走出 BLEU:我们应该如何评估代码生成模型的质量?
摘要。
近年来,研究人员创建并引入了大量各种代码生成模型。 由于人类对每个新模型版本进行评估是不可行的,社区采用了 BLEU 等自动评估指标来近似人类判断的结果。 这些指标源自机器翻译领域,目前尚不清楚它们是否适用于代码生成任务以及它们与人类对该任务的评估的一致性如何。 还有其他指标,CodeBLEU 和 RUBY,用于估计代码的相似性,并考虑到源代码的属性。 然而,对于这些指标,几乎没有任何研究表明它们与人类评估的一致性。 尽管如此,最近的论文仍然使用度量分数的最小差异来声称某些代码生成模型相对于其他模型的优越性。
在本文中,我们研究了 BLEU、ROUGE-L、METEOR、ChrF、CodeBLEU 和 RUBY 这六个指标在代码生成模型评估中的适用性。 我们对两个不同的代码生成数据集进行了研究,并使用人工注释器来评估在这些数据集上运行的所有模型的质量。 结果表明,对于 Python one-liners 的 CoNaLa 数据集,如果模型得分的差异小于 5 分,则没有任何指标可以准确地模拟人类对哪个模型更好的判断,并具有 的确定性。 对于由特定结构的类组成的 HearthStone 数据集,模型分数至少有 2 分的差异就足以表明一个模型优于另一个模型。 我们的研究结果表明,与常用的 BLEU 和 CodeBLEU 相比,ChrF 指标更适合代码生成模型的评估。 然而,找到与人类密切一致的代码生成指标需要额外的工作。
1. 介绍
代码生成系统是一种使源代码编写过程变得更容易、更容易访问的方法。 在常见的表述中,此类系统将意图(自然语言的描述)作为输入,并生成实现该意图的代码片段。 正确的代码生成是一个长期存在的问题(balzer1985,),如果实施得当,将有助于教育,简化非程序员的程序实现起草,并吸引编程经验有限的新程序员以给定语言(chen2021evaluating,)。 因此,拥有强大的代码生成模型可能对软件开发行业非常有利。
目前,有许多不同的代码生成模型(Yin, ; GCNN, ; tranx, ; reranking, ; chen2021evaluating, )和几个数据集(spider, ; oda, ; agashe, ; card2code, ; Docstrings, ; conala, ; lu2021codexglue, ) 用于评估这些模型。 代码生成模型通常使用准确性、BLEU 指标 (BLEU, ) 或 CodeBLEU 指标 (CodeBLEU, ) 进行评估。 BLEU 最初是为了评估自然语言处理的机器翻译质量而创建的,并且经过实证验证,它与人类对自然语言文本翻译质量的判断相关。 然而,代码生成任务不存在这样的验证。 此外,对于密切相关的代码迁移问题,Tran 等人 (RUBY, ) 表明 BLEU 结果与人类判断的相关性很弱。 对于相关的代码摘要问题,Roy 等人 (roy2021reassessing, ) 已经表明,与其他指标(例如 METEOR 或 ChrF)相比,BLEU 指标是人类判断的不太可靠的指标。
我们确定了将 BLEU 指标应用于代码生成任务时可能出现的三个问题,据我们所知,这些问题几乎尚未得到解决(RUBY, ; CodeBLEU, ):
-
•
目前尚不清楚现有指标是否适合评估代码生成模型。
-
•
目前尚不清楚指标得分有多大,以及得分差异应有多大才能表明一种模型优于另一种模型。
-
•
目前尚不清楚这些指标与人类对现有代码生成数据集的判断的相关性如何。
在我们的研究中,我们考虑两个不同的数据集。 CoNaLa 数据集 (conala, ) 是 Stack Overflow 上发布的问题数据集111Stack Overflow: https://stackoverflow.com/ 以及 Python 中的解决方案。 解决方案很短,通常只有一行。 Card2code Hearthstone (card2code, ) 是一个专门用于生成类的数据集,这些类是《炉石传说》游戏中使用的卡牌的描述。 这些类是严格的,并且每个片段的大多数类结构都是相同的。 对于每个数据集,我们考虑了几种用于代码生成的机器学习模型。
对于CoNaLa数据集,我们比较了五种不同模型的结果:1)CoNaLa基线(conala,),2)Codex (chen2021evaluating,),3)没有预的TranX训练 (tranx, )、4) TranX 预训练,以及 5) TranX 预训练和重新排名 (reranking, )。 虽然是公开的,但所选模型的质量和复杂性差异很大,因此可以判断模型的质量、指标值和人工评估之间的关系。 对于 Hearthstone 数据集,我们比较了之前在此数据集上评估的两个模型的结果:NL2Code (Yin, ) 和 GCNN (GCNN, )。
为了解决自动化指标的适用性问题,我们进行了配对引导重采样(efron1983estimating,)。 我们考虑模型的 BLEU、METEOR、ROUGE-L、ChrF、CodeBLEU 和 RUBY (BLEU, ; ROUGE, ; METEOR, ; RUBY, ; CodeBLEU, ; popovic2015chrf, ) 模型的度量分数。
为了解决人工评估和计算机指标分数之间的相关性问题,我们对生成的片段进行人工评估。 软件开发人员评估了建议的片段是否有助于解决所提出的问题,评分范围为 0 到 4。 对于 CoNaLa 数据集,有 12 名开发人员参与了评估,我们从每个片段的不同开发人员那里得到了平均 分。 对于《炉石传说》数据集,有四个评分者,每个评分者都会评估整个数据集。
我们收集的每个片段的评分数量不足以分析片段级别的指标性能,正如 Mathur 等人 (mathur2020tangled, ) 认为每个片段有必要有 15 个评分才能提供稳定的评分分数。 因此,我们重点关注语料库级别的模型比较。 可用的 ML 模型集不够大,无法研究指标分数差异的显着性:例如,对于 CoNaLa 数据集,只有 5 个原始模型,因此只有 10 个不同的模型对可供比较。 为了提供语料库级别分数差异的统计分析,我们用一组合成模型增强了原始模型集。 其中,我们按照 Roy 等人 (roy2021reassessing, ) 将部分模型预测替换为具有更高或更低人类评估分数的预测。
我们的发现和贡献如下:
-
•
我们发现现有的指标不适合评估代码生成,因为对于每个数据集和每个指标,指标在超过 5% 的情况下与人类的判断不一致。
-
•
我们发现,在超过 5% 的情况下,两个模型在 0-100 分制上的指标得分差异在统计上不显着(0-100 分)。 这一发现不依赖于人类评估,并且表明当报告指标分数的增加少于两分时,有必要测试统计显着性。
-
•
我们发现,当考虑到人类评估时,如果分数差异小于 5 分,所有指标在 CoNaLa 数据集上都是不可靠的;如果分数差异小于 2 分,所有指标在 HearthStone 数据集上都是不可靠的。 在我们考虑的所有指标中,ChrF 和 ROUGE-L 是代码生成任务中表现最好的指标。
此篇文章的结构如下。 在第 2 节中,我们描述了代码生成问题,简要描述了我们用于评估生成代码的指标,并描述了 Roy 等人 (roy2021reassessing, ) 的类似研究,该研究针对代码摘要问题。 在第 3 节中,我们将自动化指标的使用与基于测试的评估进行比较,并概述自动化指标当前使用可能存在的问题。 在第 4 节中,我们描述了我们的研究方法:概述研究流程、解释我们对数据集和模型的选择、研究问题以及我们回答这些问题的方法。 在第 5 节中,我们展示了我们的结果并回答了上一节中提出的 RQ。 在第6节中,我们总结了我们的发现,为想要使用自动指标评估代码生成模型的从业者提供指导,并提出未来工作的方向。 在第 7 节中,我们解决了对我们研究有效性的威胁。 在第 8 节中,我们总结了我们的论文。 在附录A中,我们更详细地描述了我们研究的指标。 最后,我们的复制包可以在 https://github.com/JetBrains-Research/codegen-metrics 找到。
2. 背景
2.1. 代码生成
代码生成是一个长期存在的问题(balzer1985, ),良好的代码生成模型可以减少编写代码的障碍,自动化工程师的一些日常任务,并帮助非程序员创建编程他们的问题的解决方案。 这个问题也与机器学习在编码中的其他应用有关。 在代码相关任务的更大背景下,代码生成是与代码摘要互补的任务,与代码迁移和代码完成密切相关。
深度学习的发展使得各种神经模型能够成功应用于代码生成问题。 特别是,Ling 等人(card2code, )提出了一种序列到序列模型来从自然语言描述生成代码。 Yin 等人 (Yin, ) 和 Rabinovich 等人 (Rabinovich, ) 修改了标准解码器,该解码器通过首先生成 Abstract 语法树来生成标记序列以强制执行语法规则然后将其转换为代码。 Sun 等人(GCNN, )建议用基于语法的结构卷积神经网络替换循环神经网络。 与循环神经网络不同,卷积神经网络甚至可以跟踪分析数据的遥远区域之间的上下文。 相比之下,当相关信息相距较远时,循环神经网络无法跟踪上下文,也称为长依赖问题(hochreiter, ; bengio, )。 Wei 等人 (Wei, ) 建议对代码生成和代码摘要模型进行双重训练,以提高两个模型的质量。
与循环神经网络相比,基于 Transformer 架构(vaswani2017, )的模型同时处理整个序列,这在计算速度和捕获远程标记之间的依赖关系方面都更加高效。 如今,由于 Codex (chen2021evaluating, )、AlphaCode (alphacode, ) 和 CodeParrot 等基于 Transformer 的大型模型,我们观察到代码生成模型质量的快速进步.222CodeParrot’s page on HuggingFace: https://huggingface.co/codeparrot/codeparrot
表 1 总结了研究人员在上述论文中使用的神经网络类型和指标。
| Paper | NN type | Metrics | Year |
| Barone et al. (Docstrings, ) | NMT | BLEU | 2017 |
| Chen et al. (chen2021evaluating, ) | Transformer | BLEU, Pass@k | 2021 |
| CodeParrot | Transformer | Pass@k | 2021 |
| AlphaCode (alphacode, ) | Transformer | Evaluation on Codeforces | 2022 |
| Ling et al. (card2code, ) | RNN | BLEU, Accuracy | 2016 |
| Lu et al. (lu2021codexglue, ) | RNN, Transformer | BLEU, Accuracy, CodeBLEU | 2021 |
| Rabinovich et al. (Rabinovich, ) | RNN | BLEU, Accuracy, F1 | 2017 |
| Ren et al. (CodeBLEU, ) | PBSMT, Transformer | BLEU, Accuracy, CodeBLEU | 2020 |
| Sun et al. (GCNN, ) | CNN, RNN | Accuracy, BLEU | 2019 |
| Wei et al. (Wei, ) | RNN | BLEU, Percentage of valid code | 2019 |
