VAID:视觉分析系统中的索引视图设计
摘要。
可视化分析(VA)系统已广泛应用于各个应用领域。 然而,VA系统设计复杂,这带来了一个严重的问题:尽管学术界不断设计和实现新的设计,但这些设计很难被后续设计者查询、理解和参考。 为了标志着解决这一问题的重大一步,我们以一种富有表现力和可访问的方式索引 VA 设计,将设计转换为结构化格式。 我们首先与 VA 设计师进行了研讨会研究,以了解用户对理解和检索 VA 系统专业设计的要求。 此后,我们提出了一个索引结构 VAID 来描述先进的复合可视化设计,并带有关于其分析任务和视觉设计的全面标签。 VAID 的实用性通过用户研究得到了验证。 我们的工作为增强专业可视化设计的可访问性和可重用性开辟了新的视角。
1. 介绍
可视化分析(VA)结合了数据挖掘和可视化技术,帮助用户进行不同领域的数据探索,例如生物学(Krueger等人,2020;Lekschas等人,2018)、体育( Stein 等人, 2018; Cao 等人, 2021), 城市(Deng 等人, 2023b; Lu 等人, 2023), 可解释人工智能 (Gou 等人, 2021;小野等人,2021)。 VA 的研究人员开发了先进的 VA 系统,具有高度定制的可视化设计,用于深入了解数据(Sacha 等人,2014)。 设计有效的 VA 系统极具挑战性和高要求,需要经验丰富的可视化从业者和领域专家之间的密切合作。
视图是 VA 系统的基本构建块。 要创建有效的 VA 系统,通过将领域问题派生的数据和任务映射到可视化设计来设计视图至关重要(Munzner,2009)。 可视化领域的最新进展试图实现此类映射过程的自动化(Srinivasan 等人,2018;Deng 等人,2022;Chen 等人,2021b)。 然而,这些研究建议使用基本统计图表(例如条形图和折线图)来执行低级分析任务,例如查找分布。 它们很难支持在处理复杂数据集和任务的 VA 系统中设计视图(Keim 等人,2008a)。 现有的VA设计流程严重依赖研究人员的经验,需要调查相关研究并总结新场景的设计要求。 由于存在多种设计风格,传递示例可以提供宝贵的灵感(Lee 等人,2010;Herring 等人,2009;Bigelow 等人,2014)。 为了更好地支持视觉分析的设计者和研究人员,受到创造力支持研究(Shneiderman,2002)的启发,我们认为通过探索以前的 VA 视图设计来促进构思过程非常重要。 然而,由于没有有效的索引方法,目前这些视图设计只能通过领域问题等简单的关键词进行搜索,无法满足VA设计者的需求。 由于无法搜索更细粒度的需求,他们很难从大量先前的成功设计中汲取灵感。
为了应对这一挑战,我们的目标是为 VA 系统中的视图设计提出一种索引方法,综合考虑任务、数据和可视化 (芒兹纳,2009)。 然而,目前尚不清楚如何根据这些因素定义指数结构。 例如,从可视化的角度来看,VA 设计可能包含不同视觉元素的混合使用,例如复合可视化 (Javed 和 Elmqvist,2012) 和字形 (Borgo 等人,2013) )。 当用索引表示这些复杂的设计时,保留所有细节可能会导致设计者难以指定其搜索标准以及理解其结构和语义。 另一方面,如果信息被过度抽象为高级描述,例如几个关键词,那么设计者在从返回的视觉设计的索引中搜索所需的设计信息时可能难以准确地表达他们的设计。 在设计索引结构时,平衡表达力和效率很重要。 因此,为了了解设计者对索引结构的要求,我们对12位VA设计者进行了workshop研究,其中大多数人都以第一作者身份在IEEE VAST会议上发表过论文。 通过这项研究,我们验证了对过去的设计进行索引以创建新设计的必要性,并收集了构建此类索引的要求。
根据研讨会研究的用户反馈,我们受 Vega-Lite (Satyanarayan 等人,2017)的启发,为 VA 设计制定了名为 VAID 的索引结构。 VAID 通过分析任务和视觉设计实现可视化的富有表现力的特征。 为了保证索引的覆盖性和全面性,我们迭代地标注了视图设计,并细化了索引结构的键和值。 结果,我们从 124 个 VA 系统中获得了 442 个视图设计,并为它们形成了信息丰富的索引结构。 为了证明 VAID 的实用性,我们使用原型对 12 名参与者进行了探索 VAID 的用户研究。 具体来说,我们要求参与者查询特定分析任务、数据类型、标记类型等的设计。 用户反馈表明,VAID 可以帮助他们查询多样化且有用的视觉设计,从而帮助他们进行设计探索。 利用 VAID 在呈现视图设计方面的实用性,我们继续进行深入分析并获得了 VA 视图设计模式的发现。 最后,我们通过讨论未来的方向和局限性来结束我们的研究。 本文的贡献包括:
-
•
理解和索引源自研讨会研究的 VA 视图的要求;
-
•
用于 VA 设计(包括分析任务和视觉设计)的有效索引结构 VAID;
-
•
基于探索原型的用户研究111https://VIS-VAID.github.io/ 演示 VAID 的实用性;
-
•
基于 VAID 的对现有视图设计和研究机会的深入分析。
2. 相关工作
本文涉及可视化索引、可视化分析设计研究和可视化类型学的研究。
2.1. 可视化索引
鉴于可视化通常具有复杂的视觉组件结构,因此大量研究调查了可视化的索引和搜索。 索引的一种方法是为可视化分配标签。 许多可视化数据集收集可视化数据并按类型对其进行分类,例如 MASSVIS (Borkin 等人, 2013)、VizNet (Hu 等人, 2019)、VIS30K ( Chen 等人, 2021a)、VisImages (Deng 等人, 2023c) 和 Many Eyes (Viegas 等人, 2007)。 标记可视化对于机器学习模型训练很有用,但在分析可视化配置时标签有局限性。 视觉编码、组合和相关任务等重要配置对于理解视觉分析的设计至关重要,这些方面超出了传统标签的范围。
计算方法已用于提取和索引可视化。 例如,在检索SVG图表时,为了保证视觉结构和数据分布的相似性,Li等人(Li 等人, 2022)提出了一种基于图神经网络进行特征建模的方法。 Hoque 等人(Hoque and Agrawala,2020)收集了 D3.js 实现的可视化效果,并解析了可视化效果的层次结构。 然而,与 SVG 图表相比,解析和分析位图图表是一项更具挑战性的任务。 一系列方法采用计算机视觉方法对可视化进行逆向工程(Savva等人,2011;Poco和Heer,2017;Ying等人,2023b;Zhou等人,2023)或提取数值表示图表索引(叶等人,2022)。 虽然有效,但这些方法可能不适用于可视化出版物中的图表,这些图表通常具有复杂的布局和复合设计。 在这项工作中,我们专注于在可视化分析的背景下分析可视化,这对数据标记提出了更高的要求。 具体来说,它不仅需要标记图表位置等元信息,还需要标记与可视化素养相关的信息(例如视觉编码和任务)。 我们的努力形成了来自最先进的 VA 系统的可视化设计的有价值的索引结构。
2.2. 视觉分析中的可视化设计
近年来,由于分析问题和数据结构变得越来越复杂,可视化分析(VA)系统配备了更多功能来满足分析要求。 因此,研究人员反思了VA的范围和挑战(Keim等人,2008b;Kui等人,2022)并提出了一系列概念模型。 例如,Sacha 等人 (Sacha 等人, 2014) 提出了一种知识生成模型来表征 VA 系统及其在意义建构中的应用。 根据该模型,VA 系统应该很好地融入人类从假设到行动的知识生成循环中,以得出结果和见解。 而且,他们认为VA系统由数据、可视化和算法三个部分组成,涉及信息可视化的管道以及知识发现和数据挖掘的过程。
为了设计与知识生成管道兼容的可视化(Sacha等人,2014),Munzner(Munzner,2009)提出了一种用于可视化设计和评估的嵌套模型。 嵌套模型由四个阶段组成:1)领域问题和数据表征,2)操作和数据类型抽象,3)可视化设计,4)算法设计。 前两个阶段被认为是数据和任务的不同抽象级别。 通过抽象的数据和任务,可以根据信息可视化的理论进一步推导可视化的设计选择,例如表达性和有效性标准(Mackinlay,1986)以及视觉映射规则(Card等人,1999;Munzner,2014)。 嵌套模型为可视化专家构建 VA 系统提供了规范性指导。 受该模型的启发,我们构建了可视化分析的索引结构,从分析任务和视觉设计中描述可视化。 与概念模型相比,我们提出的结构是对数据驱动分析和设计灵感社区的独特贡献,以促进 VA 系统的研究。
2.3. 可视化分类和语法
