YOLO-FaceV2:尺度和遮挡感知人脸检测器
摘要
近年来,基于深度学习的人脸检测算法取得了长足的进步。 这些算法通常可以分为两类,即像 Faster R-CNN 这样的两级检测器和像 YOLO 这样的一级检测器。 由于精度和速度之间具有更好的平衡,一级探测器已广泛应用于许多应用中。 在本文中,我们提出了一种基于单级检测器YOLOv5的实时人脸检测器,命名为YOLO-FaceV2。 我们设计了一个名为 RFE 的感受野增强模块来增强小脸的感受野,并利用 NWD 损失来弥补 IoU 对微小物体位置偏差的敏感性。 对于人脸遮挡,我们提出了一个名为 SEAM 的注意力模块,并引入排斥损失来解决它。 此外,我们使用权重函数Slide来解决简单样本和困难样本之间的不平衡,并使用有效感受野的信息来设计锚点。 WiderFace 数据集上的实验结果表明,我们的人脸检测器优于 YOLO,并且它的变体可以在所有简单、中等和困难子集中找到。 源代码位于https://github.com/Krasjet-Yu/YOLO-FaceV2
关键词—人脸检测、YOLO、尺度感知、损失函数、不平衡问题
1简介
人脸检测是许多人脸相关应用中必不可少的步骤,例如人脸识别、人脸验证和人脸属性分析等。随着近年来深度卷积神经网络的蓬勃发展,人脸检测器的性能得到了极大的提高。 许多基于深度学习的高性能人脸检测算法被提出。 一般来说,这些算法可以分为两个分支。 典型的基于深度学习的人脸检测算法的一个分支[1,2,3]使用神经网络的级联手段作为特征提取器和分类器来检测从粗到细的人脸。 尽管取得了巨大的成功,但值得注意的是,级联检测器也存在一些缺点,例如训练困难和检测速度慢。 另一个分支是对通用目标检测算法[4,5,6]的改进。 通用目标检测器考虑了目标的更常见特征和更广泛的特征。 因此,特定任务的探测器可以共享这些信息,然后通过特殊设计来增强这些惊人的特性。 一些流行的人脸检测器包括 YOLO [7, 8, 9, 10]、Faster R-CNN [5] 和 RetinaNet [6] 下降归入这一类。 在本文中,受到 YOLOv5 [11]、TridentNet [12] 和 FAN [13] 中的注意力网络的启发,我们提出了一种新颖的人脸检测器实现了最先进的一级人脸检测。
尽管深度卷积网络显着改进了人脸检测,但在现实场景中检测尺度、姿势、遮挡、表情、外观和照明变化较大的人脸仍然是巨大的挑战。 在我们之前的工作中,我们提出了YOLO-Face [14],一种基于YOLOv3 [9]改进的人脸检测器,主要关注尺度方差问题,设计适合人脸的锚点比例,并利用更准确的回归损失函数。 Easy、Medium 和 Hard 在 WiderFace [15] 验证集上的 mAP 分别达到 0.899、0.872 和 0.693。 此后,各种新型检测器相继出现,人脸检测性能得到了显着提高。 然而,对于小物体,一级检测器必须以更细的粒度划分搜索空间,因此容易导致正负样本不平衡的问题[16]。 此外,复杂场景中的人脸遮挡[13]会显着影响人脸检测器的准确性。 为了解决人脸尺度变化、易难样本不平衡以及人脸遮挡等问题,我们提出了一种基于 YOLOv5 的人脸检测方法 YOLO-FaceV2。
通过仔细分析人脸检测器遇到的困难以及YOLOv5检测器的缺点,我们进行了以下解决方案。
多尺度融合: 在许多场景中,图像中通常存在不同尺度的人脸,这对于人脸检测器来说很难全部检测到。 因此,解决不同尺度的人脸是人脸算法的一项非常重要的任务。 目前解决尺度变化问题的主要方法是构建金字塔来融合人脸[17,18,19,20]的多尺度特征。 例如,在YOLOv5中,FPN [20]融合了P3、P4和P5层的特征。 然而,对于小尺度物体,多层卷积后信息很容易丢失,保留的像素信息很少,即使在较浅的P3层也是如此。 因此,提高特征图的分辨率无疑有利于小物体的检测。
注意力机制: 在许多复杂场景中,经常会出现人脸遮挡的情况,这是人脸检测器精度下降的主要原因之一。 为了解决这个问题,一些研究人员尝试使用注意力机制来提取面部特征。 FAN [13]提出了anchor级别的注意力。 他们提出解决方案是维持未遮挡区域的响应值,并通过注意力机制来补偿遮挡区域减少的响应值。 然而,它并没有充分利用渠道之间的信息。
硬样本: 在一级检测器中,许多边界框没有被迭代过滤掉。 所以一级探测器中的简单样本数量非常大。 在训练过程中,它们的累积贡献主导了模型的更新,导致模型[16]过拟合。 这就是所谓的样本不平衡问题。 为了解决这个问题,Lin等人提出了Focal损失来动态地为困难的样本分配更多的权重[6]。 与焦点损失类似,梯度协调机制(GHM)[21]抑制正负简单样本的梯度,以更多地关注困难样本。 曹等人提出的Prime Sample Attention(PISA)[22]根据不同的标准为正样本和负样本分配权重。 然而,目前的硬样本挖掘方法需要设置的超参数过多,在实践中非常不方便。