| Yin et al. (Yin, ) | RNN | BLEU, Accuracy | 2017 |
| Yin et al. (tranx, ) | RNN | Execution accuracy, exact match accuracy | 2018 |
| Yin et al. (reranking, ) | RNN | BLEU, Accuracy | 2019 |
2.2. 代码生成模型的评估
为了能够跟踪模型的改进,有必要评估其性能。 人工评估是大多数机器翻译或机器生成问题的黄金标准。 然而,人工评估也非常昂贵且缓慢,并且在模型开发过程中对每个生成的样本进行人工评估是不切实际的。 因此,拥有一个易于计算的指标来评估模型的输出至关重要。
代码生成任务也不例外。 代码生成的评估方法可以分为三类:
-
(1)
来自机器翻译领域的指标;
-
(2)
为比较代码片段而开发的指标;
-
(3)
运行并测试生成的代码。
此外,我们详细讨论这三者。
2.2.1. 机器翻译的指标
如表 1所示,代码生成模型的质量通常通过 BLEU 指标得分(BLEU, ) 来评估> 或准确性。 BLEU(双语评估研究)指标最初是为机器翻译文本的自动质量评估而开发的指标。 BLEU 度量是基于修改的 -gram 精度度量的语料库级度量,并对比参考句子短的候选句子进行长度惩罚。
研究人员还考虑其他机器翻译指标:
-
•
ROUGE-L (ROUGE, ) 是一种面向召回的度量,用于查找参考和候选之间的最长公共子序列。
-
•
METEOR (denkowski2014meteor, ) 是一种混合召回率-精度度量,它还会惩罚不具有参考示例中相邻的相邻一元组的候选者。
-
•
ChrF (popovic2015chrf, ) 是字符 n-gram F-score 指标,其中 F-score 计算中的精度和召回率是对 1 到 6-gram 字符进行平均。
除了上述指标之外,研究人员经常将准确性报告为附加指标。 虽然它支持一个模型优于另一个模型的事实,但由于过于严格且鲁棒性较差,很少用作生成任务中的主要指标。 因此,我们在研究中不分析准确性,因为我们专注于用于直接模型比较的指标。
2.2.2. 为代码设计的指标
红宝石。 Tran 等人 (RUBY, ) 建议使用 RUBY 指标作为自然语言指标的替代方案。 事实上,尽管 BLEU(如 METEOR 和 ROUGE-L)最初是为了评估自然语言的机器翻译模型而创建的,但它广泛用于评估代码生成、代码迁移和代码摘要模型。 Tran 等人 (RUBY, ) 对 BLEU 进行了实证研究,以检查其在代码迁移任务中的适用性。 在他们的论文中,他们表明 BLEU 指标与人类评估的相关性相当弱,为 0.583。 作者还构建了一个综合数据集来说明 BLEU 可能会为那些质量与人类评分者的角度不同的模型产生类似的结果。 为了解决这个问题,作者设计了一个新的度量 RUBY,它考虑了代码结构。 该指标比较参考和候选的程序依赖图(PDG);如果无法构建 PDG,则它会回退到比较摘要语法树 (AST),如果也无法构建 AST,则该指标会比较(标记化的)参考 之间的加权字符串编辑距离> 和候选序列。
代码BLEU。 Ren 等人(CodeBLEU, )提出了一种名为CodeBLEU的新指标来评估代码生成、代码翻译和代码细化任务的生成代码的质量。 CodeBLEU 是一个复合指标,其分数是 4 个不同子指标的加权平均值,这些子指标以不同的方式处理代码:作为数据流图、作为 Abstract 语法树和作为文本。 对于文本,CodeBLEU 提供了两种不同的子指标,其中一种将所有标记视为同等重要,另一种则为关键字赋予更高的权重。
2.2.3. 基于测试的评估
最近的大型模型令人印象深刻的性能(chen2021evaluating,;alphacode,)允许使用更接近实际应用的评估技术:在预先编写的单元测试和检查上实际运行生成的代码是否解决了所提出的问题。 例如,Codex (chen2021evaluating, ) 的作者还提出了一个名为 HumanEval 的数据集,其中包含编程任务和验证生成代码正确性的测试。
虽然这种方法是合理的,但我们认为,目前它还不能完全取代依赖于使用自动化指标的现有评估技术。 为了应用基于测试的评估,研究人员需要为每个特定的代码生成设置精心创建数据集。 此外,所研究的模型应该通过足够多的测试,以便可靠地区分它们。
2.3. 代码摘要度量研究
自动化指标用于各种其他与代码相关的生成任务,例如代码翻译、代码摘要或代码细化(lu2021codexglue, )。 最近,Roy 等人(roy2021reassessing, )研究了自动化指标对于代码摘要任务的适用性,该任务与代码生成密切相关。 对于此任务,BLEU 等指标被广泛用作人类评估的代理。 作者表明,根据任何考虑的指标,语料库得分相差小于 1.5 分的模型之间不存在统计上的显着差异。 此外,如果根据指标,语料库分数的差异小于两分,那么作者考虑的所有指标都不是人类评估的可靠代理。 在 Roy 等人考虑的所有指标中,METEOR、ChrF 和 BERTScore 在语料库级别上显示出与人类判断的最佳一致性。 由于 Roy 等人对与代码生成密切相关的任务的度量性能进行了广泛的研究,因此我们采用了他们在研究中使用的许多方法。
2.3.1. 数据集和标签
Roy等人使用LeClair等人的Java代码摘要数据集(leclair2019recommendations, )。 他们从中随机抽取 383 个片段,并使用不同的模型生成 5 个摘要。 然后,人工注释者按照五点李克特量表评估生成的五个摘要和参考摘要,以评估每个摘要的简洁性、流畅性和内容充分性。 他们还给出了 0-100 分的直接评估 (DA) 分数,以反映他们对摘要总体质量的看法。 仅使用直接评估分数来分析相对指标绩效。
2.3.2. 语料库级别的指标评估
Roy 等人对指标适用性的语料库级别评估追求两个略有不同的目标。 首先,作者感兴趣的是这些指标是否能够区分现有模型的质量。 为此,他们对 383 个片段数据集进行了随机显着性测试,发现在研究中考虑的五个模型中,最好的五个模型的分数差异并不具有统计显着性。 需要强调的是,这种统计差异的缺乏仅是从指标分数中发现的,并不依赖于人工标记。
语料库级指标评估的第二个目标是确定常用的语料库级指标是否反映了人类对生成摘要的质量评估。 可用的机器学习模型相对短缺(Roy 等人在他们的研究中使用了五种代码摘要模型)。 因此,不可能直接研究人类认为一个模型比另一个模型更好所需的度量分数差异——没有足够的模型对来获得有关模型分数差异的足够数据。 然而,如果有更多的独立模型,研究人员将不得不标记更多的模型输出,从而增加研究的成本和劳力。 为了在不增加要标记的摘要数量的情况下获得更多的度量分数多样性,Roy 等人使用合成模型。
合成模型是一种基于五个原始模型之一生成一组摘要的模型,其中不同比例的摘要被其他模型的预测替换。 特别是,为了创建一个将原始模型 A 提高 1% 的综合模型,作者用其他模型的更好预测替换了该模型预测的 1% 的摘要。 预测的质量根据人类 DA 评分进行评估。 Roy 等人创建了一组合成模型,然后选择其中的 100 个。 然后,他们将它们添加到五个原始模型中,并根据度量分数差异以及差异大小的统计显着性对几个不同的桶进行成对比较。 例如,可以针对两个和五个之间统计上显着的度量差异来定义存储桶。 对于每一对,Roy 等人还计算了其相应的人类 DA 分数差异的显着性。 然后可以通过查看度量分数和人类评估分数之间的一致性来确定语料库级度量的有效性。 对于可靠的自动评估指标,人们期望在指标分数和人类评估分数的显着差异之间找到一一对应的关系。
使用成对比较方法,Roy 等人能够分析以下内容:
-
•
根据每个指标,他们发现给定桶中有多少对,该对中的两个模型显着不同。 这可以推断出两个模型输出的度量分数的差异是必要的,因此从度量的角度来看,这两个模型也将存在显着不同。
-
•
对于每个存储桶和每个指标,他们都会考虑一组对,其中根据指标,一个模型明显优于另一个模型。 然后,对于每一对,他们根据人类评估检查其中的两个模型是否也存在显着差异。 这使他们能够研究每个指标的 I 类错误,并检查它在不同存储桶之间的变化。
-
•
对于每个存储桶和每个指标,他们根据指标考虑两个模型没有显着差异的对组。 然后,对于该组中的每一对,他们根据人类评估检查其中的两个模型是否存在显着差异。 这使他们能够研究每个指标的 II 类错误,并检查它在不同桶之间的变化。
Roy等人通过分析发现,当度量差异小于两点时,自动评估度量无法准确捕获两种方法之间摘要质量的差异。 METEOR、BERTScore 和 ChrF 在 I 类和 II 类错误率方面表现最好。 无论差异大小如何,BLEU 都具有最高的 I 类错误率。
2.3.3. 片段级分析
Roy 等人还考虑了片段级别的指标性能。 原则上,片段级度量结果分析可以通过跟踪模型的细粒度性能来提供优于语料库级分析的优势。 为了进行片段级分析,Roy 等人使用直接评估相对排名技术,该技术比较两个片段的成对相对分数 (ma2019results, )。 该技术依赖于直接评估评分,不能应用于五分制的注释。
3. 动机
在机器学习管道的验证阶段使用指标并比较不同的模型。 然而,如果人工评估是黄金标准,则所使用的指标应尽可能与人工判断保持一致。 例如,在机器翻译中,各种指标之间每年都会进行一场竞赛,最佳指标是最能模拟人类判断的指标(ma2018results, ; ma2019results, )。
即使过去已使用某些指标(例如 BLEU)来模拟人类判断,考虑与人类评估可能具有更好相关性的其他指标可能会有所帮助。 自然语言生成中也出现了类似的情况:尽管 BLEU 最初被应用于该领域,但后来发现,在某些自然语言生成任务中,基于单词重叠的度量(例如 BLEU)与人类判断的相关性非常低,例如作为对话响应生成 (liu, )。
在本节的其余部分中,我们将详细讨论为什么研究代码生成的自动化指标很重要,以及在这方面哪些问题值得回答。
3.1. 指标和基于测试的评估
随着最近推出 HumanEval (chen2021evaluating, )(一个允许在接近实际的设置中运行和测试生成的 Python 代码的数据集),自动化指标的使用似乎很快就会过时。 然而,我们认为在不久的将来情况不会如此。
首先,收集基于测试的评估数据集需要大量的人力来开发一组任务并用测试覆盖它们。 鉴于代码生成任务可以以不同的方式制定并应用于不同的语言和领域,因此每种特定情况都需要单独的手动制作的评估系统。 因此,在新领域中采用代码生成时,使用自动化指标非常有帮助。
其次,像 Codex 这样的大型模型的训练和推理既昂贵又具有技术挑战性(chen2021evaluating, )。 因此,一个重要的研究方向是开发更小的代码生成模型,这些模型尚未达到与基于 Transformer 的大型模型相媲美的质量。 对于较小的模型,像 HumanEval 这样的评估框架会导致指标分数较差,并且在这种情况下它们对模型比较的鲁棒性仍然是一个悬而未决的问题。
最后,即使两个模型生成的代码没有通过任何测试,仍然可以说哪一段代码更接近正确的解决方案。 例如,对于“摆脱字典 d 中的无值”问题以及下面给出的两段代码,第一段代码更接近正确的解决方案,即使它仍然没有通过测试。
1. print(dict((k,v) for k,v in d.items() if v)))
2. list(d.values())
因此,即使生成的代码片段未通过测试,也能够评估生成的代码片段的质量非常重要,因为开发人员可能会发现某些生成的代码片段更容易修复并集成到他们的代码中。
3.2. 现有指标是否适合代码生成?
