一种用于通用逼近的无重复量子神经网络
摘要
量子神经网络的普适性是指其逼近任意函数的能力,是其有效性的理论保证。 非通用神经网络可能无法完成机器学习任务。 通用性的一个建议是将量子数据编码成张量积的相同副本,但这将大大增加系统尺寸和电路复杂性。 为了解决这个问题,我们提出了一种简单的无重复量子神经网络设计,其通用性可以得到严格证明。 与其他已建立的提案相比,我们的模型需要更少的量子位和更浅的电路,从而大大降低了实施的资源开销。 它的抗噪声能力也更强,并且更容易在近期设备上实现。 模拟表明我们的模型可以解决广泛的经典和量子学习问题,展示了其广泛的应用潜力。
我简介
机器学习(ML)是一种强大的数据分析工具,在图像识别[1,2,3]、自然语言处理[4,5,6方面产生了一系列有影响力的结果]、自动驾驶[7,8,9]等 同时,量子机器学习已成为机器学习与量子计算相结合的新兴交叉学科。 它研究两个基本问题[10],一个是经典机器学习在量子问题上的应用[11,12,13,14,15,16],另一个是关于机器学习算法在量子处理器上的实现。 最近的研究指出,在量子计算机上实施机器学习算法来处理量子数据所需的实验比在经典计算机上处理相同的任务要少得多[17]。 此外,事实证明,许多机器学习算法可以在量子机上实现,并具有一定程度的优势,包括数据拟合[18]、支持向量机[19]、最近邻[20]、主成分分析[21]、线性回归[22]、PageRank算法 [23]、强化学习[24,25,26]、异常检测[27]和玻尔兹曼机[28] 。 对于其他机器学习主题,尤其是量子神经网络 (QNN),量子优势的存在在很大程度上是未知的[29],尽管最近取得了有关 QNN 预测优势的有趣结果 [30]。
神经网络(NN)是由激活函数组成的参数化复合映射,在数据拟合方面非常强大。 QNN 是在量子计算机 [31] 上实现的神经网络,有多种设计方案,例如变分 QNN [32, 33]。 除了量子优势之外,设计有效且高效的 QNN 也很重要。 并非每个 QNN 设计都能有效解决给定的 ML 问题,引入通用逼近的概念来解释为什么某些神经网络无法工作[34, 35]。 通用逼近,或神经网络的通用性,是指它逼近任意函数的能力。 对于经典神经网络来说,普适性很容易实现;对于 QNN,需要进行智能设计以使其通用且实用。 事实上,神经网络的普适性与非线性激活函数密切相关,设计通用QNN的关键是生成函数拟合所需的非线性。 一种方法是构建量子神经元,它是一些 QNN 的构建块[36,37,38,39,40,41];另一种方法是从参数化量子电路构造变分QNN,通过将量子数据复制为多个副本的张量积[42, 43]来实现非线性。 后一种方法的示例包括量子电路学习(QCL)算法[32]和以电路为中心的量子分类器(CCQ)算法[33]。 到目前为止,QCL算法的普适性已经利用Weierstrass定理得到了证明,而CCQ算法的普适性仍然是开放的。 对于QCL和CCQ来说,逼近高度非线性的函数需要许多数据编码子系统的张量积,导致系统整体规模较大,电路复杂度相当大,这与NISQ计算的原理相冲突,NISQ计算的原理是相对较小的量子系统最好采用浅电路。
为了解决这个问题,我们提出了一种基于变分量子电路的无重复量子神经网络(DQNN),并严格证明了其普适性。 我们的模型利用经典的 sigmoid 函数来生成非线性,而无需将量子数据复制为多个副本的张量积。 与 CCQ 或 QCL 算法相比,我们的 DQNN 显着降低了系统尺寸和门复杂度,从而降低了整体噪声影响。 因此,它更有可能在近期设备上实现。 数值模拟表明,我们的 DQNN 优于其他两种变分 QNN 算法,在典型回归和分类问题上具有更好的性能,并且对噪声具有更强的鲁棒性。 此外,通过解决广泛的经典和量子学习问题,我们的模型很好地展示了其广泛的应用潜力。
II万能逼近的两种设计
在讨论 DQNN 设计之前,我们先简要回顾一下经典神经网络通用逼近的两种常见设计类型。 事实证明,普遍性与不同类型的趋同密切相关。 I 型近似依赖于逐点收敛;一个典型的例子是多项式逼近,利用Weierstrass定理和多项式来逼近任意函数; II 型近似取决于勒贝格积分的收敛性,例如 -范数收敛性。 对于多项式近似,有几个限制。 首先,Weierstrass 定理仅在紧集上有效,而许多神经网络问题是在无界集上定义的,在无界集上多项式可能无法逼近 Lebesgue 可积函数。 例如,在 上定义的函数 不能用多项式很好地近似,因为后者发散到 而 消失为。 其次,当多项式阶数变得很大时,多项式逼近会出现一个称为龙格现象[44]的数值问题,这就是为什么在实际使用中不赞成使用高阶多项式进行函数拟合。 由于这些限制,多项式在设计通用神经网络时无效。 已经证明,通用前馈神经网络的充要条件是其激活函数不是多项式[35]。 相比之下,II 类近似利用有限元方法中的 hat 函数等基函数[45]或神经网络中的 sigmoid/ReLU 函数与线性函数的复合[46]. 通常,最优近似是最小化问题的解,并且以合适的函数范数来评估误差。 特别是,基于-范数近似的通用神经网络得到了广泛应用,并且被发现非常有效。 此类示例包括具有激活函数的示例,例如 sigmoid 或 ReLU 函数。 因此,本文旨在讨论如何使用类似于 sigmoid 函数的技巧而不是多项式来构建基于 近似的通用且有效的 QNN。 与基于多项式近似的 QNN 相比,我们期望这种 QNN 在广泛的应用中有效。
