FedEgo:使用自我图进行隐私保护的个性化联合图学习
摘要。
图作为包含结构和特征信息的特殊信息载体,广泛应用于图挖掘,例如图神经网络(GNN)。 然而,在一些实际场景中,图数据分别存储在多个分布式各方中,由于利益冲突,可能无法直接共享。 因此,提出了联合图神经网络来解决此类数据孤岛问题,同时保护各方(或客户)的隐私。 然而,各方之间不同的图数据分布(称为统计异质性)可能会降低 FedAvg 等朴素联邦学习算法的性能。 在本文中,我们提出了 FedEgo,一个基于自我图的联合图学习框架,以解决上述挑战,其中每个客户将训练他们的本地模型,同时也为全局模型的训练做出贡献。 FedEgo 将 GraphSAGE 应用于自我图,以充分利用结构信息,并利用 Mixup 来解决隐私问题。 为了处理统计异质性,我们将个性化融入学习中,并提出自适应混合系数策略,使客户能够实现最佳个性化。 大量的实验结果和深入的分析证明了FedEgo的有效性。
1. 介绍
图神经网络(GNN)在从图数据中提取信息和导出表达性节点嵌入方面表现出了令人难以置信的性能,这有助于节点分类和链接预测等下游任务。 然而,之前的 GNN 工作侧重于集中式节点表示学习,而没有考虑现实世界中普遍存在的数据孤岛问题。 在传统的数据竖井情况下,数据存储在多个分布式各方中,并且只允许私下访问。 因此,如何与本地数据所有者协作单独的图,同时保护高质量的基于图的模型的训练隐私是一个关键问题。
联邦学习(FL)是一种将机器学习的实现与直接数据共享的要求分离的技术,在协作训练模型中显示出巨大的前景,同时保护数据隐私(Li等人,2020)。 联邦学习的关键思想是在本地数据所有者(或客户端)的贡献下在中央服务器中训练全局模型。 在处理图数据时,一个直观的想法是将朴素的联邦算法直接与图神经网络结合起来。 然而,基于权重聚合的朴素FL算法(例如FedAvg)无法从图数据中的结构信息中受益,因此在图挖掘中可能表现不佳。 对于 GNN 和 FL 的有机结合,我们称之为联邦图学习,图数据的结构信息应该得到充分利用。
此外,联邦图学习还存在高度非独立同分布(non-IID)问题。 由于图挖掘任务中经常出现客户端之间的统计异质性,单个全局模型可能无法很好地泛化所有客户端的本地数据(Jiang等人,2019)。 因此,有必要将个性化集成到训练联合图学习中,而不是单一的共识模型。 也就是说,客户将让全局模型适应他们自己的数据集,并训练他们的本地模型以实现个性化,我们将其称为个性化联合图学习。
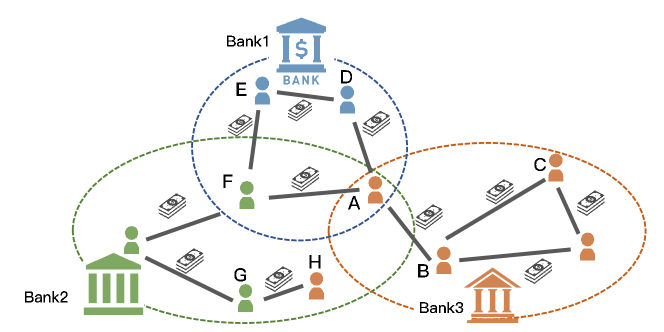
以金融体系中的一个实际问题为例。 一个城市有多家银行构成金融体系,如图1所示。 出于隐私考虑和利益冲突,每家银行的记录都单独存储,不与其他银行共享。 以客户为节点,以交易为边,可以从银行数据库中存储的记录中得出本地图。 图挖掘可以进一步应用,最常应用的任务之一可能是节点分类,例如区分不同类型的客户。 此外,银行还可以合作提高本地模型的泛化能力。 然而,在很多情况下,各个银行可能针对不同的市场,并且分布式图数据处于严重的非独立同分布场景,使得情况变得困难。 换句话说,银行的本地数据集可以被视为对现实世界的有限观察,而银行参与协作的关键动机是借助其他银行的数据来减少其本地泛化误差。 鉴于这些观察,银行需要在协作的收益与潜在的统计异质性带来的劣势之间实现权衡,这形成了典型的个性化联邦图学习。
一般来说,这种现实场景对个性化联合图学习提出了三个主要挑战:
-
挑战一: 联邦训练时如何充分利用图数据的结构信息? 由于拓扑信息是图挖掘不可或缺的一部分,因此将它们有机地融入联邦学习中非常重要。
-
挑战2: 如何缓解联邦学习框架中潜在的非独立同分布图数据的问题? 从不同角度观察真实数据集会导致严重的非独立同分布图数据,并导致朴素的 FL 算法无法正常运行。
-
挑战3: 如何在合作的利与弊之间实现最佳权衡? 在潜在的非独立同分布场景下,客户的理想情况是利用其他人的数据来补偿其本地数据集,同时最大限度地减少彼此之间统计异质性造成的损害。
上述挑战促使我们设计 FedEgo,一个基于自我图的个性化联合图学习系统。 FedEgo 能够应对上述挑战,并通过在结构和功能方面保持数据匿名来保护隐私。
-
为了解决挑战 1,可以将图视为具有结构和节点特征的一系列 跳自我图。 自我图是中心节点最多k跳邻居的采样子图,是一种有用的信息载体,可以在图挖掘过程中实现结构和特征信息的消息传递。 FedEgo 通过在自我图中应用 GraphSAGE (Hamilton 等人, 2017) 来从自我图中提取拓扑信息。 此外,从采样的自我图中只能得出局部拓扑信息,不可能恢复原始结构,这意味着它们是结构匿名的。
-
为了解决挑战 2,我们在中央服务器中训练一个全局模型来处理非 IID 图数据。 考虑到挑战 1,我们寻求开发一个能够捕获自我图包含的结构信息的全局模型。 为此,受(Arivazhagan等人,2019;Collins等人,2021)的启发,我们引入了一个由约简层和个性化层组成的网络,以利用共享的低维嵌入并执行个性化图分别采矿。 在 FedEgo 中,客户端的模型由用于本地训练的还原层和个性化层组成,而服务器中的全局模型仅由用于全局数据集中自我图的信息蒸馏的个性化层组成。 通过在客户端的每个批次中应用 Mixup (Yoon 等人,2021;Zhang 等人,2017),生成混合的自我图,随后将其发送到服务器并形成全局数据集。 在服务器中,全局模型处理非独立同分布图数据的能力是通过对上传的混合自我图进行训练来开发的。 混合的自我图仅包含混合的嵌入和局部结构,防止原始数据的传输并保护隐私,因此它们进一步是特征匿名的。
-
为了解决挑战 3,客户在全局模型的帮助下执行更新。 客户端将在归约层中遵循 FedAvg (McMahan 等人, 2017) 的普通算法,在加密自我图方面达成共识,然后根据自适应混合系数。 混合系数有助于为每个客户实现更好的个性化,它是根据本地数据集和全局数据集的分布之间的差异自适应确定的。
我们在非 IID 设置中的真实数据集上验证 FedEgo,以更好地模拟应用场景。 实验结果表明FedEgo显着优于基线,充分验证了FedEgo的有效性。 我们总结了我们的主要贡献如下。
-
我们介绍了一种基于自我图的新型个性化联合图学习框架。 FedEgo 通过在自我图上应用 GraphSAGE 来充分利用图数据的结构信息。
-
出于隐私问题,我们将 Mixup 应用于自我图,并通过对上传的混合自我图进行训练,开发全局模型捕获结构信息和处理非独立同分布图数据的能力。
-
