Tensor4D:高效神经 4D 分解,用于高保真动态重建和渲染
摘要
我们推出 Tensor4D,这是一种高效且有效的动态场景建模方法。 我们解决方案的关键是一种高效的4D张量分解方法,使得动态场景可以直接表示为4D时空张量。 为了解决伴随的内存问题,我们首先将 4D 张量投影到三个时间感知体积,然后投影到九个紧凑特征平面,从而分层分解 4D 张量。 通过这种方式,可以以紧凑且节省内存的方式同时捕获随时间变化的空间信息。 当应用 Tensor4D 进行动态场景重建和渲染时,我们进一步将 4D 场分解为不同的尺度,即可以从粗到细地学习结构运动和动态细节变化。 我们的方法的有效性在合成场景和现实场景中得到了验证。 大量的实验表明,我们的方法能够从稀疏视图相机设备甚至单目相机实现高质量的动态重建和渲染。 代码和数据集将在https://github.com/DSaurus/Tensor4D发布。
![[Uncaptioned image]](teaser-thz.jpg)
1简介
对于 AR/VR、3D 内容制作和娱乐等许多应用来说,从一组输入图像中对动态场景进行高质量重建和逼真渲染是必要的。 传统方法使用经典的基于网格的表示来重建动态场景,不幸的是,当场景包含薄结构、镜面表面和拓扑变化时,很容易产生重建错误和渲染伪影[25,22,18,8 ,48]。
神经渲染方法的最新进展以神经辐射场 (NeRF) 的形式学习场景表示,在仅给定多视图图像的情况下,显示了令人印象深刻的一般静态场景的新颖视图合成[31]。 它们立即扩展到动态场景:一些方法(例如,NeRF-T)将时间视为 NeRF 表示 [62, 56] 的附加输入维度,而其他方法(例如,D-NeRF)将动态场景分解为规范辐射场和动态运动场[39,55,10,36,27]。 无论哪种方式,学习 4D 函数都是主要基石之一。 不幸的是,直接使用 MLP 来拟合此类函数通常会花费大量时间和计算成本,即在高端 GPU 上需要花费数十个小时。
事实上,传统的基于NeRF的静态场景方法也存在上述局限性,研究人员提出使用离散数据结构,如体素网格[65]或三平面[6] 加速 NeRF 训练和渲染。 然而,这些技术很难扩展到动态领域,因为引入额外的时间维度将成倍增加内存占用,阻碍它们建模高质量的外观细节。
在这项工作中,我们追求一种动态场景表示,它还利用显式特征网格来加速网络训练,同时避免在引入额外的时间维度时消耗大量内存。 为此,我们绕过了高分辨率4D张量的构造;相反,我们建议使用分层三投影分解来建模 4D 场。 我们的分解方法扩展了 EG3D [6] 中的三投影。 它首先将完整的 4D 场投影为三个时间感知体积,然后每个体积进一步分解为三个特征平面。 通过这种方式,我们仅使用九个 2D 特征平面对 4D 场进行建模,并且根据经验发现,尽管高度紧凑,但这种表示方式足以表示包含复杂运动的动态场景。 此外,显式数据结构的使用还允许我们设计从粗到细的策略,以进一步提高我们方法的性能。
通过利用和分解显式 4D 张量,我们的方法能够实现动态场景的高效重建和紧凑表示。 此外,分解方案还引入了对表示的隐式约束,因为只有低秩张量可以用少量的低维分量来近似。 当输入观测受到限制时,例如,在稀疏和固定的摄像机设置下,甚至在单目输入情况下,这种约束可以作为一种固有的正则化。 在本文中,我们首先通过将 Tensor4D 分解应用于“NeRF-T”中的时间条件辐射场,将我们的方法应用于稀疏视图动态重建。 此外,我们的分解方法还可以用于单视图动态重建。 这是通过分解“D-NeRF”中的 4D 动态运动场和规范辐射场来实现的。 通过适当的正则化,我们的系统可以在两种相机设置下高效、高质量地重建动态对象。
2相关工作
多视图重建和渲染。 捕捉和重建3D动态场景的方法有多种,包括基于轮廓[23, 54]、立体[29, 45]、流[ 16, 70, 43],分割[40, 41],以及光度[2, 19]。 借助 RGBD 相机,DynamicFusion [33] 等实时解决方案可估计动态场景的非刚性变形,并集成深度帧以重建规范空间中的几何模型。 该方法后来被扩展到远程呈现和全息通信[9,24,66]。 然而,这些系统严重依赖深度传感器来获得精确的几何形状。 相比之下,我们的方法可以使用稀疏视图 RGB 相机重建和渲染动态场景。