机器翻译指标是针对自然语言开发的,没有考虑编程语言的属性。 由于多种因素,此类指标的使用对于代码生成评估可能不是最佳的。
3.2.1. 编程和自然语言之间的差异
编程语言有严格的句法结构,而自然语言结构则比较宽松。 例如,虽然交换自然语言句子中的两组标记通常不会强烈影响其含义,但这种转换通常会使代码片段无效。 其次,机器翻译(MT)指标衡量模型输出的词汇精度,而对于生成的代码,我们希望评估其功能。
可以使 MT 指标对代码更加友好,例如,可以根据其出现顺序重命名候选变量和引用中的所有变量,从而消除由于不同的命名约定。 然而,如果不考虑代码结构,某些问题显然无法得到解决。 因此,考虑到代码片段的结构和语法的指标可能会更好地代表人工评估。
3.2.2. BLEU 在其他任务中表现优于
人工评估是评估代码生成模型质量的最佳选择,并且被认为是许多不同任务中指标评估的基本事实,请参见例如(reiter2018结构化,)。 然而,由于人工评估的成本非常高,显然不可能让一组程序员对模型的每个新输出进行评估。 首先,尚不清楚 BLEU 或任何其他指标分数是否与代码生成任务的人工评估良好相关。 机器翻译指标的原始论文(BLEU, ; ROUGE, ; METEOR, ; popovic2015chrf, ) 包含的研究表明指标分数与人类对机器翻译任务的判断之间存在高度相关性。 然而,Reiter (reiter2018structed, ) 的评论表明,BLEU 与人类的相关性对于自然语言生成任务来说很差,BLEU 只能用于评估机器翻译 NLP 系统。
对于密切相关的代码迁移问题,结果表明,BLEU 分数与人类成绩之间的相关性为 0.583,该相关性相当弱(RUBY, )。 还有一项关于 BLEU、准确度和 CodeBLEU 指标 (CodeBLEU, ) 的指标与人类相关性的研究,该研究表明 CodeBLEU 指标比准确度或 BLEU 与人类意见的相关性更好。 然而,这项研究没有考虑其他指标。 最后,Roy 等人(roy2021reassessing, )对代码摘要问题的自动化指标的适用性进行了广泛的研究,发现事实上的标准 BLEU 指标是最差的指标之一。从他们考虑的六个指标中评估代码摘要模型。
所有这些观察结果都强调,特定指标的适用性很大程度上取决于问题。 因此,使用成功解决一个问题的指标来解决另一个问题可能是没有根据的。
3.2.3. 从指标到人工评估的转化
目前尚不清楚指标分数的增加与代码片段“真实”质量的增加是否呈线性相关。 为了便于说明,让我们考虑 CoNaLa 数据集中的一项任务:
任务:连接字符串列表['a', 'b', 'c']基线模型解决方案: 设置(['a','b','b'])最佳 tranx 重新排序解决方案: ''''''.join(['a','b','c'])
尽管基线片段未能解决任务问题(甚至无法重现需要连接的字符串列表),但它的 BLEU 分数相对较高,为 48.09。 第二个片段成功解决了问题,BLEU 得分为 100。
现在,让我们考虑两个不同模型 A 和 B 的假设输出。 两个输出的 BLEU 均为 50,但对于模型 A,每个候选者的 BLEU 为 50,并且质量与上述类似,而对于模型 B,一半候选者的 BLEU 为 0,另一半的候选者为 BLEU 100。 在这种情况下,可能有人认为模型 B 比模型 A 更好,即使它们具有接近的语料库级别 BLEU 分数:根据上面的示例,模型 A 始终可以生成几乎不相关的代码片段,而模型 B 则生成完美的代码片段一半情况下的代码。
如果人类评估和指标值之间的依赖性不是线性的,我们就不能简单地对所有片段的指标值进行平均以反映模型的人类评估。 此外,可能还有其他原因导致 BLEU 分数和人类分数可能无法很好地相关,因此有必要研究两者之间的相关性,以便能够推断出如何解释 BLEU 分数并从中评估模型质量的知识。
3.3. 我们正确使用自动化指标吗?
使用自动化指标评估模型的常见方法是报告单个语料库级别的数字(Yin, ; Rabinovich, ; tranx, ; lu2021codexglue, )。 虽然这种方法很简单,并且在训练过程中可能非常实用,但目前尚不清楚指标分数的原始差异如何转化为差异的统计显着性的陈述。
在代码生成领域,不同模型的比较通常通过简单地比较它们的 BLEU 或 CodeBLEU 分数来完成,在整个测试数据集上取平均值(参见 例如, (Yin, ; Rabinovich, ; tranx , ; lu2021codexglue, ))。 然而,当声称从例如 BLEU 分数 29 提高到 BLEU 分数 30 时,很少得到关于改进的统计显着性的数据支持。 正如 Roy 等人 (roy2021reassessing, ) 所表明的,对于密切相关的代码摘要任务,度量分数的微小差异在统计上是微不足道的,代码生成可能存在相同的现象。
因此,重要的是要研究特定数据集的两个模型的度量分数之间的差异应该有多大,才能声称其中一个模型比另一个模型具有所需的置信度更好。
4. 方法
我们在部分3中列出的问题促使我们提出以下研究问题:
-
RQ1
所考虑模型的性能在语料库级别上是否存在显着差异?
-
RQ2
自动化指标的结果有多显着,两个模型的语料库级指标分数差异应该有多大才能声称一个模型(根据给定指标)比另一个具有预定义显着性的模型更好?
-
RQ3
语料库级别的指标分数在多大程度上反映了人类对生成代码的评估?

受 Section 2.3 中详细描述的 Roy 等人 (roy2021reassessing, ) 工作的启发,管道我们的做法如下:
-
1.
我们收集模型在我们考虑的数据集上的输出。
-
2.
我们评估生成的代码片段的自动化指标,获取每个生成的代码片段的每个指标分数。
-
3.
我们对生成的片段进行人工评估(下面将详细描述),为每个生成的片段收集一组人工评分。
-
4.
使用获得的一组人类评分,我们通过将评分与 M-MSR 算法 (ma2020adversarial, ) 聚合在一起来获得“真实”人类评分,为由专家。 我们使用Ustalov等人(HCOMP2021/CrowdKit, )实现的M-MSR算法。
-
5.
使用模型的输出,我们通过将一些预测替换为获得更高或更低人类评估分数的预测来创建合成模型。 例如,为了获得一个改进了 1% 预测的合成 tranx-annot 模型,我们考虑其输出,并用其他模型提供的最佳预测替换 1% 的最差预测。 预测的质量来自人类评估分数。
-
6.
对于在同一数据集上评估的每一对合成和非合成模型,我们进行配对引导重采样。 我们这样做是为了根据指标分数找出其中一个模型优于另一个模型的统计显着性。 我们使用 阈值来声明模型之间存在统计显着差异。
-
7.
对于人类评估的每个数据集以及对其评估的每对模型,我们对地面真实等级进行配对引导重采样。 我们使用统计测试结果来检查我们可以根据人类的意见推断出其中一个模型比另一个模型更好的统计显着性。
-
8.