III DQNN及其普适性
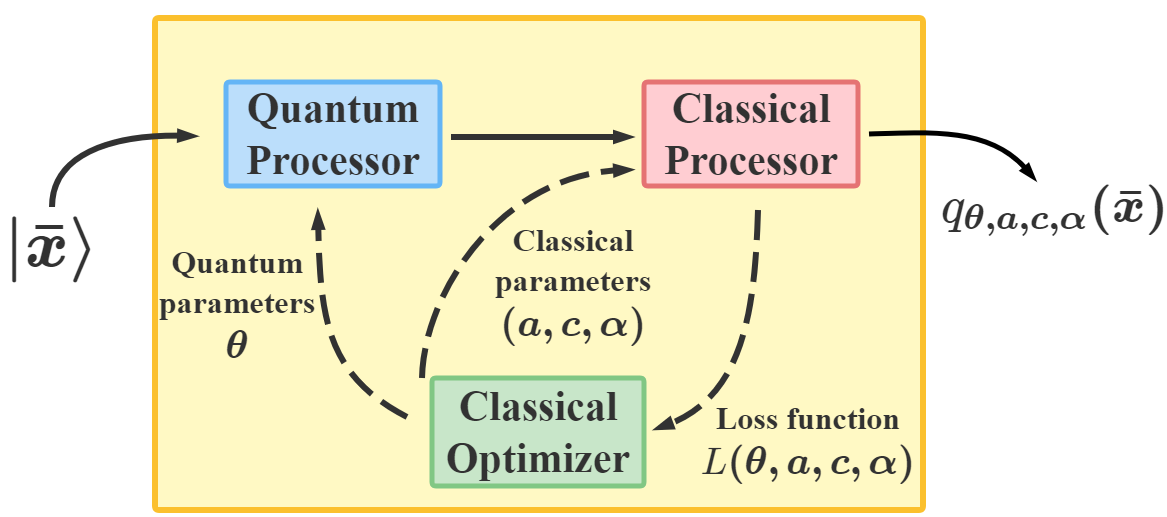
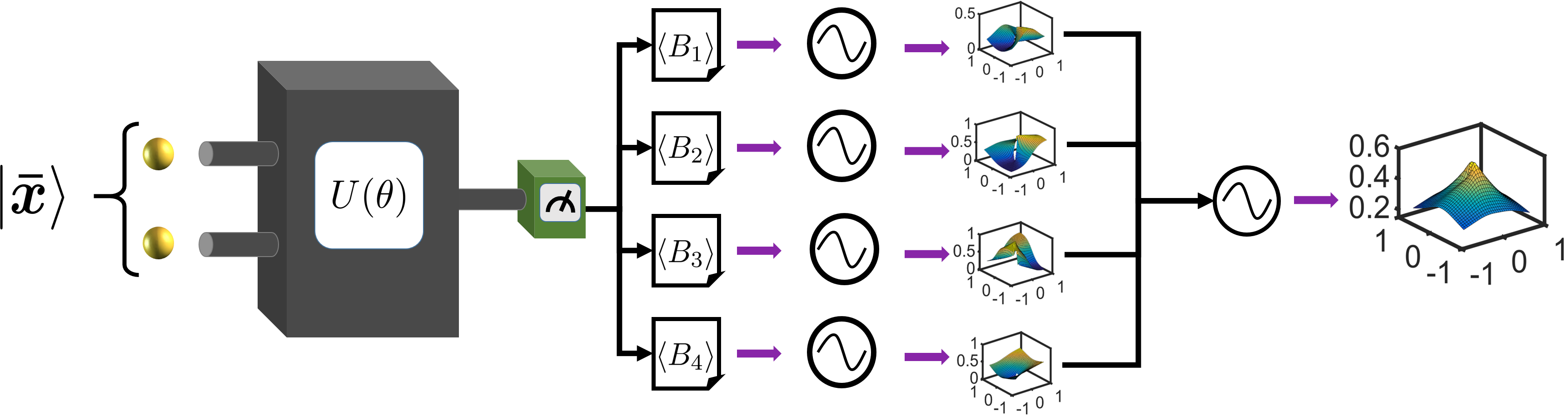
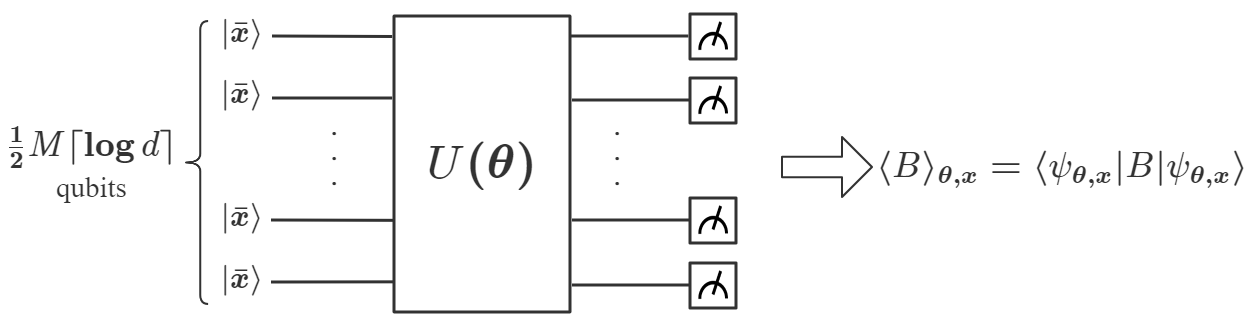
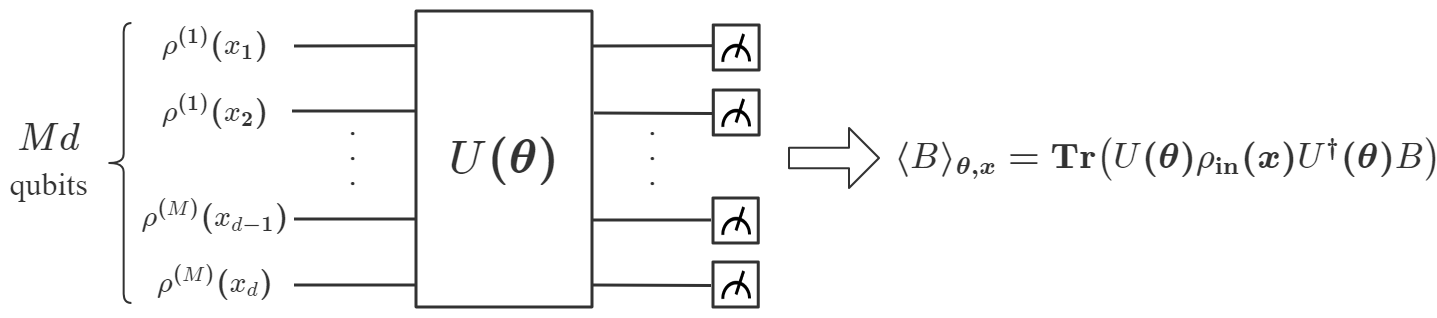
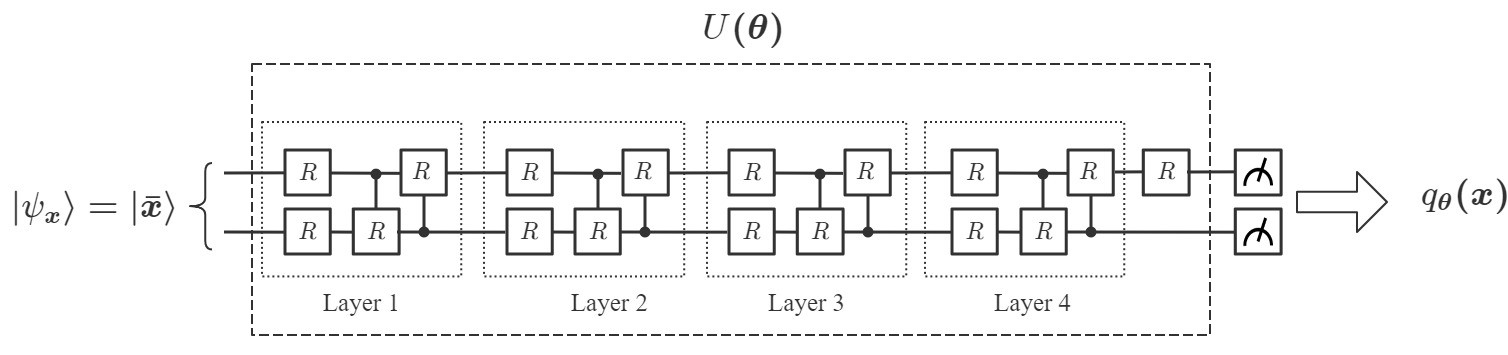
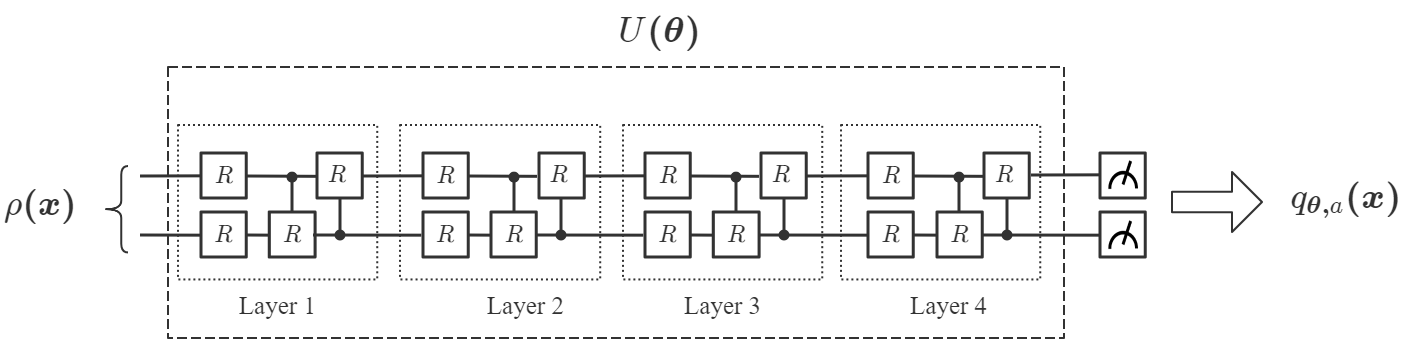
从数学上讲,变分 QNN 是建立在参数化量子电路 上的映射 。 它涉及一种混合量子经典算法,利用量子处理器为每个输入生成输出,并使用经典处理器优化来解决学习问题。 具体来说,给定一个未知函数 和一个数据集 ,其中 是 的标签,QNN 的目标就是找到一个最佳的,使得最接近目标函数。我们的DQNN模型由三部分组成,量子处理器、经典处理器和经典优化器,如图1(a)所示。 首先,每个数据点 被编码为 -qubit 寄存器 () 的状态:
| (1) |
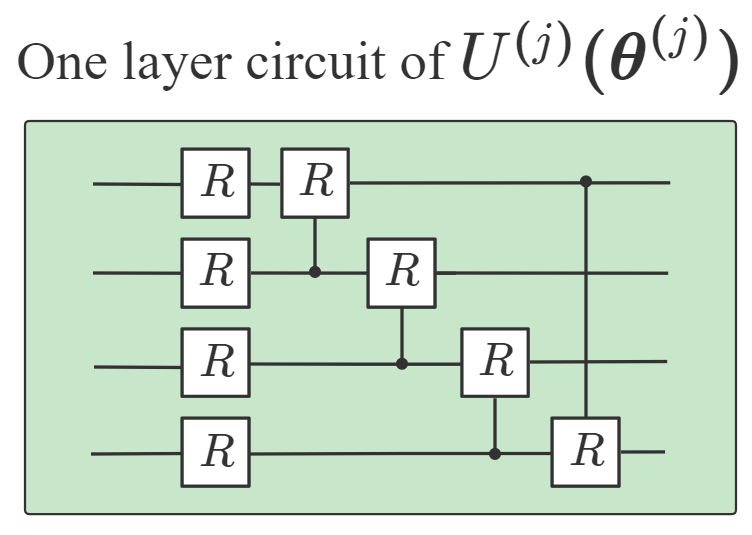
使用幅度编码方法[47],其中是用户选择的填充项,是归一化因子(附录A)。 在初始状态准备之后,我们根据应用于一系列变分量子电路,然后测量一组可观测量,得到结果。 的选择不是唯一的,它们可以从广义泡利基 中随机选择,其中 与 和 是泡利矩阵。 包含 层量子电路。 每层由 参数化 旋转(每个量子位一个)和 参数化受控 门组成,如下所示如图1所示,其中
请注意,每层中门的顺序不是唯一的,可以随机选择[33]。 接下来,基于和sigmoid函数,经典处理器计算并获得输出:
| (2) |
其中 、,其中 和 是要训练的参数。 从到的整个过程总结在图1中。 最后,通过使用 SGD [48]、ADAM [49 等算法进行基于梯度的优化,可以找到 的最佳值来解决给定的学习问题] 或 BFGS [50]。 这种构造的好处是可以基于 近似证明 DQNN 是通用的,概括为以下定理:
Theorem 1。
令 为 中复杂球体 的子集, 为 。 我们定义以下参数化函数:
| (3) |
并将 表示为所有此类函数的集合,其中 、、、、和。 那么 在 中是稠密的,意义如下:对于任何 ,
| (4) |
定理1的详细证明可以参见附录B。 事实证明,等式中的任何。 (3) 可以作为等式 1 中 DQNN 的输出生成。 (2)。 具体来说,给定参数,我们可以设计一个具有单个可观测、和一系列量子电路的DQNN > 这样。 然后是等式中 DQNN 的输出。 (2) 减少为:
| (5) |
由此我们证明了以下推论:
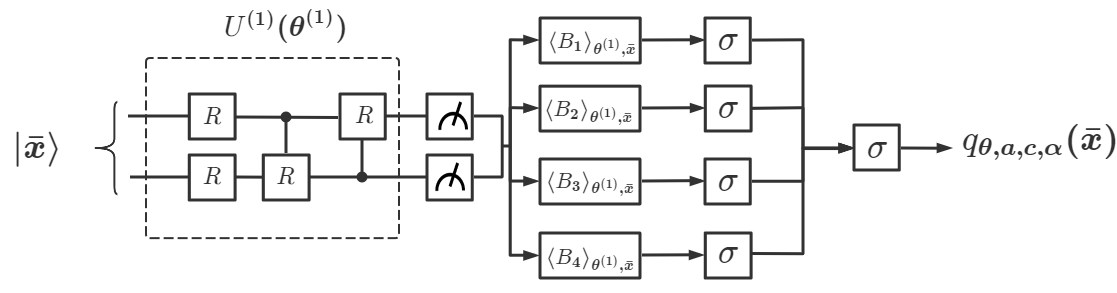
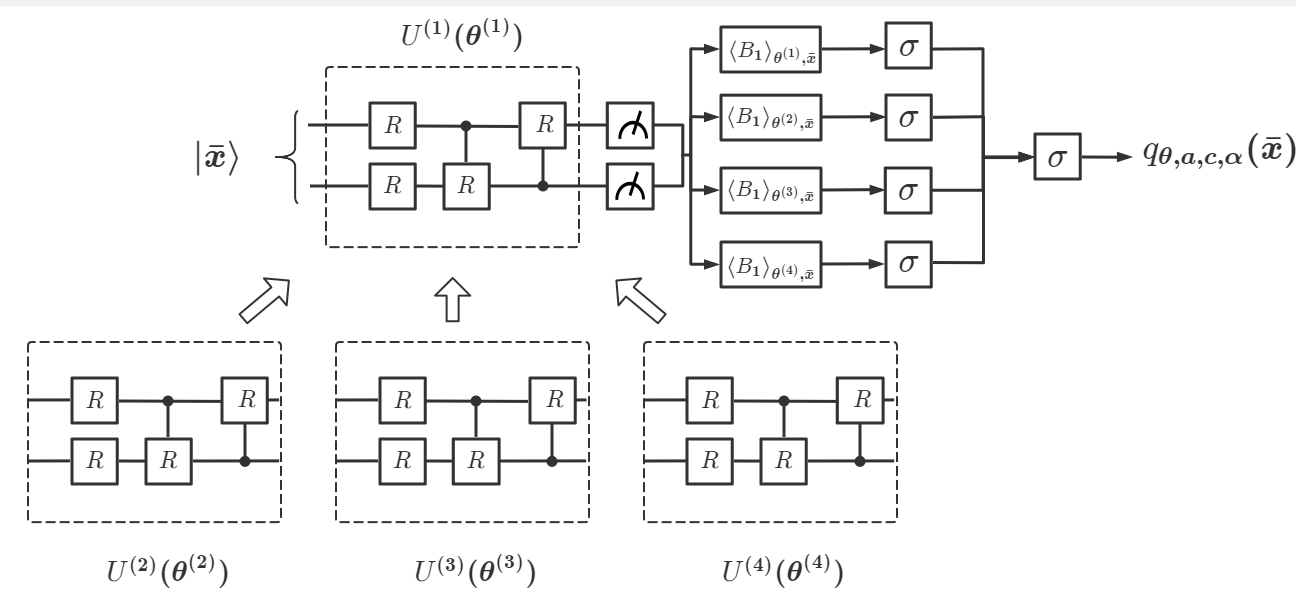
请注意,选择多个 和单个可观察的 仅是证明推论 1 中普遍性的充分条件。 在实践中,我们经常设计一个具有单个 () 和一组 的 DQNN 作为解决给定问题的第一次尝试。 如果还不够好,我们就构建一个具有更大 的新 DQNN。 事实证明,具有 的 DQNN 通常足以解决我们研究过的大多数学习问题。 此外,在推论1的证明中,我们假设我们设计的多层变分电路可以生成具有的变分电路如图1(b)所示。 中的层数越多,逼近任意单一门的能力就越强,但也会使优化过程的计算成本更高。 因此,在实践中,我们经常从由一层或两层组成的单个 开始构建 DQNN。 接下来,我们将研究不同值的DQNN的性能,为了简单起见,我们将相应的网络表示为DQNN。
IV QNN模型的性能比较
在第二节中,我们提到通用性是构建有效 QNN 的必要条件,在两种通用设计中,使用 sigmoid 基函数实现 收敛的 NN 在更广泛的范围内工作得更有效。应用范围。 如上所示,DQNN 的非线性和普适性本质上源于 sigmoid 函数的收敛,这与其他基于多项式逼近的 QNN 模型不同,包括 CCQ [33] 和 QCL [32],其非线性主要是通过将相同的数据编码状态复制到多个子系统的张量积中产生的。 通过这种方式,DQNN 显着减少了构建通用 QNN 所需的量子位数量。 接下来,我们将通过将 DQNN 的性能与两个成熟的 QNN 模型 CCQ 和 QCL 的性能进行比较来展示 DQNN 的优势。
