联合集群的机器遗忘
摘要
联合集群(FC)是一个无监督学习问题,出现在许多实际应用中,包括个性化推荐和医疗保健系统。 随着最近确保“被遗忘权”的法律的通过,FC方法的机器遗忘问题变得非常重要。 我们首次引入了 FC 的机器遗忘问题,并为定制的安全 FC 框架提出了一种有效的遗忘机制。 我们的 FC 框架利用了特殊的初始化过程,我们证明这些过程非常适合遗忘。 为了保护客户端数据隐私,我们开发了安全压缩多集聚合(SCMA)框架,该框架可以解决集群过程中遇到的稀疏安全联邦学习(FL)问题以及更常见的问题。 为了同时促进低通信复杂性和秘密共享协议,我们将具有特殊评估点的 Reed-Solomon 编码集成到我们的 SCMA 管道中,并证明客户端通信成本在向量维度上是对数。 此外,为了证明我们的忘却机制相对于完全再训练的优势,我们为我们的方法的忘却性能提供了理论分析。 仿真结果表明,当集群大小高度不平衡时,与之前报道的 FC 基线相比,新的 FC 框架表现出优异的集群性能。 与针对每个删除请求在本地和全局完全重新训练 -means++ 相比,我们的取消学习过程在七个数据集上提供了大约 x 的平均加速。 我们对所提出方法的实现可在 https://github.com/thupchnsky/mufc 上找到。
1简介
大量用户训练数据的可用性有助于现代机器学习模型的成功。 例如,大多数最先进的计算机视觉模型都是在大规模图像数据集上进行训练的,包括 Flickr (Thomee 等人,2016) 和 ImageNet (Deng 等人,2009) 。 收集和存储用户数据的组织和存储库必须遵守隐私法规,例如最近的欧盟通用数据保护条例(GDPR)、加州消费者隐私法案(CCPA)和加拿大消费者隐私保护法案(CPPA),所有其中保证用户从数据集中删除其数据的权利(被遗忘的权利)。 数据删除请求在实践中经常出现,特别是与医疗记录相关的敏感数据集(计算生物学中的许多机器学习模型都是使用英国生物银行(Sudlow等人,2015)进行训练的,该银行托管着一系列遗传和大约 50 万患者的医疗记录(Ginart 等人,2019))。 从数据集中删除用户数据不足以确保足够的隐私,因为训练数据通常可以从经过训练的模型重建(Fredrikson等人,2015;Veale等人,2018)。 这激发了机器取消学习 (Cao & Yang,2015)的研究,旨在有效消除某些数据点对模型的影响。 天真地,人们可以从头开始重新训练模型以确保完全删除,但重新训练的计算成本很高,因此在适应频繁的删除请求时并不实用。 为了避免完全的再训练,必须为每个不可学习的应用开发专门的方法(Ginart 等人,2019;Guo 等人,2020;Bourtoule 等人,2021;Sekhari 等人,2021)。
与此同时,联邦学习(FL)已成为一种有前途的方法,可以在大量用户上进行分布式训练,同时保护他们的隐私(McMahan 等人,2017;Chen 等人,2020;Kairouz 等人, 2021;王等人,2021;博纳维茨等人,2021)。 FL 的关键思想是将用户数据保留在其设备上,并通过以通信高效且安全的方式聚合本地模型来训练全局模型。 由于模型反转攻击(Zhu等人,2019;Geiping等人,2020),服务器端的安全本地模型聚合是FL中的一个关键考虑因素,因为它保证服务器无法获取特定信息基于本地模型的客户数据(Bonawitz 等人,2017;Bell 等人,2020;So 等人,2022;Chen 等人,2022)。 由于数据隐私是 FL 的主要目标,因此 FL 框架自然应该允许在跨孤岛设置中频繁删除客户端数据子集的数据(例如,当多个患者请求在医院数据库),或跨设备设置中客户端的整个本地数据集(例如,当用户请求应用程序不要跟踪其手机上的数据时)。 这导致了一个很大程度上未被研究的问题,称为联合失学习(Liu等人,2021;Wu等人,2022;Wang等人,2022)。 然而,现有的联合取消学习方法在模型更新后并没有理论上的性能保证,而且通常容易受到对抗性攻击。
我们的贡献总结如下。 1) 我们引入了FC中的机器失学习问题,并设计了一种新的端到端系统(图1),该系统能够执行具有隐私性和低功耗的高效FC。沟通成本保证,在需要时还可以实现简单而有效的忘却。 2) 作为具有不可学习特征的 FC 方案的一部分,我们描述了一种新颖的一次性 FC 算法,该算法为联合 均值聚类目标提供阶次最优近似,并且也优于少数现有的相关方法(Dennis等人,2021;Ginart等人,2019),特别是对于集群大小高度不平衡的情况。 3) 对于FC,我们还描述了一种新颖的稀疏压缩多集聚合(SCMA)方案,该方案确保服务器只能访问各个集群中点的聚合计数,但没有有关点分布的信息在个人客户。 SCMA 安全地恢复了输入稀疏向量的精确总和,通信复杂度在向量维度上为对数,优于现有的稀疏安全聚合工作(Beguier 等人,2020;Ergun 等人,2021),具有线性复杂度。 4) 我们从理论上建立了 FC 方法的遗忘复杂度,并表明它明显低于完全再训练的复杂度。 5) 我们编译了一系列数据集,用于对联合集群的遗忘进行基准测试,其中包括两个新数据集,其中包含癌症基因组中的甲基化模式和肠道微生物组信息,这对于计算生物学家和医学研究人员来说可能非常重要经常面临忘记学习的要求。 实验结果表明,与跨七个数据集的完全再训练相比,我们的一次性算法的平均速度提高了大约 x。

2相关作品
由于篇幅限制,相关工作的完整讨论包含在附录A中。
联合集群。 此学习任务的目标是使用驻留在不同边缘设备上的数据执行聚类。 大多数 FC 方法都以发送精确的 (Dennis 等人,2021) 或量化客户端(本地)质心 (Ginart 等人,2019) 为中心直接发送到服务器,这可能无法确保所需的隐私级别,因为它们会泄露每个客户端的数据统计或集群信息。 为了避免发送精确的质心,Li 等人(2022)建议将数据点和质心之间的距离发送到服务器,而不向任何相关方透露数据点的成员资格,但他们的方法带有很大的风险。计算和通信开销。 我们的工作引入了一种新颖的通信高效的安全 FC 框架,具有直观上有吸引力的新隐私标准,因为它涉及将客户端的模糊点计数通信到服务器,并且经常在 FL 文献中使用(Bonawitz 等人,2017) 。
机器忘却。 先前的工作提出了两种类型的忘却要求:精确忘却(Cao & Yang, 2015; Ginart 等人, 2019; Bourtoule 等人, 2021; Chen 等人, 2021)和近似忘却(Guo 等人, 2020; Golatkar 等人, 2020a; b; Sekhari 等人, 2021; Fu 等人, 2022; Chien 等人, 2022)。 为了实现精确的遗忘,未学习的模型需要与完全重新训练的模型具有相同的性能。 对于近似遗忘,未学习模型和完全再训练模型之间的行为“差异”应适当限制。 最近的一些工作也研究了 FL 设置中的数据删除(Liu 等人,2021;Wu 等人,2022;Wang 等人,2022);然而,它们大多数都是经验方法,并没有对去除后的模型性能和/或遗忘效率提供理论保证。 相比之下,我们提出的 FC 框架不仅能够在实践中实现高效的数据删除,而且还为未学习模型的性能和未学习过程的预期时间复杂度提供了理论保证。
3 预赛
我们从集中式 均值问题的正式定义开始。 给定 中的一组点排列成矩阵,以及簇数, - 意味着问题要求找到一组点 来最小化目标
| (1) |