可视化分类(Harris, 1999; Chi, 2000; Lohse 等人, 1994; Engelhardt and Richards, 2018; Meirelles, 2013)已经被研究了很长时间。 例如,Borkin 等人 (Borkin 等人, 2013) 将可视化分为 12 类,例如 Area、Bar 和 Circle ,每个都包含多个子类型。 然而,用于视觉分析的可视化设计通常具有新颖的布局和复杂的组成。 Chen 等人 (Chen 等人, 2021b) 尝试将 VA 系统中的每个视图映射到 Borkin 分类法中的特定可视化类别。 然而,他们发现视图对于特定类别可能不明确,因为许多设计包含多个类别的各种视觉组件。 他们对分类进行了反思,并提出在进一步研究中遵循Javed等人的复合可视化理论(Javed and Elmqvist,2012)来表征视觉设计。 基于这种反思,我们将 VA 系统中的可视化视为复合可视化,并用分层规范来表征组件之间的关系。
图形语法(Wilkinson,2012)是可视化系统的基础,指示从数据到视觉通道和布局的视觉映射。 Mackinlay (Mackinlay,1986)将可视化表述为图形表示问题,并采用关系元组来指定数据特征和视觉编码。 Heer等人(Heer and Bostock, 2010)提出使用声明性语言来描述和指定可视化,这对于程序员来说是直观的。 之后,Bostock 等人(Bostock 等人, 2011) 交付了 D3,一种对文档对象模型页面的图形元素进行操作的编程语法。 为了进一步减轻可视化规范的负担,Satyanarayan 等人 (Satyanarayan 等人, 2017) 提出了 Vega-Lite,一种基于 JSON 的声明式编程语言,用户可以通过它甚至用几行代码来渲染可视化JSON 文本。 此后,使用 JSON 文件指定可视化被广泛使用,类似的语言也在不断发展,例如 ECharts (Li 等人, 2018)。 在本文中,我们参考 Vega-Lite 并扩展其风格以支持 VA 系统中视图设计的索引。
3. 初步知识学习
我们与 VA 设计师进行了研讨会研究,目的是 1) 了解审查最先进的视觉设计是否可以帮助可视化设计师获得设计灵感,2) 获得理解和索引 VA 视图设计的要求。
3.1. 数据准备。
在研究之前,我们首先准备了最先进的 VA 设计,并基于任务、数据和可视化得出了初始索引设计(Sacha 等人,2014)。
收集数字。 我们首先收集了基于 VisImages (Deng 等人, 2023c) 的 VA 设计图,该图由从可视化和可视化分析的顶级场所 IEEE InfoVis 和 VAST 收集的位图图像组成。 我们选择了 2016 年至 2020 年 IEEE VAST 中的论文,这是 VA 研究的主要场所(253)。 然后我们确定了提出可视化分析系统的论文,其论文类型通常称为应用或设计研究(124)。 对于每篇论文,我们选择了一张包含完整系统界面的图,这通常是预告片。
分离各个可视化视图。 我们进一步分离了系统图中不同视图的区域。 在大多数情况下,视图会被分配一个特定的名称以供识别。 然而,一个视图有时由多个独立的子视图组成。 如果子视图之间的数据不直接相关(例如共享轴或通过视觉链接连接),我们将视图分解为子视图以进行不同的可视化。 每个子视图都被视为一个单独的可视化,并且是整篇论文的基本分析单元。 标注之后,我们获得了来自 124 个 VA 系统的 442 个视图的图像集合。 为简单起见,本文其余部分中的术语“视图设计”指的是 VA 系统中默认视图的设计。
注释任务/数据/类型。 这些视图源自 VisImages,包括有关图表类型及其位置的信息,但不提供 VA 系统内视图(包括子视图)的标签。 我们首先通过任务类型、数据类型和可视化类型的元组来表征视图设计。
-
•
对于任务类型,我们使用了标注数据分析的任务分类(Amar 等人,2005)。 分类法包含十种类型,包括检索值、导出值、过滤、查找极值、排序、确定范围、表征分布、查找异常、聚类、关联 和比较0>。 为了避免标注过程中出现偏差,我们仅在原始作者明确提及时才确定任务。 在标注之后,98.87% (437/442) 的可视化包含至少一种任务类型。
-
•
对于数据类型,我们通过视觉编码通道中的类型来表示编码数据。 数据类型包括定量(Q)、时间(T)、序数(O)、名义(N)和图相关(G)数据(Satyanarayan等人,2017)。 对于视图设计,我们总结了每种数据类型的计数,例如“”。
-
•
我们进一步标记了每个可视化的可视化类型。 对于大多数视图,我们遵循 VisImages 中使用的标签,因为它们最初是根据 Borkin 等人 (Borkin 等人, 2013) 概述的分类法分配的。 对于复合可视化,我们通过将其分解为多个视觉组件来表征其类型。 例如,散点图矩阵可以被视为将散点图嵌套到矩阵中,该矩阵表示为元组:“”。
根据注释结果,我们创建了一个名为 VAID-Alpha 的原型。 该界面包括收集的图形、相关任务、数据及其各自的类型作为可搜索索引。 此外,它还具有可直接访问的搜索引擎。
3.2. 研究设置
在研讨会研究中,我们要求参与者模仿设计可视化原型的过程,特别关注创建多个视图来完成 VA 任务。 我们遵循出声思考协议并收集了参与者的定性反馈。
问题。 由于需要具有适当复杂程度的任务和数据集,我们从 IEEE VAST Challenge 2021 中选择了迷你挑战 2,这是视觉分析领域的经典问题。 特别是,一家名为 GAStech 的公司希望调查员工私自使用公司汽车的可能性。 为了便于分析,提供了每辆车的 GPS 数据、车辆分配记录以及信用卡和会员卡购买记录。 在我们的研究中,参与者需要通过设计可视化原型来完成三项任务。 第一个任务 (T1) 是仅使用信用卡和会员卡数据设计可视化,以识别热门位置和购买时间,并可能发现一些异常情况(例如,奇怪的购买时间和频繁更改的购买位置)。 第二个任务 (T2) 是使用汽车分配数据和 GPS 数据来帮助确定每张卡的所有者并尝试发现一些异常情况(例如,卡所有者和购买活动不在同一个地方) )。 第三个任务(T3)是揭示员工之间潜在的非正式关系。
参与者。 我们从社交媒体和我们的网络招募了 12 名 VA 设计师。 参与者是研究生(6 名女性和 6 名男性),对数字人文、体育分析、医学和城市规划等各个领域的视觉分析有研究兴趣。 其中10人以第一作者在IEEE VIS发表论文。 我们要求参与者报告他们在设计数据分析可视化方面的经验。 根据研究前面试,6名参与者(P1、P3、P4、P8、P10、P11)是博士学位。拥有三年以上视觉分析研究经验的学生,其中 3 名(P2、P9、P12)的研究时间少于一年,其余 3 名参与者的研究时间少于两年。 具体来说,3名参与者(P1、P3、P12)拥有设计学士学位。
过程。 工作坊研究的每次试验都是通过在线会议一对一进行的。 审判持续了大约60分钟。 在试验之前,我们首先要求参与者同意收集他们的设计过程、评论和结果以供研究使用。 之后,学习课程以 15 分钟的教程开始,介绍原型 VAID-Alpha 的索引(即我们如何定义数据表示、任务类型和可视化类型)以及说明如何使用该界面的几个示例。 在研究过程中,参与者被要求解释他们如何理解问题和任务,以及他们想要设计可视化的内容和原因。 参与者需要在纸上绘制原型可视化草图,并说明如何使用设计来完成任务。 会议以研究后访谈结束,我们通过一系列问题收集了参与者的定性反馈。
3.3. 结果
参与者的总体反应是积极的。 在此我们总结了参与者的反馈。
3.3.1. 有用性分析
从参与者的反馈中,我们发现 VAID-Alpha 对于激发新的设计理念和增强用户的原创想法很有用。 为了了解对设计的影响,我们进一步分析了用户的设计过程,包括系统日志、录音和笔记。 我们总共从 12 名参与者那里获得了 36 种可视化设计,其中 16 种 (44.4%) 是从头开始获得灵感的,14 种 (38.9%) 是从原始想法中增强的。 这些数字也符合参与者的反馈,证明了我们系统的实用性。
该系统有利于“热启动”。 我们发现,与 T2 和 T3 相比,更多参与者(P2、P5、P7、P8、P10、P11、P12)在 T1 上工作时受到启发。 这可能是由于可视化设计过程的“冷启动”,即从头开始贡献原型需要灵感,因此一开始可能会很困难。 大三博士生P5的评论佐证了这个推论:“一开始,我对设计一无所知。 因此,我更愿意去探索,从建议中寻找一些灵感”。完成 T1 后,她对 T2 的设计遵循了之前的想法,并根据建议进行了一些改进。 P2、P7、P12作为初级研究员,也有类似的设计过程。 此外,高年级博士生(P8、P10、P11)也往往在T1获得灵感。 P10表示,他在查找数据类型后,受到了一个类似“故事情节”的设计的启发,得出了最初的设计。
该系统应该帮助用户理解设计。 用户还表达了对理解的担忧。 初级(P2、P3、P8)和高级(P10、P11)博士生在理解视图设计时都遇到了问题。 P2 指出,“我需要了解不同设计的视觉编码”,欣赏有关数据结构和任务类型的文本解释,但仍然发现一些复杂的设计难以理解。 P11还认为标题提供的上下文信息不足。
