同音字揭示真相:Speech2Vec 的现实检验
摘要
生成拥有语义信息的口语词嵌入是一个令人着迷的话题。 与基于文本的嵌入相比,它们涵盖了语音和语义特征,可以提供更丰富的信息,并且可能有助于改进 ASR 和语音翻译系统。 在本文中,我们回顾并检验了该领域一项开创性工作的真实性:Speech2Vec。 首先,提出了一种基于同音词的检查方法来检查 Speech2Vec 作者发布的语音嵌入。 没有迹象表明这些嵌入是由 Speech2Vec 模型生成的。 此外,通过对词汇组成的进一步分析,我们怀疑基于文本的模型制造了这些嵌入。 最后,我们参考原论文中的官方代码和最优设置,重现了Speech2Vec模型。 实验表明该模型未能学习有效的语义嵌入。 在单词相似度基准测试中,它在 MEN 测试中的相关性得分为 0.08,在 WS-353-SIM 测试中的相关性得分为 0.15,比原始论文中描述的相关性得分低了 0.5 以上。 我们的数据和代码已公开111https://github.com/my-yy/s2v_rc。
1简介
词嵌入是词的固定长度表示,它携带句法和语义信息,成为自然语言处理任务的构建块,例如命名实体识别[24]和问答[23 ]。 语音作为信息的另一种载体,也反映了语义意义,这意味着直接使用它来学习语义词表示的可能性。 为此,人们做出了一些尝试来生成语义语音嵌入[7,18,5,6]。 与学习基于文本的嵌入相比,这是一项困难得多的任务。 因为语音和语义之间存在内在的干扰[5]。 例如,“ate”和“eight”这两个词的发音几乎相同,但语义不同。 如果模型无法区分这些声音相似的输入,就不可能获得有效的语义表示。
在本文中,我们重点关注 Speech2Vec [6, 7],这是该领域最早且最有影响力的研究之一。 它可以被视为Word2Vec [17]的语音版本,它利用skip-gram和CBOW策略来学习语义语音嵌入。 尽管它是 Word2Vec 的模仿者,但它似乎神奇地解决了上述语音语义干扰,并且据报道在 13 个单词相似性基准上超过了 Word2Vec [10]。 这一现象引起了我们探索这项研究有效性的兴趣。 具体来说,我们从官方发布的语音嵌入和我们的再现结果两个角度分析Speech2Vec的真实性。 结论可概括如下:
1)官方的语音嵌入无法反映语音特征,这意味着它们不是由 Speech2Vec 模型生成的。
2)对词汇组成的分析表明,这些发布的嵌入可能来自基于文本的模型。
3)我们的再现结果表明 Speech2Vec 模型未能生成有效的语义语音嵌入。 即使经过 500 个 epoch 的训练,其性能在大多数基准指标中仍然可以忽略不计。
2 回顾 Speech2Vec
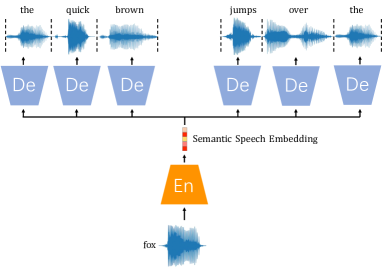
Speech2Vec可以看作是Word2Vec的语音版本,它依靠skip-gram或CBOW策略来学习语义语音嵌入。 在这里,我们重点关注 Speech2Vec 的skip-gram 风格,据报道它具有更好的性能。 图 1显示了其结构。
训练时,输入的语音句子被预先分割成口语单词序列。 然后编码器网络将当前所说的单词转换为嵌入向量。 这个向量用于解码上下文单词。 在语料库中,与同一文本单词对应的音频片段出现多次(具有不同的说话人、环境、情绪或语速)。 为了获得确定性的单词表示,将同一文本单词对应的所有嵌入的平均值作为最终嵌入。
Speech2Vec 的官方代码并未公开,但预训练的语音嵌入已在 GitHub 上发布 222https://github.com/iamyuanchung/speech2vec-pretrained-vectors。 这些嵌入是根据在 500 小时的 LibriSpeech [19] 数据集上训练的 Skip-gram 样式 Speech2Vec 模型来描述的:
...在这个存储库中,我们发布了 Speech2Vec 使用 skip-grams 作为训练方法学习的不同维度的语音嵌入。 该模型在由 LibriSpeech 的约 500 小时语音(clean-360 + clean-100 子集)组成的语料库上进行训练……
我们进一步为此存储库提供了一个分支 333https://github.com/my-yy/speech2vec-pretrained-vectors。
3现实检查
本节旨在检查已发布的语音嵌入的真实性。 我们从语音特征和词汇构成两个角度进行分析。
3.1同音字检查
同音词是指具有相同发音但反映不同含义的单词(例如,“吃,八”,“亲爱的,鹿”和“呜呜,酒”)。 由于这些口语单词在发音上是一致的,因此在语音识别系统中,通常需要语音上下文和语言模型[3]来区分它们。 对于skip-gram 风格的Speech2Vec,其输入是不包含上下文信息的单个口语单词。 因此,这个模型应该无法有效地区分这些同音词。 并且同音词对的嵌入相似度应该具有更高的值。 我们使用了 307 个同音词对444 来源:http://www.singularis.ltd.uk/bifroest/misc/homophones-list.html 并计算了它们的相似度。 结果显示在 选项卡。 1.
| Embedding | Dim | Pair Similarity | |
|---|---|---|---|
| Homophone | Random | ||
| Official | 50 | 0.33±0.15 | 0.39±0.17 |
| 100 | 0.28±0.14 | 0.35±0.15 | |
| 200 | 0.23±0.12 | 0.31±0.14 | |
| 300 | 0.21±0.11 | 0.29±0.14 | |
| Ours | 50 | 0.95±0.05 | 0.77±0.10 |
正如我们所看到的,对于官方嵌入,它们的同音相似度低于随机结果,这与直觉相反。 这表明官方模型可能不会受到语音相似性的影响,并且可以成功地区分这些高度相似的输入。 然而,我们复制的模型并没有“展现出魔力”。 尽管随机对的相似度为 0.77(这意味着嵌入空间分布不均匀),但同音词对的相似度仍然较高,为 0.95。
| Homophone Pair | Similarity | |||
| Raw | Official | Ours | ||
| ate | eight | 1.00 | 0.22 | 1.00 |
| hail | hale | 0.99 | 0.34 | 0.97 |
| know | no | 1.00 | 0.63 | 0.97 |
| made | maid | 1.00 | 0.25 | 0.98 |
| meat | meet | 1.00 | 0.13 | 0.99 |
| peace | piece | 1.00 | 0.15 | 0.99 |
| sea | see | 1.00 | 0.31 | 0.98 |
| steal | steel | 1.00 | 0.19 | 0.99 |
| tale | tail | 1.00 | 0.23 | 1.00 |
| whine | wine | 1.00 | 0.13 | 0.97 |
| MEAN | 0.99 | 0.32 | 0.95 | |
| Word | Official | Ours | ||||||
|---|---|---|---|---|---|---|---|---|
| K Nearest Neighbor | HR | K Nearest Neighbor | HR | |||||
| ate | eating | drank | eat | 25,099 | eight | agent | aid | 1 |
| hail | thunder | blast | thunders | 15,253 | hell | handle | held | 9 |
| know | tell | think | why | 2,305 | narrow | natural | no | 3 |
| made | making | gave | make | 35,582 | me | mid | necessity | 15 |
| meat | roasting | roasted | venison | 33,108 | meet | mate | mute | 1 |
| peace | tranquility | liberty | deliverer | 33,609 | plates | place | patience | 7 |
| sea | ocean | shore | waters | 18,610 | city | safety | succeed | 100 |
| steal | flay | stealing | kill | 29,506 | still | steel | special | 2 |
| tale | story | adventure | tales | 28,617 | tail | title | tackle | 1 |
| whine | snarling | growls | growl | 34,575 | watering | washing | wide | 4 |
| MEAN | 25,626 | 14 | ||||||
选项卡。 2 进一步给出了一些配对的例子。 在此表中,我们引入了“原始”指标来衡量音频输入的相似性。 该指标是从预训练的 wav2vec [21] 模型中提取的特征的余弦相似度。
可以清楚地看到,大多数同音词对的原始分数接近 1.0,这意味着这些同音词之间具有很高的相似度。 而 wav2vec 模型无法区分它们。 此外,我们的重现模型具有相似的行为,平均相似度为 0.95。 然而,官方嵌入的相似度相对较低。 以“ate, 8”对为例,Raw 和我们的相似度都是 1.00,而官方给出的相似度分数是 0.22。
k 最近邻结果 (选项卡。 3)进一步揭示了官方嵌入的异常情况。 虽然官方的近邻反映了相似的语义,但发音却存在相当大的差异。 例如,“冰雹”的最近邻居是“雷、爆炸、雷霆”,而其同音对应词(“hale”)排名高达 15,253。 相比之下,我们的再现中的同音字等级是 9。
官方嵌入的上述异常行为可以用一个大胆的假设来解释:官方嵌入来自基于文本的模型。 与基于文本的模型(如 Word2Vec)一样,不同拼写的单词被分配不同的编码值。 在学习过程中,模型不依赖发音来识别单词;因此,它不会受到他们的干扰。 此外,由于同音词对具有不同的含义,因此它们的相似度可能小于随机对。 这解释了为什么官方结果与随机结果的相似度较小 选项卡。 1.
