使用对抗性训练进行加密语义通信以保护隐私
摘要
语义通信是基于共享背景知识实现的,但共享机制存在隐私泄露的风险。 在这封信中,我们提出了一种用于隐私保护的加密语义通信系统(ESCS),它结合了通用性和保密性。 通用性体现在所提出的ESCS的所有网络模块都是基于共享数据库进行训练,适合实际场景中的大规模部署。 同时,通过对称加密来实现保密性。 基于对抗性训练,我们设计了一种对抗性加密训练方案,以保证加密和非加密模式下语义通信的准确性。 实验结果表明,无论语义信息是否加密,所提出的具有对抗性加密训练方案的 ESCS 都能表现良好。 攻击者很难从窃听的消息中重构出原始的语义信息。
索引术语:
加密语义通信、对称加密、对抗训练。我简介
语义通信建立在公共背景知识库上,其中两个通信节点私有化相同的背景知识库。 共享的背景知识和私人训练的语义编解码器可以为隐私保护提供障碍。 即使第三个节点窃听了所传输的语义消息,他也很难基于其他背景知识库重建原始语义内容。 在这种情况下,语义通信的保密性较高,但通用性较差。 任意两个通信代理之间必须建立私有通信模型,并联合训练私有语义编码器和解码器。 这样的语义系统在实际场景中部署起来会非常复杂且具有挑战性。
因此,目前的大多数研究都支持集中式语义通信系统,即基于一个或多个标准背景知识库[1,2,3]训练的统一的多用户语义通信系统。 在[1]中,所有智能体通过联合学习参与模型更新,以训练广义语义模型。 通过协作学习,该模型可以显着提高其效用,但也不可避免地遇到隐私泄露的问题[3]。 因此,平衡语义通信的通用性和保密性是语义通信的主要挑战之一。
最近,提出了基于神经网络(NN)的语义通信模型。 在[4]训练中,作者设计了一种用于文本语义通信的端到端(E2E)模型,并将迁移学习应用到训练过程中,显着减少了时间。 工作[5]提出了中继语义通信模型,并设计了语义转发(SF)方案来解决端到端语义通信的异构背景知识问题,但缺乏隐私保护。 在[6]中,提出了一种数据适应网络来解决背景知识异构性问题并保护接收器处传输图像数据的实用使用的隐私。 在[7]中,作者证明神经网络可以学习通过对抗性神经加密来保持通信并保护比特流的传输。
在本文中,我们更加关注语义通信中编码信息是否可以被窃听者获取。 我们针对文本通信任务提出了一种具有语义加密功能的通用语义通信模型,称为加密语义通信系统(ESCS)。 所提出的ESCS提供了加密和未加密两种语义传输模式,而无需改变语义编码器和解码器。 此外,我们设计了用于语义通信的密钥、加密器和解密器的结构,它们可以成功地嵌入到共享语义通信模型中。 最后,采用对抗性加密训练方案,有效保证加密和非加密模式下语义通信的准确性,防止攻击者窃听语义信息[7,8,9]。 仿真结果验证了所提出的对抗训练 ESCS 可以有效保护隐私。
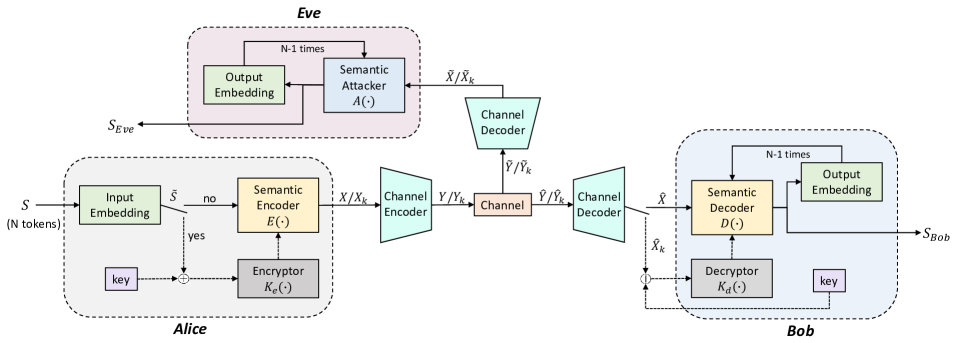
II 系统模型
在本节中,我们设计了一个加密语义通信系统,并介绍了如何使用密钥来保护语义信息的机密性。
II-A 语义对称密码系统
我们考虑安全领域的经典场景,其中涉及三个用户(Alice、Bob 和 Eve)。 Alice和Bob想要实现安全的语义通信,Eve试图窃听他们的通信。 安全属性主要防止窃听,因为对手 Eve 仅限于拦截信息,无法注入或修改传输的消息。
如图1所示,Alice希望向Bob发送机密语义消息。语义消息是Alice的输入,Alice可以通过语义和通道编码器处理该输入,产生新的消息。 通常,我们在经典加密场景中将这种新消息称为“密文”。 在语义通信系统中,Alice不仅对消息进行了语义编码,还对消息进行了加密,因此我们用来表示Alice的加密语义消息,其中下标表示密钥加密。 然后,经过信道编码后,通过无线信道传输,Bob接收,Eve接收。 它们都处理收到的消息并尝试恢复。我们分别使用和来表示它们的恢复结果。 鲍勃比夏娃有一个优势,因为他与爱丽丝共享密钥。 我们将密钥视为 Alice 和 Bob 的附加输入。 每个语义消息在通信过程中匹配一个新密钥。
II-B 加密语义通信系统
我们还考虑了所提出的加密语义通信系统的普遍性和保密性。 因此,本系统的语义加密功能是可选的。 如果消息不需要隐私保护,则可以不加密的方式传输消息。 由于语义编码模块是通用的,因此任何人都可以在这种情况下对其进行解码。 系统的这种通用性适用于各种场景,例如广播频道。 而且系统模型的训练是统一的,提高了模型训练的效率,降低了语义通信组件的部署复杂度。