其中表示矩阵的Frobenius范数,表示向量的范数,记录最接近的质心 到每个数据点 (即 )。 不失一般性,为了便于更简单的分析和讨论,我们假设最优解是唯一的,并用表示最优解。 质心集 在 上产生最佳划分 ,其中 。 我们使用 表示集中式 均值问题的目标函数的最优值。 稍微滥用了符号,我们还使用 来表示最佳集群 贡献的目标值。 附录B中提供了解决-means问题的常用方法-means++的详细描述。
在 FC 中,数据集 在集中式服务器上不再可用。 相反,数据存储在边缘设备(客户端)上,FC的目标是在服务器上学习一组全局质心客户发送的信息。 为简单起见,我们假设客户端之间不存在相同的数据点,并且整个数据集 是排列为 的数据集 的并集。设备。 服务器将以安全的方式接收所有客户端的聚合集群统计信息,并生成集合。 在这种情况下,联合 -means 问题要求找到最小化目标的 全局质心
| (2) |
其中记录客户端上的数据点所属的诱导全局簇的质心。 请注意,集中式 -means 的分配矩阵 的定义与通过联邦 -means 获得的分配矩阵不同。 :的第行仅取决于的位置,而中的行对应于 取决于 所属的诱导全局簇(正式定义参见 3.1 在附录L中,我们提供了一个简单的示例,进一步说明了和之间的区别。 请注意,Dennis 等人 (2021) 中也使用了诱导全局簇的概念。
Definition 3.1。
假设客户端处的本地集群用表示,服务器端的集群用表示。 全局聚类等于 ,其中 是客户端 上 的质心。请注意,形成整个数据集的分区,的代表性质心定义为。
完全不学习。 对于聚类问题,精确遗忘标准可以表述如下。 令 为给定数据集, 为在 上训练并输出一组质心 的(随机)聚类算法,其中 是选择的模型空间。 令 为一种取消学习算法,应用于 以消除一个数据点 的影响。 如果,那么就是一个精确的遗忘算法。 为了避免混淆,在某些情况下,该标准被称为 概率(模型)等价。
隐私-准确性-效率三难困境。 如何权衡数据隐私、模型性能、通信和计算效率是分布式学习中长期存在的问题(Acharya & Sun, 2019; Chen 等人, 2020; Gandikota 等人, 2021)这也适用于 FL 和 FC。 仍然缺乏同时解决后一种情况下所有这些挑战的解决方案。 例如,Dennis 等人 (2021) 提出了一种一次性算法,通过将每个客户端的精确质心发送到服务器来考虑模型性能和通信效率一种非匿名时尚。 在严格的隐私约束下,这种方法可能并不理想,因为服务器可以获得有关各个客户端数据的信息。 另一方面,Li 等人 (2022) 中通过执行 解决了隐私问题 - 意味着 Lloyd 通过在不同客户端之间分配计算来匿名进行迭代。 由于该方法依赖于混淆每个客户端的成对距离,因此它会产生计算开销来隐藏服务器上贡献客户端的身份,并且会产生由于交互计算而产生的通信开销。 上述方法都不适合取消学习应用程序。 为了同时实现忘却并解决忘却环境中的三难困境,我们的隐私标准涉及传输本地客户端集群内的客户端数据点数量,使得服务器无法了解任何特定的数据统计信息客户端,但仅是客户端数据集并集的总体统计数据。 在这种情况下,计算量是有限的,并且客户端可以执行有效的取消学习,这与提供数据点/质心距离时的情况不同。
随机和对抗性删除。 大多数遗忘文献都关注所有数据点都同样可能被删除的情况,这种设置称为随机删除。 然而,当用户恶意忘记对模型训练至关重要的某些点(即最佳集群中的边界点)时,可能会出现对抗性数据删除请求。 我们将此类删除请求称为对抗性删除。 在第5节中,我们为这两种类型的去除提供了理论分析。
4 具有安全模型聚合的联合集群
对于客户端和服务器端集群(Alg. 的 和 行) 1),我们采用 -means++,因为它有助于高效的忘却,如 5 节中所述。 具体来说,我们只在每个客户端运行 -means++ 初始化过程,但在服务器上运行完整的 -means++ 集群(初始化和 Lloyd 算法)。
Alg 的 行和 行。 1描述了用于处理本地客户端集群信息的过程。 如图1所示,我们首先将局部质心量化到量化仓的最近中心,量化仓的空间位置自然形成一个张量,其中存储局部簇的大小。 为每个客户端 生成一个张量,然后将其展平以形成向量 。 为简单起见,我们对每个维度使用步长 的统一量化(Alg.1 的第 3 行)。 1,更多详细信息请参见附录H)。 参数确定每个维度中量化仓的数量。 如果客户端数据不限于以原点为中心的单位超立方体,我们会对数据进行缩放以满足此要求。 那么每个维度的量化仓数量等于,而维度的量化仓总数为。
Alg 的 行。 1描述了如何在服务器上有效聚合信息而不泄露单个客户端数据统计信息。 该方案在4.1节中讨论。 第 行涉及根据相应的空间位置为第 个量化仓生成 点。 最简单的想法是选择量化仓的中心作为代表点并为其分配权重。 然后,在行中,我们可以在服务器端使用加权-means++算法来进一步降低计算复杂度。
4.1 服务器上的 SCMA
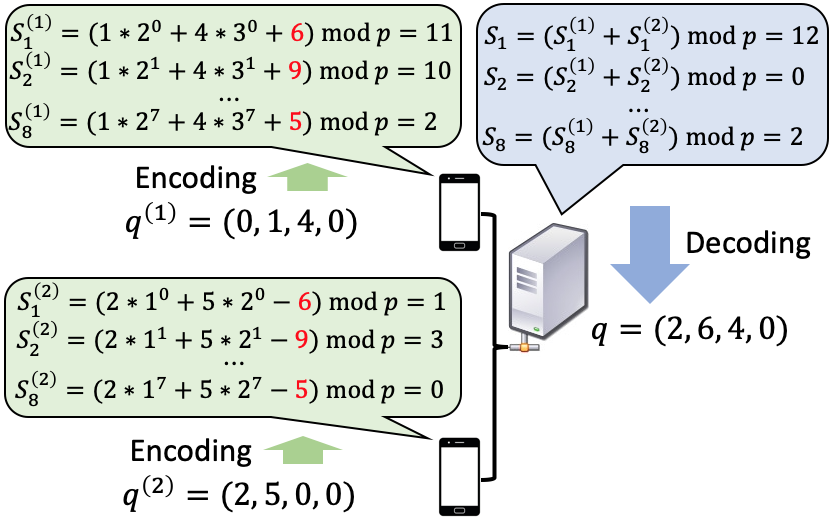
一旦生成了客户端的长度为的向量表示(Alg.的第行)。 1),我们可以使用标准安全模型聚合方法(Bonawitz 等人,2017;Bell 等人,2020;So 等人,2022)来总结所有 安全地在服务器上获取聚合结果。 然而,由于每个向量 的长度为 ,因此安全地聚合整个向量将导致每个客户端的通信复杂性呈指数级增长。 此外,每个 都是一个稀疏向量,因为客户端质心的数量远小于量化仓的数量(即 )。 每个客户端都发送带有噪声掩码的整个 进行聚合是低效且不必要的。 这促使我们首先压缩向量,然后执行安全聚合,我们将此过程称为 SCMA(Alg.1)。 2),如图2所示的一个示例。
通过观察 中最多可以有 个非零条目, 中最多可以有 个非零条目,我们调用 Reed -用于设计 SCMA 的 Solomon 代码构造(Reed & Solomon,1960)。 令为素数阶的有限域。 我们将量化仓的索引视为与底层有限域不同的元素,并将它们用作编码器多项式的评估点。 此外,我们将向量 中的非零条目 视为代码字中第 条目的替换错误。 然后,我们使用 Alg 中所示的 SCMA 方案。 2,其中客户端发送到服务器的消息可以被视为Reed-Solomon解码中的综合症。 请注意,在我们的方案中,除了 之外,服务器不知道 ,这符合我们的隐私标准。 这是因为 均匀分布在 上,并为不同的 独立选择。 详情请参阅附录J。
4.2性能分析
Theorem 4.1.
假设我们在算法1中执行步长的均匀量化。 然后我们有
4.3复杂度分析
5 机器通过专门的播种进行忘却
我们首先描述了一种直观的精确忘却机制(Alg. 3) for - 表示集中设置中的集群,稍后将用作 5.3。 Alg 背后的想法。 3 很简单:需要重新运行 -means++ 初始化,对应于仅当当前质心集 包含至少一个请求的点时才重新训练移动。 这是从两个观察得出的。 首先,由于通过 -means++ 初始化选择的质心是真实的数据点,因此 Alg 返回更新的质心集 。 3 保证不包含有关已删除的数据点的信息。 其次,我们将在下一节中解释,Alg。 3 还满足确切的遗忘标准(在 3 节中定义)。
5.1性能分析
5.2复杂度分析
我们提出了通过我们的算法同时删除一批 数据点的预期时间复杂度的下一个分析结果。 3. 为此,我们考虑随机和对抗性删除场景。 虽然随机删除的分析相当简单,但对对抗性删除请求的分析要求我们确定哪些删除会迫使从头开始频繁地重新训练。 在这方面,我们提出了关于最佳簇大小和异常值的两个假设,这将使我们能够描述最坏情况的去除设置。
Assumption 5.2.
令为常量,表示聚类大小不平衡,其中等于最佳聚类中最小聚类的大小;当 时,所有簇的大小均为 。
Assumption 5.3.
假设是固定常数。 中的离群值 满足 和 。
Theorem 5.4.
