密集环境下
编队飞行的稳健高效的轨迹规划
摘要
编队飞行对于空中机器人群在各种应用中具有巨大的潜力。 然而,现有方法缺乏在密集环境下实现完全自主的大规模编队飞行的能力。 为了弥补这一差距,我们提出了一个完整的编队飞行系统,该系统可以有效地将现实世界的约束融入空中编队导航中。 本文提出了一种基于可微图的度量来量化地层之间的整体相似性误差。 该度量对于旋转、平移和缩放是不变的,为编队协调提供了更多的自由度。 我们设计了一个分布式轨迹优化框架,考虑了编队相似性、避障和动态可行性。 优化是解耦的,使得大规模编队飞行在计算上可行。 为了提高高度受限场景中编队导航的弹性,我们提出了一种群体重组方法,通过生成局部导航目标来自适应调整编队参数和任务分配。 这项工作提出了一种称为全局重映射局部重规划的新型群体协议策略和编队级路径规划器来协调全局规划和局部轨迹优化。 为了验证所提出的方法,我们在适应性、可预测性、弹性、复原力和效率方面与其他前沿工作设计了全面的基准和模拟。 最后,该方法与带有机载计算机和传感器的手掌大小的集群平台集成,通过在密集的室外环境中实现最大规模的编队飞行,展示了其效率和鲁棒性。
索引术语:
空中集群、编队飞行、避障、运动规划、分布式轨迹优化。我简介
编队飞行已成为自主集群实现协调空中机动的基本能力。 在杂乱的荒野和复杂的城市地区,编队导航在搜索救援[1]、协作测绘[2]、包裹投递[3]方面具有广泛的潜力,等等。 然而,将现实世界的约束有效地融入空中编队仍然是一个尚未解决的问题。 本文旨在通过提出完整的编队飞行系统,使空中集群能够在密集环境中保持合作编队行为。
受鸟群、鱼群等自然群体系统的启发,理想的编队飞行系统应具备在密集环境中灵活适应和变形的能力。 通过努力将集群维持在“临界状态”,集群编队可以动态平衡维持编队与躲避障碍之间的冲突。
虽然大量的研究工作集中在编队导航上,但很少有研究能够在障碍物丰富的区域实现稳健的编队飞行。 三个核心挑战限制了实际编队应用:(a)编队维持和避障之间的固有冲突是不可避免的且难以缓解。 (b) 预定阵型缺乏对受限环境的弹性适应性。 (c) 集群系统无法从未知障碍物或所需编队形状突然变化引起的无序状态中快速恢复。
基于上述挑战,我们得出的结论是,理想的编队飞行系统应具有在避障的同时保持编队的能力,根据受限环境调整集群编队分布,并在突发事件后快速重组编队的能力。 这些特征被总结为PAPER标准:
-
•
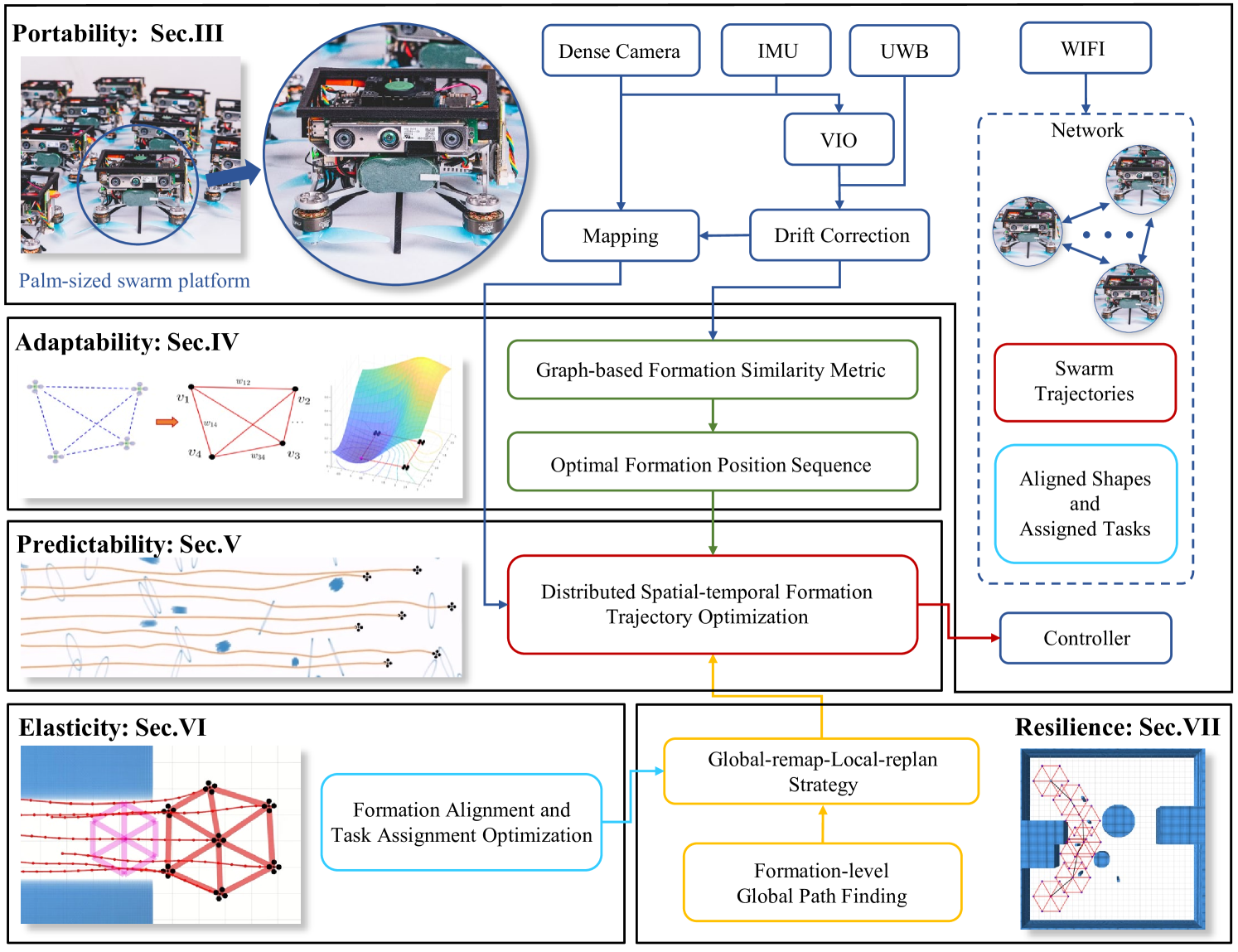
Portability:空中机器人群应由具有可扩展系统和分布式结构的轻型平台组成。 可扩展的系统意味着每个机器人的主要组件(例如估计、决策、规划和控制模块)都是相同的。 分布式架构本质上对单个硬件故障具有鲁棒性。 这些是大规模编队飞行的基础。
-
•
适应性:当面对障碍物时,机器人应该局部调整其轨迹,以避免碰撞,从而对整体编队性能的损害最小。 这种能力减轻了编队维持和避障之间的冲突。
-
•
P可预测性:反应式局部反馈方法目光短浅,无法提前考虑约束条件。 机器人应该优化预测范围内的运动,以便编队能够平稳地响应其附近未来的环境变化,这对于密集区域来说是必要的。
-
•
弹性:在狭窄的走廊或洞等受限环境中,固定地层形状的可行且安全的轨迹可能不存在。 因此,群体机器人需要具备弹性、灵活的变形能力,通过调整编队分布(如形态规模或任务分配),同时保持编队的充分机动性。
-
•
弹性:编队飞行可能会遇到许多由于未知障碍物或所需编队形状突然变化而导致的不利情况。 导航系统应能够对整个编队进行弹性重组和引导,使飞行能够及时从混乱状态中恢复过来。
完整的编队飞行系统应满足上述PAPER标准,并确保每个标准的条件与其他标准兼容。
我们之前的工作[4]仅部分满足PAPER标准的前三项。 我们将编队飞行作为耦合协作轨迹优化问题来解决,主要适用于小规模编队场景。 然而,使用基于图的相似性度量来解决地层的协作约束计算量很大,导致每次优化迭代期间的开销增加。 此外,将动态机器人间关系集成到耦合轨迹优化问题中会极大地影响优化过程的效率,使其不太适合更大的编队或更复杂的场景。
在本文中,我们提出了一个完整的编队飞行系统,满足所有PAPER标准。 为了解决[4]中的挑战,我们引入了一种解耦的编队优化方法来显着提高计算效率。 该方法由两个部分组成。 首先,预先计算最佳编队位置序列,避免优化过程中重复的度量计算。 其次,采用固定时间间隔采样的方法,将动态的机器人间关系转化为静态约束,大大降低了优化问题的复杂度。 这些改进使我们的方法适用于大规模群体。 此外,以往的方法缺乏重新组织编队的能力,在不利条件下,特别是在初始位置或任务分配不合适的情况下,可能会导致编队飞行无序。 为了解决这个问题,我们提出了一种群体重组方法,该方法可以通过响应外部约束优化编队参数和任务分配来弹性调整编队分布。 随后,我们开发了一种名为“global-remap-local-replan”的群体协议策略,该策略能够快速实施群体重组结果,以在群体代理之间达成共识。 此外,还设计了一种将集群编队视为一个实体的编队级全局寻路方法,旨在引导集群摆脱障碍僵局。 最后,我们将估计、测绘、决策、规划和控制模块集成到带有机载计算机和传感器的手掌大小的集群平台[5]中,从而实现在密集环境中的大规模编队飞行。 详细贡献如下。
-
1.
我们引入了一个最佳编队位置序列,该序列使用基于可微图的度量[4]预先计算。 该序列代表了相似性误差最低的最佳位置,减少了优化过程中重复计算的需要。
-
2.
我们设计了一个解耦的时空轨迹优化框架,可以有效处理动态机器人间关系、避障和动态可行性。 与我们之前的工作[4]相比,我们对大规模群体实现了更高的计算效率。
-
3.
我们提出了一种群体重组方法来实现群体分布的弹性变形,同时解决了最佳编队对齐和任务分配问题(简称ALAS)。 该方法提高了群体形成针对受限环境的弹性。 它减轻了对适当编队排列和任务分配的依赖。
-
4.
我们设计了一种全局重映射局部重规划策略(简称GRLR),该策略利用了集中式地层参数重映射和分散式局部轨迹重规划的优点。 通过这种策略,分布式异步集群能够快速从无序状态中恢复并快速返回编队飞行。
-
5.
