事件级视觉问答的跨模态因果关系推理
摘要
现有的视觉问答方法经常受到跨模式虚假相关性和过于简化的事件级推理过程的影响,无法捕获视频中的事件时间性、因果关系和动态。 在这项工作中,为了解决事件级视觉问答的任务,我们提出了一个跨模式因果关系推理的框架。 特别是,引入了一组因果干预操作来发现跨视觉和语言模式的潜在因果结构。 我们的框架,名为Cross-Modal Causal RelatIonal R推理(CMCIR),涉及三个模块:i)因果感知视觉语言推理(CVLR)模块,用于通过前门和后门因果干预来协作解开视觉和语言的虚假相关性; ii) 时空变换器(STT)模块,用于捕获视觉和语言语义之间的细粒度交互; iii)视觉语言特征融合(VLFF)模块,用于自适应地学习全局语义感知视觉语言表示。 对四个事件级数据集的广泛实验证明了我们的 CMCIR 在发现视觉语言因果结构和实现稳健的事件级视觉问答方面的优越性。 数据集、代码和模型可在 https://github.com/HCPLab-SYSU/CMCIR 获取。
索引术语:
视觉问答、因果推理、跨模态推理、视频事件理解。1 简介
随着深度学习[1]的快速发展,事件理解[2]已成为视频分析中的一个突出研究课题[3,4,5] 因为视频具有超越图像级理解(场景、人物、物体、活动等)的巨大潜力,可以理解事件的时间性、因果关系和动态。 对复杂事件准确高效的认知和推理 是 对于视频语言理解极其重要。 由于自然语言可以潜在地描述更丰富的事件空间[6],这有助于 更深 事件理解,我们专注于复杂(时间、因果)事件级视觉问答任务 a 跨模式(视觉、语言)设置。 我们的任务旨在充分理解更丰富的多模式事件空间,并以因果关系意识的方式回答给定的问题. 为了实现事件级视觉问答[7,8,9],模型需要对涉及各种复杂关系(例如时空视觉关系)的视频和语言内容有细粒度的理解、语言语义关系和视觉语言因果依赖性。 因此,鲁棒可靠的多模态关系推理在事件级视觉问答中至关重要。 事实上,在多模态视觉语言背景下理解事件是一个长期存在的挑战。 现有的视觉问答方法[10,11,12,13]使用循环神经网络(RNN)[14],注意力机制[15] 或图卷积网络 [16] 用于视觉和语言模态之间的关系推理。 尽管取得了有希望的结果,但这些方法存在两个常见的局限性。

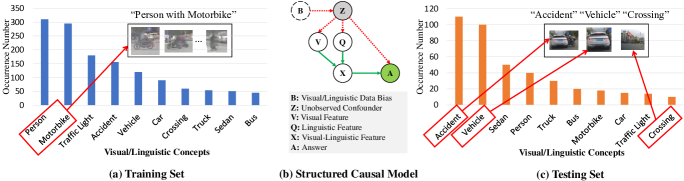
首先,现有的视觉问答方法通常关注简单的事件,不需要深入理解因果关系、时间关系和语言交互,并且往往会忽略更具挑战性的事件。 在图1中,给定一个视频和一个相关问题,典型的人类推理过程首先需要记住每个视频帧中的相关对象及其交互(例如,汽车在路上行驶,人骑着一辆汽车)摩托车穿过十字路口),然后根据所记忆的视频内容得出相应的答案。 然而,图1中的事件级反事实视觉问答任务需要某些假设的结果(例如,“该人没有骑摩托车穿过十字路口”),而这些假设在给定视频。 如果不发现隐藏的时空和因果依赖关系,简单地关联相关的视觉内容就无法得到正确的推理结果。 为了准确推理反事实条件下的想象事件,模型必须进行层次关系推理,充分探索视觉和语言内容的因果关系、逻辑和时空动态结构。 这涉及进行因果干预,以发现真正的因果结构,从而有助于根据想象的视觉证据和正确的问题意图如实回答问题。 然而,复杂多模态事件的语言与时空结构之间的多层次相互作用和因果关系尚未得到充分探索。
其次,当前的视觉问答模型倾向于捕获混杂因素引入的虚假语言或视觉相关性,而不是真正的因果结构和因果感知的多模态表示,导致推理过程不可靠[17,18,19 ,20]。 图2显示,一些在语言和视觉模态中频繁出现的概念可以被视为混杂因素。 “语言偏差”代表问题和答案之间的强相关性,而“视觉偏差”代表某些关键视觉特征和答案之间的强相关性。 例如,训练数据集是根据视觉和语言偏差构建的,其中经常出现“人”和“摩托车”概念(图2)。 这种有偏见的数据集会带来两个因果效应:视觉和语言偏见导致混杂因素,然后影响视觉特征、问题特征,视觉语言特征,以及答案。 因此,我们可以画出两个因果联系来描述这些因果效应:和。 如果我们想在使用有偏差的数据集到该模型时学习真正的因果训练(图2(a)),该模型可以简单地将概念“人”相关联”和“摩托车”,即通过,然后利用这些有偏见的知识来推断答案,即通过。 这样,该模型通过混杂因素 引起的后门路径 学习 和 之间的虚假相关性,如下如图2(b)所示。 因此,模型可以学习“摩托车”和“人”之间的虚假相关性,而不考虑“车辆”概念(即利用真实的问题意图和主导视觉证据)来推理事故是如何发生的。 由于复杂训练事件中潜在的视觉和语言相关性很复杂,因此测试集和测试集之间的视觉和语言偏差存在显着差异。 为了减轻数据集偏差,因果推理[21]在场景图生成[22]、图像分类[23]和图片问答[24, 17]。 然而,由于视觉领域中不可观察的混杂因素以及视觉和语言内容之间复杂的交互,直接将现有的因果方法应用于事件级视觉问答任务可能会产生不令人满意的结果。
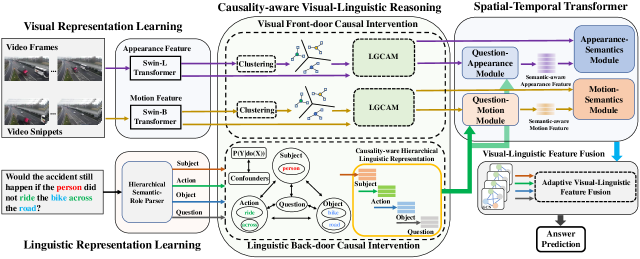
为了缓解上述局限性,本文提出了一个用于事件级 VQA 的框架,名为 Cross-Modal Causal RelatIonal Reasoning (CMCIR)。 所提出的因果感知视觉语言推理(CVLR)模块解决了混杂因素的偏见,并通过前门和后门因果干预揭示了视觉和语言模式中的因果结构。 为了解决视觉模态中不可观察的混杂因素,提出了局部全局因果注意力模块(LGCAM),该模块使用注意力来聚合局部和全局视觉表示因果关系。 此外,后门干预模块旨在发现语言模态中的因果效应。 引入时空变换器(STT)来模拟外观-运动和语言表示之间的多模态交互,包括问题-外观(QA)、问题-运动(QM)、外观-语义(AS)和运动-语义 (MS) 模块。 最后,提出了一种新颖的视觉语言特征融合(VLFF)模块来自适应地融合因果感知的视觉和语言特征。 各种数据集的实验结果表明,CMCIR 优于最先进的方法。 论文的主要贡献可概括如下:
-
•
我们提出了一个因果感知的事件级视觉问答框架,名为Cross-Modal Causal RelatIonal R推理(CMCIR),通过对视觉和语言模态整合的因果干预来发现真正的因果结构,并实现强大的事件级视觉问答性能。 据我们所知,我们是第一个发现事件级视觉问答任务的跨模式因果结构的人。
-
•
我们引入了一种由语言语义关系引导的语言后门因果干预模块,以减轻虚假偏差并揭示语言模态内的因果依赖性。 为了理清视觉虚假相关性,我们提出了Local-Global Causal Attention 模块(LGCAM)通过前门因果干预聚合局部和全局视觉表示。
-
•
我们构建了一个S空间-T时间T变换器(STT)来模拟视觉和语言知识之间的多模态共现交互,发现语言语义、空间和时间表示之间的细粒度相互作用。
-
•
为了自适应地融合因果感知的视觉和语言特征,我们引入了Visual-L语言F特征Fusion(VLFF)模块,利用分层语言语义关系来学习全局语义感知视觉语言特征。
-
•
在 SUTD-TrafficQA、TGIF-QA、MSVD-QA 和 MSRVTT-QA 数据集上进行的大量实验表明,我们的 CMCIR 在发现视觉语言因果结构和实现有希望的事件级视觉问答性能方面是有效的。
2 相关作品
2.1 视觉问答
比较的 到 基于图像的视觉问答(即 ImageQA)[25,26,27],事件级视觉问答(即 VideoQA)由于额外的时间维度而更具挑战性。 到 解决 对于 VideoQA 问题,模型需要捕获时空和视觉语言关系来推断答案。 为了探索VideoQA中的关系推理,Xu等人[28]提出了一种注意力机制,以问题为指导来利用外观和运动知识。 Jang 等人[29, 30]发布了名为TGIF-QA的大规模VideoQA数据集,并提出了一种具有空间和时间注意力的基于双LSTM的方法。 随后,提出了一些基于分层注意力和共同注意力的方法[11,31,32]来学习外观运动和问题相关的多模态交互。 Le等人[12]提出了分层条件关系网络(HCRN)来构建用于视频表示和推理的复杂结构。 Jiang等人[33]介绍了异构图对齐(HGA)网络,该网络可以对齐模态间和模内信息以进行跨模态推理。 黄等人[10]提议 a 位置感知图卷积网络对检测到的对象进行推理。 Lei 等人[34]采用稀疏采样构建了基于 Transformer 的模型CLIPBERT,并实现了端到端的视频和语言理解。 Liu等人[35]提出了一种分层视觉语义关系推理(HAIR)框架来执行分层关系推理。
