量子信息瓶颈的有效算法
摘要
提取相关信息的能力对于学习至关重要。 信息瓶颈是一种巧妙的方法,它是一个优化问题,其解对应于从大型系统中提取相关信息的忠实且内存高效的表示。 量子计算时代的到来呼吁对处理有关量子系统的信息的有效方法。 在这里,我们通过提出一种针对信息瓶颈的量子推广的新通用算法来解决这个问题。 与先前结果相比,我们的算法在收敛速度和确定性方面表现出色。 它也适用于更广泛的问题,包括确定性信息瓶颈的量子扩展,这是原始信息瓶颈问题的一个重要变体。 值得注意的是,我们发现量子系统在量子信息瓶颈方面可以实现比相同大小的经典系统严格更好的性能,为证明量子机器学习的优势提供了新的视角。
1 引言
学习是当代世界中一项至关重要的任务。 因此,寻找强大的学习信息工具一直是重中之重。 信息瓶颈 [32] 就是一个很好的例子,它在深度学习 [33, 28, 8]、视频处理 [16]、聚类 [29] 和极性编码 [30] 等许多应用中都有用。 具体来说,信息瓶颈是一种提取信息片段的方法 关于系统 从系统 中, 并被表述为差值最小化问题 具有正参数 ,其中 是 和 之间的互信息。 特别地,我们对 为经典的情况感兴趣。 通过设计,信息瓶颈实现了不可逆压缩,通过提取关于 的基本信息并同时去除 中包含的非必要信息。

随着我们进入量子信息时代, 对有效学习量子系统信息的方法的需求正在增长。 为此,让我们考虑量子信息瓶颈 (QIB) 的设置,如图 1 所示。 与其经典对应物类似,QIB 的目标是压缩 到更小的系统 ,同时保持与 的相关性,其中一些系统是量子系统。 在这项工作之前,QIB 已在几篇最近的作品中被讨论过 [9, 24, 6, 14, 2],并已应用于量子信息论 [6, 14] 和量子机器学习 [2]。 另一方面,QIB 的基本特性,如收敛性尚未得到分析,这阻碍了它在更实际任务中的应用。 量子信息瓶颈首先在 [9] 中被提议作为信息瓶颈方法的量子扩展。 它还推导出最小化问题解的必要条件 (参见 [9, 附录 A]) 通过使用拉格朗日乘子方法,与 [1, 4] 中的方法相同。 利用获得的条件,还提出了一种迭代算法来寻找满足必要条件的解 [9, 附录 C]。 然后,参考文献 [24] 在量子通信场景中考虑了 QIB。 1 11参考文献 [24, 附录 A] 推导出最小化问题解的必要条件 通过使用拉格朗日乘子方法,与 [1, 4] 中的方法相同。 利用获得的条件,还提出了一种迭代算法来寻找满足必要条件的解 [24, 附录 C 的末尾]。 然而,没有研究讨论迭代算法的行为,即 尚不清楚该算法是否单调地减少目标函数 [32, 31, 9, 24]。 [9,附录 B] 中还声称,如果 都是经典的,则使用量子 没有优势。
在这项工作中,我们对量子信息瓶颈进行了系统研究,重点关注系统 为经典的情况。 与现有工作 [9, 24, 6, 14, 2] 相比,我们的工作在几个方面做出了重大贡献:
首先,我们对 QIB 的两个关键属性——效率和收敛性进行了全面分析。 受 Arimoto-Blahut 算法 [1, 4] 的最新推广 [22] 的启发,我们引入了一种新的量子信息瓶颈算法,该算法具有一个加速参数 ,当选择得当时,可以使 QIB 的值比以前收敛得快得多。 我们证明了我们的算法收敛并达到最小值的严格准则。 特别是,我们证明了 的选择对收敛起着重要作用。
其次,与参考文献中的说法相反 [9, 24],我们提供了具体的例子,证明使用量子而不是经典 可以降低 QIB 的最小值。 值得注意的是,我们的结果证明了量子机器学习 [34, 27, 3] 中的真正量子优势,在量子机器学习中,量子电路的使用已经很普遍 [26, 11, 5, 17, 20, 25],但量子优势很少得到证明。
最后但同样重要的是,我们通过考虑一个通用的目标函数 (具有参数 )来推广 QIB,当 时,它简化为标准 QIB。 这样做,广义 QIB 包含 QDIB,即确定性信息瓶颈的量子版本 [31],通过设置 来实现。 我们表明,我们的分析和算法适用于这种广义设置,特别是适用于 QDIB。 然后,我们澄清了 QDIB 可以用来寻找一个好的近似充分统计量 ,用于 ,用于 ,这需要更小的熵 和更大的互信息 。 我们通过一个数值例子证明了我们的发现,其中 QDIB 提取了关于量子系综的信息的良好近似充分统计量。
总之,我们的工作解决了 QIB 的几个关键问题,包括收敛性、效率、参数选择和量子优势。 我们还将 QIB 扩展到一个广义设置,并引入了 QDIB 的概念。 我们的结果包括严格的分析分析和数值实验,这些实验证明了 QIB 和 QDIB 在学习基本任务中的重要性。
2 量子信息瓶颈 (QIB) 问题
2.1 问题定义
考虑一个由 和 组成的经典-量子联合系统,其联合状态为
| (1) |
其中 是一个经典系统, 是一个量子系统。 我们的量子信息瓶颈 (QIB) 问题旨在构建一个信息处理器,由一个从 到 的 c-q 通道 模拟(当经典寄存器为 时准备一个量子状态 ),该处理器从 中提取关于量子系统 的有效信息。 在信息处理器作用之后,联合状态变为:
| (2) |
为此,QIB 问题关注构建一个经典-量子通道 ,该通道最小化信息瓶颈函数,该函数由关于联合状态 定义的熵量组成:
| (3) |
