图神经网络的通用提示调整
摘要
近年来,及时调整引发了适应预训练模型的研究热潮。 与语言领域采用的统一预训练策略不同,图领域呈现出多样化的预训练策略,这给设计适当的基于提示的图神经网络调整方法带来了挑战。 虽然一些开创性工作为采用边缘预测作为预训练任务的模型设计了专门的提示函数,但这些方法仅限于特定的预训练 GNN 模型,缺乏更广泛的适用性。 在本文中,我们介绍了一种通用的基于提示的调整方法,称为图形提示特征(GPF),适用于任何预训练策略下的预训练 GNN 模型。 GPF对输入图的特征空间进行操作,理论上可以达到与任何形式的提示函数等效的效果。 因此,我们不再需要明确说明每个预训练策略对应的提示功能。 相反,我们使用 GPF 以自适应方式获取下游任务的提示图。 我们提供严格的推导来证明GPF的普适性并保证其有效性。 各种预训练策略下的实验结果表明,我们的方法比微调表现更好,在全镜头场景中平均提高约,在少样本中平均提高约场景。 此外,当应用于利用其专门的预训练策略的模型时,我们的方法显着优于现有的基于提示的专门调整方法。 这些众多优势使我们的方法成为下游适应微调的引人注目的替代方案。 我们的代码位于:https://github.com/zjunet/GPF。
1简介
图神经网络(GNN)因其在图表示学习方面取得的巨大成功而受到了研究人员的极大关注(Kipf 和 Welling,2017;Hamilton 等人,2017;Xu 等人,2019)。 然而,两个基本挑战阻碍了 GNN 的大规模实际应用。 一是现实世界中标记数据的稀缺(Zitnik 等人, 2018),二是训练模型的分布外泛化能力低(Hu 等人,2020a;Knyazev 等人,2019;Yehudai 等人,2021;Morris 等人,2019)。 为了克服这些挑战,研究人员近年来在设计预训练的 GNN 模型(Xia 等人,2022b;Hu 等人,2020a,b;Lu 等人,2021)方面做出了大量努力。 与语言领域的预训练模型类似,预训练的 GNN 模型在广泛的预训练数据集上进行训练,随后适应下游任务。 大多数现有的预训练 GNN 模型都遵循“预训练,过度”学习策略(Xu 等人,2021a)。 具体来说,我们使用大量预训练图语料库训练 GNN 模型,然后利用预训练的 GNN 模型作为初始化,并根据特定的下游任务调整模型参数。
然而,预训练 GNN 模型的“pre-train, 过度”框架也提出了几个关键问题(Jin 等人,2020)。 首先,预训练任务与下游任务目标不一致(刘等人,2022a)。 现有的预训练模型大多采用边缘预测、属性屏蔽等自监督任务(Liu 等人, 2021e)作为预训练的目标,而下游任务则涉及图或节点分类。 这种目标差异导致绩效不佳(Liu 等人,2023)。 此外,确保模型保留其泛化能力具有挑战性。 预训练模型在下游适应过程中可能会遭受灾难性遗忘(周和曹,2021;刘等人,2020)。 当下游数据规模较小,接近少样本场景时,这个问题变得尤为严重(张等人,2022)。 在这种情况下,预训练模型往往会过度拟合下游数据,从而导致预训练过程无效。
“如果您的问题没有得到所需的答复,请尝试重新表述。”近年来,一种称为即时调整的新颖方法已成为下游适应的强大方法,可解决上述挑战。 该技术在自然语言处理(Li和Liang,2021;Lester等人,2021a;Liu等人,2022a,b)和计算机视觉(Bahng等人,2022)方面取得了巨大成功;贾等人,2022)。 提示调整提供了一种使预训练模型适应特定下游任务的替代方法:它冻结预训练模型的参数并修改输入数据。 与微调不同,即时调整不同于调整预训练模型的参数,而是侧重于通过转换输入来调整数据空间。
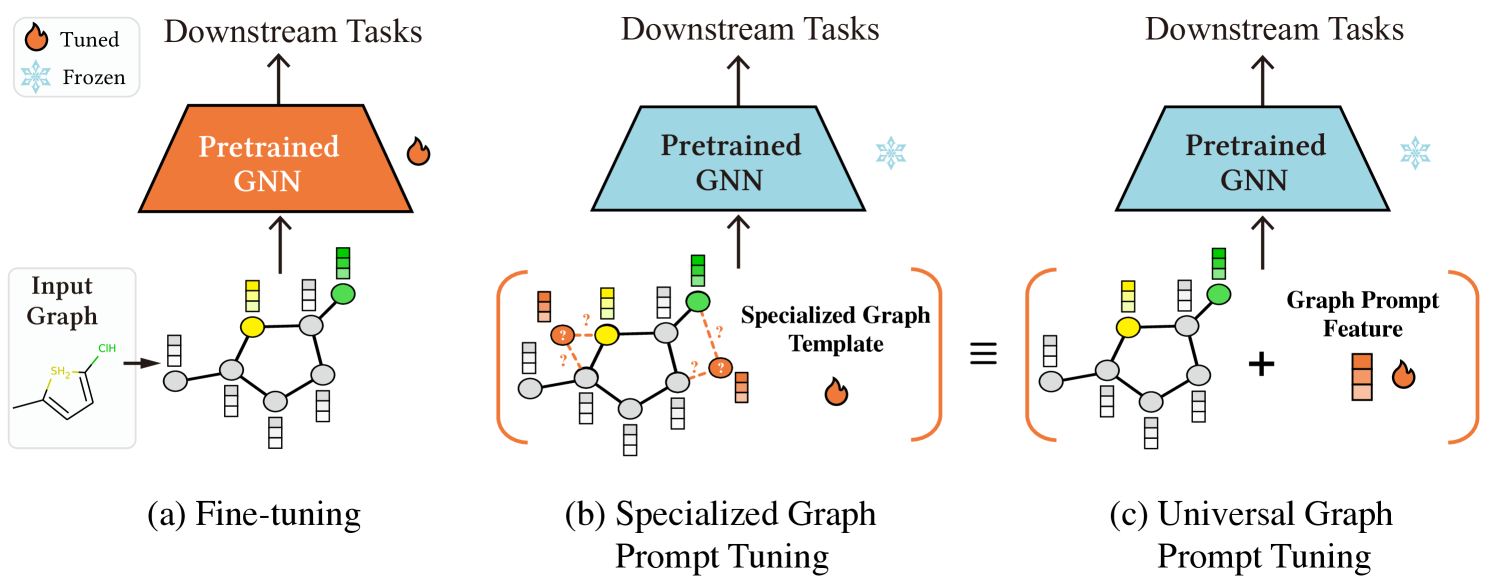
尽管如此,对预先训练的 GNN 模型进行快速调整仍会带来重大挑战,而且远非那么简单。 首先,图上采用的多样化预训练策略使得设计合适的提示功能变得困难。 先前的研究(Liu等人,2022a)表明提示功能应与预训练策略紧密结合。 对于预训练的语言模型,典型的预训练任务涉及掩码句子补全(Brown等人,2020)。 为了与这个任务保持一致,我们可以将“我收到了一份礼物”这样的句子修改为“我收到了一份礼物,我感觉[面具]”,使其更接近句子完成的任务。 然而,在图预训练的情况下,没有统一的预训练任务,这使得设计可行的提示功能具有挑战性。 一些开创性研究(Sun等人,2022;Liu等人,2023)已将基于提示的调优方法应用于边缘预测预训练的模型(Kipf和Welling,2016b) t1>. 他们将具有可学习链接的虚拟类原型节点/图引入到原始图中,使适应过程更类似于边缘预测。 然而,这些方法的适用性有限,并且仅与特定模型兼容。 当涉及到更复杂的预训练策略时,以与链接预测相同的方式设计手动提示功能变得具有挑战性。 因此,对于使用属性屏蔽(Hu等人,2020a)等替代策略预训练的模型,没有基于提示的调优方法可用。 此外,现有的基于提示的 GNN 模型调整方法主要是基于直觉设计的,缺乏对其有效性的理论保证。
在本文中,我们解决了图形提示调整的上述问题。 为了应对图预训练策略的多样性,我们提出了一种通用的基于提示的调整方法,该方法可以应用于采用任何预训练策略的预训练 GNN 模型。 图1说明了我们基于提示的通用调整方法与现有方法之间的区别。 我们的解决方案称为图提示特征(GPF),在输入图的特征空间上运行,并涉及向图中的所有节点特征添加共享的可学习向量。 这种方法很容易适用于任何 GNN 架构。 我们严格证明,当应用于任意预训练的 GNN 模型时,GPF 可以实现与任何形式的提示函数相当的结果。 因此,我们没有明确说明每个预训练策略对应的提示功能,而是采用GPF动态获取下游任务的提示图。 我们还为实际应用引入了理论上更强的 GPF 变体,称为 GPF-plus,它针对图中的不同节点合并了不同的提示特征。 为了保证我们提出的GPF和GPF-plus的有效性,我们提供了理论分析来证明GPF和GPF-plus并不弱于完全微调,并且在某些情况下可以获得更好的理论调整结果。 此外,我们进行了广泛的实验来验证我们方法的有效性。 尽管使用的可调参数数量比微调要少得多,但 GPF 和 GPF-plus 在所有预训练策略中都取得了更好的结果。 对于使用边缘预测预训练的模型,GPF 和 GPF-plus 比现有的基于提示的专门调整方法表现出显着的性能优势。 总的来说,我们的工作贡献可总结如下:
-
•
据我们所知,我们首次对现有预训练 GNN 模型的基于提示的通用调整方法进行了研究。 我们提出 GPF 及其变体 GPF-plus 作为通用图形提示调整的新方法。 我们的方法可以应用于采用任何预训练策略的预训练 GNN 模型。
-
•
我们为GPF和GPF-plus的有效性提供了理论保证。 我们证明GPF和GPF-plus可以达到与任何提示功能等效的效果,并且在某些情况下与微调相比可以获得更好的调整结果。
-
•
我们进行了大量的实验(包括完整样本和少样本场景)来验证 GPF 和 GPF-plus 的有效性。 实验结果表明,GPF和GPF-plus的性能优于微调,在全样本场景中平均提高约,在少样本场景中平均提高约。 此外,当应用于利用它们专门研究的预训练策略的模型时,GPF 和 GPF-plus 的性能显着优于现有的基于提示的调整方法。
2相关工作
预训练的GNN模型 受到预训练模型在自然语言处理(Qiu等人,2020b)和计算机视觉(Long等人)方面取得的卓越成就的启发,2022),近年来,人们在预训练 GNN 模型(PGM)(Xia 等人,2022b)方面投入了大量精力。 这些方法利用自监督策略(Jin等人,2020)从广泛的预训练图中获取有意义的表示。 GAE (Kipf 和 Welling,2016a) 首先使用边缘预测作为训练图表示的目标任务。 Deep Graph Infomax (DGI) (Velickovic 等人, 2019b) 和 InfoGraph (Sun 等人, 2019) 被提出通过最大化节点之间的互信息来获取节点或图表示不同粒度的图级和子结构级表示。 Hu 等人 (2020a) 采用属性屏蔽和上下文预测作为预训练任务来预测分子特性和蛋白质功能。 GROVER (Rong 等人, 2020) 和 MGSSL (Zhang 等人, 2021a) 都提出预测主题的存在或生成它们,考虑到丰富的领域知识分子隐藏在图案中。 图对比学习(GCL)是另一种广泛采用的 GNN 模型预训练策略。 GraphCL (You 等人, 2020) 和 JOAO (You 等人, 2021) 提出了各种增强策略来生成不同的增强视图以进行对比学习。 总之,GNN 模型存在多种预训练策略,每种策略都有独特的目标。