我们设计了一种策略来自适应地学习个性化模型,以在协作的利弊之间进行权衡。
-
我们对广泛使用的数据集进行了广泛的实验,并凭经验证明了 FedEgo 在非 IID 场景下的优越性能。
2. 相关工作
2.1. 图联邦学习
最近,图的联邦学习引起了人们的极大兴趣,并且利用联邦学习和图神经网络的力量提出了几种联邦图框架(Chen 等人,2021;Zhang 等人,2021;He 等人,2021 ;王等人,2020;谢等人,2021;裴等人,2021)。 GraphFL (Wang 等人, 2020) 是一种与模型无关的元学习方法,专为少样本学习而设计,而 D-FedGNN (Pei 等人, 2021) 是一种分布式联邦学习方法图形框架允许在没有集中服务器的情况下在客户端之间进行协作。 FedSage+ (Zhang 等人, 2021) 训练缺失邻居生成器来恢复跨客户端的缺失边,主要针对实践中不太常见的分布式子图系统。 FedGL (Chen 等人, 2021) 上传节点全局信息的预测结果和嵌入,FedGCN (Yao and Joe-Wong, 2022) 交换节点的平均信息客户之间的邻居。 他们都面临着严重的隐私问题,因为其他人知道特定节点是否在某个客户端的本地数据集中。 相比之下,FedEgo 通过在结构和特征方面保持数据匿名,在现实环境中保护节点分类任务的隐私。
2.2. 个性化联邦学习
联邦学习中的个性化引起了广泛关注,并在最近的方法中得到了广泛的探索(Arivazhagan 等人,2019;Jiang 等人,2019;Deng 等人,2020;Hanzely 和 Richtárik,2020;Mansour 等人,2020) 。 (Arivazhagan 等人,2019)提出了一种神经网络,其具有用于联合平均的基础层和用于个性化的个性化层。 (Collins 等人, 2021) 是 (Arivazhagan 等人, 2019) 的进一步扩展,获得低维嵌入,加快训练过程的收敛速度。 其他一些作品(Jiang 等人,2019;Chen 等人,2018)借鉴了 MAML 的思想,(Jiang 等人,2019)将联邦学习视为 MAML 的一个实例。 此外,(Wang等人,2020)将MAML引入联邦图学习框架,并设计了用于少样本学习的GraphFl。 此外,事实证明,通过使用全局模型和局部模型混合(Deng等人,2020;Mansour等人,2020)、多任务学习(Smith等人,2017)以及添加近端项进行局部微调(Hanzely和Richtárik,2020),可以有效提高个性化模型的性能。 与现有工作不同,本文讨论如何根据本地和全球分布的差异实现更好的个性化,并具有理论依据。
3. 初步知识
3.1. 自我图谱
令 为具有 个节点的图,其中 表示节点集, 表示边集。 继(Bai and Hancock,2016;朱等人,2020)之后,我们得到了跳自我图的定义。
定义 3.1。
(-跳跃自我图)。 如果图 具有 层质心扩展,则称为以节点 为中心的 跳自我图从 出发的最短路径的长度为 ,即 ,其中 是从 到和
给定,图的基于深度的表示可以被描述为一系列自我图(Bai和Hancock,2016;Zhu等人,2020) 。 每个节点的标签都保留在自我图中,表示为一个单热向量。 作为有用的信息载体,自我图表将在 FedEgo 的每个客户端中进行采样训练。 在实践中,我们遵循 GraphSAGE (Hamilton 等人, 2017) 中的方法,在每层中对节点的固定大小的邻居集进行采样。 请注意,采样的自我图将具有固定的形状,并且可以独立于原始图进行训练。
当使用自我图族进行训练时,我们不关心原始图中的具体信息,而只关心局部属性。 从这个意义上说,我们无法知道中心节点在原始图中的位置,也无法通过采样的自我图来恢复原始图。 因此,采样的自我图是结构匿名的。
3.2. 图圣人
GraphSAGE (Hamilton 等人, 2017) 是一种适用于归纳图学习的方法,通过它我们可以实现自我图中的信息流。 它关注目标节点的局部属性,并聚合邻域的特征以获得下游任务的嵌入。 令 表示节点 在层 中的嵌入,带有均值聚合器的卷积层可以定义为
| (1) |
以作为权重矩阵,作为的1跳邻居。特别地,表示输入特征。 对于监督节点分类任务,我们使用交叉熵作为损失函数。 令表示具有特征和标签的节点样本,是从特征空间到标签空间的映射函数, 为标签的指示函数,为整个模型中的权重。 那么交叉熵损失可以表示为
| (2) |
其中表示数据分布的概率向量,表示。 分布向量可以进一步由下式得到。
| (3) |
其中是标签的one-hot向量,是节点数。
3.3. 联邦学习
联邦学习的主要目标是通过客户协作学习全局模型,典型的实现是 FedAvg (McMahan 等人, 2017)。 在FedAvg中,客户端迭代执行本地更新和全局平均值,最终学习全局模型。 形式上,我们假设有 个客户端,其中 作为客户端 的本地权重。 在训练纪元中,服务器首先向所有客户端广播最新的全局权重。 随后,客户端加载权重,然后执行多次本地更新:
| (4) |
之后,服务器对上传的本地参数进行平均,得到新的全局模型:
| (5) |
重复该过程以实现收敛,并学习全局模型以进行预测。 FedAvg 聚合来自模型的信息,但忽略了客户端之间的差异。 之前的研究表明,在严重的非独立同分布情况下,它可能表现不佳(Xie等人,2021)。
3.4. 混合
Mixup (Zhang 等人,2017)是一种数据增强技术,它对数据样本应用线性组合来生成附加数据。 在联邦框架中,Yoon 等人 (Yoon 等人, 2021) 提出了 FedMix 并对每个批次内的样本应用 Mixup。 形式上,给定一批 数据样本 ,FedMix 通过平均特征和标签来构造增强数据样本:
| (6) |
4. 建议的方法:FedEgo
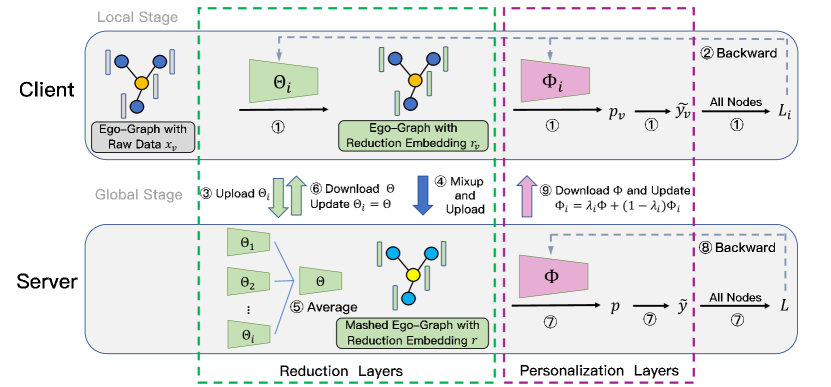
