以色列耶路撒冷希伯来大学
%First␣names␣are␣abbreviated␣在␣the␣running␣head.%如果␣有␣有␣超过␣两个␣作者,␣'et␣al.'␣is␣used.http://www.vision.huji.ac.il/ssrl_ad /
异常检测需要更好的表示
摘要
异常检测旨在识别异常现象,这是科学和工业的核心任务。 该任务本质上是无人监督的,因为训练过程中出现意外且未知的异常情况。 自监督表示学习的最新进展直接推动了异常检测的改进。 在这篇立场文件中,我们首先解释如何轻松地使用自监督表示在常见报告的异常检测基准中实现最先进的性能。 然后我们认为,解决下一代异常检测任务需要表示学习方面的新技术和概念改进。
关键词:
异常检测、自监督学习、表示学习1简介
发现始于对异常的认识,即认识到自然在某种程度上违反了规范正常科学的范式引发的期望。
————库恩,《科学革命的结构》(1970)
我不知道我在这个世界上会是什么样子,但对我自己来说,我似乎只是一个在海边玩耍的男孩,时不时地寻找比平常更光滑的卵石或更漂亮的贝壳,而伟大的一切未被发现的真理之海就摆在我面前。
- -艾萨克·牛顿
异常检测,即发现数据中的异常模式,是人类和机器智能的核心任务。 这项任务的重要性源于发现科学和工业中独特或不寻常现象的中心地位。 例如,粒子物理学和宇宙学领域在很大程度上是由新的基本粒子和恒星物体的发现所推动的。 同样,新的、未知的生物有机体和系统的发现是生物学背后的驱动力。 这项任务还具有巨大的经济潜力。 异常检测方法用于检测信用卡欺诈、生产线故障以及网络通信中的异常模式。
检测异常基本上是无人监督的,因为在训练过程中只看到“正常”数据,但看不到异常。 虽然该领域已经进行了数十年的深入研究,但最近最成功的方法使用非常简单的两阶段范式:(i)每个数据点都转换为表示,通常以自我监督的方式学习。 (ii) 密度估计模型,通常与 最近邻估计器一样简单,适合训练集中提供的正常数据。 为了将新样本分类为正常或异常,需要计算其估计概率密度 - 低似然样本被表示为异常。
在这篇立场文件中,我们首先解释表示学习的进步是最近异常检测(AD)算法性能的主要解释因素。 我们表明,这种范例本质上“解决”了最常报告的图像异常检测基准(第 4 节)。 虽然这令人鼓舞,但我们认为现有的自我监督表示无法解决下一代 AD 任务(第 5 节)。 我们特别强调以下问题:(i) 掩码自动编码器对于 AD 的效果比早期的自监督表示学习 (SSRL) 方法要差得多 (ii) 当前的方法在每个图像有多个对象、复杂背景的数据集中表现不佳,细粒度的异常。 (iii) 在某些情况下,SSRL 的表现比手工制作的表示更差 (iv) 对于“表格”数据集,没有任何表示的表现比数据的原始表示(即数据本身)更好 (v) 在存在变化的干扰因素的情况下,目前尚不清楚 SSRL 是否可以原则上识别有效 AD 的最佳表示。
异常检测既为表示学习带来了丰富的回报,也带来了重大挑战。 克服这些问题需要技术和概念方面的重大进展。 我们期望增加自监督表示学习社区在异常检测中的参与将使这两个领域互惠互利。
2相关工作
经典 AD 方法通常基于密度估计 [9, 20] 或重建 [15]。 随着深度学习的出现,经典方法得到了深度表示的增强[23,38,19,24]。 学习这些表示的一种流行方法是使用自我监督方法,例如自动编码器 [30]、旋转分类 [10, 13] 和对比方法 [36, 35]。 另一种方法是将预训练表示与异常评分函数[25,32,27,28]结合起来。 性能最佳的方法[27, 28]结合了辅助数据集上的预训练和训练集中提供的正常样本的第二个微调阶段。 最近建立的[27]给出了足够强大的表示(例如ImageNet分类),基于NN与正常训练数据的距离的简单标准实现了强大的性能。 因此,我们将本文中对 AD 的讨论限制在这种简单的技术上。
