AAAI 2023
基于语言模型的具体任务规划
摘要
语言模型(LM)已经证明了它们拥有物理世界常识知识的能力,这是执行日常生活任务的一个重要方面。 然而,目前尚不清楚他们是否有能力为具体任务制定切实可行的计划。 这是一项具有挑战性的任务,因为 LM 缺乏通过视觉和物理环境反馈来感知环境的能力。 在本文中,我们解决了这个重要的研究问题,并提出了对该主题的首次调查。 我们的新颖问题表述名为 G-PlanET,输入一个高级目标和一个有关特定环境中对象的数据表,然后输出一个机器人代理要遵循的分步可行计划。 为了促进研究,我们建立了评估协议并设计了专用指标 KAS 来评估计划的质量。 我们的实验表明,使用表格对环境进行编码和迭代解码策略可以显着增强 LM 的落地规划能力。 我们的分析还揭示了有趣且重要的发现。 111Project website: https://yuchenlin.xyz/g-planet/
1简介
预训练的语言模型 (LM) 在各种自然语言处理 (NLP) 任务(例如问答、机器翻译和摘要)中表现出卓越的熟练程度。 它们确实捕捉到了有关我们物理世界的一些常识性知识,例如“鸟可以飞”。 然而,LM 是否能够在接地、现实的环境中表现出推理能力仍然是一个悬而未决的问题。 这是因为 LM 缺乏与环境的感官体验和物理交互,而这些体验和物理交互使人类无法掌握现实生活中的细微差别并计划完成任务。
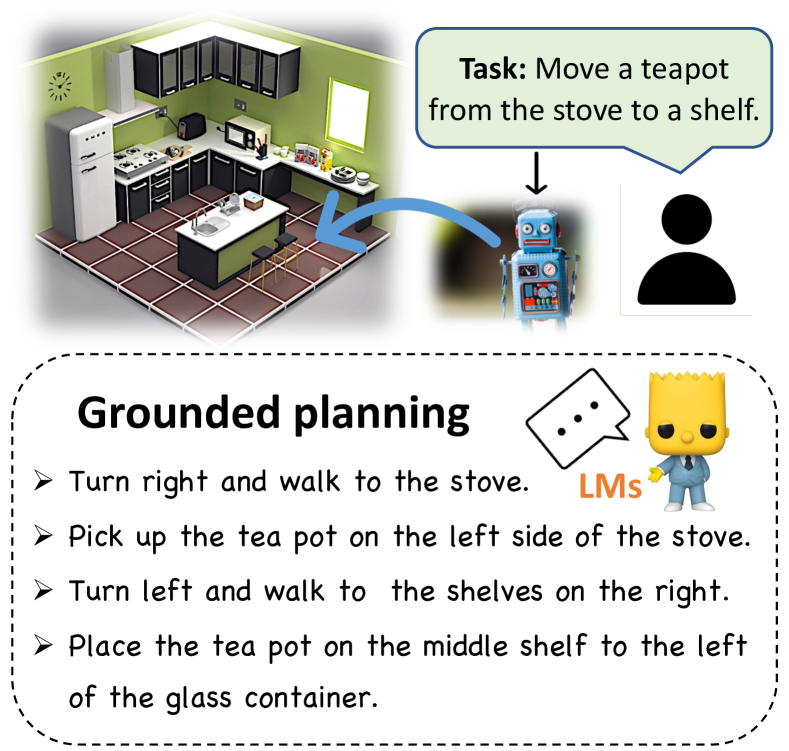
具身机器人学习是一个不断发展的领域,旨在创建能够在现实世界环境中导航和执行任务的人工智能代理,通常通过 AI2THOR (Kolve 等人 2017) 等物理引擎进行模拟。 ALFRED 基准(Shridhar 等人 2020) 代表了弥补 NLP 和机器人技术之间差距的开创性数据集之一,为研究语言导向代理提供了一个平台。 这些研究的目的是设计和测试代理,这些代理可以将语言指令翻译成低级操作序列,使代理能够操纵环境中的对象并实现所需的结果(例如,清洁对象并将其放置在其他地方)。
然而,ALFRED 基准和相关数据集的主要重点是对预先制定计划的理解,而不是在现实环境中推理和独立计划的能力。 先前的研究侧重于智能体理解和执行分步计划的能力,而不是分解任务和生成此类计划的能力,这代表了更高级的技能。 此外,语言模型的作用在这些基准测试中受到了有限的检验,它们主要用作嵌入词符序列的编码器,而不是用于规划或推理。
先前的研究已经探索了 LM 的规划能力,Huang 等人 (2022) 证明 GPT-3 和类似模型能够生成执行日常任务的总体计划。 然而,这些计划缺乏现实环境的基础,因为 LM 不是特定于环境的。 因此,这些计划不一定可由代理人执行。 例如,在阿尔弗雷德任务“将茶壶从炉子移到架子上”的背景下,具体代理需要了解茶壶的位置以及到达它的路径。 另一方面,人类可以很容易地观察茶壶在炉子上的位置以及他们当前在厨房中的位置,从而使他们能够制定一个以“右转并走到炉子处”开始的接地计划。这凸显了为机器人代理生成详细的、逐步的动作序列以在其执行过程中使用的需要。
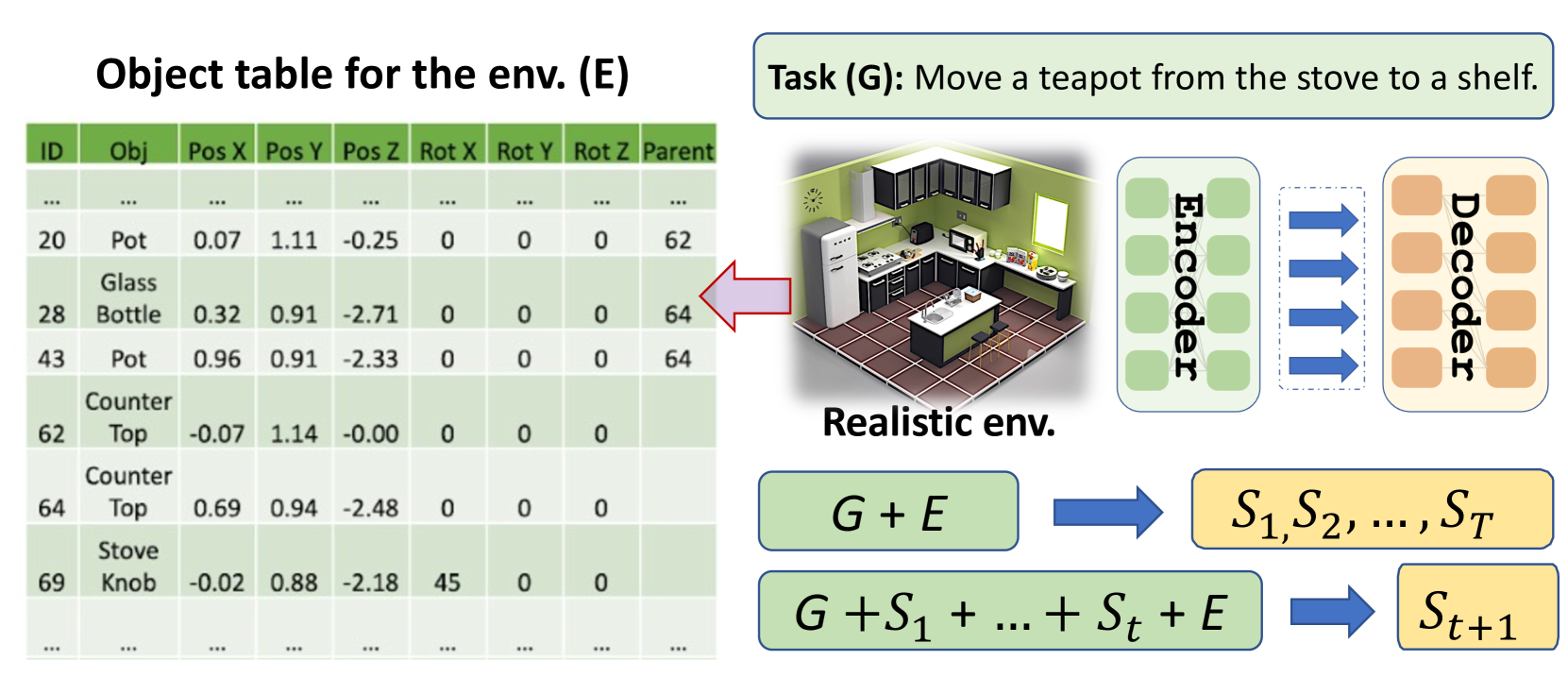
LM 也能学习扎实的规划能力吗? 我们应该如何评估和改进 LM 以进行接地规划? 在本文中,我们解决了 LM 是否也可以学习扎根规划能力的问题。 为此,我们提出了一项关于语言模型用于具体任务的扎根规划能力的研究(G-PlanET)。 我们的方法涉及向 LM 提供两个输入:高级任务描述和对象表形式的现实环境。 输出是由可执行的分步操作组成的计划。 我们将 G-PlanET 制定为语言生成任务,并专注于编码器-解码器语言模型,例如 BART (Lewis 等人 2020)。
为了建立 G-PlanET 的数据集和评估协议,我们通过开发一套数据转换程序来利用 ALFRED 数据。 他们从环境中提取对象信息并将其格式化为数据表,从而使模型能够访问现实场景中的观察结果。 此外,我们制定了一个新的评估指标,称为 KAS,它比现有的文本生成指标更适合该任务。 关于 G-PlanET 的方法,我们建议将对象表扁平化为标记序列,并将其附加到任务描述中作为模型的输入。 然后使用这些 seq2seq 数据对基础 LM 进行微调,以学习生成计划。 此外,我们提出了一种简单而有效的解码策略,通过将前一代合并到输入中来迭代生成后续步骤。 我们的实证结果和分析表明,将对象表纳入输入和提出的迭代解码策略对于增强 G-PlanET 中语言模型的性能都至关重要。
总而言之,我们的主要贡献是:
-
•
G-PlanET 的任务:据我们所知,这是最早研究 LM 在现实环境中进行具体规划的能力的研究之一。 G-PlanET 对于推进大型 LM 的基础泛化以及弥合 NLP 和实体智能之间的差距至关重要。 (第 2 节)
-
•
全面的评估协议:我们投入了大量精力将 ALFRED 和 AI2THOR 数据转换为数据表,以支持 G-PlanET 的评估。 我们还创建了一个新的评估指标 KAS,以有效评估 LM 生成的计划。
-
•