继 Mathur 等人 (mathur2020tangled, ) 和 Roy 等人 (roy2021reassessing, ) 之后,我们对 CoNaLa 和 Hearthstone 数据集的人类评估和语料库级别指标进行了成对模型比较。 我们首先计算在给定数据集上评估的所有模型对的语料库级别指标分数的差异。 然后,我们根据指标得分的差异将这些模型对分为几个桶;我们还有一个额外的容器用于存放指标无法区分的对。 对于每个分区中的每对模型,我们都要检查人类评价与度量评价是否一致,即人类是否区分了这对模型。
在片段级别上对指标进行比较分析会很有趣。 然而,Mathur 等人 (mathur2020tangled, ) 认为,每个片段有必要收集至少 15 次人工评估,以便提供稳定的分数并分析片段级别的指标性能。 由于我们能够为 Hearthstone 数据集的每个片段收集 4 个等级,为 CoNaLa 数据集的每个片段收集 4.5 个等级,因此我们选择不分析片段级别的指标性能。
4.1. 数据集和模型
在我们的研究中,我们考虑两个不同的数据集:CoNaLa (conala, ) 和 Card2code Hearthstone (card2code, )。 我们关注包含通用Python代码的数据集,留下非Python数据集,例如Spider(包含SQL)(spider,)和JuICe(包含Jupyter Notebooks)(juice,) 超出范围。 我们还忽略了 CodeXGLUE 数据集 (lu2021codexglue, ),因为 CodeXGLUE 数据集中的代码到文本问题来自 Concode 数据集 (iyer2018mapping, ),该数据集专注于Java代码。 鉴于 CodeXGLUE 数据集最近非常受欢迎,稍后将我们的研究扩展到该数据集将会很有趣。
对于这两个数据集,我们使用作者在之前的作品中建议的模型。 我们采用作者提供的原始实现、超参数,以及(如果可能)原始训练权重或模型生成的代码。
4.1.1. 科纳拉
CoNaLa 数据集由 Yin 等人 (yin2018learning, ) 收集,包含 2,879 个示例(分为 2,379 个训练示例和 500 个测试示例),从 Stack Overflow 抓取,然后由人类注释者手动整理。 除了主数据集之外,Yin 等人还提供了一个大型自动挖掘数据集,其中包含作为训练意图的 Stack Overflow“如何”问题和作为该意图的候选实现的答案中代码块的连续行。 该数据集有超过十万个示例。 我们考虑的一些模型将其用于训练。 CoNaLa数据集具有以下特点:
-
•
CoNaLa 数据集的意图种类繁多,涵盖了 Python 中使用的许多方法(相比之下,例如,Card2Code 数据集 (card2code, ) 专门用于生成结构非常僵化的类)。
-
•
CoNaLa 数据集中的意图是详细的,并以自然语言编写,这与例如 Docstrings (Docstrings, ) 数据集区分开来,后者的意图相当短并且在很多情况下,人类程序员在仅给出意图的情况下编写正确的代码时会遇到问题。
-
•
在该数据集上评估的公开模型有相对丰富的选择(与其他数据集相比),使我们能够进行更多比较。
-
•
在 CoNaLa 数据集上评估的性能最佳模型的 BLEU 分数约为 30,可以生成高质量和低质量的测试片段。 例如,在 Docstrings 数据集上评估的最佳模型具有 BLEU 12.1,这对应于大多数片段质量较低,使得人类评分者更难可靠地区分它们。
-
•
CoNaLa 片段通常非常短,其中绝大多数都是单行代码。 它限制了考虑代码结构的 CodeBLEU 和 RUBY 指标的可能可用性。
我们在 CoNaLa 数据集上评估了五个模型。 我们考虑的模型之一是基线 CoNaLa 模型 (conala, ),另一个是 Codex (chen2021evaluating, ),另外三个是基于 Transformer 的 tranX 型号。 tranx-annot 模型在主要 CoNaLa 数据集上进行训练;在主要 CoNaLa 数据集上进行训练之前,best-tranx 还在更大的自动挖掘版本的 CoNaLa 上进行了预训练; best-tranx-rerank 是第二个模型的增强版本,它使用重新排名后处理(即重新排名-最佳预测以提高质量的输出)。 对于每个模型,我们都使用复制包中提供的标准设置。 最后,我们在问答模式下运行 Codex (chen2021evaluating, ),特别是其 davinci 版本。 按照作者的建议,我们不会在 CoNaLa 部分上进行 Codex 训练,而是提供三个代码片段作为示例。 也就是说,每个代码片段都是通过用于 Python 代码生成的 OpenAI Q&A API 生成的,并且提供了三个意图片段对作为示例。 需要强调的是,模型的确切设置(例如超参数选择或配置)对于我们的研究并不重要,因为我们不会尝试估计哪个模型客观上更好,而是专注于研究输出的指标评估代码生成模型。 因此,输出应该满足的唯一重要要求是,不同的模型应该为相同的问题公式生成不同质量的片段(以便可以创建质量显着不同的合成模型)。
4.1.2. Card2Code 炉石传说
Card2Code 是一对数据集,分别来自可收集的交易卡游戏 Magic the Gathering 和 Hearthstone;在我们的研究中,我们重点关注 Hearthstone 数据集,因为它在研究人员中更受欢迎。 《炉石传说》数据集包含 665 对《炉石传说》卡牌描述和相应的 Python 片段。 每个代码片段都是一个类实现,可以在 Hearthbreaker 炉石传说模拟器 (heartbreaker, ) 中使用来描述卡牌的逻辑。 数据集分为 533 个训练对、66 个验证对和 66 个测试对。 《炉石传说》数据集具有以下特点:
-
•
由于意图是对炉石卡牌的描述,应遵循 Hearthbreaker 表示法,因此生成的代码具有相对严格的结构。
-
•
代码生成问题非常奇特:每个任务都需要模型生成一个类。 这些片段具有非常相似的轮廓,并且各个片段之间的差异是有限的:每个片段都是从三个父类(MinionCard、SpellCard 和 WeaponCard)之一继承的类。 几乎每个代码片段都有两个方法:一个构造函数和一个名称取决于父类的方法(对于 SpellCard 为 use,对于 WeaponCard 为 create_weapon)。 因此,我们从结果中推断出的结论的普遍性是有限的。
-
•
生成的代码相对较长且复杂,允许应用考虑底层代码结构的 CodeBLEU 和 RUBY 指标。
只有两个公开可用的模型在《炉石传说》数据集上进行了评估。 其中一个模型是句法神经模型NL2code (Yin, ),另一个是基于语法的结构卷积神经网络GCNN (GCNN,)。 对于 NL2code,我们使用作者提供的模型的输出,对于 GCNN,我们使用复制包中提供的标准设置,但将训练限制为 30 epoch,因为1000 个 epoch 的标准设置(如复制包中所写)对于我们的计算资源来说是不可行的。 预训练的 Codex 模型显然熟悉该数据集,因为它提供了参考片段作为输出,因此我们没有考虑它。 特别是,在对生成的 Token 数量没有严格限制的情况下,Codex 在一次运行中成功地从测试数据集中生成了多个类。 这表明 Codex 能够重现训练期间看到的整个文件,包括来自《炉石传说》数据集的文件。
为了检查指标分数差异的显着性,我们对在数据集测试部分评估的模型的指标分数使用配对引导重采样 (efron1983estimating, )。
4.2. RQ1:语料库级模型性能
为了解决 RQ1,我们比较了语料库级别上度量分数差异的显着性。 对于将语料库级别分数定义为片段级别分数聚合的指标,可以使用 Wilcoxon 符号秩检验 (wilcoxon1992individual, ) 等技术来比较模型。 然而,像 BLEU 这样的指标在设计上是语料库级别的,因此对语料库中每个片段分数的简单平均并不能给出语料库级别的指标分数(有关更多信息,请参阅附录 A.1细节)。 因此,Wilcoxon 检验不适用于这种情况。 这限制了我们使用随机显着性测试来比较语料库级别分数,这是机器翻译社区的常见做法(graham2014randomized,)。 根据 Graham 等人 (graham2014randomized, ) 的说法,使用 bootstrap、配对 bootstrap 和近似随机化来检验显着性几乎没有实际差异。 我们选择配对引导重采样来测试显着性。 为了测试统计显着性,我们采取了 1000 个引导样本。
4.3. RQ2:自动指标分数的意义
为了解决 RQ2,我们考虑了不同模型对的度量分数差异的显着性。 我们预计指标分数差异的显着性将随着分数的差异而变化(因此,对于 BLEU 分数为 20 和 80 的一对模型,其中一个模型更有可能优于另一个模型,如下所示与 BLEU 分数分别为 29.5 和 30 的一对模型相比)。 因此,我们遵循 Roy 等人 (roy2021reassessing, ) 并根据分数的差异将模型对分成 bin。 Hearthstone 和 CoNaLa 数据集的 bin 组成( 等)略有不同。 根据经验确定每个箱中具有相似数量的对。 我们努力在每个箱中拥有相当数量的对,以便在每个箱中拥有大量的对,以便可以得出统计上可靠的结论。
我们使用根据 Roy 等人 (roy2021reassessing, ) 的方法构建的合成模型来增强我们的原始 ML 模型集。 我们根据真实模型的输出构建合成模型的输出。 我们使用合成模型有几个原因:
-
(1)
可用模型相对稀缺。 在 CoNaLa 数据集的最佳情况下,我们只有五个不同质量的模型,这可能无法提供足够的数据来评估指标的适用性。 句法模型的使用使我们能够覆盖更加多样化的度量值范围,而无需训练许多新模型。
-
(2)
即使有各种各样的模型,以便有足够的数据点进行适当的指标比较,也需要在标记数据方面进行大量投资。 例如,在这项研究中,我们仅针对 CoNaLa 数据集研究了总共 85 个模型(包括原始模型和合成模型)的输出,每个输出由 472 个片段组成。 如果所有 85 个模型都是独立的,则需要有 Python 经验的人来标记 40,000 多个片段。 由于我们认为有必要为每个片段收集至少三个分数,因此这样的过程将非常困难或昂贵。
-
(3)
提高或降低模型分数会产生一组综合模型,其中指标分数和人类分数彼此相对接近。 这使我们能够比较许多得分相对接近的模型,并检查它们之间相对较小差异的显着性。 这与研究人员和实践者相关,因为对最先进模型的改进通常是小增量。
4.3.1. 构建综合模型
我们从一些原始模型的输出开始,用该问题的最佳评价片段替换 X% 的最差评价片段,从而创建一个综合模型。 片段的质量是根据人类评估分数来评估的。 如果所选片段已经是评分最高的片段,则会跳过该片段。 相反的过程适用于综合恶化模型。 我们继续替换过程,直到 X% 的片段被更改或者没有更多的片段需要更改。
继Roy等人(roy2021reassessing, )之后,我们考虑了八种不同的替换比例:替换1%、3%、5%、10%、15%、20%、25%、30%生成的片段。 我们的替换比例与 Roy 等人的替换比例相同,但略有不同:我们替换了数据集的 3%,而不是 Roy 等人替换的 2% 此过程生成 CoNaLa 的 合成模型和 Hearthstone 数据集的 合成模型。 然后,我们添加原始模型,并通过丢弃具有完全相同输出的模型来删除它们的重复项。 这使得我们在 RQ2 中使用 CoNaLa 的 81 个模型和 Hearthstone 的 29 个模型。 我们考虑模型的所有成对组合(合成的和原始的),并对每个指标进行成对差异测试。
4.4. RQ3:指标与人类评估之间的一致性
为了解决 RQ3,我们评估了人工评估和语料库级别指标分数之间的一致性程度。 为此,我们进行了语料库级别的显着性测试,以检查每对模型的指标和人类预测是否一致。 与之前的研究问题类似,我们利用 RQ2 中使用的原始模型和合成模型。
4.4.1. 用于语料库级别评估的容器
对于给定的一对模型 A 和 B,人类评估者和指标之间存在分歧,有多种选择:
-
•
根据指标,A 优于 B,但根据人类评估者的说法,模型是等效的(I 类错误)。
-
•
当模型 A 和 B 根据度量标准等效时,但根据人类评估者的判断,其中一个模型更好(II 类错误)。
-
•
当根据指标模型 A 优于模型 B,但根据人类评估者,模型 B 优于模型 A(I 类错误)。
我们考虑模型的所有成对组合(合成的和原始的),并对人类和指标评估进行配对差异测试。 使用汇总的人类分数作为基本事实,我们量化了指标的 I 类和 II 类错误。 由于我们预计某个指标对一对模型出错的概率取决于模型分数的差异,因此我们将指标错误的数据分为几个箱。 NS bin 对应于根据给定指标模型分数差异不显着的情况。 此 bin 中的所有错误都是 I 类错误。 根据指标,其他箱对应于模型得分差异显着的情况。 RQ3 的箱组成与我们为 RQ2 选择的箱组成相同。
4.4.2. 人工评价
为了对所考虑的模型进行人工评估,我们创建了一项调查,要求程序员评估代码片段。 这些片段是一一呈现的,并且是从模型和参考片段生成的片段组合池中随机选择的。 评分者不知道每个片段的来源。 评分者按照从 0 到 4 的等级对片段进行评分,并具有以下等级描述:
-
0:
该片段根本没有帮助,它与问题无关。
-
1:
该代码片段略有帮助,它包含与问题相关的信息,但从头开始编写解决方案更容易。
-
2:
该代码片段有些帮助,它需要进行重大更改(与代码片段的大小相比),但仍然有用。
-
3:
该代码片段很有帮助,但需要稍作修改才能解决问题。
-
4:
该片段非常有帮助,它解决了问题。
评分者不必评估数据集中的所有片段,并且可以随时停止。
4.4.3. CoNaLa 数据集
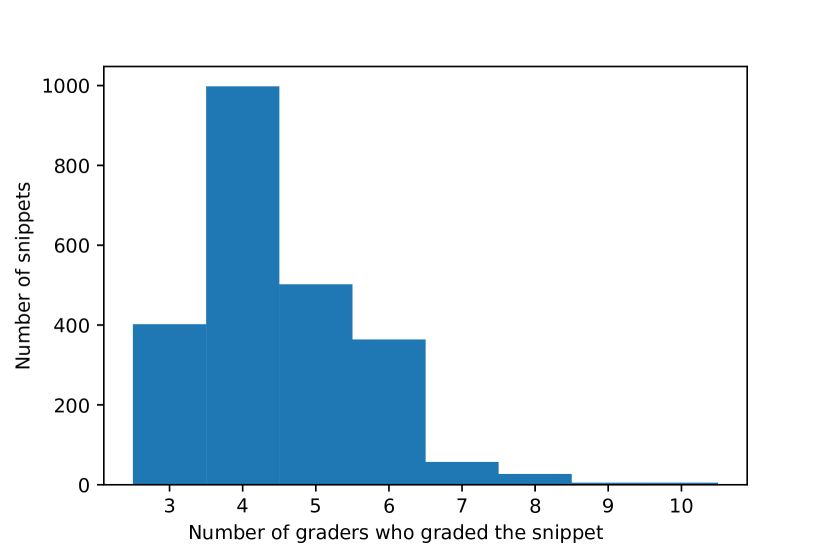
对于 CoNaLa 数据集,有 2,860 个片段需要评估:模型生成的 片段加上 参考片段(对于某些意图,数据集包含多个参考片段)。 16 名参与者参与了我们的调查,平均每个模型生成的片段我们获得了 4.49 分。 图2显示了等级数的分布。 其中三名评分者的 Python 经验不足两年,六名具有两到三年的经验,七名具有四年或以上的 Python 编程经验。 我们从同事中以及通过科学 Twitter 帐户中的帖子招募了评分员。 在评分时,所有评分者都在计算机科学软件工程领域进行研究。