3 异常检测作为表示学习的下游任务
在本节中,我们描述异常检测的计算任务、方法和评估设置。
任务定义。 我们假设从正态数据的分布中访问个随机样本,用表示。 在测试时,算法观察来自真实世界分布 的样本 ,该分布由正常和异常数据分布的组合组成:和。 任务是将样本分类为正常或异常。
用于异常检测的表示。 在AD中,通常假设异常在正态数据分布下的可能性较低,即很小。 在此假设下,正常数据的PDF充当有效的异常分类器。 然而,在实践中,使用 训练估计器 来对异常进行评分是一项具有挑战性的统计任务。 当出现以下情况时,挑战会更大:(i)数据是高维的(例如图像)(ii)稀疏或不规则(iii)正常数据和异常数据无法使用简单函数分离。 表示学习可以通过将样本 转换为表示 来克服这些问题,表示 具有较低的维度,其中 相对平滑,正常和异常数据更加可分离。 由于没有提供异常标签,因此需要自监督表示学习。
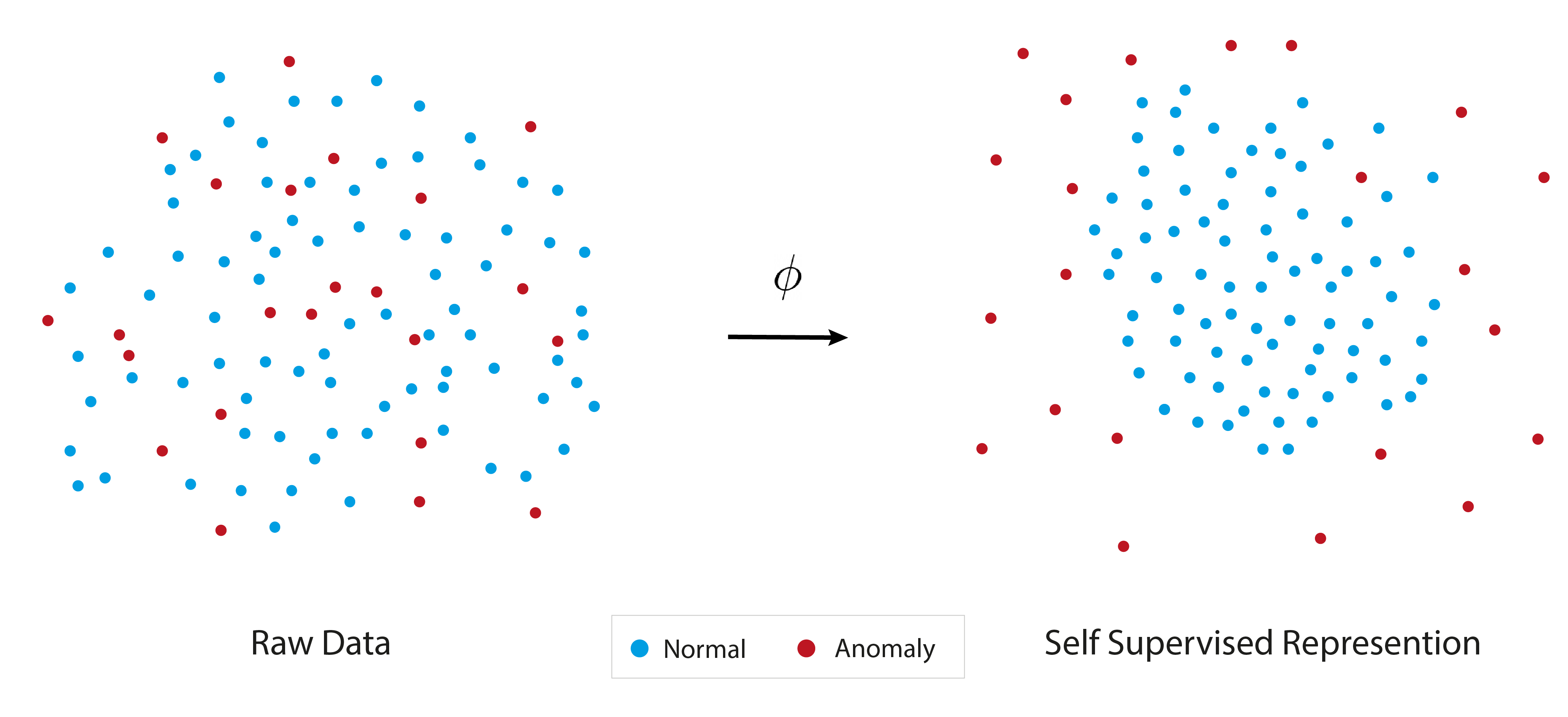
两阶段异常检测范例。 给定一个自监督表示,我们遵循一个简单的两阶段异常检测范例:(i)表示编码器:训练或测试期间的每个样本都使用映射到特征描述符映射函数。 (ii)密度估计:将概率估计器拟合到正态样本特征的分布。 在测试时对样本进行评分,首先将其映射到表示空间 并根据密度估计器对其进行评分。 给定正常概率密度的估计器,异常得分由给出。 正常数据通常会比异常样本获得较低的分数。 然后,用户可以根据适当的误报率设置用于异常预测的阈值。
4 成功的表示学习可实现异常检测
检测图像中的异常可能是深度学习异常检测社区研究最多的任务。 在本节中,我们将展示第 2 节中提出的简单范例。 3 取得了最先进的结果。 由于大多数密度估计器获得非常相似的结果,异常检测性能主要取决于学习表示的质量。 这使得异常检测成为表征的绝佳测试场。 此外,我们讨论了微调正常训练数据表示的不同方法,并显示出显着的收益。
从正常数据中学习表示。 也许最近 AD 方法采用的最常见方法是仅使用正常样本(即训练数据集)以自我监督的方式学习表示。 此类方法的示例有 RotNet [13]、CSI [36] 等。 这种方法的主要缺点是大多数数据集都很小,因此不足以学习强大的表示。
从预训练模型中提取表示。 一个非常简单的替代方案是使用现成的预训练模型并从中提取正常(即训练)数据的特征。 预训练可以是监督的(例如使用 ImageNet 标签 [8, 12])或自我监督的(例如 DINO),在这两种情况下预训练都可以在 ImageNet 上执行。 这些表示往往比从仅在正常数据上训练的模型中提取的表示表现得更好。
混合方法。 上述方法的自然扩展是将两者结合起来。 这是通过使用预训练模型作为自监督微调阶段(在正常数据上)的初始化来完成的。 通过这种方式,可以在异常检测数据集和任务的上下文中使用和细化预训练模型的强大表示。 多种方法[27, 28]已用于自监督微调阶段。 然而,在本文中,我们提出了可能是最简单的方法,使用 DINO 的目标进行微调阶段。 在这种方法中,使用预训练的 DINO 模型作为初始化。 在微调阶段,仅使用原始 DINO 目标,以自我监督的方式对目标异常检测训练数据集(即仅正常数据)对模型进行训练。
