用于分布外检测的极其简单的激活整形
摘要
机器学习模型的训练和部署之间的分离意味着,并非所有部署中遇到的场景都可以在训练期间预见到,因此仅仅依靠训练的进步有其局限性。 分布外 (OOD) 检测是压力测试模型处理未见情况的能力的一个重要领域: 模型在不知道的时候知道吗? 现有的 OOD 检测方法要么需要额外的训练步骤、额外的数据,要么对训练的网络进行重大修改。 相比之下,在这项工作中,我们提出了一种极其简单的事后动态a激活整形方法,ASH ,其中样本在后期层的大部分(例如 90%)激活被删除,其余部分(例如 10%)被简化或轻微调整。 整形在推理时应用,不需要根据数据计算任何统计数据。 实验表明,这种简单的处理增强了分布内和分布外的区别,从而允许在 ImageNet 上进行最先进的 OOD 检测,并且不会明显降低分布内的精度。 视频、动画和代码可以在:https://andrijazz.github.io/ash 找到。
1简介
机器学习通过迭代进行。 我们开发出越来越好的训练技术(在闭环验证设置中进行验证),一旦模型被训练,我们就会观察到部署中的问题、缺点、陷阱和失调,这促使我们回去修改或完善训练过程。 然而,随着我们进入大型模型时代,最近的进展在很大程度上是由扩展的进步推动的,这体现在模型、数据、物理硬件以及研究人员和工程师团队的各个方面(Kaplan 等人,2020;Ramesh 等人,2022;Yu 等人,2022)。 因此,对通常的训练部署循环进行多次迭代变得更加困难;出于这个原因,事后提高模型能力而不需要修改训练的方法是非常受欢迎的。 零样本学习(Radford等人, 2021)、即插即用控制(Dathathri等人, 2020)以及特征后处理等方法(Guo 等人, 2017) 利用事后操作使通用且灵活的预训练模型更适应下游应用。
分布外 (OOD) 泛化失败是部署中经常观察到的此类陷阱之一。 OOD 检测的核心问题是“模型在不知道的时候知道吗?理想情况下,经过足够的训练后,神经网络 (NN) 应该对分布之外的数据产生低置信度或高不确定性度量。 然而,情况并非总是如此(Szegedy 等人,2013;Moosavi-Dezfooli 等人,2017;Hendrycks & Gimpel,2017;Nguyen 等人,2015;Amodei 等人,2016)。 事实证明,区分 OOD 与分布内 (ID) 样本是一项比预期困难得多的任务。 许多人将 OOD 检测的失败归因于神经网络校准不佳,这导致了一系列令人印象深刻的工作来改进校准措施(Guo 等人,2017;Lakshminarayanan 等人,2017;Minderer 等人,2021)。 经过所有这些努力,OOD 检测已经取得了巨大进步,但是仍然有空间建立 Pareto 边界,以提供最佳的 OOD 检测和 ID 准确性权衡:理想情况下,OOD 检测管道不应降低 ID 任务性能,也不应需要繁琐的并行分别处理 ID 任务和 OOD 检测的设置。
最近的一项工作 ReAct (Sun 等人, 2021) 观察到特定(倒数第二)层的单元激活模式在 ID 和 OOD 数据之间显示出显着差异,因此提出纠正激活上限——换句话说,将层输出限制在上限可以极大地改善 ID 和 OOD 数据的分离。 另一项单独的工作 DICE (Sun & Li, 2022) 在某一层上采用了权重稀疏化,并与 ReAct 结合使用,在多个基准上实现了最先进的 OOD 检测。 同样,在本文中,我们假设不了解或测试数据分布,通过对预训练网络进行轻微修改来解决 OOD 训练检测问题。 我们证明,通过对输入表示进行事后一次性简化,可以实现出乎意料的有效、最先进的 OOD 检测。
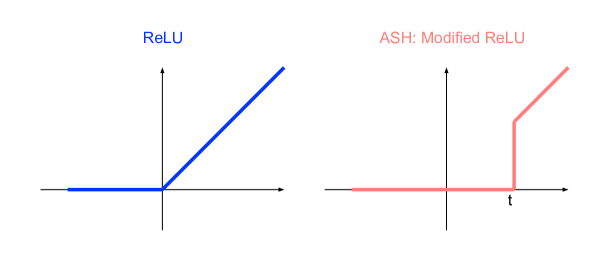
极其简单的A激活SHaping(ASH)方法采用输入的特征表示(通常来自较晚的层)并执行两阶段操作:1)基于简单的 top-K 标准删除大部分(例如 90%)激活值,2)通过按比例放大剩余的(例如 10%)激活值或简单地为其分配一个常数值来调整它们。 然后将得到的简化表示填充到网络的其余部分,像往常一样生成分类和 OOD 检测的分数。 图1说明了这个过程。
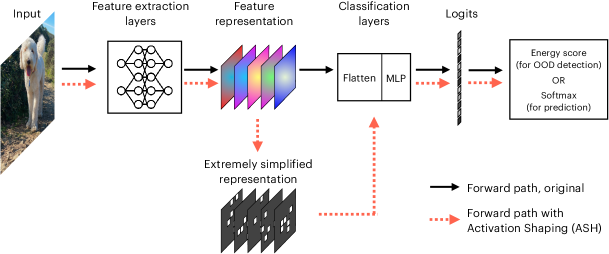
ASH 与 ReAct (Sun 等人, 2021) 类似,其在网络中间的激活空间中采取的训练后一次性方式,以及对能量得分的使用OOD 检测。 与 DICE (Sun & Li, 2022) 类似,ASH 执行稀疏化操作。 然而,与 ReAct 相比,我们提供了许多优势:没有根据训练数据计算出全局阈值,因此完全事后;图层放置更加灵活;全面更好的 OOD 检测性能;更好地保留 ID 数据的准确性,从而建立更好的帕累托前沿。 对于 DICE,我们不对训练后的网络进行任何修改,并且仅在激活空间中进行操作(ASH 和 DICE 之间的更多差异在附录中的 K 部分中突出显示)。 此外,我们的方法是即插即用的,可以与其他现有方法结合使用,包括ReAct(结果如表5所示)。
在本文的其余部分,我们通过以下贡献开发和评估 ASH:
2 分发外检测设置
OOD 检测方法通常按照以下配方开发:
-
1.
使用一些数据(即分布中(ID)数据)训练模型(例如分类器)。 训练结束后,冻结模型参数。
-
2.
在推理时,向模型提供分布外 (OOD) 数据。
-
3.
通过从模型输出中得出分数,将模型转变为检测器,以区分输入是 ID 还是 OOD。
-
4.
使用各种评估指标来确定检测器的性能。
突出显示的关键字是在 OOD 检测的每个实验设置中要做出的选择。 遵循这一惯例,我们对本文的设计选择解释如下。
数据集和模型(步骤 1-2)
我们采用了代表先前 SOTA 的实验设置:DICE(在 CIFAR 上)和 ReAct(在 ImageNet 上)。 表1总结了所使用的数据集和模型架构。 对于 CIFAR-10 和 CIFAR-100 实验,我们使用了 DICE (Sun & Li, 2022) 中采用的 6 个 OOD 数据集:SVHN (Netzer 等人, 2011), LSUN-Crop (于等人, 2015)、LSUN-Resize (于等人, 2015)、iSUN (徐等人, 2015)、Places365 (Zhou 等人, 2017) 和Textures (Cimpoi 等人, 2014),而 ID 数据集是各自的 CIFAR。 使用的模型是预训练的 DenseNet-101 (Huang 等人,2017)。 对于 ImageNet 实验,我们继承了 ReAct (Sun 等人, 2021) 的精确设置,其中 ID 数据集是 ImageNet-1k,OOD 数据集包括 iNaturalist (Van Horn 等人, 2018 )、SUN (Xiao 等人, 2010)、Places365 (Zhou 等人, 2017)、Textures (Cimpoi 等人, 2014) 。 我们使用 ResNet50 (He 等人, 2016) 和 MobileNetV2 (Sandler 等人, 2018) 网络架构。 所有网络均使用 ID 数据进行预训练,并且在训练后从未进行修改;它们的参数在 OOD 检测阶段保持不变。
| ID Dataset | OOD Datasets | Model architectures |
|---|---|---|
| CIFAR-10 | SVHN, LSUN C, LSUN R, iSUN, Places365, Textures | DenseNet-101 |
| CIFAR-100 | SVHN, LSUN C, LSUN R, iSUN, Places365, Textures | DenseNet-101 |
| ImageNet | iNaturalist, SUN, Places365, Textures | ResNet50, MobileNetV2 |
检测分数(步骤 3)
OOD 检测常用的评分函数是 Softmax 输出的最大/预测类别概率(Hendrycks & Gimpel,2017)和能量评分(Liu 等人,2020)。 由于 Energy 分数已被证明优于 Softmax (Liu 等人, 2020; Sun 等人, 2021),因此我们默认使用前者。 在我们的消融研究中,我们还尝试了与 Softmax 评分相结合的方法版本以及其他方法(参见表 5)。 对于给定的输入 和经过训练的网络函数 ,能量函数 映射网络的 logit 输出 ,为标量:,其中 是类的数量, 是类 的 logit 输出。 OOD检测使用的分数是负能量分数,因此ID样本会产生更高的分数,与约定一致。 我们将我们的方法与其他评分方法进行比较,例如Mahalanobis 距离 (Lee 等人, 2018),以及基于它们的其他高级方法:ODIN (Liang 等人, 2017)(基于 Softmax 分数) 、ReAct (Sun 等人, 2021) 和 DICE (Sun & Li, 2022)(基于能量得分)。
评估指标(步骤 4)
我们使用 Hendrycks & Gimpel (2017) 中标准化的 OOD 检测无阈值指标来评估我们的方法: (i) AUROC:接收者操作特征曲线下的面积; (ii)AUPR:精确率-召回率曲线下的面积; (iii) FPR95:假阳性率——当真阳性率高达 95% 时,阴性(例如 OOD)示例被错误分类为阳性(例如 ID)的概率 (Liang 等人,2017) 。 除了 OOD 指标之外,我们还评估每种方法的 ID 性能,在本例中是分布内数据的分类准确性,例如ImageNet 验证集上的 Top-1 准确率。
3 用于 OOD 检测的激活整形
经过训练的网络将原始输入数据(例如 RGB 像素值)转换为有用的表示(例如空间激活堆栈)。 我们认为,现代的、过度参数化的深度神经网络产生的表示对于当前的任务来说是过多的,因此可以大大简化,而不会对原始性能(例如分类准确性)造成太大影响,同时在其他任务上带来令人惊讶的收益(例如 OOD 检测)。 这样的假设是通过a激活shaping方法ASH进行测试的,该方法通过以下配方简化了输入的特征表示:
-
1.