锚设计: 正如[23]中指出的,CNN特征图中的区域有两种类型的感受野,理论感受野和实际感受野。 实验表明,感受野中的所有像素并非均等响应,而是服从高斯分布。 这使得基于理论感受野的anchor尺寸大于其实际尺寸,这使得边界框的回归变得更加困难。 张等。 al 根据有效感受野设计了锚点的大小 [24]。 FaceBoxes [25] 设计了多尺度锚点来丰富感受野,并在不同层上离散锚点以处理各种尺度的人脸。 因此,锚框的尺度和比例的设计非常重要,这可能极大地有利于模型的准确性和收敛过程。
回归损失: 回归损失用于衡量预测边界框与地面真实边界框之间的差异。 目标检测器中常用的回归损失函数有L1/L2损失、smooth L1损失、IoU损失及其变体[26,27,28,29]。 YOLOv5以IoU损失作为目标回归函数。 然而,对于不同尺度的物体,IoU 的灵敏度差异很大。 容易理解的是,对于小目标,轻微的位置偏差会导致 IoU 显着下降。 王等人[30]提出一种基于Wasserstein距离的小目标评估方法,有效减轻小目标的影响。 然而,他们的方法对于大目标的表现并不那么重要。
在本文中,为了解决上述问题,我们设计了一种基于YOLOv5的新型人脸检测器。 我们的目标是找到一种最佳的组合检测器,有效解决小人脸、大尺度变化、遮挡场景以及难易样本不平衡的问题。 首先,我们融合FPN的P2层信息,以获得更多的像素级信息并补偿小人脸的信息。 但这样一来,由于输出特征图感知野变小,大中型目标的检测精度会略有下降。 为了改善这种情况,我们为 P5 层设计了感受野增强(RFE),它通过使用扩张卷积来增加感受野。 其次,受 FAN 和 ConvMixer [31] 的启发,我们重新设计了多头注意力网络来补偿被遮挡的面部响应值的损失。 此外,我们还引入了排斥损失[32]来提高类内遮挡的召回率。 第三,为了挖掘硬样本,受 ATSS [33] 的启发,我们设计了具有自适应阈值的 Slide 权重函数,使模型在训练过程中更加关注硬样本。 第四,为了使anchor更适合回归,我们根据有效感受野和人脸比例重新设计anchor的大小和比例。 第五,我们借用了归一化 Wasserstein 距离度量[30]并将其引入到回归损失函数中,以平衡 IoU 在预测小人脸方面的不足。
综上所述,我们提出了一种新的人脸检测器 YOLO-FaceV2,其中突出的贡献如下。
1. 对于检测多尺度人脸,感知场和分辨率是关键因素。 因此,我们设计了一个感受野增强模块(称为RFE)来学习特征图的不同感受野并增强特征金字塔表示。
2. 我们将人脸遮挡分为两类,即不同人脸之间的遮挡和人脸被其他物体遮挡。 前者使得检测精度对NMS阈值非常敏感,从而导致漏检。 我们使用排斥损失来进行人脸检测,它会惩罚预测框转移到其他真实对象的行为,并要求每个预测框远离具有不同指定目标的其他预测框,以使检测结果对 NMS 不太敏感。 后者会导致特征消失导致定位不准确,我们设计了注意力模块SEAM来增强人脸特征的学习。
3. 为了解决困难样本和简单样本之间不平衡的问题,我们根据 IoU 对简单样本和困难样本进行加权。 为了减少超参数调整,我们将所有具有ground-truth的候选正样本的IoU平均值设置为正负样本之间的分界线。 我们设计了一个名为 Slide 的加权函数,为困难样本赋予更高的权重,这有助于模型学习更困难的特征。 该功能的详细信息将在第 3-5 节中介绍。
本文的其余部分安排如下:在第二节中,我们回顾了该领域的相关文献;在第3节中,我们详细描述了模型结构,以及主要的改进,包括感受野增强模块、注意力模块、自适应样本加权函数、anchor设计、Replusion损失和归一化高斯Wasserstein距离(NWD)损失,分别;在第 4 节中,我们描述了实验和相应的结果分析,包括消融实验以及与其他模型的比较;在第五节中,我们总结了我们的工作,并对未来的研究提出了一些建议。
2相关作品
人脸检测。 几十年来,人脸检测一直是计算机视觉领域的热门研究领域。 在深度学习的早期,人脸检测算法通常使用神经网络自动提取图像特征进行分类。 CascadeCNN [1]提出了一种级联结构,其中包含三级精心设计的深度卷积网络,以从粗到细的方式预测人脸和地标位置。 MTCNN [2] 开发了类似的级联架构来联合对齐面部标志并检测面部位置。 PCN[3]使用角度预测网络来校正人脸并提高人脸检测精度。 但早期基于深度学习的人脸检测算法存在训练繁琐、局部最优、检测速度慢、检测精度低等缺点。