假设中的数据点数量为,并且数据集包含至少一个异常值的概率上限为。 算法 3 支持在单个请求中删除 点,随机删除的预期时间为 ,预期的预期时间为 敌对性移除。 完整再训练的复杂度等于。
Remark。
由于基于距离的-means++初始化过程,数据集中异常值的存在不可避免地导致更高的再训练概率。 情况就是如此,因为异常值更有可能位于初始质心集中。 因此,出于分析目的,我们在定理5.4中假设数据集包含至少一个异常值的概率的上限为。 这并不是一个过度限制性的假设,因为在聚类之前存在许多不同的方法来删除异常值 Chawla & Gionis (2013);甘和吴 (2017); Hautamäki 等人 (2005),这有效地使异常值的概率可以忽略不计。
5.3 忘记联邦集群
接下来我们将描述使用 Alg 的新 FC 框架的完整遗忘算法。 3 用于客户端级集群。 在FL设置中,数据驻留在客户端存储设备上,因此联合取消学习的基本假设是删除请求只会出现在客户端,并且其他不受影响的客户端和服务器不会知道删除集。 我们在 FC 设置中考虑两种类型的删除请求:从一个客户端 中删除 点(跨孤岛,单客户端删除),以及从 客户端(跨设备、多客户端删除)。 对于多个客户端只想忘记一部分数据的情况,该方法类似于单客户端删除,可以通过简单的联合边界来处理。
Alg 中描述了遗忘过程。 4. 对于单客户端数据删除,算法将首先在 Alg 之后的客户端(例如客户端 )执行取消学习。 3. 如果客户端的本地集群发生变化(即客户端重新运行初始化),则会生成一个新的向量并通过SCMA将其发送到服务器。 服务器将使用新的聚合向量重新运行聚类过程,并生成一组新的全局质心。 请注意,其他客户端在此阶段不需要执行额外的计算。 对于多客户端删除,我们遵循类似的策略,只是没有客户端需要执行额外的计算。 与引理 5.1 中描述的集中式取消学习相同,我们可以证明 Alg. 4也是一种精确的忘却方法。
移除时间复杂度。 对于单客户端删除,我们从定理5.4知道,客户端的预期删除时间复杂度为和分别是随机删除和对抗性删除。 表示客户端上的数据点数量。其他客户端不需要额外的计算,因为它们的质心不会受到删除请求的影响。 同时,服务器的去除时间复杂度上限为,其中是Lloyd算法在收敛之前在服务器上的最大迭代次数。 对于多客户端删除,客户端不需要执行额外的计算,服务器的删除时间复杂度等于。
6实验结果
为了凭经验描述我们新提出的 FC 方法的数据删除效率和性能之间的权衡,我们将其与合成数据集和真实数据集上的基线方法进行了比较。 由于篇幅限制,更深入的实验和讨论委托给附录M。
数据集和基线。 我们在实验中使用由高斯混合模型 (Gaussian) 生成的一个合成数据集和六个真实数据集(Celltype、Covtype、FEMNIST、Postures、TMI、TCGA)。 我们对数据集进行预处理,使数据分布是非独立同分布的。 跨不同的客户。 图3中的符号表示客户端之间(真实)聚类的最大数量,而表示全局数据集中真实聚类的数量。 数据统计和预处理过程的详细描述参见附录M。由于目前没有专为取消联邦集群而设计的现成算法,因此我们采用 Ginart 等人 (2019) 中的 DC-Kmeans (DC-KM) 来应用于我们的问题设置,并使用完全再训练作为基线比较方法。 为了评估完整数据集上的 FC 性能(数据删除之前),我们还使用 Dennis 等人 (2021) 的 K-FED 算法作为基线方法。 在所有图中,我们的 Alg。 1 称为 MUFC。 请注意,在 FL 中,客户端通常是并行训练的,因此估计的时间复杂度等于客户端的最长处理时间与服务器的处理时间之和。
聚类性能。 Tab 的第一行显示了所有方法在完整数据集上的聚类性能。 1. 损失率定义为111 通过多次运行 -means++ 并选择最小的目标值来近似。,这是用于评估所获得的聚类质量的度量。 对于七个数据集,MUFC 在 TMI 和 Celltype 上提供了最佳性能,这些数据集的不同簇中的数据点数量高度不平衡。 这可以通过指出MUFC和K-FED/DC-KM之间的一个重要区别来解释:客户端发送的量化质心可能具有非单位权重,而MUFC本质上是执行加权-means++在服务器上。 相比之下,K-FED 和 DC-KM 都为客户端的质心分配相同的单位权重。 请注意,根据局部聚类为客户端的质心分配权重不仅可以对方案进行简单分析,而且还可以提高经验性能,特别是对于聚类分布高度不平衡的数据集。 对于除 Gaussian 之外的所有其他数据集,与 K-FED/DC-KM 相比,MUFC 获得了有竞争力的聚类性能。 DC-KM 在高斯数据上优于 MUFC 的主要原因是在这种情况下所有簇的大小相同。 另请注意,DC-KM 为每个客户端运行完整的 -means++ 集群,而 MUFC 仅执行初始化。 虽然在客户端运行完整的-means++聚类可以提高某些数据集上的经验性能,但它也大大增加了训练过程中的计算复杂度和取消学习过程中的重新训练概率,如图3。 尽管如此,我们还在附录 M 中的 MUFC 客户端上运行完整 -means++ 聚类时,将 MUFC 与 K-FED/DC-KM 的性能进行了比较。
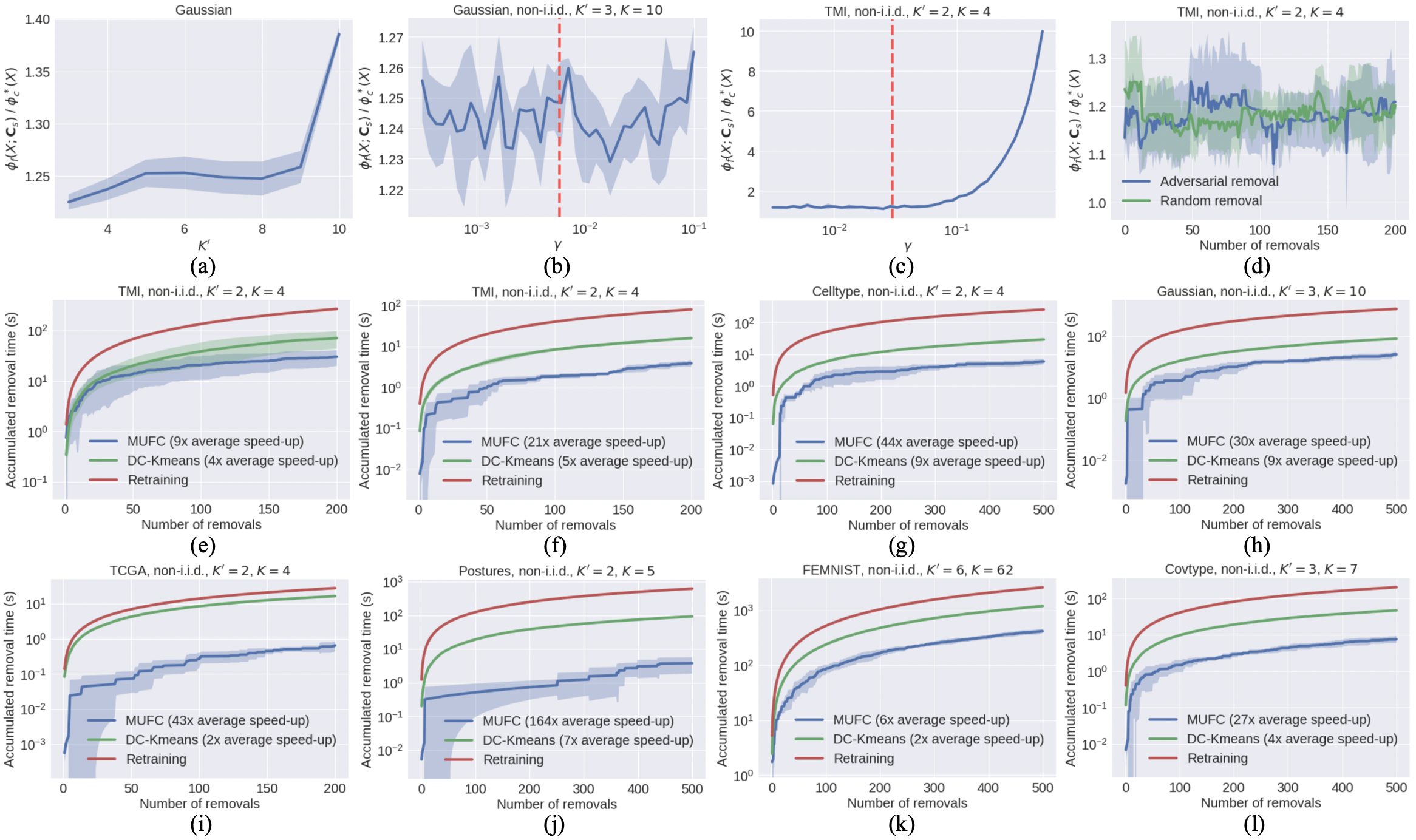
我们还研究了和对聚类性能的影响。 图3(a)显示,当时,MUFC可以获得较低的损失率,表明数据是非独立同分布的。 分布在各个客户端。 图3(b)表明,由于我们使用均匀采样,的选择似乎对高斯数据集的聚类性能没有很大影响在 Alg 的第 6 步中。 1 生成服务器数据集。 同时,图3(c)表明可以对现实数据集的聚类性能产生显着影响,这与我们在定理4.1。 两个图中的红色垂直线表示默认选择 ,其中 代表跨客户端的总数据点数量。
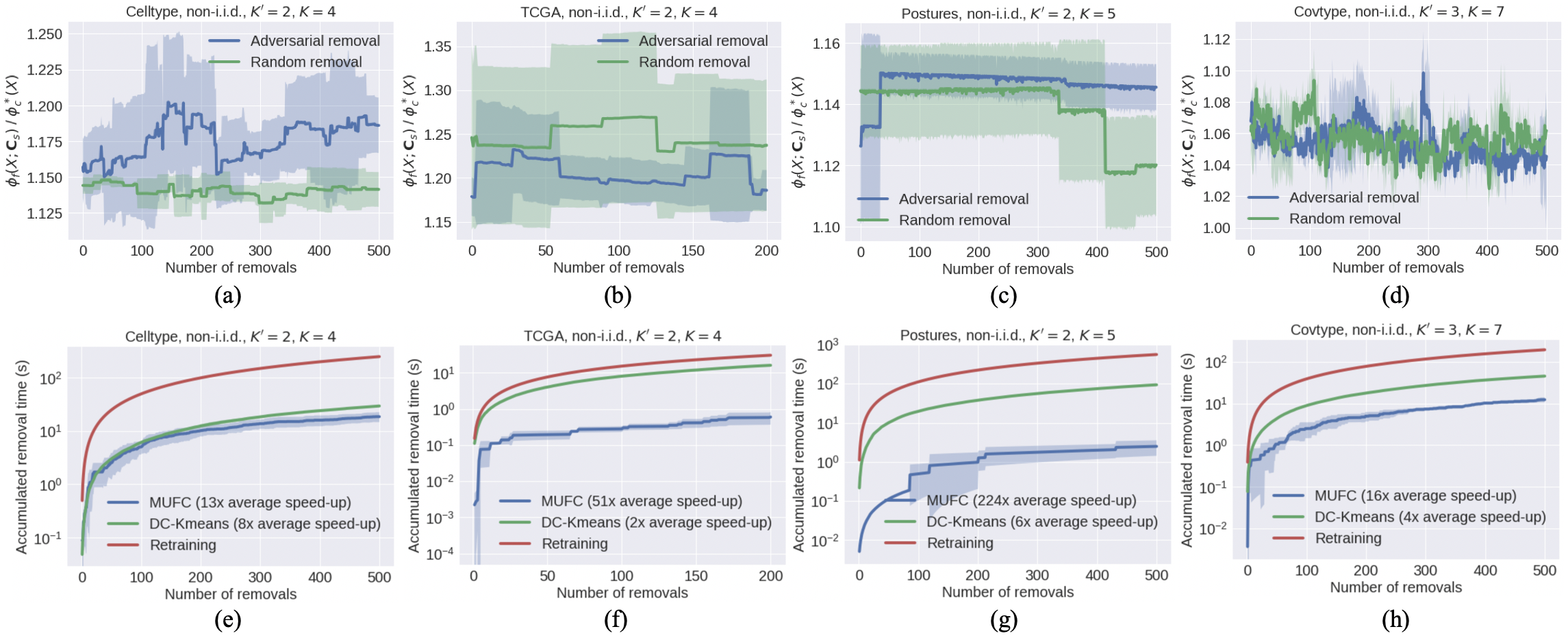
忘却表现。 由于K-FED不支持数据去除,计算复杂度较高,其经验聚类性能比DC-KM差(见表1)。 1),我们只比较MUFC和DC-KM的遗忘性能。 为简单起见,我们考虑在每一轮取消学习时从均匀随机选择的客户端 中删除一个数据点。 Tab 的第二行。 1记录加速比w.r.t。 一轮 MUFC 遗忘的完整再训练(Alg. 4),当删除的点不在客户端选择的质心集中时。图3(e)显示了TMI数据集上对抗性去除的累积去除时间,通过去除每轮对目标函数当前值贡献最大的数据点来模拟,图3(f)-(l)显示了随机去除的不同数据集上的累积去除时间。 结果表明,与所有其他基线方法相比,MUFC 保持了较高的遗忘效率,并且与七个数据集上随机删除的完全再训练相比,提供了 x 的平均加速比。 我们还在图3(d)中报告了遗忘过程中MUFC损失率的变化。 每次删除后损失率几乎保持不变,这表明我们的忘却方法不会显着降低聚类性能。 类似的结论也适用于其他测试数据集,如附录M所示。
| TMI | Celltype | Gaussian | TCGA | Postures | FEMNIST | Covtype | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Loss ratio | MUFC | |||||||||
| K-FED | ||||||||||
| DC-KM | ||||||||||
|
x | x | x | x | x | x | x | |||
道德声明
我们模拟中使用的七个数据集都是公开的。 其中TCGA和TMI包含潜在敏感的生物数据,登录数据库后下载。 我们在处理这些匿名数据时遵守所有规定,并且只会发布数据处理管道以及在 TCGA 和 TMI 不受限制的数据。 不包含敏感信息的数据集可以直接从其开源存储库下载。
再现性声明
我们的实现可在 https://github.com/thupchnsky/mufc 获取。 源代码中包含详细说明。
致谢
这项工作由 NSF 拨款 1816913 和 1956384 资助。 作者感谢 Eli Chien 的有益讨论。
参考
- Acharya & Sun (2019) Jayadev Acharya and Ziteng Sun. Communication complexity in locally private distribution estimation and heavy hitters. In International Conference on Machine Learning, pp. 51–60. PMLR, 2019.
- Ailon et al. (2009) Nir Ailon, Ragesh Jaiswal, and Claire Monteleoni. Streaming k-means approximation. Advances in neural information processing systems, 22, 2009.
