TSRFormer:使用 Transformer 进行表结构识别
摘要。
我们提出了一种新的表格结构识别(TSR)方法,称为 TSRFormer,可以从各种表格图像中稳健地识别具有几何扭曲的复杂表格的结构。 与之前的方法不同,我们将表格分隔线预测制定为线回归问题而不是图像分割问题,并提出了一种新的基于 DETR 的两阶段分隔符预测方法,称为 Separator REgression TRansformer (SepRETR),直接从表格图像预测分隔线。 为了使两阶段DETR框架高效且有效地工作于分隔线预测任务,我们提出了两项改进:1)先验增强匹配策略来解决DETR收敛速度慢的问题; 2)一种新的交叉注意模块,可以直接从高分辨率卷积特征图中采样特征,从而以较低的计算成本实现高定位精度。 在分离线预测之后,使用基于简单关系网络的小区合并模块来恢复跨越小区。 借助这些新技术,我们的 TSRFormer 在多个基准数据集(包括 SciTSR、PubTabNet 和 WTW)上实现了最先进的性能。 此外,我们还在更具挑战性的真实内部数据集上验证了我们的方法对具有复杂结构、无边界单元、大空白、空单元或跨越单元以及扭曲甚至弯曲形状的表格的稳健性。
1. 介绍
表格提供了在科学出版物、财务报表、发票、网页等许多场景中有效表示和交流结构化数据的手段。由于数字化转型的趋势,自动表格结构识别(TSR)已成为一个重要的研究课题。文档理解并引起了许多研究人员的关注。 TSR 旨在通过提取单元格框的坐标和行/列跨越信息来从表格图像中识别表格的单元格结构。 这项任务非常具有挑战性,因为桌子可能具有复杂的结构、多样的样式和内容,并且在图像捕获过程中会发生几何扭曲甚至弯曲。
最近,基于深度学习的 TSR 方法,例如 (Schreiber 等人, 2017; Paliwal 等人, 2019; Siddiqui 等人, 2019a, b; Qasim 等人, 2019; Tensmeyer 等人, 2019; Raja 等人, 2020;Zheng等人,2021;Long等人,2021;Qiao等人,2021),在识别具有复杂结构和多样性的非扭曲表格方面取得了令人瞩目的进展。风格。 然而,除了 Cycle-CenterNet (Long 等人, 2021) 之外的这些方法都不能直接应用于几何扭曲甚至弯曲的桌子,而这些桌子经常出现在相机捕获的图像中。 尽管 Cycle-CenterNet (Long 等人, 2021) 提出了一种有效的方法来解析野生复杂场景中扭曲边框表的结构,并在 WTW (Long 等人, 2021 ) 数据集,这项工作没有考虑无边框表格。 因此,识别各种几何扭曲桌子的结构这一更具挑战性的问题仍然缺乏研究。
在本文中,我们提出了一种新的 TSR 方法,称为 TSRFormer,可以稳健地识别有边框和无边框扭曲表格的结构。 TSRFormer 包含两个有效组件:1)基于两阶段 DETR (Zhu 等人,2021) 的分离器回归模块,用于直接从输入表格图像预测线性和曲线行/列分离线; 2)基于关系网络的单元格合并模块,通过合并由相交的行和列分隔符生成的相邻单元格来恢复跨单元格。 与之前基于分割和合并的方法(例如,(Tensmeyer 等人, 2019))不同,我们将分隔线预测制定为线回归问题而不是图像分割问题,并提出了一种新的分隔线预测方法,称为 Separator REgression TRansformer (SepRETR),直接从表格图像预测分隔线。 通过这种方式,我们的方法可以摆脱启发式掩模到行模块,并对扭曲的表变得更加鲁棒。 具体来说,SepRETR 首先为每个行/列分隔符预测一个参考点,然后将这些参考点的特征作为对象查询并将其输入 DETR (Carion 等人, 2020) 解码器以回归直接获取其相应分隔线的坐标。 为了使两阶段DETR框架高效且有效地工作于分离线预测任务,我们进一步提出了两个改进:1)先验增强匹配策略来解决DETR收敛速度慢的问题; 2)一种新的交叉注意模块,可以直接从高分辨率卷积特征图中采样特征,从而以较低的计算成本实现高定位精度。 借助这些新技术,我们的 TSRFormer 在多个公共 TSR 基准测试中取得了最先进的性能,包括 SciTSR (Chi 等人,2019)、PubTabNet (Zhong 等人,2020) ) 和 WTW (Long 等人, 2021)。 此外,我们还证明了我们的方法在更具挑战性的真实世界内部数据集上处理具有复杂结构、无边界单元、大空白、空或跨越单元以及扭曲甚至弯曲形状的表格的稳健性。
2. 相关工作
2.1. 表结构识别
早期的TSR方法主要基于手工特征和启发式规则(例如,(Laurentini and Viada, 1992; Itonori, 1993; Kieninger and Dengel, 1998; Shigarov 等人, 2016; Rastan 等人, 2019)),因此它们只能处理简单的表结构或特定的数据格式,例如PDF文件。 后来,一些基于统计机器学习的方法(例如(Ng等人,1999;Wang等人,2004))被提出来减少对启发式规则的依赖。 然而,这些方法仍然对表格布局做出了强烈的假设,并依赖于手工制作的特征,这限制了它们的泛化能力。 近年来,出现了许多基于深度学习的方法,并且在准确性和能力方面都显着优于这些传统方法。 这些方法可以大致分为三类:基于行/列提取的方法、基于图像到标记生成的方法和自下而上的方法。