目前的人脸检测算法主要是通过继承通用目标检测算法的优点进行改进,如SSD [4]、Faster R-CNN [5]、RetinaNet [6]等。CMS-RCNN [34]使用Faster R-CNN作为主干,引入上下文信息和多尺度特征来检测人脸。 张等人[25]设计了一种基于SSD结构的轻量级网络,名为FaceBoxes,通过32倍下采样快速缩小特征尺寸,并使用多尺度网络模块来增强特征尺寸网络宽度和深度尺寸。 SRN [35]在通用目标检测算法RefineDet [36]和RetinaNet [6]的基础上进行了改进,通过引入两阶段分类和回归,并设计了多分支模块来增强感受野的效果。
尺度不变性。 作为人脸检测中最具挑战性的问题之一,复杂场景中较大的人脸尺度变化对检测器的准确性产生重要影响。 多尺度检测能力主要依赖于尺度不变性特征,许多工作致力于解决这个问题,以更准确、更有效地提取特征[13,24,37,38]。 对于小物体检测,使用较少的下采样层和扩张卷积可以显着提高检测性能[39, 40]。 解决这个问题的另一种方法是使用更多的锚点。 Anchor可以提供良好的先验信息,因此使用更密集的anchor和相应的匹配策略可以有效提高目标提案的质量[24,25,37,40]。 多尺度训练有助于构建图像金字塔并增加样本多样性,是提高多尺度目标检测性能的简单而有效的方法。 另一方面,感受野会增大,语义信息相应丰富,但空间信息可能相应缺失。 一个自然的想法是将深层语义信息与浅层特征融合,例如 [20, 41, 42]。 此外,SNIP[43]和TridentNet[12]也为解决多尺度问题提供了新的思路,将在下面的章节中详细讨论。
遮挡问题。 拥挤的人脸和随后的遮挡问题会导致被遮挡人脸的数据不完整和信息缺乏,因为某些区域不可见或边界模糊,这很容易导致漏检和低召回率。 一些工作已经证明上下文信息有助于人脸检测缓解遮挡问题。 SSH [37] 使用简单卷积层的方法通过扩大候选提案周围的窗口来合并上下文。 FAN [13]提出了锚点级注意力机制,通过突出面部区域的特征来检测被遮挡的面部。 PyramidBox [44]设计了一个上下文相关的预测模块,用DSSD的残差预测模块代替了SSH中上下文模块的卷积层。 RetinaFace [45]在五个特征金字塔级别上应用独立的上下文模块,以增加感受野并增强刚性上下文建模能力。 上述方法在遮挡问题上取得了良好的效果。 因此,利用上下文信息来提高遮挡区域的有效性是一个可行的方向,值得进一步探索。
简单样品和困难样品的不平衡。 对于一阶段人脸检测,简单样本的数量非常多,它们主导了损失的变化,使得模型只能学习简单样本的特征,而忽略了困难样本的学习。 为了解决这个问题,OHEM[46]算法根据样本损失选择困难样本,并将困难样本的损失应用到随机梯度下降的训练中。 针对OHEM算法中忽略简单样本的问题,Focal Loss[6]通过对所有样本进行加权,更好地利用了所有样本,获得了更高的准确率。 SRN[35]也遵循这个想法。 Faceboxes[25]根据IoU损失对样本进行排序,并控制正负样本的比例小于1:3。 上述方法虽然可以有效解决样本不平衡的问题,但也人为地引入了一些超参数,增加了调整的难度。 因此,我们设计了一个具有自适应参数的样本平衡函数。
3YOLO-FaceV2
3.1网络架构
YOLOv5 是一个优秀的通用目标检测器。 我们将YOLOv5引入人脸检测领域,尝试解决小人脸、人脸遮挡等问题。
我们的YOLO-FaceV2检测器的架构如图1所示. 它由三部分组成:脊柱结构、颈部和头部。 我们以CSPDarknet53为骨干,在P5层用RFE模块替换Bottleneck,以融合多尺度特征。 在颈部,我们保持SPP [47]和PAN [48]的结构。 此外,为了提高目标位置感知的能力,我们还将P2层集成到PAN中。 头部用于对类别进行分类并回归目标的位置。 我们还在头部添加了一个特殊的分支,以增强模型的遮挡检测能力。
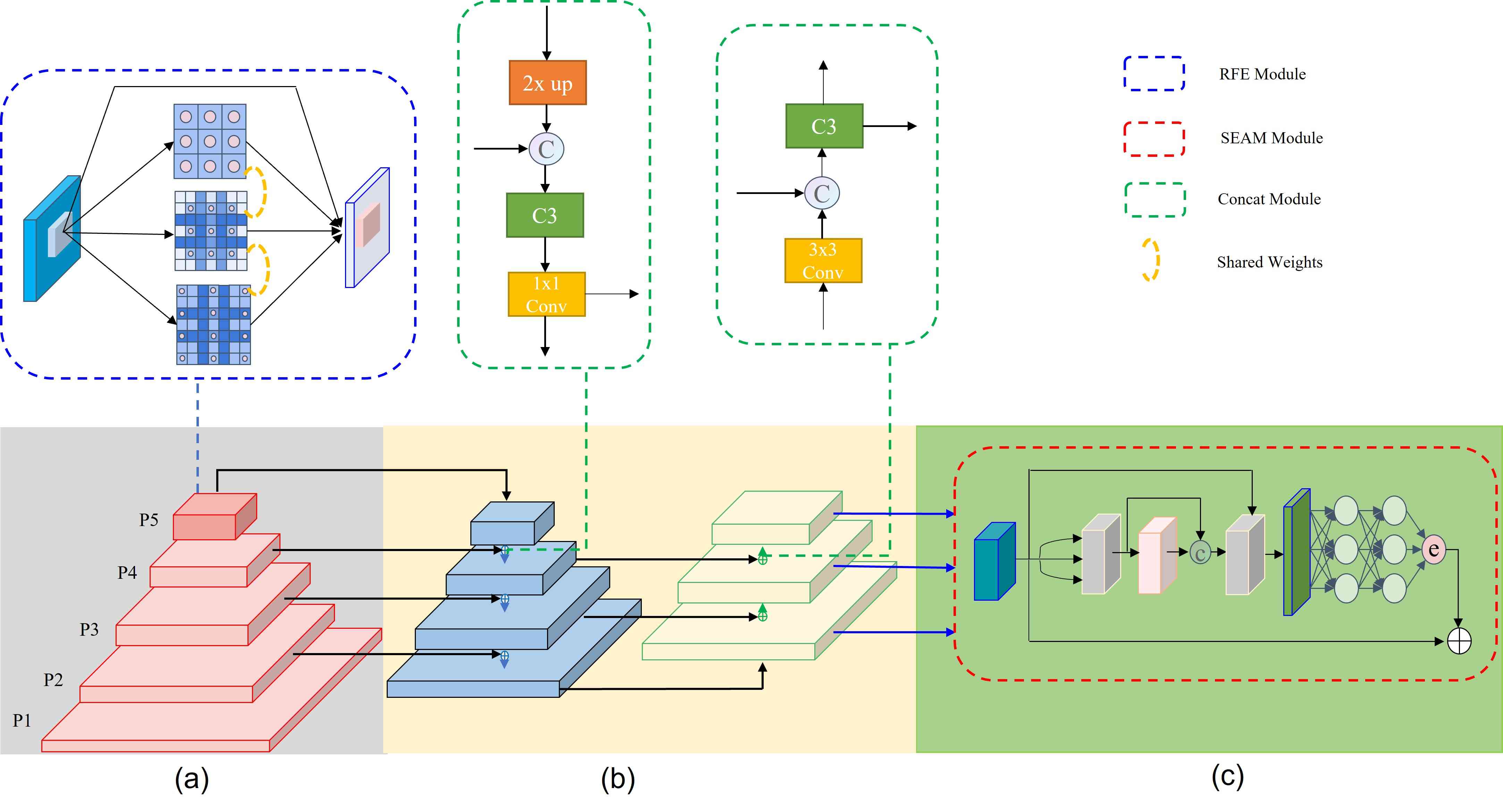
3.2 规模感知 RFE 模型
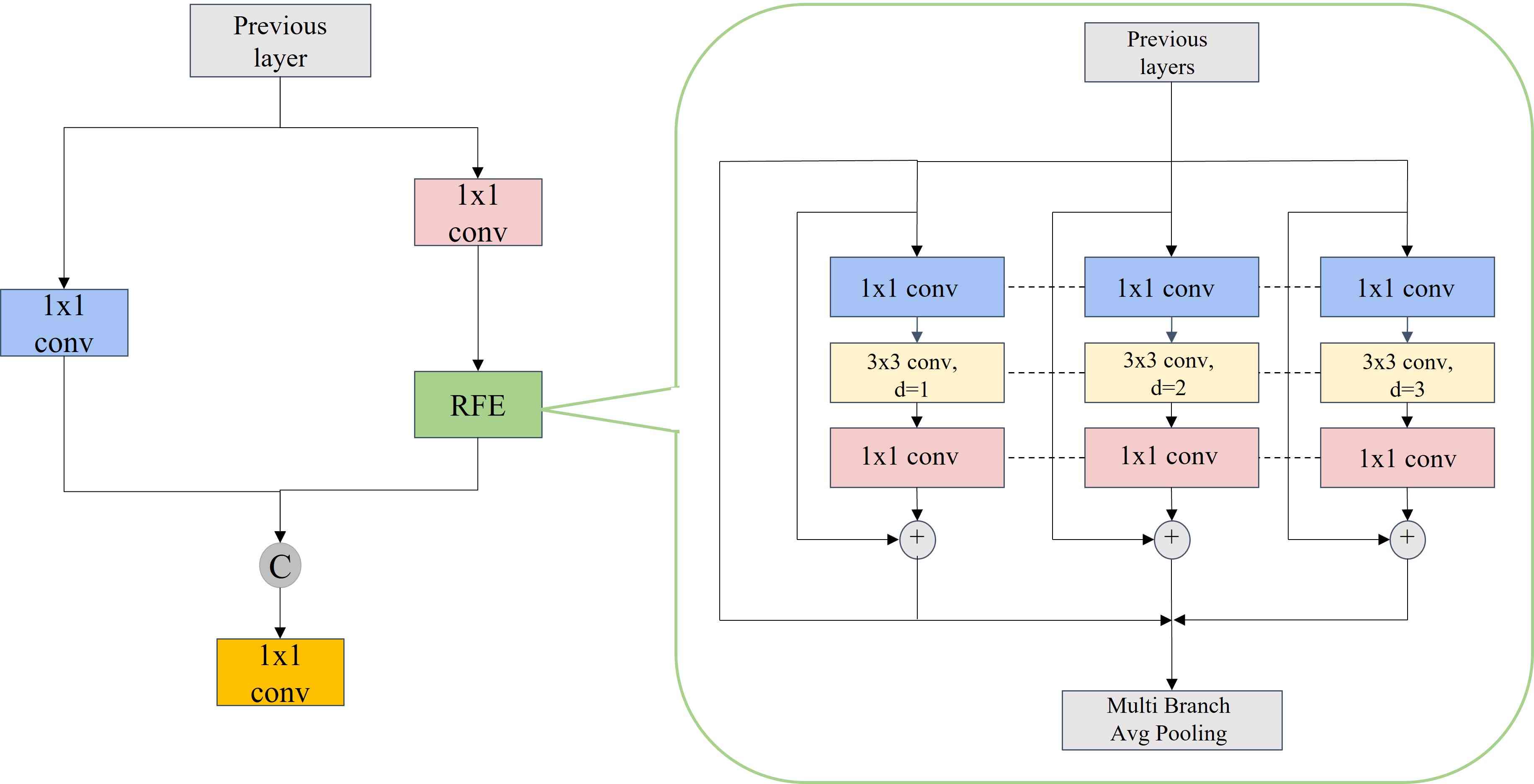
由于不同大小的感受野意味着不同的捕获长程依赖性的能力,因此我们设计 RFE 模块,通过使用扩张卷积来充分利用特征图中感受野的优势。 受 TridentNet 的启发,我们使用四个不同扩张卷积率的分支来捕获多尺度信息和不同范围的依赖关系。 所有分支都有共享权重,唯一的区别是它们独特的感受野。 一方面,它减少了参数的数量,从而减少了潜在的过度拟合的风险。 另一方面,它可以充分利用每个样本。 所提出的 RFE 模块可以分为两部分:基于扩张卷积的多分支以及聚集和加权层,如图所示 2. 多分支部分分别取1,2和3作为不同扩张卷积的速率,它们都使用固定的卷积核大小3x3。 此外,我们添加了残差连接来防止训练过程中梯度爆炸和消失的问题。 收集和加权层用于收集来自不同分支的信息并对每个分支的特征进行加权。 加权操作用于平衡不同分支的表示。
明确一点,我们用RFE模块替换YOLOv5中C3模块的瓶颈,增加特征图的感受野,从而提高多尺度目标检测和识别的准确率,如图2.