在过去的几年里,神经隐式表示得到了快速发展,并已应用于静态场景的多视图重建和渲染。 一些方法将几何图形表示为神经网络的零水平集,并使用可微表面渲染来优化网络权重[34,46,64]。 鉴于对物体的密集观察,这些方法能够准确地恢复其表面。 另一方面,NeRF [31] 使用体积渲染来优化场景表示。 它的简单性和令人印象深刻的结果启发了许多后续工作,包括野外重建[30, 51]、照明和材质估计[3,47, 67] 、生成[17,21,5,42,53,52],人工渲染[44,68,50,57,69]等等。 最近,多种方法统一了表面和体积渲染,实现了精确的几何重建和高质量的新颖视图合成[63,35,59]。 与这些静态场景表示相比,我们的目标是从极其稀疏的摄像机中实现动态场景的自由视图合成。
用于动态场景的 NeRF。 在包含时间维度的 4D 域中建模场景是将 NeRF 扩展到动态域的直接解决方案。 典型的方法包括VideoNeRF [62]、NeRFlow [10]、DyNeRF [26]和DCT-NeRF [56]. 具体来说,VideoNeRF [62] 直接从单个视频中学习时空辐照度场,并使用深度估计来解决单目输入中的形状运动模糊性,而 NeRFlow [10] DCT-NeRF[56]使用点轨迹来正则化网络优化。 为了解决形变场中拓扑变化建模的局限性,Park 等人 [37]提出了 HyperNeRF,它可以将 NeRF 提升到更高的维度。
动态场景也可以通过使规范空间中的辐射场变形来渲染。 例如,Nerfies [36] 通过将每个观察点扭曲为规范的 5D NeRF 来优化附加的连续变形场。 D-Nerf [39] 和 NR-Nerf [55] 遵循类似的框架,但仅将单目视频作为训练数据。 此外,DeVRF [27] 使用基于体素的表示而不是 MLP 来对 3D 规范空间和 4D 变形场进行建模。 使用参数化身体模板作为语义先验,Neural Body [38] 和 HumanNeRF [60] 等方法可以实现复杂人类表现的逼真新颖视图合成。 [15]显示了单目视频的实际捕获过程与现有实验协议之间的差异。
NeRF 加速。 许多工作的目的是使用显式数据结构(包括特征图、体素和张量)来加速静态 NeRF。 例如,DVGO [49] 通过密度体素网格和特征体素网格的显式表示实现快速收敛。 利用稀疏体素八叉树结构,NSVF [28] 通过以从粗到细的方式丢弃空体素来加速新颖的视图重建。 类似地,Plenoxels [13] 和 PlenOctree [65] 通过球谐函数的分层 3D 网格对场景进行建模,可以实现比 NeRF 快两个数量级的优化。 在 DIVeR[61] 中,光线行进仅在体素网格上查找固定数量的命中,以加速体积渲染。 此外,哈希编码[32]和张量分解[7]也被用作NeRF加速的紧凑表示。
对于动态场景建模,DeVRF [27] 支持使用 3D 体积和 4D 体素场进行快速非刚性神经渲染。 此外,V4D [14]为4D数据引入了有效的条件位置编码,以实现快速新颖的视图合成。 TiNeuVox [11] 表示具有可优化的显式数据结构的场景并加速辐射场建模,而 Wang 等人将 PlenOctrees [65] 扩展为免费-查看视频渲染[58]。 然而,这些作品的低分辨率体积设计阻碍了渲染高质量图像的能力。 此外,还有几部并行作品[12,4,20]采用了动态场景的6平面分解。 与这些方法相比,我们的层次分解可以更有效地捕获时间变化并表示动态场景。
3方法
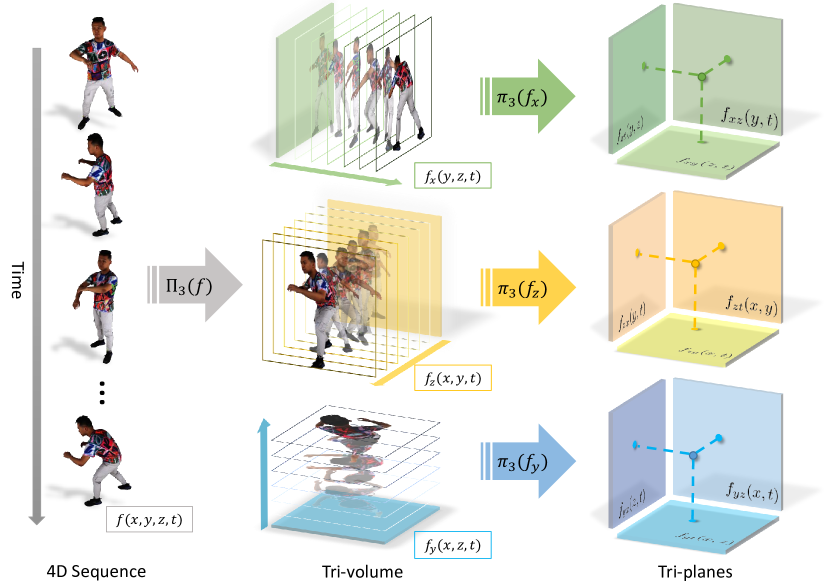
基于先前的时空表示和三投影分解(第 3.1 节)工作,我们提出了一种分层三投影分解方法(第 3.2 节)和从粗到细的策略(第 3.3 节),它允许我们以适度的训练时间和 GPU 内存成本来学习 4D 领域。
3.1初步
时空 4D NeRF 表示。 为了使用神经辐射场表示动态对象,一种简单的方法是将原始神经辐射场限制在时间戳 [62, 56] 上,我们将其称为 NeRF-T。 从数学上讲,NeRF-T 可以表述为:
| (1) |
其中 是一个动态隐式字段,它为位置 处的点生成高维特征 和密度值 和时间实例 和 是一个考虑观看方向 来预测最终 RGB 颜色的函数。
为了更好地解开形状和运动,一些方法如 D-NeRF [39] 提出了可变形神经辐射场,它采用具有 4D 流场的规范 3D 表示:
| (2) |
其中是规范配置中的辐射场,是场景流场,表示时刻的场景与规范空间之间的映射。
