意大利佛罗伦萨大学
11email: {andrea.gemelli, enrico.civitelli, simone.marinai}@unifi.it 22institutetext: Computer Vision Center & Computer Science Department
Universitat Autònoma de Barcelona, Spain
22email: {sbiswas, josep}@cvc.uab.es。
Doc2Graph:基于图神经网络的任务无关文档理解框架
摘要
几何深度学习最近引起了包括文档分析在内的广泛机器学习领域的极大兴趣。 图神经网络(GNN)的应用在各种与文档相关的任务中变得至关重要,因为它们可以揭示重要的结构模式,这是关键信息提取过程的基础。 先前的文献工作提出了任务驱动模型,但没有考虑到图的全部功能。 我们提出了 Doc2Graph,一种基于 GNN 模型的任务无关文档理解框架,用于解决给定不同类型文档的不同任务。 我们在两个具有挑战性的数据集上评估了我们的方法,用于表单理解、发票布局分析和表格检测中的关键信息提取。 我们的代码可以在 https://github.com/andreagemelli/doc2graph 上免费访问。
关键词:
文档分析与识别图神经网络文档理解关键信息提取表格检测1简介
文档智能涉及阅读、理解和解释文档的能力。 文档理解可以通过图形表示来支持,图形表示可以稳健地表示对象和关系。 文档解析的图形推理涉及使用组合规则来操作具有语义意义的文档对象(标题、表格、图形)和关系的结构化表示。 通常,图被选择作为利用文档中的结构信息的适当框架,因为它们固有的表示能力可以编码对象组件(或语义实体)及其成对关系。 在这种背景下,最近图神经网络(GNN)已成为解决关键信息提取(KIE)[6, 35]、文档布局分析(DLA)问题的强大工具,其中包括- 研究了表格检测[25, 26]、表格结构识别[20, 34]和表格提取[9]等子任务,视觉问答(VQA)[18, 17]、合成文档生成[4]等。
同时,文档理解社区中常见的最先进实践是利用巨大的预训练视觉语言模型 [1, 32, 33] 的力量来学习视觉语言是否,文档的文本和布局线索是相关的。 尽管在大多数文档理解任务上实现了卓越的性能,但大规模文档预训练在内存和训练时间方面都伴随着较高的计算成本。 我们提出了一种解决方案,它不依赖于巨大的视觉语言模型预训练模块,而是利用图形从文档中识别语义文本实体及其关系。 该解决方案使用极少量的标记数据对表单 [15] 和发票 [10] 的两个具有挑战性的基准进行了实验。
受到一些先前作品[8,25,26]的启发,我们引入了Doc2Graph,这是一种新颖的任务无关框架,用于利用基于图形的表示来进行文档理解。 所提出的模型在三个不同的挑战中得到验证,即表单理解中的 KIE、发票布局分析和表格检测。 提出了图形表示模块来组织文档对象。 图节点表示单词或语义实体,而边缘则表示它们之间的成对关系。 找到创建图形的最佳边集绝非易事:通常在文献中应用启发式方法,例如使用可见性图[25]。 在这项工作中,我们不对连接性做出任何先验假设:相反,我们尝试在文档上构建完全连接的图表示,并让网络自行学习相关内容。
总而言之,这项工作的主要贡献可概括如下:
-
•
Doc2Graph,第一个与任务无关的基于 GNN 的文档理解框架,针对三个重要任务在两个具有挑战性的基准(表单和发票理解)上进行了评估,不需要大量的预训练数据;
-
•
我们提出了一种通用的文档图形表示模块,该模块不依赖于启发式方法来构建单词或实体之间的成对关系;
-
•
一种新颖的 GNN 架构管道,具有适合文档的节点和边缘聚合功能,通过极坐标利用文档对象的相对定位。
2相关工作
由于深度学习的出现,文档理解在过去几年中得到了广泛的研究,但在 Borchmann 等人最近的一项调查中重新阐述了这一点。 等人。 [5]。 任务范围从用于理解表单 [15]、收据 [14] 和发票 [10] 的 KIE 到对视觉和视觉的多模式理解以及文档中用于分类的文本提示[32, 33]。 它还包括 DLA 任务,其中最近的工作重点是构建用于页面区域 [3, 2] 检测和分类的端到端框架。 DLA 中的表检测 [25, 26]、结构识别 [20, 24] 和提取 [9, 30] 引起了一些特别关注近年来,由于布局的高度可变性,使得既需要解决又具有挑战性。 此外,问题回答 [21, 29] 已作为 KIE 任务原则的扩展出现,其中自然语言问题取代了属性名称。 当前在这些文档理解任务上最先进的方法[1,13,22,32,33]利用了大型预训练语言模型的力量,更多地依赖于语言而不是文档中的视觉和几何信息,并最终在此过程中使用数亿个参数。 此外,这些模型大多数都是使用巨大的 Transformer 管道进行训练的,这在预训练期间需要大量的数据。 对此,Davis等人[7]和Sarkar等人[28]提出了语言不可知模型。 在 [7] 中,他们重点研究了 [15] 形式中的实体关系检测问题,使用简单的 CNN 作为文本行检测器,然后使用基于模型生成的每个关系候选分数的启发式。 Sarkar 等人[28]更专注于通过将问题重新表述为语义分割(像素标记)任务来提取表单结构。 他们使用基于 U-Net 的架构管道,并行预测文档层次结构的所有级别,使其非常高效。