- Beguier et al. (2020) Constance Beguier, Mathieu Andreux, and Eric W Tramel. Efficient sparse secure aggregation for federated learning. arXiv preprint arXiv:2007.14861, 2020.
- Bell et al. (2020) James Henry Bell, Kallista A Bonawitz, Adrià Gascón, Tancrède Lepoint, and Mariana Raykova. Secure single-server aggregation with (poly) logarithmic overhead. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, pp. 1253–1269, 2020.
- Berlekamp (1968) Elwyn R. Berlekamp. Algebraic coding theory. In McGraw-Hill series in systems science, 1968.
- Blackard & Dean (1999) Jock A Blackard and Denis J Dean. Comparative accuracies of artificial neural networks and discriminant analysis in predicting forest cover types from cartographic variables. Computers and electronics in agriculture, 24(3):131–151, 1999.
- Bonawitz et al. (2021) Kallista Bonawitz, Peter Kairouz, Brendan McMahan, and Daniel Ramage. Federated learning and privacy: Building privacy-preserving systems for machine learning and data science on decentralized data. Queue, 19(5):87–114, 2021.
- Bonawitz et al. (2017) Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. Practical secure aggregation for privacy-preserving machine learning. In proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, pp. 1175–1191, 2017.
- Bourtoule et al. (2021) Lucas Bourtoule, Varun Chandrasekaran, Christopher A Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine unlearning. In 2021 IEEE Symposium on Security and Privacy (SP), pp. 141–159. IEEE, 2021.
- Caldas et al. (2018) Sebastian Caldas, Sai Meher Karthik Duddu, Peter Wu, Tian Li, Jakub Konečnỳ, H Brendan McMahan, Virginia Smith, and Ameet Talwalkar. LEAF: A Benchmark for Federated Settings. arXiv preprint arXiv:1812.01097, 2018.
- Cao & Yang (2015) Yinzhi Cao and Junfeng Yang. Towards making systems forget with machine unlearning. In 2015 IEEE Symposium on Security and Privacy, pp. 463–480. IEEE, 2015.
- Chawla & Gionis (2013) Sanjay Chawla and Aristides Gionis. k-means–: A unified approach to clustering and outlier detection. In Proceedings of the 2013 SIAM international conference on data mining, pp. 189–197. SIAM, 2013.
- Chen et al. (2021) Min Chen, Zhikun Zhang, Tianhao Wang, Michael Backes, Mathias Humbert, and Yang Zhang. Graph unlearning. arXiv preprint arXiv:2103.14991, 2021.
- Chen et al. (2020) Wei-Ning Chen, Peter Kairouz, and Ayfer Ozgur. Breaking the communication-privacy-accuracy trilemma. Advances in Neural Information Processing Systems, 33:3312–3324, 2020.
- Chen et al. (2022) Wei-Ning Chen, Christopher A Choquette Choo, Peter Kairouz, and Ananda Theertha Suresh. The fundamental price of secure aggregation in differentially private federated learning. In International Conference on Machine Learning, pp. 3056–3089. PMLR, 2022.
- Chien et al. (2022) Eli Chien, Chao Pan, and Olgica Milenkovic. Certified graph unlearning. In NeurIPS 2022 Workshop: New Frontiers in Graph Learning, 2022. URL https://openreview.net/forum?id=wCxlGc9ZCwi.
- Chien et al. (2023) Eli Chien, Chao Pan, and Olgica Milenkovic. Efficient model updates for approximate unlearning of graph-structured data. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=fhcu4FBLciL.
- Chung et al. (2022) Jichan Chung, Kangwook Lee, and Kannan Ramchandran. Federated unsupervised clustering with generative models. In AAAI 2022 International Workshop on Trustable, Verifiable and Auditable Federated Learning, 2022.
- Cohen et al. (2017) Gregory Cohen, Saeed Afshar, Jonathan Tapson, and Andre Van Schaik. EMNIST: Extending MNIST to handwritten letters. In 2017 international joint conference on neural networks (IJCNN), pp. 2921–2926. IEEE, 2017.
