PanGu-Coder:使用函数级语言建模进行程序综合
摘要
我们提出了 PanGu-Coder,这是一种预训练的仅解码器语言模型,采用 PanGu- 架构进行文本到代码生成,即合成给出自然语言问题描述的编程语言解决方案。 我们使用两阶段策略训练PanGu-Coder:第一阶段采用因果语言模型(CLM)对原始编程语言数据进行预训练,而第二阶段结合使用因果语言模型掩码语言建模 (MLM) 训练目标侧重于文本到代码生成的下游任务以及松散管理的自然语言程序定义和代码函数对。 最后,我们讨论 PanGu-Coder-FT,它结合了竞争性编程问题和持续集成测试的代码进行了微调。 我们评估 PanGu-Coder 的重点是它是否生成功能正确的程序,并证明它比类似大小的模型(例如 CodeX [16])实现了相同或更好的性能,同时参加较小的上下文窗口并使用较少的数据进行训练。
1简介
基于 Transformer [66] 架构的越来越多的大型预训练语言模型 [56, 23, 58, 32] 已经被提出并被证明可以实现状态 -在各种自然语言处理(NLP)任务上取得了最先进的成果。 最近,此类模型已适应更具体的语言领域,例如生物医学[37,46,9]、法律[14]、网络安全[2]和金融[6 ] 领域,同时扩展到包括来自自然语言以外的模式的信号,例如 视觉 [65, 18, 15, 13, 64, 25],蛋白质 [11],时间序列 [71, 72, 55]和代码[42,70,26,31,54]。
在这项工作中,我们专注于专门为文本到代码生成而创建的预训练语言模型,即从自然语言(NL)描述(例如问题定义或文档字符串)合成程序的任务。 虽然针对此任务提出的一些模型采用了编码器-解码器架构[47],但大多数模型都被训练为仅解码器的 Transformer 模型[16,51,27]。 编码器-解码器架构要求输入和输出之间有明确的区别和关联。 相比之下,单个组件(仅编码器或仅解码器)架构将输入视为连续序列,因此非常适合对大量原始数据进行训练。 无论架构如何,最近的工作都是对从 GitHub111github.com,Stack Exchange222stackoverflow.com 和其他来源,其中一些是从专门在 NL 上预训练的现有语言模型初始化的(例如从 GPT [12]2> 或 BERT [23] 初始化>)。
我们提出了 PanGu-Coder,这是一种用于文本到代码生成的预训练语言模型。 PanGu-Coder遵循引入的PanGu-架构(见图LABEL:fig:pangu_alpha) Zeng 等人[73],它由一个单向解码器 Transformer 和一个堆叠在顶部的额外查询层组成。 在每个时间步,查询层都会关注位置嵌入以确定下一个词符。 虽然 PanGu- 被提议用于处理英文和中文 NL 文本,但 PanGu-Coder 目前专注于从专门的文本到代码生成英文提示。 PanGu-Coder 目前仅支持 Python 输出,但该模型可以轻松扩展到其他语言。
我们使用两阶段策略来训练 PanGu-Coder,第一阶段作为无监督原始编程语言数据的预训练。 在此阶段,自然语言以文档字符串或内联注释(如果有)的形式包含在内。 为了充分利用原始数据,我们遵循现有仅解码器模型的训练机制,并采用常规因果语言建模 (CLM) [56],同时将所有数据视为连续序列。 训练的第二阶段旨在关注文本到代码生成的下游任务,并利用它包含不同的源序列和目标序列的事实,即输入 NL 问题定义和输出代码。 因此,第二阶段专门关注 NL 和代码的对齐对。 我们尝试了各种训练目标,包括因果和掩码语言建模 (MLM) 目标的组合,从编码器-解码器架构的训练方案中汲取灵感。 通过这种两阶段方法,我们的模型能够在第一阶段通过原始数据学习一般代码结构与自然语言的关系,然后在第二阶段关注如何在给定 NL 输入的情况下最好地生成正确的输出代码。 最后,我们还使用与目标域更密切相关的数据PanGu-Coder(第3节)。 我们根据所使用的数据的性质将阶段 2 训练与微调区分开来,即从可能未对齐或嘈杂的在线源中提取的数据与更适合文本到代码生成的数据,例如从编程竞赛中检索。
2 任务定义
| Problem Description |
3 Fine-Tuning Methodology
In this section, we evaluate a version of PanGu-Coder that was fine-tuned on a combination of competitive programming problems and code from continuous integration tests. The model, called PanGu-Coder-FT, allows us to estimate the improvement in problem solve rates given additional data from a more similar domain / distribution, which we describe in the following paragraphs.
Competitive Programming Data
The following two datasets provide dozens of successful code completions for each problem. Therefore, we can upsample each dataset by pairing up to five solutions with each problem description to avail the model of different correct solutions for the same problem specification. APPS [34] was proposed to benchmark the programming capability of code-generating models. It includes 10,000 programming tasks (5,000 train, 5,000 test) that require code generation / completion given a detailed problem description999https://github.com/hendrycks/apps. Program arguments are provided from standard input as well as function calls, sometimes embedded inside the class. We use the train and test set programs, which we filter for the maximum input length of the model (1,024), retaining 43K examples. Code Contests (CC) is a similar dataset [47] for training and evaluation of competition-level code generation101010https://github.com/deepmind/code_contests, containing over 13K programming problems. After upsampling and length filtering, we retain 18K instances for fine-tuning.
