未来互联网的语义通信:基础知识、应用和挑战
摘要
随着智能业务需求的不断增长,第六代(6G)无线网络将从单纯注重高传输速率的传统架构转向基于万物智能连接的新架构。 语义通信(SemCom)是一种革命性的架构,它将用户和应用需求以及信息的含义集成到数据处理和传输中,预计将成为 6G 的新核心范式。 虽然 SemCom 有望超越经典的香农范式,但在实现 SemCom 支持的智能无线互联网的道路上还需要克服一些障碍。 在本文中,我们首先强调 SemCom 在 6G 领域的动机和令人信服的理由。 然后,我们概述了 SemCom 相关的理论发展。 之后,我们介绍了 SemCom 的三种类型,即面向语义的通信、面向目标的通信和语义感知通信。 接下来,我们将通信系统的设计分为三个维度,即语义信息(SI)提取、SI传输和SI度量。 对于每个维度,我们回顾现有技术并讨论它们的优点和局限性,以及剩余的挑战。 然后,我们介绍了SemCom在6G中的潜在应用,并描绘了未来SemCom赋能的网络架构的愿景。 最后,我们概述了未来的研究机会。 简而言之,本文对 SemCom 的基本原理、其在 6G 网络中的应用以及现有的挑战和未决问题进行了全面回顾,并为进一步深入研究提供了见解。
索引术语:
语义通信、第六代互联网、目标导向通信、有效性编码、人工智能我简介
I-A 动机
当我们重新审视从第一代(1G)到5G通信的发展路径时,很明显,传统的重点一直是优化面向数据的性能指标,例如通信数据速率和误码率概率,同时忽略与服务、目标或语义相关的指标。 例如,3G重点发展移动宽带。 它承诺数据速率是 2G 的一千倍,而 4G 则可以实现高速互联网流媒体传输,提供的数据速率是 3G 的一千倍。 这一约定的动机可以追溯到香农在经典信息论 (CIT) 文献 [1] 中首次证明在噪声信道中可靠通信是可能的。 香农认为“通信的语义方面应被视为与工程问题无关”。 原因是消息的含义可能与“某些物理和概念实体”相关,而将含义涉及到数学模型可能会影响理论的普遍性[1]。
随着CIT技术的不断进步,5G的到来带来了通信网络设计的突破[2],使能数字孪生、边缘计算、物联网(IoT)等多种业务。 )等,通过超可靠和低延迟通信(URLLC)、大规模机器类型通信(mMTC)和增强移动宽带(eMBB)通信等支持技术。 然而,以内容为中心的数据驱动的通信架构越来越被视为向最终用户提供需要高质量体验(QoE)的服务的障碍。 尤其是考虑到 6G 的新兴应用将以人为中心、数据和资源密集型。 Metaverse [3] 就是这样一个应用程序,它被设想为未来的互联网。 正如我们浏览当今互联网的网页一样,我们很快将通过头戴式显示器 (HMD) 探索 Metaverse 的虚拟世界,或通过增强现实 (AR) 眼镜浏览增强的物理世界。 虚拟世界是通过虚拟世界和物理世界的同步而形成的,其结果是一个人在虚拟世界和物理世界中的行为将密不可分。 在人工智能 (AI)、边缘智能、虚拟和增强现实以及区块链技术[4,5,6]的驱动下,成功实施 Metaverse 调用所需的以用户为中心的 QoE 指标重新思考经典信息论(CIT)驱动的通信网络,因为来自新应用的海量数据显着增加了传统通信网络的处理延迟[7]。 具体来说,6G网络需要解决以下难点:
-
D1)
元界等新业务的出现,需要6G网络支持海量数据的无线传输。
-
D2)
协作机器人、超智能物联网等海量节点的6G应用,需要快速的系统响应和可靠、高效的信息交互。
-
D3)
信息的实时更新和用户数据的分析需要消耗更多的网络资源,以保证更好的服务体验。
对此,一种被称为语义通信 (SemCom) 的新颖范式被激发为 6G 中的一项全新技术,旨在突破“香农陷阱”,即在互联网通信过程中识别并利用消息的含义。 与传统的面向数据的通信网络相比,其容量的提高是以系统复杂性为代价的,SemCom使所有通信参与者能够通过在接收者或通信任务的目标之后传输最相关的信息来减轻网络负担。基于先进的人工智能技术对数据进行预处理[8,9,10]。 SemCom的发展与6G的推进相辅相成,为上述三个难题带来解决方案。 一方面,6G 中分布式计算和无处不在的 AI 网络的可用性和连接性将使 SemCom 能够大规模部署[11]。 另一方面,SemCom 克服了传统的通信限制,将实现网络性能的前所未有的提升。 因此,随着SemCom的成功训练和发展,6G的愿景,例如比5G更低的延迟和增强的可靠性,可以完全实现。 具体来说,SemCom具有以下能力,分别寻址D1)、D3)和D3)。
-
A1)
减轻6G网络的无线数据传输负担。
-
A2)
提升6G网络控制和管理效率。
-
A3)
利用信息语义设计有效的网络资源分配方案。
然而,虽然 6G 和 SemCom 相辅相成的融合特性引起了学术界的关注,但目前还没有一份全面的调查论文来全面概述基于 SemCom 的 6G 和 SemCom 的发展、挑战和未来趋势。超越网络。 由于 SemCom 是一个相对较新的话题,我们的调查旨在为希望将 SemCom 概念融入未来通信架构的研究人员和从业者提供有用且富有洞察力的未来研究指南。
I-B 比较和主要贡献
| Key contributions | Main limitations | ||
| [11] | Comprehensive survey |
• Highlight 6G use cases, services and related KPIs • Motivate the need of SemCom and suggest an efficient cross-layer design architecture • Motivate a paradigm shift towards semantic and goal-oriented communications • Highlight the importance of learning-based approach in SemCom |
• Fail to provide a roadmap for the system design in a cross-layer architecture • Only provide a highly abstract theoretical analytical model for the encoding and decoding in the semantic and goal-oriented communication system, without any practical approaches for specific applications |
| [8] |
• Define semantic and effectiveness encoding according to the destination type • Introduce two SemCom architectures: layer-coupling approach and SplitNet approach • Discuss the potential role of KG technique in SemCom |
• Only a few encoding methods for natural language and model/gradient compression are elaborated closely • The communication part of SemCom, such as transmission and decoding processes, is rarely covered |
|
| [12] |
• Compare the conventional and semantic communication systems and theories • Presents SemCom system components, frameworks, and performance metrics • Discuss recent advancements on DL-enabled SemCom systems for transmitting multimodal data |
• Goal-oriented communication studies are not included • Only DL-based SemCom methods are reviewed, and there is no technical discussion about the selection and design of DL models • Simply introduce error-based metrics, without discussing their usage, as well as their advantages and disadvantages |
|
| Key contributions | |||
| [9] | Short brief |
• Review classical SemCom frameworks • Propose an architecture based on federated edge intelligence for supporting semantic-aware networking |
|
| [10] |
• Apply SemCom to a communication scenario where the destination is tasked with real-time source reconstruction for the purpose of remote actuation |
||
| [13] |
• An overview of the latest deep DL-based end-to-end SemCom is given and the open issues that need to be tackled are discussed explicitly |
||
| [14] |
• Conceive an intelligent semantic communication-empowered ubiquitous-X 6G framework • Present three promising application scenarios for SemCom |
||
| Our paper | Comprehensive survey | Overlapping Contributions | Distinct Contributions |
|
• Classify SemCom into three categories, and present their system models and application scenarios • Provide an overview of SemCom related theory development • Discuss the challenges from three design dimensions of SemCom system • Based on the ubiquitous-X 6G framework proposed in [14], we envision the 6G Internet with examples • Identify and outline a series of directions for future research of SemCom |
• Review four types of SE method in SemCom, and discuss their pros and cons, as well as suitable scenarios • Summary the existing technical DL-based SE models, and discuss their benefits and limitations • Discuss the communication-related techniques and challenges for SemCom • Classify semantic metrics into three basic types, and discuss their limitations and usages • Discuss the potential links between the SemCom and promising 6G applications |
||
由于 SemCom 最近的关注,出现了一些讨论该主题的评论论文。 在[11]中,作者指出需要整合传统通信中的语义和有效性级别,并提出了一种高效的跨层设计架构。 而且,根据所达到的沟通水平,他们将香农以外的沟通分为SemCom和面向目标的沟通。 然而,对于语义和面向目标的通信中的编码和解码,仅提供高度抽象的分析模型。 尽管他们强调了 SemCom 中机器学习的重要性,但缺少相关的技术细节,例如适合不同数据类型的语义信息(SI)提取的神经网络(NN)。 在[8]中,作者介绍了两种SemCom架构。 一种是层耦合方法,类似于[11]中提出的跨层设计架构。 另一种是 SplitNet 方法,该方法用于大多数现有的基于 DL 的 SemCom 研究。 然而,与[11]类似,他们的大部分工作都集中在构思概念和路线图上,相对较少关注技术细节。 而且,与[11]不同的是,他们根据接收者将SemCom分为两种类型。 这两种类型的编码过程称为语义编码和有效性编码。 回顾了一些自然语言和模型/梯度压缩的编码方法,但没有详细讨论传输和解码过程。 在[12]中,[12]中的作者比较了传统的语义通信系统和理论,并提出了 SemCom 系统组件、框架和性能指标。 然后,他们回顾了支持 DL 的 SemCom 系统在传输多模态数据方面的最新进展。 在他们的工作中,主要关注面向语义的沟通,而没有涉及面向目标的沟通的研究。 此外,没有详细讨论语义度量和基于 DL 的 SemCom 技术的使用、优点和局限性。
此外,还有几个简短的简介[9,10,13],从不同角度提供了有关 SemCom 系统设计的见解,例如支持 FL 的 SemCom 网络[9]、面向目标的 SemCom 系统 [10] 和支持 DL 的 E2E 语义网络 [13]。 然而,这些研究仅从某个角度回顾了这些作品,并没有对挑战和技术进行全面的回顾。
为此,我们旨在通过彻底回顾现有研究并讨论 SemCom 赋能的潜在网络架构中的 6G 应用,为 SemCom 在 6G 中的实施提供全面的调查。 在我们的论文中,我们将所有考虑语义或有效性层的通信分类为 SemCom。 同时,我们将SemCom分为三类:面向语义的通信、面向目标的通信和语义感知通信。 前两类属于传统的面向连接的通信,遵循[11]中两类通信的定义。 我们论文中定义的SemCom的第三类属于面向任务的通信111这里的面向任务的通信是指6G中新兴的通信类型,其中不同终端和网络节点之间以主动或被动的方式存在多个显式或隐式连接[15]。 它可以被视为传统的面向连接的通信的对应物,其中很容易根据它们想要通信的内容来区分明确的源终端和目标终端对[15]。. 同时,为了给SemCom的实施提供清晰的路线图,我们将通信系统的设计分为三个维度,即SI提取、SI传输和SI指标。 对于每个维度,基于对文本、图像和音频等传统数据类型的最新方法的回顾,我们总结了其适用的 SemCom 类别和场景的经验教训以及它们的好处和限制。 此外,我们还分别讨论了每个维度中剩余的挑战。 然后,我们重点介绍了 SemCom 在 6G 应用和网络方面的潜力。 确定了一系列未来的研究方向。 我们的讨论旨在阐明 SemCom 研究的未来道路。
I-C 调查范围
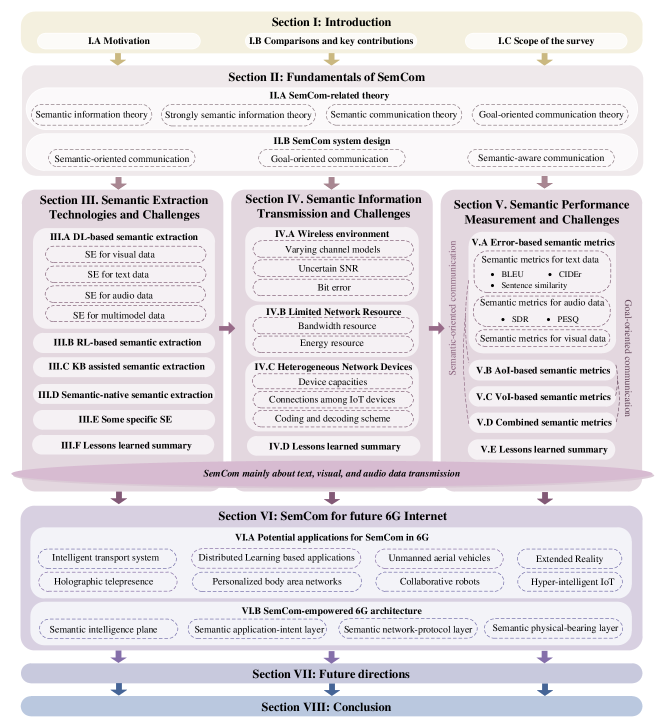
调查范围如图1所示。 在第II节中,我们首先全面概述了SemCom相关理论从语义信息理论到目标导向通信理论的发展。 同时,我们确定了SemCom的三个类别以及相应的系统设计。 然后,在III-V节中,我们分别讨论 SI 提取、SI 传输和 SI 度量方面的最先进技术和剩余挑战。 在第III节中,我们首先回顾第III-A节-第III-D节中的四种通用语义提取(SE)方法。 其中,基于DL的SE和基于RL的SE主要适用于面向语义的通信,而KB辅助的SE和语义原生的SE可用于面向目标的通信。 同时,在III-E节中,我们还通过两个典型例子来说明SE在语义感知通信中的作用。 在第IV节中,我们重点关注传输过程。 我们在IV-A节-IV-C1 在第V节中,我们首先讨论三种基本类型的语义度量:基于错误的语义度量、基于信息年龄(AoI)的语义度量和基于信息价值(VoI)的语义度量指标分别位于第V-A部分-第V-C部分。 然后,在V-D节中,我们基于三种基本类型回顾现有的组合语义度量。 在VI-A节和VI-B节中,我们旨在强调SemCom在6G中的潜力。 在VI-A节中,我们介绍了SemCom在6G中的潜在应用,并讨论了SemCom在每个应用中可能扮演的角色。 此外,在VI-B节中,我们讨论了SemCom在6G互联网中的实现以及基于[14]中建议的ubiquitous-X 6G框架的一些具体应用。 最后,除了VII节中面临的挑战之外,我们还确定并概述了 SemCom 未来研究的一系列方向。 VIII 部分总结了调查。
| Abbr. | Description | Abbr. | Description | Abbr. | Description |
| SI | Semantic information | SE | Semantic extraction | ML | Machine Llearning |
| DL | Deep learning | RL | Reinforcement learning | KB | knowledge base |
| KG | Knowledge graph | CR | Compression ratio | CE | Cross entropy |
| MSE | Mean square error | GAN | Generative adversarial net | DNN | Deep neural network |
| CNN | Convolutional neural network | CV | Computer vision | NLP | Natural language processing |
II SemCom 基础知识
II-A SemCom相关理论
语义的概念最早是在符号学研究[16]中引入的。 在[17]中,作者将符号学定义为句法学、语义学和语用学的三重组合。 句法侧重于符号(视觉和语言)形式特征的相互关系,而不考虑含义。 语义学专门研究不同层次的符号的含义。 语用学关注符号系统[16, 18]中符号相对于使用者的效用之间的关系。 与符号的三重定义相比,Weaver [19]将沟通划分为以下三个层次,以进一步刻画沟通的句法、语义和语用特征[20]。
-
A级
通信符号的传输精度如何? (技术水平。)
-
B级
传输的符号如何精确地传达所需的含义? (语义级别。)
-
C级
收到的意义如何有效地以期望的方式影响行为? (有效性水平。)
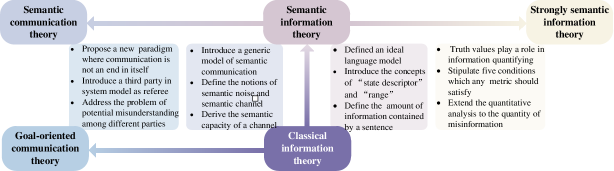
香农的 CIT 在基于概率模型推导出严格的通信数学理论方面取得了巨大成功,其中信息的概念被定义为可以用来消除不确定性的东西和分析基于熵域中的互信息。 然而,CIT只关注技术层面。 因此,一些研究者追随香农的工作,尝试将其扩展到语义层面和有效性层面。 图2突出显示了经典SemCom的发展。
II-A1 语义信息论
[21, 22] 的作者在 20 世纪 50 年代首次为语义信息理论(TSI)做出了贡献。 他们提出了一个由 名词和 形容词组成的理想语言模型。 任意名词和任意形容词可以通过动词变位。 例如, 表示“ 是”或“ 具有属性”。 此外,所提出的模型中存在五个连接:(Not)、(Or)、(And)、(如果……则)和 (当且仅当)。 从这个意义上说,根据上述连词可以生成很多句子。 根据 CIT 中信息的定义,一个单词的 SI 量可以定义为该单词在所考虑的语言模型中可以暗示的句子数量的函数,即,一个单词的句子越多。单词在语言模型中的含义越多,单词包含的SI越多[16]。 此外,为了量化句子的信息量,他们进一步提出了一个名为“状态描述符”的概念,它被定义为一个名词和一个形容词的连词(正或负)[16]。 句子的有效句子的由表示。 通过引入由 表示的描述的测量函数,其中 [16],句子 的测量等于内所有的总和,类似于句法信息的香农理论,句子的SI量可以计算为它的熵,即.