基于行/列提取的方法。 这些方法利用对象检测或语义分割方法首先检测整个行和列,然后将它们相交以形成单元格网格。 DeepDeSRT (Schreiber 等人, 2017)首先将基于FCN的语义分割方法(Long 等人, 2015)应用于表结构提取。 TableNet (Paliwal 等人, 2019) 提出了一种基于 FCN 的端到端模型,可以同时检测表格并识别表格结构。 然而,由于接受域有限,这些基于 FCN 的 TSR 方法对于包含大空白的表并不稳健。 为了缓解这个问题,(Siddiqui 等人, 2019b; Tensmeyer 等人, 2019; Khan 等人, 2019) 等方法尝试了不同的上下文增强技术,例如,沿着像素的行和列池化特征FCN 模型的一些中间特征图或使用双向门控循环单元网络 (GRU) 等序列模型,以提高行/列分割精度。 另一组方法(Siddiqui等人,2019a;Hashmi等人,2021)将TSR视为对象检测问题,并使用一些对象检测方法来直接检测行和列的边界框。 这些方法中,只有SPLERGE(Tensmeyer等人,2019)可以处理跨度单元格,该方法提出在行/列提取模块之后添加一个简单的单元格合并模块,通过合并相邻单元格来恢复跨度单元格。 后来,提出了一些工作来进一步改进单元格合并模块。 TGRNet (Xue 等人, 2021)设计了一个网络来联合预测表格单元格的空间位置和跨越信息。 SEM (Zhang 等人,2022)融合了视觉和文本模式中每个细胞的特征。 Raja 等人 (Raja 等人, 2022) 通过将行、列和单元格检测作为目标检测任务,并通过基于图形的公式形成直线关联,改进了这种“拆分和合并”范式生成行/列跨越信息。 与这种两阶段范式不同,Zou 等人(Zou and Ma,2020)提出了一种单阶段方法来预测真实的行和列分隔符以处理跨单元格。 尽管这些方法在之前的一些基准测试中取得了令人印象深刻的性能,例如(Göbel等人,2013;Chi等人,2019;Zhong等人,2020),但它们无法处理扭曲的表格,因为它们依赖于假设表格是轴对齐的。 我们之前的工作 RobusTabNet (Ma 等人, 2022) 通过结合空间 CNN 模块提出了一种新的基于拆分和合并的方法(Pan 等人, 2018)到基于图像分割的分割模块中,以提高其对扭曲表的鲁棒性,这使得这种新的 TSR 方法能够在某种程度上鲁棒地识别扭曲表。 然而,这种方法的性能受到启发式掩模到线模块的影响,该模块与分割模块预测的一些低质量分隔符掩模相矛盾。
基于图像到标记生成的方法。 此类方法将 TSR 视为图像到标记生成问题,并采用现有的图像到标记模型将每个源表格图像直接转换为目标表示标记,该标记完全描述其结构和单元格内容。 现有技术尝试了不同的图像到标记模型将表格图像转换为LaTeX符号(Deng等人,2019;He等人,2021)或HTML序列(Li等人,2020) ;钟等人,2020)。 这些方法依赖大量数据来训练模型,但仍然难以处理大型且复杂的表格(Li 等人,2020;Zhong 等人,2020)。
自下而上的方法。 自下而上的方法可以进一步分为两类。 第一组(Qasim等人,2019;Chi等人,2019;Li等人,2021a;Xue等人,2019)将单词或单元格内容视为图中的节点,并使用图神经网络预测每个采样节点对是否位于同一单元格、行或列中。 但是,当输入是表格图像时,这些方法使用的单元格内容无法直接获得。 为了绕过这个问题,第二组方法(Zheng 等人, 2021; Prasad 等人, 2020; Raja 等人, 2020; Li 等人, 2021b; Qiao 等人, 2021; Liu 等人, 2021) 直接检测表格单元格或单元格内容的边界框,并使用不同的方法将它们分组为行和列。 细胞检测后,(Zheng 等人, 2021; Li 等人, 2021b; Qiao 等人, 2021) 等方法使用启发式规则将检测到的细胞聚类为行和列。 CascadeTabNet (Prasad 等人, 2020) 基于无边框表格的一些规则恢复单元格关系,同时与检测到的分隔线相交以提取有边框表格的网格。 TabStruct-Net (Raja 等人, 2020)提出了一种端到端网络来联合检测细胞并预测细胞关系。 FLAG-Net (Liu 等人, 2021) 预测检测到的单词边界框而不是单元格之间的邻接关系。 然而,这些方法无法处理包含大量空单元格的表格或扭曲/弯曲的表格。 Cycle-CenterNet (Long 等人, 2021) 同时检测细胞的顶点和中心点,并通过学习共同的顶点将细胞分组为表格对象。 该方法可以处理野外场景中的弯曲边框表格,但不考虑无边框表格。
2.2. DETR 及其变体
DETR (Carion 等人, 2020) 是一种新颖的基于 Transformer 的 (Vaswani 等人, 2017) 对象检测算法,引入了对象查询和集合预测损失的概念到物体检测。 这些新颖的属性使 DETR 摆脱了之前基于 CNN 的目标检测器中的许多手工设计组件,例如锚点设计和非极大值抑制 (NMS)。 然而,DETR也有其自身的问题:1)训练收敛速度慢; 2)对象查询物理意义不明确; 3)由于计算复杂度高,难以利用高分辨率特征图。 Deformable DETR (Zhu 等人, 2021)提出了几种有效的技术来解决这些问题:1)将查询公式化为2D锚点; 2)设计一个可变形注意力模块,仅关注参考点周围的某些采样点,以有效利用多尺度特征图; 3)提出两阶段DETR框架和迭代边界框细化算法以进一步提高准确性。 受 Deformable DETR 中参考点概念的启发,一些后续工作尝试通过为对象查询提供空间先验来解决收敛速度慢的问题。 例如,Conditional DETR (Meng 等人, 2021) 将交叉注意力权重分为两部分,即内容注意力权重和空间注意力权重,并提出了条件空间查询来使每个交叉注意力每个解码器层中的 head 关注对象的不同部分。 Anchor DETR (Wang 等人, 2021) 直接从 2D 锚点生成对象查询。 DAB-DETR (Liu 等人, 2022)提出使用4D锚框坐标来表示查询并动态更新每个解码器层中的框。 SMCA (Gao 等人, 2021) 首先为每个查询预测一个参考 4D 框,然后在 Transformer 解码器中使用高斯先验直接生成其相关的空间交叉注意权重。 受两阶段 Deformable DETR 的启发,Efficient DETR (Yao 等人, 2021) 将第一个密集预测阶段输出的 top-K 评分提案及其编码器特征分别作为参考框和对象查询。 与上述工作不同的是,TSP(Sun 等人, 2021)放弃了整个 DETR 解码器,提出了仅编码器的 DETR。 最近,DN-DETR (Li 等人, 2022)指出匈牙利损失中使用的二分匹配算法是收敛速度慢的另一个原因,并提出了一种基于去噪的训练方法来加速 DETR 收敛。