3.3遮挡感知排斥损失
类内遮挡可能会导致人脸A包含人脸B的特征,从而导致较高的误检率。 斥力损失的引入可以通过斥力有效缓解这个问题。 排斥损失分为两部分:RepGT和RepBox。 RepGT损失的作用是使当前边界框尽可能远离周围的groundtruth框。 这里的周围groundtruth box是指除了bounding box本身要返回的物体之外,与人脸IoU最大的人脸标签。 RepGT损失函数的公式如下:
| (1) |
在哪里
| (2) |
式中P为人脸预测框, 是面部周围 IoU 最大的地面事实。 P 和 P 之间的重叠 定义为与真实值的交集 (IoG): 和。 是 (0, 1) 连续可微。 在函数中, 是一个平滑参数,用于调整排斥损失对异常值的敏感性。
RepBox损失的目的是使预测框与周围的预测框尽可能远离,并减少它们之间的IOU,以避免属于两个人脸的预测框之一被NMS抑制。 我们将预测帧分为多个组。 假设有g个个体面,划分形式如式(2)所示: 3. 同一组之间的预测帧返回相同的人脸标签,不同组之间的预测帧对应不同的人脸标签。
| (3) |
然后,对于不同组之间的预测框和,我们希望得到的预测框越小 和 之间的重叠区域。 RepBox 还使用 作为优化函数。 总体损失函数如下:
| (4) |
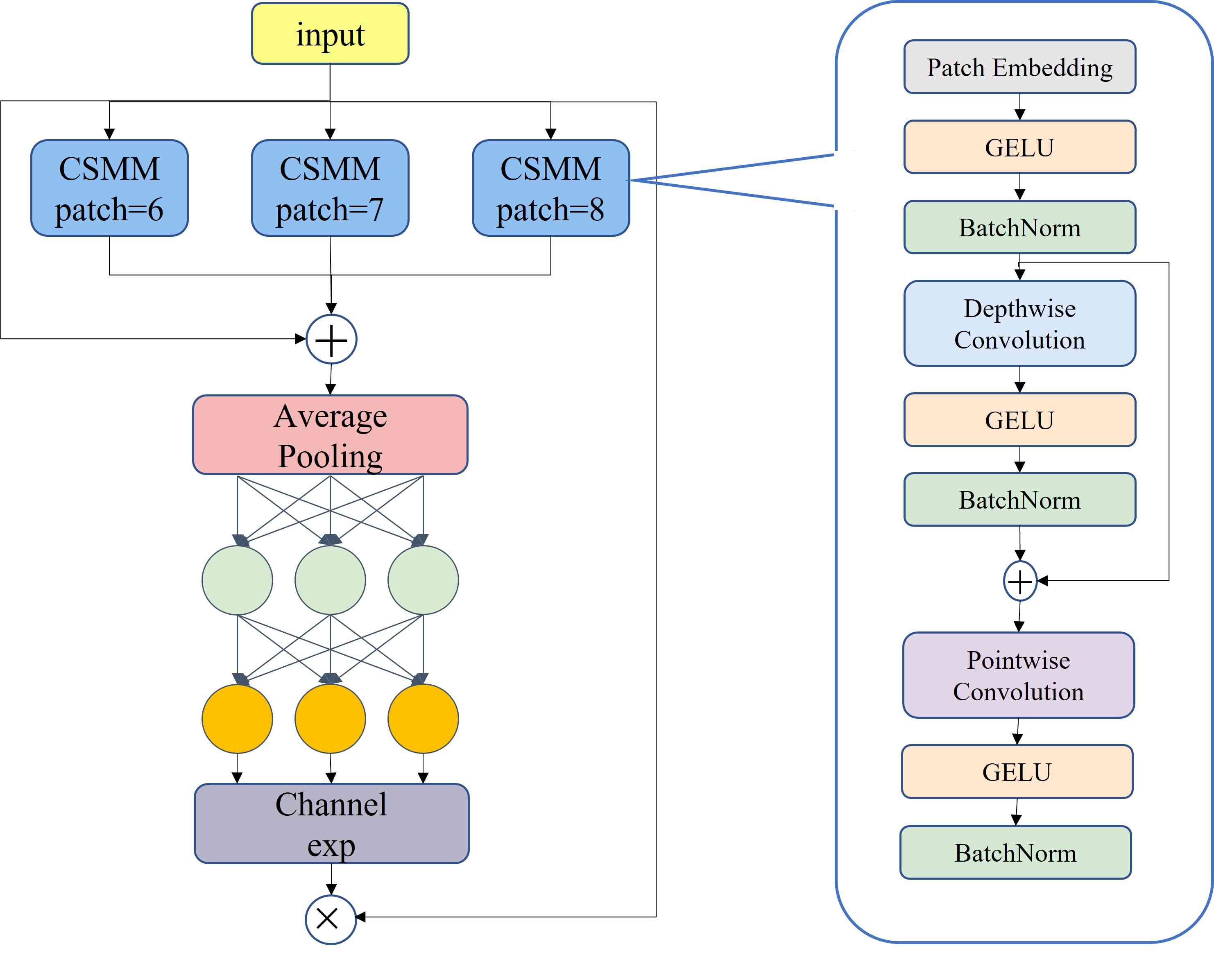
3.4遮挡感知注意网络
类间遮挡会导致对齐错误、局部锯齿和特征丢失。 我们添加多头注意力网络,即SEAM模块(见图 3),其中我们有三个目的:实现多尺度人脸检测,强调图像中的人脸区域,相反弱化背景区域。 SEAM 的第一部分是带有残差连接的深度可分离卷积。 深度可分离卷积是按深度进行操作,即逐个通道分离的卷积。 深度可分离卷积虽然可以学习不同通道的重要性并减少参数量,但它忽略了通道之间的信息关系。 为了弥补这一损失,不同深度卷积的输出随后通过逐点(1x1)卷积进行组合。 然后使用两层全连接网络来融合各个通道的信息,使网络能够加强所有通道之间的连接。 希望该模型能够通过上一步学习到的被遮挡人脸和无遮挡人脸之间的关系来弥补上述遮挡场景下的损失。 然后将全连接层学习到的输出logits通过指数函数处理,将值范围从[0, 1]扩展到[1, e]。 这种指数归一化提供了单调映射关系,使结果更能容忍位置误差。 最后将SEAM模块的输出作为注意力乘以原始特征,使模型能够更有效地处理人脸遮挡。
3.5样本加权函数
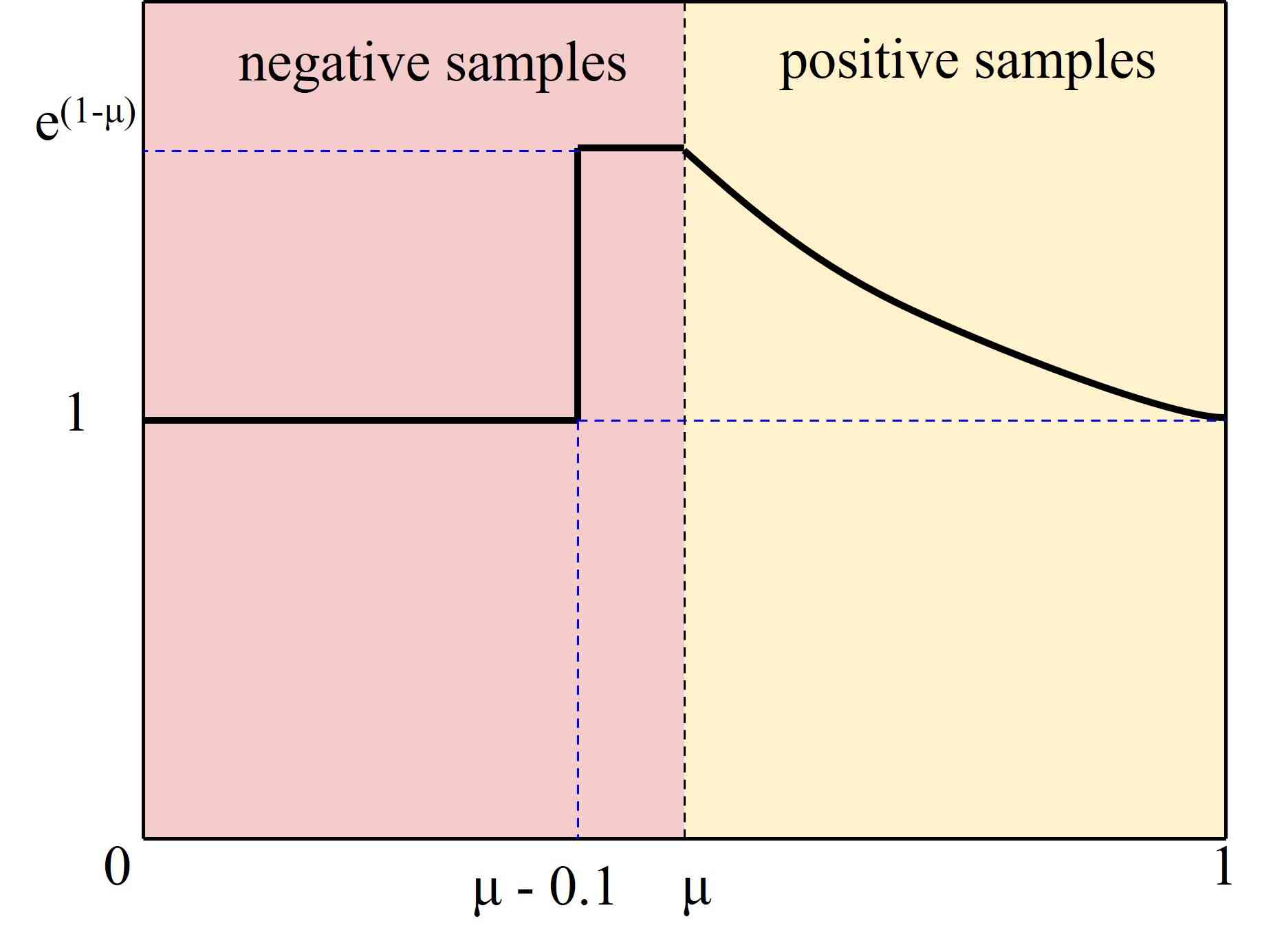
样本不平衡问题,即大多数情况下简单样本数量较多,而困难样本相对稀疏,引起了人们的广泛关注。 在我们的工作中,我们设计了一个看起来像“幻灯片”的Slide损失函数来解决这个问题。 简单样本和困难样本的区别是基于预测框和真实框的 IoU 大小。 为了减少超参数,我们将所有边界框的 IoU 值的平均值作为阈值 ,小于的为负样本,大于. 然而,由于分类不明确,边界附近的样本常常遭受较大损失。 我们希望模型能够学习优化这些样本,并更充分地使用这些样本训练到网络。 然而,此类样本的数量相对较少。 因此,我们尝试为困难样本分配更高的权重。 我们首先通过参数将样本分为正样本和负样本 。然后,我们通过加权函数Slide对边界处的样本进行强调,如图4。幻灯片权重函数可以表示为方程5。
| (5) |
3.6锚定设计策略
| Layer | Stride | Ratio | Anchor |