4.4.4. 炉石传说数据集
与 CoNaLa 数据集类似,我们还进行了一项调查,其中程序员评估了代码片段。 这些片段与《炉石传说》卡牌图像一一呈现,评分者评估该片段是否正确代表了该卡牌。 图 3显示了卡片图像的示例以及相应的代码片段。
[] 大法师类(MinionCard) : def __init__(self) : super().__init__(“Archmage”, 6, CHARACTER_CLASS.ALL, CARD_RARITY.COMMON)
def create_minion (self, 玩家) : 返回 Minion(4, 7,pell_damage = 1)

有 198 个片段需要评估:模型生成的 片段加上 66 个参考片段。 四名参与者参与了调查,每个参与者都对所有片段进行了评分。 其中两名参与者有三年或以上玩《炉石传说》的经验,另外两名参与者通过视频和手册学习了规则。 其中一名评分者拥有 1.5 年的 Python 经验,两名评分者有两年的经验,一名评分者有四年的 Python 编程经验。
5. 结果
5.1. RQ1:语料库级模型性能
5.1.1. CoNaLa 数据集
CoNaLa 数据集的测试部分由 500 个参考片段组成,但有些意图出现多次,因此总共有 472 个独特意图。 对应于相同意图的不同参考文献被视为参考语料库的一部分。 我们考虑在 CoNaLa 数据集上训练的五种不同模型:基线 CoNaLa (baseline)、在主数据集上训练的 tranX (tranx-annot)、Yin 的 tranX 的最佳版本等人 (tranx, ) 在 CoNaLa 的非清理版本上进行预训练且无需重新排名 (best-tranx),具有相同预训练的 tranX 的最佳版本和重新排名 (best-tranx-rerank) (重新排名, ) 和 Codex (chen2021evaluating, )。 我们计算这些模型输出的 BLEU、ROUGE-L、METEOR、ChrF、CodeBLEU 和 RUBY 分数(获取每个测试片段的分数)。 表 2 显示 CoNaLa 数据集上所有模型的指标值。
| baseline | tranx-annot | best-tranx | best-tranx-rerank | Codex | |
| BLEU | |||||
| ROUGE-L | |||||
| ChrF | |||||
| METEOR | |||||
| RUBY | |||||
| CodeBLEU | |||||
| Human |
| Delta: [0, 2) | Delta: [2, 5) | Delta: [5, 10) | Delta: [10, 100) | |||||
| Significant | NS | Significant | NS | Significant | NS | Significant | NS | |
| BLEU | 192 | 398 | 732 | 42 | 893 | 0 | 1064 | 0 |
| ROUGE-L | 252 | 296 | 736 | 0 | 1023 | 0 | 1014 | 0 |
| ChrF | 253 | 212 | 633 | 1 | 922 | 0 | 1300 | 8 |
| METEOR | 195 | 324 | 699 | 7 | 914 | 0 | 1182 | 48 |
| RUBY | 235 | 437 | 828 | 9 | 972 | 0 | 840 | 0 |
| CodeBLEU | 382 | 474 | 895 | 6 | 857 | 0 | 707 | 0 |
除了自动化指标之外,我们还报告汇总的评估者分数(请参阅表2中的人类行)。 我们通过乘以适当的系数将所有指标转换为 0-100 等级:如果指标分数在 范围内,我们将评估员分数乘以 25,并将自动指标分数乘以 100。 我们与分数一起报告每个指标的置信区间。 置信区间是借助超过 1,000 次重采样的 bootstrap 计算得出的; 应理解为“95% 的重采样模型的得分在 范围内”。
BLEU 指标无法识别 Codex 与 best-tranx-rerank 之间以及 Codex 与 best-tranx 之间的质量差异。 RUBY 指标无法识别以下三个模型之间的质量差异:基线、tranx-annot 和 best-tranx。 CodeBLEU 指标无法识别以下模型中任何两个模型之间的质量差异:tranx-annot、best-tranx 和 best-tranx -重新排序模型。 对于在 CoNaLa 数据集上评估的五个原始模型,BLEU、RUBY 或 CodeBLEU 分数的差异并不总是具有统计显着性。 这很重要,因为当前代码生成模型是使用 CodeBLEU 或 BLEU 进行评估的,并且提供的模型分数通常没有任何统计显着性数据。
| Delta: [0, 2) | Delta: [2, 5) | Delta: [5, 10) | Delta: [10, 100) | Delta: NS | Total mismatch | ||||||
| Mismatches | Pairs | Mismatches | Pairs | Mismatches | Pairs | Mismatches | Pairs | Mismatches | Pairs | ||
| BLEU | 2.7% | 187 | 15.1% | 747 | 12.0% | 890 | 0.6% | 1070 | 85.5% | 427 | 17.95% |
| ROUGE-L | 6.7% | 254 | 12.0% | 740 | 3.7% | 1016 | 0 | 1018 | 72.0% | 293 | 10.69% |
| ChrF | 5.2% | 248 | 16.2% | 627 | 2.8% | 923 | 0 | 1305 | 64.7% | 218 | 8.49% |
| METEOR | 4.7% | 190 | 14.8% | 694 | 9.3% | 914 | 0 | 1187 | 81.5% | 336 | 14.18% |
| RUBY | 6.6% | 213 | 21.0% | 837 | 4.7% | 965 | 0 | 838 | 85.9% | 468 | 19.21% |
| CodeBLEU | 6.0% | 382 | 9.4% | 896 | 5.8% | 842 | 0 | 715 | 80.9% | 486 | 16.53% |
5.1.2. 炉石传说数据集
对于炉石数据集,我们仅评估两种不同的可用模型:句法神经模型 NL2Code (Yin, ) 和基于语法的结构卷积神经网络 (GCNN) (GCNN, ). 我们计算这些模型输出的 BLEU、ROUGE-L、METEOR、ChrF、CodeBLEU 和 RUBY 分数,获得每个测试片段的分数。 我们报告分数的格式与我们呈现 CoNaLa 分数的格式相同。 我们将 GCNN 模型训练了 30 个 epoch,因为原论文 (GCNN, ) 中没有推荐的 epoch 数,并且默认值 1,000 个 epoch 是不可行的。 这可能是我们训练的 GCNN 模型的性能比 NL2Code 相对较差的原因,这与原始论文 (GCNN, ) 的结果相反。
| gcnn | nl2code | |
| BLEU | ||
| ROUGE-L | ||
| ChrF | ||
| METEOR | ||
| RUBY | ||
| CodeBLEU | ||
| Human |
| Delta: [0, 1) | Delta: [1, 2) | Delta: [2, 4) | Delta: [4, 100) | |||||
| Significant | NS | Significant | NS | Significant | NS | Significant | NS | |
| BLEU | 30 | 91 | 16 | 56 | 98 | 16 | 128 | 0 |
| ROUGE-L | 58 | 138 | 67 | 35 | 137 | 0 | 0 | 0 |
| ChrF | 71 | 134 | 90 | 33 | 99 | 0 | 8 | 0 |
| METEOR | 21 | 144 | 22 | 33 | 159 | 8 | 48 | 0 |
| RUBY | 60 | 164 | 76 | 73 | 62 | 0 | 0 | 0 |
| CodeBLEU | 31 | 243 | 22 | 102 | 24 | 13 | 0 | 0 |
| Delta: [0, 1) | Delta: [1, 2) | Delta: [2, 4) | Delta: [4, 100) | Delta: NS | Total mismatch | ||||||
| Mismatches | Pairs | Mismatches | Pairs | Mismatches | Pairs | Mismatches | Pairs | Mismatches | Pairs | ||
| BLEU | 3.7% | 27 | 0.0% | 16 | 24.4% | 98 | 27.3% | 128 | 81.9% | 166 | 45.1% |
| ROUGE-L | 1.6% | 64 | 7.7% | 65 | 0.0% | 137 | 0 | 50.3% | 169 | 20.9% | |
| ChrF | 1.4% | 73 | 27.2% | 92 | 0.0% | 99 | 0.0% | 8 | 59.5% | 163 | 28.3% |
| METEOR | 5.9% | 17 | 0.0% | 22 | 18.9% | 159 | 22.9% | 48 | 74.6% | 189 | 42.1% |
| RUBY | 2.6% | 39 | 4.5% | 110 | 3.0% | 66 | 0 | 62.7% | 220 | 33.6% | |
| CodeBLEU | 15.2% | 33 | 0.0 | 22 | 0.0% | 24 | 0 | 75.0% | 356 | 62.5% | |
根据ROUGE-L、METEOR和BLEU指标,NL2Code模型在置信度上优于GCNN,参见表5 。
我们发现,即使对于我们在 CoNaLa 和 Hearthstone 数据集上考虑的非合成模型,指标分数的改进也可能是肤浅的并且在统计上微不足道。
这凸显了测试模型质量改进对于代码生成任务的重要性的必要性。
5.2. RQ2:自动指标分数的意义
5.2.1. CoNaLa 数据集
在表3中,我们展示了有关模型得分差异显着性的数据。 对于每对模型,我们根据我们考虑的每个指标计算它们分数的差异,并根据配对引导重采样程序检查差异是否显着。 每个表格单元格包含分别对应于行和列中提到的度量和差异的模型对的数量。 例如,有 192 对模型的 BLEU 分数差异在 范围内,并且这种差异非常显着。 我们将可能的分数分为四个不同的分箱 - 、、、 - 并将每对模型放入对应的bin。 结果表明,除 BLEU 指标外,如果两个模型的指标分数差异大于两分,则可以至少 置信度声称差异显着。 关于差异显着性置信度的数据可以直接从表中获得:对于每个 bin 度量对,置信度由 给出。 其中是分数差异显着的模型对的数量,是分数差异不具有统计显着性的模型对的数量。 结果还表明,如果两个模型的分数差异小于两分,则在不进行额外统计测试的情况下不可能声称其中一个模型更好。 此外,如果 BLEU 分数的差异小于 5 分,则需要进行额外的统计测试来声明差异显着。
5.2.2. 炉石传说数据集
表 6显示了根据指标的模型得分差异与他们确定哪个模型更好的能力之间的依赖性,至少有 95%信心。
结果表明,对于《炉石传说》数据集,根据任何指标,分数差异均小于两分,因此如果不进行额外的统计测试,就不可能声称其中一个模型明显更好。
对于社区采用的 BLEU 和 CodeBLEU 指标(且仅适用于它们),如果模型得分差异小于 4 分,则不可能声称其中一个模型明显更好。
与我们在 CoNaLa 数据集上的结果类似,这一发现强调了指标分数的微小差异应与证明差异显着性的统计测试一起报告。
我们对指标分数改进重要性的发现扩展了我们在上一节中所做的观察。
我们发现,对于我们认为的任何指标,如果分数提高不到两分,就足以在不进行额外测试的情况下声称有统计上的显着改善。
此外,社区采用的 BLEU 和 CodeBLEU 指标的分数改进足以证明统计上显着的改进甚至更高。
5.3. RQ3:指标与人类评估之间的一致性
5.3.1. CoNaLa 数据集
我们还对 CoNaLa 数据集进行人工评估,并将其与自动化指标的结果进行比较。 我们根据 Ma 等人 (ma2020adversarial, ) 建议的 M-MSR 算法计算“真实”人类等级。
对于非综合模型,各种指标在识别模型输出质量差异的显着性方面显示出不同的结果。 我们从收集的成绩中获得的人类基本事实表明,模型分数的所有差异都是显着的。 模型的排名如下:Codex ¿ best-tranx-rerank ¿ best-tranx ¿ tranx-annot ¿ baseline 。 ChrF、ROUGE-L 和 METEOR 指标的结果与人类的判断一致(参见表 2),而 BLEU、RUBY、 CodeBLEU 与至少一对模型的评估者意见不一致。
我们在表4中展示了人工评估与合成模型的自动化指标的比较。 每列包含给定范围内指标分数具有统计显着差异的模型对的数据。 Delta: NS 列包含所有模型对,其分数差异不具有统计显着性。 每个表格单元格包含与相应行中提到的指标和列中提到的差异相对应的模型对的数量。 例如,有 187 对模型的 BLEU 分数差异在 范围内,这种差异非常显着。 “不匹配”列列出了指标评估与人工评估不一致的模型对的数量。 例如,在 BLEU 分数差异在 范围内且差异显着的 187 个模型对中,有 2.7% 的模型对的指标评估与人类评估不一致。
对于语料库级别指标与人类汇总得分的不一致率,我们可以看到以下内容:
-
1.
