PP-YOLOE-R: 一种高效的无锚点旋转目标检测器
摘要
任意方向目标检测是视觉场景中涉及航空图像和场景文本的一项基本任务。 在本报告中,我们介绍了 PP-YOLOE-R,一种基于 PP-YOLOE 的高效无锚点旋转目标检测器。 我们在 PP-YOLOE-R 中引入了一组有用的技巧,以在边际额外的参数和计算成本下提高检测精度。 结果,PP-YOLOE-R-l 和 PP-YOLOE-R-x 在 DOTA 1.0 数据集上分别以单尺度训练和测试实现了 78.14 和 78.28 mAP,优于几乎所有其他旋转目标检测器。 通过多尺度训练和测试,PP-YOLOE-R-l 和 PP-YOLOE-R-x 将检测精度进一步提高到 80.02 和 80.73 mAP。 在这种情况下,PP-YOLOE-R-x 超越了所有无锚点方法,并在性能方面与最先进的基于锚点的两阶段模型相媲美。 此外,PP-YOLOE-R 易于部署,PP-YOLOE-R-s/m/l/x 在 RTX 2080 Ti 上使用 TensorRT 和 FP16 精度分别可以达到 69.8/55.1/48.3/37.1 FPS。 源代码和预训练模型可在 PaddleDetection111https://github.com/PaddlePaddle/PaddleDetection 上获得,它由 PaddlePaddle222https://github.com/PaddlePaddle/Paddle 提供支持。
1 引言
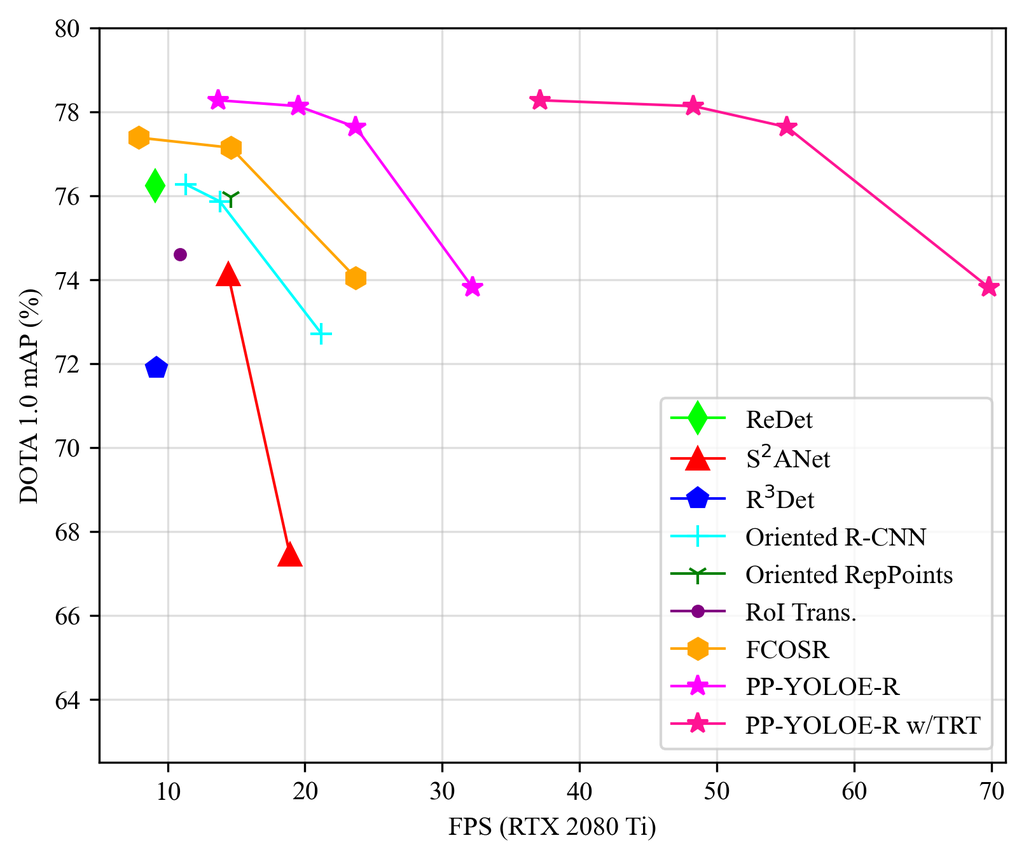
检测任意方向的目标对于理解遥感图像至关重要,并已引起越来越多的关注。 由于物体尺寸和方向的巨大变化,旋转目标检测仍然具有挑战性。 得益于水平目标检测的快速发展,越来越多的旋转目标检测器[2, 5, 7, 24, 6, 16, 13, 10, 8, 11, 20] 逐渐出现,这些检测器主要来自相应的水平目标检测器[14, 17, 18, 28]。 在这些旋转目标检测器中,定向目标的表示大致可以分为三种方式,分别是具有五个参数的旋转边界框、具有八个参数的四边形和一组关键点。 目前,基于五参数表示的旋转目标检测器在该研究领域占主导地位。 尽管取得了可喜的成果,但直接五参数回归仍然存在一些理论问题,例如边界不连续问题[22, 23, 25]。 边界不连续问题主要是由角度的周期性和边的交换能力造成的,而后者与旋转边界框的具体定义相关,例如长边定义。 许多工作被提出用来解决边界不连续问题,例如[15, 25, 26, 27, 22, 23]。 [15, 25, 26, 27] 将旋转边界框建模为高斯分布,并提出计算友好的基于IoU的损失作为可微SkewIoU损失的替代,以避免直接角度回归。 [22, 23] 将角度预测视为分类,并设计平滑标签以避免边界不连续问题。 我们充分借鉴了先进的水平和定向检测器的优秀思想,提出了 PP-YOLOE-R,这是一种基于 PP-YOLOE[21] 的高效无锚点旋转目标检测器。
与 PP-YOLOE 相比,PP-YOLOE-R 的主要变化可以归结为四个方面:(1) 我们引入了类似[13] 的 ProbIoU 损失[15] 作为回归损失,以避免边界不连续问题。 (2) 我们引入了旋转任务对齐学习,使其适用于基于任务对齐学习[4] 的旋转目标检测。 (3) 我们设计了一个解耦角度预测头,并通过 DFL 损失[12] 直接学习角度的一般分布,以实现更准确的角度预测。 (4) 我们对重新参数化机制[3] 进行了一些小的修改,通过添加可学习的门控单元来控制来自前一层的的信息量。 结果表明,PP-YOLOE-R 在 DOTA 1.0 数据集上以速度和精度折衷方面取得了最先进的性能。 具体来说,PP-YOLOE-R-l 和 PP-YOLOE-R-x 在单尺度训练和测试中分别实现了 78.14 和 78.28 的 mAP。 通过多尺度训练和测试,PP-YOLOE-R-l 和 PP-YOLOE-R-x 进一步将检测精度提高到 80.02 和 80.73 mAP。 在保持高精度的同时,PP-YOLOE-R-l 可以使用 TensorRT 和 FP16 精度在 10241024 分辨率下达到 48.3 FPS 的速度。 此外,PP-YOLOE-R-s 和 PP-YOLOE-R-m 也有着出色的性能,适合计算能力相对较低的边缘设备。 我们的代码可以在 PaddleDetection[1] 中获得。