Continuous Integration Data
In addition to the competitive programming data, we also gathered a dataset consisting of correctly-implemented functions from open source projects. Following recent work on evaluating language models trained on code [16], we considered public Python repositories on GitHub using Travis111111https://www.travis-ci.com/ or Tox121212https://tox.wiki/en/latest/ as their continuous integration (CI) system(s). First, we reproduced the CI environment of each project locally in docker instances, then injected a tracing function in the environment, which would capture the input, output, invocation location and context code for each function invoked during integration testing. After that, the CI script was triggered and the data of invoked functions were recorded into a database. We further clustered the collected data into 4 groups, according to the external contextual information (dependencies) that a function requires to run. That is, functions depending on Python-builtin objects, Python-standard libraries, Pypi-public libraries, and the residing class. We expect this variety could enable the generation of different function types, e.g., self-contained, module, member or class functions. After filtering for maximum model input length, 49K examples are retained for fine-tuning.
Training Details
We fine-tune PanGu-Coder-FT for 5 epochs on the aforementioned data, using the Code-CLM objective. We decrease the batch size to 32 and use a linear decay learning rate scheduler. All other model training and program generation settings follow the Stage-2 protocol (Section LABEL:sec:pretraining-results-analysis).
3.1 Fine-tuning Results
PanGu-Coder-FT clearly benefits from additional fine-tuning on data that is closer to the target distribution, i.e. short programming tasks solving competitive and technical interview questions (Table 7). The pass rate improvement is more pronounced for MBPP, which may be due to the lower difficulty of problems (relative to HumanEval). Recall that the B in MBPP stands for ’basic’. In the following paragraphs, we discuss the importance of appropriate fine-tuning data and provide additional methods for boosting the pass rates of solutions generated by PanGu-Coder(-FT).
3.1.1 Impact of In-domain Data
MBPP and HumanEval provide a challenging zero-shot evaluation of models designed to generate functionally correct programs. MBPP131313https://github.com/google-research/google-research/tree/master/mbpp additionally provides a small training/prompting set of 474 instances, which we can use to contrast the rate of improvement between out-of-domain and in-domain data. Fine-tuning PanGu-Coder on just a few hundred relevant problems increases pass@ almost as much as tens of thousands of correctly implemented but mostly out-of-domain examples (see Table 7). Models therefore need to acquire a wide spectrum of problem solving and programming knowledge to perform well on these datasets. Note that despite their superficial similarity, MBPP fine-tuning provides no benefit to HumanEval (Table 7).
| Models | MBPP (%) | HumanEval (%) | ||||
|---|---|---|---|---|---|---|
| pass@ | pass@ | pass@ | pass@ | pass@ | pass@ | |
| PanGu-Coder | 16.20 | 34.39 | 53.74 | 17.07 | 24.05 | 34.55 |
| PanGu-Coder-FT | 24.60 | 44.19 | 63.07 | 19.50 | 25.96 | 40.80 |
| PanGu-Coder-MBPP | 25.40 | 43.32 | 60.03 | 15.24 | 22.73 | 32.65 |
3.1.2 Impact of Unit Tests
HumanEval provides input/output pairs in the problem description that can be used to verify the correctness of a solution, e.g. "remove_letters(PHP, P) == H". MBPP problem descriptions can be augmented with test cases provided for evaluation in order to investigate whether the model benefits from the additional insights. Table 8 shows the pass rates for models trained/fine-tuned (Train) with and without unit tests as well as programs generated (Sample) with and without asserts. We observe that for MBPP, the pass rates substantially increase with unit tests in the prompt, particularly when this is provided during sampling as well. This is not the case for HumanEval, however, possibly because the problem descriptions are longer, more detailed and less formulaic. Similar observations were made during the zero-shot analysis in Section LABEL:sec:prompt_effect. A more effective way of improving HumanEval scores is to use the same unit tests to filter out dysfunctional programs with our proposed methods, outlined in section 3.1.3.
| Model | Train | Sample | MBPP (%) | HumanEval (%) | ||||
| pass@ | pass@ | pass@ | pass@ | pass@ | pass@ | |||
| PanGu-Coder | N/A | ✓ | 16.20 | 34.39 | 53.74 | 17.07 | 24.05 | 34.55 |
| PanGu-Coder | N/A | ✗ | 17.40 | 34.29 | 50.91 | 16.46 | 23.38 | 33.58 |
| + MBPP-train | ✗ | ✗ | 20.00 | 37.70 | 53.04 | 15.85 | 24.11 | 33.66 |
| + MBPP-train | ✗ | ✓ | 23.60 | 40.91 | 58.91 | 13.41 | 23.52 | 33.44 |
| + MBPP-train | ✓ | ✗ | 21.00 | 36.44 | 51.92 | 16.46 | 23.79 | 31.50 |
| + MBPP-train | ✓ | ✓ | 25.40 | 43.32 | 60.03 | 15.24 | 22.73 | 32.65 |
3.1.3 Filtering Generated Programs
In order to continue to improve PanGu-Coder’s pass rates, we can follow the program generation stage with an additional post-processing step, e.g. filtering on unit tests, declared function types and checking for syntactic correctness. The solutions () to each HumanEval problem are filtered before being evaluated on the held-out unit tests. Not all problems have embedded/parsable unit tests or have declared all function arguments and return types. Therefore, we evaluate the effectiveness of our filtering methods on problem subsets that have the specific filter available, i.e. 136 of 164 with unit tests and 30 of 164 with full type declarations (all 164 problems can be checked for syntax errors). This gives us a baseline score when no filtering is applied. The number of problems with each filter and the corresponding pass rates are shown in Table 9.