我们将所有这些模块集成到分层编队飞行系统中。 进行了广泛的基准测试和模拟来验证我们方法的PAPER标准。 一系列真实世界的实验旨在证明所提出的分布式自主编队飞行系统的出色性能。
II 相关作品
II-A 分布式群体轨迹规划
分布式集群的轨迹规划有大量的工作。 Van Den Berg 等人[6,7,8]利用并推广了速度障碍(VO)的概念,以实现多个机器人的相互避碰。 然而,基于 VO 的方法无法保证所得轨迹的平滑性,这显着损害了实际机器人系统的可用性。
为了产生高质量的无碰撞轨迹,分布式多旋翼群文献中广泛引入了基于优化的方法[9,10,11]。 Zhou等人[12]将Voronoi单元细分纳入后退地平线QP方案中,以防止机器人在规划时发生碰撞。 在[13]中,Chen等人利用SCP通过逐步收紧碰撞约束来解决非凸空间中的多智能体规划问题。 Baca 等人[14]将 MPC 与冲突解决策略相结合,以确保室外集群操作的相互避免碰撞。 然而,上述基于优化的方法的计算量很大,这可能会妨碍规划器在高密度场景中的适用性。
最近,Zhou等人[5]提出了一种利用时空轨迹优化的分布式自主四旋翼集群系统,该系统在密集环境中仅需几毫秒即可产生无碰撞运动。 我们的分布式编队轨迹优化基于这项工作。
II-B 自由空间编队飞行
人们提出了多种技术来实现多机器人导航信息,包括虚拟结构[15]、领导者-跟随者[16]、导航功能[17 ]、反应行为[18]、基于共识的局部控制法则[19]以及基于重心坐标的控制[20]. 然而,大多数现有方法仅考虑无障碍情况。
Weinstein 等人[21]提出了一种 VIO-swarm 系统,该系统可以执行机载所有模块,并且可以在自由空间中执行编队飞行而不会发生机器人间碰撞。 Parker等人[22]提出了一种分布式编队控制方法,放宽了公共参考系的依赖性。
随着群体规模的增加,研究人员开始注意到仅通过轨迹规划很难维持队形,特别是当机器人之间存在死锁时。 Turpin等人[23]考虑并发分配和无碰撞轨迹生成问题。 Turpin针对这个问题给出了集中式和分散式的解决方案,允许大规模的航班编队。 Morgan等人[24]还使用模型预测控制在给定所需的队形形状时同时解决任务分配和轨迹生成问题。 除了考虑任务分配之外,Agarwal 和 Akella[25] 还考虑编队对准问题,以优化规模和位置等编队参数。 该方法降低了编组成本,加快了收敛速度。 然而,这些方法忽略了受限环境的影响,在这种环境中,地层应该弹性变形才能导航。
II-C 受限环境下的编队飞行
在存在各种障碍和限制的受限环境中,编队飞行可能是一项具有挑战性的任务,需要不断调整以维持集群结构。 直接的解决方案是通过使用多层势场[26]来设计将编队飞行和防撞相结合的复合控制律,这很容易出现死锁。 更好的解决方案是允许编队形状变形,同时保持整体蜂群结构。 Han等人[27]提出了一种基于复值图拉普拉斯算子的编队控制器,该控制器可以在穿过走廊等群体机动过程中调节编队形状的缩放。 在[28]中,赵提出了一种领导者-跟随者控制律,使得编队能够响应环境变化而进行仿射变换。 基于方位的本地控制器[29, 30]表现出编队飞行的平移、缩放和旋转不变性。 然而,这些方法依赖于领导者或预定义的轨迹,并与复杂的障碍或突然的潜在碰撞作斗争。
与局部反馈方法相比,基于预测优化的方法主动规划群体机器人的未来运动,在编队飞行和避障之间取得平衡。 Alonso-Mora 等人[31]通过优化地重新安排所需的编队并为每架无人机规划局部轨迹来控制群体机器人。 然而,由于分布式规划器中没有车辆间协调,因此在局部规划期间不进行编队维护。 彭等人[32]提出了一种通过对编队形状进行仿射变换并将其作为B样条优化时的软约束来提高飞行安全性的方法。 然而,这种方法需要同时优化所有机器人的轨迹,并且不能应用于大规模群体。 为了解决编队保存问题,Parys等人[33]提出了一种分布式模型预测编队控制器。 该框架对群体施加相对位置约束,并协调代理在障碍物违反位置约束时被动突破。 总体而言,这些方法为群体机器人中的轨迹规划提供了独特的解决方案,但在处理不同场景和机器人系统规模时,它们各自都有局限性。
为了解决这些缺点,我们在轨迹优化中使用可微分度量来制定总体编队要求。 这使得我们能够充分利用群体的协作能力,有效避免僵局,并预见避障。 此外,我们采用分布式、解耦的优化方法来保证动态实时性能。 这种方法可以应用于大规模群体,同时仍然保持有效的轨迹规划。
三系统概述
本文旨在通过协调群体机器人的运动以形成所需的编队形状来优化现实环境中群体机器人的自主性。 为了实现这一目标,我们采用分布式集群空中机器人系统,并提出编队飞行的时空轨迹优化。 为了增强系统的鲁棒性,我们还通过结合自适应群体重组方法和有效的群体协议策略来解决群体无序的情况。
III-A 群体空中机器人系统
集群空中机器人系统由手掌大小的四旋翼平台[5]和深度立体相机111https://www.intelrealsense.com/depth-camera-d435/用于图像和深度传感,如图2所示。 状态估计、环境感知、决策、轨迹规划、飞行控制等软件模块在机载计算机上实时运行222https://www.nvidia.com/en-us/autonomous-machines/embedded-systems/jetson-xavier-nx/。 这种轻量级且可扩展的平台适合密集的环境。
我们使用视觉惯性里程计 (VIO)[34] 来估计每个机器人相对于其起始帧的位姿,并且在我们之前的工作中仅使用匿名方位测量来恢复与起始帧相关的变换[35]。 为简单起见,在我们的实验中,通过要求机器人从预定义位置起飞来了解这些转换。 为了校正群体机器人之间的定位漂移,我们使用带有机载超宽带(UWB)的漂移校正方法[5]。
分布式系统架构使得每个机器人能够充分利用其计算资源来处理更多信息,缓解网络通信压力。 机器人仅共享重要信息,例如用于高保真无线通信的轨迹,并且没有地面站发送控制输入。
III-B 分布式局部编队轨迹优化
III-C 群体重组和协议方法
仅依靠分布式局部轨迹优化,在遇到狭窄走廊或编队形态瞬间转变时,可能会导致编队飞行质量较差。 因此,我们提出群体重组(Sec.VI)和协议方法(Sec.VII)来快速达成群体共识。 受鸟类群体飞行行为的启发,我们设计了一种全局重映射局部重规划(简称GRLR)策略,该策略仅集中重新映射群体形成的关键参数,并通过分布式重新规划局部轨迹使群体形成快速收敛。 首先,当群体编队的稳定状态被破坏或即将被破坏时,群体机器人指定一个领导者(本文中为无人机0)。 通过编队对齐和任务分配优化(简称ALAS)和编队级全局寻路方法分别计算集群编队的关键参数。 从群体重组和一致的角度来看,通过优化编队排列缓解了群体编队与障碍物之间的冲突,通过优化任务分配大大加快了编队收敛速度。 GRLR策略简单但非常有效,结合了分布式方法的效率和集中式方法的最优性。
IV 群体形成的自适应描述
IV-A 基于图的编队定义
在本文中,机器人的群体编队通过无向图建模,其中是顶点集, 是边的集合。 在图中 中,顶点 表示具有位置向量 的 机器人。 连接顶点和顶点的边意味着机器人和可以测量几何形状彼此之间的距离。 在我们的工作中,每个机器人都可以获得所有机器人的位置,因此图是完整的。 然后我们确定形成图的邻接矩阵和度矩阵:
| (1) |
| (2) |
其中非负边权重是和机器人之间的平方距离,表示欧几里德范数。 因此,对应的拉普拉斯矩阵为
| (3) |
利用上述矩阵,图的对称归一化拉普拉斯矩阵定义为
| (4) |
其中 是单位矩阵。 包含对缩放、平移和旋转不变的信息。
最后,我们使用图论来描述各种所需的地层形状,例如正方形、六边形和金字塔。 通过指定位置 ,计算 很简单。 需要注意的是,只要提供了相对位置,所需的地层形状就与坐标系无关。
IV-B 可微分阵相似性误差度量
为了评估与所需队形的偏差,我们提出了一个可微的队形相似性误差度量:
| (5) | ||||
其中表示矩阵的迹,是当前群体编队的对称归一化拉普拉斯算子,是所需编队的对应部分。 弗罗贝尼乌斯范数 用于我们的距离度量。 作为图表示矩阵,包含有关图结构[36]的信息。 这允许 仅考虑地层的几何形状,而不受缩放、平移或旋转的影响。 另外,是无量纲值,仅反映地层形状相似度的误差。
特别是在分布式框架下,每个机器人只能改变自己的位置,以减少整体编队相似度误差。 因此,(5)中机器人的唯一变量是,而可以简化为.
IV-C 最佳编队位置顺序
在我们之前的工作[4]中,我们将直接纳入轨迹优化中,使编队飞行成为耦合轨迹优化问题。 虽然该方法适用于小规模编队飞行,但随着机器人数量 的增加,计算效率会降低。 考虑耦合轨迹优化的简化方程
| (9) |
为了方便起见,其中表示(19)中机器人轨迹的样本点。 代表所有其他成本函数,是具有相应时间戳的样本点的数量。 计算的主要目的是提供梯度信息以最小化地层相似误差。 然而,由于图是一个完全图,计算的复杂度为。 因此,耦合轨迹优化(9)在每次迭代中也表现出的高复杂性,限制了其对大规模群体操作的适用性。
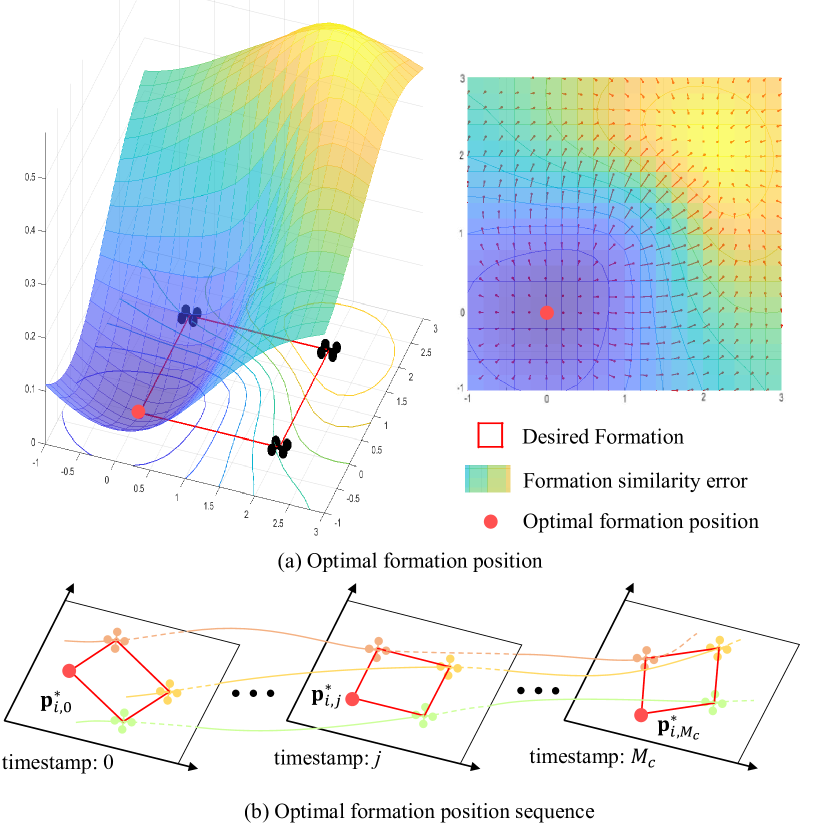