改进 G-PlanET 的 LM:我们提出了两个简单但有效的组件来增强 LM 的基础规划能力 - 扁平化对象表和迭代解码策略。 我们的实验表明,这些组件可以带来显着的性能提升。 (第3)此外,通过广泛的实验和深入的分析,我们对 G-PlanET 的 LM 行为有了更深入的了解,并在我们的研究中提出了一系列重要的发现。
2 问题表述
在这里,我们介绍 G-PlanET 的背景知识、问题表述和数据源。
2.1背景知识
体现任务。
ALFRED 基准(Shridhar 等人 2020) 是首批关注现实环境中具体任务的基准之一,尽管大多数示例都是家庭任务。 它旨在测试代理在现实场景中执行具体任务的能力。 具体来说,智能体需要理解基于语言的指令并输出一系列动作来与名为 AI2-THOR (Kolve 等人 2017) 的引擎交互,从而实现给定的任务。
语言说明。
语言指令在 ALFRED 基准测试中发挥着重要作用。 所体现的任务用自然语言标注了高层次目标和低层次计划(即,机器人可执行的行动序列),这两者都是代理的输入。 代理需要理解此类语言指令并将其解析为动作模板。 请注意,代理无需计划任务,因为他们已经有了要遵循的分步说明。
任务规划。
先前的工作表明,大型预训练语言模型(LM),例如 GPT-3 (Brown 等人 2020) 可以生成完成任务的通用过程。 然而,此类计划与我们感兴趣的特定环境并不相符。 这是因为这些方法从不将环境编码为 LM 输入的一部分,以便将计划扎根于给定环境。 因此,这种不接地气的计划对于指导智能体在现实世界中工作几乎没有用处。
2.2 带有LM的G-PlanET
正如第 2 节中所讨论的。 2.1,ALFRED 基准没有明确测试规划能力,而之前使用 LM 进行规划的工作并未考虑扎根到特定环境。 在这项工作中,我们专注于评估和提高使用 LM 为具体任务生成接地计划的能力,我们将其称为 G-PlanET。 对于机器人技术和 NLP 社区来说,这一直是一个尚未得到充分探索的开放问题。
任务制定。
2.3 G-PlanET 数据
为了构建用于研究 G-PlanET 任务的大规模数据集,我们重新使用 ALFRED 的目标和计划,并从 AI2THOR 中提取对齐环境的对象信息。 ALFRED 数据集使用 AI2THOR 引擎为具有自我中心愿景的代理提供执行操作的交互环境。 但是,数据集并不包含环境中物体的明确数据(例如,相互之间的协调、旋转和空间关系)。
我们开发了一套转换程序,用于使用 AI2THOR 重新调整 ALFRED 基准的用途,以评估第 3 节中所示的方法。 我们设法得到一个结构化数据表来描述 ALFRED 数据集中每个任务的环境。 我们探索 AI2THOR 引擎并编写转换程序,以便我们可以获得所有对象的完整观察:属性(可移动、可打开等)、位置(3D 坐标和旋转)、大小和空间关系(例如, 对象 A 在对象 B 的顶部)。 我们相信我们的 ALFRED 数据变体将成为社区研究 G-PlanET 和扎根推理未来方向的重要资源。
3方法
在这里,我们介绍了我们采用或提出的解决 G-PlanET 问题的方法。 首先,我们介绍基本语言模型,即编码器-解码器架构。 然后,我们详细展示了如何对环境数据进行编码并将其与 seq2seq 学习框架集成。 最后,我们提出了一种可显着提高性能的交互式解码策略。
3.1 基础语言模型
预训练的编码器-解码器语言模型,例如 BART (Lewis 等人 2020) 和 T5 (Raffel 等人 2020),在许多知名语言生成中取得了可喜的性能诸如总结和回答问题之类的任务。 它们在 CommonsenseQA (Talmor 等人 2019) 等一般常识推理任务中也表现出了巨大的潜力,这表明这些大型 LM 在某种程度上具有常识。 由于 G-PlanET 也可以被视为文本生成问题,因此我们使用这些 LM 作为开发进一步规划方法的支柱,希望它们的常识能够扎根于具体任务的现实情况中。
普通基线方法。
正如许多论文所示,当大小相似时,BART 和 T5 在许多生成任务中表现出相当的性能。 因此,我们使用 BART-base 和 BART-large 作为两个选定的 LM 进行评估。 使用此类 LM 解决 G-PlanET 的最简单、最直接的基线方法是忽略环境,仅使用目标作为唯一输入。 然后,我们使用训练数据来构建基础 LM,并期望它们可以直接将整个计划输出为单个标记序列(包括特殊的分隔符标记)。 这种简单的方法不允许 LM 感知环境,尽管大规模数据的训练仍然可以教会 LM 一些通用的规划策略。 因此,我们认为这是一个重要的基线分析方法。
3.2 对现实环境进行编码
为了使 LM 能够感知环境,我们需要对第 2 节中描述的对象表进行编码。 2.2。 继之前基于表格的 NLP 任务(Chen 等人 2020; Liu 等人 2022b) 的工作之后,我们将表格逐行扁平化为词符序列,从而创建对象表的线性化版本。 然后,我们将展平的表格附加到目标后面以形成完整的输入序列。 因此,编码器-解码器的输入侧最终具有用于生成接地计划的环境信息。