至此,可以发现一个重要的限制,即它完全忽略了当前通信的动机和目的。 事实上,TSI 和 CIT [16] 之间并没有根本区别。 从这个意义上说,一个恰好说了很多话的假句子也可能含有丰富的信息,因为在这种 SI 量的测量中,SI 并不意味着意味着真理[21]。
II-A2 强语义信息论
为了解决上述问题,[23]的研究提出了强语义信息理论(TSSI)。 与“弱”TSI 相比,真值在 TSSI 中发挥作用。 定义为语句与实际情况的差异程度。 作者在[23]中规定了任何可行且令人满意的度量应满足以下五个条件。
-
C 1
对于一个真正最符合实际情况的,。
-
C 2
对于在每种情况下都成立的 ,即同义反复,。
-
碳3
对于在任何情况下都成立的 ,即矛盾,。
-
碳4
对于偶然错误的,。
-
碳5
对于偶然为真的 ,它也可以通过实际情况以外的情况变为真,。
C4和C5的不准确度和空度的计算具体可以参考[23]。 根据差异程度,语句的信息程度计算为。 显然,偏离0越多的陈述,其信息量就越多,也更符合人类的本能。 然而,它只能对逻辑空间中的整类命题进行定量分析,无法提供严格的度量。 [24]中的作者在现有的truthlikeness研究的基础上进一步改进了这项工作,通过扩展定量的方法来衡量与真实情况的相似程度[25]对错误信息数量的语义概念进行分析,其中SI定义为真实语义内容,语义错误信息定义为虚假语义内容。 信息的相关概念植根于使用信息流[26]的SI框架。 通过采用经典系统[27, 28]的真实性方面的先前工作,所提出的 SI 量化方法可以支持更广泛的用例。 然而,处理非经典系统仍然是一个悬而未决的问题。 尽管如此,[23, 24]中从不确定性测量到信息内容的转变,在语义信息论的发展中迈出了里程碑式的一步。
II-A3 语义沟通理论
[29]作者基于SI量化方法[21]首次提出了语义沟通理论,旨在实现语义层面的沟通通讯。 他们提出了一个用于基本类型源的 SemCom 模型,该模型只能在命题逻辑中做出事实陈述。 在他们的模型中,源和目的地被建模为 世界模型 、背景知识 、推理 的 4 元组> 和消息解释器。 此外,利用香农熵来量化源的信息量,即语义熵。 此外,他们考虑了一组有限的允许消息,可以将其视为可用语义代码的集合。 在这方面,语义编码是将世界模型的观察值映射到特定消息的过程。 该策略是条件概率分布,确定性编码是将观测值编码为,其中最高。 此外,语义熵和消息熵之间的关系为,其中衡量编码的语义冗余度,衡量编码的语义歧义[29]。 与 CIT 的主要区别在于 SI 度量基于由背景知识和推理确定的逻辑概率,而不是统计概率。 其次,在编码过程中还可以考虑辅助信息,即目的地对源的先验知识,以减少代码长度。 关于基于语义熵的编码方法的更多细节可以在[30]中找到。 此外,通过用表示接收到的消息,可以通过的分布来表征语义通道。 此外,与CIT不同,离散无记忆信道的语义信道容量取决于三个要素。 第一个是和之间的互信息,这也是CIT的信道容量。 第二个是和语义编码中引入的语义歧义程度,即。 最后一个是接收消息的平均逻辑信息,由和决定,即。 如果 () 和 () 不匹配,则会生成过多的语义噪声 。 为了推导语义通道容量的极限,[29]中的作者通过假设 = 和简化了模型= ,上限为 。
这些作品可以被视为 SemCom 的初步但开创性的探索。 然而,它只是一个模型理论框架,对于实际的通信场景来说可能不切实际。 更重要的是,上述工作只是基于经典香农熵来量化信息量,与SI的本质——意义因子无关——与SemCom最初的愿景不符。
II-A4 目标导向的沟通理论
与[21]的研究侧重于香农CIT的扩展不同,[31]的研究侧重于经典通信系统模型的发展。 无论是 Shannon 的经典系统模型还是 SemCom 模型[29],所有通信各方都需要有共同的语言或背景。 面对当时多样化计算机间日益增多的交互,[31]的研究试图在通用SemCom上取得进展,其中通信双方人们希望在没有任何共同语言的情况下通过学习彼此的行为来获得共同的理解。 在[31]中,作者重点研究了Alice和Bob之间的特定通信模型,其中Bob是一个概率多项式时间有界交互机器,其目标是解决困难计算问题,而Alice具有无界计算能力权力并愿意帮助鲍勃。 同时,他们说不同的语言,并希望通过某种二进制渠道进行讨论。 为了解决这个问题,作者引入了一个“可信第三方”,它知道 Alice 和 Bob 的两种语言,并且可以给出有限的编码规则来翻译本次讨论。 理论分析的结果表明,当且仅当Bob想要解决的问题在PSPACE[32]中时,Alice才能帮助Bob,(即问题的解决方案对于Bob来说是可验证的) 。 尽管上述主张是在有限的背景下进行的,但它首先强调了沟通本身并不是目的,而是沟通双方实现某些总体目标的手段。
在[31]中提出的沟通模型的基础上,作者对沟通的一般目标进行了延伸研究,并首次提出了“目标导向的沟通”的概念。 [33]。 在这项工作中,他们澄清了与沟通中的目标相关的两个定义。 一个是元目标,它捕获通信代理的意图,另一个是句法目标,它捕获代理可以观察到的效果。 结果表明,具有不同句法版本的元目标也是可以实现的,即两个通信者在某些技术条件下(不一定)不共享共同语言。 基于此,可以为具有不同协议的多个代理之间的通信启用一种新颖的架构,其中被称为“解释器”的可信方发挥了重要作用。 需要注意的是,在上述通信模型中,虽然通信双方没有共同语言,但假设他们“有足够的帮助”。 在[34]中,作者进一步概括了上述工作。 在这种普遍性水平上,沟通双方之间可能会发生误解。 在这项工作中,第三方被重命名为裁判,它假设监视通信双方之间的对话并评估目标是否达到。 此外,他们确定并强调了一个名为传感的新概念,它捕捉了通信双方模拟裁判评估的能力。 基于这个概念,他们提出了一种通信系统的设计原则,可以在所需策略的描述长度中实现多项式开销。 在[35]中,作者声称从这种感知功能构建通用用户相当于在线学习算法的设计。 然而,上述工作大多依赖于“尝试并检查”范式。 它们只能为简单的通信系统的协议或策略的设计提供指导,例如服务器和打印机之间的对话。 尽管该系列作品仅关注传统计算机通信模型的面向目标通信的数学理论,但他们工作中提出的系统模型为现代面向目标的通信奠定了基础。
II-B SEMCOM系统设计
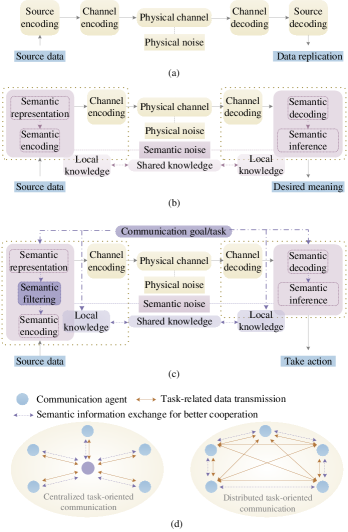
正如II-A节开头提到的,传统通信系统只关注Weaver和Shannon确定的三个通信层次中的第一层次(即技术层次)。 SemCom 建议将剩余的两个更高级别集成到通信系统的设计中。 在我们的调查中,我们根据 SemCom 的水平和作用将 SemCom 现有的工作分为三类,即面向语义的通信、面向目标的通信和语义感知通信。 通信模型的比较如图3所示。 接下来,我们描述 SemCom 通用系统模型的细节。
II-B1 面向语义的通信
与内容盲目的经典通信系统不同,面向语义的通信设计中重要的是源数据语义内容的准确性,而不是与源[11]。 因此,如图3(a)和图3(b)所示,面向语义的通信系统的主要变化在于数据处理阶段发送前和接收后。 传统的源编码旨在寻找一种将源数据转换为短代码的方法。 同时,由于传输的消息对底层含义是盲目的,好的源编码方法意味着它可以应对源数据的更多可能性,这符合CIT中的信息量化。 然而,在SemCom中,“信息”的定义需要修改。
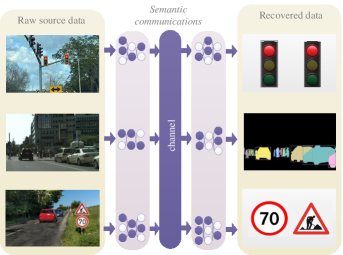
正如[36]所述,信息是能够产生知识的商品,信号所携带的信息就是我们可以从中学习的信息。 从这个意义上说,SemCom在编码之前引入了一个语义表示模块,负责捕获源数据中嵌入的核心信息并过滤掉不必要的冗余信息。 在许多研究中,语义表示和语义编码的功能被集成到一个称为语义编码的模块中,共同起到类似于传统通信中的短码来源的作用。 同样,语义推理和语义解码的组合作用相当于源解码的作用。 在一般的 SemCom 场景中,解码是编码的逆过程,它基于人工智能技术,例如 Transformer 和自动编码器,这些技术具有强大的先验知识。 由于SemCom的目标是使接收者能够成功推断SI,因此我们将联合语义编码和解码过程视为SE。 以图4中的交通系统图像传输为例。 在以图像复制为目标的传统通信中,基于内容盲方法的压缩图像期望保留原始图像的所有细节。 相比之下,在面向语义的通信中,SE进程可以通过执行适当的图像处理技术,在传输之前过滤掉不同任务的不相关图像细节,从而在不影响系统性能的情况下减轻网络负担。
此外,与人类对话一样,有效的对话需要对彼此的语言和文化有共同的了解。 在SemCom中,通信双方的本地知识需要实时共享,以确保所有源数据的理解和推理过程能够很好地匹配。 如果局部知识不匹配,就会产生语义噪声,即使在物理传输过程中没有语法错误,也会导致语义歧义。
II-B2 以目标为导向的沟通
回想一下符号的三重定义,即句法、语义和语用。 在上述面向语义的沟通中,SE主要关注SI,而在面向目标的沟通中,需要捕获语用信息。 在[16]中,作者阐述了三种信息类型之间的相互关系。 如图5所示,语用信息可以被视为所有SI的一部分,可以通过句法信息来传达,而句法信息可以被视为由通信源生成的原始数据。 它只与特定的沟通目标相关。 因此,为了简洁的表述,我们也将实用信息称为SI。
因此,如图3(c)所示,面向目标的沟通与面向语义的沟通中SE的主要区别在于,沟通任务的目标需要在沟通过程中发挥重要作用。 SE也是如此。 同时,通信目标还必须涉及通信双方的本地知识,这有助于在通信目标频繁变化时进一步过滤掉每次传输中不相关的SI。 以图像传输为例。 不同的任务(例如基于不同属性的分类、不同目标的检测或简单的复制)所需的图像的特征(即SI)是不同的。 因此,在多任务的传输系统中,在面向目标的通信中,对于某个任务,可能每次只需要传输图像的局部特征。 相比之下,在面向语义的通信中,由于SE是非目标特定的,提取的SI应该包括所有可能任务的特征,这不可避免地导致传输过程中的信息冗余和资源浪费。
通过比较图3(b)和图3(c),另一个区别是SemCom系统的输出。 对于面向语义的通信,系统的输出是所传输消息的恢复含义。 然后,接收方根据接收到的消息的含义进行下一步操作,但通信系统的设计中没有考虑这个过程。 相反,面向目标的通信系统的输出是要执行的直接动作。 回想一下如图4所示的交通场景中图像传输的面向语义的通信示例,接收者推断的结果可能是类似于图右侧的特征图的组合4。 相比之下,在面向目标的通信中,推理模块的输出是动作执行指令,例如加速、制动、方向盘角度、大灯闪烁等,以响应行人、路障和交通信号状态变化。 综上所述,面向目标的通信关注的是有效层面,旨在在有限的网络资源下以期望的方式完成任务,而不是面向语义的通信中关注语义层面的SI准确性。
而且,与面向语义的通信类似,通信各方的局部知识和通信目标需要保持一致,否则产生的语义噪声可能会导致任务失败。
II-B3 语义感知通信
如图3(b)和图3(c)所示,面向语义和面向目标的通信都在两个特定代理之间建立了连接。 它们属于传统的面向连接的通信,根据它们想要通信的内容,很容易分辨出一对显式的源代理和目标代理[15]。 相比之下,本次调查中的语义感知通信是指在面向任务的通信中发挥作用的 SemCom,例如自动驾驶和无人机群。
在面向任务的通信中,多个Agent以集中式或分布式的方式协作完成任务,如图3(d)所示。 任务中的语义感知通信以主动或被动的方式在不同终端之间建立多个显式或隐式连接,以增强代理之间的知识。 换句话说,语义感知通信可以被视为任务的一种“开销”,以便更好地协作以促进任务的完成。 在语义感知通信中,这里的SI是通过分析代理行为和当前执行任务的环境来获得的,而不是从数据源中提取。 例如,在自动驾驶中,SI可以表示两辆车之间发生碰撞的风险,该风险由车辆位置和运动学信息、交通密度、道路状况、红绿灯部署等共同确定。 此外,SI 还可以描述一系列连续的汽车在经过围墙分区的出口时所捕获的视图。 聚合SI后,可以获得细分出口的连续视图的语义表示,这可以促进细分[37]内沿出口车道的出口监控和活动跟踪。 在语义感知通信中,可能没有显式的收发器或完整的成对语义编码和解码过程。 因此,目前还没有一个用于语义感知通信的通用系统模型。
III语义提取技术及挑战
正如I节中所讨论的,传统通信系统所达到的传输速率正在接近香农极限,而剩余的可用频谱资源正变得越来越稀缺[38] [ 39]。 SemCom被推进解决带宽瓶颈的关键在于将先传输后理解通信范式转变为先理解后传输通信范式。 这样就可以将SE集成到通信模型中,实现SemCom[20, 8],只允许接收方感兴趣的信息进行传输,而不是原始数据,从而缓解带宽压力通过减少和隐藏要交换的冗余数据来增强隐私保护。
事实上,SE并不是一个全新的话题,但它一直在不断演化[40]、[41]。 其他研究领域也探索了一些类似的工作,例如计算机视觉中的语义分割,它用于将属于同一对象类的图像部分聚类在一起[42]、语义计算,它解决计算内容的语义以及用户检索、使用、操作甚至创建内容的意图的推导和匹配[43]和语义网,可以认为是链接数据与智能内容相结合形成的知识图谱,广泛应用于推荐系统中,以促进智能和集成的用户体验[44 ],[45]。 与[42,43,44,45]相比,SemCom是SE的另一个关键领域。 在这个领域,通信各方必须在语义表示和解释上高度一致,这给SE带来了挑战。 此外,6G通信系统中的信息具有很强的时间敏感性,对准确性要求很高[46],这也是其他领域所没有的严格要求。
因此,下面我们只关注 SemCom 中的 SE 方法。 在III-A节和III-B节中,我们介绍了两种面向语义通信的通用SE方法。 然后,在III-C节和III-D节中,提出了两种用于面向目标的通信的通用SE方法,其中通信目标被集成到SE中。 最后,我们在III-E节中通过两个例子来说明语义感知通信中的SE。
III-A 基于深度学习的SE
继DL在物理层单个块优化[47,48,49,50,51]的成功之后,基于DL的端到端通信系统已成为另一个潜在方向在误块率 (BLER) 和 BER 性能方面优于传统通信结构[52,53,54]。 受此启发,一些研究人员进一步引入了计算机视觉(CV)领域的DL方法[55,56,57],(自然语言处理)NLP[58,59, 60] 和语音处理[61, 62, 63] 作为 SE 方法进入端到端通信系统,开创了现代 SemCom 研究[64]。
III-A1 视觉数据SE
由于图像数据量较大,[65]作者首先关注图像传输场景,物联网设备将图像传输到服务器进行识别。 IoT 设备与服务器保持直接的点对点无线链路。 与传统的多个模块级联的通信模型不同,他们提出了一种DL构建的联合传输识别方案(JTRS),其设计指标为识别精度。 在设计方案中,由于其良好的性能和较少的参数,采用了ResNet架构[66]。 为了在传输前完成特征提取,ResNet的深度神经网络(DNN)被分为两部分。 前几层在发送器处充当特征提取器(即语义提取器),其余层在接收器处充当识别器。 此外,为了实现噪声通道中的自适应语义提取,通过使用 DNN 作为通道编码器和解码器来实现联合语义通道编码(JSCC),这将在第四节中详细讨论。
| JTRS | JPEG | CS-DR | CS-R | ||
| runtime | 7e-5 s | 7e-2 s | 1e-3 s | 4e-1 s | |
| accuracy | 0.9 | 0.5 | 0.1 | 0.14 | analog |
| -4 dB | 5 dB | 15 dB | 15 dB | ||
| runtime | 1e-2 s | 9e-3 s | 1e-3 s | 4e-1 s | |
| accuracy | 0.9 | 0.7 | 0.47 | 0.14 | digital |
| 0 dB | 5 dB | 5 dB | 4 dB |
为了证明 DNN 构建的 JTRS 的有效性,[65] 中的作者将该方案与其他三种级联压缩和识别方案进行了比较,假定压缩比 (CR) 为 0.04。 三种基线方案是 JPEG 压缩方案(JPEG)、直接识别压缩感知(CS-DR)和重构压缩感知(CS-R)。 表III分别显示了数字和模拟传输的四种方案的复杂度(就运行时间而言)、最高识别精度以及相应的信道条件阈值222这里的模拟传输是指直接使用数据值来调制信号,而不经过量化的步骤。 数字传输意味着数据值在调制和传输之前需要被量化并转换为比特。. 从表III可以看出,由于CR过低,CS-DR和CS-R方案即使在有利的信道条件下也几乎失去了识别能力。 在这三种基线中,只有JPEG方案能够在LDPC码数字传输中达到50%以上的准确率。 相比之下,所提出的 JTRS 在模拟和数字传输的较差信道条件下都可以实现高达 0.9 的精度。 令人惊讶的是,JTRS 在模拟传输中的表现比在数字传输中更好。 更令人鼓舞的是,由于在调制和传输之前缺乏量化和比特转换过程,JTRS在模拟传输中的运行时间远低于其他方法,这意味着基于DL的SemCom在低功耗方面具有先天的优势。延迟通信。
然而,该方案仅设计用于在特定SNR水平下运行。 当信道条件发生变化时,SE模型需要重新训练或细化,这会带来相当大的额外开销。 在传统的通信系统中,通用的信源编码器和信道编码器可以根据SNR实现自适应CR和信道编码率,以在有限带宽的情况下实现最优性能。 为了填补 SemCom 和传统通信之间的这一差距,[67] 中的作者考虑了一种具有 SNR 反馈的点对点图像传输系统。 他们将 CV 中广泛使用的注意力机制[55, 57]集成到 SE 中。 注意力机制采用额外的神经网络来严格选择某些特征或为原始神经网络中的不同特征分配不同的权重。 在他们提出的设计中,联合语义通道编码由单个网络执行,该网络由两个模块组成:特征提取(FE)模块和注意特征(AF)模块。 FE 模块用于从输入图像中学习特征。 然后,AF 模块将 FE 模块的输出和 SNR 作为输入,并生成一系列缩放参数。 特征学习模块和注意力特征模块的输出的乘积可以被视为特征学习模块输出的过滤版本。 解码器的设计类似。 在仿真中,作者比较了在 0 dB 和 20 dB 的 SNR 均匀分布下训练的基于注意力的 DL JSCC 方案和在 1 dB、4 dB、7 dB 的 SNR 下训练的五种基于 DL 的基本 JSCC 方案的性能、 13 dB 和 19 dB 分别。 从结果来看,该方案实现的峰值信噪比(PSNR)曲线可以看作是在不同SNR下训练的基线方案的其他PSNR曲线的上包络,表现出更高的鲁棒性、通用性、以及对基于注意力的方法的广泛信噪比的适应性。
上述两项工作分别侧重于图像识别和图像恢复。 [68]中的作者重点关注图像分类对抗语义噪声的应用。 他们利用图像数据的大量空间冗余,提出了一种具有非对称编码器-解码器架构的资源高效型 SE 模型。 该编码器采用带有视觉 Transformer (ViT) 架构的屏蔽自动编码器 (MAE) [69]。 MAE 可以根据部分观察重建图像。 具体来说,在所提出的架构中,原始图像的一部分首先被掩盖并忽略。 然后,未遮蔽的部分嵌入有关其在原始图像中的位置的信息,然后进入 Transformer 块以提取图像特征[69]。 由于编码器只需要处理未屏蔽补丁的部分,这显着减少了内存消耗。 相反,解码器的输入是由未屏蔽补丁和屏蔽 Token 的编码特征组成的完整 Token 集,这是一个共享和学习的向量,表明要预测的补丁的存在[68 ]。 此外,与上述端到端SE模型不同,解码器可以独立于编码器进行设计,因为解码器仅用于执行图像重建任务,这使得系统设计具有更大的灵活性。
同时,MAE还可以防御恶意攻击者,即通过向图像添加语义噪声。 由于MAE在编码过程中随机屏蔽图像的部分补丁,因此可以在一定程度上消除图像补丁中添加的语义噪声的影响[68]。 此外,为了进一步增强对恶意攻击的抵抗力,[68]的作者提出了一种用于编码特征表示的码本,它由与编码器和解码器参数一起训练的多个离散基向量组成。 基于训练有素的码本,编码神经网络输出的连续编码特征通过最近邻搜索[68]映射为基向量的离散索引。 因此,在发射机处进行离散表示时,可以高概率地纠正由语义噪声引起的失真,这大大增强了通信的鲁棒性。 在训练过程中,采用对抗性学习,其中语义噪声是通过快速梯度符号方法生成的。
| JPEG+LDPC | MAE | Ratio | |
| total symbols | 20432 | 196 | 0.95% |
由于MAE有效降低了图像的空间冗余,因此待传输图像的符号数是传统方案(JPEG+LDPC)编码图像的0.95%,如表IV。 由于有效的SE,MAE方案即使在SNR为-6 dB的情况下也能达到0.6的分类精度。 相比之下,传统方案(JPEG + LDPC)由于带宽有限,分类精度接近于零,SNR范围为-6 dB至6 dB。 只有当信噪比达到14 dB时,传统方案才能达到0.6的分类精度。 然而,用于训练和测试的JEPG图像的大小相对较小(5108字节)。 考虑到训练过程的复杂性,该方案的可行性和有效性有待进一步验证。 尽管如此,这一结果充分证明了SemCom通过有效的SE减少数据传输负担来提高通信性能的重要性。
III-A2 SE 用于文本数据
受到 DL 在机器翻译等 NLP 领域的成功启发,[70] 中的作者率先实现了 SemCom 用于文本传输。 他们考虑了一个简单的系统模型,其中发射器使用有限数量的比特通过擦除通道向接收器发送句子。 在所提出的方案中,首先使用 GloVe [71] 通过嵌入向量来表示单词,这是可用于提取 SI 的预训练查找表。 然后,受机器翻译中序列到序列学习框架[58, 72]成功的推动,采用了基于长短期记忆(LSTM)的编码器和解码器,其中将先前估计的单词的嵌入向量作为下一步的输入,并使用波束搜索算法来查找最可能的单词序列[72, 73]。 从这个意义上说,SI可以嵌入到句子恢复中。 与 Gzip 和 Huffman 相比,基于 LSTM 的 SE 在给定编码长度下实现了最低的误码率,同时具有较高的丢码率。 同时,在一定的丢码率下,由于提取信息的有效性,随着句子长度的增加,基于LSTM的SE的优越性变得更加显着。 然而,Glove或Word2Vec等单词表示模型[74]只能捕获单词之间的关系,无法描述语法信息[38]。 因此,所提出的方法只能描述句子中某个单词接连出现的概率,这使得处理复杂句子变得困难。
面对上述挑战,一种新提出的名为 Transformer 的架构引起了广泛关注,因为它可以有效地从整个句子中提取 SI 和语法[38]。 Transformer 网络与多头注意力机制相结合,使其能够并行提取输入句子的多个特征[39]。 因此,与基于循环神经网络(RNN)的架构(例如 LSTM)相比,Transformer 网络在学习输入句子中的长程依赖关系的同时,实现了更低的计算复杂度和更多的可并行计算[39] [60]。 因此,在最近的工作[75, 38]中,Transformer网络取代了RNN网络,并将信道模型扩展到加性高斯白噪声(AWGN)信道和衰落信道。 在他们的工作中,采用了更专业的语义度量,例如 BLEU 和句子相似度(在第 V 节中介绍)来衡量 SemCom 性能。 该方案在低SNR区域下语义度量方面的优越性证明了Transformer在SE中对于文本数据的有效性。
然而,标准 Transformer 具有固定的注意力结构,这使得它冷漠地对待所有输入,并限制了它在学习过程中的适应性。 事实上,在句子处理系统中,某些单词或短语更容易因一词多义或噪声干扰而造成语义歧义。 考虑到这一点,[76]中的作者提出了一种基于Universal Transformer(UT)[77]的灵活SE方法,通过在Transformer中引入自适应循环机制打破原有的固定结构。 与标准 Transformer 相比,UT 集成了自适应计算时间(ACT)模型[78]。 ACT 模型根据每一步预测的停止概率,动态调整处理标准 RNN 中每个输入符号所需的计算步骤数。 这种动态停止机制允许基于 UT 的 SE 为每个输入符号(即每个符号自注意力 RNN)赋予其自己的循环机制,并通过不同的周期灵活响应不同的 SI 和变化的物理通道。
在[76]中,作者将基于UT的SE方法和经典的基于Transformer的SE方法的SemCom方案与传统的源编码和通道编码级联方案的BLEU性能进行了比较源编码采用固定长度编码(5 位),信道编码采用 Turbo 编码或 Reed-Solomon 编码。 对于这两种传统方案,BLEU 分数在很宽的 SNR 范围内都保持在相当低的水平,并且只有当 SNR 增加到 15 dB 以上时才会显着提高。 相比之下,两种 SemCom 方案在各种变化的信道条件下都获得了显着更高的 BLEU 分数。 具体来说,由于自适应循环机制有助于更准确地捕获 SI,因此在整个 SNR 区域,基于 UT 的算法始终比基于 Transformer 的算法得分更高。
III-A3 SE 用于音频数据