用于文档理解的 GNN 最初主要用于关键的 DLA 子任务,包括表格检测 [25] 和表格结构识别 [23]。 其引入背后的关键思想是利用 GNN 来利用文档的强大几何特征,然后在训练过程中保护机密文本内容(特别是行政文档)的隐私,使模型与语言无关并且更加依赖于结构在 [25] 中用于检测发票中的表格。 卡博内尔等。 等人。 [6]使用图卷积网络(GCN)来解决形式分析的实体(单词)分组、标记和实体链接任务。 他们使用边界框和词嵌入的信息作为主要节点特征,并且不包含任何视觉特征,同时使用k近邻(KNN)来编码边缘信息。 随后开发了 FUDGE [8] 框架用于形式理解,作为 [7] 的扩展,以极大地提高语义实体标记的最新技术通过使用与 [7] 中相同的检测 CNN 提出关系对来进行实体链接任务。 然后部署图卷积网络 (GCN),插入来自 CNN 的视觉特征,以便与键值关系对联合预测文本实体的语义标签,因为它们是非常相关的任务。
受这项有影响力的先前工作[8]的启发,我们的目标是提出一种与任务无关的基于 GNN 的框架,称为Doc2Graph,它适应两个任务的类似联合预测,语义分别使用节点分类和边分类模块的实体标记和实体链接。 Doc2Graph 的建立是为了解决多种挑战,从用于表单理解的 KIE 到用于发票理解的布局分析和表格检测,无需任何海量数据预训练,并且轻量级且高效。
3方法
在本节中,我们将介绍所提出的方法。 首先,我们描述将文档图像转换为图形的预处理步骤。 然后,我们描述了旨在处理不同类型任务的 GNN 模型。
3.1 文档图结构
图是由节点和边组成的结构。 图可以看作是表示文档的段(文本单元)和关系的语言模型。 需要一个预处理步骤。 根据任务的不同,必须考虑不同级别的粒度来定义文档的组成对象。 它们可以是单个单词或实体,即共享特定属性(例如公司名称)的单词组。 在我们的工作中,我们尝试将两者作为管道的起点:我们应用 OCR 来识别单词,同时应用预训练的对象检测模型来检测实体。 选定的对象一旦找到,就构成了图的节点。
此时,节点需要通过边连接。 找到创建图形的最佳边集绝非易事:通常在文献中应用启发式方法,例如使用可见性图[25]。 这些方法:(i) 不能很好地概括不同的布局; (ii) 强烈依赖先前的节点检测过程,而这些过程往往容易出错; (iii) 在连接中产生噪声,因为对象的边界框可能会切断重要的关系或允许不需要的关系; (iv) 预先排除解决方案集,例如答案远离问题。 为了避免这些行为,我们不对连接性做出任何先验假设:我们构建一个完全连接的图,然后让网络自行学习哪些关系是相关的。
3.2 节点和边特征
为了学习,合适的特征应该与图的节点和边相关联。 在文档中,这些信息可以从不同模式的来源中提取,例如视觉、语言和布局。 可以应用不同的方法对节点(单词或实体)进行编码以丰富其表示。 在我们的管道中,为了尽可能保持轻量级,我们包括:
-
•
对文本进行编码的语言模型。 我们使用spaCy大型英语模型来获取单词和实体的词向量表示;
-
•
表示样式和格式的视觉编码器。 我们在 FUNSD 上预训练 U-Net[27] 以进行实体分割。 由于 U-Net 使用不同编码器层的特征图来分割图像,因此我们决定使用所有这些信息作为视觉特征。 此外,需要强调的是,对于每个特征图,我们使用 RoI 对齐层来提取相对于每个实体边界框的特征;
-
•
文档内对象的绝对标准化位置;布局和结构是工业文档中包含的有意义的特征,例如用于键值关联。
至于边,据我们所知,我们提出了两组新的特征来帮助节点和边分类任务:
-
•
节点之间的归一化欧氏距离,通过边界框之间的最小距离来实现。 由于我们使用的是完全连接的图,这对于使用的聚合节点函数在消息传递算法期间保持局部性至关重要;
-
•
使用极坐标的节点相对定位。 每个源节点被认为位于笛卡尔平面的中心,并且其所有邻居都通过距离和角度进行编码。 我们将空间离散化为不同的分段(单次编码),分段的数量可以选择,而不是使用归一化的角度:角度的连续表示具有挑战性,因为例如,角度为和的相同距离的两个点的编码会有所不同。
3.3架构
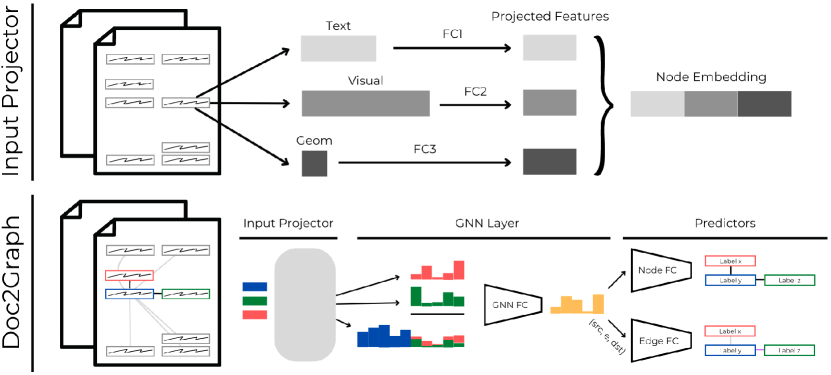
3.3.1 GNN层
我们的 GraphSAGE 版本在邻域聚合方面略有不同。 在层,给定节点、其内部表示和其邻居集,聚合定义为:
| (1) |
其中 可以是任何排列不变运算,例如总和或平均值。 通常,在其他领域,图结构自然是由数据本身给出的,但正如已经指出的,在文档中这可能具有挑战性(第 3.1 节)。 然后,给定一个文档,我们将上面的等式重新定义为:
| (2) |
其中 、 是节点 和 在其连接边上保存的欧几里德距离(标准化在 0 和 1 之间), 是一个恒定的比例因子。
3.3.2 边缘预测器
我们将每条边视为一个三元组 (): 是连接源 () 和目标 () 的边节点。 馈入二 FC 分类器的边缘表示 定义为:
| (3) |
其中和是最后一个GNN层的节点嵌入输出,和是输出logits的softmax前一个节点预测器层,是第3.2中描述的极坐标,是串联运算符。 做出这些选择是因为:(i)边缘上的相对定位比节点上的绝对定位更强:通过极坐标引入的局部属性可以扩展到不同的数据,例如不同尺寸或方向的文件; (ii) 如果所考虑的任务还包括节点的分类,则它们的类别可能有助于边的分类,例如在表单中,不可能找到与另一个答案相关的答案。
给定任务,图可以是无向图或有向图:两者分别用节点之间的两个或一个有向边表示。 在第一种情况下,顺序并不重要,因此上面的公式可以重新定义为:
| (4) |
4实验和结果
在本章中,我们将在两个不同的数据集(FUNSD 和 RVL-CDIP 发票)上对我们的方法进行实验,以解决三个任务:实体链接、布局分析和表格检测。 我们还讨论了与其他方法相比的结果。
4.1提出的模型
我们对我们提出的 FUNSD 上的实体链接模型进行了消融研究,没有节点的贡献和分类(图 1),因为我们发现这是最具挑战性的任务。 在选项卡中。 1我们报告了特征和超参数的不同组合。 几何和文本特征贡献最大,而视觉特征通过网络参数的显着增加(2.3 倍),为键值 F1 得分增加了近 3 分。 文本和几何特征对于当前的任务仍然至关重要,并且它们的组合在单独使用时会大大增加它们的分数。 这可能是由于两个事实:(i)我们的 U-Net 在 GNN 训练期间尚未包含在内(如 [8] 中所做的那样),无法调整用于发现键值的表示关系对; (ii) 用于训练骨干网的分割任务不会产生对该目标有用的特征(如表 1 所示)。 1)。 表中显示的超参数分别指边缘预测器 (EP) 内层输入维度和输入投影仪全连接 (IP FC) 层(每个模态)输出维度。 较大的 EP 对于将链接分类为“无”(切边,意味着没有关系)或“键值”提供了更多信息,而预测模式的更多维度有助于模型更好地了解其贡献的重要性。 这些更改使表中第三行和第四行之间的键值 F1 分数提高了 13 个百分点,我们保持功能固定。 我们不会报告相对于其他网络设置的分数,因为它们的更改只会带来总体指标的下降。 我们使用 的学习率和 的权重衰减,最后一个 FC 层的 dropout 为 0.2。 邻居节点的阈值及其贡献比例因子(第 3.3.1)分别固定为 0.9 和 0.1。 用于离散角度空间的箱(第3.3.2)是8。 我们在节点和边缘预测器之前应用一个 GNN 层。
| Features | F1 per classes () | |||||||
|---|---|---|---|---|---|---|---|---|
| Geometric | Text | Visual | EP Inner dim | IP FC dim | None | Key-Value | AUC-PR () | # Params () |
| ✓ | ✗ | ✗ | 20 | 100 | 0.9587 | 0.1507 | 0.6301 | 0.025 |
| ✗ | ✓ | ✗ | 20 | 100 | 0.9893 | 0.1981 | 0.5605 | 0.054 |
| ✓ | ✓ | ✗ | 20 | 100 | 0.9941 | 0.4305 | 0.7002 | 0.120 |
| ✓ | ✓ | ✗ | 300 | 300 | 0.9961 | 0.5606 | 0.7733 | 1.18 |
| ✓ | ✓ | ✓ | 300 | 300 | 0.9964 | 0.5895 | 0.7903 | 2.68 |
4.2FUNSD
4.2.1 数据集
数据集[15]包含 199 个真实的、完全注释的扫描表格。 这些文档被选为更大的 RVL-CDIP[12] 数据集的子集,该数据集是各种文档的 400,000 个灰度图像的集合。 作者将形式理解(FoUn)挑战定义为三个不同的任务:单词分组、语义实体标记和实体链接。 最近的一项工作[31]发现原始标签存在一些不一致之处,这阻碍了其对键值提取问题的适用性。 在这项工作中,我们使用 FUNSD 的修订版本。

4.2.2 实体检测
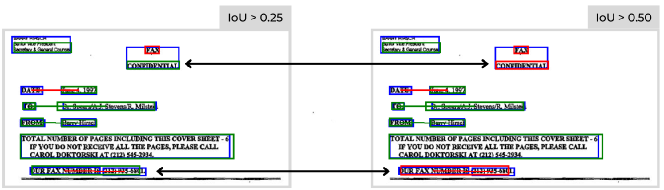
我们的重点是 GNN 性能,但出于比较的原因,我们使用 YOLOv5 小 [16] 来检测实体(在 COCO [19] 上预训练)。 在[15]中,单词分组任务使用ARI度量进行评估:由于我们不使用单词,因此我们使用两个不同的IoU阈值(表1)评估F1分数的实体检测。 2)。 对于语义实体标记和实体链接任务,我们使用 IoU ,如 [8] 中所做的那样:我们没有对检测器模型进行任何优化,这会带来高丢弃率对于实体和链接。 我们在 YOLO 检测之上创建图表,相应地链接真实情况(图 3):误报实体(红色框)被标记为“其他”类,而误报实体会导致一些关键问题-要丢失的值对(红色链接)。 由于错误检测而创建的新连接被视为误报并标记为“无”。