所提出的系统对于不同的输入形式需要不同的语义编码网络。 本文主要介绍文本型输入。 输入是一个句子,我们将输入句子标记为。 中的每个词符都是一个one-hot向量,其长度为背景知识库中单词词典的大小。 通过词嵌入层,我们可以将每个词符映射到一个固定维度的浮点数向量,输出为。 然后,发送方可以选择是否对语义消息进行加密。 如果需要加密,则将与密钥一起输入到加密器进行加密,然后将加密后的消息输入到语义编码器进行语义编码。 否则,直接输入到语义编码器进行语义编码。 语义编码器对语义消息进行编码,无论是否加密,然后分别输出语义向量和。 最后,系统对语义向量或进行通道编码,得到输出或。 在本文中,我们使用 Transformer 网络作为语义编解码器[10],它在文本任务上表现良好。 自动编码器可用作通道编解码器[5]。
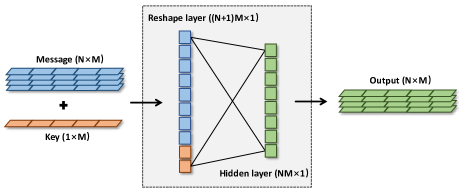
加密器和解密器的网络结构相同,如图2所示。 原始语义消息具有标记,每个词符嵌入到维度中。 密钥是维浮点数的随机向量,相当于语义消息中的词符。 它们都被输入到加密器或解密器。 加密器的第一层是重塑层,它将原始消息和密钥连接起来,然后进行维度变换。 第二层是隐藏层,维度降为原始消息的长度。 最后,输出将向量重塑为与原始消息相同。 值得注意的是,加密和解密的形式是通过学习发现的,而不是由特定算法生成的。 密钥之所以选择词符长度,是因为密钥的长度并不代表扰动的强度。 加密的效果在于网络学习到的加密方法,而不是密钥中的数据量。 另外,加密器和解密器的位置选择也多种多样,可以进行合理的调整,但网络性能相差不大。 这两点我们也通过实验验证了。
在本文中,我们考虑加性高斯白噪声(AWGN)通道,其中通道的一个输出表示为,其中。 根据接收到的信号或,Eve尝试通过语义攻击者重建原始语义消息。 同时,Bob直接通过语义解码器解码未加密的消息,而加密的消息则先通过解密器解密,然后通过语义解码器解码。 t2>。 请注意,由于攻击者可能是其他通信链路中的接收者,因此我们认为接收者和攻击者具有相同的语义解码器结构。 语义解码器逐字解码,因此前次的输出可以用作语义解码器的另一个输入。 换句话说,解码器将执行的解码操作的数量等于原始输入中的 Token 数量。
III 目标和训练
在本节中,我们详细描述了ESCS中每个参与者的目标,根据目标设计不同网络模块的损失函数,并使用特定的训练方法来实现最佳性能。
III-A 损失功能设计
如果通信内容不保密,则攻击者 Eve 会被忽略,因此目标是最小化 和 之间的错误。 如果 Alice 和 Bob 想要对 Eve 隐藏通信内容,那么目标就是使 和 之间的误差最小,同时使 和 之间的误差最大。 对于Eve来说,目标是准确地重构,即最小化和之间的误差。 因此,我们通过联合训练发射器和接收器来击败攻击者,攻击者的窃听能力在训练过程中也得到了增强。 与生成对抗网络(GAN)[11]类似,我们希望发射器和接收器击败最好的攻击者,而不是固定的攻击者。
下面仅介绍损失函数中需要更新的网络参数。 嵌入层是固定的,通道编码和解码网络是预先训练的[5]。 对于距离函数,我们使用交叉熵,它可以表示为
| (1) |
其中 和 分别是第 中第 个单词的真实概率和预测概率样本,代表句子中的token数量,代表一批样本的数量。
首先,未加密语义通信的损失函数由下式给出
| (2) |
其中和分别表示语义编码器和语义解码器的输出。 注意,在训练时并不是直接的输入,需要经过通道,但为了简化表达,没有在公式中表示。 因此,我们通过最小化这种损失来获得最佳的语义编码器和解码器,如下所示
| (3) |
类似地,我们定义加密语义通信的损失函数如下
| (4) | ||||
其中 和 分别是加密器和解密器的输出。 我们通过最小化损失来获得接收者的最佳解密器,如下所示
| (5) |
攻击者将拦截加密消息并直接使用语义攻击者重建语义信息。 攻击者的损失函数可以由下式给出
| (6) |
其中 是语义攻击者的输出。 通过最小化损失可以得到最优攻击者如下
| (7) |
因此,通过组合 和 可以给出加密器和解密器的损失函数:
| (8) | ||||
这里,超参数平衡了实用性和保密性。 我们通过最小化这种损失来获得最佳的加密器
| (9) |
一般来说,由于学习过程中加解密方法不固定、密钥大小可变、密钥值随机,所以发射方和接收方可以有多种近最优解。 我们将在下面的小节中解释详细的训练过程。
III-B 训练精炼