3. 方法
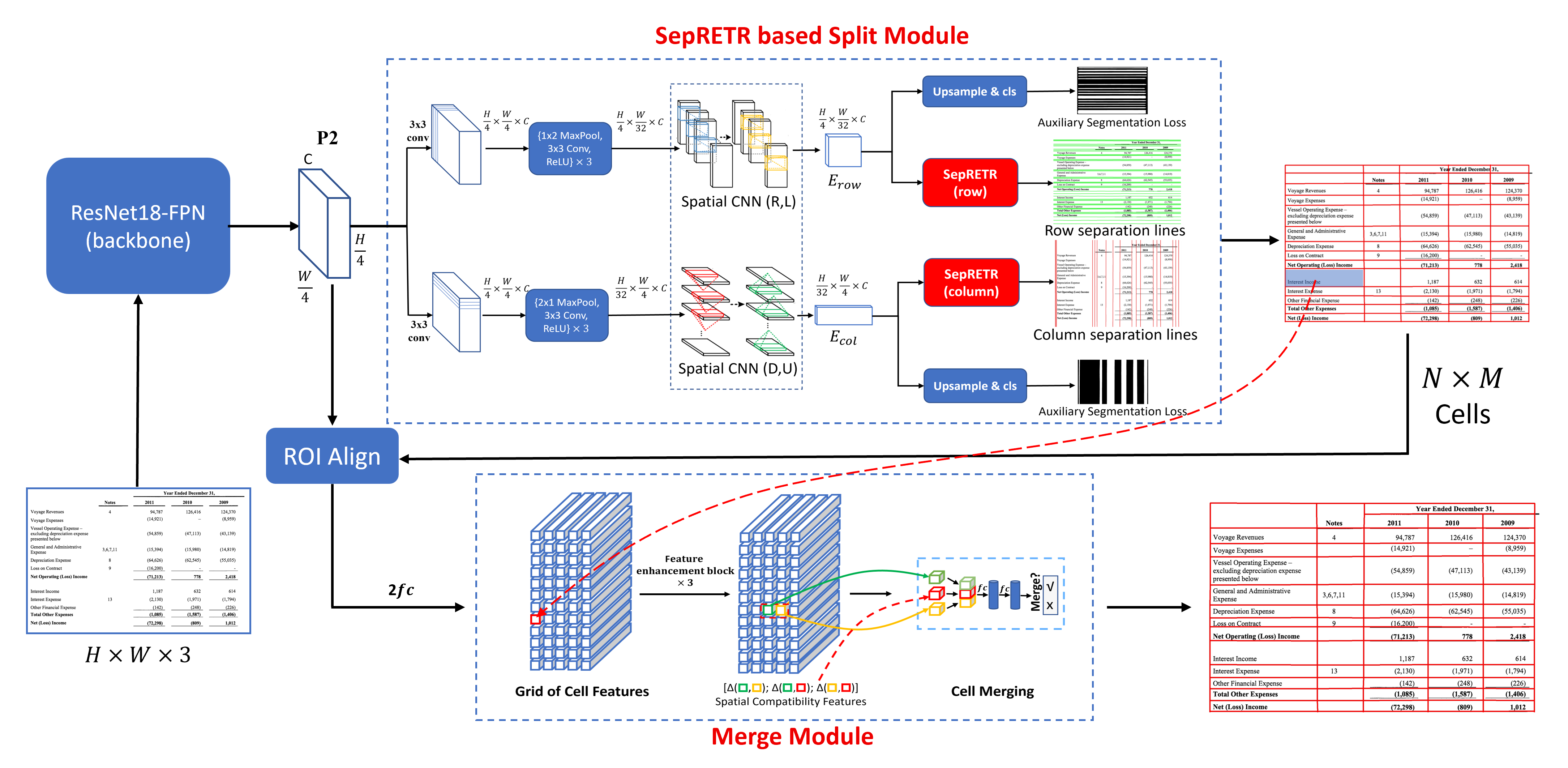
如图1所示,TSRFormer包含两个关键组件:1)基于SepRETR的分割模块,用于预测每个输入表格图像的所有行和列分隔线; 2)基于关系网络的小区合并模块来恢复跨越小区。 这两个模块附加到由 ResNet-FPN 主干网络 生成的共享卷积特征图 (He 等人,2016;Lin 等人,2017a)。
3.1. 基于 SepRETR 的分割模块
在 split 模块中,两个并行分支附加到共享特征图 上,分别预测行和列分隔符。 每个分支包括三个模块:(1)特征增强模块,用于生成上下文增强特征图; (2)基于SepRETR的分离线预测模块; (3)辅助分隔线分割模块。 在后续章节中,我们将以行分隔线预测分支为例来介绍这三个模块的详细信息。
功能增强。 如图1所示,我们添加一个卷积层和三个重复下采样块,每个下采样块由一个 max-的序列组成池化层、卷积层和ReLU激活函数,在之后依次生成下采样特征图。 然后,在(Ma 等人, 2022)之后,两个级联空间CNN (SCNN) (Pan 等人, 2018) 模块附加到通过在整个特征图上向右和向左传播上下文信息来进一步增强其特征表示能力。 以向右方向为例,SCNN模块将沿宽度方向分割为片,并从左向右逐片传播信息。 对于每个切片,它首先被发送到内核大小为的卷积层,然后通过逐元素加法与下一个切片合并。 在SCNN模块的帮助下,输出上下文增强特征图中的每个像素都可以利用两侧的结构信息来获得更好的表示能力。

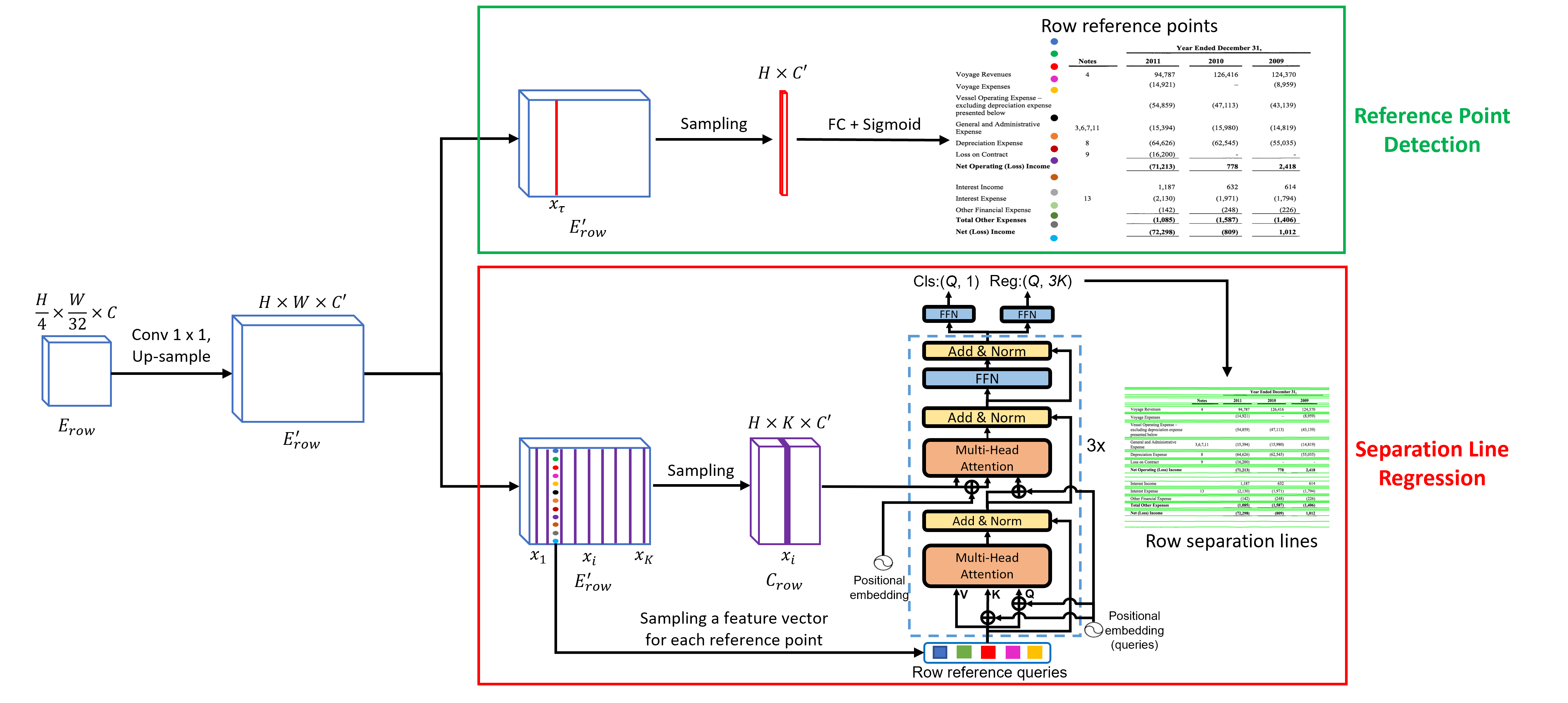
基于 SepRETR 的分离线预测。 如图3所示,我们用三条平行曲线分别表示每个行分隔符的顶部边界、中心线和底部边界。 每条曲线由 点表示,其 x 坐标分别设置为 。 对于每个行分隔符,其 点的 y 坐标由我们的 SepRETR 模型直接预测。 在这里,我们将 设置为 x 坐标。 对于列分支中的 y 坐标,我们只需要将 替换为 即可。如图2所示,我们的SepRETR包含两个模块:参考点检测模块和用于分离线回归的DETR解码器。 参考点检测模块首先尝试从增强特征图中预测每个行分隔符的参考点。 检测到的参考点的特征被视为对象查询并输入 DETR 解码器,为每个查询生成增强的嵌入。 然后,前馈网络将这些增强的查询嵌入独立解码为分隔线坐标和类标签。 这两个模块都连接到共享的高分辨率特征图 ,该特征图是通过向 依次添加 卷积层和上采样层生成的。
1)参考点检测。 该模块尝试预测沿原始图像宽度方向固定位置处的每个行分隔符的参考点。 为此, 的 列中的每个像素都被送入 sigmoid 分类器来预测分数 ,从而估计参考点是的概率位于其位置。 这里,我们在所有实验中将行线预测的超参数设置为,将列线预测的设置为 。 给定 的 列中每个像素的概率,我们通过在此列上使用 最大池层来应用非极大值抑制以去除重复的参考点。 之后,选择前 100 个行参考点,并按分数阈值 进一步过滤。 剩余的行参考点作为行分隔线回归模块中DETR解码器的对象查询。
2)分离线回归。 为了提高效率,我们不使用 Transformer 编码器来增强 CNN 主干输出的特征。 相反,我们连接高分辨率特征图 的 和 列来创建新的下采样特征图 . 然后,从 提取的行参考点的特征被视为对象查询,并输入到 3 层 Transformer 解码器中,与 交互以进行分隔线回归。 位置的位置嵌入是通过连接归一化坐标和的正弦嵌入生成的,与DETR中的相同。 经过 Transformer 解码器增强后,每个查询的特征被输入两个前馈网络,分别用于分类和回归。 行分隔符回归的 y 坐标的基本事实被标准化为 。
先验增强二分匹配。 给定一组预测及其来自输入图像的相应地面实况对象,DETR 使用匈牙利算法为系统预测分配地面实况标签。 然而,我们发现DETR中原有的二分匹配算法在训练阶段(Li等人, 2022)不稳定,即一个查询可能会在不同的场景中与同一图像中的不同对象进行匹配。训练纪元,这会显着减慢模型收敛速度。 我们发现第一阶段检测到的大多数参考点在不同的训练时期一致地位于其相应行分隔符的顶部和底部边界之间,因此我们利用此先验信息将每个参考点与其最接近的地面实况(GT ) 直接分隔符。 这样,训练过程中匹配结果就会变得稳定。 具体来说,我们通过测量每个参考点和每个 GT 分隔符之间的距离来生成成本矩阵。 如果参考点位于 GT 分隔符的顶部和底部边界之间,则成本设置为从该参考点到该分隔符的 GT 参考点的距离。 否则,成本设置为。 基于这个成本矩阵,我们使用匈牙利算法在参考点和地面真实分离器之间产生最佳的二分匹配。 在得到最佳匹配结果后,我们进一步删除成本为的对,以绕过不合理的标签分配。 秒中的实验。 4.4 表明我们的 SepRETR 的收敛速度通过我们的先验增强二分匹配策略变得更快。
辅助分隔线分割。 该辅助分支旨在预测每个像素是否位于任何分隔符的区域中。 我们在 之后添加一个上采样操作,后跟一个 卷积层和一个 sigmoid 分类器,以预测用于计算此辅助损失的二进制掩码 。
3.2. 基于关系网络的小区合并