- Deng et al. (2009) Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pp. 248–255. Ieee, 2009.
- Dennis et al. (2021) Don Kurian Dennis, Tian Li, and Virginia Smith. Heterogeneity for the win: One-shot federated clustering. In International Conference on Machine Learning, pp. 2611–2620. PMLR, 2021.
- Eisinberg & Fedele (2006) Alfredo Eisinberg and Giuseppe Fedele. On the inversion of the vandermonde matrix. Applied mathematics and computation, 174(2):1384–1397, 2006.
- Ergun et al. (2021) Irem Ergun, Hasin Us Sami, and Basak Guler. Sparsified secure aggregation for privacy-preserving federated learning. arXiv preprint arXiv:2112.12872, 2021.
- Fredrikson et al. (2015) Matt Fredrikson, Somesh Jha, and Thomas Ristenpart. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC conference on computer and communications security, pp. 1322–1333, 2015.
- Frikken (2007) Keith Frikken. Privacy-preserving set union. In International Conference on Applied Cryptography and Network Security, pp. 237–252. Springer, 2007.
- Fu et al. (2022) Shaopeng Fu, Fengxiang He, and Dacheng Tao. Knowledge removal in sampling-based bayesian inference. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=dTqOcTUOQO.
- Gan & Ng (2017) Guojun Gan and Michael Kwok-Po Ng. K-means clustering with outlier removal. Pattern Recognition Letters, 90:8–14, 2017.
- Gandikota et al. (2021) Venkata Gandikota, Daniel Kane, Raj Kumar Maity, and Arya Mazumdar. vqsgd: Vector quantized stochastic gradient descent. In International Conference on Artificial Intelligence and Statistics, pp. 2197–2205. PMLR, 2021.
- Gardner et al. (2014a) Andrew Gardner, Christian A Duncan, Jinko Kanno, and Rastko Selmic. 3D hand posture recognition from small unlabeled point sets. In 2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 164–169. IEEE, 2014a.
- Gardner et al. (2014b) Andrew Gardner, Jinko Kanno, Christian A Duncan, and Rastko Selmic. Measuring distance between unordered sets of different sizes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 137–143, 2014b.
- Geiping et al. (2020) Jonas Geiping, Hartmut Bauermeister, Hannah Dröge, and Michael Moeller. Inverting gradients-how easy is it to break privacy in federated learning? Advances in Neural Information Processing Systems, 33:16937–16947, 2020.
- Ghosh et al. (2020) Avishek Ghosh, Jichan Chung, Dong Yin, and Kannan Ramchandran. An efficient framework for clustered federated learning. Advances in Neural Information Processing Systems, 33:19586–19597, 2020.
- Ginart et al. (2019) Antonio Ginart, Melody Guan, Gregory Valiant, and James Y Zou. Making AI forget you: Data deletion in machine learning. Advances in neural information processing systems, 32, 2019.
- Golatkar et al. (2020a) Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Eternal sunshine of the spotless net: Selective forgetting in deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9304–9312, 2020a.
- Golatkar et al. (2020b) Aditya Golatkar, Alessandro Achille, and Stefano Soatto. Forgetting outside the box: Scrubbing deep networks of information accessible from input-output observations. In European Conference on Computer Vision, pp. 383–398. Springer, 2020b.
- Guha et al. (2003) Sudipto Guha, Adam Meyerson, Nina Mishra, Rajeev Motwani, and Liadan O’Callaghan. Clustering data streams: Theory and practice. IEEE transactions on knowledge and data engineering, 15(3):515–528, 2003.
- Guo et al. (2020) Chuan Guo, Tom Goldstein, Awni Hannun, and Laurens Van Der Maaten. Certified data removal from machine learning models. In Hal Daumé III and Aarti Singh (eds.), Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pp. 3832–3842. PMLR, 13–18 Jul 2020.
- Han et al. (2020) Pengchao Han, Shiqiang Wang, and Kin K Leung. Adaptive gradient sparsification for efficient federated learning: An online learning approach. In 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), pp. 300–310. IEEE, 2020.
- Han et al. (2018) Xiaoping Han, Renying Wang, Yincong Zhou, Lijiang Fei, Huiyu Sun, Shujing Lai, Assieh Saadatpour, Ziming Zhou, Haide Chen, Fang Ye, et al. Mapping the mouse cell atlas by microwell-seq. Cell, 172(5):1091–1107, 2018.
- Hartigan & Wong (1979) John A Hartigan and Manchek A Wong. Algorithm as 136: A k-means clustering algorithm. Journal of the royal statistical society. series c (applied statistics), 28(1):100–108, 1979.
- Hautamäki et al. (2005) Ville Hautamäki, Svetlana Cherednichenko, Ismo Kärkkäinen, Tomi Kinnunen, and Pasi Fränti. Improving k-means by outlier removal. In Scandinavian conference on image analysis, pp. 978–987. Springer, 2005.
- Hutter & Zenklusen (2018) Carolyn Hutter and Jean Claude Zenklusen. The Cancer Genome Atlas: Creating Lasting Value beyond Its Data. Cell, 173(2):283–285, 2018.
- Kairouz et al. (2021) Peter Kairouz, H Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, et al. Advances and open problems in federated learning. Foundations and Trends® in Machine Learning, 14(1–2):1–210, 2021.
- Kedlaya & Umans (2011) Kiran S Kedlaya and Christopher Umans. Fast polynomial factorization and modular composition. SIAM Journal on Computing, 40(6):1767–1802, 2011.
- Kissner & Song (2005) Lea Kissner and Dawn Song. Privacy-preserving set operations. In Annual International Cryptology Conference, pp. 241–257. Springer, 2005.
- Lee et al. (2017) Euiwoong Lee, Melanie Schmidt, and John Wright. Improved and simplified inapproximability for k-means. Information Processing Letters, 120:40–43, 2017.
- Li et al. (2022) Songze Li, Sizai Hou, Baturalp Buyukates, and Salman Avestimehr. Secure federated clustering. arXiv preprint arXiv:2205.15564, 2022.
- Liu et al. (2021) Gaoyang Liu, Xiaoqiang Ma, Yang Yang, Chen Wang, and Jiangchuan Liu. Federaser: Enabling efficient client-level data removal from federated learning models. In 2021 IEEE/ACM 29th International Symposium on Quality of Service (IWQOS), pp. 1–10. IEEE, 2021.
- Lloyd (1982) Stuart Lloyd. Least squares quantization in pcm. IEEE transactions on information theory, 28(2):129–137, 1982.
- Mahajan et al. (2012) Meena Mahajan, Prajakta Nimbhorkar, and Kasturi Varadarajan. The planar k-means problem is np-hard. Theoretical Computer Science, 442:13–21, 2012.
- Mansour et al. (2020) Yishay Mansour, Mehryar Mohri, Jae Ro, and Ananda Theertha Suresh. Three approaches for personalization with applications to federated learning. arXiv preprint arXiv:2002.10619, 2020.
- Massey (1969) James Massey. Shift-register synthesis and bch decoding. IEEE transactions on Information Theory, 15(1):122–127, 1969.
- McMahan et al. (2017) Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, pp. 1273–1282. PMLR, 2017.
- Pan et al. (2023) Chao Pan, Eli Chien, and Olgica Milenkovic. Unlearning graph classifiers with limited data resources. In The Web Conference, 2023.
- Peterson et al. (2009) Jane Peterson, Susan Garges, Maria Giovanni, Pamela McInnes, Lu Wang, Jeffery A Schloss, Vivien Bonazzi, Jean E McEwen, Kris A Wetterstrand, Carolyn Deal, et al. The NIH Human Microbiome Project. Genome research, 19(12):2317–2323, 2009.
- Reed & Solomon (1960) Irving S Reed and Gustave Solomon. Polynomial codes over certain finite fields. Journal of the society for industrial and applied mathematics, 8(2):300–304, 1960.
- Sattler et al. (2020) Felix Sattler, Klaus-Robert Müller, and Wojciech Samek. Clustered federated learning: Model-agnostic distributed multitask optimization under privacy constraints. IEEE transactions on neural networks and learning systems, 32(8):3710–3722, 2020.
- Sekhari et al. (2021) Ayush Sekhari, Jayadev Acharya, Gautam Kamath, and Ananda Theertha Suresh. Remember what you want to forget: Algorithms for machine unlearning. Advances in Neural Information Processing Systems, 34:18075–18086, 2021.
- Seo et al. (2012) Jae Hong Seo, Jung Hee Cheon, and Jonathan Katz. Constant-round multi-party private set union using reversed laurent series. In International Workshop on Public Key Cryptography, pp. 398–412. Springer, 2012.
- So et al. (2022) Jinhyun So, Corey J Nolet, Chien-Sheng Yang, Songze Li, Qian Yu, Ramy E Ali, Basak Guler, and Salman Avestimehr. Lightsecagg: a lightweight and versatile design for secure aggregation in federated learning. Proceedings of Machine Learning and Systems, 4:694–720, 2022.
- Sudlow et al. (2015) Cathie Sudlow, John Gallacher, Naomi Allen, Valerie Beral, Paul Burton, John Danesh, Paul Downey, Paul Elliott, Jane Green, Martin Landray, et al. Uk biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS medicine, 12(3):e1001779, 2015.