在FedEgo中,我们期望服务器能够捕获来自客户端的非IID图数据的结构和特征信息。 然后在全球模型的帮助下,客户更新其本地模型以实现更好的个性化。 为此,客户端和服务器之间存在不同的网络架构。 具体来说,客户端的本地模型由还原层和个性化层组成,而服务器中只有个性化层。 缩减层旨在利用客户端之间共享的低维嵌入,而个性化层用于个性化图挖掘。 为了将 GraphSAGE 扩展到自我图上,我们遵循 (Hamilton 等人, 2017) 并为每个给定节点采样一组固定大小的邻居。 那么FedEgo的训练主要可以分为局部阶段和全局阶段。 (1) 在本地阶段中,客户端将其本地自我图输入还原层并获得低维嵌入。 随后,将 Mixup 应用于自我图,以在每批内生成混合的自我图。 然后,从还原层获得的嵌入将进一步输入个性化层。 最终,每个客户端计算损失并更新还原层和个性化层中的参数。 (2) 在全局阶段,客户端将还原层中的参数和混合后的自我图上传到服务器进行协作。 服务器通过应用 FedAvg 算法来聚合参数,并通过对混合的自我图进行训练来更新全局个性化层。 之后,所有参数都会发送回客户端。 然后,客户端将加载缩减层并通过混合本地和全局权重来更新其个性化层。 FedEgo的框架如图3所示,算法1演示了训练过程。
4.1. 本地舞台
4.1.1. 还原层:多层感知
在联邦框架中,客户端之间的数据分布处于严重的非独立同分布情况,这给中心模型带来了困难。 然而,尽管有各种标签(Collins等人,2021),这些异构数据可能共享一个共同的表示,因此提出了减少层来捕获跨客户端的共同低维嵌入,如绿色所示图3的一部分。 而通过约简层得到的embedding,我们称之为约简嵌入,可以方便后续的计算,同时由于维数的降低也可以保护数据隐私。 此外,据观察,深度堆叠层通常会导致 GNN 的性能显着下降,这称为过度平滑(Cai 和 Wang,2020)。 为了避免这样的问题,这里我们使用多层感知来挖掘减少嵌入,因为 2 层 GNN 将应用于图挖掘的个性化层。 形式上,将视为节点的维原始特征和层感知,可以计算隐藏嵌入作为:
| (7) |
其中和分别是层的权重和偏差,是激活函数,表示层获得的节点的隐藏嵌入。具体来说,我们将原始特征作为缩减层的输入,我们有。 最终的嵌入被视为缩减嵌入。 为了方便起见,我们将整个约简层称为。
4.1.2. 捣碎的自我图谱:每批内的混合
在 FedEgo 中,客户端将为全局模型的训练生成混合的自我图,并进一步将它们发送到服务器而不是原始数据。 所有上传的混搭自我图都是结构匿名的,这意味着服务器无法知道原始图的结构以及特定节点是否存在于某个客户端的本地数据集中。 混合的自我图与自我图的形状相同,并且可以通过混合每批内自我图的减少嵌入来获得。 作为传统数据的流行数据增强技术,Mixup 由于对齐问题而不能直接应用于图数据。 传统数据样本的特征矩阵具有相同的维度,可以用于element-wise操作,而图数据结构的不规则性限制了element-wise计算,并且各种混合方式可能会对训练产生不同的影响。
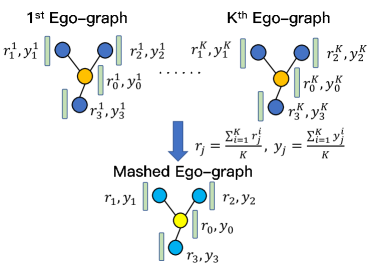
另一方面,混合相对容易应用于固定形状的自我图谱。 这种自我图中的跳邻居的数量仅由和邻居集的大小确定。为了方便起见,我们根据节点所在的层对节点进行排序,为每个节点分配一个特定的位置,并获得第层的位置集合,即、、 等等。 特定位置的节点连接到下一层中相应的邻居。 例如,第二层节点的邻居可以表示为。 只要保持层之间的特殊连通性,同一层内的位置可以任意分配。 为了在自我图上应用 Mixup,我们可以首先将中心节点对齐,即一批中所有自我图的节点 在一起,然后递归地扩展它们的邻居,为每个节点分配一个特定的位置在其相应的层中。 然后,根据对齐方式简单地对相应节点的嵌入进行平均即可获得混合自我图中每个位置的嵌入,如图2b所示。 形式上,根据对齐方式,给定 th 自我图 和 中 -th 位置的嵌入和单次标签,我们就可以得到混杂嵌入 以及混杂自我图中节点的标签 。
| (8) |
混合的自我图平均减少嵌入以防止隐私泄漏,使它们除了结构匿名之外还具有特征匿名。 此外,虽然有很多方法可以对齐自我图,但根据定理 4.1,所有这些方法对特定的 GNN 模型都有相同的效果。
定理4.1。
从各种对齐生成的混合自我图对于没有激活函数的线性 GraphSAGE 层的训练是等效的。 如果有两个不同的对齐方式和,则在对齐方式和下聚合后中心节点的最终嵌入将为相同。
4.1.3. 个性化层:基于自我图和分类的 GraphSAGE
一旦获得归约嵌入,我们进一步将自我图输入到线性GraphSAGE层中以向前实现图挖掘,如图3中的粉红色部分所示。 形式上,我们有个性化层
| (9) |
其中表示由层获得的节点的隐藏嵌入。我们有 ,即使用归约嵌入作为输入。 此外,值得注意的是,我们使用线性 GraphSAGE 层,它们之间没有激活函数。 之后,由后续的带有softmax函数的线性分类器生成预测,并最终计算损失。 为了方便起见,我们将整个个性化层称为。
4.2. 全球舞台
4.2.1. 全球训练
在全局阶段,服务器根据客户端上传的混合自我图训练全局模型,并更新全局模型中的参数。 服务器中存在与客户端中相同的个性化层,并且我们的 GNN 层定义如下式: (9) 在全局模型中使用分类器。
| (10) |
其中 表示第 层全局个性化层权重。
在考虑通信成本时,FedEgo 的另一个变体是用 GNN 替换缩减层,用 MLP 替换个性化层。 这种变体的一个动机是,客户只需要上传中心节点的简化嵌入,而不是混合自我图中的结构。 然而,拓扑结构的信息流以约简嵌入的形式隐含,这使得服务器的训练相当具有挑战性,尤其是在高度非独立同分布数据的情况下。 对缩减层中的 GNN 参数进行平均也可能是不合适的,因为客户端之间的不同数据分布会导致不同的节点连接模式。 因此,由于合作不力,客户将获得有限甚至消极的帮助。
当使用 GNN 层作为个性化层时,由于所有客户端都可以访问加密数据,全局模型的泛化能力明显优于任何局部模型。 之后,客户执行以下更新以增强本地模型的性能。
4.2.2. 减少层中的平均
为了利用客户端之间的共享表示,减少层中的参数通过坐标权重平均进行更新。 正式地,我们对缩减层进行了以下更新。
| (11) |
| (12) |
其中 表示客户端 中的缩减层, 表示平均层。 随着缩减层的更新,即使来自其数据集中的图形数据可能是非独立同分布的,客户也会在某种程度上达成共识。 换句话说,客户以相同的方式加密他们的原始数据,并将他们的数据投影到低维空间中。
4.2.3. 混合个性化层
当更新个性化层中的参数时,客户将混合局部权重和全局权重,以实现全局模型的优缺点的权衡。 给定客户端 的混合系数 ,我们按如下方式更新个性化层。
| (13) |
其中 表示客户端 中的个性化层, 表示全局个性化层。 直观上,选择混合系数的策略取决于局部分布和全局分布之间的多样性。 由于多样性很大,混合系数预计会很大,因为客户端倾向于从全局模型中获得更多收益来纠正其偏差并减少局部泛化误差。 否则, 需要很小,以便更好地个性化本地模型。
4.2.4. 每个客户端的自适应混合系数