为了解决这个问题,我们必须找到一种计算复杂度较低的等效方法来替换(9)中的函数。 我们引入了机器人在时间戳的最佳编队位置的概念,即最小化编队相似度的位置错误。 图3(a)以二维地层为例说明了这一概念。 从图中可以看出,存在一个使队形相似误差最小的最佳队形位置,其偏导数为。 在未来一段时间内,用时间戳序列,用最优编队位置序列表示机器人的预期位置>,如图3(b)所示。 通过预先计算,我们可以利用其二次距离来代替(11)中提供的梯度信息,从而降低计算量,如下所示
| (10) |
由于的最优解和二次距离成本是等价的,因此轨迹以最小的队形相似误差接近位置,保持期望的队形。 因此,我们可以通过两步程序有效地解决耦合轨迹优化问题
| (11) | ||||
这样一来,之前每次轨迹优化过程中所需的的计算就被二次距离的计算所取代,简化了优化问题。 这显着减少了计算需求并实现了大规模群体形成。
公式(11)表示Sec.V中的轨迹优化是针对离散点进行的。 不均匀的离散点可能会导致轨迹不佳和性能次优。 因此,确保这些点的均匀分布对于保持优化过程的有效性至关重要。 在工程实践中,由于图是由一系列离散化时间戳构建而成,如图3(b)所示,因此每个都是独立的。
为了保证轨迹更加平滑,我们引入了均匀最优编队位置序列,该序列是通过考虑编队相似误差和均匀分布成本生成的
| (12) |
| (13) | ||||
其中 和 是相对权重。 是数学期望,平方距离向量 是
| (14) |
V 编队飞行时空轨迹优化
V-A 轨迹表示
多旋翼飞行器的微分平坦度[38]有利于轨迹生成,无需积分微分方程。 此外,多旋翼飞行器的运动规划可以在低维平滑轨迹上进行。 在本文中,我们采用一种名为 MINCO [39] 的最先进的轨迹表示来实现三维环境中群体空中机器人的最小控制努力时空轨迹规划。 MINCO 通过使用线性复杂度映射 解耦空间和时间参数,对平坦输出 片段轨迹 进行时空变形
| (15) |
其中是每对连接片段之间的相邻中间点,是每个片段的持续时间。
维分段轨迹由分段多项式表示。 而块被定义为一个多次多项式(本文中的)
| (16) |
其中是系数矩阵,是自然基。
对于 s-积分器(本文中的 )链动力学系统, 段 度轨迹 定义为恒定的边界和最小的控制努力。 此外,MINCO 还使用线性时间和空间参数映射 将 转换为 ,其中 是多项式系数。
V-B 问题表述
在第 IV 节中确定所需的队形形状后,我们期望群体机器人有一组轨迹,这些轨迹是平滑的、无碰撞的并且保持队形。 在实践中,在未知的密集环境中使用有限视野的传感器和机载计算机导航群体机器人需要一个专注于本地信息的高效实时规划器。 此外,集中式优化受到群体规模的限制。 因此,我们选择分布式局部轨迹优化进行编队飞行如下
| (17a) | ||||
| (17b) | ||||
| (17c) | ||||
| (17d) | ||||
| (17e) | ||||
我们定义平稳性和攻击性的成本 (17a),以实现平稳高效的飞行。 为时间正则化参数,。 机器人(17b)的状态由优化变量参数化。 表示具有积分器的链动态系统的高阶导数。 边界条件包括初始状态(17c)和终止状态(17d)。 连续时间约束 (17e)包括群体形成相似性、动态可行性、避障和群体相互回避。
V-C 约束转录
为了实时求解连续约束优化问题(17),我们使用MINCO优化变量(15)来消除各种等式约束(17b)-(17d)。 采用惩罚函数方法[40]来处理不等式约束(17e)。 然后,通过样本点的有限和来评估每个积分。 最后将连续约束优化问题转化为离散无约束优化问题
| (18) |
其中是成本函数或惩罚的各种项,是相对权重。 下标 () 群体形成相似性,() 表示控制努力,() 总时间,()避障,()群体相互回避,()动态可行性。 是采样时间间隔。
在我们之前的工作[4]中,我们使用固定数量的采样点来变换优化问题,其中是 块轨迹, 是该块上的固定样本数。 然而,考虑到优化过程中总时间的变化,固定数量的采样点很难在整个轨迹上均匀分布。 因此,我们对整个轨迹采取固定时间间隔的采样点,以保证罚函数采样变换的准确性
| (19) | ||||
其中 是样本编号, 是任何 的先前时间。
对于群体机器人的轨迹规划,固定时间间隔采样点可以简化优化问题。 与相比,对应的时间戳是固定的,因此优化过程中其他机器人在该时间戳的状态也是恒定的。 因此,根据优化前的广播轨迹计算其他机器人w.r.t 的状态是可行的。 那么我们可以提前求解均匀编队位置序列优化(12),并用代替轨迹优化中的编队相似性度量(17a) 机器人。 这种解耦编队轨迹优化带来了更高的计算效率,使我们的方法适用于大规模群体机器人。
尽管优化问题在采样数 变化时不可微,但成本函数仍然是连续的。 持续时间。 在本文中,我们使用[37]中提出的拟牛顿方法来解决非光滑离散无约束优化问题(18)。
V-D 成本函数和梯度
给定固定的采样时间间隔,我们可以通过有限的采样点之和来评估整个轨迹的成本函数和梯度。 采样点的各种通用惩罚的成本为
| (20) |
那么(18)中的成本函数计算如下
| (21) | ||||
其中是遵循梯形规则[41]的正交系数。 并且MINCO允许任何二阶连续成本函数用表示。 因此,可以分别从和高效地获得和,这有利于优化的构造和求解问题。 在(19)中,采样时间与之前的时间相关,因此相对于 和 计算为
| (22) |
| (23) |
| (24) |
其中的计算很简单,下面给出了用于各种通用目的的的详细信息。
V-D1 群体形成相似度的成本
在IV-C节中,我们通过构造无约束优化问题来计算每个采样点的统一最优编队位置序列,将编队相似误差度量与轨迹优化解耦。 这一改进避免了编队相似性度量的多次计算。 然后,我们使用二次形式来计算群体形成相似度的成本
| (25) |
V-D2 控制努力
轨迹的(本文中的)控制输入及其梯度写为
| (26) |
| (27) |
| (28) |
V-D3 总时间
为了保证轨迹的攻击性,我们最小化总时间。 梯度由和给出。
V-D4 避障成本
受[42]的启发,避障惩罚是使用欧几里德符号距离场(ESDF)计算的。 我们对距离障碍物太近的采样点进行惩罚
| (29) |
| (30) |
其中是根据实际情况设置的安全阈值,是与其周围最近的障碍物之间的距离。 相对于的梯度是
| (31) |
其中是中ESDF的梯度。
V-D5 群体相互回避的成本
当太接近固定时间戳处的轨迹时,我们对进行惩罚,其中代表蜂群。 与我们之前的工作[4]相比,其他具有固定时间戳的机器人的状态在优化过程中是恒定的,并且不会产生关于的梯度> 成本函数。 因此优化问题和梯度被简化。
群体相互回避的成本定义为
| (32) |
| (33) |
其中是每个机器人之间的安全间隙。 相对于的梯度是
| (34) |
V-D6 动态可行性成本
我们限制速度和加速度的最大值以保证机器人能够执行轨迹。
| (35) | ||||
其中 和 是最大速度和加速度。
V-E 轨迹优化求解质量的探讨
所提出的轨迹优化过程(17)旨在解决具有挑战性的多阶段线性二次最小时间(LQMT)问题,该问题本质上是非凸和非线性的。 此外,结合 ESDF 进行避障引入了进一步的非凸约束。 因此,用拟牛顿法保证全局最优解并不总是可能的。 为了解决有关局部最小值和不可行解决方案的问题,我们采取了优先考虑安全性和动态可行性的措施,同时保持高性能编队飞行。
首先,我们利用混合A*搜索算法[42]生成无碰撞且动态可行的初始轨迹,确保有效的最终解轨迹。 在优化过程中,我们更加重视避障和动态约束,以优先考虑安全性和可行性。 此外,我们还对轨迹进行碰撞检查以提高安全性。 此外,我们的分布式群体优化框架有效地减轻了局部最小值对整体编队性能的影响。 通过实施这些措施,我们的方法可靠地实现了稳健的编队飞行,同时保持了计算效率。
VI 群体重组方法
在编队导航过程中,集群可能会遇到空间高度受限、任务分配不当、突然编队切换命令等多种不利条件。 为了从这些情况中恢复过来,我们提出了一种群体重组方法。 该方法旨在生成满足所需编队分布并尊重每个机器人当前状态的高质量局部目标。 有了这些局部目标,即使在狭窄的走廊或洞等高度受限的环境中,群体也可以快速改变所需的形状。
与高频分布式编队轨迹优化不同,集群重组方法仅在编队飞行稳定状态被破坏或即将被破坏时以低频运行。 该方法首先计算队形约束意识,然后求解最优队形AL分配和任务AS分配问题(ALAS)。 前者的感知分布式地量化了每个机器人的编队维持和避障之间的冲突,而后者则集中解决了ALAS问题。
VI-A 队形约束意识
首先,我们需要导出权重来指示环境对机器人的约束程度。 这些权重称为编队约束意识,应根据当前编队状态和障碍物信息来确定。
受我们之前的工作[43]的启发,我们希望根据不同梯度信息之间的关系来描述冲突程度。 首先,我们检索 ESDF 距离 和相应的障碍物梯度 。 同时,我们计算地层相似项的当前梯度。 其次,我们计算渐变和之间的角度的余弦
| (36) |
然后我们利用sigmoid函数将角度的余弦映射为冲突系数
| (37) |
其中 调节随着余弦值 增加,这种意识上升的速度, 调节这种基于角度的意识的死区和激活区。 当和的方向相反时,冲突系数最大,这表明冲突最严重。 当两个梯度方向相同时,达到最小值,这意味着没有冲突。