在图1中,通过一个玩具示例演示了上述过程。 标签。 1 展示了 CIFAR-10 [18] 数据集上的异常检测结果,该数据集是最常用的评估数据集。 可以看出,使用从最近的自监督方法(即 DINO)中提取的表示,遵循混合方法,并与密度估计阶段的简单 NN 估计器相结合,几乎可以解决该数据集。 尽管可能的结论是异常检测任务已经解决,但在下一节中我们将表明情况并非如此。
| Image | Nearest Neighbors | |||||
|
MAE |
 |
 |
 |
 |
 |
 |
|
DINO |
|
|
|
|
|
|
|
MAE |
 |
 |
 |
 |
 |
 |
|
DINO |
|
|
|
|
|
|
| Approach | Self-supervised | Pretrained | Hybrid | ||||
| Method | RotNet [13] | CSI [36] | ResNet | DINO | PANDA [27] | MSAD [28] | DINO-FT |
| CIFAR-10 | 90.1 | 94.3 | 92.5 | 97.1 | 96.2 | 97.2 | 98.4 |
5 异常检测中的差距指向表示学习中的瓶颈
虽然秒。 4对表示学习解决异常检测的能力提出了非常乐观的看法,在本节中我们描绘了一幅更复杂的图景。 我们用它来强调当前自我监督表示的几个局限性。
5.1 Masked-Autoencoder:自监督学习的进步并不总是意味着更好的异常检测
最近,基于掩码自动编码器 (MAE) 的方法在几个自监督表示学习基准上取得了显着改进[11]。 然而,MAE 学习到的表示在异常检测等无监督任务上的表现不如对比自监督方法。 表 1 给出了 MAE 与对比自监督方法 (DINO) 之间的比较。 2 展示了 DINO 在 AD 方面的更好性能。 对正常训练数据的微调改进了这两种方法,但仍然存在很大差距。 实验的实施细节可以在应用程序中找到。 0.A。 在许多论文中,使用监督基准来评估自监督方法,例如带有微调的分类精度。 异常检测与普通基准测试之间的主要区别在于,MAE 的优势在于异常检测是一项无监督任务。 MAE 在线性探测方面的较差性能(如原始论文所述)也表明了这一点,其中监督标签不能用于改进主干表示。
MAE 的优化目标可以解释为什么它的强表征不能转化为更好的异常检测能力。 由于 MAE 的目标是重建补丁,因此它可以学习一种对重建图像所需的本地信息进行编码的表示,而忽略语义对象属性。 因此,最近邻可能更关注局部相似性而不是全局语义属性(见图2)。 相反,基于对比的目标的目标是将语义相似的图像映射到附近的表示,而忽略一些局部属性。
结论。 在受监督的下游任务上更好的表现并不一定意味着更好的全面代表性。 在某些情况下,虽然表示可能在有监督的下游任务中表现出色,但在无监督的对应任务中可能表现不佳。 展望未来,我们建议新的自监督表示学习方法可以对无监督异常检测任务以及常见的监督基准进行评估。
| Method | CIFAR-10 | CUB-200 | INet-S |
| MAE | 78.1 | 73.1 | 83.2 |
| DINO | 97.1 | 93.9 | 99.3 |
5.2 复杂数据集:当前的表示在场景、细粒度类、多个对象上遇到困难