3.3.2. 数据、任务和可视化之间的权衡
在研究过程中,我们还调查了用户对数据、任务和可视化的选择,以搜索感兴趣的可视化设计。 结果如图1所示。
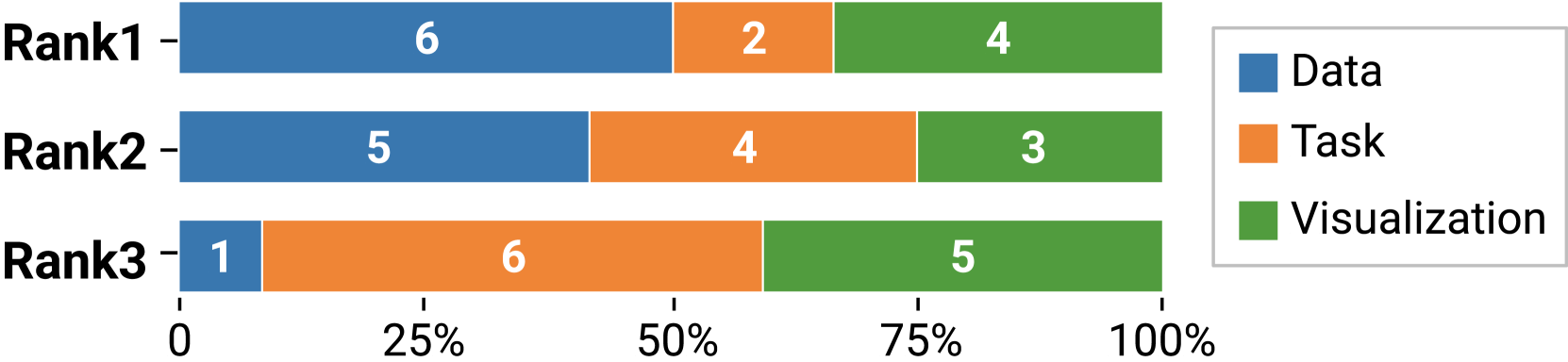
“数据”是最受青睐的。 我们发现,12 名参与者中有 6 名将数据排名第一,5 名参与者将其排名第二。 与会人员一致认为,数据是可视化设计中最需要考虑的因素。 城市规划高级分析师P4评价道,“从专家的角度来看,数据和算法是最关键的”。 另外两位前辈P10和P11也持有类似的观点。 大三学生P5也将数据作为视觉设计的首要考虑因素,她表示“相同的数据可以用不同的视觉表示来表示”。 然而,知道有多少不同数据类型的列被编码似乎还不够。 P10评论道,“在实际场景中,会进行数据转换,更重要的是告诉数据如何映射到视觉通道”。
“可视化”更受设计师青睐。 可视化排名第一的有四名参与者,其中三名(P1、P3、P12)是拥有设计学士学位的高级设计师。 按可视化类型搜索的优点是期望和输出之间的一致性。 P1 喜欢通过可视化进行搜索,因为“可视化对于理解来说非常直观,我可以想象会出现什么结果”。 在三个维度中,P3强调了他对可视化的偏好:“当我通过可视化搜索时,我更喜欢精确匹配,并排除所有没有我选择的设计”。 然而,在将检索到的设计应用到自己的场景之前,用户必须了解视觉编码。 初级(P2、P3)和高级(P10、P11)博士。学生在理解检索到的设计时遇到了问题。 P2 赞赏关于数据类型和任务类型的文字解释,并评论说“视觉编码的指示帮助我轻松理解设计”。 他们期望对可视化进行更详细的描述,而不仅仅是类型。
“任务”的理解是混杂的。 尽管两名参与者将任务排在第一位,但一半的参与者将其排在最后。 一个常见的问题是原始分析问题和低级任务之间的差距。 P12 评论道“我对任务类型比较模糊,所以我更愿意先考虑如何可视化所有数据”。 此外,P10指出他无法将诸如“获取概览”之类的任务映射到低级任务。 P3解释说他会对问题的任务有不同的理解。 这些评论呼吁继续努力对 VA 系统中的搜索任务进行分类。
讨论。 根据上述观察,参与者搜索设计期间数据、任务和可视化之间的权衡可能与两个因素有关,包括搜索标准的可访问性和搜索中使用的索引方法的表示能力引擎。 首先,参与者可能会关注 VA 设计过程的输入和输出,这是可用的搜索标准。 大多数参与者将数据列为搜索条件的首选,因为数据是数据、任务和可视化中最容易接近的一个。 为了设计可视化分析系统,研究人员和设计人员通常从数据探索开始,然后考虑适当的设计来可视化数据。 相反,擅长设计的参与者可能会转向设计的输出,即可视化,并选择通过搜索“回归”他们想要的设计。 可视化是数据的图形表示,这可能是参与者的中间搜索条件。 正如P1所说,“当我看到时间戳、位置和价格列时,我立即看到了一个折线图,用于按时间和位置表示购买情况。 然后我根据折线图搜索设计。” 在这种情况下,参与者考虑了数据,但选择使用可视化作为搜索数据的表示。 分析任务在推导设计中也很重要,但一个常见的问题是原始分析问题与低级任务之间的差距,这使得任务在设计初期具有不确定性。 此外,可以通过多种设计选择来完成分析任务。 例如,设计者可以在不同布局(例如重载和镜像)中使用不同的可视化来比较值(LYi等人,2021)。 因此,与首先考虑任务相比,从业者可能会转向诸如如何表示数据以及什么可视化可能更美观等问题。
其次,参与者可能会遇到 VAID-alpha 代表 VA 设计能力不足的问题。 如上所述,参与者转向可视化而不是数据可能是由于缺乏更具代表性的方法来搜索视觉设计的结果。 而且,任务不够明确,因此参与者选择不将任务作为搜索的第一选择。 为了帮助从业者更好地检索设计并进一步了解他们的设计偏好,我们总结了一些可能有助于提高 VAID 代表性的要求。
3.4. 指数设计要求
根据调查结果,我们得出了改进当前指数设计的三个关键要求:
-
R1:
数据和可视化的集成。 数据和可视化是最受欢迎的。 所有用户对数据和可视化的评论都提到了数据和视觉通道之间的关系,即视觉编码。 视觉编码的指示可以帮助用户更好地理解如何将数据应用到设计中。 受到这些评论的启发,我们的目标是提出一种有效的方法来描述视图设计中的视觉编码。
-
R2:
可视化构成的描述。 许多视图设计都是组合可视化,组合反映了视觉元素之间的数据关系。 例如,一种常见的 VA 技术是“字形散点图”,其中每个散点图都由附加多维属性的字形表示。 这种关系很难用现有的方法来描述。 需要对这种关系进行额外的描述。
-
R3:
分析任务的更详细描述。 用户在将真实的分析问题映射到低级任务时遇到困难可能是因为缺乏分析目标,例如总结、比较和探索(Brehmer and Munzner,2013)。 比较分布和总结分布可能需要视觉编码和布局不同的可视化设计。 此外,与图相关的任务没有得到深入研究。 因此,我们决定纳入多个级别的额外任务分类法。
4. 瓦伊德
本节我们根据上述需求介绍指标设计的流程。 我们打算在 JSON 结构中表示索引,因为索引可能包含嵌套元素(R1、R2)。 此外,我们使用 VA 任务的多级类型学详细阐述了任务表征(Brehmer 和 Munzner,2013) (R3)。 正式地,我们在论文中将该结构称为“VAID”,它由一个二元组组成:
| (1) |
在接下来的部分中,我们将详细介绍任务和设计。
4.1. 无效任务
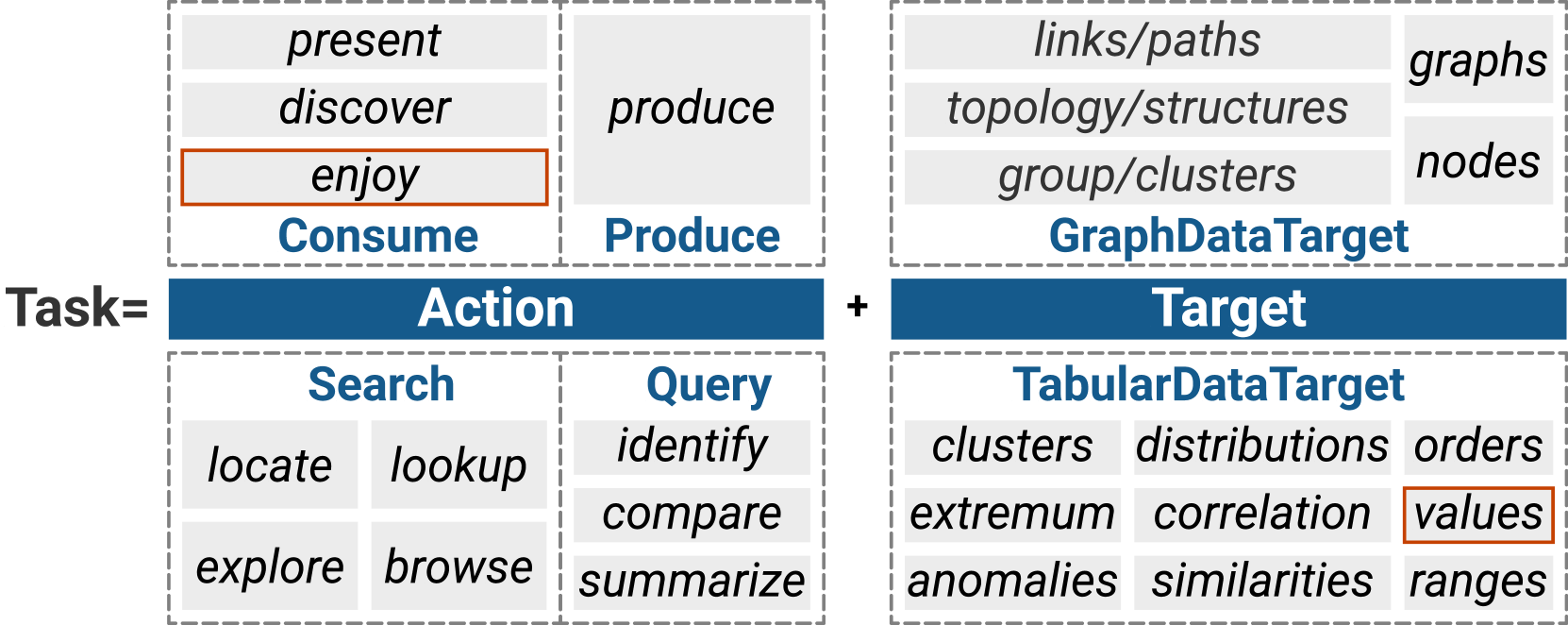
鉴于低级任务分类可能不足以让用户理解 VA 任务,我们基于 Brehmer 和 Munzner 的 VA 任务分类改进了任务结构 (Brehmer 和 Munzner,2013). 在他们的分类中,VA 任务被描述为三个级别,即为什么、什么和如何。 原因级别指的是 VA 的目标,例如呈现、比较和浏览。 该级别还描述了分析过程中人类的行为,因此将其命名为“action”(Munzner,2014)。 内容级别解释了 VA 中的分析“目标”,例如原始数据、特定属性或数据模式。 我们当前的任务分类可以被视为这些目标的子集。 此外,如何级别描述了用于实现“行动”和“目标”的方法,包括视图设计和算法。 在这项工作中,我们重点关注how级别的视图设计结构,而不将其视为分析任务结构的一部分。
我们使用动作-目标对来描述分析任务。 这些操作与原始分类中的定义相同。 对于目标,我们参考 Amar 等人针对表格数据的低级任务分类法(Amar 等人,2005) 和 Lee 等人针对图数据的任务分类法(Lee 等人) ,2006)。 动作和目标的分类总结在图2中。 任务的详细标注过程将在后续小节中介绍,与 VAID 设计一起进行。 仅当原作者明确提及时,我们才识别行动目标对,并且在此过程中的任何分歧都按照相同的策略解决。
4.2. 维德设计
对于视图设计,我们的目标是识别内部的视觉编码,即从数据到视觉通道和布局的映射。 具体来说,我们将每个设计视为复合可视化(Javed和Elmqvist,2012;Deng等人,2023a)。 我们首先识别整体布局,例如分面,然后将其分解为各种视觉组件。 每个组件都是特定类型的独立可视化,例如条形图、折线图和桑基图。 对于精心设计的字形设计,它们不仅仅是不同可视化类型的组合,我们将它们视为“其他”类型。 然后我们识别每个组件的视觉编码。
我们使用 Vega-Lite (Satyanarayan 等人, 2017) 作为起始结构,因为它们的 JSON 语法对于表示视觉结构来说很直观。 具体来说,它用“标记”和“编码”字段来表征可视化。 在字段“编码”中,进一步指定数据“字段”、“类型”和“聚合”。 此外,它还支持基本的视觉合成,例如分面、连接和分层。 我们迭代开发了结构来覆盖收集的视图设计并注释了每个设计。 延伸和标注的过程包括以下四个阶段。

在第一阶段,四位作者使用原始的 Vega-Lite 对可视化进行了注释。 我们发现Vega-Lite不支持与图形相关的可视化的描述,例如桑基图和树可视化,这些是视图设计中常见的可视化类型。 此外,不支持复杂的视觉组合,例如在图形节点中嵌入字形。 我们试图根据失败的案例来扩展结构。 我们从三个角度对原有的Vega-Lite结构进行了扩展:
-
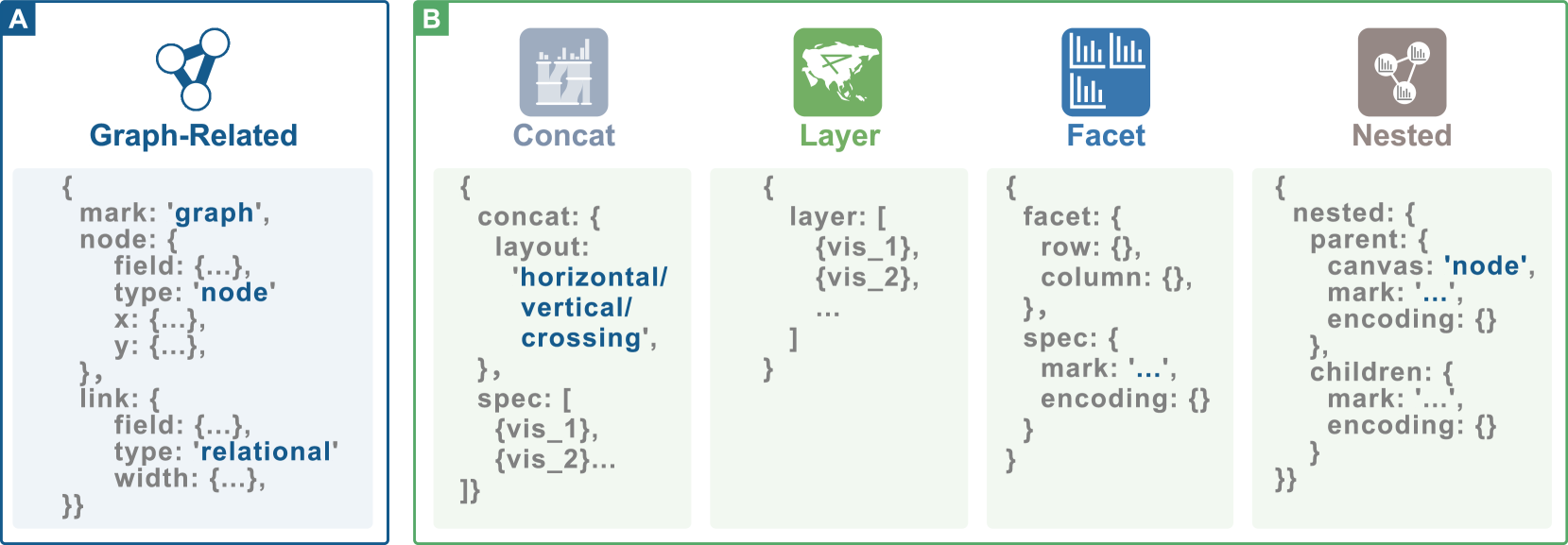
•
首先,我们添加了额外的数据类型(例如关系数据),并将“节点”和“链接”视为图形相关可视化的两个视觉通道。 我们在“节点”和“链接”标签下进一步指定了节点和链接的属性,例如位置和宽度。 图4A 给出了示例结构。
-
•
其次,为了处理复杂的视觉组合,例如在图形节点中嵌入字形(Elmqvist和Fekete,2010),我们添加了“嵌套”组合类型。 嵌套可视化通过指定“父”和“子”组件来表示。 我们还使用一个关键的“画布”来指示父组件的哪些元素是嵌入的子组件。 组合的结构,即“连续”、“层”、“面”和“嵌套”组合,如图4B所示。
