∎
明尼苏达大学
22email: zhuan143@umn.edu 33机构文本:T。李 44institutetext:计算机科学与工程
明尼苏达大学
44email: lixx5027@umn.edu 55机构文本:H.王 66institutetext:计算机科学与工程
明尼苏达大学
66email: wang9881@umn.edu 77机构文本:J。 太阳 88institutetext:计算机科学与工程
明尼苏达大学
88email: jusun@umn.edu
未知内核大小和大量噪声的盲图像去模糊
摘要
盲图像去模糊(BID)在计算机视觉和相关领域得到了广泛的研究。 现代 BID 方法可以分为两类:使用统计推断和数值优化处理单个实例的单实例方法,以及训练深度学习模型以直接对未来实例进行去模糊的数据驱动方法。 数据驱动的方法可以摆脱推导准确模糊模型的困难,但从根本上受到训练数据的多样性和质量的限制——收集足够表现力和真实的训练数据是一个长期的挑战。 在本文中,我们重点关注保持竞争力且不可或缺的单实例方法。 然而,大多数此类方法没有规定如何处理未知的内核大小和大量噪声,从而妨碍了实际部署。 事实上,我们表明,当内核大小过度指定和/或噪声水平较高时,几种最先进的(SOTA)单实例方法是不稳定的。 从积极的方面来看,我们提出了一种实用的 BID 方法,该方法对两者都稳定,同类中的第一个。 我们的方法建立在通过集成物理模型和结构化深度神经网络来解决逆问题的最新想法的基础上,无需额外的训练数据。 我们引入了一些关键的修改来实现所需的稳定性。 对标准合成数据集以及现实世界 NTIRE2020 和 RealBlur 数据集的广泛实证测试表明,与 SOTA 单实例相比,我们的 BID 方法具有卓越的有效性和实用性:以及数据驱动的方法。 我们方法的代码可在 https://github.com/sun-umn/Blind-Image-Deblurring 获取。
关键词:
盲图像去模糊、盲去卷积、未知内核大小、未知噪声类型、未知噪声水平、深度图像先验、深度生成模型、未经训练的神经网络先验1简介


图像模糊主要是由相机的光学非理想性(例如散焦、镜头畸变),即光学模糊以及场景和相机之间的相对运动,即运动模糊引起的 Szeliski2021计算机; KundurHatzinakos1996盲; JoshiEtAl2008PSF; LevinEtAl2011理解; KoehlerEtAl2012 录音; LaiEtAl2016比较; KohEtAl2021单; SunDonoho2021凸 。 它通常伴随着明显的感官噪音,例如当一个人在弱光环境下拍摄快速移动的物体时。 因此,在最简单的形式中,图像模糊通常被建模为
| (1) |
其中 是观察到的模糊和噪声图像,、、 是模糊核、干净图像和加性图像分别是感觉噪声。 这里的符号 是线性卷积,它编码了模糊效果在空间域上均匀的假设。 当存在复杂的 3D 运动(例如,多个独立移动的物体和 3D 平面内旋转)或显着的深度变化时,可以升级该模型以考虑非均匀模糊效果LevinEtAl2011理解; KoehlerEtAl2012 录音; LaiEtAl2016比较; KohEtAl2021Single 。 在本文中,我们重点关注均匀设置,并将非均匀设置留作未来的工作。
假设模型为Eq. 1。 给定和,估计被称为(非盲)反卷积,一个线性逆问题,相对容易解决。 然而,在实践中,(包括其大小和数值)通常不可用。 例如,在野外环境中,散焦和运动都无法可靠地估计KundurHatzinakos1996Blind(例如,参见图1) >)。 这导致盲反卷积 (BD),其中和是根据一起估计的。
在过去的几十年里,人们开发出了一套丰富的思想来解决 BID 和 BD,这些思想是从依赖分析处理或统计推断和数值优化来每次解决一个实例的单实例方法演变而来的,现代数据驱动方法旨在训练深度学习(DL)模型来解决所有未来的实例。 具有里程碑意义的评论文章序列KundurHatzinakos1996Blind; LevinEtAl2011理解; KoehlerEtAl2012 录音; LaiEtAl2016比较; KohEtAl2021单; ZhuangEtAl2022Deep记录了这些发展;另请参见下面的部分2.1。 评估也从合成数据转向真实世界数据,最近的 NTIRE 2020/2021 关于真实世界图像去模糊的挑战就是最好的例证 NahEtAl2020NTIRE ; NahEtAl2021NTIRE 。
在本文中,我们重点关注 BID 的单实例方法。 尽管最近的数据驱动方法作为统计学习方法显示出了巨大的前景,但它们本质上受到训练数据的限制:如果使用足够多样化和真实的数据进行训练,这些方法可能会很好地泛化。 然而,满足需求的高质量训练集的收集被认为是一个持续的挑战KohEtAl2021Single;张EtAl2022深 . 因此,单实例方法可能会成为实际 BID 中数据驱动方法的支柱,特别是对于相关数据很少或收集成本昂贵的情况。
先前的 BID 单实例方法在实用性的三个关键问题上似乎含糊不清:(1) 未知内核 () 大小:直接估计 的方法除外。 t2> 仅(例如,BD Wiggins1978Minimum ; Donoho1981MINIMUM ; Cabrelli1985Minimum ; SunDonoho2021Convex 的逆滤波方法),需要对内核大小进行近乎最优的估计SiYaoEtAl2019Understanding 。 但实际上尚不清楚如何可靠地获得如此准确的估计,以及现有方法对内核大小错误指定有多敏感; (2) 大量噪声 ():卷积后的感觉噪声可能仍然很大,而之前的大多数方法在评估时都假设无噪声或低噪声设置 泰林2012运动; zhongetal2013处理; PanEtAl2016稳健; DongEtAl2017盲;龚等人 2017 自己 ; ChenEtAl2020OID; (3)模型稳定性:图像可能仅模糊、仅噪声或两者兼而有之。 无论如何,在实践中,理想的 BID 方法应该能够在不同的制度下无缝运行。 以前的方法很少对此进行测试。 图 1总结了这三个问题。
为了快速确认这些实用性问题,我们选择了最先进的(SOTA)单实例BID方法(加上通过采用预训练模型的代表性数据驱动方法),并在低光环境下拍摄的真实世界图像上测试它们,具有未知的内核大小和未知的噪声类型/级别。 我们指定每个维度的内核大小为图像大小的一半,以提供宽松的上限。 图 2显示了这些单实例方法可能会失败得多么惨烈;更多失败可以在部分4中检查。
本文旨在解决这些实用性问题。 我们遵循 BID 统计推断和优化方法中的主要建模思想,但使用可训练的结构化深度神经网络 (DNN) 对内核和图像进行参数化。 这个想法最近被 WangEtAl2019Image 、 RenEtAl2020Neural (SelfDeblur) 和 TranEtAl2021Explore 独立引入到 BID 中,其灵感来自深度图像先验 (DIP) UlyanovEtAl2020Deep 及其变体 HeckelHand2019Deep 取得了巨大成功; SitzmannEtAl2020Implicit 解决计算机视觉和成像中的各种逆问题DarestaniHeckel2021Accelerated; GandelsmanEtAl2019双; SitzmannEtAl2020隐式; TancikEtAl2020傅里叶; QayyumEtAl2021Untrained 及以上 RavulaDimakis2019One ; MichelashviliWolf2019演讲 . 我们的主要贡献包括
- •
-
•
通过六项关键修改对 SelfDeblur 进行改造,以解决这三个问题。 在部分3.1中,我们清楚地描述了我们的修改,以及它们背后的基本原理和直觉。 弄清楚这些修改及其正确的组合是一项非常重要的任务,这使得我们的算法管道与SelfDeblur有很大不同。
- •
2 背景
2.1盲解卷积(BD)
BD是指根据式中的模型从估计的非线性反问题。1,并在地震学等众多领域找到应用 Wiggins1978Minimum ; Donoho1981MINIMUM,数字通信VembuEtAl1994Convex; DingLuo2000fast,神经科学Lewicki1998评论; EkanadhamEtAl2011blind 、显微镜 CheungEtAl2020Dictionary 和计算机视觉。
由于双线性映射,始终是一个平凡的解决方案,其中是狄拉克δ函数。 因此,如果不进一步限制和,恢复是没有希望的。 为了确保可识别性,随着时间的推移,已经提出了不同的特定领域先验。 这些领域中普遍使用的先验是 在适当的意义上是(大约)“稀疏”的 Wiggins1978Minimum ;多诺霍1981最小; Cabrelli1985最小; SunDonoho2021凸; VembuEtAl1994凸;丁洛2000快; Lewicki1998评论; EkanadhamEtAl2011盲; CheungEtAl2020Dictionary . 对于BID,作为要恢复的自然图像通常被假设在梯度域中是稀疏的。 此外, 通常是“短”或“小”,因为特征模式通常严格限制在其时间或空间范围内Lewicki1998review ; EkanadhamEtAl2011盲; CheungEtAl2020Dictionary . 对于 BID,模糊内核(无论是光学的还是运动的)在支持上往往比模糊图像本身的大小要小(如果不是很多的话)。 因此,许多BD应用的目标就是解决这种短而稀疏的BD(SSBD)。
由双线性映射引起的BD的另一个显着特征是平凡对称性。 如果我们假设 和 是一维无限序列 - 它们仍然可以具有有限支持,那么 对于任何 和,其中 对于任何 表示将 移动 时间步。 换句话说,我们具有尺度对称性和平移对称性。 因此,恢复取决于这些对称性,这通常足以满足实际目的。 当我们对 进行有限窗口观察时,更忠实的模型是
| (2) |
其中 模拟窗口的截断效果。 移位对称性和截断效应一起,如果处理不当,很容易导致算法失败,如部分 3.1.1和3.1.2。
在理论方面,Donoho1981MINIMUM ; SunDonoho2021凸; ChoudharyMitra2014稀疏 ; LiEtAl2015统一; LiEtAl2017可识别性; KechKrahmer2017Optimal讨论了不同先验下BD的可识别性。 为了保证恢复,AhmedEtAl2014Blind ; Chi2016保证; LiEtAl2019Rapid 假设 和/或 位于随机子空间上,并且 ZhangEtAl2017Global ;张EtAl2020结构; KuoEtAl2020Geometry在上的某些概率生成模型下对SSBD进行了研究。 此外,WipfZhang2014Revisiting从贝叶斯的角度得出了对BD的不同先验和公式的见解。
2.2BD专门用于盲图像去模糊(BID)
对于 BID,SSBD 通常通过额外的内核和/或图像特定先验来解决。 早期 BID 方法的一个子集以参数化分析形式(例如高斯形状)编写 ,并使用简单的分析或计算步骤 KundurHatzinakos1996Blind 求解 BID。 在过去的十年中,这种方法在很大程度上已被统计推断和数值优化方法所取代,该方法将 SSBD 表述为正则化优化问题,通常解释为最大后验 (MAP) 估计:
| (3) |
其中 是正则化参数。 规范的选择是 和 (即总变分,或 TV, 上的范数)来编码梯度中的稀疏性。 但由于 和 对于任何 来说,在没有任何进一步约束的情况下,全局解决方案是 时。 因此,最近的研究很大一部分是关于处理缩放问题以及更好的稀疏编码:
-
•
:这是一个经典的补救措施 ChanWong1998Total ,但在某些情况下更喜欢使用 的简单解决方案 LevinEtAl2011Understanding 。 事实上,即使采用 ()(相当严格的稀疏代理),也可能会出现简单的解决方案。 尽管如此,也许令人惊讶的是,精心选择的算法可以找到重要的局部解决方案,从而实现良好的恢复PerroneFavaro2014Total。
-
•
、 或 :上述方法可能更倾向于三元解 (假设 )的高层次直觉是:当 是非稀疏且满足单纯形约束时(即、)时,由于 的潜在平滑效应, 的稀疏程度往往高于 的稀疏程度,但 的数值缩放程度低于 的数值缩放程度。111确实,根据杨氏卷积不等式和事实,。. 当变得足够稠密LevinEtAl2011Understanding时,后者往往会超过前者; BenichouxEtAl2013基础 。 因此,可能的解决方法是使用尺度不变的稀疏性度量,例如 KrishnanEtAl2011盲; HurleyRickard2009比较 222另请参阅 Cabrelli1985Minimum 中关于逆向过滤方法的类似想法; SunDonoho2021凸 。 或(近) XuEtAl2013Unnatural ; PanEtAl2014去模糊; WipfZhang2014重温 .
-
•
、或(近):最近在不同设置下显示 WipfZhang2014Revisiting ;张EtAl2020结构;张EtAl2017全球; KuoEtAl2020几何; JinEtAl2018Normalized 认为 上的 标准化可以改变优化格局,并将真实的 呈现为全局解决方案,即使使用比例敏感的 。 这也和中普遍使用的正则化有关,可以理解为这样一个约束的惩罚形式XuEtAl2013Unnatural; PanEtAl2014去模糊; PanEtAl2016盲; YanEtAl2017Image; ChenEtAl2019盲; TranEtAl2021探索。
-
•
其他先验:其他特定于图像的先验,例如颜色先验 JoshiEtAl2009Image 、马尔可夫随机场先验 KomodakisParagoos2013MRF 、补丁重现先验 MichaeliIrani2014Blind 、黑暗通道先验 PanEtAl2016Blind 、极端通道先验 YanEtAl2017Image 、局部最大梯度先验 ChenEtAl2019Blind ,也有助于编码额外的图像结构并通过简单的解决方案解决问题。
另一种思路涉及数据拟合损失,结合上面讨论的不同先验和正则化器JoshiEtAl2008PSF; ChoLee2009快;徐佳2010二; SunEtAl2013Edge; zhongetal2013处理; FangEtAl2014可分离;龚等人2016盲;张EtAl2017全球; ChoLee2017融合; LiuEtAl2018去模糊;杨吉2019变体 . 他们中的大多数采用显式边缘检测和过滤来改进初始化和迭代期间的核估计,但边缘处理可能对噪声敏感ZhongEtAl2013Handling; KongEtAl2016Blind .