不像 这 专注于相对简单事件(例如电影、电视节目或合成视频)的作品,我们的 CMCIR 框架 焦点 复杂的事件级视觉问答并执行跨模式因果关系推理 在 时空和语言内容。 事件级城市视觉问答的唯一现有工作是 Eclipse[36],它构建了事件级城市交通视觉问答数据集,并提出了高效的一瞥网络以实现计算高效且可靠视频推理。 与 Eclipse 专注于探索城市交通事件中的高效和动态推理不同,我们的工作旨在揭示视觉语言模态背后的因果结构,并以因果关系对外观运动和语言知识之间的交互进行建模。意识的方式。 此外,这些先前的工作倾向于捕捉视频中虚假的语言或视觉相关性,而我们构建了一个因果感知的视觉语言推理(CVLR)模块,以减轻混杂因素造成的偏差,并揭示复杂的整合的因果结构。事件级视觉和语言模式。
2.2 事件理解的关系推理
除了VideoQA之外,关系推理还在其他事件理解任务中得到了探索,例如动作识别[37,38,39]和时空基础[40]。 为了识别和定位动作,Girdhar 等人[41]引入了 Transformer 式架构来聚合来自人周围时空背景的特征。 对于动作检测,Huang 等人[42]引入了动态图模块来对视频动作中的对象-对象交互进行建模。 Ma 等人[43]利用 LSTM 来模拟任意对象子组之间的交互。 Mavroudi 等人[44]使用动作类别构建了符号图。 Pan 等人[45]设计了一个高阶演员-情境-演员关系网络来实现时空动作定位的间接关系推理。 为了针对给定的文本查询定位视频中的某个时刻,Nan 等人[46]引入了一种双重对比学习方法,通过最大化语义和视频剪辑之间的相互信息来对齐文本和视频。 Wang 等人[47]提出了一个因果框架来学习去混杂的对象相关关联,以实现鲁棒的视频对象接地。 然而,这些方法仅对视觉模态进行关系推理而忽略了 潜在因果关系 语言语义关系的结构,导致对视觉语言内容的不完整和不可靠的理解。 此外,我们的 CMCIR 进行因果感知的时空关系推理,以揭示视觉语言模态的因果结构 和 利用分层语义知识进行时空关系推理。
2.3 视觉表示学习中的因果推理
与传统的去偏技术[48]相比,因果推断[21,49,50]显示了其在减轻虚假相关性[51]方面的潜力并解开模型效应[52]以获得更好的泛化能力。 反事实和因果推理在一些计算机视觉任务中引起了越来越多的关注,包括视觉解释[53, 54]、场景图生成[55, 22]、图像识别[24, 19]、视频分析[56, 57, 46]和视觉语言任务[58, 17, 18, 59, 60, 61]. 具体而言,唐等人[62]、张等人[63]、王等人[24]和齐等人[64]计算了直接因果效应并 减轻 基于可观察到的混杂因素的偏见。 基于反事实的解决方案也是有效的,例如Agarwal等人[65]提出了一种基于GAN的反事实样本合成方法[66]。 Chen 等人[67]尝试将批评对象和批评词替换为 a 屏蔽词符并重新分配答案以合成反事实问答对。 除了样本合成之外,Niu等人[17]开发了一个反事实VQA框架,通过使用名为自然间接效应和总直接效应的因果关系方法来消除中介效应,从而减少多模态偏差。 Li等人[20]提出了VideoQA不变接地(IGV),以强制VideoQA模型保护回答过程免受虚假相关性的负面影响。 刘等人[59]引入了视觉因果发现(VCD)架构,以在时间上找到关键问题场景,并通过前门因果干预来理清视觉虚假相关性。
然而,大多数现有的因果视觉任务都相对简单,没有考虑视频理解和事件级视觉问答等更具挑战性的任务。 虽然最近的一些作品CVL [58]、Counterfactual VQA [17]、CATT [18]、IGV [20]和VCD[59]专注于视觉问答任务,他们采用结构化因果模型(SCM)来消除语言或视觉偏差,而不考虑跨模态因果关系发现。 与之前的方法不同,我们的 CMCIR 旨在进行事件级视觉问答,需要对时空视觉关系、语言语义关系和视觉语言因果依赖性进行细粒度的理解。 此外,我们的因果感知视觉语言推理(CVLR)应用前门和后门因果干预模块来发现跨模态因果结构。
3 方法论
CMCIR的框架如图3所示,是一个事件级的可视化问答架构。 在本节中,我们将介绍 CMCIR 的详细实现。
3.1 视觉表示学习
事件级视觉问答的目标是从具有给定问题的视频中推断出答案。 答案可以在答案空间中找到,这是一个 预定义的 开放式问题的一组可能答案或候选答案列表 多项选择 问题。 帧的视频 被分为 个相等的剪辑。 每个长度为 的 剪辑由两种类型的视觉呈现 特征:逐帧外观特征向量和剪辑级别的运动特征向量。 在我们的实验中,Swin-L [68] 用于提取帧级外观特征 ,Video Swin-B [69] 是用于提取剪辑级运动特征。 然后,我们使用线性特征转换层将 和 映射到相同的 维特征空间。 因此,我们有。
3.2 语言表征学习
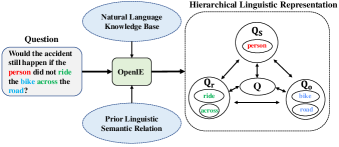
从语言语义关系的角度来看,一个问题通常包含以下词汇: a 主题, 一个 行动,以及 一个 对象,因为大多数视频可以被描述为“某人 正在做 某物”。 因此,我们提出了一种从自然语言角度近似混杂因素集分布的有效方法。 具体来说,我们构建了一个分层语义角色解析器(HSRP),将问题解析为以动词为中心的关系元组(主语、动作、宾语),并相应地构造三组词汇。 以动词为中心的关系元组是原始问题的单词围绕关键词主语、动作和宾语的子集。 HSRP 基于最先进的开放信息提取 (OpenIE) 模型[70],该模型从 a 大规模自然语言知识库,如图4所示。 对于整个问题、主语、动作、宾语和候选答案,每个单词分别嵌入到 的向量中 方面 通过采用预训练的 GloVe [71] 词嵌入,使用线性变换将其进一步映射到 维空间。 然后,我们用 、、、、 表示相应的问答语义,其中 、、、、表示 、、、 和 的长度。
为了获得聚合来自多个时间步长的动态远程时间依赖性的上下文语言表示,采用 BERT [72] 模型对 、 进行编码>、、 和答案 分别。 最后,问题、问题元组和候选答案的更新表示可以写为:
| (1) | ||||
和
| (2) |
3.3 因果感知视觉语言推理
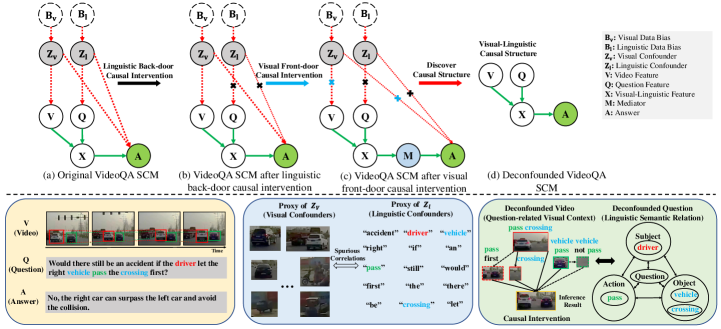
对于时空数据的视觉语言问题推理,我们采用 Pearl 的结构因果模型(SCM)[21]来建模视频问题对与答案之间的因果效应,如图 1 所示。 5 (a)。 节点是变量,边是因果关系。 传统的VQA方法仅学习:,它学习基于统计的模糊关联。 他们忽略了混杂因素带来的虚假关联,而我们的方法 地址 这些问题是有因果关系的 框架 并提出根本解决办法。 下面,我们详细介绍因果图背后的基本原理。 图5的底部呈现了视觉语言因果干预的高级解释。 在这里,我们 提供 一些子图的详细解释。
。 视觉和语言混淆和(可能 一个 分布不平衡 这 由数据采样偏差和引起的数据集可能会导致视频和某些单词之间的虚假相关性。 上的 操作可以强制执行它们的值并切断 与其父级 和 (图5(b)和(c))。
。 由于 和 是数据集的视觉和语言混杂因素,因此我们还必须将 和 连接到预测 通过除 之外的定向路径。 这确保了考虑 这 从和到的混杂影响。
。 有两个后门路径,混杂因素 和 分别影响视频 和问题 ,并且 最终 影响答案,导致模型学习虚假关联。 正如之前所讨论的,如果我们成功切断了路径 , 和 就会被解混,并且模型可以学习真正的因果效应 .
