用于工业异常检测的不对称学生-教师网络
摘要
工业缺陷检测通常通过异常检测(AD)方法来解决,其中没有或只有不完整的潜在发生缺陷的数据可用。 这项工作发现了 AD 学生-教师方法中以前未知的问题,并提出了一种解决方案,其中训练两个神经网络为无缺陷训练示例产生相同的输出。 学生-教师网络的核心假设是,对于异常,两个网络的输出之间的距离较大,因为它们在训练中不存在。 然而,以前的方法由于学生和教师架构的相似性而受到影响,因此对于异常来说距离太小。 因此,我们提出了非对称学生-教师网络(AST)。 我们作为教师训练一个用于密度估计的归一化流,作为学生训练一个传统的前馈网络,以触发大距离的异常:与正常数据相比,归一化流的双射性强制教师输出异常的发散。 在训练分布之外,由于其架构根本不同,学生无法模仿这种差异。 我们的 AST 网络通过标准化流来补偿错误估计的可能性,该流在之前的工作中也被用于异常检测。 我们表明,我们的方法在当前最相关的两个缺陷检测数据集 MVTec AD 和 MVTec 3D-AD 上产生了关于 RGB 和 3D 数据的图像级异常检测的最先进的结果。
1简介
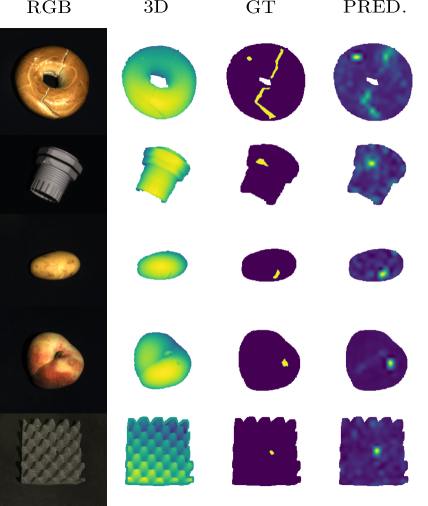
为了确保工业制造过程中的产品质量和安全标准,传统上由人工对产品进行检查,这在实践中成本高昂且不可靠。 因此,最近利用深度学习的进步开发了基于图像的自动检测方法[9,18,29,38,39]。 由于没有或只有很少的反面例子,即即。错误的产品,特别是在生产之初,并且在过程中不断出现新的错误,传统的监督算法无法应用于此任务。 相反,假设训练中只有正常类无缺陷示例的数据可用,这被称为半监督异常检测。 这项工作和其他[9,22,36,38,39]专门用于工业异常检测。 该领域与其他领域的不同之处在于,正常示例彼此相似并且与缺陷产品相似。 在这项工作中,我们不仅展示了我们的方法对常见 RGB 图像的有效性,而且还展示了对 3D 数据及其组合的有效性,如图 1 所示。
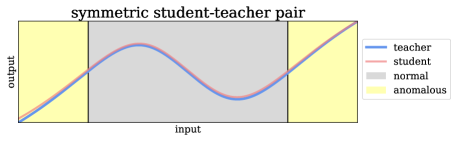
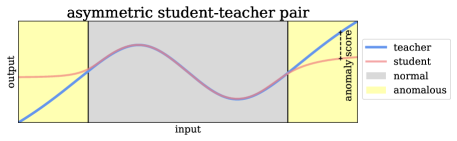
有几种方法试图通过所谓的学生-教师网络[5,7,19,51,53]来解决该问题。 首先,教师接受借口任务的训练以学习语义嵌入。 第二步,训练学生以匹配教师的输出。 动机是学生只能在正常数据上匹配教师的输出,因为它仅在正常数据上进行训练。 学生和教师的输出之间的距离用作测试时异常的指标。 假设与无缺陷示例相比,有缺陷示例的该距离更大。 然而,在之前的工作中情况不一定如此,因为我们发现教师和学生都是具有相似架构的传统(即非内射)神经网络。 具有相似架构的学生往往会进行不期望的泛化,从而对于超出训练分布的输入推断出与教师相似的输出,这反过来又给出了不期望的低异常分数。 这种效果如图2所示,使用一维数据进行解释性实验:如果学生和教师使用具有一个隐藏层的相同神经网络,则对于异常数据,输出仍然相似上图的黄色区域。 相反,如果使用具有 3 个隐藏层的 MLP 作为学生,则异常的输出会发散。
一般来说,由于普通神经网络缺乏单射性,不能保证分布外的输入会导致两个输出发生足够大的变化。 与标准化流量相比,传统网络无法保证为分布外输入提供分布外输出。 这些问题促使我们使用不对称的学生-教师对(AST):双射归一化流[34]充当教师,而传统的顺序模型充当学生。 这样,教师保证对异常引起的输入变化保持敏感。 此外,不同架构的使用以及不同可学习函数集的使用增强了分布外样本的远程输出的效果。
作为教师的借口任务,我们通过最大似然训练优化将图像特征和/或深度图的分布转换为正态分布,这相当于密度估计[15]。 这种优化本身在之前的工作[22,38,39]中用于通过利用可能性作为异常分数来进行异常检测:正常的低可能性应该是异常的指标。 然而,Le 和 Dinh [28] 表明,即使完美的密度估计器也不能保证异常检测。 例如,仅重新参数化数据就会改变样本的可能性。 此外,不稳定的训练会导致可能性的错误估计。 我们表明,与教师获得的可能性相比,我们的学生-教师距离是异常检测的更好衡量标准。 使用归一化流本身进行异常检测的优点是可以补偿可能性的可能错误估计:如果将正常的低可能性错误地分配给正常数据,则学生可以预测此输出,因此仍然会导致一个小的异常分数。 如果正常的高可能性被错误地分配给异常数据,则学生无法预测该输出,再次导致高异常分数。 通过这种方式,我们将学生-教师网络和密度估计的优点与标准化流量结合起来。 我们通过位置编码和使用 3D 图像屏蔽前景进一步增强检测。
我们的贡献总结如下:
-
•
我们的方法通过将高度不对称的网络作为学生-教师对,避免了从教师到学生的不良泛化。
-
•
我们通过将双射规范化流程作为教师来改善学生-教师网络。
-
•
我们的 AST 通过利用学生与教师的距离,超越了教师的密度估计能力。
-
•
代码可在 GitHub 上获取111https://github.com/marco-rudolph/ast。
2相关工作
2.1师生网络
最初,让学生网络学习回归教师网络输出的动机是提取知识并保存模型参数[23,31,48]。 在这种情况下,与老师相比,参数明显较少的学生几乎可以达到相同的表现。 之前的一些工作利用学生-教师的想法,通过使用学生输出之间的距离来进行异常检测:距离越大,样本越有可能是异常的。 Bergmann 等人[7]提出了一个学生集合,这些学生经过训练可以对教师的图像补丁输出进行回归。 该教师要么是 ImageNet 预训练网络的精炼版本,要么是通过度量学习进行训练。 异常分数由学生不确定性(通过整体方差衡量)和回归误差组成。 Wang 等人[51]通过回归特征金字塔而不是预训练网络的单个输出来扩展学生任务。 Bergmann 和 Sattlegger [5] 将学生-教师概念应用于点云。 以自我监督的方式学习局部几何描述符来训练老师。 肖等人[53]让教师学习对应用的图像变换进行分类。 异常分数是回归误差和学生群体的班级分数熵的加权和。 相比之下,我们的方法只需要一名学生,并且回归误差作为检测异常的唯一标准。 所有现有工作都基于学生和教师的相同且传统(非内射)网络,这会导致学生出现不期望的泛化,如第 1 节中所述。