考虑到最大序列限制,我们仅选择通过对象的类型、位置、旋转和容器对对象进行编码> 家长。 对象类型不仅告诉我们对象是什么,而且还暗示了常识性可供性(例如,微波炉可以加热某些东西,刀可以切片某些东西),这对于规划非常重要。 位置信息对于智能体导航和查找对象至关重要,因此在规划中发挥着重要作用。 旋转功能对于某些只能在特定方向使用的对象也很有用(例如,只有当代理位于冰箱前面时才能打开冰箱)。 物体的容器与其本身具有紧密的空间联系(例如钢笔在桌子上;苹果在冰箱里)。 每个对象都有一个唯一的标识符,这样当相同类型的对象是其他对象的容器时,就可以准确地引用它们。 此外,代理被表示为一个特殊的对象。
3.3 迭代解码策略
将对象信息的扁平表添加到输入序列中确实可以改善 LM 对现实环境的感知,这构成了接地规划的基础。 然而,思维过程仍然受到传统 seq2seq 学习框架的限制,该框架假设 LM 应该通过单次解码输出完整的计划。 我们认为,深思熟虑的计划过程应该仔细处理每个步骤的连贯性,否则错误会累积并导致计划失败。
因此,我们提出了一种简单而有效的解码策略,学习逐步迭代地生成计划。 具体来说,我们将先前生成的步骤附加到输入序列(即 Input = )中,直到当前步骤生成下一步(即 输出 = )。 这个迭代解码过程将结束,直到LM生成特殊的词符END。 在训练阶段,我们使用 的真实参考;在推理阶段,我们没有这样的参考,因此我们使用模型预测作为。
值得注意的是,与传统的 seq2seq 学习过程相比,迭代解码策略需要运行编码器-解码器模型次才能生成具有步的计划。 重新编码的额外计算成本是值得的。 想象一下当我们人类在房间里计划一项任务时。 我们很自然地一步一步地制定计划,并且生成不同步骤的最有用的信息很可能是关于不同的对象。 因此,时间动态注意力机制有利于 LM 的规划。 我们的迭代解码策略鼓励编码器-解码器架构学习这种能力。
3.4其他方法
预训练表编码器。
由于我们以表格形式使用环境信息,而BART并没有以表格形式输入进行预训练,因此BART可能无法很好地利用这部分信息。 因此,我们采用了 TaPEx (Liu 等人 2022b),这是一种基于表格数据的最先进的预训练语言模型。 使用 SQL 执行作为唯一的预训练任务,TaPEx 实现了比 BART 更好的表格推理能力,因此我们期望 TaPEx 能够充分利用由我们任务中的表。
使用 GPT-J 进行上下文少样本学习。
最后,为了探讨大规模语言模型是否可以通过少样本示例来完成任务,我们还在更大的语言模型 GPT-J 6B 上进行了少样本性能实验。
4评估
我们如何评估 G-PlanET 方法? 由于问题设置的新颖性,评估和分析这些方法具有挑战性。 在本节中,我们提出了一个通用评估协议和一个补充指标来衡量生成计划的质量。 我们报告了所提出的评估方案的主要实验结果。 我们将分析留在第二节。 5。
4.1指标
逐步评估。
传统的评估指标如 BLEU (Papineni 等人 2002) 和 ROUGE (Lin 2004) 衡量生成文本和真实参考文献之间的整体相似度,适合翻译和总结。 然而,规划任务(例如我们的 G-PlanET)的输出文本是高度结构化的。 一个计划自然可以分为一系列逐步的行动。 使用传统的方法来评估计划不可避免地会破坏这种内部结构,并会导致测量不准确。 例如,如果生成的计划的第一步与参考计划的最后一步相同,则常规评估仍然会为这样的生成的计划分配高分,即使它根本没有用处。 因此,我们认为逐步评估一对计划的相似性更为合理。 具体来说,我们首先将世代和事实对齐并计算每一步的分数222ALFRED 作者确保引用由原子操作步骤组成,并且所有引用共享相同的长度。 因此,我们以真值计划的长度为标准:当生成的计划的步数多于真值计划时,我们将其截断;当一代的步骤少于参考时,我们复制最后一步以使它们均匀地进行逐步评估。 通过多个指标。 然后,我们通过取所有步骤的平均值来汇总最终分数。 我们还考虑其他时间权重聚合,以便在第 2 节中进行更多分析。 5。
| Data Split | Unseen Room Layouts | Seen Room Layouts | ||||
| Methods Metrics | CIDEr | SPICE | KAS | CIDEr | SPICE | KAS |
| BART-base (vanilla) | 0.9417 | 0.1378 | 0.2455 | 0.8231 | 0.1277 | 0.2197 |
| BART-large (vanilla) | 1.4632 | 0.3168 | 0.4069 | 1.4414 | 0.3161 | 0.3900 |
| GPT-J-6B | 1.1968 | 0.2655 | 0.3622 | 1.1047 | 0.2509 | 0.3370 |
| BART-base w/table | 1.6706 | 0.3692 | 0.4584 | 1.6230 | 0.3595 | 0.4339 |
| BART-large w/table | 1.6630 | 0.3491 | 0.4411 | 1.5865 | 0.3393 | 0.4204 |
| BART-large (TaPEx) | 2.8824 | 0.5054 | 0.6373 | 2.7432 | 0.4944 | 0.6045 |