分离线预测后,我们将行线与列线相交以生成单元格网格,并使用关系网络(张等人,2017)通过合并一些相邻单元格来恢复跨越单元格。 如图1所示,我们首先使用RoI Align算法(He等人,2017),根据每个单元格的边界框,从中提取出特征图,然后将其输入每层有512个节点的双层MLP,生成512-d特征向量。 这些单元特征可以排列在具有 行和 列的网格中,形成特征图 ,然后通过三个重复的特征增强块进行增强获得更广泛的上下文信息并将其输入关系网络以预测相邻细胞之间的关系。 每个特征增强块包含三个并行分支,分别具有行级最大池层、列级最大池层和 3x3 卷积层。 这三个分支的输出特征图连接在一起,并通过卷积层进行卷积以进行降维。 在关系网络中,对于每对相邻单元,我们将它们的特征和(Zhang等人,2017)中引入的18维空间兼容性特征连接起来。 然后对该特征应用二元分类器来预测这两个单元是否应该合并。 该分类器采用 2 隐藏层 MLP 实现,每个隐藏层有 512 个节点,并具有 sigmoid 激活函数。
3.3. 损失函数
本节定义了 TSRFormer 中训练分割模块和单元合并模块的损失函数。 对于分割模块,我们以行分隔符预测为例,将相应的损失项表示为。 同样,我们还可以计算列分隔符预测的损失,表示为。
参考点检测。 我们采用焦点损失 (Lin 等人, 2017b) 的变体来训练行参考点检测模块:
| (1) |
其中是行分隔线的数量,和是两个超参数,分别设置为2和4,如(Law和Deng, 2018)、 和 是 中 像素的预测标签和真实标签> 列。 这里, 已使用非标准化高斯函数进行了增强,这些高斯函数在分隔符的边界处被截断,以减少地面实况参考点位置周围的惩罚。 具体来说,让 表示 行分隔符的真实参考点,它是该行分隔符的中心线与垂直线 将行分隔符的上下边界之间的垂直距离作为其厚度,表示为。 那么,可以定义如下:
| (2) |
其中自适应分隔符的厚度,以确保该行分隔符内的不小于0.1。
分离线回归。 令 表示真实行分隔符集,其中 和 分别表示目标类和行分隔符位置, 表示预测集。 得到最优二分匹配结果后,行分隔线回归损失可计算为:
| (3) |
其中是焦点损失,是L1损失。
辅助分割损失。 行分隔符的辅助分割损失是二元交叉熵损失:
| (4) |
其中 表示 中的采样像素集, 和 分别表示 中像素 的预测标签和地面实况标签。 仅当该像素位于行分隔符内时 才为 1,否则为 0。
细胞合并。 单元合并模块的损失是一个二元交叉熵损失:
| (5) |
其中 表示采样单元对的集合, 和 表示 单元对的预测标签和真实标签, 分别。
总体损失。 TSRFormer 中的所有模块都可以联合训练。 总体损失函数如下:
| (6) |
其中 是一个控制参数,在我们的实验中设置为 0.2。
4. 实验
4.1. 数据集和评估协议
我们在三个流行的公共基准上进行了实验,包括 SciTSR (Chi 等人, 2019)、PubTabNet (Zhong 等人, 2020) 和 WTW (Long 等人) ,2021),验证所提方法的有效性。 此外,我们还收集了一个更具挑战性的内部数据集,其中包括许多具有复杂结构、无边界单元、大空白、空白或跨越单元以及扭曲甚至弯曲形状的具有挑战性的表格,以证明我们的 TSRFormer 的优越性。
SciTSR (Chi 等人, 2019) 包含从科学文献中裁剪的轴对齐表格的 12,000 个训练样本和 3,000 个测试样本。 作者还从测试集中选择了 716 个复杂的表格,以创建更具挑战性的测试子集,称为 SciTSR-COMP。 在该数据集中,使用单元邻接关系度量(Göbel等人,2013)作为评估度量。
PubTabNet (Zhong 等人, 2020) 包含通过匹配科学文章的 XML 和 PDF 表示形式生成的 500,777 个训练图像、9,115 个验证图像和 9,138 个测试图像。 所有表格均轴对齐。 由于测试集的注释尚未发布,我们仅报告验证集上的结果。 这项工作为表格识别任务提出了一种新的基于树编辑距离的相似度(TEDS)度量,它可以识别表格结构识别和 OCR 错误。 然而,由于不同的 TSR 方法使用不同的 OCR 模型,考虑 OCR 错误可能会导致不公平的比较。 最近的一些工作(Zheng等人,2021;Raja等人,2020;Qiao等人,2021)提出了一种名为TEDS-Struct的改进的TEDS指标,仅通过忽略OCR错误来评估表格结构识别的准确性。 我们还使用这个修改后的指标来评估我们在此数据集上的方法。
WTW (Long 等人, 2021) 包含从野外复杂场景收集的 10,970 张训练图像和 3,611 张测试图像。 该数据集仅关注有边框的表格对象,包含表格 ID、表格单元格坐标和行/列信息的注释信息。 我们从原始图像中裁剪表格区域用于训练和测试,并按照 (Long 等人, 2021) 使用单元格邻接关系 (IoU=0.6) (Göbel 等人, 2012) 作为该数据集的评估指标。
内部数据集包含 40,590 个训练图像和 1,053 个测试图像,这些图像是从包括科学出版物、财务报表、发票等在内的异构文档图像中裁剪出来的。 该数据集中的大多数图像都是由相机捕获的,因此这些图像中的表格可能会倾斜甚至弯曲。 一些例子可以在图4和图5中找到。 使用cTDaR TrackB指标(Gao等人,2019)进行评估。 我们使用 GT 文本框作为表格内容,并基于 IoU=0.9 报告结果。

| Methods | SciTSR (%) | SciTSR-COMP (%) | ||||
| Prec. | Rec. | F1 | Prec. | Rec. | F1 | |
| TabStruct-Net (Raja et al., 2020) | 92.7 | 91.3 | 92.0 | 90.9 | 88.2 | 89.5 |
| GraphTSR (Chi et al., 2019) | 95.9 | 94.8 | 95.3 | 96.4 | 94.5 | 95.5 |
| LGPMA (Qiao et al., 2021) | 98.2 | 99.3 | 98.8 | 97.3 | 98.7 | 98.0 |
| FLAG-Net (Liu et al., 2021) | 99.7 | 99.3 | 99.5 | 98.4 | 98.6 | 98.5 |