基于提示的调优方法基于提示的调优方法起源于自然语言处理,已被广泛用于促进预训练语言模型适应各种下游任务(刘等人, 2021a)。 研究还探索了软提示的设计,以实现最佳性能(Lester 等人,2021b;Liu 等人,2021c)。 这些方法冻结预训练模型的参数,并在输入空间中引入额外的可学习组件,从而增强输入和预训练模型之间的兼容性。 除了语言领域提示的成功外,提示方法在其他领域也得到了运用。 Jia 等人 (2022) 和 Bahng 等人 (2022) 研究了通过在像素级别修改输入图像来适应视觉领域的大规模模型的功效。 在图神经网络领域,基于提示的调优方法的探索仍然有限。 一些开创性工作(Sun等人,2022;Liu等人,2023)将基于提示的调优方法应用于边缘预测预训练的模型(Kipf和Welling,2016b) t1>. 这些方法将具有可学习链接的虚拟类原型节点/图引入到输入图中,使下游适应更类似于边缘预测。 然而,这些方法专门用于使用边缘预测预训练的模型,不能应用于使用其他策略训练的模型。 我们是第一个研究可应用于任何预训练策略下的 GNN 模型的基于提示的通用调整方法的人。
3方法论
我们引入了图形提示调整,用于使预训练的 GNN 模型适应下游任务。 需要注意的是,图分析中有多种类型的下游任务,包括节点分类、链路预测和图分类。 我们首先专注于图分类任务,然后将我们的方法扩展到节点级任务。 我们在3.1节中定义了符号,然后在3.2节中说明了图形提示调整的过程。 我们在3.3节中介绍了我们的通用图提示调整方法,并在3.4节中提供了理论分析。 最后,我们在附录中将我们的方法扩展到节点任务(节点分类和链接预测)。
3.1预赛
令表示一个图,其中、分别表示节点集和边集。 节点特征可以表示为矩阵,其中是节点的特征,是维度节点特征。 表示邻接矩阵,其中 if 。
微调预训练模型。 给定一个预训练的 GNN 模型 、一个可学习的投影头 和一个下游任务数据集 ,我们调整预训练模型的参数 和投影头 最大化预测下游图 的正确标签 的可能性:
| (1) |
3.2图形提示调优
整体流程。 我们提出的图形提示调整通过借鉴语言领域提示调整的设计(Liu等人,2022a)来工作在输入空间。 给定一个冻结的预训练 GNN 模型 、一个可学习的投影头 和一个下游任务数据集 ,我们的目标是获得特定于任务的图形提示 由参数化。 图形提示 将输入图形转换为特定的提示图形。 然后将替换作为预训练GNN模型的输入。在下游任务训练期间,我们选择 和 的最佳参数,以最大化预测正确标签 的可能性,而无需调整预训练模型,可以表示为:
| (2) |
在评估阶段,测试图首先通过图提示进行转换,并对生成的提示图进行处理通过冻结的 GNN 模型。
实际使用。 在这一部分中,我们详细描述了图形提示调整的细化过程,其中包括两个基本步骤:模板设计和提示优化 。
A. 模板设计。 给定一个输入图,我们首先生成一个图模板,其中包括其邻接矩阵中的可学习组件和特征矩阵。 先前的研究将即时调优的成功归因于弥合预训练任务和下游任务之间的差距(Liu等人,2022a)。 因此,这意味着图模板的具体形式受到模型采用的预训练策略的影响。 对于特定的预训练任务和输入图,图模板可以表示为:
| (3) |
其中图形模板 可以在其邻接矩阵或特征矩阵中包含可学习参数(即,可调链接或节点特征)(类似于在句子中包含可学习软提示) ),的候选空间为,的候选空间为。
B. 及时优化。 一旦我们获得了图形模板,我们的下一步就是在各自的候选空间内搜索最佳的和 > 和 使用预训练模型 和可学习投影头 最大限度地提高正确预测标签 的可能性。 这个过程可以表示为:
| (4) |
由和组成的图可以认为是中提到的提示图公式2。
实际挑战。 图模板的具体形式与模型采用的预训练任务密切相关。然而,设计提示功能具有挑战性,并且针对不同的预训练任务而有所不同。 开创性工作(Sun等人,2022;Liu等人,2023)针对特定的预训练策略提出了相应的提示函数,重点关注预训练的模型使用边缘预测。 然而,许多其他预训练策略(Hu 等人, 2020a; Xia 等人, 2022b),例如属性屏蔽和上下文预测,在现有的预训练GNN模型中被广泛使用,但还没有已经开展了为这些策略设计提示功能的研究。 此外,现有的提示功能都是直观设计的,这些手动提示功能缺乏有效性的保证。 它提出了一个自然的问题: 我们是否可以设计一种通用的提示方法,可以应用于任何预训练模型,而不管底层的预训练策略如何?
3.3通用图形提示设计
在本节中,我们将介绍一种通用的提示方法及其变体。 受到计算机视觉领域像素级视觉提示(VP)技术(Bahng 等人,2022;Wu 等人,2022;Xing 等人,2022)成功的启发,我们的方法引入了可学习的组件到输入图的特征空间。 在3.4节中,我们将证明这些提示方法理论上可以达到与任何提示功能等效的效果。
图形提示功能(GPF)。 GPF 专注于将额外的可学习参数合并到输入图的特征空间中。 具体来说,可学习组件是维度的向量,其中对应于节点特征的维度。 可以表示为:
| (5) |
将可学习向量与图特征相加,生成提示特征,可以表示为:
| (6) |
提示特征替换初始特征并由预训练模型处理。
图形提示功能增强版 (GPF-plus)。 在 GPF 的基础上,我们引入了一种名为 GPF-plus 的变体,它将独立的可学习向量 分配给图中的每个节点 。 可以表示为:
| (7) | |||
| (8) |
与 GPF 类似,提示特征 替换初始特征 并由预训练模型处理。 但这样的设计并不能普遍适用于所有场景。 例如,当训练图具有不同的训练尺度(即不同的节点数)时,这样一系列的就具有挑战性。 此外,在处理大规模输入图时,由于其可学习参数,这种设计需要大量的存储资源。 为了解决这些问题,我们在的生成中引入了注意力机制,使得GPF-plus参数效率更高,并且能够处理不同尺度的图。 在实践中,我们只训练个独立的基向量,它可以表示为:
| (9) |
其中是一个超参数,可以根据下游数据集进行调整。 为了获得节点的,我们在可学习线性投影的帮助下利用这些基向量的注意聚合。 计算过程可表示为:
| (10) |
随后,使用生成提示特征,如公式8所述。
3.4理论分析
在本节中,我们为我们提出的 GPF 和 GPF-plus 提供理论分析。 我们的分析分为两部分。 首先,我们证明我们方法的普遍性。 我们证明我们的方法理论上可以达到与任何提示功能 等效的结果。 它证实了我们的方法在不同预训练策略中的多功能性和适用性。 然后,我们保证我们提出的方法的有效性。 具体来说,我们证明了我们提出的图提示调整并不弱于完全微调,这意味着在某些场景下,GPF和GPF-plus可以取得比微调更好的调整结果。 值得注意的是,我们在以下部分中的推导基于 GPF,它向图中的所有节点添加了全局额外向量 。 GPF-plus是一个更强大的版本,可以看作是GPF的扩展,当超参数设置为时,GPF-plus退化为GPF。 因此,针对 GPF 讨论的分析也适用于 GPF-plus。
在说明我们的结论之前,我们首先提供一些基本知识。 对于给定的预训练任务 和输入图 ,我们假设存在一个提示函数 ,它可以生成一个图模板 。 和的候选空间分别表示为和。
Theorem 1。
(GPF的通用能力)给定一个预训练的GNN模型,一个输入图,一个任意提示函数,对于任何提示图在图模板的候选空间中,存在满足以下条件的GPF额外特征向量:
| (11) |
定理1的完整证明可以在附录中找到。 定理1意味着GPF可以达到公式3和4中描述的任何提示函数的理论性能上限。 具体来说,如果优化某个提示函数生成的图形模板能够得到满意的图形表示,那么理论上,优化GPF的向量也可以得到满意的图形表示。实现精确的图形表示。 这个结论最初可能看起来违反直觉,因为 GPF 只向节点特征添加可学习组件,而没有显式修改图结构。 关键在于理解特征矩阵和邻接矩阵在处理过程中并不是完全独立的。 图结构修改对最终图表示的影响也可以通过对节点特征的适当修改来获得。 因此,GPF和GPF-plus通过避免提示函数的显式说明,采用了一种简单而有效的架构,使它们能够在各种预训练条件下拥有处理预训练GNN模型的通用能力。培训策略。
接下来,我们保证GPF的有效性,并证明GPF并不弱于fine-tuning,这意味着GPF在某些情况下可以比fine-tuning获得更好的理论调整结果。 在自然语言处理中,微调得到的结果通常被认为是即时调优结果的上限(Lester等人,2021a;Liu等人,2021b;Ding等人,2022)。 直觉上认为,微调允许在预训练模型中进行更灵活和全面的参数调整,可以在下游适应过程中带来更好的理论结果。 然而,在图领域,图神经网络的架构在一定程度上放大了输入空间变换对最终表示的影响。 为了进一步说明这一点,根据之前的工作(Kumar等人,2022;Tian等人,2023;Wei等人,2021),我们假设下游任务利用平方回归损失。
Theorem 2.
