E2EG:使用图拓扑和基于文本的节点属性进行端到端节点分类
摘要
利用基于文本的节点属性的节点分类具有许多实际应用,从学术引文图中论文主题的预测到社交媒体网络中用户特征的分类。 最先进的节点分类框架(例如 GIANT)使用两阶段管道:首先嵌入图节点的文本属性,然后将所得嵌入输入节点分类模型。 在本文中,我们消除了这两个阶段,并开发了一个基于 GIANT 的端到端节点分类模型,称为端到端 GIANT (E2EG)。 在我们的方法中串联使用主分类目标和辅助分类目标会产生更稳健的模型,使 BERT 主干能够切换为精炼编码器,参数数量减少 25% - 40%。 此外,该模型的端到端性质提高了易用性,因为它避免了链接多个模型进行节点分类的需要。 与 ogbn-arxiv 和 ogbn-products 数据集上的 GIANT+MLP 基线相比,E2EG 在转导设置中获得了稍高的精度 (+0.5%),同时减少了模型训练时间最多缩短 40%。 我们的模型也适用于归纳环境,比 GIANT+MLP 高出 2.23%。
索引术语:
节点分类、多任务学习、迁移学习、端到端我简介
最近,图机器学习因其现实世界的适用性而获得了更多关注[1,2,3,4,5]。 对引文网络中的论文主题进行分类[6],预测社交网络中用户之间的链接[7]或对分子结构类型进行分类[8] 都可以表示为基于图的问题。 一组基于图的问题是节点分类,其目的是在给定属性的情况下预测属于图的实体(节点)的特征。 在许多情况下,节点的属性是文本,例如社交媒体用户简介或科学论文摘要[9,6,10,11]。 从现在开始,我们将基于文本的节点属性的节点分类称为文本节点分类,这是本文的重点。
要执行文本节点分类,利用所有可用的模式非常有用:节点的文本属性和图拓扑。 文本节点分类通常包括两个阶段:1)嵌入节点的原始文本属性; 2)使用嵌入作为下游分类器的输入。 一种常见的方法是使用与图无关的文本嵌入(例如 bag-of-words 或 word2vec)作为图相关分类器(例如图神经网络 (GNN))的输入 [1, 2, 3, 4]。
当前最先进的框架 GIANT [5] 通过生成用于下游节点分类模型的依赖于图的文本嵌入,进一步利用图拓扑和原始文本之间的相关性。 GIANT 通过在称为“邻域预测”的自监督学习任务上训练编码器来嵌入节点的原始文本。 该任务的目标是在给定节点的原始文本属性的情况下预测节点的邻域,从而在嵌入原始文本的同时合并图拓扑。 GIANT 的图相关文本嵌入提高了与图无关的下游分类器(例如多层感知器 (MLP))的性能,从而减少了对计算成本高昂的 GNN 的需求。
在GIANT和其他两阶段框架中,由于自监督文本嵌入过程和后续节点分类过程之间的客观切换,可能会发生文本属性的信息丢失。 这里,节点的原始文本不直接嵌入到主节点分类目标下,因此可能会对节点分类质量产生负面影响。 这可以通过同时利用图拓扑和嵌入节点的原始文本以端到端的方式进行节点分类来解决,这尚未得到探索。 此外,由于客观表达能力的提高,同时使用原始文本和图形结构进行训练可能会产生更稳健的模型,从而允许使用更轻量级的文本编码器并提高计算效率。
现在的工作。 为了防止信息丢失和降低计算成本,我们提出了一种端到端模型,它利用图拓扑和节点的原始文本直接进行节点分类,称为E2EG(End-to-end GIANT) 111代码可在 https://github.com/TuAnh23/E2EG 获取。. 我们利用 GIANT 框架中的邻域预测任务[5]。 邻域预测已被证明是隐式包含图拓扑的有效任务,这与计算成本高昂的 GNN 不同,GNN 显式使用相邻节点上的特征传播操作[2,3,4]。 我们的 E2EG 模型以节点的原始文本属性作为输入,并同时学习主节点分类任务和邻域预测任务。 通过这种方式,E2EG 同时将文本嵌入到主要目标下,同时通过邻域预测利用图拓扑。
综上所述,本文的贡献如下:
-
1.
用于节点分类的新端到端模型 E2EG,由于其紧凑和独立的性质,非常适合实际使用,无需链接多个模型进行节点分类;
-
2.
实验表明,与 GIANT 相比,E2EG 能够使用轻量级且更快的蒸馏文本编码器,而不会损失准确性;
-
3.
实验表明,E2EG 在传导和感应设置中均优于 GIANT+MLP。
-
4.