几乎所有现有的单实例方法都接受用户指定的内核大小(希望是真实大小的严格上限)作为问题超参数。 对于合成数据集,例如由 LevinEtAl2011Understanding 发布的数据集; LaiEtAl2016Comparative,“真实”内核大小,实际上稍微过度指定了内核大小,如图图3所示>——可用。 对于现实世界的数据集,例如 LaiEtAl2016Comparative 和 NahEtAl2020NTIRE 的现实世界部分,内核大小是未知的,并且大多数先前的工作对于如何选择合适的内核大小是模糊的。 我们怀疑他们的选择可能是基于反复试验并结合恢复质量的目视检查。
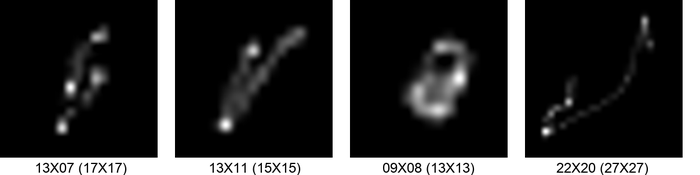
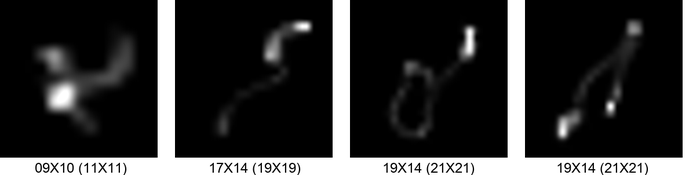

据我们所知,SiYaoEtAl2019Understanding是第一个明确解决内核大小过度指定问题的工作。 他们建议在内核上添加一个低秩先验:事实上,随着过规范的增加,内核会变得相对稀疏和低秩,这一点从图 3中可以明显看出。



虽然早期的作品在具有高斯噪声的合成数据集上测试了他们的方法(通常在 KrishnanFergus2009Fast 之后使用 ),但只有少数论文明确处理了大的、真实的噪声,例如脉冲/散粒噪声,或像素饱和度 TaiLin2012Motion ; zhongetal2013处理; PanEtAl2016稳健; DongEtAl2017盲;龚等人 2017 自己 ; ChenEtAl2020OID;参见图4中的示例。 在处理实际噪声时,一个常见的思路是学习或设计一个对大/外围像素错误不太敏感的鲁棒损失项 ,例如,通过学习像素掩模和 和 ZhongEtAl2013Handling ; PanEtAl2016稳健;龚等人 2017 自己 ; Chen等人2020OID; ChenEtAl2021Blind ,或通过使用仔细定义的稳健统计损失DongEtAl2017Blind 。
2015 年之后,出现了数据驱动的基于 DL 的 BID 方法,针对统一和非统一设置。 主要有两种方法,与解决线性逆问题的方法OngieEtAl2020Deep平行:1)端到端方法。 深度神经网络(DNN)经过直接训练来预测内核、清晰图像或两者。 我们建议读者参考优秀的调查KohEtAl2021Single; ZhuangEtAl2022Deep 和 Github 存储库 Vasu2021Image 以及相关论文的更新列表; 2) 混合方法。 这包括许多可能性:DNN 经过预训练,可以在 和 PanEtAl2021Physics 上对先验进行建模; AsimEtAl2020盲; LiEtAl2018Learning 或替换算法组件来解决 Eq. 3 (即即插即用方法,例如 张EtAl2019深); DNN 被直接训练为用于求解 Eq. 3 SchulerEtAl2016Learning 的展开数值方法的组件; AljadaanyEtAl2019道格拉斯; LiEtAl2019深0> . 再次,我们推荐这两项调查和 Github 存储库以获得全面的覆盖范围。 这些数据驱动的方法显然是有动力的,同时也受到所使用的训练数据集容量的限制;构建富有表现力和现实的训练集的困难以及因此泛化能力差仍然是关键挑战 KohEtAl2021Single 。
2.3 BID 的深度图像先验 (DIP)
顾名思义,深度图像先验 (DIP) 假设自然图像,或者一般来说,自然视觉对象,可以参数化为可训练 DNN UlyanovEtAl2020Deep 的输出。 具体来说,任何感兴趣的视觉对象 都写为 : 是一个结构化 DNN(通常是卷积 DNN,偏向于自然视觉结构) )可以被认为是一个生成器,而 是 的种子(即输入)。 通常, 是可训练的, 是随机初始化然后固定的。
视觉逆问题 (VIP) 涉及根据观察 估计视觉对象 ,其中 对观察(即前向)过程和近似符号进行建模 表示观察和建模噪声的潜在存在。 传统上,VIP 通常被视为正则化的数据拟合:
| (4) |
其中问题 (3) 是 SSBD 的特化。 将 DIP 强加到 上自然会导致
| (5) |
其中表示函数组合,编码其他先验的正则化器有时会被省略。 这个简单的想法催生了令人惊讶的竞争方法来解决众多计算视觉和成像任务,从基本图像处理UlyanovEtAl2020Deep; HeckelHand2019 深 ; HeckelSoltanolkotabi2019 去噪 ; WangEtAl2019图像; TranEtAl2021Explore,高级计算摄影GandelsmanEtAl2019Double; SitzmannEtAl2020隐式; TancikEtAl2020傅里叶; MaEtAl2021无监督; williams2019deep ,以及复杂的医学和科学成像应用 DarestaniHeckel2021Accelerated ; LawrenceEtAl2020 相; BostanEtAl2020深; TayalEtAl2021相;周Horstmeyer2020衍射; ZhuangEtAl2022实用;请参阅最近的调查QayyumEtAl2021Untrained。
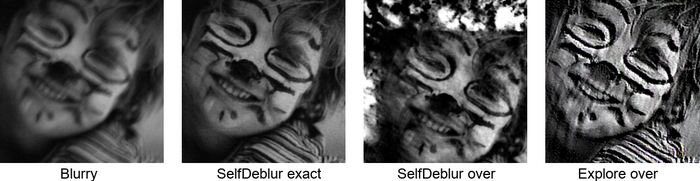

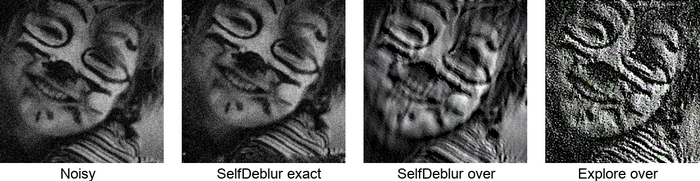
将DIP思想应用于BID时,由于内核和镜像所扮演的角色不对称,很自然地遵循Double-DIP思想GandelsmanEtAl2019Double获取:
| (6) |
即问题的 DIP 重新表述 (3)。 这是之前两部作品 WangEtAl2019Image 所遵循的确切配方; RenEtAl2020Neural;它们的不同之处在于 和 的选择,以及正则化器 和 。 我们在这里重点回顾 SelfDeblur RenEtAl2020Neural,因为我们的方法主要建立在它之上,而 WangEtAl2019Image 中的评估非常有限。
-
•
RenEtAl2020Neural (SelfDeblur): 是 MSE。 对于生成器来说,是与上面类似的卷积U-Net,而是层全连接网络。 不同的生成器将对内核和图像之间的不对称性进行编码,并反映内核往往比图像本身简单得多的事实。 然后将 Softmax 和 sigmoid 最终激活分别应用于 和 。 此外, 是经典的电视正则化器,有助于该方法在存在低电平噪声的情况下工作。 总之,
(7) 从图5可以看出,SelfDeblur只有在为仅模糊,并且内核大小是精确指定的。 当存在相当大的噪声或过度指定内核大小时,SelfDeblur 会突然崩溃。
要超越 Eq. 1 中的统一模糊模型并构建一个有望跨不同数据集泛化的模型,探索 TranEtAl2021Explore 提出从丰富的锐利-模糊图像对中学习抽象模糊算子 。 一旦学习了 ,对于任何给定的模糊图像 ,干净图像 和摘要内核 通过广义估计问题版本 (6):
| (8) |
虽然 Explore 是一个强大而大胆的想法,但目前还不清楚他们是否真的学习了可泛化的模糊模型,以及是否 Eq. 8是双DIP思想的一个很好的实现。 我们的快速测试表明,它不适用于简单的均匀模糊情况;请参见图 5的第列,尤其是在有噪声的情况下。
AsimEtAl2020Blind 在 Eq. 6 的同一行中提出了基于深度生成模型的 BID 的三种公式,但是预训练的生成器。 由于该方法需要来自某些运动模糊数据集的预训练内核生成器,因此我们稍后不会与该方法进行比较。
三个 DIP-for-BID 都不起作用 WangEtAl2019Image ; RenEtAl2020神经;上面讨论的 TranEtAl2021Explore 解决了围绕未知内核大小、大量噪声和模型稳定性的实用性问题。 接下来,我们对 SelfDeblur 提出了一些重要的修改,以完全解决这些问题。
3 我们的方法
我们的方法遵循 Eq. 6 中阐述的双 DIP 思想,并建立在之前的两项工作 WangEtAl2019Image 的基础上> 和 RenEtAl2020Neural (SelfDeblur),尤其是后者。 在部分3.1中,我们描述了我们方法的六个关键要素,并论证了为什么它们对于成功是必要的。 然后,我们在部分3.2中展示我们的整个算法流程。
3.1关键要素
3.1.1 过度指定的大小
正如我们在部分 2.2中讨论的,大多数 SOTA 单实例方法都是在合成数据集上进行评估的,例如 LevinEtAl2011Understanding和 LaiEtAl2016Comparative ,其中内核大小的上限相当严格。 然而,在更现实的数据集上,例如 NahEtAl2020NTIRE ; NahEtAl2021NTIRE ; RimEtAl2020Real,特别是在实际应用中,不存在如此严格的界限。
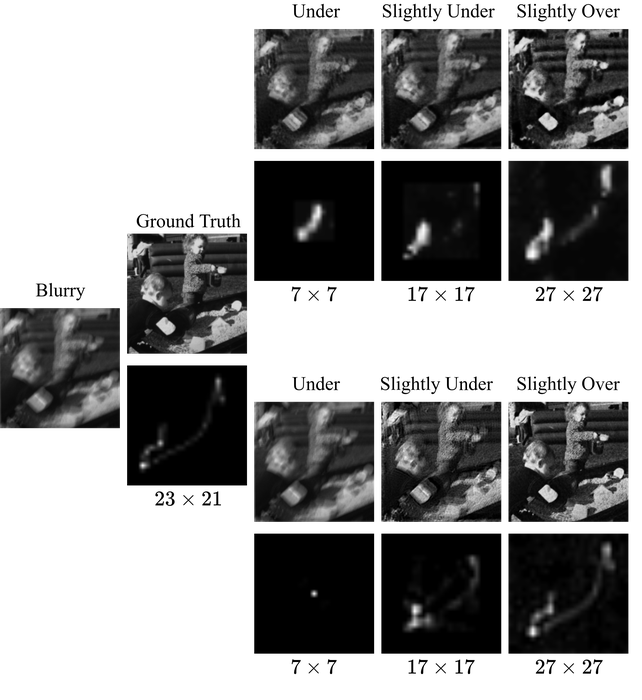
一般来说,当内核大小未指定时,不可能恢复。 事实上,在这种情况下,的恢复也是不可能的;考虑一维情况的以下论证。
实施例1
假设 、 和 由于截断。 所以
| (9) |
现在,假设内核大小指定为 ,并且使用内核估计 正确恢复 。 然后,根据截断的惯例,以下产品之一
| (10) |
应该重现。 但是,对于一般的 ,矩阵 是满级列,因此 位于 的 维列空间中,即 。 Eq. 10 中的两个产品都可能无法重现 ,因为它们在 中产生点仅 的>维子空间。 由于矛盾,使用 length- 内核规范通常无法恢复 。
事实上,如图图6所示,当内核明显未指定时,估计的内核与真实的内核不同。 当规格不足的情况很轻微时,我们最多只能恢复部分真实内核。 在这两种情况下,估计的图像仍然不同程度地模糊。
另一方面,图6还表明,在内核大小略有过度指定的情况下,我们设法以相当好的效果估计内核和图像质量。 理论上,超规格至少允许恢复用零填充的内核。 然而,内核的短小对于 SSBD 来说也至关重要。 直观上,当过度规范严重时,可能会存在基本的可识别性问题,即 的 的大小可能远大于 的大小>,其中 是 Eq. 2 中定义的截断运算符。 因此,问题是什么级别的过度规范是安全的:足够小以避免潜在的可识别性问题,同时又足够大以允许典型的模糊内核。
关于 SSBD 与模型 的可识别性,其中 相对于规范基础是稀疏的,ChoudharyMitra2014Sparse 呈现出强烈的负面结果:对于所有 ,对于 上假设的任何稀疏模式,始终存在不可识别的对(从其第 III.B 节和定理 2 中提取); ChoudharyMitra2018Properties 提供了结果的更定量版本(定理 3)。 不幸的是,如果这些无法识别的病例是罕见事件,目前仍处于开放状态333特别是,如果它们形成零测度集。 . 尽管如此,所有现有的可识别性结果都大致基于 和 的其他假设(特别是 LiEtAl2017Identifiability ; KechKrahmer2017Optimal 中的子空间约束和子空间稀疏假设)声明
| (11) |
是可识别性极限,其中代表自由度。 对于 SSBD,这可以映射到444Eq. 11 中的结果假设循环卷积模型:,但众所周知,通过对两个卷积分量进行适当的零填充,可以将线性卷积写成循环卷积。
| (12) |
其中 表示非零数。 对于 BID,假设 是稀疏的,因此我们有
| (13) |
其中 表示图像 的逐元素梯度大小。 因此 Eq. 13 告诉我们,内核大小的合理上限取决于我们处理的自然图像的梯度范数的典型稀疏程度与 BID 一起。
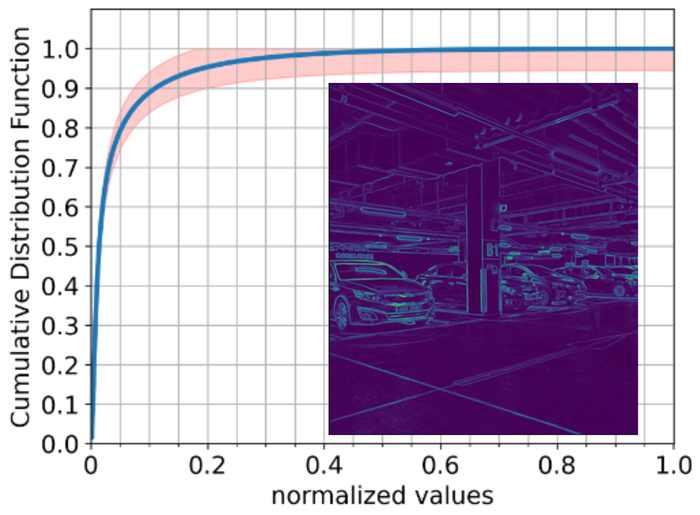
图 7提供了对来自RealBlur数据集的自然图像子集估计的平均累积分布函数RimEtAl2020Real . 平均而言,梯度范数的低于最大梯度范数的,并且低于最大梯度范数的 。 因此,如果我们将 设置为截止阈值,则 的数值稀疏级别低于 ,即不超过一半的像素值非零截止后。 因此,我们在两个方向上将 的大小过度指定为 大小的一半。 这是一个安全的选择:如果我们允许极其“薄”的图像和仅由单列组成的内核,这仍然允许恢复。 对于一般的矩形图像和内核,我们可以在过度规范方面稍微更激进一些。 据我们所知,我们的设置是第一次在这种“激进”的机制中设置内核大小。
3.1.2 过度指定的大小
假设和。 由式2的截断线性卷积模型(如图图8 ),中可以影响值的部分的大小为
| (14) |
这是我们应该为 指定的适当大小。从物理上讲,指定不足(例如,指定 的大小与 的大小相同)可能会导致恢复失败,如下所示 图 8 和9。


虽然以前的大多数作品都遵循 Eq. 14 来指定 的大小,例如SunEtAl2013Edge、PanEtAl2016Blind、DongEtAl2017Blind和SelfDeblur RenEtAl2020Neural,其中一小部分将 的大小设置为与 相同,例如、XuEtAl2013Unnatural )和 Explore TranEtAl2021Explore 。 我们在设置中遵循Eq. 14。
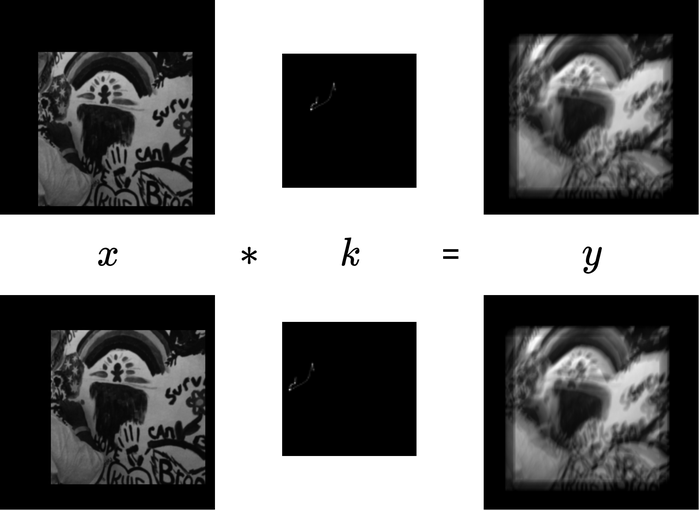

然而,我们并不确切地知道和。 根据我们在 Section 3.1.1 中描述的 的过度指定策略,我们使用的实际大小,即 ,可以远大于。 所以我们为 指定的大小现在变成
| (15) |
和 同时过度指定会导致另一个问题:有界移位效应。
3.1.3 损失和正则化因素
正如 • ‣ Section 2.3 中所总结的,SelfDeblur 使用标准 MSE 损失 和 TV 正则化,即 。 在这里,我们建议更改损失和正则化器,以使该方法即使在存在可能超出高斯的大量噪声的情况下也有效且稳健。
对于损失,我们改用著名的Huber损失Huber1964Robust
| (16) |
与 MSE 相比,Huber 损失对大值的惩罚较少,因此在回归问题中,整体损失不再受大误差的支配。 这意味着根据 Huber 损失最小化估计的回归模型对往往会导致较大回归误差的外围数据点不太敏感。 对于 BID,外围像素可能是由大噪声(例如散粒噪声)和像素饱和等原因引起的。 这种选择使我们的方法能够超越包括 SelfDeblur 在内的大多数先前作品所关注的低水平高斯噪声范围。
| Low Level | High Level | |||
|---|---|---|---|---|
| PSNR | PSNR | |||
| 32.64 (0.69) | 0.0001 (0.018) | 27.74 (0.23) | 0.0002 (0.0019) | |
| 31.12 (0.52) | 0.002 (0.07) | 24.34 (0.78) | 0.02 (0.10) | |

对于正则化器,我们选择 版本
| (17) |
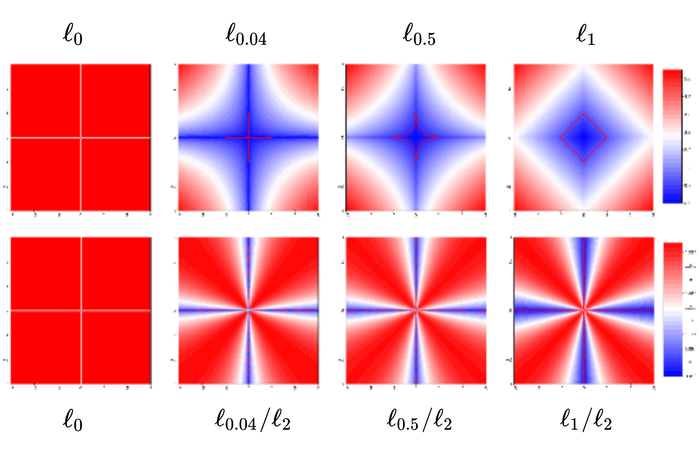
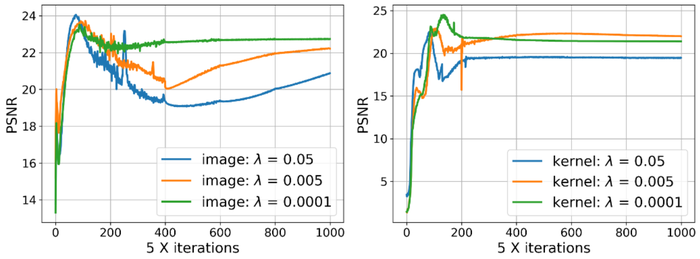
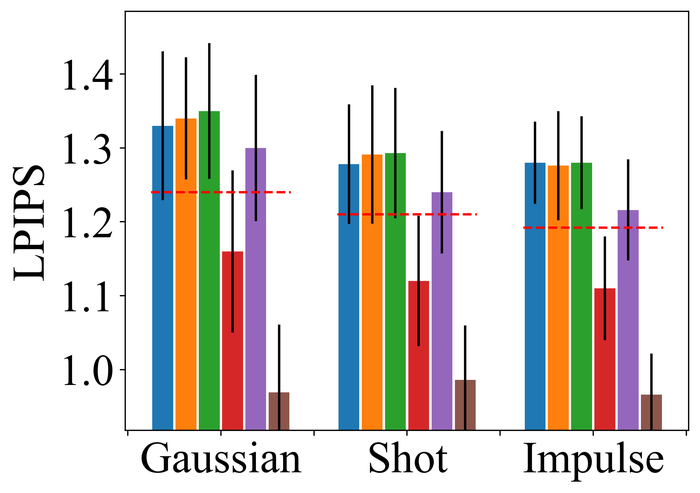