其中 表示 的熵 2 22为了方便起见,符号 表示当系统 为经典系统时香农熵,当 为量子系统时表示冯·诺依曼熵。 , 表示 在 上的条件熵,而 表示 和 之间的互信息。
也就是说,我们的目标是计算以下值:
| (4) |
在信息瓶颈 (2.1) 中, 和 是模拟任务目标的正实变量。 在信息瓶颈的最初提议 [32] 中。 的另一个常见选择是 ,该任务被称为确定性 QIB(其经典对应物在文献 [31] 中讨论)。 参数 控制着忠实度和压缩之间的权衡。 例如,在确定性信息瓶颈中,较大的 将使 在目标函数中更加突出,迫使信息处理器保留更多关于 的信息,而较小的 将体现 的作用,促使信息处理器在 中进行更多压缩。
虽然 本节讨论了具有 量子系统 和 的情况, 但具有经典系统 和量子系统 的情况 可以通过考虑对角密度 作为特例包含在内。 另一方面,具有经典系统 的情况 与 具有量子系统 的情况不同 因为我们需要讨论不同的最小化问题,该问题对最小化变量有不同的范围。 幸运的是,我们在下一小节中介绍的针对量子系统 的算法可以应用于具有经典系统 的情况。 第 3 节讨论了 为经典系统的情况。 我们注意到, 和 都是经典系统的情况已在经典信息论和机器学习中得到广泛研究;例如,参见文献 [32, 33, 31, 28]。
2.2 针对 的 QIB 算法
论文 [9] 讨论了当 为量子系统而 时的情况, 将经典信息瓶颈 [32] 扩展到量子领域。 它推导出一个必要的条件,以便 达到最小值 (4)。 必要条件 在量子系统 和经典系统 中 写成
| (5) |
其中 是一个归一化常数,
| (6) | ||||
| (7) | ||||
| (8) |
由于这个条件是自洽的, 利用这个条件,论文 [9] 提出了以下 具有以下更新规则的迭代算法:
| (9) |
2.3 加速参数
2.4 具有通用 和收敛性的 QIB 算法
为了分析算法 (12) 的收敛性, 我们引入一个基于 Ref. 中思想的双输入变量函数。 [22, 第三节-B], 而参考文献 [22, 第三节-B] 中的方法是作为 Arimoto-Blahut 算法的推广获得的 [1, 4]。 思路是,我们不直接解决 的最小化问题,因为这通常太难了,而是找到一个具有两个变量 的连续函数 。 然后,我们可以交替更新这两个输入变量 以减少 。 最后,如果函数满足
| (13) |
的最小值将接近 IB 函数的最小值。
接下来,我们需要指定交替更新 的规则。 重要的是,我们需要确保 在更新规则下是非递增的。 为此,我们首先介绍以下条件:
- (A1)
-
和 满足 关系
(18)
实际上,条件 (A1) 可以通过将 定义为 来改写为
| (19) |
该数量的评估结果为
| (20) |
因为关系
| (21) |
意味着关系
| (22) |
为了说明我们的更新规则,我们定义
| (23) | ||||
| (24) | ||||
| (25) |
特别是,当 时, 运算符 简化为
| (26) |
定理 1
在条件 (A1) 下,我们有
| (27) | ||||
| (28) |
此外,我们有
| (30) |
其中 、 和 分别来自 (17)、(23) 和 (25)。 最后,从等式 (30) 中我们可以看到,当 时, 的最小值可以达到,因为 (30) 的第一项是非负的(当 时可以达到等式),而第二项与 无关。 因此,我们得到 (28)。
推论 2
当 , 以下不等式链成立:。 因此,只要 足够大,信息瓶颈在更新规则下的单调性也能得到保证。 最后,我们提出以下算法,其中 固定, 通用:
如前所述,当 在所有迭代步骤中满足条件 (A1) 时,即, 当 足够大时, 定理 1 保证了信息瓶颈函数的单调性:
| (32) |
由于 由有界熵量组成(假设系统是有限的),因此它是一个有界量。 因此,算法中的序列 收敛。 此外,我们可以证明 c-q 通道序列 也收敛:
定理 3
当 时, 序列 收敛。
特别地,由于 , 序列 收敛于 。
我们注意到,在算法 1 中,可以选择收敛标准。
在算法 1 中, 被固定为一个足够大的值。 直观地(参见下一段的更详细讨论),(更准确地说,)是一个加速参数,如果选择一个较小的值,它可以使算法收敛更快。
首先,我们展示了 在算法收敛中的作用。 用 表示 的收敛点。 我们算法的性能可以用 和 之间平均偏差的下降速度来描述,其计算方法为
| (36) |
上述讨论表明,如果 , 使 更小会导致 和 之间的平均偏差下降更快。 另一方面,使 太小会导致违反条件 (18) 的风险(因此会破坏 的单调性)。
备注 1
参考文献 [22, Section III] 考虑了一种通用设置。 如果 是一个单一密度矩阵,我们的方法可以被认为是其设置的特例。 但是,由于在我们的案例中 是经典量子通道, 我们的分析不是其设置的特例。
备注 2
参考文献 [9, Appendix A] [24, Appendix A] 考虑了当系统 是量子系统,而 的情况。 他们使用拉格朗日乘子法,与 [1, 4] 相同的方式,推导出了最小化问题解的必要条件。 使用得到的条件,他们 [9, Appendix C] [24, Appendix C] 还提出了一种迭代算法来找到满足必要条件的解。 他们的必要条件似乎与 (31) 相同,其中 。 但是,他们没有讨论其算法中对局部极小值的收敛性。