通过获取整个表示的 百分位数 并将 以下的所有值设置为
- 2.
ASH 会即时应用于中间层的任何输入样本的特征表示,之后它继续沿着前向路径穿过网络的其余部分,如图 1 所示。 其输出(从简化表示生成)随后用于原始任务(例如分类),或者在 OOD 检测的情况下,获得分数,并应用阈值机制来区分 ID 和 OOD 样本。 因此,ASH 是原始任务和 OOD 检测的统一框架,无需任何额外的计算。
Input: Single sample activation , pruning percentile
Output: Modified activation
Input: Single sample activation , pruning percentile
Output: Modified activation
Input: Single sample activation , pruning percentile
Output: Modified activation
ASH 的放置
参数
4结果
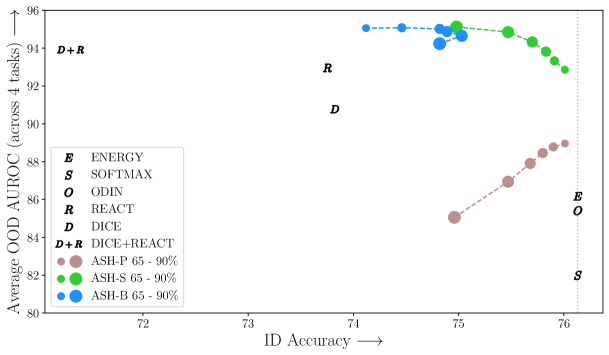
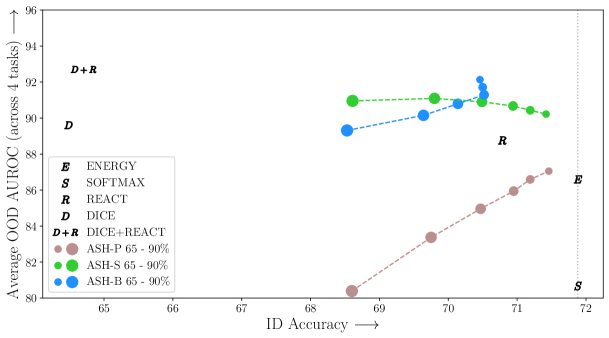
4.1 ASH 提供了最佳的 ID-OOD 权衡
ASH 作为 ID 和 OOD 任务的统一管道,在这两个方面都表现出了强大的性能。 图 2 显示了 ImageNet 各种方法的 ID-OOD 权衡。 一方面,依赖于直接从网络未经修改的输出中获取分数的方法,例如Energy、Softmax 和 ODIN (Liang 等人, 2017) 完美地保留了 ID 精度,但在 OOD 检测方面表现相对较差。 修改网络权重或表示的高级方法,例如ReAct (Sun 等人, 2021) 和 DICE (Sun & Li, 2022) 在作为统一管道应用时会损害 ID 准确性。 在 ReAct 的情况下,ID 准确率从 76.13% 下降到 73.75%。
ASH 提供了两全其美的优点:以最佳方式保留 ID 性能,同时改进 OOD 检测。 改变修剪百分比,我们可以在图2中看到这些ASH-B和ASH-S变体建立了新的帕累托前沿。 仅剪枝的 ASH-P 在每个剪枝级别上提供与 ASH-S 相同的 ID 准确度,但在 OOD 指标上落后于 ASH-S,这表明简单地通过扩展未剪枝的激活,我们观察到了巨大的性能增益OOD 检测。
4.2 ImageNet 和 CIFAR 基准上的 OOD 检测
ASH 在 OOD 检测方面非常有效。 对于 ImageNet,虽然图 2 显示了 4 个数据集的平均性能,但表 2 列出了每个数据集的详细性能,以及两个指标:FPR95 和 AUROC。 该表遵循 Sun 等人 (2021) 的精确格式,报告了文献中竞争性 OOD 检测方法的结果,以及我们计算的其他基线(例如 MobileNet 上的 DICE 和 DICE+ReAct)。 正如我们所看到的,所提出的 ASH-B 和 ASH-S 在几乎所有 OOD 数据集和 ResNet 上的评估指标上建立了新的 SOTA,并且性能与 DICE+ReAct 相当,同时算法更简单。 ASH-P 展示了仅通过修剪(简单地删除 60% 低值激活)带来的令人惊讶的收益,优于 Energy 分数、Softmax 分数和 ODIN。
在 CIFAR 基准测试中,我们遵循 Sun & Li (2022) 的精确实验设置:6 个 OOD 数据集和预训练的 DenseNet-101。 表 3 报告了我们方法的性能(所有 6 个数据集的平均值)以及所有基线方法。 附录中的表 7 和表 8 报告了每个数据集的详细性能。 所有 ASH 变体的性能都远远优于现有基线。
| OOD Datasets | |||||||||||
| Model | Methods | iNaturalist | SUN | Places | Textures | Average | |||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | ||
| ResNet | Softmax score | 54.99 | 87.74 | 70.83 | 80.86 | 73.99 | 79.76 | 68.00 | 79.61 | 66.95 | 81.99 |
| ODIN | 47.66 | 89.66 | 60.15 | 84.59 | 67.89 | 81.78 | 50.23 | 85.62 | 56.48 | 85.41 | |
| Mahalanobis | 97.00 | 52.65 | 98.50 | 42.41 | 98.40 | 41.79 | 55.80 | 85.01 | 87.43 | 55.47 | |
| Energy score | 55.72 | 89.95 | 59.26 | 85.89 | 64.92 | 82.86 | 53.72 | 85.99 | 58.41 | 86.17 | |
| ReAct | 20.38 | 96.22 | 24.20 | 94.20 | 33.85 | 91.58 | 47.30 | 89.80 | 31.43 | 92.95 | |
| DICE | 25.63 | 94.49 | 35.15 | 90.83 | 46.49 | 87.48 | 31.72 | 90.30 | 34.75 | 90.77 | |
| DICE + ReAct | 18.64 | 96.24 | 25.45 | 93.94 | 36.86 | 90.67 | 28.07 | 92.74 | 27.25 | 93.40 | |
| ASH-P (Ours) | 44.57 | 92.51 | 52.88 | 88.35 | 61.79 | 85.58 | 42.06 | 89.70 | 50.32 | 89.04 | |
| ASH-B (Ours) | 14.21 | 97.32 | 22.08 | 95.10 | 33.45 | 92.31 | 21.17 | 95.50 | 22.73 | 95.06 | |
| ASH-S (Ours) | 11.49 | 97.87 | 27.98 | 94.02 | 39.78 | 90.98 | 11.93 | 97.60 | 22.80 | 95.12 | |
| MobileNet | Softmax score | 64.29 | 85.32 | 77.02 | 77.10 | 79.23 | 76.27 | 73.51 | 77.30 | 73.51 | 79.00 |
| ODIN | 55.39 | 87.62 | 54.07 | 85.88 | 57.36 | 84.71 | 49.96 | 85.03 | 54.20 | 85.81 | |