2.2密度估计
异常检测可以从统计学的角度来看:通过估计正常样本的密度,通过较低的可能性来识别异常。 用于异常检测的密度估计的概念可以通过假设多元正态分布来简单地实现。 例如,预提取特征的马哈拉诺比斯距离可以用作异常分数[12, 35],这相当于计算多元高斯的负对数似然。 然而,这种方法对于训练分布非常不灵活,因为高斯分布的假设是一个很强的简化。
为此,许多工作尝试使用归一化流(NF)[14,22,38,39,41,44]更灵活地估计密度。 归一化流是一系列生成模型,与传统的神经网络不同,它通过构造 [3, 15, 34, 52] 进行双射映射。 与 GAN [21] 或 VAE [27] 等其他生成模型相比,此属性可以实现精确的密度估计。 Rudolph 等人[38]通过对预训练网络获得的多尺度特征向量的密度进行建模来利用这一概念。 随后,他们将其扩展到多尺度特征图而不是向量,以避免平均 [39] 造成的信息损失。 为了处理不同大小的特征图,集成了所谓的交叉卷积。 Gudovskiy 等人 [22] 提出的类似方法使用条件归一化流计算特征图上的密度,其中似然度是根据作为 NF 条件的局部位置水平进行估计的。
归一化流的一个常见问题是训练不稳定,它会牺牲密度估计[4]的灵活性。 然而,即使是真实密度估计也无法提供完美的异常检测,因为密度强烈依赖于参数化[28]。
2.3其他方法
生成模型
许多方法尝试基于其他生成模型来解决异常检测问题,而不是将流标准化为自动编码器 [9, 18, 20, 37, 55, 57] 或 GAN [1, 11, 42].
这是因为这些模型无法生成异常数据。
通常,重建误差用于异常评分。
由于该误差的大小很大程度上取决于异常的大小和结构,因此这些方法在工业检查环境中表现不佳。
这些方法的缺点是合成异常无法模仿许多真实异常。
异常合成
一些工作通过综合生成异常将半监督异常检测重新表述为监督问题。
训练图像 [29, 43, 46] 的部分或随机图像 [54] 被修补为正常图像。
创建合成掩模来训练监督分割。
传统方法
除了基于深度学习的方法之外,还有一些经典的异常检测方法。
一类 SVM [45] 是一种优化函数的最大边距方法,该函数为高密度区域分配比低密度区域更高的值。
隔离森林[30]基于决策树,其中如果可以通过一些约束将样本与其余数据分开,则样本被视为异常。
局部离群因子[10]将点的密度与其邻居的密度进行比较。
点密度相对较低可识别异常情况。
由于数据的高维度和复杂性,传统方法通常无法进行视觉异常检测。
这可以通过将它们与其他技术相结合来避免:例如,Amer 和 Goldstein 首先提出的到最近邻居的距离[2],在提取特征后用作异常分数预训练网络[32, 36]。
或者,可以使用点云特征 [24] 或基于密度的聚类 [16, 17] 来表征点邻域并相应地对其进行标记。
然而,运行时间与数据集大小线性相关。
3方法
我们的目标是训练两个模型,一个学生模型 和一个教师模型 ,以便学生学会仅在无缺陷图像数据上回归教师输出。 训练过程分为两个阶段:首先,优化教师模型,通过归一化流程将训练分布双射转换为正态分布。 其次,通过最小化训练样本 的 和 之间的距离来优化学生以匹配教师输出。 我们在测试时应用距离进行异常评分,这在 3.2 节中有进一步描述。
我们遵循 [7, 22, 39] 并使用 ImageNet [13] 上预训练网络获得的提取特征而不是 RGB 图像作为我们模型的直接输入。 此类网络已被证明是通用特征提取器,其输出携带用于工业异常检测的相关语义。
除了 RGB 数据之外,我们的方法还可以轻松扩展到包括 3D 数据在内的多模式输入。 如果 3D 数据可用,我们将深度图沿着通道连接到这些特征。 由于与深度图的分辨率相比,特征图的高度和宽度减少了 倍,因此我们采用了像素不规则处理 [56],将 个像素的深度图片段归为一个像素,并设置 个通道,以匹配特征图的尺寸。
任何可能存在的 3D 数据都用于提取前景。 当背景是静态或平面时,这是简单且合理的,几乎所有实际应用都是这种情况。 通过屏蔽距离和负对数似然损失来优化教师和学生时,背景中的像素将被忽略,这在第 3.1 和 3.2 节中介绍。 如果没有可用的 3D 数据,则整个图像被视为前景。 前景提取的详细信息在4.2.1节中给出。
与[22]类似,我们对输入图的空间维度使用正弦位置编码[50]作为归一化流的条件>。 这样,特征的出现与其位置相关,以检测物体错放等异常情况。 图 3 给出了我们的管道概述。
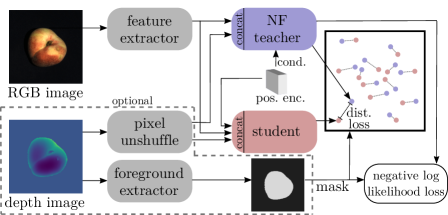
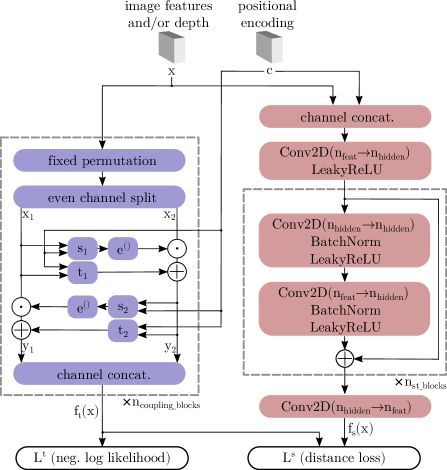
3.1老师
与[22, 38, 39]类似,我们训练基于Real-NVP [15]的归一化流程,将训练分布转换为正态分布. 与之前的工作相比,我们不使用输出来计算可能性,从而直接获得异常分数。 相反,我们将此训练解释为借口任务,为我们的学生网络创建目标。
归一化流程由多个后续仿射耦合块组成。 令输入 为具有 大小为 的特征的特征映射。 在这些块中,在随机选择保持固定的排列后,输入 的通道沿通道均匀分割为 和 部分。 这些部分均与位置编码 连接作为静态条件。 两者都用于通过每个部分的子网络 和 来计算对应部分的仿射变换的缩放和移位参数:
| (1) | |||
其中 是逐元素乘积, 表示串联。 一个耦合块的输出是 和 沿通道的串联。 请注意,输入和输出的维数不会因可逆性而改变。
为了稳定训练,我们应用标量系数的 alpha 钳位(如 [4] 中)和伽马技巧(如 [39] 中)。 使用变量变化公式和 作为我们的最终输出
| (2) |