出于三个原因/好处:1)缩放不变性和扰动鲁棒性。 为了对 上的稀疏性进行编码,自然的选择是 函数,它是尺度不变的,但对扰动敏感。 是 的流行替代品,对扰动具有鲁棒性,但具有尺度等变性。 是尺度不变的并且对小扰动具有鲁棒性。 图 11直观地显示了这些函数之间的差异; 2)估计性能对正则化参数不敏感。 根据经验,我们发现使用 正则化器我们可以修复 级别,以获得在低级和高级高斯噪声下的良好性能,而 正则化器需要将 设置为不同噪声级别的不同数量级以获得良好的性能。 此外,正则化可以带来始终如一的卓越性能。 详情请参阅表1; 3) 避免琐碎的解决方案。 正如部分2.2中所回顾的,用替换的最初动机是在 KrishnanEtAl2011Blind 上使用单纯形标准化时,避免简单的解决方案 。 尽管SelfDeblur中仍然使用单纯形归一化,但“双DIP”参数化与梯度下降一起可能会带来额外的结构偏差。 因此,从先验的角度来看,尚不清楚我们是否仍然需要担心找到简单的解决方案。 图 12表明这种担忧仍然存在:当模糊图像也有很大的噪声时,正则化器往往会产生单斑点估计类似于有限支持的 函数以及模糊图像估计。 相比之下,正则化器会产生更清晰的图像,并且内核至少捕获了真实内核的某些方面。
3.1.4 DIP模型


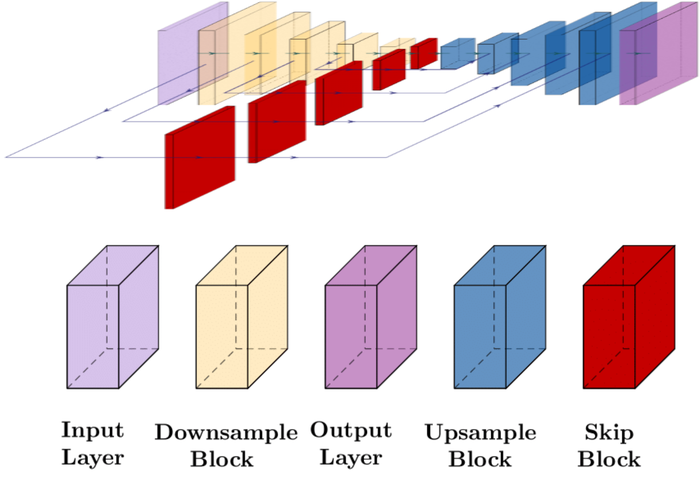
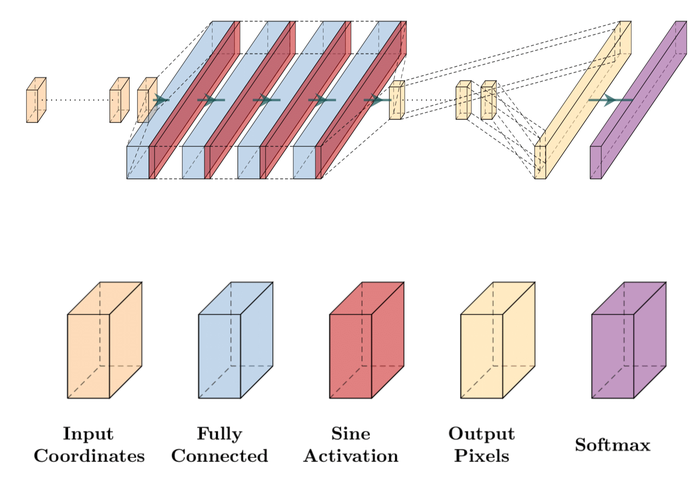
正如围绕 Eq. 6 所讨论的,并在 - ‣ Sections 2.3 和 8 中的 DNN 选择,对 和 进行参数化的 DIP 模型应为它们编码正确的结构先验,并反映 和 之间的不对称性。 与SelfDeblur相同,我们为选择卷积U-Net 。 对于 ,我们选择正弦表示网络 (SIREN) SitzmannEtAl2020Implicit 而不是 SelfDeblur 中使用的 MLP 架构。
与 DIP 相同,SIREN 也使用 DNN 对视觉对象进行参数化。 在 DIP 中,DNN 输出的是视觉对象,而在 SIREN 中,DNN 代表的是视觉对象本身。 例如,SIREN 将连续灰度图像建模为 ,即紧凑域 上的实值函数,然后生成 SIREN 中的 DNN 是一种改进的 MLP 架构,它采用两个坐标输入并返回单个值(对于灰度图像)或三个值(对于 RGB 图像)。
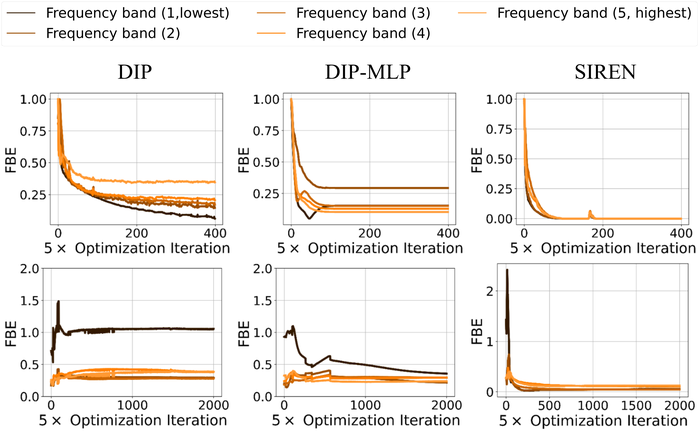
实际的模糊内核可以在傅里叶域中具有大量的高频分量,例如,大多数由卷积曲线组成的运动模糊内核(参见图 3) 和窄高斯形散焦核。 选择 SIREN 而不是 DIP 来表示 的原因是,根据经验观察,SIREN 和类似的坐标编码网络比 DIP SitzmannEtAl2020Implicit 更好地学习视觉对象的高频分量; TancikEtAl2020Fourier;另请参见脚注 6,其中我们定量地表明,在两个简化的核估计问题上,SIREN 允许恢复所有频段,特别是高频段,比使用默认编码器-解码器(称为 DIP)和 MLP 架构(称为 DIP-MLP)的 DIP 对于 来说,真实内核的效率和可靠性要高得多。 当我们将 SIREN 插入 BID 时,DIP(用于 )+SIREN(用于 )模型组合轻松优于其他组合,即 DIP+DIP(如 WangEtAl2019Image )和DIP+DIP-MLP(如SelfDeblur),特别是当存在大量噪声时,如图图 14 。 此外,我们还观察到 SIREN 在提高模型稳定性方面的好处:图15显示当图像仅被污染时高噪声时,DIP+SIREN 组合往往会返回比 DIP+DIP-MLP 更清晰的图像估计。
3.1.5 提前停止(ES)
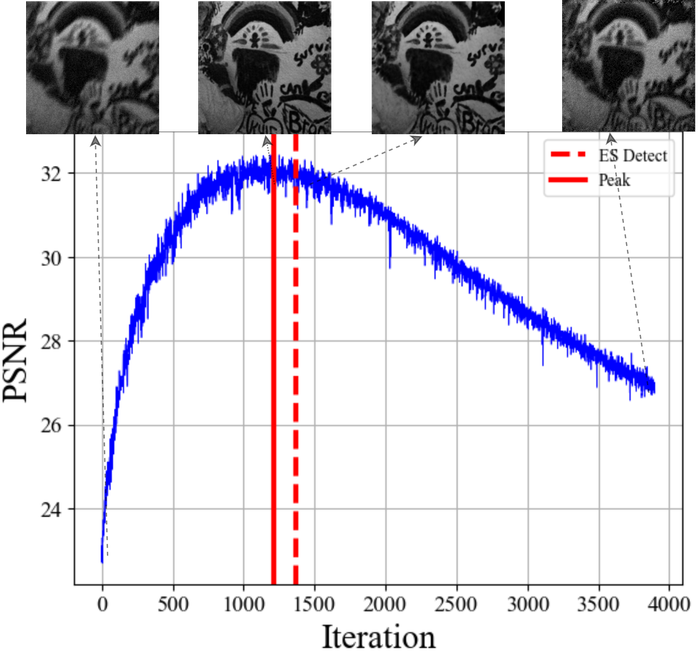
除了我们到目前为止已经解决的 BID 的三个常见实用性问题之外,双 DIP 方法还有一个更具体的问题:过度拟合。 如图图16所示,估计质量(通过相对于真实图像的PSNR来测量) SelfDeblur 首先攀升至峰值,然后随着迭代的进行而下降。
为了理解这里发生的情况,我们可以考虑一下双 DIP 损失本身:
| (18) |
来自方程6。 实际上,图像 既模糊又充满噪声,并且 DIP 模型 和 严重过度参数化。 因此,如果我们执行全局优化, 对于典型损失,例如 MSE。 因此,除了所需的图像内容之外,最终的 也可能会产生噪声,从而导致最终的质量下降。 钟形质量曲线可以通过用于执行损失最小化的一阶优化方法的隐式偏差来解释:使用一阶方法训练的过参数化 DNN 模型往往比学习非结构化噪声更快地学习结构化视觉内容;有关简化模型的完整理论,请参阅 HeckelSoltanolkotabi2020Compressive 和 HeckelSoltanolkotabi2019Denoising。 之前基于双DIP的作品 WangEtAl2019Image 、 SelfDeblur RenEtAl2020Neural 、 Explore TranEtAl2021Explore不要解决这个问题,因为它们的工作噪声水平可以忽略不计,可以避免过度拟合。 为了处理可能很大的实际噪音,我们需要在本文中解决它。
为了获得良好的重建效果,我们可以通过适当的正则化来控制 DNN 的容量,或者在峰值性能附近提前停止迭代——提前停止(ES);请参阅我们之前的作品LiEtAl2021Self和WangEtAl2021Early以获取相关工作的摘要。 我们在几篇论文中表明,正则化策略存在严重的实用性问题; 图 17显示过度拟合在不同级别的正则化中持续存在(我们选择了正则化器,如上所述)。 因此,我们提倡基于 ES 的解决方案,并采用 WangEtAl2021Early 中开发的基于窗口移动方差的 ES (WMV-ES) 方法,该方法在众多应用中证明了 DIP 及其变体的有效和轻量级场景。 顾名思义,WMV-ES 计算中间重建的加窗移动方差曲线,并检测 WMV 曲线的第一个主谷作为推荐的 ES 点。 出于我们的目的,我们观察到 和 PSNR 曲线通常会自动“同步”,并大致在同一迭代中达到峰值。 因此,我们只跟踪重建图像,而不跟踪内核。 图 16表明这种简单的方法可以有效地检测近峰值停止点,而重建质量损失很小。
3.1.6 后处理定位
As discussed in Section 3.1.2 and illustrated in Fig. 10, the simultaneous overspecification of the sizes of and leads to the bounded shift effect on and , and hence the estimated and may not be centered. 因此我们需要一种算法来自动定位估计图像,假设其大小与相同。 一旦我们可以定位 并估计与中心的偏移,我们就可以使用 和 之间的移位对称性来定位 如果需要的话也可以。
为了定位 ,我们提出了一个简单的滑动窗口策略:我们使用嘈杂且模糊的图像 作为模板,并将其滑动到来自 。 使用结构相似性指数度量(SSIM)计算和中每个加窗补丁的相似度,以强调感知接近度,并最终提取具有最大SSIM值的补丁如。
3.2 我们的算法管道
综上所述,给定模糊且有噪声的图像 ,当内核大小未知时,我们默认将内核大小指定为 (Section 3.1.1)—涉及大多数实际场景,并在估算可用时作为给定值。 根据线性卷积的性质,我们设置图像的大小为(Section 3.1.2)。 我们选择 作为 Huber 损失(与 ),并选择 正则化器来促进估计图像梯度域中的稀疏性(节 3.1.3)。 此外,我们为图像选择 DIP 模型,为内核选择 SIREN 模型。 与 • ‣ Section 2.3 中总结的 SelfDeblur 的关键优化目标相反>,我们的方法旨在解决
| (19) | ||||
| output with sigmoid activation | ||||
其中,对于 MLP 模型, 表示作为连续函数的核 , 表示产生有限分辨率核的离散化过程( 节 3.1.4)。 过拟合问题,特别是当存在大量噪声时,通过部分3.1.5中描述的WMV-ES方法和有界移位来处理部分 3.1.2中描述的效果由部分<中详细介绍的基于滑动窗口的检测方法处理/t7> 3.1.6。 完整的 BID 管道总结在算法 1中。
4实验
在本节中,我们首先在合成模糊和噪声图像上将我们的方法与 SOTA 单实例 BID 方法进行比较(部分 4.2)。 我们对所有这些方法的稳定性进行了定量评估:1)内核大小过度指定,2)大量噪声,3)模型“过度指定”,即仅应用于带有噪声的图像的 BID 方法,对应于三个我们在部分1中指出了主要的实用性问题。 一旦我们确认我们的方法在合成数据上的优越性777现有的合成 BID 数据集太小,无法支持训练数据驱动的方法。,我们转向现实世界的数据集,并将我们的方法与 SelfDeblur 和 代表性 SOTA 数据驱动的 BID 方法进行基准测试(部分 4.3)。
4.1 实验设置
我们方法的训练细节
我们使用 PyTorch 来实现我们的方法。 我们使用 ADAM 优化器优化 节 3.2 中的目标,在合成数据上, 的初始学习率 (LR) 为 , 的初始学习率 (LR) 为 ,在实际数据上, 的初始学习率 (LR) 为 , 的初始学习率 (LR) 为 。 不同的 LR 允许图像估计的更新速度比内核估计的更新速度相对更快。 所有其他参数均在 torch.optim.Adam 中默认。 我们使用预定义的 LR 计划(在 pytorch 中使用 MultiStepLR):一旦迭代达到任何 里程碑,两个 LR 都会衰减 因子。 最大迭代次数设置为。 默认情况下,我们使用 WMV-ES 来选择 和 的最终估计。 对于所有其他设置,除非另有声明,否则我们严格遵循算法1中所述的内容。
合成数据集和真实数据集
对于合成数据集,我们选择LevinEtAl2011Understanding发布的流行数据集(称为LEVIN11888Available at https://webee.technion.ac.il/people/anat.levin/papers/LevinEtalCVPR09Data.rar0>)和LaiEtAl2016Comparative1>(配音为LAI1694>99Available at http://vllab.ucmerced.edu/wlai24/cvpr16_deblur_study/ 模糊图像按照Eq.2直接合成(无噪声)。 由于两个数据集中的真实图像和内核都是已知的,因此我们可以明确控制内核过度指定的级别以及噪声的类型和级别。 此外,我们还可以合成纯噪声图像来测试模型稳定性。 因此,LEVIN11 和 LAI16 非常适合我们评估和比较我们关心的所有三种稳定性的 BID 方法。 LEVIN11 包含 大小为 和 不同内核的灰度图像,大小范围为 到 ,导致图像模糊。 LAI16 具有 RGB 自然图像,其尺寸约为 和 内核,尺寸大于 LEVIN11 :、、、分别导致图像模糊。101010LAI16 也有 轨迹来合成非均匀运动模糊,我们在本文中不考虑这一点。 此外,它还包括 没有真实内核的真实世界模糊图像。 对于这两个数据集,我们在后续实验中使用所有图像。
对于真实世界的数据集,我们采用 NTIRE2020 NahEtAl2020NTIRE 111111可在以下位置获取(下载数据集需要注册):https://competitions.codalab.org/competitions/22233#learn_the_details。 我们怀疑这是 REDS(真实和动态场景)数据集的超集(可在 https://seungjunnah.github.io/Datasets/reds.html 获得),至少是同一代的程序与 REDS 相同。 和RealBlur RimEtAl2020真实 121212Available at: http://cg.postech.ac.kr/research/realblur/ 数据集。 NTIRE2020 中的模糊图像是高速摄像机捕获的视频序列中连续帧的时间平均,训练和训练中总共有 和 个模糊图像。验证集分别131313NTIRE2020 是为需要大量训练集的数据驱动方法而开发的。 . 相机抖动和物体运动都参与其中,时间平均模拟了曝光 NahEtAl2019NTIRE 期间由于时间积分而产生的模糊过程。 由于为了保证高帧率,曝光时间很短,NTIRE2020仅覆盖光线充足的场景。 相比之下,RealBlur 强调低光环境,通常需要较长的曝光时间,因此会出现严重的模糊。 它使用定制的双摄像头系统捕获静态场景的锐利-模糊图像对,并且仅将相机抖动作为相对运动的来源。 总共,RealBlur 包含 对清晰模糊图像对,覆盖 个低光静态场景。 在我们的实验中,我们不使用整个数据集,而是重点关注反映现实世界 BID 难度和多样性的选定案例;有关详细信息,请参阅部分4.3.1。
评估指标
由于我们拥有合成数据和真实数据的真实干净图像,因此我们使用基于参考的图像质量评估指标来量化和比较所有选定的 BID 方法的性能。 除了标准的PSNR(峰值信噪比)和SSIM(相似性结构指数度量)指标外,我们还采用信息论VIF(视觉信息保真度SheikhBovik2006Image)和基于DL的度量LPIPS (学习感知图像块相似度,zhang2018unreasonable),与人类对图像质量的感知表现出良好的相关性。 我们在下面的所有定量结果中报告了所有四个指标。
模型尺寸和速度
就我们的方法而言,参数总数约为 百万,重建一幅大小为 的清晰图像平均需要 分钟(在 Nvidia V100 GPU 上)。 SelfDeblur 获取相似数量的参数,并且速度稍快( 分钟)。 在本文中,我们优先考虑质量而不是速度,因此我们没有执行系统的速度基准,特别是对于数据驱动的方法,其推理仅需要一次前向传递。 我们最近的工作LiEtAl2022Random解决了DIP的速度问题;我们将潜在的整合留作未来的工作。

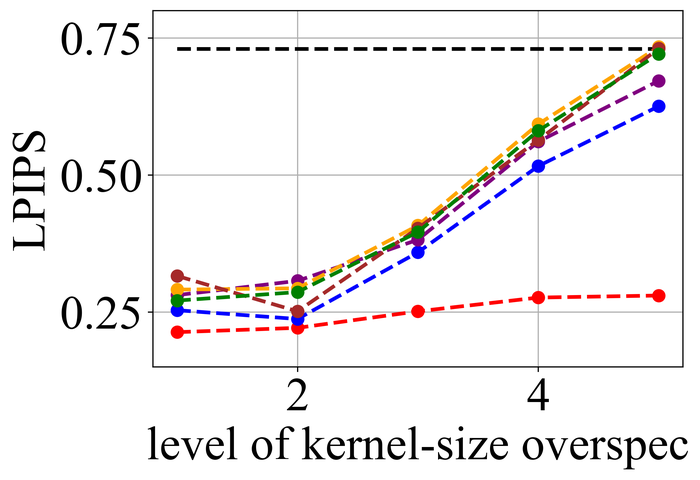
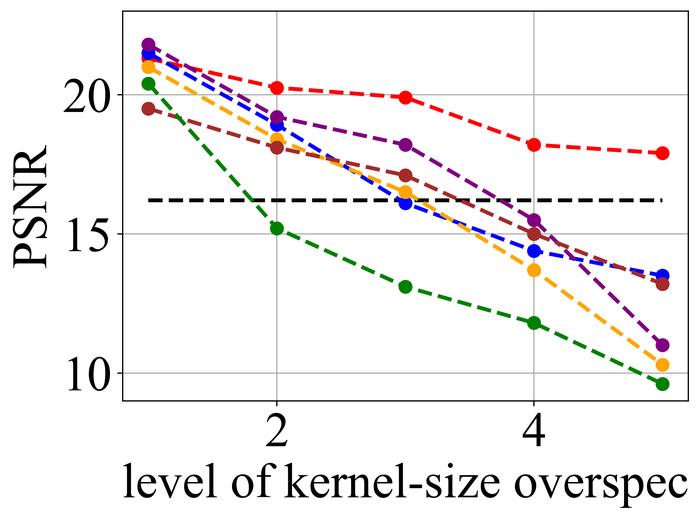
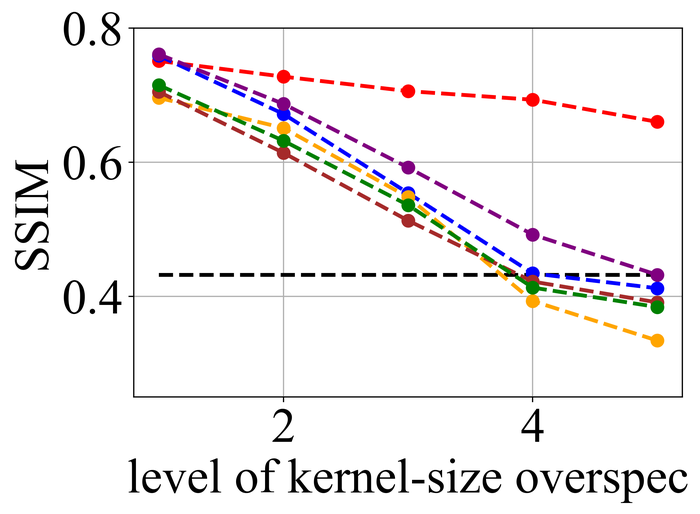
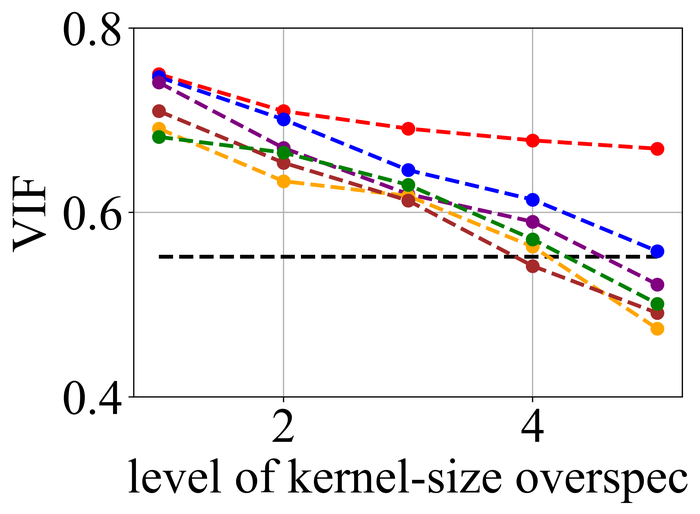
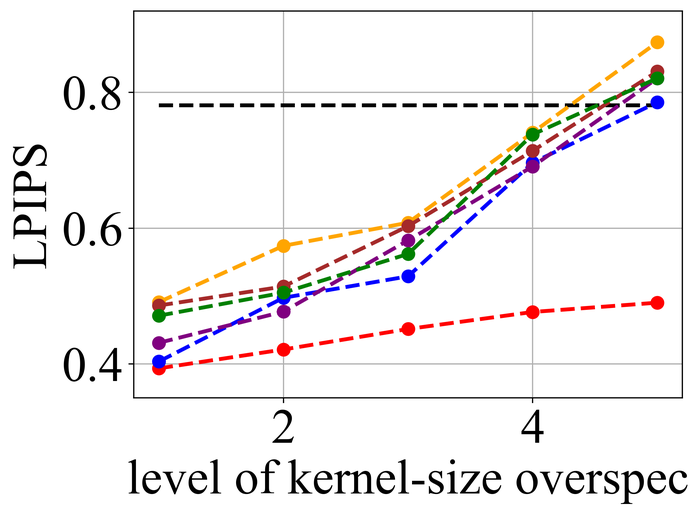
4.2 合成数据集的结果
在单实例方法中,我们选择SunEtAl2013Edge(太阳13141414代码可在: http://cs.brown.edu/~lbsun/deblur2013/deblur2013iccp.html)根据 2016 年调查论文 LaiEtAl2016Comparative 和 PanEtAl2016Blind ,该方法属于表现最佳的方法之一(PAN16151515代码可在: https://jspan.github.io/projects/dark-channel-deblur/index.html)在 BID 之前引入了暗通道,自 2016 年以来一直流行。 我们还选择DongEtAl2017Blind(东17161616代码可在: https://www.dropbox.com/s/qmxkkwgnmuwrfoj/code_iccv2017_outlier.zip?dl=0),这是一种处理像素损坏的 SOTA 方法,以及 SiYaoEtAl2019Understanding (2019年171717代码可在: https://github.com/lisiyaoATbnu/low_rank_kernel)是第一个解决未知内核大小的单实例 BID 作品。 自我去模糊 181818Code available at: https://github.com/csdwren/SelfDeblur RenEtAl2020Neural 启发了我们的方法,因此是主要竞争对手。 与我们的方法一起,所有 方法都以 Eq. 1 中的统一设置为目标。