这些指标无法可靠地确定模型之间的差异不显着,我们考虑的每个指标的错误率均高于 60%,请参阅Delta:NS 列。
-
2.
当指标分数的差异小于 5 分时,没有任何指标足够可靠,无法以至少 95% 的精度模拟人类判断。
-
3.
对于指标分数差异的 bin,只有 RUBY、ChrF 和 ROUGE-L 指标能够以至少 95% 的精度模拟人类判断,请参阅列 Delta:[5, 10) 。
-
4.
可以说,在我们考虑的指标中,BLEU 在模拟人类判断方面是最差的:尽管它具有第二高的总不匹配率,但对于分数差异更大的模型来说,它是表现最差的指标超过 5 点,请参见第 BLEU 行。 对于分数差异超过 10 分的模型对,它也是唯一有时与人类判断不一致的指标。
-
5.
RUBY 和 CodeBLEU 指标是为评估代码而开发的,但其性能并没有明显优于来自机器翻译领域的指标。 此外,就总错配率而言,它们是最不可靠的,请参阅总错配列。
-
6.
所有指标的 bin 的 I 类错误发生率最高,然后随着分数差异的增加而降低,请参阅列 Delta:[2, 5)。 这可以通过 NS bin 中的高错配率来解释,该 bin 由分数差异通常较小的模型对组成。 如果我们不单独考虑 NS bin,并根据模型对分数的差异聚合结果,则 bin 的错误率最高,类似于 Roy 等人 的结果(roy2021重新评估,)。
根据我们的研究结果,对从业者的一般建议是,度量分数的差异至少为 5 分,才能以至少 95% 的把握声称一个模型在 CoNaLa 数据集上优于另一个模型,如果人类的判断被认为是黄金真理。 在我们考虑的指标中,ChrF 和 ROUGE-L 是评估代码生成模型性能最好的指标。
5.3.2. 炉石传说数据集
我们还对《炉石传说》数据集进行了人工评估。 与 CoNaLa 数据集类似,我们根据 M-MSR 算法计算“真实”人类等级。 对于非合成模型,人类评分者无法确信 NL2Code 优于 GCNN,CodeBLEU、ChrF 和 RUBY 指标也是如此。
对于语料库级别指标与合成模型上的人类汇总得分的不一致率,我们可以看到以下内容:
-
1.
在确定模型之间的差异不显着时,指标并不可靠。 然而,相对错误率略好于 CoNaLa 数据集观察到的错误率:ChrF 和 ROUGE-L 的错误率低于 60%,请参见Delta: NS 列。
-
2.
Hearthstone 数据集的总错配率比 CoNaLa 数据集观察到的总错配率更差,请参阅总错配列。 原因可能是我们只有两个可用于数据集的模型,并且它们的指标分数相对接近。 由于所有合成模型都是由这两个模型生成的,因此合成模型的分数也相当接近也就不足为奇了,并且指标很难区分模型。
-
3.
没有一个指标足够可靠,无法以 精度区分分数差异小于两点的模型,请参阅列 Delta:[1, 2)。
-
4.
BLEU 指标再次表现不佳:它的总失配率是最差的,并且与 METEOR 一起,这是唯一两个未能很好地区分分数差异超过两分的模型的指标,请参见行BLEU。
-
5.
RUBY 和 CodeBLEU 是为评估代码而开发的指标,其性能并不比源自机器翻译领域的指标好得多。 此外,就总错配率而言,它们是最差的指标之一。
-
6.
与 CoNaLa 数据集不同,所有指标的 I 类错误发生率没有明显的趋势。 这可以通过与 CoNaLa 数据集选择的箱选择不同来解释。 不幸的是,与 CoNaLa 数据集类似的箱选择所提供的信息甚至更少:对于大多数指标,箱 和 实际上是空的,因为这两个箱该数据集可用的非合成模型具有相对接近的质量。
根据收集到的结果,对从业者的一般建议是,如果人类的判断是这样的话,则必须有至少两个点的度量分数差异,才能以至少 95% 的确定性声称一个模型在《炉石传说》数据集上优于另一个模型。被认为是金科玉律的真理。 ROUGE-L 指标是评估此数据集上的代码生成模型的最佳性能指标,ChrF 排名第二。
6. 研究意义
在这项工作中,我们研究了各种自动化指标(BLEU、ROUGE-L、METEOR、ChrF、RUBY 和 CodeBLEU)在评估代码生成模型时的适用性。
根据结果,我们向从业者提出以下建议。 首先,指标分数应与分数差异显着性的数据一起报告。 其次,小于两分的度量分数差异不足以表明一种模型优于另一种模型,即使差异具有统计显着性。 第三,尽管 BLEU 和 CodeBLEU 是评估代码生成模型最流行的指标,但我们建议使用 ChrF 作为代码生成任务的标准指标。 我们还相信,社区将受益于专为评估代码生成任务而定制的新指标。 为了支持这种指标的开发,我们将两个研究数据集收集的人类评估分数开源,并鼓励其他研究人员在工作中使用它们。 最后,我们强烈鼓励开发代码生成模型的从业者发布其模型的输出,因为如果不可能对新旧模型进行统计测试,则几乎不可能观察到代码生成方面虽小但显着的改进输出。
6.1. 未来的工作
根据我们上面的观察,我们看到未来工作的以下方向:
第一个是将这项研究扩展到其他编程语言、数据集和代码生成模型。 然后,应该使用获得的数据来评估各种指标对于特定数据集和/或编程语言的适用性。 虽然这样的评估成本高昂且耗时较长,但它可以更确定地比较代码生成模型。 The best course of action would also include full human assessment of the code generation models as it is done for e.g., machine translation (barrault2019findings, ). 标记数据集的一个特殊挑战是为每个代码片段收集超过 15 个评估。 根据 Mathur 等人 (mathur2020tangled, ) 的研究结果,这将允许在片段级别评估各种模型的质量并跟踪改进的细节。
第二个是创建新的指标来评估代码生成模型的质量。 考虑到自然语言处理任务 (ma2018results, ; ma2019results, ) 和代码摘要 (roy2021reassessing, ) 的 ML 增强指标的相对成功,我们推测这是一个有前途的方向新指标将类似于 BERTScore (bertscore, ),它将使用大型语言模型的嵌入来计算参考片段和候选片段之间的相似度得分。
7. 有效性的威胁
7.1. 外部威胁
在本文中,我们将外部有效性威胁视为可能影响我们的研究在其他情况下的推广性的缺点。 首先,我们的研究基于两个 Python 数据集:一个 Python one-liners 数据集和一个特殊的 Card2Code (card2code, ) 数据集,模型应该为其生成具有非常特定结构的类。 探索其他数据集会很有趣;不幸的是,现有数据集的选择有限,并且通常可以在特定数据集上运行的模型很少是公开可用的。 最有趣的数据集是 Docstrings (Docstrings, ),但超出了本文的范围。 不幸的是,现有的模型在其上训练的效果相当差。 特别是,最佳可用模型的 BLEU 得分为 12.1 (RUBY, ),这意味着其输出的预期人类评分会相当差。
数据集选择威胁与模型选择威胁密切相关。 对于我们查看的每个数据集,除了 CoNaLa 之外,可用模型相对短缺;特别是,我们运行了炉石数据集公开可用的所有模型。 我们联系了非开源模型的作者,但遗憾的是没有得到回复。 不同的模型选择可能会产生不同的结果。
我们使用的所有数据集都有用 Python 编写的代码片段。 虽然大多数现有的代码生成公共数据集确实有 Python 代码,但生成其他语言的代码是一项重要任务,语言的选择可能会影响像我们这样的研究结果。
所有对有效性的外部威胁都与抽样偏差问题有关。 虽然我们无法确定我们的研究结果是否适用于其他编程语言和其他 Python 数据集,但流行指标与人类对研究数据集的判断相关性较弱的事实表明,其他编程语言和其他数据集的情况也可能如此。 因此,我们需要对代码生成指标进行广泛的评估,以稳健地比较模型。
7.2. 内部威胁
在本文中,我们认为内部有效性威胁是影响所测试因果关系可信度的缺陷。 我们研究有效性的内部威胁与人类评分者的选择有关。 可能的威胁之一是每个片段可用的平均等级数较少。 由于参与评估的开发人员数量有限,我们得出的人工评分可能与分析片段的“真实”人工评分不同。 不幸的是,这个问题在许多使用人类评估的研究中都很常见。 我们每个片段收集的人类评分数量不低于其他使用人类评估代码的研究(roy2021reassessing, ; RUBY, ),并且我们的结果与 Roy 等的发现一致人 (roy2021reassessing, ) 研究代码摘要的指标。
一个相关的问题是评分者存在偏见。 评分者可能在编码风格或特定技术的使用方面有自己的偏好,这可能会影响他们分配给片段的评分。 为了改善这个问题并遵循标准调查实践(roy2021reassessing,),我们打乱了呈现的片段,并添加了正确的片段,以便评分者不知道哪个片段是正确的或不正确的,为了将可能的学习效果涂抹到不同模型的输出上。
我们相信,虽然上面列出的所有对有效性的威胁都是有形的,但我们已经采取了所有必要的措施来减轻这些威胁,并且我们的结果是有效的并且对社区有用。
8. 结论
在本研究中,我们研究了当前使用基于自动化指标的单一语料库级别评分来评估代码生成模型质量的实践。 特别是,我们检查这种评估是否产生具有统计意义的结果并与人类判断良好相关。 我们考虑了在两个不同的 Python 数据集上评估的代码生成模型的六个指标:BLEU、ROUGE-L、METEOR、ChrF、CodeBLEU 和 RUBY:CoNaLa (conala, ) 和 Hearthstone (card2code) ,)。
我们发现,即使不考虑人类评估结果,在没有额外统计测试的情况下,语料库级别指标得分的提高不到 2 分可能不足以保证质量的统计显着改善。 当我们还考虑人类评估的结果时,我们发现对于某些数据集,即使分数提高不到 5 分,根据人类的判断也可能不对应于统计上显着的改进。 在我们研究的指标中,ChrF 被证明是最接近人类评估的。 然而,它不能被认为是代码生成的“完美”指标,并且找到这样的指标需要进一步的工作。
在未来的工作中,我们的目标是将我们的研究扩展到其他代码生成数据集和模型,并进行更广泛的人类评估,以便在片段级别而不是语料库级别检查模型的改进。
参考
- (1) R. Balzer, A 15 year perspective on automatic programming, IEEE Transactions on Software Engineering (11) (1985) 1257–1268.