随着E2E SemCom在图像和文本方面的成功,[79]中的作者进一步研究了针对音频信号的SemCom。 在[79]中,作者基于基于DL的NLP模型设计了一个音频SE,名为Wav2Vec[80]。 语义编码器由两个级联的卷积神经网络(CNN)组成,分别称为 FE 和特征聚合器(FA)。 FE 负责从原始音频向量中提取粗略的音频特征,FA 负责将粗略的音频特征组合成更高级别的潜在变量,其中包含上下文音频特征之间的语义关系[80]. 因此,语义解码器也基于 Wav2Vec 架构,它由两个与编码器对称的 CNN 组成,分别称为特征分解器 (FD) 和音频生成器 (AG)。 当SNR高于0 dB时,该方案可以将MSE降低到2e-4以下。 然而,由于SE模型的简单性,提取的SI有一定的局限性。 随着SNR的增加,MSE没有明显下降的趋势。 此外,与图像 SE 中使用的 LSTM 模型类似,SE 模型是在具有固定通道系数的 AWGN 通道下训练的,这使得在更复杂的通道条件下保证良好的性能具有挑战性。
同时,与文本语义编码器的演变类似,[81, 82]中的作者进一步整合了 ,命名为SE-ResNet编码器和解码器由一个或多个顺序连接的SE-ResNet模块构成。 “SE-ResNet训练”中的术语“SE”代表一个挤压和激励网络,它被视为一个独立的单元,并用于为该阶段的基本信息对应的权重分配较高的值。 具体来说,挤压操作是聚合每个输入特征的2D空间维度,而激励操作是通过捕获相互依赖关系来学习和输出每个特征的注意力因子。 同时,采用残差网络来缓解由于网络深度而导致的梯度消失问题。 仿真结果表明,与基于 CNN 的方法相比,所提出的 SE 方法在各种衰落信道和 SNR 下表现出更好的性能。 然而,与基于CNN的SE模型类似,基于SE-ResNet的SE模型仍然无法实现适应信道条件变化的动态SE。
后来,[83]的作者进一步关注英语的语音识别任务。 在[83]中,原始语音样本序列在馈送到发射机之前被转换成频谱。 此外,他们引入了单个语音样本序列的转录,其中每个词符代表字母表中的一个字符或单词边界。 基于频谱和转录,他们设计了编码器和解码器。 语义编码器由 CNN 和基于门控循环单元的双向 RNN (BiRNN) [84] 模块构建。 利用CNN进行数据压缩,利用BiRNN在传输前提取文本相关的语义特征。 通道编码和解码由密集层执行,语义解码负责将恢复的文本相关语义特征解码为文本转录。 与文本相关的语义特征被称为概率矩阵,其中每个词符对应于每个字母的概率。 考虑到英文字母表中字母的数量有限,语义解码器被设计为贪婪解码器,其中索引所有步骤中的最大概率,并使用相应的词符来构造最终的转录。 通过仿真,与传统通信系统相比,基于 SemCom 的语音识别在低信噪比区域下实现了更低的字符错误率和单词错误率。 传统通信系统中,语音信号直接传输,然后在接收端通过自动语音识别(ASR)模块转录为文本[85],或者先在发送端将语音信号转录为文本然后由ASR模块进行传输。 然而,随着SNR的增加,由于DL[86]产生不可避免的错误层,算法的优越性逐渐减弱。

| NN Architecture | Benefits | Limitations | ||
| recognition | ResNet-CIFAR 10 [65] | The scheme greatly reduces the compression rate while ensuring recognition accuracy and dramatically reduces system complexity and processing latency. | This scheme is applicable only to a specific SNR range and requires retraining when the channel changes, thus introducing additional overhead. | |
| image | transmission | Attention-integrated DNN [67] | By integrating SNR into SE, the scheme can operate successfully over a wide range of SNRs with lower computational/storage complexity than that of the basic DNN-based structures. | The effectiveness of the scheme is just demonstrated in AWGN channel. The robustness and adaptability of the algorithm are still to be verified and studied under more general models. |
| classification | MAE with ViT and codebook [68] | Based on MAE, the scheme achieves high SE efficiency by reducing the image spatial redundancy and resists largely the interference of semantic noise on classification with codebook. | The complexity of the system is high, which poses difficulties in training the SE model. For large image transmission, the feasibility and effectiveness of this scheme are yet to be verified. | |
| LSTM [70] | Compared with Gzip and Huffuman, the scheme can achieve remarkable low word error rate for large-size sentences and high bit-drop rates. | The scheme can only capture the relationship among words and fails to describe syntax information. This makes it hard to deal with complex sentences. | ||
| text transmission | Transformer [38] | The multi-head attention module in Transformer can capture long-range dependencies in sentences in parallel with low complexity, thus extracting accurate SI. | The attention structure in Transformer is fixed, which makes it hard to deal with noise interference or polysemy, such as “mouse” has a different meaning in computing and biology. | |
| Universal Transformer [76] | The scheme can be considered as a per-symbol self-attentive RNN, which can capture more precise SI and flexibly respond to varying channel conditions. | Due to the loop play introduced by the adaptive circulation mechanism, computational complexity increases, which causes extra processing latency and computing resource demand. | ||
| CNN [79] | The SE model is simple and easy to train. The scheme is remarkably competitive at low SNRs. | The basic SE model fails to extract semantically enriched information and adapt to changing channel conditions. | ||
| transmission | Squeeze-and-excitation network [81] | Due to the introduction of the attention mechanism, SE-ResNet-based SE model can achieve higher performance in terms of PESQ and SDR at any given SNR than CNN-based one. | This scheme can only perform the training of SE model under a fixed SNR. A dynamic and flexible SE model that adapts to channel changes remains to be studied. | |
| speech | recognition | CNN & RNN [83] | The scheme achieves a much lower character-error-rate and word-error-rate compared to the traditional communication systems under low SNRs. | The scheme becomes sub-optimal as SNR increases, since the DL-based methods always generate an avoidable error floor. |
| multi-model data | VQA | ResNet & LSTM & MAC network [87] | Compared to the traditional method, where the recovered image and text are input to MAC, the end-to-end scheme achieves significantly higher answer accuracy. | Since the scheme assumes perfect channel state information, it is not robust to channel changes in a real-world environment |
| Transformer [88] | The scheme achieves comparable answer accuracy in both perfect and imperfect channel state information and is considerably higher than traditional methods. | The complex model design introduces extra computing latency and computational resource consumption for training, especially for text encoding. The size of the images used for training and testing is small. The superiority of this model over traditional methods for VQA with large image sizes is yet to be verified. | ||
III-A4 多模型数据的SE
除了上述三个代表性数据外,[87]中的作者还以视觉问答(VQA)任务为例,研究了用于多模态数据传输的 SemCom 系统。 在VQA任务中,一些用户传输图像,另一些用户传输文本来查询图像的信息。 答案在接收器处获得。 在[87]中,他们考虑了一个带有图像发送器、文本发送器和接收器的简单通信场景。 与上述图像和文本工作类似,所提出的图像传输器采用在 ImageNet [89] 上预训练的 ResNet-101 网络 [66] 和所提出的文本传输器采用 Bi-LSTM 网络。 然而,解码器的设计还没有得到很好的研究。 由于两个用户的 SI 是相关的,因此解码器需要合并文本和图像 SI 并回答视觉问题。 为了解决这个问题,作者采用记忆、注意和组合(MAC)神经网络[90]来处理相关数据。 具体地,每个MAC单元由三个单元组成。 控制单元</t0>首先通过注意力模块根据接收到的文本SI生成查询,然后读取单元接收查询并通过另一个注意力从图像SI中搜索相应的关键字模块[87]。 最后,写入单元整合信息并输出问题[87]的预测答案。 与将恢复的图像和文本输入到MAC的传统方法相比,端到端方案实现了显着更高的答案准确性。 然而,由于该方案由于缺乏注意力机制而假设了完美的通道状态信息,因此对于现实环境中的通道变化并不鲁棒。 此外,在[88]中,作者基于Transformer统一了图像传输器和文本传输器的语义编码结构。 同时,他们提出了一种新的语义解码器网络,由两个模块组成:查询模块和信息融合模块。 查询模块采用layer-wise Transformer,由Transformer编码器层和Transformer解码器层组成。 与经典 Transformer 不同,[88]中的逐层 Transformer 将每个编码器层的输出标记作为每个解码器层的输入,可以利用文本信息中更多的关键字以及文本信息中的相应区域。图像信息。 然后融合模块融合这两个信息以获得答案。 与[87]相比,该方案在完美和不完美的信道状态信息上都达到了相当的答案精度,并且大大高于传统方法。 然而,复杂的模型设计给训练带来了额外的时间消耗和计算资源消耗,尤其是文本编码。 同时,用于训练和测试的图像尺寸较小。 该模型相对于大图像尺寸 VQA 传统方法的优越性还有待验证。 一个简单的 VQA 任务的实例如图 6 所示。
III-B 基于强化学习的SE
直观地说,由复杂的语义指标指导的学习过程可以促进更准确的SE。 然而,其他领域的许多现有语义度量都是非差异性。 为了克服深度学习对损失函数可微分的严格要求,强化学习被视为一种有前途的替代方案。
强化学习被认为是解决其他一些领域中用户定义的、特定于任务的和不可微的任务度量问题的有前途的范例[91,92,93]。 考虑到强化学习在序列生成任务[94, 95, 96]中的成功,[97, 98]中的作者首次尝试将强化学习融入到序列生成任务中用于文本传输的端到端 SemCom 系统,其中编码器-解码器方案可以被视为与外部“环境”(即句子)交互的代理。 在一般的强化学习框架中,任务需要转化为马尔可夫决策过程(MDP),它由五个要素组成:状态、行动、策略、奖励和长期回报[93] 。 在他们提出的编码-解码方案中,采用 LSTM 来提供策略。 与其他序列生成任务的 MDP 类似,状态被定义为解码器和先前生成的单词的循环状态。 从这个意义上说,两个相邻状态之间的转换是由下一个生成的词符决定的。 同时,RL智能体的动作是生成一个新的词符,因此动作空间就是字典维度。 此外,整个恢复句子的语义度量可以直观地视为长期回报
然而,即时奖励函数形式的确定特别棘手。 与大多数基于强化学习的策略在每个时间步都有明确定义的奖励不同,解码过程中的奖励直到句子结束时才能直接测量。 为了克服这一挑战,已经提出了几种方法。 第一种是使用蒙特卡罗搜索来获取每个时间步[99, 96]的奖励。 第二个是训练另一个神经网络来估计奖励或不完整的序列[100]。 然而,上述方法更加耗时和资源消耗,并且在巨大的动作和状态空间中引入发散的风险[97]。 而且,量化每个时间步的奖励值可能与保证整个句子的语义不一致。 因此,在[97]中,作者采用了一种新出现的方法,称为自我批判序列训练(SCST)[101]。 SCST 的想法是利用自己的测试时推理算法的输出来规范化它所经历的长期奖励,而不是专注于估计奖励,或者应该如何规范化奖励函数[101, 102]。 在[97]中,一组选定样本的平均长期回报(即整个句子的语义度量)用于标准化奖励并被视为反对中的基线术语函数,它可以实现稳定和自我监督的训练,而几乎不需要额外的计算。 同时需要注意的是,策略网络只有在句子完整传输结束后才会更新。
在模拟中,所提出的基于 RL 的方案使用 CIDEr 的语义相似度度量进行训练,并通过从 1-gram 到 4-gram 的 BLEU 分数来评估性能。 gram的大小是指在计算参考句子和候选句子之间的相似度时考虑的短语的长度,这在V节中有详细介绍。通过将所提出的方案与交叉熵损失训练的基于 DL 的 SemCom 进行比较,可以发现,随着 gram 大小的增加,基于 RL 的算法相对于基于 DL 的方案的优越性变得更加显着。 这证明了所提出的方案捕获底层语义的能力,因为较长的短语通常携带更丰富的语义。
III-C 知识库辅助SE
直观上,给定原始数据,SI 对于不同的通信目标[8]可能是不同的。 在图9所示的图像传输中,接收方可能必须执行不同的任务,例如基于不同属性的分类、不同目标的检测或简单的复制。 从这个意义上说,应用于不同任务的SI是不同的,但仍然具有高度相关性。 因此,如果我们针对多任务采用通用的基于深度学习的 SE 模型,则提取的 SI 对于特定任务可能是多余的。 否则,基于III-A节中讨论的多个基于深度学习的SE模型对相同的原始数据重复执行SE可能会导致大量系统冗余。 为了解决这个问题,一种合适的方法是提取原始数据传达的所有 SI 单位,并将各个通信目标对应于 SI 单位的不同组合。 为此,需要在发送任务请求之前,在发送方和接收方提前建立共享知识库。 同时,SE的过程可以被视为细化每个SI单元对个人沟通目标的重要性。
KB 是一项已广泛应用于自动化 AI 系统中的技术,用于存储具有形式表示的数据,以便进行推理[106, 107, 108]。 一般来说,典型的知识库由计算本体、事实、规则和约束[11]组成。 特别是对于SemCom系统,知识库应该由SI、通信任务的目标以及所有通信参与者能够理解、识别和学习的可能推理方式组成[109, 9]. 具体来说,KB可以用来记录每个SI单元与每个任务之间的关系,并量化SI对于不同任务的重要程度,从而在通信任务发生变化时指导SE在不同的信道条件下的工作。
随后,在[109]中,作者首先尝试建立一个基于CNN的简单知识库来完成图像分类任务,并完成知识库辅助SE。 在他们的工作中,CNN 被视为 SI 生成器,其中每层输出的特征图指示源图像的 SI 的不同方面,例如颜色、纹理。 由于训练有素的 CNN 模型的参数可以识别代表原始图像(即 SI)的特征图的最佳形式,因此 CNN 输出的梯度可以被视为特征图对不同类别的重要性权重 [109]。 因此,通过存储每个类别的所有特征图的重要性权重来建立知识库。 接下来,基于KB,可以通过细化与特定任务相关的SI来完成语义编码。 另外,由于编码和解码是相互可逆的过程,因此该方案也是以端到端的方式实现的。 从这个意义上说,发送器和接收器中的知识库应该通过权威第三方的共享知识库或虚拟知识库来同步。 如果两侧的两个KB不匹配,则在SI推理[30]时可能会产生语义噪声。 由于 KB 辅助 SE 仅关注与目标相关的 SI,因此带有 CR 的 KB 辅助 SemCom333CR的值表示被忽略的特征图的百分比。 与传统通信相比,在 10 dB 下仍能实现超过 40 的分类精度增益。 但其仍有提升空间,如神经网络结构和损失函数[110,111,112]的优化。
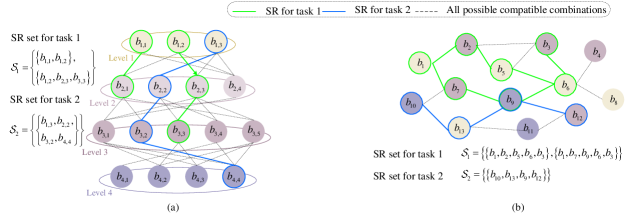
除了对语义知识库的知识库建立的研究之外,在SemCom场景下资源分配的著作[103,104,105]中,针对知识库的知识库存储模型提出了一些想法。 从现在开始,有两种可用的KB模型,如图7所示。 [103]提出了任务集语义KB的层次结构,其中不可分割的SI单元称为信念。 信念所属的层次越高,它包含的SI就越多。 对于所考虑的任务集中的一项任务,可能有多个可行的语义表示 (SR),并且每个 SR 仅包括来自层次结构的每个级别的一个信念[103]。 然而,这样的层次结构很难整合多个描述和一个任务之间的关系。 而且,在等级结构中,对更高层次的信念完全依赖于对其前一层的信念。 因此,它不够灵活,无法表示属于不连续水平的多个信念的组合。 在[9]中,作者指出图形结构是用于建模语义知识的一种潜在解决方案,其中任何两个SI单元可以在必要时通过边连接。 在[104, 105]中,作者首先根据句子的语法结构,利用图形结构对文本传输的语义知识进行建模。 在他们的作品中,以固定位长度编码的 Token 被视为顶点,两个 Token 之间的关系由边反映。 然而,对通用语义知识库进行建模的问题仍然悬而未决。
III-D 语义原生SE
上述三种 SE 方法都依赖于基于大量标记数据的训练有素的神经网络,这使得它们的工作仅适用于 SI 不变的通信系统。 因此,它们对于语义随时间或通信上下文变化的场景无能为力,而此类场景在现实生活中更为常见[113]。 具体来说,从这个意义上说,将“被动学习”转变为“主动学习”对于SE在不同语义和语境的交流中尤为必要。
事实上,已经有一些符合上述想法的初步研究,称为紧急沟通 [115],其中语义和面向目标的表示不是预定义的,需要预先定义在多个智能代理之间的迭代通信过程中学习到的[113, 115]。 然而,大多数作品仅仅关注一些简单而具体的人工智能任务,例如与图像相关的参考游戏[116],其中SE的完成可能是虚假的,因为单个传输的模式难以理解。对象[117]。
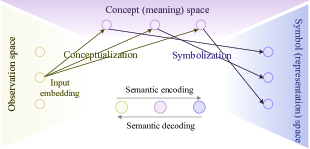
在[113]中,作者打开了SE的黑匣子,重点关注两个可以双向通信的智能体之间的点对点通信场景。 在分析可靠性(通过所考虑场景中的识别准确性来衡量)时,他们引入了语言学中人类交流架构的意义三角[114]。 如图8所示,语义三角形的顶点连接输入的观察、概念(或意义)和符号(或表示)三个空间[113]. 从输入嵌入到其概念的边缘称为概念化,从概念到其符号的边缘称为符号化,而它们的相反方向表示去概念化和去符号化[113]。 基于该模型,他们提出了两个 SemCom 系统(分别由系统 1 和系统 2 索引)。 系统 1 可以概括为具有共享输入嵌入的多三角模型。 概念化过程可以解释为随机软决策或机器学习中决策的可能性,它在无意识模式识别中与上述方法中的机器学习发挥着类似的作用。 此外,假设符号化过程是在代理之间预先确定的。 由于理性说话者对自己所说的话有自我意识,因此在系统 2 中,作者为每个代理注入了上下文推理[118]过程。 在语言学中,语境推理通常使用理性言语行为模型[119,120,121]进行计算描述,该模型植根于格莱斯的语言使用观点[122] 。 在所提出的系统中,上下文推理相当于与模仿和模拟其侦听器的虚拟代理进行通信,这使得代理能够基于推理进行有效且高效的通信。 为了证明上下文推理的重要性,作者将这两个系统都抽象为随机模型,并用香农编码推导了这两个系统中语义表示的位长。 实验结果表明,语义表示的比特长度显着减少,可靠性较高。
| Semantic-oriented communication | |||
| DL-based SE | RL-based SE | ||
![[Uncaptioned image]](x9.png)
|
Description:
The encoder and decoder are usually modeled as two separate learnable NNs, and linked through a random channel, which are trained jointly. The dataset used for training can be seen as their shared background knowledge. |
![[Uncaptioned image]](x10.png)
|
Description:
It is developed on the basis of DL-based SE. The decoding process is converted into a recurrent procedure. By employing self-critic training, the non-differentiable metrics, such as BLEU, can guide the learning process directly. |
|
Pros:
• Achieve lower CR while preserving the relevant information • Significant superiority in the low SNR region • Reduce processing latency in analog transmission without compromising communication performance Cons: • Become sub-optimal in ideal channel conditions due to the error floor of DL • The loss Function for guided learning in training can only be used for differentiable MSE and CE |
Pros:
• Achieve more precise SE guided by the specialized semantic metrics • Time-related metrics, such as AoI can also be integrated into the reward to guide SE due to the online paradigm of RL • Also features the pros of DL-based SE Cons: • Frequent interactions with the environment of RL greatly increases the training complexity • applicable only to sequence-generation tasks, such as sentence recovery |
||
| Goal-oriented communication | |||
| KB-assisted SE | Semantic-native SE | ||
![[Uncaptioned image]](x11.png)
|
Description:
The KB stores all the SI units conveyed by the raw data and the importance of each SI unit to different tasks, which is well-constructed before communication link establishment. In each transmission, only the task-related SI is transmitted according to the KB and channel states. |
![[Uncaptioned image]](x12.png)
|
Description:
It is developed based on emergent communication. It converts “passive learning” to “active learning”. SI and background knowledge are learned through interaction and feedback between the communicating parties, which does not depend on an existing database. |
|
Pros:
• Allow for flexible and more precise task-specific SE • Applicable to complex communication scenarios with multiple goals • Lay the foundation for SemCom-aware resource allocation due to the quantified data size and importance of SI units Cons: • Applicable only to the non-real-time on-demand services • The construction of KB is computation-intensive |
Pros:
• Adaptive to changes in the communication context and goal, reducing human intervention • Background knowledge does not need to be shared in real time • Some other features such as channel states and QoS requirements can be considered in the learning process Cons: • The training process is time-consuming and computing resource intensive • Convergence of training is hard to be ensured |
||
III-E 一些特定的SE
上述表VI所示的四种SE方法可以推广到不同场景下面向语义和面向目标的通信系统。 然而,在语义感知通信中没有通用的 SE 方法。 在本小节中,我们首先给出如图9所示的两个典型示例来说明将语义感知引入通信的动机,以及SE在语义感知通信中的作用。
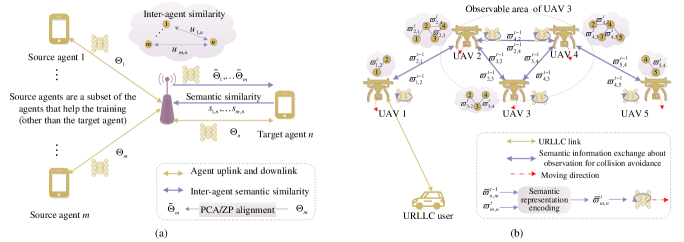
在[123]中,作者重点研究了联邦DRL任务,如图9(a)所示,其中多个异构代理在下以协作方式参与模型训练中央控制器的协调。 需要训练的智能体称为目标智能体,帮助目标智能体进行训练的智能体称为源智能体。 在所提出的方案中,SemCom 在构建记录所有代理之间相似性的知识图谱中发挥着作用。 基于知识图谱,策略性地选择具有高相似性的源智能体子集,以有助于目标智能体的训练。 在他们的工作中,他们利用语义相关性来衡量代理[125]底层学习任务的相似性。 在知识转移领域,它可以量化源代理转移的知识可以在多大程度上帮助目标代理找到其最优策略。 从这个意义上说,语义相关性可以被视为中央控制器和代理之间交换的一种SI。 它被定义为源代理在有限数量的训练集中从目标环境接收到的平均返回值。 同时,训练过程可以视为其相应的SE方法。 然而,由于平均返回值是从有限的训练步骤中获得的,因此该度量可能不准确,特别是对于具有大状态空间的复杂目标环境。 因此,在相似性KG构建过程中,要共同考虑结构相似性。 结构相似性可以由中央控制器根据从代理[126]接收到的策略网络参数的余弦相似性来测量。 此外,由于在比较相似性之前需要对齐异构代理的DNN参数维度,因此采用主成分分析(PCA)方法和零填充(ZP)方法来压缩和扩展源代理的DNN参数[127],分别。 通过仿真,通过与均匀或随机资源块分配的比较,证明了语义感知 CDRL 方案[123]在带宽受限无线网络上的良好性能。
在[124]中的另一个例子中,作者关注的是非地面超可靠低延迟通信(URLLC)系统(如图9所示)( b)),其中无人机(UAV)群采用集中训练和分散执行(CTDE)多智能体深度强化学习(MADRL)来为移动的地面用户提供服务,同时避免无人机之间的碰撞。 在他们的工作中,SemCom 并不是直接增强 URLLC 性能,而是集成到无人机之间的可微分代理间学习 (DIAL) [128] 中,以避免无人机之间的碰撞。 DIAL广泛应用于CTDE MADRL框架中。 在传统的 DIAL 中,代理交换各自的可观察状态,这些状态被视为其参与者模型的输入。 然后在训练过程中,原始状态数据逐渐转换为有意义的信息,以实现更好的代理间协作。 然而,从头开始训练可能效率很低。 为此,[124] 中的作者在交换信息之前对可观察状态执行 SE。 具体来说,每个无人机构建一个局部星形拓扑图,其中叶节点是其所有可观测的无人机。 将步骤中关于无人机的SI记录为相应边的权重(即图9中的) (b)),反映了无人机采取行动时对无人机的关注程度。 考虑到无人机应该相互同等关注以避免碰撞,无人机对无人机的关注是基于具有两个输入的RNN得出的。 一是无人机基于自注意力机制[60]从无人机的可观测状态中提取注意力特征。 另一个是无人机最后一步由无人机发送给无人机的SI。从仿真中可以看出,使用SI训练代替原始状态数据作为actor模型的输入可以显着提高效率。
III-F 经验教训总结
III-F1 基于 DL 的 SE 的经验教训
比较表V中总结的上述基于深度学习的 SE 方法,我们可以观察到,注意力机制由于其在捕获输入的长程依赖性方面的出色性能,在 SE 性能增强中发挥着至关重要的作用。 基于DL的SE的优点在于它可以从整个原始数据中提取重要信息,然后在不同层重新聚合和重新提取,从而有效去除冗余信息。 从这个意义上说,与内容盲的传统编解码相比,基于DL的SE可以在不丢失相关信息的情况下实现更低的CR。 因此,在低SNR区域下,基于DL的SemCom的优越性能尤其显着。 此外,凭借训练有素的端到端SE模型,基于DL的SemCom在模拟通信中取得了良好的性能。 由于没有量化和复杂的调制过程,如16-QAM和QPSK,传输前的数据处理延迟可以显着降低,这显示了其低延迟通信的潜力。
然而,深度学习技术有一个固有的弱点,即不可避免的错误层[86]。 因此,在理想的信道条件下,基于DL的SemCom与传统通信相比往往不是最优的。 因此,如何克服高信噪比区域下的性能瓶颈值得未来研究。 此外,在端到端训练期间,通过收发器的反向传播要求DL范式中的损失函数可微[98]。 从这个意义上说,上述所有研究仍然将深度学习中常用的损失函数(即交叉熵(CE)和均方误差(MSE))应用于训练神经网络,这使得现有的工作距离理想的 SemCom 还很远。 换句话说,上述所有架构都仅仅实现了语义编码以实现可靠且高效的传输[98]。 在这种端到端架构中,由于语义和通道编码器和解码器需要联合训练,SE和恢复被视为黑匣子[113]。 由于现有的基于深度学习的SE缺乏可解释性和可解释性,提取的SI的信息量很难衡量,也不清楚如何进行相关改进。
III-F2 基于 RL 的 SE 的经验教训
比较基于DL的SE和基于RL的SE,基于RL的SE的主要区别在于整个句子的解码被转换为循环过程。 也就是说,基于 RL 的解码器的输出是单个字,解码后的字是下一个要解码的字的输入。 这样的循环过程可以在训练过程中加强对句子内单词之间相关性的学习,从而允许解码策略学习不可微语义度量函数的相关特征。 此外,由于 RL 可以被视为一种在线范式,除了基于错误的指标之外,基于 AoI 的指标和传输延迟等其他一些指标也可以集成到奖励中,这是基于 RL 的 SE 的另一个有前途的优势方法[129]。
这种方法自然适用于序列生成任务,例如句子恢复。 在[97]、[98]中,作者还以图像传输为例讨论了非序列任务的泛化能力。 他们提出了一种像素级循环解码方案,其中MDP的状态被定义为通过少量增加或减少像素值而获得的中间解码图像。 然而,这种图像解码转换以增强 SemCom 性能的有效性和必要性尚不清楚。 此外,即使这种从解码过程到循环过程的转换在实践中是可行的,它也会增加解码时间。
此外,通过与环境的交互来学习最优策略不可避免地会增加训练的复杂性。 对于高维任务来说,从头开始训练如此复杂的模型仍然是一个严峻的挑战[98]。 在上述工作中,初始参数利用预先训练的模型,在确定性损失函数上采用随机梯度下降。 仿真结果表明,与基于DL的对应模型相比,基于非差分语义度量优化的基于RL的SemCom在中间SNR区域的准确率提高了3%。 然而,对于像Transformer这样更复杂的语言模型,基于RL的SE是否仍然可行还需要进一步探索和研究。
III-F3 知识库辅助 SE 的经验教训
事实上,KB 辅助 SE 也严重依赖 DL 模型。 与对新的原始数据执行实时 SE 的训练有素的基于 DL 的模型不同,KB 辅助 SE 要求在通信链路建立之前,在各方之间良好构建并同步原始数据的 KB。 这使得它仅适用于非实时按需服务。 此外,与基于深度学习的SE中的单一模型训练相比,复杂的知识库的构建是一项计算密集度更高的任务。 这意味着KB不能频繁更新,因此这种方法更适合数据源稳定的场景。
此外,如前所述,通过将通信目标引入SE,KB辅助SE可以从两个方面提高多任务系统效率。 一是通过在每次传输中灵活提取与某个任务相关的SI来提高通信效率。 另一个是通过避免原始数据的重复SE来提高计算效率。 除了这两个优势之外,KB的构建还为多任务的复杂SemCom场景的资源分配奠定了基础。 由于每个 SI 单元的大小和重要性可以记录在 KB 模型中,因此可以根据不同的服务质量 (QoS) 要求(例如延迟和可靠性)来完成每个 SI 单元的 SemCom 感知资源分配。 这与传统通信中的资源分配不同,传统通信中所有数据包都被平等对待,这将在第IV节中详细讨论。 此外,值得注意的是,语义知识库的构建很大程度上依赖于SE模型的可解释性。 然而,大多数可用的 SE 模型都具有黑匣子性质。 为此,增强SE的可解释性是突破现有SemCom研究瓶颈的关键。
III-F4 语义原生 SE 的经验教训
对比以上四种SE方法,语义原生SE是最接近人类对话交流的方式。 前三种SE方法要求在SE模型训练和确定之前发射器和接收器的背景知识完全同步,例如,语义编码器和解码器模型基于相同的数据集进行训练。 相比之下,语义原生 SE 放宽了这一限制。 智能体的上下文推理更像是捕捉和推断人类在与陌生人交谈时的思维方式的过程。 随着沟通双方彼此“熟悉”,代理人的背景知识就会趋同。 毫无疑问,语义原生的SemCom系统具有高度的灵活性和适应性,更符合智能自治的6G网络的愿景[130]。 然而,上述分析同样仅基于代表性模型。 将其付诸实践仍然是一个巨大的挑战。
III-F5 针对特定 SE 的经验教训
从上述III-E节讨论的多智能体协作任务的两个例子中,我们可以看出,上述任务中的SemCom仅起到促进协作并间接提高任务性能的作用。 与面向语义和面向目标的通信相比,语义感知通信中的 SE 不是对源代理直接生成的原始数据执行的。 通过分析任务本身的属性和智能体的行为来获得合作的相关SI。 这使得SE的过程必须更加量身定制,并且很难找到通用且统一的方法。 然而,很明显,语义感知通信将在面向任务的通信中发挥重要作用,因为交换 SI 可以增强代理之间的知识,从而实现更好的协作。 此外,高效的SE可以大大减少代理之间交换信息所带来的通信开销。
IV 语义信息传输与挑战
本节讨论的重点从语义相关的挑战和技术转向与通信相关的挑战和技术。 虽然传统系统和 SemCom 系统使用不同的方法来编码和解码信息,但它们都面临相同的通信限制,例如不可预测的信道条件、有限的传输和处理资源。 然而,与传统通信系统中的先前工作不同,SemCom 的解决方案需要应对现代通信系统中的新挑战。 下面,如图10所示,我们讨论了SemCom中与无线环境、有限网络资源和异构网络相关的挑战和技术。
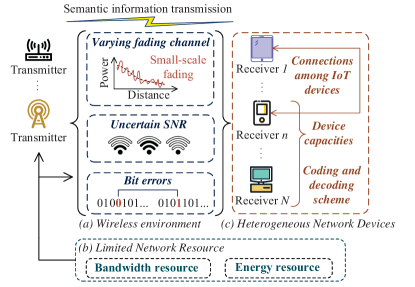
IV-A 无线环境
无论是传统通信还是SemCom,无线信道的衰落效应都会对数据传输的稳定性产生很大的负面影响。 为了减轻信道衰落的负面影响,在传统的通信系统中,源编码方案和信道编码方案都经过精心设计。 具体来说,源编码将数据编码成长度优化的符号序列,信道编码将冗余符号添加到序列中以检测和恢复无线传输期间的数据损坏。 在SemCom系统中,信源编码和通道编码可以在人工智能的帮助下连接得更紧密。 联合设计和训练源编码和信道编码有利于基于深度学习的通信系统中的数据传输[70]。 然而,基于人工智能的方法目前无法用明确的数学表达式来解释。 为了克服这一障碍,SemCom系统设计人员必须考虑如何将复杂多变的无线环境与复杂的SemCom机制联系起来,从而获得指导系统设计的见解。 因此,我们讨论了不同的衰落信道、不确定的 SNR 和误码对 SemCom 性能的影响。
IV-A1 不同的衰落通道
在传统的无线通信中,性能分析中常用几种经典的信道模型,例如莱斯信道模型、瑞利信道模型和高斯信道模型。 此外,为了统一系统性能与各种信道环境,提出了广义衰落分布,例如[131]、Fisher-Snedecor [132],FTR衰落模型[133]。 这些信道模型具有各种参数来表示无线环境的不同条件,例如阴影效应和多径效应的强度。 然而,在具有端到端结构的 SemCom 系统中,对通道层进行建模是一项具有挑战性的任务。 大多数现有工作以两种方式对信道层进行建模:使用传统无线通信中使用的衰落模型的固定信道层,以及使用神经网络的生成信道层。
固定通道层建模方案: 在固定信道层建模方案中,信道训练层被建模为在整个过程中使用的固定衰落模型。 例如,[70]中使用擦除通道来模拟数据包的丢弃。 擦除通道的输入是来自编码器的二值化位向量。 位向量中的每个元素都可以是或,被丢弃的元素将在擦除通道的输出处变为0。 掉落概率是在训练之前确定的。 最终,擦除通道之后的输出向量的元素在中。 这个过程类似于深度神经网络中用于防止过拟合问题的 dropout 技术。 因此,丢失层可用于表示通信系统的擦除通道。 对于未量化或二值化的输入,会考虑 AWGN、瑞利信道和莱斯信道等通信信道。 SemCom 最近针对文本 [38]、语音信号 [81] 和多模态数据 [87] 的研究工作将通道层视为 AWGN,瑞利通道和莱斯通道,用于训练过程。 然而,性能评估是在训练中相同的信道条件下进行的,没有考虑无线环境的变化会导致合适的信道模型的变化。 使用固定信道层建模方案的另一个缺点是,如果SemCom模型是在某个衰落信道下训练的,则针对每个可能的信道条件重新训练模型并将所有这些模型加载到发射机和接收机是不切实际的。 尽管训练后的模型表现出一定的鲁棒性,例如,[81]中的作者测试了在AWGN和瑞利通道下使用莱斯通道训练的模型,同时实现的MSE损失小于,我们无法解释鲁棒性的上限,也不确定当环境发生变化时模型是否会失败。 生成通道层建模方案不是使用固定通道层进行训练,而是用于捕获通道状态的动态行为。
生成通道层建模方案: 现有作品中采用的典型生成网络是生成对抗网络(GAN)[134]。 GAN 有两个主要组件,即生成器和判别器。 生成器的目标是生成尽可能与真实数据样本相似的数据样本。 鉴别器将随机获得真实数据和生成数据,并输出一个标签来指示给定数据是真实数据还是生成数据。 在训练过程中,目标损失函数帮助生成器生成更真实的数据,帮助判别器输出更准确的标签。 为了生成特定于类别的数据,提出了条件 GAN [134],其中向 GAN 提供额外的上下文信息以获得给定上下文的样本。 在[135]中,使用条件GAN对通道条件进行建模。 向条件 GAN 提供来自发射机的导频信息和编码信号,并要求其生成与真实数据类似的输出信号。 为了评估所提出的条件 GAN 在真实通道条件下的性能,使用 WINNER II 通道[136]测试训练后的模型。 结果表明,条件 GAN 模型在 BER 和 BLER 方面优于基线系统,特别是当 SNR 超过 dB 时。 尽管生成式信道层建模方案提高了训练模型对无线环境的适应性,但比固定信道层建模方案需要更多的训练开销。 这促使我们思考性能和资源开销之间的权衡。
总体而言,固定信道层和生成信道层在 SemCom 系统训练期间提供无线信道建模。 不同方案的选择对SemCom的性能有影响。 一种可能的解决方案是结合两种方案的优点。 例如,[54]中提出了一种两阶段训练策略来适应真实的通道。 在第一阶段,使用合适的通道模型对模型进行训练,以获得具有合理精度的模型参数。 在第二阶段,接收器在实际通道上进行微调。 经过微调的自动编码器不断获得比未经微调的自动编码器更低的 BLER。 然而,如何在不同的无线环境下选择最佳的训练方案仍然是一个悬而未决的问题。
IV-A2 不确定的信噪比
在讨论了信道环境对 SemCom 性能的影响之后,这里我们考虑 SNR 不确定性对训练的 SemCom 模型的影响。 请注意,无线环境的影响主要来自信道模型选择,由于阴影或散射的影响。 SNR 不确定性来自噪声和干扰的影响,以及发射功率的变化,例如,当使用自适应发射功率方案时。 由于SemCom模型的训练通常采用固定SNR方法,例如文本[38]、语音信号[81]和多模态数据 [87],我们需要考虑SNR的变化是否会对性能产生负面影响。
有几项工作测试了训练模型对 SNR 的鲁棒性。 在[81]中,模型以8 dB的固定SNR进行训练,然后在0 dB到20 dB的SNR下进行评估。 在AWGN通道、Rayleigh通道和Rician通道下的测试中发现模型在较低SNR区域具有较高的MSE损失。 然而,仍不确定在固定SNR值下训练的模型是否总能应用于广泛的SNR。 此外,虽然 SemCom 不断实现比传统通信系统更高的性能,但它们在较低 SNR 区域的性能都较差。 由于低SNR环境常见于蜂窝边缘、购物中心或郊区,因此我们需要考虑SemCom在SNR较低时的性能,从而降低解码信号的准确性。
为了通过使模型对不同的SNR区域,特别是低SNR区域具有鲁棒性来解决上述问题,[137]中的作者提出了一种SNR自适应机制。 在所提出的模型中,SNR 通过接收器处的导频信号来估计。 然后将估计的 SNR 值扩展到与通道输出特征图具有相同大小的 SNR 图。 SNR 和通道输出特征图在相加之前都会经过 CNN 层。 逐元素相加的结果用作去噪模块的输入。 使用一些转置卷积层来重建原始图像。 结果发现,与使用固定SNR训练的模型相比,使用所提出的SNR自适应机制训练的模型在高SNR区域和低SNR区域之间的PSNR差距更小。 通过在解码过程中考虑SNR信息,所提出的模型对SNR表现出更高的适应性。
增强SemCom模型鲁棒性的另一种方法不是将SNR值添加到信道特征中,而是根据不同的SNR值对信道特征进行缩放[67]。 [67]中提出的训练方法采用逐通道软注意力,其中每个通道特征乘以一个缩放因子。 为了获得缩放因子,SNR 值与从输入图像中提取的上下文信息向量相连接,并馈送到两个全连接层中。 输出向量中的每个元素都是特征通道的缩放因子。 结果表明,在软注意力机制的帮助下,与使用不带注意力模块的基本深度学习网络的基线模型相比,该模型可以获得更高的 PSNR。 特别是,具有软注意力机制的模型在SNR较高时可以达到35 dB以上的PSNR。
然而,这两种解决方案都是为了解决特定的通信问题而设计的。 对于广义的SemCom系统,如何保证训练好的语义模型能够适应可变的SNR的问题仍在等待更好的答案。 语义模型泛化能力的边界需要进一步研究。
IV-A3 位错误
为了适应不断变化的无线环境和 SNR 的不确定性,人们设计了许多机制来提高 SemCom 性能。 现在我们重点关注比特纠错机制[138],它可以进一步增加SI正确传输的概率。
受到传统通信系统中纠错算法的启发,研究人员为SemCom设计了几种纠错方案,以最大限度地减少SI的传输错误。 例如,在[139]中,采用混合自动重复请求(HARQ)来减少语义文本传输的传输错误。 在HARQ的帮助下,如果接收到的码块存在不可纠正的错误,则请求重传。 [139] 中的作者首先使用来自 [38] 的语义编码器和使用 HARQ 的 Reed Solomon (RS) 信道编码 [140] 开发模型。 然后通过联合设计源信道编码和HARQ进一步提高性能。 具体来说,RS信道编码被密集层取代,以将语义编码器的输出编码为比特向量。 为了减少语义错误,开发了 Sim32 编码器和解码器来检测原始句子和估计句子之间的语义相似度。 结果表明,通过联合源信道编码和HARQ,当BER大于0.06时,该模型实现了较低的误词率和误句率。 此外,将传统通信中的校正机制与SemCom相结合的新设计方案需要进一步研究。
IV-B 网络资源有限
数据传输需要多种资源,例如带宽和传输功率。 传统通信系统中的资源分配框架旨在最小化误码率、误包率和中断概率等指标。 然而,SemCom 重视比特流背后信息的重要性。 这激励我们为新颖的 SemCom 系统开发新的资源分配框架。 通常,在设计资源分配方案时,应考虑QoS和QoE以构建有效的系统。 具体来说,QoS旨在优化传输速率、时延和吞吐量[141, 142],QoE则侧重于用户满意度、清晰度和流畅性[143, 144]。 下面我们讨论SemCom中带宽和能量方面的资源分配方法。
IV-B1 带宽资源
由于带宽资源对于任何通信系统来说都是宝贵的,因此有效的带宽分配是实现SemCom以提高系统整体性能的必要条件。 与传统通信中的带宽资源分配不同,SemCom 中应考虑 SI 分布不均的情况,即应将更多带宽分配给具有更多 SI 的数据/代理。
一种可能的解决方案是在训练过程中联合进行带宽分配。 在[123]中,设计了一种CDRL算法,其中多个代理可以通过无线网络进行协调以共享其策略并协作学习各自任务的最佳策略。 然而,由于带宽有限,需要训练的座席(目标座席)只能与有限数量的座席(源座席)协作。 因此,用于识别最有帮助的代理的指标对于有效的资源分配非常重要。 在之前考虑代理模型结构相似性的工作的基础上,[123]中的作者将代理之间的语义相关性纳入其中,以构建知识图谱来帮助代理的任务选择。 代理间语义相关性定义为在源代理策略下经过固定数量的训练步骤后目标代理的返回值。 在联合优化训练损失和无线带宽分配之后,获得一个知识图谱,其中代理之间的边值捕获了连接的代理之间的结构和语义相关性。 然后,基站使用 KG 在优化过程中选择最相关的代理进行协作。 仿真结果表明,与不考虑智能体之间语义相关性的基线方法相比,系统性能可提高83%。 然而,将带宽动态分配与语义内容传输相结合的问题尚未得到充分研究。 在一些不需要训练的SemCom系统中,需要设计带宽分配方案,为更重要的传输内容分配更多的带宽,以保证信息质量。