-
•
第三,Vega-Lite支持的标记类型也不足以表示视图设计。 我们参考了 Borkin 等人 (Borkin 等人, 2013) 提出的类型学,扩展了标记类型,添加了图形、Sankey 和雷达等新标记类型。 注意,新添加的标记类型不是作为可视化的基本构建块的图形基元。 相反,其中一些是“包含多个图元标记的复杂分层图形的宏”(Satyanarayan 等人,2017),与 Vega-Lite 的定义一致。 图4提供了复杂组合关系的示例,例如将条形图嵌套到节点链接图中。
在第二阶段, 我们根据原始论文中“视觉设计”和“案例研究”部分的描述,使用我们的标签系统独立注释了视图,包括任务和设计。 在无法获得所需信息的情况下,我们审阅了整篇论文。 此外,对于设计结构,我们确定了扩展结构未解决的情况。 每周进行在线讨论以同步和解决案件。 该过程包括最初创建一个概述结构的共享文档,然后对其进行更新,直到扩展结构可以覆盖所有案例。 在此阶段得出了包含设计结构和各种案例的标注示例的最终文件。 在第三阶段,每位作者使用第二阶段的文件修改了他们的标注结果。 其中一位作者系统地比较了所有结果,并标记了任何分歧。 这些冲突被记录在我们的系统中,并通过所有作者在每周在线会议上的讨论来解决,从而直接产生更新的结果。 最后,一位作者再次仔细检查了结果的所有细节。 由此,我们获得了 VAID 设计的索引结构(图3),并根据该结构注释了 442 个视图设计。
在标注过程中,我们遵循一致性的理念。 详细来说,我们对视图进行了注释,同时努力尽可能保留原始的 Vega-Lite 结构。 与原始的Vega-Lite结构相比,我们在收集的VA设计的基础上广泛扩展了组合、标记、编码类型和数据类型的属性。 值得注意的是,Vega-Lite结构还提供了强大的数据转换运算符,例如过滤。 然而,在VA研究中,许多技术涉及复杂的数据处理方法,例如降维,这些方法的分类和识别具有挑战性。 在这项工作中,我们目前专注于视图设计,并且仅使用 Vega-Lite 结构的一部分来表征视觉编码(例如,排除与样式相关的参数),这有助于更好的视图索引和理解。
此外,我们遵循最小化的思想,即选择重复次数最少的一个,来解决当可视化有多个解决方案时的问题。 例如,图3(B2)中的组件从以下角度可以被视为“具有密度图和图形的分层可视化”和“元素为饼图的分面可视化”执行。 图形节点和饼图的位置都重复编码行和列属性。 参考原始描述(Fu等人,2017),没有链接的饼图会淡出,表明图节点和饼图是一一映射的。 因此,将可视化视为由密度图和嵌套图可视化(嵌入节点中的饼图)组合而成的分层可视化更为合适。 再例如,分面可视化可以被视为相似视觉组件列表的串联。 用“concat”表示图表必须多次复制相似视觉组件的结构。 相反,在数据可视化的背景下使用“facet”来表示它更加简洁和准确。
5. 通过基于问题的用户研究评估 VAID
我们进行了一项用户研究来评估 VAID 是否可以帮助用户进行视图设计。 为了让用户体验使用VAID进行设计搜索,我们开发了一个名为VAID Explorer的原型系统。 在本节中,我们首先简要概述原型,然后深入讨论用户研究。
5.1. VAID探索者
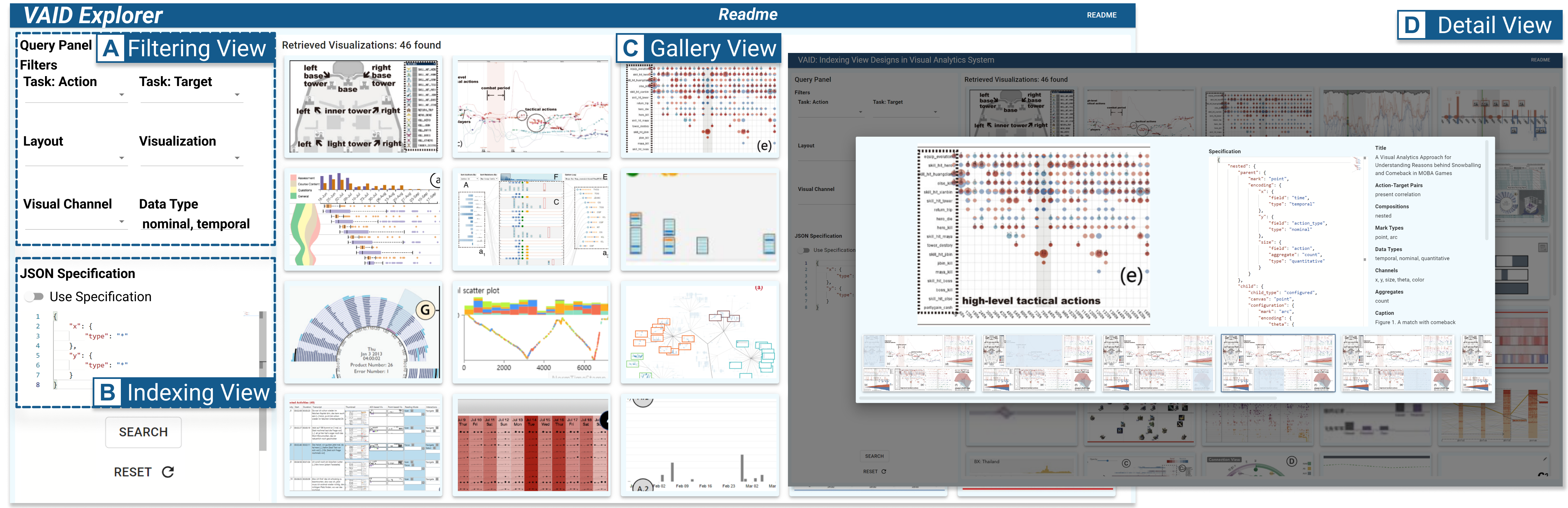
我们将在下一节中展示原型并描述它的使用方式。
原型包括过滤面板(图5A)、图库视图(图5C)、索引视图(图5) >B) 和详细视图 (图5D)。 过滤面板(图5A)支持视图设计搜索。 用户可以选择4中介绍的不同键对应的值。 我们还开发了一个索引视图(图5B),使用户能够使用 JSON 语法输入结构索引。 检索到的结果将显示在图库视图中(图5C)。 当点击结果时,会弹出详细视图(图5D), 显示 VAID 以及其他上下文元数据(例如论文标题、论文关键字、图形标题)。 用户还可以探索其他视图的设计。
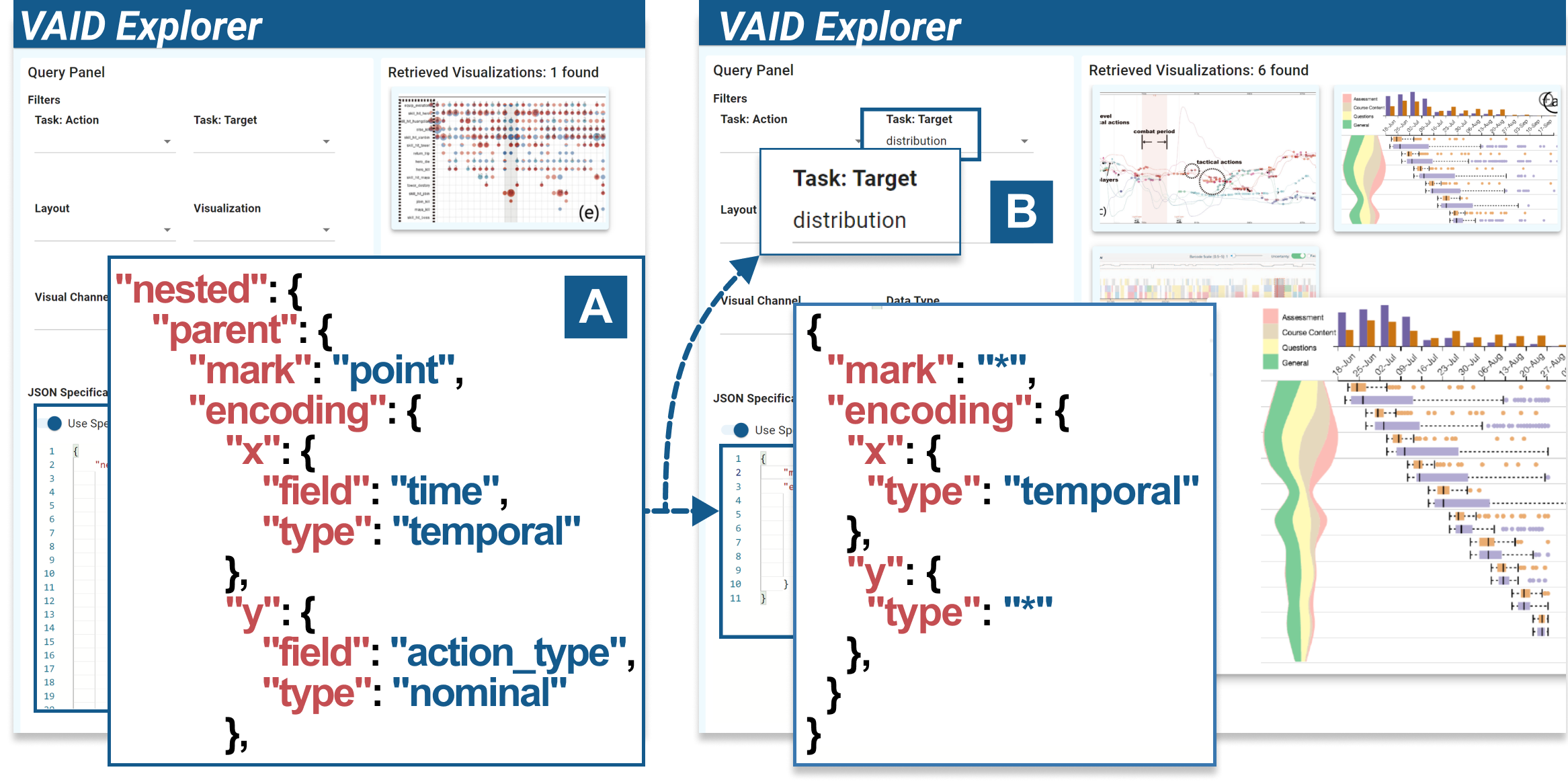
我们提出了一个由城市规划领域可视化研究员 Sherry 主持的简洁场景来演示原型的用法。 她得到了一个关于信用卡记录的数据集,其中有四列:“卡 ID”、“时间”、“商店”和“商品名称”。她想要确定最受欢迎的购买时间和商店,但她不确定如何表示这些数据。 使用 VAID Explorer,她首先从过滤面板(图 5(A))开始,选择两种数据类型:名义数据类型和时间数据类型。 她检索了 46 个视图设计,对结果进行了探索,发现第三个示例(图5D)可以显示跨“时间”和“商店”的数据。为了进一步展现不同时期、不同店铺的受欢迎程度,她思考如何用相似的设计来展现分布。 她将此设计的索引复制到索引视图中(图6A)。 她修改并仅保留索引的子结构,并选择“分布”的目标(图6B)。 她使用条形图和面积图确定了一种设计,分别显示标称维度和时间维度的摘要。 通过这个例子,她对视图设计有了一些初步的知识思考。
5.2. 研究设置
我们的目标是了解参与者是否可以理解使用 VAID 检索到的设计(例如视觉编码),并使用原型获得 VA 问题的设计灵感。 具体来说,我们要求参与者搜索可视化来解决六个精心设计的 VA 问题 随后是设计视图。 VA 问题具有不同的复杂性,并且与特定的分析任务、标记类型、组合类型或数据类型相关,例如“找到用标称、定量和时间字段对三维数据集进行编码的可视化”和“找到用于比较分布的 VA 设计”。 对于设计任务,我们选择 IEEE VAST Challenge 2022(主席,2022)中的迷你挑战 2。 详细列表可以在补充材料中找到。 根据检索到的结果,参与者被要求探索结果并选择一种感兴趣的可视化进行深入研究,即通过阅读图像、索引和其他元数据(例如标题和说明文字)来理解设计。 最后,我们要求参与者解释可视化的设计。
参与者。 我们通过社交媒体和口碑从我们的机构招募了 12 名可视化从业者 (U1-U12),他们表示拥有创建数据分析可视化的经验。 参与者包括 5 名女性和 7 名男性,拥有不同的背景,包括计算机科学、城市和数字媒体设计。 它们用于通过Python、R和MATLAB等工具包来分析数据以进行数据分析。 此外,他们使用的数据可视化库包括Vega-Lite、Excel、Python Matplotlib 和 Javascript D3。 本次用户研究的参与者都拥有足够的数据可视化或设计知识,但在设计更复杂的 VA 系统方面拥有不同的专业知识。
程序。 所有研究都是通过一对一的在线会议进行的。 每项研究由两个部分组成:训练部分(15 分钟)和实验部分(20 分钟)。 在训练课程中,我们介绍了 VAID 的定义,包括任务和设计的分类法。 然后我们介绍了原型的使用。 所有参与者都可以自由使用和探索数据以熟悉原型。 在实验过程中,每个参与者都被要求完成 七个问题(或任务,但为了避免与 VAID 中的“任务”维度混淆,我们在这里使用术语“问题”)。 在整个研究过程中,我们遵循出声思考方案。 参与者被要求说出他们对检索到的视图设计的理解以及他们在完成任务时对 VAID 或原型的想法。 该研究以研究后访谈以及从不同维度对 VAID 进行评级的调查问卷结束。 整个用户研究持续约1-1.5小时。 每位参与者获得 9 美元作为补偿。 作者在研究过程中做了笔记以记录反馈。
5.3. 结果和反馈
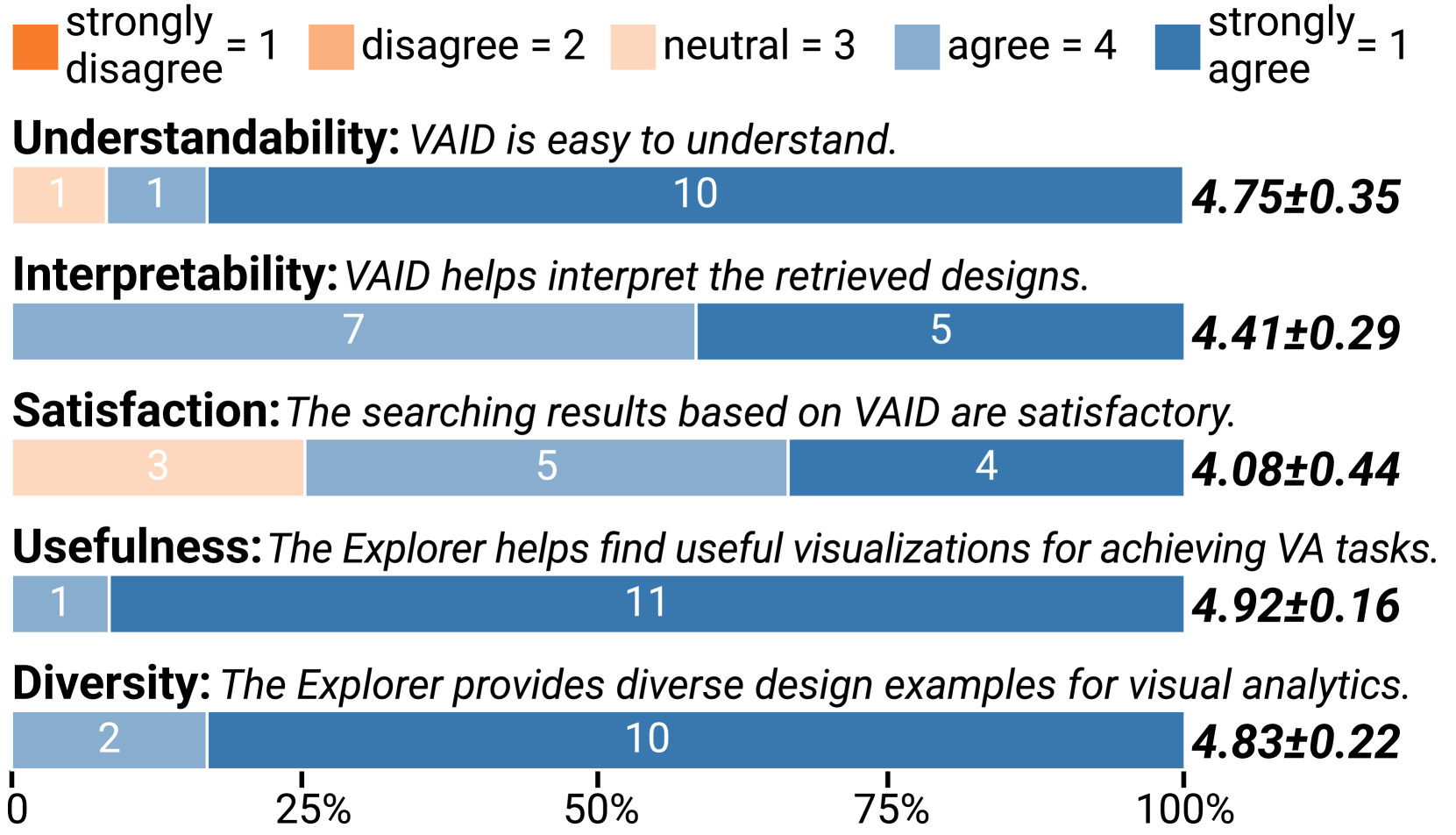
所有用户都使用 VAID 成功找到了所需的设计并理解了该设计。 对于问题 7,他们设计并绘制了几个视图。 所有草图都可以在补充材料中找到。 参与者的定量结果非常积极,如图7所示。 12 名参与者中有 11 名强烈同意,基于 VAID,原型有助于找到有用的可视化设计来实现研究中的 VA 任务。 同样,10 位参与者强烈赞赏 VAID Explorer 中 VA 设计的多样性。
VAID 易于理解,有利于设计理解。 大多数用户 (11/12) 发现 VAID 很容易理解。 一些人 (U1) 将这种轻松归因于他们对 Vega-Lite 的熟悉,从而促进了快速适应。 其他不熟悉 Vega-Lite 的人强调 VAID 的 JSON 格式和声明性语言的重要性。 U6进一步强调,基础图表知识有助于理解VAID的设计结构。 此外,用户还赞赏 VAID 在简化视觉编码理解方面的作用。 U5 和 U7 指出,VAID 补充了标题和说明文字等文本元素,提供了超出这些元素单独传达的见解。 U1 强调了 VAID 在澄清字形相关方面以防止视觉解释中的不确定性方面的重要性。 他们的观点证实了设计要求的满足 R1. 尽管很清楚,U7 仍然提到,对于更复杂的方面,参考研究论文可能仍然是必要的。