从上面的公式中,我们可以很容易地观察到 NeRF-T 和 D-NeRF 都依赖于对 4D 场 进行建模,即,即 NeRF-T 中的动态隐式场和D-NeRF 中的流场。 现有方法主要采用 MLP 来拟合这些 4D 场。 这种隐式神经表示没有显式结构,并且需要大量的训练和渲染计算时间。
三投影分解。 三投影分解在近期的工作中被广泛使用,包括 EG3D [6] 和 TensoRF [7],以加速基于 MLP 的 NeRF 框架中的训练和渲染过程。 通过将 分别沿 、 和 轴投影,这种分解将 维张量 因子化为三个低维 (-D) 张量 。 例如,EG3D 提出的基于三平面的分解将 3D 张量投影到三个 2D 特征平面。 与基于体素的表示相比,三平面表示有效地减少了内存占用并提高了 3D 生成和重建的性能。
3.2分层三投影分解
我们的目标是设计具有显式特征网格的动态场景表示,以加速网络训练和体积渲染。 然而,直接构建 4D 张量会消耗大量内存,并且对于高分辨率渲染来说是不可接受的。 因此,我们提出了一种分层三投影分解,将 4D 张量分解为几个紧凑的特征,这在很大程度上减少了内存消耗,同时保留了拟合 4D 场的能力。
具体来说,对于神经 4D 场 ,我们首先通过三投影分解将 4D 时空张量的 3D 空间部分分解为三个时间感知的体积张量:
| (3) |
其中 表示投影运算符。 为了进一步降低空间复杂度并实现高分辨率表示,我们将每个特征体积分解为三个特征平面:
| (4) |
其中 表示体积到平面的三重投影。 通过这种方式,我们使用 9 个平面紧凑地表示 4D 场。 给定任何时空坐标 ,我们可以通过将其投影到平面上并通过双线性插值检索相应的值来有效地查询其在 4D 场中的值。 图2是我们的分解方法的说明。 我们的分层三投影分解将空间复杂度从 降低到 ,其中 是网格的空间分辨率,从而在不牺牲表示能力的情况下显着降低内存占用。
与 6 平面分解的差异。 与将时间维度与仅一个空间维度()配对的 6 平面分解 [12, 4, 20] 相比,我们的方法首先在空间维度上分解 4D 张量域以获得三个时间感知体积,然后获得 9 个分解平面。 请注意,三个体积是独立分解的,使得 9 个平面彼此不同。 具体来说,当使用线性层来分解体积时 体积 、平面 和 的行为不同,因为它们独立优化以捕获体积 和 中的时间变化分别为。 通过这种方式,9 个平面可以在时间和空间维度的所有可能组合中利用时间感知信息 ()。 这一属性使我们的表示能够在不同的空间维度层次上捕获各种动态信息。 因此,我们的方法在表示动态场景方面更加有效,其中时间维度的变化通常是强烈的、复杂的和长距离的。
3.3由粗到细的策略
为了进一步提高 4D 分解的效率,我们提出了一种可选的从粗到细的策略,在不同的训练阶段将 4D 场分解为不同的尺度。 在粗略层面,我们采用低分辨率特征平面()来分解4D场,提高了训练过程的鲁棒性并实现了快速收敛。 经过粗层次训练后,我们另外使用高分辨率特征平面()进行4D分解,以表示动态细节并实现高质量渲染。 具体来说,我们将 4D 场分解为不同的尺度:
| (5) |
其中和分别是的粗级和细级组件。 在粗层次上,分解的特征平面是低分辨率的,以表示粗的3D结构和4D动态变化。 在精细层面,我们采用每个元素中的高分辨率特征平面来分解4D场,更注重恢复动态细节。
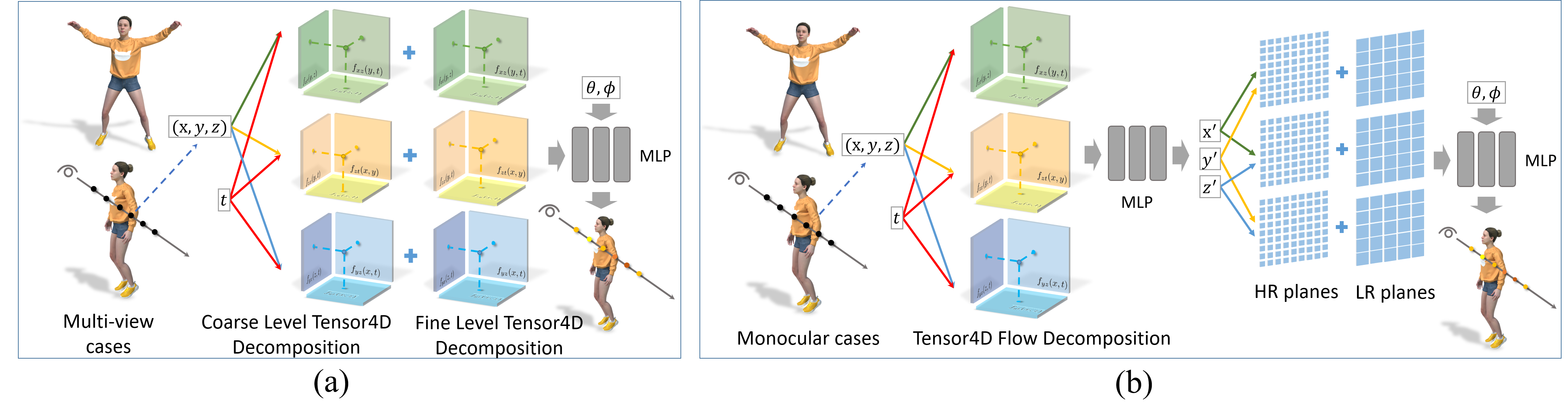
4 用于动态重建的 Tensor4D
如图3所示,我们将4D张量分解应用到具有两个输入的动态重建任务中:
1)稀疏和固定相机下的动态重建。 对于这种设置,我们使用我们提出的 4D 分解来分解 NeRF-T 而不是 D-NeRF,我们发现它更有效、更灵活地表示拓扑变化的对象(第 4.1 节)。
2)使用单目相机进行动态重建。 对于此设置,我们分别分解 4D 流场和 3D 规范表示,因为它可以确保不同帧之间的外观一致性并实现更稳健的性能(第 4.2 节)。
4.1 多视图重建
在本节中,我们介绍稀疏多视图设置下的动态重建系统。 我们系统的目标是 1) 高效、高质量的动态重建,内存和时间成本低,2) 在稀疏和固定相机设置下的鲁棒重建。
为此,我们采用 4D 分解(方程 5)以从粗到细的策略对 NeRF-T 表示进行因式分解。 具体来说,我们可以在 4D 分解后获得 9 个低分辨率特征平面 和 9 个高分辨率特征平面 来表示 4D NeRF-T 场。 然后对于体渲染,当在方向为的射线中采样处的点时,我们首先查询特征LR 和 HR 特征平面中的 的 。 以LR特征为例:
| (6) |
我们将九个 LR 平面中查询到的所有特征连接起来,作为采样点 的最终 LR 特征。然后,我们将 LR 和 HR 特征与 的位置编码连接到几何 MLP 中,以获得密度 和高维特征 :
| (7) |
其中 是位置编码函数。 接下来,我们将高维特征 与 的位置编码连接起来,并将其输入到颜色 MLP 中:
| (8) |
这样,我们就可以通过体渲染来渲染图像,并对分解的特征平面和神经网络和采用颜色损失训练:
| (9) |
通过从粗到精的设计,我们的方法可以有效且高效地恢复高保真动态细节。
为了在稀疏多视图设置下实现鲁棒的动态重建,我们进一步对所有分解的特征平面采用正则化:
| (10) |
其中 是每个特征平面 保持稀疏性的电视损失。 为了规范几何形状,我们还在体绘制中引入了表面约束。 具体来说,我们采用SDF作为基本几何表示,并遵循NeuS [59]来渲染SDF场。 然后我们添加表面约束损失以强制平滑表面:
| (11) |
最终的训练损失是正则化损失和颜色损失:
| (12) |

4.2单目重建
与稀疏视图设置不同,我们在单目捕获情况下对 D-NeRF 采用 4D 分解。 这是因为单目设置比稀疏视图输入更不适定,并且外观和运动的显式解开可以保证不同帧之间的一致性。 由于 D-NeRF 用 4D 流场和 3D 规范表示来表示动态对象,因此我们分别对这两个场进行因式分解。 首先,对于4D流场,我们仅采用粗级分解并将其分解为低分辨率特征平面:
| (13) |
我们的粗分解更多地关注粗略和刚性运动,这提高了流量估计的鲁棒性,并且可以更好地解开形状和运动。 然后对于 3D 规范表示,我们采用粗层次分解和细层次分解:
| (14) |
因此,我们可以获得4D流场的9个流特征平面和3D规范表示的6个规范特征平面。 单眼情况下的体绘制与多视图情况下类似。 对于采样点,我们首先使用式(1)获得点流特征。 6 具有九个流平面。 然后我们采用流MLP来预测点的运动:
| (15) |
然后我们通过查询规范特征平面来获得点规范特征。 以LR特征为例:
| (16) |
接下来,我们将规范特征 和 的位置编码输入到几何 MLP 中,以获得高维特征 和密度:
| (17) |
最后,我们采用等式。 8 预测体积渲染的颜色 和方程。 9表示训练颜色损失。 我们还在等式中添加了特征正则化损失。方程中的10和表面约束损失 11。 总训练损失为:
| (18) |


| Method | Lego | Standup | Jumpingjacks | |||||||||
| MSE | PSNR | SSIM | LPIPS | MSE | PSNR | SSIM | LPIPS | MSE | PSNR | SSIM | LPIPS | |
| D-NeRF [39] | 7.83e-3 | 21.26 | 0.869 | 1.72e-1 | 4.63e-4 | 34.38 | 0.989 | 2.18e-2 | 5.46e-4 | 33.37 | 0.987 | 4.84e-2 |
| NeRF-T | 3.89e-3 | 24.32 | 0.904 | 1.55e-1 | 6.82e-4 | 31.44 | 0.968 | 2.36e-2 | 5.99e-4 | 32.27 | 0.979 | 5.37e-2 |
| TiNeuVox [11] | 3.15e-3 | 25.14 | 0.924 | 8.37e-2 | 2.90e-4 | 36.18 | 0.986 | 2.02e-2 | 3.89e-4 | 34.76 | 0.983 | 3.33e-2 |
| Ours-NeRF-T | 3.10e-3 | 25.13 | 0.922 | 1.24e-1 | 5.92e-4 | 32.38 | 0.977 | 2.29e-2 | 5.62e-4 | 32.73 | 0.980 | 5.16e-2 |
| Ours-D-NeRF | 4.61e-3 | 23.37 | 0.890 | 1.19e-1 | 2.82e-4 | 35.93 | 0.981 | 2.07e-2 | 4.22e-4 | 34.10 | 0.982 | 3.41e-2 |
| Ours | 2.26e-3 | 26.71 | 0.953 | 3.49e-2 | 2.50e-4 | 36.32 | 0.983 | 1.74e-2 | 3.91e-4 | 34.43 | 0.982 | 3.18e-2 |