当前的表示对于单个对象占据图像大部分的数据集的异常检测非常有效。 此外,当正常训练集中的对象类别数量较小且差异较大(例如“猫”和“船”)时,这些方法通常表现良好。 一个典型的例子是 CIFAR-10,它实际上已得到解决。 另一方面,在包含多个小物体、复杂背景的更复杂数据集上,异常检测精度要低得多;当异常由相关对象类别组成时(例如“沙发”和“扶手椅”)。 我们修改了 MS-COCO [21] 数据集,使用来自单个超级类别(“车辆”)的所有图像作为普通数据,除了用作普通数据的单个类别(“自行车”)之外异常。 我们尝试仅裁剪对象边界框或使用整个图像(包括背景和其他对象)。 同样,我们报告了多模式 CUB-200 [37] 异常检测基准的结果。 结果显示在表中。 3(实现细节可以在附录中找到)。 显然,这些数据集远未得到解决,需要更好的表示才能实现可接受的性能。
结论。 虽然当前的表示对于相对简单的数据集是有效的,但具有小对象、背景和许多对象类别的更现实的情况需要开发新的 SSRL 方法。
| Method | MS-COCO-I | MS-COCO-O | CUB-200 |
| PANDA [27] | 61.5 | 77.0 | 78.4 |
| MSAD [28] | 61.7 | 76.9 | 80.1 |
| DINO | 61.5 | 73.4 | 74.5 |
5.3 不可识别性:如果没有进一步的指导,异常检测的表示可能不明确
在某些设置中,我们希望我们的表示集中于特定属性(我们将其表示为相关),同时忽略可能使模型产生偏差的干扰属性。 考虑两家对汽车异常检测感兴趣的不同公司。 第一家公司可能对检测新颖的汽车模型感兴趣,而第二家公司可能对不寻常的驾驶行为感兴趣。 尽管双方都可能希望使用最先进的自我监督表示来应用密度估计,但双方都会将另一家公司的真实异常情况视为误报案例。 由于每个公司对不同的异常感兴趣,因此他们可能需要不同的表示。 一家公司会要求表示仅包含驾驶模式并且与汽车型号无关,而另一家公司则力求相反。 由于这些偏好在预训练自监督骨干网络时并不存在,因此正确的解决方案通常是无法识别的。
RedPANDA [6] 是一项初步工作,建议为有害属性提供标签。 我们注意到,仅标记了要忽略的属性,而未提供其他属性(表征异常的属性)。 然后使用域监督解缠[16]执行表示学习,从而产生仅描述未标记属性的表示。 然而,领域监督解缠领域仍处于起步阶段,有害属性标签的假设通常不适用。
结论。 自监督表示学习方法旨在关注图像的语义属性,但如果没有进一步的指导,则无法识别最相关的属性。 纳入指导可以通过仔细选择归纳偏差[16](例如增强)或使用基于概念的表示技术[17]来实现。
| Modality | RGB | Depth | Depth | Depth | Depth | Depth | PC | RGB+PC |
| Method | INet | INet | NSA [33] | Raw | HoG [7] | SIFT [22] | FPFH [31] | RGB+FPFH |
| PRO [2] | 87.6 | 58.6 | 57.2 | 19.1 | 61.4 | 86.6 | 92.4 | 96.4 |
| I-ROC | 78.5 | 63.7 | 69.6 | 52.8 | 56.0 | 71.4 | 75.3 | 86.5 |
| P-ROC | 96.6 | 82.1 | 81.7 | 54.8 | 84.5 | 95.4 | 98.0 | 99.3 |
5.4 3D 点云:自监督表示并不总是比手工制作的表示有所改进
在一项实证研究[14]中,我们评估了 MVTec3D-AD 数据集[3]上为不同模式设计的代表性方法。 该论文表明,目前,用于 3D 表面匹配的手工特征优于为图像或 3D 点云设计的基于学习的方法。 一个关键的见解是,旋转不变性在这种模式中非常有益,但经常被忽视。 取自原始论文的研究结果摘要见表 1。 4.