| BART-base w/table + iterative decoding | 2.9147 | 0.5107 | 0.6334 | 2.8582 | 0.5118 | 0.6124 |
| BART-large w/table + iterative decoding | 2.8580 | 0.5194 | 0.6518 | 2.8799 | 0.5096 | 0.6326 |
| BART-large (TaPEx) + iterative decoding | 2.8440 | 0.5210 | 0.6313 | 2.6959 | 0.5036 | 0.6074 |
测量接地计划。
评估 G-PlanET 时考虑计划的基础性质是一个独特的挑战。 当计划在单词使用方面与参考相似时,诸如 BLEU、METEOR 和 ROUGE 之类的指标不会给出适当的惩罚,但会导致具体任务在交互式环境中出现完全不同的状态。 例如,“向左转”与“向右转”之间只有一个词的区别,但忠实地遵循这些指示的代理可以到达在非常不同的地方。
基于 LM 的指标,例如 BERTScore (Zhang 等人 2020) 也不合适,因为“左”和“右”的神经嵌入也非常相似。 另外,G-PlanET 的接地计划在上下文中以对象为中心,与视觉感知的一系列事件的标题非常相似,这些指标并不是专门设计的。 考虑到这些限制,我们使用了两种广泛用于字幕的典型指标,并设计了一种新的指标来进行补充测量。
前两个指标是 CIDEr (Vedantam、Zitnick 和 Parikh 2015) 和 SPICE (Anderson 等人 2016),它们都广泛用于输出高度情境化并描述日常生活中自然场景的任务,例如 VaTex (Wang 等人 2019) 和 CommonGen (林等人2020)。 特别是,SPICE 解析场景图的生成和引用,这是一种基于图的语义表示。 然后,它计算基于边缘的 F1 分数来衡量每个步骤之间的相似度。 请注意,SPICE 计算特别关注命题。 这对于评估 G-PlanET 特别有利,因为接地计划中有许多动作,其中命题可以被视为评估的原子单元。
关键动作得分(KAS)。
受 SPICE 的启发,计划中的一个步骤可以解构为多个表示为边的命题。 然而,并非 SPICE 中的所有命题对于评估 G-PlanET 计划都必然重要。 更不用说 SPICE 依赖于运行成本昂贵但有时包含噪声输出的外部解析器。 而且,ALFRED 注释中的大多数真相计划都过于具体,计划没有必要涵盖所有细节。 因此,我们设计了一个指标,重点关注生成计划的关键操作,并检查它们是否是参考的一部分,名为关键操作分数(KAS)。
具体来说,我们分别从生成的计划和真实参考中的每个步骤中提取一组关键动作短语。 我们将这两个集合表示为和。 然后,我们检查中有多少个动作短语被真值集覆盖,精度就成为中第步的KAS分数计划。 为了提高匹配质量,我们策划了一组规则和字典来映射共享相同行为的操作。 例如,“turn to the left”和“turn left”被视为单个匹配; “go直”和“walk直”也可以匹配。 此外,我们打破了复合名词,以便允许部分分数匹配以获得更平滑的评分(例如,“xxx on the table”与“xxx on the 咖啡桌”)。 简而言之,KAS 指标着眼于从计划中提取的关键操作,并检查这些重要元素是否可以(模糊)匹配以计为有效步骤。
4.2实验设置
数据统计。
表 2 显示了我们在第 2 节中描述的数据集的一些统计数据。 2.2。 我们按照 ALFRED 中的数据分割来分割训练数据集、有效数据集和测试数据集。 数据分割基于房间布局是否已在训练任务中看到。 机器人代理通常比在看不见的房间中更容易将指令映射到可见房间中的低级操作。 然而,对于本文中我们要使用 G-PlanET 研究的规划能力,这两个分割并没有太大差异。 我们继续使用这种分割,以使结果一致,并方便那些想要将我们的结果与 ALFRED 结果联系起来的人。
| split | train | valid | test | ||
| aspect | - | seen | unseen | seen | unseen |
| # tasks | 21,025 | 820 | 821 | 705 | 694 |
| avg. | 9.26 | 9.32 | 9.26 | 10.3 | 9.95 |
| avg. # | 73.71 | 74.21 | 77.91 | 75.31 | 73.9 |
| avg. # | 6.72 | 6.79 | 6.26 | 6.95 | 6.63 |
| avg. | 11.24 | 11.13 | 11.49 | 9.84 | 10.19 |
实施细节。
在单通道解码中,我们将输出序列格式化如下:“”。 当附加对象的扁平表时,我们使用“”格式化输入,其中是第对象的序列,包括其id,类型、坐标、旋转、父容器等。由于页面限制,我们将数据、方法和超参数的详细信息保留在链接到我们项目网站的附录中。
4.3 主要结果