3.2词汇分析
3.2.1 检查发布的词汇
| Corpus Division | Hours | Speakers | |||
|---|---|---|---|---|---|
| Clean | train-clean-100 | 100.6 | 475 | 251 | 1,252 |
| train-clean-360 | 363.6 | 921 | |||
| dev-clean | 5.4 | 40 | |||
| test-clean | 5.4 | 40 | |||
| Other | train-other-500 | 496.7 | 507 | 1,166 | 1,232 |
| dev-other | 5.3 | 33 | |||
| test-other | 5.1 | 33 | |||
Seepch2Vec 论文声称,训练基于 500 小时的 LibriSpeech [19],其中包含 1,252 个说话者。 我们将此数据集称为 Libri-Clean。 其统计数据显示在 选项卡。 4. 我们统计了 Libri-Clean 笔录中的不同单词,并将其与官方进行了比较。 结果显示在 选项卡。 5.
| Official | Libri-Clean | Libri-All | ||
|---|---|---|---|---|
| - | count5 | count5 | ||
| Vocab | 37,622 | 66,721 | 27,454 | 37,622 |
| Missing | - | 1,685 | 10,168 | 0 |
我们发现 Libri-Clean 中没有 1.6k 个官方单词。 如果我们只考虑出现次数 5 的频繁单词,这个数字就会上升到 10k。 然而,如果我们使用整个 LibriSpeech 语料库并过滤掉不常见的单词,则词汇构成与官方完全相同。 这证明发布的嵌入来自所有 LibriSpeech 语料库,而不是声称的“500 小时”数据。
此外,我们认为这些嵌入是由基于文本的模型生成的,该模型直接使用文本转录本进行训练。 由于训练时需要对 LibriSpeech 数据集进行预处理,因此每个语音句子应与转录文本对齐以定位单词边界。 然而,这种对齐过程并不理想,可能会导致数据丢失。
在我们的分析中,我们使用了基于广泛使用的蒙特利尔强制对准器 [16] 555https://github.com/CorentinJ/librispeech-alignments。 它对 292,367 个语音句子的整个语料库进行了对齐,遇到了 127 次失败(失败率为 0.04%)。 删除这些未对齐的语音后,语料库会发生变化,导致词汇表中额外缺失 17 个单词。 因此,如果 Speech2Vec 的作者没有实现理想的对齐,他们的词汇量将不会精确等于 37,622。 否则,它们的嵌入来自基于文本的模型。
| Benchmark | Not Found Pairs | |
|---|---|---|
| Paper Data | Libri-Clean | |
| MEN [4] | 122 | 231 |
| MTurk-287 [20] | 13 | 29 |
| MTurk-771 [12] | 22 | 43 |
| Rare-Word [15] | 783 | 1027 |
| SimLex-999 [13] | 0 | 11 |
| SimVerb-3500 [11] | 126 | 118 |
| Verb-143 [2] | 0 | 5 |
| WS-353 [26] | 21 | 34 |
| WS-353-REL [1] | 12 | 24 |
| WS-353-SIM [1] | 7 | 16 |
| YP-130 [26] | 0 | 9 |
3.2.2 检查纸张数据
虽然Speech2Vec的论文中没有提到词汇量,但我们仍然可以从单词相似度基准测试结果中找到一些线索。 在原始论文中,这些基准用于评估嵌入携带的语义信息。 每个基准测试都包含一系列预定义的单词对以及相应的预言机相关性。 在 Speech2vec [6] 的早期版本中,作者报告了这些基准中的“未找到”对(选项卡。 6)。
如果我们使用 Libri-Clean 中的所有 66,721 个单词来构建词汇表,那么在这些测试中还有更多未找到的单词对(SimVerb-3500 除外)。 例如,原始论文报告在 MEN 测试中未找到 122 对,但我们发现了 231 对。 这说明 Speech2Vec 的作者使用了比声称的 500h Libri-Clean 更大的语料库。
4 我们的复制品
4.1 复制细节
4.1.1代码实现
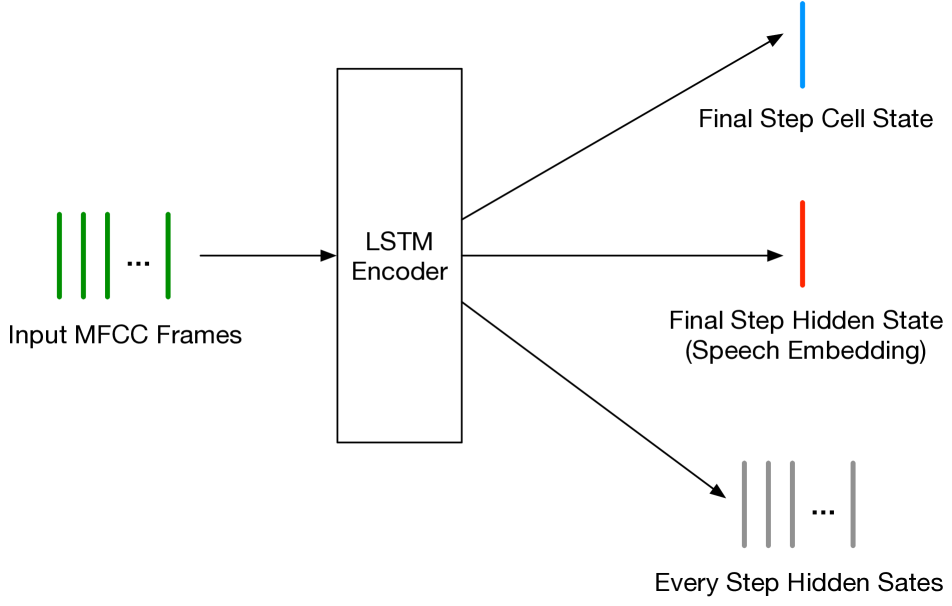
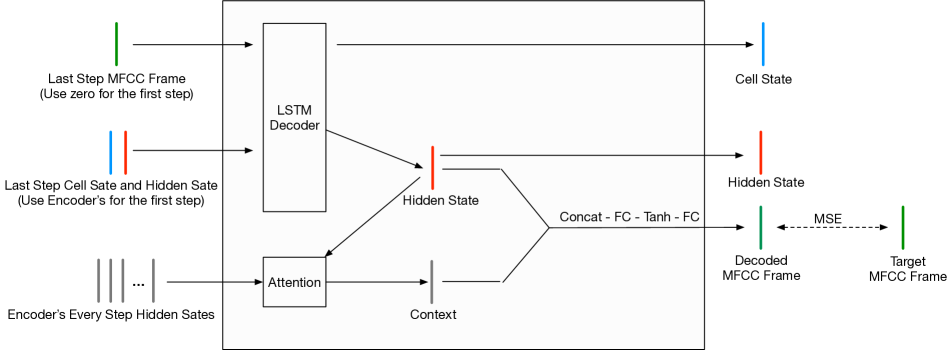
我们的复制是基于Speech2Vec作者提供的不完整代码。 该代码涵盖了模型实现和训练逻辑,但缺少数据预处理。 我们参考原始论文中的最佳设置,补充了缺失的部分并训练了 Speech2Vec。 具体来说,嵌入维度设置为50。 窗口大小取3。 编码器是单层双向 LSTM。 解码器是单层单向LSTM。 在解码过程中,注意力机制[14]用于引用编码器的输出(图5附录中详细概述了其结构)。