| Filtering Method | PanGu-Coder | PanGu-Coder-FT | |||
|---|---|---|---|---|---|
| pass@1 | pass@10 | pass@1 | pass10 | ||
| Unit Testing | Base | 14.53 | - | 16.67 | - |
| Filter | 35.48 | - | 41.52 | - | |
| Typing | Base | 25.16 | 50.65 | 30.45 | 54.61 |
| Filter | 26.99 | 52.00 | 31.30 | 55.72 | |
| Invalid Syntax | Base | 12.05 | 23.27 | 13.85 | 25.40 |
| Filter | 12.06 | 23.27 | 13.86 | 25.44 | |
Unit Tests
In many real-world scenarios, the description of a problem can include example function input(s) and output(s), which we can use to filter out unsuccessful solutions, potentially increasing the overall pass rate. In addition to the held-out tests, HumanEval typically provides unit tests embedded in the description, expressed in a natural way and usually following a simple pattern. A basic regular expression (to avoid overfitting) is used to extract the majority (136/164) of the unit tests. Table 9 shows a significantly improved pass rate after this filtering step. Only the pass@ score is available with this filter, as many problems fail to reach at least 10 solutions per problem, once filtered. The mean/median number of solutions after filtering is 115/155, an average reduction of around 40-45%.
Typing
In other scenarios, we may be provided with function argument types and the expected return type. In such cases, we can generate plausible function inputs, execute the sampled program and evaluate the type of the return value. If the program returns the expected type, it will be included for the final pass@ evaluation. As the generated programs are executed, we implicitly verify the syntactic and semantic correctness, too. Relying only on checking the return type will inevitably lead to false positives as programs often return the correct type, e.g. a float or a list of floats but with the wrong value(s). However, even this simple filter can improve the final pass rates (Table 9) and reduce the number of programs by around 25% (mean/median 150/152 after filtering).
Invalid Syntax
In the absence of unit tests and input/output type declarations retrieved from the description, filtering out syntactically invalid solutions can be a fast and simple method for eliminating incorrect problem solutions. With that in mind, Table 9 shows that PanGu-Coder is generating syntactically well-formed solutions almost all the time hence we filter out of 200 problem solutions (mean/median after filtering 199/200), leaving the pass rates unchanged.
3.2 Data Selection with Few-Shot Similarity
Transformer-based pretrained language models continue to rapidly increase in size [70, 47, 19] hence it is desirable to reduce the compute requirements while maintaining good performance, whenever possible. To this end, we simulate a scenario, in which we possess a small sample of programming problems (possibly written from scratch) and a much larger dataset of heterogeneous training data. We then experiment with choosing training examples from the much larger dataset based on their similarity to a centroid embedding that represents our ’few-shot’ sample. We randomly select 10 problems (description and code) from HumanEval and 10 from MBPP (to avoid overfitting to HumanEval) as our sample, denoted in Equation 6. The centroid embedding is obtained using a version of CodeBERT [26], which has been further trained on CodeSearchNet [38] using the Replaced Token Detection loss [20]. The model is denoted by in Equations 6 and 7.
| (6) | |||
| (7) |
A training example is ranked/chosen by its Mean Squared Error (MSE) (lowest first) from . PanGu-Coder is then fine-tuned for five epochs with training data incremented by 10K, up to 60K examples, which is 50% of the total data. The pass@k are shown in Figure 6.
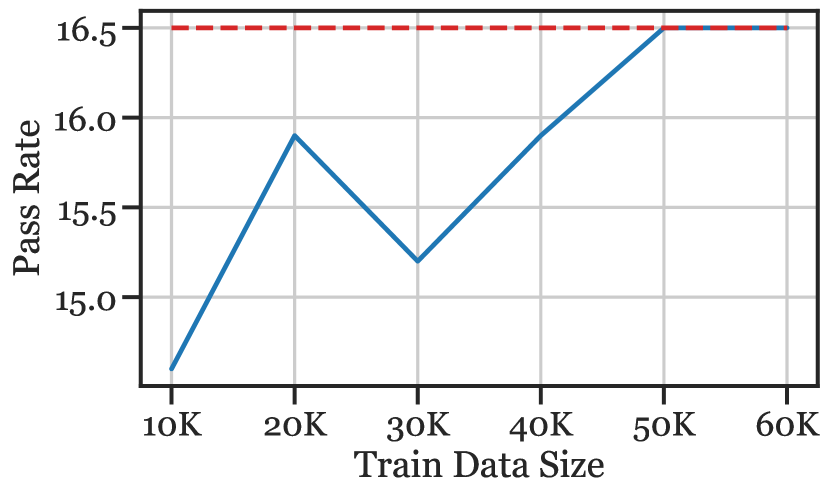
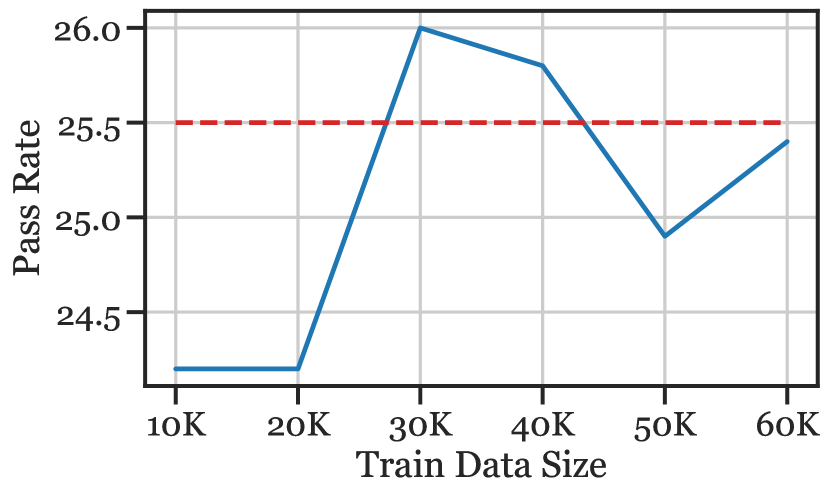
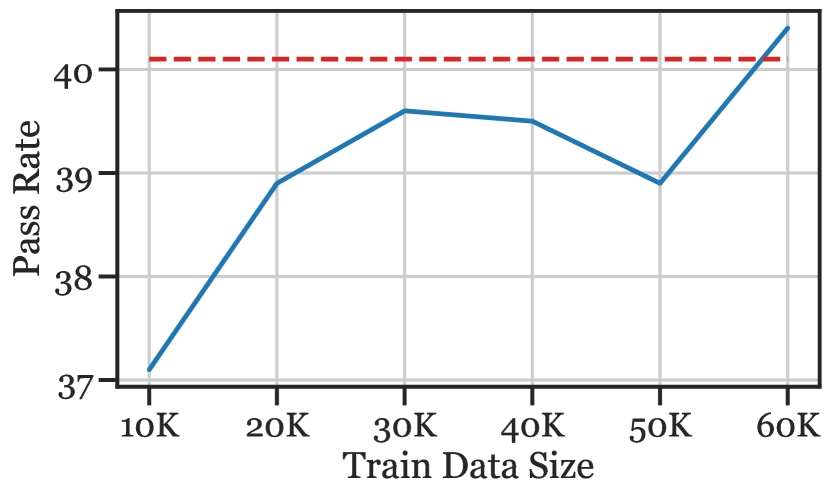
Perhaps unsurprisingly, the competitive programming share of the fine-tuning data increases from 46.4% (in the full 120K dataset) to 68.7% after our similarity-based selection. We observe that for all pass@, the full (dataset) score is reached or exceeded by fine-tuning on 25% - 50% of the larger dataset (see Figure 6). Using this method, we are able to reduce model compute requirements while maintaining (even surpassing) the original pass rate. If we wish to fine-tune PanGu-Coder on some target data distribution in the future, we require a small “few-shot” sample of problems (possibly written from scratch) to effectively subsample our larger training dataset to achieve a good pass rate while reducing computational resources.