我们努力使比较公平,同时强调不需要大量超参数调整的方法——在实践中,我们永远不知道过度规范或噪声类型/水平的确切水平。 因此,我们始终为每个方法使用相同的一组超参数。 SUN13 和 PAN16 并非旨在处理内核大小过度指定和大量噪声;我们直接使用它们的默认超参数,因为尚不清楚如何微调它们以优化这些新场景中的性能。 SY19 允许内核大小过度指定,并为两倍内核大小过度指定提供一组超参数。 我们遵循他们对两次超额指定的建议,并在超出两次超额指定的网格上搜索并选择一组最佳超参数。 对于处理大量噪声和像素异常值的 DONG17,我们使用其默认超参数设置,该设置据称在不同数据集上通用。 对于 SelfDeblur,我们使用它们的默认设置,只不过将 设置为 而不是默认的 。 这是因为我们观察到,随着噪声水平的增加,需要更大的 来优化 SelfDeblur 的性能。 对于我们的方法,我们设置。 我们下面报告的所有数字都是各个数据集图像的平均值。
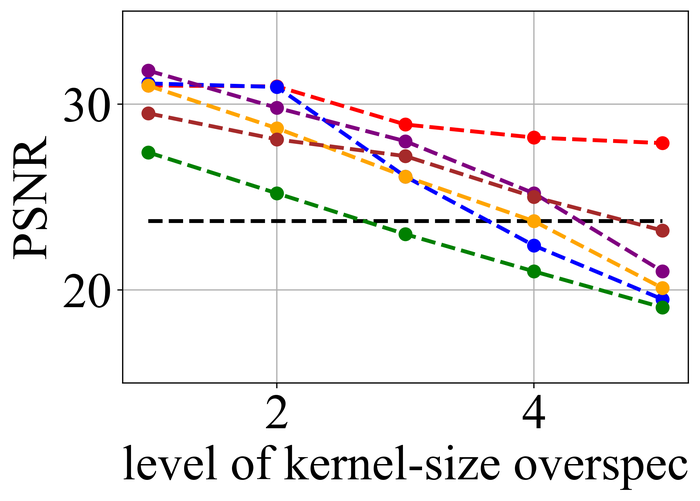
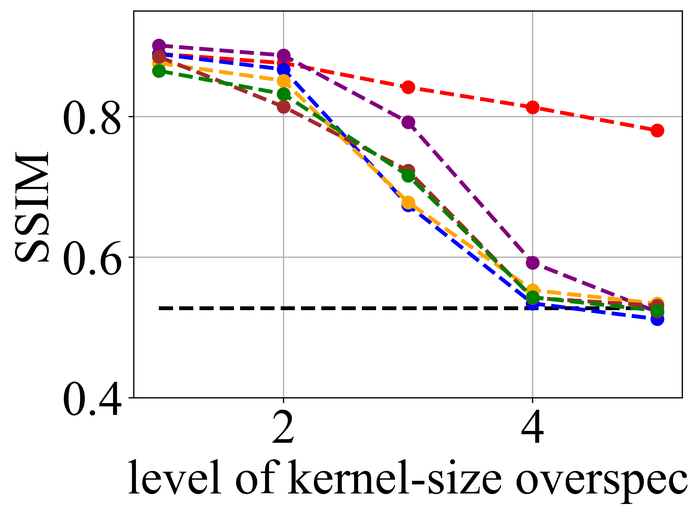
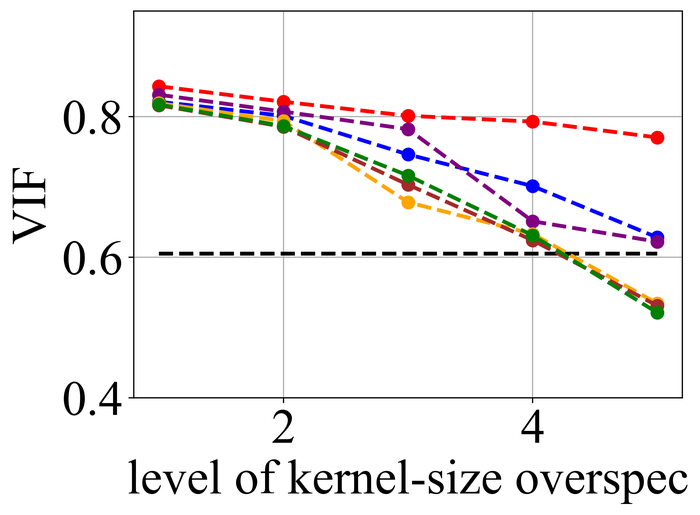
4.2.1 内核大小过度指定
我们首先评估所选方法在内核大小过度指定下的稳定性。 由于我们知道每个实例的真实内核大小,因此我们将过度指定划分为 级别:级别 对应于真实内核大小,级别 对应于在宽度和高度方向上图像大小的一半 - 这是我们方法的默认超规格级别,并且级别 – 均匀分布在两者之间。
图 20 21分别总结了LEVIN11和LAI16的结果。 我们观察到:
-
•
当没有内核大小过度指定(即级别 1)时,SelfDeblur PAN16 和我们的方法是表现最好的三种方法之一(有时与其他方法并列)所有指标。 这证实了双 DIP 思路对于 BID 的有效性;
-
•
随着过度规范水平的增长,所有方法的性能都会下降,但我们的方法比其他方法对这种过度规范更加稳定。 特别是,对于 5 级过度规范,虽然其他五种方法都变得接近甚至比基线性能更差(直接采用模糊图像 来计算指标),但我们的方法仍然表现出色并显示出与基线相比相当大的积极绩效裕度;
-
•
从LEVIN11到LAI16,所有方法的性能都变得较低。 这在基于像素的指标 PSNR 和 SSIM 上尤其明显。 我们怀疑这主要是由于LAI16中的内核尺寸较大(在LEVIN11中最大,而在LEVIN11),这会弄乱每个位置的大面积像素;
-
•
SY19 是之前唯一一个显式处理内核大小过度指定的单实例方法,尽管我们尽了最大努力来搜索一组最佳超参数,但其性能并不理想。 在他们的论文 SiYaoEtAl2019Understanding 中,他们报告了在 LEVIN11 上两次过度指定的有希望的结果,远没有我们的评估那么激进:例如,对于 内核,他们尝试了 过度规范,但在这里我们尝试使用 、、、 和。 我们怀疑令人失望的性能是由于他们的方法对不同过度规范水平的超参数的敏感性。

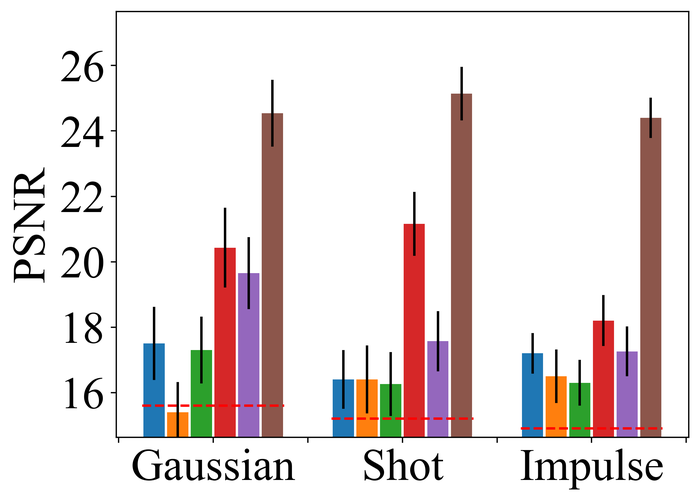
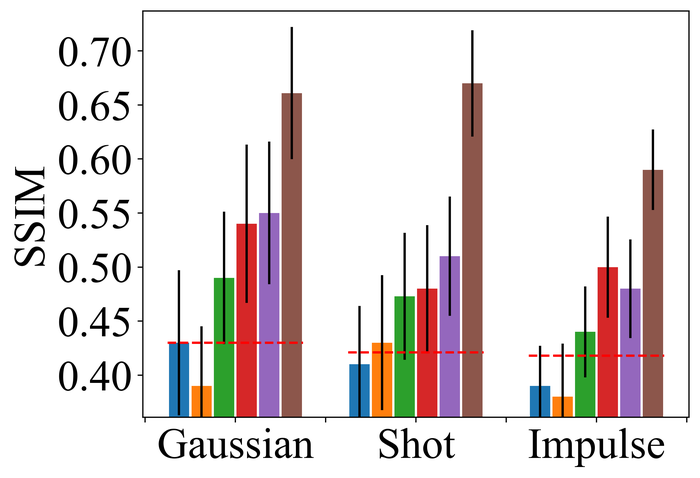
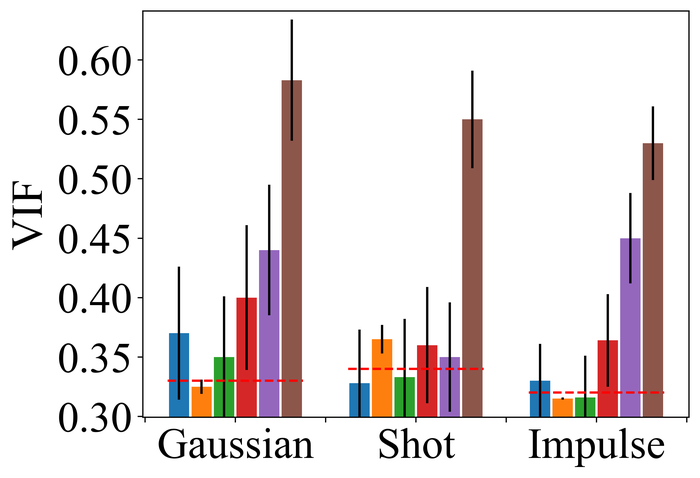
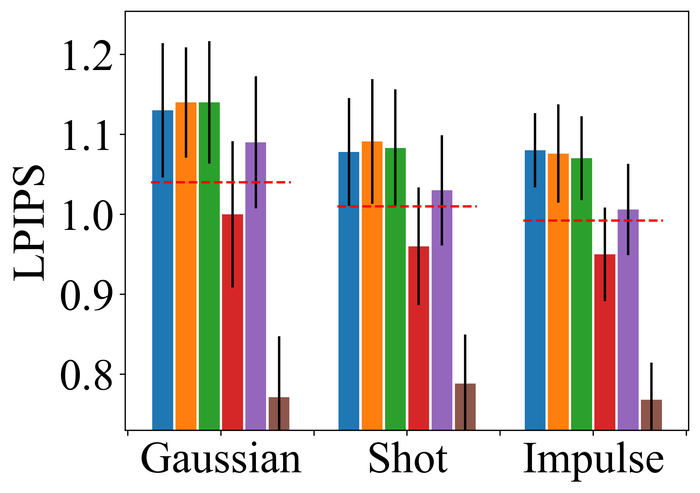
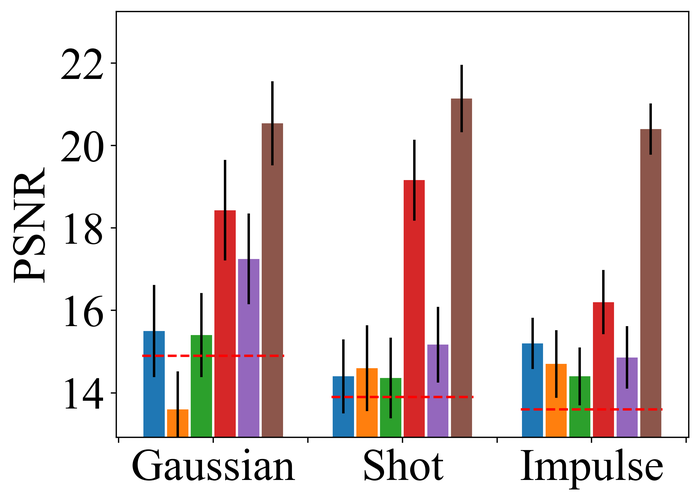
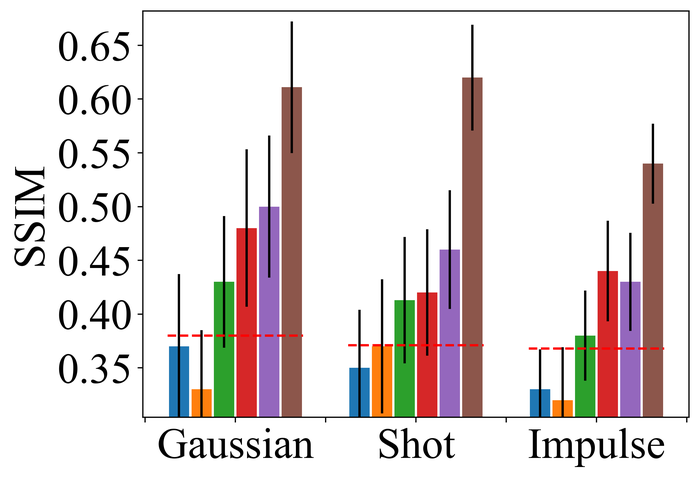
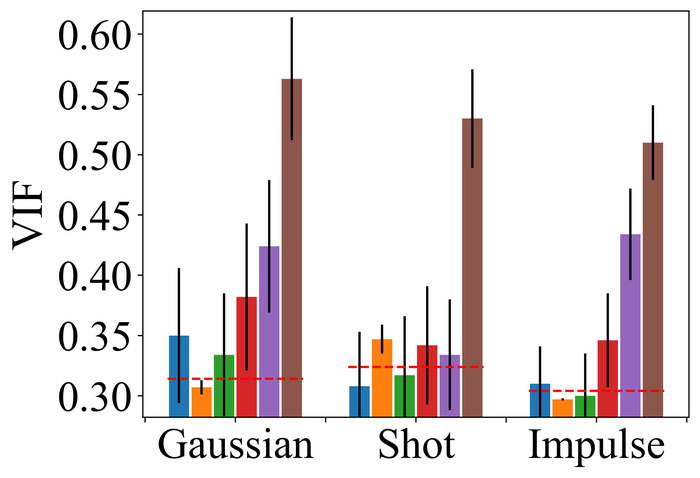
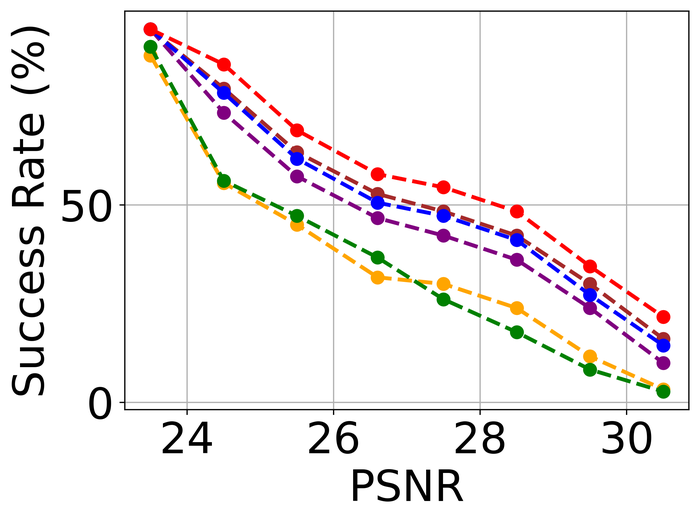
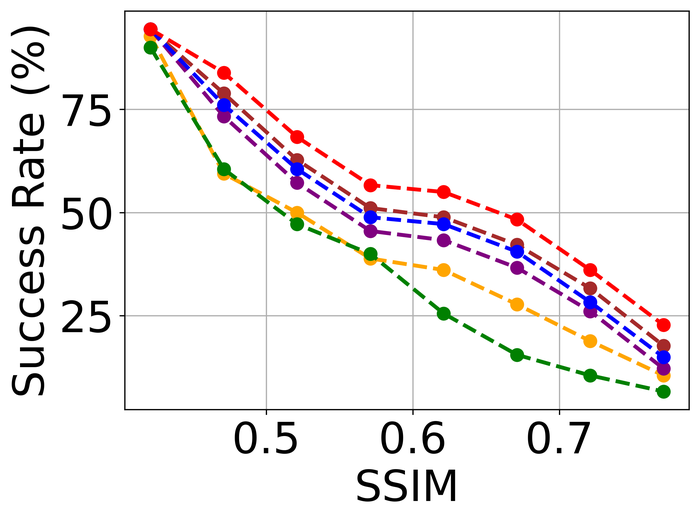
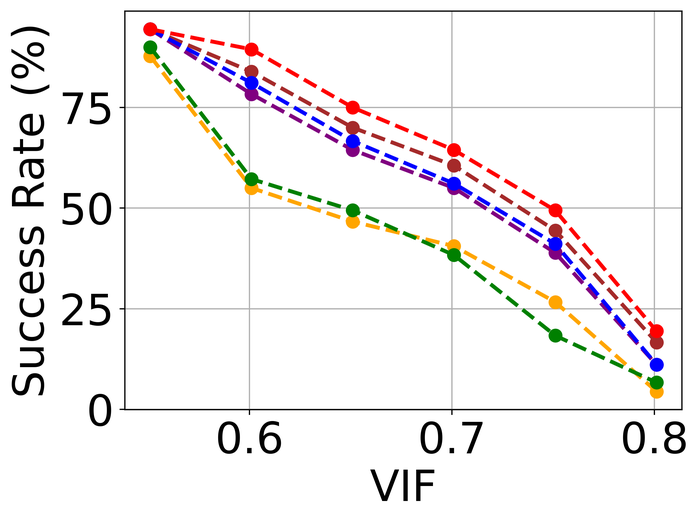
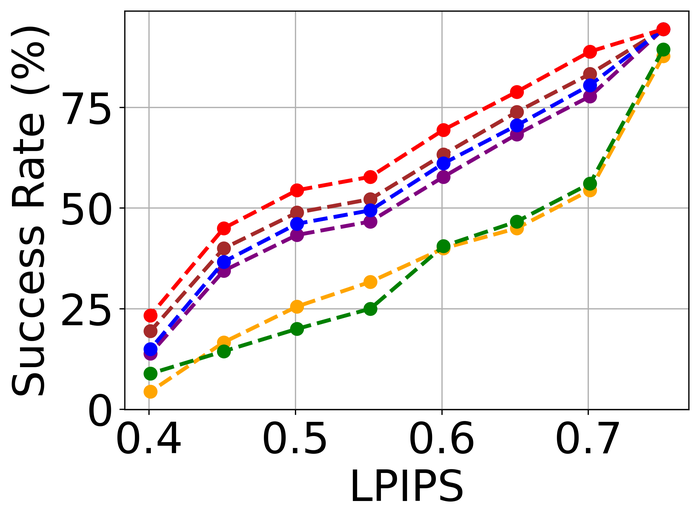
4.2.2 大量噪音
为了评估噪声稳定性,我们将所有方法的内核大小过度指定固定为两个方向上图像大小的一半(即我们方法的默认值)所有方法,并重点关注LAI16. 我们考虑之前作品中已考虑过的 类型噪声:
-
•
高斯噪声:零均值加性高斯噪声,分别针对低噪声水平和高噪声水平具有标准差和;
-
•
脉冲噪声(即椒盐噪声):将概率的每个像素替换为白色()或黑色() 像素各有一半机会。 低噪声水平和高噪声水平分别对应于和;
-
•
散粒噪声(即逐像素独立的泊松噪声):对于每个像素,噪声像素服从泊松分布,速率为,其中 分别适用于低噪音水平和高噪音水平;
-
•
像素饱和度:LAI16中的每个模糊RGB图像首先被转换为HSV(即色调-饱和度-亮度)表示 的值在 中,然后将饱和通道重新缩放 因子,移动 因子,然后裁剪为 。 然后将生成的 HSV 表示转换回 RBG 表示,并将所有值裁剪回 。 我们进一步添加具有标准偏差的像素级零均值高斯噪声。
图 22 23 分别显示前三种类型噪声的低电平和高电平的结果。 正如预期的那样,当从低水平噪声转向高水平噪声时,所有方法的性能都会变差。 对于低水平和高水平的噪声,DONG17、SelfDeblur 和我们的方法是所有指标中表现最好的三种方法。 虽然 SelfDeblur 比 LPIPS 的普通基线(即,当没有应用 BID 方法时)更糟糕,但 DONG17 和我们的总是优于基线 - 两者都使用稳健的损失191919在DONG17中,损失在于将元素逐个应用于,其中 以及 。 请注意,当较大时,与一样,并且接近常数。 与标准 MSE 损失相比,它们对大误差不太敏感。 我们的方法是表现最好的方法,并且总是在所有指标上都以大幅优势赢得第二好的方法,即 DONG17。
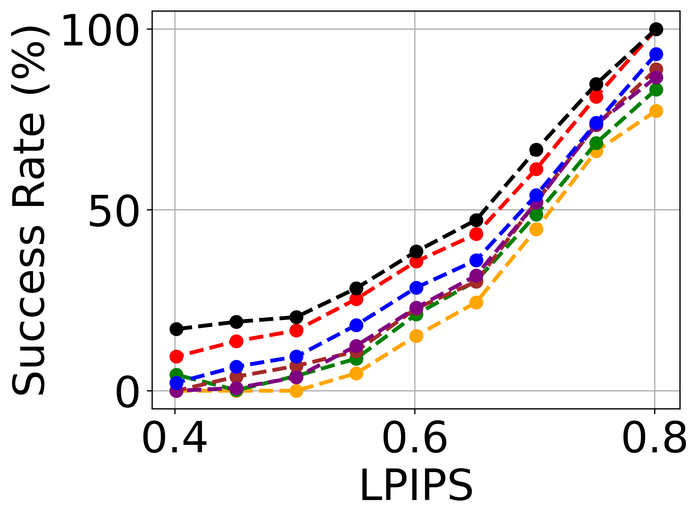
我们观察到这些方法在处理像素饱和度方面的相似性能趋势,从图24:SelfDeblur, DONG17,我们的方法是排名前三的方法,我们的方法明显优于其他两种方法。 基于这些结果,我们得出结论,使用 BID 的鲁棒损失对于实现实际噪声的鲁棒性至关重要。


4.2.3模型稳定性
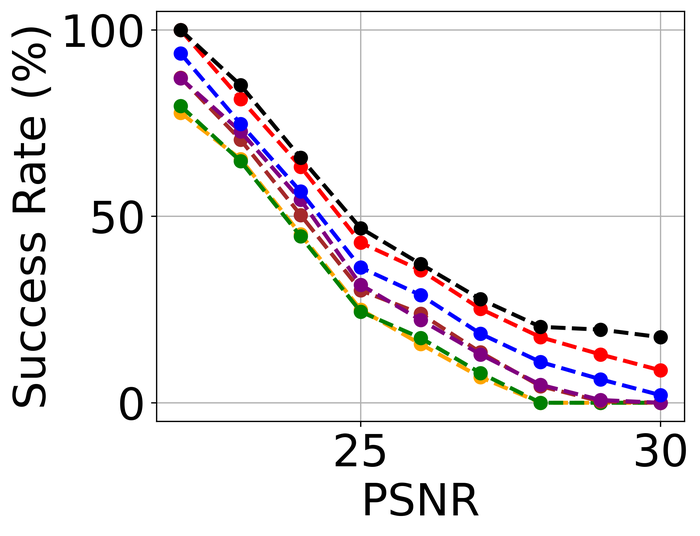
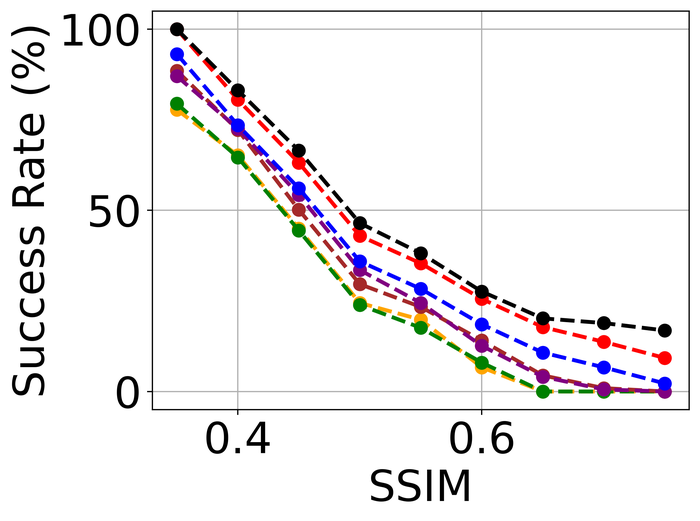
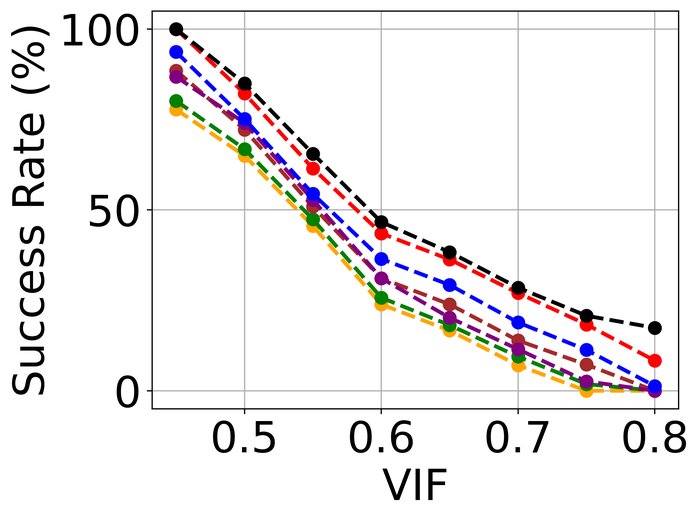
为了评估模型稳定性,我们模拟没有模糊的纯噪声图像。 对于每个图像,我们随机选择三种类型的高级噪声之一:高斯 ()、散粒 () 和脉冲 ( ),并应用它来生成模拟的噪声图像。 请注意,各个噪声水平明显高于图23中使用的噪声水平。 原因是我们希望扩大测试的难度:直观上,理想的 BID 方法应该在仅噪声输入上比在模糊和噪声输入上容忍更多的噪声。 据我们所知,这是首次对 SOTA BID 方法进行模型稳定性评估。
结果如图图25所示。 其中,DIP 表示仅直接对噪声进行建模的单 DIP 方法,即通过考虑
我们对 使用完全相同的体系结构,并使用与我们的方法中使用的相同的 体系结构。 由于该方法结合了图像没有模糊的知识,因此它表现最好也就不足为奇了。 紧接着,很明显 SelfDeblur 和我们的产品在所有指标上都是明显的赢家,并且我们的产品以明显的优势领先于 SelfDeblur。 此外,我们的方法的性能接近DIP,表明我们的方法具有很强的模型稳定性。 不幸的是,虽然DONG17可以容忍大量噪声和模糊,但在没有模糊的情况下它不能很好地工作。 事实上,四种非 Double-DIP 方法(即 SUN13、SY19、PAN16、DONG17< 的估计内核/t3>) 与 delta 函数相差甚远——在本例中,delta 函数是真正的内核,如 图 26 所示。 相反,SelfDeblur 和我们的方法恢复类似于 delta 函数的内核。 除了所有方法使用的图像上常见的稀疏梯度先验之外,SelfDeblur 和我们的方法还在图像上强制执行 DIP。 我们怀疑它们卓越的模型稳定性可归因于同时使用两个先验而不是仅一个先验。 我们重申,我们不会微调从之前的模糊噪声测试到当前仅噪声测试的任何方法的超参数:微调可能会改进某些方法,但被认为是不切实际的,因为我们通常不具备此类模型知识真实数据。
4.2.4 提前停止
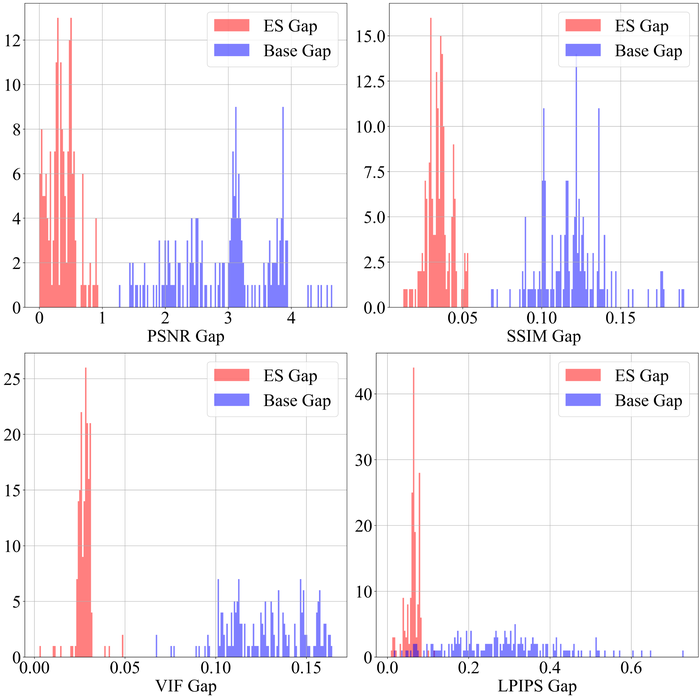
正如我们在部分3.1.5中讨论的,ES对于在存在大量噪声时防止过度拟合是必要且实用的。 在这里,我们测试默认使用的 WMV-ES 方法 WangEtAl2021Early,在 LAI16 上使用低级和高级高斯噪声(如 节 4.2.2)。 图 27展示了ES差距(峰值性能与ES方法检测到的性能之间)和基础差距(之间峰值性能和过度拟合的最终性能),使用所有四个指标。 很明显,ES 对于保存性能至关重要:如果没有 ES,双 DIP 最终对噪声的过度拟合会破坏恢复,例如,对于大部分数据,PSNR 会降低 点或更多。图片;使用自动 ES 方法 WMV-ES,我们仅稍微偏离峰值性能 - 只是可以肯定的是,在不了解实践中的基本事实的情况下,我们无法直接在峰值性能点停止算法。 WMV-ES 的成功从所有指标的 ES Gap 和 Base Gap 之间的直方图的清晰分离中可见一斑。
4.3 真实数据集的结果
4.3.1竞赛方法及数据准备
到目前为止,很明显,我们上面使用的 竞争方法对于现实世界的 BID 来说并不是一个好的选择,因为它们对内核大小过度指定和大量噪声很敏感。 另一方面,最近的大多数 SOTA BID 方法本质上都是数据驱动的:尽管它们可能因训练数据的限制而无法推广,但它们很有吸引力,因为大多数最新的变体直接从模糊图像中预测清晰的图像,从而绕过了由于未知的内核大小甚至模糊建模不准确而导致的问题 KohEtAl2021Single 。 因此,在本节中,我们通过将我们的方法以及 SelfDeblur 与 SOTA NTIRE2020 上的 SOTA 数据驱动方法进行比较来扩展它们和 RealBlur BID 数据集。
规模循环网络 (SRN) tao2018scale 和基于 GAN 的 DeblurGAN-v2 kupyn2019deblurgan 是在配对上训练的 BID 模型模糊-清晰图像对。 两者的预测模型都受到传统 BID 中从粗到细的多尺度思想的启发。 此外,DeblurGAN-v2采用基于GAN的判别器作为正则化器来提高去模糊质量。 ZHANG20 zhang2020deblurring 强调获得模糊-锐利训练对的实际困难(呼应 KohEtAl2021Single ; ZhuangEtAl2022Deep 中类似困难的讨论),并得出管道从不成对的模糊和清晰图像中学习模糊和去模糊过程。 为了下面的比较,我们直接采用方法的预训练模型 202020SRN 获取地址:https://github.com/jiansutx/SRN-Deblur; DeblurGAN-v2 可在以下位置获取:https://github.com/VITA-Group/DeblurGANv2; ZHANG20 位于:https://github.com/HDCVLab/Deblurring-by-Realistic-Blurring。 . 我们注意到 SRN 和 DeblurGAN-v2 都使用 GoPro 数据集 NahEtAl2017Deep 作为其训练集的一部分,并且ZHANG20 构建了自己的模糊训练集 RWBI zhang2020deblurring 。 据我们所知,NTIRE2020 和 RealBlur 与 GoPro 和 RWBI 没有重叠。 因此,我们相信我们的评估集可以很好地测试 所选方法的现实世界通用性。








| SRN | DeblurGAN-v2 | ZHANG20 | SelfDeblur | Ours | ||
|---|---|---|---|---|---|---|
| S1 | PSNR | 30.1 (1.159) | 31.0 (1.149) | 25.2 (1.188) | 28.2 (1.198) | 30.8 (1.168) |
| SSIM | 0.871 (0.0679) | 0.883 (0.0609) | 0.793 (0.0724) | 0.832 (0.0734) | 0.873(0.0618) | |
| VIF | 0.784 (0.0686) | 0.801 (0.0647) | 0.705 (0.0705) | 0.725 (0.0727) | 0.796 (0.0651) | |
| LPIPS | 0.972 (0.0966) | 0.827 (0.08869) | 1.025 (0.104) | 0.987 (0.101) | 0.821 (0.0879) | |
| S2 | PSNR | 27.1 (1.256) | 27.4 (1.352) | 23.4 (1.449) | 25.9 (1.471) | 28.7 (1.236) |
| SSIM | 0.851 (0.0744) | 0.859 (0.0695) | 0.789 (0.0753) | 0.821 (0.0758) | 0.870 (0.0681) | |
| VIF | 0.772 (0.0778) | 0.783 (0.0758) | 0.699 (0.0787) | 0.713 (0.0777) | 0.781 (0.0767) | |
| LPIPS | 1.021 (0.116) | 0.901 (0.0985) | 1.076 (0.108) | 1.001 (0.111) | 0.811 (0.0947) | |
| S3 | PSNR | 28.3 (1.197) | 28.7 (1.139) | 25.2 (1.236) | 26.2 (1.227) | 29.4 (1.144) |
| SSIM | 0.866 (0.0647) | 0.867 (0.0608) | 0.803 (0.0658) | 0.827 (0.0637) | 0.872 (0.0589) | |
| VIF | 0.761 (0.0772) | 0.787 (0.0727) | 0.701 (0.0766) | 0.731 (0.0776) | 0.780 (0.0679) | |
| LPIPS | 1.008 (0.0985) | 0.869 (0.0936) | 1.076 (0.107) | 0.985 (0.110) | 0.839 (0.0911) | |
| S4 | PSNR | 26.7 (1.014) | 27.1 (0.985) | 23.3 (1.043) | 25.8 (1.055) | 28.5 (0.947) |
| SSIM | 0.849 (0.0542) | 0.851 (0.0498) | 0.780 (0.0567) | 0.812 (0.0578) | 0.861 (0.0481) | |