2 相关工作
基于锚点的旋转目标检测器。 基于锚点的旋转目标检测器与水平目标检测器类似,具有单阶段和两阶段的方法。 RoI Transformer[2] 提出了一个 RRoI 学习器来预测旋转地面实况 (RGT) 相对于预测的 HRoI 的偏移量。 Oriented R-CNN[20] 设计了一个轻量级的定向 RPN 来生成高质量的定向建议。 ReDet[7] 引入了旋转等变卷积神经网络 (ReCNN) 来获得旋转等变特征图,以及旋转不变 RoI 对齐 (RiRoI Align) 来提取 RRoI 的特征。 S2ANet[6] 和 R3Det[24] 都采用了改进的单阶段框架来检测定向对象。 S2ANet 提出了基于可变形卷积网络的对齐卷积层 (ACL),而 R3Det 设计了基于插值的特征细化模块 (FRM) 来缓解特征错位。
无锚旋转目标检测器。 无锚旋转目标检测器主要基于中心点或一组关键点。 DAFNe[10] 提出了定向中心度和中心到角点预测策略,而 FCOSR[13] 侧重于基于 FCOS[18] 的标签分配策略来提高检测性能。 CFA[5] 和 Oriented RepPoints[11] 通过基于 RepPoints[28] 预测九个代表点,间接预测方向边界框。
| Model | mAP(%) | Parameters(M) | GFLOPs |
| baseline | 75.61 | 50.65 | 269.09 |
| +Rotated Task Alignment Learning | 77.24 (1.63) | 50.65 | 269.09 |
| +Decoupled Angle Prediction Head | 77.78 (0.54) | 52.20 | 272.72 |
| +Angle Prediction with DFL | 78.01 (0.23) | 53.29 | 281.65 |
| +Learnable Gating Unit for RepVGG | 78.14 (0.13) | 53.29 | 281.65 |
标签分配。 标签分配的目的是区分正样本和负样本。 标签分配可以分为静态和动态策略。 在训练过程中,动态标签分配利用模型的输出作为选择正样本和负样本的依据,而静态标签分配根据真实值和预定义规则确定正样本和负样本。 FCOSR[13] 提出了椭圆中心采样方法、模糊样本分配策略和多级采样模块来缓解采样不足的问题。 [8] 提出了形状自适应选择 (SA-S) 来根据样本的形状调整 IoU 阈值。 G-Rep[9] 用归一化的高斯分布距离代替 IoU 作为分配指标。 DAL[16] 引入了一个匹配度,考虑了空间匹配和特征对齐能力的先验来动态选择正样本。 同样,Oriented RepPoints[11] 设计了一种质量度量来分配样本。
损失。 由于角度的周期性和边的交换能力,基于直接回归的旋转目标检测器会遇到边界不连续问题。 CSL[23] 和 DCL[22] 以分类的方式预测角度。 为了避免边界不连续问题,GWD[25]、ProbIoU[15]、KLD[26] 和 KFIoU[27] 将旋转边界框转换为二维高斯分布,并构建两个高斯分布的距离度量来衡量两个旋转边界框的相似度。 GWD[25] 利用高斯瓦瑟斯坦距离来近似 SkewIoU,而 ProbIoU[15] 利用 Bhattacharyya 系数来衡量两个旋转边界框的相似度。 KLD[26] 计算两个高斯分布之间的 Kullback-Leibler 散度 (KLD) 作为回归损失。 此外,KFIoU[27] 通过采用卡尔曼滤波来模拟 SkewIoU,根据其定义实现了与 SkewIoU 的趋势级对齐。
3 方法
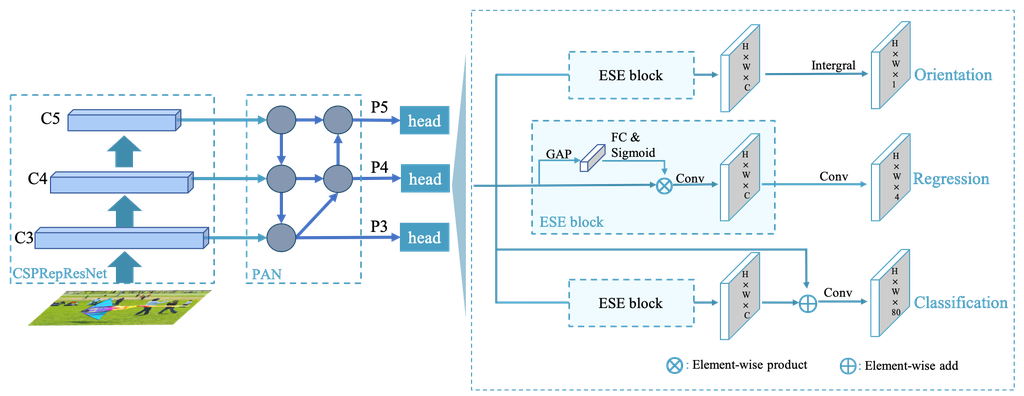
如图 2 所示,PP-YOLOE-R 的整体架构与 PP-YOLOE 相似。 PP-YOLOE-R 基于 PP-YOLOE,在参数和计算量相对较少的情况下提高了旋转边界框的检测性能。 在本节中,我们将详细介绍为旋转边界框所做的更改。