要训练一个学习真实因果效应 的视频问答模型:该模型应从以下位置推理出答案 这 视频 和 这 问题,而不是利用混杂因素和引起的虚假相关性(即过度利用视觉和语言概念之间的共现)。 例如,由于回答了“事故中车辆的颜色是什么?”这个问题。在大多数情况下是“白色”,模型将很容易学习概念“车辆”和“白色”之间的虚假相关性。 传统的视觉语言问题推理模型通常通过直接学习来关注视频和问题之间的相关性,而不考虑混杂因素和。 因此,当给定黑色车辆的事故视频时,该模型仍然很有信心地预测答案“白色”。 在我们的 SCM 中,非干预预测可以使用贝叶斯规则表示为:
| (3) |
然而,上述目标不仅从中学习主要的直接相关性,而且还从畅通的后门路径中学习虚假的相关性。 对的干预记为,切断链路,阻断后门路径和虚假信息相关性被消除。 这样,和就被解混了,模型可以学习真正的因果效应。 实际上,计算有两种技术,分别是后门调整[21, 73]和前门调整。 当可以观察到混杂因素时,后门调整是有效的。 然而,对于视觉语言问题推理,视觉和语言模态的混杂因素 是 并不总是可观察到的。 因此,我们提出了后门和前门因果干预模块,以发现因果结构并根据其特征理清语言和视觉偏见。
3.3.1 语言后门因果干预
对于语言模态而言,由于采样过程的不可用,无法直接观察到由选择偏差引起的混杂集合。 由于语言混杂因素的存在,现有的方法主要依赖于整个问题表示 趋向 捕捉虚假的语言相关性和 忽略 嵌入问题中的语义角色。 为了减轻混杂因素造成的偏差并揭示语言模态背后的因果结构,我们设计了一种后门调整策略,从语言语义关系的角度近似混杂因素集的分布。 基于3.2节中的语言表示学习,我们的潜在混杂因素集是基于整个问题、主语相关问题、动作相关问题、客体相关问题的以动词为中心的关系角色来近似的、、、。 阻断后门路径使有公平的机会纳入因果感知因素进行预测(如图5(b) )。 后门调整计算干预分布:
| (4) | ||||
实施方程中的理论和想象力的干预。 (4),我们将混杂因素集近似为一组以动词为中心的关系词汇。 我们计算等式中的先验概率。 (4) 对于每个集合中以动词为中心的关系短语 、、, 基于数据集统计:
| (5) |
其中是四个以动词为中心的关系词汇集之一,是中的样本数量,是短语 出现的次数。 的表示计算 以类似的方式 等式。 (1)。 由于是通过softmax计算的,因此我们将归一化加权几何平均(NWGM)[74]应用于方程。 (4) 来近似去混杂预测:
| (6) | ||||
其中 代表 向量串联。 根据方程。 (6),每个 元素 因果关系感知的分层语言表示 需要 集成到 QA 推理阶段 使用 等式。 (6),本质上是语言值出现次数的加权和 混杂因素 在数据集中。
3.3.2视觉前门因果干预
如方程式所示。 (4),后门调整需要我们提前确定混杂因素是什么。 然而,在视觉领域,数据偏差很复杂,很难了解和区分不同类型的混杂因素。 现有方法通常将混杂因素定义为视觉特征[24, 19]的平均值。 实际上,平均特征可能不正确 描述 特别是对于复杂的异构时空数据来说,存在一定的混杂因素。 幸好前门调节 给出 当我们无法明确表示混杂因素时,计算 的可行方法。 如图 5 (c)所示,要应用前门调整,应在 和 之间插入一个额外的调解器 ,以构建前门路径 发送 知识。 对于视觉语言问题推理任务,基于注意力的模型将根据问题从视频中选择一些区域来预测答案 ,其中 表示从中介 中选择的知识:
| (7) |
那么,答案预测器可以由两部分表示:特征提取器和答案预测器。 因此,干预概率可以表示为:
| (8) |
接下来,我们分别讨论上述特征提取器和答案预测器。
特征提取器。 如图5(c)所示,对于因果链接,和之间的后门路径: 已被阻止。 因此,干预概率等于条件概率:
| (9) |
答案预测器。 要实现,我们可以截断来堵住后门路径:
| (10) |
实施视觉前门因果干预(11) 在深度学习框架中,我们将 参数化为网络 后跟一个 softmax 层,因为大多数视觉语言任务都经过了转换分为分类公式:
| (12) |
从方程。 (11),我们可以看到和都需要采样并输入到网络中才能完成 。 然而,转发所有样本的成本为 高的. 到 处理 这个问题,我们申请 这 归一化加权几何平均值 (NWGM) [74] 至 包含 外部采样到特征级别, 因此只需要一次前向传播 网络中的“吸收输入”,如 显示 在等式中(13):
| (13) | ||||
其中和表示和、和的估计> 表示网络映射函数。
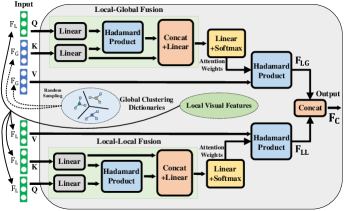
实际上,本质上是一个样本内采样过程,其中表示从当前输入样本中选择的知识, 和 本质上是一个跨样本采样过程,因为它来自其他样本。 因此,和都可以通过注意力网络[18]来计算。 具体来说,我们提出了一种新颖的局部全局因果注意力模块(LGCAM),该模块联合估计和 a 统一注意力模块,以提高因果关系感知视觉特征的表示能力。 可以通过学习局部-局部视觉特征来计算,可以通过学习局部-全局视觉特征来计算。 在这里,我们 使用 的计算为 一个 举例说明我们的LGCAM,如图6上半部分所示。
具体来说,我们 第一的 计算和并将它们用作LGCAM的输入,其中表示随后的视觉特征提取器(逐帧外观特征或运动特征)通过查询嵌入函数,表示 基于K均值 来自整个训练样本的视觉特征选择器,后跟查询嵌入函数。 因此,表示当前输入样本的视觉特征(局部视觉特征),表示全局视觉特征。 是从与大小相同的整个聚类字典中随机采样得到的。 LGCAM以和作为输入,并通过调节全局视觉特征来计算局部全局视觉特征 在 局部视觉特征。 LGCAM 的输出表示为,由下式给出:
| (14) | ||||
其中 表示 a 连接操作, 代表 哈达玛乘积,、、、 代表 的权重 这 线性层,和表示 这 线性层。 从图3可以看出,视觉前门因果干预模块有外观和运动特征两个分支。 因此,有两个变体, 为外观分支,为运动分支。
设置时,的计算方式与类似。 最后,将和连接起来来估计。
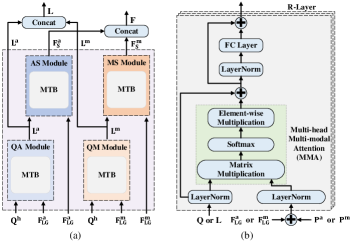
3.4 时空转换器
在进行语言和视觉因果干预后,我们需要进行视觉-语言关系建模和特征融合。 然而,现有的视觉和语言转换器通常忽略了文本和外观运动信息之间的多层次和细粒度的交互,这对于 这 事件级视觉问答任务。 因此,我们提出了一个时空变换器(STT),它包括四个子模块,即问题-外观(QA)、问题-运动(QM)、外观-语义(AS)和运动-语义(MS),如图所示在图7(a)中,揭示语言和时空表征之间的细粒度相互作用。 QA(QM)模块由R层多模态 Transformer 块(MTB)组成(图7(b)),用于问题和外观(运动)特征之间的多模态交互。 类似地,AS (MS) 使用 MTB 来推断给定问题语义的外观(运动)信息。
QA 和 AM 模块旨在分别对有关视觉外观和运动内容的问题进行全面的理解。 对于QA和QM模块,MTB的输入分别是从3.3.1节获得的和从3.3.2节获得的、。 为了维护视频序列的位置信息,首先将外观特征 和运动特征 添加到学习到的位置嵌入 和 分别。 因此,对于 MTB 的 层,输入为 、、 和 ,QA 和 QM 的多模态输出计算如下:
| (15) | ||||
其中 、 和 是中间值 特征 在 这 MTB 的层。 LN 表示层归一化操作, 和 表示线性投影。 MMA 是多头多模态注意力层。 我们将 QA 和 MA 的输出语义感知外观和运动特征分别表示为 和 。
由于 VideoQA 的一个重要步骤是推断视觉 信息 在外观运动中 特征 给定问题语义,我们建议 这 外观语义(AS)和运动语义(MS)模块从语言语义和时空表示之间的相互作用推断视觉信息, a 类似的架构 到 多模式 Transformer 块 (MTB)。 考虑到语义感知的外观和运动特征 和 ,我们使用 这 AS 和 MS 待发现 视觉信息 分别基于时空视觉表征来回答问题。
类似于等式。 (15),给定视觉外观和运动特征 、 和问题语义 、,AS 和 MS 的多模态输出计算如下:
| (16) | ||||
其中 MTB 具有 层和 、。 QA和MA的输出视觉线索分别表示为和。 然后,AS和MS的输出 是 连接起来形成最终的视觉输出。 QA 和 QM 的输出被连接起来,使最终的问题语义输出 。
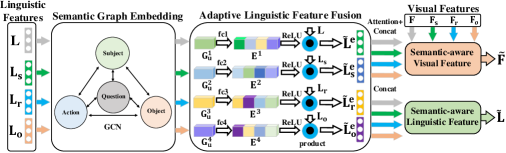
3.5 视觉语言特征融合
根据方程。 (6)在3.4.1节中,因果感知分层语言表示的每一项都需要分别进行QA预测过程,然后通过它们的结果来整合它们的结果语义关系。 因此,对于 、、、,它们各自的 STT 模型视觉和语言输出表示为 和 。 具体来说, 构建语义图,图节点的表示记为,如图8所示。 中的特征向量被视为节点。 根据HSRP学习到的、、和之间的层次语言语义关系,我们构建了全连接边,然后执行层语义图卷积(GCN)[16]嵌入:
| (17) |
其中 表示 层图卷积。
由于不同语义角色的语言特征是相关的,我们构建了一个自适应语言特征融合模块,该模块接收来自不同语义角色的特征并学习全局上下文嵌入。 然后使用这种嵌入来重新校准来自不同语义角色的输入特征,如图8所示. 从语义 GCN 学习到的节点的语言特征是 表示为 ,其中 )。 为了利用语言特征之间的相关性,我们将它们连接起来并获得联合表示 对于每个语义角色 通过将它们传递给全连接层:
| (18) |
其中表示串联操作,表示联合表示,和是全连接层的权重和偏差。 我们选择来限制模型容量并增加其泛化能力。 到 利用 联合表示 中聚合的全局上下文信息,我们预测 一个 激励信号 他们 通过全连接层:
| (19) |
其中 和 是 这 全连接层的权重和偏差。 获得激励信号后,我们用它来 适应性地 通过简单的门控机制重新校准输入特征:
| (20) |
其中 是 a 对通道维度中的每个元素进行通道乘积运算,是ReLU函数。 这样,我们可以允许一个语义角色的特征重新校准另一个语义角色的特征,同时保留不同语义角色之间的相关性。 然后,将这些细化的语言特征向量连接起来形成最终的语义件语言特征。
为了获得语义感知视觉特征,我们将视觉特征 中的每个语义角色分别与精炼语言特征 中的每个语义角色进行条件化,从而计算出视觉特征 ,其操作方法与以下相同 在 [12]。 对于每个语义角色,加权语义感知视觉特征为:
| (21) | ||||
然后,这些语义感知视觉特征被连接起来形成最终的语义感知视觉特征。 最后,我们根据语义感知视觉特征 和语言特征 推断答案。 具体来说,我们根据视觉问题推理任务应用不同的答案解码器[12],分为三种类型:开放式、多项选择和计数。
4 实验
在本节中,我们进行了大量的实验来评估 CMCIR 模型的性能。 为了验证 CMCIR 及其组件的有效性,我们将 CMCIR 与最先进的方法进行比较并进行消融研究。 然后,我们进行参数敏感性分析来评估 CMCIR 的超参数如何 影响 的表现。 我们进一步展示了一些可视化分析来验证 CMCIR 的因果推理能力。
4.1 数据集
在本文中,我们评估了我们的 CMCIR 这 事件级城市数据集 SUTD-TrafficQA [36] 和三个基准现实世界数据集 TGIF-QA [29]、MSVD-QA [28] 和 MSRVTT-QA [28]。 这些数据集的详细描述如下:
SUTD-交通质量检查。 该数据集包含从交通场景收集的 62,535 个 QA 对和 10,090 个视频。 有六种具有挑战性的推理任务,包括基本理解、事件预测、逆向推理、反事实推理、内省和归因分析。 基础理解任务是对基础层面的交通场景进行感知和理解。 事件预测任务是根据观察到的视频推断未来事件,预测问题询问当前情况的结果。 反向推理任务是询问视频开始之前发生的事件。 反事实推理任务询问某些未发生的假设的后续结果。 自省任务是测试模型是否可以提供可以避免交通事故的预防建议。 归因任务寻求对交通事件原因的解释并推断潜在因素。
| Video | QA pairs | Count | Action | Transition | FrameQA | |
|---|---|---|---|---|---|---|
| Train | 62,846 | 139,414 | 26,843 | 20,475 | 52,704 | 39,392 |
| Test | 9,575 | 25,751 | 3,554 | 2,274 | 6,232 | 13,691 |
| Total | 71,741 | 165,165 | 30,397 | 22,749 | 58,936 | 53,083 |
| Video | QA pairs | What | Who | How | When | Where | |