- Thomee et al. (2016) Bart Thomee, David A Shamma, Gerald Friedland, Benjamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li. Yfcc100m: The new data in multimedia research. Communications of the ACM, 59(2):64–73, 2016.
- Vassilvitskii & Arthur (2006) Sergei Vassilvitskii and David Arthur. k-means++: The advantages of careful seeding. In Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms, pp. 1027–1035, 2006.
- Veale et al. (2018) Michael Veale, Reuben Binns, and Lilian Edwards. Algorithms that remember: model inversion attacks and data protection law. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 376(2133):20180083, 2018.
- Wang et al. (2021) Jianyu Wang, Zachary Charles, Zheng Xu, Gauri Joshi, H Brendan McMahan, Maruan Al-Shedivat, Galen Andrew, Salman Avestimehr, Katharine Daly, Deepesh Data, et al. A field guide to federated optimization. arXiv preprint arXiv:2107.06917, 2021.
- Wang et al. (2022) Junxiao Wang, Song Guo, Xin Xie, and Heng Qi. Federated unlearning via class-discriminative pruning. In Proceedings of the ACM Web Conference 2022, pp. 622–632, 2022.
- Wu et al. (2022) Chen Wu, Sencun Zhu, and Prasenjit Mitra. Federated unlearning with knowledge distillation. arXiv preprint arXiv:2201.09441, 2022.
- Zhu et al. (2019) Ligeng Zhu, Zhijian Liu, and Song Han. Deep leakage from gradients. Advances in neural information processing systems, 32, 2019.
附录A相关作品
联合集群。 FC 的想法是使用驻留在不同边缘设备上的数据执行集群。 它与聚类 FL (Sattler 等人, 2020) 密切相关,其目标是基于数据集的聚类结构同时学习多个全局模型,并根据聚类分配进行个性化佛罗里达州客户数据(Mansour 等人,2020)。 FC 和分布式集群之间的一个区别(Guha 等人,2003;Ailon 等人,2009) 是不同客户端之间数据异构性的假设。 最近的工作(Ghosh 等人,2020;Dennis 等人,2021;Chung 等人,2022)利用客户数据的非独立同分布性质来提高一些学习者的表现。 另一个区别涉及数据隐私。 以前的大多数方法都围绕将精确的 (Dennis 等人, 2021) 或量化的客户端(本地)质心 (Ginart 等人, 2019) 发送到服务器的想法,这可能不被认为是私有的,因为它泄露了所有客户端的数据统计或集群信息。 为了避免发送精确的质心,Li 等人(2022)建议将数据点和质心之间的距离发送到服务器,而不向任何相关方透露数据点的成员资格。 请注意,目前 FC 问题的计算或信息理论保密/隐私还没有正式的定义,因此很难比较解决 FL 不同方面的方法。 我们的方法引入了一种易于忘记的聚类过程和新的隐私机制,该机制直观上很有吸引力,因为它涉及将客户端的模糊点计数传递给服务器。
稀疏安全聚合。 稀疏安全聚合旨在针对局部模型高维但稀疏的情况,以通信有效的方式安全地聚合局部模型。 稀疏安全聚合的现有工作(Beguier等人,2020;Ergun等人,2021)要么具有模型维度上线性的通信复杂性,要么只能生成聚合模型的近似值基于某些稀疏化程序(Han等人,2020)。 相比之下,我们的 SCMA 方案可以安全地恢复输入稀疏模型的精确总和,通信复杂度在模型维度上为对数。
私人集合联盟。 与稀疏安全聚合相比,私有集联合(Kissner & Song,2005;Frikken,2007;Seo 等人,2012)是一个相关但不同的问题。 它需要多方相互通信才能安全地计算其集合的并集。 在 SCMA 中,我们聚合多重集,其中包括私有集并集问题中未考虑的每个元素的频率。 另外,我们的方案仅包括从客户端到服务器的一轮通信,而私有集联合问题中没有服务器,但需要多轮客户端到客户端通信。
机器忘却。 对于集中机器遗忘问题,之前的工作中提出了两种类型的遗忘要求:精确遗忘和近似遗忘。 为了实现精确的遗忘,未学习的模型需要与完全重新训练的模型具有相同的性能。 为了实现这一目标,Cao & Yang (2015)引入了分布式学习器,Bourtoule 等人 (2021) 提出了基于分片的方法,Ginart 等人 (2019) 使用量化来消除聚类问题中删除数据的影响,Chen 等人 (2021) 将基于分片的方法应用于图神经网络。 对于近似遗忘,未学习模型和完全再训练模型之间的行为“差异”应该受到适当限制,类似于差异隐私背景下的做法。 沿着后一个方向,Guo 等人 (2020) 引入了线性模型的逆牛顿更新,Sekhari 等人 (2021) 研究了近似未学习模型的泛化性能,Fu 等人 (2022) 提出了基于采样的贝叶斯推理的 MCMC 去学习算法,Golatkar 等人 (2020a; b) 设计了基于 Fisher 的深度神经网络模型更新机制信息与神经切线核,而 Chien 等人 (2022; 2023); Pan等人(2023)将分析扩展到图神经网络。 最近的一些工作也研究了 FL 设置中的数据删除:Liu 等人 (2021) 提出在再训练期间使用更少的迭代进行联合取消学习,Wu 等人 (2022) t1>将知识蒸馏引入到遗忘过程中,以消除要求删除的数据点的影响,而Wang等人(2022)考虑通过检查每个数据点的内部影响来删除特定类别中的所有数据卷积神经网络中的通道。 这些联合取消学习方法(大部分)是经验性的,并且没有对删除后的模型性能和/或取消学习效率提供理论保证。 相比之下,我们提出的 FC 框架不仅能够在实践中实现高效的数据删除,而且还为未学习模型的性能和未学习过程的预期时间复杂度提供了理论保证。
附录B-表示++初始化
即使对于 , 均值问题也是 NP 困难的,并且当点位于二维欧几里德空间中时 (Mahajan 等人, 2012)。 解决问题的启发式算法,包括 Lloyd 方法(Lloyd,1982)和 Hartigan 方法(Hartigan & Wong,1979),不能保证获得全局最优解,除非进一步对点和簇结构进行假设(Lee等人,2017)。 尽管获得 均值问题的精确最优解很困难,但有许多方法可以获得最优质心的质量近似值。 例如,Vassilvitskii & Arthur (2006)中引入了随机初始化算法(-means++),初始化后的期望目标值为 - 逼近最佳目标 ()。 -means++ 初始化工作如下:最初,质心集 被假定为空。 然后,从第一个质心的中随机均匀采样一个点,并将其添加到中。 对于接下来的 轮,来自 的点 以概率 采样作为新质心,并添加到 。 这里,表示与迄今为止选择的中的质心之间的最小距离。 初始化步骤之后,我们到达用于运行 Lloyd 算法的 中的 初始质心。
附录C算法复杂度分析1
客户端集群的计算复杂性。 客户端集群涉及运行-means++初始化过程,其复杂性。
服务器端集群的计算复杂性。 服务器端集群涉及运行 -means++ 初始化过程,然后是具有 次迭代的 Lloyd 算法,其复杂度为 。
SCMA 在客户端的计算复杂度。 客户端 上 的计算最多需要对 进行 次乘法。 总计算复杂度等于乘法和加法运算与。
服务器端 SCMA 的计算复杂度。 服务器端的计算复杂度主要取决于 Berlekamp-Massey 解码算法 (Berlekamp,1968;Massey,1969) 的复杂度,该算法将多项式 分解为 (Kedlaya & Umans, 2011),并用已知的、求解线性方程。 上 Berlekamp-Massey 解码的复杂度为 。 使用 Kedlaya & Umans (2011) 中的算法对 进行多项式 因式分解的复杂度是 次运算,而不是 。 求解 的复杂性等于查找 Vandermonde 矩阵的逆矩阵,它需要对 进行 运算(Eisinberg & Fedele, 2006 )。 因此,服务器端的总计算复杂度是操作超过。
SCMA在客户端的通信复杂性。 由于每个都可以用位来表示,因此每个客户端发送的信息可以用 请注意,最多有长度为 的 元向量。 因此,从客户端到服务器 的通信 的成本至少为 位,这意味着我们的方案是顺序最优的。 沟通成本。 请注意,遵循该领域的标准实践,我们没有考虑安全模型聚合中噪声生成的复杂性,因为它可以离线完成并且独立于里德-所罗门编码过程。
附录D定理证明4.1
证明。
Lemma D.1.