VAID Explorer 使用户能够根据给定的问题快速得出初始设计。 所有用户都很快开始问题 7。 例如,U12 首先选择可能符合问题的“行动”和“目标”值的不同组合,并说:“以前,我需要时间来掌握背景信息;现在,我需要时间来掌握背景信息。然而,现在我可以随机选择滤波器参数来探索潜在的设计。 检查这些设计有助于我更好地理解问题并制定一个模糊的初始设计作为起点。用户一致认为 VAID 的结构符合常见的设计策略,其中他们通常通过考虑数据、任务和可视化来进行视图设计。 U11评论“过滤器选项符合我思考设计问题的方式。 鉴于问题描述提供了必要的信息,我发现启动该过程很容易。 随后,我就能很快发现灵感。”
VAID 有助于全面搜索。 大多数参与者对探索过程中的搜索结果表示满意。 用户指出,“在探索的过程中,我的目标是不遗漏地检索所有相关的设计。” U6称赞道,“我的个人偏好可能会带来偏见,并可能导致忽视有价值的论文。 然而,该系统的使用确保了更彻底的探索。”此外,U4 强调,“它作为一个基于知识的检索系统运行,有效地补充了我的知识。” 与基础知识学习相比,VAID 的扩展方便了更灵活的搜索选择。 具体来说,U3 和 U5 在设计多视图 VA 系统时欣赏灵活的任务选项。 他们强调其在 VA 系统中的有效性,其中任务目标保持不变,而行动因视图而异。 U5还举了一个例子来评论,‘“VAID 能够以渐进式探索、识别和定位异常的方式设计 VA 系统。” 他们的意见验证了设计要求 R3 已经实现了。 然而,即使 VAID 提供了增强的搜索选项灵活性,一些用户在选择操作时仍然面临挑战。 U11表示,简洁的一句话描述缺乏直观性。 她建议:“包含示例和图像作为提示将帮助我做出更明智的任务选择。随着大语言模型的发展,一个潜在的解决方案是引入大语言模型来帮助将分析问题转化为抽象的动作和目标,这可能会减轻使用系统的负担。
而且,搜索功能因其人性化而受到用户的称赞,正如U11所说,“过滤视图和索引视图可以相辅相成。 虽然过滤易于使用但不太精确,但索引搜索可以帮助检索更具体的设计,例如 x 轴上带有时间数据的条形图。尽管得到了积极的反馈,但仍有改进的空间。 当前的多个选项组合可能会导致有限的结果或没有结果,可能会导致一些用户的中性满意度,如图7所示。 U12 建议采用部分匹配机制,以保证检索到大量设计,即使在稍微严格的条件下也是如此。 U8 也表达了类似的观点,提议添加类似于常见搜索引擎的推荐机制。 此外,U5 表示希望改进过滤视图和索引视图之间的链接。 他提到,“从头开始输入 JSON 结构并不容易,但编辑结构则更简单。” U5 希望在过滤视图中选择选项后,在索引视图中得到一个初稿。 因此,未来可以开发有效的排序机制和视图设计的联动查询功能,以支持有效的可视化查询系统。
VAID促进增量设计,帮助用户逐步完善他们的设计。 视图设计主要是复合可视化(邓等人,2023a),可以进一步细分为各种基本图表(第4.2)。 设计师通常从一种可以确定的基本可视化类型开始。 例如,许多用户由于城市场景而认识问题7中的“地图”。 一些用户还通过整合数据、任务和他们的专业知识来搜索初始设计。 在此概念的基础上,VAID Explorer 使用户能够使用基本的可视化作为搜索参数,从而实现复杂和扩展的设计(R2)。 U10 表示:“我通常会使用几个基本图表来满足设计要求。 之后,我探索通过将这些图表集成到统一视图中来完善设计的方法。“她相信使用我们的工具可以使这个细化步骤比以前更容易。 U9 表达了对布局的强烈赞赏,指出由于依赖个人知识而导致基于关键字的搜索面临挑战,“VAID Explorer 通过提供嵌套或分层布局选项解决了这个问题”。 这种偏好与 U5 和 U7 的观点一致,他们强调 VA 视图中的空间限制以及在有限空间内深思熟虑的布局选择的重要性。 同时,一些用户还建议,设计的复杂性允许对检索到的设计采取选择性方法。 例如,在问题 7.3 中,U7 可能选择仅使用 TPFlow (Liu 等人,2019) 的视图设计中的颜色和尺寸编码。 U5也采用了类似的方法。 最初,他在(周等人,2019)中选择了单视图圆条设计,后来在(赵等人,2017)中选择了单视图面积图设计。 t1> 来解决这个问题。
VAID增强了设计美感。 U2 强调,VAID 不仅有助于完成设计,还提供额外的帮助,他指出 VAID 有助于增强视图设计过程中的美感。 此外,用户可以使用 VAID 进一步改进设计,即使它有效地实现了预期任务。 例如,在问题7.1中,U9最初获得了满足该问题的设计。 然而,在观察《Volia》(曹等人,2018)中的一个特定视图后,她认识到在地图分割过程中使用四边形或六边形作为最小单位的潜力,这有助于她相应地完善设计。 在问题7.3中,U6注意到以前的设计中普遍使用条形图,导致设计乏味,缺乏足够的新颖性。 这促使 U6 在最后提到的 VA 界面中探索替代视图,旨在实现更多样化的设计。 通过将这一探索与 VAID 结构的见解相结合,U6 采取了激进的方法。
6. 使用 VAID 分析 VA 设计集合
在验证了 VAID 的实用性之后,我们在 (Hoque 和 Agrawala, 2020; Battle 等人, 2018) 章中利用收集的视图,探索了基于 VAID 的视图设计 的 "设计人口统计学"3.1,这表明 VAID 能够对现有视图设计进行细粒度的探索和理解。 我们特别报告统计数据,包括分析任务和视觉设计的频率和共现模式。
6.1. 概述
我们首先分析指标以了解可视化分析中可视化设计的组成。
只有 38% 的视图设计可以使用 Vega-Lite 实现。 我们研究了这些索引,并选择了解这些可视化是否可以通过 Vega-Lite 的基本标记类型的常见组合(图层、连续和面)来实现。 我们发现只有 38.2% (169/442) 的设计可以指定为纯 Vega-Lite 结构。 结果表明,研究人员倾向于在 VA 系统中使用新技术来可视化数据,这证明了我们结构的独特价值。 Vega-Lite的局限性主要在于标记类型有限以及缺乏对图形相关数据和嵌套可视化的支持。 声明性可视化语法的表达能力有限可能是大多数现有 VA 系统的可视化设计都是使用较低级别的 Javascript 库(例如 D3.js)实现的原因,因为它们可以为设计提供灵活的定制。
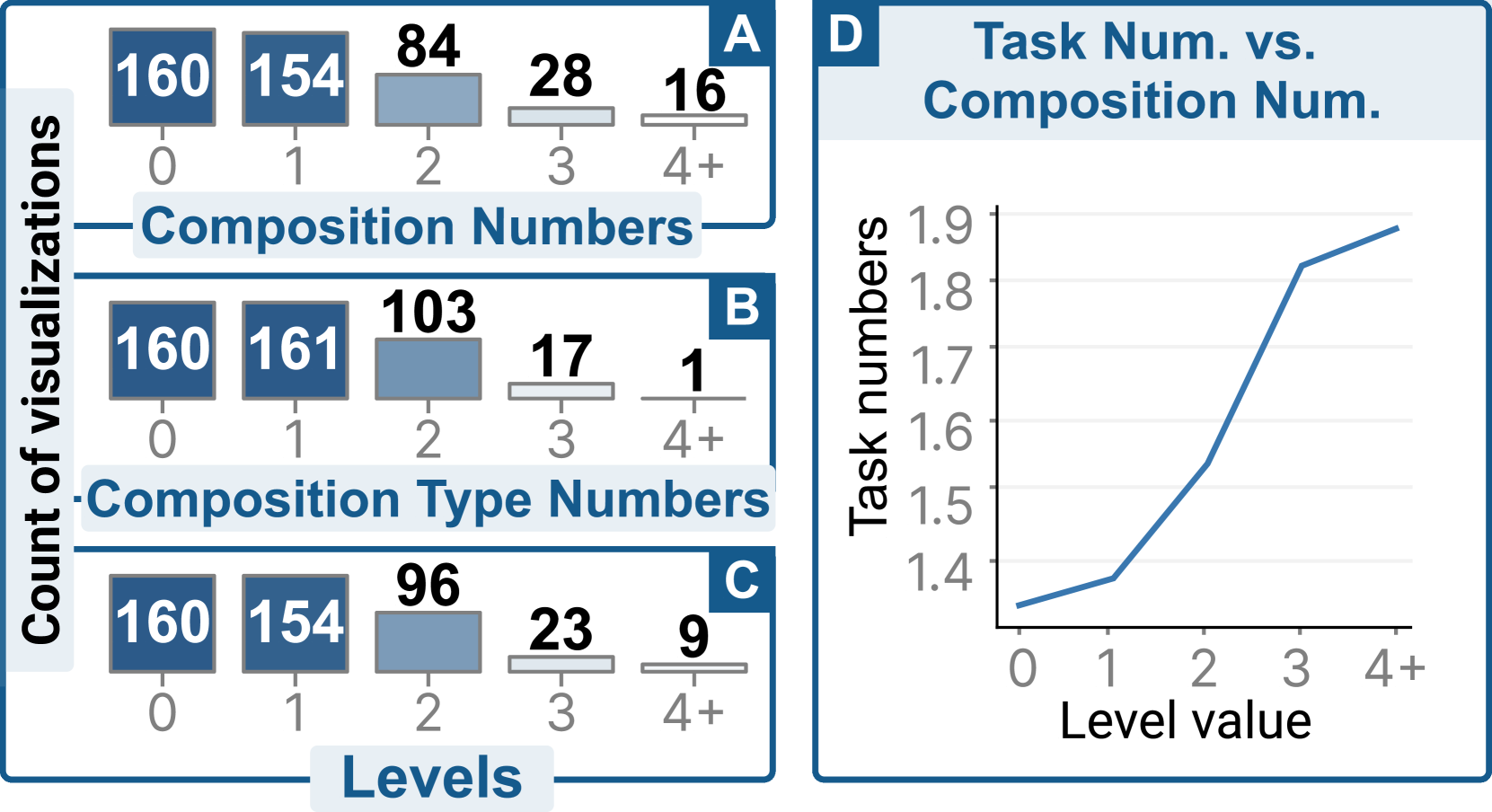
大约 64% 的视图设计是复合可视化。 复合可视化将多个视觉组件沿着特定方向(例如,Vega-Lite 中的“层”、“连续”和“面”)或以分层方式(即“嵌套”)组合在一起,这可以使视觉组件很好地有组织且易于解释。 如图 8A 所示,63.8% (282/442) 的视图设计包含复合可视化。 我们关注结构中成分标签的数量。 图 8A 显示 34.8% (154/442) 的可视化仅包含一种组合。 3.6% (16/442) 可视化至少包含四个作品。 可视化可以有多种类型的组合(总共四种不同类型)。 只有一种可视化使用了最大数量的不同构图类型,即四种(图8B)。 图 8B 显示大多数可视化的组合类型不超过两种。
90% 的复合可视化具有层次结构级别 2。 如subsection 4.2中所述,可视化以具有多个组合级别的分层 JSON 语法表示。 例如,图 3 中呈现的可视化的合成级别为三。 对于复合可视化,54.6% (154/282) 的级别为 1,34.0% (96/282) 的级别为 2,8.1% (23/282) 的级别为 3。 只有 9 个可视化的级别为四,这是层次结构的最高级别。 这些数字表明大多数复合可视化仅使用一层或两层复合。 添加更多级别的组合需要编码更多的数据列,这可能超出分析场景的要求。 此外,更多层次的构图增加了实现难度和视觉复杂性。
更多的作品,完成更多的任务。 通过研究 VAID,我们发现所有可视化都至少有一个动作目标任务。 有组合的平均完成 1.49 个任务,而没有组合的平均完成 1.33 个任务。 图8D 显示了平均任务数与作品数。 总体而言,要解决的任务数量会随着构图的增加而增加。
6.2. 频率分析
然后,我们在 VAID 中报告不同属性值的频率和发现结果。
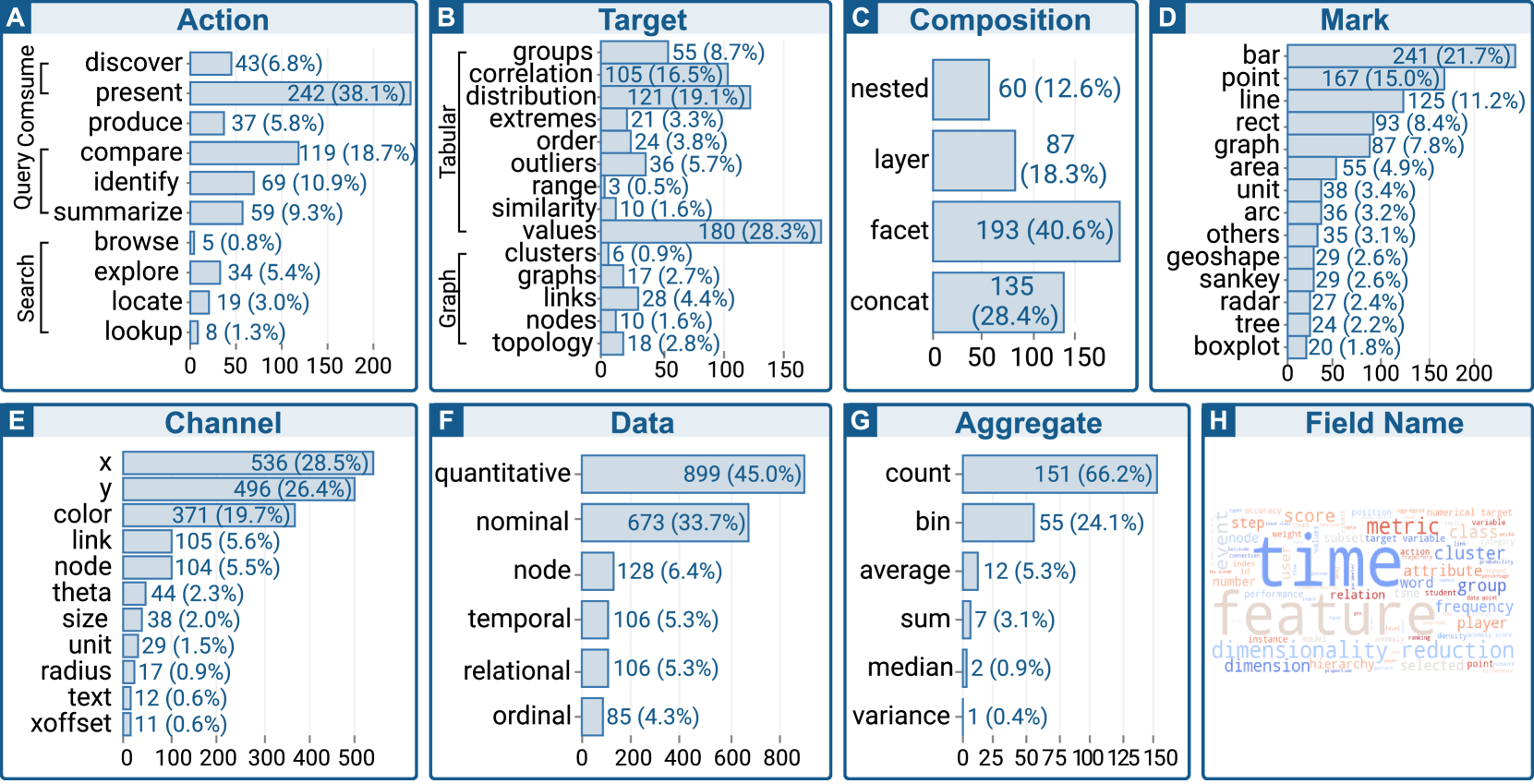
操作:“低级”操作是最常用的分析操作。 如图9A所示,present是最常见的动作。 结果表明,很多设计仅仅用于数据展示。 因此,我们在后面的分析中排除了present,因为设计师通常使用“展示”、“可视化”等术语来解释他们对此类视图设计的使用。 排除此类别后,compare、identify 和 summarize 是最受欢迎的。 Brehmer 和 Munzner 将这三个操作分类为“低级”查询操作(Brehmer and Munzner,2013)。 对于搜索的目标,explore是最流行的,它代表探索性分析。 有趣的是,我们没有发现用于享受的设计,显示视觉分析和信息图表之间的差异。