2.5 不同的影响的数值结果
为了看到不同的影响,让我们看一个具体的例子: 考虑一个单量子比特量子系统和一个大小为的经典寄存器。 然后,我们假设 是上的均匀分布, 密度给出如下 ,其中
| (37) |
其中是泡利-矩阵。 参数和是随机选择的。
现在,我们将我们的 QIB 算法(即算法 1)应用于系综(38)。 我们考虑一个大小为平方根(即)的经典。 我们设置和。 我们将重点关注加速参数的不同选择的影响。 如图 2 所示,的选择对于 QIB 算法的性能至关重要,更具体地说,对于效率和收敛性至关重要。
我们数值结果体现出两个有趣的现象:首先,选择较小的将加速收敛过程。 如图 2 所示,通过选择适当较小的值(例如,或),我们的 QIB 算法比现有的 QIB 算法[9, 24]更快地达到收敛,该算法对应于的算法1。 其次,选择过小的将破坏 QIB 算法的收敛性。 例如,当选择为时,在几次迭代后跳跃,最终达到比其初始值大得多的值。
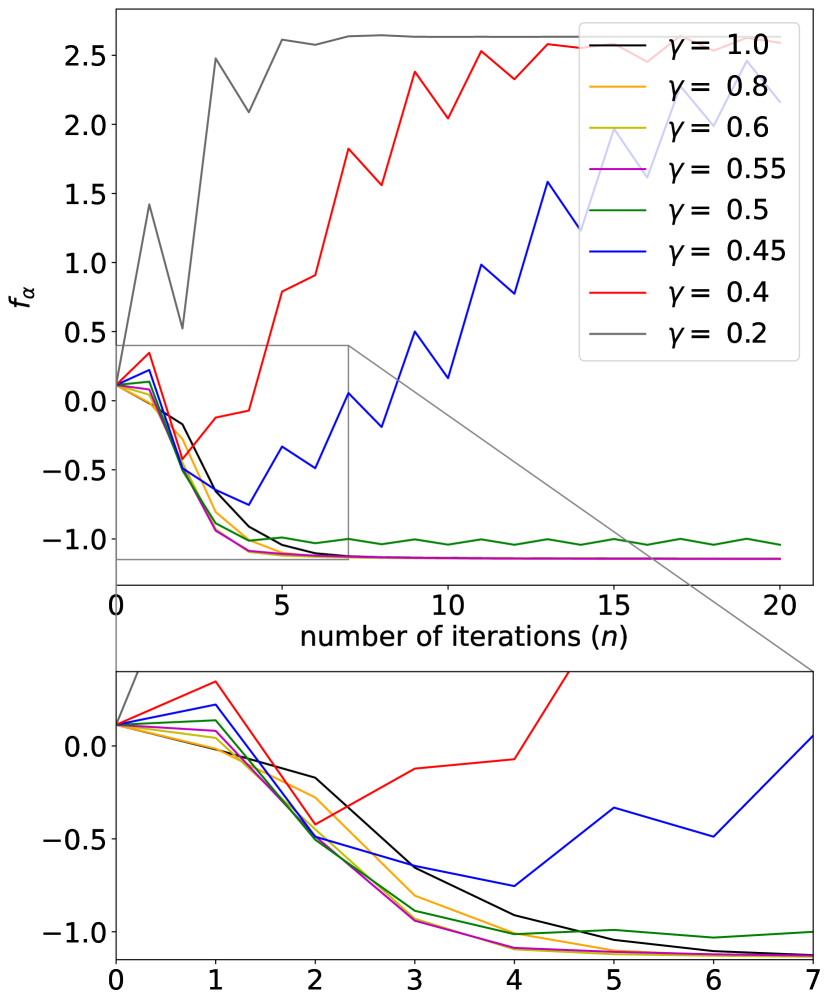
总之,数值结果证实了我们在理论分析 (见第 2.4 节) 中关于选择合适的 的重要性的结论。 我们强调,我们在这一方向上的贡献有两个方面:
-
1.
我们提出了一种加速 QIB 算法的方法,通过引入一个新的参数 并将其设置为小于 1,使其在更少的迭代轮次内收敛。
-
2.
我们证明,如果 太小,QIB 算法无法达到 的理想最小值。
2.6 的选择
我们的 QIB 算法的输出不仅取决于 [参见 (1)],还取决于 和 的选择。 直观地,较大的 提高了保真度 (因为它使 在 中更重要),而较小的 导致更多压缩 (因为它使 在 中更重要)。 令人惊讶的是, 的选择并非完全自由: 在下文中,我们将展示如果 太小,则 QIB 算法将产生一个平凡的 。
为了考虑 的选择与 上的所得信息之间的关系,我们为子集 引入以下条件, 其中 是从 到 的所有 c-q 通道的集合,即集合 :
- (A2)
-
对于任何两个不同的元素 ,
条件 (A2) 是酉不变的, 即, 对 满足条件 (A2), 当且仅当对任何在 上的酉算子 ,对 满足条件 (A2)。 因此,我们将 选为酉不变子集。
定理 4
假设一个酉不变子集 满足 (A2)。 令 为 QIB 问题的解。 当 属于 时, 对于任何 , 是 上的最大混合状态。
如果对于每个 , 都是最大混合状态,那么 与 不相关,并且不包含任何有意义的信息。 换句话说, 当定理 4 的假设成立时, QIB 问题的解没有用。 因此,我们需要选择参数 使得条件 (A2) 不成立。
现在我们讨论如何避免条件 (A2)。 (A2) 的左侧被评估为
| (39) |
其中 。 由于 , 的系数是一个负值。 因此,一个较小的 更有可能满足条件 (A2)。 也就是说, 为了获得有效的解决方案,我们需要选择 为一个足够大的值。
3 经典系统
接下来,我们考虑 被 约束 为一个经典系统的情况。 我们强调,这与之前讨论的量子 系统 的最小化不同,其最小值可能无法用经典 实现。 相反,我们现在的目标函数是
| (42) |
因此,我们需要重新检查之前分析的有效性。
让我们从 QIB 算法的形式开始。 幸运的是,我们使用量子 系统 的算法可以应用于这种情况,只是需要适应,即状态 被限制为 关于 基的 对角密度矩阵 。 在这个条件下,状态 也是 对角密度矩阵。 因此,当我们将初始状态设置为对角密度矩阵时, 算法 1 对这种情况有效。
以上讨论引出了一个有趣的观察结果,如下所示。 具有初始对角线 的收敛 满足条件 (10),并且它也是对角线。 也就是说,如果使用经典 的最小值严格大于使用量子 的最小值, 那么使用经典 的最小值就是以下陈述的一个例子: 条件 (10) 的解并不一定给出使用量子 的 的最小值。 这一事实表明,使用量子 的 的 (10) 的解可能是鞍点或局部最小值,而不是全局最小值。
当状态 限制为相对于 的基 的对角密度矩阵时, 与 可交换, 因此, 我们可以定义 。 那么, 简化为如下。
| (43) |
酉不变性的概念简化为对 上的排列的不变性,条件 (A2) 对 上的排列是不变的。 那么,定理 4 可以改写为如下。
定理 5
假设子集 满足 (A2) 并且 对 上的任何排列是不变的。 令 为 的最小化器。 当 属于 时, 是 对于任何 , 上的均匀分布。
在这种情况下,我们可以对条件 (A2) 进行更精确的讨论。 为此, 我们考虑最大比率
| (44) |
不等式 来自于映射 的信息处理不等式。 在这种情况下, 被写成 ,方法是 使用分布 。 那么, (A2) 的 LHS 简化为
| (45) |
当条件 成立时, (A2) 的 LHS 对 为正。 因此,要提取有用的 ,我们需要选择 以满足条件 以及 。 事实上,即使 , 也可能存在一个置换不变子集 满足 (A2)。 由于定理 5, 当一个置换不变子集 满足 (A2) 时, 一个有用的解不属于子集 。 因此,为了获得一个有用的解,我们需要选择 足够大,超出 上述条件 和 。
备注 3
我们考虑经典 和 的情况。 运算符 简化为如下。
| (46) |
备注 4