IV-B2 能源资源
除了带宽资源的分配之外,能源资源的分配也是一个重要问题。 对于越来越多具有能量收集功能的物联网,借助语义确定信息的重要性非常重要。 分配更多的能量来传输包含更丰富的SI的数据,保证了能量的有效利用。 此外,语义度量可用于确定所收集能量的质量,这有助于建立高效的网络市场。
基于[38]中提出的句子相似度度量,[145]中使用基于语义的评估函数来为能量收集物联网设备导出所收集能量的价值。 在所提出的系统模型中,有采用 SemCom 系统的物联网设备和向附近物联网设备传输能量的混合接入点 (HAP)。 IoT 设备通过从 HAP [146, 147] 收集能量来将文本数据传输到 HAP 进行操作。 但是,HAP 被认为在特定时间仅为一个用户提供服务。 为了获得无线能源,物联网设备将提交投标,HAP 将决定获胜者和付款。 提出了一种真实的拍卖机制,以便物联网设备根据其对能源的真实估值进行竞价。 IoT 设备不使用传统通信的性能指标,而是使用基于 BLEU 分数和相似性分数的评估函数来获取其出价。
然而,目前语义度量在能源资源配置中的应用仍处于早期阶段。 许多需要能量收集设备才能工作的 SemCom 网络尚未得到研究,例如,同时使用无线信息和电力传输协议的无人机辅助网络。
IV-C 异构网络设备
对于SemCom网络来说,无线通信层对系统性能的影响比端到端的传统通信更大。 由于许多异构设备工作在同一个SemCom网络中,设备硬件和无线环境的差异给系统建设带来了挑战。
IV-C1 设备容量
为了启用 SemCom 系统,大多数现有方法都涉及将编码器和解码器分别安装到发射器和接收器中。 虽然基于深度学习的自动编码器系统可以帮助有效地从原始数据中提取有意义的语义信息,但实施成本并不便宜。 特别是训练过程需要更多的计算能力和通信资源。 研究表明,使用正确的技术扩展深度神经网络几乎总能带来更好的性能[148, 66]。 然而,扩大模型会增加存储更多模型参数的存储要求。 实际上,通信设备的计算能力、通信资源和存储容量是有限的。 特别是在 SemCom 网络中,假设所有设备都具有足够的容量是不现实的。 因此,在SemCom网络中,开发有效的方法来平衡异构设备的性能和成本要求是重要的挑战之一。
为了使[38]中提出的模型对于计算能力有限的SemCom网络中的设备来说更便宜,[75]中的作者尝试使用模型压缩来减小模型的大小该模型。 结合模型剪枝[149]的思想,提出一种联合剪枝量化方案[75]来有效压缩模型。 在所提出的方法中,不太重要的模型权重被清零,并且保留大于剪枝阈值的模型权重。 为了确定剪枝阈值,首先将模型权重按权重值升序排序,然后选择剪枝阈值,使得剪枝结果满足预定义的0到1之间的稀疏比。 稀疏率表示模型权重的零点的所需比率。 然后对修剪后的模型进行微调以恢复模型的性能。 通过网络量化,模型的大小进一步减小,网络量化将模型权重从 32 位浮点转换为 位整数 。 需要校准过程来防止激活层溢出。 特别是,引入指数移动平均线(EMA)来抑制激活输出中异常值的影响。 与模型剪枝类似,模型在量化后进行微调。 值得注意的是,在稀疏率为 60% 的模型剪枝和 位整数量化后,压缩模型可以获得与未压缩模型相似的 BLEU 分数。 然而,由于语义模型的进一步压缩而导致的性能损失需要系统地研究。 我们需要考虑网络中不同设备的容量和性能要求。
IV-C2 物联网设备之间的连接
对于包含多个智能设备的SemCom网络,我们需要根据不同设备的不同无线链路环境进行网络设计。 一种解决方案是将无线链路视为训练过程中的智能代理。
[150]中的作者提出了一种用于车载网络频谱复用场景下语义视频传输的资源分配算法。 在所提出的算法[150]中,通过多智能体深度Q网络优化视频传输的语义理解准确性。 在网络中,车辆到基础设施(V2I)链路和车辆到车辆(V2V)链路是代理。 基于对环境状态的观察,例如资源块下的信道增益和干扰功率,代理选择重用频谱资源块。 然后,代理根据V2I平均目标检测精度和V2V平均传输速率获得奖励。 仿真结果表明,在相同的频谱和发射功率下,所提出的网络不断实现比基于QoS和QoE的资源分配框架更高的视频语义理解准确性,正确检测到的对象的密度提高了高达70%。
然而,当通道模型不可用时,监督学习的反馈环节就缺失了。 为了解决这个问题,[52]中的作者提出了一种让接收器适应未知的新信道条件的元学习方法。 元学习的意思是“学会学习”,是指学习接收器中的适应模块[52]。 元学习方法首先在训练阶段训练适应规则。 特别地,在元训练阶段,接收器将被元训练以基于物理信道的输出来更新解码器参数。 在测试阶段,接收器将使用训练好的适应规则自我优化模型参数。 仿真结果表明,当发射机在测试阶段发送多个导频帧时,采用元训练的模型可以比采用传统训练的模型实现更低的 BLER。
IV-C3 编解码方案
编解码方案需要根据SemCom网络中不同用户的各种信道情况进行改进。
与使用监督数据微调模型的两阶段训练策略不同,[98]中的作者提出了一种考虑不同通道状态的自监督机制。 特别地,允许对消息进行多次编码和解码,直到满足停止标准。 对于每个编码/解码周期,将通过置信度机制评估编码/解码信息以确定其语义置信度。 如果编码/解码的信息达到预定义的置信度阈值,编码器/解码器将释放该信息以进行下一步处理。 另一个停止标准是当编码/解码的周期长度达到预定义的最大周期长度时。 通过蒸馏和置信机制,编码器和解码器可以以自监督的方式改变编码和解码的信息,而不管通道如何。
此外,在多用户场景中,可用频谱和发射功率等资源的波动会对 SemCom 性能产生不可忽视的影响[151]。 为此,迫切需要能够与传统通信中的可伸缩视频编码[152]和多描述编码[153]相媲美的变长语义编码。研究了如何应对动态 SemCom 网络。
IV-D 经验教训总结
IV-D1 无线环境的经验教训
SemCom 应该考虑经典通信中无线环境引起的传输问题。 然而,由于SemCom的特殊性,例如不同位对于原始数据的重要性不同,为传统通信设计的方案不能直接使用。 幸运的是,许多为传统通信系统设计的方案可以启发SemCom系统的构建。 例如,端到端语义模型训练要求系统设计人员使用神经网络层对无线衰落信道进行建模。 与在传统通信系统的性能分析中使用固定信道模型相比,包含多种经典信道作为其特例的广义衰落信道可以带来更多的见解。 同样,生成通道层的引入可以为语义模型的训练提供更多的自由度。
IV-D2 有限网络资源的经验教训
与仅考虑比特传输的传统通信不同,SemCom中资源分配的目的是保证与任务相关的语义信息的准确传输。 因此,语义信息的考虑为6G网络中的资源分配方案设计引入了新的视角。 这种新颖的设计需要深入分析任务需求并联合优化设计,以提升系统性能。 正如我们上面讨论的,一些文献尝试使用语义信息来指导资源分配过程,但这种范式转变仍然为进一步研究留下了很大的空间。
IV-D3 异构网络设备的经验教训
网络中网络设备的异构性主要体现在两个方面,即设备容量的差异和各设备通信环境的差异。 如果在训练语义模型时不考虑网络设备的异构性,则训练后的模型无法直接传递到每个设备。 具体来说,为高性能设备训练的语义模型可能很大,无法部署到手机等小容量设备上。 此外,端到端语义模型还受到收发器设备之间的无线信道质量的影响。 因此,沟通渠道的差异也会影响语义模型的部署。 而且,在作为语义通信网络重要组成部分的编解码方案的设计中,我们还需要仔细考虑设备异构性的影响。
V 语义性能测量和挑战
网络性能指标的选择一直是历代网络设计和优化的核心关注点。 在传统的通信系统中,由于传输和数据的SI以及实现特定目标的有效性的分离,通信性能往往从不同的网络层分别通过BER、QoS和QoE等指标来评估。 相比之下,在 SemCom 中,层间耦合得到了很大程度的增强[154]。 因此,在实践中实施 SemCom 之前,必须确定从语义角度评估通信性能的新方法。 现有的 SemCom 评估主要集中在语义错误、AoI 和 VoI 方面。 接下来,我们详细介绍如图11所示的三种基本指标类型及其相关组合形式,并讨论相关的遗留问题。
V-A 基于错误的语义度量
如前所述,与传统通信中的 BER 和 SER 指标不同,传统通信中的 BER 和 SER 指标关注的是每个比特和每个符号的准确性,并同等重要地对待所有比特和符号,而 SemCom 中的基于错误的指标则关心是否发送者想要表达的含义等同于其目的地所理解的含义,即语义相似性[11]。 此外,可用的语义度量都是特定于任务的,并且还没有针对不同类型的嵌入[12]的通用度量。 下面我们从具体应用角度来讨论基于错误的语义度量。
V-A1 文本数据的语义度量
目前,文本传输是SemCom研究中最受关注的。 文本传输中的语义相似度通常是指整个句子所传达的含义的准确程度。 为了从数学上量化相似性,一些研究人员求助于自然语言处理领域的一些开创性工作,并在其工作的性能评估中应用以下指标。
-
•
双语评估研究(BLEU):BLEU最初是一种机器翻译自动评估方法[155],这符合语义测量在机器翻译中需要做的事情SEMCOM 系统。 BLEU 用于将候选的 -gram 与参考翻译的 -gram 进行比较,并计算匹配的数量,其中 -grams 表示词组的大小。 例如,对于句子“cat is on mat”。 1-gram:“cat”、“is”、“on”和“mat”2-克:“猫在”、“在”和“在垫子”。 它在[38]中首次被引入SemCom,其中表示的-grams精度分数取决于一个的最小频率之间的差异第 克中的元素。 从这个意义上说,整个句子的 BLEU 计算为所有大小的克的精度分数和简洁罚分 (BP) 的总和的乘积。 BP 由候选(恢复)和参考(传输)句子的长度确定。 候选句子与参考句子相比越长,BLEU 分数越低。 此外,为了使排序行为更加明显,通常使用BLEU在对数域中进行表达。
-
•
基于共识的图像描述评估(CIDEr):CIDEr在[156]中被提出作为图像描述质量的自动共识度量,最初用于衡量图像的相似度根据人类编写的一组真实句子生成句子。 因此,它也可以用作文本传输的语义度量[97]。 与 BLEU 类似,两个句子之间的相似度是根据其中呈现的 -gram 集合来计算的。 不同之处在于,在 CIDEr 中,不只考虑一个参考句子,而是一组参考句子。 在计算句子相似度时,会考虑候选句子与参考集中所有语义相似句子之间的相似度。
-
•
句子相似度:句子相似度是 SemCom 在 [38] 和 [139] 中初始化的新指标,基于 Transformers 的双向编码器表示 (BERT )。 BERT 是一种最先进的微调单词表示模型[148],它采用了一个巨大的预训练模型,其中包括用于提取 SI 的数十亿个参数。 在数十亿个句子的支持下,SI 提取的性能已在 [148] 中得到证明。 为此,直接根据BERT提取的语义特征的余弦相似度来计算句子相似度。
需要注意的是,尽管 BLEU 和 CIDEr 考虑了一些语言学规律,例如语义一致的单词通常在给定的语料库中聚集在一起[97],但它们仍然停留在计算两个句子之间的单词差异,但无法洞察整个句子的含义[139]。 从这个意义上说,句子相似度的度量更接近于所需的 SemCom 范式,因为训练有素的 BERT 模型对多义词很敏感(例如,单词“mouse”在生物学和中具有不同的含义) machine),这使得它能够提取句子级别的信息。
另一方面,这些指标的不可微性降低了它们的实用性,因为它们不能应用于基于DL的SE,并且基于RL的SE的计算复杂度相当大。 因此,即使[38]中同时提出了BLEU和句子相似度,基于DL的SemCom系统中的训练管道仍然采用CE损失。 此外,对于句子相似度,预训练的 BERT 网络嵌入在训练过程中引入了更多的资源消耗,并且很难在其他任务中推广。
V-A2 音频数据的语义度量
与文本数据类似,音频数据也非常接近人类自然语言。 因此,对于用于音频传输的SemCom,语义相似性可以通过接收器理解解码的音频信号的难易程度来解释,即可懂度。 在音频信号处理领域已经研究了一些类似的工作,如下[157,158,159]。
-
•
信号失真比(SDR):SDR最初是根据SNR的通常定义定义的,并在[157]中进行了一些修改。 在[82]中,将恢复信号作为性能指标引入SemCom,用传输的语音信号与之间的误差来表示>。 与MSE相比,SDR中和之间差异的排序行为更加显着。 此外,这种测量的数值精度对于高性能值比对于低性能值要低,这对于测量方法的设计来说更加直观。 然而,SDR 在语义感知方面并没有比 MSE 更进一步。
-
•
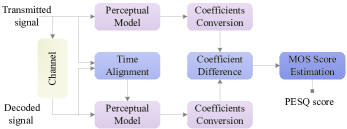
语音质量感知评估(PESQ):PESQ是一种专门的质量评估模型,专为在更广泛的网络条件下使用语音而设计,已标准化为ITU-T P.862建议书。 它在[81]和[82]中用于评估性能。 它结合了感知语音质量测量(PSQM)和感知分析测量系统(PAMS)[158]。 PESQ的基本PESQ图如图12所示。 与上述简单比较两个信号之间差异的度量不同,PESQ 假设人类感知中的短记忆,这使得它更类似于人类行为[81]。 但该方法仍然只考虑传输的准确性而不考虑语义,无法为语义压缩提供有效的指导。
简而言之,上述方法都没有评估语义理解层面的性能。 此外,在现有的工作中,DL 中仅使用 MSE 度量来表示 SE。 SemCom 到目前为止只达到了语义编码级别。 像BERT、BLEU这样的文本传输中具有语义理解的语义测量在音频SemCom领域还有待研究。
V-A3 视觉数据的语义度量
对于视觉数据的通信,目前还没有类似于人类感知的通用语义度量。 SemCom中针对视觉数据常用的指标仍然是浅层函数[160],例如PSNR[67]和结构相似性指数(SSIM)[ 161]用于传统通信系统。 此外,与文本和音频数据相比,语义相似度更依赖于上下文,即很难区分不同的“相似感”:红色圆圈与红色方块更相似还是蓝色圆圈更相似[160]? 这给视觉语义度量设计带来了挑战。 同时,与文本和音频数据类似,视觉数据的相似性判断也必须依赖于高阶结构[162]。 为此,基于深度学习的特征捕获可以被视为评估图像语义相似性的潜在方法[12]。 近年来,在高级图像分类任务上训练的深度卷积网络的内部激活被认为通常可以有效地作为更广泛任务的表示空间[160]。 例如,视觉几何组 (VGG) 架构 [163] 中的特征已用于其他任务,例如神经风格迁移 [164] 和条件图像合成 [165]。 然而,如何利用这种方法进行 SemCom 性能评估还需要进一步探索。 除了仅仅以保证视觉数据保真度为目的的图像传输之外,还有许多新兴的针对特定任务的视觉通信,如物体识别、属性分类等,其中任务执行的准确性可以直接表征SemCom的有效性。
| Semantic metrics | Advantages | Drawbacks | ||
| BLEU | BLEU is a method for automatic evaluation for machine translation. It is used to compare word groups of different sizes of the candidate with that of the reference translation and count the number of matches. | It considers the linguistic laws, such as that semantically consistent words usually come together in a given corpus. | It only calculates the differences of words between two sentences and has no insight into the meaning of the whole sentence. | |
| text data | CIDEr | CIDEr is proposed as an automatic consensus metric of image description quality, which is originally used to measure the similarity of a generated sentence against a set of ground truth sentences written by humans. | Compared to BLEU, it does not evaluate semantic similarity on the basis of a reference sentence, but a set of sentences with the same meaning | Similar to BLEU, it is also based on the comparisons between word groups, and the semantic similarity can only be made at the word level. |
| Sentence similarity | Sentence similarity is calculated as the cosine similarity of the semantic features extracted by bidirectional encoder representations from transformers (BERT) [38] from different sentences. | The SI considered in this metric is viewed from a sentence level owing to the sensitivity of BERT to polysemy. | BERT is a huge pre-trained model, which introduces much resource consumption in the training process and makes it hard to generalize in other tasks | |
| audio data | SDR | SDR is expressed by the error between the transmitted audio signal and recovered audio signal. | The numerical precision of SDR is lower for high performance values than for low performance ones. | SDR fails to capture the hidden SI of the speech signal, without any further than MSE in terms of semantic awareness. |
| PESQ | PESQ is a specialized quality assessment model designed for speech used across a wider range of network conditions, which has been standardized as Recommendation ITU-T P.862. | Instead of comparing the differences between the two signals directly, PESQ assumes the short memory in human perception. | PESQ still focuses on transmission accuracy, and thus it cannot provide effective guidance for semantic compression. | |
V-B 基于 AoI 的语义度量
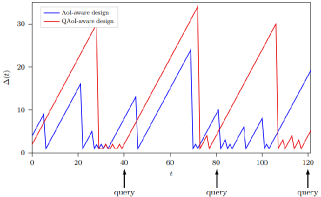
通信中的语义信息与语义网、语义分割等其他领域的语义信息的区别在于其强调时间敏感性。 此功能为语义信息的准确性引入了新的维度,即正确的时间[166]。 特别是对于一些应用,例如位置跟踪、控制和态势感知,信息的新鲜度对接收者的动作执行有重大影响。 在这方面,需要一些注重及时性的指标。
事实上,在性能评估中考虑AoI可以被认为是SemCom[167]的初步尝试。 与延迟度量主要衡量传输性能而不关心数据包内容不同,基于 AoI 的度量用于量化在目的地接收到的信息的陈旧程度。 数据包的年龄定义为当前时间与数据包时间戳[168]之间的差值,它捕获监视器接收到的数据的新鲜程度。 在传统的内容盲通信范式中,系统只追求尽可能快地发送更新并保证最小的传输延迟。 毫无疑问,这需要大量的带宽资源。 此外,如果不能保证延迟QoS,则通信系统中数据包的积压会抑制更新并导致监视器具有不必要的过时状态信息。 幸运的是,此类问题可以通过基于 AoI 最小化的调度方案来解决。 这是由于在调度过程中可以给予新鲜数据更多的重视并优先传输。
此外,由于环境的随机特性,可以根据具体系统选择合适的AoI分析方法,例如时间平均年龄和峰值年龄,详细介绍参见[169]。 然而,还应该指出的是,基于 AoI 的指标仍然存在固有缺陷,即它们忽视了恢复数据的有效性。 例如,在某些情况下,监控器只关心源[170]处的异常和突发状态。 由于AoI不考虑其监视器的当前状态值,因此一些无用的更新被传输到监视器,这也造成一定的资源浪费。
V-C 基于 VoI 的语义度量
VoI 也是通信系统中新引入的指标,特别是对于网络控制系统。 在此之前,VoI的概念在信息分析中是众所周知的,它被定义为决策者为考虑信息而愿意付出的价格[171]。 对于传统通信,VoI 可以定义为成功传输后源信息集的不确定性降低程度[172]。 相反,对于特定任务的通信,需要重新定义 VoI。 与 AoI 只关注永恒而忽略内容不同,VoI 主要用来衡量一条信息与通信任务的相关性。 换句话说,VoI可以被视为SI对有效性的量化贡献。
以远程温控系统[167]为例。 在该设置中,中央控制器不关心源的实时温度变化。 该系统的目标只是确保控制器对任何异常温升迅速做出反应。 从这个意义上说,异常温度的数据应该被赋予高VOI。 此外,在研究图像分类任务的[109]中,这里的VoI用于衡量提取的特征对于图像准确分类的重要性。 然而,大多数情况下,VoI只能在任务完成后才能知道。 在这里,我们回顾一下 [123, 124] 中语义感知通信的两个示例。 具有多个异构智能体的联邦DRL任务[123]中SI的VoI是收敛时间的减少以及收敛后长期奖励的增加。 此外,支持URLLC的无人机群协作中SI的VoI[124]提高了收敛速度并降低了无人机间碰撞概率。 因此,对于一般任务来说,将 VoI 量化为通信之前的 AoI 具有挑战性,因为 VoI 在很大程度上是由通信环境中的多种因素组合决定的。 因此,可用的基于VoI的度量是稀缺的,并且基于VoI的调度或资源分配方案仅执行简单的任务,例如异常监控。
V-D 组合语义度量
如上所述,上述三种类型的语义度量仅关注恢复数据所传达的信息的一种属性。 为了解决这一限制,新兴的研究工作一直在研究新的语义度量,这些度量在不同程度上结合了多个属性[166]。
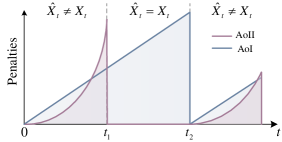
[167]中的作者将AoI集成到基于错误的度量中,并提出了一种名为错误信息年龄(AoII)的新度量。 AoII 表征了一种不准确状态的延长对语义恢复的影响。 与上述基于错误和基于 AoI 的指标相比,AoII 通过结合考虑内容和及时性,融入了更有意义的语义。 具体来说,AoII 不仅考虑瞬时状态对整体通信目标的影响,而且还考虑持续不同持续时间的状态的影响。 例如,对于视频传输[173]来说,长时间突发错误的影响远比瞬时突发错误严重。 AoI和AoII的比较如图13所示。 同时,[174]中的作者通过考虑基于拉动的系统,将 VoI 集成到基于 AoI 的指标中,并提出了一种称为查询时信息年龄(QAoI)的新指标,该指标反映了接收器实际需要数据的时刻[166]。 在基于拉动的系统中,信息仅在某些查询时刻对接收者有效。 从这个意义上说,通信预计是查询驱动的,即发送器知道查询时刻并根据查询过程的时序优化传输。 因此,对于这样的系统,基于查询驱动的 QAoI 调度方案比基于查询盲 AoI 的方案更高效、更有效,可以在查询时刻之前实现发送。 如图14所示,基于QAoI的方案更有可能在查询到达时提供新鲜的更新,尽管其平均AoI可能比基于AoI的方案差[ 174]。
V-E 经验教训总结
V-E1 基于错误的语义度量的经验教训
