STrajNet:用于自动驾驶中占用流场预测的多模态分层 Transformer
摘要
预测周围交通参与者的未来状态是自动驾驶汽车的一项关键能力。 最近提出的占用流场预测引入了可扩展且有效的表示来共同预测场景中周围代理的未来运动。 然而,具有挑战性的部分是对交通代理之间的潜在社交互动以及占用率和流量之间的关系进行建模。 因此,本文提出了一种新颖的多模态分层 Transformer 网络,该网络融合了矢量化(代理运动)和视觉(场景流、地图和占用)模态,并联合预测场景的流和占用。 具体来说,来自感官数据的视觉和矢量特征通过多级 Transformer 模块进行编码,然后通过具有时间像素级关注的后期融合 Transformer 模块进行编码。 重要的是,流量引导的多头自注意力(FG-MSA)模块旨在更好地聚合有关占用和流量的信息,并对它们之间的数学关系进行建模。 所提出的方法在 Waymo 开放运动数据集上进行了全面验证,并与几种最先进的模型进行了比较。 结果表明,我们的模型具有比其他方法更紧凑的架构和数据输入,可以实现可比的性能。 我们还证明了结合矢量化代理运动特征和所提出的 FG-MSA 模块的有效性。 与没有 FG-MSA 模块的消融模型(在 2022 年 Waymo 占用率和流量预测挑战赛中获得名次)相比,当前模型显示出更好的流量和占用率可分离性,并且进一步的性能改进。
我简介
以高效且可扩展的方式对多个交通参与者(代理)的未来运动进行稳健且准确的预测是自动驾驶车辆 (AV) 的核心功能之一[1,2,3]。 然而,由于存在一些挑战,运动预测是一项极其困难的任务。 首先,自动驾驶汽车必须面对无数复杂的交通场景,这些场景由不同数量的异构交通元素[4]组成。 其次,运动预测器不仅应该处理现有交通元素的观察状态,还应该处理它们之间潜在的复杂相互作用[5]。 此外,预测结果需要具有鲁棒性,以应对不确定性[6],因为即使在相同情况下,智能体未来的动作也可能有很大差异。
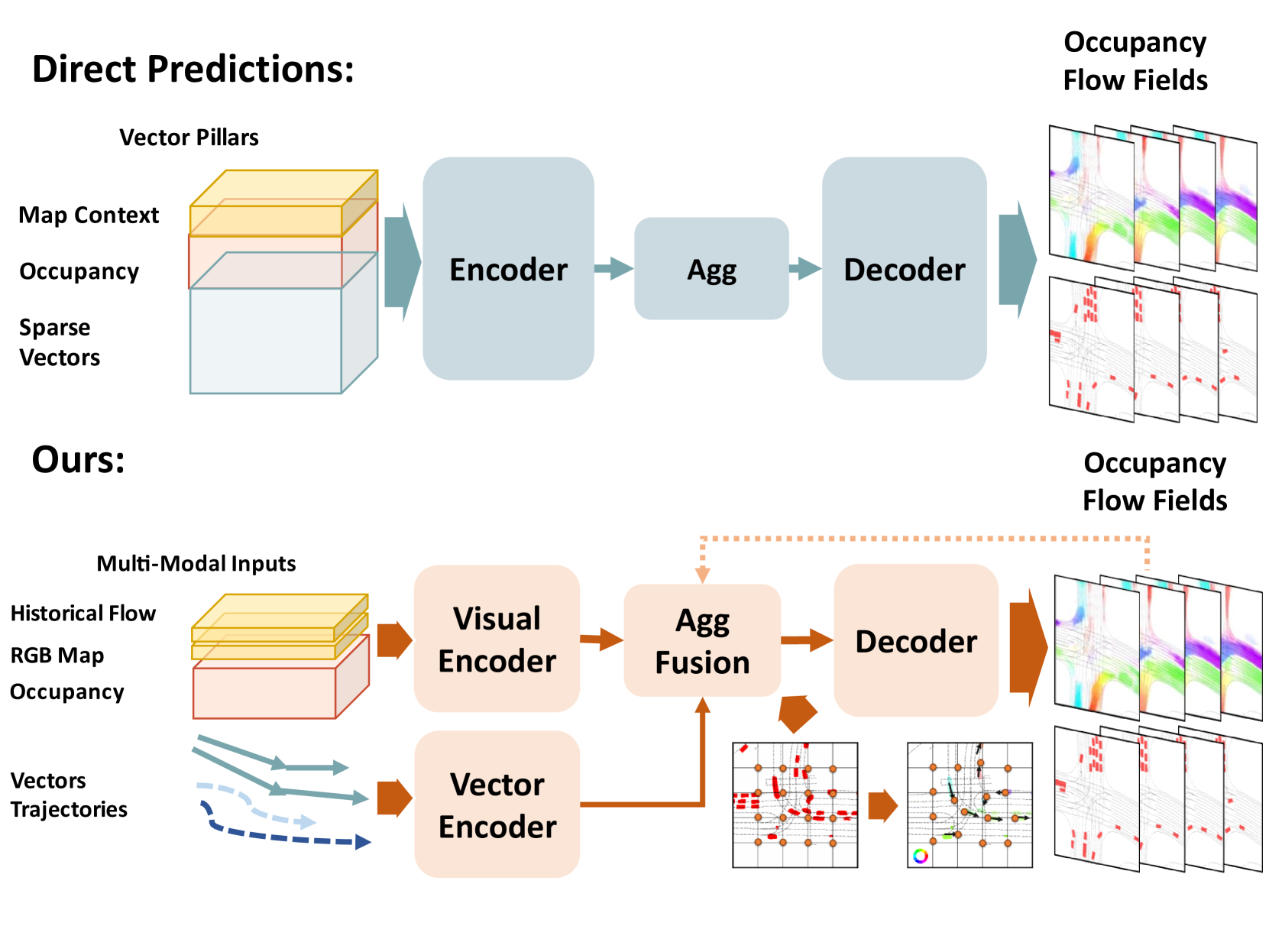
虽然大多数现有的多智能体预测工作直接预测每个智能体的未来位置序列[10,11,12],但最近提出的占用流场预测[7] 为场景中的多个代理提供更高效且可扩展的预测表示[13]。 具体来说,占用流场是一个时空网格[9],1)同时预测网格上所有代理(观察到的和遮挡的)的占用概率,2)输出一组后向占用流,预测每个占用网格单元的每个占用网格之间的扭曲(像素移位)。 它提供了一种有竞争力的替代预测表示,具有更好的可扩展性和效率,因为它能够同时预测不同数量的代理,由于闭塞(推测性)代理预测,下游决策具有更好的安全性,以及每个代理的动态可处理性通过回流。 然而,当前基于支柱启发的[14]输入的占用流场预测框架[7, 8]是冗余的并且消耗大量的内存资源。 此外,直接预测方法(见图1)缺乏流量和占用特征的可分离性,而这在数学上是相关的。
为了应对这一挑战,我们提出了一种基于多模式分层 Transformer 的时空预测任务框架。 首先,利用 Swin-Transformer [15] 视觉编码器来融合视觉模态信息并捕获历史占用、向后流动和密集路线图之间的相互作用。 我们还采用代理历史运动的矢量化表示,并通过考虑交互意识的基于 Transformer 的矢量编码器对其进行编码。 为了对未来占用网格和向后流之间的数学关系进行建模,我们为高级编码网格单元设计了一个流引导多头自注意力(FG-MSA)模块,该模块通过可学习的流偏移查询扭曲的网格单元。 然后,它为所有未来步骤输出串联的流量和占用网格单元。 为了更好地将占用网格单元与相应的代理轨迹关联起来以捕获它们的运动趋势,我们采用了交叉注意模块来查询每个网格单元在未来步骤中的编码交互轨迹。 应该指出的是,我们提出的分层 Transformer 框架非常简洁,只有三个编码阶段,但却实现了最先进的性能。 我们提出的框架的贡献总结如下:
-
1.