基线。 基于 FCOSR[13],我们将 FCOSR 分配器和 ProbIoU 损失引入 PP-YOLOE 作为我们的基线。 采用 FCOSR 分配器根据预定义规则将真实值分配到三个特征图,并使用 ProbIoU 损失作为回归损失。 我们基线的骨干网络和颈部与 PP-YOLOE 保持一致,而头部回归分支被修改为直接预测五参数旋转边界框 ()。 我们的基线在单尺度训练和测试中达到了 75.61 mAP,如表 1 所示。
旋转任务对齐学习。 任务对齐学习[4] 由任务对齐标签分配和任务对齐损失组成。 任务对齐标签分配构建任务对齐度量来从候选锚点中选择正样本,这些锚点坐标落在任何真实值框内。 任务对齐度量计算如下:
| (1) |
其中 表示预测的分类分数, 表示预测边界框与对应真值之间的 IoU 值。 在旋转任务对齐学习中,候选锚点选择过程利用了真值边界框及其中的锚点的几何属性,并采用预测边界框与真值边界框的 SkewIoU 值作为 。 通过这两个简单的更改,我们可以将任务对齐标签分配应用于旋转目标检测,并在无需修改的情况下使用任务对齐损失。 通过使用旋转任务对齐学习,如 表 1 所示,检测精度进一步提高到 77.24 mAP。
解耦角度预测头。 在回归分支中,大多数旋转目标检测器预测五个参数 () 来表示定向目标。 但是,我们假设预测 需要与预测 () 不同的特征。 为了验证这一假设,我们设计了一个解耦角度预测头,如 图 2 所示,分别预测 和 ()。 角度预测头由一个通道注意力层和一个卷积层组成,非常轻量级。 通过引入解耦角度预测头,检测精度提高了 0.54 mAP,达到 77.24 mAP,如 表 1 所示。
| Methods | Backbone | MS | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
| Anchor-based Methods | ||||||||||||||||||
| RoI-Trans.[2] | R101 | ✓ | 88.64 | 78.52 | 43.44 | 75.92 | 68.81 | 73.68 | 83.59 | 90.74 | 77.27 | 81.46 | 58.39 | 53.54 | 62.83 | 58.93 | 47.67 | 69.56 |
| DAL[16] | R101 | 88.61 | 79.69 | 46.27 | 70.37 | 65.89 | 76.10 | 78.53 | 90.84 | 79.98 | 78.41 | 58.71 | 62.02 | 69.23 | 71.32 | 60.65 | 71.78 | |
| CSL[23] | R152 | ✓ | 90.25 | 85.53 | 54.64 | 75.31 | 70.44 | 73.51 | 77.62 | 90.84 | 86.15 | 86.69 | 69.60 | 68.04 | 73.83 | 71.10 | 68.93 | 76.17 |
| R3Det[24] | R152 | ✓ | 89.80 | 83.77 | 48.11 | 66.77 | 78.76 | 83.27 | 87.84 | 90.82 | 85.38 | 85.51 | 65.57 | 62.68 | 67.53 | 78.56 | 72.62 | 76.47 |
| DCL[22] | R152 | ✓ | 89.26 | 83.60 | 53.54 | 72.76 | 79.04 | 82.56 | 87.31 | 90.67 | 86.59 | 86.98 | 67.49 | 66.88 | 73.29 | 70.56 | 69.99 | 77.37 |
| S2ANet[6] | R50 | ✓ | 88.89 | 83.60 | 57.74 | 81.95 | 79.94 | 83.19 | 89.11 | 90.78 | 84.87 | 87.81 | 70.30 | 68.25 | 78.30 | 77.01 | 69.58 | 79.42 |
| ReDet[7] | ReR50 | ✓ | 88.81 | 82.48 | 60.83 | 80.82 | 78.34 | 86.06 | 88.31 | 90.87 | 88.77 | 87.03 | 68.65 | 66.90 | 79.26 | 79.71 | 74.67 | 80.10 |