| TSRFormer | 99.5 | 99.4 | 99.4 | 99.1 | 98.7 | 98.9 |
| TSRFormer* | 99.7 | 99.6 | 99.6 | 99.4 | 99.1 | 99.2 |
| Methods | Training Dataset | TEDS (%) | TEDS-Struct (%) |
|---|---|---|---|
| EDD (Zhong et al., 2020) | PubTabNet | 88.3 | - |
| TableStruct-Net (Raja et al., 2020) | SciTSR | - | 90.1 |
| GTE (Zheng et al., 2021) | PubTabNet | - | 93.0 |
| LGPMA (Qiao et al., 2021) | PubTabNet | 94.6 | 96.7 |
| FLAG-Net (Liu et al., 2021) | SciTSR | 95.1 | - |
| TSRFormer | PubTabNet | - | 97.5 |
4.2. 实施细节
所有实验均在 Pytorch v1.6.0 中实现,并在具有 8 个 Nvidia Tesla V100 GPU 的工作站上进行。 我们使用ResNet18-FPN作为主干,并在所有实验中将的通道数设置为64。 RestNet-18 的权重使用 ImageNet 分类任务的预训练模型进行初始化。 模型通过 AdamW (Loshchilov 和 Hutter,2017) 算法进行优化,批量大小为 16。 我们使用0.9次方的多项式衰减方案来衰减学习率,初始学习率、betas、epsilon和权重衰减分别设置为1e-4、(0.9,0.999)、1e-8和5e-4 。 训练期间应用同步 BatchNorm。 在基于SepRETR的分割模块中,我们将/的通道数设置为256,并将Transformer解码器中的查询维度、头数和前馈网络维度设置为256、16和分别为1024。
在训练阶段,我们随机将表格图像的短边重新缩放为 {416, 512, 608, 704, 800} 中的数字,同时保持除 WTW 之外的所有数据集的长宽比。 对于WTW,我们通过扩展注释单元的边界来生成地面实况(GT)分隔线,并按照(Long等人,2021)将每个训练图像两侧的大小调整为1024像素。 给定分隔线的GT,我们按照(Ma等人, 2022)生成分割模块中辅助分割分支的GT掩码和单元合并模块的GT。 然后,每个掩模的中心线和两个边界将被视为回归目标的GT。 在每个图像中,为每个辅助分割分支随机采样 1024 个正像素和 1024 个负像素的小批量。 此外,我们对 64 个硬阳性细胞对和 64 个硬阴性细胞对进行小批量采样,用于细胞合并模块。 硬样本是用 OHEM (Shrivastava 等人, 2016) 算法选择的。 在训练过程中,我们首先联合训练 epoch 的参考点检测和辅助分割模块,然后联合训练 epoch 的这两个模块和分离线回归模块。 最后,进一步添加单元合并模块并联合训练另一个 epoch。 这里,PubTabNet 的 设置为 12,其他数据集设置为 20。
在测试阶段,我们将每个图像的长边重新缩放为 1024,同时保持 SciTSR、PubTabNet 和内部数据集的纵横比。 对于WTW,策略与训练中相同。
| Methods | Prec. (%) | Rrec. (%) | F1-score (%) |
|---|---|---|---|
| Cycle-CenterNet (Long et al., 2021) | 93.3 | 91.5 | 92.4 |
| TSRFormer | 93.7 | 93.2 | 93.4 |
| Methods | Dataset | Prec. (%) | Rec. (%) | F1. (%) | TEDS-Struct (%) |
|---|---|---|---|---|---|
| SPLERGE | SciTSR | 99.3 | 98.9 | 99.1 | - |
| TSRFormer | SciTSR | 99.5 | 99.4 | 99.4 | - |
| SPLERGE | SciTSR-COMP | 98.8 | 98.0 | 98.4 | - |
| TSRFormer | SciTSR-COMP | 99.1 | 98.7 | 98.9 | - |
| SPLERGE | PubTabNet | - | - | - | 97.1 |
| TSRFormer | PubTabNet | - | - | - | 97.5 |
| SPLERGE | In-house | 85.4 | 82.3 | 83.8 | - |
| TSRFormer | In-house | 95.1 | 95.3 | 95.2 | - |

4.3. 与现有技术的比较
我们将我们提出的 TSRFormer 与公共 SciTSR、PubTabNet 和 WTW 数据集上的几种最先进的方法进行比较。 对于 SciTSR,由于作者提供的评估工具包含两种不同的设置(考虑或忽略空单元格),并且之前的一些工作没有解释他们使用哪一种,因此我们报告两种设置的结果。 如表1所示,我们的方法分别在测试集和复杂子集上实现了最先进的性能。 SciTSR-COMP 上的优异结果表明我们的方法对于复杂的表格更加稳健。 在 PubTabNet 上,如表2所示,我们的方法在 TEDS-Struct 得分上取得了 97.5% 的成绩,比 LGPMA(ICDAR 2021 科学文献解析任务 B 竞赛的获胜者)好 0.8% )。 为了验证我们的方法对野生场景中带边框扭曲/弯曲的表格对象的有效性,我们在WTW数据集上进行了实验,表3中的结果表明我们的方法比Cycle-CenterNet好1.0%(专门为这种情况设计的)在F1-score中。