显然,由于潜在的统计异质性,固定的 不适合所有客户端。 我们进一步提出了一种自适应策略,通过理论分析来选择,从而针对每个客户调整以实现更好的个性化。 为了方便起见,我们将客户端和服务器中的模型权重分别称为本地权重和全局权重。 首先,遵循(Zhao等人,2018),在定义4.2中设计了一个度量来衡量局部权重和全局权重之间的距离。 我们在这里只分析个性化层,因为减少层通过平均被冻结。 然后我们将权重散度限制在定理4.3中。
定义 4.2。
令表示客户端上个性化层中的局部权重,表示全局权重,然后定义权重散度作为局部权重和全局权重之间的距离:。
定理4.3。
给定 客户端,其中 节点样本 从客户端 的本地数据分布 中绘制独立同分布,并且全球数据分布。 让客户端和服务器的训练纪元相同。 将个性化层中的更新视为一个单独的步骤,并且每 步骤进行一次。 客户端的本地权重和第个epoch的第步中的全局权重表示为和,分别。 令为每个类的-Lipschitz和混合系数,则-th 更新制定如下。
其中。
附录B中提供了证明。 右侧第二部分包括本地和全球数据集分布的差异,主要体现在上,称为推土机距离()。 EMD 与 相关,因此我们可以通过调节 来影响 EMD 的影响并优化权重差异。 当局部和全局分布差异较大(较大的)时,应选择较大的以使客户端更接近全局模型。 否则,应该很小才能完全实现个性化。 局部分布向量和全局分布向量都可以通过式(1)计算。 (3) 即使服务器中只有平均数据。 然后我们就可以获取客户端的。
| (14) |
我们进一步提供了一个通过在等式中引入超参数来自适应选择的公式。 (15)。 它确保与负相关,从0到1变化,在其范围内增加。
| (15) |
5. 实验
5.1. 数据集和实验设置
我们在四个真实数据集上进行实验:Cora (Sen 等人, 2008)、Citeseer (Sen 等人, 2008)、CoraFull (Bojchevski 和 Günnemann, 2017),以及 Wiki (Mernyei 和 Cangea,2020)。 表1显示了数据集的详细信息和相关设置。 在我们的实验中,我们为每个客户端构建了一个本地数据集,并为最终测试构建了一个全局数据集,分别用于验证模型的个性化和泛化能力。 我们首先对节点进行采样以进行全局测试,然后从原始数据集中删除它们,将剩余的节点留给客户端的本地数据集。 为了构建标签分布倾斜场景,根据标签将节点分为不同的集合。 然后每个客户端随机选择3个标签作为其主节点标签,并从相应集合中选择样本节点来组成其本地数据集中的节点。 随机未选择的节点将被添加为剩余的 节点。 在每个客户端中,采样 300 个节点用于测试,20% 的节点用于验证,其余节点用于训练。 我们为每个节点选择 2 跳邻居,并在采样自我图时将邻居数量设置为 6。
| Dataset | —V— | —E— | #C | N | |||
|---|---|---|---|---|---|---|---|
| Cora | 2708 | 5429 | 7 | 5 | 0.3 | 0.3 | 0.01 |
| Citeseer | 3312 | 4715 | 6 | 5 | 0.3 | 0.3 | 0.01 |
| Wiki | 17716 | 52867 | 4 | 10 | 0.3 | 0.2 | 0.0003 |
| CoraFull | 19793 | 63421 | 70 | 10 | 0.3 | 0.3 | 0.01 |
5.2. 比较方法
我们将 FedEgo 与以下方法进行比较:
-
Local Only:在此方法中,每个客户端通过独立提供本地数据来训练其模型。
-
FedAvg:FedAvg (McMahan 等人, 2017) 对权重参数应用平均方法以获得全局模型。 这是应对非独立同分布场景的一种简单而有效的方法。 在此方法中,参数在缩减层和个性化层中进行平均。
-
FedProx: FedProx (Li 等人, 2020) 通过向损失添加近端项来解决数据异质性。 我们根据损失的波动应用 [0.001,0.01, 0.1,1] 中的自适应 FedProx 损失系数。
-
GraphFL: GraphFL (Wang 等人, 2020) 是一种基于模型无关元学习(MAML)的少样本学习方法,解决了非模型学习的问题。客户端之间的 IID 图形数据。 我们遵循(Wang 等人, 2020)中的原始设置,并使用 100 个节点作为 GraphFL 中的支持集和查询集。
-
D-FedGNN: D-FedGNN (Pei 等人, 2021) 是一种基于客户端之间加权通信拓扑的分布式联邦图框架。 我们按照(裴等人, 2021)中的设置,使用标准环网进行汇聚。
-
FedGCN:在 FedGCN (Yao 和 Joe-Wong,2022) 中,客户端相互通信以交换有关节点邻居的平均信息。 由于其他人知道某个客户端本地数据集中的节点,因此它存在严重的隐私问题。 我们遵循 (Yao 和 Joe-Wong,2022) 中的原始设置和 FedGCN 的 2 个 GCN 层。
这些模型具有相同的结构,其中 1 层 MLP 作为还原层,2 层具有激活函数的 GraphSAGE 作为个性化层,然后是 1 个全连接层作为分类器。 我们选择Relu作为激活函数,Adam作为优化器。 此外,混合的自我图的数量和额外的通信成本都受到批量大小的强烈影响,根据开发测试观察5.7,批量大小优选为 32。 在客户端训练期间,节点将在每轮 epoch 的 5 个小批量中进行训练。 在 FedEgo 中,服务器将利用客户端上传的自我图表进行每轮 轮的训练。 我们执行所有实验 4 次,并报告平均结果 111Code available at https://github.com/FedEgo/FedEgo。
5.3. 整体表现
5.3.1. 个性化能力
表3给出的本地测试中的F1分数说明了每种方法在严重非独立同分布场景下的个性化能力。 很明显,本地测试的结果比全局测试要高得多,这主要是因为测试和训练数据的分布相同。 此外,FedEgo、FedAvg、FedProx 和 D-FedGNN 受益于所有数据集上的协作,并增强了本地模型的个性化能力。 D-FedGNN 的表现比 FedAvg 更好,因为仅与本地邻居进行平均可以在一定程度上缓解非独立同分布问题。 对于FedEgo来说,仅比FedAvg有轻微的性能提升,这是由标签倾斜场景引起的,并且来自其他人的信息只能在有限程度上补偿客户的训练。 有趣的是,GraphFL 在所有情况下都比其他 FL 方法表现更差,因为它是为少样本学习而设计的,并且在严重的标签分布倾斜场景下没有提取足够的有用信息。 同样,FedGCN 不适合非 IID 场景,并且在海量数据方面无法与本地训练相媲美,正如 Wiki 和 CoraFull 上的结果所证明的那样。