(GPF的有效性保证)对于预训练的GNN模型,非简并条件下的一系列图,以及线性投影头,对于 存在 满足:
| (12) |
4实验
4.1 实验设置
模型架构和数据集。 我们采用广泛使用的 5 层 GIN (Xu 等人, 2019) 作为模型的底层架构,这与大多数现有的预训练 GNN 模型 (Xia 等人) 保持一致,2022b;邱等人,2020a;苏雷什等人,2021b;张等人,2022a; )。 对于基准数据集,我们采用Hu等人(2020a)发布的化学和生物学数据集。 这些数据集的全面描述可以在附录中找到。
预训练策略。 我们采用了五种广泛使用的策略(任务)来预训练 GNN 模型,包括 Deep Graph Infomax(用 Infomax 表示)(Velickovic 等人, 2019a)、边缘预测(用 EdgePred 表示)(Kipf and Welling, 2016a)、属性屏蔽(用 AttrMasking 表示)(Hu 等人, 2020a)、上下文预测(用 ContextPred 表示)(Hu 等人, 2020a)和图对比学习(用GCL表示)(你等人, 2020)。 这些预训练策略的详细描述可以在附录中找到。
调整策略。 我们将预训练的模型采用不同的调整策略应用于下游任务。 给定一个预训练的 GNN 模型 ,一个特定于任务的投影头 ,
实施。 我们对每个实验设置使用不同的随机种子进行五轮实验并报告平均结果。 投影头选自具有相等宽度的[1,2,3]层MLP的范围。 GPF-plus的超参数选自范围[5,10,20]。 有关超参数设置的更多详细信息可以在附录中找到。
4.2 主要结果
| Pre-training Strategy | Tuning Strategy |
BBBP |
Tox21 |
ToxCast |
SIDER |
ClinTox |
MUV |
HIV |
BACE |
PPI | Avg. |
| Infomax | FT |
67.55 ±2.06 |
78.57 ±0.51 |
65.16 ±0.53 |
63.34 ±0.45 |
70.06 ±1.45 |
81.42 ±2.65 |
77.71 ±0.45 |
81.32 ±1.25 |
71.29 ±1.79 | 72.93 |
| GPF |
66.83 ±0.86 |
79.09 ±0.25 |
66.10 ±0.53 |
66.17 ±0.81 |
73.56 ±3.94 |
80.43 ±0.53 |
76.49 ±0.18 |
83.60 ±1.00 |
77.02 ±0.42 | 74.36 | |
| GPF-plus |
67.17 ±0.36 |
79.13 ±0.70 |
66.35 ±0.37 |
65.62 ±0.74 |
75.12 ±2.45 |
81.33 ±1.52 |
77.73 ±1.14 |
83.67 ±1.08 |
77.03 ±0.32 | 74.79 | |
| AttrMasking | FT |
66.33 ±0.55 |
78.28 ±0.05 |
65.34 ±0.30 |
66.77 ±0.13 |
74.46 ±2.82 |
81.78 ±1.95 |
77.90 ±0.18 |
80.94 ±1.99 |
73.93 ±1.17 | 73.97 |
| GPF |
68.09 ±0.38 |
79.04 ±0.90 |
66.32 ±0.42 |
69.13 ±1.16 |
75.06 ±1.02 |
82.17 ±0.65 |
78.86 ±1.42 |
84.33 ±0.54 |
78.91 ±0.25 | 75.76 | |
| GPF-plus |
67.71 ±0.64 |
78.87 ±0.31 |
66.58 ±0.13 |
68.65 ±0.72 |
76.17 ±2.98 |
81.12 ±1.32 |
78.13 ±1.12 |
85.76 ±0.36 |
78.90 ±0.11 | 75.76 | |
| ContextPred | FT |
69.65 ±0.87 |
78.29 ±0.44 |
66.39 ±0.57 |
64.45 ±0.6 |
73.71 ±1.57 |
82.36 ±1.22 |
79.20 ±0.51 |
84.66 ±0.84 |
72.10 ±1.94 | 74.53 |
| GPF |
68.48 ±0.88 |
79.99 ±0.24 |
67.92 ±0.35 |
66.18 ±0.46 |
74.51 ±2.72 |
84.34 ±0.25 |
78.62 ±1.46 |
85.32 ±0.41 |
77.42 ±0.07 | 75.86 | |
| GPF-plus |
69.15 ±0.82 |
80.05 ±0.46 |
67.58 ±0.54 |
66.94 ±0.95 |
75.25 ±1.88 |
84.48 ±0.78 |
78.40 ±0.16 |
85.81 ±0.43 |
77.71 ±0.21 | 76.15 | |
| GCL | FT |
69.49 ±0.35 |
73.35 ±0.70 |
62.54 ±0.26 |
60.63 ±1.26 |
75.17 ±2.14 |
69.78 ±1.44 |
78.26 ±0.73 |
75.51 ±2.01 |
67.76 ±0.78 | 70.27 |
| GPF |
71.11 ±1.20 |
73.64 ±0.25 |
62.70 ±0.46 |
61.26 ±0.53 |
72.06 ±2.98 |
70.09 ±0.67 |
75.52 ±1.09 |
78.55 ±0.56 |
67.60 ±0.57 | 70.28 | |
| GPF-plus |
72.18 ±0.93 |
73.35 ±0.43 |
62.76 ±0.75 |
62.37 ±0.38 |
73.90 ±2.47 |
72.94 ±1.87 |
77.51 ±0.82 |
79.61 ±2.06 |
67.89 ±0.69 | 71.39 |
我们比较了使用不同预训练和调优策略训练的模型的下游性能,总体结果总结在表1中。 我们的系统研究表明以下观察结果:
1. 在大多数情况下,我们的图形提示调整优于微调。 根据表 1 中的结果,很明显,与大多数情况下的微调相比,GPF 和 GPF-plus 实现了优越的性能。 具体来说,GPF 在 实验中优于微调,而 GPF-plus 在 实验中优于微调。 值得注意的是,GPF和GPF-plus中的可调参数的幅度明显小于fine-tuning中的可调参数(详情见附录)。 这些实验结果凸显了我们方法的有效性,并证明了它们释放预训练模型力量的能力。
2. GPF 和 GPF-plus 在各种预训练策略中表现出通用能力。 GPF 和 GPF-plus 在我们实验中检查的所有预训练策略中都呈现出良好的调优性能,始终超过微调获得的平均结果。 具体来说,GPF 实现了 的平均改进,而 GPF-plus 实现了 的平均改进。 这些结果表明 GPF 和 GPF-plus 的通用能力,使其能够应用于使用任何预训练策略训练的模型。
3. GPF-plus 的表现略胜于 GPF。 在这两种图形提示调整方法中,GPF-plus 在大多数实验中都比 GPF 表现更好 ()。 正如 3.3 节中所讨论的,与 GPF 相比,GPF-plus 提供了更大的灵活性和表现力。 结果进一步证实了GPF-plus是图形提示调整的增强版本,与理论分析一致。
4.3 与现有基于图提示的方法的比较
| Pre-training Strategy | Tuning Strategy |
BBBP |
Tox21 |
ToxCast |
SIDER |
ClinTox |
MUV |
HIV |
BACE |
PPI | Avg. |
| EdgePred | FT |
66.56 ±3.56 |
78.67 ±0.35 |
66.29 ±0.45 |
64.35 ±0.78 |
69.07 ±4.61 |
79.67 ±1.70 |
77.44 ±0.58 |
80.90 ±0.92 |
71.54 ±0.85 | 72.72 |
| GPPT |
64.13 ±0.14 |
66.41 ±0.04 |
60.34 ±0.14 |
54.86 ±0.25 |
59.81 ±0.46 |
63.05 ±0.34 |
60.54 ±0.54 |
70.85 ±1.42 |
56.23 ±0.27 | 61.80 | |
| GPPT (w/o ol) |
69.43 ±0.18 |
78.91 ±0.15 |
64.86 ±0.11 |
60.94 ±0.18 |
62.15 ±0.69 |
82.06 ±0.53 |
73.19 ±0.19 |
70.31 ±0.99 |
76.85 ±0.26 | 70.97 | |
| GraphPrompt |
69.29 ±0.19 |
68.09 ±0.19 |
60.54 ±0.21 |
58.71 ±0.13 |
55.37 ±0.57 |
62.35 ±0.44 |
59.31 ±0.93 |
67.70 ±1.26 |
49.48 ±0.96 | 61.20 | |
| GPF |
69.57 ±0.21 |
79.74 ±0.03 |
65.65 ±0.30 |
67.20 ±0.99 |
69.49 ±5.17 |
82.86 ±0.23 |
77.60 ±1.45 |
81.57 ±1.08 |
76.98 ±0.20 | 74.51 | |
| GPF-plus |
69.06 ±0.68 |
80.04 ±0.06 |
65.94 ±0.31 |
67.51 ±0.59 |
68.80 ±2.58 |
83.13 ±0.42 |
77.65 ±1.90 |
81.75 ±2.09 |
77.00 ±0.12 | 74.54 |
我们还对我们提出的方法 GPF 和 GPF-plus 与现有的基于图形提示的调优方法进行了比较分析(Sun 等人,2022;Liu 等人,2023)。 他们都专门调整边缘预测(也称为链接预测)预训练的模型。 我们应用GPPT (Sun 等人, 2022),无正交提示约束损失的GPPT(记为GPPT (w/o ol))(Sun 等人, 2022), GraphPrompt (Liu 等人, 2023) 到使用边缘预测预训练的模型,结果总结在表2中。 值得一提的是,GPPT最初是为节点分类任务而设计的。 因此,我们进行了一些小的修改,用类原型图替换类原型节点,以使其适应图分类任务。 实验结果表明,我们提出的 GPF 和 GPF-plus 明显优于现有的基于图形提示的调整方法。 在化学和生物学基准上,GPF 和 GPF-plus 相对于 GPPT、GPPT 实现了 、 和 的平均改进(w/o ol) 、 和 GraphPrompt 分别。 这些结果展示了与专为预训练策略设计的现有基于图形提示的调整方法相比,GPF 和 GPF-plus 能够获得更好的结果。 此外,值得强调的是,GPF 和 GPF-plus 是仅有的两种超越微调性能的基于图形提示的调优方法。
4.4 额外实验
样本图分类少。 快速调优也因其在解决少样本下游任务方面的有效性而得到认可(Brown 等人,2020;Schick 和 Schütze,2020b,a;Liu 等人,2021d,2023)。 我们评估了我们提出的方法在处理少样本场景中的有效性。 为了对化学和生物数据集进行少样本图分类,我们将下游任务中的训练样本数量限制为 50 个(相比于原来的 1.2k 到 72k 训练样本范围)。 结果总结于附录的表4中。 与全镜头场景相比,我们提出的图形提示调整显示出比微调更显着的性能改进(GPF 的平均改进为 ,GPF-plus 的平均改进为 )在样本场景中。 这一发现表明,与微调相比,我们的解决方案在少样本下游适应期间在预训练模型中保留了更高程度的泛化能力。
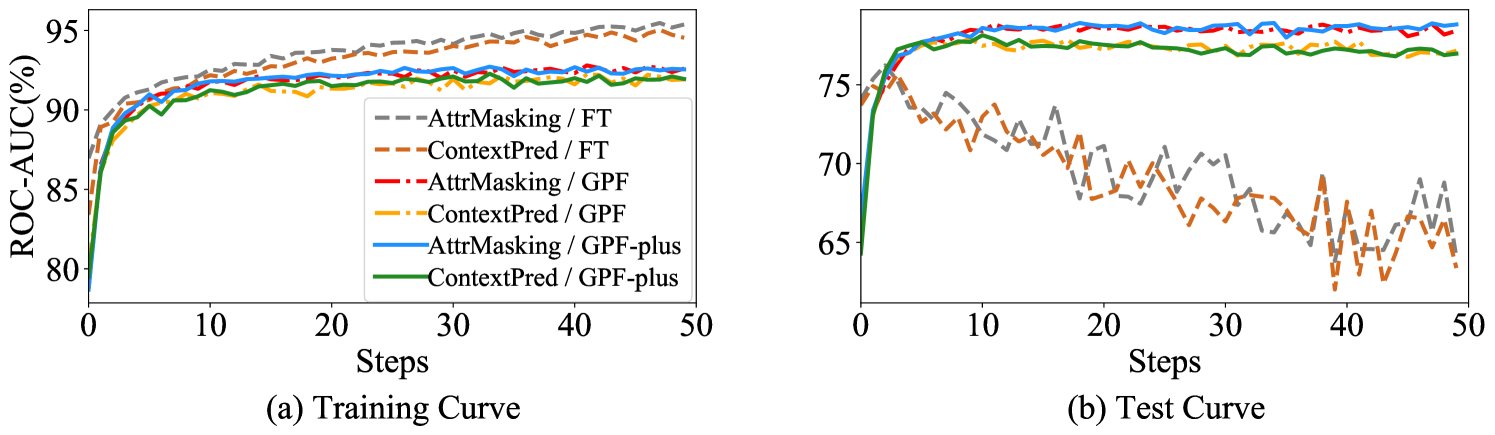
训练过程分析。 我们使用不同的调优方法对生物数据集和 GNN 模型进行了训练过程分析,该模型采用属性屏蔽和上下文预测作为预训练任务(Hu等人,2020b)。 图2展示了适应阶段的训练和测试曲线。 从图2(a)中可以看出,在我们提出的方法和微调的适应阶段,训练集的ROC-AUC分数持续增加。 然而,从图2(b)中,我们可以发现它们在测试集上的行为是非常不同的。 对于微调,测试集上的 ROC-AUC 分数呈现波动,并在最初增加后不断下降。 另一方面,当应用 GPF 或 GPF-plus 来适应预训练模型时,测试集上的 ROC-AUC 分数继续增长并保持一致的高水平。 这些结果表明,在下游任务上完全微调预训练的 GNN 模型可能会失去模型的泛化能力。 相比之下,采用我们提出的图形提示调整方法可以显着缓解这个问题并在测试集上保持卓越的性能。
5结论