编队约束感知还应考虑梯度大小和当前最近障碍物距离的影响。 因此,我们将机器人的队形约束意识设计为
| (38) |
我们将计算应用于群体中的每个机器人,从而得到整个群体的编队约束意识向量。 为了区分最受约束的,我们使用 softmax 函数来放大意识向量 的方差并对向量进行归一化
| (39) |
(38)中的用于调整中元素的方差。 是描述群体中机器人的编队-障碍冲突程度的最终意识向量。

VI-B 编队排列和任务分配优化
用于受限场景中的编队飞行,例如在狭窄的走廊中,由于障碍物不妨碍编队要求,约束意识较低的无约束机器人拥有更大的空间与其他机器人自由协调。 相反,具有较大意识的受限机器人总是陷入编队维持与避障之间的冲突。 因此,在生成编队重组的局部目标时,细化无约束机器人的位置以与受约束机器人相匹配更为合理。 在这项工作中,我们在调整编队分布时使用VI-A节中的来对机器人进行称重,并在受约束的机器人上放置更多的权重。
在本节中,我们仅详细阐述局部目标生成的 ALAS 问题。 之后,global-remap-local-replan策略使用生成的局部目标来重新组织编队,这在第VII-A节中有详细介绍。
让代表机器人的当前位置。 所需的地层形状模板由位置给出。 那么,对齐的编队位置可以写为
| (40) |
其中是缩放因子,表示平移因子。 在这项工作中,编队对齐由缩放因子和平移因子决定。
ALAS由编队对齐和任务分配组成,如图4所示。 前者旨在基于加权欧几里德距离成本找到所需编队的最佳对齐方式。 后者解决了将智能体与局部目标相匹配的最优分配。
队形对准问题可表述为
| (42) |
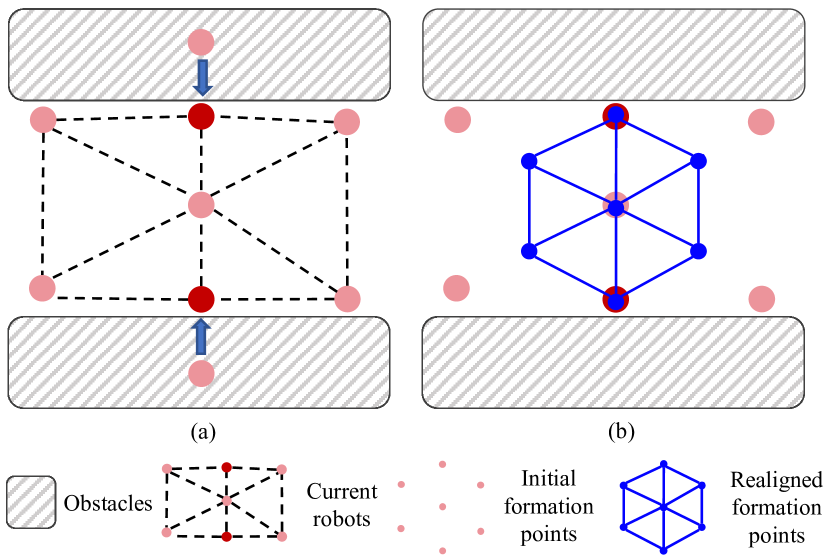
其中代表最佳分配,是来自Sec.VI-A的认知权重。 问题(42)根据约束意识加权的距离成本生成最适合当前机器人位置的标准队形。 图5说明了当蜂群穿越走廊时,队列如何调整编队分布。
问题 (41) 和 (42) 是耦合的。 整个 ALAS 问题具有三个决策变量:缩放因子 、平移 和赋值 。 ALAS 的目标是找到一组最佳决策变量,使 (42) 和 (41) 最小化。 请注意,公式中没有乘以认知权重 (41)。 因为在分配优化中,我们只关心总欧氏距离成本,与任何智能体的约束程度无关。
然而,对于仅使用缩放因子和平移的编队对齐,[25]证明相应的赋值可以是以解耦的方式进行优化,而不是迭代地交替两个优化阶段。 在[25]中,最优分配解对于编队比例因子和平移的变化是不变的。 并且 (41) 的解可以通过使用新的伪成本 求解以下整数规划来直接优化
| (43) | ||||
公式 (LABEL:equ:task_cost) 独立于比例参数 和平移 。 因此,(LABEL:equ:task_cost) 可以在编队对齐阶段之前首先求解。 然后我们使用优化的分配 确定最佳对齐方式。 具有意识权重的编队对齐问题仍然是凸的,并且在附录-A中给出了(41)的封闭形式解。
给定 ALAS 的解, 机器人生成的本地目标 的位置计算如下
| (44) |
经过 ALAS 优化后,生成的局部目标的分布符合所需的编队形状,并尊重每个机器人的编队与障碍物冲突。
七群体协议法
VII-A 全局重映射局部重规划策略
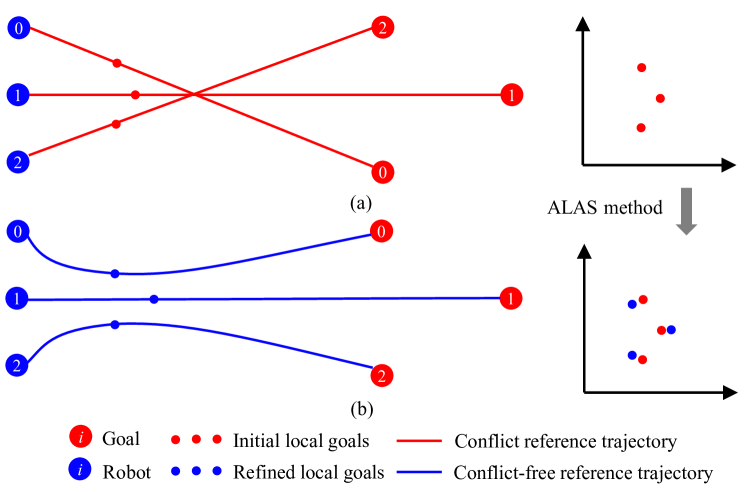
集群系统无法快速从未知障碍物或所需编队形状突然变化引起的无序状态中恢复。 为了应对这一挑战,我们提出了一种利用全局重映射局部重映射(GRLR)策略来生成轨迹的新方法。 这种方法使我们能够有效地驾驭复杂的环境,同时将集群保持在所需编队的“临界状态”,从而有效地平衡协调性和适应性。
对于分布式框架,通信有助于机器人获取其他机器人的信息并产生更好的协调行为。 特别是在编队变换的情况下,协同决策可以使集群编队快速收敛。 然而,有时会因通信延迟而出现循环依赖,难以保证决策的一致性。 因此,我们为蜂群编队系统设计了G全局-R地图-L局部-R计划(GRLR)策略,该策略只集中重新映射编队的关键参数,并通过分布式重新规划局部轨迹来保持编队协调。
GRLR策略包括单个机器人的局部重新规划和编队级系统的全局重新映射。 local-replan是一种后退地平线增量规划策略[44],它允许每个机器人在其有限的感知范围内规划一条轨迹。 局部目标是在规划范围内的全局参考轨迹上选择的,如图6(a)所示。 global-remap是一种高效的中心化策略,仅通过求解ALAS方法重新映射局部目标并细化全局参考轨迹,如图6(b)所示。 GRLR策略非常适合分布式异步系统,即使存在网络延迟,Swarm系统也不会出现死锁。
所提出的全局重映射策略的主要工作流程在算法1中描述。 在生成新的编队行为之前,全局重映射策略会检查是否存在任何紧急事件(第 1-12 行),例如群体编队的稳定状态正在被摧毁(第 9 行)或即将被摧毁(第 4 行) 。 与以固定频率触发的局部重新计划策略不同,全局重新映射策略由紧急事件启动(第 13 行)。 然后调用ALAS方法来求解最优分配和对齐(第14-15行)。 全局重映射策略重新映射局部目标和全局目标,并为每个机器人生成新的全局轨迹(第16-19行)。 最后,机器人通过执行局部重新规划策略形成新的队形。
在这项工作中,我们利用这种半分布式 GRLR 策略,通过在 1 Hz 频率下重新规划局部轨迹并检查突发事件以在 20 Hz 频率下触发全局重映射策略,使集群编队能够适应未知障碍物或所需编队形状的突然变化。 。
VII-B 编队级全局寻路
我们提出了一种编队级全局寻路方法。 给定起始和目标配置,规划器会生成一条将它们与无碰撞中间编队连接起来的可行路径。 采用双向 RRT 方法来解决此寻路问题。
许多导航任务都期望编队能够以所需的规模进行机动。 在实际应用中,编队规模过大会降低车辆的通信质量,而编队规模过小则会增加车辆碰撞的风险。 与[45]中的方法仅对地层中心位置进行采样不同,我们的方法将地层尺度添加到采样空间中,并使编队配置。 这样,可以通过最小化配置空间中路径的-范数距离来实现维持所需尺度的目标,即最小化沿路径的尺度变化。 >。
在密集环境中导航需要机器人保持队形,同时让障碍物穿过队形。 [46]中的方法对中心位置进行采样,然后通过优化无障碍凸区域的编队布置来求解比例因子 。 然而,这种方法不允许任何障碍物与地层的凸包相交,因此浪费了许多解。 相比之下,我们的方法直接对编队配置的整个状态进行采样,以充分探索解空间。 对于我们的 RRT 算法的每个边缘,都会对每个机器人而不是编队的整个凸包进行碰撞检查,以允许障碍物通过。
我们的双向 RRT 规划器的主要工作流程在 Algorithm.2 中描述,其中两棵树 和 从初始状态 和目标状态 分别。 在找到第一个解决方案之前,双向规划器以 RRT-Connect[47] 方式扩展树(第 5-7 行)。 在GreedyExtendTree()和Connect()中,采用贪婪启发式[47]积极探索环境并进行树连接尝试。 找到可行解后,即Connect()返回有限路径成本后,函数Sample()计算一个知情采样集新成本 如 [48] 中所示。 然后,在每个循环中执行标准双向 RRT*[49] 过程来更新树(第 13-17 行)。 由于路径成本是配置空间中的-范数距离,因此通知采样[48]和双向RRT*[49] 可以保证路径解的渐近最优性。
当全局环境信息可用时,部署该编队级路径规划器来渲染全局路径。 然后使用 MINCO[39] 生成连接全局路径的路点的全局轨迹,并采用 Sec.V 中的框架来优化局部运动。
八基准
在基准测试中,重要的是评估当前编队相对于飞行期间所需编队的扭曲程度。 受 [22] 的启发,我们求解了以下非线性优化问题,以找到使 与 一致的最佳相似性变换( 变换)。 然后在归一化地层尺度上计算平均地层距离度
| (45) |
其中和分别表示机器人在编队和中的位置。 变换由旋转、平移和缩放组成。 其中,为初始编队规模,为编队轨迹长度。优化 (45) 中的变换并将其应用于编队,可以消除缩放和旋转的影响,以便通过测量所需编队的位置误差来公平地评估所有编队。 较大的 表示与所需形态 的变形较大。 此外,我们还计算了平均队形相似度
| (46) |
其中 和 详见 (5),形成相似度误差 在第 IV 节中提出。 我们在表 I 中显示了以下基准、模拟和实际实验中使用的重要参数。 所有基准测试均在配备 Intel i7-12700 CPU 的台式机上运行。
| Parameter | Symbol | Value |
| Similarity error threshold | 0.05 | |
| Constraint awareness threshold | ||
| Parameter for regulation in (37) | 5 | |
| Parameter for regulation in (37) | 25 | |
| Parameter for regulation in (37) | -1 | |
| Sampling time interval () | 0.5 | |
| Planing Horizon () | 7.5 | |