| Method | Sequence1-thz | Earphone | Sequence3-yxd | |||||||||
| MSE | PSNR | SSIM | LPIPS | MSE | PSNR | SSIM | LPIPS | MSE | PSNR | SSIM | LPIPS | |
| D-NeRF [39] | 3.13e-3 | 25.15 | 0.910 | 0.185 | 8.16e-3 | 20.92 | 0.854 | 0.256 | 4.84e-3 | 23.22 | 0.937 | 0.147 |
| TiNeuVox [11] | 5.72e-3 | 22.79 | 0.832 | 0.209 | 1.49e-2 | 18.55 | 0.707 | 0.319 | 8.18e-3 | 21.19 | 0.816 | 0.233 |
| Neus-T [59] | 4.95e-3 | 23.07 | 0.887 | 0.130 | 3.75e-3 | 24.22 | 0.877 | 0.184 | 2.20e-3 | 26.59 | 0.945 | 0.099 |
| Ours-NeRF-T | 5.85e-3 | 22.46 | 0.842 | 0.191 | 1.27e-2 | 19.13 | 0.838 | 0.218 | 5.02e-3 | 23.06 | 0.914 | 0.141 |
| Ours-D-NeRF | 4.74e-3 | 23.27 | 0.864 | 0.176 | 8.17e-3 | 21.07 | 0.883 | 0.198 | 4.06e-3 | 23.98 | 0.926 | 0.130 |
| Ours | 1.53e-3 | 28.27 | 0.942 | 0.084 | 3.20e-3 | 25.00 | 0.903 | 0.153 | 1.31e-3 | 28.83 | 0.962 | 0.072 |
| Method | Lego | |||
| PSNR | Time | Iterations | #Params | |
| TiNeuVox | 25.14 | 34min | 50k | 102M |
| D-NeRF | 21.26 | 45h | 800k | 4.8M |
| Ours-D-NeRF | 23.37 | 95min | 50k | 20M |
| NeRF-T | 24.32 | 38h | 800k | 4.4M |
| Ours-NeRF-T | 25.13 | 73min | 50k | 43M |
| Ours(6-planes) | 26.34 | 135min | 50k | 17M |
| Ours | 26.71 | 144min | 50k | 20M |
| Method | Sequence1-thz | |||
| PSNR | Time | Iterations | #Params | |
| TiNeuVox | 22.79 | 30min | 50k | 102M |
| D-NeRF | 25.15 | 37h | 800k | 4.8M |
| Neus-T | 23.07 | 45h | 800k | 5.0M |
| Ours-NeRF-T | 22.46 | 68min | 50k | 43M |
| Ours(6-planes) | 27.86 | 105min | 50k | 32M |
| Ours | 28.27 | 117min | 50K | 43M |
| Method | Lego | Standup | ||
| PSNR | SSIM | PSNR | SSIM | |
| Ours(w/o regular) | 26.49 | 0.946 | 35.91 | 0.977 |
| Ours(6-planes) | 26.44 | 0.944 | 35.79 | 0.978 |
| Ours | 26.71 | 0.953 | 36.32 | 0.983 |
| Sequence-thz | Sequence-earphone | |||
| PSNR | SSIM | PSNR | SSIM | |
| Ours(w/o regular) | 27.92 | 0.932 | 24.75 | 0.885 |
| Ours(6-planes) | 27.74 | 0.934 | 24.39 | 0.889 |