定性分析表明,E2EG:1)与两阶段 GIANT+MLP 相比,潜在地减少了文本属性的信息损失; 2)由于多任务设置,与 BERT 文本分类模型相比,可以更好地利用拓扑信息。
II 背景及相关工作
在本节中,我们给出图的正式定义,然后介绍图上通用机器学习的常用方法以及这些框架固有的计算开销。 然后,我们描述了文本节点分类的相关工作。 最后,我们给出了用于文本节点分类的 GIANT 框架的详细背景描述,我们的 E2EG 模型基于该框架。
II-A 图形
图是用于表示彼此相关的实体的结构。 图由节点集和可以用邻接矩阵表示的边集组成。 每个节点可以具有表示为的属性。 邻接矩阵的切片 表示节点 的单热编码邻域 。
II-B 图上的机器学习
图机器学习(包括节点分类)的常见方法是通过消息传递图神经网络 (GNN)[2,3,4]。 例如,GraphSAGE [2] 通过聚合其直接邻居 的表示并将其与当前的表示连接来更新每个节点 的表示。 虽然被证明是有效的,但这些消息传递 GNN 的计算成本可能很高,因为随着模型的深入,消息传递涉及到计算一个节点的表示所需的支持节点数量不断增加。 这个瓶颈被更广泛地称为“邻居爆炸”问题[4]。
II-C 文本节点分类
文本节点分类框架通常嵌入要在下游分类器中使用的文本[12,13,14,15]。 传统上,与图无关的文本嵌入被用作图神经网络(GNN)分类器的输入,以便利用文本和图模态[1,2,3,4]。 与图无关的文本嵌入的示例包括词袋特征,然后进行主成分分析; word2vec 模型生成的词向量的平均值[16]。
最近对与图无关的文本嵌入的尝试有利于基于转换器的方法。 Transformers [17] 考虑句子中单词的相对位置,因此与 bag-of-words 和 word2vec 相比,生成的嵌入更具表现力。 此外, Transformer 可以直接用作文本分类模型[18]来对节点进行分类,避免了对下游节点分类器的需要并提高了易用性。 通过这种方式,模型在给定节点的原始文本属性的情况下预测节点的类别,但没有利用图拓扑。
一些工作提出了结合文本数据和图拓扑来生成节点嵌入的方法,该嵌入稍后可用于节点分类。 Paper2vec [19] 通过训练模型来学习节点嵌入,以识别两个节点是否来自给定文本属性的同一邻域。 [20] 中的作者使用给定节点原始文本的链接预测来学习节点嵌入。 Heterformer [21] 堆叠基于图注意和基于 Transformer 的模块来嵌入节点。 在这些论文中,生成的节点嵌入用作与图无关的节点分类器的输入,例如支持向量机、多层感知器或逻辑回归。
II-D 巨人框架
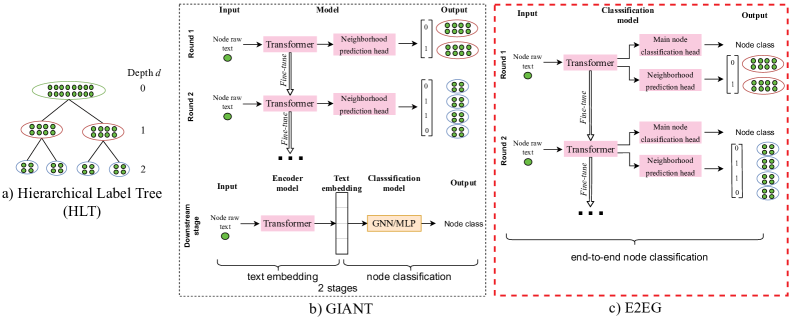
GIANT 框架[5] 目前是许多 OGB 节点分类排行榜[22] 中最好的框架之一。 GIANT 通过采用称为“邻域预测”的自我监督学习任务,为下游分类器生成依赖于图的文本嵌入。 考虑一个图 ,其中每个节点 都与一些原始文本 相关联。 邻域预测任务的目标是预测给定 的单热编码邻域 。 通过学习节点原始文本的编码器来预测节点的邻域,GIANT 利用邻域拓扑与其相关文本之间的相关性,从而利用图拓扑来增强文本嵌入。
在邻域预测中,由于目标向量 的大小等于图中节点 的数量,因此输出空间很大。 邻域预测是极限多标签分类 (XMC) 问题[5]的一个实例。 因此,GIANT采用专为XMC设计的XR-Transformer架构[23]。 遵循 XR-Transformer,节点集首先根据节点的 TF-IDF 文本特征递归地聚类为分层标签树(HLT)(图1a)。 然后,对 Transformer 模型进行递归微调以进行邻域预测,如图 1b 所示。 在每个微调轮 中,Transformer 学习将节点的文本 映射到 HLT 在深度 处定义的邻居集群。每轮微调后,簇的大小都会变小,这意味着要预测的邻域会变得更加详细。 这种邻域预测的难度逐渐增加是一种课程学习,其中在较简单的任务(预测较粗的邻域)上训练的 Transformer 的权重用于初始化后续的 Transformer 针对更困难的任务进行训练(预测更详细的邻域)。 然后,GIANT 使用最后一个微调 Transformer 生成的文本嵌入作为下游节点分类器的输入。
使用 GIANT 的图相关文本嵌入可以提高下游节点分类器的性能。 最显着的改进发生在与图无关的多层感知器 (MLP) 分类器上,缩小了这种简单的 MLP 与计算成本高昂的 GNN 之间的性能差距。 换句话说,GIANT+MLP 获得了与 GIANT+GNN 接近的性能。