| GWD[25] | R152 | ✓ | 89.66 | 84.99 | 59.26 | 82.19 | 78.97 | 84.83 | 87.70 | 90.21 | 86.54 | 86.85 | 73.47 | 67.77 | 76.92 | 79.22 | 74.92 | 80.23 |
| KLD[26] | R152 | ✓ | 89.92 | 85.13 | 59.19 | 81.33 | 78.82 | 84.38 | 87.50 | 89.80 | 87.33 | 87.00 | 72.57 | 71.35 | 77.12 | 79.34 | 78.68 | 80.63 |
| Oriented R-CNN[20] | R50 | ✓ | 89.84 | 85.43 | 61.09 | 79.82 | 79.71 | 85.35 | 88.82 | 90.88 | 86.68 | 87.73 | 72.21 | 70.80 | 82.42 | 78.18 | 74.11 | 80.87 |
| RoI-Trans. + KFIoU[27] | Swin-Tiny | ✓ | 89.44 | 84.41 | 62.22 | 82.51 | 80.10 | 86.07 | 88.68 | 90.90 | 87.32 | 88.38 | 72.80 | 71.95 | 78.96 | 74.95 | 75.27 | 80.93 |
| Anchor-free Methods | ||||||||||||||||||
| BBAVectors[29] | R101 | ✓ | 88.63 | 84.06 | 52.13 | 69.56 | 78.26 | 80.40 | 88.06 | 90.87 | 87.23 | 86.39 | 56.11 | 65.62 | 67.10 | 72.08 | 63.96 | 75.36 |
| CFA[5] | R152 | ✓ | 89.08 | 83.20 | 54.37 | 66.87 | 81.23 | 80.96 | 87.17 | 90.21 | 84.32 | 86.09 | 52.34 | 69.94 | 75.52 | 80.76 | 67.96 | 76.67 |
| Oriented RepPoints[11] | Swin-Tiny | 89.11 | 82.32 | 56.71 | 74.95 | 80.70 | 83.73 | 87.67 | 90.81 | 87.11 | 85.85 | 63.60 | 68.60 | 75.95 | 73.54 | 63.76 | 77.63 | |
| FCOSR-s[13] | MV2 | 89.09 | 80.58 | 44.04 | 73.33 | 79.07 | 76.54 | 87.28 | 90.88 | 84.89 | 85.37 | 55.95 | 64.56 | 66.92 | 76.96 | 55.32 | 74.05 | |
| FCOSR-s[13] | MV2 | ✓ | 88.60 | 84.13 | 46.85 | 78.22 | 79.51 | 77.00 | 87.74 | 90.85 | 86.84 | 86.71 | 64.51 | 68.17 | 67.87 | 72.08 | 62.52 | 76.11 |
| FCOSR-m[13] | X50 | 88.88 | 82.68 | 50.10 | 71.34 | 81.09 | 77.40 | 88.32 | 90.80 | 86.03 | 85.23 | 61.32 | 68.07 | 75.19 | 80.37 | 70.48 | 77.15 | |
| FCOSR-m[13] | X50 | ✓ | 89.06 | 84.93 | 52.81 | 76.32 | 81.54 | 81.81 | 88.27 | 90.86 | 85.20 | 87.58 | 68.63 | 70.38 | 75.95 | 79.73 | 75.67 | 79.25 |