总体而言,SemCom性能评估方法的研究才刚刚开始,落后于SE和SI传输的研究。 与传统通信中用于量化传输精度的BER、SER等指标相比,上述语义错误指标避免了浅层逐位、逐符号的僵化比较。 在比较接收信号和发送信号之间的差异时,这些语义度量进一步考虑了数据类型本身的特征,例如文本的句法结构或人类感知中的短记忆对语音信号的积极影响可理解性。 然而,上述大多数指标仍在比较发送和恢复的原始信号,尽管是从更加个性化和专业化的角度出发,而不是直接比较这些暗示的 SI。 理想的语义度量可能类似于[38]和[139]中提出的句子相似度,并且也意味着预训练不可避免地消耗计算资源和时间所依赖的AI模型的过程。
V-E2 组合语义度量的经验教训
总而言之,在根据上述三类指标进行绩效评估时,数据被赋予了不同的重要性。 由于基于错误的语义度量旨在比较传输的消息和恢复的消息所传达的含义,因此它可以被视为为面向语义的通信设计的度量。 相比之下,基于 VoI 的度量类型超越了语义层面的准确性比较,而是直接从有效性层面评估信息与任务绩效的相关性。 从这个意义上说,基于 VoIP 的指标适用于面向目标的通信。 此外,基于 AoI 的指标介于基于错误的指标和基于 VoI 的指标之间,因为消息的含义及其对任务执行的影响可能会随着时间的推移而发生变化。 将基于 AoI 的指标与基于错误的指标相结合,可以在时间维度上进一步区分信息的相关性。 在理想的 SemCom 系统中,组合的指标有望在资源分配中发挥作用,指导过滤不相关信息,提高系统效率和性能。 然而,这种想法仅在最简单的基于拉动的系统中进行了探索,原因是尚未实现 SI 的量化,并且大多数基于错误的指标和基于 VoI 的指标在传输前难以估计。
VI SemCom 面向未来 6G 互联网
在本节中,我们首先讨论 SemCom 在 6G 中的一些潜在应用。 然后,我们在 6G 中激发了一种有前途的 SemCom 赋能的网络架构。
VI-A SemCom 在 6G 中的潜在应用
VI-A1 智能交通系统
近年来,随着车辆硬件和车辆基础设施的发展,车辆可以被视为具有更强计算、缓存和数据存储能力的智能代理[175, 176]。 这为未来的 6G 智能交通系统(ITS)铺平了道路,其中无需人工参与即可实现自动驾驶和协作车辆网络[177]。 在大多数现有工作中,为了增强安全性、改善辅助驾驶决策或管理车辆,需要定期广播车辆和道路的基本信息,例如位置、制动强度、坑洼和水坑。 [37]。 这种针对不同情况的无差别车辆通信会影响通信效果和效率。 为此,SemCom 有很大潜力让 ITS 变得更加智能化。
在ITS中,SemCom最直接的应用是从原始传感器数据中提取必要的语义信息,例如车辆运动学信息、道路状况和交通标志(如图4所示)。 例如,有很多情况,例如人的突然出现和车辆前方发生的突然碰撞,都会对车辆驾驶产生类似的影响。 因此,通过提取特定情况的SI(即量化每种情况对驾驶的影响),可以因数据量的减少而大大提高传输的准确性和及时性。 除了数据本身的压缩之外,正如V-B节中讨论的那样,SE中数据采样的时间点也很关键。 例如,当车辆在各个方向上具有足够长的可视范围或足够的观看持续时间时,它可以根据自己的本地情况做出驾驶决策。 在这种情况下,不需要频繁地交换其他车辆的行驶信息。 相反,如果车辆的可见持续时间很短,那么当车辆获得视野时,它可能没有足够的信息或时间来做出正确的反应。 在这种情况下,信息交流需要更加及时。 更具体地说,有关安全的基本信息(例如制动强度)应具有更高的优先级[178]。 此外,如II-B3节所述,为了监控围墙细分的交通流量,可以与车辆共享有关细分出口连续视图的SI即将通过细分。 为此,以“定量”的方式确定何时进行沟通、共享哪些信息,正是 SemCom 需要做的事情。
VI-A2 基于分布式学习的应用
随着终端设备计算能力的增强和用户对隐私问题的日益关注,联邦学习 (FL) 等分布式学习已成为隐私保护机器学习的主导范例[179]。 它已经渗透到人类生活的各个方面[180],例如医疗诊断、网络攻击检测、BS关联等。 由于深度神经网络通常包含数百万个权重参数,终端和服务器之间频繁交换DNN模型或梯度会产生昂贵的通信开销,这给通信网络带来了挑战,特别是对于不确定的无线环境和有限的无线资源。
幸运的是,SemCom 可以通过两种方式减少不必要的通信开销,从而在有限的无线资源内提高性能。 首先,可以通过语义感知的方式压缩模型参数和梯度,例如梯度稀疏化[181]和模型参数剪枝[182],其中考虑到参数的语义或对于模型精度和收敛速度的重要性,提取原始模型参数。 例如,在[181]中,通过将除之外的具有最高条目量级的元素设置为零,采用梯度稀疏化来压缩发射机处的模型。 由于仅发送非零元素的位置,因此接收器可以通过先进的噪声测量以更可靠的方式恢复接收到的数据。 其次,根据III-E节中语义感知通信的两个示例,分布式学习中的代理可以通过 SemCom 交换自己的语义特征,以增强彼此的了解。 语义特征可以从他们的学习模型[123]、他们的可观察环境[124]、他们的任务等中提取。 基于小数据量的语义特征,可以找到用于协作的语义相关代理的最佳子集。 因此,可以有效减少不相关主体之间大数据量模型的交换。
VI-A3 无人机
无人机引起了广泛关注,特别是在用作空中基站(BS)或中继站时[183,184,185]。 与静态地面基站或中继不同,无人机可以灵活部署以满足各种服务质量要求并平衡用户之间的负载。 此外,与单个无人机系统相比,无人机群协作可以更高效、更经济地完成任务。 然而,无人机的能量限制阻碍了它们促进长期通信的能力。 同时,无人机群体导航中的碰撞问题也一直是无人机网络研究的重点关注问题。
幸运的是,由于 SemCom 可以减少需要传输的信息量,因此可以实现无人机之间的高效通信框架。 例如,当无人机充当中继时,可以借助协作通信协议来实现分集增益,例如解码转发和放大转发[186]。 从这个意义上说,一种新颖的语义处理转发方法被提出来迎合 SemCom。 除了传统的中继功能之外,无人机还可以部署为语义编码器和/或解码器。 例如,当发送方和接收方之一由于内存或计算能力不足而无法启用SemCom时,无人机可以改为进行编码或解码,以减少某条链路的数据量而不影响通信性能。 当然,这需要无人机了解通信双方的背景知识。 这也对通信、计算、缓存资源的联合优化提出了新的挑战。 而且,在双方都可以启用SemCom的情况下,无人机可以根据发射机的背景知识对接收到的信号进行语义解码,然后根据接收机的背景知识对信号进行重新编码。 这大大减少了同步发送和接收背景知识的开销以及由于不同步背景知识而引起的语义噪声[187]。 此外,正如III-E节中所讨论的,SemCom 还可以在无人机集群导航中发挥重要作用。 如[124]所示,通过引入SemCom,基于图注意力交换网络的无人机集群导航可以实现x低于目标的延迟与最先进的基于 CTDE 的方法相比,错误率更高。
VI-A4 扩展现实
6G网络技术的进步为下一代互联网业务提供技术支撑。 特别是,通过扩展现实(XR)实现物理世界和虚拟世界同步的可能性,催生了元宇宙(Metaverse)的诞生,元宇宙被称为互联网的继承者。 XR的性能在很大程度上取决于反映或描述人类运动和周围环境变化的数据的收集和处理,例如移动渲染目标、显示特定视频以及给出相应的触觉反馈。 为了保证用户获得理想的沉浸式元界业务体验,必须严格满足端到端时延和数据速率要求[188, 189]。
为此,SemCom 可以被视为基于 XR 的 Metaverse 访问[190]的推动者。 在 SemCom 范式中,终端设备跟踪的数据,例如头部运动、手臂摆动、手势和语音,需要首先进行语义提取。 这允许终端设备在理解并过滤掉不相关信息后传输XR服务器关注的信息进行操作,以节省带宽并减少XR服务器的计算延迟。 同时,XR服务器还可以根据用户的偏好提取SI,在带宽限制的情况下忽略不相关的细节,从而减轻下行压力。
VI-A5 全息远程呈现(HT)
作为向用户提供下一代服务的另一种技术,全息远程呈现 (HT) 可以投影远处人类或物理物体的逼真、全动态、实时三维 (3D) 图像,其逼真度可与物理存在[177][191]。 它不仅可以应用于虚拟会议、虚拟游戏和娱乐领域,还可以应用于远程修复、远程手术[177][192]。 然而,与沉浸式XR应用一样,为了保证足够真实的虚拟无缝服务体验,HT也需要严格的QoS。 此外,几乎所有的人类感官,例如嗅觉和味觉,都有望通过未来的网络传输,从而获得完全身临其境的体验。
对于这种通信计算密集型业务,传统的内容盲通信范式导致了带宽资源和计算资源的浪费。 为此,SemCom的先理解后传输范式不失为一种缓解带宽和接收端处理压力的有前途的方法。 这得益于SemCom可以进行自适应网络状况的SI提取,增强传输可靠性,使用户无法感知网络状况的变化,从而保证高质量的业务体验。
VI-A6 个性化身体区域网络
个人数据管理以及可穿戴设备的传输是未来的趋势,将影响个人服务和程序的发展。 一个重要元素是无线体域网 (WBAN)。 WBAN 由 IEEE (任务组 )正式定义为针对低功耗设备优化的通信标准,可服务于各种应用,例如医疗、消费电子产品和个人娱乐[191]。 由于微型传感器节点的电源能源有限,有效的能源消耗是 WBAN 的一个关键挑战。 SemCom 促使我们思考是否可以通过减少实际传输的位数来节省能源并延长可穿戴设备的使用寿命。 在 WBAN 中,事实证明,现代低功耗可穿戴设备上的特征提取不仅可行,而且有利于系统寿命的延长[192]。 尽管资源受限的传感系统需要在语义特征输出的准确性和分析提取数据的成本之间取得平衡,但减少用于传输的无线电占空比所带来的好处远远超过了增加用于语义特征提取的处理器占空比[193]。 由于从原始数据中提取知识可以显着减少需要传输的信息,因此基于 SemCom 的方法将可穿戴设备的寿命提高了一个数量级,但代价是分类精度下降了约 5% [193]。 SemCom的发展以及与WBAN的更深入融合将催生更耐用、更方便的可穿戴设备。
VI-A7 协作机器人
一组协作机器人可以比单独工作的单个机器人更有效地探索、交互和感知环境[194]。 在灾难管理、仓库自动化、监控等场景中,协作机器人的应用正在迅速增加。 然而,每个机器人有限的计算能力限制了其在计算密集型任务中的广泛部署[195]。 一种有前途的解决方案是应用 SemCom 技术来实现高效的数据交换和处理。 [196]中提出了SEMIoTICS,一种新的基于SemCom的控制系统架构,它能够利用基于逻辑的推理而不是声明性语言模型来减少决策时间。 在[196]中,SEMIoTICS部署在由15个物联网组件组成的建筑物中,用于温度调节控制。 结果表明,总体控制处理时间可以维持在分钟内,仅为传统基于模糊逻辑控制的方法的[197]. 为了进一步减少协作机器人之间的通信开销,可以使用名为-DeepSC [75]的精简分布式SemCom系统。 当协作机器人之间的通信环境信噪比较低时,-DeepSC可以实现高效的信息交换。 特别是,通过-DeepSC,机器人之间交互所需的数据量可以被压缩到传统方法所需的信息量。
VI-A8 超智能物联网
超智能(HI)是指完成复杂任务的更高智能和超智能能力。 HI 与物联网的结合将带来更加智能、数据驱动的社会[198, 199]。 未来几年的一个普遍且可合理预测的趋势将是网络、网络节点和链接设备的本地智能的崛起。 以前仅用作感知和传输实体的设备将被赋予各种级别的嵌入式智能,可直接对所获取的数据进行操作。 日益智能的通信各方的必要性为创建“更智能”的内容进行交换和推理以及确保有效和准确完成的创新方法打开了大门[200],这与随着SemCom的蓬勃发展。 在 SemCom 的帮助下,仅传输最有用的数据,因此优化了通信工作。 为了在 HT IoT 中部署 SemCom 技术以提高效率,一个潜在的解决方案是考虑使接收器能够有效执行给定任务的任何方法,同时依靠 SemCom 仅从数据中提取必要的信息。 通过赋予HI在语义甚至有效层面处理和推理信息的能力,HI物联网将更加互联,进一步推进互联互通社会的建设。
VI-B SemCom赋能的6G架构
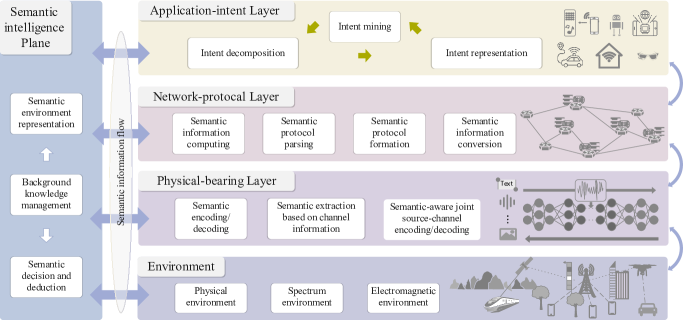
在传统的通信网络中,网络节点不关心数据试图传达的内容。 网络中层间和层内节点之间交换的信息通常可以看作是同质的比特序列。 然而,在具有泛在意识的SemCom架构中,信息表示可以达到更高的水平。 与香农信息论中“Bit”的概念相一致,[20]作者为SI引入了一个新概念“Seb”。 与传统通信系统相比,Seb 设计的 SemCom 系统经过高度调制。
类比建造过程,基于比特流的网络架构就像是一砖一瓦建造的建筑物,而基于Seb流的网络架构则类似于由层压板和集成窗建造的建筑物或门[20]。 随着原材料的整合简化了构建流程,原始数据的SE也呼唤简化的网络架构来高效支持SemCom。
为此,[20]的作者提出了一种新颖的智能高效SemCom(IE-SC)架构,如图15所示。 与著名的七层开放系统互连(OSI)模型相比,他们提出的 IE-SC 架构将网络分为三个语义授权层:语义应用意图(S-AI)层、语义网络协议( S-NP)层和语义物理承载(S-PB)层。 同时,这三个层以及物理环境由一个独立的语义智能平面通过语义信息流(S-IF)进行协调。 下面我们首先介绍语义智能平面的三个主要功能。 然后,我们通过示例详细介绍其他三层。
VI-B1 语义智能平面
语义智能平面作为整个IE-SC网络的协调者,包含三个主要功能:
-
•
语义环境表示:该函数根据S-AI层提供的语义意图信息,从原始数据和通信上下文中提取SI,详细信息请参见VI-B2。 同时,语义智能平面生成语义提取组件,如SemCom协议设计、语义编解码等,并将其映射到各层的功能。 同时,SI嵌入到S-IF中,通过语义智能平面和各层接口在网络中传输。
-
•
背景知识管理:正如人类沟通需要了解对方的语言和文化一样,SemCom要求沟通双方具有相同的背景知识,这为S-AI层意图分析奠定了基础。 语义智能平面作为协调器,完成背景知识的同步、整合和存储。
-
•
语义决策与推导:语义智能平面还负责根据S-AI层馈送的意图分析结果评估可实现的性能,并对所有网络层进行决策。
VI-B2 语义应用意图层
在传统的OSI模型中,应用层主要允许用户从存储或数据集中下载数据,或者将数据发送到目的地,而不管数据的用途和方式。 相比之下,S-AI层增加了针对特定通信的意图分析的功能。 它可以支持将用户意图分解并转化为网络的部署、配置或控制策略。 下面重点介绍了 S-AI 层中的三个主要功能。
-
•
意图挖掘:S-AI层负责提取、分析、聚合和综合从用户或应用程序接收到的原始意图。 例如,对于图像,一些请求者可能将其用于目标识别,一些请求者可能关心局部细节,而一些请求者可能仅对图像质量感兴趣。 不同的意图可能对应于不同的通信过程。
-
•
意图分解:为了方便后续从原始数据中进行SE,将意图挖掘后得到的意图分解为一组子意图,这些子意图可能是请求者对不同段落、句子的关注、文本中的单词或图像不同特征的重要性。 此外,回想一下智能交通系统中的一个应用程序,其目的是为即将通过围墙分区的车辆提供有关分区出口交通流量的信息。 在意图分解过程中,子意图可以是细分出口的一系列连续视图。 为了指导整个通信过程的实现,可以将子意图通知给S-NP层和S-PB层,并分别用于设计协议和SE。
-
•
语义表示:获得子意图集合后,S-AI层给出子意图的语义表示。 语义表示被传递到语义智能平面,促进SE。
VI-B3 语义网络协议层
S-NP层旨在通过智能网络协议高效地服务于上层应用的意图。 该层的设计主要集中在语义交互策略上,包括学习经验积累(例如多轮对话)、实时知识共享和简化语义交互。 从这个意义上说,S-NP层应该包含一些关键模块:
-
•
SI计算:在传统通信中,大多数协议主要关注目的地址和端口,而忽略数据的内容。 然而,在SemCom支持的网络架构中,如果中间转发节点仍然平等地对待所有数据,则会损害应用程序的分析意义。 为此,该模块用于识别S-IF上的意图信息并从其他模块获取知识。
-
•
语义协议解析:该模块用于分析现有协议可用的功能。
-
•
语义协议形成:该模块负责优化现有协议或形成新的协议以适应应用程序的意图。
-
•
SI转换:在传统的网络架构中,不同网络层的协议有单独的帧封装、分组封装、段封装等。 同样,在支持SemCom的协议中,SI需要单独封装。 该模块负责根据生成的协议完成SI封装。
以沉浸式AR应用为例,该应用是视频、音频和触觉数据共存的应用,需要高带宽和超可靠的低延迟。 假设通过与语义智能平面交互,S-NP层可以映射子意图,例如对视野中不同声源和不同物体的关注,以及具有高度关键延迟要求的触觉数据,到 S-IF 内的数据。 对于触觉数据包,传统的媒体访问控制帧设计通常会预留专用资源以确保满足延迟QoS要求。 然而,触觉数据包的请求是随机且间歇性的,这不可避免地导致资源利用率低或传输失败。 为了解决上述问题,需要设计语义协议来协调不同子意图对应的数据的传输。 例如,由于最严格的时间延迟要求,触觉数据在转发时被赋予最高优先级。 此外,当网络负载较重时,可以自适应地检测和删除用户关注度较低的冗余数据,并为延迟敏感流量[154]释放资源。
VI-B4 语义物理承载层
S-PB层负责将来自上层的SI转换为物理信号。 与传统通信不同,SemCom的目标是传递SI而不是原始数据,因此传统的信源编解码和信道编解码将被取代。 下面列出了 S-PB 层中使用的三种可能类型的语义相关模块:
七未来方向
在前面的章节中,我们回顾了 SemCom 在 6G 中的潜在应用以及 SemCom 中应用的最先进技术。 除了III-V节讨论的剩余问题外,其他几个与SemCom相关的方向可以在系统有效性、可持续性和可信性方面进一步探索。
VII-A SE的可解释性和可解释性
通信环境总是经历着各种不确定性,例如网络环境的意外变化或全新的源信息。 黑箱性质使得SE模型在实践中对于不确定输入对应的输出是不可预测的,这限制了SE模型的社会接受度和实用性,也没有为SE模型优化提供依据。 同时,可用的 SE 模型很少或根本不了解隐藏层中的内部状态和特征如何以及为何有助于给定示例产生决策或结果[201],这失败了为 SemCom 系统和 SI 传输的设计提供宝贵的见解。 因此,SE的可解释性和可解释性问题必须得到解决。
正如[202]中所定义的,可解释性用于衡量人类能够一致预测模型决策的程度。 深入了解 SE 模型如何以及为何得出特定决策或结果,不仅可以增强模型处理未知情况的信心,从而降低不确定性风险,还有助于了解模型的整体优势和劣势并指导模型[203]的改进。 与可解释性相反,可解释人工智能的研究重点是DNN中的隐藏状态,旨在打开黑匣子。 例如,可以通过分析语义解码器的梯度信息来量化每个输入语义特征对语义推理准确性的贡献。 基于此,发送端的无线资源分配可以实现更加灵活和细粒度的实现,例如为关键的语义特征分配更高的发射功率,以保证其传输的可靠性和语义推理的准确性。
VII-B SE 准确性和通信开销之间的权衡
现有的工作大多集中在如何执行精确的SE以节省无线电资源并增强通信性能,而忽略了SE的额外通信开销。 事实上,SE 模型的训练和更新需要大量的额外资源。 例如,精确语义提取模型的训练依赖于发送者和接收者的完整知识库,这首先需要足够的存储资源。 此外,随着通信环境的发展,每个用户的本地知识库都会不断地单独更新。 从这个意义上说,确保所有通信参与者的本地数据库的更新能够实时共享是极具挑战性的,特别是对于大量地理上遥远的参与用户的情况,这可能会导致巨大的通信开销。 此外,在理想情况下,知识库更新后需要立即对SE模型进行重新训练或微调。 然而,这对于计算资源有限的实际系统来说是不现实的。 因此,在SE准确性和通信过度之间做出有利的权衡对于SemCom的实施至关重要。
例如,我们可以利用边缘智能,首先根据存储在本地MEC服务器中的本地发送者和接收者的共享知识库来训练SE模型。 然后,借助联邦学习等分布式学习范式,可以通过聚合不同地理区域的多个训练有素的 SE 模型来获得广义的 SE 模型。 这样,可以有效利用分散在边缘的存储资源,减轻终端设备或中心云的存储压力,并且可以大大减少远距离共享数据带来的通信开销。 但地理区域的合理划分以及边缘服务器的战略部署仍有待探索。 此外,聚合周期和每轮选择的参与者也是在 SE 准确性和通信开销之间进行权衡时可以优化的基本问题。
VII-C SemCom 和语义缓存的结合
在传统通信中,在路由器、MEC 服务器、基站等设备上实施数据缓存已经证明在避免 [204] 不必要的延迟和网络开销方面大有裨益。 通过联合优化缓存和通信,缓存命中率每增加 1%,感知延迟就会降低 35%[205]。 然而,传统的原始数据缓存不再理想地适用于 SemCom 系统,因为频繁且重复的原始数据语义提取导致系统冗余和低效率。 同时,提取的SI数据量与原始数据相比要小得多。 从这个意义上说,适合SemCom的语义缓存策略不仅可以提高系统效率,还可以节省内存资源。
然而,语义缓存提出了新的问题。 例如,与传统的数据缓存主要关注数据内容的命中率不同,语义缓存更关注请求者是否能够准确推断出缓存中的SI。 由于同一数据内容可能存在多个SI,因此缓存哪些SI需要更多的先验知识,例如特定SI的流行程度。 此外,由于 SemCom 的背景不断变化,SI 的生命周期更难以确定。 为此,还需要新的语义缓存估计刷新算法。
VII-D 隐式 SemCom 中的推理
SemCom 之前的大部分研究都集中在传输显式 SI,例如可以从源信号中直接识别的事物的标签,例如图像、语音和文本。 然而,用户之间的交流不仅限于显性信息,还包含丰富的难以表达、识别或恢复的隐性信息。 例如,在 [206] 中,一个孩子向她的父亲发送了一条语音消息,询问“什么是 Tweety?”该消息的主要语义部分“Tweety”可以用多种方式解释,例如智能手机应用程序、金丝雀鸟或卡通电视节目中的角色。 因此,为了推断出消息的确切含义,接收者必须能够从发送者的上下文和背景中推断出隐含的信息。 因此,假设目标用户具有明确定义的分析表达式(例如奖励函数或效用函数),直接对其进行优化以最大化其对语义的理解是不现实的。
一些作品考虑了这一点并试图提出解决方案。 [206]中设计了一种基于生成对抗性模仿学习的推理机制学习(GAML),供目标用户学习和模仿源用户的推理过程以获得隐含语义。 结果表明,GAML 可以实现显着的纠错性能,并且与基于遗传算法 (GA) 的推理解决方案相比,精度提高了 20%。 在另一项工作[207]中,作者开发了一种新颖的基于推理函数的方法,可以推断隐藏信息,例如无法从消息中直接观察到的不完整实体和关系,解决方案达到了 76%使用加法和线性推理函数时,恢复丢失信息的准确度分别为 48%。 然而,[206, 207]中的两种解决方案都增加了额外的推理开销,并且性能仍有进一步提升的空间。 此外,由于显式SI通常占主导地位,因此通信资源应在显式SI和隐式SI之间按比例分配,这启发我们进一步设计联合优化算法。
VII-E SemCom 渠道管理中的人工智能
在SemCom中,AI更多地部署在发射端和接收端进行编解码,服务于上层应用。 然而,在具有更高数据速率和更频繁切换的6G无线通信中,信道建模比传统的随机或确定性方法变得越来越复杂[208]。 这促使我们思考是否可以将 AI 引入 SemCom 通道层,以帮助建模、估计和更改通道条件。 与简单地将AI应用于端到端SemCom模型训练不同,新型智能材料的开发赋予AI在无线信道上更多的自由[209]。 相信通过可重构超表面(RMS)和人工智能等新兴技术,下一代无线通信网络中的无线电环境将变得可控和智能化[210]。 RMS 可以有效地控制波前,例如撞击信号的相位、幅度、频率,甚至偏振。 通过使用支持AI的可编程智能材料,SemCom网络可以通过联合优化发射器、接收器和环境,进一步超越经典香农理论预测的极限。
VII-F SemCom 性能和安全性之间的权衡
数据安全和隐私问题一直是无线通信领域的重要话题[211]。 由于SemCom只需要传输部分数据,而SI的解码依赖于接收者的背景知识,因此它也被认为是一种潜在的安全通信方法[30]。 此外,通过对提取的SI进行加密可以进一步增强数据的安全性。 然而,这也导致我们考虑计算资源开销和数据安全之间的权衡。 一种可能的解决方案是使用物理层安全技术。 考虑到隐蔽通信[212]的成功,我们可以通过对安全无线传输的物理层引入干扰来使数据窃听者不确定SemCom是否正在进行。 然而,虽然减少了加密数据的计算资源,但我们需要保持发射功率不要太高,以保证通信的隐蔽性。 此外,干扰信号对SI的传输产生负面影响,这带来了隐蔽性和信号质量之间的权衡。
八结论
在本文中,我们对 SemCom 的 6G 进行了全面的调查。 首先,我们强调了 6G 和 SemCom 相辅相成的特性。 然后,我们介绍了SemCom相关理论的发展,并识别了SemCom的三种类型。 接下来,我们将通信系统的设计分为SI提取、SI传输和SI度量三个维度,并分别讨论了最先进的技术和挑战。 同时,我们还介绍了SemCom在6G网络中的潜在应用以及SemCom赋能的有前景的网络架构。 此外,我们还强调了一些未来的方向,并提供了进一步深入研究的见解。
参考
- [1] C. E. Shannon, “A mathematical theory of communication,” Bell Sys. Tech. J., vol. 27, no. 3, pp. 379–423, Oct. 1948.