| P2 | 4 | 1.2 | [16, 20.16, 25.40] |
| P3 | 8 | 1.2 | [32, 40.32, 50.80] |
| P4 | 16 | 1.2 | [64, 80.63, 101.59] |
锚点设计策略在人脸检测中至关重要。 在我们的模型中,三个检测头中的每一个都与特定的锚尺度相关联。 锚杆的设计包括锚杆的宽高比和尺寸,根据P2、P3、P4的步幅设计(见表) 1)。 对于宽高比,我们根据真实人脸比例计算 WiderFace 训练集的统计数据。 这里在人脸检测中,根据统计,我们将长宽比设置为1:1.2。 对于anchor的大小,我们根据每层的感受野来设计,可以通过卷积层和池化层的数量来计算。 然而,并非理论感受野中的每个像素对最终输出的贡献相同。 一般来说,中心像素比外围像素影响更大,如图 5 (A)。 也就是说,只有一小部分区域对产值有有效影响。 实际效果可以相当于一个有效的感受野。 根据这个假设,为了匹配有效感受野,anchor应该明显小于理论感受野(具体例子见图 5 (b))。因此,我们重新设计了初始锚点大小,如表1所示。

3.7归一化高斯 Wasserstein 距离
归一化 Wasserstein Distance(NWD)是一种新的小目标检测评估方法。 首先,将边界框建模为二维高斯分布,通过其对应的高斯分布计算预测目标与真实目标之间的相似度,即根据Eqn计算它们之间的归一化wasserstein距离 6. 对于检测到的目标,无论是否重叠,都可以通过分布相似度来衡量。 NWD对目标的规模不敏感,因此更适合测量小目标之间的相似性。 在我们的回归损失函数中,我们添加了 NWD 损失来弥补 IoU 损失对于小目标检测的缺点。 但我们仍然保留 IoU 损失,因为它适合大物体检测。
| (6) |
| (7) |
其中C是与数据集密切相关的常数,是距离度量,和 是由 和 建模的高斯分布。0>
4实验
在这一部分中,我们对我们提出的方法进行了全面的消融,包括我们的注意力模块的有效性、多尺度融合金字塔结构和损失函数设计。 然后,我们比较了我们提出的检测器和其他 SOTA 人脸检测器之间的性能。
4.1数据集
我们在 WiderFace 数据集上评估了我们的模型,该数据集有 32203 张图像,其中包括超过 40 万张面孔。 它由三部分组成:40%为训练集,10%为验证集,50%为测试集。 训练集和验证集的结果可以从WiderFace官网获取。 根据难度,数据集可分为三个部分:简单、中等和困难。 其中,硬子集最具挑战性,其性能更能体现人脸检测器的有效性。 我们在 WiderFace 训练集上训练我们的模型,并在验证集和测试集上对其进行评估。
4.2训练
我们使用 YOLOv5 作为基线,方法由 PyTorch 实现。我们使用的优化器是带有动量的 SGD。 初始学习率设置为1e-2,最终学习率设置为1e-3,权重衰减设置为5e-3。 前 3 个预热阶段使用动量 0.8。 之后,动量为 0.937。 NMS 的 IoU 设置为 0.5。 我们在有 4 个 CPU 工作线程的 1080ti 上训练模型。 微调需要 100 次迭代,批量大小为 16 张图像。
4.3消融研究
在本节中,我们在 WiderFace 数据集上对各个模块进行综合实验,以评估它们对模型性能的影响。 然后对模块进行一一组合分析。 此外,还评估了所有损失函数。
| SEAM | PAN+P2 | RFE | Slide | Anchor | NWD 损失 | RPLoss | Easy | Medium | Hard | 参数 (中) | 失败 (G) |