| FCOSR-l[13] | X101 | 89.50 | 84.42 | 52.58 | 71.81 | 80.49 | 77.72 | 88.23 | 90.84 | 84.23 | 86.48 | 61.21 | 67.77 | 76.34 | 74.39 | 74.86 | 77.39 | |
| FCOSR-l[13] | X101 | ✓ | 88.78 | 85.38 | 54.29 | 76.81 | 81.52 | 82.76 | 88.38 | 90.80 | 86.61 | 87.25 | 67.58 | 67.03 | 76.86 | 73.22 | 74.68 | 78.80 |
| PP-YOLOE-R-s | CRN-s | 88.80 | 79.24 | 45.92 | 66.88 | 80.41 | 82.95 | 88.20 | 90.61 | 82.91 | 86.37 | 55.80 | 64.11 | 65.09 | 79.50 | 50.43 | 73.82 | |
| PP-YOLOE-R-s | CRN-s | ✓ | 88.93 | 83.95 | 56.60 | 79.40 | 82.57 | 85.89 | 88.64 | 90.87 | 87.82 | 87.54 | 68.94 | 63.46 | 76.66 | 79.19 | 70.87 | 79.42 |
| PP-YOLOE-R-m | CRN-m | 89.23 | 79.92 | 51.14 | 72.94 | 81.86 | 84.56 | 88.68 | 90.85 | 86.85 | 87.48 | 59.16 | 68.34 | 73.78 | 81.72 | 68.10 | 77.64 | |
| PP-YOLOE-R-m | CRN-m | ✓ | 88.63 | 84.45 | 56.27 | 79.12 | 83.52 | 86.16 | 88.77 | 90.81 | 88.01 | 88.39 | 70.41 | 61.44 | 77.65 | 77.70 | 74.30 | 79.71 |
| PP-YOLOE-R-l | CRN-l | 89.18 | 81.00 | 54.01 | 70.22 | 81.85 | 85.16 | 88.81 | 90.81 | 86.99 | 88.01 | 62.87 | 67.87 | 76.56 | 79.13 | 69.65 | 78.14 | |
| PP-YOLOE-R-l | CRN-l | ✓ | 88.40 | 84.75 | 58.91 | 76.35 | 83.13 | 86.10 | 88.79 | 90.87 | 88.74 | 87.71 | 67.71 | 68.44 | 77.92 | 76.17 | 76.35 | 80.02 |
| PP-YOLOE-R-x | CRN-x | 89.49 | 79.70 | 55.04 | 75.59 | 82.40 | 85.20 | 88.35 | 90.76 | 85.69 | 87.70 | 63.17 | 69.52 | 77.09 | 75.08 | 69.38 | 78.28 | |
| PP-YOLOE-R-x | CRN-x | ✓ | 88.45 | 84.46 | 60.57 | 77.70 | 83.34 | 85.36 | 88.97 | 90.78 | 88.53 | 87.47 | 69.26 | 65.96 | 77.86 | 81.36 | 80.93 | 80.73 |
使用 DFL 进行角度预测。 采用 ProbIoU 损失作为回归损失,以共同优化 ()。 为了计算 ProbIoU 损失,旋转边界框被转换为高斯边界框。 当旋转边界框大致为正方形时,无法确定旋转边界框的方向,因为高斯边界框中的方向是从椭圆表示继承的。 为了克服这个问题,我们引入了分布焦点损失 (DFL) [12] 来预测角度。 与 -范数学习狄拉克 delta 分布不同,DFL 旨在学习角度的通用分布。 具体来说,我们用等间隔 对角度进行离散化,并获得积分形式的预测 ,其可以表述如下:
| (2) |
其中 表示角度落在每个间隔内的概率。 在本文中,旋转边界框是在 OpenCV 定义中定义的, 设置为 。 通过引入 DFL,检测精度提高了 0.23 mAP,达到 78.01 mAP。