4.1.2培训详情
根据 Speech2Vec 的论文,Libri-Clean 数据集用于训练。 每个语音句子都被预先分割成口语单词。 然后我们过滤掉出现次数少于四次的低频词,最终得到大小为30,788的词汇表。 对于每个口语单词,我们将其转换为 13 维 MFCC 帧。
在小批量构建过程中,我们将批量大小设置为 4096,并使用 0.001 学习率的 SGD 优化器对模型进行 500 轮训练。 此训练过程在 AMD 3900XT + RTX3090 设备上花费了 8.4 天。 保存每个epoch的输出模型,并使用第500个epoch的模型进行评估。
4.2结果与分析
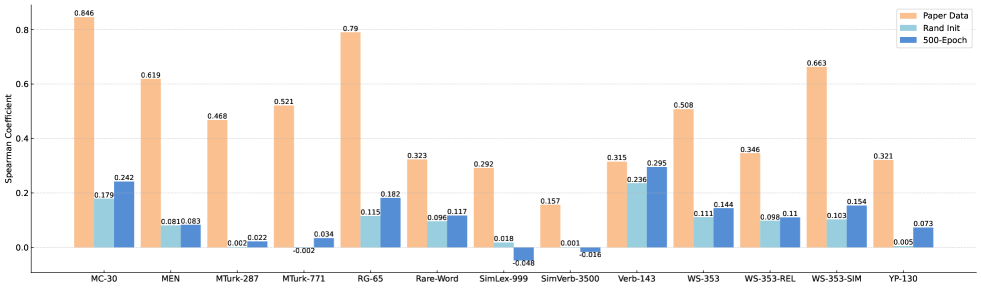
与官方相同,我们在 13 个相似性基准[10]上测试了我们的重现模型。 评价分数为Spearman等级相关系数。 它的取值范围为[-1,1],值越大表示结果越好。 结果如图图2所示。
显然,复制的模型在这些基准上给出了微不足道的结果。 与随机初始化相比,500 epoch 模型在 SimLex-999 和 SimVerb-3500 的指标上仅有微小的改进甚至下降。 此外,与声称的纸质数据相比,性能出现大幅下降,某些指标(MC-30、MEN、RG-65、WS-353-SIM)甚至超过 0.5。
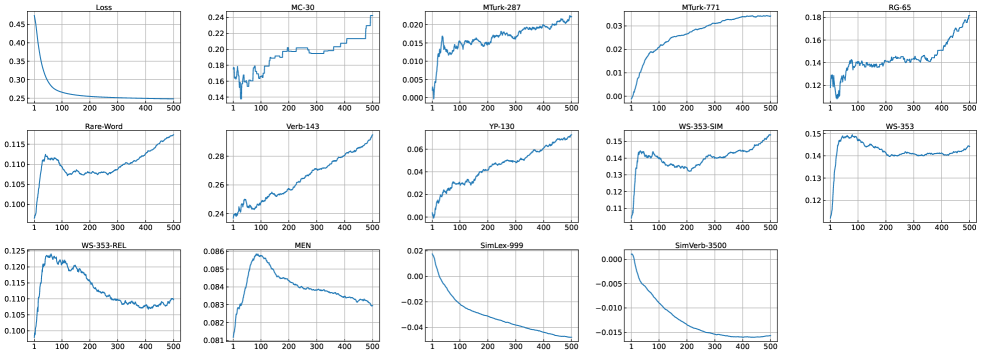
我们在图3中进一步描述了训练过程。 随着损失的减少,大部分指标呈现上升趋势。 但增加速度相对缓慢,最终被限制在一个较小的范围内(例如,MTurk-287 为 00.022)。 更多训练纪元可能会在这些指标上提供更好的结果,但它应该比声称的“500 纪元”大得多。 此外,两个指标似乎已经过了高峰期,表现由升转降(WS-353-REL和MEN)。 然而,它们的峰值性能仍然相对低于原始论文。 有两个指标的性能持续下降,这意味着没有成功学习所需的语义(SimLex-999 和 SimVerb-3500)。
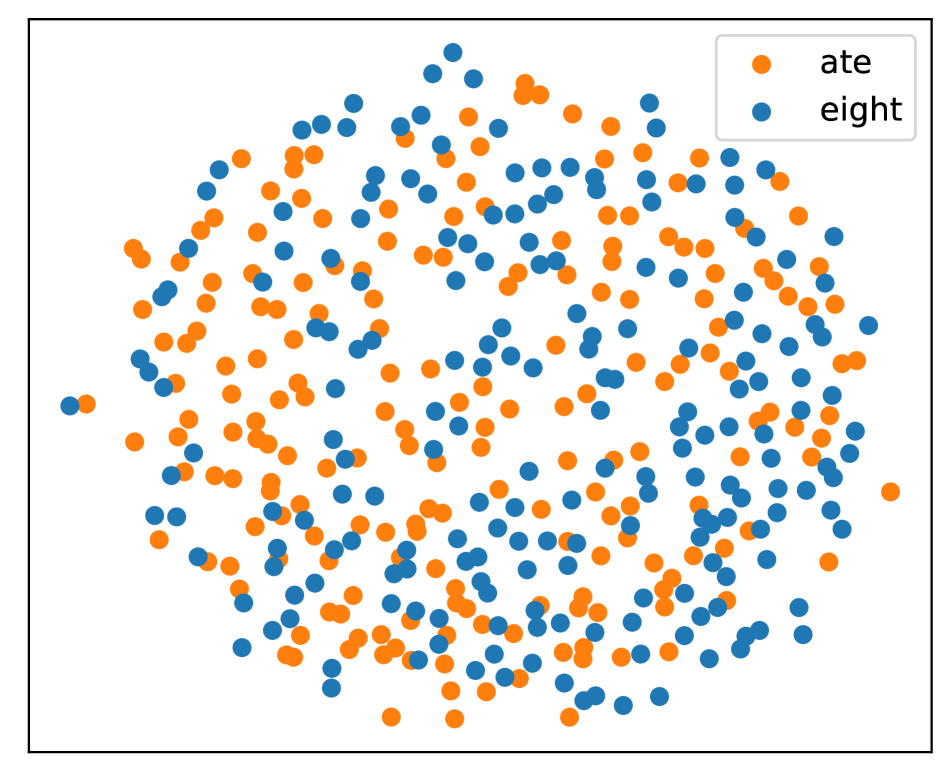
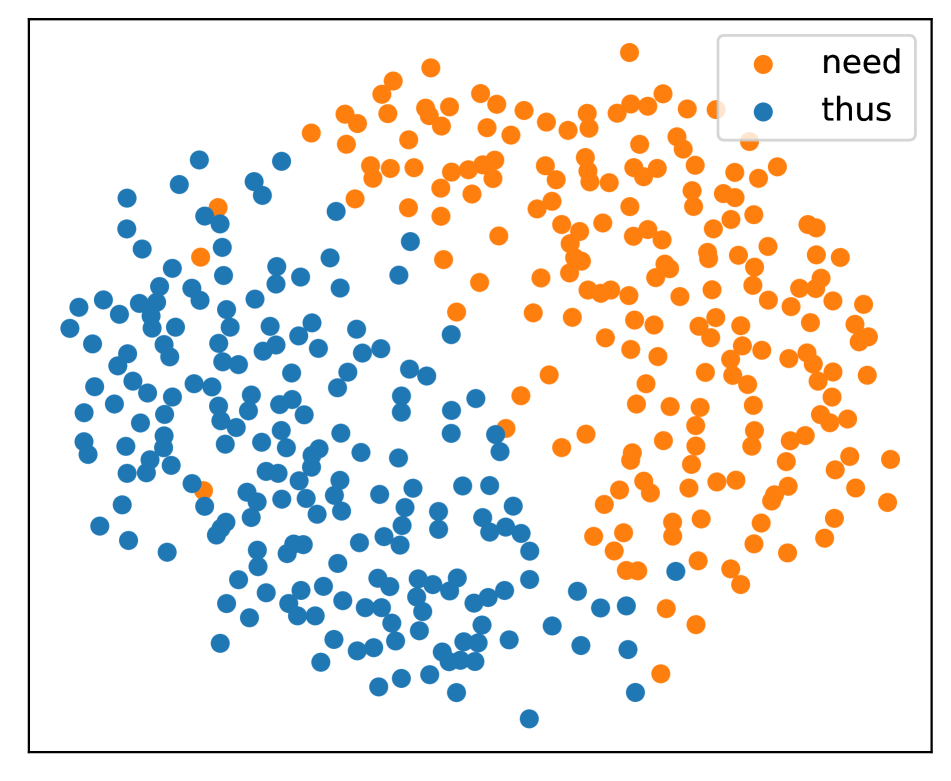
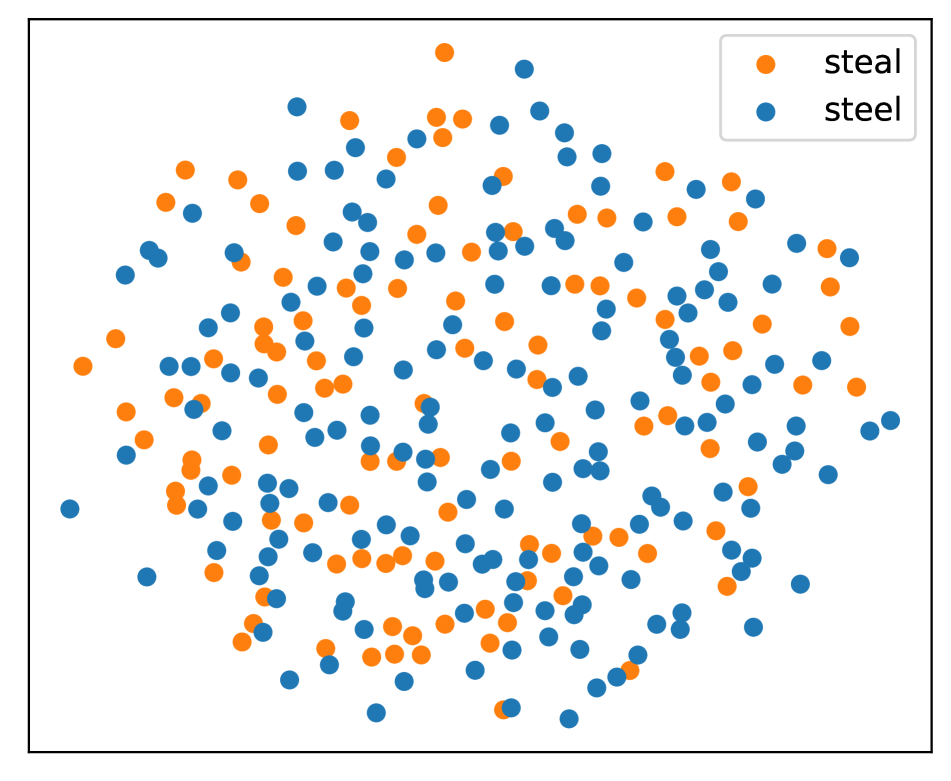
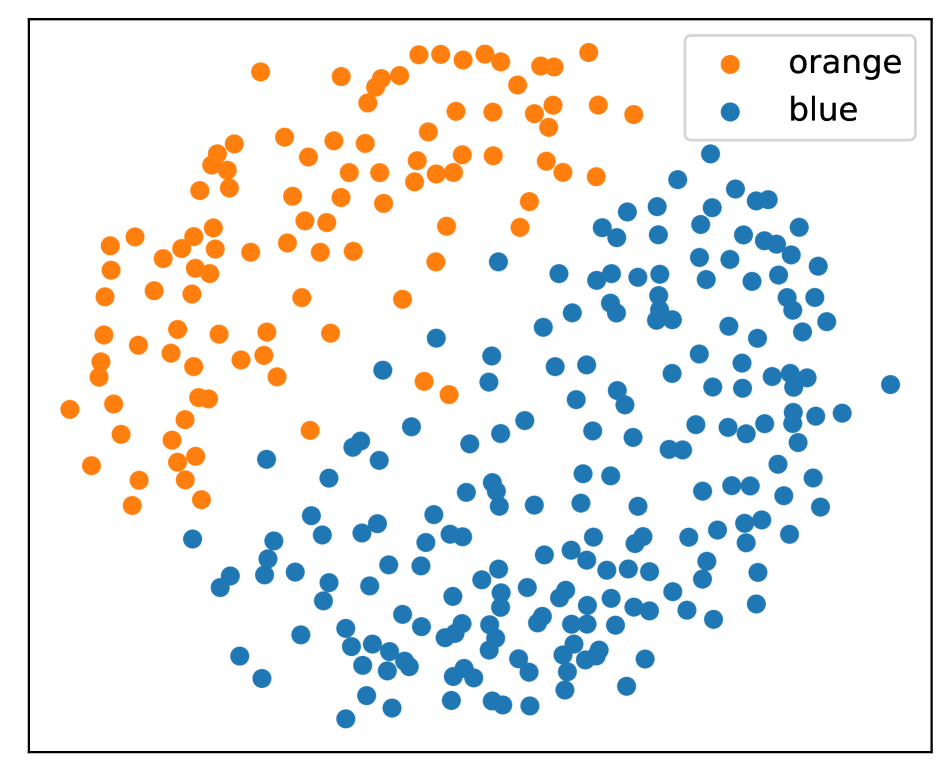
正如Sec.2中提到的,每个文本单词对应多个语音片段。 在图4中,我们可视化了特定单词的嵌入分布。 具体来说,多维尺度(MDS)[25]用于可视化。 与流行的T-SNE相比,MDS保留了距离和全局结构。
我们可以看到,同音词是混合的,而不同发音的词往往是分开的。 这个结果证实了Speech2Vec的编码器不能成功区分同音异义词。 此外,我们注意到“需要因此”对的一些混合点。 这表明即使对于声音不相似的配对,该模型也没有很好的辨别力,这可能是由于语音和语义之间的干扰造成的。
5相关作品
5.1 致力于学习语义语音嵌入
自 Speech2Vec 提出五年以来,学习语义语音嵌入领域的工作很少。 Speech2Vec 迄今为止已获得 158 次引用,但没有文章直接与其进行比较,也没有后续工作证明其有效性。
5.1.1陈等人的工作
Chen等人[5]指出,在学习语义语音嵌入时,语音和语义不可避免地相互干扰。 因此,他们设计了两阶段的学习方案来降低学习难度。 在第一阶段,编码器-解码器结构生成语音嵌入,其中说话者特征被解开。 在第二阶段,这些嵌入通过上下文预测任务具有语义意义。 实验验证了它们嵌入的语音和语义特征。 然而,这项工作并未在相似性基准上与 Speech2Vec 进行比较。
5.1.2CAWE
CAWE [18]是一种基于编码器-解码器的语音识别模型,它依靠注意力机制自动将语音句子分割成口语单词并生成语音嵌入。 该模型在 16 个句子评估任务上进行了测试,并显示了与 Word2Vec 竞争的结果。 与skip-gram 风格的Speech2Vec 相比,CAWE 可以利用上下文信息。 因此它们的有效性不能横向证明 Speech2Vec 的有效性。 此外,我们还没有发现任何成功的第三方复制 CAWE 的情况。
5.1.3音频2Vec
Audio2Vec [22] 是一个基于 CNN 的模型,它使用skip-gram、CBOW 和时间间隙策略来生成固定长度的音频表示。 尽管它的训练风格与 Speech2Vec 类似,但 Audio2Vec 的目标是生成通用的音频表示。 在训练过程中,语音句子被分割成固定长度的切片,而不参考单词边界。 因此,该模型没有在单词相似性基准上进行测试,也没有与 Speech2Vec 进行比较。
5.2 直接基于 Speech2Vec 嵌入工作
理想情况下,如果实验数据有问题,则无法保证结论的有效性。 我们注意到有一些工作[8,9,27]直接基于Speech2Vec的嵌入。 其中,有两篇作品来自Speech2vec的作者[8, 9],将语音空间和文本空间对齐,实现跨语言的语音到文本翻译。