前面提到的文本节点分类框架遵循常见的两阶段设置:首先嵌入节点的文本属性,然后将生成的嵌入作为输入提供给下游节点分类器。 由于节点的文本属性没有直接嵌入到主要目标中,可能会发生信息丢失。 据我们所知,尚未探索以端到端方式直接嵌入图拓扑和节点原始文本以进行节点分类的可能性。 为了避免信息损失并在准确性和计算效率方面提高节点分类质量,我们通过提出一种端到端节点分类模型来探索这个方向,称为端到端GIANT(E2EG)。 该模型将在下一节中描述。
III 方法论
我们提出了 E2EG - 一种多任务模型,它同时利用图拓扑并直接嵌入节点的原始文本,以端到端的方式进行节点分类。 E2EG的架构如图1c所示。该模型学习两个任务:
-
•
主节点分类任务。
给定输入节点的原始文本,模型学习预测所需的节点类别。 这样,原始文本就直接嵌入到节点分类目标下。 -
•
辅助邻域预测任务。
受到 GIANT 有效性的启发,我们使用邻域预测作为 E2EG 的辅助任务。 通过这种方式,图拓扑与文本属性同时编码,减少了对计算成本高昂的 GNN 的需求。 此外,我们假设由于包含辅助任务而导致的表达学习目标可以允许使用更轻量级的文本编码器。
由于其端到端的性质,即直接嵌入节点的原始文本以进行节点分类,E2EG 有望减少文本属性的信息损失(假设是两阶段框架固有的问题)。 多任务设置通过同时使用原始文本(通过主节点分类任务)和图拓扑(通过邻域预测任务)来促进这种端到端训练。
由于我们使用与 GIANT 相同的邻域预测任务,因此我们也以 XR-Transformer [23] 为基础。 E2EG 将节点的原始文本作为输入,并输出节点的类以及节点的单热编码邻域。 因此,我们通过为主节点分类任务添加预测头来修改 XR-Transformer。 我们扩展的 XR-Transformer 包括 3 部分:Transformer 组件(即文本编码器)、主分类头和邻域预测头(图1c)。 遵循 XR-Transformer,E2EG 经过多轮微调训练,邻域预测目标变得更加详细。 主节点分类任务通过微调轮次固定。 邻域预测和节点分类的损失是串联反向传播的。
我们提出了在准确性和计算效率方面改进基本 E2EG 模型的方法,如下所示。
III-A 主要任务延迟
在多轮微调中训练相同的节点分类任务以及不同分辨率的邻域预测可能会导致节点分类任务的过度拟合。 节点分类性能可能在早期的微调轮次中达到峰值,因此在后面的轮次中不会利用更详细的邻域信息。 因此,我们建议通过排除主要任务损失并仅在早期微调轮中学习邻域预测来延迟学习主要节点分类任务。
III-B 额外的微调轮
为了优化节点分类性能,我们在最后进行了额外的微调,其中模型仅学习主节点分类任务,并排除辅助邻域预测任务。 为了保留前几轮中学到的邻域信息,我们在附加轮中冻结了 Transformer 组件,并且仅影响节点分类头。
III-C 传导数据利用
在传导设置中,根据定义,整个图形结构在训练期间可用。 因此,利用测试和验证节点的拓扑进行训练将很有用。 我们通过仅反向传播邻域预测损失并排除测试和验证样本的主要任务损失来实现这一点。 这样,我们充分利用了数据,同时确保实际测试和验证目标类不会泄漏。 这类似于 GIANT 的数据使用,因为 GIANT 的模型是在整个图上进行邻域预测训练的,即包括训练、验证和测试集中的所有节点。
III-D 编码器
我们模型的表达学习目标和端到端性质可能允许使用更轻量级和更快的 Transformer 文本编码器。 我们建议使用 Transformer 的精炼版本来替换 GIANT 使用的原始 BERT 组件[24]。 第一个版本是 DistilBERT [25]。 我们选择 DistilBERT,因为它可以与 GIANT 使用的 BERT 编码器进行公平比较。 第二个版本是 Distil-SentenceBERT [26]。 我们选择这个编码器是因为它的预训练目标是在句子级别,而不是单词/标记级别。 这可能更适合手头的任务,因为对于 GIANT 和 E2EG,目标是在句子级别,即嵌入一段文本或根据一段文本对节点进行分类。
IV 实验设置
我们在 ogbn-arxiv [6] 和 ogbn-products [10] 数据集上训练和评估我们的模型来自开放图基准 (OGB) [22],这是两个使用最广泛的节点属性预测基准数据集,具有对比大小和密度。 Ogbn-arxiv 是 arXiv 论文之间的引用网络,其中节点是论文,边指示一篇论文何时引用另一篇论文。 节点的文本属性是论文的标题和摘要。 要预测的节点类别是论文的主题领域。 Ogbn-products 是一个亚马逊产品网络,其中节点是产品,边表示何时同时购买两种产品。 节点的文本属性是产品的标题和描述。 要预测的节点类别是产品的类别。 数据集的统计数据如表I所示。
| #Nodes | #Edges | Split ratio (%) * | |
| ogbn-arxiv | 0.17M | 1.17M | 54/18/28 |