对于-qubit QNN模型,我们将其复杂度定义为,其中表示量子门的数量,表示量子测量的数量。 请注意,给定测量精度, 与测量可观测值 的数量成正比。 因此,进一步假设可以有效地生成QNN变分电路,即,则QNN的整体复杂度变为。 我们希望分别使用 CCQ、QCL 和 DQNN 计算出用 逼近 阶多项式函数 所需的量子位和可观测量数。 我们用 表示数据编码寄存器中的量子位数量,用 表示 QNN 模型中使用的数据编码寄存器的副本数量。 为了近似这样的 ,CCQ 需要 个数据编码寄存器 的副本,以便输入状态的幅度 ,是 的 阶多项式。 应用电路后,我们根据测量给定可观察值的期望值。 CCQ 的输出是 的 阶多项式。 那么CCQ的目标是通过优化找到最佳值,使得是逼近的最优函数。 数据编码寄存器中的量子位数量为,可观察量的数量为。 因此CCQ的总复杂度等于。 对于 QCL,使用多个单个将 维经典数据 编码到 量子位数据编码寄存器中,作为 -量子位旋转门。 为了生成 阶多项式, 被复制为张量积中的 相同副本,如 。 将电路 应用于 ,我们测量给定可观察值 的期望值。 结果 是 的 阶多项式。 通过优化,我们可以找到最佳值,使得能够很好地逼近。 QCL 中的量子位总数为 ,可观测值的数量为 。 因此QCL的总复杂度为。
与上述两种基于复制的 QNN 模型不同,DQNN 仅使用 量子位将 编码为 。 我们依次将一组变分量子电路 应用于 ,并测量一组选定的可观察量 的期望 。 接下来我们应用参数化的经典 sigmoid 函数 并得出最终输出 。 通过优化,我们可以找到逼近函数的最优值。测量观测值的数量由确定。因此DQNN的总复杂度为。 表1总结了比较结果。 可以看出,对于大的和大的,我们的DQNN可以显着降低生成非线性的总复杂度。 更多详细信息请参见附录C。
| Algorithm | Complexity | ||
|---|---|---|---|
| QCL | |||
| CCQ | |||
| DQNN |
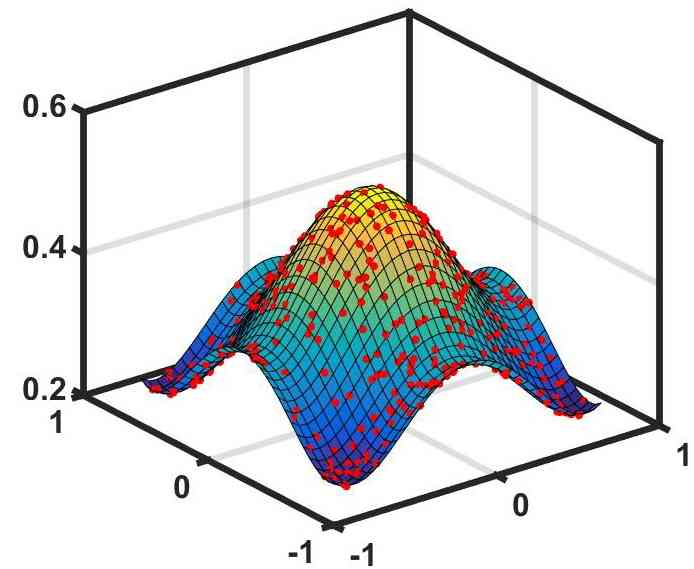
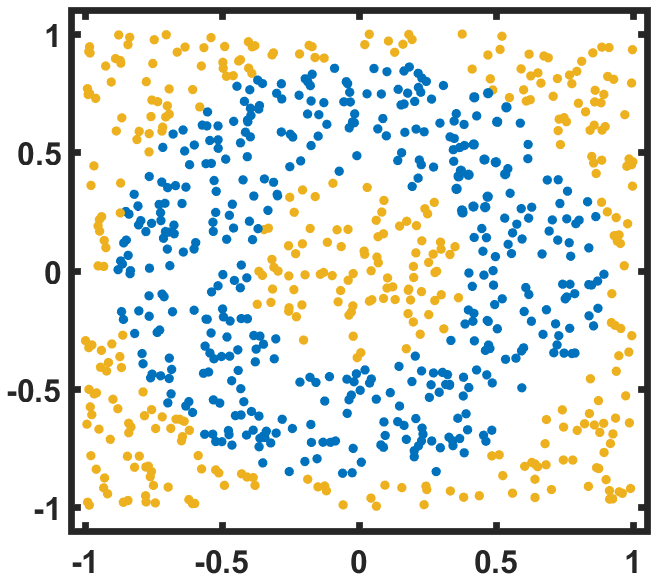
为了证明我们的 DQNN 在解决经典 ML 问题和降低电路复杂性方面具有优势,我们将 DQNN、QCL 和 CCQ 应用于两个典型的监督学习问题(回归问题和分类问题),并比较它们的性能。 第一个问题是从数据集中学习,用逼近高度非线性多项式(图2)。 对于输入 ,QNN 的输出表示为 。 我们可以定义相对误差来衡量QNN解决回归问题的性能。 微小的相对误差意味着 QNN 很好地逼近目标函数 。 首先,我们根据数据集对每个模型运行混合优化过程。 为了显示三个 QNN 模型的有效性,我们为每个模型选择不同的层数值,以便它们的电路复杂度 大小相似。 我们使用与上一节相同的 定义。 然后,我们比较每个模型实现的最佳相对误差。 我们选择两种类型的 DQNN 来解决回归问题。 其中一个具有单层变分量子电路和多个可观测量。 我们将其命名为 DQNN。 另一个具有单层变分量子电路和一个可观测量。 我们将其命名为 DQNN。 我们发现,在没有重复 的情况下,DQNN 实现的相对误差大大低于 QCL 和 CCQ 实现的相对误差,如表 2(a) 所示。 如果我们在 QCL 和 CCQ 模型中再添加一个副本,它们的最优相对误差将会降低,但它们的复杂性将会增加并超过 DQNN。 此外,我们对其他几个例子进行了这样的比较,仿真结果表明,与 QCL 和 CCQ 相比,DQNN 可以显着降低电路复杂度来逼近高度非线性函数。 DQNN与可观测量的逼近过程如图2所示,更多详细的比较可以参见附录D。
我们将这三个模型应用于第二个任务中环形数据集的二元分类问题。 两个子数据集的边界由六条曲线、和确定(图2)。 可以使用分类精度来量化QNN模型解决分类问题的性能,其定义为,其中是QNN的输出,代表的标签,是狄拉克δ函数[51]。 与第一个任务类似,我们选择具有一个变分量子电路和多个可观测量的 DQNN (DQNN) 以及具有 变分量子电路和一个可观测量的 DQNN (DQNN)用于分类任务。 我们为和选择合适的值,使得三个模型的电路复杂度大小相似。 优化三个 QNN 模型后,我们发现 DQNN 实现的精度明显高于 QCL 和 CCQ 实现的精度。 此外,增加重复的数量确实有助于 QCL 和 CCQ 提高其最佳精度,但即使是 QCL 或 CCQ 的 复制模型(具有 12 个量子位)也无法与仅具有两个量子位(表2(b))。 接下来,我们对其他几个例子进行这样的比较。 仿真结果表明,与QCL和CCQ相比,DQNN可以显着降低电路复杂度,但在解决分类问题时保持良好的性能。
| Model | Copy number () | # Qubits () | # Layers () | # Observables () | Relative error | ||
| DQNN | 2 | 1 | 2 | 1 | 4 | 48 | 6.79% |
| DQNN | 2 | 1 | 2 | 1 | 1 | 48 | 5.46% |
| QCL | 2 | 1 | 2 | 4 | 1 | 48 | 8.21% |
| CCQ | 2 | 1 | 2 | 4 | 1 | 51 | 12.92% |
| QCL | 2 | 2 | 4 | 5 | 1 | 120 | 7.35% |
| CCQ | 2 | 2 | 4 | 4 | 1 | 99 | 4.74% |
| Model | Copy number () | # Qubits () | # Layers () | # Observables () | Accuracy | ||