|---|---|---|---|---|---|---|---|
| Train | 1,200 | 30,933 | 19,485 | 10,479 | 736 | 161 | 72 |
| Val | 250 | 6,415 | 3,995 | 2,168 | 185 | 51 | 16 |
| Test | 520 | 13,157 | 8,149 | 4,552 | 370 | 58 | 28 |
| Total | 1,970 | 50,505 | 31,629 | 17,199 | 1,291 | 270 | 116 |
| Video | QA pairs | What | Who | How | When | Where | |
|---|---|---|---|---|---|---|---|
| Train | 6,513 | 158,581 | 108,792 | 43,592 | 4,067 | 1,626 | 504 |
| Val | 497 | 12,278 | 8,337 | 3,439 | 344 | 106 | 52 |
| Test | 2,990 | 72,821 | 49,869 | 20,385 | 1,640 | 677 | 250 |
| Total | 10,000 | 243,680 | 166,998 | 67,416 | 6,051 | 2,409 | 806 |
| Method | Question Type | ||||||
|---|---|---|---|---|---|---|---|
| Basic | Attribution | Introspection | Counterfactual | Forecasting | Reverse | All | |
| (4759) | (348) | (482) | (302) | (166) | (565) | (6622) | |
| VIS+LSTM [75] | - | - | - | - | - | - | 29.91 |
| I3D+LSTM[76] | - | - | - | - | - | - | 33.21 |
| BERT-VQA [77] | - | - | - | - | - | - | 33.68 |
| TVQA [78] | - | - | - | - | - | - | 35.16 |
| [79] | 34.02 | 49.43 | 34.44 | 39.74 | 38.55 | 49.73 | 36.00 |
| [80] | 33.83 | 50.86 | 34.23 | 41.06 | 41.57 | 50.80 | 36.03 |
| [81] | 33.91 | 50.57 | 33.40 | 41.39 | 41.57 | 50.62 | 36.07 |
| HCRN [12] | - | - | - | - | - | - | 36.49 |
| [12] | 34.17 | 50.29 | 33.40 | 40.73 | 44.58 | 50.09 | 36.26 |
| Eclipse [36] | - | - | - | - | - | - | 37.05 |
| CMCIR (ours) | 36.10 (+1.93) | 52.59 (+1.73) | 38.38 (+3.94) | 46.03 (+4.64) | 48.80 (+4.22) | 52.21 (+1.41) | 38.58 (+1.53) |
TGIF-QA。 该数据集包含从 72K 个动画 GIF 中收集的 165K 个 QA 对。 它有四个任务:重复计数、重复动作、状态转换和帧 QA。 重复计数是一项计数任务,需要模型计算某个动作的重复次数。 重复动作和状态转换是 多项选择 具有 可选答案的任务。 FrameQA 是一项开放式任务 预定义的 答案集,可以从单个视频帧中回答。 表I显示了TGIF-QA数据集的统计数据。
MSVD-QA。 该数据集是根据 Microsoft Research 视频描述语料库 [82] 创建的, 哪个 广泛应用于视频字幕任务中。 它由 50,505 个算法生成的问答对和 1,970 个修剪过的视频剪辑组成。 每个视频持续约 10 秒。 它包含五种问题类型: 什么、谁、如何、何时、何地。 MSVD-QA数据集的统计数据如表II所示。
MSRVTT-QA。 这个更大的数据集包含 由 MSRVTT [83] 构建的更复杂的场景。 它包含 10,000 个剪辑后的视频剪辑,每个剪辑大约 15 秒。 该数据集中包含的总共 243,680 个问答对是由 NLP 算法自动生成的。 该数据集包含五种问题类型:什么、谁、如何、何时和何地。 MSRVTT-QA 数据集的统计数据如表III所示。
4.2 实现细节
为了与其他方法进行公平比较,对于 SUTD-TrafficQA 和 TGIF-QA 数据集,我们按照 [12] 将视频分为 8 个剪辑,对于 MSVD- 数据集,我们按照 剪辑进行划分。包含长视频的 QA 和 MSRVTT-QA 数据集。 在ImageNet-22K数据集上预训练的Swin-L [68]用于提取帧级外观特征,在Kinetics上预训练的视频Swin-B [84] -600 用于提取剪辑级运动特征。 对于该问题,我们采用预训练的维GloVe [71]词嵌入来初始化句子中的词特征。 对于参数设置,我们将隐藏层的维度设置为512。 对于多模态 Transformer 块 (MTB),SUTD-TrafficQA 的层数 设置为 3,TGIF-QA 的层数 设置为 3,对于 MSVD-QA, 对于 MSRVTT-QA。 注意力头的数量设置为8。 通过对整个训练集的整个视觉特征应用 K-means 来初始化字典,以获得 簇,并在端到端训练期间进行更新。 在语义图嵌入中,GCN 层数 设置为 。 在训练过程中,我们使用 Adam 优化器训练模型,初始学习率为 2e-4,动量为 0.9,权重衰减为 0。 当每 epoch 后损失停止减少时,学习率减半。 批量大小设置为 64。 Dropout率设置为0.15以防止过度拟合。 所有实验均在 epoch 后终止。 我们通过 PyTorch 和 NVIDIA RTX 3090 GPU 实现我们的模型。 对于多项选择和开放式任务,我们使用准确性来评估模型的性能。 对于 TGIF-QA 数据集中的计数任务,我们采用预测答案和正确答案之间的均方误差(MSE)。
4.3 与最先进方法的比较
4.3.1 SUTD-TrafficQA 数据集的结果
由于原始SUTD-TrafficQA数据集[36]没有提供六个推理任务的划分,因此我们根据问题类型将SUTD-TrafficQA数据集划分为六个推理任务。 报告总体准确性和每种推理类型的准确性。
表IV中的结果表明,我们的CMCIR在基本理解、事件预测、逆向推理、反事实推理、内省和归因分析等六种推理任务上取得了最佳性能。 具体来说,CMCIR 将所有推理任务的最佳最先进方法 Eclipse [36] 改进了 。 与重新实现的方法、、和相比,我们的CMCIR在所有六个方面都比这些方法表现更好任务大幅领先。 例如,与相比,我们的CMCIR在基本理解方面提高了的准确性,在归因分析方面提高了的准确性,在内省方面提高了的准确性, 用于反事实推理, 用于事件预测, 用于反向推理, 用于所有任务。 显然,我们的方法对三类问题的改进最多:内省、反事实推理和事件预测。 自省任务是测试模型是否能够提供预防交通事故的预防建议。 事件预测任务是根据观察到的视频推断未来事件,预测问题询问当前情况的结果。 反事实推理任务询问某些未发生的假设的后续结果。 所有这三种问题类型都需要视觉和语言内容的因果、逻辑和时空结构之间的因果关系推理。 这验证了我们的 CMCIR 可以对事件级城市数据的语言和时空结构之间的多层次交互和因果关系进行建模。
4.3.2 其他基准数据集的结果
为了评估 CMCIR 在其他事件级数据集上的泛化能力,我们在 TGIF-QA、MSVD-QA 和 MSRVTT-QA 数据集上进行实验,并将我们的模型与最先进的方法进行比较。 比较结果为 这 TGIF-QA 数据集如表V所示。我们可以看到我们的 CMCIR 达到了最佳性能 这 Action 和 FrameQA 任务。 此外,我们的 CMCIR 还实现了相对较高的性能 这 转换和计数任务。 具体来说,CMCIR 将 Action 任务的最佳执行方法 HAIR [35] 改进为 ,将 改进为 这 FrameQA 任务。 对于 Transition 任务,CMCIR 的性能也优于除 CASSG [85] 和 Bridge2Answer [13] 之外的其他比较方法。 对于 Count 任务,我们的 CMCIR 还实现了具有竞争力的 MSE 损失值。
| Method | Task Type | |||
|---|---|---|---|---|
| Action | Transition | FrameQA | Count | |
| ST-VQA [29] | 62.9 | 69.4 | 49.5 | 4.32 |
| Co-Mem [86] | 68.2 | 74.3 | 51.5 | 4.10 |
| PSAC [11] | 70.4 | 76.9 | 55.7 | 4.27 |
| HME [31] | 73.9 | 77.8 | 53.8 | 4.02 |
| GMIN [87] | 73.0 | 81.7 | 57.5 | 4.16 |
| L-GCN [10] | 74.3 | 81.1 | 56.3 | 3.95 |
| HCRN [12] | 75.0 | 81.4 | 55.9 | 3.82 |
| HGA [33] | 75.4 | 81.0 | 55.1 | 4.09 |
| QueST [88] | 75.9 | 81.0 | 59.7 | 4.19 |
| Bridge2Answer [13] | 75.9 | 82.6 | 57.5 | 3.71 |
| QESAL[89] | 76.1 | 82.0 | 57.8 | 3.95 |
| ASTG [90] | 76.3 | 82.1 | 61.2 | 3.78 |
| CASSG [85] | 77.6 | 83.7 | 58.7 | 3.83 |
| HAIR [35] | 77.8 | 82.3 | 60.2 | 3.88 |
| CMCIR (ours) | 78.1 | 82.4 | 62.3 | 3.83 |
| Method | Question Type | |||||
|---|---|---|---|---|---|---|
| What | Who | How | When | Where | All | |
| (8,149) | (4,552) | (370) | (58) | (28) | (13,157) | |
| Co-Mem [86] | 19.6 | 48.7 | 81.6 | 74.1 | 31.7 | 31.7 |
| AMU [28] | 20.6 | 47.5 | 83.5 | 72.4 | 53.6 | 32.0 |
| HME [31] | 22.4 | 50.1 | 73.0 | 70.7 | 42.9 | 33.7 |
| HRA [91] | - | - | - | - | - | 34.4 |
| HGA [33] | 23.5 | 50.4 | 83.0 | 72.4 | 46.4 | 34.7 |
| GMIN [87] | 24.8 | 49.9 | 84.1 | 75.9 | 53.6 | 35.4 |
| QueST [88] | 24.5 | 52.9 | 79.1 | 72.4 | 50.0 | 36.1 |
| HCRN [12] | - | - | - | - | - | 36.1 |
| CASSG [85] | 24.9 | 52.7 | 84.4 | 74.1 | 53.6 | 36.5 |
| QESAL[89] | 25.8 | 51.7 | 83.0 | 72.4 | 50.0 | 36.6 |
| Bridge2Answer [13] | - | - | - | - | - | 37.2 |
| HAIR [35] | - | - | - | - | - | 37.5 |
| VQAC [79] | 26.9 | 53.6 | - | - | - | 37.8 |
| MASN [80] | - | - | - | - | - | 38.0 |
| HRNAT [92] | - | - | - | - | - | 38.2 |