Yi 等人 [27] 报告称,他们通过在输入中引入已发布的 Speech2Vec 嵌入,成功提高了标点符号预测性能。 但他们没有探索这些语音嵌入是如何工作的。 我们认为他们的结果是真实的,但无意中提供了错误的解释。 正如我们所分析的,这些 Speech2Vec 嵌入不能反映语音信息。 因此,他们的改进来自于涉及更多的输入特征。 而且这些特征与来自基于文本的模型还是基于语音的模型无关。 因此,我们认为上述工作不能为Speech2Vec的真实性提供证据。
5.3 其他研究人员的复制尝试
我们调查了其他研究人员的复制尝试,包括 Jang 的666https://github.com/yjang43/Speech2Vec 和王的777https://github.com/ZhanpengWang96/pytorch-speech2vec。 和我们一样,他们未能达到 Speech2Vec 论文中声称的结果。 Jang 报告说,该模型得到的结果微不足道。 至于 Wang 的模型,复制的模型也很容易受到攻击,在 WS-353-REL 中仅获得 ,在 YP-130 中仅获得 。
6讨论
“如果说我看得更远,那是因为我站在了巨人的肩膀上。 ——艾萨克·牛顿,1675。”
科学进步建立在前人的创新基础上。 如果一项有影响力的创新被证伪,那它就不是“巨人的肩膀”。 相反,它成为一个绊脚石,给该领域的发展带来巨大的障碍。 我们认为科学不是一种宗教,尤其是在计算机科学方面。 创新的真实性应该取决于可重复性,而不是作者、机构或论文等级的声誉。
2018年,一名硕士生被分配到一个新兴领域开始学术研究。 不幸的是,他相信了一项虚假的研究,从而走上了错误的道路。 他对此充满热情,多年来为实现一个不可能的目标而奋斗,但最终却一无所获。 出发四年后,他反思人生的失败,写下了这篇文章。 防止别人重蹈他的覆辙,这就是这项研究的价值。
参考
- [1] Eneko Agirre, Enrique Alfonseca, Keith Hall, Jana Kravalova, Marius Pasca, and Aitor Soroa. A study on similarity and relatedness using distributional and wordnet-based approaches. 2009.
- [2] Simon Baker, Roi Reichart, and Anna Korhonen. An unsupervised model for instance level subcategorization acquisition. In EMNLP, pages 278–289, 2014.
- [3] Yoshua Bengio, Réjean Ducharme, and Pascal Vincent. A neural probabilistic language model. Advances in neural information processing systems, 13, 2000.
- [4] Elia Bruni, Gemma Boleda, Marco Baroni, and Nam-Khanh Tran. Distributional semantics in technicolor. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 136–145, 2012.
- [5] Yi-Chen Chen, Sung-Feng Huang, Chia-Hao Shen, Hung-Yi Lee, and Lin-Shan Lee. Phonetic-and-semantic embedding of spoken words with applications in spoken content retrieval. In 2018 IEEE Spoken Language Technology Workshop (SLT), pages 941–948. IEEE, 2018.
- [6] Yu-An Chung and James Glass. Learning word embeddings from speech. arXiv preprint arXiv:1711.01515, 2017.
- [7] Yu-An Chung and James Glass. Speech2vec: A sequence-to-sequence framework for learning word embeddings from speech. In INTERSPEECH, 2018.
- [8] Yu-An Chung, Wei-Hung Weng, Schrasing Tong, and James Glass. Unsupervised cross-modal alignment of speech and text embedding spaces. Advances in neural information processing systems, 31, 2018.