我们通过优化均值来最小化以 作为正态分布 的负对数似然
| (3) |
像素位置 处的所有(前景)像素。
| Dataset | MVTec AD | MVTec 3D-AD |
| Alias | (MVT2D) | (MVT3D) |
| RGB images | ✓ | ✓ |
| 3D scans | ✓ | |
| #categories | 15 | 10 |
| image side length | 700-1024 | 400-800 |
| #train samples per cat. | 60-320 | 210-300 |
| #test samples per cat. | 42-160 | 100-159 |
| #defect types per cat. | 1-7 | 3-5 |
| Category | ARNet | DRÆM | GAN | Rippel | PatchCore | DifferNet | PaDiM | CFlow | CS-Flow | Uninf. | STFPM* | AST | |
| [18] | [54] | [1] | [35] | [36] | [38] | [12] | [22] | [39] | Stud. [7] | [51] | (ours) | ||
| Grid | 88.3 | 99.9 | 70.8 | 93.7 | 98.2 | 84.0 | - | 99.6 | 99.0 | 98.1 | 100 | 99.1 0.2 | |
| Leather | 86.2 | 100 | 84.2 | 100 | 100 | 97.1 | - | 100 | 99.9 | 94.7 | 100 | 100 0.0 | |
| Tile | 73.5 | 99.6 | 79.4 | 100 | 98.7 | 99.4 | - | 99.9 | 100 | 94.7 | 95.5 | 100 0.0 | |
| Carpet | 70.6 | 97.8 | 69.9 | 99.6 | 98.7 | 92.9 | - | 98.7 | 100 | 99.9 | 98.9 | 97.5 0.4 | |
|
Textures |
Wood | 92.3 | 99.1 | 83.4 | 99.2 | 98.8 | 99.8 | - | 99.1 | 100 | 99.1 | 99.2 | 100 0.0 |
| Avg. Text. | 82.2 | 99.3 | 77.5 | 98.5 | 98.3 | 94.6 | 99.0 | 99.5 | 99.8 | 97.3 | 98.7 | 99.3 0.08 | |
| Bottle | 94.1 | 99.2 | 89.2 | 99.0 | 100 | 99.0 | - | 100 | 99.8 | 99.0 | 100 | 100 0.0 | |
| Capsule | 68.1 | 98.5 | 73.2 | 96.3 | 98.1 | 86.9 | - | 97.7 | 97.1 | 92.5 | 88.0 | 99.7 0.1 | |
| Pill | 78.6 | 98.9 | 74.3 | 91.4 | 96.6 | 88.8 | - | 96.8 | 98.6 | 92.2 | 93.8 | 99.1 0.1 | |
| Transistor | 84.3 | 93.1 | 79.2 | 98.2 | 100 | 91.1 | - | 95.2 | 99.3 | 79.4 | 93.7 | 99.3 0.1 | |
| Zipper | 87.6 | 100 | 74.5 | 98.8 | 99.4 | 95.1 | - | 98.5 | 99.7 | 94.4 | 93.6 | 99.1 0.1 | |
| Cable | 83.2 | 91.8 | 75.7 | 99.1 | 99.5 | 95.9 | - | 97.6 | 99.1 | 78.7 | 92.3 | 98.5 0.2 | |
|
Objects |
Hazelnut | 85.5 | 100 | 78.5 | 100 | 100 | 99.3 | - | 100 | 99.6 | 99.1 | 100 | 100 0.0 |
| Metal Nut | 66.7 | 98.7 | 70.0 | 97.4 | 100 | 96.1 | - | 99.3 | 99.1 | 89.1 | 100 | 98.5 0.2 | |
| Screw | 100 | 93.9 | 74.6 | 94.5 | 98.1 | 96.3 | - | 91.9 | 97.6 | 86.0 | 88.2 | 99.7 0.1 | |
| Toothbrush | 100 | 100 | 65.3 | 94.1 | 100 | 98.6 | - | 99.7 | 91.9 | 100 | 87.8 | 96.6 0.1 | |
| Avg. Obj. | 84.8 | 97.4 | 75.5 | 96.9 | 99.2 | 94.7 | 97.2 | 97.7 | 98.2 | 91.0 | 93.7 | 99.1 0.03 | |
| Average | 83.9 | 98.0 | 76.2 | 97.5 | 99.1 | 94.7 | 97.9 | 98.3 | 98.7 | 93.2 | 95.4 | 99.2 0.04 |
3.2学生
与教师相反,学生是一个传统的前馈网络,不会单射或满射映射。 我们提出了一个带有残差块的简单全卷积网络,如图4所示。 每个残差块由两个卷积层序列、批量归一化[25]和泄漏ReLU激活组成。 我们添加卷积作为第一层和最后一层来增加和减少特征维度。
与教师类似,学生将图像特征作为输入,并与 3D 数据(如果有)连接起来。 另外,位置编码被连接起来。 输出尺寸与教师相匹配,以实现像素级距离计算。 我们最小化训练样本 上学生输出 和教师输出 之间的平方 距离,给定训练集 ,在输出的像素位置处:
| (4) |
对所有(前景)像素进行平均 得出最终损失。 距离 还用于测试以获得图像级别的异常分数:忽略背景像素的异常分数,我们通过计算像素上的最大值或平均值来聚合一个样本的像素距离。
4实验
4.1数据集
为了展示我们的方法在各种工业检测场景中的优势,我们对总共 25 个场景进行了评估,包括自然物体、工业组件以及 2D 和 3D 纹理。 表 1 显示了所使用的基准数据集 MVTec AD [6] 和 MVTec 3D-AD [8] 的概述。 对于这两个数据集,训练集仅包含无缺陷数据,测试集包含无缺陷和有缺陷的示例。 除了图像级标签之外,数据集还提供有关缺陷区域的像素级注释,我们用它来评估缺陷的分割。
MVTec AD,以下称为MVT2D,是一个高分辨率的2D RGB图像数据集,包含10个对象和5个纹理类别。 测试集中总共出现了 73 种缺陷类型,例如各种尺寸和形状的位移、裂纹或划痕。 图像的边长为 700 到 1024 像素。
MVTec 3D-AD(我们称为 MVT3D)是一个最新的 3D 数据集,包含 2D RGB 图像以及 10 个类别的 3D 扫描。 这些类别包括可变形和不可变形的物体,部分具有自然变化(例如桃子和胡萝卜)。 除了 MVT2D 中的缺陷类型之外,还存在只能从深度图识别的缺陷,例如压痕。 另一方面,也存在只能从 RGB 数据中感知到的变色等异常现象。 RGB 图像每边的分辨率为 400 至 800 像素,并与相同分辨率的光栅化 3D 点云配对。
4.2实现细节
4.2.1 图像预处理
在[12, 39]之后,我们使用在ImageNet [13]上预训练的EfficientNet-B5 [47]的第36层输出作为特征提取器。 该特征提取器在学生和教师网络的训练期间未经过训练。 图像大小调整为 像素的分辨率,从而生成具有 304 个通道的大小 的特征图。
4.2.2 3D预处理
由于信息内容较少,我们丢弃 和 坐标,仅使用以厘米为单位的深度分量 。 通过使用来自 8 个连通邻域的有效像素的平均值进行 3 次迭代来重复填充缺失的深度值。 我们通过插值 4 个角像素的深度将背景建模为 2D 平面。 如果某个像素距背景平面的深度超过 ,则该像素被假定为前景。 作为模型的输入,我们首先通过双线性下采样将掩码大小调整为 像素,然后按照所述使用 执行像素解组 [56]在第 3 部分中以匹配特征图分辨率。 为了检测对象边缘的异常并填充缺失值的孔,使用大小为 8 的方形结构元素来扩展前景掩模。 我们从每个深度图中减去平均前景深度,并将其背景像素设置为 0。 将 1 作为前景、0 作为背景的二进制前景掩模 下采样到特征图分辨率,以掩盖学生和教师的损失。 这是通过双线性插值 和随后的二值化来完成的,其中所有大于零的条目都被假定为前景,以掩盖位置 处的损失:
| (5) |
4.2.3老师
对于教师的归一化流架构,我们使用 4 个耦合块,这些耦合块以 32 个通道的位置编码为条件。 每对内部子网络和被设计为一个浅层卷积网络,具有一个隐藏层,其输出被分成尺度和移位分量。 在 内部,我们使用 ReLU 激活,并且 MVT2D 的隐藏通道大小为 1024,MVT3D 的隐藏通道大小为 64。 我们为 MVT2D 选择 alpha 钳位参数 ,为 MVT3D 选择 。 使用 Adam 优化器 [26],使用作者给定的动量参数 和 ,学习率为,权重衰减为。
4.2.4学生
对于学生网络,我们使用 残差卷积块,如 3.2 节中所述。 Leaky-ReLU 激活对负值使用 0.2 的斜率。 我们为残差块选择隐藏通道大小 。 同样,我们从老师那里接管了 epoch 的数量和优化器参数。 如果前景蒙版可用,则按最大距离(如果前景蒙版可用)聚合特征图分辨率下的分数,以便在图像级别进行评估,否则按平均距离(仅限 RGB)。
4.3评估指标
与异常检测一样,我们通过计算接收器操作特性下的面积(AUROC)来评估我们的方法在图像级别的性能。 ROC 根据不同异常分数阈值的假阳性率来测量真阳性率。 因此,它与阈值的选择无关,并且对测试集中的类平衡保持不变。 为了测量像素级异常的分割,我们根据数据集中的真实掩模计算像素级的 AUROC。
| Method | Bagel |
|
Carrot | Cookie | Dowel | Foam | Peach | Potato | Rope | Tire | Mean | |||
| 3D | Voxel GAN [8] | 38.3 | 62.3 | 47.4 | 63.9 | 56.4 | 40.9 | 61.7 | 42.7 | 66.3 | 57.7 | 53.7 | ||
| Voxel AE [8] | 69.3 | 42.5 | 51.5 | 79.0 | 49.4 | 55.8 | 53.7 | 48.4 | 63.9 | 58.3 | 57.1 | |||
| Voxel VM [8] | 75.0 | 74.7 | 61.3 | 73.8 | 82.3 | 69.3 | 67.9 | 65.2 | 60.9 | 69.0 | 69.9 | |||
| Depth GAN [8] | 53.0 | 37.6 | 60.7 | 60.3 | 49.7 | 48.4 | 59.5 | 48.9 | 53.6 | 52.1 | 52.3 | |||
| Depth AE [8] | 46.8 | 73.1 | 49.7 | 67.3 | 53.4 | 41.7 | 48.5 | 54.9 | 56.4 | 54.6 | 54.6 | |||
| Depth VM [8] | 51.0 | 54.2 | 46.9 | 57.6 | 60.9 | 69.9 | 45.0 | 41.9 | 66.8 | 52.0 | 54.6 | |||
| 1-NN (FPFH) [24] | 82.5 | 55.1 | 95.2 | 79.7 | 88.3 | 58.2 | 75.8 | 88.9 | 92.9 | 65.3 | 78.2 | |||