用于 RepVGG 的可学习门控单元。 RepVGG 提出了一个由 33 卷积、11 卷积和捷径路径组成的多分支架构。 RepVGG 的训练时间信息流可以表述如下:
| (3) |
其中 是一个 33 卷积, 是一个 11 卷积。 在推理期间,我们可以将此架构重新参数化为等效的 33 卷积。 尽管 RepVGG 等同于一个卷积层,但在训练期间使用 RepVGG 收敛效果更好。 我们将此结果归因于 RepVGG 的设计引入了有用的先验知识。 受此启发,我们在 RepVGG 中引入了一个可学习的门控单元来控制来自先前层的的信息量。 这种设计主要是为了适应性地融合具有不同感受野的特征的小物体或密集物体,可以表述如下:
| (4) |
其中 和 是可学习的参数。 在我们的 RepResBlock[21] 中,没有使用捷径路径,因此我们为每个 RepResBlock 引入了一个参数。 在推理过程中,可学习的参数可以与卷积层一起重新参数化,这样既不会改变速度也不会改变参数量。 通过引入可学习的门控单元,检测精度提高了 0.13 mAP,达到 78.14 mAP。
ProbIoU 损失。 通过将旋转边界框建模为高斯边界框,在 ProbIoU[15] 中使用两个高斯分布的 Bhattacharyya 系数来衡量两个旋转边界框的相似性。 GWD[25]、KLD[26] 和 KFIoU [27] 也是基于高斯边界框的相似性度量。 为了验证 ProbIoU 损失的效果,我们选择 KLD 损失进行实验,因为 KLD 损失是尺度不变的,并且适用于无锚方法。 如 表 3 所示,用 KLD 损失替换 ProbIoU 损失会导致性能显著下降,从 78.14 mAP 降至 76.03 mAP,这表明 ProbIoU 损失更适合我们的设计。
| Loss | mAP(%) |
| ProbIoU loss[15] | 78.14 |
| KLD loss[26] | 76.03 |
4 实验
4.1 数据集
DOTA[19] 是一个用于面向对象检测的大规模遥感数据集,其中包含 15 个类别:飞机 (PL)、棒球场 (BD)、桥梁 (BR)、跑道 (GTF)、小型车辆 (SV)、大型车辆 (LV)、船舶 (SH)、网球场 (TC)、篮球场 (BC)、储油罐 (ST)、足球场 (SBF)、环岛 (RA)、港口 (HA)、游泳池 (SP) 和直升机 (HC)。 DOTA 包含 2806 张航空图像,大小约为 4000 × 4000 像素,以及 188,282 个实例,具有多种比例、方向和形状。 将一半的航空图像随机选为训练集,1/6 为验证集,1/3 为测试集。 对于单尺度训练和测试,我们将原始图像裁剪成 10241024 的块,重叠 256 像素。 对于多尺度训练和测试,原始图像被调整为 0.5、1.0 和 1.5 的比例,然后被裁剪成 10241024 的块,重叠 500 像素。
4.2 实现细节
PP-YOLOE-R 采用 CSPRepResNet 作为主干网络,PAN 作为颈部网络,以提取 P3、P4 和 P5 金字塔特征用于旋转目标检测。 在我们的训练中,使用了带动量 = 0.9 和权重衰减 = 5e-4 的随机梯度下降 (SGD)。 初始学习率设置为 0.008,预热 1000 次迭代,预热后使用余弦学习率调度。 我们使用 DOTA 1.0 数据集训练所有模型共 36 个 epoch,并使用 4 个具有 32G 内存的 Tesla V100 GPU 设备进行训练,总批次大小为 8。 在训练过程中,还采用了衰减 = 0.9998 的指数移动平均 (EMA) 策略。 我们采用随机翻转,并遵循 FCOSR[13] 采用两步旋转增强方法生成随机增强数据。
4.3 与其他最先进检测器比较