| Max velocity () | 1.0 | |
| Max acceleration () | 6.0 | |
| Weight for control effort | 10000.0 | |
| Weight for total time | 80.0 | |
| Weight for swarm reciprocal avoidance | 10000.0 | |
| Weight for obstacle avoidance | 10000.0 | |
| Weight for swarm formation similarity | 10000.0 | |
| Weight for dynamic feasibility | 10000.0 |
| Formation type | Regular hexagon | Irregular shape | Triangular prism | Octahedron | |||||
| Scenario | (%) | ||||||||
| Same to same | Position | 39.120 | 0.384 | 35.649 | 0.384 | 34.506 | 0.374 | 21.534 | 0.341 |
| Displacement | 16.231 | 0.172 | 15.023 | 0.159 | 14.952 | 0.125 | 11.645 | 0.153 | |
| Distance | 15.489 | 0.164 | 14.295 | 0.131 | 14.009 | 0.118 | 10.285 | 0.113 | |
| Ours | 15.443 | 0.161 | 14.287 | 0.128 | 14.012 | 0.119 | 10.281 | 0.112 | |
| Rotation change | Position | 57.456 | 0.945 | 51.298 | 0.732 | 49.821 | 0.612 | 34.124 | 0.542 |
| Displacement | 39.456 | 0.412 | 31.012 | 0.439 | 29.546 | 0.345 | 23.125 | 0.353 | |
| Distance | 27.513 | 0.312 | 22.312 | 0.234 | 21.031 | 0.201 | 14.173 | 0.159 | |
| Ours | 19.234 | 0.218 | 17.032 | 0.171 | 15.013 | 0.151 | 12.146 | 0.138 | |
| Scale change | Position | 59.654 | 1.098 | 58.416 | 0.784 | 53.246 | 0.741 | 37.845 | 0.555 |
| Displacement | 42.516 | 0.629 | 40.021 | 0.624 | 39.412 | 0.398 | 29.845 | 0.395 | |
| Distance | 59.542 | 1.030 | 59.105 | 0.799 | 54.126 | 0.632 | 38.451 | 0.578 | |
| Ours | 18.332 | 0.192 | 18.196 | 0.185 | 16.023 | 0.179 | 12.264 | 0.164 | |
| Scale & rotation change | Position | 62.584 | 1.304 | 60.124 | 0.796 | 56.213 | 0.832 | 41.856 | 0.635 |
| Displacement | 45.627 | 0.755 | 40.194 | 0.631 | 40.168 | 0.423 | 31.288 | 0.504 | |
| Distance | 62.154 | 1.250 | 61.059 | 0.804 | 54.317 | 0.684 | 42.138 | 0.684 | |
| Ours | 20.231 | 0.243 | 18.345 | 0.204 | 16.851 | 0.183 | 12.357 | 0.175 | |
| Formation type | Regular hexagon | ||||
| Scenario | |||||
| Sparse | VRB[26] | 75 | 22.978 | 57.962 | 0.984 |
| Spatial-only | 100 | 21.923 | 15.023 | 0.152 | |
| Spatial-temporal | 100 | 21.756 | 11.240 | 0.138 | |
| Medium | VRB[26] | 25 | - | - | - |
| Spatial-only | 100 | 22.130 | 14.927 | 0.158 | |
| Spatial-temporal | 100 | 21.932 | 13.274 | 0.153 | |
| Dense | VRB[26] | 0 | - | - | - |
| Spatial-only | 100 | 22.283 | 17.630 | 0.185 | |
| Spatial-temporal | 100 | 22.133 | 15.443 | 0.161 | |
VIII-A 基于图的地层定义的适应性
为了证明第IV节中基于图的地层定义的适应性,我们与[50]中总结的主流地层定义方法进行了多次基准测试,这些方法是基于基于受控变量的方法,即基于位置的[51]、基于距离的[52]和基于位移的方法[53]。
我们在我们的框架中实现这些方法,并通过替换(12)中的原始成本来适应密集环境,以生成统一的最佳编队位置序列 对于每个机器人。 对于基于位置的方法,我们将 Drone_0 设置为领导者,并为所有其他机器人预定义绝对相对位置以指定所需的编队。 所以它的成本是。 基于距离的方法优化了期望代理间距离的误差
| (47) |
其中 是机器人的数量, 是 机器人所需的位置向量。 基于位移的方法优化了所需相对位移的误差
| (48) |
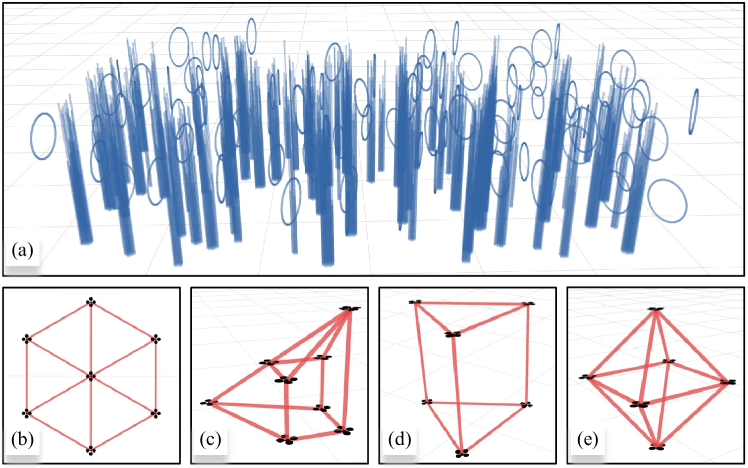
然后,我们在大小的高密度环境中模拟四种不同的几何形态类型,并随机生成障碍物,如图7(a)所示。 考虑不规则和规则几何形状的2D和3D地层,即正六边形、不规则几何、三棱柱和八面体的地层类型,如图7(b)-(e)所示。 为了充分比较这些方法的适应性,我们设计了四种不同的场景,考虑地层形状的缩放和旋转变化。 编队的初始位置和最终位置可能在规模和旋转方面有所不同。 然后将场景相应分类为“相同到相同”、“旋转变化”、“比例变化”和“比例和旋转变化”。 我们针对每种场景和编队类型对每种方法进行 20 次测试。 表II总结了(45)和(46)的相应结果>。
与我们基于图形的编队定义不同,在其他方法中,在飞行过程中不允许改变编队的规模和旋转。 如表II所示,在相同地层类型和相同场景下,数据表明我们的方法取得了有希望的结果,和几乎是最低的。 此外,当场景变得更加复杂时,我们的方法显示出最低的错误增长率。 在同一场景下,随着地层类型从2D到3D中心对称结构的变化,所有方法的畸变程度均减小,这说明地层的维持也与地层本身的结构稳定性有关。 此外,基于距离的方法对旋转具有不变性,并且在“旋转变化”场景中实现了相对可接受的性能。 然而,它无法处理尺寸变化的情况。 同样,其他方法对旋转或缩放敏感,导致此类场景中的性能显着下降。 一般来说,我们基于图的地层定义方法实现了缩放和旋转不变性。 这种不变性提高了编队飞行的适应性,在复杂场景下优于主流方法。

VIII-B 时空轨迹优化的可预测性
为了证明第V节中编队轨迹优化的可预测性,我们将我们的工作与虚拟刚体(VRB)方法[26]进行比较,这是一种SOTA编队控制框架,利用势场避开障碍物。 此外,我们还比较了仅空间优化和时空优化之间的性能,以说明时域对于编队飞行的重要性。 我们模拟七架无人机在正六边形中从一侧飞行到另一侧,速度限制为 。 杂乱区域的大小为,测试了三种障碍物密度进行比较。 参数经过微调以获得每种方法的最佳性能。
结果如表III所示,表明VRB方法[26]在处理中等和密集障碍物时的成功率并不理想。 这主要是由于多个相互作用的势场产生的短期避障,往往会导致走廊附近出现局部极小值,导致机器人被困而失败。 然而,优化方法考虑了编队未来的运动,因此可以平衡编队维持和避障,但不会破坏编队形状。 因此,优化方法可以获得更好的性能并保持成功率。
我们还可以得出结论,在考虑时间优化时,时空方法更加省力、稳健和灵活。 仅空间方法无法在时域中调整轨迹,从而导致轨迹发生过度的空间变形。 因此,仅空间方法中的轨迹长度和编队误差和较大。
VIII-C 群体重组方法的弹性
为了验证VI节中的蜂群重组方法,我们设计了两个基准来说明任务分配的必要性和编队排列的适应性。
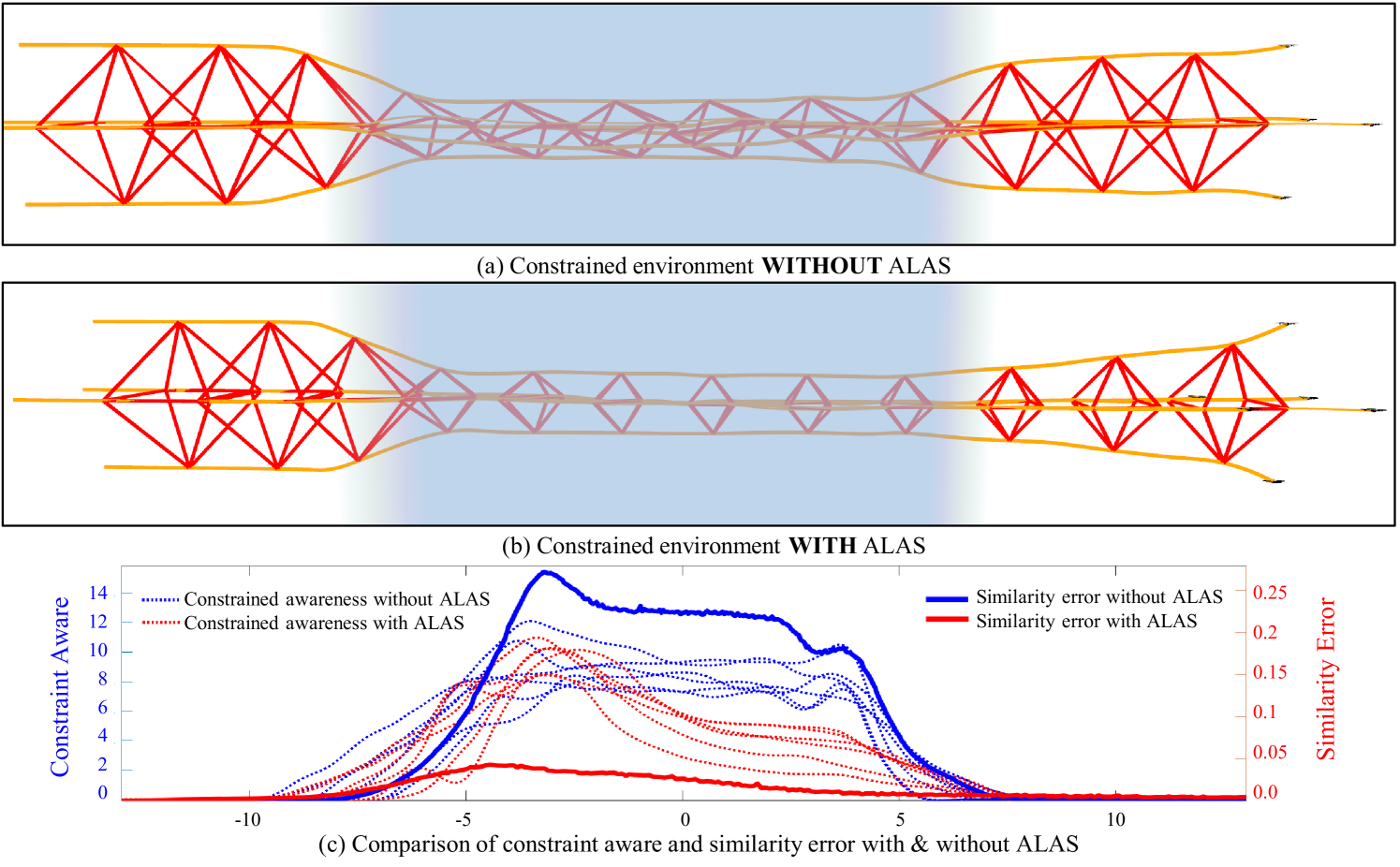