| ogbn-products | 2.44M | 61.86M | 8/2/90 |
| * train/validation/test split | |||
E2EG的超参数与GIANT大多相似。 我们调整其中一些以最大限度地提高验证准确性。 其中包括值为 的最大学习率、值为 的丢弃概率、值为 的主节点分类头中的层数。 最终的超参数如下:线性衰减学习率,最大值为,batch size为32,dropout概率为0.1,邻域预测的微调轮数(即HLT深度)为4对于ogbn-arxiv和2对于ogbn-products,邻域预测的加权平方铰链损失和节点分类的交叉熵损失。 我们在 ogbn-products 的直推设置中使用一半的验证和测试数据进行邻域预测训练,因为这里的测试数据部分非常大。 主节点分类头是单个线性投影层,它将文本的隐藏维度映射到类的数量。 每个多任务微调轮均训练 1 个 epoch。 额外的一轮是通过早期停止进行训练的,即训练直到主要任务的验证准确性停止增加。 对于ogbn-arxiv,我们排除了前2轮微调中的主要任务(也由超参数调整确定)以避免过度拟合。
我们将 E2EG 与一些基线进行比较:
-
•
仅使用图拓扑进行节点分类的基线。 我们选择带有节点度数输入的 GraphSAGE,省略了节点文本属性的使用。
-
•
仅使用节点的文本属性进行节点分类的基线。 我们选择BERT模型进行文本分类,仅将节点的原始文本作为输入,从而省略了图拓扑的使用。
-
•
同时使用节点的文本属性和图拓扑,但不是端到端的架构:1) GraphSAGE,使用 OGB 的与图无关的文本嵌入,2) GIANT+MLP,使用依赖图的文本嵌入。
我们不包括复杂的集成管道(例如 GIANT+GraphSAGE 或 GIANT+DRGAT+KD)作为基线,因为这些管道对于具有大量参数的训练成本更高,因此与我们提出的端到端模型无法相比。 在基线中,我们特别对我们的 E2EG 模型和 GIANT+MLP 基线进行了全面的比较,因为我们是从 GIANT+MLP 扩展而来的。 我们在使用不同 Transformer 版本时将 E2EG 与 GIANT+MLP 进行比较:原始 BERT 编码器以及更轻量级的 DistilBERT 和 Distil-SentenceBERT 编码器。 我们还在归纳设置中比较它们,其中测试和验证集中的节点不用于学习邻域预测。
尽管 E2EG 被设计为独立的节点分类模型,但我们还尝试使用 E2EG 以与 GIANT 相同的方式为其他下游分类器生成文本嵌入。 我们通过将 GIANT 的文本编码器生成的嵌入替换为 E2EG 的文本编码器生成的嵌入来进行此实验,这些嵌入位于 OGB 排行榜上 ogbn-arxiv 的顶级节点分类管道之一(即 GIANT+DRGAT +KD)和ogbn-产品(即GIANT+SAGN+MCR+C&S)。
为了研究 E2EG 性能增益的来源,我们通过调查 E2EG 正确预测但 BERT 或 GIANT+MLP 错误预测的样本来进行定性分析。 我们还调查了 E2EG 错误预测的样本。 对于每个模型,我们考虑使用不同随机种子训练的不同版本,并研究所有版本预测正确或错误的样本。 我们将节点样本的文本及其两跳邻域视为图拓扑的指示。
实验在配备 2 个 NVIDIA GeForce GTX 1080 Ti GPU(每个 11GB 内存)和 12 个 CPU(总共 128GB RAM)的机器上完成。 我们在 0 到 9 的 10 个随机种子上重复每个实验,并报告节点分类精度的平均值和标准偏差。
V 结果
V-A 拟议训练策略的效果
|
|
|
|||||||
| Base model | 74.41 ± 0.09 | 2/4 | 73.06 ± 0.14 | ||||||
| With delay | 74.81 ± 0.16 | 4/4 | 73.60 ± 0.16 | ||||||
|
|||||||||
延迟E2EG主任务的效果如表II所示。 我们观察到过度拟合问题,即在早期微调轮中获得的最佳验证分数,仅发生在 ogbn-arxiv 中。 因此,我们只在ogbn-arxiv上应用该方法。 观察到基础模型的最佳验证精度是在第二轮(总共 4 轮中)的早期获得的。 排除前几轮中的主要损失有助于避免过度拟合,因为最佳验证分数增加了 0.4%,并且是在最后一轮微调中获得的。 使用该方法,模型的测试精度提高了0.54%。
表 III 显示了包含额外的仅主任务微调回合的效果。 可以看出,额外的轮次使 ogbn-arxiv 的测试精度提高了 +0.56%,ogbn-products 的测试精度提高了 +0.71%。
|
|
||||||