4 Related Work
Recently, there has been an increasing interest in applying deep learning methods for NLP to code understanding and generation tasks. Among others, this is evidenced by the introduction of new NLP venues, e.g. Natural Language Processing Advancements for Software Engineering (NLPaSE) [1], which had its second installment at APSEC 2021 and the 2nd International Workshop on Software Engineering Automation: A Natural Language Perspective (NLP-SEA 2021) [5] at ASE 2021. Other new venues include the 1st Workshop on Natural Language Processing for Programming (NLP4Prog 2021) at ACL 2021 [45], the Deep Learning for Code (DL4C) Workshop at ICLR 2022 [62] and the 1st International Workshop on Natural Language-based Software Engineering (NLBSE 2022), co-located with ICSE 2022 [63].
4.1 Pre-trained Language Models for Programming Language
From an NLP research perspective, the recent advancements in code understanding and generation have been mostly focused on revisiting proven effective natural language understanding (NLU) and generation (NLG) methods. CodeBERT [26], for instance, was trained using a combination of Masked Language Modeling inspired by [23, BERT] and Replaced Token Detection [20, ELECTRA]. CodeT5 [70] and PYMT5 [22] were built on top of [58, T5] while UniXcoder [31] was based on UniLM [24]. The most notable works in the area are discussed next. We distinguish between models focused on code understanding, where the goal is to learn contextual representations of source code, and code generation, where the aim is to translate between different programming and / or natural languages as well as to perform code completion and / or code repair.
Code Understanding
Research on this topic started with the seminal work of Alon et al. [4] who introduced code2vec[4], a neural model for representing snippets of code as continuous distributed vectors, extending the idea from Mikolov et al. [49, word2vec]. Inspired by the introduction of BERT [23], Kanade et al. [42] proposed CuBERT (Code Understanding BERT), a natural adaptation of the model trained on source code. CodeBERT [26] instead, used both source code and Natural Language (NL) with a discriminative objective, inspired by [21, ELECTRA]. The model receives a masked NL-code pair and the generator then predicts the masked tokens (the prediction might be different from the original token). Subsequently, CodeBERT is trained to predict which tokens were replaced by the generator. Guo et al. [30] noted that previous pretrained models treat code snippets as sequences of tokens while ignoring the inherent structure of code. They presented GraphCodeBERT, which showed that incorporating the data flow, i.e. a semantic-level structure of code extracted from the abstract syntax tree (AST), leads to richer code representations. Jiang et al. [41, TREEBert] instead used the actual AST together with code snippets.
SynCoBERT [68] trained the model with natural language, code and ASTs, but updated the training objective to include identifier prediction and AST Edge Prediction. In addition, Contrastive Learning [33, 17] has been used as a training regime to help associate snippets of code with syntactically diverse but equivalent programs as well as with corresponding natural language descriptions [40, 50, ContraCode] or with different modalities [69, Code-MVP].
Code Generation
Earlier approaches for code generation were mostly limited to simplified versions of code completion or code translation tasks [35, 59]. However, recent work has been proposed to tackle more complex problems, e.g. text-to-code generation (program synthesis) and code summarization. Lu et al. [48] introduced CodeGPT, an adaptation of GPT [57] applied to code, as a baseline for the CodeXGLUE benchmark. TransCoder [61] presented a pre-trained language model specifically focused on unsupervised translation of code between different programming languages. PLBART [3] employed a denoising objective over code and natural language via token masking, token deletion, and token infilling as noising strategies. CoText [54] was build on top of T5 with a special focus on multi-task learning over multiple programming languages. Another model variant was introduced by Fried et al. [27, InCoder]. Instead of training to perform code/text generation in a single left-to-right pass, InCoder is also able to edit existing/partial programs via an infilling training objective. The training regime involved randomly replacing spans of code/comments with a placeholder and asking the model to generate the replaced lines.