| 94.65 | 93.00 | 83.30 | 7.063 | 16.4 | |||||||
| 95.53 | 93.82 | 84.36 | 7.464 | 17.1 | |||||||
| 93.67 | 92.14 | 83.87 | 6.101 | 17.1 | |||||||
| 95.06 | 93.60 | 85.47 | 5.097 | 17.1 | |||||||
| 95.13 | 93.41 | 83.67 | - | 17.1 | |||||||
| 94.89 | 93.75 | 84.20 | - | - | |||||||
| 94.62 | 92.87 | 83.31 | - | - | |||||||
| 95.27 | 93.63 | 83.80 | - | - | |||||||
| 95.06 | 93.64 | 85.57 | 5.201 | 17.9 | |||||||
| 95.34 | 93.85 | 85.66 | |||||||||
| 96.22 | 94.79 | 85.82 | |||||||||
| 96.30 | 94.99 | 85.94 | |||||||||
| 98.78 | 97.39 | 87.75 | 18.2 |
4.3.1SEAM 块
我们提出的 SEAM 块是注意力网络。 通过使用这个块,我们通过加强无障碍面的响应来弥补被遮挡面的响应损失。 结果如表第二行所示 2. 我们可以看到,在简单、中等和困难子集验证集上,准确率分别提高了 0.88、0.82 和 1.06。
4.3.2多尺度特征融合
4.3.3 幻灯片损失
Slide Loss函数的主要目的是让模型更加关注硬样本。 根据表格第五行的结果,Slide函数对模型在中等和困难子集上的模型略有改进。
4.3.4 锚点设计
Anchor的比例和大小与有效感受野密切相关。 不同的模型有不同的有效感受野。 根据有效感受野和脸形特征,设计的锚固件的性能影响如表第六行所示 2. 它在简单、中等和困难数据集上分别提高了 0.24、0.75、0.9。 正如我们所期望的,正确设计的锚点可以回忆起更多的小面部目标。
4.3.5NWD损失
我们首先采用 NWD 而不是 IOU 作为回归损失。 然而,结果并没有改善。 因此,我们选择保留 IoU 损失,并通过调整它们之间的比例关系来提高模型对小目标检测的鲁棒性。 因为实验结果表明,对于大中型目标,IoU测量的效果要优于NWD,并且NWD可以有效提高小目标的检测精度。 结果见表 3:
| IoU | NWD | Easy | Medium | Hard | Epochs |
| 1 | 0 | 94.4 | 92.74 | 82.91 | 20 |
| 0 | 1 | 81.13 | 84.4 | 75.77 | 20 |
| 0.5 | 0.5 | 94.62 | 92.87 | 83.31 | 20 |
| 0.4 | 0.6 | 91.13 | 90.38 | 80.11 | 20 |
| 0.6 | 0.4 | 92.87 | 91.39 | 80.91 | 20 |
4.3.6 RepGT和RepBox的平衡
受行人检测中遮挡解决方案的启发,我们将排斥损失添加到人脸检测中,并分析不同的人脸遮挡阈值,使该损失函数适用于人脸检测。 根据表第八行的结果,斥力损失函数在简单、中等和困难子集上将模型精度提高了 0.71、0.63 和 0.5。