| DQNN | 2 | 1 | 2 | 1 | 20 | 240 | 91.40% |
| DQNN | 2 | 1 | 2 | 1 | 1 | 48 | 97.63% |
| QCL | 2 | 2 | 4 | 5 | 2 | 240 | 74.18% |
| CCQ | 2 | 2 | 4 | 10 | 1 | 243 | 75.20% |
| QCL | 2 | 6 | 12 | 10 | 2 | 1440 | 76.93% |
| CCQ | 2 | 6 | 12 | 10 | 1 | 723 | 80.63% |
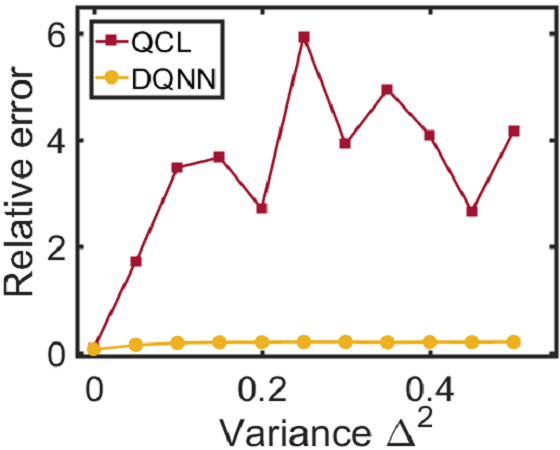
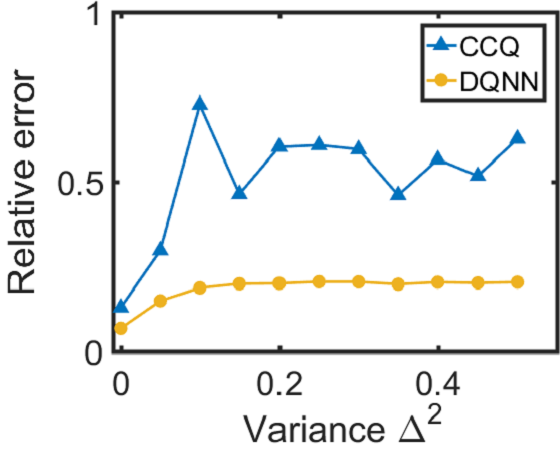
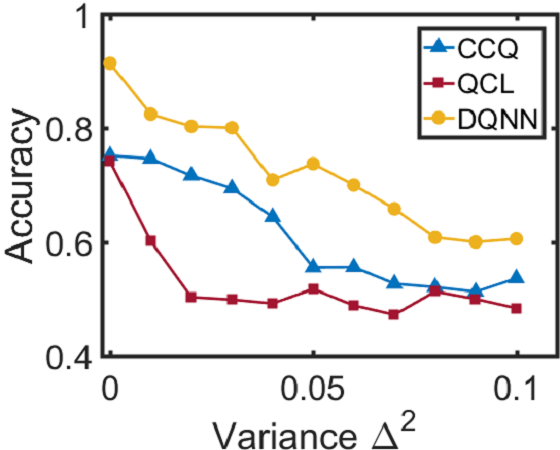
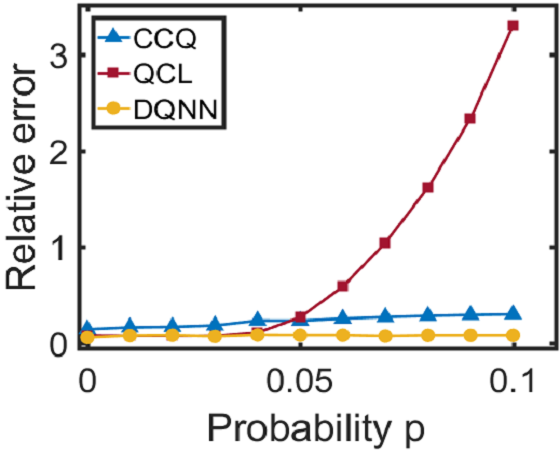
由于DQNN可以降低电路复杂度,我们期望它在存在噪声的情况下能够获得更好的性能,因此更容易在NISQ设备上实现。 在这项工作中,我们将考虑两种类型的噪声:一种是由于 QNN 电路中参数值的经典控制不精确而引起的相干噪声;另一个是量子寄存器与其环境之间相互作用产生的退相干。 我们在训练三个 QNN 模型时,根据 在变分电路中的 参数 中加入相干噪声 ,并测试它们在噪声环境下的性能。 相干噪声是通过对高斯分布进行采样而生成的,其中表示噪声强度。 从图3和3可以看出,对于回归任务,当我们增加相干噪声时,DQNN 实现了比 QCL 和 CCQ 更低的相对误差。 同时,对于分类任务(如图3所示),当相干噪声增加时,DQNN比其他两者更鲁棒。 除了相干噪声之外,我们还根据 将退相干 应用于量子电路中包含的双量子位控制门 > 其中表示完整的泡利基,表示退相干发生的概率。 从图3中我们可以发现,在回归任务中,随着退相干概率的增加,DQNN 的相对误差明显低于 QCL 和 CCQ。 这些数值结果表明,DQNN 可以减少训练过程中噪声积累的影响,并且更有可能在近期设备上实现。
除了比较三个 QNN 模型在两个监督学习问题上的比较之外,我们还进一步展示了不同 QNN 在解决基于手写数字数据集 MNIST [52] 的典型现实世界机器学习问题时的性能>。 在此任务中,首先使用 数字训练 QNN,每个数字的范围从 到 ,然后使用 新的数字来生成分类精度。 将MNIST数据集中的图形重塑为维向量,并通过幅度编码方法编码为量子位量子态。 由于 QCL 需要 个量子位来编码经典数据,因此在解决此任务时实现 QCL 很困难,我们只比较 DQNN 和 CCQ 的性能。 对于我们的 DQNN,我们使用 层变分电路和一个可观察的 。 对个新数字的分类精度可以达到。 对于 CCQ,我们使用一个变分量子电路和一组 POVM 算子 来生成最终输出。 我们对变分量子电路采用了不同的层,但是,CCQ 的性能仍然明显低于 DQNN。 例如,具有层变分量子电路的CCQ仅达到精度。 结果表明,没有严格的普适性保证的 QNN 将无法解决机器学习问题。
V与经典神经网络的比较
为了证明我们的 DQNN 至少可以与经典 NN 一样有效地执行,我们应用 DQNN 来解决三个典型的现实世界分类问题,并进一步在实现分类所需的最小参数和迭代次数方面与经典 NN 进行比较。相似的分类精度。 由于我们的 DQNN 本质上是单隐藏层,因此我们将选择单隐藏层经典神经网络进行比较。 在手写数字数据集 MNIST [52] 上,我们实现了二元分类(MNIST)来区分数字 和 和 目标分类 (MNIST),用于识别数字 、、. 每个样本被重塑为维向量,并作为DQNN和经典NN的输入。 同时,我们基于Wine数据集[53]和乳腺癌数据集[53]实现了另外两个分类任务。 我们使用 -qubit 状态来存储 Wine 问题的 维经典数据,并使用 -qubit 状态来存储 如表 3 所示,DQNN 在发现隐藏在现实世界数据集中的复杂模式方面与经典神经网络表现相同。 请注意,与经典对应物相比,DQNN 使用更少的参数来实现相似的精度,但在某些情况下需要额外的迭代成本。
| Model | Task | # Parameters | # Iterations | ||||
| DQNN | MNIST | ||||||
| Classical NN | MNIST | ||||||
| DQNN | MNIST | ||||||
| Classical NN | MNIST | ||||||
| DQNN | Wine | ||||||
| Classical NN | Wine | ||||||
| DQNN | Breast Cancer | ||||||
| Classical NN | Breast Cancer |
VI 量子相位识别
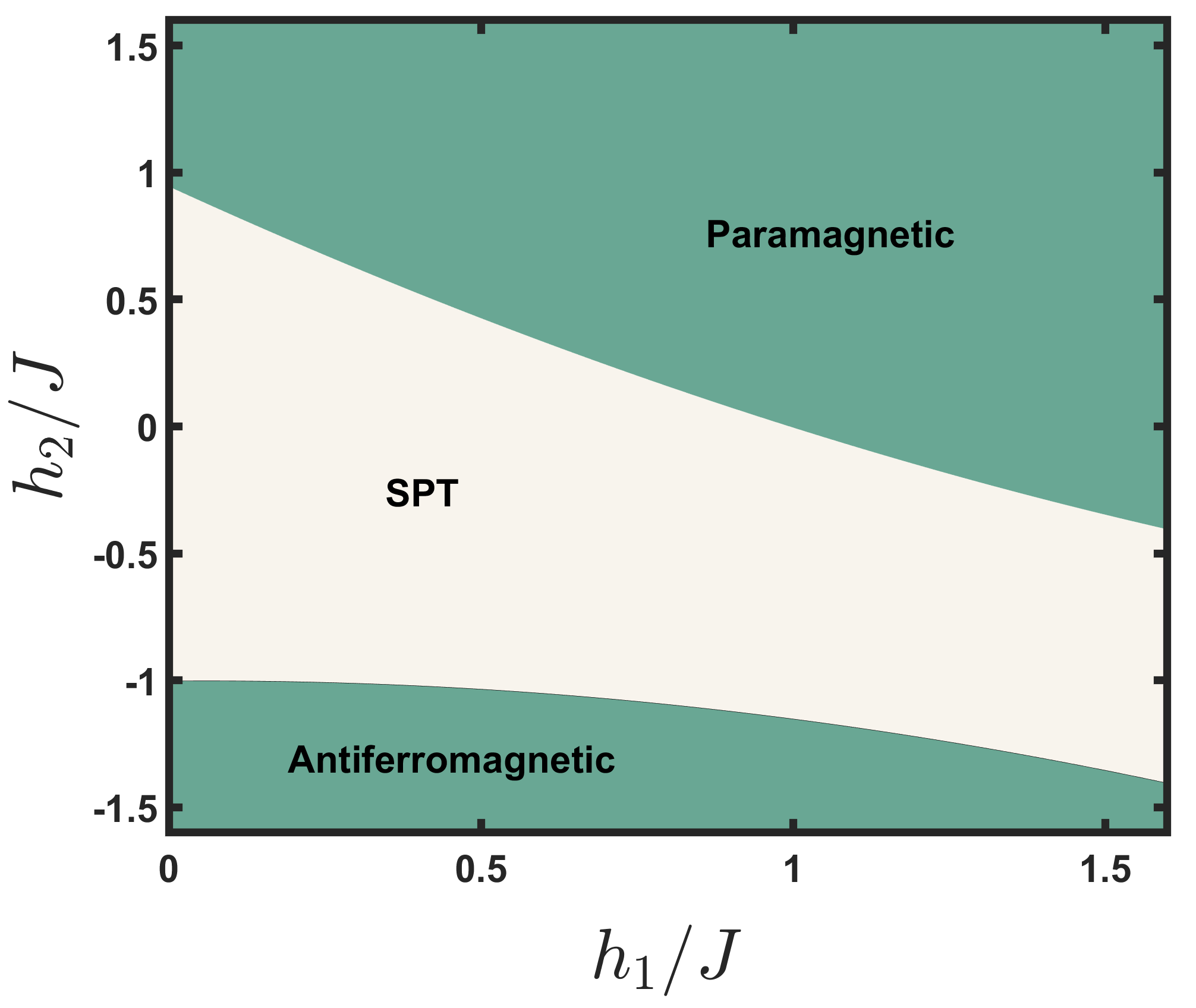
除了经典的机器学习问题外,我们的 DQNN 模型还可以解决量子数据集上的机器学习问题。 接下来,我们集中讨论一类量子相识别问题,即 Haldane链上对称保护拓扑(SPT)相的辨别[54 ]。 哈密顿量的基态,