5.3.2. 泛化能力
从表2的结果可以看出,比较中最引人注目的观察结果是FedEgo始终优于其他方法,并提高了客户本地模型的泛化能力。 通过减少和个性化层的更新,客户端训练的性能比本地训练提高了约 11%-15%。 这一显着的改进表明FedEgo能够完成客户端的协作并处理非IID图数据。
与 FedProx 类似,FedAvg 提供了一定程度的提升,但仍低于 FedEgo。 客户可以从减少和个性化训练层的协作中受益,FedAvg 和本地之间的差距就证明了这一点。 此外,由于其独特的聚合,D-FedGNN 的性能略好于 FedAvg。 与FedAvg相比,FedEgo是一种个性化模式,而不是在个性化层中平均更新。 FedEgo 显着超过 FedAvg 和 D-FedGNN,这意味着在严重的非 IID 场景中,本地和全局模型的混合远远优于朴素平均值。 至于 GraphFL 和 FedGCN,它们也遇到了上面提到的同样的问题,并且在所有情况下都表现不佳。
| Dataset | Local Only | FedAvg | FedProx | GraphFL | D-FedGNN | FedGCN | FedEgo |
|---|---|---|---|---|---|---|---|
| Cora | 0.691 | 0.769 | 0.77 | 0.739 | 0.776 | 0.681 | 0.794 |
| Citeseer | 0.634 | 0.701 | 0.701 | 0.649 | 0.712 | 0.655 | 0.727 |
| Wiki | 0.7 | 0.785 | 0.784 | 0.677 | 0.795 | 0.439 | 0.818 |
| CoraFull | 0.501 | 0.544 | 0.549 | 0.35 | 0.576 | 0.486 | 0.653 |
| Dataset | Local Only | FedAvg | FedProx | GraphFL | D-FedGNN | FedGCN | FedEgo |
|---|---|---|---|---|---|---|---|
| Cora | 0.851 | 0.952 | 0.954 | 0.861 | 0.954 | 0.884 | 0.959 |
| Citeseer | 0.757 | 0.917 | 0.915 | 0.766 | 0.917 | 0.894 | 0.920 |
| Wiki | 0.874 | 0.922 | 0.924 | 0.789 | 0.915 | 0.819 | 0.926 |
| CoraFull | 0.639 | 0.874 | 0.875 | 0.479 | 0.883 | 0.838 | 0.901 |
5.4. 统计异质性的努力
FedAvg 和 FedEgo 的性能很大程度上受到由主节点速率控制的客户端之间的统计异质性的影响。 主节点率越大,客户端往往在同一类中拥有更多节点,导致统计异质性越高。 据此,我们改变主节点速率并提供表4中的结果。 不出所料,随着主节点率变大,FedEgo 和 FedAvg 的泛化能力都会降低。 也许更令人惊讶的是,主节点速率的提高在一定程度上提高了个性化能力。 在这种情况下,本地数据集中的更多节点将共享相同的标签,并且节点之间的互连模式变得相对恒定且易于学习。
| Global Test | Local Test | |||||
|---|---|---|---|---|---|---|
| Major Node Rate | 0.0 | 0.3 | 0.8 | 0.0 | 0.3 | 0.8 |
| FedAvg | 0.803 | 0.800 | 0.785 | 0.907 | 0.906 | 0.922 |
| FedEgo | 0.823 | 0.826 | 0.818 | 0.903 | 0.907 | 0.926 |
5.5. 消融研究
为了验证 Mixup 的有效性,我们采用了一种名为 FedEgo w/o Mixup 的比较方法,其中客户端将批次中的第一个自我图上传到服务器,而不是混合的自我图。 请注意,在实际场景中这样做是不可行的,因为原始自我图的传输可能会导致隐私泄露的风险。 我们还将 FedEgo 与其线性变体(表示为 FedEgo-Linear)进行比较,以评估个性化层中激活函数的影响。 FedEgo-Linear 保证中心节点嵌入的无偏估计,而 FedEgo 应用激活函数来学习数据中更复杂的模式。
表5的结果表明,Mixup在保护隐私的同时提高了模型的泛化能力和个性化能力。 原因是客户端之间的图数据是严重非独立同分布的,而Mixup生成的虚拟样本可以被认为是客户端对现实世界数据集中未知分布的探索,从而提高了模型的鲁棒性。 通过将 FedEgo 与无 Mixup 的 FedEgo 进行比较,我们还可以推断,应用 Mixup 后,结构信息仍然高度保留在混合的自我图中。 Mixup中的平均操作提取了结构信息的重要部分,这有利于在服务器中的训练并导致模型更好的性能。 此外,我们观察到,在个性化层中没有激活函数时,性能略有下降,这表明模型不一定会受到激活函数引入的偏差的影响,特别是在极端非独立同分布的情况下。
| Global Test | Local Test | |||
| Dataset | Cora | Citeseer | Cora | Citeseer |
| FedEgo w/o Mixup | 0.783 | 0.717 | 0.951 | 0.912 |
| FedEgo-Linear | 0.793 | 0.717 | 0.958 | 0.918 |
| FedEgo | 0.794 | 0.727 | 0.959 | 0.920 |
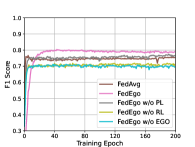
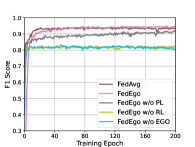
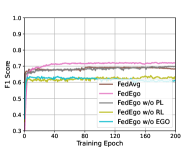
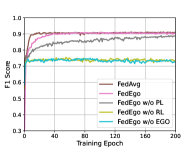