为了验证 TSRFormer 对于更具挑战性的无边框表格的有效性,我们重新实现了另一种基于拆分和合并的方法 SPLERGE (Tensmeyer 等人, 2019) 并在多个数据集上与我们的方法进行比较。 为了公平比较,我们利用 TSRFormer 相同的模型架构,只实现另一个分隔线预测模块,该模块首先通过行/列级别池化增强特征图,然后通过对水平/垂直切片中的像素进行分类来预测轴对齐分隔符。 如表4所示,重新实现的 SPLERGE 可以在 SciTSR 和 PubTabNet 数据集上取得有竞争力的结果,但在我们具有挑战性的内部数据集上,其 F1 分数仍比 TSRFormer 差 11.4%。 图 5 和图 4 中的定性结果表明,我们的方法对于结构复杂、无边框单元格、大空白区域、空单元格或跨单元格的表格也具有鲁棒性扭曲甚至弯曲的形状。
| SCNN | Aux-seg. | SepRETR | Cell Merging | F1. (%) | |
| Segmentation based | ✓ | 83.5 | |||
| ✓ | ✓ | 90.0 | |||
| ✓ | ✓ | ✓ | 92.3 | ||
| Regression based | ✓ | 88.6 | |||
| ✓ | ✓ | 91.0 | |||
| ✓ | ✓ | ✓ | 92.6 | ||
| ✓ | ✓ | ✓ | ✓ | 95.2 |
| Cross-attention Feature | Transformer Decoder | Set Prediction | F1. (%) |
|---|---|---|---|
| — | 90.5 | ||
| — | ✓ | 90.7 | |
| ✓ | 92.2 | ||
| ✓ | ✓ | 92.1 | |
| ✓ | ✓ | 92.6 |
| Matching Strategy | #Epochs | F1. (%) |
|---|---|---|
| Original in DETR | 20 | 90.1 |
| Prior-enhanced | 20 | 92.6 |
| Original in DETR | 40 | 91.6 |
| Prior-enhanced | 40 | 92.8 |
4.4. 消融研究
我们进行了一系列实验,以评估我们的方法中不同模块对内部数据集的有效性。
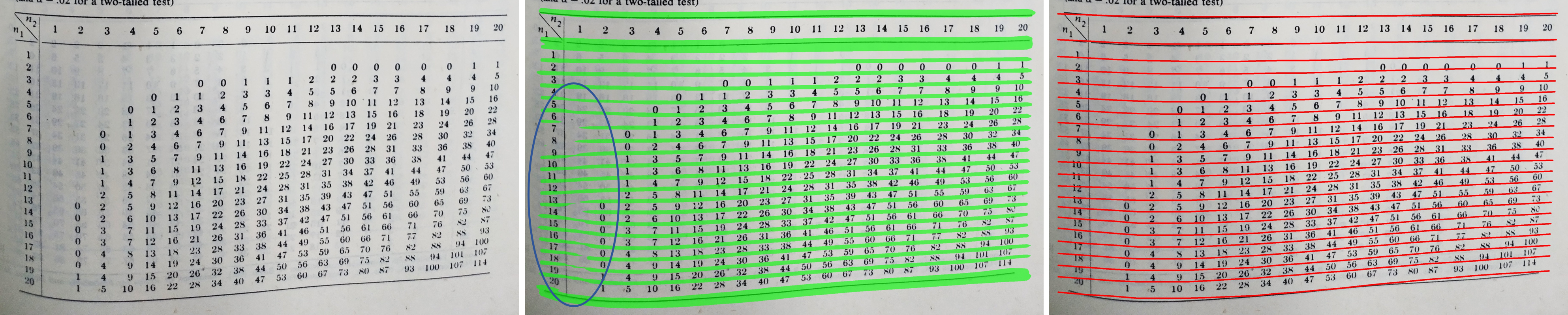
基于 SepRETR 的分割模块的有效性。 为了验证基于回归的分隔线预测模块的有效性,我们按照RobusTabNet (Ma等人,2022)通过删除基于SepRETR的分隔线回归模块并直接使用辅助分割来实现另一个基于分割的分割模块用于分离线预测的分支。 启发式 mask-to-line 模块也与(Ma 等人, 2022)中的相同。 表5中的结果表明,我们的分离器回归模块明显优于基于分割的分割模块。 图6显示了一些定性结果。 后处理模块很难很好地处理这种低质量的掩模。 相比之下,我们基于回归的方法是自由启发式的,并且对于此类具有挑战性的表具有鲁棒性。
SepRETR 设计的消融研究。 我们还进行了以下消融研究,以进一步检查 SepRETR 中三个关键组件的贡献,即 Transformer 解码器、交叉注意力和集合预测中使用的特征。 对于没有集合预测的实验,我们设计了标签分配的启发式规则。 如果参考点位于分隔符的两个边界之间,则其对应的查询被视为正样本,回归目标是其所在的分隔符。 否则,该参考点的查询就是负样本。 由于这一策略可能会将多个查询分配给一条分隔线,为了删除重复结果,我们对从每条预测线的两个边界生成的多边形应用 NMS。 如表6所示,使用Transformer解码器帮助每个查询利用全局上下文和本地信息可以显着提高基于SepRETR的分割模块的性能。 此外,表6中的最后两行表明,使用采样的高分辨率特征图和可以进一步将F1-score提高0.5% 。 虽然没有集合预测的结果很好,但我们发现这种方法对一些启发式设计(例如标签分配和 NMS 的规则)非常敏感。 相反,训练带有集合预测损失的SepRETR不仅可以取得更好的结果,而且可以摆脱此类启发式设计的局限性。
先验增强二分匹配策略的有效性。 我们通过使用不同的匹配策略和时期训练基于 SepRETR 的分割模块进行了多次实验。 如表7所示,在DETR中使用原始策略训练模型40个epoch比训练20个epoch获得了更高的精度,这意味着分割模块尚未完全收敛。 相比之下,使用所提出的先验增强匹配策略可以取得更好的结果。 经过 20 和 40 个 epoch 训练的模型之间的较小性能差距表明这两个模型已经很好地收敛,这表明我们的先验增强匹配策略可以使收敛速度更快。
5. 结论
在本文中,我们提出了 TSRFormer,一种新的表格结构识别方法,它包含两个有效组件:用于分离线预测的基于 SepRETR 的分割模块和用于跨越单元恢复的基于关系网络的单元合并模块。 与之前基于图像分割的分离线检测方法相比,我们基于 SepRETR 的分离线回归方法可以在不依赖启发式掩模到线模块的情况下实现更高的 TSR 精度。 此外,实验结果表明,所提出的先验增强二分匹配策略可以有效加快两阶段DETR的收敛速度。 因此,我们的方法在 SciTSR、PubTabNet 和 WTW 等三个公共基准测试中取得了最先进的性能。 我们在更具挑战性的真实内部数据集上进一步验证了我们的方法对具有复杂结构、无边界单元、大空白、空或跨越单元以及扭曲或弯曲形状的表格的稳健性。
参考
- (1)
- Carion et al. (2020) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. 2020. End-to-end object detection with transformers. In European conference on computer vision. Springer, 213–229.