在本文中,我们介绍了一种针对预训练 GNN 模型的通用的基于提示的调整方法。 我们的方法 GPF 及其变体 GPF-plus 在下游输入图的特征空间上运行。 GPF和GPF-plus理论上可以达到与任何形式的提示功能等效的效果,这意味着我们不再需要明确说明每个预训练策略对应的提示功能。 相反,我们可以自适应地使用 GPF 来获取提示图以进行下游任务适配。 与微调相比,我们的方法的优越性在理论和经验上都得到了证明,使其成为下游适应的引人注目的替代方案。
6致谢
该工作得到了浙江省国家科学基金项目(LR22F020005)、国家重点研发计划项目(2018AAA0101900)和中央高校基本科研业务费专项资金的部分支持。
参考
- Bahng et al. [2022] Hyojin Bahng, Ali Jahanian, Swami Sankaranarayanan, and Phillip Isola. Exploring visual prompts for adapting large-scale models. 2022.
- Bevilacqua et al. [2022] Beatrice Bevilacqua, Fabrizio Frasca, Derek Lim, Balasubramaniam Srinivasan, Chen Cai, G. Balamurugan, Michael M. Bronstein, and Haggai Maron. Equivariant subgraph aggregation networks. ICLR, 2022.
- Brown et al. [2020] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, T. J. Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeff Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. NeurIPS, 2020.
- Cotta et al. [2021] Leonardo Cotta, Christopher Morris, and Bruno Ribeiro. Reconstruction for powerful graph representations. NeurIPS, 2021.
- Ding et al. [2022] Ning Ding, Yujia Qin, Guang Yang, Fu Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, Jing Yi, Weilin Zhao, Xiaozhi Wang, Zhiyuan Liu, Haitao Zheng, Jianfei Chen, Yang Liu, Jie Tang, Juan Li, and Maosong Sun. Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models. ArXiv, abs/2203.06904, 2022.
- Du et al. [2020] Simon Shaolei Du, Wei Hu, Sham M. Kakade, J. Lee, and Qi Lei. Few-shot learning via learning the representation, provably. ICLR, 2020.
- Frasca et al. [2022] Fabrizio Frasca, Beatrice Bevilacqua, Michael Bronstein, and Haggai Maron. Understanding and extending subgraph gnns by rethinking their symmetries. NeurIPS, 2022.
- Gaulton et al. [2012] Anna Gaulton, Louisa J. Bellis, A. Patrícia Bento, Jon Chambers, Mark Davies, Anne Hersey, Yvonne Light, Shaun McGlinchey, David Michalovich, Bissan Al-Lazikani, and John P. Overington. Chembl: a large-scale bioactivity database for drug discovery. Nucleic Acids Research, 40:D1100 – D1107, 2012.
- Hamilton et al. [2017] Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. In NeurIPS, pages 1024–1034, 2017.
- He et al. [2021] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll’ar, and Ross B. Girshick. Masked autoencoders are scalable vision learners. ArXiv, abs/2111.06377, 2021.
- Hu et al. [2020a] Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay S. Pande, and Jure Leskovec. Strategies for pre-training graph neural networks. ICLR, 2020a.
- Hu et al. [2020b] Ziniu Hu, Yuxiao Dong, Kuansan Wang, Kai-Wei Chang, and Yizhou Sun. Gpt-gnn: Generative pre-training of graph neural networks. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2020b.
- Jia et al. [2022] Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Visual prompt tuning. ECCV, 2022.
- Jin et al. [2020] Wei Jin, Tyler Derr, Haochen Liu, Yiqi Wang, Suhang Wang, Zitao Liu, and Jiliang Tang. Self-supervised learning on graphs: Deep insights and new direction. ArXiv, abs/2006.10141, 2020.
- Kipf and Welling [2016a] Thomas Kipf and Max Welling. Variational graph auto-encoders. ArXiv, abs/1611.07308, 2016a.
- Kipf and Welling [2016b] Thomas N Kipf and Max Welling. Variational graph auto-encoders. In ArXiv, volume abs/1611.07308, 2016b.
- Kipf and Welling [2017] Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations, 2017.
- Klicpera et al. [2019] Johannes Klicpera, Stefan Weißenberger, and Stephan Günnemann. Diffusion improves graph learning. In Neural Information Processing Systems, 2019.
- Knyazev et al. [2019] Boris Knyazev, Graham W. Taylor, and Mohamed R. Amer. Understanding attention and generalization in graph neural networks. In NeurIPS, 2019.
- Kumar et al. [2022] Ananya Kumar, Aditi Raghunathan, Robbie Jones, Tengyu Ma, and Percy Liang. Fine-tuning can distort pretrained features and underperform out-of-distribution. ICLR, 2022.
- Lester et al. [2021a] Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. EMNLP, 2021a.
- Lester et al. [2021b] Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021b.
- Li and Liang [2021] Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), abs/2101.00190, 2021.
- Liu et al. [2020] Huihui Liu, Yiding Yang, and Xinchao Wang. Overcoming catastrophic forgetting in graph neural networks. In AAAI Conference on Artificial Intelligence, 2020.
- Liu et al. [2021a] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. arXiv preprint arXiv:2107.13586, 2021a.
- Liu et al. [2022a] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys (CSUR), 2022a.
- Liu et al. [2021b] Xiao Liu, Kaixuan Ji, Yicheng Fu, Zhengxiao Du, Zhilin Yang, and Jie Tang. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. ArXiv, abs/2110.07602, 2021b.
- Liu et al. [2021c] Xiao Liu, Kaixuan Ji, Yicheng Fu, Zhengxiao Du, Zhilin Yang, and Jie Tang. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. arXiv preprint arXiv:2110.07602, 2021c.
- Liu et al. [2021d] Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. Gpt understands, too. ArXiv, abs/2103.10385, 2021d.
- Liu et al. [2022b] Xiao Liu, Kaixuan Ji, Yicheng Fu, Weng Lam Tam, Zhengxiao Du, Zhilin Yang, and Jie Tang. P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. In ACL, 2022b.
- Liu et al. [2021e] Yixin Liu, Shirui Pan, Ming Jin, Chuan Zhou, Feng Xia, and Philip S. Yu. Graph self-supervised learning: A survey. IEEE Transactions on Knowledge and Data Engineering, 35:5879–5900, 2021e.
- Liu et al. [2023] Zemin Liu, Xingtong Yu, Yuan Fang, and Xinming Zhang. Graphprompt: Unifying pre-training and downstream tasks for graph neural networks. Proceedings of the ACM Web Conference 2023, 2023.