首先设计了不正确初始条件下带ALAS和不带ALAS的正六边形编队飞行对比,验证编队任务分配的必要性,如图8所示。 蓝线代表每个机器人的全局轨迹及其在编队中分配的任务。 在图8(a)中,由于任务分配不当,全局轨迹部分交叉,导致轨迹优化冲突。 所以橙色线所示的执行轨迹看起来非常混乱,而红色线所示的队形形状收敛缓慢。 图8(b)中,通过考虑ALAS,上述问题得到有效解决。 经过一次ALAS计算后,集群机器人重新分配编队任务,并迅速达成集群共识。 然后,蜂群编队平稳地收敛到所需的形状,并以节能的方式导航到目的地。 本次测试的结果验证了任务分配的必要性。
然后,我们比较了通过受限孔时有和没有 ALAS 的编队飞行,以显示 ALAS 的适应性。 图9(a)和图9(b)的结果表明,在没有ALAS的情况下通过走廊时,地层形状可能会发生变形。 另外,ALAS 的情况可以自适应地调整编队形状以适应受限环境。 从图9(c)的定量分析结果来看,使用ALAS的情况可以快速调整编队规模,使群体达成共识,从而使每个机器人的编队相似误差和约束意识下降迅速。 然而,在没有ALAS的情况下,直到群体编队离开洞口之前,都会保持较高的相似性误差和约束意识,这意味着群体编队始终处于环境的限制之内,从而导致编队形状无法收敛。 该基准证明了队形对准的适应性。
| Alonso-Mora’s method[46] | Ours | |
| Sampling time | 2.0 | 2.0 |
| Desired scale | 3.0 | 3.0 |
| Path length | 50.77 | 24.10 |
| Min scale along the path | 1.88 | 2.98 |
VIII-D 群体协议方法的弹性
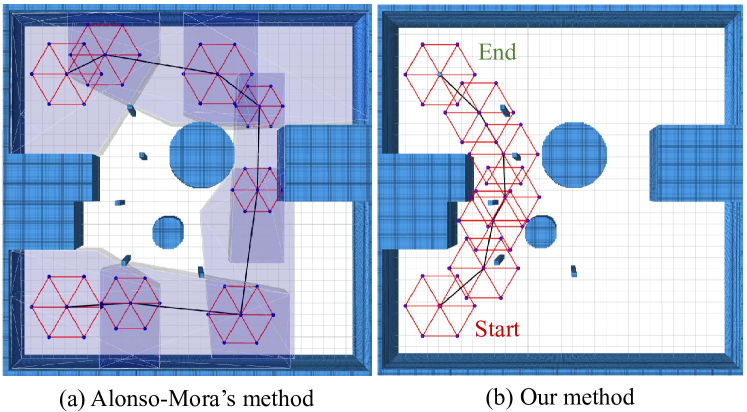
为了突出我们的群体协议方法的弹性,我们在约束地图中比较了 Alonso-Mora 的全局规划方法[46]和我们的编队级寻路方法,如图 10。 这张地图由几个方块和一些微小的障碍物组成,群体机器人需要在其中找到允许编队安全通过的路径。 我们对规划器进行了 20 次测试,表 IV 显示了平均结果数据。 结果表明,Alonso-Mora 的方法[46]在处理这种情况时效果并不理想。 方法[46]对地层规模变化没有惩罚,可以选择导致地层规模突变的廊道路线。 此外,它无法处理微小的障碍物,因此会屈服于较小尺度的较长路径,如图10(a)所示。 与阿隆索-莫拉的方法不同,我们的编队级寻路方法直接在增强的3D尺度空间中采样,可以更好地保持所需的编队尺度。 如图10(b)所示,我们的方法生成了更短的路径,并且只牺牲了少量的地层尺度。 因此,我们的方法可以处理带有块和微小障碍物的地图,并为群体形成找到安全的指导,这更适合密集的环境。
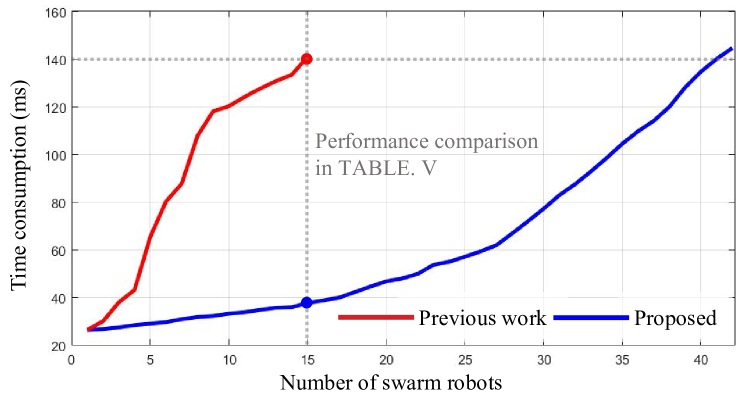
VIII-E 解耦编队优化的效率
| Previous method[4] | Proposed method | |
| Time consumption | 141.7 | 38.2 |
| success rate | 95.0 | 100.0 |
| length | 47.387 | 45.282 |
| 12.439 | 11.724 | |
| 0.147 | 0.139 |
我们将我们提出的解耦编队优化与之前的耦合编队优化[4]进行比较,后者在优化过程中多次直接调用编队相似距离度量(5)。 为了确保公平比较,我们在此基准测试中排除了 ALAS 问题。 两种方法的结果如图11所示。 之前的方法[4]仅支持小规模的群体形成,因为计算时间呈指数增长。 由于采用了解耦的方法,我们提出的方法对于42个机器人的集群的时间消耗不超过150ms,可以支持大规模集群的实时应用。
我们从 15 架无人机场景中选择实验数据,如表 V 所示。我们的方法不仅比以前的方法显着缩短了计算时间,而且在编队维护、成功率和轨迹长度方面表现出了更好的性能。 这验证了我们方法的有效解耦,从而实现了全面的性能改进。
IX 现实世界的实验和模拟
IX-A 现实世界的实验
我们的方法与III节中所述的自主分布式空中集群系统集成。 群体通过广播网络共享一些信息,例如轨迹,这是所有机器人之间的唯一连接。 如图12所示,我们使用带有本地传感器和机载计算机的手掌大小的四旋翼平台[5]。 估计、感知、规划、控制等软件模块都在船上实时运行。 实际实验中群体机器人的最大数量为 16 个。 设计了三个不同的真实世界实验来充分验证所提出的编队飞行系统的特性。

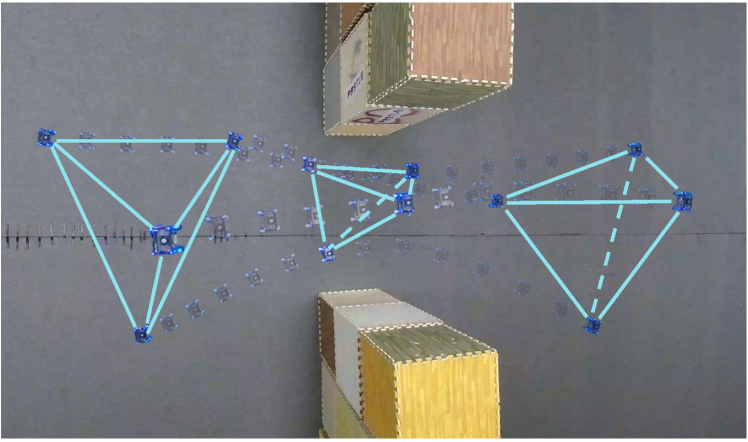
在第一个实验中,如图13所示,四架四旋翼飞行器组成三维正四面体,成功地安全通过了狭窄的走廊。 在飞行过程中,集群会根据环境变化自适应地旋转和压缩编队形状。 该测试证明,缩放和旋转不变性为受限空间中的编队飞行提供了更大的灵活性。

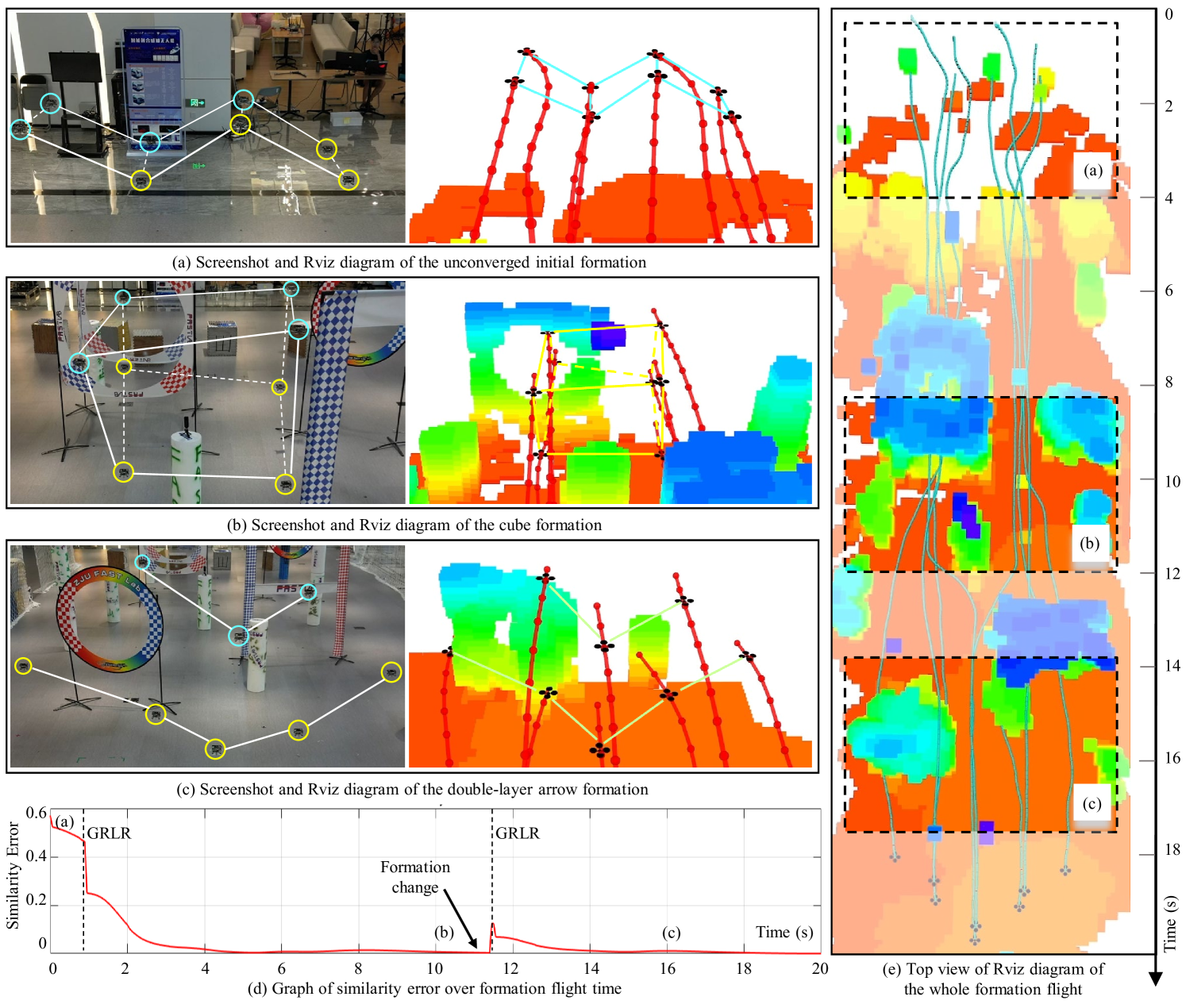
然后我们设计了一个3D地层形状变换实验来验证我们方法的重组能力,如图14所示。 在图14(a)中,所需的队形是立方体形状,但群体机器人从未收敛的初始位置和不正确的初始任务分配中导航。 一开始,集群机器人快速调用GRLR策略,使编队形状快速收敛到所需的正方形,如图14(b)所示。 然后,集群机器人接收来自站位笔记本电脑的编队变换命令,并汇聚成双箭头形状,如图14(c)所示。 导航过程的俯视图如图14(e)所示。 从浅蓝色的执行轨迹可以看出,群体机器人的飞行行为在时间和时间期间趋于一致。 此外,在时间和时间期间,群体机器人试图达成群体共识并频繁调整飞行行为以形成所需的编队形状。 从图14(d)可以看到更准确的数值分析。 当编队系统远离收敛状态或满足编队变换命令时,集群机器人通过在虚线对应时刻调用GRLR策略来调整编队排列和任务分配。 根据红线代表的相似度误差,我们可以看到,除了初始时刻的不收敛状态和突然的队形变换之外,集群编队在避开障碍物的同时,能够保持所需的形状。
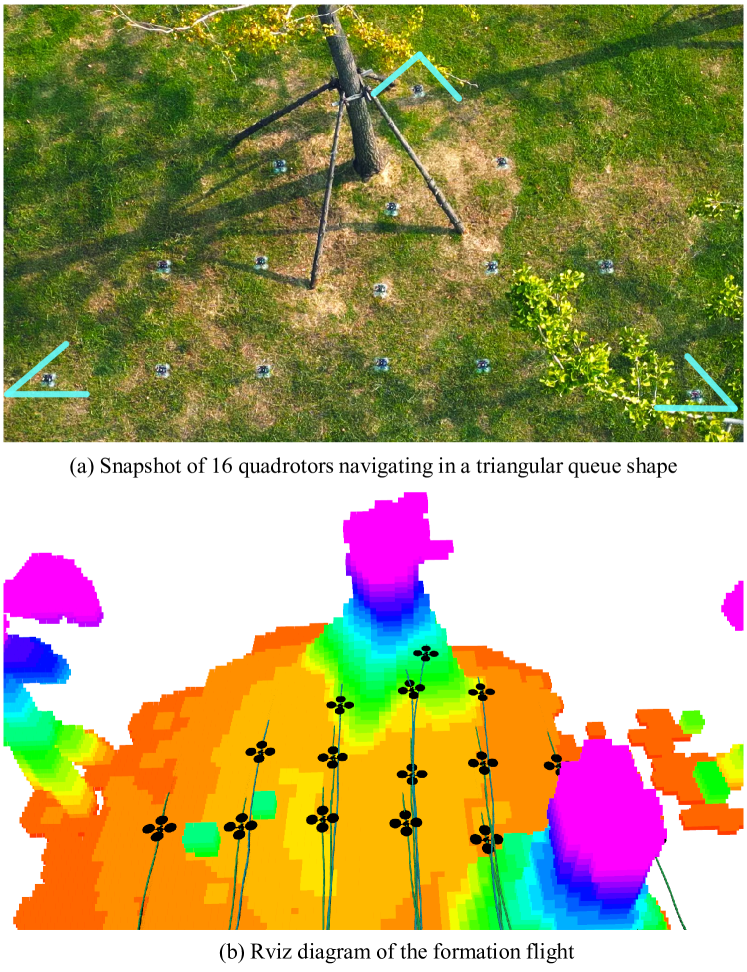
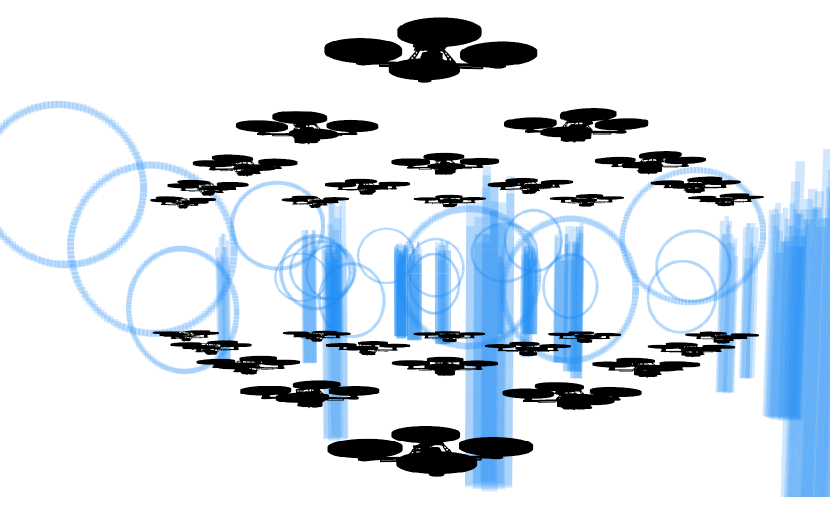
最后,我们在室外进行了16架无人机编队飞行实验。 据我们所知,这是复杂户外环境下最大规模的全自主编队飞行实验。 如图1所示,16架无人机排成三角形队列,成功穿越障碍物丰富的区域,且未发生碰撞。 该地区有许多行道树、木桩和路灯。 该实验证明了我们提出的方法的鲁棒性和大规模能力。 更多详情请观看实验视频333https://www.youtube.com/watch?v=uEMyvPxYqmA。
IX-B 模拟实验
为了全面展示所提出的编队飞行方法的特点,我们还进行了多次模拟实验来补充现实世界的实验。 所有模拟实验均在配备 Intel i7-12700 CPU 的台式机上实时运行。
首先,我们设计了编队多重变换模拟,以验证在应对密集环境中的紧急变化时群体重组能力,如图15所示。 不同颜色的轨迹代表编队飞行从左到右的时间流。 相同颜色的机器人对应于该时间戳处的编队形状。 队形变换的命令是实时下达的,而不是预先设定的。 群体机器人必须克服所需编队形状的瞬时变化并快速收敛到新的编队状态。 由于所提出的方法在复杂环境中快速变换队形的出色能力,我们最终为我们的实验室生成了缩写“FAST”。
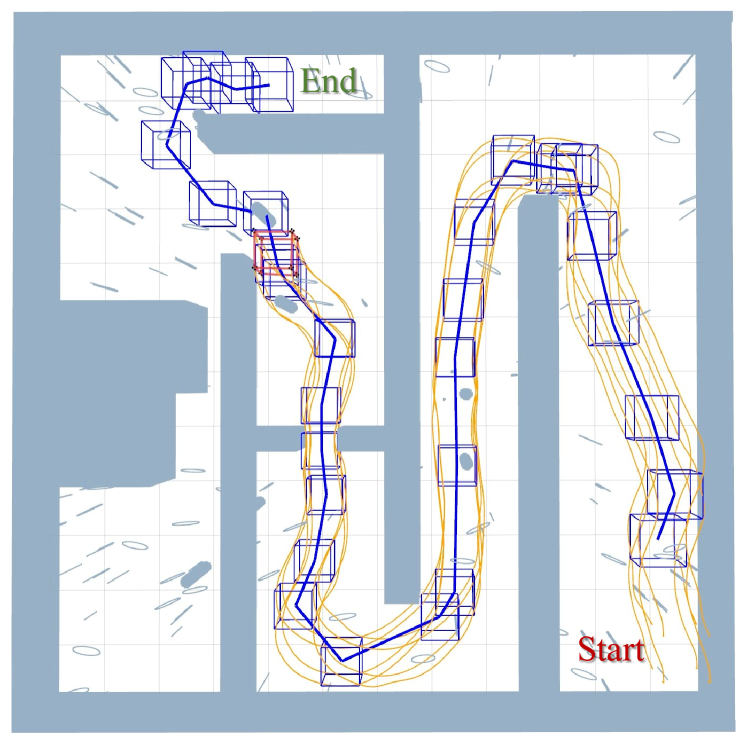
然后,我们建立了一个特殊的迷宫模拟环境,由墙壁和许多小障碍物(如柱子和圆环)组成。 在这个模拟中,我们的目的是验证群体协议的能力。 编队级全局寻路方法首先在全局地图中运行,这是VII-B中提出的集中式方法。 然后,它生成考虑地层形状尺度的全局路径,如图16中的蓝线所示。 蓝色立方体形状代表采样点。 之后,8 个机器人形成立方体队形,遵循全局路径进行导航,并使用第 V 节中的分布式方法生成局部队形轨迹。 此次仿真表明,我们的编队飞行系统能够更好地适应障碍物约束,为编队飞行提供更安全的引导。
最后,为了测试我们的方法在大规模不规则编队中的有效性,我们设计了一个由 30 架无人机组成的双箭编队。 如图17所示,集群成功避开了障碍物,并且在飞行过程中很好地保持了所需的队形。
X 结论和未来工作
本文详细分析了密集环境下实现编队飞行的核心困境,准确总结了解决上述问题的PAPER标准。 然后,我们提出了一种分层编队飞行架构,由基于图的编队定义、分布式编队轨迹优化、群体重组方法和群体协议方法组成。 所提出的完整编队飞行系统满足所有PAPER标准,并在密集环境中保持协作编队飞行方面取得了优异的性能。 我们在适应性、可预测性、弹性、弹性和效率方面设计了全面的基准,以验证我们提出的方法的出色性能。 最后,我们进行了大量的现实世界实验和模拟,证明我们解决了大规模集群密集环境下的自主编队飞行问题。
未来,我们打算通过子图的局部信息传播,进一步提高分布式编队飞行方法的效率。 此外,虽然我们目前的工作需要操作员手动确定地层形状,但优化地层形状的研究是一个有前途的领域。 我们相信它有潜力展示更智能、更协作的群体行为,最终提高任务能力。
-A 对准问题的闭式解
参考