- (2) M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, et al., Evaluating large language models trained on code, arXiv preprint arXiv:2107.03374 (2021).
- (3) P. Yin, G. Neubig, A syntactic neural model for general-purpose code generation, arXiv preprint arXiv:1704.01696 (2017).
- (4) Z. Sun, Q. Zhu, L. Mou, Y. Xiong, G. Li, L. Zhang, A grammar-based structural cnn decoder for code generation, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33, 2019, pp. 7055–7062.
- (5) P. Yin, G. Neubig, Tranx: A transition-based neural abstract syntax parser for semantic parsing and code generation, arXiv preprint arXiv:1810.02720 (2018).
- (6) P. Yin, G. Neubig, Reranking for neural semantic parsing, in: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 4553–4559.
- (7) T. Yu, R. Zhang, K. Yang, M. Yasunaga, D. Wang, Z. Li, J. Ma, I. Li, Q. Yao, S. Roman, et al., Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task, arXiv preprint arXiv:1809.08887 (2018).
- (8) Y. Oda, H. Fudaba, G. Neubig, H. Hata, S. Sakti, T. Toda, S. Nakamura, Learning to generate pseudo-code from source code using statistical machine translation (t), in: 2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE), IEEE, 2015, pp. 574–584.
- (9) R. Agashe, S. Iyer, L. Zettlemoyer, Juice: A large scale distantly supervised dataset for open domain context-based code generation, arXiv preprint arXiv:1910.02216 (2019).
- (10) W. Ling, E. Grefenstette, K. M. Hermann, T. Kočiskỳ, A. Senior, F. Wang, P. Blunsom, Latent predictor networks for code generation, arXiv preprint arXiv:1603.06744 (2016).
- (11) A. V. M. Barone, R. Sennrich, A parallel corpus of python functions and documentation strings for automated code documentation and code generation, arXiv preprint arXiv:1707.02275 (2017).
- (12) P. Yin, B. Deng, E. Chen, B. Vasilescu, G. Neubig, Learning to mine aligned code and natural language pairs from stack overflow, in: International Conference on Mining Software Repositories, MSR, ACM, 2018, pp. 476–486. doi:https://doi.org/10.1145/3196398.3196408.
- (13) S. Lu, D. Guo, S. Ren, J. Huang, A. Svyatkovskiy, A. Blanco, C. Clement, D. Drain, D. Jiang, D. Tang, et al., Codexglue: A machine learning benchmark dataset for code understanding and generation, arXiv preprint arXiv:2102.04664 (2021).
- (14) K. Papineni, S. Roukos, T. Ward, W.-J. Zhu, Bleu: a method for automatic evaluation of machine translation, in: Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318.
- (15) S. Ren, D. Guo, S. Lu, L. Zhou, S. Liu, D. Tang, M. Zhou, A. Blanco, S. Ma, Codebleu: a method for automatic evaluation of code synthesis, arXiv preprint arXiv:2009.10297 (2020).
- (16) N. Tran, H. Tran, S. Nguyen, H. Nguyen, T. Nguyen, Does bleu score work for code migration?, in: 2019 IEEE/ACM 27th International Conference on Program Comprehension (ICPC), IEEE, 2019, pp. 165–176.
- (17) D. Roy, S. Fakhoury, V. Arnaoudova, Reassessing automatic evaluation metrics for code summarization tasks, in: Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2021, pp. 1105–1116.
- (18) B. Efron, Estimating the error rate of a prediction rule: improvement on cross-validation, Journal of the American statistical association 78 (382) (1983) 316–331.
- (19) C.-Y. Lin, Rouge: A package for automatic evaluation of summaries, in: Text summarization branches out, 2004, pp. 74–81.
- (20) S. Banerjee, A. Lavie, Meteor: An automatic metric for mt evaluation with improved correlation with human judgments, in: Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, 2005, pp. 65–72.
- (21) M. Popović, chrf: character n-gram f-score for automatic mt evaluation, in: Proceedings of the Tenth Workshop on Statistical Machine Translation, 2015, pp. 392–395.
- (22) N. Mathur, T. Baldwin, T. Cohn, Tangled up in bleu: Reevaluating the evaluation of automatic machine translation evaluation metrics, arXiv preprint arXiv:2006.06264 (2020).
- (23) M. Rabinovich, M. Stern, D. Klein, Abstract syntax networks for code generation and semantic parsing, arXiv preprint arXiv:1704.07535 (2017).
- (24) S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural computation 9 (8) (1997) 1735–1780.
- (25) Y. Bengio, P. Simard, P. Frasconi, Learning long-term dependencies with gradient descent is difficult, IEEE transactions on neural networks 5 (2) (1994) 157–166.
- (26) B. Wei, G. Li, X. Xia, Z. Fu, Z. Jin, Code generation as a dual task of code summarization, in: Advances in Neural Information Processing Systems, 2019, pp. 6563–6573.
-
(27)
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u.
Kaiser, I. Polosukhin,
Attention
is all you need, in: I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach,
R. Fergus, S. Vishwanathan, R. Garnett (Eds.), Advances in Neural Information
Processing Systems, Vol. 30, Curran Associates, Inc., 2017.
URL https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf -
(28)
Y. Li, D. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles,
J. Keeling, F. Gimeno, A. D. Lago, T. Hubert, P. Choy, C. d. M. d’Autume,
I. Babuschkin, X. Chen, P.-S. Huang, J. Welbl, S. Gowal, A. Cherepanov,
J. Molloy, D. J. Mankowitz, E. S. Robson, P. Kohli, N. de Freitas,
K. Kavukcuoglu, O. Vinyals,
Competition-level code generation
with alphacode (2022).
doi:10.48550/ARXIV.2203.07814.
URL https://arxiv.org/abs/2203.07814 - (29) M. Denkowski, A. Lavie, Meteor universal: Language specific translation evaluation for any target language, in: Proceedings of the ninth workshop on statistical machine translation, 2014, pp. 376–380.
- (30) A. LeClair, C. McMillan, Recommendations for datasets for source code summarization, arXiv preprint arXiv:1904.02660 (2019).
- (31) Q. Ma, J. Wei, O. Bojar, Y. Graham, Results of the wmt19 metrics shared task: Segment-level and strong mt systems pose big challenges, in: Proceedings of the Fourth Conference on Machine Translation (Volume 2: Shared Task Papers, Day 1), 2019, pp. 62–90.
- (32) Q. Ma, O. Bojar, Y. Graham, Results of the wmt18 metrics shared task: Both characters and embeddings achieve good performance, in: Proceedings of the third conference on machine translation: shared task papers, 2018, pp. 671–688.
- (33) C.-W. Liu, R. Lowe, I. V. Serban, M. Noseworthy, L. Charlin, J. Pineau, How not to evaluate your dialogue system: An empirical study of unsupervised evaluation metrics for dialogue response generation, arXiv preprint arXiv:1603.08023 (2016).
- (34) E. Reiter, A structured review of the validity of bleu, Computational Linguistics 44 (3) (2018) 393–401.
- (35) Q. Ma, A. Olshevsky, Adversarial crowdsourcing through robust rank-one matrix completion, arXiv preprint arXiv:2010.12181 (2020).
-
(36)
D. Ustalov, N. Pavlichenko, V. Losev, I. Giliazev, E. Tulin,
A
General-Purpose Crowdsourcing Computational Quality Control Toolkit for
Python, in: The Ninth AAAI Conference on Human Computation and
Crowdsourcing: Works-in-Progress and Demonstration Track, HCOMP 2021, 2021.
arXiv:2109.08584.
URL https://www.humancomputation.com/assets/wips_demos/HCOMP_2021_paper_85.pdf -
(37)
R. Agashe, S. Iyer, L. Zettlemoyer,
JuICe: A large scale distantly
supervised dataset for open domain context-based code generation, in:
Proceedings of the 2019 Conference on Empirical Methods in Natural Language
Processing and the 9th International Joint Conference on Natural Language
Processing (EMNLP-IJCNLP), Association for Computational Linguistics, Hong
Kong, China, 2019, pp. 5436–5446.
doi:10.18653/v1/D19-1546.
URL https://aclanthology.org/D19-1546 - (38) S. Iyer, I. Konstas, A. Cheung, L. Zettlemoyer, Mapping language to code in programmatic context, arXiv preprint arXiv:1808.09588 (2018).