| 3D-ST128 [5]☎ | 86.2 | 48.4 | 83.2 | 89.4 | 84.8 | 66.3 | 76.3 | 68.7 | 95.8 | 48.6 | 74.8 | |||
| AST (ours) | 88.1 2.0 | 57.6 6.9 | 96.5 1.0 | 95.7 0.6 | 67.9 1.1 | 79.7 1.2 | 99.0 0.9 | 91.5 2.1 | 95.6 0.7 | 61.1 3.4 | 83.3 0.8 | |||
| RGB | PatchCore [36] | 87.6 | 88.0 | 79.1 | 68.2 | 91.2 | 70.1 | 69.5 | 61.8 | 84.1 | 70.2 | 77.0 | ||
| DifferNet [38]☎ | 85.9 | 70.3 | 64.3 | 43.5 | 79.7 | 79.0 | 78.7 | 64.3 | 71.5 | 59.0 | 69.6 | |||
| PADiM [12]* | 97.5 | 77.5 | 69.8 | 58.2 | 95.9 | 66.3 | 85.8 | 53.5 | 83.2 | 76.0 | 76.4 | |||
| CS-Flow [39]☎ | 94.1 | 93.0 | 82.7 | 79.5 | 99.0 | 88.6 | 73.1 | 47.1 | 98.6 | 74.5 | 83.0 | |||
| STFPM [51]* | 93.0 | 84.7 | 89.0 | 57.5 | 94.7 | 76.6 | 71.0 | 59.8 | 96.5 | 70.1 | 79.3 | |||
| AST (ours) | 94.7 0.7 | 92.8 1.2 | 85.1 1.2 | 82.5 0.8 | 98.1 0.4 | 95.1 0.6 | 89.5 1.1 | 61.3 2.4 | 99.2 0.2 | 82.1 0.9 | 88.0 0.6 | |||
| 3D + RGB | Voxel GAN [8] | 68.0 | 32.4 | 56.5 | 39.9 | 49.7 | 48.2 | 56.6 | 57.9 | 60.1 | 48.2 | 51.7 | ||
| Voxel AE [8] | 51.0 | 54.0 | 38.4 | 69.3 | 44.6 | 63.2 | 55.0 | 49.4 | 72.1 | 41.3 | 53.8 | |||
| Voxel VM [8] | 55.3 | 77.2 | 48.4 | 70.1 | 75.1 | 57.8 | 48.0 | 46.6 | 68.9 | 61.1 | 60.9 | |||
| Depth GAN [8] | 53.8 | 37.2 | 58.0 | 60.3 | 43.0 | 53.4 | 64.2 | 60.1 | 44.3 | 57.7 | 53.2 | |||
| Depth AE [8] | 64.8 | 50.2 | 65.0 | 48.8 | 80.5 | 52.2 | 71.2 | 52.9 | 54.0 | 55.2 | 59.5 | |||
| Depth VM [8] | 51.3 | 55.1 | 47.7 | 58.1 | 61.7 | 71.6 | 45.0 | 42.1 | 59.8 | 62.3 | 55.5 | |||
| PatchCore+FPFH [24] | 91.8 | 74.8 | 96.7 | 88.3 | 93.2 | 58.2 | 89.6 | 91.2 | 92.1 | 88.6 | 86.5 | |||
| AST (ours) | 98.3 0.4 | 87.3 3.3 | 97.6 0.5 | 97.1 0.3 | 93.22.1 | 88.5 1.4 | 97.4 1.4 | 98.1 1.2 | 100 0.0 | 79.7 1.0 | 93.7 0.2 |
| Method | MVT2D | MVT3D (RGB+3D) |
| AE-SSIM [9] | 87.0 | - |
| PatchCore [36] | 98.4 | - |
| PatchCore+FPFH [24] | - | 99.2 |
| AST (ours) | 95.0 0.03 | 97.6 0.02 |
4.4结果
4.4.1检测
表 2 显示了我们的方法和之前的 MVT2D 15 类异常检测工作的 AUROC 以及纹理、对象和所有类的平均值。 我们在所有类别的平均检测 AUROC 上设置了新的最先进性能,将其略微提高到 99.2%。 这主要是由于在更具挑战性的对象上表现良好,除了 PatchCore [36] 之外,我们的表现比之前的工作高出 0.9%。 CS-Flow [39] 几乎已经解决了纹理异常检测问题,平均 AUROC 为 99.8%,在 99.3% 时仍然非常可靠。 特别是与两种学生-教师方法[7, 51]相比,分别实现了 6% 和 3.6% 的显着改进。 此外,与当前最先进的密度估计器 [22, 39] 的可能性相比,我们的学生-教师距离显示出更好的异常指标,与我们的老师一样,密度估计器基于关于流量正常化。
尽管 MVT2D 过去已成为标准基准,但该数据集(尤其是纹理)对于最近的方法来说很容易解决,并且差异主要在百分之几的范围内,就相对而言,这只是一个微小的差异数据集较小。 接下来,我们将重点关注更新、更具挑战性的 MVT3D 数据集,其中正常数据显示出更多方差,而异常仅部分出现在 RGB 和 3D 两种数据模式之一中。