| Mahalanobis | 62.11 | 81.00 | 47.82 | 86.33 | 52.09 | 83.63 | 92.38 | 33.06 | 63.60 | 71.01 | |
| Energy score | 59.50 | 88.91 | 62.65 | 84.50 | 69.37 | 81.19 | 58.05 | 85.03 | 62.39 | 84.91 | |
| ReAct | 42.40 | 91.53 | 47.69 | 88.16 | 51.56 | 86.64 | 38.42 | 91.53 | 45.02 | 89.47 | |
| DICE | 43.09 | 90.83 | 38.69 | 90.46 | 53.11 | 85.81 | 32.80 | 91.30 | 41.92 | 89.60 | |
| DICE + ReAct | 32.30 | 93.57 | 31.22 | 92.86 | 46.78 | 88.02 | 16.28 | 96.25 | 31.64 | 92.68 | |
| ASH-P (Ours) | 54.92 | 90.46 | 58.61 | 86.72 | 66.59 | 83.47 | 48.48 | 88.72 | 57.15 | 87.34 | |
| ASH-B (Ours) | 31.46 | 94.28 | 38.45 | 91.61 | 51.80 | 87.56 | 20.92 | 95.07 | 35.66 | 92.13 | |
| ASH-S (Ours) | 39.10 | 91.94 | 43.62 | 90.02 | 58.84 | 84.73 | 13.12 | 97.10 | 38.67 | 90.95 | |
| CIFAR-10 | CIFAR-100 | |||
| Method | FPR95 | AUROC | FPR95 | AUROC |
| Softmax score | 48.73 | 92.46 | 80.13 | 74.36 |
| ODIN | 24.57 | 93.71 | 58.14 | 84.49 |
| Mahalanobis | 31.42 | 89.15 | 55.37 | 82.73 |
| Energy score | 26.55 | 94.57 | 68.45 | 81.19 |
| ReAct | 26.45 | 94.95 | 62.27 | 84.47 |
| DICE | ||||
| ASH-P (Ours) | 23.45 | 95.22 | 64.53 | 82.71 |
| ASH-B (Ours) | 20.23 | 96.02 | 48.73 | 88.04 |
| ASH-S (Ours) | 15.05 | 96.61 | 41.40 | 90.02 |
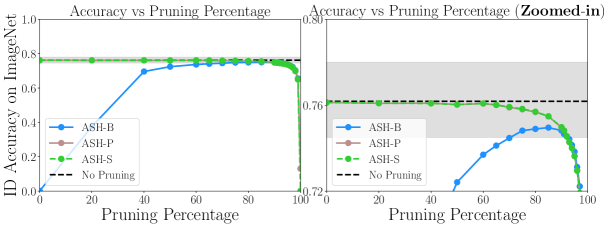
4.3 关于保持分布内精度
ASH 保留了分布内性能,因此可以用作 ID 和 OOD 任务的统一管道。 正如我们在图 2 中看到的,在接近剪枝百分比的低端 (65%) 时,ASH-S 和 ASH-P 的 ID 准确度仅略有下降(ImageNet Top-1 验证准确度) ; 76.13% 至 76.01%)。 我们修剪得越多,准确率下降就越大111ASH-P 和 ASH-S 在 ID 任务上产生精确的准确性,因为线性缩放最后一层激活,因此 logits(除非数值不稳定)不会影响模型的 softmax 输出。. 在 90% 时(即消除 90% 的激活值时),ASH-S 和 ASH-P 的 ID 准确度保持在 74.98%。 当尝试更大范围和粒度的剪枝级别时,如图 3 所示,我们观察到 ASH-S 和 ASH-P 确实始终保持准确性,直到达到相当高的剪枝值(例如在剪枝 99% 时,ID 准确率下降至 64.976%)。
然而,在 ASH-B 中观察到相反的趋势:如图 3 所示,在剪枝 50-90% 之间,ID 准确率呈上升趋势,而在 80% 到 80% 之间达到最佳准确率。 90% 的修剪激活。 原因是当剪枝率较低(修改更多值)时,ASH-B 中相当极端的二值化操作(将所有剩余激活设置为常数)会产生更大的影响。 对于 0% 剪枝的极端情况,ASH-B 只是将所有激活值设置为其平均值,这完全破坏了分类器(图3,曲线左端)。
4.4 ASH-RAND:随机化激活值
鉴于 ASH 在 ID 和 OOD 任务上都取得了成功,特别是 ASH-B,其中整个特征图的值设置为 或正常数,我们很好奇推动激活整形的程度更深入。 我们尝试了一个相当极端的变体:ASH-RAND,它将修剪后剩余的激活值设置为 之间的随机非负值。 结果如表4所示。 即使对于特征图进行如此极端的修改,它也能很好地工作。
ASH 的强劲结果促使我们问:为什么对特征图进行根本性的改变可以改善 OOD? 为什么剪掉大部分特征不会影响准确性? 一开始的表述是多余的吗? 我们在附录部分 E 中讨论 ASH 的有用解释。
| ImageNet benchmark | ||||
|---|---|---|---|---|
| Method | FPR95 | AUROC | AUPR | ID ACC |
| ASH-RAND@65 | 45.37 | 90.80 | 98.09 | 72.16 |
| ASH-RAND@70 | 46.93 | 90.67 | 98.05 | 72.87 |
| ASH-RAND@75 | 46.93 | 90.67 | 98.05 | 73.19 |
| ASH-RAND@80 | 51.24 | 89.94 | 97.89 | 73.57 |
| ASH-RAND@90 | 59.35 | 87.88 | 97.44 | 73.51 |
| ASH-B@65 | 22.73 | 95.06 | 98.94 | 74.12 |
| ASH-S@90 | 22.80 | 95.12 | 98.90 | 74.98 |
5消融研究
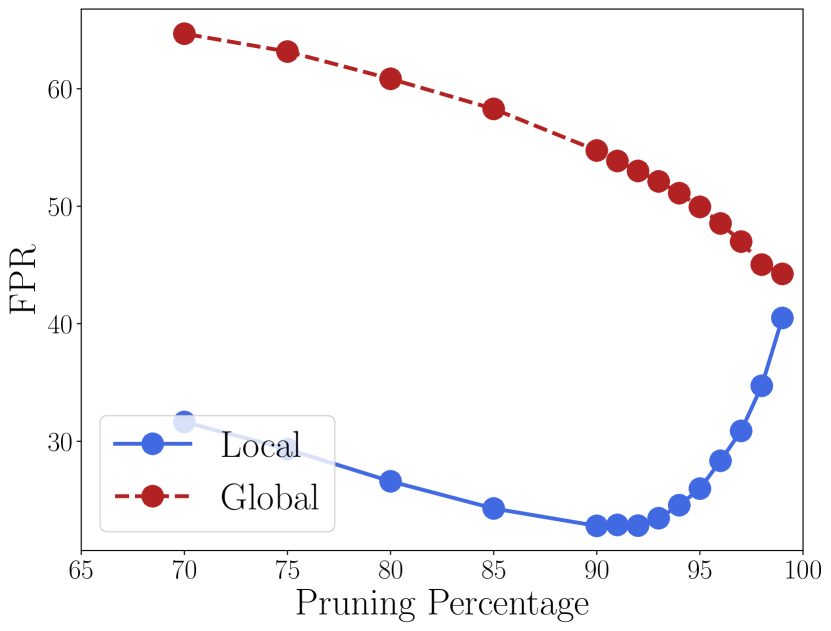
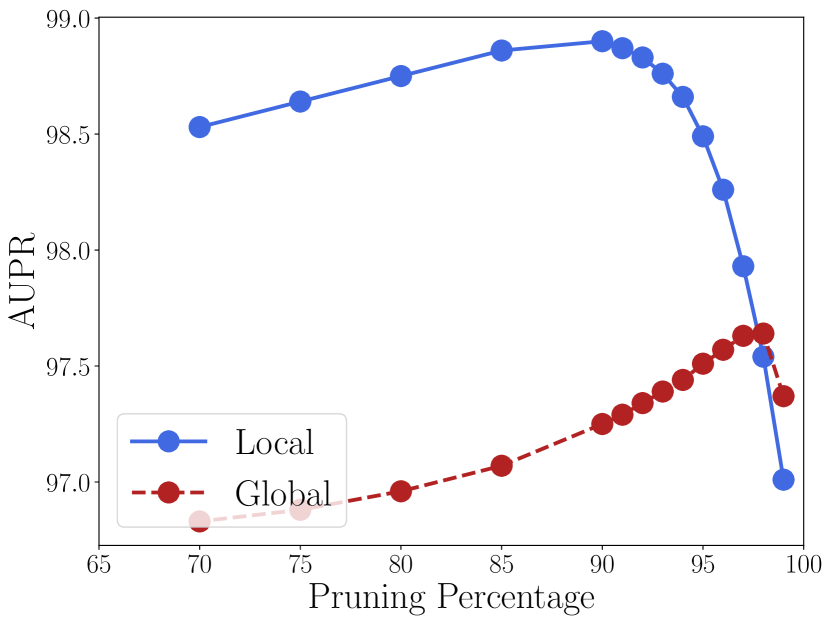
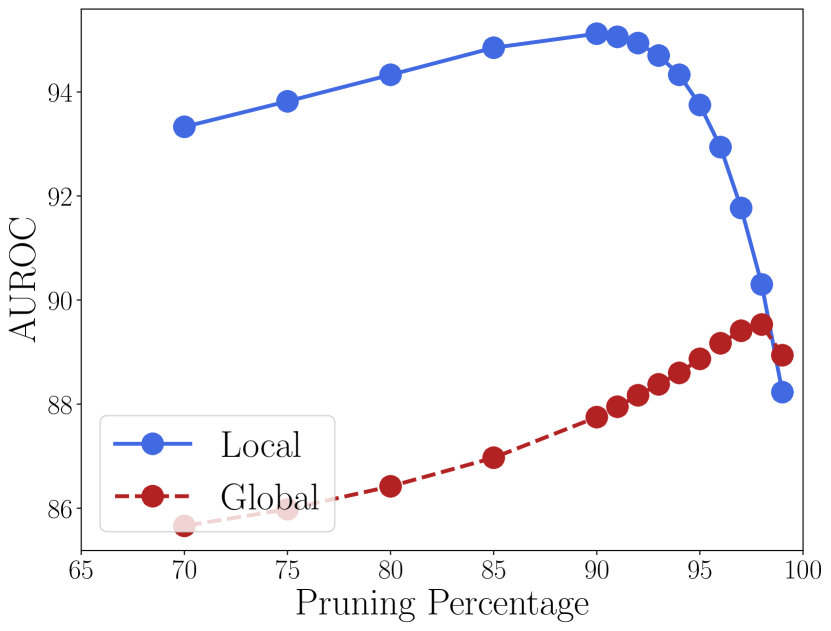
全局阈值与局部阈值
ASH 的工作版本计算每个图像的修剪阈值 (根据固定百分位数 ;参见算法 1-3),即每个输入图像将应用不同阈值的修剪步骤。 这种设计选择不需要有关网络、训练或测试数据的全局信息,但在推理时会产生轻微的计算开销。 另一种方法是根据所有训练数据计算“全局”阈值,假设我们可以在训练后访问它们。 90%剪枝水平意味着从所有训练数据中收集某个特征图的统计数据并获得反映90%百分位数的值。