我们在表1中报告了主要结果,并在下一节中进行更深入的分析。 综上所述,我们发现将对象表编码为输入的一部分将显着提高性能,并且对其他与表相关的任务进行预训练可以使 G-PlanET 受益匪浅。 迭代解码策略也是一个重要组成部分,可以在一定程度上进一步改善结果。
表格效应案例分析
虽然我们在输入中添加了环境信息,但是模型是否有效地利用这些信息仍然是一个问题。 为了验证这一点,我们在这里提供一个案例研究。 在许多情况下,我们已经证明引入环境信息是有帮助的。 这是一个例子:
-
•
真相:合上桌子上的笔记本电脑。
-
•
vanilla:合上笔记本电脑并将其从床上拿起
-
•
带桌子: 拿起咖啡桌上上的笔记本电脑。
如示例所示,模型借助对象表成功识别了笔记本电脑的位置。
模型尺寸的影响。
表1显示,在某些情况下,小型模型的性能与大型模型一样好,甚至更好。 这主要是由于以下几个原因。 1)计划中的句子比其他NLG任务相对简单,词汇量较小,长度较短。 这使得大型模型在生成方面的威力无法表达,2)G-PlanET 是一项检查计划而不是编写能力的任务。 这种能力是否会随着模型尺寸的变化而变化还有待探索。 3)对于有表的场景,任务的形式与传统的生成任务不太一样,所以阶段会产生较大的影响。 参数较少的模型可以通过有限的数据进行更充分的调整。
5分析
在本节中,我们从多个方面深入分析表1中方法的性能,并提供有助于未来研究的重要发现。 为了公平比较,所有分析实验都是在 BART-large 模型中对测试数据的不可见分割进行的。
5.1 分数的时间重新加权
当我们使用指标计算计划的总体得分时,我们使用平均得分来汇总每个步骤的得分。 然而,在现实环境中,代理完成这些步骤存在因果关系约束 - 即某些任务只能在其先决步骤完成后才能完成。 例如,只有当智能体到达微波炉时,它才能加热手中的面包。
因此,计划中较早的步骤应该具有更高的重要性,而我们之前的评估是基于跨步骤的权重的均匀分布。 为此,我们采用几何分布来重新加权加权聚合的逐步重要性。 几何分布可用于对重复的相互独立的伯努利试验中第一次成功之前的失败次数进行建模,每次试验都有成功的概率。
这非常适合我们的设置,因为当第一步不正确时,整个任务很难在 ALFRED 生成的计划中完成和执行。 几何分布原始设置中的范围被限制在和之间。 当时,每个步骤具有相同的权重(统一重要性),这正是我们在Tab中所做的。 1. 当 时,第一步是我们评估时唯一考虑的因素,这意味着其他步骤将被赋予零聚合权重。
图3显示了未见子集上的结果,更加真实。 在第一步的情况下,迭代和非迭代方法的性能非常接近。 这主要是因为迭代方法在生成第一步时与非迭代方法类似,仅在第二步之后有所不同。 同时可以看到,随着重心向前期转移,业绩整体呈现下滑趋势。 主要原因是子任务越靠后,越接近高层指令。 例如,如果任务目标是将海绵放入水槽中,则最后一步必须是将海绵放入水槽中。 此功能使得子任务生成的最后一步变得非常简单,从而获得高性能。 我们还看到,KAS 中非迭代方法的性能先上升后下降,SPICE 中出现下降趋势的变化。 主要原因是非迭代法的步数有误差,接下来会解释。
5.2计划长度误差分析
我们发现迭代方法和非迭代方法在任务步骤数的预测上存在巨大差距,这可能是最终性能差异的重要原因。 如图4所示,迭代方法有更高的概率预测正确任务的步骤数,而非迭代方法确实会低估步骤数。 在我们的评估框架中,非迭代方法缺失的后续步骤通常是通过复制生成的。 这可能是非迭代方法性能较差的原因,并且非迭代方法的性能在重新加权步骤过程中首先提高。
5.3 任务长度对性能的影响
尽管数据集中的所有任务都是日常生活任务的一部分,但它们的难度有所不同。 评估任务难度的一个简单指标是任务所需的步骤数。 图5说明了随着任务步骤数量的增加,生成步骤的质量下降。 该图还反映出不同方法在较短任务上的性能差异相对较小。 在最长的任务上,所有方法的性能都会迅速下降。 迭代方法对于较长的任务具有更显着的性能优势。 这可能是因为这种方法更好地利用了中间步骤导致的状态变化,并修复了一些先前的错误。
6相关工作
扎根的常识推理。
ALFWorld (Shridhar 等人 2021) 还使用 LM 生成基于 ALFRED 的文本游戏中的下一步。 SciWorld (Wang 等人 2022) 设计了一个文本游戏来判断 LM 是否学会了推理常识。 SayCan (Ahn 等人 2022) 也使用 LM 来寻找现实世界中潜在的下一步。 这三部作品都只期望在文字游戏中学习下一步。 我们的方法与决策 Transformer (Chen 等人 2021) 和行为克隆 (Farag 和 Saleh 2018) 有着相似的动机,但我们致力于非常不同的应用程序。
基于表的 NLP。
我们的工作与 NLP 中的两类表格数据使用密切相关:表格表示建模方法和表作为中间表示的应用。 对于第一线工作,有丰富的文献专注于表格表示建模,包括 TabNet (Arik and Pfister 2021)、TAPAS (Herzig 等人 2020)、TaBERT (Yin 等人 2020) 和 TaPEx (Liu 等人 2022b)。 我们在实验中探索了最先进的表表示模型(例如 TaPEx)对我们任务的影响。 至于第二行工作,之前的工作已经探索了在几个下游任务中使用表格,包括视觉问答(Yi等人2018),代码建模(Pashakhanloo等人2022) ,以及数字推理(Pi 等人 2022;Yoran、Talmor 和 Berant 2022)。 与他们不同的是,我们的工作是第一个探索表格表示在具体任务中的使用。