我们在 DOTA 1.0 数据集上进行了大量实验,实验结果如 表 2 所示。 在单尺度训练和测试中,PP-YOLOE-R-l 和 PP-YOLOE-R-x 分别达到了 78.14 和 78.28 mAP,优于几乎所有旋转目标检测器。 通过多尺度训练和测试,PP-YOLOE-R-l 和 PP-YOLOE-R-x 将检测精度进一步提高到 80.02 和 80.73 mAP。 PP-YOLOE-R-x 优于所有无锚方法,并且仅比精度最高的基于锚的两阶段模型低 0.2 mAP。 此外,PP-YOLOE-R-s 和 PP-YOLOE-R-m 通过多尺度训练和测试可以达到 79.42 和 79.71 mAP,考虑到这两个模型的参数和 GLOPS,这些都是非常出色的结果。 PP-YOLOE-R 在保持高精度的同时,避免使用可变形卷积或旋转 RoI 对齐等特殊算子,以便在各种硬件上友好地部署。 因此,PP-YOLOE-R 可以使用 TensorRT 轻松加速,而目前大多数其他 SOTA 模型并不容易使用 TensorRT 部署。 在 10241024 的输入分辨率下,PP-YOLOE-R-s/m/l/x 在 RTX 2080Ti 上可以达到 32.2/23.7/19.5/13.7 FPS。 使用 TensorRT 和 FP-16 精度,PP-YOLOE-R-s/m/l/x 可以进一步加速到分别为 69.8/55.1/48.3/37.1 FPS。
5 结论
在本报告中,我们提出了 PP-YOLOE-R,这是一种基于 PP-YOLOE 的高效无锚旋转目标检测器。 PP-YOLOE-R 以微不足道的额外参数和计算成本实现了高精度和实时速度,超越了所有无锚旋转目标检测器。 PP-YOLOE-R 易于部署,并针对不同计算能力的设备提供了一系列模型,命名为 s/m/l/x。 在未来,我们将针对更多旋转目标检测数据集进行实验,并将 PP-YOLOE-R 扩展到相关场景。
参考文献
- [1] PaddlePaddle Authors. Paddledetection, object detection and instance segmentation toolkit based on paddlepaddle. https://github.com/PaddlePaddle/PaddleDetection, 2019.
- [2] Jian Ding, Nan Xue, Yang Long, Gui-Song Xia, and Qikai Lu. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2849–2858, 2019.
- [3] Xiaohan Ding, Xiangyu Zhang, Ningning Ma, Jungong Han, Guiguang Ding, and Jian Sun. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13733–13742, 2021.
- [4] Chengjian Feng, Yujie Zhong, Yu Gao, Matthew R Scott, and Weilin Huang. Tood: Task-aligned one-stage object detection. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 3490–3499. IEEE Computer Society, 2021.
- [5] Zonghao Guo, Chang Liu, Xiaosong Zhang, Jianbin Jiao, Xiangyang Ji, and Qixiang Ye. Beyond bounding-box: Convex-hull feature adaptation for oriented and densely packed object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8792–8801, 2021.
- [6] Jiaming Han, Jian Ding, Jie Li, and Gui-Song Xia. Align deep features for oriented object detection. IEEE Transactions on Geoscience and Remote Sensing, 60:1–11, 2021.
- [7] Jiaming Han, Jian Ding, Nan Xue, and Gui-Song Xia. Redet: A rotation-equivariant detector for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2786–2795, 2021.