- [9] Yu-An Chung, Wei-Hung Weng, Schrasing Tong, and James Glass. Towards unsupervised speech-to-text translation. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7170–7174. IEEE, 2019.
- [10] Manaal Faruqui and Chris Dyer. Community evaluation and exchange of word vectors at wordvectors. org. In Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 19–24, 2014.
- [11] Daniela Gerz, Ivan Vulić, Felix Hill, Roi Reichart, and Anna Korhonen. Simverb-3500: A large-scale evaluation set of verb similarity. arXiv preprint arXiv:1608.00869, 2016.
- [12] Guy Halawi, Gideon Dror, Evgeniy Gabrilovich, and Yehuda Koren. Large-scale learning of word relatedness with constraints. In Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 1406–1414, 2012.
- [13] Felix Hill, Roi Reichart, and Anna Korhonen. Simlex-999: Evaluating semantic models with (genuine) similarity estimation. Computational Linguistics, 41(4):665–695, 2015.
- [14] Minh-Thang Luong, Hieu Pham, and Christopher D Manning. Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025, 2015.
- [15] Minh-Thang Luong, Richard Socher, and Christopher D Manning. Better word representations with recursive neural networks for morphology. In Proceedings of the seventeenth conference on computational natural language learning, pages 104–113, 2013.
- [16] Michael McAuliffe, Michaela Socolof, Sarah Mihuc, Michael Wagner, and Morgan Sonderegger. Montreal forced aligner: Trainable text-speech alignment using kaldi. In Interspeech, volume 2017, pages 498–502, 2017.
- [17] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems, 26, 2013.
- [18] Shruti Palaskar, Vikas Raunak, and Florian Metze. Learned in speech recognition: Contextual acoustic word embeddings. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6530–6534. IEEE, 2019.
- [19] Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: an asr corpus based on public domain audio books. In 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5206–5210. IEEE, 2015.
- [20] Kira Radinsky, Eugene Agichtein, Evgeniy Gabrilovich, and Shaul Markovitch. A word at a time: computing word relatedness using temporal semantic analysis. In Proceedings of the 20th international conference on World wide web, pages 337–346, 2011.