目标:特定领域的值是最受欢迎的目标。 从目标分布(图9B)中,我们发现最流行的目标是值,它指的是根据指标或算法计算的可视化值。 这体现了VA与领域紧密协作、利用数据挖掘技术进行数据预处理的特点。 分布和相关性是第二和第三受欢迎的目标。 结果表明,理解属性的相关性和分布是 VA 数据模式的关键指标。对于图形数据,链接和整个图形是最常见的可视化目标。
组成:简单的更好。 成分分布如图9C所示。 Facet 按行和列组织相同类型的可视化,是 VA 中最常用的组合类型。 这种简单的组合可以使用简单的可视化构建块(例如散点图矩阵)方便地可视化一个或两个以上维度。 Concat 是第二种流行的类型,它指的是并排放置不同类型的可视化效果。 原始 Vega-Lite 不包含嵌套组合。 虽然比例最小,但也占了10%以上。
标记:基本类型占主导地位。 在复合可视化中,每个视觉组件都被视为特定的标记类型。 我们显示超过 20 条记录的标记类型(图9D)。 分布表明,bar、point、line 和 rect 是最流行的标记类型,它们也是Vega-Lite 中的基本标记类型。 对于 Vega-Lite 未涵盖的类型,graph 和 unit (Park 等人, 2017) 可视化排名 和 在所有类型中。 others 类型排名 ,表明字形可视化也常用于视图设计中。
通道:大多数与笛卡尔坐标系相关。 我们在图 9E 中显示了超过 10 条记录的视觉通道。通道 x、y 和 color 最受欢迎。 由于与图形相关的可视化(例如桑基图、图形和树),通道 link 和 node 也经常使用。
数据类型:大约 90% 的字段是定量和名义的。 在所有数据类型中,定量数据和名义数据在可视化中最常编码(图9F),其次是node数据,常用于图数据。
聚合:分箱/计数,或更复杂的操作。 聚合类型基于 Vega-Lite 聚合操作进行标记(图9G)。 聚合count和bin是最常用的类型,这通常是因为直方图的可视化。 其他聚合类型在视图设计中不经常使用。 原因可能是VA采用了复杂的数据处理方法和指标,而不是基本的聚合策略,例如sum、median和variance。
字段名称:时间和特征分析是主要特征。 字段名称是描述字段的原始 VA 研究论文中使用的术语。 我们使用词云显示字段名称的词频(图9H)。 从词云中,我们立即发现单词时间、特征、度量和降维具有规模较大,表明这些术语的值在 VA 研究中经常使用。
7. 讨论
在本节中,我们将讨论 VAID 未来研究的潜在途径及其局限性。
7.1. 未来研究的机会
我们确定了多个研究机会,分为三个主要途径。
首先,VAID 提供了增强视图设计评估的潜力。 虽然我们对 442 种设计的统计分析产生了宝贵的见解(第 6 节),但仍然有机会通过集成 VAID 进行更深入的分析。 例如,在当前的VA设计过程中,设计方案的选择主要以设计原则(吴等人,2023)为指导。 VAID 可以检索有关数据和任务的潜在有用设计,这补充了设计替代方案以进行更全面的讨论和论证。 这样的索引结构配合数据库有助于提高VA研究的严谨性。 未来的研究可以集中于开发基于 VAID 的 VA 设计评估方法,因为这种结构化方法将 Abstract 设计转换为更易于分析的格式,从而能够应用各种分析技术(例如回归、聚类)。
其次,VAID 提供了简化视图设计比较的机会。 尽管 VA 设计长期以来因其针对特定领域问题的过度设计而受到批评(Wu 等人,2023),但它们在特定视图、组件和任务方面可能有相似之处。 正如 U5 和 U9 所强调的,在探索过程中比较设计的重要性不可低估。 VAID 允许在不同维度进行比较,揭示分析任务和视觉设计的共性和差异。 未来的研究可以集中于提高不同设计之间比较的有效性。
第三,我们将 VAID 视为增强 VA 自动化的第一步。 尽管人们一直在努力实现可视化创建的自动化(Wu等人,2022),但在复杂的VA设计领域对自动化的探索仍然有限。 自动化 VA 设计需要需要训练的大规模数据集,这需要 VA 设计的详细信息。 这方面的一个挑战是所传达的密集视觉信息与通过标题和图表获得的有限信息之间的不匹配。 在这方面,VAID 作为增强可访问信息的第一步发挥着至关重要的作用。 此外,我们鼓励开源更多 VA 系统,因为它们代表了迭代设计的宝贵成果。 通过开源项目共享的设计和系统代码将成为社区的宝贵资源。 通过这些共同努力,我们可以逐步简化VA系统的生产流程,最终实现VA设计的自动化。
7.2. 局限性
作为从任务和视觉设计的角度构建 VA 设计索引结构的首次尝试,我们的工作有一些局限性,值得未来的研究。
互动。 交互是 VA 系统的重要特征。 然而,即使以完全手动的方式,也很难识别 VA 设计中的交互,因为原始论文中并未介绍视图内/视图之间的所有交互。 此外,静态图像的使用隐藏了我们对可配置VA系统的分析(例如,Turkay等人(Turkay等人, 2016)),因为配置框架没有反映在图像中。 为了更好地分析视图关系,需要解析实时 VA 系统并构建视图之间的数据流。
普遍性。 在本研究中,我们根据顶级会议论文中的高质量 VA 设计来设计和评估 VAID。 这些设计构成了一个由复合和多视图可视化组成的语料库,这些设计被认为是复杂且难以理解的(Wu等人,2023)。 因此,VAID 能够表示具有复杂结构的可视化设计。 我们相信 VAID 可用于索引和表示更广泛的可视化设计,例如信息图表,这些设计通常通过新颖的布局和字形(Ying 等人,2022)来促进,从而提高了表达能力信息。 然而,它带来了额外的挑战,因为信息图表通常包含用于隐喻表示的扭曲图形元素(Ying等人,2023a)以及附加模式(例如文本和图像)的组合。 在本研究中,我们从 VA 社区开始,派生出 VAID 作为对此类复杂可视化进行索引研究的开端。 未来的研究需要使用更通用的数据集来评估和扩展 VAID。
评估。 在我们的两项实验室研究中,参与者需要在短时间内完成 VAST 迷你挑战。 我们希望综合创建 VA 设计的场景,但现实世界的 VA 设计通常需要与领域专家合作。 虽然我们试图避免需要专业知识的任务,但完全模拟真实的协作场景仍然是一个挑战。 未来,我们希望与VAID进行实地研究,请VA专家在日常设计过程中使用VAID,观察他们的行为,并从他们的经验中收集更全面的反馈。
可扩展性。 在这项工作中,标注的可扩展性受到限制,因为它需要广泛的可视化知识来注释如此细粒度的结构。 我们的工作植根于这样一个事实:在 VA 中分解视图设计缺乏实用的规则和指导。作为起点,我们通过研讨会研究迭代地手动注释和调整结构,旨在为索引构建坚实的基础。 这种手动工作成本高昂,并且数据集大小相对较小。 未来,我们计划结合机器学习方法来改进 VAID。 这些方法不仅减轻了手动标记的工作量,而且还增强了可用信息。 就前者而言,像 VisImages (Deng 等人, 2023c) 这样的方法利用计算机视觉模型来检测研究论文中的视图位置。 还可以努力提取视觉结构,例如地图(Poco等人,2018),图表(Poco和Heer,2017;Savva等人,2011;Ying等人,2023b) ,以及 PowerPoint 幻灯片(石等人,2022)。 可以采用深度学习模型来检测视觉元素的位置并重建它们的关系。 对于后者,额外的信息可能很有价值。 例如,利用计算机视觉模型导出调色板有助于分析设计的情感基调(Lan等人,2023)并启发未来的设计师(Shi等人,2023)。 使用 OCR 技术从图表中提取的注释和其他文本信息(Memon 等人,2020)可以作为补充材料,帮助用户理解数据叙述和上下文等基本信息(Ren 等)人,2017)。
8。 结论
我们根据视觉分析研究论文构建了一个索引结构 VAID。 该结构具有一个索引,用于从分析任务和视觉设计的角度描述复杂的 VA 设计。 VAID 是通过 12 名 VA 设计师的研讨会研究迭代构建的。 该结构提供了理解和利用最先进的可视化设计的机会,这些设计通过用户研究进行了演示。 然而,鉴于设计可视化分析系统是一个复杂的过程,我们注意到我们的工作是理解和索引 VA 系统的第一步。 我们希望我们的 VAID 和经验教训能为进一步的研究提供有用的基础。
致谢。
该工作得到了国家自然科学基金(U22A2032)以及教育部和浙江省人工智能协同创新中心的支持。 这项工作还得到了新加坡教育部二级学术研究基金(提案 ID:T2EP20222-0049)的部分支持。参考
- (1)
- Amar et al. (2005) R. Amar, J. Eagan, and J. Stasko. 2005. Low-Level Components of Analytic Activity in Information Visualization. In Proceedings of IEEE Symposium on Information Visualization. 111–117.