- [2] R. Li, Z. Zhao, X. Zhou, G. Ding, Y. Chen, Z. Wang, and H. Zhang, “Intelligent 5G: When cellular networks meet artificial intelligence,” IEEE Wireless Commun., vol. 24, no. 5, pp. 175–183, May 2017.
- [3] M. Xu, W. C. Ng, W. Y. B. Lim, J. Kang, Z. Xiong, D. Niyato, Q. Yang, X. S. Shen, and C. Miao, “A full dive into realizing the edge-enabled metaverse: Visions, enabling technologies, and challenges,” arXiv preprint arXiv:2203.05471, 2022.
- [4] W. Y. B. Lim, Z. Xiong, D. Niyato, X. Cao, C. Miao, S. Sun, and Q. Yang, “Realizing the metaverse with edge intelligence: A match made in heaven,” arXiv preprint arXiv:2201.01634, 2022.
- [5] H. Du, J. Liu, D. Niyato, J. Kang, Z. Xiong, J. Zhang, and D. I. Kim, “Attention-aware resource allocation and QoE analysis for metaverse xURLLC services,” arXiv preprint arXiv:2208.05438, 2022.
- [6] H.-j. Jeon, H.-c. Youn, S.-m. Ko, and T.-h. Kim, “Blockchain and ai meet in the metaverse,” Advances in the Convergence of Blockchain and Artificial Intelligence, p. 73, 2022.
- [7] H. Du, B. Ma, D. Niyato, and J. Kang, “Rethinking quality of experience for metaverse services: A consumer-based economics perspective,” arXiv preprint arXiv:2208.01076, 2022.
- [8] Q. Lan, D. Wen, Z. Zhang, Q. Zeng, X. Chen, P. Popovski, and K. Huang, “What is semantic communication? a view on conveying meaning in the era of machine intelligence,” Journal of Communications and Information Networks, vol. 6, no. 4, pp. 336–371, Apr. 2021.
- [9] G. Shi, Y. Xiao, Y. Li, and X. Xie, “From semantic communication to semantic-aware networking: Model, architecture, and open problems,” IEEE Commun. Mag., vol. 59, no. 8, pp. 44–50, Aug. 2021.
- [10] M. Kountouris and N. Pappas, “Semantics-empowered communication for networked intelligent systems,” IEEE Commun. Mag., vol. 59, no. 6, pp. 96–102, Jun. 2021.
- [11] E. C. Strinati and S. Barbarossa, “6G networks: Beyond shannon towards semantic and goal-oriented communications,” Comput. Netw., vol. 190, p. 107930, 2021.
- [12] Z. Qin, X. Tao, J. Lu, and G. Y. Li, “Semantic communications: Principles and challenges,” arXiv preprint arXiv:2201.01389, 2021.
- [13] X. Luo, H.-H. Chen, and Q. Guo, “Semantic communications: Overview, open issues, and future research directions,” IEEE Wireless Commun., to appear, 2022.
- [14] P. Zhang, W. Xu, H. Gao, K. Niu, X. Xu, X. Qin, C. Yuan, Z. Qin, H. Zhao, J. Wei et al., “Toward wisdom-evolutionary and primitive-concise 6G: A new paradigm of semantic communication networks,” Engineering, vol. 8, pp. 60–73, 2022.
- [15] J. Wu, R. Li, X. An, C. Peng, Z. Liu, J. Crowcroft, and H. Zhang, “Toward native artificial intelligence in 6G networks: System design, architectures, and paradigms,” arXiv preprint arXiv:2103.02823, 2021.
- [16] Y. Zhong, “A theory of semantic information,” China Commun., vol. 14, no. 1, pp. 1–17, Jan. 2017.
- [17] C. W. Morris, “Foundations of the theory of signs,” in International encyclopedia of unified science. Chicago University Press, 1938, pp. 1–59.
- [18] M. Ch, “Writings on the general theory of signs,” Mouton, The Hague, 1971.
- [19] W. Weaver, “Recent contributions to the mathematical theory of communication,” ETC: A review of general semantics, pp. 261–281, 1953.
- [20] P. Zhang, W. Xu, H. Gao, K. Niu, X. Xu, X. Qin, C. Yuan, Z. Qin, H. Zhao, J. Wei et al., “Toward wisdom-evolutionary and primitive-concise 6G: A new paradigm of semantic communication networks,” Engineering, 2021.
- [21] Y. Bar-Hillel and R. Carnap, “Semantic information,” Br. J. Philos. Sci., vol. 4, no. 14, pp. 147–157, 1953.
- [22] P. Elias, “An outline of a theory of semantic information,” 1954.
- [23] L. Floridi, “Outline of a theory of strongly semantic information,” Minds. Mach., vol. 14, no. 2, pp. 197–221, Feb. 2004.
- [24] S. D’Alfonso, “On quantifying semantic information,” Information, vol. 2, no. 1, pp. 61–101, 2011.
- [25] I. Niiniluoto, Truthlikeness. Springer Science & Business Media, 2012, vol. 185.
- [26] J. Barwise, J. Seligman et al., Information flow: The logic of distributed systems. Cambridge University Press, 1997.
- [27] G. Oddie, “Likeness to truth,” 1986.
- [28] I. Niiniluoto, “Truthlikeness,” 1987.
- [29] J. Bao, P. Basu, M. Dean, C. Partridge, A. Swami, W. Leland, and J. A. Hendler, “Towards a theory of semantic communication,” in 2011 IEEE Network Science Workshop. IEEE, 2011, pp. 110–117.
- [30] P. Basu, J. Bao, M. Dean, and J. Hendler, “Preserving quality of information by using semantic relationships,” Pervasive and Mobile Computing, vol. 11, pp. 188–202, 2014.
- [31] B. Juba and M. Sudan, “Universal semantic communication i,” in Proc. fortieth annual ACM symposium on Theory of computing, 2008, pp. 123–132.
- [32] C. Lund, L. Fortnow, H. Karloff, and N. Nisan, “Algebraic methods for interactive proof systems,” J. ACM, vol. 39, no. 4, pp. 859–868, Apr. 1992.
- [33] B. Juba and M. Sudan, “Universal semantic communication II: A theory of goal-oriented communication,” in Elec. Colloq. Comput. Complex. (ECCC), vol. 15, no. 095. Citeseer, 2008.
- [34] O. Goldreich, B. Juba, and M. Sudan, “A theory of goal-oriented communication,” J. ACM, vol. 59, no. 2, pp. 1–65, Feb. 2012.
- [35] B. Juba and S. Vempala, “Semantic communication for simple goals is equivalent to on-line learning,” in Proc. Int. Conf. Algo. Learn. Theory. Springer, 2011, pp. 277–291.
- [36] F. I. Dretske, “Knowledge and the flow of information,” 1981.
- [37] H. Bista, I.-L. Yen, F. Bastani, M. Mueller, and D. Moore, “Semantic-based information sharing in vehicular networks,” in 2018 IEEE International Conference on Web Services (ICWS). IEEE, 2018, pp. 282–289.
- [38] H. Xie, Z. Qin, G. Y. Li, and B.-H. Juang, “Deep learning enabled semantic communication systems,” IEEE Trans. Signal Process., vol. 69, pp. 2663–2675, 2021.
- [39] M. Sana and E. C. Strinati, “Learning semantics: An opportunity for effective 6G communications,” arXiv preprint arXiv:2110.08049, 2021.
- [40] A. Meroño-Peñuela, A. Ashkpour, M. Van Erp, K. Mandemakers, L. Breure, A. Scharnhorst, S. Schlobach, and F. Van Harmelen, “Semantic technologies for historical research: A survey,” Semantic Web, vol. 6, no. 6, pp. 539–564, 2015.
- [41] L. Rachana and S. Shridevi, “A literature survey: Semantic technology approach in machine learning,” Advances in Smart Grid Technology, pp. 467–477, 2021.
- [42] M. Thoma, “A survey of semantic segmentation,” arXiv preprint arXiv:1602.06541, 2016.
- [43] P. C.-y. Sheu, “Semantic computing,” Semantic computing, pp. 1–9, 2010.
- [44] P. Hitzler, “A review of the semantic web field,” Communications of the ACM, vol. 64, no. 2, pp. 76–83, 2021.
- [45] W. Chen, “Recommendation system based on semantic web,” in Int. Conf. Machine Learning and Big Data Analytics for IoT Security and Privacy. Springer, 2021, pp. 511–517.
- [46] C. She, R. Dong, Z. Gu, Z. Hou, Y. Li, W. Hardjawana, C. Yang, L. Song, and B. Vucetic, “Deep learning for ultra-reliable and low-latency communications in 6G networks,” IEEE Netw., vol. 34, no. 5, pp. 219–225, 2020.
- [47] Z. Qin, H. Ye, G. Y. Li, and B.-H. F. Juang, “Deep learning in physical layer communications,” IEEE Wireless Commun., vol. 26, no. 2, pp. 93–99, 2019.
- [48] T. O’shea and J. Hoydis, “An introduction to deep learning for the physical layer,” IEEE Trans. Cogn. Commun. Netw., vol. 3, no. 4, pp. 563–575, 2017.
- [49] H. Ye, G. Y. Li, and B.-H. Juang, “Power of deep learning for channel estimation and signal detection in OFDM systems,” IEEE Wireless Commun. Lett., vol. 7, no. 1, pp. 114–117, 2017.
- [50] C.-J. Chun, J.-M. Kang, and I.-M. Kim, “Deep learning-based joint pilot design and channel estimation for multiuser MIMO channels,” IEEE Communications Letters, vol. 23, no. 11, pp. 1999–2003, 2019.
- [51] J. Guo, C.-K. Wen, and S. Jin, “Canet: Uplink-aided downlink channel acquisition in FDD massive MIMO using deep learning,” arXiv preprint arXiv:2101.04377, 2021.
- [52] S. Park, O. Simeone, and J. Kang, “End-to-end fast training of communication links without a channel model via online meta-learning,” in 2020 IEEE 21st International Workshop on Signal Processing Advances in Wireless Communications (SPAWC). IEEE, 2020, pp. 1–5.
- [53] H. Ye, G. Y. Li, and B.-H. F. Juang, “Deep learning based end-to-end wireless communication systems without pilots,” IEEE Trans. Cogn. Commun. Netw., 2021.
- [54] S. Dörner, S. Cammerer, J. Hoydis, and S. Ten Brink, “Deep learning based communication over the air,” IEEE J. Sel. Top. Signal Process., vol. 12, no. 1, pp. 132–143, 2017.
- [55] V. Mnih, N. Heess, A. Graves et al., “Recurrent models of visual attention,” in Advances in neural information processing systems, 2014, pp. 2204–2212.
- [56] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2015, pp. 1–9.
- [57] F. Wang, M. Jiang, C. Qian, S. Yang, C. Li, H. Zhang, X. Wang, and X. Tang, “Residual attention network for image classification,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2017, pp. 3156–3164.
- [58] D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” arXiv preprint arXiv:1409.0473, 2014.
- [59] M.-T. Luong, H. Pham, and C. D. Manning, “Effective approaches to attention-based neural machine translation,” arXiv preprint arXiv:1508.04025, 2015.
- [60] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in neural information processing systems, 2017, pp. 5998–6008.
- [61] H. Purwins, B. Li, T. Virtanen, J. Schlüter, S.-Y. Chang, and T. Sainath, “Deep learning for audio signal processing,” IEEE J. Sel. Top. Signal Process., vol. 13, no. 2, pp. 206–219, Feb. 2019.
- [62] T. Ogunfunmi, R. P. Ramachandran, R. Togneri, Y. Zhao, and X. Xia, “A primer on deep learning architectures and applications in speech processing,” Circuits, Systems, and Signal Processing, vol. 38, no. 8, pp. 3406–3432, 2019.
- [63] R. Haeb-Umbach, S. Watanabe, T. Nakatani, M. Bacchiani, B. Hoffmeister, M. L. Seltzer, H. Zen, and M. Souden, “Speech processing for digital home assistants: Combining signal processing with deep-learning techniques,” IEEE Signal Process. Mag., vol. 36, no. 6, pp. 111–124, 2019.
- [64] H. Xie, Z. Qin, G. Y. Li, and B.-H. Juang, “Deep learning based semantic communications: An initial investigation,” in GLOBECOM 2020-2020 IEEE Global Communications Conference. IEEE, 2020, pp. 1–6.
- [65] C.-H. Lee, J.-W. Lin, P.-H. Chen, and Y.-C. Chang, “Deep learning-constructed joint transmission-recognition for internet of things,” IEEE Access, vol. 7, pp. 76 547–76 561, 2019.
- [66] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2016, pp. 770–778.
- [67] J. Xu, B. Ai, W. Chen, A. Yang, P. Sun, and M. Rodrigues, “Wireless image transmission using deep source channel coding with attention modules,” IEEE Trans. Circuits Syst. Video Technol., 2021.
- [68] Q. Hu, G. Zhang, Z. Qin, Y. Cai, and G. Yu, “Robust semantic communications against semantic noise,” arXiv preprint arXiv:2202.03338, 2022.
- [69] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” arXiv preprint arXiv:2111.06377, 2021.
- [70] N. Farsad, M. Rao, and A. Goldsmith, “Deep learning for joint source-channel coding of text,” in 2018 IEEE Int. Conf. Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 2326–2330.
- [71] J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,” in Proc. 2014 conference on empirical methods in natural language processing (EMNLP), 2014, pp. 1532–1543.
- [72] Y. Wu, M. Schuster, Z. Chen, Q. V. Le, M. Norouzi, W. Macherey, M. Krikun, Y. Cao, Q. Gao, K. Macherey et al., “Google’s neural machine translation system: Bridging the gap between human and machine translation,” arXiv preprint arXiv:1609.08144, 2016.
- [73] A. Graves, “Sequence transduction with recurrent neural networks,” arXiv preprint arXiv:1211.3711, 2012.
- [74] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” arXiv preprint arXiv:1301.3781, 2013.
- [75] H. Xie and Z. Qin, “A lite distributed semantic communication system for internet of things,” IEEE J. Sel. Areas Commun., vol. 39, no. 1, pp. 142–153, 2020.
- [76] Q. Zhou, R. Li, Z. Zhao, C. Peng, and H. Zhang, “Semantic communication with adaptive universal transformer,” IEEE Wireless Commun. Lett., to apper, 2021.
- [77] M. Dehghani, S. Gouws, O. Vinyals, J. Uszkoreit, and Ł. Kaiser, “Universal transformers,” arXiv preprint arXiv:1807.03819, 2018.
- [78] A. Graves, “Adaptive computation time for recurrent neural networks,” arXiv preprint arXiv:1603.08983, 2016.
- [79] H. Tong, Z. Yang, S. Wang, Y. Hu, O. Semiari, W. Saad, and C. Yin, “Federated learning for audio semantic communication,” Front. Commun. Netw., vol. 2, 2021.
- [80] S. Schneider, A. Baevski, R. Collobert, and M. Auli, “wav2vec: Unsupervised pre-training for speech recognition,” arXiv preprint arXiv:1904.05862, 2019.
- [81] Z. Weng, Z. Qin, and G. Y. Li, “Semantic communications for speech signals,” in Proc. IEEE Intel. Conf. Commun., 2021, pp. 1–6.
- [82] Z. Weng and Z. Qin, “Semantic communication systems for speech transmission,” IEEE J. Sel. Areas Commun., to appear, 2021.
- [83] Z. Weng, Z. Qin, and G. Y. Li, “Semantic communications for speech recognition,” arXiv preprint arXiv:2107.11190, 2021.
- [84] M. Schuster and K. K. Paliwal, “Bidirectional recurrent neural networks,” IEEE Trans. Signal Process., vol. 45, no. 11, pp. 2673–2681, Nov. 1997.
- [85] D. Amodei, S. Ananthanarayanan, R. Anubhai, J. Bai, E. Battenberg, C. Case, J. Casper, B. Catanzaro, Q. Cheng, G. Chen et al., “Deep speech 2: End-to-end speech recognition in english and mandarin,” in International conference on machine learning. PMLR, 2016, pp. 173–182.
- [86] Y. Jiang, S. Kannan, H. Kim, S. Oh, H. Asnani, and P. Viswanath, “Deepturbo: Deep turbo decoder,” in 2019 IEEE 20th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC). IEEE, 2019, pp. 1–5.
- [87] H. Xie, Z. Qin, and G. Y. Li, “Task-oriented semantic communications for multimodal data,” arXiv preprint arXiv:2108.07357, 2021.
- [88] H. Xie, Z. Qin, X. Tao, and K. B. Letaief, “Task-oriented multi-user semantic communications,” arXiv preprint arXiv:2112.10255, 2021.
- [89] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein et al., “Imagenet large scale visual recognition challenge,” International journal of computer vision, vol. 115, no. 3, pp. 211–252, Mar. 2015.
- [90] D. A. Hudson and C. D. Manning, “Compositional attention networks for machine reasoning,” arXiv preprint arXiv:1803.03067, 2018.
- [91] M. Ranzato, S. Chopra, M. Auli, and W. Zaremba, “Sequence level training with recurrent neural networks,” arXiv preprint arXiv:1511.06732, 2015.
- [92] S. J. Rennie, E. Marcheret, Y. Mroueh, J. Ross, and V. Goel, “Self-critical sequence training for image captioning,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2017, pp. 7008–7024.
- [93] R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction. MIT press, 2018.
- [94] D. Bahdanau, P. Brakel, K. Xu, A. Goyal, R. Lowe, J. Pineau, A. Courville, and Y. Bengio, “An actor-critic algorithm for sequence prediction,” arXiv preprint arXiv:1607.07086, 2016.
- [95] Z. Ren, X. Wang, N. Zhang, X. Lv, and L.-J. Li, “Deep reinforcement learning-based image captioning with embedding reward,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2017, pp. 290–298.
- [96] L. Yu, W. Zhang, J. Wang, and Y. Yu, “Seqgan: Sequence generative adversarial nets with policy gradient,” in Proc. AAAI Conf. Artif. Intell., vol. 31, no. 1, 2017.
- [97] K. Lu, R. Li, X. Chen, Z. Zhao, and H. Zhang, “Reinforcement learning-powered semantic communication via semantic similarity,” arXiv preprint arXiv:2108.12121, 2021.
- [98] K. Lu, Q. Zhou, R. Li, Z. Zhao, X. Chen, J. Wu, and H. Zhang, “Rethinking modern communication from semantic coding to semantic communication,” arXiv preprint arXiv:2110.08496, 2021.
- [99] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot et al., “Mastering the game of Go with deep neural networks and tree search,” nature, vol. 529, no. 7587, pp. 484–489, 2016.
- [100] V. R. Konda and J. N. Tsitsiklis, “Actor-critic algorithms,” in Advances in neural information processing systems, 2000, pp. 1008–1014.
- [101] F. Carpi, C. Häger, M. Martalò, R. Raheli, and H. D. Pfister, “Reinforcement learning for channel coding: Learned bit-flipping decoding,” in 2019 57th Annual Allerton Conference on Communication, Control, and Computing (Allerton). IEEE, 2019, pp. 922–929.
- [102] R. Luo, “A better variant of self-critical sequence training,” arXiv preprint arXiv:2003.09971, 2020.
- [103] M. K. Farshbafan, W. Saad, and M. Debbah, “Curriculum learning for goal-oriented semantic communications with a common language,” arXiv preprint arXiv:2204.10429, 2022.
- [104] Y. Wang, M. Chen, W. Saad, T. Luo, S. Cui, and V. Poor, “Performance optimization for semantic communications: An attention-based learning approach,” in Proc. IEEE Global Commun. Conf., 2021.
- [105] F. Zhou, Y. Li, X. Zhang, Q. Wu, X. Lei, and R. Q. Hu, “Cognitive semantic communication systems driven by knowledge graph,” arXiv preprint arXiv:2202.11958, 2022.
- [106] R. L. Rosa, G. M. Schwartz, W. V. Ruggiero, and D. Z. Rodríguez, “A knowledge-based recommendation system that includes sentiment analysis and deep learning,” IEEE Trans. Industr. Inform., vol. 15, no. 4, pp. 2124–2135, 2018.
- [107] X. Lin, H. Li, H. Xin, Z. Li, and L. Chen, “Kbpearl: A knowledge base population system supported by joint entity and relation linking,” Proc. VLDB Endowment, vol. 13, no. 7, pp. 1035–1049, Jul. 2020.
- [108] W. Zheng, L. Yin, X. Chen, Z. Ma, S. Liu, and B. Yang, “Knowledge base graph embedding module design for visual question answering model,” Pattern Recognit., vol. 120, p. 108153, 2021.