我们为占用流量预测任务提出了一种新颖的多模式分层 Transformer 框架。 它可以融合场景的光栅化和矢量化特征并捕获底层交互。
-
2.
我们设计了一个流引导的注意力模块,可以有效地查询由可学习流偏移扭曲的网格单元特征,这显示出更好的可分离性。
-
3.
我们在大规模现实世界驾驶数据集上验证了该框架,并且所提出的模型具有简洁的结构,实现了最先进的性能。
II 相关工作
II-A 用于运动预测的 Transformer
由于多头注意力机制在时间序列或类图交互编码中的计算效率和有效性,基于 Transformer 的结构在运动预测任务中取得了巨大的成功。 Transformer 已广泛应用于历史智能体轨迹和高保真地图片段[16, 17]的矢量化场景编码。 另一方面,在视觉变换器(ViT)[18]的帮助下,与基于CNN的方法相比,光栅化场景特征也可以通过更大的视觉接收场进行有效编码。 在我们的方法中,我们在编码过程中进一步利用这两类场景表示,并使用不同类型和阶段的 Transformer 编码器将它们组合起来,这显示出性能的提高。 运动预测的另一个重要因素是交通代理和地图信息之间的交互建模,Transformers 可以通过注意力机制很好地处理交互图。 例如,VectorNet[16]首先提出将交通元素建模为全连接图。 SceneTransformer [10] 进一步统一了矢量化地图和代理历史序列之间和内部的交互建模。 在我们的工作中,我们考虑占用网格单元之间以及不同时间步长的矢量化代理运动之间的交互,使用自注意力 Transformers 模块单独处理它们,以及这两种模式与交叉注意力 Transformer 之间的交互模块。 此外,受目标检测中 DAT [19] 的启发,我们提出了一种流引导注意力机制,适用于结合流和占用网格预测,以便可以自适应地查询网格单元特征流量补偿的指导。
II-B 用于运动预测的占用流场
通过占用网格预测未来运动可以追溯到 ChauffeurNet [20],它预测未来占用图以执行自动驾驶中的行为规划。 StopNet [13] 进一步利用这一目标并改进整体场景表示以实现高效的运动预测。 然而,它们忽略了未来时间步之间的可处理性,[7]解决了这个问题,并通过预测反向流使每个网格单元的动态特征变得可处理。 遵循相同的表示,HOPE [8]提出了一种分层时空预测器,包括深层多级编码器-解码器以及 3 层聚合器[21] 用于融合高级视觉特征。 然而,使用传统的时空层次结构需要更深的模型和更多的模型参数,并且需要预训练视觉编码器[15]。 与我们的工作同时,VectorFlow [22] 使用交叉注意力与简单的基于 CNN 的编码器-解码器融合矢量和视觉特征。 然而,它在矢量化输入中涉及太多冗余,并且视觉特征是用小的接收场编码的。 与上述方法不同,我们设计了一种更紧凑的分层 Transformers 结构,只需 3 个编码阶段即可处理多模态融合。 此外,所提出的流引导自注意力的单层聚合还可以帮助改进多任务学习过程并提高最终性能。