我们实施了具有全局和局部阈值的 ASH-S 和 ASH-B; ASH-S 的图 4 显示了两种设计选择之间的差异。 ASH-B 结果包含在附录的 D 部分中。 正如我们所看到的,在修剪百分比一致的情况下,使用局部阈值总是比设置全局阈值效果更好,而最佳的整体性能也是通过局部阈值实现的。
去哪里 ASH
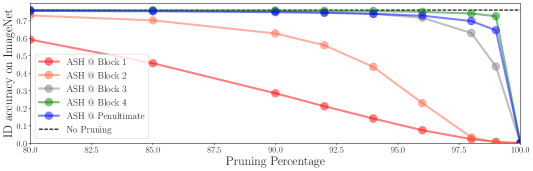
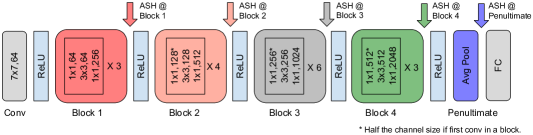
我们注意到 ASH 的工作位置是针对经过训练的网络的后面层,例如倒数第二层。 我们实验了其他展示位置如何影响其性能。 在图 5 中,我们展示了在网络的不同层上执行 ASH-S 的效果。 我们可以看到,当我们移动到网络的早期部分时,剪枝率的准确性下降变得更加严重。 有关这些展示位置的完整 OOD 检测结果,请参阅附录中的 A 部分。
将 ASH 与其他方法即插即用
ASH 作为两步操作与其他现有方法非常兼容。 在表 5 中,我们演示了如何轻松地将其与 Softmax 分数、Energy 分数、ODIN 和 ReAct 结合起来,以立即改进它们。 使用 CIFAR-10、CIFAR-100 和 ImageNet 进行实验。 所有的方法都是我们重新实现的。 有关实施细节,请参阅附录中的 F 节。
| CIFAR-10 | CIFAR-100 | ImageNet | |||||||
| Method | FPR95 | AUROC | AUPR | FPR95 | AUROC | AUPR | FPR95 | AUROC | AUPR |
| Softmax score | 48.69 | 92.52 | 80.75 | 80.06 | 74.45 | 76.99 | 64.76 | 82.82 | 95.94 |
| Softmax score + ASH tr. | 48.86 | 92.61 | 77.03 | 76.04 | 75.00 | 78.61 | 37.86 | 90.90 | 97.97 |
| ODIN | 25.71 | 94.72 | 95.60 | 64.87 | 82.43 | 84.85 | 50.80 | 87.57 | 97.19 |
| ODIN + ASH tr. | 15.38 | 96.41 | 96.62 | 38.54 | 90.49 | 91.51 | 28.59 | 93.34 | 98.40 |
| Energy score | 26.59 | 94.63 | 95.61 | 68.29 | 81.23 | 83.64 | 57.47 | 87.05 | 97.15 |
| Energy score + ASH tr. | 15.05 | 96.61 | 96.88 | 41.40 | 90.02 | 91.23 | 22.80 | 95.12 | 98.90 |
| ReAct | 29.00 | 94.92 | 96.14 | 69.94 | 82.07 | 85.43 | 31.43 | 92.95 | 98.50 |
| ReAct + ASH tr. | 16.35 | 96.91 | 97.41 | 41.64 | 88.93 | 90.14 | 24.88 | 94.27 | 98.66 |
6相关工作
事后模型增强
我们的方法对经过训练的数据表示进行事后修改。 类似的做法已被纳入其他领域。 例如,蒙特卡罗 dropout (Gal & Ghahramani,2016) 通过在训练和测试时添加 dropout 层来估计预测不确定性,生成同一输入实例的多个预测。 在对抗性防御中,随机平滑(Cohen等人,2019)对输入应用随机高斯扰动以获得稳健的输出。 这些方法的缺点是它们都需要对每个输入图像进行多次推理运行。 模型编辑领域(Santurkar等人,2021;Meng等人,2022)和公平性(Alabdulmohsin & Lucic,2021;Celis等人,2019)也修改训练好的数据增强稳健性和公平性保证的模型。 然而,它们都涉及领域专业知识以及额外的数据,而我们的工作中都不需要这些。 温度缩放(Guo等人,2017)通过从单独的验证数据集中学习的标量重新缩放神经网络的logits。 ODIN (Liang 等人, 2017) 然后将温度缩放与输入扰动结合起来。 我们在实验中与 ODIN 进行了密切比较,并显示出优越的结果。
稀疏表示
ASH 和激活剪枝以及更一般的稀疏表示概念之间可以进行类似比较。 随机激活剪枝(SAP)(Dhillon 等人,2018)已被提出作为对抗对抗攻击的有用技术。 SAP 在每次前向传递期间修剪低幅度激活的随机子集,并扩展其他激活。 对抗性防御超出了本文的范围,但可以作为未来卓有成效的工作方向。 Ahmad & Scheinkman (2019) 使用随机向量的组合来展示稀疏激活如何使单元能够使用较低的阈值,这可以带来许多好处,例如提高噪声容忍度。 他们在网络中使用 top-K 作为激活函数,代替 ReLU。 与 ASH 的主要区别在于即使在训练期间也使用 top-K 来创建稀疏激活,并删除了 ReLU。
7结论
在本文中,我们提出了 ASH,这是一种极其简单、事后、即时、即插即用的激活整形方法,应用于推理输入。 ASH 的工作原理是修剪输入样本的大部分激活并稍微调整剩余部分。 当与能量分数相结合时,它在中型和大规模图像分类基准上都优于所有当代 OOD 检测方法。 它还与现有方法兼容并为其带来好处。 在 3 个 ID 数据集、10 个 OOD 数据集上进行的广泛实验设置以及在 4 个指标上评估的性能,全面证明了 ASH 的有效性:在 OOD 检测上达到 SOTA,同时在 OOD 检测和 ID 分类准确性之间提供最佳权衡。
致谢
这项工作得到了 Google Cloud 资助的 ML Collective 计算拨款的支持,并被 ICLR 2022 DEI 计划(Liu & Maughan,2021;2022)选为赞助项目。 作者要感谢 Marcus Lewis 校对并提供与稀疏性文献的联系,感谢 Dumitru Erhan 对早期草稿提供反馈,感谢 Milan Misic 在项目早期阶段进行富有成效的讨论和集思广益。 我们感谢法戈狗的犬齿表情。 我们感谢 ML Collective 社区和 ICLR CoSubmitting Summer 社区对本研究的持续支持和反馈。
参考
- Ahmad & Scheinkman (2019) Subutai Ahmad and Luiz Scheinkman. How can we be so dense? the benefits of using highly sparse representations. arXiv preprint arXiv:1903.11257, 2019.