More recently, a number of large pretrained language models have been proposed, primarily focused on the task of text-to-functional-code generation. Chen et al. [16] introduced CodeX [16], a set of GPT-based language models trained on publicly available code from GitHub, up to 12B parameters in size. In addition, the authors fine-tuned their models using a set of training problems from competitive programming websites and repositories with continuous integration for better program synthesis, called Codex-S. Codex-D was fine-tuned on the reverse task of generating the program description given a particular function/code.
Li et al. [47] introduced AlphaCode, a set of sequence-to-sequence models with up to 41B parameters, trained on data from programming competitions, e.g. Codeforces141414https://codeforces.com/ (similar to Codex-S) as well as GitHub code in several programming languages. AlphaCode produces problem solutions by overgeneration-and-ranking, i.e. the model samples multiple solutions and uses filtering and clustering to determine the best ones. Finally, CodeGen [51] was proposed as a conversational text-to-code approach using large language models with sizes of up to 16B parameters. CodeGen-NL was trained on The Pile [28], which contains around 6GB of Python code. CodeGen-Multi was then further trained on BigQuery, which includes data from 6 different programming languages (C, C++, Go, Java, JavaScript and Python). A third model, CodeGen-Mono, builds on top of CodeGen-Multi and was additionally trained on Python-only data.
4.2 Code Datasets and Evaluation
There is a number of datasets proposed for code understanding and generation tasks, many of which have recently been included in the CodeXGLUE benchmark [48]. CodeXGLUE comprises 14 datasets across 11 tasks, including clone detection, defect detection, cloze test and code search for understanding as well as code completion, code translation, code summarization, code repair, code refinement, document translation and text-to-code generation. Among these datasets are CONCODE [39], a Java-based dataset with more than 100,000 examples of Java classes built from public Github projects and containing environment information along with Javadocs and the corresponding code. CodeSearchNet [38] is a benchmark specifically designed to evaluate systems on semantic code search, i.e. a code retrieval task based on natural language queries.
The above tasks have mostly adopted NLP evaluation metrics, for example, text-to-code generation still widely uses CodeBLUE [60] and exact match of the outputs. CodeBLUE is an extension of the standard n-gram overlap metric BLEU [52], designed to improve the evaluation of generated code. More recently, evaluation datasets and metrics started focusing on the functional correctness of generated programs. Chen et al. [16, Codex] introduced the HumanEval dataset (c.f. SectionLABEL:sec:eval_data) and Austin et al. [7] introduced the Mostly Basic Programming Problems [7, MBPP] dataset. Both datasets are relatively small, comprising of 164 and 974 instances where descriptions of programming problems and their corresponding coding solutions are included. These problems are then evaluated in terms of their behavior, instead of being treated as natural language (either syntantically or semantically). Specifically, the datasets provide unit tests that can be used to evaluate how close outputs are to what is expected. The main difference between HumanEval and MBPP is that the former does not include a training set as it was meant to be used for zero-shot evaluation. Other datasets, such as APPS [34], containing 10,000 problems and Code Contests [47, CC] (13,610 problems) (c.f. Section 3), leverage data from existing online coding platforms, resulting in a significantly larger dataset size but also more noise.
5 Conclusions
In this report, we presented PanGu-Coder, a pre-trained language model for the task of text-to-code generation. PanGu-Coder is based on the Pangu- architecture and was initially pre-trained on raw natural language and programming data using the CLM objective, and subsequently trained specifically on pairs of docstrings and functions using combinations of Code-CLM, Docstr-MLM, and Docstr-MCLM training objectives. Zero-shot evaluation of PanGu-Coder on the HumanEval and MBPP datasets, designed to measure whether outputs comprise functionally correct programs, shows that this training can help reach equivalent or better performance than similarly sized models while using a smaller context window and less training data. Further analysis examined the impact of various decoding and sampling strategies, training objectives, and embedding sharing.
PanGu-Coder-FT demonstrated that the scores of the base model can be improved at a faster rate by curating data more closely related to our target task as the model is quite sensitive to mismatches and shifts in fine-tuning data distributions. If we possess a small set of example problems from the target distribution, this sensitivity can be somewhat mitigated by choosing a subset of our fine-tuning data based on the similarity to a centroid embedding. We also evaluated various post-processing methods, some of which allowed us to significantly improve pass rates by filtering out failing programs.
6 Acknowledgements
The authors thank Wei Zhang, Jun Yao, Qian Zhao, Feng Xu, Zongwei Tan for their great support to this work. The authors also thank Philip John Gorinski for his feedback on an early version of this report.
References
- NLP [2021] NLPaSE 2021 Organization. In 2021 28th Asia-Pacific Software Engineering Conference Workshops (APSEC Workshops), pages 13–13, 2021. doi: 10.1109/APSECW53869.2021.00008.
- Aghaei et al. [2022] Ehsan Aghaei, Xi Niu, Waseem Shadid, and Ehab Al-Shaer. Language model for text analytic in cybersecurity, 2022. URL https://arxiv.org/abs/2204.02685.
- Ahmad et al. [2021] Wasi Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang. Unified pre-training for program understanding and generation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2655–2668, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.211. URL https://aclanthology.org/2021.naacl-main.211.
- Alon et al. [2019] Uri Alon, Meital Zilberstein, Omer Levy, and Eran Yahav. Code2vec: Learning distributed representations of code. 3(POPL), jan 2019. doi: 10.1145/3290353. URL https://doi.org/10.1145/3290353.
- Anwar et al. [2022] Sajid Anwar, Mehrdad Saadatmand, Abdul Rauf, Muhammad Ramzan, and Imran Razzak. 2nd International Workshop on Software Engineering Automation: A Natural Language Perspective (NLP-SEA 2021) at ASE 2021. http://nlpsea.bsoft.pk/, 2022. [Online; accessed 9-June-2022].