- Long et al. [2022] Siqu Long, Feiqi Cao, Soyeon Caren Han, and Haiqing Yang. Vision-and-language pretrained models: A survey. IJCAI, 2022.
- Lu et al. [2021] Yuanfu Lu, Xunqiang Jiang, Yuan Fang, and Chuan Shi. Learning to pre-train graph neural networks. In AAAI, 2021.
- Mayr et al. [2018] Andreas Mayr, Günter Klambauer, Thomas Unterthiner, Marvin N. Steijaert, Jörg Kurt Wegner, Hugo Ceulemans, Djork-Arné Clevert, and Sepp Hochreiter. Large-scale comparison of machine learning methods for drug target prediction on chembl† †electronic supplementary information (esi) available: Overview, data collection and clustering, methods, results, appendix. see doi: 10.1039/c8sc00148k. Chemical Science, 9:5441 – 5451, 2018.
- Mesquita et al. [2020] Diego Mesquita, Amauri H. de Souza, and Samuel Kaski. Rethinking pooling in graph neural networks. ArXiv, abs/2010.11418, 2020.
- Morris et al. [2019] Christopher Morris, Martin Ritzert, Matthias Fey, William L. Hamilton, Jan Eric Lenssen, Gaurav Rattan, and Martin Grohe. Weisfeiler and leman go neural: Higher-order graph neural networks. AAAI, 2019.
- Qiu et al. [2020a] Jiezhong Qiu, Qibin Chen, Yuxiao Dong, Jing Zhang, Hongxia Yang, Ming Ding, Kuansan Wang, and Jie Tang. Gcc: Graph contrastive coding for graph neural network pre-training. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2020a.
- Qiu et al. [2020b] Xipeng Qiu, Tianxiang Sun, Yige Xu, Yunfan Shao, Ning Dai, and Xuanjing Huang. Pre-trained models for natural language processing: A survey. Science China Technological Sciences, 63:1872 – 1897, 2020b.
- Rong et al. [2020] Yu Rong, Yatao Bian, Tingyang Xu, Weiyang Xie, Ying Wei, Wenbing Huang, and Junzhou Huang. Self-supervised graph transformer on large-scale molecular data. Advances in Neural Information Processing Systems, 33:12559–12571, 2020.
- Schick and Schütze [2020a] Timo Schick and Hinrich Schütze. Exploiting cloze-questions for few-shot text classification and natural language inference. In Conference of the European Chapter of the Association for Computational Linguistics, 2020a.
- Schick and Schütze [2020b] Timo Schick and Hinrich Schütze. It’s not just size that matters: Small language models are also few-shot learners. NAACL, 2020b.
- Sterling and Irwin [2015] T. Sterling and John J. Irwin. Zinc 15 – ligand discovery for everyone. Journal of Chemical Information and Modeling, 55:2324 – 2337, 2015.
- Sun et al. [2019] Fan-Yun Sun, Jordan Hoffmann, Vikas Verma, and Jian Tang. Infograph: Unsupervised and semi-supervised graph-level representation learning via mutual information maximization. arXiv preprint arXiv:1908.01000, 2019.
- Sun et al. [2022] Mingchen Sun, Kaixiong Zhou, Xingbo He, Ying Wang, and Xin Wang. Gppt: Graph pre-training and prompt tuning to generalize graph neural networks. Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022.
- Suresh et al. [2021] Susheel Suresh, Pan Li, Cong Hao, and Jennifer Neville. Adversarial graph augmentation to improve graph contrastive learning. In Neural Information Processing Systems, 2021.
- Tian et al. [2023] Junjiao Tian, Xiaoliang Dai, Chih-Yao Ma, Zecheng He, Yen-Cheng Liu, and Zsolt Kira. Trainable projected gradient method for robust fine-tuning. ArXiv, abs/2303.10720, 2023.
- Tripuraneni et al. [2020] Nilesh Tripuraneni, Michael I. Jordan, and Chi Jin. On the theory of transfer learning: The importance of task diversity. NeurIPS, 2020.
- Velickovic et al. [2019a] Petar Velickovic, William Fedus, William L. Hamilton, Pietro Lio’, Yoshua Bengio, and R. Devon Hjelm. Deep graph infomax. ICLR, 2019a.
- Velickovic et al. [2019b] Petar Velickovic, William Fedus, William L. Hamilton, Pietro Lio’, Yoshua Bengio, and R. Devon Hjelm. Deep graph infomax. ICLR, 2019b.
- Wei et al. [2021] Colin Wei, Sang Michael Xie, and Tengyu Ma. Why do pretrained language models help in downstream tasks? an analysis of head and prompt tuning. ArXiv, abs/2106.09226, 2021.
- Wu et al. [2022] Junyang Wu, Xianhang Li, Chen Wei, Huiyu Wang, Alan Loddon Yuille, Yuyin Zhou, and Cihang Xie. Unleashing the power of visual prompting at the pixel level. ArXiv, abs/2212.10556, 2022.
- Wu et al. [2020] Sen Wu, Hongyang Zhang, and Christopher Ré. Understanding and improving information transfer in multi-task learning. ICLR, 2020.
- Wu et al. [2017] Zhenqin Wu, Bharath Ramsundar, Evan N. Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S. Pappu, Karl Leswing, and Vijay S. Pande. Moleculenet: A benchmark for molecular machine learning. arXiv: Learning, 2017.
- Xia et al. [2022a] Jun Xia, Lirong Wu, Jintao Chen, Bozhen Hu, and Stan Z. Li. Simgrace: A simple framework for graph contrastive learning without data augmentation. Proceedings of the ACM Web Conference 2022, 2022a.
- Xia et al. [2022b] Jun Xia, Yanqiao Zhu, Yuanqi Du, and Stan Z Li. A survey of pretraining on graphs: Taxonomy, methods, and applications. arXiv preprint arXiv:2202.07893, 2022b.
- Xing et al. [2022] Yinghui Xing, Qirui Wu, De Cheng, Shizhou Zhang, Guoqiang Liang, and Yanning Zhang. Class-aware visual prompt tuning for vision-language pre-trained model. ArXiv, abs/2208.08340, 2022.
- Xu et al. [2021a] Dongkuan Xu, Ian En-Hsu Yen, Jinxi Zhao, and Zhibin Xiao. Rethinking network pruning – under the pre-train and fine-tune paradigm. NAACL, 2021a.
- Xu et al. [2019] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? ICLR, 2019.
- Xu et al. [2021b] Minghao Xu, Hang Wang, Bingbing Ni, Hongyu Guo, and Jian Tang. Self-supervised graph-level representation learning with local and global structure. In International Conference on Machine Learning, 2021b.
- Yanardag and Vishwanathan [2015] Pinar Yanardag and S. V. N. Vishwanathan. Deep graph kernels. Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2015.
- Yehudai et al. [2021] Gilad Yehudai, Ethan Fetaya, Eli A. Meirom, Gal Chechik, and Haggai Maron. From local structures to size generalization in graph neural networks. In ICML, 2021.
- You et al. [2020] Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. Graph contrastive learning with augmentations. NeurIPS, 2020.
- You et al. [2021] Yuning You, Tianlong Chen, Yang Shen, and Zhangyang Wang. Graph contrastive learning automated. In International Conference on Machine Learning, pages 12121–12132. PMLR, 2021.
- You et al. [2022] Yuning You, Tianlong Chen, Zhangyang Wang, and Yang Shen. Bringing your own view: Graph contrastive learning without prefabricated data augmentations. Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, 2022.
- Zhang et al. [2022] Chuxu Zhang, Kaize Ding, Jundong Li, Xiangliang Zhang, Yanfang Ye, N. Chawla, and Huan Liu. Few-shot learning on graphs. In International Joint Conference on Artificial Intelligence, 2022.
- Zhang and Li [2021] Muhan Zhang and Pan Li. Nested graph neural networks. NeurIPS, 2021.
- Zhang et al. [2016] Richard Zhang, Phillip Isola, and Alexei A. Efros. Colorful image colorization. In ECCV, 2016.
- Zhang et al. [2021a] Z. Zhang, Q. Liu, H. Wang, C. Lu, and C. K. Lee. Motif-based graph self-supervised learning for molecular property prediction. 2021a.
- Zhang et al. [2021b] Zaixin Zhang, Qi Liu, Hao Wang, Chengqiang Lu, and Chee-Kong Lee. Motif-based graph self-supervised learning for molecular property prediction. In Neural Information Processing Systems, 2021b.
- Zhao et al. [2022] Lingxiao Zhao, Wei Jin, Leman Akoglu, and Neil Shah. From stars to subgraphs: Uplifting any gnn with local structure awareness. ICLR, 2022.
- Zhou and Cao [2021] Fan Zhou and Chengtai Cao. Overcoming catastrophic forgetting in graph neural networks with experience replay. In AAAI Conference on Artificial Intelligence, 2021.
- Zitnik et al. [2018] Marinka Zitnik, Rok Sosi, and Jure Leskovec. Prioritizing network communities. Nature Communications, 9, 2018.
附录 A第 3 节的额外材料
A.1 节点级任务的扩展
在本节中,我们将说明节点级任务(节点分类和链接预测)的图提示调整过程。 这些任务与图分类不同,需要节点级表示而不是图级表示。 为了弥补这一差距,我们采用子图 GNN [Cotta 等人, 2021, Zhuang and Li, 2021, Bevilacqua 等人, 2022, Zhuo 等人, 2022] 来捕获图级和节点级表示。 子图 GNN 模型在从原始输入图中提取的子图集上使用 MPNN。 他们随后聚合生成的表示[Frasca 等人, 2022]。 因此,节点表示也可以解释为导出子图的图形表示。 具体来说,节点的节点表示可以计算为:
| (13) |
其中 是子图 GNN 模型, 是节点 的诱导子图。 为了通过图形提示调整获得节点表示,我们冻结模型 并引入可学习的图形提示 ,由 参数化,如公式 2 所示,可以表示为:
| (14) |
一旦我们获得了节点表示,我们就可以无缝地继续下游节点分类或链接预测任务。 我们提出的方法 GPF 和 GPF-plus,能够通过公式 14 中描述的方法有效执行节点级任务。
A.2 定理1的证明
定理1。 (GPF的通用能力)给定一个预训练的GNN模型,一个输入图,一个任意提示函数,对于任何提示图在图模板的候选空间中,存在满足以下条件的GPF额外特征向量:
其中 、 和 分别是 和 的候选空间。
为了说明定理 1,我们提供了预训练的 GNN 模型的具体架构。为了分析简单起见,我们最初假设 是一个具有线性变换的单层 GIN [Xu 等人, 2019]。 随后,我们将结论扩展到利用各种转换矩阵的多层模型[Klicpera等人,2019]。 在生成图表示的过程中,我们首先获得节点表示,然后使用读出函数来计算最终的图表示。 现有的预训练 GNN 模型通常采用 sum 或 mean 池化来实现此目的。 之前的研究[Mesquita等人, 2020]表明复杂的池化机制是不必要的,因为简单的读出函数可以产生卓越的性能。 值得一提的是,当我们使用任何其他加权聚合读出函数(例如平均池化、最小/最大池化和分层池化)时,后续推导仍然成立。 因此,我们假设预训练的GNN模型的具体架构可以表示为:
| (15) | |||
| (16) |
其中 是线性投影。 参数和已提前预训练,并在下游适应期间保持固定。 接下来,我们继续进行定理1的推导。 定理1中,我们对提示函数的形式不作任何限制,允许和表示任意图的邻接矩阵和特征矩阵。 我们定义图级转换,它满足。 因此,定理1等价于命题1。
Proposition 1。
给定一个预训练的GNN模型,一个输入图,对于任何图级变换,都存在一个GPF额外特征向量 满足:
| (17) |
为了进一步说明图级转换,我们将其分解为几个具体的转换。
Proposition 2。
给定输入图 ,任意图级转换 可以解耦为以下一系列转换:
-
•
特征转换。修改节点特征并生成新的特征矩阵.