| Ours | 28.27 | 0.942 | 25.00 | 0.903 |
5实验
数据集。 为了评估我们的多视图输入方法的性能,我们构建了一个稀疏视图捕获系统,该系统在 32 英寸 Looking Glass 3D 全息显示器的边框上安装了 6 个前置 RGB 摄像头[1]。 所有相机均已同步和校准。 使用该系统,我们捕获了各种具有挑战性的人体动作的多个序列,包括跳舞、竖起大拇指、挥手、戴帽子和操纵袋子。 我们在所有实验中使用其中的 4 个进行重建和渲染,而将另外两个用于定量评估。 我们还使用由相机环上均匀分布的相机拍摄的三个 360° 多视图全身序列进行定性评估。 对于单目评估,我们使用 D-NeRF [39] 提供的合成数据集,并从该数据集中选择 3 个场景(“lego”、“standup”和“jumpingjacks”),其中包含训练数量帧数从 50 到 200 不等。 有关数据收集和预处理的更多详细信息,请参阅Supp.Mat.。
基线。 我们主要将我们的方法与以下与我们的工作最相关的最先进的基线进行比较:D-NeRF [39]、NeRF-T、TiNeuVox [11] 和 NeuS-T。 在这里,NeRF-T 是我们通过引入额外的时间输入对普通 NeRF [31] 的扩展,NeuS-T 类似地从 NeuS [59] 扩展而来。 在这些基线中,D-NeRF 和 TiNeuVox 通过变形规范场景来表示动态场景,而 NeRF-T 和 NeuS-T 直接学习时间调节的 4D 辐射场。 TiNeuVox 使用显式体素网格来加速网络训练,而其他人则纯粹使用 MLP 来对场景进行建模。
5.1结果与比较
定性结果。 我们为每个单独的序列训练我们的模型,并在图 4 和 Supp.Mat. 中提供新颖视图合成的一些示例结果。 结果涵盖各种身体动作、服装风格和配饰。 如图4所示,我们的方法可以为动态场景渲染高质量的图像,并忠实地恢复外观细节,如细手指运动、半透明丝绸、手部物体交互、面部表情和布料皱纹。 请参阅我们的补充视频。 为了更好的可视化。
单目动态数据集的比较。 我们首先将我们的方法与单目合成数据集的基线进行比较。 定性结果如图5所示。 与其他方法相比,我们的方法恢复了更多的外观细节并产生了更少的伪影。 表中的数值结果。 1 还证明我们的方法在渲染质量和准确性方面优于最先进的方法。
5.2消融研究
正则化。 我们定量地消除了我们方法中的正则化项。 我们实现了两个强大的基线“Ours-NeRF-T”和“Ours-D-NeRF”,其中我们直接将 Tensor4D 分解应用于 NeRF-T 和 D-NeRF,而无需正则化项。 结果报告在表中。 1 和选项卡。 2. 受益于我们的 4D 分解,它们实现了比原始 NeRF-T 和 D-NeRF 更好的性能。 然而,它们的渲染质量仍然比我们的正则化完整方法差。 此外,我们还消除了电视常规平滑度术语(我们的vs。 我们的(没有常规))和结果报告在表中。 5,这进一步验证了我们的平滑项对于渲染质量增强的有效性。
分层分解 我们用 6 平面分解定量地消除了分层分解。 如表5所示,我们的方法在多视图和单目情况下都取得了优异的性能,这验证了我们的层次分解的有效性。
6讨论
限制。 由于我们的方法需要将 4D 场分解为多个 2D 特征平面,因此需要预先设置场景的边界框。 因此,我们的方法很难重建边界框之外的背景或对象。 另一个限制是我们强大的正则化项。 尽管这些术语有利于我们在稀疏视图下重建的稳健性,但它们也限制了我们处理流体和雾等具有挑战性的情况的能力。
结论。 我们提出了 Tensor4D,这是一种从稀疏视图视频甚至单目视频中学习动态场景的高质量神经表示的新方法。 为了以紧凑且节省内存的方式捕获时空信息,我们提出了一种新颖的分层三投影分解方法,该方法用九个 2D 特征平面对 4D 张量进行建模。 通过正确设计训练损失和正则化,我们的方法提供了一种高效且有效的解决方案来对动态场景的辐射场进行建模。 我们相信我们的工作可以激发未来对低成本、便携式和沉浸式远程呈现系统的研究。
致谢。
该论文得到国家重点研发计划(2022YFF0902200)、国家自然科学基金项目(62125107和61827805)和北京市科技计划项目(Z211100004021006)的资助。
参考
- [1] The looking glass holographic display. https://lookingglassfactory.com/.