- [1] L. Marconi, C. Melchiorri, M. Beetz, D. Pangercic, R. Siegwart, S. Leutenegger, R. Carloni, S. Stramigioli, H. Bruyninckx, P. Doherty, A. Kleiner, V. Lippiello, A. Finzi, B. Siciliano, A. Sala, and N. Tomatis, “The sherpa project: Smart collaboration between humans and ground-aerial robots for improving rescuing activities in alpine environments,” in 2012 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), 2012, pp. 1–4.
- [2] N. Mahdoui, V. Frémont, and E. Natalizio, “Communicating multi-uav system for cooperative slam-based exploration,” Journal of Intelligent & Robotic Systems, vol. 98, no. 2, pp. 325–343, 2020.
- [3] K. Dorling, J. Heinrichs, G. G. Messier, and S. Magierowski, “Vehicle routing problems for drone delivery,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 47, no. 1, pp. 70–85, 2016.
- [4] L. Quan, L. Yin, C. Xu, and F. Gao, “Distributed swarm trajectory optimization for formation flight in dense environments,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 4979–4985.
- [5] X. Zhou, X. Wen, Z. Wang, Y. Gao, H. Li, Q. Wang, T. Yang, H. Lu, Y. Cao, C. Xu et al., “Swarm of micro flying robots in the wild,” Science Robotics, vol. 7, no. 66, p. eabm5954, 2022.
- [6] J. Van Den Berg, S. J. Guy, M. Lin, and D. Manocha, “Reciprocal n-body collision avoidance,” in Robotics research. Springer, 2011, pp. 3–19.
- [7] J. Van Den Berg, J. Snape, S. J. Guy, and D. Manocha, “Reciprocal collision avoidance with acceleration-velocity obstacles,” in 2011 IEEE International Conference on Robotics and Automation. IEEE, 2011, pp. 3475–3482.
- [8] D. Bareiss and J. Van den Berg, “Reciprocal collision avoidance for robots with linear dynamics using lqr-obstacles,” in 2013 IEEE International Conference on Robotics and Automation. IEEE, 2013, pp. 3847–3853.
- [9] S. H. Arul and D. Manocha, “Dcad: Decentralized collision avoidance with dynamics constraints for agile quadrotor swarms,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 1191–1198, 2020.
- [10] C. E. Luis and A. P. Schoellig, “Trajectory generation for multiagent point-to-point transitions via distributed model predictive control,” IEEE Robotics and Automation Letters, vol. 4, no. 2, pp. 375–382, 2019.
- [11] J. Park, J. Kim, I. Jang, and H. J. Kim, “Efficient multi-agent trajectory planning with feasibility guarantee using relative bernstein polynomial,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 434–440.
- [12] D. Zhou, Z. Wang, S. Bandyopadhyay, and M. Schwager, “Fast, on-line collision avoidance for dynamic vehicles using buffered voronoi cells,” IEEE Robotics and Automation Letters, vol. 2, no. 2, pp. 1047–1054, 2017.
- [13] Y. Chen, M. Cutler, and J. P. How, “Decoupled multiagent path planning via incremental sequential convex programming,” in 2015 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2015, pp. 5954–5961.
- [14] T. Baca, D. Hert, G. Loianno, M. Saska, and V. Kumar, “Model predictive trajectory tracking and collision avoidance for reliable outdoor deployment of unmanned aerial vehicles,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 6753–6760.
- [15] M. A. Lewis and K.-H. Tan, “High precision formation control of mobile robots using virtual structures,” Autonomous robots, vol. 4, no. 4, pp. 387–403, 1997.
- [16] D. Panagou and V. Kumar, “Cooperative visibility maintenance for leader–follower formations in obstacle environments,” IEEE Transactions on Robotics, vol. 30, no. 4, pp. 831–844, 2014.
- [17] M. C. De Gennaro and A. Jadbabaie, “Formation control for a cooperative multi-agent system using decentralized navigation functions,” in 2006 American Control Conference. IEEE, 2006, pp. 6–pp.
- [18] T. Balch and R. C. Arkin, “Behavior-based formation control for multirobot teams,” IEEE transactions on robotics and automation, vol. 14, no. 6, pp. 926–939, 1998.
- [19] Z. Lin, W. Ding, G. Yan, C. Yu, and A. Giua, “Leader–follower formation via complex laplacian,” Automatica, vol. 49, no. 6, pp. 1900–1906, 2013.