| Metrics () | % Drop Rate () | |||||
|---|---|---|---|---|---|---|
| IoU | Precision | Recall | F1 | Entity | Link | |
| 0.25 | 0.8728 | 0.8712 | 0.8720 | 12.72 | 16.63 | |
| 0.50 | 0.8132 | 0.8109 | 0.8121 | 18.67 | 25.93 | |
| F1 () | ||||
| Method | GNN | Semantic Entity Labeling | Entity Linking | # Params () |
| BROS [13] | ✗ | 0.8121 | 0.6696 | 138 |
| LayoutLM [33, 13] | ✗ | 0.7895 | 0.4281 | 343 |
| FUNSD [15] | ✓ | 0.5700 | 0.0400 | - |
| Carbonell et al. [6] | ✓ | 0.6400 | 0.3900 | 201 |
| FUDGE w/o GCN [8] | ✗ | 0.6507 | 0.5241 | 12 |
| FUDGE [8] | ✓ | 0.6652 | 0.5662 | 17 |
| Doc2Graph + YOLO | ✓ | 0.6581 0.006 | 0.3882 0.028 | 13.5 |
| Doc2Graph + GT | ✓ | 0.8225 0.005 | 0.5336 0.036 | 6.2 |
4.2.3数值结果
我们通过 10 倍交叉验证来训练我们的架构(第 3.3 节)。 由于我们发现结果存在很大差异,因此我们报告了在各自验证集上选择的 10 个最佳模型的均值和方差。 使用的目标函数 () 基于节点 () 和边缘 () 分类任务:。 在选项卡中。 3 我们报告了模型 Doc2Graph 与其他语言模型 [13, 33] 和基于图的技术 [6, 8] 的性能比较。 参数数量 # Params 指的是可训练的 Doc2Graph 管道(包括 U-Net 和 YOLO 主干);有关 spaCy 词嵌入的详细信息,请参阅他们的文档。 使用 YOLO,我们的网络在语义实体标记方面优于 [6],并且仅使用 13.5 个参数就满足其实体链接模型的要求。 我们无法比 FUDGE 做得更好,它的成绩仍然优于我们。 他们的骨干网络与 GCN 一起接受了这两项任务的训练(GCN 只增加了一些小的改进)。 这种差距,特别是在实体链接方面,主要是由于我们的视觉特征的贡献较低(表 1)。 1)和所使用的检测器(表 1) 3)。 我们还报告了使用地面实况(GT)实体初始化的模型的结果,以展示它在最佳情况下的表现。 与语义实体标记相比,实体链接仍然是一项更艰巨的任务,并且似乎只有复杂的语言模型才能解决它。 此外,为了完整起见,我们强调,凭借良好的实体表示,我们的模型优于语义实体标记任务的所有考虑的架构。 最后,我们想进一步强调,基于图的方法的主要贡献是产生更简单但更轻量级的解决方案。
4.2.4定性结果
顺序对于检测键值关系很重要,因为链接的方向会导致目标实体具有丰富其含义的属性。 与 FUDGE [8] 不同,我们确实利用了有向边,这使得我们可以更好地理解具有可解释结果的文档。 在图 5 中,我们展示了使用 Doc2Graph 在 groundtruth 上得到的定性结果:绿点和红点分别表示源节点和目标节点。 如不同示例情况所示,图 55(a) 和 55(b) 类似于一个简单的结构化表单布局,具有定向的一对一键值关联对,Doc2Graph 设法提取它们。 相反,当布局看起来更复杂时,如图 55(d) 所示,Doc2Graph 无法概括一对多键的概念 -值关系对。 这可能是由于我们的训练数据中的可训练样本数量较少,而且标题单元通常呈现不同的定位和语义。 未来我们会将表结构识别路径集成到我们的管道中,希望能够在这种更复杂的布局场景中改进各种键值关系的提取。
4.3 RVL-CDIP 发票
4.3.1 数据集
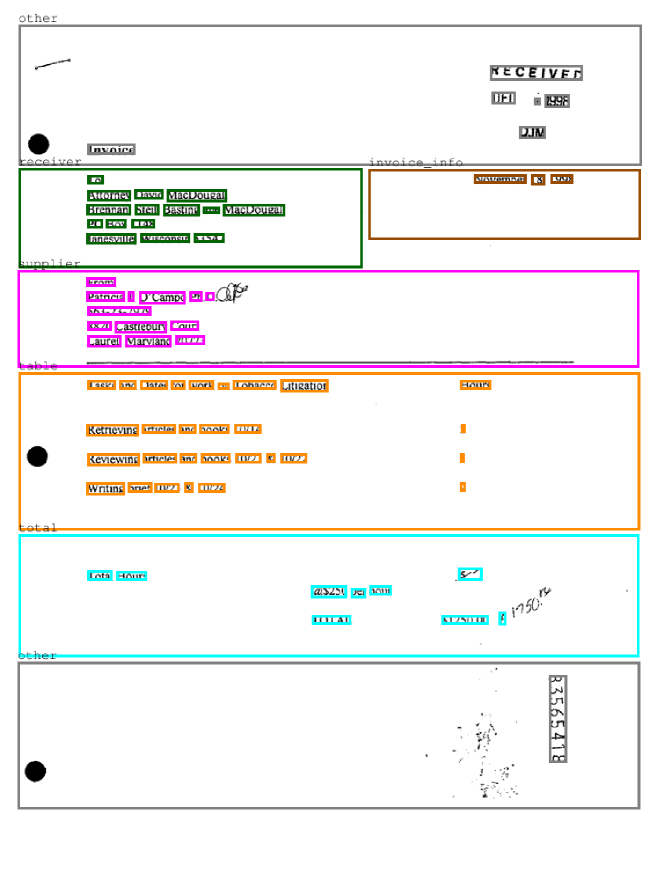
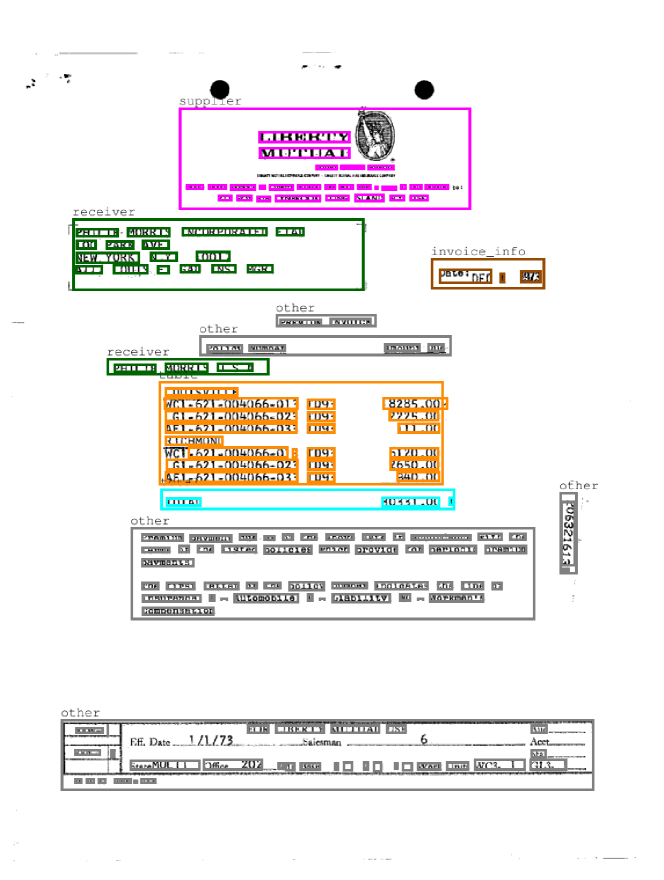
在 Riba 等人[25]的工作中,RVL-CDIP 的另一个子集已经发布。 作者从发票类中选择了 518 个文档,注释了 6 个不同的区域(图 4 中显示了两个注释示例)。 可以执行的任务是节点分类方面的布局分析和边界框方面的表检测(IoU 50)。