- [109] Y. Yang, C. Guo, F. Liu, C. Liu, L. Sun, Q. Sun, and J. Chen, “Semantic communications with AI tasks,” arXiv preprint arXiv:2109.14170, 2021.
- [110] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in Proc. IEEE Int. Conf. computer vision, 2017, pp. 618–626.
- [111] R. Fong and A. Vedaldi, “Net2vec: Quantifying and explaining how concepts are encoded by filters in deep neural networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2018, pp. 8730–8738.
- [112] J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” in European conference on computer vision. Springer, 2016, pp. 694–711.
- [113] H. Seo, J. Park, M. Bennis, and M. Debbah, “Semantics-native communication with contextual reasoning,” arXiv preprint arXiv:2108.05681, 2021.
- [114] C. K. Ogden and I. A. Richards, “The meaning of meaning: A study of the influence of thought and of the science of symbolism,” 1923.
- [115] A. Lazaridou and M. Baroni, “Emergent multi-agent communication in the deep learning era,” arXiv preprint arXiv:2006.02419, 2020.
- [116] A. Lazaridou, A. Peysakhovich, and M. Baroni, “Multi-agent cooperation and the emergence of (natural) language,” arXiv preprint arXiv:1612.07182, 2016.
- [117] J. Mu and N. Goodman, “Emergent communication of generalizations,” arXiv preprint arXiv:2106.02668, 2021.
- [118] J. Bell, “Pragmatic reasoning–A model-based theory,” 1992.
- [119] N. D. Goodman and A. Stuhlmüller, “Knowledge and implicature: Modeling language understanding as social cognition,” Topics in cognitive science, vol. 5, no. 1, pp. 173–184, Jan. 2013.
- [120] J. Kao, L. Bergen, and N. Goodman, “Formalizing the pragmatics of metaphor understanding,” in Proc. annual meeting of the Cognitive Science Society, vol. 36, no. 36, 2014.
- [121] N. D. Goodman and M. C. Frank, “Pragmatic language interpretation as probabilistic inference,” Trends Cogn. Sci., vol. 20, no. 11, pp. 818–829, Nov. 2016.
- [122] H. P. Grice, “Logic and conversation,” in Speech acts. Brill, 1975, pp. 41–58.
- [123] F. Lotfi, O. Semiari, and W. Saad, “Semantic-aware collaborative deep reinforcement learning over wireless cellular networks,” arXiv preprint arXiv:2111.12064, 2021.
- [124] W. J. Yun, B. Lim, S. Jung, Y.-C. Ko, J. Park, J. Kim, and M. Bennis, “Attention-based reinforcement learning for real-time uav semantic communication,” in 2021 17th International Symposium on Wireless Communication Systems (ISWCS). IEEE, 2021, pp. 1–6.
- [125] Y. Tao, S. Genc, J. Chung, T. Sun, and S. Mallya, “Repaint: Knowledge transfer in deep reinforcement learning,” in Int. Conf. Machine Learning. PMLR, 2021, pp. 10 141–10 152.
- [126] Á. Visús, J. García, and F. Fernández, “A taxonomy of similarity metrics for markov decision processes,” arXiv preprint arXiv:2103.04706, 2021.
- [127] I. Goodfellow, Y. Bengio, and A. Courville, Deep learning. MIT press, 2016.
- [128] J. Foerster, I. A. Assael, N. De Freitas, and S. Whiteson, “Learning to communicate with deep multi-agent reinforcement learning,” Advances in neural information processing systems, vol. 29, 2016.
- [129] X. Kang, B. Song, J. Guo, Z. Qin, and F. R. Yu, “Task-oriented image transmission for scene classification in unmanned aerial systems,” arXiv preprint arXiv:2112.10948, 2021.
- [130] E. Calvanese Strinati, S. Barbarossa, J. L. Gonzalez-Jimenez, D. Kténas, N. Cassiau, and C. Dehos, “6G: The next frontier,” arXiv e-prints, pp. arXiv–1901, 2019.
- [131] M. D. Yacoub, “The - distribution: A physical fading model for the stacy distribution,” IEEE Trans. Veh. Technol., vol. 56, no. 1, pp. 27–34, Jan. 2007.
- [132] H. Du, J. Zhang, J. Cheng, and B. Ai, “Sum of fisher-snedecor random variables and its applications,” IEEE Open J. Commun. Soc., vol. 1, pp. 342–356, 2020.
- [133] J. Zhang, W. Zeng, X. Li, Q. Sun, and K. P. Peppas, “New results on the fluctuating two-ray model with arbitrary fading parameters and its applications,” IEEE Trans. Veh. Technol., vol. 67, no. 3, pp. 2766–2770, Mar. 2017.
- [134] M. Mirza and S. Osindero, “Conditional generative adversarial nets,” arXiv preprint arXiv:1411.1784, 2014.
- [135] H. Ye, L. Liang, G. Y. Li, and B.-H. Juang, “Deep learning-based end-to-end wireless communication systems with conditional GANs as unknown channels,” IEEE Trans. Wireless Commun., vol. 19, no. 5, pp. 3133–3143, May 2020.
- [136] J. Meinilä, P. Kyösti, T. Jämsä, and L. Hentilä, “Winner II channel models,” in Radio Technologies and Concepts for IMT-Advanced, 2009.
- [137] M. Ding, J. Li, M. Ma, and X. Fan, “SNR-adaptive deep joint source-channel coding for wireless image transmission,” in ICASSP 2021-2021 IEEE Int. Conf. Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 1555–1559.
- [138] T. K. Moon, Error correction coding: Mathematical methods and algorithms. John Wiley & Sons, 2020.
- [139] P. Jiang, C.-K. Wen, S. Jin, and G. Y. Li, “Deep source-channel coding for sentence semantic transmission with HARQ,” arXiv preprint arXiv:2106.03009, 2021.
- [140] P. Shrivastava and U. P. Singh, “Error detection and correction using reed solomon codes,” Int. J. Adv. Comput. Sci. Appl., vol. 3, no. 8, Aug. 2013.
- [141] Y. Xuan, C. Guo, C. Feng, and Z. Li, “Multi-graph based spectrum sharing scheme in vehicular network with integration of heterogenous spectrum,” in Proc. IEEE Intel. Conf. Commun. Workshops (ICC Workshops). IEEE, 2019, pp. 1–6.
- [142] L. Liang, S. Xie, G. Y. Li, Z. Ding, and X. Yu, “Graph-based resource sharing in vehicular communication,” IEEE Trans. Wireless Commun., vol. 17, no. 7, pp. 4579–4592, Jul. 2018.
- [143] A. Khan, L. Sun, and E. Ifeachor, “QoE prediction model and its application in video quality adaptation over UMTS networks,” IEEE Trans. Multimedia, vol. 14, no. 2, pp. 431–442, Feb. 2011.
- [144] C. Xu, F. Zhao, J. Guan, H. Zhang, and G.-M. Muntean, “QoE-driven user-centric VoD services in urban multihomed P2P-based vehicular networks,” IEEE Trans. Veh. Technol., vol. 62, no. 5, pp. 2273–2289, May 2012.
- [145] Z. Q. Liew, Y. Cheng, W. Y. B. Lim, D. Niyato, C. Miao, and S. Sun, “Economics of semantic communication system in wireless powered internet of things,” arXiv preprint arXiv:2110.01423, 2021.
- [146] P. Ramezani and A. Jamalipour, “Toward the evolution of wireless powered communication networks for the future internet of things,” IEEE Netw., vol. 31, no. 6, pp. 62–69, Nov./Dec. 2017.
- [147] S. H. Chae, C. Jeong, and S. H. Lim, “Simultaneous wireless information and power transfer for internet of things sensor networks,” IEEE Internet Things J., vol. 5, no. 4, pp. 2829–2843, Aug. 2018.
- [148] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [149] Z. Liu, J. Li, Z. Shen, G. Huang, S. Yan, and C. Zhang, “Learning efficient convolutional networks through network slimming,” in Proc. IEEE Intel. Conf. Comput. Vis., 2017, pp. 2736–2744.
- [150] M. Zhu, C. Feng, J. Chen, C. Guo, and X. Gao, “Video semantics based resource allocation algorithm for spectrum multiplexing scenarios in vehicular networks,” in 2021 IEEE/CIC Int. Conf. Commun. China (ICCC Workshops). IEEE, 2021, pp. 31–36.
- [151] W. Yang, Z. Q. Liew, W. Y. B. Lim, Z. Xiong, D. Niyato, X. Chi, X. Cao, and K. B. Letaief, “Semantic communication meets edge intelligence,” arXiv preprint arXiv:2202.06471, 2022.
- [152] H. Schwarz, D. Marpe, and T. Wiegand, “Overview of the scalable video coding extension of the H.264/AVC standard,” IEEE Trans. Circuits Syst. Video Technol., vol. 17, no. 9, pp. 1103–1120, Sep. 2007.
- [153] V. K. Goyal, “Multiple description coding: Compression meets the network,” IEEE Signal Process Mag., vol. 18, no. 5, pp. 74–93, May 2001.
- [154] P. Popovski, O. Simeone, F. Boccardi, D. Gündüz, and O. Sahin, “Semantic-effectiveness filtering and control for post-5G wireless connectivity,” J. Indian Inst. Sci., vol. 100, no. 2, pp. 435–443, Feb. 2020.
- [155] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “BLEU: A method for automatic evaluation of machine translation,” in Proc. 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318.
- [156] R. Vedantam, C. Lawrence Zitnick, and D. Parikh, “CIDEr: Consensus-based image description evaluation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2015, pp. 4566–4575.
- [157] E. Vincent, R. Gribonval, and C. Févotte, “Performance measurement in blind audio source separation,” IEEE Trans. Audio Speech Lang. Process., vol. 14, no. 4, pp. 1462–1469, Apr. 2006.
- [158] A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,” in 2001 IEEE Int. Conf. acoustics, speech, and signal processing. Proceedings (Cat. No. 01CH37221), vol. 2. IEEE, 2001, pp. 749–752.
- [159] R. V. Cox, “Three new speech coders from the ITU cover a range of applications,” IEEE Commun. Mag., vol. 35, no. 9, pp. 40–47, 1997.
- [160] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2018, pp. 586–595.
- [161] M. Yang, C. Bian, and H.-S. Kim, “Deep joint source channel coding for wirelessimage transmission with OFDM,” arXiv preprint arXiv:2101.03909, 2021.
- [162] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: From error visibility to structural similarity,” IEEE Trans. Image Process., vol. 13, no. 4, pp. 600–612, Apr. 2004.
- [163] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [164] L. A. Gatys, A. S. Ecker, and M. Bethge, “Image style transfer using convolutional neural networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2016, pp. 2414–2423.
- [165] A. Dosovitskiy and T. Brox, “Generating images with perceptual similarity metrics based on deep networks,” Advances in neural information processing systems, vol. 29, 2016.
- [166] E. Uysal, O. Kaya, A. Ephremides, J. Gross, M. Codreanu, P. Popovski, M. Assaad, G. Liva, A. Munari, T. Soleymani et al., “Semantic communications in networked systems,” arXiv preprint arXiv:2103.05391, 2021.
- [167] A. Maatouk, M. Assaad, and A. Ephremides, “The age of incorrect information: An enabler of semantics-empowered communication,” arXiv preprint arXiv:2012.13214, 2020.
- [168] S. Kaul, R. Yates, and M. Gruteser, “Real-time status: How often should one update?” in Proc. IEEE INFOCOM. IEEE, 2012, pp. 2731–2735.
- [169] R. D. Yates, Y. Sun, D. R. Brown, S. K. Kaul, E. Modiano, and S. Ulukus, “Age of information: An introduction and survey,” IEEE J. Sel. Areas Commun., vol. 39, no. 5, pp. 1183–1210, May 2021.
- [170] Y. Sun, Y. Polyanskiy, and E. Uysal, “Sampling of the wiener process for remote estimation over a channel with random delay,” IEEE Trans. Inf. Theory, vol. 66, no. 2, pp. 1118–1135, Feb. 2019.
- [171] R. A. Howard, “Information value theory,” IEEE Trans. Syst. Man Cybern. Syst., vol. 2, no. 1, pp. 22–26, Mar. 1966.
- [172] O. Ayan, M. Vilgelm, M. Klügel, S. Hirche, and W. Kellerer, “Age-of-information vs. value-of-information scheduling for cellular networked control systems,” in Proc. 10th ACM/IEEE Int. Conf. Cyber-Physical Systems, 2019, pp. 109–117.
- [173] Y. J. Liang, J. G. Apostolopoulos, and B. Girod, “Analysis of packet loss for compressed video: Effect of burst losses and correlation between error frames,” IEEE Trans. Circuits Syst. Video Technol., vol. 18, no. 7, pp. 861–874, Jul. 2008.
- [174] J. Holm, A. E. Kalør, F. Chiariotti, B. Soret, S. K. Jensen, T. B. Pedersen, and P. Popovski, “Freshness on demand: Optimizing age of information for the query process,” in Proc. IEEE Int. Conf. Commun., 2021, pp. 1–6.
- [175] M. Li, J. Gao, L. Zhao, and X. Shen, “Adaptive computing scheduling for edge-assisted autonomous driving,” IEEE Trans. Veh. Technol, vol. 70, no. 6, pp. 5318–5331, Jun. 2021.
- [176] Q. Ye, W. Shi, K. Qu, H. He, W. Zhuang, and X. Shen, “Joint RAN slicing and computation offloading for autonomous vehicular networks: A learning-assisted hierarchical approach,” IEEE Open J. Veh. Technol., vol. 2, pp. 272–288, Feb. 2021.
- [177] C. De Alwis, A. Kalla, Q.-V. Pham, P. Kumar, K. Dev, W.-J. Hwang, and M. Liyanage, “Survey on 6G frontiers: Trends, applications, requirements, technologies and future research,” IEEE Open J. Commun. Soc., vol. 2, pp. 836–886, 2021.
- [178] A. Nanda, D. Puthal, J. J. Rodrigues, and S. A. Kozlov, “Internet of autonomous vehicles communications security: Overview, issues, and directions,” IEEE Wireless Commun., vol. 26, no. 4, pp. 60–65, Apr. 2019.
- [179] S. Samarakoon, M. Bennis, W. Saad, and M. Debbah, “Distributed federated learning for ultra-reliable low-latency vehicular communications,” IEEE Trans. Commun., vol. 68, no. 2, pp. 1146–1159, Feb. 2019.
- [180] W. Zhang, D. Yang, W. Wu, H. Peng, N. Zhang, H. Zhang, and X. Shen, “Optimizing federated learning in distributed industrial IoT: A multi-agent approach,” IEEE J. Sel. Areas Commun., vol. 39, no. 12, pp. 3688–3703, Dec. 2021.
- [181] M. M. Amiri and D. Gündüz, “Federated learning over wireless fading channels,” IEEE Trans. Wireless Commun., vol. 19, no. 5, pp. 3546–3557, 2020.
- [182] Y. Jiang, S. Wang, V. Valls, B. J. Ko, W.-H. Lee, K. K. Leung, and L. Tassiulas, “Model pruning enables efficient federated learning on edge devices,” arXiv preprint arXiv:1909.12326, 2019.
- [183] S. Hayat, E. Yanmaz, and R. Muzaffar, “Survey on unmanned aerial vehicle networks for civil applications: A communications viewpoint,” IEEE Commun. Surv. Tutor., vol. 18, no. 4, pp. 2624–2661, Apr. 2016.
- [184] N. Cheng, F. Lyu, W. Quan, C. Zhou, H. He, W. Shi, and X. Shen, “Space/aerial-assisted computing offloading for IoT applications: A learning-based approach,” IEEE J. Sel. Areas Commun., vol. 37, no. 5, pp. 1117–1129, May 2019.
- [185] C. Zhou, W. Wu, H. He, P. Yang, F. Lyu, N. Cheng, and X. Shen, “Deep reinforcement learning for delay-oriented iot task scheduling in SAGIN,” IEEE Trans. Wirel. Commun., vol. 20, no. 2, pp. 911–925, Feb. 2020.
- [186] J. N. Laneman, D. N. Tse, and G. W. Wornell, “Cooperative diversity in wireless networks: Efficient protocols and outage behavior,” IEEE Trans. Inf. Theory, vol. 50, no. 12, pp. 3062–3080, Dec. 2004.
- [187] X. Luo, Z. Chen, B. Xia, and J. Wang, “Autoencoder-based semantic communication systems with relay channels,” arXiv preprint arXiv:2111.10083, 2021.
- [188] H. Du, J. Wang, D. Niyato, J. Kang, Z. Xiong, D. I. Kim et al., “Exploring attention-aware network resource allocation for customized metaverse services,” arXiv preprint arXiv:2208.00369, 2022.
- [189] Y.-J. Liu, H. Du, D. Niyato, G. Feng, J. Kang, and Z. Xiong, “Slicing4Meta: An intelligent integration framework with multi-dimensional network resources for metaverse-as-a-service in web 3.0,” arXiv preprint arXiv:2208.06081, 2022.
- [190] L. Ismail, D. Niyato, S. Sun, D. I. Kim, M. Erol-Kantarci, and C. Miao, “Semantic information market for the metaverse: An auction based approach,” arXiv preprint arXiv:2204.04878, 2022.
- [191] S. Movassaghi, M. Abolhasan, J. Lipman, D. Smith, and A. Jamalipour, “Wireless body area networks: A survey,” IEEE Commun. Surv. Tutor., vol. 16, no. 3, pp. 1658–1686, Mar. 2014.
- [192] A. Elsts, R. McConville, X. Fafoutis, N. Twomey, R. J. Piechocki, R. Santos-Rodriguez, and I. Craddock, “On-board feature extraction from acceleration data for activity recognition.” in EWSN, 2018, pp. 163–168.
- [193] P. Zalewski, L. Marchegiani, A. Elsts, R. Piechocki, I. Craddock, and X. Fafoutis, “From bits of data to bits of knowledge—an on-board classification framework for wearable sensing systems,” Sensors, vol. 20, no. 6, p. 1655, 2020.
- [194] S. Bragança, E. Costa, I. Castellucci, and P. M. Arezes, “A brief overview of the use of collaborative robots in industry 4.0: Human role and safety,” Occup. Environ. Saf. Health, pp. 641–650, 2019.
- [195] Y. Yue, C. Zhao, Z. Wu, C. Yang, Y. Wang, and D. Wang, “Collaborative semantic understanding and mapping framework for autonomous systems,” IEEE/ASME Trans. Mechatron., vol. 26, no. 2, pp. 978–989, Feb. 2020.
- [196] G. M. Milis, C. G. Panayiotou, and M. M. Polycarpou, “Semiotics: Semantically enhanced IoT-enabled intelligent control systems,” IEEE Internet Things J., vol. 6, no. 1, pp. 1257–1266, Jan. 2017.
- [197] D. Kolokotsa, “Comparison of the performance of fuzzy controllers for the management of the indoor environment,” Build. Environ., vol. 38, no. 12, pp. 1439–1450, Dec. 2003.
- [198] L. Da Xu, W. He, and S. Li, “Internet of things in industries: A survey,” IEEE Trans. Industr. Inform., vol. 10, no. 4, pp. 2233–2243, Apr. 2014.
- [199] J. Gao, W. Zhuang, M. Li, X. Shen, and X. Li, “MAC for machine-type communications in industrial IoT—Part I: Protocol design and analysis,” IEEE Internet Things J., vol. 8, no. 12, pp. 9945–9957, Aug. 2021.
- [200] P. Popovski, F. Chiariotti, V. Croisfelt, A. E. Kalør, I. Leyva-Mayorga, L. Marchegiani, S. R. Pandey, and B. Soret, “Internet of things (IoT) connectivity in 6G: An interplay of time, space, intelligence, and value,” arXiv preprint arXiv:2111.05811, 2021.
- [201] G. Montavon, W. Samek, and K.-R. Müller, “Methods for interpreting and understanding deep neural networks,” Digit. Signal Process., vol. 73, pp. 1–15, 2018.
- [202] B. Kim, R. Khanna, and O. O. Koyejo, “Examples are not enough, learn to criticize! criticism for interpretability,” Adv. Neural Inf. Process. Syst. (NIPS), vol. 29, 2016.
- [203] Y. Dong, H. Su, J. Zhu, and B. Zhang, “Improving interpretability of deep neural networks with semantic information,” in Proc. IEEE Comput. Soc. Conf. (CVPR), 2017, pp. 4306–4314.
- [204] M. Sheraz, M. Ahmed, X. Hou, Y. Li, D. Jin, Z. Han, and T. Jiang, “Artificial intelligence for wireless caching: Schemes, performance, and challenges,” IEEE Commun. Surv. Tutor., vol. 23, no. 1, pp. 631–661, Jan. 2020.
- [205] A. Cidon, A. Eisenman, M. Alizadeh, and S. Katti, “Cliffhanger: Scaling performance cliffs in web memory caches,” in 13th USENIX Symposium on Networked Systems Design and Implementation (NSDI 16), 2016, pp. 379–392.
- [206] Y. Xiao, Y. Li, G. Shi, and H. V. Poor, “Reasoning on the air: An implicit semantic communication architecture,” arXiv preprint arXiv:2202.01950, 2022.
- [207] J. Liang, Y. Xiao, Y. Li, G. Shi, and M. Bennis, “Life-long learning for reasoning-based semantic communication,” arXiv preprint arXiv:2202.01952, 2022.
- [208] C.-X. Wang, J. Huang, H. Wang, X. Gao, X. You, and Y. Hao, “6G wireless channel measurements and models: Trends and challenges,” IEEE Veh. Technol. Mag., vol. 15, no. 4, pp. 22–32, Apr. 2020.
- [209] J. Hu, H. Zhang, K. Bian, Z. Han, H. V. Poor, and L. Song, “Metasketch: Wireless semantic segmentation by reconfigurable intelligent surfaces,” IEEE Trans. Wireless Commun., to apper, 2022.
- [210] H. Gacanin and M. Di Renzo, “Wireless 2.0: Toward an intelligent radio environment empowered by reconfigurable meta-surfaces and artificial intelligence,” IEEE Veh. Technol. Mag., vol. 15, no. 4, pp. 74–82, Apr. 2020.
- [211] K. B. Letaief, Y. Shi, J. Lu, and J. Lu, “Edge artificial intelligence for 6G: Vision, enabling technologies, and applications,” IEEE Journal on Selected Areas in Communications, vol. 40, no. 1, pp. 5–36, 2021.
- [212] M. R. Bloch, “Covert communication over noisy channels: A resolvability perspective,” IEEE Trans. Inf. Theory, vol. 62, no. 5, pp. 2334–2354, May 2016.