具有三个拓扑相,SPT相、顺磁相和反铁磁相,其中和是参数。 我们的目标是确定从图4中的相图中采样的给定状态是否属于SPT阶段。 为了完成这样的任务,我们将 和 中的 等距点作为训练集,将 等距点作为训练集测试集。 如果基态属于SPT相,则标记为;否则,它被标记为。我们使用具有 参数和 可观测量的单个 -qubit 变分量子电路来数值实现 DQNN。 经过训练,DQNN在测试数据上的准确率达到。 这表明我们的 DQNN 模型以良好的性能解决了量子相位识别问题。 然而,训练 DQNN 的训练集大于训练量子卷积神经网络 [55] 用于相位识别任务的训练集。 造成差异的原因在于,对比中使用的DQNN只是一个原型,而[55]中的量子卷积神经网络已经针对该任务进行了优化,具有更强的局部分析能力。量子态的信息。 因此,作为未来的工作,我们希望改进 DQNN 设计,以优化其针对给定 ML 问题的性能。
七结论
在实现更大规模和更高保真度的 NISQ 设备方面已经取得了许多成功。 这些改进为量子神经网络提供了处理更大数据集的机会,甚至超越了经典的对应网络。 本文提出了一种无重复量子神经网络模型 DQNN 来解决机器学习问题。 同时,我们为它提供了使用多个变分量子电路、多个测量可观测量和经典参数化 sigmoid 函数逼近任意连续函数的通用保证。 我们可以通过增加量子电路的数量和可观测量的数量来增强 DQNN 的可表达性,而不需要辅助量子位。 量子位数量的这一特性使得 DQNN 更有可能在中型量子计算机上实现。
与其他变分 QNN 方案不同,DQNN 利用混合系统中的经典计算机来生成非线性。 与两个著名的 QNN 模型相比,DQNN 没有重复项,显着减少了所需的量子位数量并降低了电路复杂性。 我们的仿真结果表明,与 QCL 和 CCQ 相比,DQNN 使用更少的量子位和更少的量子门,优于其他两种 QNN 模型,从而削弱了电路噪声的影响。 此外,DQNN 需要的参数比经典对应的参数少,但在某些情况下会产生额外的迭代成本。 DQNN 也可用于解决量子问题。 这些结果表明 DQNN 是一种有效的 QNN 模型,可以找到隐藏在经典和量子数据集中的模式。
与经典的朴素神经网络一样,DQNN 可以被视为构建更复杂的量子深度学习模型的子程序。 此外,还可以通过针对给定的 ML 问题优化其结构来改进 DQNN。 例如,DQNN可以与循环神经网络的概念相结合来有效地解决自然语言处理任务,或者集成到量子强化学习框架中。 此外,由于其设计简单,DQNN 相对容易在 NISQ 设备上实现以进行 QNN 演示。
致谢
作者衷心感谢国家重点研发计划的资助,批准号: 2018YFA0306703。 我们还感谢楚果、吴布娇、吴雨森、吴绍君、黄雨涵、韩东红、杨英丽和田逸的有益讨论。
附录A幅度编码方法
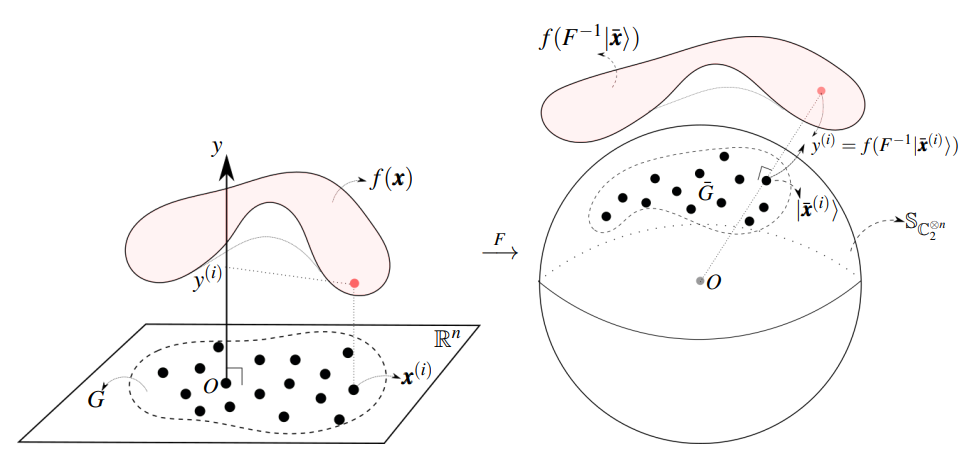
假设数据集的包含在的子集中。 在不违背一般性的前提下,我们可以通过平移选择一个合适的坐标系,从而使 和每个 满足 以及常数 和 的要求。 为了应用变分 QNN,我们将经典数据编码到量子寄存器的状态中。 在这项工作中,我们定义了编码映射,使得是希尔伯特空间中的-qubit状态,其中:
| (6) |
其中,。 很容易验证 和
| (7) |
与。 这种编码方法称为幅度编码,因为经典信息被编码为的幅度,如图5所示。 因此,近似相当于近似。
附录B定理1的证明
足以证明 在 中是密集的。 我们用反证法来证明。 假设关闭。 根据 Hahn-Banach 定理 [56], 上存在有界线性泛函 ,使得 和 。 根据Riesz表示定理[57],存在函数,使得线性泛函可以表示为
| (8) |
请注意, 隐含 上的 。 因此,以下两组和是可测的,并且其中至少一个具有正测度。 在不失一般性的情况下,我们假设 在具有 的开放子集 中几乎无处不在。 将代入上式,鉴于,我们有:
| (9) |
由于开集 包含一个小球 ,我们将证明,通过选择足够大的 和 ,函数 趋向于 在较小的球 中并在 之外快速消失,这导致与等式矛盾。 (9)。
由于 是单位球面的实数子集,
| (10) |
这意味着 相当于以下两种情况之一:
| (11) |
对于,情况(i)意味着足够接近,并且(ii)意味着足够接近,但后一种情况是不可能的。 具体来说,对于足够接近 的 以及给定值 ,我们可以选择 使得 ,并与等式一起。 (7),我们有:
| (12) |
如果(ii)为真,那么通过,我们会发现,与等式矛盾。 (12)。 因此情况(ii)是不可能的。 因此,当时,仅相当于情况(i)。 传递到极限,我们得到
| (13) |
与。 使 足够接近 ,我们有 ,并且从等式: (9) 我们得到
| (14) | ||||
| (15) |
Remark 1。
如果是一个ReLU类型的函数,那么结论仍然成立。 事实上,我们对所有 和 都有 ,而不是 Eq.(13),这导致了矛盾:
附录C其他变分QNN模型介绍
为了比较 DQNN 与其他模型的性能,在本节中,我们将简要介绍两个已建立的变分 QNN 模型:以电路为中心的量子分类器(CCQ)[33]和量子电路学习(QCL)[32],并将应用这些模型来解决以下量子学习问题:构造一个 QNN 来近似 阶多项式 :,其中是偶数。