- Araci [2019] Dogu Araci. Finbert: Financial sentiment analysis with pre-trained language models. CoRR, abs/1908.10063, 2019. URL http://arxiv.org/abs/1908.10063.
- Austin et al. [2021] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021.
- Bao et al. [2020] Hangbo Bao, Li Dong, Furu Wei, Wenhui Wang, Nan Yang, Xiaodong Liu, Yu Wang, Jianfeng Gao, Songhao Piao, Ming Zhou, and Hsiao-Wuen Hon. UniLMv2: Pseudo-masked language models for unified language model pre-training. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 642–652. PMLR, 13–18 Jul 2020. URL https://proceedings.mlr.press/v119/bao20a.html.
- Beltagy et al. [2019] Iz Beltagy, Arman Cohan, and Kyle Lo. Scibert: Pretrained contextualized embeddings for scientific text. CoRR, abs/1903.10676, 2019. URL http://arxiv.org/abs/1903.10676.
- Black et al. [2021] Sid Black, Leo Gao, Phil Wang, Connor Leahy, and Stella Biderman. GPT-Neo: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow, March 2021. URL https://doi.org/10.5281/zenodo.5297715. If you use this software, please cite it using these metadata.
- Brandes et al. [2022] Nadav Brandes, Dan Ofer, Yam Peleg, Nadav Rappoport, and Michal Linial. ProteinBERT: A universal deep-learning model of protein sequence and function. Bioinformatics, 38(8):2102–2110, 2022.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877–1901, 2020.
- Carion et al. [2020] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In European Conference on Computer Vision, pages 213–229. Springer, 2020.
- Chalkidis et al. [2020] Ilias Chalkidis, Manos Fergadiotis, Prodromos Malakasiotis, Nikolaos Aletras, and Ion Androutsopoulos. LEGAL-BERT: The muppets straight out of law school. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 2898–2904, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.findings-emnlp.261. URL https://aclanthology.org/2020.findings-emnlp.261.
- Chen et al. [2020a] Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative pretraining from pixels. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 1691–1703. PMLR, 13–18 Jul 2020a. URL https://proceedings.mlr.press/v119/chen20s.html.
- Chen et al. [2021] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Joshua Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code. CoRR, abs/2107.03374, 2021. URL https://arxiv.org/abs/2107.03374.
- Chen et al. [2020b] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org, 2020b.
- Chen et al. [2022] Xiangning Chen, Cho-Jui Hsieh, and Boqing Gong. When vision transformers outperform resnets without pre-training or strong data augmentations. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=LtKcMgGOeLt.
- Chowdhery et al. [2022] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Clark et al. [2020a] Kevin Clark, Minh-Thang Luong, Quoc V. Le, and Christopher D. Manning. Electra: Pre-training text encoders as discriminators rather than generators. In International Conference on Learning Representations, 2020a. URL https://openreview.net/forum?id=r1xMH1BtvB.
- Clark et al. [2020b] Kevin Clark, Minh-Thang Luong, Quoc V. Le, and Christopher D. Manning. ELECTRA: Pre-training text encoders as discriminators rather than generators. In ICLR, 2020b. URL https://openreview.net/pdf?id=r1xMH1BtvB.
- Clement et al. [2020] Colin B Clement, Dawn Drain, Jonathan Timcheck, Alexey Svyatkovskiy, and Neel Sundaresan. PyMT5: Multi-mode translation of natural language and python code with transformers. arXiv preprint arXiv:2010.03150, 2020.
- Devlin et al. [2019] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1423. URL https://aclanthology.org/N19-1423.
- Dong et al. [2019] Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. Unified Language Model Pre-Training for Natural Language Understanding and Generation. Curran Associates Inc., Red Hook, NY, USA, 2019.
- Dosovitskiy et al. [2021] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=YicbFdNTTy.
- Feng et al. [2020] Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. CodeBERT: A pre-trained model for programming and natural languages. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1536–1547, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.findings-emnlp.139. URL https://aclanthology.org/2020.findings-emnlp.139.
- Fried et al. [2022] Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Wen-tau Yih, Luke Zettlemoyer, and Mike Lewis. Incoder: A generative model for code infilling and synthesis. arXiv preprint arXiv:2204.05999, 2022.
- Gao et al. [2021] Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The pile: An 800gb dataset of diverse text for language modeling. CoRR, abs/2101.00027, 2021. URL https://arxiv.org/abs/2101.00027.
- Gousios [2013] Georgios Gousios. The ghtorrent dataset and tool suite. In Proceedings of the 10th Working Conference on Mining Software Repositories, MSR ’13, pages 233–236, Piscataway, NJ, USA, 2013. IEEE Press. ISBN 978-1-4673-2936-1. URL http://dl.acm.org/citation.cfm?id=2487085.2487132.
- Guo et al. [2021] Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie LIU, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang, and Ming Zhou. Graphcode{bert}: Pre-training code representations with data flow. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=jLoC4ez43PZ.
- Guo et al. [2022] Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. UniXcoder: Unified cross-modal pre-training for code representation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7212–7225, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.499. URL https://aclanthology.org/2022.acl-long.499.
- Han et al. [2021] Xu Han, Zhengyan Zhang, Ning Ding, Yuxian Gu, Xiao Liu, Yuqi Huo, Jiezhong Qiu, Liang Zhang, Wentao Han, Minlie Huang, Qin Jin, Yanyan Lan, Yang Liu, Zhiyuan Liu, Zhiwu Lu, Xipeng Qiu, Ruihua Song, Jie Tang, Ji-Rong Wen, Jinhui Yuan, Wayne Xin Zhao, and Jun Zhu. Pre-trained models: Past, present and future. AI Open, 2021. ISSN 2666-6510. doi: https://doi.org/10.1016/j.aiopen.2021.08.002. URL https://www.sciencedirect.com/science/article/pii/S2666651021000231.