| ogbn-arxiv | Before * | 74.41 ± 0.09 | 73.06 ± 0.14 | ||||
| After * | 74.87 ± 0.11 | 73.62 ± 0.14 | |||||
| ogbn-products | Before * | 92.24 ± 0.18 | 80.27 ± 0.32 | ||||
| After * | 92.34 ± 0.09 | 80.98 ± 0.40 | |||||
|
|||||||
以下部分将报告传导/感应数据利用和轻量级编码器的效果以及与 GIANT+MLP 基线的比较。
V-B 基线性能
| No. | Model | Accuracy (%) | |||
|---|---|---|---|---|---|
| ogbn-arxiv | ogbn-products | ||||
| 1 | BERT text classifier | 69.66 ± 0.50 | 76.04 ± 0.72 | ||
| 2 | GraphSAGE with node degree | 39.57 ± 0.59 | 39.00 ± 0.70 | ||
| 3 | GraphSAGE with nodes’ graph-agnostic embedded text | 71.49 ± 0.27 * | 78.50 ± 0.14 * | ||
| 4 | GIANT+MLP | 73.06 ± 0.11 * | 80.49 ± 0.28 * | ||
| 5 | GIANT+MLP - BERT a | 73.06 ± 0.11 * | 80.49 ± 0.28 * | ||
| 6 | GIANT+MLP - DistilBERT b | 70.99 ± 0.16 | 79.49 ± 0.25 | ||
| 7 | GIANT+MLP - Distil-SentenceBERT c | 72.50 ± 0.25 | 79.46 ± 0.23 | ||
| 8 | GIANT+MLP - inductive | 70.46 ± 0.22 | 77.52 ± 0.25 | ||
| 9 | E2EG - BERT a | 73.12 ± 0.20 (+0.06) | 81.11 ± 0.37 (+0.62) | ||
| 10 | E2EG - DistilBERT b | 72.97 ± 0.19 (+1.98) | 80.98 ± 0.40 (+1.49) | ||
| 11 | E2EG - Distil-SentenceBERT c | 73.62 ± 0.14 (+1.12) | 80.88 ± 0.40 (+1.42) | ||
| 12 | E2EG - inductive | 72.69 ± 0.17 (+2.23) | 78.57 ± 0.26 (+1.05) | ||
|
|||||
基线的性能如表IV中的第1-4行所示。 仅使用图拓扑的具有节点度的 GraphSAGE 的性能最差,两个数据集的性能均低于 40%。 另一方面,具有与图无关的嵌入文本的 GraphSAGE 具有明显更好的性能,与具有节点度的 GraphSAGE 相比,精度几乎提高了一倍。 BERT 文本分类器在不使用图拓扑的情况下也表现良好,在 ogbn-arxiv 上实现了 69.66% 的准确率,在 ogbn-products 上实现了 76.04% 的准确率。 GIANT+MLP 在 ogbn-arxiv 上具有最佳性能,准确率为 73.06%,在 ogbn-products 上准确率为 80.49%。
V-C E2EG 与基线
E2EG 与基线的性能比较如表IV所示。 E2EG 第 9-12 行括号中的数字是与 GIANT+MLP 第 5-8 行中相应设置的比较。 总体而言,在默认传导设置中,最佳 E2EG 模型优于所有选定的基线。 它在与图无关的文本嵌入方面优于 GraphSAGE,在 ogbn-arxiv 上优于 GraphSAGE +2.13%,在 ogbn-products 上优于 GraphSAGE +2.61%。 E2EG 在 ogbn-arxiv 上的性能也比 BERT 文本分类器高出 3.96%,在 ogbn-products 上的性能比 BERT 文本分类器高出 5.07%。 最重要的是,对于两个数据集,E2EG 的性能均略优于强大的 GIANT+MLP 基线 +0.5% 以上。