- [21] Steffen Schneider, Alexei Baevski, Ronan Collobert, and Michael Auli. wav2vec: Unsupervised pre-training for speech recognition. arXiv preprint arXiv:1904.05862, 2019.
- [22] Marco Tagliasacchi, Beat Gfeller, Félix de Chaumont Quitry, and Dominik Roblek. Self-supervised audio representation learning for mobile devices. arXiv preprint arXiv:1905.11796, 2019.
- [23] Stefanie Tellex, Boris Katz, Jimmy Lin, Aaron Fernandes, and Gregory Marton. Quantitative evaluation of passage retrieval algorithms for question answering. In Proceedings of the 26th annual international ACM SIGIR conference on Research and development in informaion retrieval, pages 41–47, 2003.
- [24] Joseph Turian, Lev Ratinov, and Yoshua Bengio. Word representations: a simple and general method for semi-supervised learning. In Proceedings of the 48th annual meeting of the association for computational linguistics, pages 384–394, 2010.
- [25] Florian Wickelmaier. An introduction to mds. Sound Quality Research Unit, Aalborg University, Denmark, 46(5):1–26, 2003.
- [26] Dongqiang Yang and David MW Powers. Verb similarity on the taxonomy of WordNet. Masaryk University, 2006.
- [27] Jiangyan Yi and Jianhua Tao. Self-attention based model for punctuation prediction using word and speech embeddings. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7270–7274. IEEE, 2019.
附录A编码-解码详细信息
图 5描述了编码-解码过程。 为了清楚起见,该插图采用单个口头单词作为输入,而模型以批处理模式进行训练。 由于输入单词的时间长度不同,官方代码中实现了长度统一。 官方代码缺少数据处理部分,我们不知道具体的时间长度。 据统计,我们的数据集平均 MFCC 帧为 10,并且有 94.6% 的单词少于 21 帧。 因此,我们将输入字填充(或截断)为固定的 20 个 MFCC 帧。
在编码阶段,官方代码使用了PyTorch的pack_padded_sequence来消除padding效果。
然而,在解码阶段,仍然考虑填充帧对应的重建损失。
我们在复制中解决了这个问题。
更多详细信息可以在我们发布的代码中找到。
附录 B相似性基准比较
我们注意到官方代码中的优化器是Adam优化器(不是官方论文中描述的SGD)。 为了排除优化器的影响,我们尝试了 Adam 设置。 然而,我们没有观察到结果的本质差异,如图所示 选项卡。 7.
| Benchmark | Paper Data | SGD | Adam | ||
|---|---|---|---|---|---|
| Rand Init | 500-Epoch | Rand Init | 500-Epoch | ||
| MC-30 | 0.85 | 0.18 | 0.24↓0.60 | 0.37 | -0.28↓1.13 |
| MEN | 0.62 | 0.08 | 0.08↓0.54 | 0.06 | 0.04↓0.58 |
| MTurk-287 | 0.47 | 0.00 | 0.02↓0.45 | 0.04 | 0.08↓0.39 |
| MTurk-771 | 0.52 | -0.00 | 0.03↓0.49 | -0.00 | 0.04↓0.48 |
| RG-65 | 0.79 | 0.11 | 0.18↓0.61 | 0.25 | 0.05↓0.74 |
| Rare-Word | 0.32 | 0.10 | 0.12↓0.21 | 0.10 | 0.04↓0.28 |
| SimLex-999 | 0.29 | 0.02 | -0.05↓0.34 | -0.06 | -0.04↓0.33 |
| SimVerb-3500 | 0.16 | 0.00 | -0.02↓0.17 | -0.03 | -0.03↓0.18 |
| Verb-143 | 0.32 | 0.24 | 0.29↓0.02 | 0.34 | 0.24↓0.07 |
| WS-353 | 0.51 | 0.11 | 0.14↓0.36 | 0.18 | 0.12↓0.39 |
| WS-353-REL | 0.35 | 0.10 | 0.11↓0.24 | 0.12 | 0.11↓0.24 |
| WS-353-SIM | 0.66 | 0.10 | 0.15↓0.51 | 0.22 | 0.16↓0.51 |
| YP-130 | 0.32 | 0.01 | 0.07↓0.25 | 0.11 | -0.01↓0.33 |
附录C同音词列表
LABEL:tab:homo_full_list 中列出了完整的 307 个同音词对。 由于我们的复制是基于 Libri-Clean,它的词汇量比发布的嵌入要小。 因此,我们的复制品中有 33 对缺失(用“-”标记)。
| Homophone Pairs | Raw | Official | Ours | Homophone Pairs | Raw | Official | Ours | ||
|---|---|---|---|---|---|---|---|---|---|
| ad | add | 0.99 | 0.09 | 0.92 | lieu | loo | 0.98 | 0.43 | 0.91 |
| ail | ale | 0.98 | 0.49 | 0.75 | links | lynx | 1.00 | 0.24 | 0.96 |
| air | heir | 1.00 | 0.07 | 0.97 | lo | low | 0.99 | 0.22 | 0.98 |
| all | awl | - | 0.40 | - | loan | lone | 1.00 | 0.09 | 0.94 |
| allowed | aloud | 1.00 | 0.21 | 0.96 | loot | lute | 0.99 | 0.17 | 0.92 |
| alms | arms | 0.95 | 0.26 | 0.95 | made | maid | 1.00 | 0.25 | 0.98 |
| altar | alter | 0.99 | 0.13 | 0.95 | male | 1.00 | 0.23 | 0.98 | |
| arc | ark | 0.98 | 0.19 | 0.91 | main | mane | 0.99 | 0.17 | 0.97 |
| aren’t | aunt | 0.96 | 0.44 | 0.95 | maize | maze | 0.99 | 0.25 | 0.93 |
| ate | eight | 1.00 | 0.22 | 1.00 | manna | manner | 0.97 | 0.33 | 0.89 |
| auger | augur | - | 0.51 | - | mantel | mantle | 1.00 | 0.43 | 0.95 |
| awe | oar | 0.92 | 0.26 | 0.78 | mare | mayor | 0.99 | 0.38 | 0.96 |
| axel | axle | 0.99 | 0.41 | 0.86 | marshal | martial | 1.00 | 0.60 | 0.98 |
| aye | eye | 0.99 | 0.29 | 0.89 | marten | martin | - | 0.36 | - |
| bail | bale | 0.99 | 0.36 | 0.98 | mask | masque | - | 0.51 | - |
| bait | bate | 0.98 | 0.41 | 0.95 | mean | mien | 0.98 | 0.24 | 0.90 |
| baize | bays | 0.99 | 0.50 | 0.91 | meat | meet | 1.00 | 0.13 | 0.99 |
| bald | bawled | 0.99 | 0.21 | 0.96 | medal | meddle | 0.99 | 0.11 | 0.90 |
| bard | barred | 0.98 | 0.01 | 0.96 | metal | mettle | 1.00 | 0.31 | 0.92 |
| bare | bear | 1.00 | 0.51 | 1.00 | meter | metre | 0.99 | 0.59 | 0.95 |
| bark | barque | 0.96 | 0.33 | 0.86 | might | mite | 0.99 | 0.38 | 0.96 |
| baron | barren | 1.00 | 0.07 | 0.97 | mind | mined | - | 0.21 | - |
| base | bass | 0.99 | 0.28 | 0.98 | miner | minor | 1.00 | 0.17 | 0.95 |
| bazaar | bizarre | 0.98 | 0.12 | 0.92 | missed | mist | 0.99 | 0.20 | 0.98 |
| be | bee | 0.99 | 0.35 | 0.98 | moat | mote | 0.99 | 0.46 | 0.93 |