- Alabdulmohsin & Lucic (2021) Ibrahim M Alabdulmohsin and Mario Lucic. A near-optimal algorithm for debiasing trained machine learning models. Advances in Neural Information Processing Systems, 34:8072–8084, 2021.
- Amodei et al. (2016) Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in ai safety. arXiv preprint arXiv:1606.06565, 2016.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners, 2020. URL https://arxiv.org/abs/2005.14165.
- Celis et al. (2019) L Elisa Celis, Lingxiao Huang, Vijay Keswani, and Nisheeth K Vishnoi. Classification with fairness constraints: A meta-algorithm with provable guarantees. In Proceedings of the conference on fairness, accountability, and transparency, pp. 319–328, 2019.
- Cimpoi et al. (2014) Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3606–3613, 2014.
- Cohen et al. (2019) Jeremy Cohen, Elan Rosenfeld, and Zico Kolter. Certified adversarial robustness via randomized smoothing. In International Conference on Machine Learning, pp. 1310–1320. PMLR, 2019.
- Dathathri et al. (2020) Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. Plug and play language models: A simple approach to controlled text generation. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=H1edEyBKDS.
- Dhillon et al. (2018) Guneet S Dhillon, Kamyar Azizzadenesheli, Zachary C Lipton, Jeremy Bernstein, Jean Kossaifi, Aran Khanna, and Anima Anandkumar. Stochastic activation pruning for robust adversarial defense. arXiv preprint arXiv:1803.01442, 2018.
- Gal & Ghahramani (2016) Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In international conference on machine learning, pp. 1050–1059. PMLR, 2016.
- Guo et al. (2017) Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. In International conference on machine learning, pp. 1321–1330. PMLR, 2017.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- Hendrycks & Gimpel (2017) Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks. Proceedings of International Conference on Learning Representations, 2017.
- Huang et al. (2017) Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4700–4708, 2017.
- Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020. URL https://arxiv.org/abs/2001.08361.
- Lakshminarayanan et al. (2017) Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (eds.), Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper/2017/file/9ef2ed4b7fd2c810847ffa5fa85bce38-Paper.pdf.
- Lee et al. (2018) Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. Advances in neural information processing systems, 31, 2018.
- Li et al. (2018) Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. Measuring the intrinsic dimension of objective landscapes. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018. URL https://openreview.net/forum?id=ryup8-WCW.
- Liang et al. (2017) Shiyu Liang, Yixuan Li, and Rayadurgam Srikant. Enhancing the reliability of out-of-distribution image detection in neural networks. arXiv preprint arXiv:1706.02690, 2017.
- Liu & Maughan (2021) Rosanne Liu and Krystal Maughan. Broadening our call for participation to iclr 2022, 2021. URL https://blog.iclr.cc/2021/08/10/broadening-our-call-for-participation-to-iclr-2022.
- Liu & Maughan (2022) Rosanne Liu and Krystal Maughan. Reflection on the dei initiative at iclr 2022, 2022. URL https://blog.iclr.cc/2022/05/12/reflection-on-the-dei-initiative-at-iclr-2022.
- Liu et al. (2020) Weitang Liu, Xiaoyun Wang, John Owens, and Yixuan Li. Energy-based out-of-distribution detection. In Advances in Neural Information Processing Systems (NeurIPS), 2020.
- Meng et al. (2022) Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt, 2022. URL https://arxiv.org/abs/2202.05262.
- Minderer et al. (2021) Matthias Minderer, Josip Djolonga, Rob Romijnders, Frances Hubis, Xiaohua Zhai, Neil Houlsby, Dustin Tran, and Mario Lucic. Revisiting the calibration of modern neural networks. Advances in Neural Information Processing Systems, 34, 2021.
- Moosavi-Dezfooli et al. (2017) Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, Omar Fawzi, and Pascal Frossard. Universal adversarial perturbations. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1765–1773, 2017.
- Netzer et al. (2011) Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y. Ng. Reading digits in natural images with unsupervised feature learning. In NIPS Workshop on Deep Learning and Unsupervised Feature Learning 2011, 2011. URL http://ufldl.stanford.edu/housenumbers/nips2011_housenumbers.pdf.
- Nguyen et al. (2015) Anh Nguyen, Jason Yosinski, and Jeff Clune. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 427–436, 2015.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pp. 8748–8763. PMLR, 2021.
- Ramesh et al. (2022) Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents, 2022.
- Saharia et al. (2022) Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding, 2022. URL https://arxiv.org/abs/2205.11487.
- Sandler et al. (2018) Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4510–4520, 2018.
- Santurkar et al. (2021) Shibani Santurkar, Dimitris Tsipras, Mahalaxmi Elango, David Bau, Antonio Torralba, and Aleksander Madry. Editing a classifier by rewriting its prediction rules. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan (eds.), Advances in Neural Information Processing Systems, volume 34, pp. 23359–23373. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper/2021/file/c46489a2d5a9a9ecfc53b17610926ddd-Paper.pdf.
- Simonyan & Zisserman (2014) Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- Sun & Li (2022) Yiyou Sun and Yixuan Li. Dice: Leveraging sparsification for out-of-distribution detection. In European Conference on Computer Vision, 2022.
- Sun et al. (2021) Yiyou Sun, Chuan Guo, and Yixuan Li. React: Out-of-distribution detection with rectified activations. Advances in Neural Information Processing Systems, 34:144–157, 2021.
- Sun et al. (2022) Yiyou Sun, Yifei Ming, Xiaojin Zhu, and Yixuan Li. Out-of-distribution detection with deep nearest neighbors. arXiv preprint arXiv:2204.06507, 2022.
- Szegedy et al. (2013) Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199, 2013.
- Van Horn et al. (2018) Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, and Serge Belongie. The inaturalist species classification and detection dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 8769–8778, 2018.
- Xiao et al. (2010) Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In 2010 IEEE computer society conference on computer vision and pattern recognition, pp. 3485–3492. IEEE, 2010.
- Xu et al. (2015) Pingmei Xu, Krista A Ehinger, Yinda Zhang, Adam Finkelstein, Sanjeev R Kulkarni, and Jianxiong Xiao. Turkergaze: Crowdsourcing saliency with webcam based eye tracking. arXiv preprint arXiv:1504.06755, 2015.
- Yu et al. (2015) Fisher Yu, Ari Seff, Yinda Zhang, Shuran Song, Thomas Funkhouser, and Jianxiong Xiao. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365, 2015.
- Yu et al. (2022) Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge, and Yonghui Wu. Scaling autoregressive models for content-rich text-to-image generation, 2022.
- Zhang et al. (2022) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. Opt: Open pre-trained transformer language models, 2022. URL https://arxiv.org/abs/2205.01068.
- Zhou et al. (2017) Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. IEEE transactions on pattern analysis and machine intelligence, 40(6):1452–1464, 2017.