阿尔弗雷德 特工。
自 ALFRED 出现以来,之前已经发表了一些关于现实环境中的具体任务的研究。 外星人 (Pashevich、Schmid 和 Sun 2021) 首先使用 Transformer 对历史进行编码来解决组合任务,并证明预训练和与合成指令的联合训练可以提高性能。 FILM (Min 等人 2022) 提出了显式空间记忆和语义搜索策略,为状态跟踪和指导提供更有效的表示。 LEBP (Liu 等人 2022a) 是当前发布的 SOTA 方法,通过理解语言指令生成一系列子步骤,并使用预定义的实际动作模板来完成子步骤。 我们还尝试使用这些方法来评估我们生成的低级指令。 然而,由于低级指令的重要性有限,我们生成的指令与 ALFRED 中的指令之间没有明显的差距。
7结论
在这项工作中,我们首次研究了使用语言模型对具体任务进行基础规划的研究。 G-PlanET 问题对于推进 LM 的体现智能至关重要,是迈向通用人工智能的关键一步。 为了评估编码器-解码器 LM 在求解 G-PlanET 时的性能,我们开发了一个基准以及名为 KAS 的专门评估指标来评估生成计划的质量。 此外,我们提出了两种提高 LM 在 G-PlanET 中能力的方法——展平对象表和迭代解码策略。 我们的实验和分析证明了它们的有效性并产生了重要的发现。 这项研究预计将鼓励对 G-PlanET 的进一步研究,并为在现实环境中集成 LM 和具体任务铺平道路。
这项工作在新任务 G-PlanET 上的主要局限性如下:
-
•
评估:虽然我们已经采用并设计了自动指标来评估 G-PlanET 的方法,但我们还没有一种直接的方法来测试此类计划的最终成功率(如果它们由预言机执行)代理)。 我们尝试使用最先进的 ALFRED 代理,例如 FILM (Min 等人 2022),但使用分步指令它们没有表现出明显的差异(即使使用 oracle 版本) )。 我们相信更多的人工评估将帮助我们进一步完善指标,但这可能非常昂贵。 这是因为人类注释者在遵循这些指令时会大量使用 3D 引擎,以评估此类计划的质量。
-
•
方法:将对象表逐行展平为标记序列很简单,但可能不是最佳选择。 对于一个复杂的房间来说,物体的数量可能会很大。 如何才能缩小每一步的重要对象范围? 我们认为需要用于动态表编码的更高级版本的注意力模块。 我们可能不需要在所有步骤中输入整个表来进行解码。 作为一项初级知识研究,我们创建了一种检索增强方法,仅包含预言机对象(下一步提到的)作为输入,但我们看到的改进很少。 我们认为更多的物理规则和数学计算与对象特征将帮助我们获得更多的进步。
参考
- Ahn et al. (2022) Ahn, M.; Brohan, A.; Brown, N.; Chebotar, Y.; Cortes, O.; David, B.; Finn, C.; Gopalakrishnan, K.; Hausman, K.; Herzog, A.; Ho, D.; Hsu, J.; Ibarz, J.; Ichter, B.; Irpan, A.; Jang, E.; Ruano, R. J.; Jeffrey, K.; Jesmonth, S.; Joshi, N. J.; Julian, R. C.; Kalashnikov, D.; Kuang, Y.; Lee, K.-H.; Levine, S.; Lu, Y.; Luu, L.; Parada, C.; Pastor, P.; Quiambao, J.; Rao, K.; Rettinghouse, J.; Reyes, D. M.; Sermanet, P.; Sievers, N.; Tan, C.; Toshev, A.; Vanhoucke, V.; Xia, F.; Xiao, T.; Xu, P.; Xu, S.; and Yan, M. 2022. Do As I Can, Not As I Say: Grounding Language in Robotic Affordances. In Conference on Robot Learning.
- Anderson et al. (2016) Anderson, P.; Fernando, B.; Johnson, M.; and Gould, S. 2016. SPICE: Semantic Propositional Image Caption Evaluation. In Proc. of ECCV.
- Arik and Pfister (2021) Arik, S. Ö.; and Pfister, T. 2021. TabNet: Attentive Interpretable Tabular Learning. In Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021, 6679–6687. AAAI Press.