当系统 是经典的,并且 时, 参考文献 [9, Appendix B] 声称,量子 的最优值与 经典 的最优值之间没有区别。 由于他们的算法使用大小固定的 , 可以认为 他们声称上述陈述 是在 的大小固定时。 但是,他们的证明(见 [9, Appendix B II])存在一个漏洞: 等式 (B23) 下的陈述“拉格朗日量在选定基 中对内存 的测量下是不变的”没有得到严格的数学证明的支撑。 因此,尚不清楚该陈述以及随之得出的量子优势不存在的说法是否正确。 另一方面,正如我们将在下一节中展示的那样,使用量子 的最优值可能严格小于使用经典 的最优值。 也就是说,[9, Appendix B] 中的断言 与我们下一节的结果相矛盾。
4 量子优势对于
为了看到量子系统 相对于经典系统 的优势, 我们讨论了几个具有严格不等式的例子
| (51) |
我们在本节中提供了一个解析示例 以及在第 5.2 节中,在量子机器学习应用中的一个数值示例 当系统 的大小固定时。 通常,为了获得最佳性能, 我们需要将系统 选择为一个足够高维的系统。 然而,在本节中, 为了提供解析示例, 我们固定系统 的大小为某个特定值。
假设 是一个大小为 的经典系统。 的大小是 倍于 的大小 。 我们假设 被给出为 其中有 以及 。 我们假设 的分布是均匀的。 我们关注维数为 的量子系统 。
引理 6
当 且 时,我们有
| (52) |
证明: 首先,我们展示了对通用(量子) 的 QIB 的界限。 对于任何 ,我们有 。 因此,关系 意味着 。 因此,我们有
| (53) |
由于 且 ,我们得到
| (54) |
上述界限是紧的。 实际上,我们将 作为纯状态 。 然后,我们有 。 同样,。 因此,。
接下来,我们关注 为维度为 的经典系统的情况。
引理 7
假设 且 。 当 时,我们有
| (55) |
证明: 任何信道 可以写成确定性信道的概率混合 。 也就是说,我们有
| (56) |
由于 与 独立,且 随机变量 描述了 的选择, 我们有
| (57) |
同样,我们有
| (58) |
然后,我们有
| (59) |
其中 由 (53) 推出,而 由 (57) 和 (58) 推出。 的最小化等于 在 为确定性信道且 仅取决于 的条件下 对相同函数的最小化。
在此条件下,我们有 ,这说明在 (59) 处 等于。 因此,为了最小化,我们可以施加这个条件,即变量 仅由 确定,这意味着 。 在这种情况下,我们有 。 在经典情况下,确定性信道中最大熵 在分布 尽可能接近均匀分布时达到,即 。 因此,最大熵 为 。 因此,我们得到了所需的陈述。
5 具有 QIB 的量子特征映射
5.1 监督学习中的信息瓶颈
监督学习是机器学习的基石。 给定一个从未知概率分布 中采样的数据集 ,一般监督学习任务是找到一个分类器,使得对于从相同分布 中采样的任何测试数据 ,它在给定 的情况下,以尽可能高的准确率预测标签 。
值得注意的是,最近关于信息瓶颈理论的研究 [33, 28, 8] 表明深度学习的训练阶段可以分为两个阶段。 在第一个阶段,找到 的表示 ,它忠实地编码了它与 的相关性,其特征是 的增加。 在第二阶段, 的大小被压缩,其特征是 的减少。 这个结果表明,找到 的有效和压缩表示有助于数据分类。
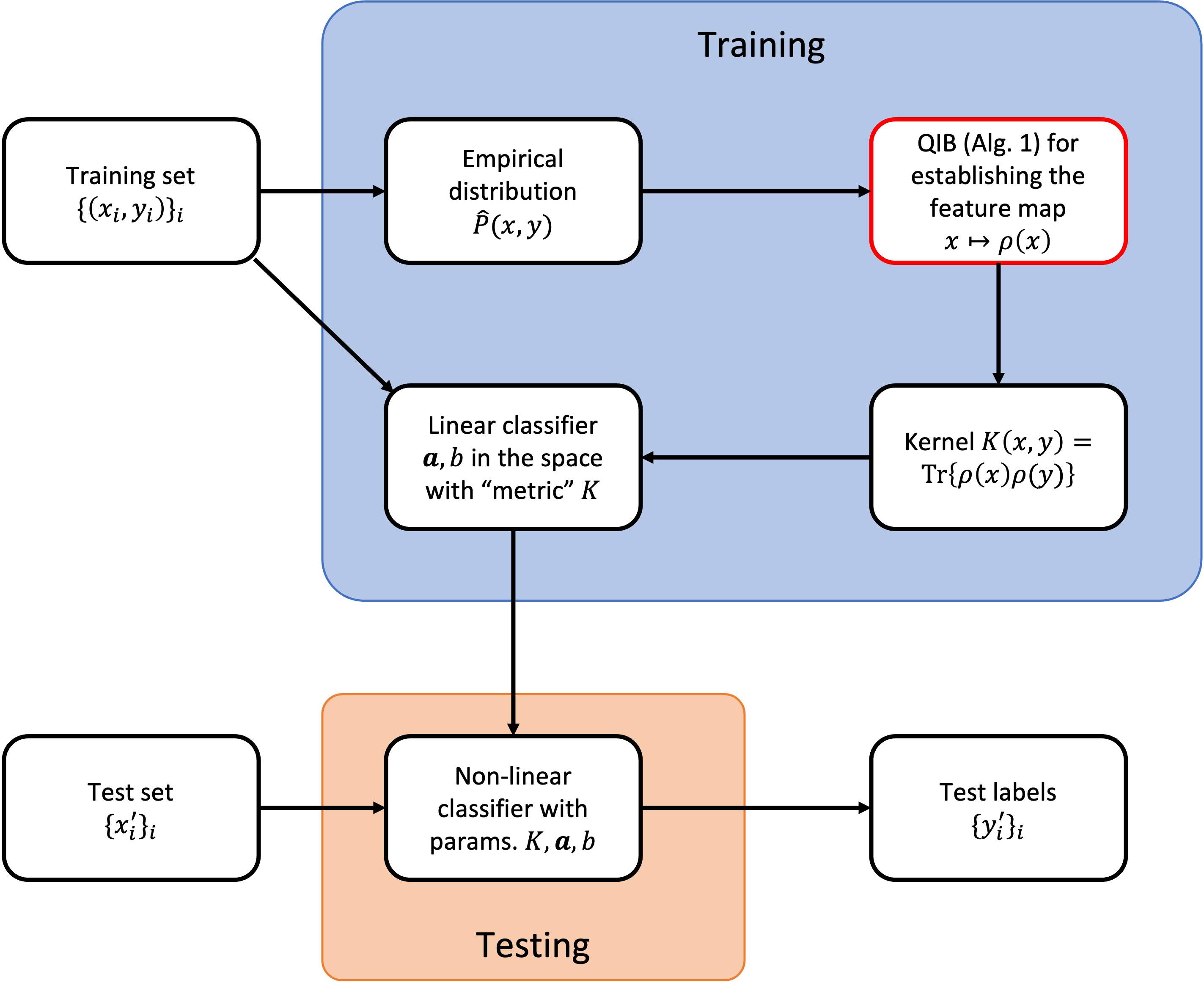
5.2 量子特征映射
遵循上述直觉,我们通过将 QIB 算法与核方法结合,提出了一种经典-量子混合数据分类算法。 该想法在图 3 中的流程图中进行了说明。 给定一个训练数据集 ,该算法首先通过最小化信息瓶颈 来识别 的有效表示 。 然后构建一个分类器,该分类器根据对应于 值的 中的状态生成预测 。 为简单起见,我们现在考虑 为二进制的情况。 在第一步中,我们将表示 设置为依赖于数据 的量子态 ,并通过算法 1 获得 。 在第二步中,我们使用线性分类器
| (60) |
其中 是一个厄米算符,而 。 我们进一步考虑 可以表示为线性组合 ,并且分类器具有简化的形式
| (61) |
其中 是 核 函数,在我们的情况下,由量子态的希尔伯特-施密特 (HS) 内积给出,可以通过在量子计算机上执行交换测试来评估:
| (62) |
该算法总结如下:
我们注意到,量子核方法,其中构建了一个映射 用于更好的分类,最近已成为一个热门话题(例如,参见 [26, 11, 5, 17, 20, 25])。 现有工作与我们目前方法的关键区别在于:在现有工作中,参数 被传递给一个参数化的(也称为 变分)量子电路,该电路准备状态 。 人们需要在量子计算机上训练电路参数以获得良好的映射 ,这被称为特征映射。 在近期,这种方法可能会受到量子器件物理限制的影响。 相反,在我们目前的方法中, 是通过简单的迭代算法直接计算出来的。 因此,实现我们目前方法,即算法 2,有两种可能的方式。 在近期,我们可以将算法 2 视为一种“受量子启发的”经典算法,并在经典计算机上评估所有内容。 当大规模量子计算成为可能时,算法 2 可以很容易地“量子化”。 实际上,每次迭代中 的评估需要子例程来计算矩阵幂和对数并求解线性系统,这些子例程已在参考文献中开发。 [10, 19, 18, 7]。
5.3 数值实验
作为一项原理验证实验,我们测试了我们的 QIB 分类器在 上的数据集上的性能,该数据集以以下方式生成: 首先,我们定义离散集 和 , 其中 和 。 为了应用我们的分类方法, 我们任意选择置换 , 并生成 个独立同分布数据 ,用于 ,如下所示。 我们独立地生成 ,根据 以下分布