附录:用于分布外检测的极其简单的激活整形
附录 AASH 展示位置的完整结果
论文中显示的主要结果是通过将 ASH 放置在网络的后面层(ResNet-50 和 MobileNet 的倒数第二层)生成的。 在这里,我们展示了将 ASH 放置在网络的不同位置时的结果:ResNet-50 的第 1、2、3 和 4 个块,位于激活函数 (ReLU) 之前每个块的最后一个卷积层的末尾。 图5(底部)说明了此类放置,以及精度下降曲线(顶部)。 在这里,我们在表 6 中显示了这些 ASH 位置的 OOD 检测结果。
正如我们所看到的,倒数第二层放置确实在 ID 准确性保留和 OOD 检测方面给出了最佳结果。 当我们将 ASH 移向网络的开头时,准确性和 OOD 检测率都会下降。
值得注意的是,表6中的结果对每个层块采用了不同版本的ASH。 对于倒数第二层和第4层,我们使用ASH-S@90(与主论文中的设置相同),而对于1-3层我们使用ASH-P@90。 原因是 ASH-S 极大地降低了性能。 通过简单地在第 3 层添加缩放因子(从 ASH-P 更改为 ASH-S),ID 准确度从 75% 下降到 5%。
| ID: ImageNet; OOD: iNaturalist, Places, Textures, Sun | ||||
|---|---|---|---|---|
| ASH placement | FPR95 | AUROC | AUPR | ID ACC |
| ASH-P@90 before last ReLU of 1st Block | 93.55 | 59.46 | 89.89 | 28.57 |
| ASH-P@90 before last ReLU of 2nd Block | 70.45 | 81.45 | 95.93 | 62.78 |
| ASH-P@90 before last ReLU of 3rd Block | 63.38 | 85.83 | 96.91 | 75.36 |
| ASH-S@90 before last ReLU of 3rd Block | 98.51 | 41.39 | 83.59 | 5.21 |
| ASH-S@70 before last ReLU of 3rd Block | 97.72 | 49.50 | 87.27 | 19.32 |
| ASH-S@90 before last ReLU of 4th Block | 34.69 | 92.11 | 98.38 | 75.83 |
| ASH-B@90 before last ReLU of 4th Block | 33.74 | 92.37 | 98.48 | 75.70 |
| ASH-S@90 after penultimate Layer* | 22.80 | 95.12 | 98.90 | 74.98 |
| No ASH (Energy score alone) | 58.41 | 86.17 | 96.88 | 76.13 |
附录 B详细的 CIFAR 结果
| Method | SVHN | LSUN-c | LSUN-r | iSUN | Textures | Places365 | Average | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| Softmax score | 47.24 | 93.48 | 33.57 | 95.54 | 42.10 | 94.51 | 42.31 | 94.52 | 64.15 | 88.15 | 63.02 | 88.57 | 48.73 | 92.46 |
| ODIN | 25.29 | 94.57 | 4.70 | 98.86 | 3.09 | 99.02 | 3.98 | 98.90 | 57.50 | 82.38 | 52.85 | 88.55 | 24.57 | 93.71 |
| GODIN | 6.68 | 98.32 | 17.58 | 95.09 | 36.56 | 92.09 | 36.44 | 91.75 | 35.18 | 89.24 | 73.06 | 77.18 | 34.25 | 90.61 |
| Mahalanobis | 6.42 | 98.31 | 56.55 | 86.96 | 9.14 | 97.09 | 9.78 | 97.25 | 21.51 | 92.15 | 85.14 | 63.15 | 31.42 | 89.15 |
| Energy score | 40.61 | 93.99 | 3.81 | 99.15 | 9.28 | 98.12 | 10.07 | 98.07 | 56.12 | 86.43 | 39.40 | 91.64 | 26.55 | 94.57 |
| ReAct | 41.64 | 93.87 | 5.96 | 98.84 | 11.46 | 97.87 | 12.72 | 97.72 | 43.58 | 92.47 | 43.31 | 91.03 | 26.45 | 94.67 |
| DICE | 25.99±5.10 | 95.90±1.08 | 0.26±0.11 | 99.92±0.02 | 3.91±0.56 | 99.20±0.15 | 4.36±0.71 | 99.14±0.15 | 41.90±4.41 | 88.18±1.80 | 48.59±1.53 | 89.13±0.31 | 20.83±1.58 | 95.24±0.24 |
| ASH-P (Ours) | 30.14 | 95.29 | 2.82 | 99.34 | 7.97 | 98.33 | 8.46 | 98.29 | 50.85 | 88.29 | 40.46 | 91.76 | 23.45 | 95.22 |
| ASH-B (Ours) | 17.92 | 96.86 | 2.52 | 99.48 | 8.13 | 98.54 | 8.59 | 98.45 | 35.73 | 92.88 | 48.47 | 89.93 | 20.23 | 96.02 |
| ASH-S (Ours) | 6.51 | 98.65 | 0.90 | 99.73 | 4.96 | 98.92 | 5.17 | 98.90 | 24.34 | 95.09 | 48.45 | 88.34 | 15.05 | 96.61 |
| Method | SVHN | LSUN-c | LSUN-r | iSUN | Textures | Places365 | Average | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| Softmax score | 81.70 | 75.40 | 60.49 | 85.60 | 85.24 | 69.18 | 85.99 | 70.17 | 84.79 | 71.48 | 82.55 | 74.31 | 80.13 | 74.36 |
| ODIN | 41.35 | 92.65 | 10.54 | 97.93 | 65.22 | 84.22 | 67.05 | 83.84 | 82.34 | 71.48 | 82.32 | 76.84 | 58.14 | 84.49 |
| GODIN | 36.74 | 93.51 | 43.15 | 89.55 | 40.31 | 92.61 | 37.41 | 93.05 | 64.26 | 76.72 | 95.33 | 65.97 | 52.87 | 85.24 |
| Mahalanobis | 22.44 | 95.67 | 68.90 | 86.30 | 23.07 | 94.20 | 31.38 | 93.21 | 62.39 | 79.39 | 92.66 | 61.39 | 55.37 | 82.73 |
| Energy score | 87.46 | 81.85 | 14.72 | 97.43 | 70.65 | 80.14 | 74.54 | 78.95 | 84.15 | 71.03 | 79.20 | 77.72 | 68.45 | 81.19 |
| ReAct | 83.81 | 81.41 | 25.55 | 94.92 | 60.08 | 87.88 | 65.27 | 86.55 | 77.78 | 78.95 | 82.65 | 74.04 | 62.27 | 84.47 |
| DICE | 54.65±4.94 | 88.84±0.39 | 0.93±0.07 | 99.74±0.01 | 49.40±1.99 | 91.04±1.49 | 48.72±1.55 | 90.08±1.36 | 65.04±0.66 | 76.42±0.35 | 79.58±2.34 | 77.26±1.08 | 49.72±1.69 | 87.23±0.73 |
| ASH-P (Ours) | 81.86 | 83.86 | 11.60 | 97.89 | 67.56 | 81.67 | 70.90 | 80.81 | 78.24 | 74.09 | 77.03 | 77.94 | 64.53 | 82.71 |
| ASH-B (Ours) | 53.52 | 90.27 | 4.46 | 99.17 | 48.38 | 91.03 | 47.82 | 91.09 | 53.71 | 84.25 | 84.52 | 72.46 | 48.73 | 88.04 |
| ASH-S (Ours) | 25.02 | 95.76 | 5.52 | 98.94 | 51.33 | 90.12 | 46.67 | 91.30 | 34.02 | 92.35 | 85.86 | 71.62 | 41.40 | 90.02 |
附录 C 其他架构的 ID-OOD 权衡
虽然图 2 描述了 ResNet-50 架构上 ImageNet 数据集的 ID-OOD 权衡,但我们用额外的架构补充了该图:MobileNetV2,其 OOD 结果包含在表 2 中>。 正如我们在图 6 中看到的,ASH-S(绿色)和 ASH-B(蓝色)系列均提供卓越的 ID 精度保留,同时提供与最先进的 OOD 性能相当的性能 (DICE+ReAct )。 请注意,虽然平均而言,对于此特定架构,ASH 在 OOD 指标上的表现并不优于 DICE+ReAct,但它仍然具有许多优势:算法更简单、转动工作更轻松、零预计算成本以及保持 ID 准确性。