| ASTG [90] | 26.3 | 55.3 | 82.4 | 72.4 | 50.0 | 38.2 |
| DualVGR [81] | 28.6 | 53.8 | 80.0 | 70.6 | 46.4 | 39.0 |
| CMCIR (ours) | 33.1 | 58.9 | 84.3 | 77.5 | 42.8 | 43.7 |
表VI显示了MSVD-QA数据集上的比较结果。 从结果中,我们可以看到我们的 CMCIR 优于几乎所有最先进的 比较 方法具有显着的优势。 例如,我们的 CMCIR 实现了 的最佳总体精度,这导致 比最佳性能方法 DualVGR [81] 有所改进。 对于 What、Who 和 When 类型,CMCIR 显著地 优于所有比较方法。 尽管 GMIN [87] 和 CASSG [85] 在 How 和 Where 类型上的表现略好于我们的 CMCIR,我们的 CMCIR 在“内容”()、“人物”()、“时间”() 和总体 () 方面的表现明显优于 GMIN t7>) 任务。
表VII为对比结果 为了 MSRVTT-QA 数据集。 可以看出,我们的 CMCIR 表现优于 性能最佳的方法 ASTG [90],精度最高为 。 对于 What、Who 和 When 问题类型,CMCIR 的表现最佳 到 所有以前最先进的方法。 尽管 CASSG [85] 和 GMIN [87] 对于 How 和 Where 问题类型的准确率比我们的 CMCIR 更高我们的 CMCIR 分别实现了 a 显着提高性能 超过 这两种方法适用于其他问题类型。
| Method | Question Type | |||||
|---|---|---|---|---|---|---|
| What | Who | How | When | Where | All | |
| (49,869) | (20,385) | (1,640) | (677) | (250) | (72,821) | |
| Co-Mem [86] | 23.9 | 42.5 | 74.1 | 69.0 | 42.9 | 31.9 |
| AMU [28] | 26.2 | 43.0 | 80.2 | 72.5 | 30.0 | 32.5 |
| HME [31] | 26.5 | 43.6 | 82.4 | 76.0 | 28.6 | 33.0 |
| QueST [88] | 27.9 | 45.6 | 83.0 | 75.7 | 31.6 | 34.6 |
| HRA [91] | - | - | - | - | - | 35.0 |
| MASN [80] | - | - | - | - | - | 35.2 |
| HRNAT [92] | - | - | - | - | - | 35.3 |
| HGA [33] | 29.2 | 45.7 | 83.5 | 75.2 | 34.0 | 35.5 |
| DualVGR [81] | 29.4 | 45.5 | 79.7 | 76.6 | 36.4 | 35.5 |
| HCRN [12] | - | - | - | - | - | 35.6 |
| VQAC [79] | 29.1 | 46.5 | - | - | - | 35.7 |
| CASSG [85] | 29.8 | 46.3 | 84.9 | 75.2 | 35.6 | 36.1 |
| GMIN [87] | 30.2 | 45.4 | 84.1 | 74.9 | 43.2 | 36.1 |
| QESAL[89] | 30.7 | 46.0 | 82.4 | 76.1 | 41.6 | 36.7 |
| Bridge2Answer [13] | - | - | - | - | - | 36.9 |
| HAIR [35] | - | - | - | - | - | 36.9 |
| ClipBERT [34] | - | - | - | - | - | 37.4 |
| ASTG [90] | 31.1 | 48.5 | 83.1 | 77.7 | 38.0 | 37.6 |
| CMCIR (ours) | 32.2 | 50.2 | 82.3 | 78.4 | 38.0 | 38.9 |
在表VI和表VII中,当问题类型为How和Where时,我们的方法的性能低于以前的最佳方法t5>. 从表VI和表VII可以看出,How和Where样本数量远小于其他问题类型的问题。 由于这两个数据集中存在数据偏差,该模型倾向于从其他问题类型中学习虚假相关性。 这可能会导致测试这两种问题类型时的性能下降。 尽管如此,对于问题类型When,我们仍然可以获得有希望的性能,该问题的样本也有限。 这验证了我们的 CMCIR 确实减轻了大多数问题类型的虚假相关性,包括 What、Who 和 When。
表 V-VII 中的实验结果表明,我们的 CMCIR 在三个大型基准事件级数据集上优于最先进的方法。 这验证了我们的 CMCIR 可以很好地泛化不同的事件级数据集,包括城市交通和现实世界场景。 我们的 CMCIR 比现有的关系推理方法(如 HGA、QueST、GMIN、Bridge2Answer、QESAL、ASTG、PGAT、HAIR 和 CASSG)取得了更有前景的性能,这验证了我们的 CMCIR 在建模语言之间的多层次交互和因果关系方面具有良好的潜力以及视频的时空结构。 不同数据集之间良好泛化的主要原因是我们的 CMCIR 可以通过前门和后门因果干预模块减轻视觉和语言偏差。 由于 CMCIR 强大的多模态关系推理能力,我们可以理清视觉语言模态中的虚假相关性,实现鲁棒的时空关系推理。
比较不同数据集的平均改进,我们注意到 CMCIR 在 SUTD-TrafficQA (+1.53%)、MSVD-QA (+4.7%) 上实现了最佳改进,而在 TGIF-QA (+0.3%0.9%) 和 MSRVTT-QA (+1.3%)。 造成这种差异的原因是 SUTD-TrafficQA 和 MSVD-QA 的规模相对较小,这通过限制骨干模型对实例的暴露来限制其推理能力。 作为比较,SUTD-TrafficQA 在 QA 对方面比 MSRVTT-QA 小四倍(60K vs 243K),而 MSVD-QA 在 QA 对方面比 MSRVTT-QA 小五倍(43K vs 243K)。 然而,这种缺陷迎合了我们的 CMCIR 的重点,它在不太普遍的情况下发展得更好,从而导致 MSVD-QA 上更好的增长。 这验证了我们的因果感知视觉语言表示具有良好的泛化能力。
| CMCIR | CMCIR | CMCIR | CMCIR | CMCIR | CMCIR | ||
|---|---|---|---|---|---|---|---|
| Datasets | w/o | w/o | w/o | w/o | w/o | w/o | CMCIR |
| HSRP | LBCI | VFCI | CVLR | SGE | ALFF | ||
| SUTD | 37.65 | 37.71 | 37.68 | 37.42 | 37.93 | 37.84 | 38.58 |
| TGIF (Action) | 75.4 | 75.1 | 75.5 | 75.0 | 75.4 | 75.2 | 78.1 |
| TGIF (Transition) | 81.2 | 81.3 | 80.6 | 80.4 | 81.0 | 81.2 | 82.4 |
| TGIF (FrameQA) | 62.0 | 61.9 | 61.6 | 61.2 | 61.3 | 61.1 | 62.3 |
| TGIF (Count) | 4.03 | 3.89 | 4.10 | 4.05 | 3.91 | 4.12 | 3.83 |
| MSVD | 42.4 | 42.7 | 42.2 | 42.0 | 42.9 | 42.5 | 43.7 |
| MSRVTT | 38.5 | 38.3 | 38.1 | 38.0 | 38.2 | 38.4 | 38.9 |
4.4 消融研究
我们进一步使用以下 CMCIR 变体进行消融实验,以验证方法中设计的组件的贡献。
-
•
CMCIR w/o HSRP:我们删除了分层语义角色解析器 (HSRP),它将问题解析为以动词为中心的关系元组(主语、关系、宾语)。 仅 CMCIR 模型 用途 作为语言表征的原始问题。
-
•
CMCIR w/o LBCI:我们删除了语言后门因果干预 (LBCI) 模块。 CVLR模块仅包含视觉前门因果干预(VFCI)模块。
-
•
CMCIR w/o VFCI:我们删除了视觉前门因果干预 (VFCI) 模块。 CVLR模块仅包含语言后门因果干预(LBCI)模块。
-
•
CMCIR w/o CVLR:我们删除了因果感知视觉语言推理 (CVLR) 模块。 CMCIR 模型使用时空变换器 (STT) 和视觉语言特征融合模块将视觉和语言表示结合起来。
-
•
CMCIR w/o SGE:我们在进行视觉语言特征融合时删除了语义图嵌入(SGE)模块。 语言特征直接用于自适应语言特征融合。
-
•
CMCIR w/o ALFF:我们在进行视觉语言特征融合时删除了自适应语言特征融合(ALFF)模块。 嵌入语言特征的语义图直接用于与视觉特征融合。
表VIII显示了SUTD-TrafficQA、TGIF-QA、MSVD-QA和MSRVTT-QA数据集上的消融研究的评估结果。 可以看出,与所有数据集和任务中的六个变体相比,我们的 CMCIR 实现了最佳性能。 如果没有 HSRP,由于缺乏分层语言特征表示,性能会显着下降。 这表明我们提出的分层语义角色解析器确实提高了问题语义的表示能力。 值得注意的是,CMCIR w/o LBCI、CMCIR w/o VFCI 和 CMCIR w/o CVLR 的性能均低于 CMCIR。 这验证了语言后门和视觉前门因果干预都有助于发现因果结构并学习因果感知的视觉语言表示,从而提高模型性能。 对于 CMCIR w/o SGE 和 CMCIR w/o ALFF,它们的性能高于 CMCIR w/o LBCI、CMCIR w/o VFCI 和 CMCIR w/o CVLR,但低于我们的 CMCIR,这表明语义图嵌入和自适应语言特征融合的有效性,利用分层语言语义关系作为自适应学习全局语义感知视觉语言表示的指导。 借助所有组件,我们的 CMCIR 表现最佳,因为所有这些组件都是有益的并且协同工作以实现强大的事件级视觉问答。
| SUTD-TrafficQA | TGIF-QA | TGIF-QA | TGIF-QA | TGIF-QA | MSVD-QA | MSRVTT-QA | ||
| (Action) | (Transisition) | (FrameQA) | (Count) | |||||
| MMA Heads | 1 | 37.83 | 75.8 | 80.7 | 61.2 | 3.92 | 42.3 | 38.5 |
| 2 | 38.17 | 75.7 | 79.7 | 60.6 | 3.96 | 42.0 | 38.5 | |
| 4 | 37.51 | 75.8 | 79.2 | 61.1 | 3.93 | 42.2 | 38.3 | |
| 8 | 38.58 | 78.1 | 82.4 | 62.3 | 3.83 | 43.2 | 38.9 | |
| MTB Layers | 1 | 37.81 | 74.5 | 79.4 | 60.3 | 4.26 | 42.9 | 38.7 |
| 2 | 37.98 | 74.8 | 80.4 | 61.0 | 4.20 | 42.8 | 38.2 | |
| 3 | 38.58 | 75.1 | 80.1 | 61.0 | 4.03 | 43.0 | 38.4 | |
| 4 | 37.84 | 76.6 | 80.2 | 61.6 | 3.96 | 42.6 | 38.7 | |
| 5 | 37.63 | 75.5 | 80.6 | 61.0 | 3.94 | 43.7 | 38.7 | |
| 6 | 37.73 | 76.2 | 80.8 | 61.4 | 4.12 | 43.2 | 38.9 | |
| 7 | 37.73 | 75.4 | 80.3 | 61.2 | 3.98 | 43.1 | 38.3 | |
| 8 | 37.58 | 78.1 | 82.4 | 62.3 | 3.83 | 42.8 | 38.6 | |
| GCN Layers | 1 | 38.58 | 78.1 | 82.4 | 62.3 | 3.83 | 43.2 | 38.9 |
| 2 | 37.84 | 74.9 | 80.3 | 61.0 | 4.07 | 41.8 | 38.3 | |