III 方法论
III-A 问题表述
预测占用流场可以表示为同时预测多任务输出,其中包含观察到的占用、遮挡占用的关键未来帧,以及每个未来步骤相应的反向流,以特定区域内交通代理的过去和当前状态以及场景上下文为条件。 更具体地说,占用网格被建模为二进制单通道图像,其中表示当前观察到的代理的未来占用,表示未来可能发生的被遮挡的情况。 后向流被视为一个双通道图像式张量,用于占用交通代理沿 和 轴 进行网格运动移动。 的值沿每个轴的范围从 开始。 从数学上讲,给定扭曲函数,流扭曲占用率定义为:
| (1) |
对于输入表示X,它包含多种模态,详细公式如下:
1)视觉特征: 为了获取交通主体的时空占用状态,我们首先构建历史和当前占用网格;密集道路图 ,将道路网络(按类别着色)和交通灯状态渲染为栅格化 RGB 图像 [23]。 为了促进流量预测,我们还提供了基于时间步之间占用网格中的代理位移构建的历史向后流量:。
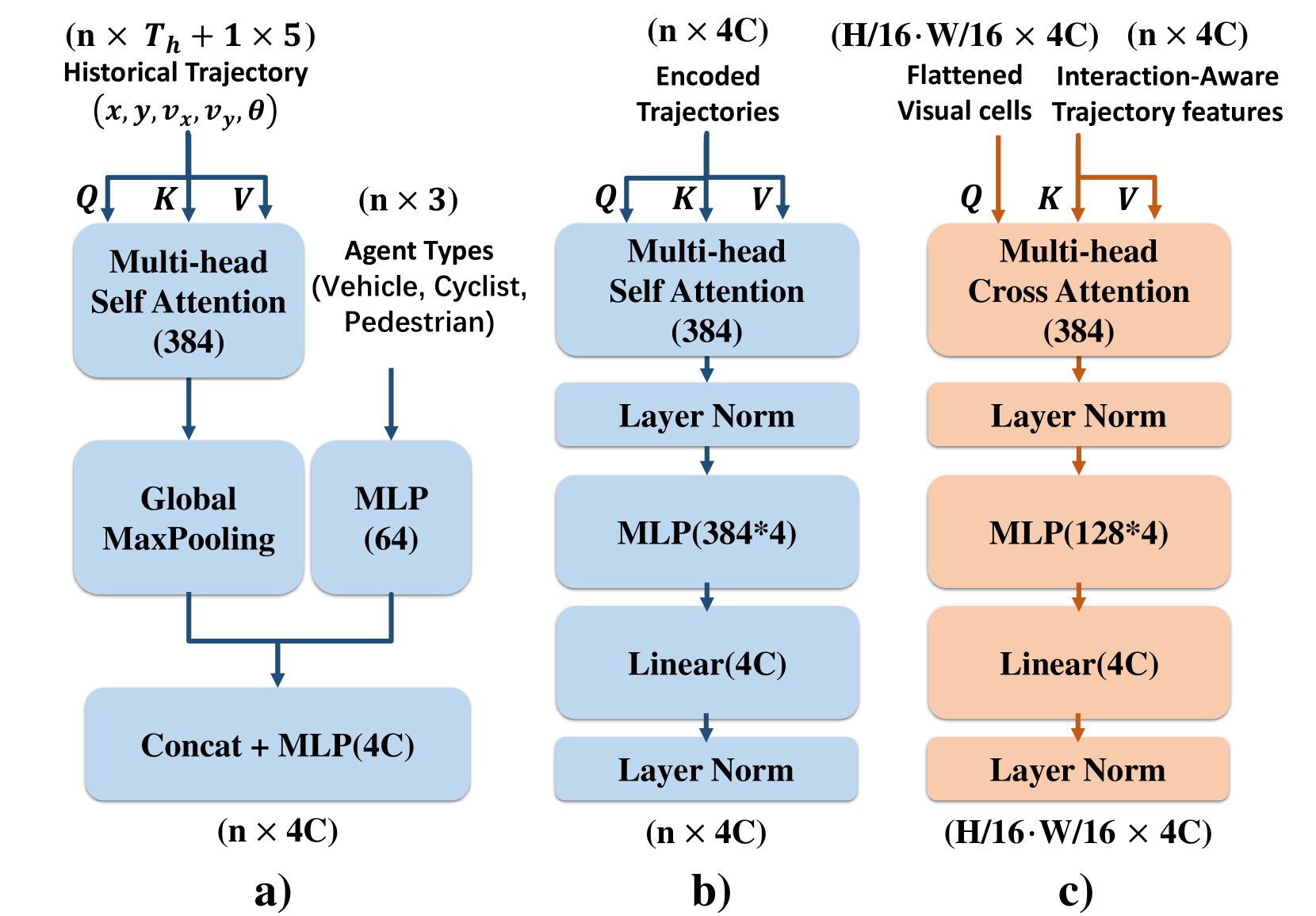
2)矢量特征: 对于矢量化输入,当前发生在网格区域内的交通主体被收集以形成一组其历史轨迹,每个轨迹表示一个运动序列并且每个运动状态由组成。 我们还将交通代理类型(车辆、骑自行车者或行人)的独热编码连接到状态。 上述所有表示均根据自我车辆的当前状态进行标准化。
假设预测模型具有参数,占用流场预测任务公式为:
| (2) | ||||
III-B 模型框架
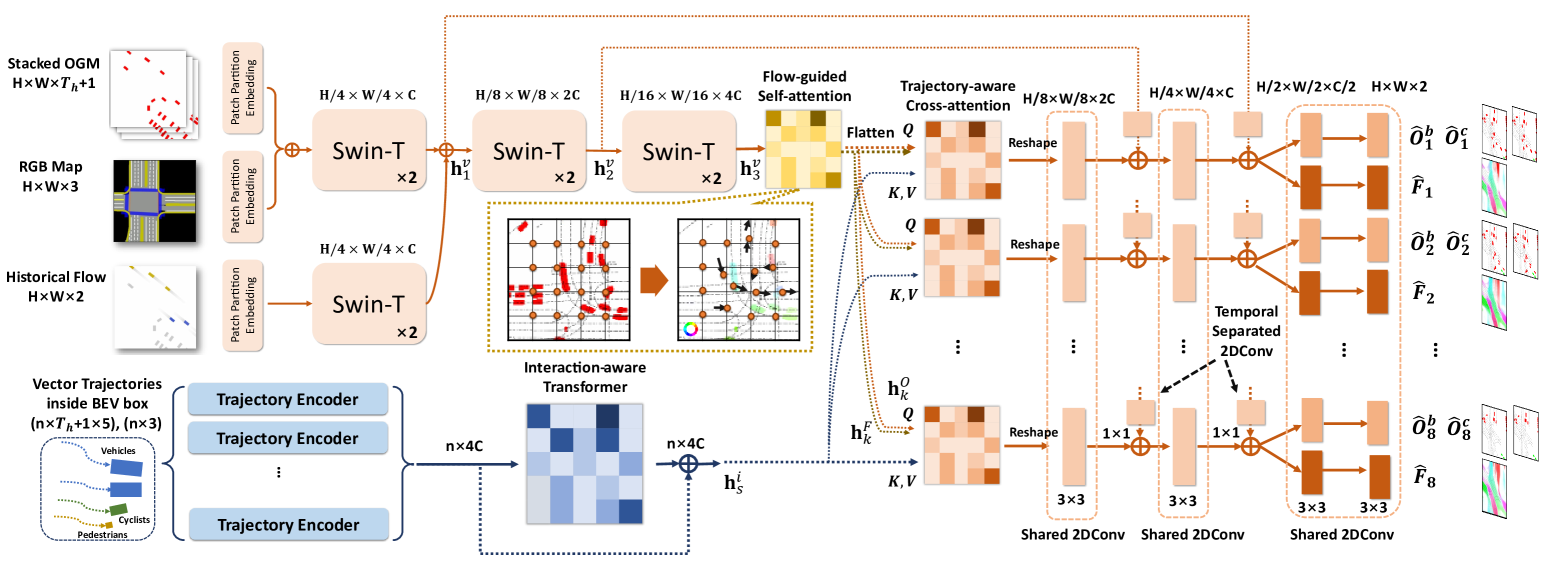
图2显示了我们模型的整体结构,其中包含用于占用流场预测的三个基本模块。 首先,多模态输入被单独编码。 矢量化轨迹 使用轨迹编码器和交互感知 Transformer 进行编码,以获得潜在特征 。 视觉特征 通过基于 Swin Transformer 的 [15] 编码器进行早期融合并编码为具有多个尺度的潜在特征 。 然后,我们采用所提出的流量引导注意力来聚合来自最高级别视觉潜在特征的流量和占用特征。 流引导注意力层被展平后获得的特征作为对时间分离的交叉注意力模块的查询,以 作为键和值。 最后,具有残差连接的时间共享反卷积解码器输出占用率和流量的联合预测。
III-C 多模态编码器
1)视觉编码器: 多模态视觉输入由基于 Swin-Transformer 的编码器进行编码,并为历史流 设置单独的 Swin-Transformer 块,作为直接通往未来流预测的信息“捷径”。 占用图 、密集道路图 和流量 最初由步长为 4 的分离式卷积核 嵌入并向下采样到形状 中。 我们遵循 Swin-Transformer [15] 的简洁设置。 更具体地说,每个 Swin-Transformer 模块都是一个两层 Transformer,具有窗口自注意力(W-SA)和移位窗口自注意力(SW-SA)。 它支持针对视觉特征的全局和基于交叉注意力的交互建模。 每个注意力模块都是具有相对位置编码偏差B的多头注意力:
| (3) | |||
其中随着模块的深入,头部编号为,是关键词符的维度。 视觉编码器输出一组不同尺度的视觉特征:。
III-D 聚合与融合
1)流引导多头自注意力(FG-MSA): 为了更好地聚合流量和占用特征,我们设计了FG-MSA模块。 核心思想是使用跨未来时间步骤的可学习流偏移,通过 MSA 机制立即引导流扭曲占用特征,以便所有未来步骤的流和流扭曲占用特征可以同时聚合。
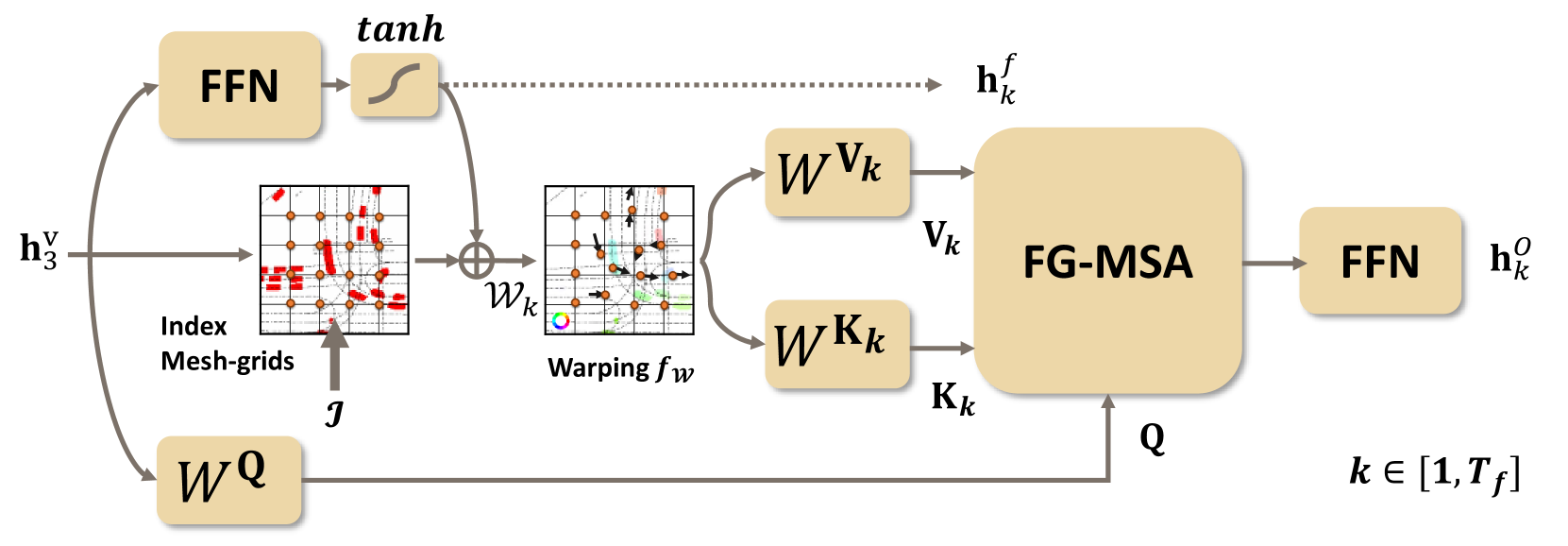
给定潜在视觉特征 ,使用 tanh 归一化前馈网络 (FFN) 来投影流偏移:。 然后,给定索引网格 ,扭曲索引变为 。 我们使用双线性插值作为扭曲函数:
| (4) |
其中。 然后,从流程引导查询中投影键和值:
| (5) |
最后,我们利用 MSA 模块使每个头能够处理每个未来的时间步:
| (6) | |||
然后通过标准FFN获得流引导占用特征。
2)轨迹感知交叉注意力: 该模块的目的是将每个网格单元与所呈现的代理的轨迹信息相关联,使得信息更有针对性并且不再受到补丁或附近特征的约束。 如图3(c)所示,我们使用聚合的占用和流量特征作为查询,键和值是矢量化的代理运动特征。 我们为不同的未来时间步实现了 8 个交叉注意力模块,并且输出被重塑回视觉特征的原始形状。
III-E 解码器
采用特征金字塔网络(FPN)[24]解码器来解码融合特征的占用率和流量。 如图2所示,2D-CNN(内核大小)在未来的时间步中共享,并分离2D-CNN(内核大小) )用于处理来自残差路径的信息。 我们选择金字塔解码器的维度为。 我们还根据占用率和流量分割解码头,以实现来自共享特征和直接信息路径的不同投影。 时间步 占用头的输出是每个网格单元的二维向量,表示观察到的 和遮挡 占用,而流头也是一个二维向量,表示沿和方向的流量。
III-F 损失函数
为了获得更好的联合占用和流量预测性能,我们修改了 [7] 中的损失函数,但保留遮挡占用 和观测占用 由于真实样本在零(未占用区域)附近严重不平衡,因此我们用焦点损失 [25] 替换交叉熵损失。 对于流扭曲损失,我们使用真实占用率而不是预测的来稳定流训练。 最终的多任务学习目标总结了以下由输出时间步的高度、宽度和长度平均得到的损失项:
| (7) |
| Evalutation Metrics | Observed Occupancy | Occluded Occupancy | Flow | Combined | |||
|---|---|---|---|---|---|---|---|
| Model | AUC | Soft-IOU | AUC | Soft-IOU | EPE | FT-AUC | FT-Soft-IOU |
| HorizonOccFlow(HOPE) [8] | 0.803 | 0.235 | 0.165 | 0.017 | 3.672 | 0.839 | 0.633 |