| VIF | 0.756 (0.0621) | 0.767 (0.0592) | 0.687 (0.0663) | 0.721 (0.0674) | 0.776 (0.0574) | |
| LPIPS | 1.015 (0.0941) | 0.925 (0.0862) | 1.050 (0.0927) | 0.996 (0.0674) | 0.893 (0.0848) | |
| S5 | PSNR | 28.6 (1.352) | 28.7 (1.314) | 24.7 (1.410) | 26.4 (1.400) | 29.2 (1.284) |
| SSIM | 0.846 (0.0754) | 0.855 (0.0694) | 0.781 (0.0762) | 0.818 (0.0771) | 0.867 (0.0674) | |
| VIF | 0.756 (0.0756) | 0.771 (0.0754) | 0.692 (0.0784) | 0.710 (0.0793) | 0.776 (0.0761) | |
| LPIPS | 1.012 (0.1093) | 0.874 (0.1085) | 1.065 (0.1141) | 0.992 (0.1149) | 0.856 (0.0945) |
如上所述,NTIRE2020 和 RealBlur 都有各自的优点和局限性:NTIRE2020 中的图像可能包含多个运动,但捕捉得很好- 照明环境; RealBlur 覆盖了许多黑暗场景,但这些场景是静态的,相对运动仅由相机抖动引起。 在基本知识测试中,我们发现 所选的数据驱动方法在图像之间的表现差异很大,即使在同一数据集中也是如此。 决定因素似乎包括场景深度对比度、亮度对比度及其组合:不同的场景深度可能对应于不同的相对运动,尤其是在NTIRE2020的数据中,以及不同级别的相对运动。散焦模糊,而相对于明亮区域,黑暗区域往往较少受到典型损失的影响。 因此,我们选择NTIRE2020和RealBlur:前者包含大量具有良好深度对比度和多个运动物体的图像,后者提供具有良好亮度和深度的样本对比。
我们从两个数据集中选择具有代表性、具有视觉挑战性的图像:对于NTIRE 2020,我们从包含一系列连续帧的每个文件夹中选择最模糊的帧;类似地,对于 RealBlur,我们从同一场景的图像中选择最模糊的一张。 图 28给出了几个例子来说明我们的选择。 图像分为 场景 — 图像,每个场景:(S1) 具有高深度对比度的明亮场景(参见 图29); (S2)具有高深度对比度的黑暗场景(参见图30中的示例); (S3) 低深度对比度的明亮场景(参见图0>311>中的示例); (S4) 低深度对比度的暗场景(参见图3>324>2>中的示例); (S5)具有高深度对比度和高亮度对比度的场景(参见图6>337>5>中的示例)。 NTIRE2020仅包含明亮场景,我们从中选取图像:用于S1,用于S3。 然后,从RealBlur中,我们分别选择图像来完成S3,并分别为S2、S4和S5中的每一个选择图像。 为了确保结果的可重复性,所选图像的 ID 可以在我们的 Github 存储库中找到:https://github.com/sun-umn/Blind-Image-Deblurring。
4.3.2定性和定量结果
图 29, 33, 30, 31 and 32 present blurry images (Fig. 30 and Fig. 32 are too dark to reveal enough details; we apply histogram equalization to enhance the contrast and include them in Section 6.2), each representing one of the scenarios, and the recovery results from SRN, ZHANG20, DeblurGAN-v2, SelfDeblur, and our method. 表 2使用以下指标总结了所选图像的定量结果:PSNR 、SSIM、VIF 和 LPIPS。
我们的方法在大多数情况下获胜,其次是基于 GAN 的 DeblurGAN-v2。 事实上,他们在所有情况下都是前两名。 DeblurGAN-v2 在除 LPIPS 之外的所有指标以及 S2 和 上领先于我们在 S1 上的方法S3 仅由 VIF 提供。 这可能是因为 S1 完全从 NTIRE2020 采样,仅包含明亮场景,类似于 DeblurGAN-v2 的 GoPro 数据集 接受训练; S3 中的 个图像中只有 来自 NTIRE2020。 在 S2、S4 和 S5 上,每张图像都包含部分黑暗场景,我们的方法显然是赢家。 这可以通过 RealBlur 数据集强调黑暗场景来解释,这些场景的分布与仅包含明亮场景的 GoPro 不同。 值得注意的是,我们的方法是一种非数据驱动方法,可以在后者训练的类似数据上与 SOTA 数据驱动方法表现相媲美,并且可以在新数据上始终表现得更好。 DeblurGAN-v2 在不同场景下的性能差异再次强调了数据驱动方法如何受到训练数据的限制,尽管总体上 DeblurGAN-v2 确实显示了对新颖的数据集RealDeblur。
ZHANG20 是我们评估中表现最差的,在真实世界模糊图像 (RWBI) 数据集 212121Available at: https://drive.google.com/file/d/1fHkPiZOvLQSc4HhT8-wA6dh0M4skpTMi/view同一组作者收藏zhang2020deblurring。 对 RWBI 的目视检查表明,模糊场景与 GoPro 的模糊场景大多相似:明亮的场景,没有或很少有移动物体,相机运动明显。 因此,原始论文 zhang2020deblurring 报告其预训练模型在 GoPro 上的泛化性能令人鼓舞,也就不足为奇了。 相比之下,NTIRE2020 图像主要拍摄更复杂的场景,其中包含多个移动物体以及合成相机运动,而 RealBlur 则强调黑暗场景。 显着的分布变化解释了我们的评估中预训练模型的相对较差的性能,如从 Table 2 和中的视觉结果所示 图 29、33、30、31 和 32,并再次强调了数据驱动方法的普遍性问题。 请注意,SRN 最初是在 GoPro 上进行训练和测试的,因此会出现类似的分布变化和性能下降。 但是,SRN是在锐利-模糊图像对上训练的,而ZHANG20是在不成对的锐利和模糊图像上训练的,因此输入知识要弱得多,学习任务更具挑战性,解释为什么 SRN 性能更强并且接近 DeblurGAN-v2。 我们的方法所基于的 SelfDeblur 显然落后了。 从 图 33,30,31和32,我们可以在SelfDeblur恢复的图像内容中看到明显的纹理伪影,如以及边界噪声(特别是在 图 30 和 32),由于 SelfDeblur 使用不当裁剪(在部分 3.1.2中讨论))。
4.4失败案例和限制
我们强调了可能导致失败的三个主要因素:1)显着的深度对比度使均匀模型不太准确; 2) 内核大小过度指定,使得内核估计具有挑战性; 3)估计的定位不准确,导致边界噪声。 下面,我们提供了几个失败示例以及针对这些因素的简要说明。
在图 31中,我们可以从SelfDeblur和我们的方法中看到窗口区域中的条带伪影。 我们怀疑这些条带是由上述 1) 和 2) 的综合影响造成的。 这在下面的图 35中得到了实验证实:当我们减少内核大小过度指定时,条带消失了,但恢复了前景层区域也变得过于平滑并错过细节。

图 34显示了一个困难的情况,所有方法都失败了,包括我们的方法。 失败的原因可能是:1)巨大的深度对比度违反了统一模型,导致不同的散焦和运动模糊。 很明显,DeblurGAN-v2、SelfDeblur 和我们的都是表现最好的,但它们只能恢复前景中的合理细节,而不能恢复远处的灯光; 2) 特定于 SelfDeblur 和我们的估计 的本地化。 我们可以通过这两种方法在重建的右上角附近看到清晰的杂散光点。
| LR | ||||||
|---|---|---|---|---|---|---|
| PSNR | 26.9 | 29.3 | 28.7 | 27.9 | 27.8 | 27.8 |
| SSIM | 0.774 | 0.869 | 0.828 | 0.813 | 0.793 | 0.790 |
| VIF | 0.691 | 0.781 | 0.735 | 0.725 | 0.716 | 0.709 |
| LPIPS | 0.972 | 0.844 | 0.875 | 0.901 | 0.921 | 0.927 |
| PSNR | 26.3 | 27.7 | 29.3 | 28.3 | 27.7 | 27.2 |
| SSIM | 0.763 | 0.813 | 0.869 | 0.822 | 0.803 | 0.793 |
| VIF | 0.681 | 0.725 | 0.781 | 0.745 | 0.716 | 0.703 |
| LPIPS | 1.021 | 0.902 | 0.844 | 0.887 | 0.925 | 0.931 |
4.5消融研究
学习率(分别针对 和 )和正则化参数 是我们方法的两个关键超参数组。 因此,在本次消融研究中,我们重点关注这两个因素,并对部分 4.3中使用的真实世界图像进行实验。 我们将所有其他超参数锁定为默认设置。
我们将和的LR比率锁定为,因此在呈现结果时仅指定的LR比率。 表 3(顶部)包含我们尝试过的 LR 组以及最终的性能。 当LR高于时,训练无法正常收敛。 当我们将 LR 降低到 以下时,性能逐渐下降。 这是因为小 LR 需要更多迭代才能收敛,而我们为了提高效率而限制了最大迭代次数。
5讨论
在本文中,我们对最近用于 BID 的 SelfDeblur 方法 RenEtAl2020Neural 提出了关键修改,这些修改有助于成功解决围绕 BID 的紧迫实用性问题:未知的内核大小、大量的噪声和模型稳定性。 对我们的方法对合成数据和真实数据的系统评估证实了我们方法的有效性。 值得注意的是,虽然我们的方法仅假设简单的均匀模糊模型(即 Eq. 1),但它的性能与 SOTA 数据相当或优于 SOTA 数据 -现实世界模糊图像上的驱动方法——这些数据驱动方法不假设明确的前向模型,因此可能受到的约束要少得多,但受到各自难以收集的数据的表达能力的限制。
有多个方向可以扩展和概括当前的工作。 首先,如果我们对非均匀模糊进行建模,我们的方法在现实世界数据上的性能可能会进一步提高;我们即将推出的工作ZhuangEtAl2023NBID正是这样做的。 第二,与基于迭代优化的传统 BID 方法类似,我们的方法与新兴的数据驱动方法相比速度较慢。 人们可以通过设计允许高效优化的紧凑 DIP 模型(例如,参见 LiEtAl2022Random )以及使用 SOTA 数据驱动方法初始化当前基于 DIP 的方法来解决这一问题。 第三,原则上我们的方法可以很容易地扩展到盲视频去模糊,尽管似乎需要解决增加的建模差距和计算成本的问题。 第四,通过多个 DIP 模型或变体对感兴趣的对象进行建模的原理似乎对于解决其他逆问题来说是通用的(例如,参见我们最近的应用,以在傅里叶相位检索中获得突破性结果杨EtAl2022应用;庄EtAl2022实用)。
致谢
Zhuang Zhuang、Hengkang Wang 和 Ju Sun 得到 NSF CMMI 2038403 的部分支持。 我们感谢匿名审稿人和副主编富有洞察力的评论,这些评论极大地帮助我们改进了本文的呈现。 我们感谢彭乐和张文杰允许我们使用他们拍摄的图1的电动滑板车图像。 作者感谢明尼苏达大学的明尼苏达超级计算研究所 (MSI) 提供的资源为本论文中报告的研究结果做出了贡献。
数据可用性声明
当前研究中使用的部分代码和数据集是解释、复制和构建文章中报告的研究结果所必需的,可在 Github 存储库中获取 https://github.com/sun-umn/Blind-图像去模糊
参考
- (1) Ahmed, A., Recht, B., Romberg, J.: Blind deconvolution using convex programming. IEEE Transactions on Information Theory 60(3), 1711–1732 (2014). DOI 10.1109/tit.2013.2294644
- (2) Aljadaany, R., Pal, D.K., Savvides, M.: Douglas-rachford networks: Learning both the image prior and data fidelity terms for blind image deconvolution. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE (2019). DOI 10.1109/cvpr.2019.01048
- (3) Asim, M., Shamshad, F., Ahmed, A.: Blind image deconvolution using deep generative priors. IEEE Transactions on Computational Imaging 6, 1493–1506 (2020). DOI 10.1109/tci.2020.3032671
- (4) Benichoux, A., Vincent, E., Gribonval, R.: A fundamental pitfall in blind deconvolution with sparse and shift-invariant priors. In: IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE (2013). DOI 10.1109/icassp.2013.6638838
- (5) Bostan, E., Heckel, R., Chen, M., Kellman, M., Waller, L.: Deep phase decoder: self-calibrating phase microscopy with an untrained deep neural network. Optica 7(6), 559–562 (2020)
- (6) Cabrelli, C.A.: Minimum entropy deconvolution and simplicity: A noniterative algorithm. Geophysics 50(3), 394–413 (1985). DOI 10.1190/1.1441919
- (7) Chan, T., Wong, C.K.: Total variation blind deconvolution. IEEE Transactions on Image Processing 7(3), 370–375 (1998). DOI 10.1109/83.661187
- (8) Chen, L., Fang, F., Wang, T., Zhang, G.: Blind image deblurring with local maximum gradient prior. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2019). DOI 10.1109/cvpr.2019.00184