| (63) |
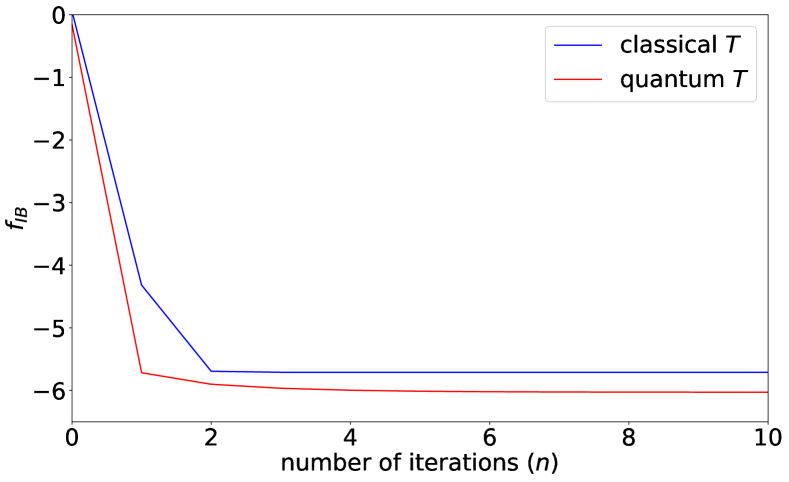
其中 是在 上的均匀分布, 、 和 。 接下来,我们生成随机变量 ,其中 随机变量 服从区间 内的均匀分布 除非 或 , 否则它服从区间 内的均匀分布。 然后,使用获得的数据 ,其中 , 我们定义其经验分布 。 我们将算法 1 应用于分布 ,如图 4 所示。 在具有分布 的情况下, 具有量子 的算法 1 可以实现更小的 ,而不是具有经典 的算法 1, 这表明量子 相比经典 的优势。
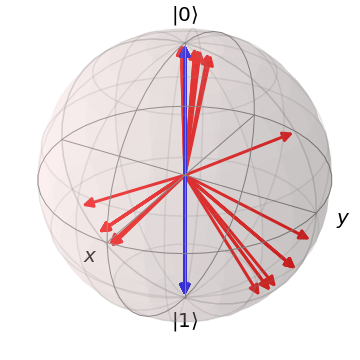
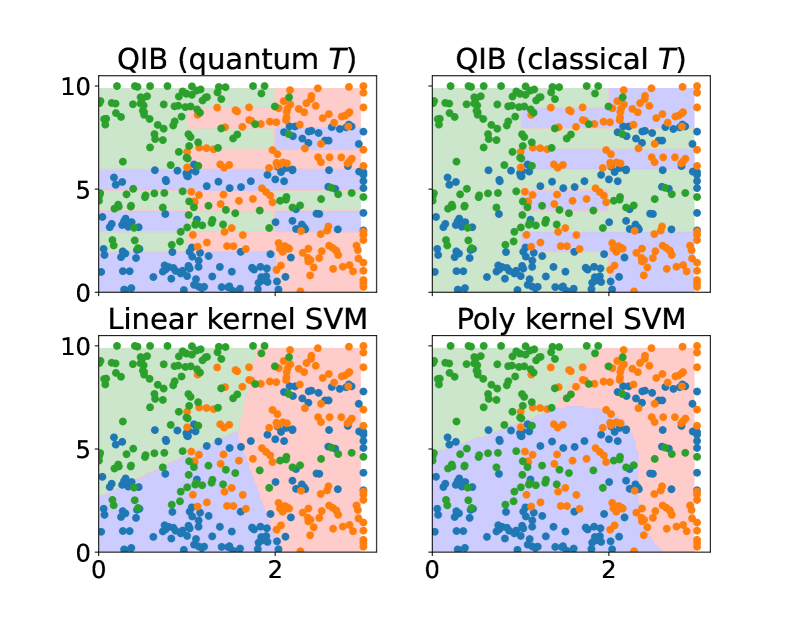
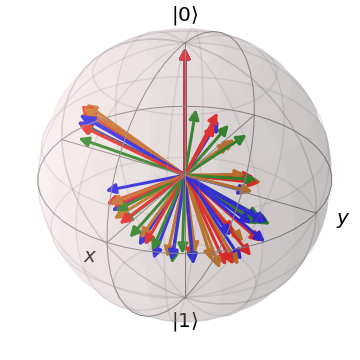
在分类实验中, 的数据用作训练集,其余数据用作测试集。 该核使用算法 2 构建,并包含 、一个单量子比特寄存器 以及 10 次迭代。 我们分别考虑了 是一个通用量子比特系统和 被限制为一个二进制经典系统的情况,并比较了它们的性能。 从图 4 可以看出,量子 的 IB 值低于经典 的 IB 值。量子 情况下的最终特征图 由于随机噪声 而存在一定程度的离散,但量子特征仍然形成了 3 个簇。 相比之下,经典 情况下的最终 将 的不同值映射到两个簇中。
上述区别的影响在分类性能中显而易见。 在图 5 中,通过分类器的决策区域说明了从核中构建的分类器的性能。 可以看出,由于经典- 特征图将 分组到两个簇中,因此其生成的分类器对任何输入数据都给出二进制预测,放弃了尽可能少的标签。 相反,量子- 特征图利用完整的布洛赫球来生成 3 个簇,从而导致更高的预测精度。 因此,这个数值例子体现了真正量子特征图的优势。
作为参考,在图 5 中,我们还绘制了两种标准的经典特征图方法的性能。 参考方法(线性核和多项式核)的准确率(由测试集中正确预测的比率定义)为 和 ,这略高于经典- 信息瓶颈核 (),但远低于 QIB 核 ()。 这进一步证明了我们的 QIB 方法在分类方面的优越性能。
6 量子确定性信息瓶颈 (QDIB)
考虑到极限 , 论文 [31] 提出了确定性 IB,它最小化 。 现在,我们考虑用量子系统 和经典系统 进行这种最小化。 首先,我们定义
| (64) |
其中 是对算子 的最大特征值的投影。
给定一个初始点 ,我们提出以下更新规则
| (65) |
如下所示,该算法的每一步都提高了目标函数 的值。
7 从 DIB 中近似获取充分统计量
7.1 任务公式化
接下来,我们讨论 DIB 如何用于提取经典-量子 (c-q) 联合系统中包含有用信息的 和 的联合状态 , 其中 是经典系统, 是量子系统。 例如,假设我们感兴趣的是量子系统 中的量子现象。 该量子系统 与经典系统 相关联。 但是,经典系统 可能包含冗余信息。 在这种情况下,从 中提取必要的信息来描述量子系统 中量子现象的行为是有用的。 为了讨论必要信息,我们引入了 -(近似) 充分统计量 的概念,它是经典系统 相对于量子系统 的统计量, 而论文 [36, 12] 在系统 是经典系统时讨论了 这个概念。
从 到 的函数 被称为 量子系统 的 充分统计量, 当存在条件分布 使得
| (70) |
上述条件等价于条件
| (71) |
而一般情况下我们有不等式 。
然而,当我们使用充分统计量时,我们无法消除由噪声产生的微弱相关性。 例如,假设经典系统 由两个经典系统 和 组成。 假设我们有一个 c-q 状态 ,其中包含两个经典系统 和 。
我们假设我们已经知道分布 ,但我们不知道 。 此外,我们假设我们多次生成此状态并将状态估计应用于生成的状态。 结果,我们得到了我们的估计
| (72) |
由于我们的估计始终存在很小的误差, 与 不完全相同,但它接近于 。 在这种情况下,这种差异应被视为噪声。 也就是说, 的依赖关系并不重要。 最好考虑将相关性作为 给出,以便我们对 的估计作为 给出。
对于 ,函数 被称为 充分统计量,当不等式
| (73) |
成立。 因此,具有 小尺寸的充分统计量和 -充分统计量可以被视为 关于 的压缩数据。
在上面的例子中, 是 的充分统计量。 当 对于 足够小时, 接近 ,即 是 -充分统计量。 因此,我们可以移除非必要信息 。 事实上,如果 被随机排列 打乱, 提取基本信息将变得不 trivial 。 为了涵盖这种非 trivial 的情况,我们需要一种系统的方法 来找到一个具有小尺寸 的函数。 为此,我们可以使用信息瓶颈算法。
为了提取近似充分统计量 , 我们关注两个要求。 互信息 应该更大, 而熵 应该更小。 为了满足这些要求, 我们只需使用 确定性信息瓶颈算法与 最小化 。 由于算法最小化了 , 并且解中的条件分布 是确定性的, 因此解中 的支撑预计将小于 原始集合 。
7.2 数值
为了证明以上想法,让我们看一个具体的例子,它是第 2.5 节中例子的修改。 考虑一个单量子比特量子系统 和一个经典寄存器 ,它编码有关 的信息。 寄存器 进一步被分成两个子寄存器 和 ,它们在 集合 和 中取值。 然后,我们假设 是在 上的均匀分布,并且 密度 被给出为 与 (37)。 参数 和 取决于 ,如