| Look Around [26] | 0.801 | 0.234 | 0.139 | 0.029 | 2.619 | 0.825 | 0.549 |
| Temp-Q | 0.757 | 0.393 | 0.171 | 0.041 | 3.308 | 0.778 | 0.465 |
| VectorFlow [22] | 0.755 | 0.488 | 0.174 | 0.045 | 3.583 | 0.767 | 0.531 |
| 3D-STCNN [27] | 0.691 | 0.412 | 0.115 | 0.021 | 4.181 | 0.733 | 0.468 |
| Motionnet [28] | 0.694 | 0.411 | 0.141 | 0.032 | 4.275 | 0.732 | 0.469 |
| FTLS | 0.618 | 0.318 | 0.085 | 0.019 | 9.612 | 0.689 | 0.431 |
| Ours | 0.778 | 0.491 | 0.178 | 0.045 | 3.204 | 0.785 | 0.531 |
IV 实验
IV-A 实验装置
我们在实验中使用 Waymo Open Motion 数据集 (WOMD) [29],该数据集包含超过 500,000 个样本,涵盖不同的真实驾驶场景以及包括车辆、骑自行车者和行人在内的交通主体之间的动态交互。 历史代理状态在过去一秒 () 内以 10Hz 采样,目标是预测未来 8 秒内以 1Hz () 的占用率和流量。 输入和输出的光栅化图像分辨率为,代表现实世界中的区域;隐藏维度保留为;向量输入根据它们与自我车辆的当前距离进行排序,并且我们保留最多代理。 WOMD 分割了 485,568 个样本用于训练以及一些用于验证和测试的感兴趣场景(每个样本 4,400 个)。
为了公平地评估我们方法的性能,我们遵循挑战[7]中提出的标准指标。 1) 占用率指标:对于 和 ,我们测量一对精确召回面积值的 AUC 和 Soft-IOU 与真实值重叠的区域。 2)流量指标:EPE通过测量流量终点误差的平均L2像素距离。 3)组合指标:我们根据等式(1)测量流量跟踪占用率的 AUC 和 Soft-IOU。 1(FT-AUC、FT-Soft-IOU)。
IV-B 实施细节
我们在所有编码器中选择 GELU 作为激活函数,在金字塔解码器中选择 ELU。 为了减轻过度拟合,在每个 MLP 层之后以及图像编码器中添加了 dropout,所有 dropout 率为 0.1。 由于数据输入和预测的规模很大,我们在 4 个 Tesla V100 GPU 上使用分布式训练策略,总批量大小为 16。 Adam 优化器的初始学习率为 1e-4,学习率每 3 个 epoch 衰减 50%。 总训练次数设置为 10。
IV-C 定量结果