- (9) Chen, L., Fang, F., Zhang, J., Liu, J., Zhang, G.: OID: Outlier identifying and discarding in blind image deblurring. In: European Conference on Computer Vision (ECCV), pp. 598–613. Springer International Publishing (2020). DOI 10.1007/978-3-030-58595-2˙36
- (10) Chen, L., Zhang, J., Lin, S., Fang, F., Ren, J.S.: Blind deblurring for saturated images. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2021). DOI 10.1109/cvpr46437.2021.00624
- (11) Cheung, S.C., Shin, J.Y., Lau, Y., Chen, Z., Sun, J., Zhang, Y., Müller, M.A., Eremin, I.M., Wright, J.N., Pasupathy, A.N.: Dictionary learning in fourier-transform scanning tunneling spectroscopy. Nature Communications 11(1) (2020). DOI 10.1038/s41467-020-14633-1
- (12) Chi, Y.: Guaranteed blind sparse spikes deconvolution via lifting and convex optimization. IEEE Journal of Selected Topics in Signal Processing 10(4), 782–794 (2016). DOI 10.1109/jstsp.2016.2543462
- (13) Cho, S., Lee, S.: Fast motion deblurring. In: ACM Trans. Graph. ACM Press (2009). DOI 10.1145/1661412.1618491
- (14) Cho, S., Lee, S.: Convergence analysis of MAP based blur kernel estimation. In: IEEE International conference on computer vision (ICCV). IEEE (2017). DOI 10.1109/iccv.2017.515
- (15) Choudhary, S., Mitra, U.: Sparse blind deconvolution: What cannot be done. In: IEEE International Symposium on Information Theory. IEEE (2014). DOI 10.1109/isit.2014.6875385
- (16) Choudhary, S., Mitra, U.: On the properties of the rank-two null space of nonsparse and canonical-sparse blind deconvolution. IEEE Transactions on Signal Processing 66(14), 3696–3709 (2018). DOI 10.1109/tsp.2018.2815014
- (17) Darestani, M.Z., Heckel, R.: Accelerated MRI with un-trained neural networks. IEEE Transactions on Computational Imaging 7, 724–733 (2021). DOI 10.1109/tci.2021.3097596
- (18) Ding, Z., Luo, Z.Q.: A fast linear programming algorithm for blind equalization. IEEE Transactions on Communications 48(9), 1432–1436 (2000). DOI 10.1109/26.870004
- (19) Dong, J., Pan, J., Su, Z., Yang, M.H.: Blind image deblurring with outlier handling. In: IEEE International conference on computer vision (ICCV). IEEE (2017). DOI 10.1109/iccv.2017.271
- (20) Donoho, D.: ON minimum entropy deconvolution. In: Applied Time Series Analysis II, pp. 565–608. Elsevier (1981). DOI 10.1016/b978-0-12-256420-8.50024-1
- (21) Ekanadham, C., Tranchina, D., Simoncelli, E.: A blind sparse deconvolution method for neural spike identification. In: Advances in Neural Information Processing Systems (2011)
- (22) Fang, L., Liu, H., Wu, F., Sun, X., Li, H.: Separable kernel for image deblurring. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2014). DOI 10.1109/cvpr.2014.369
- (23) Gandelsman, Y., Shocher, A., Irani, M.: “double-DIP”: Unsupervised image decomposition via coupled deep-image-priors. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2019). DOI 10.1109/cvpr.2019.01128
- (24) Gong, D., Tan, M., Zhang, Y., van den Hengel, A., Shi, Q.: Self-paced kernel estimation for robust blind image deblurring. In: IEEE International conference on computer vision (ICCV). IEEE (2017). DOI 10.1109/iccv.2017.184
- (25) Gong, D., Tan, M., Zhang, Y., Hengel, A.V.D., Shi, Q.: Blind image deconvolution by automatic gradient activation. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2016). DOI 10.1109/cvpr.2016.202
- (26) Heckel, R., Hand, P.: Deep decoder: Concise image representations from untrained non-convolutional networks. In: International Conference on Learning Representations (2019)
- (27) Heckel, R., Soltanolkotabi, M.: Denoising and regularization via exploiting the structural bias of convolutional generators. arXiv preprint arXiv:1910.14634 (2019)
- (28) Heckel, R., Soltanolkotabi, M.: Compressive sensing with un-trained neural networks: Gradient descent finds the smoothest approximation. arXiv:2005.03991 (2020)
- (29) Hendrycks, D., Dietterich, T.: Benchmarking neural network robustness to common corruptions and perturbations. In: International Conference on Learning Representations (2019). URL https://openreview.net/forum?id=HJz6tiCqYm
- (30) Huber, P.J.: Robust estimation of a location parameter. The Annals of Mathematical Statistics 35(1), 73–101 (1964). DOI 10.1214/aoms/1177703732
- (31) Hurley, N., Rickard, S.: Comparing measures of sparsity. IEEE Transactions on Information Theory 55(10), 4723–4741 (2009). DOI 10.1109/tit.2009.2027527
- (32) Jin, M., Roth, S., Favaro, P.: Normalized blind deconvolution. In: European Conference on Computer Vision (ECCV), pp. 694–711. Springer International Publishing (2018). DOI 10.1007/978-3-030-01234-2˙41
- (33) Joshi, N., Szeliski, R., Kriegman, D.J.: PSF estimation using sharp edge prediction. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2008). DOI 10.1109/cvpr.2008.4587834
- (34) Joshi, N., Zitnick, C.L., Szeliski, R., Kriegman, D.J.: Image deblurring and denoising using color priors. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2009). DOI 10.1109/cvpr.2009.5206802
- (35) Kech, M., Krahmer, F.: Optimal injectivity conditions for bilinear inverse problems with applications to identifiability of deconvolution problems. SIAM Journal on Applied Algebra and Geometry 1(1), 20–37 (2017). DOI 10.1137/16m1067469
- (36) Koh, J., Lee, J., Yoon, S.: Single-image deblurring with neural networks: A comparative survey. Computer Vision and Image Understanding 203, 103134 (2021). DOI 10.1016/j.cviu.2020.103134
- (37) Komodakis, N., Paragios, N.: MRF-based blind image deconvolution. In: Asian Conference on Computer Vision (ACCV), pp. 361–374. Springer Berlin Heidelberg (2013). DOI 10.1007/978-3-642-37431-9˙28
- (38) Krishnan, D., Fergus, R.: Fast image deconvolution using hyper-laplacian priors. In: Advances in Neural Information Processing Systems (2009). URL https://proceedings.neurips.cc/paper/2009/file/3dd48ab31d016ffcbf3314df2b3cb9ce-Paper.pdf
- (39) Krishnan, D., Tay, T., Fergus, R.: Blind deconvolution using a normalized sparsity measure. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2011). DOI 10.1109/cvpr.2011.5995521
- (40) Kundur, D., Hatzinakos, D.: Blind image deconvolution. IEEE Signal Processing Magazine 13(3), 43–64 (1996). DOI 10.1109/79.489268
- (41) Kuo, H.W., Zhang, Y., Lau, Y., Wright, J.: Geometry and symmetry in short-and-sparse deconvolution. SIAM Journal on Mathematics of Data Science 2(1), 216–245 (2020). DOI 10.1137/19m1237569
- (42) Kupyn, O., Martyniuk, T., Wu, J., Wang, Z.: Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 8878–8887 (2019)