首先,我们考虑 CCQ 模型,其中带有 的经典数据 被映射到带有 的 -qubit 寄存器,使用以下编码方案:
| (17) |
其中 是用户选择的填充项, 是归一化因子。 请注意,仅 不足以作为输入来生成所需的非线性,并且需要输入状态作为 副本的张量积来生成。 具体来说,为了逼近多项式,CCQ的输入状态选择为:
| (18) | ||||
| (19) |
其中。 这里我们选择中的副本数量为。
用表示CCQ中的变分量子电路,输出状态变为:
| (20) |
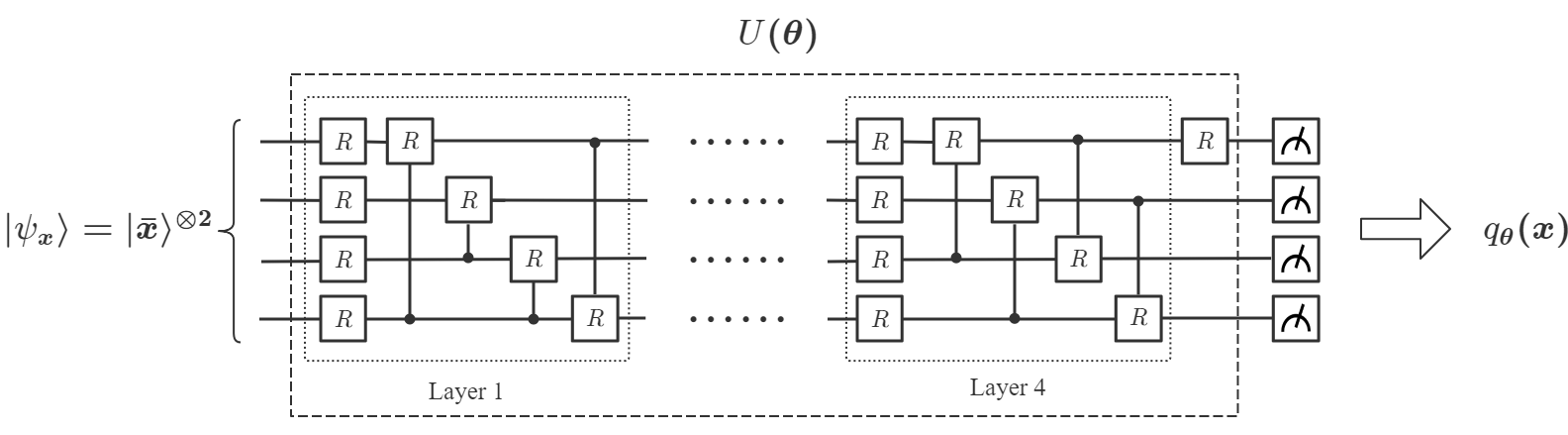
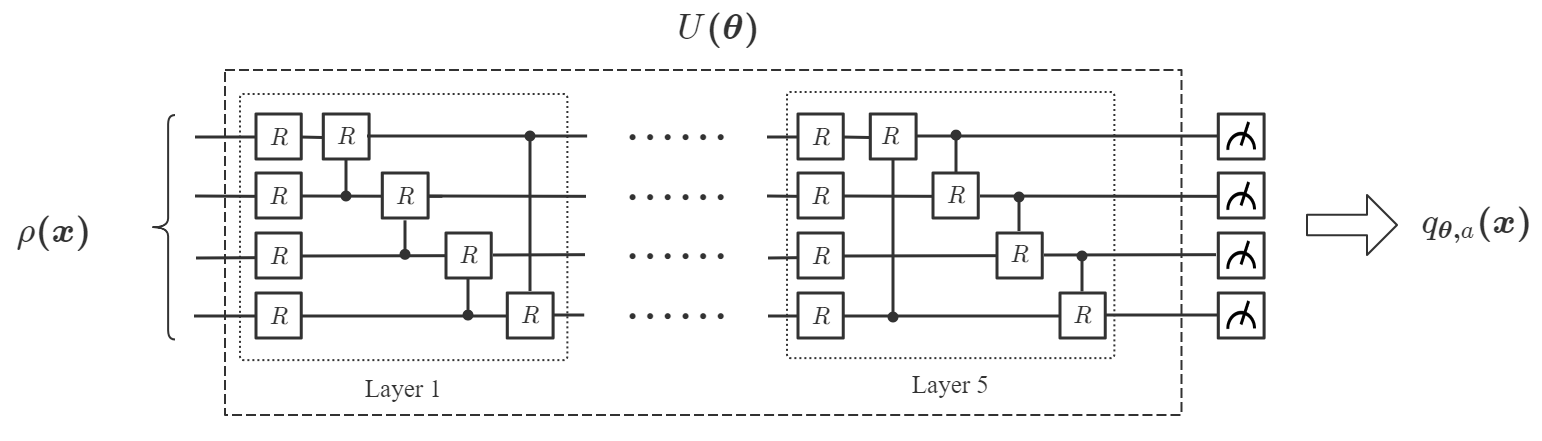
其中的每个幅度是的阶多项式。 因此,对于选定的可观测,测量结果是的阶多项式。 那么CCQ的目标是选择一个合适的,并通过量子经典混合优化找到最佳值,使得是最优函数近似。 CCQ 的量子电路如图6 所示。
接下来,我们考虑 QCL 模型,其中数据点 被编码为 量子位数据编码纯态密度算子:
| (21) |
其中 表示第 个量子位上的泡利- 旋转。 与 CCQ 情况类似, 不足以作为输入来生成所需的非线性。 为了生成 阶多项式,将 复制为张量积中的 个相同副本。 具体来说,QCL的输入状态选择为:
| (22) |
将参数化量子电路 应用于 ,然后测量选定的可观测值 ,我们获得测量结果作为 QCL 的输出:
| (23) |
将 定义为一组广义泡利算子。 由于方程。 (22),可以根据展开:
| (24) |
其中 、 是关于所有 变量的多项式。 假设 单位对角化为
| (25) |
我们代入等式。 (24) 和等式。 (25) 代入等式。 (23) 并获得:
其中是计算基础的集合。 因此,QCL的任务是选择合适的可观测值,并通过量子经典混合优化找到最佳值,使得能够很好地近似。 QCL 的量子电路如图7所示。
总之,为了准备所需的初始状态来解决相同的多项式逼近问题,CCQ 需要 个量子位,QCL 需要 个量子位。 相比之下,DQNN 只需要 个量子位即可将输入状态准备为等式 1 中的 。 (17)。 对于大 和大 来说,这是一个显着的减少。具体来说,对于 DQNN,在我们准备好输入状态 后,我们依次应用一系列变分量子电路 和量子测量来导出测量结果 用于一组选定的可观察量。 接下来,我们将参数化的经典 sigmoid 函数 应用于每个 来构造最终输出 。 最后,我们实施混合优化来找到 的最佳值来逼近目标多项式,其中 、、是用于构造最终输出的参数,详细信息如下。
附录 D 使用 DQNN、CCQ 和 QCL 解决回归问题
接下来,我们的目标是解决近似高度非线性函数的回归任务:
| (26) |
使用 DQNN、QCL 和 CCQ。 数据集的大小为,是从方块中随机选择的,每个标签根据计算。 QNN 的目标是通过优化 QNN 的参数 来生成非线性函数 来近似 。
首先,我们使用DQNN模型来解决这个问题。 我们在任务中为 DQNN 选择了两种情况。 案例 (DQNN) 基于 -qubit 单层变分量子电路 和四个测量可观测量,,在两个量子比特上随机选择广义泡利基,如图8(a)所示。 案例 (DQNN) 基于四个 量子位单层变分量子电路 和一个测量可观测值,如图8(b)所示。 通过状态修复,每个数据点被编码为输入状态:
| (27) |
其中 和 。 然后我们依次应用变分电路和量子测量以获得测量结果:
| (28) |
将 sigmoid 函数表示为 ,其中
| (29) |
对于 DQNN,我们得到
| (30) |
并最终得出
| (31) |
其中参数来自量子电路,参数来自之后的经典处理。 对于 DQNN,我们得到
| (32) |
并推导出
| (33) |
最后,通过优化,我们可以找到与目标函数的最优近似相对应的参数的最优值。
其次,我们考虑CCQ模型。 对于任何数据点 , 可以编码为 2 量子位状态 ,如方程式 1 所示。 (17)。 对于等式中的输入状态 (19),副本数可选择为。 这里我们考虑两种情况,和。 对于,我们将CCQ中的设计为-qubit 层变分量子电路;对于,CCQ中的被选择为-qubit 层电路。 前一种情况下的电路深度为,后一种情况下。 相应地,输入状态要么是2量子位状态,要么是4量子位状态,如图9所示。 在每种情况下准备好输入状态后,我们将 和测量应用于 ,并得出测量结果
| (34) |
其中可观测量被选择为 ,即第一个量子位上的局部 Pauli-Z 门。 然后我们得出以下输出
| (35) |
通过优化,我们可以找到与目标函数最接近的对应的最优值。
参考
- Zheng et al. [2017] H. Zheng, J. Fu, T. Mei, and J. Luo, Learning multi-attention convolutional neural network for fine-grained image recognition, in IEEE International Conference on Computer Vision (ICCV), edited by K. Ikeuchi, G. Medioni, and M. Pelillo (Venice, Italy, 2017) p. 5219.