4.3.2数值结果
如前所述,我们执行 k 折交叉验证,为每个折保留相同数量的测试 (104)、val (52) 和训练文档 (362)。 这次我们应用 OCR 来构建图表。 有两个任务:布局分析(准确度方面)和表格检测(使用 F1 分数和 作为表格区域)。 我们的模型在这两项任务中均优于 [25],如表 4 和 5 所示。 特别是,对于表检测,我们提取了由分类为“表”的边引起的子图(如果两个节点位于同一个表中,则将它们链接起来)以提取目标区域。 Riba 等人 [25] 将问题表述为二元分类:为简洁起见,我们在表 1 中报告。 5 他们用来剪切边缘的置信度阈值,在我们的多类设置(“none”或“table”)中,softmax 隐式将其设置为 0.50。
| Accuracy () | ||
|---|---|---|
| Method | Max | Mean |
| Riba et al. [25] | 62.30 | - |
| Doc2Graph + OCR | 69.80 | 67.80 1.1 |
| Metrics () | ||||
|---|---|---|---|---|
| Method | Threshold | Precision | Recall | F1 |
| Riba et al. [25] | 0.1 | 0.2520 | 0.3960 | 0.3080 |
| Riba et al. [25] | 0.5 | 0.1520 | 0.3650 | 0.2150 |
| Doc2Graph + OCR | 0.5 | 0.3786 0.07 | 0.3723 0.07 | 0.3754 0.07 |



4.3.3 定性结果
在图 6 中,我们显示了定性结果。 复制这两个文档是为了更好地可视化这两个任务。 对于布局分析,较大的框颜色表示内部单词应具有的真实标签(颜色反映类别,如图 4 所示)。 对于表检测,我们使用一个简单的启发式:我们采用由“表”边连接的节点的封闭矩形(绿色),然后评估与目标区域(橙色)的 IoU。 这种启发式方法有效但简单,因此容易出错:如果在表区域之外发现误报,则可能会导致检测结果不佳,例如边界框还包括“发送者项目”实体或“接收者项目”实体。 另外,从图1至图3可知。 66(a)和66(b),可以取出“全部”区域。 将来,我们将通过增强节点分类任务并将“total”作为边训练的表区域来完善这种行为。


5结论
在这项工作中,我们提出了一种基于图神经网络的与任务无关的文档理解框架。 我们提出将文档作为图形进行一般表示,充分利用文档对象之间的连接性,并让网络自动学习有意义的成对关系。 节点和边聚合函数是通过考虑文档对象的相对位置来定义的。 我们在三个不同任务的两个具有挑战性的基准上评估了我们的模型:表单上的实体链接、发票上的布局分析和表格检测。 我们的基本知识结果表明,我们的模型可以取得有希望的结果,使网络维数保持在相当低的水平。 在未来的工作中,我们将把我们的框架扩展到其他文档和任务,以更深入地研究 GNN 的泛化特性。 我们希望更广泛地探索不同源特征的贡献以及如何以更有意义和可学习的方式将它们组合起来。
致谢
这项工作得到了西班牙项目 MIRANDA RTI2018-095645-B-C21 和 GRAIL PID2021-126808OB-I00、CERCA 计划/加泰罗尼亚自治区、FCT-19-15244 和 AGAUR 博士奖学金 (2021FIB- 10010)。
参考
- [1] Appalaraju, S., Jasani, B., Kota, B.U., Xie, Y., Manmatha, R.: Docformer: End-to-end transformer for document understanding. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 993–1003 (2021)
- [2] Biswas, S., Banerjee, A., Lladós, J., Pal, U.: Docsegtr: An instance-level end-to-end document image segmentation transformer. arXiv preprint arXiv:2201.11438 (2022)
- [3] Biswas, S., Riba, P., Lladós, J., Pal, U.: Beyond document object detection: instance-level segmentation of complex layouts. International Journal on Document Analysis and Recognition (IJDAR) 24(3), 269–281 (2021)