- (43) Köhler, R., Hirsch, M., Mohler, B., Schölkopf, B., Harmeling, S.: Recording and playback of camera shake: Benchmarking blind deconvolution with a real-world database. In: European Conference on Computer Vision (ECCV), pp. 27–40. Springer Berlin Heidelberg (2012). DOI 10.1007/978-3-642-33786-4˙3
- (44) Lai, W.S., Huang, J.B., Hu, Z., Ahuja, N., Yang, M.H.: A comparative study for single image blind deblurring. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2016). DOI 10.1109/cvpr.2016.188
- (45) Lawrence, H., Bramherzig, D., Li, H., Eickenberg, M., Gabrié, M.: Phase retrieval with holography and untrained priors: Tackling the challenges of low-photon nanoscale imaging. arXiv preprint arXiv:2012.07386 (2020)
- (46) Levin, A., Weiss, Y., Durand, F., Freeman, W.T.: Understanding blind deconvolution algorithms. IEEE Transactionson Pattern Analysis and Machine Intelligence 33(12), 2354–2367 (2011). DOI 10.1109/tpami.2011.148
- (47) Lewicki, M.S.: A review of methods for spike sorting: the detection and classification of neural action potentials. Network: Computation in Neural Systems 9(4), R53–R78 (1998). DOI 10.1088/0954-898x˙9˙4˙001
- (48) Li, L., Pan, J., Lai, W.S., Gao, C., Sang, N., Yang, M.H.: Learning a discriminative prior for blind image deblurring. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE (2018). DOI 10.1109/cvpr.2018.00692
- (49) Li, T., Wang, H., Zhuang, Z., Sun, J.: Deep random projector: Accelerated deep image prior. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 18176–18185 (2023)
- (50) Li, T., Zhuang, Z., Liang, H., Peng, L., Wang, H., Sun, J.: Self-validation: Early stopping for single-instance deep generative priors. In: British Machine Vision Conference (BMVC) (2021)
- (51) Li, X., Ling, S., Strohmer, T., Wei, K.: Rapid, robust, and reliable blind deconvolution via nonconvex optimization. Applied and Computational Harmonic Analysis 47(3), 893–934 (2019). DOI 10.1016/j.acha.2018.01.001
- (52) Li, Y., Lee, K., Bresler, Y.: A unified framework for identifiability analysis in bilinear inverse problems with applications to subspace and sparsity models. arXiv:1501.06120 (2015)
- (53) Li, Y., Lee, K., Bresler, Y.: Identifiability and stability in blind deconvolution under minimal assumptions. IEEE Transactions on Information Theory 63(7), 4619–4633 (2017). DOI 10.1109/tit.2017.2689779
- (54) Li, Y., Tofighi, M., Geng, J., Monga, V., Eldar, Y.C.: Deep algorithm unrolling for blind image deblurring. arXiv:1902.03493 (2019)
- (55) Liu, Y., Dong, W., Gong, D., Zhang, L., Shi, Q.: Deblurring natural image using super-gaussian fields. In: European Conference on Computer Vision (ECCV), pp. 467–484. Springer International Publishing (2018). DOI 10.1007/978-3-030-01246-5˙28
- (56) Ma, X., Hill, P., Achim, A.: Unsupervised image fusion using deep image priors. arXiv:2110.09490 (2021)
- (57) Michaeli, T., Irani, M.: Blind deblurring using internal patch recurrence. In: European Conference on Computer Vision (ECCV), pp. 783–798. Springer International Publishing (2014). DOI 10.1007/978-3-319-10578-9˙51
- (58) Michelashvili, M., Wolf, L.: Speech denoising by accumulating per-frequency modeling fluctuations. arXiv:1904.07612 (2019)
- (59) Nah, S., Baik, S., Hong, S., Moon, G., Son, S., Timofte, R., Lee, K.M.: NTIRE 2019 challenge on video deblurring and super-resolution: Dataset and study. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE (2019). DOI 10.1109/cvprw.2019.00251
- (60) Nah, S., Kim, T.H., Lee, K.M.: Deep multi-scale convolutional neural network for dynamic scene deblurring. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE (2017). DOI 10.1109/cvpr.2017.35
- (61) Nah, S., Son, S., Lee, S., Timofte, R., Lee, K.M.: Ntire 2021 challenge on image deblurring. arXiv:2104.14854 (2021)
- (62) Nah, S., Son, S., Timofte, R., Lee, K.M.: NTIRE 2020 challenge on image and video deblurring. arXiv:2005.01244 (2020)
- (63) Ongie, G., Jalal, A., Metzler, C.A., Baraniuk, R.G., Dimakis, A.G., Willett, R.: Deep learning techniques for inverse problems in imaging. IEEE Journal on Selected Areas in Information Theory 1(1), 39–56 (2020). DOI 10.1109/jsait.2020.2991563
- (64) Pan, J., Dong, J., Liu, Y., Zhang, J., Ren, J., Tang, J., Tai, Y.W., Yang, M.H.: Physics-based generative adversarial models for image restoration and beyond. IEEE Transactions on Pattern Analysis and Machine Intelligence 43(7), 2449–2462 (2021). DOI 10.1109/tpami.2020.2969348
- (65) Pan, J., Hu, Z., Su, Z., Yang, M.H.: Deblurring text images via l0-regularized intensity and gradient prior. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2014). DOI 10.1109/cvpr.2014.371
- (66) Pan, J., Lin, Z., Su, Z., Yang, M.H.: Robust kernel estimation with outliers handling for image deblurring. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2016). DOI 10.1109/cvpr.2016.306
- (67) Pan, J., Sun, D., Pfister, H., Yang, M.H.: Blind image deblurring using dark channel prior. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2016). DOI 10.1109/cvpr.2016.180
- (68) Perrone, D., Favaro, P.: Total variation blind deconvolution: The devil is in the details. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2014). DOI 10.1109/cvpr.2014.372
- (69) Qayyum, A., Ilahi, I., Shamshad, F., Boussaid, F., Bennamoun, M., Qadir, J.: Untrained neural network priors for inverse imaging problems: A survey. TechRxiv (2021). DOI 10.36227/techrxiv.14208215
- (70) Ravula, S., Dimakis, A.G.: One-dimensional deep image prior for time series inverse problems. arXiv:1904.08594 (2019)
- (71) Ren, D., Zhang, K., Wang, Q., Hu, Q., Zuo, W.: Neural blind deconvolution using deep priors. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2020). DOI 10.1109/cvpr42600.2020.00340
- (72) Rim, J., Lee, H., Won, J., Cho, S.: Real-world blur dataset for learning and benchmarking deblurring algorithms. In: European Conference on Computer Vision (ECCV), pp. 184–201. Springer International Publishing (2020). DOI 10.1007/978-3-030-58595-2˙12
- (73) Schuler, C.J., Hirsch, M., Harmeling, S., Scholkopf, B.: Learning to deblur. IEEE Transactions on Pattern Analysis and Machine Intelligence 38(7), 1439–1451 (2016). DOI 10.1109/tpami.2015.2481418
- (74) Sheikh, H., Bovik, A.: Image information and visual quality. IEEE Transactions on Image Processing 15(2), 430–444 (2006). DOI 10.1109/tip.2005.859378
- (75) Shi, Z., Mettes, P., Maji, S., Snoek, C.G.M.: On measuring and controlling the spectral bias of the deep image prior. International Journal of Computer Vision 130(4), 885–908 (2022). DOI 10.1007/s11263-021-01572-7
- (76) Si-Yao, L., Ren, D., Yin, Q.: Understanding kernel size in blind deconvolution. In: IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE (2019). DOI 10.1109/wacv.2019.00224