| beach | beech | 1.00 | 0.47 | 0.97 | mode | mowed | 0.99 | 0.21 | 0.94 |
| bean | been | 0.92 | 0.29 | 0.96 | moor | more | 0.99 | 0.41 | 0.94 |
| beat | beet | - | 0.41 | - | morning | mourning | 1.00 | 0.46 | 0.99 |
| beer | bier | 0.99 | 0.24 | 0.96 | muscle | mussel | 0.99 | 0.48 | 0.95 |
| bel | bell | 0.99 | 0.29 | 0.98 | naval | navel | - | 0.34 | - |
| berry | bury | 0.99 | 0.16 | 0.97 | nay | neigh | - | 0.34 | - |
| berth | birth | 1.00 | 0.08 | 1.00 | none | nun | 0.99 | 0.35 | 0.84 |
| bitten | bittern | - | 0.63 | - | ode | owed | 0.99 | 0.30 | 0.95 |
| blew | blue | 1.00 | 0.48 | 1.00 | oh | owe | 0.97 | 0.55 | 0.82 |
| boar | bore | 0.99 | 0.39 | 0.96 | one | won | 1.00 | 0.39 | 1.00 |
| board | bored | 1.00 | 0.13 | 0.99 | pail | pale | 1.00 | 0.27 | 0.99 |
| boarder | border | 0.99 | 0.34 | 0.92 | pain | pane | 1.00 | 0.38 | 0.98 |
| bold | bowled | 0.99 | 0.50 | 0.92 | pair | pare | 0.99 | 0.35 | 0.95 |
| born | borne | 1.00 | 0.29 | 0.99 | palate | palette | 0.98 | 0.50 | 0.88 |
| bough | bow | 0.99 | 0.48 | 0.97 | pause | paws | 1.00 | 0.34 | 0.99 |
| boy | buoy | 0.96 | 0.35 | 0.88 | pea | pee | 0.93 | 0.54 | 0.87 |
| braid | brayed | - | 0.60 | - | peace | piece | 1.00 | 0.15 | 0.99 |
| brake | break | 1.00 | 0.38 | 0.99 | peak | peek | - | 0.30 | - |
| bread | bred | 1.00 | 0.24 | 0.99 | peal | peel | 0.99 | 0.21 | 0.96 |
| bridal | bridle | 1.00 | 0.36 | 0.97 | peer | pier | 0.99 | 0.33 | 0.96 |
| broach | brooch | 0.98 | 0.52 | 0.89 | plain | plane | 1.00 | 0.40 | 0.99 |
| but | butt | 0.97 | 0.37 | 0.92 | pleas | please | - | 0.42 | - |
| buy | by | 0.99 | 0.25 | 0.98 | plum | plumb | 0.99 | 0.57 | 0.96 |
| calendar | calender | 0.98 | 0.39 | 0.95 | pole | poll | 0.98 | 0.19 | 0.96 |
| canvas | canvass | 0.99 | 0.41 | 0.98 | practice | practise | 1.00 | 0.74 | 0.99 |
| cast | caste | 0.99 | 0.33 | 0.98 | praise | prays | 0.99 | 0.51 | 0.99 |
| caught | court | 0.95 | 0.11 | 0.91 | principal | principle | 1.00 | 0.48 | 1.00 |
| ceiling | sealing | 1.00 | 0.63 | 0.95 | profit | prophet | 1.00 | 0.30 | 0.99 |
| cell | sell | 0.99 | 0.06 | 0.95 | quarts | quartz | 0.99 | 0.49 | 0.95 |
| censer | censor | 0.98 | 0.35 | 0.78 | rain | reign | 1.00 | 0.18 | 0.99 |
| cent | scent | 0.99 | 0.00 | 0.98 | raise | rays | 1.00 | 0.10 | 0.99 |
| check | cheque | 0.99 | 0.61 | 0.98 | rap | wrap | 0.99 | 0.40 | 0.96 |
| chord | cord | 1.00 | 0.42 | 0.98 | raw | roar | 0.96 | 0.18 | 0.88 |
| cite | sight | 0.99 | 0.24 | 0.97 | read | reed | 0.97 | 0.28 | 0.97 |
| clew | clue | 0.99 | 0.83 | 0.96 | real | reel | 1.00 | 0.27 | 0.97 |
| climb | clime | 0.99 | 0.29 | 0.93 | reek | wreak | 0.98 | 0.33 | 0.92 |
| coarse | course | 1.00 | 0.20 | 0.99 | rest | wrest | 0.99 | 0.54 | 0.95 |
| coign | coin | - | 0.37 | - | right | rite | 1.00 | 0.19 | 0.96 |
| colonel | kernel | 0.98 | 0.02 | 0.94 | ring | wring | 0.99 | 0.48 | 0.97 |
| complacent | complaisant | - | 0.54 | - | road | rode | 1.00 | 0.66 | 0.96 |
| complement | compliment | 1.00 | 0.27 | 0.96 | roe | row | 0.95 | 0.23 | 0.80 |
| coo | coup | 0.98 | 0.35 | 0.87 | role | roll | 1.00 | 0.18 | 0.99 |
| cops | copse | 0.98 | 0.39 | 0.96 | rood | rude | - | 0.32 | - |
| council | counsel | 1.00 | 0.52 | 0.99 | root | route | 0.98 | 0.06 | 0.98 |
| creak | creek | 0.99 | 0.37 | 0.98 | rose | rows | 1.00 | 0.37 | 0.99 |
| crews | cruise | 1.00 | 0.67 | 0.95 | rote | wrote | 0.98 | 0.46 | 0.91 |
| currant | current | 0.99 | 0.11 | 0.97 | rough | ruff | 0.99 | 0.51 | 0.94 |
| dam | damn | 0.99 | 0.21 | 0.95 | rung | wrung | 1.00 | 0.33 | 0.97 |
| days | daze | 0.99 | 0.47 | 0.94 | rye | wry | 0.99 | 0.35 | 0.92 |
| dear | deer | 0.99 | 0.08 | 0.98 | sale | sail | 1.00 | 0.32 | 0.99 |
| descent | dissent | 1.00 | 0.42 | 0.98 | sane | seine | - | 0.09 | - |
| desert | dessert | 0.99 | 0.14 | 0.97 | sauce | source | 0.97 | 0.22 | 0.97 |
| dew | due | 1.00 | 0.25 | 0.98 | saw | soar | 0.96 | 0.33 | 0.92 |
| die | dye | 0.99 | 0.26 | 0.89 | scene | seen | 1.00 | 0.41 | 1.00 |
| done | dun | 0.99 | 0.21 | 0.97 | sea | see | 1.00 | 0.31 | 0.98 |
| draft | draught | 0.99 | 0.30 | 0.96 | seam | seem | 0.98 | 0.30 | 0.93 |
| dual | duel | 0.98 | 0.48 | 0.88 | sear | seer | 0.98 | 0.57 | 0.86 |
| earn | urn | 0.99 | 0.04 | 0.89 | seas | sees | 0.99 | 0.18 | 0.96 |
| ewe | yew | 0.99 | 0.45 | 0.90 | sew | so | 0.99 | 0.55 | 0.98 |
| faint | feint | 0.99 | 0.55 | 0.95 | shear | sheer | 0.99 | 0.25 | 0.94 |
| fair | fare | 1.00 | 0.42 | 0.99 | side | sighed | 1.00 | 0.31 | 0.99 |
| farther | father | 0.98 | 0.29 | 0.99 | sign | sine | - | 0.39 | - |
| feat | feet | 1.00 | 0.37 | 0.99 | slay | sleigh | 0.99 | 0.30 | 0.97 |