与表IV中第5-7行的GIANT+MLP相比,E2EG使用更轻量级文本编码器的效果如第9-11行所示。 当使用BERT时,E2EG的性能与GIANT+MLP类似。 使用 DistilBERT 代替 BERT 会使 GIANT+MLP 的准确性下降高达 -2.07%。 另一方面,E2EG 在使用 DistilBERT 时保持其性能,精度下降幅度可以忽略不计,最多 -0.15%。 使用 Distil-SentenceBERT 可以将 ogbn-arxiv 上的 E2EG 准确性提高 +0.65%,同时在 ogbn-products 上与 DistilBERT 具有相似的性能。 使用蒸馏 Transformer 可以减少参数数量,DistilBERT 减少 -40%,Distil-SentenceBERT 减少 -25%,从而实现更好的运行时间。 表V中详细列出了模型在同一台机器上训练时的参数数量和运行时间。
|
|
|||||
| ogbn-arxiv | GIANT+MLP a | 111M | 3.27 ± 0.07 | |||
| E2EG b | 84M | 2.94 ± 0.23 | ||||
| ogbn-products | GIANT+MLP a | 110M | 16.85 ± 0.77 | |||
| E2EG c | 67M | 9.89 ± 1.21 | ||||
|
||||||
表IV中的第8行和第12行显示了在归纳设置中使用E2EG的结果与GIANT+MLP的比较。 我们的模型在 ogbn-arxiv 上比 GIANT+MLP 好 2.23%,在 ogbn-products 上比 GIANT+MLP 好 1.05%。
我们还在表 VI 中显示了仅使用 E2EG 生成文本嵌入的结果,并与 GIANT 进行了比较。 生成的嵌入用于将多个模型链接在一起以进行节点分类的集成管道。 可以看出,使用 E2EG 嵌入的管道的性能在 ogbn-arxiv 上比使用 GIANT 嵌入的管道的性能差了 -0.72%,在 ogbn-products 上比使用 GIANT 嵌入的管道的性能差了 -2.16% >。
| Ensemble pipeline | Accuracy (%) | |
|---|---|---|
| ogbn-arxiv | GIANT+DRGAT+KD | 76.33 ± 0.08 |
| E2EG+DRGAT+KD | 75.61 ± 0.56 | |
| ogbn-products | GIANT+SAGN+MCR+C&S | 86.73 ± 0.08 |
| E2EG+SAGN+MCR+C&S | 84.57 ± 0.06 |
V-D 定性分析
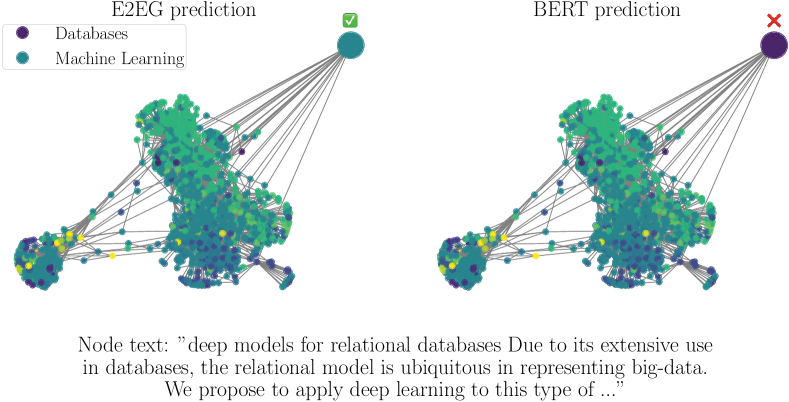
我们观察到,E2EG 正确预测但 BERT 错误预测的节点样本具有丰富的拓扑信息,与 BERT 相比,E2EG 成功地利用了这些信息。 图2a 显示了一个示例。 E2EG 正确预测节点主题为机器学习,而 BERT 错误预测节点主题为数据库。 从节点的原始文本中,很难判断该类是机器学习还是数据库,因为它是关于“关系数据库的深度模型”的。. 相比之下,两跳邻域信息量更大,因为大多数邻域具有与预测节点相同的机器学习类。
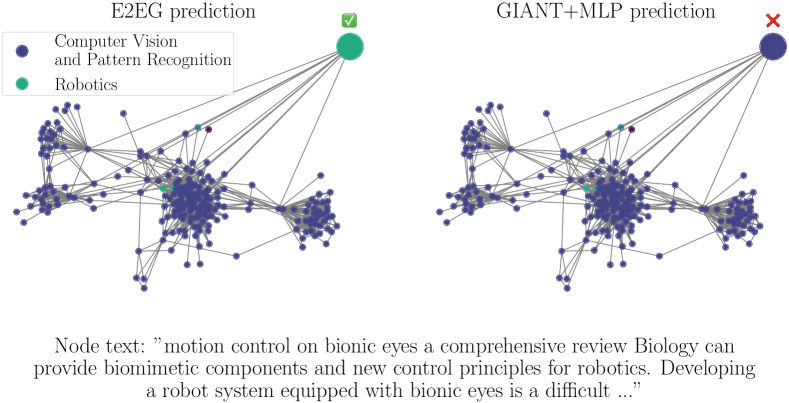
我们观察到,E2EG 正确预测但 GIANT+MLP 错误预测的节点样本具有信息性文本属性,与 GIANT+MLP 相比,E2EG 成功地利用了这一点。 图2b 显示了一个示例。 E2EG 正确预测节点主题为 Robotics,而 GIANT+MLP 错误预测为 Computer Vision and Pattern Recognition。 从节点的原始文本中,可以清楚地看出该类是 Robotics,因为文本提到了“运动控制”和“机器人系统”。 相比之下,两跳邻域相当具有误导性,因为邻域的大部分来自计算机视觉和模式识别类。
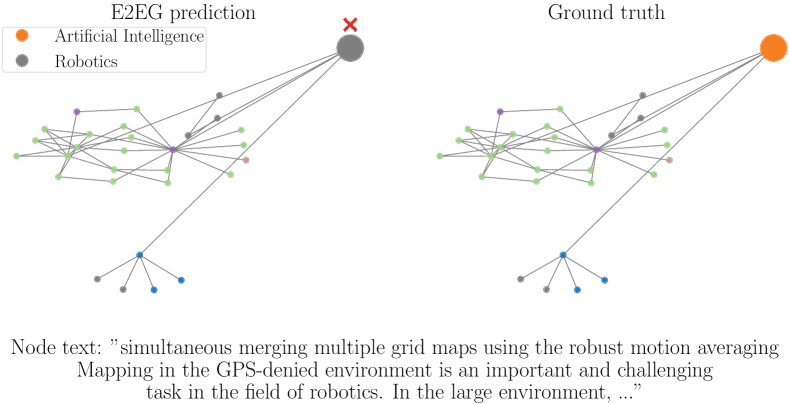
我们观察到,E2EG 错误预测的节点样本在文本和拓扑信息这两种模式上都具有误导性。 图2c 显示了一个示例。 E2EG 错误地将节点主题预测为 Robotics,而正确的类别为 Artificial Intelligence。 该节点的原始文本非常具有误导性,因为它是关于“机器人领域”的人工智能任务。 该邻域的信息量也不是很多,因为没有一个邻域具有与所考虑的节点样本相同的人工智能类。
六讨论
我们观察到,我们提出的延迟学习主要任务的训练策略有助于提高 E2EG 在遭受过度拟合的较小数据集(即 ogbn-arxiv)上的性能。 包括仅学习主要任务的额外一轮,已证明可以提高 E2EG 在两个数据集上的性能。
基线结果表明文本属性在节点分类中发挥的关键作用。 与文本嵌入特征相比,GraphSAGE 在节点度特征方面的表现明显较差。 BERT 文本分类器在不使用图拓扑的情况下具有不错的性能,这表明对于 ogbn-arxiv 和 ogbn-products 上的节点分类,节点的文本属性更多与图拓扑相比的信息方式。 它还显示了直接嵌入节点的原始文本用于节点分类的有效性,这是我们端到端模型的动机之一。