- He et al. [2020] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9726–9735, 2020. doi: 10.1109/CVPR42600.2020.00975.
- Hendrycks et al. [2021] Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. Measuring coding challenge competence with apps. In J. Vanschoren and S. Yeung, editors, Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, volume 1, 2021. URL https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/file/c24cd76e1ce41366a4bbe8a49b02a028-Paper-round2.pdf.
- Hindle et al. [2012] Abram Hindle, Earl T. Barr, Zhendong Su, Mark Gabel, and Premkumar Devanbu. On the naturalness of software. ICSE ’12, page 837–847. IEEE Press, 2012. ISBN 9781467310673.
- Holtzman et al. [2020] Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. In ICLR, 2020. URL http://dblp.uni-trier.de/db/conf/iclr/iclr2020.html#HoltzmanBDFC20.
- Huang et al. [2019] Kexin Huang, Jaan Altosaar, and Rajesh Ranganath. Clinicalbert: Modeling clinical notes and predicting hospital readmission. CoRR, abs/1904.05342, 2019. URL http://arxiv.org/abs/1904.05342.
- Husain et al. [2019] Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. Codesearchnet challenge: Evaluating the state of semantic code search. CoRR, abs/1909.09436, 2019. URL http://arxiv.org/abs/1909.09436.
- Iyer et al. [2018] Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. Mapping language to code in programmatic context. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1643–1652, Brussels, Belgium, October-November 2018. Association for Computational Linguistics. doi: 10.18653/v1/D18-1192. URL https://aclanthology.org/D18-1192.
- Jain et al. [2021] Paras Jain, Ajay Jain, Tianjun Zhang, Pieter Abbeel, Joseph Gonzalez, and Ion Stoica. Contrastive code representation learning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5954–5971, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.482. URL https://aclanthology.org/2021.emnlp-main.482.
- Jiang et al. [2021] Xue Jiang, Zhuoran Zheng, Chen Lyu, Liang Li, and Lei Lyu. Treebert: A tree-based pre-trained model for programming language. In Uncertainty in Artificial Intelligence, pages 54–63. PMLR, 2021.
- Kanade et al. [2020] Aditya Kanade, Petros Maniatis, Gogul Balakrishnan, and Kensen Shi. Pre-trained contextual embedding of source code, 2020. URL https://openreview.net/forum?id=rygoURNYvS.
- Kingma and Ba [2015] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Yoshua Bengio and Yann LeCun, editors, 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015. URL http://arxiv.org/abs/1412.6980.
- Kudo and Richardson [2018] Taku Kudo and John Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 66–71, Brussels, Belgium, November 2018. Association for Computational Linguistics. doi: 10.18653/v1/D18-2012. URL https://aclanthology.org/D18-2012.
- Lachmy et al. [2021] Royi Lachmy, Ziyu Yao, Greg Durrett, Milos Gligoric, Junyi Jessy Li, Ray Mooney, Graham Neubig, Yu Su, Huan Sun, and Reut Tsarfaty, editors. Proceedings of the 1st Workshop on Natural Language Processing for Programming (NLP4Prog 2021), Online, August 2021. Association for Computational Linguistics. URL https://aclanthology.org/2021.nlp4prog-1.0.
- Lee et al. [2020] Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240, 2020.
- Li et al. [2022] Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pushmeet Kohli, Nando de Freitas, Koray Kavukcuoglu, and Oriol Vinyals. Competition-level Code Generation with AlphaCode, 2022. URL https://arxiv.org/abs/2203.07814.
- Lu et al. [2021] Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin B. Clement, Dawn Drain, Daxin Jiang, Duyu Tang, Ge Li, Lidong Zhou, Linjun Shou, Long Zhou, Michele Tufano, Ming Gong, Ming Zhou, Nan Duan, Neel Sundaresan, Shao Kun Deng, Shengyu Fu, and Shujie Liu. Codexglue: A machine learning benchmark dataset for code understanding and generation. CoRR, abs/2102.04664, 2021.
- Mikolov et al. [2013] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.
- Neelakantan et al. [2022] Arvind Neelakantan, Tao Xu, Raul Puri, Alec Radford, Jesse Michael Han, Jerry Tworek, Qiming Yuan, Nikolas Tezak, Jong Wook Kim, Chris Hallacy, Johannes Heidecke, Pranav Shyam, Boris Power, Tyna Eloundou Nekoul, Girish Sastry, Gretchen Krueger, David Schnurr, Felipe Petroski Such, Kenny Hsu, Madeleine Thompson, Tabarak Khan, Toki Sherbakov, Joanne Jang, Peter Welinder, and Lilian Weng. Text and code embeddings by contrastive pre-training. CoRR, abs/2201.10005, 2022. URL https://arxiv.org/abs/2201.10005.
- Nijkamp et al. [2022] Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. A conversational paradigm for program synthesis. arXiv preprint arXiv:2203.13474, 2022.
- Papineni et al. [2002] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA, July 2002. Association for Computational Linguistics. doi: 10.3115/1073083.1073135. URL https://aclanthology.org/P02-1040.
- Paszke et al. [2019] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019.
- Phan et al. [2021] Long Phan, Hieu Tran, Daniel Le, Hieu Nguyen, James Annibal, Alec Peltekian, and Yanfang Ye. CoTexT: Multi-task learning with code-text transformer. In Proceedings of the 1st Workshop on Natural Language Processing for Programming (NLP4Prog 2021), pages 40–47, Online, August 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.nlp4prog-1.5. URL https://aclanthology.org/2021.nlp4prog-1.5.