| 3 | 37.58 | 74.7 | 80.3 | 60.8 | 4.03 | 42.1 | 38.4 | |
| Dimension | 256 | 37.60 | 73.9 | 79.9 | 61.0 | 3.96 | 42.8 | 38.8 |
| 512 | 38.58 | 78.1 | 82.4 | 62.3 | 3.83 | 43.2 | 38.9 | |
| 768 | 37.74 | 75.0 | 80.0 | 62.2 | 3.90 | 42.8 | 38.0 |
4.5 参数灵敏度
评估CMCIR的超参数 影响 性能方面,我们报告了多头多模态注意力(MMA)模块的头、多模态 Transformer 块的层的不同值的结果( MTB),以及语义图嵌入中的 GCN 层 。 此外,还分析了隐藏状态的维度。 结果 为了 SUTD-TrafficQA、TGIF-QA、MSVD-QA 和 MSRVTT-QA 数据集如表IX所示。 我们可以看到,与具有较少 MMA 头的 CMCIR 相比,具有 MMA 头的 CMCIR 在所有数据集和任务中的性能表现最佳。 这表明更多的头可以方便MMA模块 到 运用更多的视角来探讨不同模式之间的关系。 对于 MTB 层,不同数据集的最佳层数不同。 当MTB层数为时,CMCIR的性能最佳 这 SUTD-TrafficQA 数据集,TGIF-QA 数据集上的 , 上 这 MSVD-QA 数据集,以及 上 这 MSRVTT-QA 数据集。 对于GCN层,我们可以看到更多的GCN层会增加可学习参数的数量,从而使模型收敛更加困难。 由于一层GCN可以达到最好的性能,我们选择 一层 GCN。 对于隐藏状态的维度,我们可以看到是VLICR模型隐藏状态的最佳维度,因为它在特征表示能力和模型复杂度之间取得了良好的折衷。
| Method | Appearance | Motion | Accuracy | |
|---|---|---|---|---|
| SUTD-QA | Eclipse [36] | ResNet-101 | MobileNetV2 | 37.05 |
| Ours | Swin-L | Video Swin-B | 38.58 (+1.54) | |
| Ours | ResNet-101 | ResNetXt-101 | 38.10 (+1.05) | |
| MSVD-QA | DualVGR [81] | ResNet-101 | ResNetXt-101 | 39.0 |
| Ours | Swin-L | Video Swin-B | 43.7 (+4.70) | |
| Ours | ResNet-101 | ResNetXt-101 | 40.3 (+1.30) | |
| MSRVTT-QA | HCRN [12] | ResNet-101 | ResNeXt-101 | 35.6 |
| Ours | Swin-L | Video Swin-B | 38.9 (+3.30) | |
| Ours | ResNet-101 | ResNeXt-101 | 37.0 (+1.40) |
验证我们的 CMCIR 是否 能 推广到不同的视觉外观和运动特征,我们评估了 CMCIR 的性能 这 使用不同视觉外观和运动特征的 SUTD-TrafficQA、MSVD-QA 和 MSRVTT-QA 数据集,如表X所示。 性能最佳的比较方法 这 SUTD-TrafficQA、MSVD-QA 和 MSRVTT-QA 数据集也显示在表 X 中。 可以看出,当使用 Swin-L 和 Video Swin-B 作为视觉和运动特征时,与其他方法相比,我们的 CMCIR 可以实现最先进的性能。 在我们的实验中,视觉外观特征是 ResNet-101[93] 的 pool5 输出,视觉运动特征由 ResNetXt-101 [94, 95] 导出。 当使用 ResNet-101 和 ResNetXt-101 作为视觉和运动特征时,我们的 CMCIR 还可以在 SUTD-TrafficQA、MSVD-QA 和 MSRVTT-QA 数据集上实现有竞争力的准确性。 对于SUTD-TrafficQA数据集,使用ResNet和ResNetXt的性能为,这也是所有比较方法中精度最好的(表IV)。 为了 这 MSVD-QA数据集,使用ResNet-101和ResNetXt-101的性能为,也优于其他比较方法(表VI)。 为了 这 MSRVTT-QA数据集,使用ResNet-101和ResNetXt-101的性能为,也达到了有竞争力的性能 相比 其他比较方法(表VI)。 这些结果证实,由于学习了因果关系感知的视觉语言表示,我们的 CMCIR 可以很好地概括不同的视觉外观和运动特征。 更重要的是,我们的 CMCIR 性能的提高主要归功于我们精心设计的视觉语言因果推理模型。
4.6 减少虚假相关性的证据
实际上,构建 VideoQA 数据集的过程会引入不需要的虚假相关性,而不是总体现实[46]。 因此,我们可以假设所有评估数据集都包含虚假相关性。 为了验证 CVLR 模块在减少非因果框架中的虚假相关性方面的有效性,我们将 CVLR 应用于三个最先进的模型 Co-Mem [86]、HGA [33] 和 HCRN [12]。 由于我们的 CVLR 与主干正交,因此我们可以将 CVLR 直接插入到这些模型的特征提取层之后,这与我们的 CMCIR 相同。 如表XI所示,我们的 CVLR 使每个主干网在所有基准数据集上都获得了大幅提升(+0.9%6.5%),这证明了其与模型无关的特性。 尽管如此,我们注意到骨干网的改进有所不同。 相比之下,在 MSVD-QA 和 MSRVTT-QA 基准上,CVLR 使用 Co-Mem、HGA 和 HCRN 主干网获得了比我们的主干网更有利的增益。 这是因为语言语义和时空表示之间的细粒度交互使我们的主干网络具有鲁棒性,特别是对于 MSVD-QA 和 MSRVTT-QA 基准上的描述性类型的问题。 因此,它在关注描述性问题的基准测试(即 MSVD-QA 和 MSRVTT-QA)上实现了更强的主干性能,这反过来又在一定程度上解释了 CVLR 的贡献,从而使我们主干的改进不那么显着。 相比之下,当涉及因果和时间问题(即 SUTD-TrafficQA)时,CVLR 在所有四个主干上显示出同等的改进(+1.05%2.02%)。 这些结果验证了我们的 CVLR 能够有效捕获因果关系并减少不同模型之间的虚假相关性。
| Models | SUTD-TrafficQA | MSVD-QA | MSRVTT-QA |
|---|---|---|---|
| Co-Mem [86] | 35.10 | 34.6 | 35.3 |
| Co-Mem [86]+ CVLR | 37.12 (+2.02) | 40.7 (+6.1) | 38.0 (+2.7) |
| HGA [33] | 35.81 | 35.4 | 36.1 |
| HGA [33]+ CVLR | 37.23 (+1.42) | 41.9 (+6.5) | 38.2 (+2.1) |
| HCRN [12] | 36.49 | 36.1 | 35.6 |
| HCRN [12]+ CVLR | 37.54 (+1.05) | 42.2 (+6.1) | 37.8 (+2.2) |
| Our Backbone | 37.42 | 42.0 | 38.0 |
| Our Backbone + CVLR | 38.58 (+1.16) | 43.7 (+1.7) | 38.9 (+0.9) |
4.7 定性结果
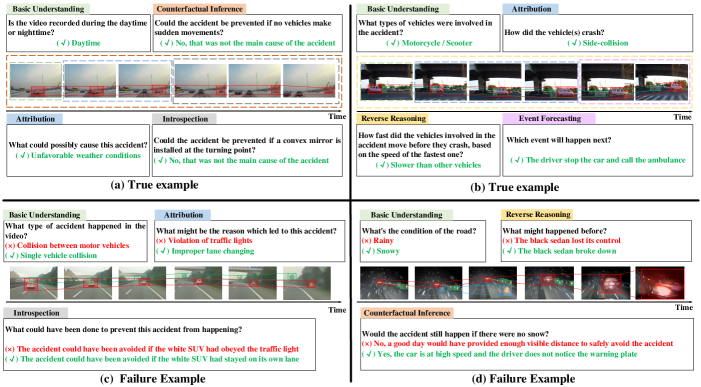
为了验证 CMCIR 在稳健时空关系推理方面的能力,我们通过检查 SUTD-TrafficQA 数据集中的一些正确和失败示例来深入了解其视觉语言因果推理能力,并在图 9 中显示了可视化结果。 我们展示了我们的模型如何进行稳健的时空关系推理并减少虚假相关性。
推理可靠. 如图9(a)所示,存在模糊问题,事故的主要视觉区域可能会被其他视觉概念(即道路上的不同汽车/车辆)分散注意力。 在我们的 CMCIR 中,我们通过因果关系学习来学习与问题相关的视觉语言关联,从而减轻我们的推理结果中的模糊性,其中视频-问题-答案三元组在主要时空场景和问题语义之间表现出很强的相关性。 这验证了 CMCIR 在做出决策时能够可靠地关注正确的视觉区域。
减少杂散相关性. 在图9(b)中,我们提出了一个反映虚假相关性的案例,其中“van”的视觉区域由于频繁共现而与“sedan”相关。 。 换句话说,该模型没有明确考虑减少虚假相关性(例如,Co-Mem [86]、HGA [33] 和 HCRN [12])在遇到“货车”和“摩托车”等关于区域-对象对应的视觉概念时会犹豫。 在我们的 CMCIR 中,我们通过采用视觉语言因果干预来减少这种虚假相关性并追求真正的因果关系,从而获得更好的主导视觉证据和问题意图。
泛化能力. 从图9(a)-(b)中,我们可以看到CMCIR可以很好地泛化不同的问题类型。 这表明 CMCIR 对问题很敏感,并且可以通过进行稳健且可靠的时空关系推理来有效捕获视频中的主导时空内容。
内省和反事实学习. 对于具有挑战性的问题类型,例如内省和反事实推理,CMCIR模型可以准确地确定所关注的场景是否反映了答案背后的逻辑。 这证明了 CMCIR 可以充分探索视觉和语言内容的因果、逻辑和时空结构,因为它具有执行强大的视觉语言因果推理的能力,可以解开视觉语言的虚假相关性。
其他失败案例。 此外,我们在图 9 (c)-(d) 中提供了失败示例,以进一步了解我们方法的局限性。 在图9(c)中,我们的模型在进行视觉语言推理时错误地将视觉概念“suv”与绿色“交通牌”相关联。 这是因为“交通牌照”的视觉区域看起来像“卡车”,而视频中只存在白色的“suv”。 在图9(d)中,由于“雨”和“雪”在视频中的视觉外观相似,因此很难区分它们。 此外,沿路的“反光条纹”被错误地视为主导视觉概念。 由于我们的 CMCIR 模型缺乏明确的对象检测管道,因此一些视觉上模糊的概念很难确定。 而且,在没有外部交通规则先验知识的情况下,一些诸如“如何预防事故”、“事故原因”等问题很难回答。 一种可能的解决方案可能是将对象检测和交通规则的外部知识纳入我们的方法中,我们将在未来的工作中探索这一点。
5 结论
我们提出了一种名为跨模态因果关系推理(CMCIR)的事件级视觉问答框架,以减轻虚假相关性并发现视觉语言模态的因果结构。 为了揭示视觉和语言模态的因果结构,我们提出了一种因果感知视觉语言推理(CVLR)模块,该模块利用前门和后门因果干预来理清视觉和语言模态之间的虚假相关性。 对事件级城市数据集 SUTD-TrafficQA 和三个基准现实世界数据集 TGIF-QA、MSVD-QA 和 MSRVTT-QA 进行的广泛实验证明了 CMCIR 在发现视觉语言因果结构和实现稳健的事件级视觉方面的有效性问题回答。 与之前简单地消除语言或视觉偏差而不考虑跨模态因果关系发现的方法不同,我们应用前门和后门因果干预模块来发现跨模态因果结构。
我们相信我们的工作可以帮助探索视觉语言任务中因果分析的新界限(因果VL推理111我们的视觉语言因果学习框架https://github.com/HCPLab-SYSU/Causal-VLReasoning,这是一个Python开源框架,为视觉语言推理任务实现了最先进的因果发现算法,例如 VQA、图像/视频字幕、医疗报告生成等。)。 未来,我们将进一步探索更全面的因果发现方法,以发现事件级视觉问答中的问题关键场景元素,特别是在时间方面。 通过进一步利用视频中细粒度的时间一致性,我们可以实现一个追求更好因果关系的模型。 此外,我们可以利用对象级因果关系推理来减轻以对象为中心的实体的虚假相关性。 此外,我们会将外部专家知识纳入我们的干预过程中。 此外,由于属性固有的不可观察性,如何定量分析数据集中的虚假相关性仍然是一个具有挑战性的问题。 因此,我们将发现更直观、更合理的指标来比较不同方法在减少虚假相关性方面的有效性。
致谢
该工作得到国家重点研发计划项目(2021ZD0111601)、国家自然科学基金项目(62002395和61976250)、广东省基础与应用基础研究中心的资助2023A1515011530、2021A1515012311和2020B1515020048号资助,部分由广州市科技计划项目资助。 2023A04J2030。
参考
- [1] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Advances in neural information processing systems, vol. 25, pp. 1097–1105, 2012.