4.4与现有人脸检测器的比较
| Method | Detector | Easy | Medium | Hard |
| Faster R-CNN | ||||
| CMS-RCNN | 0.899 | 0.874 | 0.624 | |
| HR | 0.925 | 0.91 | 0.806 | |
| Face R-CNN | 0.937 | 0.921 | 0.831 | |
| FDNet | 0.959 | 0.945 | 0.879 | |
| SSD | ||||
| SFD | 0.937 | 0.925 | 0.859 | |
| SSH | 0.931 | 0.921 | 0.845 | |
| PyramidBox | 0.961 | 0.95 | 0.889 | |
| DSFD | 0.966 | 0.957 | 0.904 | |
| SFDet | 0.954 | 0.945 | 0.888 | |
| RetinaNet | ||||
| FAN | 0.952 | 0.94 | 0.9 | |
| SRN | 0.964 | 0.952 | 0.901 | |
| DFS | 0.969 | 0.959 | 0.912 | |
| RetinaFace | 0.969 | 0.961 | 0.918 | |
| RefineFace | 0.971 | 0.962 | 0.92 | |
| YOLO | ||||
| YOLO-FaceV1 | 0.899 | 0.872 | 0.693 | |
| YOLO5Face | 0.963 | 0.956 | 0.913 | |
| YOLO-FaceV2 | 0.987 | 0.972 | 0.877 |
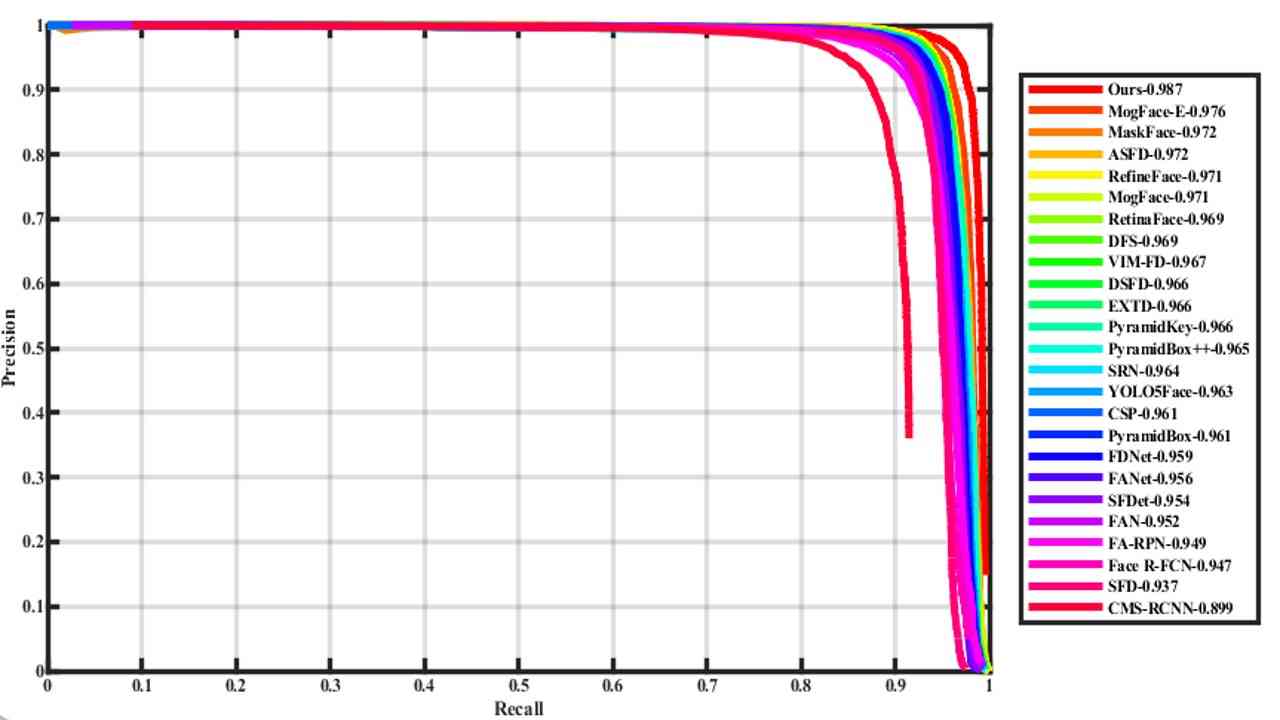
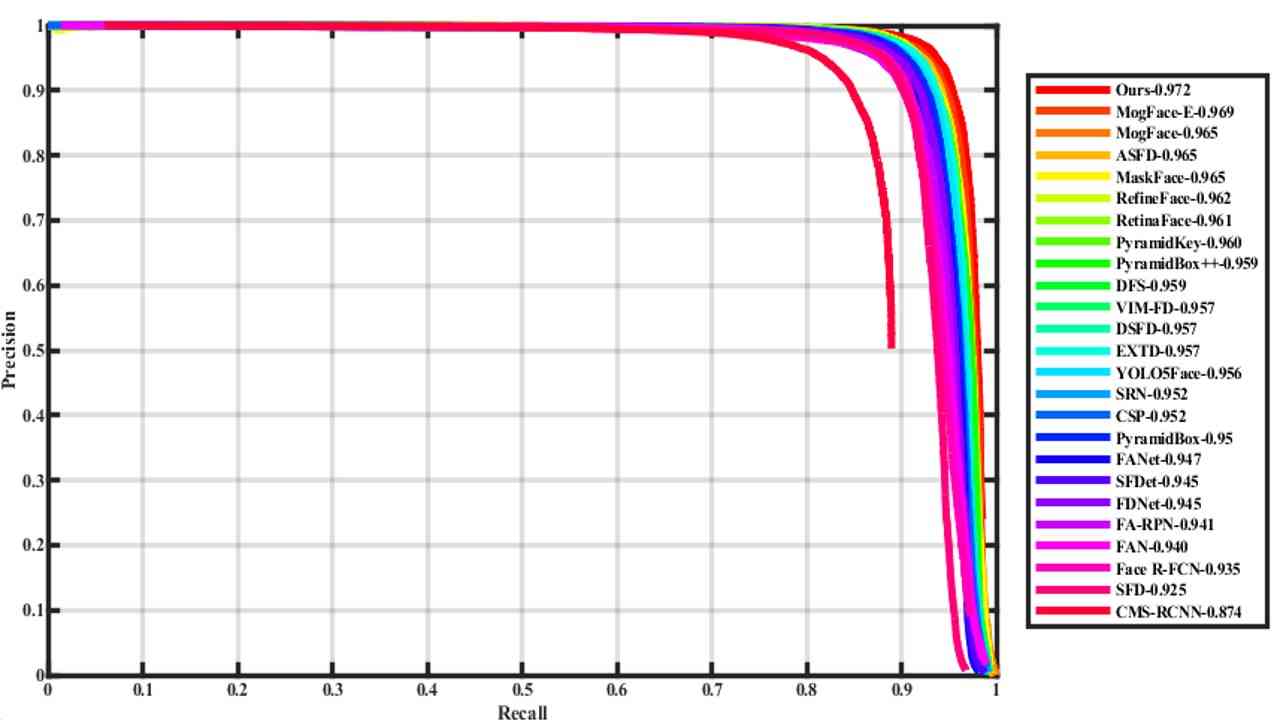
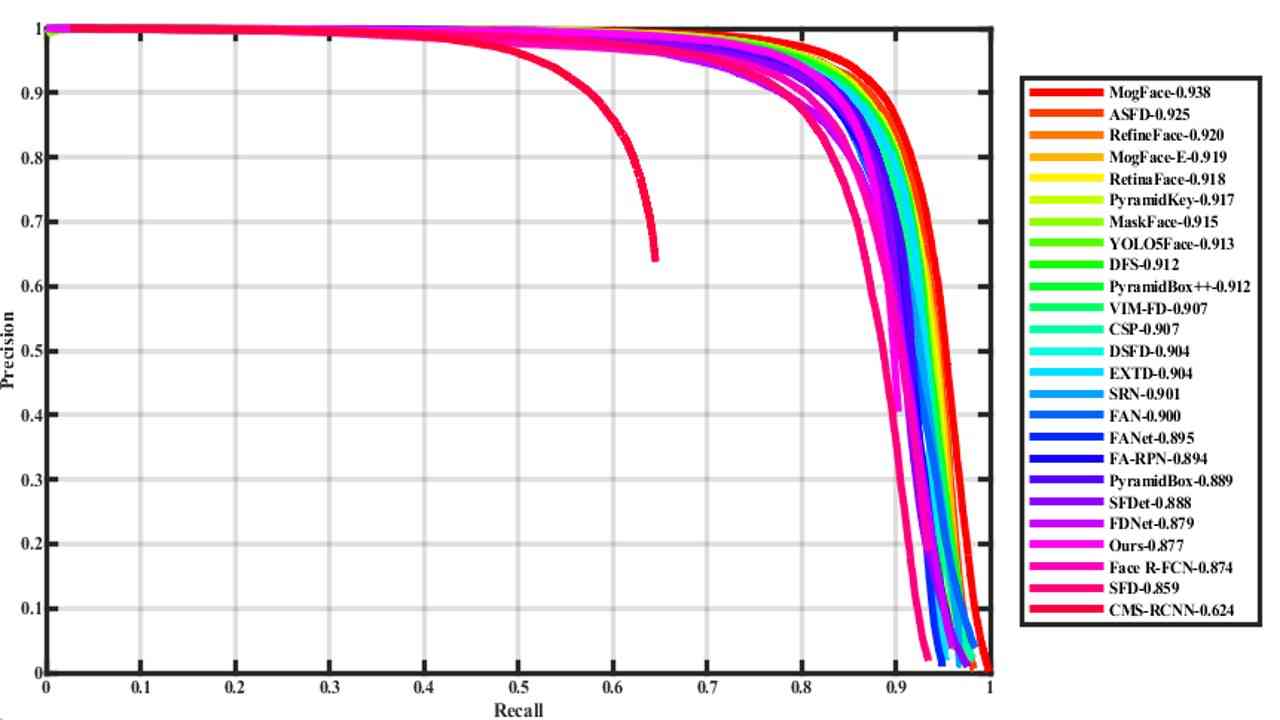
我们主要与最近推出的各种优秀的人脸检测器进行比较。 桌子 4 根据人脸检测器基于不同的通用检测器进行分类,如fast RCNN、SSD、Yolo等。 表中数据来自WiderFace官网。
我们的 YOLO-FaceV2 人脸检测器以及竞争对手的精确召回 (PR) 曲线如图 6 所示。
5结论
本文针对人脸尺度变化、易难样本不平衡以及人脸遮挡等问题,提出了一种基于 YOLOv5 的人脸检测方法 YOLO-FaceV2。 针对不同人脸尺度的问题,我们将P2层融合到特征金字塔中以提高小目标的分辨率,设计RFE模块以增强感受野并使用NWD损失来提高模型对小目标检测的鲁棒性。 我们引入了 Slide 功能来缓解易样本和难样本的不平衡。 对于人脸遮挡,我们使用SEAM模块和Repulsion损失来解决。 此外,我们使用有效感受野的信息来设计锚点。 最后,我们在 WiderFace 验证 Easy 和 Medium 子集上实现了接近或超过 SOTA 的性能。
参考
- [1] Haoxiang Li, Zhe Lin, Xiaohui Shen, Jonathan Brandt, and Gang Hua. A convolutional neural network cascade for face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015.