1) 基准测试的性能: 表I报告了我们提出的方法与 Waymo 预测基准上其他最先进方法的测试性能。 截至 2022 年 8 月,我们的方法已经实现了三个最佳指标,即观察和遮挡占用预测的 Soft-IOU,以及遮挡占用的 AUC。 此外,我们的方法实现了与大型预训练模型相当的性能,即 HOPE (Honorable Mention) [8] 和 Look围绕(地点)[26],两者都使用在ImageNet [15上预训练的非常大的图像编码器,30]。 与类似的框架VectorFlow(处)[22]相比,它也使用扁平化的视觉特征来关注向量特征,我们的方法在各种指标上表现更好,即占用率指标提高了 2% 以上,流量预测误差提高了 8%,以及更好的组合指标。 总的来说,我们的方法的优异测试结果表明:1)我们的方法在检测流量代理的出现(用于检测的Soft-IOU)方面表现出出色的能力; 2)框架适应性更强,能够预测被遮挡(投机)的智能体(高AUC),这增强了下游规划的安全性; 3)第III-D节中描述的拟议FG-MSA模块可以改进流量和占用预测的学习管道。
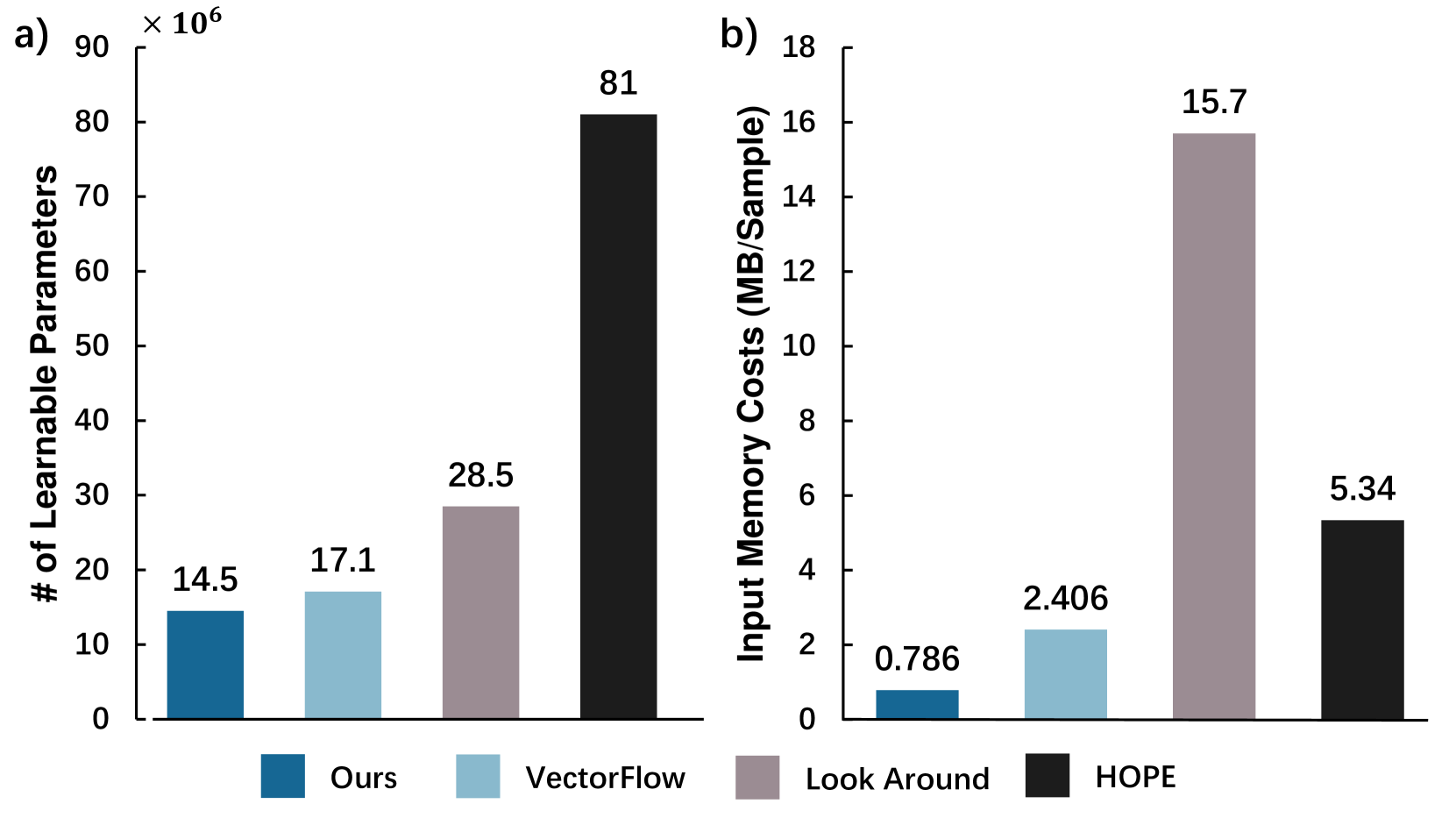
2)计算效率: 为了评估现有方法的计算效率,我们报告网络参数的数量(图5(a))并粗略计算每个样本输入张量的内存使用情况(图5(b)) 对于每种方法。 张量内存使用量的计算解释如下。 我们对每个网格单元(布尔类型)的占用情况计算 1 位,对 int 类型数据计算 2 个字节,对每个单元的矢量化输入(浮点类型)计算 4 个字节。 图5(b)的结果显示了该方法出色的内存效率,仅为VectorFlow [22]的32%和Look around 的5% [26] 在内存使用方面。 同样,在图 5(a) 中,将我们的网络参数数量(完整模型)与其他 SOTA 方法(仅编码器)进行比较,我们的模型更加简洁,即 18% HOPE [8] 和 Look around [26] 的 51%,但能够提供有竞争力的性能。 因此,我们可以得出结论:1)使用结合所有特征的统一大张量会消耗更多的内存,而所提出的模型可以通过结合占用的视觉图像和矢量化轨迹来解决这个问题; 2)没有必要在视觉编码器中使用深层和编码阶段来执行占用流场预测任务,因为我们提出的方法只需几个编码阶段即可提供有竞争力的结果。
IV-D 定性结果
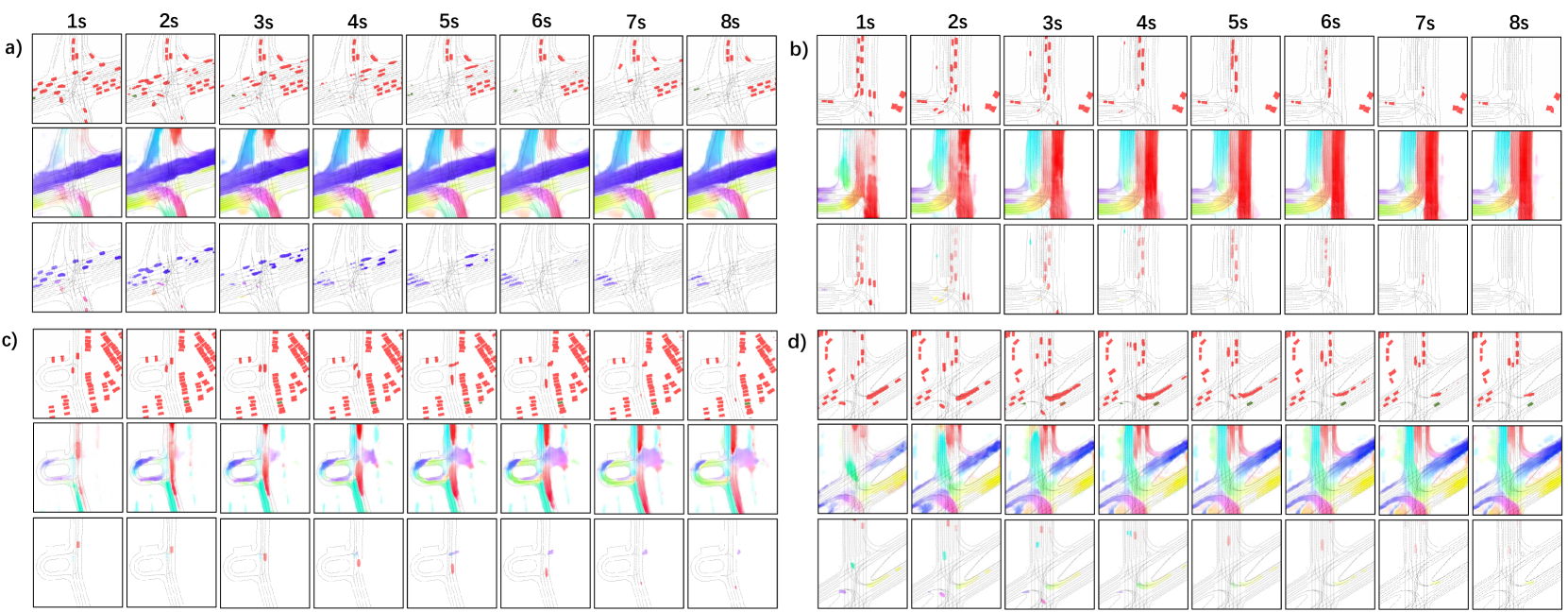
为了直观地评估我们方法的性能,我们将图 6 中几个代表性驾驶场景的测试结果可视化。 结果表明,我们的方法可以对动态(a、b、d)和静态(c)交通代理进行有效且准确的占用预测。 即使对于弹出的代理(c,d),遮挡意识也表现出来(a,c,d)。 流量跟踪占用预测进一步确保了动态代理的易处理性。
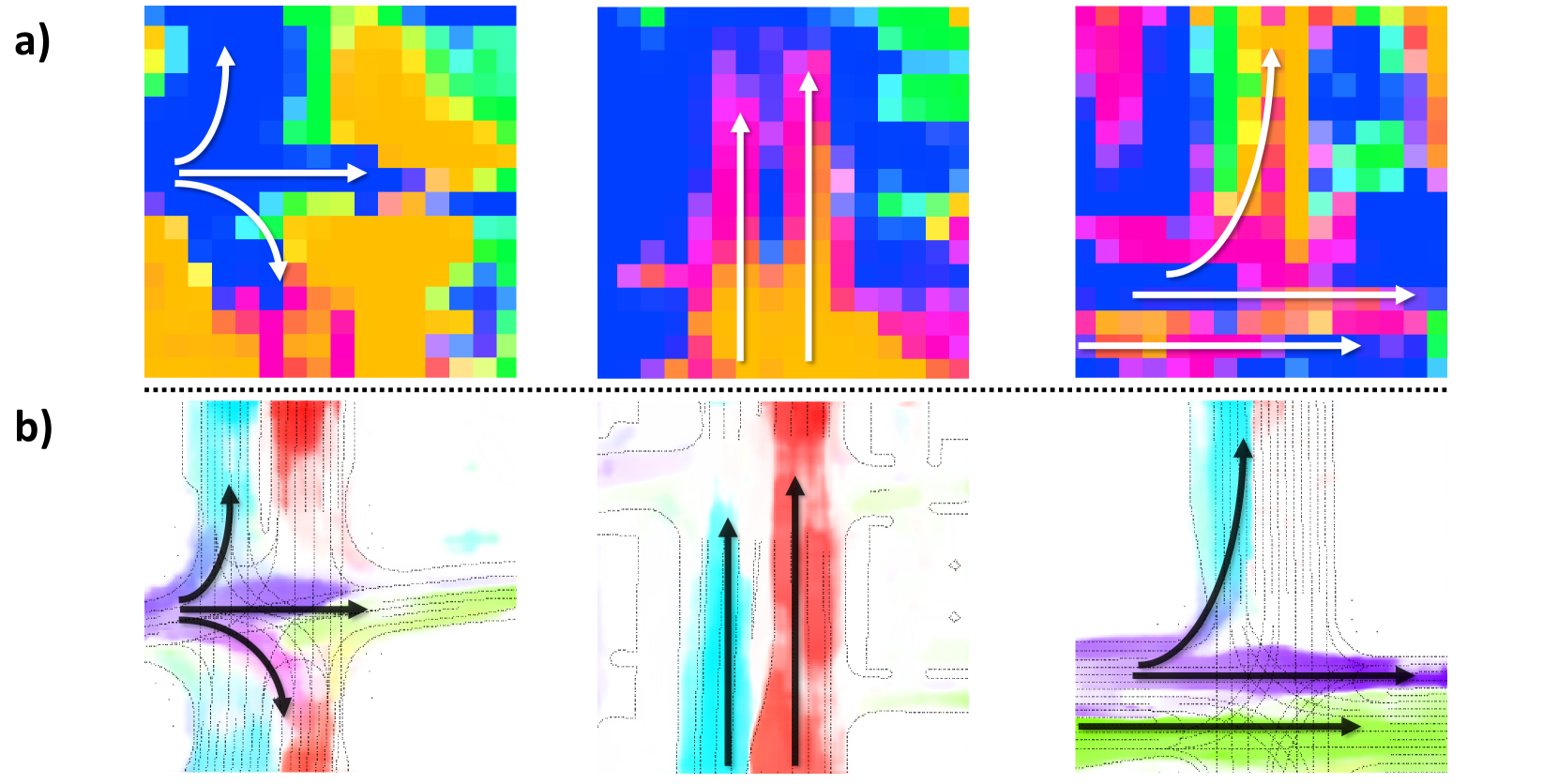
为了研究FG-MSA模块带来的性能提升,我们将模块内部的流偏移形状(a)与图7中的流输出(b)进行比较。 流量偏移和流量输出的相似形状表明所提出的 FG-MSA 模块的功能是指导流量和占用的特征聚合。