- Battle et al. (2018) Leilani Battle, Peitong Duan, Zachery Miranda, Dana Mukusheva, Remco Chang, and Michael Stonebraker. 2018. Beagle: Automated Extraction and Interpretation of Visualizations from the Web. In Proceedings of CHI Conference on Human Factors in Computing Systems. 1–8.
- Bigelow et al. (2014) Alex Bigelow, Steven Drucker, Danyel Fisher, and Miriah Meyer. 2014. Reflections on How Designers Design with Data. In Proceedings of the International Working Conference on Advanced Visual Interfaces. 17–24. https://doi.org/10.1145/2598153.2598175
- Borgo et al. (2013) Rita Borgo, Johannes Kehrer, David HS Chung, Eamonn Maguire, Robert S Laramee, Helwig Hauser, Matthew Ward, and Min Chen. 2013. Glyph-Based Visualization: Foundations, Design Guidelines, Techniques and Applications.. In Proceedings of Eurographics Conference on Visualization (State of the Art Reports). 39–63.
- Borkin et al. (2013) Michelle A. Borkin, Azalea A. Vo, Zoya Bylinskii, Phillip Isola, Shashank Sunkavalli, Aude Oliva, and Hanspeter Pfister. 2013. What Makes a Visualization Memorable? IEEE Transactions on Visualization and Computer Graphics 19, 12 (2013), 2306–2315. https://doi.org/10.1109/TVCG.2013.234
- Bostock et al. (2011) Michael Bostock, Vadim Ogievetsky, and Jeffrey Heer. 2011. D Data-Driven Documents. IEEE Transactions on Visualization and Computer Graphics 17, 12 (2011), 2301–2309. https://doi.org/10.1109/TVCG.2011.185
- Brehmer and Munzner (2013) Matthew Brehmer and Tamara Munzner. 2013. A Multi-Level Typology of Abstract Visualization Tasks. IEEE Transactions on Visualization and Computer Graphics 19, 12 (2013), 2376–2385. https://doi.org/10.1109/TVCG.2013.124
- Cao et al. (2021) Anqi Cao, Xiao Xie, Ji Lan, Huihua Lu, Xinli Hou, Jiachen Wang, Hui Zhang, Dongyu Liu, and Yingcai Wu. 2021. MIG-Viewer: Visual Analytics of Soccer Player Migration. Visual Informatics 5, 3 (2021). https://doi.org/10.1016/j.visinf.2021.09.002
- Cao et al. (2018) Nan Cao, Chaoguang Lin, Qiuhan Zhu, Yu-Ru Lin, Xian Teng, and Xidao Wen. 2018. Voila: Visual Anomaly Detection and Monitoring with Streaming Spatiotemporal Data. IEEE Transactions on Visualization and Computer Graphics 24, 1 (2018), 23–33. https://doi.org/10.1109/TVCG.2017.2744419
- Card et al. (1999) Stuart K. Card, Jock D. Mackinlay, and Ben Shneiderman. 1999. Readings in Information Visualization: Using Vision to Think. Academic Press.
- Chairs (2022) VAST Challenge Committee Chairs. 2022. VAST Challenge 2022.
- Chen et al. (2021a) Jian Chen, Meng Ling, Rui Li, Petra Isenberg, Tobias Isenberg, Michael Sedlmair, Torsten Möller, Robert S. Laramee, Han-Wei Shen, Katharina Wünsche, and Qiru Wang. 2021a. VIS30K: A Collection of Figures and Tables from IEEE Visualization Conference Publications. IEEE Transactions on Visualization and Computer Graphics 27, 9 (2021), 3826–3833. https://doi.org/10.1109/TVCG.2021.3054916
- Chen et al. (2021b) Xi Chen, Wei Zeng, Yanna Lin, Hayder Mahdi AI-maneea, Jonathan Roberts, and Remco Chang. 2021b. Composition and Configuration Patterns in Multiple-View Visualizations. IEEE Transactions on Visualization and Computer Graphics 27, 2 (2021), 1514–1524. https://doi.org/10.1109/TVCG.2020.3030338
- Chi (2000) Ed Huai-hsin Chi. 2000. A Taxonomy of Visualization Techniques Using the Data State Reference Model. In IEEE Symposium on Information Visualization. 69–75.
- Deng et al. (2023a) Dazhen Deng, Weiwei Cui, Xiyu Meng, Mengye Xu, Yu Liao, Haidong Zhang, and Yingcai Wu. 2023a. Revisiting the Design Patterns of Composite Visualizations. IEEE Transactions on Visualization and Computer Graphics 29, 12 (2023), 5406–5421. https://doi.org/10.1109/TVCG.2022.3213565
- Deng et al. (2022) Dazhen Deng, Aoyu Wu, Huamin Qu, and Yingcai Wu. 2022. DashBot: Insight-Driven Dashboard Generation Based on Deep Reinforcement Learning. IEEE Transactions on Visualization and Computer Graphics 29, 1 (2022), 690–700. https://doi.org/10.1109/TVCG.2022.3209468
- Deng et al. (2023c) Dazhen Deng, Yihong Wu, Xinhuan Shu, Jiang Wu, Siwei Fu, Weiwei Cui, and Yingcai Wu. 2023c. VisImages: A Fine-Grained Expert-Annotated Visualization Dataset. IEEE Transactions on Visualization and Computer Graphics 29, 7 (2023), 3298–3311. https://doi.org/10.1109/TVCG.2022.3155440
- Deng et al. (2023b) Zikun Deng, Di Weng, Shuhan Liu, Yuan Tian, Mingliang Xu, and Yingcai Wu. 2023b. A Survey of Urban Visual Analytics: Advances and Future Directions. Computational Visual Media 9, 1 (2023), 3–39. https://doi.org/10.1007/s41095-022-0275-7
- Elmqvist and Fekete (2010) Niklas Elmqvist and Jean-Daniel Fekete. 2010. Hierarchical Aggregation for Information Visualization: Overview, Techniques, and Design Guidelines. IEEE Transactions on Visualization and Computer Graphics 16, 3 (2010), 439–454. https://doi.org/10.1109/TVCG.2009.84
- Engelhardt and Richards (2018) Yuri Engelhardt and Clive Richards. 2018. A Framework for Analyzing and Designing Diagrams and Graphics. In Proceedings of International Conference on Theory and Application of Diagrams. 201–209.
- Fu et al. (2017) Siwei Fu, Jian Zhao, Weiwei Cui, and Huamin Qu. 2017. Visual Analysis of MOOC Forums with iForum. IEEE Transactions on Visualization and Computer Graphics 23, 1 (2017), 201–210. https://doi.org/10.1109/TVCG.2016.2598444
- Gou et al. (2021) Liang Gou, Lincan Zou, Nanxiang Li, Michael Hofmann, Arvind Kumar Shekar, Axel Wendt, and Liu Ren. 2021. VATLD: A Visual Analytics System to Assess, Understand and Improve Traffic Light Detectio. IEEE Transactions on Visualization and Computer Graphics 27, 2 (2021), 261–271. https://doi.org/10.1109/TVCG.2020.3030350
- Harris (1999) Robert L Harris. 1999. Information Graphics: A Comprehensive Illustrated Reference.
- Heer and Bostock (2010) Jeffrey Heer and Michael Bostock. 2010. Declarative Language Design for Interactive Visualization. IEEE Transactions on Visualization and Computer Graphics 16, 6 (2010), 1149–1156. https://doi.org/10.1109/TVCG.2010.144
- Herring et al. (2009) Scarlett R. Herring, Chia-Chen Chang, Jesse Krantzler, and Brian P. Bailey. 2009. Getting Inspired!: Understanding How and Why Examples Are Used in Creative Design Practice. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. 87–96. https://doi.org/10.1145/1518701.1518717
- Hoque and Agrawala (2020) Enamul Hoque and Maneesh Agrawala. 2020. Searching the Visual Style and Structure of D3 Visualizations. IEEE Transactions on Visualization and Computer Graphics 26, 1 (2020), 1236–1245. https://doi.org/10.1109/TVCG.2019.2934431
- Hu et al. (2019) Kevin Hu, Snehalkumar’Neil’S Gaikwad, Madelon Hulsebos, Michiel A Bakker, Emanuel Zgraggen, César Hidalgo, Tim Kraska, Guoliang Li, Arvind Satyanarayan, and Çağatay Demiralp. 2019. Viznet: Towards a Large-Scale Visualization Learning and Benchmarking Repository. In Proceedings of the CHI Conference on Human Factors in Computing Systems. 1–12.
- Javed and Elmqvist (2012) Waqas Javed and Niklas Elmqvist. 2012. Exploring the Design Space of Composite Visualization. In Proceedings of IEEE Pacific Visualization Symposium. 1–8.
- Keim et al. (2008a) Daniel Keim, Gennady Andrienko, Jean-Daniel Fekete, Carsten Görg, Jörn Kohlhammer, and Guy Melançon. 2008a. Visual Analytics: Definition, Process, and Challenges. In Information Visualization. 154–175.