| (74) |
显然,量子系统仅取决于 和 ,不包含关于量子系统的任何信息。 然而,拥有该系综的实验者并不知道这一点。 为了提取关于量子系统的信息,对于每对 ,实验者通过在 上重复进行适当的测量( 次)来估计其密度矩阵。 根据量子态估计理论 [15, 13],估计值的不准确度与 成正比。 考虑到这一点,我们将估计的密度矩阵建模为 当实际密度矩阵为 时,其中
| (75) | ||||
| (76) |
和 表征估计误差。 估计的系综然后承认以 (72) 给出的密度矩阵,其中 由方程给出。 (37),(75), 和 (76)。 注意,现在寄存器 与 在估计的联合状态 中相关,即使估计引起的噪声遵循不依赖于 值的分布。
现在,任务是压缩寄存器 ,通过从 到更小的经典寄存器 建立映射。这里我们取 与 大小相同。 一种直观的方法是丢弃 寄存器, 因为 包含比 多得多的关于量子位状态的信息。 然而,这样的简单映射在更一般的情况下不存在。 例如,如果 Eq. (72) 中的 值被置换,丢弃 将不会导致忠实的压缩。 为了说明这一点,我们进一步对 Eq. (72) 中的经典寄存器 应用一个任意选择的未知重排 。 然后,系综承认以下联合密度矩阵:
| (77) |
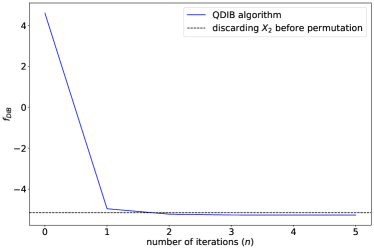
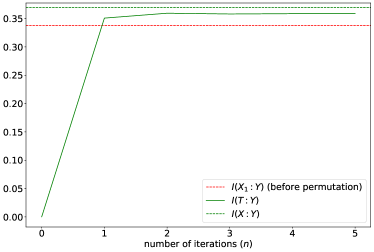
8 讨论与结论
We have proposed a generalized algorithm for QIB with an acceleration parameter and an additional parameter , and have derived a necessary condition for the monotonic decrease of the objective function with quantum systems and classical system when we extract information with respect to from . 我们还证明了它在相同条件下的收敛性,并证明了明智地选择参数 可以加速收敛。 我们的数值计算进一步证实了上述分析,如下所示。 在我们的数值实验中,减小可以加速收敛,但如果小于阈值,算法将无法收敛。 此外,我们还提供了一些例子,表明量子系统 比经典系统 具有优势,即使 和 是经典系统。
接下来,取限制,我们提出了一种QDIB迭代算法,最小化目标函数。 我们已经证明,这种迭代算法总是使目标函数单调递减。 QDIB可以用来找到近似充分的统计量,因为它实现了较小的熵和较大的互信息。 然后,我们通过数值证明了我们的 QDIB 算法作为近似充分统计量能够很好地工作。
我们在这项工作中展示的一个重要应用是,我们的 QIB 算法提供了一种构建用于分类的量子特征图的新方法。 在我们的数值示例中,量子系统 实现的目标函数值比经典系统 更小。该数值分析显示了使用量子存储器进行分类的优势。 尽管最近取得了重大进展 [34, 27, 3, 26, 11, 5, 17, 20, 25],但量子机器学习相对于其经典对应物的优势尚未得到广泛讨论。 我们的工作为解决这个问题提供了一个新的角度,阐明了在学习领域严格论证和量化量子霸权的新方案。
对于未来的研究,一个悬而未决的问题是如何将我们的结果扩展到 也是量子系统的情况,例如,压缩量子系统同时保持其与经典标签的相关性 [21, 23, 35, 36, 37, 38]。 值得注意的是,在这种情况下,如果 是经典的,无论其大小如何,一些相关性都会丢失 [37]。 因此,我们预计,对于具有量子 的 QIB,量子 的优势可能会持续甚至变得更强。
最后,我们注意到,目前还没有有效的方法来计算定理 3 中对 的限制。 在未来的工作中解决这个问题将加速我们的信息瓶颈算法的收敛。
致谢
MH 部分得到中国国家自然科学基金(项目编号: 62171212)和广东省重点实验室(项目编号:2019B121203002)的资助。 YY 由广东省基础与应用基础研究基金(项目编号: 2022A1515010340)和香港研究资助局(RGC)通过早期职业计划(ECS)拨款 27310822 资助。
参考文献
- Arimoto [1972] S. Arimoto. An algorithm for computing the capacity of arbitrary discrete memoryless channels. IEEE Transactions on Information Theory, 18(1):14–20, 1972. doi: 10.1109/TIT.1972.1054753.
- Banchi et al. [2021] Leonardo Banchi, Jason Pereira, and Stefano Pirandola. Generalization in quantum machine learning: A quantum information standpoint. PRX Quantum, 2:040321, Nov 2021. doi: 10.1103/PRXQuantum.2.040321.