为了进一步弄清楚是否值得构建自我图谱并验证还原层和个性化层的有效性,我们将 FedEgo 与三种消融方法进行比较: (1) FedEgo w/o EGO:在此方法中,我们用 GNN 代替归约层,用 MLP 代替个性化层。 在这种情况下,图挖掘是在本地执行的,只需要上传归约嵌入,而不是混合自我图的显式结构。 (2) FedEgo w/o RL:在此方法中,客户端将仅更新其个性化层,而不执行缩减层中的平均更新。 在这种情况下,客户端会以各种方式对图数据进行加密,使得服务器中的全局模型变得困难。 (3) FedEgo w/o PL:在此方法中,客户端将仅更新其缩减层,而不在个性化层中执行混合更新。 在这种情况下,客户端将不会得到全局模型的帮助,而只能受益于缩减层的平均更新。 此外,我们还包括 FedAvg,因为与 FedEgo 相比,FedAvg 是没有 PL 的 Fedego 的平均版本。
从图 4 可以看出,没有 EGO 的 FedEgo 的性能较差,这表明有必要在联邦框架中上传混合的自我图以实现结构信息流。 如果没有混合的 ego-grpahs,服务器很难仅从约简嵌入中捕获结构信息并进一步为客户端提供适当的帮助。 此外,很明显,还原层在提高性能方面发挥着更重要的作用。 毫不奇怪,删除减少层中的平均更新会阻碍客户以同样的方式加密自我图,上传的混合自我图甚至可能对早期训练中的全局模型有害。 此外,没有 PL 的 FedEgo 和 FedEgo 之间仍然存在显着差异,这证明了个性化层中混合更新的有效性。 对于 FedAvg,由于其简单的聚合模式,它需要的收敛时间最短。 FedAvg 和 FedEgo w/o PL 之间的微小差距验证了个性化层平均更新带来的好处,而 FedAvg 的性能在大约 15 个 epoch 后开始下降,然后在全局测试中稳定下来。 然而在本地测试中,FedAvg 的 F1 分数持续增加,直到最后。 因此,FedAvg倾向于以牺牲泛化能力为代价来提高客户的个性化能力。 最后,正如我们之前讨论的,在本地测试中观察到的 FedAvg 和 FedEgo 之间的差异是有限的,而在全球测试中存在很大差距。
5.6. 参数研究
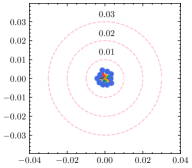
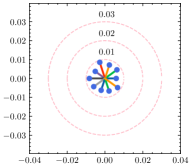
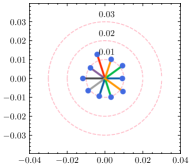
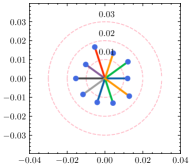
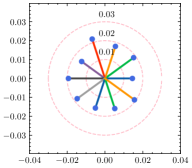
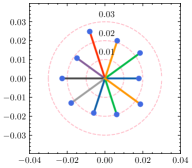
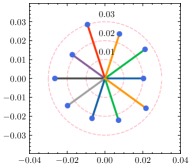
为了更好地理解超参数 ,我们使用不同的 来估计每个客户端的权重差异。 如图5所示,全局权重固定在圆心,散点代表客户端的局部权重,到中心的距离表示权重散度。 还绘制了具有相同中心但不同半径的圆以供参考。 从结果中可以看出,权重散度受影响,并且随着的增加而变大。 根据方程。 (15), 与 负相关,因此权重差异随着 的减小而增大,这是合理的支持定理4.1。 除了权重差异的可视化之外,我们还在表 6 中提供了 不同值的 F1 分数。 通过微调,自适应策略能够为每个客户端发现最佳的。 请注意,由于统计异质性,泛化能力和个性化能力的最佳并不总是相同。 由于与全局真实值的偏差相对较大,减少客户端的泛化误差可能会降低其在本地数据集中的性能。
5.7. 批量大小的通信成本分析
在FedEgo中,客户不仅上传参数,还上传带有减少嵌入的混合自我图,因此额外的通信成本是否负担得起是一个重要问题。 影响沟通成本和混合自我图质量的关键因素是批量大小。 在批量大小较低的情况下,更多的混合自我图会导致更大的通信成本,并且原始数据中更多的敏感信息将被传递,从而产生隐私泄露的问题。 然而,在另一个极端,大批量会导致大量信息损失。 根据以上分析,适当的批量大小正是隐私保护和客户端协作的权衡。 因此,我们进行了大量的实验并以兆字节 (MB) 为单位评估通信成本。 表 7 中提供了不同批量大小下的结果。
结果表明,较小的批次会带来更高的性能和更大的通信成本。 上传的自我图谱的高质量有助于改进,而通信成本和更多数据的训练使训练时间更长。 随着批量大小变小,减少批量大小的改进也会减少,而另一方面,由于本地训练中的批量增多,通信开销将增加一倍。 此外,较小的批量大小无法满足隐私保护的需求。 因此,我们认为根据结果选择 32 作为批量大小是一个公平的权衡。 另外,权重参数主要考虑在这样适当的批量大小下的通信成本,以额外成本为代价来提升性能是可以接受的。
| 0.125 | 0.25 | 0.375 | 0.5 | 0.625 | 0.75 | 0.875 | |
|---|---|---|---|---|---|---|---|
| Local Test | 0.899 | 0.901 | 0.9 | 0.901 | 0.899 | 0.902 | 0.899 |
| Global Test | 0.652 | 0.653 | 0.648 | 0.649 | 0.649 | 0.648 | 0.646 |
| Cora | Citeseer | |||||||||||
| FedAvg | FedEgo | FedAvg | FedEgo | |||||||||
| Batch Size | 32 | 8 | 16 | 32 | 64 | 128 | 32 | 8 | 16 | 32 | 64 | 128 |
| Global Test | 0.769 | 0.797 | 0.794 | 0.793 | 0.792 | 0.764 | 0.701 | 0.724 | 0.724 | 0.725 | 0.72 | 0.711 |
| Local Test | 0.952 | 0.958 | 0.959 | 0.958 | 0.955 | 0.945 | 0.917 | 0.92 | 0.919 | 0.918 | 0.918 | 0.917 |
| Time (mins) | 10.190 | 57.674 | 38.775 | 20.661 | 15.6 | 10.201 | 11.679 | 90.539 | 41.525 | 32.742 | 13.89 | 6.307 |
| Ego-graphs Cost (MB) | 0 | 6071 | 3055 | 1545 | 790 | 425 | 0 | 6895 | 3477 | 1769 | 899 | 471 |