Input: Channel SNR value and hyper-parameter .
Output: Network , , , , .
加密语义通信网络的训练分为两个步骤。 第一个是训练具有对称结构的通道编码器和解码器。 它们各自有两个隐藏层,每个隐藏层都会对输入向量进行一定程度的压缩,最终将其映射到具有实部和虚部的符号。 我们使用随机生成的向量进行训练,类似于编码的语义向量。 设置通道参数在训练过程中在一定范围内动态变化,可以增强鲁棒性。 并使用均方误差(MSE)作为损失函数来减少失真。
与 GAN 类似,我们交替用发射器和接收器训练攻击者。 直观上,训练算法大致在算法 1 中概述。 通过几个训练步骤,语义编码器 和解码器 找到了满足常见语义通信要求的方法。 此外,解密者继续学习稳定的解密方法,而语义攻击者逐渐学习直接解码加密语义消息的方法。 在这个过程中,接收者和攻击者同时试图最小化重建误差,因此我们交替更新加密器以减少接收者的重建误差但增加攻击者的重建误差。 直观上,学习使得加密方法对接收者更加友好。
IV 性能评估
在本节中,我们提出数值结果来评估所提出的 ESCS 方案的性能。 实验中的数据集是欧洲议会的标准程序[12],由大约200万个句子组成。 算法1的学习率设置为,超参数设置为,信噪比(SNR)为无线通道设置为 10 dB。 我们采用双语评估学生(BLEU)分数[13]作为评估指标。 BLEU 中 1-gram 和 2-gram 的权重分别设置为 0.6 和 0.4。 在实验中,我们比较了基于所提出的 ESCS 方案和非对抗性加密训练方案的接收者和攻击者之间重建语义消息的准确性。
图3显示了使用对抗性加密训练或非对抗性加密训练时、和随着训练步数的增加而变化。对抗性加密训练。 我们可以看到,使用所提出的 ESCS 方案, 和 可以收敛到 0。 但无法收敛到0,最终在0.5左右波动。 由于使用交叉熵作为距离函数,如果损失值不能收敛到0,解码器将无法正确重建原始消息。 另一方面,采用非对抗性训练方案,即不参与训练更新时,、和都可以收敛到0。 这意味着该系统虽然实用性高,但保密性较差。 Eve 可以轻松地从加密消息中重建原始语义消息。
从图3中我们还可以看到,使用对抗性加密训练方案,每个损失值的收敛速度比非对抗性加密训练方案慢。 为了击败最好的攻击者,加密器将在一定数量的训练步骤后更新其网络参数。 这次更新适合Bob,但对Eve不友好,因此Eve的损失值波动很大。 更重要的是,这样的对抗性训练过程使得所有损失值下降得更慢,最终阻止伊芙的损失收敛到0。


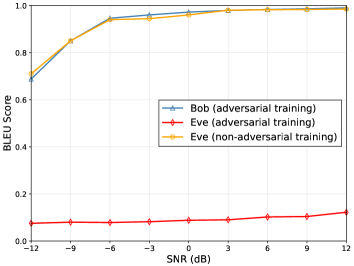
在图 4 训练中,我们显示了不同方案的 BLEU 分数与 SNR 的关系。 我们可以看到,在使用对抗性加密训练方案时,在任何 SNR 下,Bob 的 BLEU 分数都远高于 Eve。 在高信噪比信道条件下,Bob的BLEU得分接近1,而Eve的BLEU得分小于0.2。 作为比较,我们验证了 Eve 在使用非对抗性加密时窃听语义信息的性能。 此时,Eve 的 BLEU 分数与 Bob 的 BLEU 分数几乎相同,这意味着隐私泄露严重,证明对抗性加密训练可以有效保护隐私。
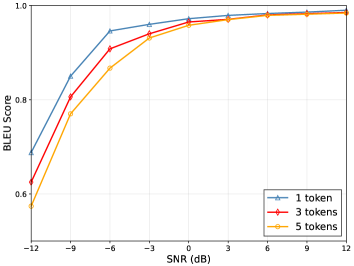
图5展示了不同长度的密钥对ESCS的影响。 可以看出,当信道条件较差时,长密钥会降低通信性能。 由于长密钥的加密方法复杂,加密信息的抗噪声能力不足。 因此我们可以使用一个词符的密钥来保证较低的加密复杂度和ESCS的最佳性能。
V 结论
在这封信中,我们应用对称加密来解决语义通信系统中的窃听安全问题。 为了使所提出的ESCS兼具通用性和保密性,我们提出了一种对抗性加密训练方案,该方案可以有效保证加密和非加密模式下语义通信的准确性,并防止攻击者窃听语义信息。 仿真结果表明,所提出的使用对抗训练方案的ESCS可以显着提高语义通信系统的隐私保护能力。
参考
- [1] G. Shi, Y. Xiao, Y. Li, and X. Xie, “From semantic communication to semantic-aware networking: Model, architecture, and open problems,” IEEE Communications Magazine, vol. 59, no. 8, pp. 44–50, 2021.