- Brown et al. (2020) Brown, T. B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; Agarwal, S.; Herbert-Voss, A.; Krueger, G.; Henighan, T.; Child, R.; Ramesh, A.; Ziegler, D. M.; Wu, J.; Winter, C.; Hesse, C.; Chen, M.; Sigler, E.; Litwin, M.; Gray, S.; Chess, B.; Clark, J.; Berner, C.; McCandlish, S.; Radford, A.; Sutskever, I.; and Amodei, D. 2020. Language Models are Few-Shot Learners. In Larochelle, H.; Ranzato, M.; Hadsell, R.; Balcan, M.; and Lin, H., eds., Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Chen et al. (2021) Chen, L.; Lu, K.; Rajeswaran, A.; Lee, K.; Grover, A.; Laskin, M.; Abbeel, P.; Srinivas, A.; and Mordatch, I. 2021. Decision Transformer: Reinforcement Learning via Sequence Modeling. In Ranzato, M.; Beygelzimer, A.; Dauphin, Y. N.; Liang, P.; and Vaughan, J. W., eds., Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, 15084–15097.
- Chen et al. (2020) Chen, W.; Wang, H.; Chen, J.; Zhang, Y.; Wang, H.; Li, S.; Zhou, X.; and Wang, W. Y. 2020. TabFact: A Large-scale Dataset for Table-based Fact Verification. In Proc. of ICLR. OpenReview.net.
- Farag and Saleh (2018) Farag, W. A.; and Saleh, Z. 2018. Behavior Cloning for Autonomous Driving using Convolutional Neural Networks. 2018 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT).
- Herzig et al. (2020) Herzig, J.; Nowak, P. K.; Müller, T.; Piccinno, F.; and Eisenschlos, J. 2020. TaPas: Weakly Supervised Table Parsing via Pre-training. In Proc. of ACL, 4320–4333. Online: Association for Computational Linguistics.
- Huang et al. (2022) Huang, W.; Abbeel, P.; Pathak, D.; and Mordatch, I. 2022. Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents. In Chaudhuri, K.; Jegelka, S.; Song, L.; Szepesvári, C.; Niu, G.; and Sabato, S., eds., International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 of Proceedings of Machine Learning Research, 9118–9147. PMLR.
- Kolve et al. (2017) Kolve, E.; Mottaghi, R.; Han, W.; VanderBilt, E.; Weihs, L.; Herrasti, A.; Deitke, M.; Ehsani, K.; Gordon, D.; Zhu, Y.; Kembhavi, A.; Gupta, A. K.; and Farhadi, A. 2017. AI2-THOR: An Interactive 3D Environment for Visual AI. ArXiv preprint, abs/1712.05474.