| Parameters Cost (MB) | 6819 | 2801 | 2801 | 2801 | 2801 | 2801 | 11250 | 7234 | 7234 | 7234 | 7234 | 7234 |
| Total Cost (MB) | 6819 | 8872 | 5856 | 4346 | 3591 | 3226 | 11250 | 14129 | 10711 | 9003 | 8133 | 7705 |
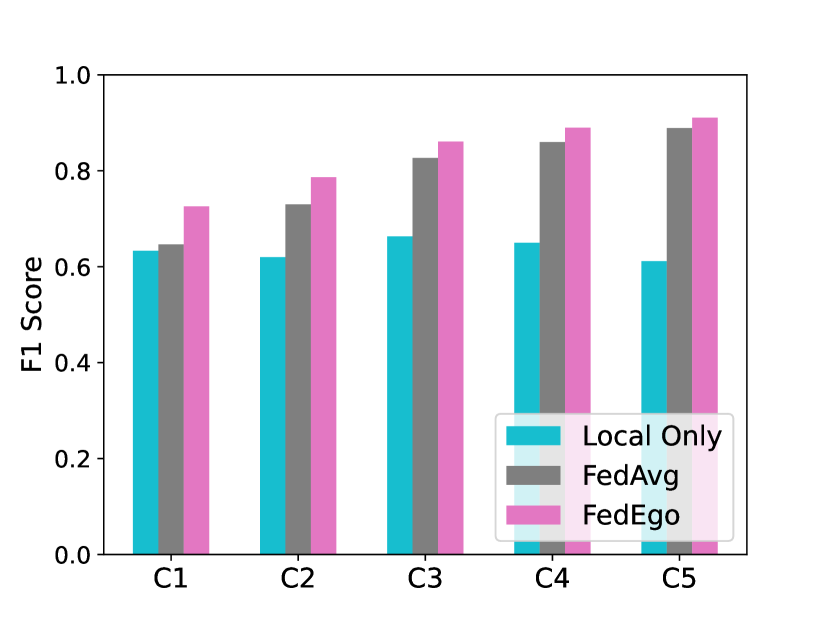
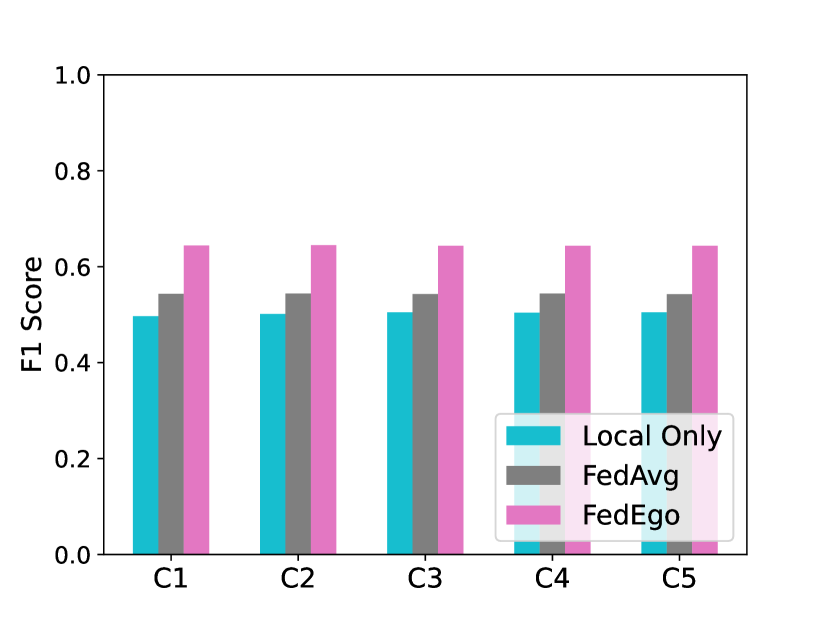
5.8. 每个客户的改进
为了进一步探讨FedEgo如何提高特定客户端的性能,我们提供了每个客户端在本地和全局测试中的比较结果,如图6所示。 结果表明FedEgo增强了所有客户端的泛化能力和个性化能力。 与FedAvg相比,FedEgo为客户提供了更实质性的好处。 而且,尽管图数据在客户端之间存在严重的非独立同分布,但全局测试中客户端的性能相对稳定。 性能的稳定和显着提升证明了FedEgo的效果。
| Number of Clients | 5 | 10 | 15 | 20 | 25 | 30 | 35 |
|---|---|---|---|---|---|---|---|
| Local Test | 0.9261 | 0.9256 | 0.9245 | 0.9255 | 0.9254 | 0.9237 | 0.9247 |
| Global Test | 0.8179 | 0.8187 | 0.8175 | 0.8174 | 0.8169 | 0.8158 | 0.8157 |
5.9. 客户参与的努力
在真实场景中,参与的客户越多,带来的信息和数据越多,可能对统计异质性产生潜在影响。 因此,我们在本次实验中研究了客户参与对FedEgo的影响。 特别是,我们在 Wiki 上选择 5、10、15、20、30 和 35 个客户端参与每轮,实验结果如表所示。 8. 个性化能力主要取决于客户自己的数据集,因此由于引入的偏差,随着客户的增加而略有下降。 在泛化能力方面,全局模型将有能力收集更多的图数据以更好地拟合真实数据集,并在更多客户的参与下进一步发展泛化能力。 当客户数量较少时尤其如此。 然而,随着客户数量的增加,引入新客户的好处就会减少,并且训练时间也会增加。 当有足够多的客户端并且数据不再短缺时,冗余客户端可能不会提高模型性能。
| Global Test | Local Test | |||
|---|---|---|---|---|
| Dataset | Cora | CoraFull | Cora | CoraFull |
| FedEgo w/o PL (Fixed ) | 0.7705 | 0.6173 | 0.9345 | 0.8488 |
| FedEgo (Fixed ) | 0.7843 | 0.6437 | 0.9585 | 0.9005 |
| FedEgo-Server (Fixed ) | 0.7921 | 0.6418 | 0.9535 | 0.8985 |
| FedEgo (Adaptive ) | 0.7939 | 0.6442 | 0.959 | 0.9012 |
5.10. 自适应混合系数的好处
我们进一步在 Cora 和 CoraFull 上进行了额外的实验,以验证 FedEgo 是否受益于自适应混合系数 。 我们将自适应与以下方法进行比较:(1)FedEgo w/o PL:如前所述,在此方法中客户端不会在个性化层中执行混合更新。 因此,当固定为0时,可以将其视为变体。 (2) FedEgo(固定):在此方法中,我们在个性化层中执行混合更新时将固定为0.5。 (3) FedEgo-Server:在该方法中,客户端完全用服务器中的权重代替个性化层进行图挖掘。 因此,当固定为1时,可以将其视为变体。
从表9可以看出,自适应在一定程度上为客户的绩效带来了提升。 在固定模式中,没有全局模型帮助的 FedEgo w/o PL 的性能最差。 在另一个极端,由于缺乏个性化,FedEgo-Server 不如具有自适应 的 FedEgo。 然而,就折衷策略而言,固定的 对于某些 较大的客户端来说可能太小,但对于那些 较小的客户端来说又太大,从而妨碍了客户取得更好的绩效。 相比之下,自适应允许客户找到参与联邦学习的最佳水平。 通过自适应,客户在本地测试中表现更好并实现更好的个性化。 同时,每个客户适当的也提高了他们在全局测试中的F1分数,这表明个性化层中的混合系数对模型的泛化能力有显着影响。
5.11. 可视化
6. 结论
在本文中,我们研究了图上的个性化联合节点分类任务,并讨论了现实环境中的三个主要挑战。 所提出的基于自我图的联邦框架 FedEgo 充分利用结构信息,并通过在服务器中训练全局模型来处理非 IID 图数据。 此外,客户通过混合本地和全局权重来使全局模型适应其本地数据集。 此外,Mixup 技术还应用于模型鲁棒性和隐私问题。 最终,FedEgo 的经验证据显着优于基线,表明其有能力解决联邦图学习中的困难挑战。 与现有的 FL 方法类似,未来需要做的工作是处理 FedEgo 的通信成本,最好是关于自我图和模型权重的有效压缩方法。
参考
- (1)
- Arivazhagan et al. (2019) Manoj Ghuhan Arivazhagan, Vinay Aggarwal, Aaditya Kumar Singh, and Sunav Choudhary. 2019. Federated learning with personalization layers. arXiv preprint arXiv:1912.00818 (2019).
- Bai and Hancock (2016) Lu Bai and Edwin R Hancock. 2016. Fast depth-based subgraph kernels for unattributed graphs. Pattern Recognition 50 (2016), 233–245.
- Bojchevski and Günnemann (2017) Aleksandar Bojchevski and Stephan Günnemann. 2017. Deep gaussian embedding of graphs: Unsupervised inductive learning via ranking. arXiv preprint arXiv:1707.03815 (2017).