事实证明,E2EG 在节点分类方面优于某些基线。 E2EG 的性能优于 BERT 文本分类器。 这表明E2EG的有效性来自于辅助邻域预测任务的多任务设置,而不仅仅是直接嵌入原始文本进行节点分类。 E2EG 的性能也优于 GraphSAGE,且无需使用计算成本较高的消息传递。 最重要的是,E2EG 略优于 GIANT+MLP,显示了端到端时尚的有效性。 E2EG 在感应设置中也优于 GIANT+MLP。 这使得 E2EG 适用于现实场景,其中社交网络或引文网络等图数据随着新的节点和边不断变化。
我们的实验结果表明,E2EG 的表达能力足以利用更轻量级的文本编码器,而准确性的损失可以忽略不计。 当使用 BERT 时,E2EG 的性能与 GIANT+MLP 类似,因为 BERT 是一种复杂的文本编码器,可能在嵌入过程中从原始文本中捕获所需的大部分信息。 相比之下,当使用 DistilBERT 或 Distil-SentenceBERT 时,GIANT+MLP 的准确性损失增加,这可能是由于使用更轻量级的编码器时文本嵌入阶段的信息损失增加所致。 我们提出的 E2EG 模型能够保持其性能,强化了我们的假设,即具有表达学习目标的端到端过程允许使用更轻量级的文本编码器。 通过使用 Distil-SentenceBERT 代替 DistilBERT,E2EG 在 ogbn-arxiv 上的性能进一步提高。 这强化了句子级预训练更合适的假设。 对于ogbn-products,句子级预训练的效果并不显着,可能是因为与学术ogbn-arxiv相比,数据量更大且句子复杂度较低。数据集。
虽然 E2EG 以独立方式优于 GIANT+MLP 基线,但在用于为下游分类器生成文本嵌入时,它落后于 GIANT。 这可以被视为 E2EG 适用性的限制。 但是,请注意,集成管道涉及多个链接模型。 同时,E2EG被设计为以端到端的方式使用。 这将使 E2EG 更适合现实场景,因为该模型将是紧凑且独立的,同时保持良好的性能。
定性分析提供了对 E2EG 性能增益的深入了解。 我们观察到 E2EG 对 BERT 的正确预测可能来自于图拓扑的利用。 这表明了具有辅助邻域预测任务的多任务设置对于利用拓扑信息的有效性。 另一方面,我们发现 E2EG 对 GIANT+MLP 的正确预测可能来自于更好地利用节点的原始文本属性。 这表明了端到端方式的有效性:它通过直接嵌入原始文本进行节点分类来减少信息损失。 总体而言,观察到的模式表明 E2EG 更好地利用了节点的原始文本和图形拓扑。
七结论
我们引入了一种称为 E2EG 的端到端节点分类模型。 E2EG同时学习两个任务:对图拓扑进行编码的邻域预测任务和主节点分类任务。 与之前的两阶段方法相比,E2EG 具有以下优势:它允许使用轻量级文本编码器,并可能减少信息损失。 我们的实验表明,在使用更快、精炼的 Transformer 组件时,在 ogbn-arxiv 和 ogbn-products 上的默认传导设置中,与 GIANT+MLP 相比,准确率提高了 +0.5%参数减少 25% - 40%。 E2EG 也适用于电感设置,与 GIANT+MLP 相比,精度提高高达 +2.23%。 E2EG 更适合以独立方式使用,而不是在复杂的集成管道中使用。 这使得 E2EG 非常适合首选紧凑模型的现实场景。 我们的定性分析表明,E2EG 的性能增益归因于多任务和端到端设置,从而可以更好地利用图拓扑和节点的原始文本。
参考
- [1] T. N. Kipf and M. Welling, “Semi-Supervised Classification with Graph Convolutional Networks,” in International Conference on Learning Representations (ICLR 2017), 2017.
- [2] W. Hamilton, Z. Ying, and J. Leskovec, “Inductive representation learning on large graphs,” in Advances in neural information processing systems, vol. 30, 2017.
- [3] P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Bengio, “Graph attention networks,” in International Conference on Learning Representations (ICLR 2018), 2018.