IV-E 消融研究
我们进行了一项消融研究,以研究我们提出的框架中关键模块的影响,即 FG-MSA 模块和矢量化轨迹编码和融合模块。 因此,我们分别训练了两个没有 FG-MSA 模块和矢量编码分支的消融版本,并且所有消融模型都在同一测试集上进行了验证。 我们在表II中报告了占用指标的AUC和流量EPE,这表明两个消融模型的整体性能有所下降。 由于缺乏代理运动信息,使用纯粹基于视觉的编码模型会显着恶化预测性能。 像其他基线方法一样,在视觉图像中结合稀疏代理运动信息可以帮助缓解此问题,但会消耗大量内存使用和计算资源。 另一方面,我们建议使用矢量化运动信息和时间交叉注意力来融合视觉和矢量特征可以带来可比的性能,但内存和计算使用量要少得多。 与没有 FG-MSA 模块的消融模型(将解决方案纳入挑战)相比,当前版本在观察到的 AUC 方面显示出显着改进( )和流动 EPE ()。 由于FG-MSA模块可以更好地分离和聚合占用率和流量的特征,并明确表示它们的关系(方程1),因此结合FG-MSA模块可以进一步提升模型性能,特别是对于流量预测。
| Vector | FG- | Observed | Occluded | FT- | Flow |
|---|---|---|---|---|---|
| Encoding | MSA | AUC | AUC | AUC | EPE |
| ✕ | ✕ | 0.741 | 0.138 | 0.751 | 3.712 |
| ✓ | ✕ | 0.751 | 0.161 | 0.777 | 3.586 |
| ✓ | ✓ | 0.778 | 0.178 | 0.785 | 3.204 |
V 结论
在本文中,我们提出了一种多模态分层 Transformer 框架来预测自动驾驶的占用流场。 多模态场景表示输入,包括视觉特征和矢量化运动轨迹,通过精心设计的分层 Transformer 模块单独编码,并且两种模态都与时间交叉注意力融合。 此外,设计的流量引导注意力模块可以通过自注意力以及对其数学关系的显式建模来更好地聚合流量和占用特征。 在 Waymo 开放数据集上进行的综合实验表明,即使网络规模小得多,该方法也比 SOTA 模型具有优越的性能。 消融研究表明,添加矢量化运动信息融合和流引导注意力聚合可以显着提高预测性能。
参考
- [1] S. Mozaffari, O. Y. Al-Jarrah, M. Dianati, P. Jennings, and A. Mouzakitis, “Deep learning-based vehicle behavior prediction for autonomous driving applications: A review,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 1, pp. 33–47, 2020.