- Keim et al. (2008b) Daniel A. Keim, Florian Mansmann, Jörn Schneidewind, Jim Thomas, and Hartmut Ziegler. 2008b. Visual Analytics: Scope and Challenges. In Proceedings of Visual Data Mining: Theory, Techniques and Tools for Visual Analytics. Lecture Notes in Computer Science, Vol. 4404. 76–90. https://doi.org/10.1007/978-3-540-71080-6_6
- Krueger et al. (2020) Robert Krueger, Johanna Beyer, Won-Dong Jang, Nam Wook Kim, Artem Sokolov, Peter K. Sorger, and Hanspeter Pfister. 2020. Facetto: Combining Unsupervised and Supervised Learning for Hierarchical Phenotype Analysis in Multi-Channel Image Data. IEEE Transactions on Visualization and Computer Graphics 26, 1 (2020), 227–237. https://doi.org/10.1109/TVCG.2019.2934547
- Kui et al. (2022) Xiaoyan Kui, Naiming Liu, Qiang Liu, Jingwei Liu, Xiaoqian Zeng, and Chao Zhang. 2022. A Survey of Visual Analytics Techniques for Online Education. Visual Informatics 6, 4 (2022). https://doi.org/10.1016/j.visinf.2022.07.004
- Lan et al. (2023) Xingyu Lan, Yanqiu Wu, and Nan Cao. 2023. Affective Visualization Design: Leveraging the Emotional Impact of Data. IEEE Transactions on Visualization and Computer Graphics (2023), 1–11. https://doi.org/10.1109/TVCG.2023.3327385
- Lee et al. (2006) Bongshin Lee, Catherine Plaisant, Cynthia Sims Parr, Jean-Daniel Fekete, and Nathalie Henry. 2006. Task Taxonomy for Graph Visualization. In Proceedings of AVI Workshop on BEyond Time and Errors: Novel Evaluation Methods for Information Visualization. 1–5. https://doi.org/10.1145/1168149.1168168
- Lee et al. (2010) Brian Lee, Savil Srivastava, Ranjitha Kumar, Ronen Brafman, and Scott R. Klemmer. 2010. Designing with Interactive Example Galleries. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. 2257–2266. https://doi.org/10.1145/1753326.1753667
- Lekschas et al. (2018) Fritz Lekschas, Benjamin Bach, Peter Kerpedjiev, Nils Gehlenborg, and Hanspeter Pfister. 2018. HiPiler: Visual Exploration of Large Genome Interaction Matrices with Interactive Small Multiples. IEEE Transactions on Visualization and Computer Graphics 24, 1 (2018), 522–531. https://doi.org/10.1109/TVCG.2017.2745978
- Li et al. (2018) Deqing Li, Honghui Mei, Yi Shen, Shuang Su, Wenli Zhang, Junting Wang, Ming Zu, and Wei Chen. 2018. ECharts: A Declarative Framework for Rapid Construction of Web-Based Visualization. Visual Informatics 2, 2 (2018), 136–146. https://doi.org/10.1016/j.visinf.2018.04.011
- Li et al. (2022) Haotian Li, Yong Wang, Aoyu Wu, Huan Wei, and Huamin Qu. 2022. Structure-Aware Visualization Retrieval. In Proceedings of CHI Conference on Human Factors in Computing Systems. https://doi.org/10.1145/3491102.3502048
- Liu et al. (2019) Dongyu Liu, Panpan Xu, and Liu Ren. 2019. TPFlow: Progressive Partition and Multidimensional Pattern Extraction for Large-Scale Spatio-Temporal Data Analysis. IEEE Transactions on Visualization and Computer Graphics 25, 1 (2019), 1–11. https://doi.org/10.1109/TVCG.2018.2865018
- Lohse et al. (1994) Gerald L Lohse, Kevin Biolsi, Neff Walker, and Henry H Rueter. 1994. Classification with Invariant Scattering Representations. Commun. ACM 37, 12 (1994), 36–50. https://doi.org/10.1145/198366.198376
- Lu et al. (2023) Qiang Lu, Yifan Ge, Jingang Rao, Liang Ling, Ye Yu, and Zhenya Zhang. 2023. WaterExcVA: A System for Exploring and Visualizing Data Exception in Urban Water Supply. Journal of Visualization 26, 4 (2023). https://doi.org/10.1007/s12650-023-00911-9
- LYi et al. (2021) Sehi LYi, Jaemin Jo, and Jinwook Seo. 2021. Comparative Layouts Revisited: Design Space, Guidelines, and Future Directions. IEEE Transactions on Visualization and Computer Graphics 27, 2 (2021), 1525–1535. https://doi.org/10.1109/TVCG.2020.3030419
- Mackinlay (1986) Jock Mackinlay. 1986. Automating the Design of Graphical Presentations of Relational Information. ACM Transactions on Graphics 5, 2 (1986), 110–141. https://doi.org/10.1145/22949.22950
- Meirelles (2013) Isabel Meirelles. 2013. Design for Information: An Introduction to the Histories, Theories, and Best Practices behind Effective Visualizations.
- Memon et al. (2020) Jamshed Memon, Maira Sami, Rizwan Ahmed Khan, and Mueen Uddin. 2020. Handwritten Optical Character Recognition (OCR): A Comprehensive Systematic Literature Review (SLR). IEEE access : practical innovations, open solutions 8 (2020), 142642–142668. https://doi.org/10.1109/ACCESS.2020.3012542
- Munzner (2009) Tamara Munzner. 2009. A Nested Model for Visualization Design and Validation. IEEE Transactions on Visualization and Computer Graphics 15, 6 (2009), 921–928. https://doi.org/10.1109/TVCG.2009.111
- Munzner (2014) Tamara Munzner. 2014. Visualization Analysis and Design.
- Ono et al. (2021) Jorge Piazentin Ono, Sonia Castelo, Roque Lopez, Enrico Bertini, Juliana Freire, and Claudio Silva. 2021. PipelineProfiler: A Visual Analytics Tool for the Exploration of AutoML Pipelines. IEEE Transactions on Visualization and Computer Graphics 27, 2 (2021), 390–400. https://doi.org/10.1109/TVCG.2020.3030361
- Park et al. (2017) Deokgun Park, Steven M Drucker, Roland Fernandez, and Niklas Elmqvist. 2017. Atom: A Grammar for Unit Visualizations. IEEE Transactions on Visualization and Computer Graphics 24, 12 (2017), 3032–3043. https://doi.org/10.1109/TVCG.2017.2785807
- Poco and Heer (2017) Jorge Poco and Jeffrey Heer. 2017. Reverse-Engineering Visualizations: Recovering Visual Encodings from Chart Images. Computer Graphics Forum 36, 3 (2017), 353–363. https://doi.org/10.1111/cgf.13193
- Poco et al. (2018) Jorge Poco, Angela Mayhua, and Jeffrey Heer. 2018. Extracting and Retargeting Color Mappings from Bitmap Images of Visualizations. IEEE Transactions on Visualization and Computer Graphics 24, 1 (2018), 637–646. https://doi.org/10.1109/TVCG.2017.2744320
- Ren et al. (2017) Donghao Ren, Matthew Brehmer, Bongshin Lee, Tobias Hollerer, and Eun Kyoung Choe. 2017. ChartAccent: Annotation for Data-Driven Storytelling. In IEEE Pacific Visualization Symposium. 230–239. https://doi.org/10.1109/PACIFICVIS.2017.8031599
- Sacha et al. (2014) Dominik Sacha, Andreas Stoffel, Florian Stoffel, Bum Chul Kwon, Geoffrey Ellis, and Daniel A. Keim. 2014. Knowledge Generation Model for Visual Analytics. IEEE Transactions on Visualization and Computer Graphics 20, 12 (2014), 1604–1613. https://doi.org/10.1109/TVCG.2014.2346481
- Satyanarayan et al. (2017) Arvind Satyanarayan, Dominik Moritz, Kanit Wongsuphasawat, and Jeffrey Heer. 2017. Vega-Lite: A Grammar of Interactive Graphics. IEEE Transactions on Visualization and Computer Graphics 23, 1 (2017), 341–350. https://doi.org/10.1109/TVCG.2016.2599030
- Savva et al. (2011) Manolis Savva, Nicholas Kong, Arti Chhajta, Li Fei-Fei, Maneesh Agrawala, and Jeffrey Heer. 2011. ReVision: Automated Classification, Analysis and Redesign of Chart Images. In In Proceedings of Annual ACM Symposium on User Interface Software and Technology. 393–402.
- Shi et al. (2022) Danqing Shi, Weiwei Cui, Danqing Huang, Haidong Zhang, and Nan Cao. 2022. Reverse-Engineering Information Presentations: Recovering Hierarchical Grouping from Layouts of Visual Elements. CoRR abs/2201.05194 (2022).
- Shi et al. (2023) Xinyu Shi, Ziqi Zhou, Jing Wen Zhang, Ali Neshati, Anjul Kumar Tyagi, Ryan Rossi, Shunan Guo, Fan Du, and Jian Zhao. 2023. De-Stijl: Facilitating Graphics Design with Interactive 2D Color Palette Recommendation. In Proceedings of the CHI Conference on Human Factors in Computing Systems. 1–19. https://doi.org/10.1145/3544548.3581070
- Shneiderman (2002) Ben Shneiderman. 2002. Creativity Support Tools. Commun. ACM 45, 10 (2002), 116–120. https://doi.org/10.1145/570907.570945
- Srinivasan et al. (2018) Arjun Srinivasan, Steven M Drucker, Alex Endert, and John Stasko. 2018. Augmenting Visualizations with Interactive Data Facts to Facilitate Interpretation and Communication. IEEE Transactions on Visualization and Computer Graphics 25, 1 (2018), 672–681. https://doi.org/10.1109/TVCG.2018.2865145
- Stein et al. (2018) Manuel Stein, Halldor Janetzko, Andreas Lamprecht, Thorsten Breitkreutz, Philipp Zimmermann, Bastian Goldlücke, Tobias Schreck, Gennady Andrienko, Michael Grossniklaus, and Daniel A. Keim. 2018. Bring It to the Pitch: Combining Video and Movement Data to Enhance Team Sport Analysis. IEEE Transactions on Visualization and Computer Graphics 24, 1 (2018), 13–22. https://doi.org/10.1109/TVCG.2017.2745181
- Turkay et al. (2016) Cagatay Turkay, Erdem Kaya, Selim Balcisoy, and Helwig Hauser. 2016. Designing Progressive and Interactive Analytics Processes for High-Dimensional Data Analysis. IEEE transactions on visualization and computer graphics 23, 1 (2016), 131–140. https://doi.org/10.1109/TVCG.2016.2598470
- Viegas et al. (2007) Fernanda B. Viegas, Martin Wattenberg, Frank van Ham, Jesse Kriss, and Matt McKeon. 2007. ManyEyes: A Site for Visualization at Internet Scale. IEEE Transactions on Visualization and Computer Graphics 13, 6 (2007), 1121–1128. https://doi.org/10.1109/TVCG.2007.70577
- Wilkinson (2012) Leland Wilkinson. 2012. The Grammar of Graphics: The Ggplot2 Package. In Handbook of Computational Statistics. 375–414.
- Wu et al. (2023) Aoyu Wu, Dazhen Deng, Furui Cheng, Yingcai Wu, Shixia Liu, and Huamin Qu. 2023. In Defence of Visual Analytics Systems: Replies to Critics. IEEE Transactions on Visualization and Computer Graphics 29, 1 (2023), 1026–1036. https://doi.org/10.1109/TVCG.2022.3209360
- Wu et al. (2022) Aoyu Wu, Yun Wang, Xinhuan Shu, Dominik Moritz, Weiwei Cui, Haidong Zhang, Dongmei Zhang, and Huamin Qu. 2022. AI4VIS: Survey on Artificial Intelligence Approaches for Data Visualization. , 5049–5070 pages. https://doi.org/10.1109/TVCG.2021.3099002
- Ye et al. (2022) Yilin Ye, Rong Huang, and Wei Zeng. 2022. VISAtlas: An Image-Based Exploration and Query System for Large Visualization Collections via Neural Image Embedding. IEEE Transactions on Visualization and Computer Graphics (2022), 1–15. https://doi.org/10.1109/TVCG.2022.3229023
- Ying et al. (2023a) Lu Ying, Xinhuan Shu, Dazhen Deng, Yuchen Yang, Tan Tang, Lingyun Yu, and Yingcai Wu. 2023a. MetaGlyph: Automatic Generation of Metaphoric Glyph-based Visualization. IEEE Transactions on Visualization and Computer Graphics 29, 1 (2023), 331–341. https://doi.org/10.1109/TVCG.2022.3209447
- Ying et al. (2022) Lu Ying, Tan Tangl, Yuzhe Luo, Lvkeshen Shen, Xiao Xie, Lingyun Yu, and Yingcai Wu. 2022. GlyphCreator: Towards Example-based Automatic Generation of Circular Glyphs. IEEE Transactions on Visualization and Computer Graphics 28, 1 (2022). https://doi.org/10.1109/TVCG.2021.3114877
- Ying et al. (2023b) Lu Ying, Yun Wang, Haotian Li, Shuguang Dou, Haidong Zhang, Xinyang Jiang, Huamin Qu, and Yingcai Wu. 2023b. Reviving Static Charts into Live Charts.
- Zhao et al. (2017) Jian Zhao, Michael Glueck, Simon Breslav, Fanny Chevalier, and Azam Khan. 2017. Annotation Graphs: A Graph-Based Visualization for Meta-Analysis of Data Based on User-Authored Annotations. IEEE Transactions on Visualization and Computer Graphics 23, 1 (2017), 261–270. https://doi.org/10.1109/TVCG.2016.2598543
- Zhou et al. (2023) Yuhua Zhou, Xiyu Meng, Yanhong Wu, Tan Tang, Yongheng Wang, and Yingcai Wu. 2023. An Intelligent Approach to Automatically Discovering Visual Insights. Journal of Visualization 26, 3 (2023). https://doi.org/10.1007/s12650-022-00894-z
- Zhou et al. (2019) Zhiguang Zhou, Linhao Meng, Cheng Tang, Ying Zhao, Zhiyong Guo, Miaoxin Hu, and Wei Chen. 2019. Visual Abstraction of Large Scale Geospatial Origin-Destination Movement Data. IEEE Transactions on Visualization and Computer Graphics 25, 1 (2019), 43–53. https://doi.org/10.1109/TVCG.2018.2864503