表 3 中给出了按数据模态分组的 MVT3D 各个类别的结果。 对于所有数据模式,我们能够在所有类别的平均值方面优于之前的所有方法,3D 为 5.1%,RGB 为 5%,组合为 7.2%。 面对各个类和数据域,我们在 30 个案例中的 21 个案例中设置了新的 state-of-the-art。 请注意,在比较之前工作的最佳结果时(MVT2D 为 99.1%,MVT3D 为 86.5% AUROC),该数据集更具挑战性。 尽管如此,我们在 RGB+3D 的 10 个案例中检测到了 7 个缺陷,AUROC 至少为 93%,这证明了我们方法的稳健性。 相比之下,最近邻方法 PatchCore [36] 在 MVT2D 上提供了与我们相当的性能,但它难以满足数据集不断增长的需求,并且在 RGB 上表现优于 11%。 尽管也使用了前景蒙版,但这同样适用于使用 FPFH [40] 的 3D 扩展 [24]。 图 1 显示了给定输入和真实注释的 RGB+3D 情况的定性结果。 更多示例可以在补充材料中找到。 尽管分辨率较低,但出于实际目的,仍然可以很好地定位异常区域。 表 4 报告了我们的方法和之前工作的像素 AUROC。
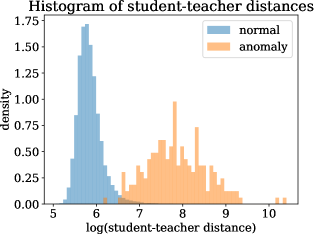
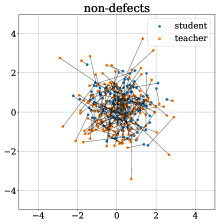
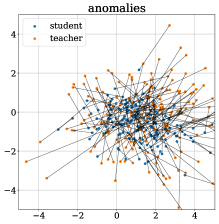
对于 RGB+3D 设置中的桃类,图 5 顶部比较了异常区域和正常区域的学生-教师距离分布。 异常样本的分布显示出明显的向更大距离的转变。 在图 5 的底部,学生和教师的输出以及代表异常分数的相应对的距离通过随机正交 2D 投影进行可视化。 请注意,通过 t-SNE [49] 或 PCA [33] 等技术进行的可视化在这里没有意义,因为教师输出(因此大多数学生输出) )遵循各向同性标准正态分布。 因此,不同的随机预测在质量上几乎没有区别。
4.4.2 消融研究
我们通过多项消融研究证明了我们的贡献和设计决策的有效性。 表5比较了学生和教师变体的表现,它可以用作密度估计器本身,通过使用其可能性来进行异常检测,由等式1给出。 2,作为异常分数。 相比之下,对称的学生-教师对会使结果恶化 1% 到 2%(RGB 情况除外)。 然而,通过将耦合块的数量增加一倍至 8,通过使用比教师更深的学生版本创建不对称性,RGB 和 3D+RGB 的性能已经得到改善。 如果按照我们的建议将 NF 教师的架构替换为传统的前馈网络,这种效果会进一步增强。 我们还改变了学生网络的深度,并在表 6 中分析了其与性能、模型大小和推理时间的关系。 随着残差块 数量的增加,我们观察到性能不断提高,在 4 个块后几乎饱和。 由于检测性能的剩余潜力与每个块线性增加的额外计算量无关,因此我们建议选择 4 个块以进行良好的权衡。
在表7中,我们研究了位置编码和前景掩模的影响。 对于 MVT3D,当使用 3D 数据作为唯一输入进行训练时,位置编码将 AST 对的检测率提高了 1.4%。 尽管在组合两种数据模式时不存在效果,但我们认为使用位置编码通常是合理的,因为仅使用 32 个附加通道进行集成不会显着增加计算量。
为了掩盖训练损失和测试异常分数而进行的前景提取也非常有效。 由于大部分图像区域通常由背景组成,因此教师必须将大部分分布花在背景上。 掩蔽使教师和学生能够专注于基本结构。 此外,噪声背景分数被消除。
| Method | 3D | RGB | 3D+RGB |
| Teacher only | 82.2 | 69.8 | 90.9 |
| NF student (symm.) | 81.8 | 76.0 | 88.9 |
| NF student (deeper) | 81.8 | 76.7 | 92.7 |
| AST (ours) | 83.3 | 88.0 | 93.7 |
| AUROC | #Params. [M] | inf. time [ms] | |
| 1 | 92.8 | 26.0 | 3.4 |
| 2 | 93.3 | 44.8 | 6.1 |
| 4 | 93.7 | 82.6 | 10.4 |
| 8 | 93.7 | 151.1 | 19.8 |
| 12 | 93.8 | 233.6 | 29.4 |
| teacher | 90.9 | 3.8 | 4.5 |
| input | pos. enc. | mask | teacher | AST |
| ✗ | ✓ | 78.4 | 81.9 | |
| 3D | ✓ | ✗ | 59.4 | 67.2 |
| ✓ | ✓ | 82.2 | 83.3 | |
| ✗ | ✗ | 69.3 | 87.8 | |
| RGB | ✓ | ✗ | 69.8 | 88.0 |
| ✓ | ✓ | n. a. | n. a. | |
| ✗ | ✓ | 90.9 | 93.8 | |
| 3D+RGB | ✓ | ✗ | 66.2 | 84.0 |
| ✓ | ✓ | 90.9 | 93.7 |
5结论
我们发现了以前的 AD 学生教师配对的泛化问题,并引入了一种替代的学生-教师方法,通过为学生和教师使用高度不同的架构来防止这个问题。 我们能够通过额外使用学生来补偿标准化基于流程的教师的偏差可能性,该教师在之前的工作中直接用于检测。 未来的工作可以将该方法扩展到更多数据域并提高本地化分辨率。
致谢。
这项工作得到了德国联邦教育和研究部 (BMBF) 项目 LeibnizKILabor 的支持(拨款号:2017)。 01DD20003)、数字创新中心 (ZDIN) 和德国卓越战略下的德国卓越战略集群 PhoenixD (EXC 2122)。
参考
- [1] Samet Akcay, Amir Atapour-Abarghouei, and Toby P. Breckon. Ganomaly: Semi-supervised anomaly detection via adversarial training. In Computer Vision – ACCV 2018, pages 622–637, Cham, 2019. Springer International Publishing.