- Shi et al. [2017] B. Shi, X. Bai, and C. Yao, An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition, IEEE Trans. Pattern Anal. Mach. Intell. 39, 2298 (2017).
- Albawi et al. [2017] S. Albawi, T. A. Mohammed, and S. Al-Zawi, Understanding of a convolutional neural network, in 2017 International Conference on Engineering and Technology (ICET), edited by O. Bayat, S. A. Aljawarneh, and H. F. Carlak (Akdeniz University, Antalya, Turkey, 2017) p. 1.
- Goldberg [2016] Y. Goldberg, A primer on neural network models for natural language processing, J. Artif. Intell. Res. 57, 345 (2016).
- Goldberg [2017] Y. Goldberg, Neural Network Methods for Natural Language Processing, Vol. 37 (Morgan & Claypool, 2017).
- Collobert and Weston [2008] R. Collobert and J. Weston, A unified architecture for natural language processing: Deep neural networks with multitask learning, in Proceedings of the 25th International Conference on Machine Learning, edited by W. Cohen, A. McCallum, and S. Roweis (Helsinki, Finland, 2008) p. 160.
- Nugraha et al. [2017] B. T. Nugraha, S. F. Su, and Fahmizal, Towards self-driving car using convolutional neural network and road lane detector, in International conference on automation, cognitive science, optics, micro electro-mechanical system, and information technology, edited by T. Arjon, H. Taufik, and K. D. Esti (Jakarta, Indonesia, 2017) p. 65.
- Do et al. [2018] T. D. Do, M. T. Duong, Q. V. Dang, and M. H. Le, Real-time self-driving car navigation using deep neural network, in International Conference on Green Technology and Sustainable Development, edited by D. T. Trung (Ho Chi Minh City, Vietnam, 2018) p. 7.
- Bojarski et al. [2017] M. Bojarski, P. Yeres, A. Choromanska, K. Choromanski, B. Firner, L. Jackel, and U. Muller, Explaining how a deep neural network trained with end-to-end learning steers a car (2017), arXiv e-prints, ArXiv:1704.07911.
- Biamonte et al. [2017] J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, Quantum machine learning, Nature 549, 195 (2017).
- Carleo and Troyer [2017] G. Carleo and M. Troyer, Solving the quantum many-body problem with artificial neural networks, Science 355, 602 (2017).