附录 D 关于全局阈值与局部阈值的更多实验
| Local threshold | Global threshold | |||||
|---|---|---|---|---|---|---|
| Method | FPR95 | AUROC | AUPR | FPR95 | AUROC | AUPR |
| ASH-S@99 | 40.49 | 88.23 | 97.01 | 44.24 | 88.94 | 97.37 |
| ASH-S@98 | 34.72 | 90.30 | 97.54 | 45.03 | 89.53 | 97.64 |
| ASH-S@97 | 30.88 | 91.77 | 97.93 | 46.99 | 89.41 | 97.63 |
| ASH-S@96 | 28.34 | 92.94 | 98.26 | 48.53 | 89.17 | 97.57 |
| ASH-S@95 | 25.97 | 93.75 | 98.49 | 49.94 | 88.87 | 97.51 |
| ASH-S@94 | 24.56 | 94.33 | 98.66 | 51.11 | 88.60 | 97.44 |
| ASH-S@93 | 23.45 | 94.70 | 98.76 | 52.11 | 88.38 | 97.39 |
| ASH-S@92 | 22.82 | 94.94 | 98.83 | 53.00 | 88.17 | 97.34 |
| ASH-S@91 | 22.88 | 95.06 | 98.87 | 53.85 | 87.95 | 97.29 |
| ASH-S@90 | 22.80 | 95.12 | 98.90 | 54.74 | 87.75 | 97.25 |
| ASH-S@85 | 24.28 | 94.85 | 98.86 | 58.28 | 86.97 | 97.07 |
| ASH-S@80 | 26.59 | 94.33 | 98.75 | 60.84 | 86.42 | 96.96 |
| ASH-S@75 | 29.32 | 93.82 | 98.64 | 63.16 | 85.98 | 96.88 |
| ASH-S@70 | 31.64 | 93.33 | 98.53 | 64.68 | 85.66 | 96.83 |
| Local threshold | Global threshold | |||||
|---|---|---|---|---|---|---|
| Method | FPR95 | AUROC | AUPR | FPR95 | AUROC | AUPR |
| ASH-B@99 | 45.43 | 89.09 | 97.55 | 41.70 | 89.75 | 97.55 |
| ASH-B@98 | 39.59 | 91.22 | 98.08 | 41.64 | 90.57 | 97.87 |
| ASH-B@97 | 36.54 | 92.17 | 98.30 | 42.73 | 90.57 | 97.88 |
| ASH-B@96 | 34.26 | 92.79 | 98.44 | 43.55 | 90.43 | 97.85 |
| ASH-B@95 | 32.64 | 93.20 | 98.52 | 44.38 | 90.20 | 97.79 |
| ASH-B@94 | 31.09 | 93.51 | 98.59 | 45.39 | 89.99 | 97.75 |
| ASH-B@93 | 30.03 | 93.76 | 98.64 | 45.77 | 89.86 | 97.72 |
| ASH-B@92 | 29.01 | 93.95 | 98.68 | 46.29 | 89.71 | 97.68 |
| ASH-B@91 | 28.43 | 94.10 | 98.71 | 46.97 | 89.55 | 97.64 |
| ASH-B@90 | 27.58 | 94.24 | 98.74 | 48.25 | 89.39 | 97.61 |
| ASH-B@85 | 25.26 | 94.65 | 98.83 | 51.04 | 88.77 | 97.48 |
| ASH-B@80 | 24.04 | 94.88 | 98.88 | 53.63 | 88.24 | 97.37 |
| ASH-B@75 | 22.95 | 95.02 | 98.91 | 56.66 | 87.63 | 97.25 |
| ASH-B@70 | 22.39 | 95.08 | 98.93 | 60.19 | 86.93 | 97.12 |
附录EASH的直观与解释
ASH 作为事后正则化
ASH 可以被认为是一个简单的“特征清理”步骤,或者特征的事后正则化。 由于我们现在都承认神经网络被过度参数化,因此我们可以认为此类网络学习到的表示可能是“过度表示”。虽然过度参数化的力量主要体现在使训练变得更容易——为客观景观添加更多维度,同时手头任务的内在维度保持不变(Li等人,2018),我们认为从从表示学习的角度来看,过度参数化网络“过度”特征表示,即输入产生的表示包含太多冗余。 我们推测,训练后的一个简单的特征清理步骤可以帮助更好地奠定所得到的学习表示。 验证或推翻这一猜想的未来工作将包括测试简化或正则化表示是否在其他问题领域(从泛化到迁移学习和持续学习)中表现良好。
连接到修改后的 ReLU
解释 ASH 的另一个视角是将其视为修改后的 ReLu 函数,根据输入样本进行动态调整。 由于我们对 ReLU 之前的特征激活进行操作,如图 7 所示,最基本的版本 ASH-P 与后续的 ReLU 函数相结合,就变成了简单的调整后的 ReLU。 由于截止值是根据每个输入实时确定的,因此它本质上是一个依赖于数据的激活函数。 ASH 的成功凸显了在推理时研究更灵活、自适应、数据依赖的激活函数的必要性。
修剪的幅度与价值
许多现有的修剪方法依赖于数字的大小(权重或激活)。 然而在这项工作中我们使用直接值。 也就是说,如果较大的负值位于值分布的 百分位数内,则将被修剪。 其中的原因是,我们的操作要么是在 ReLU 之前的 激活,在这种情况下,所有负值都将被去除,要么是在倒数第二层的激活,在这种情况下,所有值都已经是非负值。
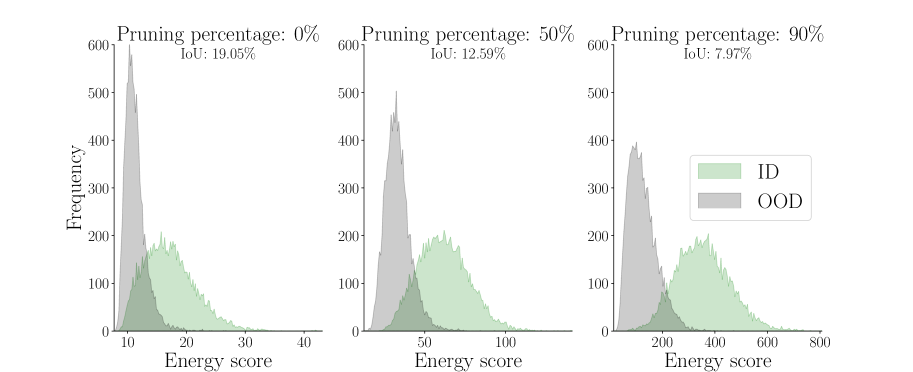
ASH 如何改变分数分布
解释 ASH 有效性的一种视角是检查它如何改变分数分布以最大化 ID 和 OOD 之间的分离。 由于我们默认使用能量作为评分函数,因此我们演示了能量评分分布如何随着不同强度的 ASH 处理而变化,如图 8 所示。 从左图的无 ASH 处理(修剪:0%)到右图的完全处理(90%),我们可以看到 ID 和 OOD 分布如何变化以最大化分离。 222For animated plots, see: https://andrijazz.github.io/ash/#dist。
附录F实施注意事项
所有实验均使用 NVIDIA GTX1080Ti GPU 完成。 重现结果的代码与本附录一起提交。
ImageNet 结果注释(表2):
-
•
对于 ResNet 和 MobileNet 结果,“ASH-P(我们的)”是用 实现的,“ASH-B(我们的)”是用 实现的,“ASH-S”是用 实现的。 (我们的)”是用 实现的。
-
•
为了使用 MobileNet 重新实现 DICE,我们使用了 DICE 修剪阈值 。
-
•
为了在 MobileNet 上重新实现 DICE + ReAct,由于 DICE 和 ReAct 都有自己的超参数,因此我们尝试了网格搜索,其中 DICE 剪枝阈值包括 和 ReAct 剪裁阈值 。 为网格搜索选择这些值的理由是:10% 和 15% 取自 DICE 代码库中的超参数设置333https://github.com/deeplearning-wisc/dice/blob/4d393c2871a80d8789cc97c31adcee879fe74b29/demo-imagenet.sh,建议70%单独使用时的 DICE 阈值。 在 ReAct 裁剪阈值的情况下, 和 取自同一代码库,而 是根据训练数据计算的 90% 百分位,遵循反应程序。 我们报告了所有超参数组合中的最佳结果,由 DICE 剪枝和 ReAct 剪裁给出。
-
•
对于 CIFAR-10,“ASH-P(我们的)”通过 实现,“ASH-B(我们的)”通过 实现,“ASH-S(我们的)”通过 实现。 )”是用实现的。
-
•
对于 CIFAR-100,“ASH-P(我们的)”通过 实现,“ASH-B(我们的)”通过 实现,“ASH-S(我们的)”通过 实现。 )”是用实现的。
-
•
其他方法的结果是从 DICE 复制的。
兼容性结果注释(表5):
-
•
“Softmax 分数 + ASH”是通过 CIFAR-10 的 ASH-P @ 、CIFAR-100 的 ASH-B @ 和 ASH-B @
-
•
“能量分数 + ASH”通过 CIFAR-10 的 ASH-S @ 、CIFAR-100 的 ASH-S @ 和 ASH-S @
-
•
“ODIN”和“ODIN + ASH”使用预训练的 CIFAR DenseNet-101,其中幅度参数为 ,以及预训练的 ResNet-50,其中幅度参数为 。
-
•
“ODIN + ASH”通过 CIFAR-10 的 ASH-S @ 、CIFAR-100 的 ASH-S @ 和 ASH-S @
-
•
CIFAR-10 和 CIFAR-100 的“ReAct”结果由我们实施。 我们无法复制 DICE 论文补充表 9 中显示的确切结果。
-
•
对于所有 CIFAR-10、CIFAR-100 和 ImageNet,“ReAct + ASH”是通过 ASH-S @ 和 ReAct Clippign 阈值 实现的。
附录 G其他架构
在表2中,我们使用了 2 种架构(ResNet50 和 MobileNetV2)进行 ImageNet 实验。 我们在表 11 中添加了另外 2 个:VGG16 (Simonyan & Zisserman,2014) 和 DenseNet-121 (Huang 等人,2017)。
| OOD Datasets | |||||||||||