- (39) P. Yin, B. Deng, E. Chen, B. Vasilescu, G. Neubig, Learning to mine aligned code and natural language pairs from stack overflow, in: 2018 IEEE/ACM 15th international conference on mining software repositories (MSR), IEEE, 2018, pp. 476–486.
- (40) earthbreaker – open source hearthstone simulator, https://github.com/danielyule/hearthbreaker, accessed: 2022-06-06.
- (41) F. Wilcoxon, Individual comparisons by ranking methods, in: Breakthroughs in statistics, Springer, 1992, pp. 196–202.
- (42) Y. Graham, N. Mathur, T. Baldwin, Randomized significance tests in machine translation, in: Proceedings of the Ninth Workshop on Statistical Machine Translation, 2014, pp. 266–274.
- (43) L. Barrault, O. Bojar, M. R. Costa-Jussa, C. Federmann, M. Fishel, Y. Graham, Findings of the 2019 conference on machine translation (wmt19), Association for Computational Linguistics (ACL), 2019.
- (44) T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger, Y. Artzi, Bertscore: Evaluating text generation with bert, arXiv preprint arXiv:1904.09675 (2019).
- (45) B. Chen, C. Cherry, A systematic comparison of smoothing techniques for sentence-level bleu, in: Proceedings of the ninth workshop on statistical machine translation, 2014, pp. 362–367.
- (46) M. Post, A call for clarity in reporting bleu scores, arXiv preprint arXiv:1804.08771 (2018).
- (47) Rouge 1.5.5 perl script, https://github.com/andersjo/pyrouge/tree/master/tools/ROUGE-1.5.5, accessed: 2022-05-19.
- (48) M. Popović, chrf deconstructed: beta parameters and n-gram weights, in: Proceedings of the First Conference on Machine Translation: Volume 2, Shared Task Papers, 2016, pp. 499–504.
附录A指标计算
A.1。 蓝线
BLEU 度量基于修改后的 -gram 精度度量,并对比参考句子短的候选句子进行长度惩罚。 BLEU 分数由以下公式确定:
| (1) |
其中 是简洁性惩罚, 是参考文献的长度, 是候选翻译长度。 对应于 n-gram 包之间的加权重叠(重复项最多允许达到参考文献中的最大重复次数)。 如果 和 分别是参考和候选的 n 元包,那么
| (2) |
最后,是各种n-gram贡献的权重;标准权重为、。 原始 BLEU 实现 (BLEU, ) 是一个语料库级别的度量,因为它考虑了微平均精度。 也就是说,为了计算精度,必须在除法之前对每个假设-参考对的分子和分母求和。 通过将每个假设和参考文献视为独立的,可以定义句子BLEU度量来对单个假设进行评分(如例如、Roy等人(roy2021reassessing, )所做的那样)语料库。 然而,必须记住,整个数据集上的 SentenceBLEU 平均值不一定等于在数据集上评估的 BLEU。
BLEU 值的范围为 0 到 1,分数越高,n 元语法精度越高。 然而,从业者经常在模型质量报告中将 BLEU 分数乘以 100。 BLEU 指标的默认实现为 4 克与参考重叠为零的候选者提供零分。 此限制可能会过于严厉地惩罚质量平庸的候选句子(例如,对于七个标记的参考,候选者猜对了 6 个标记,但错过了词符 #4,将获得零分)。 为了避免这些情况,人们提出了几种平滑算法,对机器翻译任务的句子级 BLEU 平滑技术的系统比较可以在 Chen 等人的论文 (chen2014systematic, ) 中找到
在我们的研究中,我们使用 sacrebleu 包 (post2018call, ) 中的参考 BLEU 实现。
A.2。 胭脂-L
ROUGE-L 是 Lin (ROUGE, ) 首先建议的 ROUGE 系列度量中的一个度量。 它最初被建议用于评估短文本摘要的质量,但后来被用于其他任务。 ROUGE-L 计算的基本概念是(假设和参考的)最长公共子序列。 两个序列之间的公共子序列是序列,它是两个的子序列。 那么最长公共子序列就是最大长度的公共子序列。 这使我们能够将假设 和参考 的精度、召回率和 ROUGE-L 度量定义为
是决定召回率权重的参数,在我们的评估中我们使用(精确率和召回率的权重相等)。 可能的值范围从 0 到 1,但与 BLEU 和其他指标类似,语料库级别分数通常乘以 100 以简化感知。 ROUGE-L 通常用作片段级指标(roy2021reassessing, )。 这意味着要获得语料库级别的 ROUGE-L 分数,必须对片段级别的分数进行平均。 举一个简单的例子,让我们考虑一个参考和两个假设:
-
: 警察击毙了枪手
-
: 警察击毙枪手
-
: 枪手杀死了警察
之间的最长公共子序列为 3 个词符(第一、第三和第四个词符), 之间的最长公共子序列为 2 个词符(第一和第二词符,或者第三、第四词符)。 因此,。
我们使用 rouge-score 包中的 ROUGE-L 实现,它产生与原始 Perl 脚本 (rouge-perl, ) 相同的结果。
A.3。 铬F
ChrF 是 Popovic (popovic2015chrf, ) 首先提出的基于 F 度量字符的度量。 它最初是为了自动评估机器翻译输出而提出的。 作为基于字符的指标,ChrF 不依赖于标记化规则。 它考虑了除空格之外的每个字符。 要计算其标准定义中的 ChrF,首先必须计算字符级精度并召回字符 -grams 的 、,其中 。 总 n 元语法精度和召回率 、 分别是 、 的算术平均值。 最后,ChrF 计算为
| (3) |
我们使用的标准 ChrF 定义集 ,因为选择 在机器翻译任务 (popovic2016chrf, ) 中产生最佳结果。
我们使用 sacrebleu 包中 ChrF 的参考实现。
A.4。 流星
METEOR 是作为机器翻译评估的指标(METEOR, )而创建的。 该指标有多个版本,计算规则略有不同。 在我们的计算中,我们使用了该指标的最新版本 – METEOR 1.5 (denkowski2014meteor, )。 其计算由以下步骤组成:
-
•
在假设和参考字符串之间创建对齐。 假设和参考字符串之间的对齐是这些字符串的一元组之间的映射,使得每个字符串中的每个一元组映射到另一个字符串中的零个或一个一元组。 对齐是在多个阶段中创建的,每个阶段中的一元匹配具有不同的规则。 在第一阶段,当且仅当两个单词相同时才匹配。 在第二阶段,如果波特词干后它们相同,则进行匹配。 在第三阶段,根据WordNet数据库,如果两个单词是同义词,则匹配它们。 最后,如果两个短语在相应语言表中列为释义,则匹配它们。 映射被迭代地应用,最终的对齐是使用波束搜索构建的所有匹配的最大子集。 为了确定最终的对齐方式,按照重要性顺序应用以下标准:
-
–
两个句子中涵盖的单词数量应该最大化。
-
–
块的数量应该最小化。 chunk 是一系列连续的匹配,在两个句子中具有相同的顺序。
-
–
两个句子中匹配开始索引之间的绝对距离之和应最小化。 这是通过优先对齐两个句子中相似位置出现的短语来打破联系。
-
–
-
•
建立对齐后,假设和参考中的单词根据特殊的功能词列表分为内容词和功能词。 对于每个应用的匹配器,应该计算这种类型的匹配所涵盖的内容和功能词的数量。 然后使用匹配器权重和内容功能词权重计算加权精度和召回率。 然后根据计算加权调和平均值。 最后,为了惩罚词序中的间隙和差异,我们使用匹配词的总数和块的数量来计算碎片惩罚。 METEOR 分数最终由 和碎片惩罚计算得出。
我们使用 sacrerouge 包中的 METEOR 实现,它利用原始脚本并为其提供 Python 包装器。
A.5。 红宝石
该指标定义为
| (4) |
这里PDG代表程序依赖图,AST代表摘要语法树,对应参考,对应候选。 测量 的两个程序依赖图之间的相似性:
| (5) |
其中是参考代码的PDG和候选代码的PDG之间的编辑距离。 是图的顶点数和边数之和。 计算为将一个图转换为另一图的最小图形编辑操作数,顶点和边上允许的图形编辑操作包括插入、删除和替换。
如果 PDG 不可用于候选片段,则下一个后备选项是 ,它测量参考和候选片段的 AST 之间的相似性:
| (6) |
其中是AST中的节点数,是参考代码和候选代码。 TED 由 AST 节点上使 和 相同的最小编辑操作数(包括添加、删除、替换和移动)给出。
最后,RUBY 的最后一个后备选项(始终可以计算)是字符串相似度函数 ,定义为
| (7) |
其中是参考序列和候选序列之间的字符串编辑距离。 它测量用户将候选代码转换为参考代码必须执行的词符删除/添加操作的次数; 是序列 的长度。 Tran 等人通过观察发现越多的摘要指标与人类判断具有更好的相关性,从而激发了这种指标的选择。 由于 Tran 等人没有提供 RUBY 的参考实现,因此在我们的研究中我们使用我们自己的 RUBY 度量实现。
A.6。 代码BLEU
Ren 等人 (CodeBLEU, ) 建议的 CodeBLEU 指标由下式给出
| (8) | ||||
| (9) |
在哪里:
-
•
BLEU 是通常的 BLEU 指标。
-
•
是仅在关键词权重提高 5 倍的情况下通过一元语法计算的 BLEU 指标。 换句话说, 是具有 BLEU 简洁性惩罚的一元组的精度。 例如,对于 Python 参考 for x in lst 和假设对于 0>x1> 2>的3>
-
•
是语法 AST 匹配。 为了计算这个子指标,首先必须为参考和假设构建 AST,并从两个 AST 中提取所有子树。 为了跟踪句法结构,作者忽略了叶子节点中的值。 由 给出,其中 是参考 AST 中子树的总数, 是参考 AST 中的子树总数。假设 AST 中的子树与参考中的子树相匹配。
-
•
是语义数据流匹配,通过比较参考和假设的数据流图来考虑假设和参考之间的语义相似性。 子指标的计算分为以下几个步骤:
-
1.
构建参考和假设的数据流图。 为此,首先必须从 AST 获取变量序列 。 然后,每个变量都成为数据流图的一个节点,有向边 表示第 变量的值来自第 变量。多变的。 图 是数据流图。
-
2.
标准化数据流项目。 为此,必须收集数据流项中的所有变量并将它们重命名为 ,其中 是变量在所有数据流项中出现的顺序。
-
3.
计算语义数据流匹配分数为 ,其中 是参考数据流的总数,
是参考数据流的数量匹配的候选数据流。
-
1.
Ren等人将CodeBLEU与BLEU以及准确率进行了比较。 由于除了 BLEU 和准确性之外,CodeBLEU 没有与其他自动指标进行比较,因此我们需要进行进一步的评估。 在我们的研究中,我们使用自己的 CodeBLEU 指标实现。