatial rectifier. In: Proc. of the European Conference on Computer Vision. Virtual Conference (August 23–28 2020)
- [7] Gropp, A., Yariv, L., Haim, N., Atzmon, M., Lipman, Y.: Implicit geometric regularization for learning shapes. arXiv preprint arXiv:2002.10099 (2020)
- [8] Gropp, A., Yariv, L., Haim, N., Atzmon, M., Lipman, Y.: Implicit geometric regularization for learning shapes. In: Proceedings of Machine Learning and Systems 2020, pp. 3569–3579 (2020)
- [9] Huang, J., Zhou, Y., Funkhouser, T., Guibas, L.J.: Framenet: Learning local canonical frames of 3d surfaces from a single rgb image. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8638–8647 (2019)
- [10] Im, S., Jeon, H.G., Lin, S., Kweon, I.S.: Dpsnet: End-to-end deep plane sweep stereo. arXiv preprint arXiv:1905.00538 (2019)
- [11] Kazhdan, M., Hoppe, H.: Screened poisson surface reconstruction. ACM Transactions on Graphics (ToG) 32(3), 1–13 (2013)
- [12] Liu, L., Ceylan, D., Lin, C., Wang, W., Mitra, N.J.: Image-based reconstruction of wire art 36(4), 63:1–63:11 (2017)
- [13] Liu, L., Chen, N., Ceylan, D., Theobalt, C., Wang, W., Mitra, N.J.: Curvefusion: Reconstructing thin structures from rgbd sequences 37(6) (2018)
- [14] Liu, L., Gu, J., Lin, K.Z., Chua, T.S., Theobalt, C.: Neural sparse voxel fields. NeurIPS (2020)
- [15] Long, X., Lin, C., Liu, L., Li, W., Theobalt, C., Yang, R., Wang, W.: Adaptive surface normal constraint for depth estimation. ICCV (2021)
- [16] Long, X., Liu, L., Li, W., Theobalt, C., Wang, W.: Multi-view depth estimation using epipolar spatio-temporal network. CVPR (2021)
- [17] Long, X., Liu, L., Theobalt, C., Wang, W.: Occlusion-aware depth estimation with adaptive normal constraints. In: European Conference on Computer Vision. pp. 640–657. Springer (2020)
- [18] Luo, X., Huang, J., Szeliski, R., Matzen, K., Kopf, J.: Consistent video depth estimation 39(4) (2020)
- [19] Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., Geiger, A.: Occupancy networks: Learning 3d reconstruction in function space. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4460–4470 (2019)
- [20] Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: European conference on computer vision. pp. 405–421. Springer (2020)
- [21] Müller, T., Evans, A., Schied, C., Keller, A.: Instant neural graphics primitives with a multiresolution hash encoding. arXiv:2201.05989 (Jan 2022)
- [22] Murez, Z., van As, T., Bartolozzi, J., Sinha, A., Badrinarayanan, V., Rabinovich, A.: Atlas: End-to-end 3d scene reconstruction from posed images. In: ECCV (2020), https://arxiv.org/abs/2003.10432
- [23] Niemeyer, M., Mescheder, L., Oechsle, M., Geiger, A.: Differentiable volumetric rendering: Learning implicit 3d representations without 3d supervision. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3504–3515 (2020)
- [24] Oechsle, M., Peng, S., Geiger, A.: Unisurf: Unifying neural implicit surfaces and radiance fields for multi-view reconstruction. In: International Conference on Computer Vision (ICCV) (2021)
- [25] Park, J.J., Florence, P., Straub, J., Newcombe, R., Lovegrove, S.: Deepsdf: Learning continuous signed distance functions for shape representation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 165–174 (2019)
- [26] Ramasinghe, S., Lucey, S.: Beyond periodicity: Towards a unifying framework for activations in coordinate-mlps. arXiv preprint arXiv:2111.15135 (2021)
- [27] Roessle, B., Barron, J.T., Mildenhall, B., Srinivasan, P.P., Nießner, M.: Dense depth priors for neural radiance fields from sparse input views. arXiv preprint arXiv:2112.03288 (2021)