- Lewis et al. (2020) Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; and Zettlemoyer, L. 2020. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proc. of ACL, 7871–7880. Online: Association for Computational Linguistics.
- Lin et al. (2020) Lin, B. Y.; Zhou, W.; Shen, M.; Zhou, P.; Bhagavatula, C.; Choi, Y.; and Ren, X. 2020. CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2020, 1823–1840. Online: Association for Computational Linguistics.
- Lin (2004) Lin, C.-Y. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out, 74–81. Barcelona, Spain: Association for Computational Linguistics.
- Liu et al. (2022a) Liu, H.; Liu, Y.; He, H.; and Yang, H. 2022a. LEBP - Language Expectation & Binding Policy: A Two-Stream Framework for Embodied Vision-and-Language Interaction Task Learning Agents. ArXiv preprint, abs/2203.04637.
- Liu et al. (2022b) Liu, Q.; Chen, B.; Guo, J.; Ziyadi, M.; Lin, Z.; Chen, W.; and Lou, J. 2022b. TAPEX: Table Pre-training via Learning a Neural SQL Executor. In Proc. of ICLR. OpenReview.net.
- Min et al. (2022) Min, S. Y.; Chaplot, D. S.; Ravikumar, P. K.; Bisk, Y.; and Salakhutdinov, R. 2022. FILM: Following Instructions in Language with Modular Methods. In Proc. of ICLR. OpenReview.net.
- Papineni et al. (2002) Papineni, K.; Roukos, S.; Ward, T.; and Zhu, W.-J. 2002. Bleu: a Method for Automatic Evaluation of Machine Translation. In Proc. of ACL, 311–318. Philadelphia, Pennsylvania, USA: Association for Computational Linguistics.
- Pashakhanloo et al. (2022) Pashakhanloo, P.; Naik, A.; Wang, Y.; Dai, H.; Maniatis, P.; and Naik, M. 2022. CodeTrek: Flexible Modeling of Code using an Extensible Relational Representation. In Proc. of ICLR. OpenReview.net.
- Pashevich, Schmid, and Sun (2021) Pashevich, A.; Schmid, C.; and Sun, C. 2021. Episodic Transformer for Vision-and-Language Navigation. In 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, 15922–15932. IEEE.
- Pi et al. (2022) Pi, X.; Liu, Q.; Chen, B.; Ziyadi, M.; Lin, Z.; Fu, Q.; Gao, Y.; Lou, J.-G.; and Chen, W. 2022. Reasoning Like Program Executors. In Proc. of EMNLP, 761–779. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics.
- Raffel et al. (2020) Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; and Liu, P. J. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res., 21: 140:1–140:67.
- Shridhar et al. (2020) Shridhar, M.; Thomason, J.; Gordon, D.; Bisk, Y.; Han, W.; Mottaghi, R.; Zettlemoyer, L.; and Fox, D. 2020. ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020, 10737–10746. IEEE.
- Shridhar et al. (2021) Shridhar, M.; Yuan, X.; Côté, M.; Bisk, Y.; Trischler, A.; and Hausknecht, M. J. 2021. ALFWorld: Aligning Text and Embodied Environments for Interactive Learning. In Proc. of ICLR. OpenReview.net.
- Talmor et al. (2019) Talmor, A.; Herzig, J.; Lourie, N.; and Berant, J. 2019. CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge. In Proc. of NAACL-HLT, 4149–4158. Minneapolis, Minnesota: Association for Computational Linguistics.
- Vedantam, Zitnick, and Parikh (2015) Vedantam, R.; Zitnick, C. L.; and Parikh, D. 2015. CIDEr: Consensus-based image description evaluation. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, June 7-12, 2015, 4566–4575. IEEE Computer Society.
- Wang et al. (2022) Wang, R.; Jansen, P.; Côté, M.-A.; and Ammanabrolu, P. 2022. ScienceWorld: Is your Agent Smarter than a 5th Grader? In Proc. of EMNLP, 11279–11298. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics.
- Wang et al. (2019) Wang, X.; Wu, J.; Chen, J.; Li, L.; Wang, Y.; and Wang, W. Y. 2019. VaTeX: A Large-Scale, High-Quality Multilingual Dataset for Video-and-Language Research. In 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, 4580–4590. IEEE.
- Yi et al. (2018) Yi, K.; Wu, J.; Gan, C.; Torralba, A.; Kohli, P.; and Tenenbaum, J. 2018. Neural-Symbolic VQA: Disentangling Reasoning from Vision and Language Understanding. In Bengio, S.; Wallach, H. M.; Larochelle, H.; Grauman, K.; Cesa-Bianchi, N.; and Garnett, R., eds., Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, 1039–1050.
- Yin et al. (2020) Yin, P.; Neubig, G.; Yih, W.-t.; and Riedel, S. 2020. TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data. In Proc. of ACL, 8413–8426. Online: Association for Computational Linguistics.
- Yoran, Talmor, and Berant (2022) Yoran, O.; Talmor, A.; and Berant, J. 2022. Turning Tables: Generating Examples from Semi-structured Tables for Endowing Language Models with Reasoning Skills. In Proc. of ACL, 6016–6031. Dublin, Ireland: Association for Computational Linguistics.
- Zhang et al. (2020) Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K. Q.; and Artzi, Y. 2020. BERTScore: Evaluating Text Generation with BERT. In Proc. of ICLR. OpenReview.net.