- Biamonte et al. [2017] Jacob Biamonte, Peter Wittek, Nicola Pancotti, Patrick Rebentrost, Nathan Wiebe, and Seth Lloyd. Quantum machine learning. Nature, 549(7671):195–202, 2017. doi: 10.1038/nature23474.
- Blahut [1972] R. Blahut. Computation of channel capacity and rate-distortion functions. IEEE Transactions on Information Theory, 18(4):460–473, 1972. doi: 10.1109/TIT.1972.1054855.
- Blank et al. [2020] Carsten Blank, Daniel K Park, June-Koo Kevin Rhee, and Francesco Petruccione. Quantum classifier with tailored quantum kernel. npj Quantum Information, 6(1):1–7, 2020. doi: 10.1038/s41534-020-0272-6.
- Datta et al. [2019] Nilanjana Datta, Christoph Hirche, and Andreas Winter. Convexity and operational interpretation of the quantum information bottleneck function. In 2019 IEEE International Symposium on Information Theory (ISIT), pages 1157–1161, 2019. doi: 10.1109/ISIT.2019.8849518.
- Gilyén et al. [2019] András Gilyén, Yuan Su, Guang Hao Low, and Nathan Wiebe. Quantum singular value transformation and beyond: exponential improvements for quantum matrix arithmetics. In Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, pages 193–204, 2019. doi: 10.1145/3313276.3316366.
- Goldfeld and Polyanskiy [2020] Ziv Goldfeld and Yury Polyanskiy. The information bottleneck problem and its applications in machine learning. IEEE Journal on Selected Areas in Information Theory, 1(1):19–38, 2020. doi: 10.1109/JSAIT.2020.2991561.
- Grimsmo and Still [2016] Arne L. Grimsmo and Susanne Still. Quantum predictive filtering. Phys. Rev. A, 94:012338, Jul 2016. doi: 10.1103/PhysRevA.94.012338.
- Harrow et al. [2009] Aram W Harrow, Avinatan Hassidim, and Seth Lloyd. Quantum algorithm for linear systems of equations. Physical review letters, 103(15):150502, 2009. doi: 10.1103/PhysRevLett.103.150502.
- Havlíček et al. [2019] Vojtěch Havlíček, Antonio D Córcoles, Kristan Temme, Aram W Harrow, Abhinav Kandala, Jerry M Chow, and Jay M Gambetta. Supervised learning with quantum-enhanced feature spaces. Nature, 567(7747):209–212, 2019. doi: 10.1038/s41586-019-0980-2.
- Hayashi and Tan [2018] Masahito Hayashi and Vincent Y. F. Tan. Minimum rates of approximate sufficient statistics. IEEE Transactions on Information Theory, 64(2):875–888, 2018. doi: 10.1109/TIT.2017.2775612.