- Chi et al. (2019) Zewen Chi, Heyan Huang, Heng-Da Xu, Houjin Yu, Wanxuan Yin, and Xian-Ling Mao. 2019. Complicated table structure recognition. arXiv preprint arXiv:1908.04729 (2019).
- Deng et al. (2019) Yuntian Deng, David Rosenberg, and Gideon Mann. 2019. Challenges in end-to-end neural scientific table recognition. In 2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 894–901.
- Gao et al. (2019) Liangcai Gao, Yilun Huang, Hervé Déjean, Jean-Luc Meunier, Qinqin Yan, Yu Fang, Florian Kleber, and Eva Lang. 2019. ICDAR 2019 competition on table detection and recognition (cTDaR). In 2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 1510–1515.
- Gao et al. (2021) Peng Gao, Minghang Zheng, Xiaogang Wang, Jifeng Dai, and Hongsheng Li. 2021. Fast convergence of detr with spatially modulated co-attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3621–3630.
- Göbel et al. (2012) Max Göbel, Tamir Hassan, Ermelinda Oro, and Giorgio Orsi. 2012. A methodology for evaluating algorithms for table understanding in PDF documents. In Proceedings of the 2012 ACM symposium on Document engineering. 45–48.
- Göbel et al. (2013) Max Göbel, Tamir Hassan, Ermelinda Oro, and Giorgio Orsi. 2013. ICDAR 2013 table competition. In 2013 12th International Conference on Document Analysis and Recognition. IEEE, 1449–1453.
- Hashmi et al. (2021) Khurram Azeem Hashmi, Didier Stricker, Marcus Liwicki, Muhammad Noman Afzal, and Muhammad Zeshan Afzal. 2021. Guided table structure recognition through anchor optimization. IEEE Access 9 (2021), 113521–113534.
- He et al. (2017) Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. 2017. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision. 2961–2969.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 770–778. https://doi.org/10.1109/CVPR.2016.90
- He et al. (2021) Yelin He, Xianbiao Qi, Jiaquan Ye, Peng Gao, Yihao Chen, Bingcong Li, Xin Tang, and Rong Xiao. 2021. PingAn-VCGroup’s Solution for ICDAR 2021 Competition on Scientific Table Image Recognition to Latex. arXiv preprint arXiv:2105.01846 (2021).
- Itonori (1993) Katsuhiko Itonori. 1993. Table structure recognition based on textblock arrangement and ruled line position. In ICDAR. 765–768.
- Khan et al. (2019) Saqib Ali Khan, Syed Muhammad Daniyal Khalid, Muhammad Ali Shahzad, and Faisal Shafait. 2019. Table structure extraction with bi-directional gated recurrent unit networks. In ICDAR. 1366–1371.
- Kieninger and Dengel (1998) Thomas Kieninger and Andreas Dengel. 1998. The t-recs table recognition and analysis system. In International Workshop on Document Analysis Systems. Springer, 255–270.
- Laurentini and Viada (1992) A Laurentini and P Viada. 1992. Identifying and understanding tabular material in compound documents. In International Conference on Pattern Recognition. IEEE COMPUTER SOCIETY PRESS, 405–405.
- Law and Deng (2018) Hei Law and Jia Deng. 2018. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European conference on computer vision (ECCV). 734–750.
- Li et al. (2022) Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M Ni, and Lei Zhang. 2022. DN-DETR: Accelerate DETR Training by Introducing Query DeNoising. arXiv preprint arXiv:2203.01305 (2022).
- Li et al. (2020) Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, Ming Zhou, and Zhoujun Li. 2020. Tablebank: Table benchmark for image-based table detection and recognition. In Proceedings of The 12th language resources and evaluation conference. 1918–1925.
- Li et al. (2021b) Xiao-Hui Li, Fei Yin, Xu-Yao Zhang, and Cheng-Lin Liu. 2021b. Adaptive Scaling for Archival Table Structure Recognition. In International Conference on Document Analysis and Recognition. Springer, 80–95.
- Li et al. (2021a) Yiren Li, Zheng Huang, Junchi Yan, Yi Zhou, Fan Ye, and Xianhui Liu. 2021a. GFTE: graph-based financial table extraction. In International Conference on Pattern Recognition. Springer, 644–658.
- Lin et al. (2017a) Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. 2017a. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition. 2117–2125.
- Lin et al. (2017b) Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. 2017b. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision. 2980–2988.
- Liu et al. (2021) Hao Liu, Xin Li, Bing Liu, Deqiang Jiang, Yinsong Liu, Bo Ren, and Rongrong Ji. 2021. Show, Read and Reason: Table Structure Recognition with Flexible Context Aggregator. In Proceedings of the 29th ACM International Conference on Multimedia. 1084–1092.
- Liu et al. (2022) Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang. 2022. DAB-DETR: Dynamic anchor boxes are better queries for DETR. arXiv preprint arXiv:2201.12329 (2022).
- Long et al. (2015) Jonathan Long, Evan Shelhamer, and Trevor Darrell. 2015. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition. 3431–3440.