- Qin and Zong [2022] Jiahao Qin and Lu Zong. TS-BERT: A fusion model for pre-trainning time series-text representations, 2022. URL https://openreview.net/forum?id=Fia60I79-4B.
- Radford et al. [2018] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018.
- Radford et al. [2019] Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019.
- Raffel et al. [2020] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020. URL http://jmlr.org/papers/v21/20-074.html.
- Raychev et al. [2014] Veselin Raychev, Martin Vechev, and Eran Yahav. Code completion with statistical language models. In Proceedings of the 35th ACM SIGPLAN Conference on Programming Language Design and Implementation, pages 419–428, 2014.
- Ren et al. [2020] Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. Codebleu: a method for automatic evaluation of code synthesis. CoRR, abs/2009.10297, 2020. URL https://arxiv.org/abs/2009.10297.
- Roziere et al. [2020] Baptiste Roziere, Marie-Anne Lachaux, Lowik Chanussot, and Guillaume Lample. Unsupervised translation of programming languages. Advances in Neural Information Processing Systems, 33:20601–20611, 2020.
- Scholak et al. [2022] Torsten Scholak, Gabriel Orlanski, Disha Shrivastava, Arun Raja, Dzmitry Bahdanau, and Jonathan Herzig. Deep Learning For Code (DL4C) Workshop at ICLR 2022. https://dl4c.github.io/, 2022. [Online; accessed 9-June-2022].
- Sorbo et al. [2022] Andrea Di Sorbo, Sebastiano Panichella, Oscar Chaparro, Rafael Kallis, and Yang Song. The 1st Intl. Workshop on Natural Language-based Software Engineering Co-located with ICSE 2022. https://nlbse2022.github.io/, 2022. [Online; accessed 20-June-2022].
- Touvron et al. [2021] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve Jegou. Training data-efficient image transformers & distillation through attention. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 10347–10357. PMLR, 18–24 Jul 2021. URL https://proceedings.mlr.press/v139/touvron21a.html.
- Trinh et al. [2019] Trieu H. Trinh, Minh-Thang Luong, and Quoc V. Le. Selfie: Self-supervised pretraining for image embedding. CoRR, abs/1906.02940, 2019. URL http://arxiv.org/abs/1906.02940.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems, 30, 2017.
- Wang [2021] Ben Wang. Mesh-Transformer-JAX: Model-Parallel Implementation of Transformer Language Model with JAX. https://github.com/kingoflolz/mesh-transformer-jax, May 2021.
- Wang et al. [2021a] Xin Wang, Yasheng Wang, Pingyi Zhou, Fei Mi, Meng Xiao, Yadao Wang, Li Li, Xiao Liu, Hao Wu, Jin Liu, and Xin Jiang. CLSEBERT: contrastive learning for syntax enhanced code pre-trained model. CoRR, abs/2108.04556, 2021a. URL https://arxiv.org/abs/2108.04556.
- Wang et al. [2022] Xin Wang, Yasheng Wang, Yao Wan, Jiawei Wang, Pingyi Zhou, Li Li, Hao Wu, and Jin Liu. Code-mvp: Learning to represent source code from multiple views with contrastive pre-training, 2022. URL https://arxiv.org/abs/2205.02029.
- Wang et al. [2021b] Yue Wang, Weishi Wang, Shafiq Joty, and Steven C.H. Hoi. CodeT5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 8696–8708, Online and Punta Cana, Dominican Republic, November 2021b. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.685. URL https://aclanthology.org/2021.emnlp-main.685.
- Wu et al. [2020a] Neo Wu, Bradley Green, Xue Ben, and Shawn O’Banion. Deep transformer models for time series forecasting: The influenza prevalence case. CoRR, abs/2001.08317, 2020a. URL https://arxiv.org/abs/2001.08317.
- Wu et al. [2020b] Zonghan Wu, Shirui Pan, Guodong Long, Jing Jiang, Xiaojun Chang, and Chengqi Zhang. Connecting the dots: Multivariate time series forecasting with graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’20, page 753–763, New York, NY, USA, 2020b. Association for Computing Machinery. ISBN 9781450379984. doi: 10.1145/3394486.3403118. URL https://doi.org/10.1145/3394486.3403118.
- Zeng et al. [2021] Wei Zeng, Xiaozhe Ren, Teng Su, Hui Wang, Yi Liao, Zhiwei Wang, Xin Jiang, ZhenZhang Yang, Kaisheng Wang, Xiaoda Zhang, Chen Li, Ziyan Gong, Yifan Yao, Xinjing Huang, Jun Wang, Jianfeng Yu, Qi Guo, Yue Yu, Yan Zhang, Jin Wang, Hengtao Tao, Dasen Yan, Zexuan Yi, Fang Peng, Fangqing Jiang, Han Zhang, Lingfeng Deng, Yehong Zhang, Zhe Lin, Chao Zhang, Shaojie Zhang, Mingyue Guo, Shanzhi Gu, Gaojun Fan, Yaowei Wang, Xuefeng Jin, Qun Liu, and Yonghong Tian. Pangu-: Large-scale autoregressive pretrained chinese language models with auto-parallel computation. CoRR, abs/2104.12369, 2021. URL https://arxiv.org/abs/2104.12369.
Appendix A Qualitative Analysis of Example Outputs
We show some examples of code solutions generated by the different versions of PanGu-Coder after stage-1 pre-training (c.f. Section LABEL:sec:stage_1_training), after stage-2 training with the Code-CLM objective (c.f. Section LABEL:sec:stage_2_training), and after fine-tuning (c.f. Section 3).
In this first example from HumanEval in Table LABEL:tab:example_1, we can see that both Stage-1 and Stage-2 models are attempting to generate solutions, but only the fine-tuned model produces a correct one.
| Prompt |