结论。 在处理 3D 点云时,自监督表示在异常检测方面的性能尚未优于手工制作的特征。 对于不如图像成熟的模式,可能仍需要将特定领域的先验集成到架构或目标中。 这强调了对更好的 3D 点云表示的需求。
5.5 表格数据:当表示没有比原始数据有所改进时
表格设置可能是最常见的异常检测设置,其中数据集中的每个样本都包含一组数值和分类变量。 这比任何其他设置都严格困难,因为无法假设数据的规律性。 此类数据经常遇到,因为非结构化数据库非常常见。 近年来,人们提出了用于表格异常检测的自监督方法[39,1,34,26]。 这些方法的不同之处在于它们用于表示学习(也可能用于异常评分)的辅助任务。 两种代表性的深度学习方法是预测几何变换并使用预测误差来检测异常的 GOAD [1] 和采用对比学习任务的 ICL [34]通过区分窗口内和窗口外特征进行训练和异常评分。 作为我们评估的一部分,我们使用了他们的标准流程(即异常评分的辅助任务)和我们的 AD 密度估计范例(参见附录)。 然后将这些结果与未经任何修改的原始原始特征上的 NN 进行比较。 结果显示在表中。 5. 与原始特征相比,自监督表示学习并没有提高性能。
结论。 通用数据集的表示学习是一个开放的研究问题。 必须使用数据集的一些先验知识才能学习重要的数据表示,至少在异常检测的情况下是这样。
| Method | GOAD [1] | ICL [34] | Raw | ||
| Scoring | Auxiliary | kNN | Auxiliary | kNN | kNN |
| F1 | 54.4 | 63.2 | 68.1 | 69.8 | 69.9 |
| ROC-AUC | 78.2 | 87.6 | 88.9 | 89.4 | 90.2 |
6 最后评论
在这篇立场文件中,我们提倡研究异常检测任务的自监督表示。 我们解释说,表示学习的进步是异常检测进步的主要驱动力。 另一方面,我们证明了当前的自监督表示学习方法在具有挑战性的异常检测设置中常常达不到要求。 我们希望自监督表示学习和异常检测领域之间的相互作用将为两个社区带来互惠互利。
7致谢
这项工作得到了 Malvina 和 Solomon Pollack 奖学金、Facebook 奖、以色列网络理事会、以色列高级委员会和以色列科学基金会的部分支持。 我们还感谢 Oracle 研究计划提供的 Oracle 云积分和相关资源的支持。
附录0.A附录
在本文中,我们使用标准单模协议报告异常检测结果,该协议在异常检测社区中广泛使用。 在单模态协议中,通过将一个类设置为正常并将所有其他类设置为异常,将多类数据集转换为异常检测。 对所有类重复该过程,将具有 类的数据集转换为 数据集。 最后,我们报告所有 数据集的平均 ROC-AUC % 作为异常检测结果。
0.A.1 MAE和DINO异常检测对比
我们比较 DINO [5] 和 MAE [11] 作为基于 NN 的异常检测算法的表示。 对于 MAE,我们对异常评分的NN 和重建误差进行了实验,发现后者效果不佳,因此我们仅报告 NN 结果。 我们在上述单模态设置中使用各种数据集进行评估。 我们使用了以下数据集:
INet-S [29]:数据集是取自 ImageNet21k 的 10 个动物类别的子集(例如“海燕”、“霸王龙”、“鼠蛇”、“鸭子”) 、“蜂蝇”、“羊”、“啤酒幼崽”、“红鹿”、“银背”、“负鼠”)未出现在 ImageNet1K 数据集中。 该数据集是粗粒度的,包含与 ImageNet1K 数据集相对接近的图像。 它旨在传达这样的信息:即使对于简单的任务,MAE 也无法取得与 DINO 一样好的结果。
CIFAR-10 [18]:由来自 10 个不同类别的低分辨率 图像组成。
CUB-200 [37]:鸟类图像数据集,包含 200 个子类别的 11,788 张图像。 在实验中,我们计算了前 20 个类别的平均 ROC-AUC %。
0.A.2 多模态数据集
在这些实验中,我们将单个类别指定为异常,并将所有不包含该类别的图像视为正常。
MS-COCO-I [21]:我们构建了一个由场景基准组成的多模态异常检测数据集,其中每个图像都根据具有相似场景的其他图像进行评估。 我们选择 10 个对象类别(“自行车”、“交通灯”、“鸟”、“背包”、“飞盘”、“瓶子”、“香蕉”、“椅子”、“电视”、“微波炉”、“书”) )来自不同的 MS-COCO 超级类别。 为了构建多模态异常检测基准,我们从列表中指定一个对象类别作为异常类,并将不包含它的类似超类别的训练图像作为我们的正常训练集。 我们的测试集包含该超类别的所有测试图像,其中包含异常对象的图像被标记为异常。 对 10 个对象类别重复此过程,从而产生 10 种不同的评估。 我们报告他们的平均 ROC-AUC %。
MS-COCO-O:我们引入了与 MS-COCO-I 类似的基准,重点关注单个对象而不是场景。 我们根据 MS-COCO 提供的边界框从 10 个超级类别(如上所述)中裁剪所有对象。 我们重复类似的过程,使用类似的对象类别作为正常对象,其余的作为异常对象。
CUB-200 [37]:我们基于 CUB-200 数据集创建了多模态异常检测基准。 我们重点关注前 20 个类别,每次仅指定一个为异常。
0.A.3 表格域
用于表格数据异常检测的各种数据集用于实验。 来自异常值检测数据集 (ODDS)111http://odds.cs.stonybrook.edu/ 已就业。 为了评估 GOAD 和 ICL,我们使用了官方存储库,并努力选择可用的最佳配置。 对于所有密度估计评估,我们使用 NN 和 最近邻。 为了将 GOAD 和 ICL 转换为表示学习的标准范式,然后进行密度估计: i) 我们使用原始方法来训练特征编码器(后面是我们丢弃的分类器) ii) 我们使用特征编码器来表示每个样本 iii )密度估计是使用 NN 对表示进行的,与第 2 节中完全相同。 3。
参考
- [1] Bergman, L., Hoshen, Y.: Classification-based anomaly detection for general data. In: ICLR (2020)