- [2] Naveed Ahmed, Christian Theobalt, Petar Dobrev, Hans-Peter Seidel, and Sebastian Thrun. Robust fusion of dynamic shape and normal capture for high-quality reconstruction of time-varying geometry. In 2008 IEEE Conference on Computer Vision and Pattern Recognition, pages 1–8, 2008.
- [3] Mark Boss, Raphael Braun, Varun Jampani, Jonathan T. Barron, Ce Liu, and Hendrik P.A. Lensch. Nerd: Neural reflectance decomposition from image collections. In IEEE International Conference on Computer Vision (ICCV), 2021.
- [4] Ang Cao and Justin Johnson. Hexplane: A fast representation for dynamic scenes. arXiv preprint arXiv:2301.09632, 2023.
- [5] Eric Chan, Marco Monteiro, Petr Kellnhofer, Jiajun Wu, and Gordon Wetzstein. pi-gan: Periodic implicit generative adversarial networks for 3d-aware image synthesis. In arXiv, 2020.
- [6] Eric R. Chan, Connor Z. Lin, Matthew A. Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas Guibas, Jonathan Tremblay, Sameh Khamis, Tero Karras, and Gordon Wetzstein. Efficient geometry-aware 3D generative adversarial networks. In CVPR, 2022.
- [7] Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. Tensorf: Tensorial radiance fields. In Proceedings of the European Conference on Computer Vision, 2022.
- [8] Alvaro Collet, Ming Chuang, Pat Sweeney, Don Gillett, Dennis Evseev, David Calabrese, Hugues Hoppe, Adam Kirk, and Steve Sullivan. High-quality streamable free-viewpoint video. 34(4), jul 2015.
- [9] Mingsong Dou, Philip Davidson, Sean Ryan Fanello, Sameh Khamis, Adarsh Kowdle, Christoph Rhemann, Vladimir Tankovich, and Shahram Izadi. Motion2fusion: Real-time volumetric performance capture. ACM Trans. Graph., 36(6), nov 2017.
- [10] Yilun Du, Yinan Zhang, Hong-Xing Yu, Joshua B. Tenenbaum, and Jiajun Wu. Neural radiance flow for 4d view synthesis and video processing. In Proceedings of the IEEE International Conference on Computer Vision, pages 14304–14314, 2021.
- [11] Jiemin Fang, Taoran Yi, Xinggang Wang, Lingxi Xie, Xiaopeng Zhang, Wenyu Liu, Matthias Nießner, and Qi Tian. Fast dynamic radiance fields with time-aware neural voxels. In arXiv preprint arXiv:2205.15285, 2022.
- [12] Sara Fridovich-Keil, Giacomo Meanti, Frederik Warburg, Benjamin Recht, and Angjoo Kanazawa. K-planes: Explicit radiance fields in space, time, and appearance. arXiv preprint arXiv:2301.10241, 2023.
- [13] Sara Fridovich-Keil, Alex Yu, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. Plenoxels: Radiance fields without neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5491–5500, 2022.
- [14] Wanshui Gan, Hongbin Xu, Yi Huang, Shifeng Chen, and Naoto Yokoya. V4d: Voxel for 4d novel view synthesis. In arXiv preprint arXiv:2205.14332, 2022.
- [15] Hang Gao, Ruilong Li, Shubham Tulsiani, Bryan Russell, and Angjoo Kanazawa. Monocular dynamic view synthesis: A reality check. In In Neural Information Processing Systems (NeurIPS), 2022.