- Deng et al. [2017] D. L. Deng, X. P. Li, and S. Das Sarma, Quantum entanglement in neural network states, Phys. Rev. X 7, 021021 (2017).
- Garrido Torres et al. [2021] J. A. Garrido Torres, V. Gharakhanyan, N. Artrith, T. H. Eegholm, and A. Urban, Augmenting zero-kelvin quantum mechanics with machine learning for the prediction of chemical reactions at high temperatures, Nat. Commun. 12, 1 (2021).
- Schütt et al. [2019] K. Schütt, M. Gastegger, A. Tkatchenko, K.-R. Müller, and R. J. Maurer, Unifying machine learning and quantum chemistry with a deep neural network for molecular wavefunctions, Nat. Commun. 10, 1 (2019).
- Gao and Duan [2017] X. Gao and L. M. Duan, Efficient representation of quantum many-body states with deep neural networks, Nat. Commun. 8, 1 (2017).
- Paruzzo et al. [2018] F. M. Paruzzo, A. Hofstetter, F. Musil, S. De, M. Ceriotti, and L. Emsley, Chemical shifts in molecular solids by machine learning, Nat. Commun. 9, 1 (2018).
- Huang et al. [2022] H.-Y. Huang, M. Broughton, J. Cotler, S. Chen, J. Li, M. Mohseni, H. Neven, R. Babbush, R. Kueng, J. Preskill, and J. R. McClean, Quantum advantage in learning from experiments, Science 376, 1182 (2022).
- Wiebe et al. [2012] N. Wiebe, D. Braun, and S. Lloyd, Quantum algorithm for data fitting, Phys. Rev. Lett. 109, 050505 (2012).
- Rebentrost et al. [2014] P. Rebentrost, M. Mohseni, and S. Lloyd, Quantum support vector machine for big data classification, Phys. Rev. Lett. 113, 130503 (2014).
- Wiebe et al. [2015] N. Wiebe, A. Kapoor, and K. M. Svore, Quantum algorithms for nearest-neighbor methods for supervised and unsupervised learning, Quantum Info. Comput. 15, 316 (2015).
- Lloyd et al. [2014] S. Lloyd, M. Mohseni, and P. Rebentrost, Quantum principal component analysis, Nat. Phys. 10, 631 (2014).
- Schuld et al. [2016] M. Schuld, I. Sinayskiy, and F. Petruccione, Prediction by linear regression on a quantum computer, Phys. Rev. A 94, 022342 (2016).
- Paparo and Martin-Delgado [2012] G. D. Paparo and M. Martin-Delgado, Google in a quantum network, Sci. Rep. 2, 1 (2012).
- Dong et al. [2008] D. Y. Dong, C. L. Chen, H. X. Li, and T.-J. Tarn, Quantum reinforcement learning, IEEE Transactions on Systems, Man, and Cybernetics, Part B 38, 1207 (2008).
- Saggio et al. [2021] V. Saggio, B. E. Asenbeck, A. Hamann, T. Strömberg, P. Schiansky, V. Dunjko, N. Friis, N. C. Harris, M. Hochberg, D. Englund, S. Wölk, H. Briegel, and P. Walther, Experimental quantum speed-up in reinforcement learning agents, Nature 591, 229 (2021).
- Paparo et al. [2014] G. D. Paparo, V. Dunjko, A. Makmal, M. A. Martin-Delgado, and H. J. Briegel, Quantum speedup for active learning agents, Phys. Rev. X 4, 031002 (2014).
- Liu and Rebentrost [2018] N. Liu and P. Rebentrost, Quantum machine learning for quantum anomaly detection, Phys. Rev. A 97, 042315 (2018).
- Amin et al. [2018] M. H. Amin, E. Andriyash, J. Rolfe, B. Kulchytskyy, and R. Melko, Quantum boltzmann machine, Phys. Rev. X 8, 021050 (2018).
- Aaronson [2015] S. Aaronson, Read the fine print, Nat. Phys. 11, 291 (2015).
- Huang et al. [2021] H. Y. Huang, M. Broughton, M. Mohseni, R. Babbush, S. Boixo, H. Neven, and J. R. McClean, Power of data in quantum machine learning, Nat. Commun. 12 (2021).
- Schuld et al. [2014] M. Schuld, I. Sinayskiy, and F. Petruccione, The quest for a quantum neural network, Quantum Inf. Process 13, 2567 (2014).
- Mitarai et al. [2018] K. Mitarai, M. Negoro, M. Kitagawa, and K. Fujii, Quantum circuit learning, Phys. Lett. A 98, 032309 (2018).
- Schuld et al. [2020] M. Schuld, A. Bocharov, K. M. Svore, and N. Wiebe, Circuit-centric quantum classifiers, Phys. Lett. A 101, 032308 (2020).
- Hornik et al. [1989] K. Hornik, M. Stinchcombe, and H. White, Multilayer feedforward networks are universal approximators, Neural Networks 2, 359 (1989).
- Leshno et al. [1993] M. Leshno, V. Y. Lin, A. Pinkus, and S. Schocken, Multilayer feedforward networks with a nonpolynomial activation function can approximate any function, Neural Networks 6, 861 (1993).
- Cao et al. [2017] Y. D. Cao, G. G. Guerreschi, and A. Aspuru-Guzik, Quantum neuron: an elementary building block for machine learning on quantum computers (2017), arXiv e-prints, ArXiv:1711.11240.
- Yan et al. [2020] S. Yan, H. Qi, and W. Cui, Nonlinear quantum neuron: A fundamental building block for quantum neural networks, Phys. Lett. A 102, 052421 (2020).
- Tacchino et al. [2019] F. Tacchino, C. Macchiavello, D. Gerace, and D. Bajoni, An artificial neuron implemented on an actual quantum processor, npj Quantum Inf. 5, 1 (2019).
- Kristensen et al. [2021] L. B. Kristensen, M. Degroote, P. Wittek, A. Aspuru-Guzik, and N. T. Zinner, An artificial spiking quantum neuron, npj Quantum Inf. 7, 1 (2021).
- Torrontegui and García-Ripoll [2019] E. Torrontegui and J. J. García-Ripoll, Unitary quantum perceptron as efficient universal approximator, Europhys. Lett. 125, 30004 (2019).
- Beer et al. [2020] K. Beer, D. Bondarenko, T. Farrelly, T. J. Osborne, R. Salzmann, D. Scheiermann, and R. Wolf, Training deep quantum neural networks, Nat. Commun. 11, 1 (2020).
- Schuld et al. [2015] M. Schuld, I. Sinayskiy, and F. Petruccione, Simulating a perceptron on a quantum computer, Phys. Lett. A 379, 660 (2015).
- Wan et al. [2017] K. H. Wan, O. Dahlsten, H. Kristjánsson, R. Gardner, and M. Kim, Quantum generalisation of feedforward neural networks, npj Quantum Inf. 3, 1 (2017).
- Runge [1901] C. Runge, über empirische funktionen und die interpolation zwischen äquidistanten ordinaten, Zeitschrift für Mathematik und Physik 46, 224 (1901).
- Brenner and Scott [2007] S. C. Brenner and L. R. Scott, The Mathematical Theory of Finite Element Methods (Springer, 2007).
- Goodfellow et al. [2016] I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning (MIT Press, 2016).
- Plesch and Brukner [2011] M. Plesch and Č. Brukner, Quantum-state preparation with universal gate decompositions, Phys. Rev. A 83, 032302 (2011).
- Bottou [2010] L. Bottou, Large-scale machine learning with stochastic gradient descent, Comput. Stat. , 177 (2010).
- Kingma and Ba [2015] D. Kingma and J. Ba, Adam: A method for stochastic optimization, in International Conference on Learning Representations, edited by Y. Bengio and Y. Lecun (San Diego, CA, 2015) p. 13.
- Buckley and LeNir [1985] A. Buckley and A. LeNir, Algorithm 630: Bbvscg–a variable-storage algorithm for function minimization, ACM Trans. Math. Softw. 11, 103 (1985).
- Bishop [2006] C. M. Bishop, Pattern Recognition and Machine Learning (Springer Press, Berlin, 2006).
- LeCun et al. [2010] Y. LeCun, C. Cortes, and C. Burges, Mnist handwritten digit database (2010), figshare http://yann.lecun.com/exdb/mnist (2010).
- Dua and Graff [2017] D. Dua and C. Graff, UCI machine learning repository (2017), http://archive.ics.uci.edu/ml (2017).
- Haldane [1983] F. D. M. Haldane, Nonlinear field theory of large-spin heisenberg antiferromagnets: semiclassically quantized solitons of the one-dimensional easy-axis néel state, Phys. Rev. Lett. 50, 1153 (1983).
- Cong et al. [2019] I. Cong, S. Choi, and M. D. Lukin, Quantum convolutional neural networks, Nat. Phys. 15, 1273 (2019).
- Hahn [1927] H. Hahn, Über lineare gleichungssysteme in linearen räumen., J. für die Reine und Angew. Math. 1927, 214 (1927).
- Fréchet [1907] M. Fréchet, Sur les ensembles de fonctions et les opérations linéaires, CR Acad. Sci. Paris 144, 1414 (1907).