-
•
链接转换。 添加或删除边并生成新的邻接矩阵。
-
•
孤立的组件转换。 添加或删除孤立组件(子图)并生成新的邻接矩阵和特征矩阵。
这里,“孤立”一词是指不与图的其余部分链接的组件(子图)。 命题2表明任意图级变换是上述三种变换的组合。 例如,删除初始图中的节点可以分解为两个步骤:删除其连通边,然后删除孤立节点。
Proposition 3。
给定一个预训练的GNN模型,一个输入图,对于任何特征变换,都存在一个GPF额外特征向量 满足:
| (18) |
证明。
我们设置。 然后,我们有:
| (19) | ||||
| (20) | ||||
| (21) | ||||
| (22) |
对于 GPF ,我们可以执行类似的分割:
| (23) | ||||
| (24) | ||||
| (25) | ||||
| (26) |
其中表示具有的列向量,表示具有值的列向量>第行是,表示的度数。 为了获得相同的图形表示,我们有:
| (27) |
其中 表示计算矩阵中每一行的向量和的运算。 我们可以将上式进一步简化为:
| (28) | ||||
| (29) | ||||
| (30) | ||||
| (31) |
其中的结果,以及冻结的线性变换。 我们首先计算。 我们可以得到:
| (32) | ||||
| (33) |
其中表示中第维度的值,表示整个图中所有节点的总度数,表示GPF 中的第个可学习参数,表示中的冻结参数>。 对于,我们假设。 然后我们有:
| (34) |
其中表示中的可学习参数。 根据上面的分析,要获得与特定相同的图形表示,我们有:
| (35) | ||||
| (36) | ||||
| (37) |
因此,对于任意的特征变换,存在一个满足上述条件的GPF,并且可以获得预训练的GNN模型。 ∎
命题3展示了我们提出的GPF对所有图级特征转换的全面覆盖。 GPF 为图中的每个节点引入了统一的特征修改。 然而,它可以达到与上述预训练GNN模型下单独为每个节点添加独立特征修改等效的效果。
Proposition 4。
给定一个预训练的GNN模型,一个输入图,对于任何链接变换,都存在一个GPF额外特征向量 满足:
| (38) |
证明。
命题4的证明与命题3类似。 我们设置。 值得一提的是和,这意味着它们的大小相同,的值只能是或,的值可以是、或。 我们有:
| (39) | ||||
| (40) | ||||
| (41) |
由命题3的证明,我们得到:
| (42) |
其中 表示我们可学习的 GPF, 表示列向量,第 行的值为 和 表示的度数。 通过,我们可以得到:
| (43) | ||||
| (44) |
其中表示中第维度的值,表示整个图中所有节点的总度数,表示GPF 中的第个可学习参数,表示中的冻结参数>。 对于,我们有:
| (45) |
其中表示的元素,表示的元素。 为了获得具有特定 的相同图形表示 ,我们有:
| (46) | ||||
| (47) | ||||
| (48) |
因此,对于任意的链接变换,存在满足上述条件的GPF,并且可以获得与预训练的GNN模型相同的图表示。 ∎
命题4表明GPF还可以涵盖所有链接转换。 直观上,链接变换与邻接矩阵的变化密切相关,而邻接矩阵的变化与节点特征无关。 然而,我们的研究结果表明,在大多数现有 GNN 模型的架构中,特征空间的修改和结构空间的修改可以产生相同的效果。
Proposition 5。
给定一个预训练的 GNN 模型 、一个输入图 ,对于任何孤立分量变换 ,都存在一个 GPF 额外特征向量 满足:
| (49) |
证明。
与特征变换和线性变换不同,孤立分量变换会改变图中的节点数量,这意味着修改后的和的规模是不确定的。 我们首先更详细地表达孤立分量变换。 邻接矩阵和特征矩阵可以分为多个孤立的分量,可以表示为:
| (58) |
移除孤立分量意味着同时移除邻接矩阵中的和特征矩阵中对应的。 添加新的孤立分量意味着将添加到邻接矩阵中,并将添加到。 然后我们有:
| (59) |
为了与命题3和命题4的证明保持一致,我们设置,它可以表示为:
| (60) |
其中 是满足以下条件的指示符:
| (61) |
从命题3的证明,我们得到以下结论:
| (62) |
其中 表示我们可学习的 GPF, 表示列向量,第 行的值为 和 表示的度数。 通过,我们可以得到:
| (63) | ||||
| (64) |
其中表示中第维度的值,表示整个图中所有节点的总度数,表示GPF 中的第个可学习参数,表示中的冻结参数>。 为了获得具有特定 的相同图形表示 ,我们有:
| (65) | ||||
| (66) | ||||
| (67) |
其中 表示矩阵 的第 列。 因此,对于任意孤立分量变换,存在满足上述条件的GPF,并且可以获得与预训练GNN模型相同的图表示>。 ∎
孤立分量变换具有改变图尺度的能力,之前的研究对这种图级变换的关注有限。
Proposition 6。
给定一个预先训练过的 GNN 模型 、一个输入图 ,对于由 、 和 组成的一系列变换 ,存在一个满足以下条件的 GPF 额外特征向量 :
| (68) |
证明。
基于前面的分析,我们确定GPF可以复制任何图级变换对公式15和16定义的预训练GNN模型的影响。 因此,我们在简单模型架构的框架内成功证明了命题1和定理1。 接下来,我们的目标是将我们的发现推广到更复杂的场景。
A.3 定理2的证明
定理2。 (GPF的有效性保证)对于预训练的GNN模型,非简并条件下的一系列图,以及线性投影头,对于 存在 满足:
为了演示定理 2,我们需要对 GNN 模型的架构进行更详细的描述。我们假设的图形表示是通过以下过程获得的:
| (79) | |||
| (80) |
其中表示的扩散矩阵,如公式73,表示图的节点号、表示线性投影,是节点特征的维度,表示计算每行的和向量的操作矩阵。 当我们在上述模型 中采用我们提出的 GPF 时,图形表示 计算如下:
| (81) | |||
| (82) |
其中是全1的列向量,是GPF的额外可学习向量。 平方回归损失可表示为:
| (83) |
其中是线性投影头。 在这种情况下,微调和GPF 的最优调整损失可以表示为:
| (84) | |||
| (85) |
在证明定理2之前,我们首先说明以下命题。
Proposition 7。
给定一系列图 和线性投影 ,存在 、 和 满足:
| (86) |
对于任何,。
为了简化分析,我们将中的所有独特节点特征收集到一个集合中。 因此,任何图的节点特征矩阵都可以由集合中的元素构造。 接下来,我们继续将函数 扩展为:
| (87) | ||||
| (88) |
其中 表示 的第 行和 列中的元素, 表示 的第 行向量。 为了以统一的形式表达不同图的表示,我们重写上面的公式,从中的节点表示计算出图表示和 >:
| (89) | ||||
| (90) |
其中是图的的系数,对于所有计算为满足。 我们也可以得到。 然后,我们将公式86重写为矩阵形式如下:
| (91) |
其中 表示满足 的 的特征矩阵, 表示系数矩阵,且 第 1 行和 第 1 列 中的元素等于 , 表示列向量,其 第 1 行的值为 。 我们代表,那么我们有:
| (92) | ||||
| (93) |
给定一系列图 和线性投影 ,存在 、 和 满足:
| (94) |
对于任何。
我们假设 是一个列满秩矩阵,这意味着不同图之间不存在共享的统一特征分布,与现实世界场景保持一致。 需要注意的是,是预先预先训练好的,对于任何满足的和,非简并性公式94的条件如下:
| (95) | |||
| (96) |
最后,我们回顾一下定理 2。 给定非简并条件下的一系列图,满足的预训练线性投影、和 ,我们可以将 构造为:
| (97) |
附录 B有关实验的更多信息
B.1 数据集详细信息
数据集概述我们使用Hu等人[2020a]提供的数据集作为我们的预训练数据集。 这些数据集由两个领域组成:化学和生物学。 化学领域数据集包含从 ZINC15 数据库采样的 200 万个未标记分子[Sterling and Irwin, 2015],以及从预处理的 ChEMBL 数据集获得的 256K 个标记分子[Mayr 等人, 2018, Gaulton 等人,2012]。 另一方面,生物领域数据集包括 395K 个未标记的蛋白质自我网络和从 PPI 网络中提取的 88K 个标记的蛋白质自我网络。 对于在化学数据集上预训练的模型,我们采用 MoleculeNet [Wu 等人, 2017] 中提供的八个二进制图分类数据集作为下游任务。 至于在生物数据集上预训练的模型,我们将预训练的模型应用于 40 个二元分类任务,每个任务都涉及特定细粒度生物功能的预测。
预训练数据集。 Hu等人[2020a]提供的数据集由两个不同的数据集组成:Biology和Chemistry,分别对应生物学领域和化学领域。 Biology 数据集包含从 50 个物种的 PPI 网络中获得的 395K 个未标记的蛋白质自我网络。 这些网络用于节点级自监督预训练。 此外,88K 标记的蛋白质自我网络用作预测 5000 个粗粒度生物功能的训练数据。 这种图级多任务监督预训练旨在联合预测这些函数。 关于化学数据集,它包含从 ZINC15 数据库采样的 200 万个未标记分子[Sterling 和 Irwin,2015]。 这些分子用于节点级自监督预训练。 对于图级多任务监督预训练,采用预处理的 ChEMBL 数据集[Mayr 等人, 2018, Gaulton 等人, 2012]。 该数据集包含 456K 个分子,涵盖 1310 种不同的生化检测。
下游数据集。 表3列出了生物和化学预训练模型所使用的下游数据集的统计数据。
| Dataset | BBBP | Tox21 | ToxCast | SIDER | ClinTox | MUV | HIV | BACE | PPI |
| Proteins / Molecules | 2039 | 7831 | 8575 | 1427 | 1478 | 93087 | 41127 | 1513 | 88K |
| Binary prediction tasks | 1 | 12 | 617 | 27 | 2 | 17 | 1 | 1 | 40 |
B.2 预训练策略细节
我们采用五种广泛使用的策略(任务)来预训练 GNN 模型,如下所示:
-
•
Deep Graph Infomax(用Infomax表示)。 它首先由Velickovic等人[2019a]提出。 深度图infomax通过最大化不同粒度的图级表示和子结构级表示之间的互信息来获得图或节点的表达表示。
-
•
边缘预测(用EdgePred表示)。 它是许多模型使用的常规图重建任务,例如 GAE [Kipf and Welling, 2016a]。 预测目标是一对节点之间是否存在边。
-
•
属性屏蔽(用AttrMasking表示)。 由胡等人[2020a]提出。 它屏蔽节点/边缘属性,然后让 GNN 根据邻近结构预测这些属性。
-
•