- [20] K. Fathian, S. Safaoui, T. H. Summers, and N. R. Gans, “Robust distributed planar formation control for higher order holonomic and nonholonomic agents,” IEEE Transactions on Robotics, vol. 37, no. 1, pp. 185–205, 2020.
- [21] A. Weinstein, A. Cho, G. Loianno, and V. Kumar, “Visual inertial odometry swarm: An autonomous swarm of vision-based quadrotors,” IEEE Robotics and Automation Letters, vol. 3, no. 3, pp. 1801–1807, 2018.
- [22] P. C. Lusk, X. Cai, S. Wadhwania, A. Paris, K. Fathian, and J. P. How, “A distributed pipeline for scalable, deconflicted formation flying,” IEEE Robotics and Automation Letters, vol. 5, no. 4, pp. 5213–5220, 2020.
- [23] M. Turpin, N. Michael, and V. Kumar, “Capt: Concurrent assignment and planning of trajectories for multiple robots,” The International Journal of Robotics Research, vol. 33, no. 1, pp. 98–112, 2014.
- [24] D. Morgan, G. P. Subramanian, S.-J. Chung, and F. Y. Hadaegh, “Swarm assignment and trajectory optimization using variable-swarm, distributed auction assignment and sequential convex programming,” The International Journal of Robotics Research, vol. 35, no. 10, pp. 1261–1285, 2016.
- [25] S. Agarwal and S. Akella, “Simultaneous optimization of assignments and goal formations for multiple robots,” in 2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018, pp. 6708–6715.
- [26] D. Zhou, Z. Wang, and M. Schwager, “Agile coordination and assistive collision avoidance for quadrotor swarms using virtual structures,” IEEE Transactions on Robotics, vol. 34, no. 4, pp. 916–923, 2018.
- [27] Z. Han, L. Wang, and Z. Lin, “Local formation control strategies with undetermined and determined formation scales for co-leader vehicle networks,” in 52nd IEEE Conference on Decision and Control. IEEE, 2013, pp. 7339–7344.
- [28] S. Zhao, “Affine formation maneuver control of multiagent systems,” IEEE Transactions on Automatic Control, vol. 63, no. 12, pp. 4140–4155, 2018.
- [29] S. Zhao, Z. Li, and Z. Ding, “Bearing-only formation tracking control of multiagent systems,” IEEE Transactions on Automatic Control, vol. 64, no. 11, pp. 4541–4554, 2019.
- [30] S. Zhao and D. Zelazo, “Bearing rigidity theory and its applications for control and estimation of network systems: Life beyond distance rigidity,” IEEE Control Systems Magazine, vol. 39, no. 2, pp. 66–83, 2019.
- [31] J. Alonso-Mora, E. Montijano, M. Schwager, and D. Rus, “Distributed multi-robot formation control among obstacles: A geometric and optimization approach with consensus,” in 2016 IEEE international conference on robotics and automation (ICRA). IEEE, 2016, pp. 5356–5363.
- [32] P. Peng, W. Dong, G. Chen, and X. Zhu, “Obstacle avoidance of resilient uav swarm formation with active sensing system in the dense environment,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 10 529–10 535.
- [33] R. Van Parys and G. Pipeleers, “Distributed model predictive formation control with inter-vehicle collision avoidance,” in 2017 11th Asian Control Conference (ASCC). IEEE, 2017, pp. 2399–2404.
- [34] T. Qin, P. Li, and S. Shen, “Vins-mono: A robust and versatile monocular visual-inertial state estimator,” IEEE Transactions on Robotics, vol. 34, no. 4, pp. 1004–1020, 2018.
- [35] Y. Wang, X. Wen, L. Yin, C. Xu, Y. Cao, and F. Gao, “Certifiably optimal mutual localization with anonymous bearing measurements,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 9374–9381, 2022.
- [36] M. Tantardini, F. Ieva, L. Tajoli, and C. Piccardi, “Comparing methods for comparing networks,” Scientific Reports, vol. 9, 11 2019.
- [37] A. S. Lewis and M. L. Overton, “Nonsmooth optimization via quasi-newton methods,” Mathematical Programming, vol. 141, no. 1, pp. 135–163, 2013.
- [38] D. Mellinger and V. Kumar, “Minimum snap trajectory generation and control for quadrotors,” in Proc. of the IEEE Intl. Conf. on Robot. and Autom., Shanghai, China, May 2011, pp. 2520–2525.
- [39] Z. Wang, X. Zhou, C. Xu, and F. Gao, “Geometrically constrained trajectory optimization for multicopters,” IEEE Transactions on Robotics, 2022.
- [40] L. S. Jennings and K. L. Teo, “A computational algorithm for functional inequality constrained optimization problems,” Automatica, vol. 26, no. 2, pp. 371–375, 1990.
- [41] W. H. Press, S. A. Teukolsky, W. T. Vetterling, and B. P. Flannery, Numerical Recipes 3rd Edition: The Art of Scientific Computing, 3rd ed. USA: Cambridge University Press, 2007.
- [42] B. Zhou, F. Gao, L. Wang, C. Liu, and S. Shen, “Robust and efficient quadrotor trajectory generation for fast autonomous flight,” IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 3529–3536, 2019.
- [43] L. Quan, Z. Zhang, X. Zhong, C. Xu, and F. Gao, “Eva-planner: Environmental adaptive quadrotor planning,” in 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 398–404.
- [44] F. Gao, Y. Lin, and S. Shen, “Gradient-based online safe trajectory generation for quadrotor flight in complex environments,” in Proc. of the IEEE/RSJ Intl. Conf. on Intell. Robots and Syst., Sept 2017.
- [45] F. Båberg and P. Ögren, “Formation obstacle avoidance using rrt and constraint based programming,” in 2017 IEEE International Symposium on Safety, Security and Rescue Robotics (SSRR). IEEE, 2017, pp. 1–6.
- [46] J. Alonso-Mora, S. Baker, and D. Rus, “Multi-robot formation control and object transport in dynamic environments via constrained optimization,” The International Journal of Robotics Research, vol. 36, no. 9, pp. 1000–1021, 2017.
- [47] J. J. Kuffner and S. M. LaValle, “Rrt-connect: An efficient approach to single-query path planning,” in Proceedings 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No. 00CH37065), vol. 2. IEEE, 2000, pp. 995–1001.
- [48] J. D. Gammell, S. S. Srinivasa, and T. D. Barfoot, “Informed rrt*: Optimal sampling-based path planning focused via direct sampling of an admissible ellipsoidal heuristic,” in Proc. of the IEEE/RSJ Intl. Conf. on Intell. Robots and Syst., Chicago, IL, Sept 2014.
- [49] A. H. Qureshi and Y. Ayaz, “Intelligent bidirectional rapidly-exploring random trees for optimal motion planning in complex cluttered environments,” Robotics and Autonomous Systems, vol. 68, pp. 1–11, 2015.
- [50] K.-K. Oh, M.-C. Park, and H.-S. Ahn, “A survey of multi-agent formation control,” Automatica, vol. 53, pp. 424–440, 2015.
- [51] M. Turpin, N. Michael, and V. Kumar, “Trajectory design and control for aggressive formation flight with quadrotors,” Autonomous Robots, vol. 33, no. 1, pp. 143–156, 2012.
- [52] R. Olfati-Saber and R. M. Murray, “Consensus problems in networks of agents with switching topology and time-delays,” IEEE Transactions on automatic control, vol. 49, no. 9, pp. 1520–1533, 2004.
- [53] L. Krick, M. E. Broucke, and B. A. Francis, “Stabilisation of infinitesimally rigid formations of multi-robot networks,” International Journal of control, vol. 82, no. 3, pp. 423–439, 2009.
![[Uncaptioned image]](quanlun.jpg) |
Lun Quan received the B.Eng. degree in control science and engineering in 2019 from Zhejiang University, Hangzhou, China, where he is currently working toward a Ph.D. degree in control science and engineering. His research interests include motion planning for multi-robot systems, swarm intelligence, and autonomous navigation for unmanned vehicles. |
![[Uncaptioned image]](yinlongji.jpg) |
Longji Yin received the B.Eng. degree in automation from Zhejiang University, Zhejiang, China, in 2019 and the M.Sc. degree in robotics from Johns Hopkins University, Maryland, U.S. in 2021. In 2022, he worked as a research assistant at Zhejiang University, Zhejiang, China. He is currently working toward a Ph.D. degree in mechanical engineering at the University of Hong Kong, Hong Kong. His research interests include motion planning and mapping for autonomous aerial robots. |
![[Uncaptioned image]](zhangtingrui.jpg) |
Tingrui Zhang received the B.Eng. degree in automotive engineering from Beijing Institute of Technology, Beijing, China, in 2022. He is currently pursuing an M.Phil. degree in control engineering at Zhejiang University, Hangzhou, China. His research interests include motion planning for autonomous robots and numerical optimization. |
![[Uncaptioned image]](wangmingyang.jpg) |
Mingyang Wang received the B.Eng. degree in control science and engineering from Zhejiang University, Hangzhou, China, in 2022. He is currently working toward an M.Phil. degree in control science and engineering from Zhejiang University, Hangzhou, China. His research interests include motion planning and control for aerobatic flight. |
![[Uncaptioned image]](wangruilin.png) |
Ruilin Wang received the B.Eng. degree in control science and engineering from Zhejiang University, Hangzhou, China, in 2023. He is currently working toward an M.Phil. degree in artificial intelligence at Sun Yat-sen University, Zhuhai, China. His research interests include aerial robots and motion planning. |
![[Uncaptioned image]](zhongsheng.jpg) |
Sheng Zhong received the B.Eng. degree in control science and engineering from Zhejiang University, China, in 2023. He is currently working toward a Ph.D. degree in control science and engineering at Hunan University, Changsha, China. His research interests include motion estimation based on event cameras. |
![[Uncaptioned image]](zhouxin.jpg) |
Xin Zhou received the B.Eng. degree in electrical engineering and automation from China University of Mining and Technology, Xuzhou, China, in 2019. He is currently working toward the Ph.D. degree in control engineering from Zhejiang University, Hangzhou, China. His research interests include motion planning and mapping for aerial swarm robotics. |
![[Uncaptioned image]](caoyanjun.jpg) |
Yanjun Cao received his Ph.D. degree in computer and software engineering from the University of Montreal, Polytechnique Montreal, Canada, in 2020. He is currently an associate researcher at the Huzhou Institute of Zhejiang University, as a PI in the Center of Swarm Navigation. He leads the Field Intelligent Robotics Engineering (FIRE) group of the Field Autonomous System and Computing Lab (FAST Lab). His research focuses on key challenges in multi-robot systems, such as collaborative localization, autonomous navigation, perception, and communication. |
![[Uncaptioned image]](xuchao.jpg) |
Chao Xu received his Ph.D. in Mechanical Engineering from Lehigh University in 2010. He is currently Associate Dean and Professor at the College of Control Science and Engineering, Zhejiang University. He serves as the inaugural Dean of ZJU Huzhou Institute, as well as plays the role of the Managing Editor for IET Cyber-Systems & Robotics. His research expertise is Flying Robotics, Control-theoretic Learning. Prof. Xu has published over 100 papers in international journals, including Science Robotics (Cover Paper), Nature Machine Intelligence (Cover Paper), etc. Prof. Xu will join the organization committee of the IROS-2025 in Hangzhou. |
![[Uncaptioned image]](gaofei.png) |
Fei Gao received the Ph.D. degree in electronic and computer engineering from the Hong Kong University of Science and Technology, Hong Kong, in 2019. He is currently a tenured associate professor at the Department of Control Science and Engineering, Zhejiang University, where he leads the Flying Autonomous Robotics (FAR) group affiliated with the Field Autonomous System and Computing (FAST) Laboratory. His research interests include aerial robots, autonomous navigation, motion planning, optimization, and localization and mapping. |