- Cai and Wang (2020) Chen Cai and Yusu Wang. 2020. A note on over-smoothing for graph neural networks. arXiv preprint arXiv:2006.13318 (2020).
- Chen et al. (2021) Chuan Chen, Weibo Hu, Ziyue Xu, and Zibin Zheng. 2021. FedGL: federated graph learning framework with global self-supervision. arXiv preprint arXiv:2105.03170 (2021).
- Chen et al. (2018) Fei Chen, Mi Luo, Zhenhua Dong, Zhenguo Li, and Xiuqiang He. 2018. Federated meta-learning with fast convergence and efficient communication. arXiv preprint arXiv:1802.07876 (2018).
- Collins et al. (2021) Liam Collins, Hamed Hassani, Aryan Mokhtari, and Sanjay Shakkottai. 2021. Exploiting Shared Representations for Personalized Federated Learning. arXiv preprint arXiv:2102.07078 (2021).
- Deng et al. (2020) Yuyang Deng, Mohammad Mahdi Kamani, and Mehrdad Mahdavi. 2020. Adaptive personalized federated learning. arXiv preprint arXiv:2003.13461 (2020).
- Hamilton et al. (2017) Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems. 1024–1034.
- Hanzely and Richtárik (2020) Filip Hanzely and Peter Richtárik. 2020. Federated learning of a mixture of global and local models. arXiv preprint arXiv:2002.05516 (2020).
- He et al. (2021) Chaoyang He, Keshav Balasubramanian, Emir Ceyani, Carl Yang, Han Xie, Lichao Sun, Lifang He, Liangwei Yang, Philip S Yu, Yu Rong, et al. 2021. Fedgraphnn: A federated learning system and benchmark for graph neural networks. arXiv preprint arXiv:2104.07145 (2021).
- Jiang et al. (2019) Yihan Jiang, Jakub Konečnỳ, Keith Rush, and Sreeram Kannan. 2019. Improving federated learning personalization via model agnostic meta learning. arXiv preprint arXiv:1909.12488 (2019).
- Li et al. (2020) Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. 2020. Federated optimization in heterogeneous networks. Proceedings of Machine Learning and Systems 2 (2020), 429–450.
- Mansour et al. (2020) Yishay Mansour, Mehryar Mohri, Jae Ro, and Ananda Theertha Suresh. 2020. Three approaches for personalization with applications to federated learning. arXiv preprint arXiv:2002.10619 (2020).
- McMahan et al. (2017) Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics. PMLR, 1273–1282.
- Mernyei and Cangea (2020) Péter Mernyei and Cătălina Cangea. 2020. Wiki-cs: A wikipedia-based benchmark for graph neural networks. arXiv preprint arXiv:2007.02901 (2020).
- Pei et al. (2021) Yang Pei, Renxin Mao, Yang Liu, Chaoran Chen, Shifeng Xu, Feng Qiang, and Blue Elephant Tech. 2021. Decentralized Federated Graph Neural Networks. In International Workshop on Federated and Transfer Learning for Data Sparsity and Confidentiality in Conjunction with IJCAI.
- Sen et al. (2008) Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi-Rad. 2008. Collective classification in network data. AI magazine 29, 3 (2008), 93–93.
- Smith et al. (2017) Virginia Smith, Chao-Kai Chiang, Maziar Sanjabi, and Ameet Talwalkar. 2017. Federated multi-task learning. arXiv preprint arXiv:1705.10467 (2017).
- Wang et al. (2020) Binghui Wang, Ang Li, Hai Li, and Yiran Chen. 2020. Graphfl: A federated learning framework for semi-supervised node classification on graphs. arXiv preprint arXiv:2012.04187 (2020).
- Xie et al. (2021) Han Xie, Jing Ma, Li Xiong, and Carl Yang. 2021. Federated graph classification over non-iid graphs. Advances in Neural Information Processing Systems 34 (2021).
- Yao and Joe-Wong (2022) Yuhang Yao and Carlee Joe-Wong. 2022. FedGCN: Convergence and Communication Tradeoffs in Federated Training of Graph Convolutional Networks. arXiv preprint arXiv:2201.12433 (2022).
- Yoon et al. (2021) Tehrim Yoon, Sumin Shin, Sung Ju Hwang, and Eunho Yang. 2021. Fedmix: Approximation of mixup under mean augmented federated learning. arXiv preprint arXiv:2107.00233 (2021).
- Zhang et al. (2017) Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. 2017. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412 (2017).
- Zhang et al. (2021) Ke Zhang, Carl Yang, Xiaoxiao Li, Lichao Sun, and Siu Ming Yiu. 2021. Subgraph federated learning with missing neighbor generation. Advances in Neural Information Processing Systems 34 (2021).
- Zhao et al. (2018) Yue Zhao, Meng Li, Liangzhen Lai, Naveen Suda, Damon Civin, and Vikas Chandra. 2018. Federated learning with non-iid data. arXiv preprint arXiv:1806.00582 (2018).
- Zhu et al. (2020) Qi Zhu, Yidan Xu, Haonan Wang, Chao Zhang, Jiawei Han, and Carl Yang. 2020. Transfer learning of graph neural networks with ego-graph information maximization. arXiv preprint arXiv:2009.05204 (2020).
附录A定理证明4.1
在本节中,我们提供定理4.1的详细证明。
证明。
假设一批自我图具有固定形状,具有 跳邻居,并且每层中的节点扩展 邻居。 为了方便起见,我们根据节点的层数对节点进行排序,为每个节点分配一个特定的位置,并获得第层的位置集合,即、、 等等。 特定位置的节点连接到下一层中相应的邻居。 例如,第二层节点的邻居可以表示为。 只要保持层之间的特殊连通性,同一层内节点的位置可以任意分配。 然后,在生成混合自我图时,特定层中节点的嵌入总和不会因不同的对齐而改变。 形式上,给定一批自我图和对齐 下的混合自我图,令 为节点 在混合自我中的嵌入-图,我们有
| (16) |
其中 等于采样批量自我图的第 层中原始嵌入的总和。
为了方便起见,我们进一步扩展和如下。
| (18) |
我们关注中心节点并计算其最终嵌入如下。
| (21) |
由于混杂自我图的对称性,在给定层 的情况下,节点 和层 中每个节点 之间的边的权重在最终邻接矩阵 中应该是相同的。 因此我们有
| (22) |
其中 是仅取决于 和 的常量。
附录B定理证明4.3
在本节中,我们提供定理4.3的详细证明。
证明。
根据和的定义,我们进一步将第次更新后的epoch的模型定义为 和 。 为简单起见,个性化层中的更新被定义为第 次更新之后的第 步。 个性化层更新后的权重可以写为:
| (24) |
因此,在个性化层中进行单次更新后,我们得到了权重散度的变化:
| (25) | ||||
现在考虑客户端和服务器的 SGD 更新。 给定交叉熵损失定义为方程。 (2),第 步骤中的 SGD 更新执行:
| (26) |
因此,我们有:
| (27) |
接下来我们计算权重散度如下:
| (28) | ||||
最后一个不等式由于绝对值不等式而成立。
为了简单起见,我们将标签的的梯度表示为,它仅取决于模型权重:
| (29) |
由于 是 -Lipschitz,我们有
| (30) |