- [2] Bergmann, P., Fauser, M., Sattlegger, D., Steger, C.: Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9592–9600 (2019)
- [3] Bergmann, P., Jin, X., Sattlegger, D., Steger, C.: The mvtec 3d-ad dataset for unsupervised 3d anomaly detection and localization. arXiv preprint arXiv:2112.09045 (2021)
- [4] Bradley, A.P.: The use of the area under the roc curve in the evaluation of machine learning algorithms. Pattern recognition 30(7), 1145–1159 (1997)
- [5] Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9650–9660 (2021)
- [6] Cohen, N., Kahana, J., Hoshen, Y.: Red panda: Disambiguating anomaly detection by removing nuisance factors. arXiv preprint arXiv:2207.03478 (2022)
- [7] Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In: 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05). vol. 1, pp. 886–893. Ieee (2005)
- [8] Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
- [9] Eskin, E., Arnold, A., Prerau, M., Portnoy, L., Stolfo, S.: A geometric framework for unsupervised anomaly detection. In: Applications of data mining in computer security, pp. 77–101. Springer (2002)
- [10] Golan, I., El-Yaniv, R.: Deep anomaly detection using geometric transformations. In: NeurIPS (2018)
- [11] He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16000–16009 (2022)
- [12] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
- [13] Hendrycks, D., Mazeika, M., Kadavath, S., Song, D.: Using self-supervised learning can improve model robustness and uncertainty. In: NeurIPS (2019)
- [14] Horwitz, E., Hoshen, Y.: An empirical investigation of 3d anomaly detection and segmentation (2022)
- [15] Jolliffe, I.: Principal component analysis. Springer (2011)
- [16] Kahana, J., Hoshen, Y.: A contrastive objective for learning disentangled representations. arXiv preprint arXiv:2203.11284 (2022)
- [17] Koh, P.W., Nguyen, T., Tang, Y.S., Mussmann, S., Pierson, E., Kim, B., Liang, P.: Concept bottleneck models. In: International Conference on Machine Learning. pp. 5338–5348. PMLR (2020)
- [18] Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
- [19] Larsson, G., Maire, M., Shakhnarovich, G.: Learning representations for automatic colorization. In: ECCV (2016)
- [20] Latecki, L.J., Lazarevic, A., Pokrajac, D.: Outlier detection with kernel density functions. In: International Workshop on Machine Learning and Data Mining in Pattern Recognition. pp. 61–75. Springer (2007)
- [21] Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
- [22] Lowe, D.G.: Distinctive image features from scale-invariant keypoints. International journal of computer vision 60(2), 91–110 (2004)