- [2] Z. Huang, J. Wu, and C. Lv, “Driving behavior modeling using naturalistic human driving data with inverse reinforcement learning,” IEEE Transactions on Intelligent Transportation Systems, 2021.
- [3] Z. Huang, H. Liu, J. Wu, and C. Lv, “Differentiable integrated motion prediction and planning with learnable cost function for autonomous driving,” arXiv preprint arXiv:2207.10422, 2022.
- [4] X. Mo, Z. Huang, Y. Xing, and C. Lv, “Multi-agent trajectory prediction with heterogeneous edge-enhanced graph attention network,” IEEE Transactions on Intelligent Transportation Systems, 2022.
- [5] X. Mo, Y. Xing, and C. Lv, “Interaction-aware trajectory prediction of connected vehicles using cnn-lstm networks,” in IECON 2020 The 46th Annual Conference of the IEEE Industrial Electronics Society. IEEE, 2020, pp. 5057–5062.
- [6] N. Djuric, V. Radosavljevic, H. Cui, T. Nguyen, F.-C. Chou, T.-H. Lin, N. Singh, and J. Schneider, “Uncertainty-aware short-term motion prediction of traffic actors for autonomous driving,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2020, pp. 2095–2104.
- [7] R. Mahjourian, J. Kim, Y. Chai, M. Tan, B. Sapp, and D. Anguelov, “Occupancy flow fields for motion forecasting in autonomous driving,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 5639–5646, 2022.
- [8] Y. Hu, W. Shao, B. Jiang, J. Chen, S. Chai, Z. Yang, J. Qian, H. Zhou, and Q. Liu, “Hope: Hierarchical spatial-temporal network for occupancy flow prediction,” arXiv preprint arXiv:2206.10118, 2022.
- [9] S. Hoermann, M. Bach, and K. Dietmayer, “Dynamic occupancy grid prediction for urban autonomous driving: A deep learning approach with fully automatic labeling,” in 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 2056–2063.
- [10] J. Ngiam, B. Caine, V. Vasudevan, Z. Zhang, H.-T. L. Chiang, J. Ling, R. Roelofs, A. Bewley, C. Liu, A. Venugopal et al., “Scene transformer: A unified architecture for predicting multiple agent trajectories,” arXiv preprint arXiv:2106.08417, 2021.
- [11] B. Varadarajan, A. Hefny, A. Srivastava, K. S. Refaat, N. Nayakanti, A. Cornman, K. Chen, B. Douillard, C. P. Lam, D. Anguelov et al., “Multipath++: Efficient information fusion and trajectory aggregation for behavior prediction,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 7814–7821.
- [12] J. Gu, C. Sun, and H. Zhao, “Densetnt: End-to-end trajectory prediction from dense goal sets,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 303–15 312.
- [13] J. Kim, R. Mahjourian, S. Ettinger, M. Bansal, B. White, B. Sapp, and D. Anguelov, “Stopnet: Scalable trajectory and occupancy prediction for urban autonomous driving,” arXiv preprint arXiv:2206.00991, 2022.
- [14] A. H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom, “Pointpillars: Fast encoders for object detection from point clouds,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 12 697–12 705.
- [15] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 012–10 022.
- [16] J. Gao, C. Sun, H. Zhao, Y. Shen, D. Anguelov, C. Li, and C. Schmid, “Vectornet: Encoding hd maps and agent dynamics from vectorized representation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 525–11 533.
- [17] Z. Huang, X. Mo, and C. Lv, “Multi-modal motion prediction with transformer-based neural network for autonomous driving,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 2605–2611.
- [18] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [19] Z. Xia, X. Pan, S. Song, L. E. Li, and G. Huang, “Vision transformer with deformable attention,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 4794–4803.
- [20] M. Bansal, A. Krizhevsky, and A. Ogale, “Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst,” arXiv preprint arXiv:1812.03079, 2018.
- [21] A. Hu, Z. Murez, N. Mohan, S. Dudas, J. Hawke, V. Badrinarayanan, R. Cipolla, and A. Kendall, “Fiery: Future instance prediction in bird’s-eye view from surround monocular cameras,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 273–15 282.
- [22] X. Huang, X. Tian, J. Gu, Q. Sun, and H. Zhao, “Vectorflow: Combining images and vectors for traffic occupancy and flow prediction,” arXiv preprint arXiv:2208.04530, 2022.
- [23] Z. Huang, X. Mo, and C. Lv, “Recoat: A deep learning-based framework for multi-modal motion prediction in autonomous driving application,” arXiv preprint arXiv:2207.00726, 2022.
- [24] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125.
- [25] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2980–2988.
- [26] P. Dmytro, “Waymo open dataset occupancy and flow prediction challenge solution: Look around,” 2022. [Online]. Available: https://storage.googleapis.com/waymo-uploads/files/research/OccupancyFlow/Dmytro1.pdf
- [27] Z. He, C.-Y. Chow, and J.-D. Zhang, “Stcnn: A spatio-temporal convolutional neural network for long-term traffic prediction,” in 2019 20th IEEE International Conference on Mobile Data Management (MDM). IEEE, 2019, pp. 226–233.
- [28] Y. Wang, M. Long, J. Wang, and P. S. Yu, “Spatiotemporal pyramid network for video action recognition,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 1529–1538.
- [29] S. Ettinger, S. Cheng, B. Caine, C. Liu, H. Zhao, S. Pradhan, Y. Chai, B. Sapp, C. R. Qi, Y. Zhou et al., “Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9710–9719.
- [30] K. Sun, B. Xiao, D. Liu, and J. Wang, “Deep high-resolution representation learning for human pose estimation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5693–5703.