- [8] Liping Hou, Ke Lu, Jian Xue, and Yuqiu Li. Shape-adaptive selection and measurement for oriented object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, 2022.
- [9] Liping Hou, Ke Lu, Xue Yang, Yuqiu Li, and Jian Xue. G-rep: Gaussian representation for arbitrary-oriented object detection. arXiv preprint arXiv:2205.11796, 2022.
- [10] Steven Lang, Fabrizio Ventola, and Kristian Kersting. Dafne: A one-stage anchor-free deep model for oriented object detection. arXiv preprint arXiv:2109.06148, 2021.
- [11] Wentong Li, Yijie Chen, Kaixuan Hu, and Jianke Zhu. Oriented reppoints for aerial object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1829–1838, 2022.
- [12] Xiang Li, Wenhai Wang, Lijun Wu, Shuo Chen, Xiaolin Hu, Jun Li, Jinhui Tang, and Jian Yang. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Advances in Neural Information Processing Systems, 33:21002–21012, 2020.
- [13] Zhonghua Li, Biao Hou, Zitong Wu, Licheng Jiao, Bo Ren, and Chen Yang. Fcosr: A simple anchor-free rotated detector for aerial object detection. arXiv preprint arXiv:2111.10780, 2021.
- [14] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017.
- [15] Jeffri M Llerena, Luis Felipe Zeni, Lucas N Kristen, and Claudio Jung. Gaussian bounding boxes and probabilistic intersection-over-union for object detection. arXiv preprint arXiv:2106.06072, 2021.
- [16] Qi Ming, Zhiqiang Zhou, Lingjuan Miao, Hongwei Zhang, and Linhao Li. Dynamic anchor learning for arbitrary-oriented object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 2355–2363, 2021.
- [17] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 28, 2015.
- [18] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9627–9636, 2019.
- [19] Gui-Song Xia, Xiang Bai, Jian Ding, Zhen Zhu, Serge Belongie, Jiebo Luo, Mihai Datcu, Marcello Pelillo, and Liangpei Zhang. Dota: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3974–3983, 2018.
- [20] Xingxing Xie, Gong Cheng, Jiabao Wang, Xiwen Yao, and Junwei Han. Oriented r-cnn for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3520–3529, 2021.
- [21] Shangliang Xu, Xinxin Wang, Wenyu Lv, Qinyao Chang, Cheng Cui, Kaipeng Deng, Guanzhong Wang, Qingqing Dang, Shengyu Wei, Yuning Du, et al. Pp-yoloe: An evolved version of yolo. arXiv preprint arXiv:2203.16250, 2022.
- [22] Xue Yang, Liping Hou, Yue Zhou, Wentao Wang, and Junchi Yan. Dense label encoding for boundary discontinuity free rotation detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15819–15829, 2021.
- [23] Xue Yang and Junchi Yan. Arbitrary-oriented object detection with circular smooth label. In European Conference on Computer Vision, pages 677–694. Springer, 2020.
- [24] Xue Yang, Junchi Yan, Ziming Feng, and Tao He. R3det: Refined single-stage detector with feature refinement for rotating object. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 3163–3171, 2021.
- [25] Xue Yang, Junchi Yan, Qi Ming, Wentao Wang, Xiaopeng Zhang, and Qi Tian. Rethinking rotated object detection with gaussian wasserstein distance loss. In International Conference on Machine Learning, pages 11830–11841. PMLR, 2021.
- [26] Xue Yang, Xiaojiang Yang, Jirui Yang, Qi Ming, Wentao Wang, Qi Tian, and Junchi Yan. Learning high-precision bounding box for rotated object detection via kullback-leibler divergence. Advances in Neural Information Processing Systems, 34:18381–18394, 2021.
- [27] Xue Yang, Yue Zhou, Gefan Zhang, Jitui Yang, Wentao Wang, Junchi Yan, Xiaopeng Zhang, and Qi Tian. The kfiou loss for rotated object detection. arXiv preprint arXiv:2201.12558, 2022.
- [28] Ze Yang, Shaohui Liu, Han Hu, Liwei Wang, and Stephen Lin. Reppoints: Point set representation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9657–9666, 2019.
- [29] Jingru Yi, Pengxiang Wu, Bo Liu, Qiaoying Huang, Hui Qu, and Dimitris Metaxas. Oriented object detection in aerial images with box boundary-aware vectors. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2150–2159, 2021.