- [23] Mathieu, M., Couprie, C., LeCun, Y.: Deep multi-scale video prediction beyond mean square error. ICLR (2016)
- [24] Noroozi, M., Favaro, P.: Unsupervised learning of visual representations by solving jigsaw puzzles. In: ECCV (2016)
- [25] Perera, P., Patel, V.M.: Learning deep features for one-class classification. IEEE Transactions on Image Processing 28(11), 5450–5463 (2019)
- [26] Qiu, C., Pfrommer, T., Kloft, M., Mandt, S., Rudolph, M.: Neural transformation learning for deep anomaly detection beyond images. In: International Conference on Machine Learning. pp. 8703–8714. PMLR (2021)
- [27] Reiss, T., Cohen, N., Bergman, L., Hoshen, Y.: Panda: Adapting pretrained features for anomaly detection and segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2806–2814 (2021)
- [28] Reiss, T., Hoshen, Y.: Mean-shifted contrastive loss for anomaly detection. arXiv preprint arXiv:2106.03844 (2021)
- [29] Ridnik, T., Ben-Baruch, E., Noy, A., Zelnik-Manor, L.: Imagenet-21k pretraining for the masses (2021)
- [30] Ruff, L., Gornitz, N., Deecke, L., Siddiqui, S.A., Vandermeulen, R., Binder, A., Müller, E., Kloft, M.: Deep one-class classification. In: ICML (2018)
- [31] Rusu, R.B., Blodow, N., Beetz, M.: Fast point feature histograms (fpfh) for 3d registration. In: 2009 IEEE International Conference on Robotics and Automation. pp. 3212–3217 (2009)
- [32] Salehi, M., Sadjadi, N., Baselizadeh, S., Rohban, M.H., Rabiee, H.R.: Multiresolution knowledge distillation for anomaly detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14902–14912 (2021)
- [33] Schlüter, H.M., Tan, J., Hou, B., Kainz, B.: Self-supervised out-of-distribution detection and localization with natural synthetic anomalies (nsa). arXiv preprint arXiv:2109.15222 (2021)
- [34] Shenkar, T., Wolf, L.: Anomaly detection for tabular data with internal contrastive learning. In: International Conference on Learning Representations (2021)
- [35] Sohn, K., Li, C.L., Yoon, J., Jin, M., Pfister, T.: Learning and evaluating representations for deep one-class classification. arXiv preprint arXiv:2011.02578 (2020)
- [36] Tack, J., Mo, S., Jeong, J., Shin, J.: Csi: Novelty detection via contrastive learning on distributionally shifted instances. NeurIPS (2020)
- [37] Welinder, P., Branson, S., Mita, T., Wah, C., Schroff, F., Belongie, S., Perona, P.: Caltech-ucsd birds 200 (2010)
- [38] Zhang, R., Isola, P., Efros, A.A.: Colorful image colorization. In: ECCV (2016)
- [39] Zong, B., Song, Q., Min, M.R., Cheng, W., Lumezanu, C., Cho, D., Chen, H.: Deep autoencoding gaussian mixture model for unsupervised anomaly detection. In: International conference on learning representations (2018)