- [4] Biswas, S., Riba, P., Lladós, J., Pal, U.: Graph-based deep generative modelling for document layout generation. In: International Conference on Document Analysis and Recognition. pp. 525–537. Springer (2021)
- [5] Borchmann, Ł., Pietruszka, M., Stanislawek, T., Jurkiewicz, D., Turski, M., Szyndler, K., Graliński, F.: Due: End-to-end document understanding benchmark. In: Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) (2021)
- [6] Carbonell, M., Riba, P., Villegas, M., Fornés, A., Lladós, J.: Named entity recognition and relation extraction with graph neural networks in semi structured documents. In: 2020 25th International Conference on Pattern Recognition (ICPR). pp. 9622–9627. IEEE (2021)
- [7] Davis, B., Morse, B., Cohen, S., Price, B., Tensmeyer, C.: Deep visual template-free form parsing. In: 2019 International Conference on Document Analysis and Recognition (ICDAR). pp. 134–141. IEEE (2019)
- [8] Davis, B., Morse, B., Price, B., Tensmeyer, C., Wiginton, C.: Visual fudge: Form understanding via dynamic graph editing. In: International Conference on Document Analysis and Recognition. pp. 416–431. Springer (2021)
- [9] Gemelli, A., Vivoli, E., Marinai, S.: Graph neural networks and representation embedding for table extraction in PDF documents. In: accepted for publication at ICPR22 (2022)
- [10] Goldmann, L.: Layout Analysis Groundtruth for the RVL-CDIP Dataset (Sep 2019). https://doi.org/10.5281/zenodo.3257319
- [11] Hamilton, W., Ying, Z., Leskovec, J.: Inductive representation learning on large graphs. Advances in neural information processing systems 30 (2017)
- [12] Harley, A.W., Ufkes, A., Derpanis, K.G.: Evaluation of deep convolutional nets for document image classification and retrieval. In: International Conference on Document Analysis and Recognition (ICDAR)
- [13] Hong, T., Kim, D., Ji, M., Hwang, W., Nam, D., Park, S.: Bros: a pre-trained language model for understanding texts in document (2020)
- [14] Huang, Z., Chen, K., He, J., Bai, X., Karatzas, D., Lu, S., Jawahar, C.: Icdar2019 competition on scanned receipt ocr and information extraction. In: 2019 International Conference on Document Analysis and Recognition (ICDAR). pp. 1516–1520. IEEE (2019)