- [2] Mennatallah Amer and Markus Goldstein. Nearest-neighbor and clustering based anomaly detection algorithms for rapidminer. In Proc. of the 3rd RapidMiner Community Meeting and Conference (RCOMM 2012), pages 1–12, 2012.
- [3] Lynton Ardizzone, Jakob Kruse, Sebastian Wirkert, Daniel Rahner, Eric W Pellegrini, Ralf S Klessen, Lena Maier-Hein, Carsten Rother, and Ullrich Köthe. Analyzing inverse problems with invertible neural networks. In ICLR, 2019.
- [4] Lynton Ardizzone, Carsten Lüth, Jakob Kruse, Carsten Rother, and Ullrich Köthe. Guided image generation with conditional invertible neural networks. arXiv preprint arXiv:1907.02392, 2019.
- [5] Paul Bergmann, Kilian Batzner, Michael Fauser, David Sattlegger, and Carsten Steger. Beyond dents and scratches: Logical constraints in unsupervised anomaly detection and localization. Int. J. Comput. Vis., 130(4):947–969, 2022.
- [6] Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9592–9600, 2019.
- [7] Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4183–4192, 2020.
- [8] Paul Bergmann, Xin Jin, David Sattlegger, and Carsten Steger. The mvtec 3d-ad dataset for unsupervised 3d anomaly detection and localization. 17th International Conference on Computer Vision Theory and Applications, 2022.
- [9] Paul Bergmann, Sindy Löwe, Michael Fauser, David Sattlegger, and C. Steger. Improving unsupervised defect segmentation by applying structural similarity to autoencoders. In VISIGRAPP, 2019.
- [10] Markus M Breunig, Hans-Peter Kriegel, Raymond T Ng, and Jörg Sander. Lof: identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD international conference on Management of data, pages 93–104, 2000.
- [11] Haoqing Cheng, Heng Liu, Fei Gao, and Zhuo Chen. Adgan: A scalable gan-based architecture for image anomaly detection. In 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), volume 1, pages 987–993. IEEE, 2020.
- [12] Thomas Defard, Aleksandr Setkov, Angelique Loesch, and Romaric Audigier. Padim: a patch distribution modeling framework for anomaly detection and localization. In pattern Recognition, ICPR International Workshops and Challenges, 2021.
- [13] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- [14] Madson LD Dias, César Lincoln C Mattos, Ticiana LC da Silva, José Antônio F de Macedo, and Wellington CP Silva. Anomaly detection in trajectory data with normalizing flows. arXiv preprint arXiv:2004.05958, 2020.
- [15] Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using real nvp. ICLR 2017, 2016.
- [16] Alexander Dockhorn, Christian Braune, and Rudolf Kruse. An alternating optimization approach based on hierarchical adaptations of dbscan. In 2015 IEEE Symposium Series on Computational Intelligence (SSCI), number 2, pages 749–755, 2015.
- [17] Alexander Dockhorn, Christian Braune, and Rudolf Kruse. Variable density based clustering. In 2016 IEEE Symposium Series on Computational Intelligence (SSCI), pages 1–8, Dec. 2016.
- [18] Ye Fei, Chaoqin Huang, Cao Jinkun, Maosen Li, Ya Zhang, and Cewu Lu. Attribute restoration framework for anomaly detection. IEEE Transactions on Multimedia, 2020.
- [19] Mariana-Iuliana Georgescu, Antonio Barbalau, Radu Tudor Ionescu, Fahad Shahbaz Khan, Marius Popescu, and Mubarak Shah. Anomaly detection in video via self-supervised and multi-task learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12742–12752, 2021.
- [20] Dong Gong, Lingqiao Liu, Vuong Le, Budhaditya Saha, Moussa Reda Mansour, Svetha Venkatesh, and Anton van den Hengel. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. In Proceedings of the IEEE International Conference on Computer Vision, pages 1705–1714, 2019.
- [21] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014.
- [22] Denis Gudovskiy, Shun Ishizaka, and Kazuki Kozuka. Cflow-ad: Real-time unsupervised anomaly detection with localization via conditional normalizing flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 98–107, 2022.
- [23] Geoffrey Hinton, Oriol Vinyals, Jeff Dean, et al. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2(7), 2015.