假设跨客户端的整个数据集用表示,算法5返回的服务器质心集是。 然后我们有
证明。
让 表示最小化整个数据集 的目标 (1) 的最佳质心集,让 为记录中与每个数据点最接近的质心的矩阵,是Alg返回的质心集。 1,以及 矩阵,该矩阵根据定义 3.1 中定义的全局聚类,在 中记录了每个数据点的相应中心点。 由于我们对每个客户端数据集执行 -means++ 初始化,因此对于客户端 它保持
| (3) |
其中 记录了 中与 中每个数据点 最近的中心点, 是可以最小化客户 的局部 均值目标的最优解, 表示 中与客户 相对应的行。对所有客户求和 (D) 得出
| (4) |
在服务器端,客户端质心被重新组织成矩阵。 客户端质心的权重转换为 中行的重复。 由于我们在服务器上执行完整的 -means++ 集群,因此可以得出以下结论
| (5) |
其中 是最小化服务器上的 意味着目标的最佳解决方案。 值得指出的是,与不同,它们是针对不同优化目标的最优解。 请注意,我们仍然保留 的 RHS 期望。 随机性来自于 是通过 -means++ 初始化获得的,这是一个概率过程。
如果我们只关心整个数据集中非离群点的性能,我们可以将项 的上限设置为
| (8) |
在这里,我们使用了这样一个事实: 行都是由 -means++ 初始化过程采样的真实数据点。 对于每个数据点,它保存,其中。 在这种情况下,我们到达 ,其中 对应于所有非离群点。 ∎
Remark。
在 Guha 等人 (2003) 的定理 4 中,作者表明,对于分布式 中值问题,如果我们使用 逼近算法(即,)用于分布式计算机上子数据集的中值问题,并使用-近似算法来解决 -集中式机器上的中值问题,整体分布式算法有效地实现了集中式中值问题最优解的-近似。 这与我们的观察一致,即 Alg。 5 可以为集中式 -means 问题的最优解提供预期的 -近似值,因为 -means++初始化在客户端和服务器端实现了 近似。
我们还指出,在 Dennis 等人 (2021) 中,作者假设客户端 上全局最优聚类的准确聚类数量已知且等于 ,并提出-FED算法,该算法在时表现良好。 和 之间的差异表示不同客户端之间的数据异构性。 只要对证明稍作修改,当事先知道每个客户机的 时,我们也可以得到 ,并在客户机 上执行 -means++ 而不是 Alg 中的 -means++ 。 1. 对于每个客户端保护整个集群数据的极端设置(w.r.t.) 全局最优聚类()),Alg的性能保证。 1 变为 ,这与通过从该簇中均匀随机采样的数据点为每个最佳簇播种相同。 从Vassilvitskii & Arthur (2006)的引理3.1我们看到,我们确实可以有,其中近似因子不依赖于。这表明不同客户端之间的数据异构性可以使整个 FC 框架受益。
附录E引理证明5.1
证明。
假设中的数据点数为,的大小为,初始质心设置为是。 我们用归纳法证明是由Alg返回的。 3 在概率上相当于在 上重新运行 -means++ 初始化。
归纳的基本情况相当于研究 的删除过程,即 -means++ 选择的第一个点。 有两种可能的情况: 和 。 在第一种情况下,我们将重新运行 上的初始化过程,这相当于重新训练模型。 在第二种情况下,由于我们知道,因此从中选择作为第一个质心的概率等于条件概率
接下来假设,。 Alg 返回的质心 。 3 可以被视为在概率上等同于通过在前 轮中重新运行 上的初始化过程而获得的模型。 然后我们有
其中根据的定义成立,表明第质心不在中。 因此,Alg 返回的质心 。 3 可以看作是在第 轮中对 重新运行初始化过程而获得的。 再次基于 的定义,很明显,对于 , 是 -means++ 过程选择的质心超过。 这证明了我们的说法, 由 Alg 返回。 3 的概率相当于在 上重新运行 -means++ 初始化所获得的结果。
Vassilvitskii & Arthur (2006) 的定理 1.1 证明
| (12) |
这就完成了证明。 ∎
附录F定理证明5.4
证明。
Lemma F.1.
假设中的数据点数量为,并且数据集包含至少一个异常值的概率上限为。 令为在上运行-means++获得的质心集。 对于大小为 的任意移除集 ,我们有
| for random removals: | |||
| for adversarial removals: |
证明。
由于根据定义,异常值可以与所有真实聚类点任意远,因此在初始化期间,它们可能会以非常高的概率被采样为质心。 为了简化分析,我们假设异常值如果存在于数据集中,则以概率 采样为质心,这意味着我们始终需要在以下情况下重新运行 -means++ 初始化:在进行任何删除之前,异常值存在于完整数据集中。
对于随机删除,要求取消学习的点 是从 中均匀随机抽取的,显然 ,因为 包含 中的 个不同数据点。
对于对抗性删除,我们需要分析选择 作为第 个质心的概率,假设第一个 质心已经确定并且 。 为简单起见,我们首先假设 中没有异常值。 然后我们有
| (13) |
对于分母 ,以下三个观察结果成立
所以,
| (14) |
其中 分别是 和 中距 最近的质心。 这里,是这一事实的结果。 由于根据我们的假设, 不是 的异常值,因此我们有
最后,
| (15) |
对于,它保存。 因此,(F) 的下界可以为
| (16) |
在 (13) 中使用此表达式会导致
| (17) |
这适用于。 因此,概率可以计算为
| (18) |
这里,我们假设。
对于数据集中存在异常值的情况,我们有
这就完成了对抗性移除场景的证明。 最后,通过并集,我们可以得到大小为 的移除集 ,
| random removals: | |||
| adversarial removals: |
而且,概率自然满足
∎
附录G算法3与量化-means之间的比较
在Ginart等人(2019)中,提出了量化-means来解决集中式环境中类似的机器失学习问题。 然而,这种方法与 Alg 有很大不同。 3. 首先,量化 -means 背后的直觉是,质心是通过取平均值来计算的,当删除后簇中剩余足够的项时,少量点的影响可以忽略不计。 因此,如果我们在每次劳埃德迭代后量化所有质心,那么当我们从数据集中删除少量点时,量化质心将不会以很高的概率发生变化。 与此同时,Alg 背后的直觉。 3如引理F.1中所述。 其次,量化 -means 的预期移除时间复杂度等于 ,该复杂度很高,因为需要检查每次迭代移除后所有量化质心是否保持不变,其中 表示收敛前Lloyd迭代的最大次数,是一些内在参数。 相比之下,阿尔格. 即使对于对抗性删除,3也只需要。 另请注意,所描述的量化 均值算法不提供删除时间复杂度的性能保证,除非它是随机初始化的。
附录 H量化
对于均匀量化,我们设置 ,其中 222我们还可以按照 Ginart 等人 (2019) 中的建议在量化过程中添加随机移位,以使数据在量化仓。. 参数确定每个维度中量化仓的数量。 假设所有客户端数据都位于以原点为中心的单位超立方体中,并且如果需要,则执行预处理以满足此要求。 那么每个维度的量化仓数量等于,而维度的量化仓总数为。
在第 4 节中,我们提到可以通过选择量化仓中心作为代表点,并赋予其等于 的权重来生成 点。 然后,在行中,我们可以在服务器端使用加权-means++算法来进一步降低计算复杂度,因为服务器端的有效问题大小从到。 然而,在实践中我们发现,当服务器的计算能力不是 FL 系统的瓶颈时,在量化仓内均匀随机生成数据点通常可以提高聚类性能。 因此,这是我们后续数值模拟的默认方法。
附录一简化联合 - 表示集群
当未执行第 3 节中所述的隐私标准时,如在 Dennis 等人 (2021) 的框架中所做的那样,可以跳过第 3-6 行藻类。 1并将客户端获得的质心集以及簇大小直接发送到服务器。 然后,可以在服务器端对聚合质心集运行加权-means++算法,得到。 Alg 中显示了该简化情况的伪代码。 5. 它遵循与 Guha 等人 (2003) 的分而治之方案类似的想法; Ailon 等人 (2009),为分布式集群而开发。
在 Alg 的第 5 行中。 5,加权-means++会在初始化过程中计算采样概率以及在劳埃德迭代期间计算集群平均值时为数据点分配权重。 由于我们在这里考虑的权重始终是正整数,因此加权数据点也可以被视为数据集中存在相同的数据点,其重数等于权重。
附录 J 给定 的向量 的唯一性
证明 Alg 生成的消息。 2可以被唯一解码,我们证明存在唯一的,它在服务器上产生聚合值。 证明是通过反证法。 假设存在两个不同的向量和,它们产生相同的。 在这种情况下,我们有以下一组线性方程。 假设 和 最多表示 个未知数和 个系数,线性方程可以使用范德蒙方阵来描述系数,其中 的列由 中非零条目的索引生成。 这导致了矛盾,因为具有不同列生成器的范德蒙方阵是可逆的,如下所示。 因此,对于不同的,聚合值必须不同。 类似地,对于不同的向量、、选择,总和是不同的。
如果两个向量 和 产生相同的 ,则所有 都产生 。 令 为整数集,使得 和 中至少有一个对于 来说不为零。 请注意。 将这个方程重写为
| (26) |
从开始,我们取(26)中的第一个方程并将它们重写为
在哪里
是范德蒙方阵并且
自 以来是一个非零向量。 众所周知,范德蒙方阵 的行列式由 给出,在我们的例子中它是非零的,因为所有 都是不同的。 因此,是可逆的,并且不允许有非零解,这与方程相矛盾。