- [28] Schönberger, J.L., Zheng, E., Pollefeys, M., Frahm, J.M.: Pixelwise view selection for unstructured multi-view stereo. In: European Conference on Computer Vision (ECCV) (2016)
- [29] Shen, S.: Accurate multiple view 3d reconstruction using patch-based stereo for large-scale scenes. IEEE transactions on image processing 22(5), 1901–1914 (2013)
- [30] Sitzmann, V., Martel, J.N., Bergman, A.W., Lindell, D.B., Wetzstein, G.: Implicit neural representations with periodic activation functions. arXiv preprint arXiv:2006.09661 (2020)
- [31] Sun, J., Xie, Y., Chen, L., Zhou, X., Bao, H.: NeuralRecon: Real-time coherent 3D reconstruction from monocular video. CVPR (2021)
- [32] Tabb, A.: Shape from silhouette probability maps: Reconstruction of thin objects in the presence of silhouette extraction and calibration error. pp. 161–168 (June 2013). https://doi.org/10.1109/CVPR.2013.28
- [33] Teed, Z., Deng, J.: Deepv2d: Video to depth with differentiable structure from motion. arXiv preprint arXiv:1812.04605 (2018)
- [34] Wang, K., Shen, S.: Mvdepthnet: real-time multiview depth estimation neural network. In: International Conference on 3D Vision (3DV) (Sep 2018)
- [35] Wang, P., Liu, L., Chen, N., Chu, H.K., Theobalt, C., Wang, W.: Vid2curve: Simultaneous camera motion estimation and thin structure reconstruction from an rgb video. ACM Trans. Graph. 39(4) (Jul 2020)
- [36] Wang, P., Liu, L., Liu, Y., Theobalt, C., Komura, T., Wang, W.: Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. arXiv preprint arXiv:2106.10689 (2021)
- [37] Wang, R., Geraghty, D., Matzen, K., Szeliski, R., Frahm, J.M.: Vplnet: Deep single view normal estimation with vanishing points and lines. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 689–698 (2020)
- [38] Wei, Y., Liu, S., Rao, Y., Zhao, W., Lu, J., Zhou, J.: Nerfingmvs: Guided optimization of neural radiance fields for indoor multi-view stereo. In: ICCV (2021)
- [39] Xiangli, Y., Xu, L., Pan, X., Zhao, N., Rao, A., Theobalt, C., Dai, B., Lin, D.: Citynerf: Building nerf at city scale. arXiv preprint arXiv:2112.05504 (2021)
- [40] Yariv, L., Gu, J., Kasten, Y., Lipman, Y.: Volume rendering of neural implicit surfaces. Advances in Neural Information Processing Systems 34 (2021)
- [41] Yariv, L., Kasten, Y., Moran, D., Galun, M., Atzmon, M., Ronen, B., Lipman, Y.: Multiview neural surface reconstruction by disentangling geometry and appearance. Advances in Neural Information Processing Systems 33 (2020)
- [42] Yin, W., Liu, Y., Shen, C., Yan, Y.: Enforcing geometric constraints of virtual normal for depth prediction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 5684–5693 (2019)
- [43] Yu, Z., Peng, S., Niemeyer, M., Sattler, T., Geiger, A.: Monosdf: Exploring monocular geometric cues for neural implicit surface reconstruction. arXiv:2022.00665 (2022)
- [44] Zhao, W., Liu, S., Wei, Y., Guo, H., Liu, Y.J.: A confidence-based iterative solver of depths and surface normals for deep multi-view stereo. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6168–6177 (2021)
- [45] Zheng, E., Dunn, E., Jojic, V., Frahm, J.M.: Patchmatch based joint view selection and depthmap estimation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 1510–1517 (2014)
- [46] Zhou, T., Brown, M., Snavely, N., Lowe, D.G.: Unsupervised learning of depth and ego-motion from video. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1851–1858 (2017)