- [2] R. Krishna, K. Hata, F. Ren, L. Fei-Fei, and J. Carlos Niebles, “Dense-captioning events in videos,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 706–715.
- [3] B. Zhou, A. Andonian, A. Oliva, and A. Torralba, “Temporal relational reasoning in videos,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 803–818.
- [4] Y. Liu, K. Wang, G. Li, and L. Lin, “Semantics-aware adaptive knowledge distillation for sensor-to-vision action recognition,” IEEE Transactions on Image Processing, vol. 30, pp. 5573–5588, 2021.
- [5] Y. Liu, K. Wang, L. Liu, H. Lan, and L. Lin, “Tcgl: Temporal contrastive graph for self-supervised video representation learning,” IEEE Transactions on Image Processing, vol. 31, pp. 1978–1993, 2022.
- [6] S. Buch, C. Eyzaguirre, A. Gaidon, J. Wu, L. Fei-Fei, and J. C. Niebles, “Revisiting the” video” in video-language understanding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 2917–2927.
- [7] A. Das, S. Kottur, K. Gupta, A. Singh, D. Yadav, J. M. Moura, D. Parikh, and D. Batra, “Visual dialog,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 326–335.
- [8] P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. Sünderhauf, I. Reid, S. Gould, and A. Van Den Hengel, “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 3674–3683.
- [9] R. Zellers, Y. Bisk, A. Farhadi, and Y. Choi, “From recognition to cognition: Visual commonsense reasoning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 6720–6731.
- [10] D. Huang, P. Chen, R. Zeng, Q. Du, M. Tan, and C. Gan, “Location-aware graph convolutional networks for video question answering,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 11 021–11 028.
- [11] X. Li, J. Song, L. Gao, X. Liu, W. Huang, X. He, and C. Gan, “Beyond rnns: Positional self-attention with co-attention for video question answering,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 8658–8665.
- [12] T. M. Le, V. Le, S. Venkatesh, and T. Tran, “Hierarchical conditional relation networks for video question answering,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 9972–9981.
- [13] J. Park, J. Lee, and K. Sohn, “Bridge to answer: Structure-aware graph interaction network for video question answering,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 15 526–15 535.
- [14] S. Sukhbaatar, A. Szlam, J. Weston, and R. Fergus, “End-to-end memory networks,” Advances in Neural Information Processing Systems, vol. 2015, pp. 2440–2448, 2015.
- [15] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in neural information processing systems, 2017, pp. 5998–6008.
- [16] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” arXiv preprint arXiv:1609.02907, 2016.
- [17] Y. Niu, K. Tang, H. Zhang, Z. Lu, X.-S. Hua, and J.-R. Wen, “Counterfactual vqa: A cause-effect look at language bias,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 12 700–12 710.
- [18] X. Yang, H. Zhang, G. Qi, and J. Cai, “Causal attention for vision-language tasks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 9847–9857.
- [19] T. Wang, C. Zhou, Q. Sun, and H. Zhang, “Causal attention for unbiased visual recognition,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 3091–3100.
- [20] Y. Li, X. Wang, J. Xiao, W. Ji, and T.-S. Chua, “Invariant grounding for video question answering,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 2928–2937.
- [21] J. Pearl, M. Glymour, and N. P. Jewell, Causal inference in statistics: A primer. John Wiley & Sons, 2016.
- [22] K. Tang, Y. Niu, J. Huang, J. Shi, and H. Zhang, “Unbiased scene graph generation from biased training,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 3716–3725.
- [23] Z. Yue, H. Zhang, Q. Sun, and X.-S. Hua, “Interventional few-shot learning,” Advances in Neural Information Processing Systems, vol. 33, 2020.
- [24] T. Wang, J. Huang, H. Zhang, and Q. Sun, “Visual commonsense r-cnn,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 10 760–10 770.
- [25] S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, and D. Parikh, “Vqa: Visual question answering,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 2425–2433.
- [26] Z. Yang, X. He, J. Gao, L. Deng, and A. Smola, “Stacked attention networks for image question answering,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 21–29.
- [27] P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, and L. Zhang, “Bottom-up and top-down attention for image captioning and visual question answering,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 6077–6086.
- [28] D. Xu, Z. Zhao, J. Xiao, F. Wu, H. Zhang, X. He, and Y. Zhuang, “Video question answering via gradually refined attention over appearance and motion,” in Proceedings of the 25th ACM international conference on Multimedia, 2017, pp. 1645–1653.
- [29] Y. Jang, Y. Song, Y. Yu, Y. Kim, and G. Kim, “Tgif-qa: Toward spatio-temporal reasoning in visual question answering,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2758–2766.
- [30] Y. Jang, Y. Song, C. D. Kim, Y. Yu, Y. Kim, and G. Kim, “Video question answering with spatio-temporal reasoning,” International Journal of Computer Vision, vol. 127, no. 10, pp. 1385–1412, 2019.
- [31] C. Fan, X. Zhang, S. Zhang, W. Wang, C. Zhang, and H. Huang, “Heterogeneous memory enhanced multimodal attention model for video question answering,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 1999–2007.
- [32] C. JiayinCai, C. Shi, L. Li, Y. Cheng, and Y. Shan, “Feature augmented memory with global attention network for videoqa,” in IJCAI, 2020, pp. 998–1004.
- [33] P. Jiang and Y. Han, “Reasoning with heterogeneous graph alignment for video question answering,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 11 109–11 116.
- [34] J. Lei, L. Li, L. Zhou, Z. Gan, T. L. Berg, M. Bansal, and J. Liu, “Less is more: Clipbert for video-and-language learning via sparse sampling,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 7331–7341.
- [35] F. Liu, J. Liu, W. Wang, and H. Lu, “Hair: Hierarchical visual-semantic relational reasoning for video question answering,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 1698–1707.
- [36] L. Xu, H. Huang, and J. Liu, “Sutd-trafficqa: A question answering benchmark and an efficient network for video reasoning over traffic events,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 9878–9888.
- [37] Y. Liu, Z. Lu, J. Li, T. Yang, and C. Yao, “Global temporal representation based cnns for infrared action recognition,” IEEE Signal Processing Letters, vol. 25, no. 6, pp. 848–852, 2018.
- [38] Y. Liu, Z. Lu, J. Li, and T. Yang, “Hierarchically learned view-invariant representations for cross-view action recognition,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 29, no. 8, pp. 2416–2430, 2018.
- [39] Y. Liu, Z. Lu, J. Li, T. Yang, and C. Yao, “Deep image-to-video adaptation and fusion networks for action recognition,” IEEE Transactions on Image Processing, vol. 29, pp. 3168–3182, 2019.
- [40] Y. Zhu, Y. Zhang, L. Liu, Y. Liu, G. Li, M. Mao, and L. Lin, “Hybrid-order representation learning for electricity theft detection,” IEEE Transactions on Industrial Informatics, vol. 19, no. 2, pp. 1248–1259, 2022.
- [41] R. Girdhar, J. Carreira, C. Doersch, and A. Zisserman, “Video action transformer network,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 244–253.
- [42] H. Huang, L. Zhou, W. Zhang, J. J. Corso, and C. Xu, “Dynamic graph modules for modeling object-object interactions in activity recognition,” in British Machine Vision Conference, 2019.
- [43] C.-Y. Ma, A. Kadav, I. Melvin, Z. Kira, G. AlRegib, and H. P. Graf, “Attend and interact: Higher-order object interactions for video understanding,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6790–6800.
- [44] E. Mavroudi, B. B. Haro, and R. Vidal, “Representation learning on visual-symbolic graphs for video understanding,” in European Conference on Computer Vision. Springer, 2020, pp. 71–90.
- [45] J. Pan, S. Chen, M. Z. Shou, Y. Liu, J. Shao, and H. Li, “Actor-context-actor relation network for spatio-temporal action localization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 464–474.
- [46] G. Nan, R. Qiao, Y. Xiao, J. Liu, S. Leng, H. Zhang, and W. Lu, “Interventional video grounding with dual contrastive learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 2765–2775.