- [2] K. Zhang, Z. Zhang, Z. Li, and Y. Qiao. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Processing Letters, 23(10):1499–1503, 2016.
- [3] X. Shi, S. Shan, M. Kan, S. Wu, and X. Chen. Real-time rotation-invariant face detection with progressive calibration networks. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018.
- [4] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y. Fu, and A. C. Berg. Ssd: Single shot multibox detector. 2015.
- [5] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis & Machine Intelligence, 39(6):1137–1149, 2017.
- [6] T. Y. Lin, P. Goyal, R. Girshick, K. He, and P Dollár. Focal loss for dense object detection. IEEE Transactions on Pattern Analysis & Machine Intelligence, PP(99):2999–3007, 2017.
- [7] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. IEEE, 2016.
- [8] J. Redmon and A. Farhadi. Yolo9000: Better, faster, stronger. In IEEE Conference on Computer Vision & Pattern Recognition, pages 6517–6525, 2017.
- [9] J. Redmon and A. Farhadi. Yolov3: An incremental improvement. arXiv e-prints, 2018.
- [10] A. Bochkovskiy, C. Y. Wang, and Hym Liao. Yolov4: Optimal speed and accuracy of object detection. 2020.
- [11] Glenn Jocher. Yolov5. https://github.com/ultralytics/yolov5.
- [12] Y. Li, Y. Chen, N. Wang, and Z. Zhang. Scale-aware trident networks for object detection. IEEE, 2019.
- [13] J. Wang, Y. Yuan, and G. Yu. Face attention network: An effective face detector for the occluded faces. 2017.
- [14] Weijun Chen, Hongbo Huang, Shuai Peng, Changsheng Zhou, and Cuiping Zhang. Yolo-face: a real-time face detector. The Visual Computer, 37(4):805–813, 2021.
- [15] S. Yang, P. Luo, C. C. Loy, and X. Tang. Wider face: A face detection benchmark. IEEE, pages 5525–5533, 2016.
- [16] K. Oksuz, B. C. Cam, S. Kalkan, and E. Akbas. Imbalance problems in object detection: A review. IEEE Transactions on Pattern Analysis and Machine Intelligence, PP(99):1–1, 2020.
- [17] S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia. Path aggregation network for instance segmentation. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [18] M. Tan, R. Pang, and Q. V. Le. Efficientdet: Scalable and efficient object detection. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [19] S. Qiao, L. C. Chen, and A. Yuille. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. arXiv, 2020.
- [20] T. Y. Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [21] Min Chen, Xuemei Ren, and Zhanyi Yan. Real-time indoor object detection based on deep learning and gradient harmonizing mechanism. In 2020 IEEE 9th Data Driven Control and Learning Systems Conference (DDCLS), 2020.
- [22] Y. Cao, K. Chen, C. C. Loy, and D. Lin. Prime sample attention in object detection. 2019.
- [23] W. Luo, Y. Li, R. Urtasun, and R. Zemel. Understanding the effective receptive field in deep convolutional neural networks. 2017.
- [24] S. Zhang, X. Zhu, Z. Lei, H. Shi, X. Wang, and S. Z. Li. Sfd: Single shot scale-invariant face detector. In IEEE Computer Society, 2017.
- [25] S. Zhang, X. Zhu, Z. Lei, H. Shi, X. Wang, and S. Z. Li. Faceboxes: A cpu real-time face detector with high accuracy. 2017.
- [26] J. Yu, Y. Jiang, Z. Wang, Z. Cao, and T. Huang. Unitbox: An advanced object detection network. ACM, 2016.
- [27] H. Rezatofighi, N. Tsoi, J. Y. Gwak, A. Sadeghian, and S. Savarese. Generalized intersection over union: A metric and a loss for bounding box regression. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [28] Z. Zheng, P. Wang, W. Liu, J. Li, R. Ye, and D. Ren. Distance-iou loss: Faster and better learning for bounding box regression. arXiv, 2019.
- [29] Y. F. Zhang, W. Ren, Z. Zhang, Z. Jia, L. Wang, and T. Tan. Focal and efficient iou loss for accurate bounding box regression. 2021.
- [30] J. Wang, C. Xu, W. Yang, and L. Yu. A normalized gaussian wasserstein distance for tiny object detection. 2021.
- [31] A. Trockman and J Zico Kolter. Patches are all you need? arXiv e-prints, 2022.
- [32] X. Wang, T. Xiao, Y. Jiang, S. Shao, J. Sun, and C. Shen. Repulsion loss: Detecting pedestrians in a crowd. 2017.
- [33] S. Zhang, C. Chi, Y. Yao, Z. Lei, and S. Z. Li. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [34] Chenchen Zhu, Yutong Zheng, Khoa Luu, and Marios Savvides. Cms-rcnn: Contextual multi-scale region-based cnn for unconstrained face detection. 2017.
- [35] C. Chi, S. Zhang, J. Xing, Z. Lei, S. Z. Li, and X. Zou. Selective refinement network for high performance face detection. 2018.
- [36] S. Zhang, L. Wen, X. Bian, Z. Lei, and S. Z. Li. Single-shot refinement neural network for object detection. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018.
- [37] M. Najibi, P. Samangouei, R. Chellappa, and L. Davis. Ssh: Single stage headless face detector. In 2017 IEEE International Conference on Computer Vision (ICCV), 2017.
- [38] S. Yang, Y. Xiong, C. L. Chen, and X. Tang. Face detection through scale-friendly deep convolutional networks. 2017.
- [39] Songtao Liu, Di Huang, et al. Receptive field block net for accurate and fast object detection. In Proceedings of the European conference on computer vision (ECCV), pages 385–400, 2018.
- [40] J. Li, Y. Wang, C. Wang, Y. Tai, J. Qian, J. Yang, C. Wang, J. Li, and F. Huang. Dsfd: Dual shot face detector. 2018.
- [41] Z. Li, P. Chao, Y. Gang, X. Zhang, and S. Jian. Detnet: A backbone network for object detection. 2018.
- [42] T. Kong, A. Yao, Y. Chen, and F. Sun. Hypernet: Towards accurate region proposal generation and joint object detection. IEEE, 2016.
- [43] B. Singh and L. S. Davis. An analysis of scale invariance in object detection - snip. 2017.
- [44] Xu Tang, Daniel K Du, Zeqiang He, and Jingtuo Liu. Pyramidbox: A context-assisted single shot face detector. In Proceedings of the European conference on computer vision (ECCV), pages 797–813, 2018.
- [45] J. Deng, J. Guo, Y. Zhou, J. Yu, I. Kotsia, and S. Zafeiriou. Retinaface: Single-stage dense face localisation in the wild. 2019.
- [46] A. Shrivastava, A. Gupta, and R. Girshick. Training region-based object detectors with online hard example mining. In IEEE Conference on Computer Vision & Pattern Recognition, pages 761–769, 2016.
- [47] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Transactions on Pattern Analysis & Machine Intelligence, 37(9):1904–16, 2014.
- [48] S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia. Path aggregation network for instance segmentation. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.