上下文预测(用ContextPred表示)。 也是由胡等人[2020a]提出的。 上下文预测使用子图来预测其周围的图结构,旨在将出现在相似结构上下文中的节点映射到附近的嵌入。
-
•
图对比学习(用GCL表示)。 它将锚点的增强版本嵌入到彼此靠近的位置(正样本),并将其他样本(负样本)的嵌入推开。 我们使用You等人[2020]中提出的增强策略来生成正样本和负样本。
为了预训练我们的模型,我们遵循 Hu 等人 [2020a] 中概述的 Infomax、EdgePred、AttrMasking 和 ContextPred 任务的训练步骤。 然后,我们执行有监督的图级属性预测,以进一步增强预训练模型的性能。 对于使用 GCL 预训练的模型,我们遵循 You 等人 [2020] 中详细的训练步骤。
B.3少样本图分类结果
50 个镜头场景的结果。 表 4 总结了 50 次图分类的结果。
| Pre-training Strategy | Tuning Strategy |
BBBP |
Tox21 |
ToxCast |
SIDER |
ClinTox |
MUV |
HIV |
BACE |
PPI | Avg. |
| Infomax | FT |
53.81 ±3.35 |
61.42 ±1.19 |
53.93 ±0.59 |
50.77 ±2.27 |
58.6 ±3.48 |
66.12 ±0.63 |
65.09 ±1.17 |
52.64 ±2.64 |
48.79 ±1.32 | 56.79 |
| GPF |
55.52 ±1.84 |
65.56 ±0.64 |
56.76 ±0.54 |
50.29 ±1.61 |
62.44 ±4.11 |
68.00 ±0.61 |
67.68 ±1.09 |
54.49 ±2.54 |
54.03 ±0.34 | 59.41 | |
| GPF-plus |
58.09 ±2.12 |
65.71 ±0.37 |
57.13 ±0.48 |
51.33 ±1.14 |
62.96 ±3.27 |
67.88 ±0.42 |
66.80 ±1.43 |
56.56 ±6.81 |
53.78 ±0.45 | 60.02 | |
| EdgePred | FT |
48.88 ±0.68 |
60.95 ±1.46 |
55.73 ±0.43 |
51.30 ±2.21 |
57.78 ±4.03 |
66.88 ±0.53 |
64.22 ±1.57 |
61.27 ±6.10 |
47.62 ±1.50 | 57.18 |
| GPF |
50.53 ±1.35 |
64.46 ±0.93 |
57.33 ±0.65 |
51.35 ±0.76 |
68.74 ±6.03 |
68.08 ±0.39 |
66.22 ±1.90 |
62.85 ±5.91 |
52.81 ±0.38 | 60.26 | |
| GPF-plus |
54.49 ±4.60 |
64.99 ±0.53 |
57.69 ±0.61 |
51.30 ±1.18 |
66.64 ±2.40 |
68.16 ±0.48 |
62.05 ±3.39 |
62.60 ±2.48 |
53.30 ±0.34 | 60.13 | |
| AttrMasking | FT |
51.26 ±2.33 |
60.28 ±1.73 |
53.47 ±0.46 |
50.11 ±1.63 |
61.51 ±1.45 |
59.35 ±1.31 |
67.18 ±1.59 |
55.62 ±5.04 |
48.17 ±2.45 | 56.32 |
| GPF |
54.24 ±0.74 |
64.24 ±0.40 |
56.84 ±0.28 |
50.62 ±0.88 |
65.34 ±1.93 |
61.34 ±0.60 |
67.94 ±0.48 |
57.31 ±6.71 |
51.26 ±0.32 | 58.79 | |
| GPF-plus |
58.10 ±1.92 |
64.39 ±0.30 |
56.78 ±0.25 |
50.30 ±0.78 |
63.34 ±0.85 |
63.84 ±1.13 |
68.05 ±0.97 |
57.29 ±4.46 |
51.35 ±0.32 | 59.27 | |
| ContextPred | FT |
49.45 ±5.74 |
58.77 ±0.70 |
54.46 ±0.54 |
49.89 ±1.16 |
48.60 ±3.40 |
56.14 ±4.82 |
60.91 ±1.84 |
56.37 ±1.90 |
46.33 ±1.76 | 53.43 |
| GPF |
52.55 ±1.24 |
59.73 ±0.86 |
55.70 ±0.29 |
50.54 ±0.91 |
53.03 ±5.98 |
61.93 ±5.84 |
60.59 ±1.28 |
59.91 ±6.31 |
50.14 ±0.33 | 56.01 | |
| GPF-plus |
53.76 ±4.47 |
60.59 ±0.51 |
55.91 ±0.22 |
51.44 ±1.70 |
52.37 ±4.30 |
64.51 ±4.48 |
60.84 ±1.11 |
64.21 ±7.30 |
50.52 ±0.41 | 57.12 | |
| GCL | FT |
54.40 ±2.87 |
48.35 ±1.67 |
50.29 ±0.19 |
53.23 ±0.87 |
54.05 ±4.16 |
46.73 ±1.88 |
60.05 ±3.80 |
49.87 ±1.78 |
49.94 ±1.77 | 51.62 |
| GPF |
53.87 ±2.17 |
50.58 ±0.49 |
52.64 ±0.50 |
53.86 ±0.45 |
64.44 ±4.64 |
47.22 ±3.55 |
64.86 ±1.29 |
67.56 ±2.29 |
50.40 ±1.17 | 55.62 | |
| GPF-plus |
55.89 ±1.58 |
50.14 ±1.09 |
53.25 ±0.95 |
55.46 ±0.96 |
65.22 ±4.51 |
47.88 ±1.77 |
63.99 ±1.60 |
64.10 ±1.85 |
51.19 ±1.53 | 55.89 |
100 个镜头场景的结果。 我们还进行了实验,其中化学和生物学数据集的下游任务中的训练样本数量都限制为 100 个。 总体结果总结见表5。 实验结果与 50 次拍摄场景中观察到的结果一致。 我们提出的图形提示调整方法在 45 种情况中的 42 种中取得了最佳结果(GPF 为 45 种中的 14 种,GPF-plus 为 45 种中的 28 种)。 此外,GPF 和 GPF-plus 的平均结果都超过了所有预训练策略微调的平均结果,展示了我们提出的图提示调整方法的优越性。
| Pre-training Strategy | Tuning Strategy |
BBBP |
Tox21 |
ToxCast |
SIDER |
ClinTox |
MUV |
HIV |
BACE |
PPI | Avg. |
| Infomax | FT |
56.29 ±1.65 |
60.46 ±0.66 |
55.34 ±0.20 |
50.49 ±1.29 |
50.90 ±4.92 |
65.88 ±1.76 |
65.81 ±1.43 |
57.35 ±2.67 |
49.74 ±0.72 | 56.91 |
| GPF |
56.38 ±2.84 |
61.54 ±0.28 |
57.31 ±0.35 |
54.49 ±0.72 |
56.49 ±1.98 |
66.52 ±0.67 |
68.02 ±1.22 |
61.67 ±2.76 |
54.57 ±0.51 | 59.66 | |
| GPF-plus |
56.97 ±3.46 |
62.48 ±0.80 |
57.64 ±0.30 |
54.86 ±0.49 |
57.68 ±0.89 |
67.00 ±0.47 |
67.66 ±1.13 |
61.76 ±2.80 |
54.66 ±0.52 | 60.07 | |
| EdgePred | FT |
51.27 ±3.89 |
61.48 ±1.21 |
58.28 ±0.81 |
52.23 ±1.27 |
58.50 ±2.54 |
64.32 ±2.48 |
59.82 ±1.47 |
50.86 ±0.85 |
48.06 ±2.00 | 56.09 |
| GPF |
55.13 ±1.27 |
63.35 ±0.94 |
59.09 ±0.55 |
52.30 ±0.54 |
65.02 ±4.13 |
65.47 ±0.31 |
63.19 ±1.49 |
48.64 ±1.70 |
52.52 ±0.46 | 58.30 | |
| GPF-plus |
54.20 ±5.05 |
64.80 ±0.95 |
59.42 ±0.23 |
52.47 ±0.64 |
62.73 ±3.54 |
65.37 ±0.37 |
63.18 ±1.28 |
50.02 ±5.65 |
53.00 ±0.44 | 58.35 | |
| AttrMasking | FT |
54.56 ±4.82 |
60.95 ±1.28 |
55.84 ±0.40 |
50.64 ±1.16 |
61.16 ±1.19 |
64.90 ±1.43 |
61.65 ±3.31 |
59.03 ±2.89 |
47.29 ±1.43 | 57.33 |
| GPF |
55.23 ±3.14 |
63.36 ±0.61 |
57.66 ±0.34 |
50.08 ±0.59 |
63.05 ±4.41 |
65.58 ±0.69 |
69.79 ±1.78 |
59.37 ±3.90 |
52.31 ±0.41 | 59.60 | |
| GPF-plus |
53.58 ±2.19 |
63.89 ±0.58 |
57.72 ±0.37 |
51.70 ±0.61 |
62.68 ±2.50 |
66.47 ±0.43 |
69.35 ±1.58 |
58.50 ±2.36 |
52.28 ±0.89 | 59.57 | |
| ContextPred | FT |
50.42 ±0.57 |
60.74 ±0.88 |
56.00 ±0.29 |
51.81 ±1.77 |
51.48 ±2.86 |
64.87 ±2.30 |
59.82 ±2.00 |
50.43 ±3.74 |
45.39 ±0.42 | 54.55 |
| GPF |
52.33 ±5.07 |
63.91 ±0.82 |
57.32 ±0.30 |
53.55 ±0.88 |
54.31 ±2.58 |
65.80 ±0.45 |
68.51 ±2.23 |
54.70 ±5.89 |
50.44 ±0.64 | 57.87 | |
| GPF-plus |
53.62 ±6.59 |