- [15] Jaume, G., Ekenel, H.K., Thiran, J.P.: Funsd: A dataset for form understanding in noisy scanned documents. In: 2019 International Conference on Document Analysis and Recognition Workshops (ICDARW). vol. 2, pp. 1–6. IEEE (2019)
- [16] Jocher, G., Chaurasia, A., Stoken, A., Borovec, J., NanoCode012, Kwon, Y., TaoXie, Fang, J., imyhxy, Michael, K.: ultralytics/yolov5: v6. 1-tensorrt, tensorflow edge tpu and openvino export and inference. Zenodo, Feb 22 (2022)
- [17] Li, X., Wu, B., Song, J., Gao, L., Zeng, P., Gan, C.: Text-instance graph: Exploring the relational semantics for text-based visual question answering. Pattern Recognition 124, 108455 (2022)
- [18] Liang, Y., Wang, X., Duan, X., Zhu, W.: Multi-modal contextual graph neural network for text visual question answering. In: 2020 25th International Conference on Pattern Recognition (ICPR). pp. 3491–3498. IEEE (2021)
- [19] Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
- [20] Liu, H., Li, X., Liu, B., Jiang, D., Liu, Y., Ren, B.: Neural collaborative graph machines for table structure recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4533–4542 (2022)
- [21] Mathew, M., Karatzas, D., Jawahar, C.: Docvqa: A dataset for vqa on document images. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 2200–2209 (2021)
- [22] Powalski, R., Borchmann, Ł., Jurkiewicz, D., Dwojak, T., Pietruszka, M., Pałka, G.: Going full-tilt boogie on document understanding with text-image-layout transformer. In: International Conference on Document Analysis and Recognition. pp. 732–747. Springer (2021)
- [23] Qasim, S.R., Mahmood, H., Shafait, F.: Rethinking table recognition using graph neural networks. In: 2019 International Conference on Document Analysis and Recognition (ICDAR). pp. 142–147. IEEE (2019)
- [24] Raja, S., Mondal, A., Jawahar, C.: Table structure recognition using top-down and bottom-up cues. In: European Conference on Computer Vision. pp. 70–86. Springer (2020)