- (77) Sitzmann, V., Martel, J., Bergman, A., Lindell, D., Wetzstein, G.: Implicit neural representations with periodic activation functions. Advances in Neural Information Processing Systems 33 (2020)
- (78) Sun, L., Cho, S., Wang, J., Hays, J.: Edge-based blur kernel estimation using patch priors. In: IEEE International Conference on Computational Photography (ICCP). IEEE (2013). DOI 10.1109/iccphot.2013.6528301
- (79) Sun, Q., Donoho, D.: Convex sparse blind deconvolution. arXiv:2106.07053 (2021)
- (80) Szeliski, R.: Computer Vision: Algorithms and Applications, 2nd edn. Springer London (2021)
- (81) Tai, Y.W., Lin, S.: Motion-aware noise filtering for deblurring of noisy and blurry images. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2012). DOI 10.1109/cvpr.2012.6247653
- (82) Tancik, M., Srinivasan, P., Mildenhall, B., Fridovich-Keil, S., Raghavan, N., Singhal, U., Ramamoorthi, R., Barron, J., Ng, R.: Fourier features let networks learn high frequency functions in low dimensional domains. In: Advances in Neural Information Processing Systems (2020)
- (83) Tao, X., Gao, H., Shen, X., Wang, J., Jia, J.: Scale-recurrent network for deep image deblurring. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 8174–8182 (2018)
- (84) Tayal, K., Manekar, R., Zhuang, Z., Yang, D., Kumar, V., Hofmann, F., Sun, J.: Phase retrieval using single-instance deep generative prior. In: OSA Optical Sensors and Sensing Congress 2021 (AIS, FTS, HISE, SENSORS, ES). OSA (2021). DOI 10.1364/ais.2021.jw2a.37
- (85) Tran, P., Tran, A., Phung, Q., Hoai, M.: Explore image deblurring via encoded blur kernel space. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2021). DOI 10.1109/CVPR46437.2021.01178
- (86) Ulyanov, D., Vedaldi, A., Lempitsky, V.: Deep image prior. International Journal of Computer Vision 128(7), 1867–1888 (2020). DOI 10.1007/s11263-020-01303-4
- (87) Vasu, S.: Image and video deblurring: A curated list of resources for image and video deblurring. https://github.com/subeeshvasu/Awesome-Deblurring (2021). URL https://github.com/subeeshvasu/Awesome-Deblurring. Accessed: Dec 12 2021
- (88) Vembu, S., Verdu, S., Kennedy, R., Sethares, W.: Convex cost functions in blind equalization. IEEE Transactions on Signal Processing 42(8), 1952–1960 (1994). DOI 10.1109/78.301833
- (89) Wang, H., Li, T., Zhuang, Z., Chen, T., Liang, H., Sun, J.: Early stopping for deep image prior. arXiv:2112.06074 (2021)
- (90) Wang, Z., Wang, Z., Li, Q., Bilen, H.: Image deconvolution with deep image and kernel priors. In: 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW). IEEE (2019). DOI 10.1109/iccvw.2019.00127
- (91) Wiggins, R.A.: Minimum entropy deconvolution. Geoexploration 16(1-2), 21–35 (1978). DOI 10.1016/0016-7142(78)90005-4
- (92) Williams, F., Schneider, T., Silva, C., Zorin, D., Bruna, J., Panozzo, D.: Deep geometric prior for surface reconstruction. arXiv:1811.10943 (2019)
- (93) Wipf, D., Zhang, H.: Revisiting bayesian blind deconvolution. Journal of Machine Learning Research 15(111), 3775–3814 (2014)
- (94) Xu, L., Jia, J.: Two-phase kernel estimation for robust motion deblurring. In: European Conference on Computer Vision, pp. 157–170. Springer Berlin Heidelberg (2010). DOI 10.1007/978-3-642-15549-9˙12
- (95) Xu, L., Zheng, S., Jia, J.: Unnatural l0 sparse representation for natural image deblurring. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2013). DOI 10.1109/cvpr.2013.147
- (96) Yan, Y., Ren, W., Guo, Y., Wang, R., Cao, X.: Image deblurring via extreme channels prior. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2017). DOI 10.1109/cvpr.2017.738
- (97) Yang, D., Zhuang, Z., Phillips, N.W., KaySong, Zdora, M.C., Harder, R., Cha, W., Liu, W., Barmherzig, D.A., Sun, J., Hofmann, F.: Application of single-instance deep generative priors for reconstruction of highly strained gold microcrystals in bragg coherent x-ray diffraction. In preparation (2022)
- (98) Yang, L., Ji, H.: A variational EM framework with adaptive edge selection for blind motion deblurring. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2019). DOI 10.1109/cvpr.2019.01041
- (99) Zhang, K., Luo, W., Zhong, Y., Ma, L., Stenger, B., Liu, W., Li, H.: Deblurring by realistic blurring. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2737–2746 (2020)
- (100) Zhang, K., Ren, W., Luo, W., Lai, W.S., Stenger, B., Yang, M.H., Li, H.: Deep image deblurring: A survey. International Journal of Computer Vision 130(9), 2103–2130 (2022). DOI 10.1007/s11263-022-01633-5
- (101) Zhang, K., Zuo, W., Zhang, L.: Deep plug-and-play super-resolution for arbitrary blur kernels. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE (2019). DOI 10.1109/cvpr.2019.00177
- (102) Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric (2018)
- (103) Zhang, Y., Kuo, H.W., Wright, J.: Structured local optima in sparse blind deconvolution. IEEE Transactions on Information Theory 66(1), 419–452 (2020). DOI 10.1109/tit.2019.2940657
- (104) Zhang, Y., Lau, Y., Kuo, H.W., Cheung, S., Pasupathy, A., Wright, J.: On the global geometry of sphere-constrained sparse blind deconvolution. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2017). DOI 10.1109/cvpr.2017.466
- (105) Zhong, L., Cho, S., Metaxas, D., Paris, S., Wang, J.: Handling noise in single image deblurring using directional filters. In: IEEE Conference on computer vision and pattern recognition (CVPR). IEEE (2013). DOI 10.1109/cvpr.2013.85
- (106) Zhou, K.C., Horstmeyer, R.: Diffraction tomography with a deep image prior. Optics Express 28(9), 12872 (2020). DOI 10.1364/oe.379200
- (107) Zhuang, Z., Li, T., Wang, H., Zhang, W., Sun, J.: Practical blind image deblurring with non-uniform blurs. In preparation (2023)
- (108) Zhuang, Z., Yang, D., Hofmann, F., Barmherzig, D., Sun, J.: Practical phase retrieval using double deep image priors. arXiv preprint arXiv:2211.00799 (2022)
6附录
6.1 常见缩写词列表
| BID | blind image deblurring |
|---|---|
| BD | blind deconvolution |
| DIP | deep image prior |
| DL | deep learning |
| DNN | deep neural network |
| ES | early stopping |
| LPIPS | learned perceptual image patch similarity |
| LR | learning rate |
| MAP | maximum a posterior |
| MLP | multi-layer perceptron |
| MSE | mean squared error |
| PSNR | peak signal-to-noise ratio |
| SIREN | sinusoidal representation networks |
| SOTA | state-of-the-art |
| SSBD | short-and-sparse blind deconvolution |
| SSIM | structural similarity index measure |
| TV | total-variation |
| VAR | variance |
| VIF | visual information fidelity |
| VIP | visual inverse problem |
| WMV-ES | windowed-moving-variance-based ES |
6.2对比度增强版本 图 30 和 32