| few | phew | - | 0.38 | - | sole | soul | 1.00 | 0.43 | 0.98 |
| find | fined | 0.99 | 0.24 | 0.97 | some | sum | 0.99 | 0.34 | 0.99 |
| fir | fur | 1.00 | 0.32 | 0.99 | son | sun | 1.00 | 0.26 | 1.00 |
| flaw | floor | 0.97 | 0.30 | 0.87 | sort | sought | 0.96 | 0.21 | 0.96 |
| flea | flee | 0.99 | 0.36 | 0.98 | staid | stayed | 1.00 | 0.55 | 0.99 |
| floe | flow | 0.99 | 0.42 | 0.89 | stair | stare | 1.00 | 0.27 | 0.99 |
| flour | flower | 1.00 | 0.30 | 0.99 | stake | steak | 1.00 | 0.19 | 0.98 |
| for | fore | 0.95 | 0.26 | 0.99 | stalk | stork | 0.96 | 0.55 | 0.92 |
| fort | fought | 0.95 | 0.42 | 0.93 | stationary | stationery | 0.99 | 0.27 | 0.85 |
| forth | fourth | 1.00 | 0.25 | 1.00 | steal | steel | 1.00 | 0.19 | 0.99 |
| foul | fowl | 1.00 | 0.36 | 0.97 | stile | style | 0.99 | 0.21 | 0.89 |
| franc | frank | 0.98 | 0.31 | 0.95 | storey | story | 0.99 | 0.37 | 0.95 |
| freeze | frieze | - | 0.38 | - | straight | strait | 1.00 | 0.39 | 0.97 |
| furs | furze | - | 0.56 | - | sweet | suite | 1.00 | 0.03 | 0.99 |
| gait | gate | 1.00 | 0.31 | 0.99 | tacks | tax | 0.98 | 0.25 | 0.96 |
| gamble | gambol | - | 0.41 | - | tale | tail | 1.00 | 0.23 | 1.00 |
| gild | guild | - | 0.41 | - | taught | taut | 0.99 | 0.12 | 0.93 |
| gilt | guilt | 1.00 | 0.21 | 0.99 | team | teem | - | 0.28 | - |
| gnaw | nor | 0.95 | 0.38 | 0.84 | tear | tier | 0.98 | 0.24 | 0.92 |
| grate | great | 1.00 | 0.15 | 0.97 | teas | tease | 0.99 | 0.35 | 0.97 |
| greys | graze | 0.98 | 0.65 | 0.90 | tern | turn | - | 0.32 | - |
| grisly | grizzly | 0.99 | 0.64 | 0.88 | there | their | 0.99 | 0.34 | 0.98 |
| groan | grown | 0.99 | 0.25 | 0.95 | threw | through | 0.99 | 0.39 | 0.99 |
| guessed | guest | 1.00 | 0.33 | 0.99 | throes | throws | 0.99 | 0.31 | 0.95 |
| hail | hale | 0.99 | 0.34 | 0.97 | throne | thrown | 1.00 | 0.30 | 0.96 |
| hair | hare | 1.00 | 0.32 | 0.98 | thyme | time | 0.99 | 0.25 | 0.97 |
| hall | haul | 1.00 | 0.13 | 0.93 | tide | tied | 1.00 | 0.10 | 0.99 |
| hart | heart | 0.99 | 0.23 | 0.94 | tire | tyre | 0.99 | 0.21 | 0.90 |
| haw | hoar | 0.91 | 0.12 | 0.71 | to | too | 0.97 | 0.63 | 0.97 |
| hay | hey | 0.98 | 0.37 | 0.92 | toad | toed | 0.98 | 0.55 | 0.96 |
| he’d | heed | 0.99 | 0.39 | 0.98 | told | tolled | 0.98 | 0.33 | 0.96 |
| heal | heel | 1.00 | 0.37 | 0.95 | ton | tun | - | 0.55 | - |
| hear | here | 1.00 | 0.58 | 0.98 | vain | vane | 0.99 | 0.19 | 0.96 |
| heard | herd | 0.99 | 0.32 | 0.97 | vale | veil | 1.00 | 0.65 | 0.98 |
| hew | hue | 0.99 | 0.34 | 0.94 | vial | vile | 0.99 | 0.33 | 0.94 |
| hi | high | 0.98 | 0.18 | 0.98 | wain | wane | 0.98 | 0.73 | 0.86 |
| higher | hire | 1.00 | 0.27 | 0.98 | waist | waste | 1.00 | 0.13 | 0.99 |
| him | hymn | 0.99 | 0.28 | 0.98 | wait | weight | 1.00 | 0.21 | 0.99 |
| ho | hoe | 0.98 | 0.40 | 0.96 | waive | wave | 0.99 | 0.22 | 0.95 |
| hoard | horde | 0.99 | 0.47 | 0.89 | war | wore | 0.99 | 0.23 | 0.96 |
| hoarse | horse | 1.00 | 0.21 | 0.99 | ware | wear | 0.99 | 0.32 | 0.97 |
| hour | our | 0.98 | 0.28 | 0.94 | warn | worn | 1.00 | 0.02 | 0.98 |
| idle | idol | 1.00 | 0.46 | 0.97 | watt | what | - | 0.52 | - |
| in | inn | 0.98 | 0.38 | 0.95 | wax | whacks | - | 0.48 | - |
| it’s | its | 0.99 | 0.20 | 0.95 | way | weigh | 0.99 | 0.36 | 0.96 |
| key | quay | 0.97 | 0.33 | 0.95 | we | wee | 0.97 | 0.21 | 0.96 |
| knave | nave | 0.99 | 0.06 | 0.90 | we’d | weed | 0.96 | 0.26 | 0.94 |
| knead | need | 0.99 | 0.51 | 0.98 | weak | week | 1.00 | 0.10 | 1.00 |
| knew | new | 1.00 | 0.31 | 0.99 | weal | we’ll | 0.94 | 0.15 | 0.90 |
| knight | night | 1.00 | 0.26 | 0.99 | wean | ween | - | 0.57 | - |
| knob | nob | - | 0.59 | - | weather | whether | 0.99 | 0.21 | 0.95 |
| knot | not | 1.00 | 0.26 | 0.98 | weir | we’re | - | 0.08 | - |
| know | no | 1.00 | 0.63 | 0.97 | were | whirr | 0.96 | 0.27 | 0.83 |
| knows | nose | 1.00 | 0.18 | 0.99 | which | witch | 0.99 | 0.28 | 0.94 |
| lac | lack | - | 0.10 | - | whig | wig | 0.99 | 0.16 | 0.96 |
| lain | lane | 0.99 | 0.30 | 0.96 | whine | wine | 1.00 | 0.13 | 0.97 |
| laps | lapse | - | 0.32 | - | whirl | whorl | 0.97 | 0.37 | 0.78 |
| larva | lava | - | 0.45 | - | whirled | world | 1.00 | 0.26 | 0.96 |
| law | lore | 0.96 | 0.33 | 0.89 | whit | wit | 0.99 | 0.50 | 0.96 |
| lea | lee | 0.98 | 0.53 | 0.89 | white | wight | 0.99 | 0.32 | 0.95 |
| lead | led | 0.94 | 0.59 | 0.97 | who’s | whose | 0.99 | 0.26 | 0.99 |
| lessen | lesson | 1.00 | 0.26 | 0.92 | woe | whoa | 0.97 | 0.23 | 0.90 |
| levee | levy | 0.98 | 0.45 | 0.82 | wood | would | 0.98 | 0.26 | 0.96 |
| liar | lyre | 0.99 | 0.31 | 0.93 | yoke | yolk | 0.99 | 0.32 | 0.88 |
| licence | license | 0.99 | 0.72 | 0.94 | you’ll | yule | 0.95 | 0.48 | 0.91 |
| lie | lye | 0.97 | 0.47 | 0.71 | |||||