- [25] Riba, P., Dutta, A., Goldmann, L., Fornés, A., Ramos, O., Lladós, J.: Table detection in invoice documents by graph neural networks. In: 2019 International Conference on Document Analysis and Recognition (ICDAR). pp. 122–127. IEEE (2019)
- [26] Riba, P., Goldmann, L., Terrades, O.R., Rusticus, D., Fornés, A., Lladós, J.: Table detection in business document images by message passing networks. Pattern Recognition 127, 108641 (2022)
- [27] Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. CoRR abs/1505.04597 (2015), http://arxiv.org/abs/1505.04597
- [28] Sarkar, M., Aggarwal, M., Jain, A., Gupta, H., Krishnamurthy, B.: Document structure extraction using prior based high resolution hierarchical semantic segmentation. In: European Conference on Computer Vision. pp. 649–666. Springer (2020)
- [29] Singh, A., Natarajan, V., Shah, M., Jiang, Y., Chen, X., Batra, D., Parikh, D., Rohrbach, M.: Towards vqa models that can read. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8317–8326 (2019)
- [30] Smock, B., Pesala, R., Abraham, R.: Pubtables-1m: Towards comprehensive table extraction from unstructured documents. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4634–4642 (2022)
- [31] Vu, H.M., Nguyen, D.T.N.: Revising funsd dataset for key-value detection in document images. arXiv preprint arXiv:2010.05322 (2020)
- [32] Xu, Y., Xu, Y., Lv, T., Cui, L., Wei, F., Wang, G., Lu, Y., Florencio, D., Zhang, C., Che, W., et al.: Layoutlmv2: Multi-modal pre-training for visually-rich document understanding. arXiv preprint arXiv:2012.14740 (2020)
- [33] Xu, Y., Li, M., Cui, L., Huang, S., Wei, F., Zhou, M.: Layoutlm: Pre-training of text and layout for document image understanding. In: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. pp. 1192–1200 (2020)
- [34] Xue, W., Yu, B., Wang, W., Tao, D., Li, Q.: Tgrnet: A table graph reconstruction network for table structure recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1295–1304 (2021)
- [35] Yu, W., Lu, N., Qi, X., Gong, P., Xiao, R.: Pick: processing key information extraction from documents using improved graph learning-convolutional networks. In: 2020 25th International Conference on Pattern Recognition (ICPR). pp. 4363–4370. IEEE (2021)