| Model | Methods | iNaturalist | SUN | Places | Textures | Average | |||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | ||
| DenseNet-121 | Energy score | 39.69 | 92.66 | 51.98 | 87.40 | 57.84 | 85.17 | 52.11 | 85.42 | 50.40 | 87.66 |
| ASH-S@90 (Ours) | 15.53 | 97.03 | 37.14 | 91.53 | 46.50 | 88.79 | 22.04 | 95.01 | 30.30 | 93.09 | |
| ASH-B@65 (Ours) | 34.05 | 92.28 | 42.98 | 89.11 | 55.09 | 84.90 | 56.21 | 83.10 | 47.08 | 87.35 | |
| ASH-B@90 (Ours) | 18.22 | 96.36 | 35.17 | 92.48 | 45.38 | 89.15 | 22.75 | 95.38 | 30.38 | 93.34 | |
| VGG-16 | Energy score | 51.35 | 90.30 | 57.54 | 87.55 | 64.20 | 84.83 | 44.24 | 89.98 | 54.33 | 88.17 |
| ASH-B@65 (Ours) | 25.98 | 94.20 | 30.04 | 93.19 | 42.52 | 89.01 | 30.25 | 92.35 | 32.20 | 92.19 | |
| ASH-S@90 (Ours) | 47.14 | 91.34 | 55.20 | 88.41 | 61.58 | 85.92 | 44.43 | 89.96 | 52.09 | 88.91 | |
| ASH-S@95 (Ours) | 38.36 | 92.98 | 47.41 | 94.02 | 54.63 | 87.81 | 39.08 | 90.95 | 44.87 | 90.47 | |
| ASH-S@99 (Ours) | 29.30 | 93.18 | 43.59 | 90.17 | 49.46 | 87.79 | 43.60 | 86.36 | 41.49 | 89.38 | |
附录 H 附加缩放功能
ASH-S 可与不同的缩放功能一起使用。 表 12 显示了与线性 () 和指数缩放 () 函数一起使用时 ASH-S 性能的比较。 我们观察到与指数函数一起使用时的最佳性能。
| OOD Datasets | ||||||||||
| Scaling functions | iNaturalist | SUN | Places | Textures | Average | |||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| Linear (ASH-S@90) | 23.68 | 95.97 | 44.03 | 90.80 | 54.92 | 87.90 | 24.24 | 94.55 | 36.72 | 92.31 |
| Exponential (ASH-S@90) | 11.49 | 97.87 | 27.98 | 94.02 | 39.78 | 90.98 | 11.93 | 97.60 | 22.80 | 95.12 |
附录一CIFAR 10 与 CIFAR 100
我们在实验中使用 CIFAR 10 和 CIFAR 100 作为 ID 数据集,同时使用其他六个相当不同的数据集(SVHN、LSUN C、LSUN R、iSUN、Places365、Textures)作为 OOD。 如果使用 CIFAR 10 和 CIFAR 100(两个相似的数据集但复杂性不同)作为 ID 和 OOD 会发生什么? 在这种情况下 ASH 方法仍然有效吗? 我们使用不同的阈值进行 ASH-S 实验;结果如图9所示。 我们可以看到 ASH 在这种相当困难的情况下仍然有效。 我们在这里仅包含简单的基线,例如 Energy 和 Softmax。
附录 JASH 改进了 OOD 的 KNN
在表 5 中,我们表明 ASH 治疗比现有方法有所改进:Softmax 评分、ODIN、能量评分和 ReAct。 在本节中,我们尝试将 ASH 添加到方法上不同的检测器,即 K 最近邻 (KNN)。 按照(Sun等人,2022)中的设置,我们将ASH添加到在CIFAR-10上训练的ResNet18中。 OOD 数据集为 SVHN、LSUN、iSUN、Textures、Places365(与 (Sun 等人, 2022) 中使用的相同)。 由于原来的“ResNet18 倒数第二层”现在是生成用于聚类的特征向量的最后一层,因此我们将 ASH 放在之前的层上,就在 ResNet18 的第 4 个块之后。 正如我们在表 13 中看到的那样,采用 ASH 处理的 KNN 在一系列修剪百分比方面均优于基线(仅 KNN),ASH-S 比 ASH-B 更可靠。
| OOD Datasets | ||||||||||||
| Method | SVHN | LSUN | iSUN | Textures | Places365 | Average | ||||||
| FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | |
| Baseline (KNN only) | 27.97 | 95.48 | 18.50 | 96.84 | 24.68 | 95.52 | 26.74 | 94.96 | 44.56 | 90.85 | 28.49 | 94.73 |
| ASH-S@65 | 27.38 | 95.55 | 17.58 | 96.96 | 24.68 | 95.53 | 26.45 | 95.00 | 44.42 | 90.89 | 28.10 | 94.78 |
| ASH-S@70 | 26.71 | 95.62 | 16.80 | 97.06 | 24.48 | 95.53 | 26.26 | 95.00 | 43.99 | 90.96 | 27.65 | 94.84 |
| ASH-S@75 | 25.86 | 95.70 | 15.97 | 97.18 | 24.67 | 95.50 | 26.22 | 94.97 | 43.46 | 91.04 | 27.24 | 94.88 |
| ASH-S@80 | 25.06 | 95.79 | 14.84 | 97.31 | 25.02 | 95.38 | 26.21 | 94.88 | 43.35 | 91.10 | 26.90 | 94.89 |
| ASH-S@85 | 24.61 | 95.86 | 14.07 | 97.43 | 26.64 | 95.13 | 26.74 | 94.70 | 43.78 | 91.08 | 27.17 | 94.84 |
| ASH-S@90 | 24.26 | 95.93 | 13.49 | 97.53 | 30.11 | 94.59 | 28.09 | 94.34 | 44.97 | 90.87 | 28.18 | 94.65 |
| ASH-B@40 | 11.21 | 97.70 | 4.38 | 99.11 | 27.29 | 95.48 | 24.02 | 94.99 | 40.72 | 92.22 | 21.53 | 95.90 |
| ASH-B@65 | 37.21 | 93.65 | 33.75 | 93.40 | 24.67 | 95.83 | 27.71 | 94.40 | 52.25 | 89.31 | 35.12 | 93.32 |
| ASH-B@90 | 49.13 | 92.78 | 27.25 | 95.80 | 31.78 | 94.83 | 31.90 | 94.01 | 47.64 | 90.48 | 37.54 | 93.58 |
附录KASH和DICE的区别
在这里,我们强调 ASH(我们的工作)和 DICE (Sun & Li,2022) 在性能和方法方面的主要区别:
-
1.
(性能)ASH 总体性能要好得多,并且 ID 精度不会下降(图2)
-
2.
(性能)DICE单独使用效果不太好,只有与ReAct结合使用时,超参数调优的开销会增加一倍
-
3.
(方法论)ASH 完全是动态的,不需要像 DICE 那样进行预先计算
-
4.
(方法论)ASH 不对经过训练的训练网络进行任何修改,也无需访问数据
我们认为 DICE 是一项并行工作,而不是一个先驱,尽管在哲学上相似,但 ASH 的表现全面优于后者。
附录 L要求解释和验证
我们在本文的同时发布了两项呼吁,以鼓励、增加和扩大科学互动与合作的范围。 这两个电话邀请其他研究人员解决这项工作尚未充分回答的两个问题:
-
•
对于 ASH(一种简单的激活修剪和重新调整技术)在 ID 和 OOD 任务上的有效性,有哪些合理的解释?
-
•
是否还有其他适用 ASH(或类似程序)的研究领域、应用领域、主题和任务?研究结果是什么?
对这些呼吁的答复将被仔细审查并有选择地包含在本文的未来版本中,其中将邀请个人贡献者进行合作。 444Please follow instructions when submitting to the calls: https://andrijazz.github.io/ash/#calls。 对于每个电话,我们都会提供探索答案的可能方向,但是,我们鼓励超出以下建议的新颖任务。
要求解释
对 ASH 有效性的一个合理解释是,故意过度参数化的神经网络可能会过度表示学习,即为数据生成特征,而这些特征对于手头的优化任务来说在很大程度上是多余的。 这既是一个优点,也是一个危险:一方面,表示不太可能过度适应单个任务,并且可能保留更多的泛化潜力,但另一方面,它在已见数据和未见数据之间的区分能力较差。
呼吁在其他领域进行验证
我们认为,在优化训练任务时使用深度神经网络(或任何类似的智能系统)学习数据表示的相邻领域将成为验证 ASH 的沃土。 一个简单的领域是自然语言处理,其中预训练的语言模型通常适用于下游任务。 使用这些大型语言模型学习的本机表示是否可以简化? 激活的重塑(在基于转换器的语言模型的情况下,激活可以是键、值或查询)会增强还是损害性能?