- Long et al. (2021) Rujiao Long, Wen Wang, Nan Xue, Feiyu Gao, Zhibo Yang, Yongpan Wang, and Gui-Song Xia. 2021. Parsing Table Structures in the Wild. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 944–952.
- Loshchilov and Hutter (2017) Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017).
- Ma et al. (2022) Chixiang Ma, Weihong Lin, Lei Sun, and Qiang Huo. 2022. Robust Table Detection and Structure Recognition from Heterogeneous Document Images. arXiv preprint arXiv:2203.09056 (2022).
- Meng et al. (2021) Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, and Jingdong Wang. 2021. Conditional detr for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3651–3660.
- Ng et al. (1999) Hwee Tou Ng, Chung Yong Lim, and Jessica Li Teng Koo. 1999. Learning to recognize tables in free text. In Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics. 443–450.
- Paliwal et al. (2019) Shubham Singh Paliwal, D Vishwanath, Rohit Rahul, Monika Sharma, and Lovekesh Vig. 2019. Tablenet: Deep learning model for end-to-end table detection and tabular data extraction from scanned document images. In 2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 128–133.
- Pan et al. (2018) Xingang Pan, Jianping Shi, Ping Luo, Xiaogang Wang, and Xiaoou Tang. 2018. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the AAAI Conference on Artificial Intelligence.
- Prasad et al. (2020) Devashish Prasad, Ayan Gadpal, Kshitij Kapadni, Manish Visave, and Kavita Sultanpure. 2020. CascadeTabNet: An approach for end to end table detection and structure recognition from image-based documents. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. 572–573.
- Qasim et al. (2019) Shah Rukh Qasim, Hassan Mahmood, and Faisal Shafait. 2019. Rethinking table recognition using graph neural networks. In ICDAR. 142–147.
- Qiao et al. (2021) Liang Qiao, Zaisheng Li, Zhanzhan Cheng, Peng Zhang, Shiliang Pu, Yi Niu, Wenqi Ren, Wenming Tan, and Fei Wu. 2021. LGPMA: Complicated Table Structure Recognition with Local and Global Pyramid Mask Alignment. In ICDAR.
- Raja et al. (2020) Sachin Raja, Ajoy Mondal, and CV Jawahar. 2020. Table structure recognition using top-down and bottom-up cues. In European Conference on Computer Vision. 70–86.
- Raja et al. (2022) Sachin Raja, Ajoy Mondal, and CV Jawahar. 2022. Visual Understanding of Complex Table Structures from Document Images. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2299–2308.
- Rastan et al. (2019) Roya Rastan, Hye-Young Paik, and John Shepherd. 2019. Texus: A unified framework for extracting and understanding tables in pdf documents. Information Processing & Management 56, 3 (2019), 895–918.
- Schreiber et al. (2017) Sebastian Schreiber, Stefan Agne, Ivo Wolf, Andreas Dengel, and Sheraz Ahmed. 2017. Deepdesrt: Deep learning for detection and structure recognition of tables in document images. In ICDAR, Vol. 1. 1162–1167.
- Shigarov et al. (2016) Alexey Shigarov, Andrey Mikhailov, and Andrey Altaev. 2016. Configurable table structure recognition in untagged PDF documents. In Proceedings of the 2016 ACM symposium on document engineering. 119–122.
- Shrivastava et al. (2016) Abhinav Shrivastava, Abhinav Gupta, and Ross Girshick. 2016. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE conference on computer vision and pattern recognition. 761–769.
- Siddiqui et al. (2019a) Shoaib Ahmed Siddiqui, Imran Ali Fateh, Syed Tahseen Raza Rizvi, Andreas Dengel, and Sheraz Ahmed. 2019a. DeepTabStR: deep learning based table structure recognition. In ICDAR. 1403–1409.
- Siddiqui et al. (2019b) Shoaib Ahmed Siddiqui, Pervaiz Iqbal Khan, Andreas Dengel, and Sheraz Ahmed. 2019b. Rethinking semantic segmentation for table structure recognition in documents. In ICDAR. 1397–1402.
- Sun et al. (2021) Zhiqing Sun, Shengcao Cao, Yiming Yang, and Kris M Kitani. 2021. Rethinking transformer-based set prediction for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3611–3620.
- Tensmeyer et al. (2019) Chris Tensmeyer, Vlad I. Morariu, Brian Price, Scott Cohen, and Tony Martinez. 2019. Deep Splitting and Merging for Table Structure Decomposition. In 2019 International Conference on Document Analysis and Recognition (ICDAR). 114–121. https://doi.org/10.1109/ICDAR.2019.00027
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).
- Wang et al. (2004) Yalin Wang, Ihsin T Phillips, and Robert M Haralick. 2004. Table structure understanding and its performance evaluation. Pattern recognition 37, 7 (2004), 1479–1497.
- Wang et al. (2021) Yingming Wang, Xiangyu Zhang, Tong Yang, and Jian Sun. 2021. Anchor detr: Query design for transformer-based detector. arXiv preprint arXiv:2109.07107 (2021).
- Xue et al. (2019) Wenyuan Xue, Qingyong Li, and Dacheng Tao. 2019. ReS2TIM: Reconstruct syntactic structures from table images. In 2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 749–755.
- Xue et al. (2021) Wenyuan Xue, Baosheng Yu, Wen Wang, Dacheng Tao, and Qingyong Li. 2021. TGRNet: A Table Graph Reconstruction Network for Table Structure Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 1295–1304.
- Yao et al. (2021) Zhuyu Yao, Jiangbo Ai, Boxun Li, and Chi Zhang. 2021. Efficient detr: improving end-to-end object detector with dense prior. arXiv preprint arXiv:2104.01318 (2021).
- Zhang et al. (2017) Ji Zhang, Mohamed Elhoseiny, Scott Cohen, Walter Chang, and Ahmed Elgammal. 2017. Relationship proposal networks. In Proceedings of the IEEE conference on computer vision and pattern recognition. 5678–5686.
- Zhang et al. (2022) Zhenrong Zhang, Jianshu Zhang, Jun Du, and Fengren Wang. 2022. Split, embed and merge: An accurate table structure recognizer. Pattern Recognition (2022), 108565.
- Zheng et al. (2021) Xinyi Zheng, Douglas Burdick, Lucian Popa, Xu Zhong, and Nancy Xin Ru Wang. 2021. Global table extractor (gte): A framework for joint table identification and cell structure recognition using visual context. In Proceedings of the IEEE/CVF winter conference on applications of computer vision. 697–706.
- Zhong et al. (2020) Xu Zhong, Elaheh ShafieiBavani, and Antonio Jimeno Yepes. 2020. Image-based table recognition: data, model, and evaluation. In European Conference on Computer Vision. Springer, 564–580.
- Zhu et al. (2021) Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. 2021. Deformable detr: Deformable transformers for end-to-end object detection. In International Conference on Learning Representations.
- Zou and Ma (2020) Yajun Zou and Jinwen Ma. 2020. A deep semantic segmentation model for image-based table structure recognition. In 2020 15th IEEE International Conference on Signal Processing (ICSP), Vol. 1. IEEE, 274–280.