64.89 ±0.89 |
58.02 ±0.52 |
54.13 ±1.38 |
54.02 ±2.38 |
65.89 ±0.54 |
68.75 ±3.80 |
54.41 ±5.85 |
50.79 ±0.50 | 58.28 | |
| GCL | FT |
44.06 ±2.55 |
48.47 ±1.63 |
51.91 ±0.33 |
56.10 ±0.45 |
48.13 ±3.23 |
53.93 ±0.91 |
32.63 ±0.93 |
55.41 ±1.28 |
49.44 ±1.53 | 48.89 |
| GPF |
51.34 ±1.01 |
55.46 ±1.54 |
53.78 ±0.58 |
53.37 ±0.99 |
60.44 ±4.10 |
54.06 ±2.56 |
44.23 ±0.75 |
49.20 ±2.94 |
54.35 ±0.65 | 52.91 | |
| GPF-plus |
52.47 ±1.19 |
57.42 ±1.36 |
53.07 ±0.81 |
52.90 ±1.05 |
60.22 ±3.81 |
55.68 ±1.25 |
46.24 ±3.35 |
51.64 ±4.25 |
54.47 ±1.25 | 53.79 |
B.4参数效率分析
我们计算了化学和生物学数据集上完全微调、GPF 和 GPF-plus(不包括特定于任务的投影头 )的可调参数的数量。 统计数据如表6所示。 结果表明,GPF和GPF-plus中的可调参数数量比微调参数少了几个数量级。 具体来说,GPF 在微调中使用的可调参数不超过 个,而 GPF-plus 在微调中使用的可调参数不超过 个。 与微调相比,我们提出的图提示调整方法在参数效率方面表现出显着的优势。 它减少了下游适应所需的训练时间和存储空间。
| Dataset | Tuning Strategy | Tunable Parameters | Relative Ratio (%) |
| Chemistry | FT | M | 100 |
| GPF | K | 0.02 | |
| GPF-plus | -K | 0.17-0.68 | |
| Biology | FT | M | 100 |
| GPF | K | 0.01 | |
| GPF-plus | -K | 0.11-0.44 |
B.5与线性探测的比较
在自然语言处理和计算机视觉领域,线性探测 [Kumar 等人, 2022, Wu 等人, 2020, Tripuraneni 等人, 2020, Du 等人, 2020] 是一种广泛采用的方法,用于使预训练模型适应下游任务。 这种方法涉及冻结预训练模型的参数并单独优化线性投影头。 为了评估线性探测的有效性,我们在化学数据集 Toxcast 和 SIDER 上进行了实验,结果总结在表7中。 从结果中可以明显看出,与微调和我们提出的图形提示调整相比,线性探测表现出显着的性能下降。 线性探测和我们提出的图形提示调整之间的主要区别在于在输入空间中加入了额外的可学习图形提示。 这些方法之间观察到的巨大性能差距强调了集成图形提示对于有效适应预训练模型的重要性。
| Pre-training Strategy | Tuning Strategy |
ToxCast |
SIDER |
Avg. |
| Infomax | FT |
65.16 ±0.53 |
63.34 ±0.45 |
64.25 |
| Linear Probing |
63.84 ±0.10 |
59.62 ±0.73 |
61.73 |
|
| GPF |
66.10 ±0.53 |
66.17 ±0.81 |
66.13 | |
| GPF-plus |
66.35 ±0.37 |
65.62 ±0.74 |
65.98 |
|
| EdgePred | FT |
66.29 ±0.45 |
64.35 ±0.78 |
65.32 |
| Linear Probing |
65.25 ±0.09 |
61.47 ±0.03 |
63.36 |
|
| GPF |
65.65 ±0.30 |
67.20 ±0.99 |
66.42 |
|
| GPF-plus |
65.94 ±0.31 |
67.51 ±0.59 |
66.72 | |
| AttrMasking | FT |
65.34 ±0.30 |
66.77 ±0.13 |
66.05 |
| Linear Probing |
64.75 ±0.07 |
62.60 ±0.57 |
63.67 |
|
| GPF |
66.32 ±0.42 |
69.13 ±1.16 |
67.72 | |
| GPF-plus |
66.58 ±0.13 |
68.65 ±0.72 |
67.61 |
|
| ContextPred | FT |
66.39 ±0.57 |
64.45 ±0.60 |
65.42 |
| Linear Probing |
65.35 ±0.09 |
61.28 ±0.39 |
63.31 |
|
| GPF |
67.92 ±0.35 |
66.18 ±0.46 |
67.05 |
|
| GPF-plus |
67.58 ±0.54 |
66.94 ±0.95 |
67.26 | |
| GCL | FT |
62.54 ±0.26 |
60.63 ±1.26 |
61.58 |
| Linear Probing |
50.92 ±0.22 |
52.91 ±0.62 |
51.91 |
|
| GPF |
62.70 ±0.46 |
61.26 ±0.53 |
61.98 |
|
| GPF-plus |
62.76 ±0.75 |
62.37 ±0.38 |
62.56 |
B.6与其他调优方法的比较
我们还将我们提出的图形提示调整与其他调整方法进行比较,如下所述:
-
•
PARTIAL-:我们用投影头调整预训练模型的最后层,并冻结其他部分,在 Zhang 等人 [2016]、He 等人 [2021]、Jia 等人 [2022] 中使用。
-
•
MLP-:我们冻结预训练模型,并利用具有层的多层感知器(MLP)作为投影头来执行分类。
我们在生物学数据集(PPI)上进行了实验,表8总结了结果。 实验结果表明,我们的方法在所有情况下都优于其他调整方法。
| Pre-training Strategy | FT | MLP-3 | Partial-1 | Partial-3 | GPF | GPF-plus |
| Infomax | 71.29 ±1.79 | 74.68 ±0.56 | 74.36 ±0.92 | 73.28 ±0.18 | 77.02 ±0.42 | 77.03 ±0.32 |
| EdgePred | 71.54 ±0.85 | 74.60 ±0.88 | 73.24 ±0.68 | 73.35 ±0.77 | 76.98 ±0.20 | 77.00 ±0.12 |
| AttrMasking | 73.93 ±1.17 | 77.99 ±0.42 | 75.91 ±0.10 | 74.02 ±0.37 | 78.91 ±0.25 | 78.90 ±0.11 |
| ContextPred | 72.10 ±1.94 | 76.01 ±0.68 | 76.62 ±0.92 | 74.86 ±0.79 | 77.42 ±0.07 | 77.71 ±0.21 |
B.7 GCC 上的额外结果
另一种流行的图对比学习预训练策略涉及遵循 Qiu 等人 [2020a] 中概述的训练步骤。 首先,我们介绍用于预训练 GCC 的数据集。 GCC的自监督预训练任务是在六个图数据集上进行的,表9提供了每个数据集的详细统计数据。 对于预训练 GCC 的下游任务,我们采用 IMDB-BINARY 和 IMDB-MULTI 数据集[Yanardag and Vishwanathan, 2015]。 每个数据集由与特定目标标签关联的图形集合组成。 我们在这些数据集上评估 GPF,结果如表10所示。 实验结果一致表明,在调整使用 GCC 策略预训练的模型时,GPF 的性能优于微调。
| Dataset | Academia | DBLP(SNALP) | DBLP(NetRep) | IMDB | LiveJournal | |
| 137,969 | 317,080 | 540,486 | 896,305 | 3,097,165 | 4,843,953 | |
| 739,984 | 2,099,732 | 30,491,158 | 7,564,894 | 47,334,788 | 85,691,368 |
| Pre-training Strategy | Tuning Strategy | IMDB-B | IMDB-M | Avg. |
| GCC (E2E) | FT | 72.60 ±4.72 | 49.07 ±3.59 | 60.83 |
| GPF | 73.40 ±3.80 | 49.17 ±3.12 | 61.28 | |
| GCC (MoCo) | FT | 71.70 ±4.98 | 48.07 ±2.91 | 59.88 |
| GPF | 72.50 ±3.20 | 49.33 ±3.93 | 60.91 |
B.8 超参数设置
本节介绍了在下游任务上预训练 GNN 模型的适应阶段使用的超参数,以实现我们提出的图提示调整。 表11总结了超参数设置。 您还可以访问我们的代码库来获取重现实验结果的具体命令。
| Dataset | Pre-training Strategy | Prompt Dimension | Learning Rate | Weight Decay | Batch Size | Training Epoch |
| Biology | Infomax | 300 | 0.001 | 0 | 32 | 50 |
| EdgePred | 300 | 0.001 | 0 | 32 | 50 | |
| Masking | 300 | 0.001 | 0 | 32 | 50 | |
| ContextPred | 300 | 0.001 | 0 | 32 | 50 | |
| GCL | 300 | 0.0001 | 0 | 32 | 50 | |
| Chemistry | Infomax | 300 | 0.001 | 0 | 32 | 100 |
| EdgePred | 300 | 0.001 | 0 | 32 | 100 | |
| Masking | 300 | 0.001 | 0 | 32 | 100 | |
| ContextPred | 300 | 0.001 | 0 | 32 | 100 | |
| GCL | 300 | 0.001 | 0 | 32 | 100 | |
| IMDB-B | GCC | 64 | 0.005 | Linear | 128 | 100 |
| IMDB-M | GCC | 64 | 0.005 | Linear | 128 | 100 |