- [2] Q. Zhou, R. Li, Z. Zhao, C. Peng, and H. Zhang, “Semantic communication with adaptive universal transformer,” IEEE Wireless Communications Letters, vol. 11, no. 3, pp. 453–457, 2022.
- [3] B. Hitaj, G. Ateniese, and F. Perez-Cruz, “Deep models under the gan: information leakage from collaborative deep learning,” in Proceedings of the 2017 ACM SIGSAC conference on computer and communications security, 2017, pp. 603–618.
- [4] H. Xie, Z. Qin, G. Y. Li, and B.-H. Juang, “Deep learning enabled semantic communication systems,” IEEE Trans. on Signal Processing, vol. 69, pp. 2663–2675, 2021.
- [5] X. Luo, Z. Chen, B. Xia, and J. Wang, “Autoencoder-based semantic communication systems with relay channels,” in Proc. 2022 IEEE International Conference on Communications Workshops (ICC Workshops), 2022, pp. 1–6.
- [6] H. Zhang, S. Shao, M. Tao, X. Bi, and K. B. Letaief, “Deep learning-enabled semantic communication systems with task-unaware transmitter and dynamic data,” arXiv preprint arXiv:2205.00271, 2022.
- [7] M. Abadi and D. G. Andersen, “Learning to protect communications with adversarial neural cryptography,” arXiv preprint arXiv:1610.06918, 2016.
- [8] J. M. Perero-Codosero, F. M. Espinoza-Cuadros, and L. A. Hernández-Gómez, “X-vector anonymization using autoencoders and adversarial training for preserving speech privacy,” Computer Speech & Language, p. 101351, 2022.
- [9] B.-W. Tseng and P.-Y. Wu, “Compressive privacy generative adversarial network,” IEEE Trans. on Information Forensics and Security, vol. 15, pp. 2499–2513, 2020.
- [10] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances Neural Info. Process. Systems, vol. 30, 2017.
- [11] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014.
- [12] P. Koehn et al., “Europarl: A parallel corpus for statistical machine translation,” in MT summit, vol. 5. Citeseer, 2005, pp. 79–86.
- [13] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318.