- Helstrom [1969] Carl W Helstrom. Quantum detection and estimation theory. Journal of Statistical Physics, 1(2):231–252, 1969. doi: 10.1007/BF01007479.
- Hirche and Winter [2020] Christoph Hirche and Andreas Winter. An alphabet-size bound for the information bottleneck function. In 2020 IEEE International Symposium on Information Theory (ISIT), pages 2383–2388, 2020. doi: 10.1109/ISIT44484.2020.9174416.
- Holevo [2011] Alexander S Holevo. Probabilistic and statistical aspects of quantum theory, volume 1. Springer Science & Business Media, 2011. doi: 10.1007/978-88-7642-378-9.
- Hsu et al. [2006] Winston H. Hsu, Lyndon S. Kennedy, and Shih-Fu Chang. Video search reranking via information bottleneck principle. MM ’06, pages 35–44, New York, NY, USA, 2006. Association for Computing Machinery. ISBN 1595934472. doi: 10.1145/1180639.1180654.
- Lloyd et al. [2020] Seth Lloyd, Maria Schuld, Aroosa Ijaz, Josh Izaac, and Nathan Killoran. Quantum embeddings for machine learning. arXiv preprint arXiv:2001.03622, 2020. doi: 10.48550/arXiv.2001.03622.
- Low and Chuang [2017] Guang Hao Low and Isaac L Chuang. Hamiltonian simulation by uniform spectral amplification. arXiv preprint arXiv:1707.05391, 2017. doi: 10.48550/arXiv.1707.05391.
- Low and Chuang [2019] Guang Hao Low and Isaac L Chuang. Hamiltonian simulation by qubitization. Quantum, 3:163, 2019. doi: 10.22331/q-2019-07-12-163.
- Pérez-Salinas et al. [2020] Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, and José I Latorre. Data re-uploading for a universal quantum classifier. Quantum, 4:226, 2020. doi: 10.22331/q-2020-02-06-226.
- Plesch and Bužek [2010] Martin Plesch and Vladimír Bužek. Efficient compression of quantum information. Physical Review A, 81(3):032317, 2010. doi: 10.1103/PhysRevA.81.032317.
- Ramakrishnan et al. [2021] Navneeth Ramakrishnan, Raban Iten, Volkher B. Scholz, and Mario Berta. Computing quantum channel capacities. IEEE Transactions on Information Theory, 67(2):946–960, 2021. doi: 10.1109/TIT.2020.3034471.
- Rozema et al. [2014] Lee A Rozema, Dylan H Mahler, Alex Hayat, Peter S Turner, and Aephraim M Steinberg. Quantum data compression of a qubit ensemble. Physical Review Letters, 113(16):160504, 2014. doi: 10.1103/PhysRevLett.113.160504.
- Salek et al. [2019] Sina Salek, Daniela Cadamuro, Philipp Kammerlander, and Karoline Wiesner. Quantum rate-distortion coding of relevant information. IEEE Transactions on Information Theory, 65(4):2603–2613, 2019. doi: 10.1109/TIT.2018.2878412.
- Schuld [2021] Maria Schuld. Supervised quantum machine learning models are kernel methods. arXiv preprint arXiv:2101.11020, 2021. doi: 10.48550/arXiv.2101.11020.
- Schuld and Killoran [2019] Maria Schuld and Nathan Killoran. Quantum machine learning in feature Hilbert spaces. Physical Review Letters, 122(4):040504, 2019. doi: 10.1103/PhysRevLett.122.040504.
- Schuld et al. [2015] Maria Schuld, Ilya Sinayskiy, and Francesco Petruccione. An introduction to quantum machine learning. Contemporary Physics, 56(2):172–185, 2015. doi: 10.1080/00107514.2014.964942.
- Shwartz-Ziv and Tishby [2017] Ravid Shwartz-Ziv and Naftali Tishby. Opening the black box of deep neural networks via information. arXiv preprint arXiv:1703.00810, 2017. doi: 10.48550/arXiv.1703.00810.
- Slonim and Tishby [2000] Noam Slonim and Naftali Tishby. Document clustering using word clusters via the information bottleneck method. SIGIR ’00, pages 208–215, New York, NY, USA, 2000. Association for Computing Machinery. ISBN 1581132263. doi: 10.1145/345508.345578.
- Stark et al. [2018] Maximilian Stark, Aizaz Shah, and Gerhard Bauch. Polar code construction using the information bottleneck method. In 2018 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), pages 7–12, 2018. doi: 10.1109/WCNCW.2018.8368978.
- Strouse and Schwab [2017] DJ Strouse and David J. Schwab. The Deterministic Information Bottleneck. Neural Computation, 29(6):1611–1630, 06 2017. ISSN 0899-7667. doi: 10.1162/NECO_a_00961.
- Tishby et al. [1999] N. Tishby, F. C. Pereira, and W. Bialek. The information bottleneck method. In The 37th annual Allerton Conference on Communication, Control, and Computing, pages 368–377. Univ. Illinois Press, 1999. doi: 10.48550/arXiv.physics/0004057.
- Tishby and Zaslavsky [2015] Naftali Tishby and Noga Zaslavsky. Deep learning and the information bottleneck principle. In 2015 IEEE information theory workshop (ITW), pages 1–5. IEEE, 2015. doi: 10.1109/ITW.2015.7133169.
- Wittek [2014] Peter Wittek. Quantum machine learning: what quantum computing means to data mining. Academic Press, 2014. doi: 10.1016/C2013-0-19170-2.
- Yang et al. [2016a] Yuxiang Yang, Giulio Chiribella, and Daniel Ebler. Efficient quantum compression for ensembles of identically prepared mixed states. Physical Review Letters, 116(8):080501, 2016a. doi: 10.1103/PhysRevLett.116.080501.
- Yang et al. [2016b] Yuxiang Yang, Giulio Chiribella, and Masahito Hayashi. Optimal compression for identically prepared qubit states. Phys. Rev. Lett., 117:090502, Aug 2016b. doi: 10.1103/PhysRevLett.117.090502.
- Yang et al. [2018a] Yuxiang Yang, Ge Bai, Giulio Chiribella, and Masahito Hayashi. Compression for quantum population coding. IEEE Transactions on Information Theory, 64(7):4766–4783, 2018a. doi: 10.1109/TIT.2017.2788407.
- Yang et al. [2018b] Yuxiang Yang, Giulio Chiribella, and Masahito Hayashi. Quantum stopwatch: how to store time in a quantum memory. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 474(2213):20170773, 2018b. doi: 10.1098/rspa.2017.0773.