- [47] W. Wang, J. Gao, and C. Xu, “Weakly-supervised video object grounding via causal intervention,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- [48] T. Wang, Y. Li, B. Kang, J. Li, J. Liew, S. Tang, S. Hoi, and J. Feng, “The devil is in classification: A simple framework for long-tail instance segmentation,” in European Conference on computer vision. Springer, 2020, pp. 728–744.
- [49] X. Yang, H. Zhang, and J. Cai, “Deconfounded image captioning: A causal retrospect,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- [50] Y. Liu, Y.-S. Wei, H. Yan, G.-B. Li, and L. Lin, “Causal reasoning meets visual representation learning: A prospective study,” Machine Intelligence Research, pp. 1–27, 2022.
- [51] E. Bareinboim and J. Pearl, “Controlling selection bias in causal inference,” in Artificial Intelligence and Statistics. PMLR, 2012, pp. 100–108.
- [52] M. Besserve, A. Mehrjou, R. Sun, and B. Schölkopf, “Counterfactuals uncover the modular structure of deep generative models,” in Eighth International Conference on Learning Representations (ICLR 2020), 2020.
- [53] Y. Goyal, Z. Wu, J. Ernst, D. Batra, D. Parikh, and S. Lee, “Counterfactual visual explanations,” in International Conference on Machine Learning. PMLR, 2019, pp. 2376–2384.
- [54] P. Wang and N. Vasconcelos, “Scout: Self-aware discriminant counterfactual explanations,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 8981–8990.
- [55] L. Chen, H. Zhang, J. Xiao, X. He, S. Pu, and S.-F. Chang, “Counterfactual critic multi-agent training for scene graph generation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 4613–4623.
- [56] Z. Fang, S. Kong, C. Fowlkes, and Y. Yang, “Modularized textual grounding for counterfactual resilience,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 6378–6388.
- [57] A. Kanehira, K. Takemoto, S. Inayoshi, and T. Harada, “Multimodal explanations by predicting counterfactuality in videos,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 8594–8602.
- [58] E. Abbasnejad, D. Teney, A. Parvaneh, J. Shi, and A. v. d. Hengel, “Counterfactual vision and language learning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 10 044–10 054.
- [59] Y. Liu, G. Li, and L. Lin, “Causality-aware visual scene discovery for cross-modal question reasoning,” arXiv preprint arXiv:2304.08083, 2023.
- [60] W. Chen, Y. Liu, C. Wang, G. Li, J. Zhu, and L. Lin, “Visual-linguistic causal intervention for radiology report generation,” arXiv preprint arXiv:2303.09117, 2023.
- [61] Y. Wei, Y. Liu, H. Yan, G. Li, and L. Lin, “Visual causal scene refinement for video question answering,” arXiv preprint arXiv:2305.04224, 2023.
- [62] K. Tang, J. Huang, and H. Zhang, “Long-tailed classification by keeping the good and removing the bad momentum causal effect,” Advances in Neural Information Processing Systems, vol. 33, 2020.
- [63] D. Zhang, H. Zhang, J. Tang, X.-S. Hua, and Q. Sun, “Causal intervention for weakly-supervised semantic segmentation,” Advances in Neural Information Processing Systems, vol. 33, 2020.
- [64] J. Qi, Y. Niu, J. Huang, and H. Zhang, “Two causal principles for improving visual dialog,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 10 860–10 869.
- [65] V. Agarwal, R. Shetty, and M. Fritz, “Towards causal vqa: Revealing and reducing spurious correlations by invariant and covariant semantic editing,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 9690–9698.
- [66] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014.
- [67] L. Chen, X. Yan, J. Xiao, H. Zhang, S. Pu, and Y. Zhuang, “Counterfactual samples synthesizing for robust visual question answering,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 10 800–10 809.
- [68] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 012–10 022.
- [69] Z. Liu, J. Ning, Y. Cao, Y. Wei, Z. Zhang, S. Lin, and H. Hu, “Video swin transformer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 3202–3211.
- [70] G. Stanovsky, J. Michael, L. Zettlemoyer, and I. Dagan, “Supervised open information extraction,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 2018, pp. 885–895.
- [71] J. Pennington, R. Socher, and C. D. Manning, “Glove: Global vectors for word representation,” in Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 2014, pp. 1532–1543.
- [72] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [73] J. Pearl and D. Mackenzie, The book of why: the new science of cause and effect. Basic books, 2018.
- [74] K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, and Y. Bengio, “Show, attend and tell: Neural image caption generation with visual attention,” in International conference on machine learning, 2015, pp. 2048–2057.
- [75] M. Ren, R. Kiros, and R. Zemel, “Exploring models and data for image question answering,” Advances in neural information processing systems, vol. 28, pp. 2953–2961, 2015.
- [76] J. Carreira and A. Zisserman, “Quo vadis, action recognition? a new model and the kinetics dataset,” in proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6299–6308.
- [77] Z. Yang, N. Garcia, C. Chu, M. Otani, Y. Nakashima, and H. Takemura, “Bert representations for video question answering,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2020, pp. 1556–1565.
- [78] J. Lei, L. Yu, M. Bansal, and T. L. Berg, “Tvqa: Localized, compositional video question answering,” arXiv preprint arXiv:1809.01696, 2018.
- [79] N. Kim, S. J. Ha, and J.-W. Kang, “Video question answering using language-guided deep compressed-domain video feature,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 1708–1717.
- [80] A. Seo, G.-C. Kang, J. Park, and B.-T. Zhang, “Attend what you need: Motion-appearance synergistic networks for video question answering,” in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, 2021, pp. 6167–6177.
- [81] J. Wang, B. Bao, and C. Xu, “Dualvgr: A dual-visual graph reasoning unit for video question answering,” IEEE Transactions on Multimedia, 2021.
- [82] D. Chen and W. B. Dolan, “Collecting highly parallel data for paraphrase evaluation,” in Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, 2011, pp. 190–200.
- [83] J. Xu, T. Mei, T. Yao, and Y. Rui, “Msr-vtt: A large video description dataset for bridging video and language,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 5288–5296.
- [84] Z. Liu, H. Hu, Y. Lin, Z. Yao, Z. Xie, Y. Wei, J. Ning, Y. Cao, Z. Zhang, L. Dong et al., “Swin transformer v2: Scaling up capacity and resolution,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 12 009–12 019.
- [85] Y. Liu, X. Zhang, F. Huang, B. Zhang, and Z. Li, “Cross-attentional spatio-temporal semantic graph networks for video question answering,” IEEE Transactions on Image Processing, vol. 31, pp. 1684–1696, 2022.
- [86] J. Gao, R. Ge, K. Chen, and R. Nevatia, “Motion-appearance co-memory networks for video question answering,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6576–6585.
- [87] M. Gu, Z. Zhao, W. Jin, R. Hong, and F. Wu, “Graph-based multi-interaction network for video question answering,” IEEE Transactions on Image Processing, vol. 30, pp. 2758–2770, 2021.
- [88] J. Jiang, Z. Chen, H. Lin, X. Zhao, and Y. Gao, “Divide and conquer: Question-guided spatio-temporal contextual attention for video question answering,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 11 101–11 108.
- [89] F. Liu, J. Liu, R. Hong, and H. Lu, “Question-guided erasing-based spatiotemporal attention learning for video question answering,” IEEE Transactions on Neural Networks and Learning Systems, 2021.
- [90] W. Jin, Z. Zhao, X. Cao, J. Zhu, X. He, and Y. Zhuang, “Adaptive spatio-temporal graph enhanced vision-language representation for video qa,” IEEE Transactions on Image Processing, vol. 30, pp. 5477–5489, 2021.
- [91] M. I. H. Chowdhury, K. Nguyen, S. Sridharan, and C. Fookes, “Hierarchical relational attention for video question answering,” in 2018 25th IEEE International Conference on Image Processing (ICIP). IEEE, 2018, pp. 599–603.
- [92] L. Gao, Y. Lei, P. Zeng, J. Song, M. Wang, and H. T. Shen, “Hierarchical representation network with auxiliary tasks for video captioning and video question answering,” IEEE Transactions on Image Processing, 2022.
- [93] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [94] S. Xie, R. Girshick, P. Dollár, Z. Tu, and K. He, “Aggregated residual transformations for deep neural networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1492–1500.
- [95] K. Hara, H. Kataoka, and Y. Satoh, “Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet?” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018, pp. 6546–6555.
![[Uncaptioned image]](x10.png) |
Yang Liu (M’21) is currently a research associate professor working at the School of Computer Science and Engineering, Sun Yat-sen University. He received his Ph.D. degree from Xidian University in 2019. His current research interests include multi-modal cognitive reasoning and causal relation discovery. He is the recipient of the First Prize of the Third Guangdong Province Young Computer Science Academic Show. He has authorized and co-authorized more than 20 papers in top-tier academic journals and conferences. He has been serving as a reviewer for numerous academic journals and conferences such as TPAMI, TIP, TNNLS, TMM, TCSVT, CVPR, ICCV, ECCV, AAAI, and ACM MM. More information can be found on his personal website https://yangliu9208.github.io. |
![[Uncaptioned image]](x11.png) |
Guanbin Li (M’15) is currently an associate professor in School of Computer Science and Engineering, Sun Yat-Sen University. He received his PhD degree from the University of Hong Kong in 2016. His current research interests include computer vision, image processing, and deep learning. He is a recipient of ICCV 2019 Best Paper Nomination Award. He has authorized and co-authorized on more than 100 papers in top-tier academic journals and conferences. He serves as an area chair for the conference of VISAPP. He has been serving as a reviewer for numerous academic journals and conferences such as TPAMI, IJCV, TIP, TMM, TCyb, CVPR, ICCV, ECCV and NeurIPS. |
![[Uncaptioned image]](x12.png) |
Liang Lin (M’09, SM’15) is a Full Professor of computer science at Sun Yat-sen University. He served as the Executive Director and Distinguished Scientist of SenseTime Group from 2016 to 2018, leading the R&D teams for cutting-edge technology transferring. He has authored or co-authored more than 200 papers in leading academic journals and conferences, and his papers have been cited by more than 26,000 times. He is an associate editor of IEEE Trans.Neural Networks and Learning Systems and IEEE Trans. Multimedia, and served as Area Chairs for numerous conferences such as CVPR, ICCV, SIGKDD and AAAI. He is the recipient of numerous awards and honors including Wu Wen-Jun Artificial Intelligence Award, the First Prize of China Society of Image and Graphics, ICCV Best Paper Nomination in 2019, Annual Best Paper Award by Pattern Recognition (Elsevier) in 2018, Best Paper Dimond Award in IEEE ICME 2017, Google Faculty Award in 2012. His supervised PhD students received ACM China Doctoral Dissertation Award, CCF Best Doctoral Dissertation and CAAI Best Doctoral Dissertation. He is a Fellow of IET/IAPR. |