- [4] H. Zeng, H. Zhou, A. Srivastava, R. Kannan, and V. Prasanna, “GraphSAINT: Graph Sampling Based Inductive Learning Method,” in International Conference on Learning Representations (ICLR 2020), 2020.
- [5] E. Chien, W.-C. Chang, C.-J. Hsieh, H.-F. Yu, J. Zhang, O. Milenkovic, and I. S. Dhillon, “Node feature extraction by self-supervised multi-scale neighborhood prediction,” in International Conference on Learning Representations (ICLR 2022), 2022.
- [6] K. Wang, Z. Shen, C. Huang, C.-H. Wu, Y. Dong, and A. Kanakia, “Microsoft Academic Graph: When experts are not enough,” Quantitative Science Studies, vol. 1, no. 1, pp. 396–413, 02 2020. [Online]. Available: https://doi.org/10.1162/qss_a_00021
- [7] N. N. Daud, S. H. Ab Hamid, M. Saadoon, F. Sahran, and N. B. Anuar, “Applications of link prediction in social networks: A review,” Journal of Network and Computer Applications, vol. 166, p. 102716, 2020.
- [8] O. Wieder, S. Kohlbacher, M. Kuenemann, A. Garon, P. Ducrot, T. Seidel, and T. Langer, “A compact review of molecular property prediction with graph neural networks,” Drug Discovery Today: Technologies, vol. 37, pp. 1–12, 2020.
- [9] S. Bhagat, G. Cormode, and S. Muthukrishnan, “Node classification in social networks,” in Social network data analytics. Springer, 2011, pp. 115–148.
- [10] K. Bhatia, K. Dahiya, H. Jain, P. Kar, A. Mittal, Y. Prabhu, and M. Varma, “The extreme classification repository: Multi-label datasets and code,” 2016. [Online]. Available: http://manikvarma.org/downloads/XC/XMLRepository.html
- [11] P. Sen, G. Namata, M. Bilgic, L. Getoor, B. Galligher, and T. Eliassi-Rad, “Collective classification in network data,” AI Magazine, vol. 29, no. 3, p. 93, Sep. 2008. [Online]. Available: https://ojs.aaai.org/index.php/aimagazine/article/view/2157
- [12] P. Hajibabaee, M. Malekzadeh, M. Heidari, S. Zad, O. Uzuner, and J. H. Jones, “An empirical study of the graphsage and word2vec algorithms for graph multiclass classification,” in 2021 IEEE 12th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), 2021, pp. 0515–0522.
- [13] Z. Liu, Y. Dou, P. S. Yu, Y. Deng, and H. Peng, Alleviating the Inconsistency Problem of Applying Graph Neural Network to Fraud Detection. New York, NY, USA: Association for Computing Machinery, 2020, p. 1569–1572.
- [14] K. M. Saifuddin, M. I. K. Islam, and E. Akbas, “Drug abuse detection in twitter-sphere: Graph-based approach,” in 2021 IEEE International Conference on Big Data (Big Data). IEEE, 2021, pp. 4136–4145.
- [15] N. Shilov, W. Othman, M. Fellmann, and K. Sandkuhl, “Machine learning-based enterprise modeling assistance: Approach and potentials,” in IFIP Working Conference on The Practice of Enterprise Modeling. Springer, 2021, pp. 19–33.
- [16] T. Mikolov, K. Chen, G. S. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” in International Conference on Learning Representations (ICLR), 2013.
- [17] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in neural information processing systems, vol. 30, 2017.
- [18] C. Sun, X. Qiu, Y. Xu, and X. Huang, “How to fine-tune bert for text classification?” in China national conference on Chinese computational linguistics. Springer, 2019, pp. 194–206.
- [19] S. Ganguly and V. Pudi, “Paper2vec: Combining graph and text information for scientific paper representation,” in European conference on information retrieval. Springer, 2017, pp. 383–395.
- [20] D. Daza, M. Cochez, and P. Groth, “Inductive entity representations from text via link prediction,” in Proceedings of the Web Conference 2021, 2021, pp. 798–808.
- [21] B. Jin, Y. Zhang, Q. Zhu, and J. Han, “Heterformer: A transformer architecture for node representation learning on heterogeneous text-rich networks,” arXiv preprint arXiv:2205.10282, 2022.
- [22] W. Hu, M. Fey, M. Zitnik, Y. Dong, H. Ren, B. Liu, M. Catasta, and J. Leskovec, “Open graph benchmark: Datasets for machine learning on graphs,” arXiv preprint arXiv:2005.00687, 2020.
- [23] J. Zhang, W.-c. Chang, H.-f. Yu, and I. Dhillon, “Fast multi-resolution transformer fine-tuning for extreme multi-label text classification,” in Advances in Neural Information Processing Systems, vol. 34, 2021.
- [24] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, Minnesota: Association for Computational Linguistics, Jun. 2019, pp. 4171–4186.
- [25] V. Sanh, L. Debut, J. Chaumond, and T. Wolf, “Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter,” in The 5th Workshop on Energy Efficient Machine Learning and Cognitive Computing - NeurIPS 2019, 2019.
- [26] N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019.