附录 K 服务器端 SCMA 的确定性低复杂度算法
在我们在 Alg 中描述的 SCMA 方案中。 1,服务器的目标是重建向量,给定的值。 为此,我们首先使用Berlekamp-Massey算法来计算多项式。 然后,我们使用 Kedlaya & Umans (2011) 中描述的算法在有限域 上分解 。 4.3 节中提到的复杂度 对应于平均复杂度(找到一种确定性算法,该算法在有限域上分解多项式,其最坏情况复杂度为 是一个开放性问题)。 SCMA方案的附录C中提到的复杂度表示平均复杂度。
接下来我们表明,SCMA 方案在服务器端的确定性解码算法下也具有较小的最坏情况复杂度。 为此,我们替换 Alg 中的整数 。 2 具有较大的数字 ,使得 大于最大可能的 ,并且在应用模数时不会溢出 对 进行操作。 已知(伯特兰公设)任何整数 和 之间都存在一个素数,因此必定存在一个下界为 的素数> 和下限 的两倍。 然而,由于搜索这种大小的素数在计算上可能很困难,因此我们删除了 是素数的要求。 相应地,不一定是有限域。 然后,客户端、将发送到服务器,而不是发送,其中随机密钥 独立且均匀地分布在 上并对服务器隐藏。 服务器获取到、后,由于计算时不会发生溢出,因此可以继续对实数域进行运算。 我们注意到,虽然 是指数级的大数据,但 和 、 和 的计算仍然是可控的,并且是通过使用 浮点数计算和存储 和 来实现的,而不是使用单个浮点数计算和存储 。 请注意, 可以使用 浮点数计算,其复杂度几乎与 成线性关系(即对于某个常数 ,)。
我们现在在服务器上提出一种低复杂度的安全聚合算法。 重建后,我们有。 服务器切换到真实领域的计算。 首先,它使用Berlekamp-Massey算法求多项式(该算法最初是为有限域上的BCH码解码而提出的,但它适用于任意域)。 令 为 的次数。 然后。 目标是在实数域上对 进行因式分解,其中已知根是 中的整数,并且每个根的重数为 1。
如果的次数是奇数,则和。 然后我们可以使用二分搜索来找到 的根,这需要对 进行 多项式计算,从而进行 乘法和大小最多为 的整数的加法运算。 找到一个根后,我们可以将除以并开始下一次寻根迭代。
如果的次数是偶数,那么的次数是奇数,并且的根不同并且局限于。 我们使用二分搜索来查找 的根 。 如果,那么我们对使用二分搜索来找到的根,并在 如果,则和。 我们使用二分搜索在中找到的另一个根。 请注意,对于满足 和 的 的每两个根 和 (),我们总能在 中找到 的另一个根 。 我们不断迭代搜索每两个这样的根,直到找到的根列表,使得为奇数 中的 和 甚至 。 然后我们可以对集合进行二分搜索,找到的根。 请注意,在迭代期间,我们需要 二分搜索迭代来查找 的根 和 二分搜索迭代来查找 是 的根。
因此,总计算复杂度最多为 次多项式求值,次数最多为 且最多为 次多项式除法,这最多需要 大小最多为 的整数的乘法和加法。 对于某些常量 ,这会导致总体复杂度为 。
附录L 分配矩阵和之间的差异
解释这两个分配矩阵之间差异的一个示例如下。 假设集中式和 FC 设置的全局数据集和质心集相同,即
假设对于 (即 的第一行),我们有
那么,的第一行等于。 但是,如果驻留在客户端的内存上并且属于本地集群,并且记录的本地质心满足
那么的第一行是,即使是。 这里 是客户端 上矩阵 的行串联。此示例显示赋值矩阵 和 不同,这也意味着 和 不同。
附录 M实验设置和其他结果
M.1数据集
在下文中,我们描述了数值实验中使用的数据集。 请注意,我们对所有数据集进行了预处理,使得数据矩阵中每个元素的绝对值小于。 每个数据集都有一个表示最佳簇数量的内在参数,这些参数在集中式-means++算法中用于计算最佳目标值的近似值。 我们在后续推导中使用来表示-means++算法返回的目标值。 除了之外,我们还为每个客户端数据设置一个附加参数,以便客户端级别的真实集群数量不大于。 这个非 i.i.d. Dennis 等人 (2021) 中讨论了跨客户端的数据分发。 对于小型数据集(例如 TCGA、TMI),我们将客户端数量 视为 ,并为所有其他数据集设置 。
Celltype [] (Han 等人, 2018; Gardner 等人, 2014b) 包含属于四种细胞类型混合物的单细胞 RNA 序列:成纤维细胞、小胶质细胞、内皮细胞和间充质干细胞。 从小鼠细胞图谱中检索的数据由 数据点组成,每个样本具有 特征维度,使用 Primary 从原始维度 减少成分分析(PCA)。 四个簇的大小333通过多次运行集中式-means++聚类并选择导致最低目标值的聚类来获得聚类。 是。
姿势 [] (Gardner 等人, 2014b; a) 包括通过动作捕捉系统和不同的用户执行五种手势——握拳、用一根手指指向、用两根手指指向、停止(手平放)和抓住(手指卷曲)。 为了建立旋转和平移不变的局部坐标系,利用了手套背面的刚性未标记图案。 数据集中共有个样本,数据维度为。 给定簇的大小为。
Covtype [] (Blackard & Dean,1999) 包含从美国林务局 (USFS) 获得的七种森林覆盖类型的数字空间数据,以及美国地质调查局 (USGS)。 有 制图变量,包括坡度、高程和坡向。 数据集有 个样本。 七个簇的大小为。
高斯 []包含十个簇,每个簇都是根据变量高斯分布生成的,该分布均匀地集中在单位超立方体中随机选择的位置。 从每个簇中提取 个样本,总共 个样本。 每个高斯簇都是球形的,方差为 。
FEMNIST [] (Caldas 等人, 2018) 是一个流行的 FL 基准数据集,包含数字 (0-9) 和字母的图像来自超过 个用户的英文字母(大写和小写)。 它的数据集本质上是从扩展 MNIST 存储库(Cohen 等人,2017) 构建的,根据数字/字符的作者对其进行分区。 我们提取与个不同客户端相对应的数据,每个客户端至少贡献了个数据点。 每个图像都有尺寸。 最大簇的大小为,最小簇的大小为。
TCGA [] 甲基化由癌症基因组图谱 (TCGA) 中 样本的甲基化微阵列数据组成 (Hutter & Zenklusen, 2018) 对应四种不同的癌症类型:低级别胶质瘤(LGG)、肺腺癌(LUAD)、肺鳞状细胞癌(LUSC)和胃腺癌(STAD)。 The observed features correspond to a subset of values, representing the coverage of the methylated sites, at locations on the promoters of different genes (ATM, BRCA1, CASP8, CDH1, IGF2, KRAS, MGMT, MLH1, PTEN, SFRP5 and TP53). 选择该基因子集是因为其与癌发生的相关性。 四个簇的大小为。
TMI [] 包含来自人类肠道微生物组的样本。 我们从 NIH 人类肠道微生物组(Peterson 等人,2009)中检索了人类肠道微生物组样本。 每个数据点的维度为,捕获样本中已识别细菌种类或属的频率(浓度)。 该数据集可以根据性别和年龄大致分为四类。 四个簇的大小为。
M.2基线设置。
我们使用 K-FED 和 DC-KM 的公开实现作为我们的基准方法。 对于DC-KM,我们将计算树的高度设置为,并观察叶子代表客户端。 由于K-FED原本不支持数据去除,计算复杂度较高,其聚类性能无法与DC-KM相比(见表1)。 1),因此我们仅比较 MUFC 与 DC-KM 的忘却性能。 在训练期间,所有方法的集群参数 在客户端和服务器中设置为相同,无论数据如何在客户端之间分布。 除 FEMNIST 之外的所有数据集上的实验均重复 次以获得均值和标准差,并且由于训练复杂度较高,FEMNIST 上的实验重复 次。 请注意,我们使用了与 Ginart 等人 (2019) 中相同数量的重复实验。
M.3 为 MUFC 启用完整客户端训练
请注意,K-FED 和 DC-KM 都允许客户端执行完整的 -means++ 集群,以提高服务器上的集群性能。 因此,为 MUFC 启用完整的客户端训练以及比较完整数据集上的集群性能是合理的。 尽管在这种情况下,我们需要根据每个删除请求重新训练受影响的客户端和 MUFC 服务器,从而导致与 DC-KM 类似的遗忘复杂性,但 MUFC 的集群性能始终优于其他两种基线方法(参见选项卡) 。 2)。 这是因为我们利用了有关客户端质心的聚合权重的信息。
| TMI | Celltype | Gaussian | TCGA | Postures | FEMNIST | Covtype | ||
|---|---|---|---|---|---|---|---|---|
| Loss ratio | MUFC | |||||||
| K-FED | ||||||||
| DC-KM |
M.4损失率和遗忘效率
M.5批量移除
在图5中,我们绘制了与在一个删除请求(批量删除)中删除多个点有关的结果。 由于在这种情况下,受影响的客户端更有可能为每个请求重新运行 -means++ 初始化,因此预计我们算法的性能(即累积删除时间)将在以下情况下表现得更类似于重新训练:与图 3 中我们仅在一个删除请求中删除一个点的情况相比,我们在一个删除请求中删除了更多点。