- [24] Eliahu Horwitz and Yedid Hoshen. An empirical investigation of 3d anomaly detection and segmentation. arXiv preprint arXiv:2203.05550, 2022.
- [25] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, pages 448–456. PMLR, 2015.
- [26] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR), 2015.
- [27] Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. CoRR, abs/1312.6114, 2013.
- [28] Charline Le Lan and Laurent Dinh. Perfect density models cannot guarantee anomaly detection. Entropy, 23(12):1690, 2021.
- [29] Chun-Liang Li, Kihyuk Sohn, Jinsung Yoon, and Tomas Pfister. Cutpaste: Self-supervised learning for anomaly detection and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9664–9674, 2021.
- [30] Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. Isolation forest. In 2008 eighth ieee international conference on data mining, pages 413–422. IEEE, 2008.
- [31] Seyed Iman Mirzadeh, Mehrdad Farajtabar, Ang Li, Nir Levine, Akihiro Matsukawa, and Hassan Ghasemzadeh. Improved knowledge distillation via teacher assistant. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 5191–5198, 2020.
- [32] Tiago Nazare, Rodrigo de Mello, and Moacir Ponti. Are pre-trained cnns good feature extractors for anomaly detection in surveillance videos? arXiv preprint arXiv:1811.08495, 2018.
- [33] Karl Pearson. Liii. on lines and planes of closest fit to systems of points in space. The London, Edinburgh, and Dublin philosophical magazine and journal of science, 2(11):559–572, 1901.
- [34] Danilo Rezende and Shakir Mohamed. Variational inference with normalizing flows. In International Conference on Machine Learning, pages 1530–1538. PMLR, 2015.
- [35] Oliver Rippel, Patrick Mertens, and Dorit Merhof. Modeling the distribution of normal data in pre-trained deep features for anomaly detection. arXiv preprint arXiv:2005.14140, 2020.
- [36] Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, and Peter Gehler. Towards total recall in industrial anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14318–14328, 2022.
- [37] Marco Rudolph, Bastian Wandt, and Bodo Rosenhahn. Structuring autoencoders. In Proceedings of the IEEE International Conference on Computer Vision Workshops, 2019.
- [38] Marco Rudolph, Bastian Wandt, and Bodo Rosenhahn. Same same but differnet: Semi-supervised defect detection with normalizing flows. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1907–1916, 2021.
- [39] Marco Rudolph, Tom Wehrbein, Bodo Rosenhahn, and Bastian Wandt. Fully convolutional cross-scale-flows for image-based defect detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1088–1097, 2022.
- [40] Radu Bogdan Rusu, Nico Blodow, and Michael Beetz. Fast point feature histograms (fpfh) for 3d registration. In 2009 IEEE international conference on robotics and automation, pages 3212–3217. IEEE, 2009.
- [41] Artem Ryzhikov, Maxim Borisyak, Andrey Ustyuzhanin, and Denis Derkach. Normalizing flows for deep anomaly detection. arXiv preprint arXiv:1912.09323, 2019.
- [42] Thomas Schlegl, Philipp Seeböck, Sebastian M Waldstein, Georg Langs, and Ursula Schmidt-Erfurth. f-anogan: Fast unsupervised anomaly detection with generative adversarial networks. Medical image analysis, 54:30–44, 2019.
- [43] Hannah M Schlüter, Jeremy Tan, Benjamin Hou, and Bernhard Kainz. Self-supervised out-of-distribution detection and localization with natural synthetic anomalies (nsa). arXiv preprint arXiv:2109.15222, 2021.
- [44] Maximilian Schmidt and Marko Simic. Normalizing flows for novelty detection in industrial time series data. arXiv preprint arXiv:1906.06904, 2019.
- [45] Bernhard Schölkopf, Robert C Williamson, Alex Smola, John Shawe-Taylor, and John Platt. Support vector method for novelty detection. Advances in neural information processing systems, 12, 1999.
- [46] Jouwon Song, Kyeongbo Kong, Ye-In Park, Seong-Gyun Kim, and Suk-Ju Kang. Anoseg: Anomaly segmentation network using self-supervised learning. arXiv preprint arXiv:2110.03396, 2021.
- [47] Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning, pages 6105–6114. PMLR, 2019.
- [48] Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive representation distillation. arXiv preprint arXiv:1910.10699, 2019.
- [49] Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of machine learning research, 9(11), 2008.
- [50] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [51] Guodong Wang, Shumin Han, Errui Ding, and Di Huang. Student-teacher feature pyramid matching for anomaly detection. arXiv preprint arXiv:2103.04257, 2021.
- [52] Tom Wehrbein, Marco Rudolph, Bodo Rosenhahn, and Bastian Wandt. Probabilistic monocular 3d human pose estimation with normalizing flows. Proceedings of the IEEE International Conference on Computer Vision, 2021.
- [53] Qinfeng Xiao, Jing Wang, Youfang Lin, Wenbo Gongsa, Ganghui Hu, Menggang Li, and Fang Wang. Unsupervised anomaly detection with distillated teacher-student network ensemble. Entropy, 23(2):201, 2021.
- [54] Vitjan Zavrtanik, Matej Kristan, and Danijel Skočaj. Draem-a discriminatively trained reconstruction embedding for surface anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8330–8339, 2021.
- [55] Shuangfei Zhai, Yu Cheng, Weining Lu, and Zhongfei Zhang. Deep structured energy based models for anomaly detection. In Proceedings of the 33rd International Conference on International Conference on Machine Learning-Volume 48, pages 1100–1109, 2016.
- [56] Kai Zhang, Wangmeng Zuo, and Lei Zhang. Ffdnet: Toward a fast and flexible solution for cnn-based image denoising. IEEE Transactions on Image Processing, 27(9):4608–4622, 2018.
- [57] Chong Zhou and Randy C Paffenroth. Anomaly detection with robust deep autoencoders. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pages 665–674, 2017.