- [16] Paulo FU Gotardo, Tomas Simon, Yaser Sheikh, and Iain Matthews. Photogeometric scene flow for high-detail dynamic 3d reconstruction. In Proceedings of the IEEE international conference on computer vision, pages 846–854, 2015.
- [17] Jiatao Gu, Lingjie Liu, Peng Wang, and Christian Theobalt. Stylenerf: A style-based 3d aware generator for high-resolution image synthesis. In International Conference on Learning Representations, 2022.
- [18] Kaiwen Guo, Peter Lincoln, Philip Davidson, Jay Busch, Xueming Yu, Matt Whalen, Geoff Harvey, Sergio Orts-Escolano, Rohit Pandey, Jason Dourgarian, Danhang Tang, Anastasia Tkach, Adarsh Kowdle, Emily Cooper, Mingsong Dou, Sean Fanello, Graham Fyffe, Christoph Rhemann, Jonathan Taylor, Paul Debevec, and Shahram Izadi. The relightables: Volumetric performance capture of humans with realistic relighting. ACM Trans. Graph., 38(6), nov 2019.
- [19] Yannan He, Anqi Pang, Xin Chen, Han Liang, Minye Wu, Yuexin Ma, and Lan Xu. Dynamic shape capture using multi-view photometric stereo. In ACM SIGGRAPH Asia 2009 Papers, New York, NY, USA, 2009. Association for Computing Machinery.
- [20] Hankyu Jang and Daeyoung Kim. D-tensorf: Tensorial radiance fields for dynamic scenes. arXiv preprint arXiv:2212.02375, 2022.
- [21] Wonbong Jang and Lourdes Agapito. Codenerf: Disentangled neural radiance fields for object categories. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 12949–12958, 2021.
- [22] T. Kanade, P. Rander, and P.J. Narayanan. Virtualized reality: constructing virtual worlds from real scenes. IEEE MultiMedia, 4(1):34–47, 1997.
- [23] Hansung Kim, Jean-Yves Guillemaut, Takeshi Takai, Muhammad Sarim, and Adrian Hilton. Outdoor dynamic 3-d scene reconstruction. IEEE Transactions on Circuits and Systems for Video Technology, 22(11):1611–1622, 2012.
- [24] Jason Lawrence, Danb Goldman, Supreeth Achar, Gregory Major Blascovich, Joseph G. Desloge, Tommy Fortes, Eric M. Gomez, Sascha Häberling, Hugues Hoppe, Andy Huibers, Claude Knaus, Brian Kuschak, Ricardo Martin-Brualla, Harris Nover, Andrew Ian Russell, Steven M. Seitz, and Kevin Tong. Project starline: A high-fidelity telepresence system. ACM Trans. Graph., 40(6), dec 2021.
- [25] Hao Li, Linjie Luo, Daniel Vlasic, Pieter Peers, Jovan Popović, Mark Pauly, and Szymon Rusinkiewicz. Temporally coherent completion of dynamic shapes. ACM Trans. Graph., 31(1), feb 2012.
- [26] Tianye Li, Mira Slavcheva, Michael Zollhofer, Simon Green, Christoph Lassner, Changil Kim, Tanner Schmidt, Steven Lovegrove, Michael Goesele, Richard Newcombe, and Zhaoyang Lv. Neural 3d video synthesis from multi-view video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5521–5531, 2022.
- [27] Jia-Wei Liu, Yan-Pei Cao, Weijia Mao, Wenqiao Zhang, David Junhao Zhang, Jussi Keppo, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Devrf: Fast deformable voxel radiance fields for dynamic scenes. In arXiv preprint, arXiv:2205.15723, 2022.
- [28] Lingjie Liu, Jiatao Gu, Kyaw Zaw Lin, Tat-Seng Chua, and Christian Theobalt. Neural sparse voxel fields. In Advances in Neural Information Processing Systems, 2020.
- [29] Zhaoyang Lv, Kihwan Kim, Alejandro Troccoli, Deqing Sun, James M. Rehg, and Jan Kautz. Learning rigidity in dynamic scenes with a moving camera for 3d motion field estimation. In Vittorio Ferrari, Martial Hebert, Cristian Sminchisescu, and Yair Weiss, editors, Computer Vision – ECCV 2018, pages 484–501, Cham, 2018. Springer International Publishing.
- [30] Ricardo Martin-Brualla, Noha Radwan, Mehdi S. M. Sajjadi, Jonathan T. Barron, Alexey Dosovitskiy, and Daniel Duckworth. NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections. In CVPR, 2021.
- [31] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020.
- [32] Thomas Muller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. 41(4), jul 2022.
- [33] Richard A. Newcombe, Dieter Fox, and Steven M. Seitz. Dynamicfusion: Reconstruction and tracking of non-rigid scenes in real-time. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 343–352, 2015.
- [34] Michael Niemeyer, Lars Mescheder, Michael Oechsle, and Andreas Geiger. Differentiable volumetric rendering: Learning implicit 3d representations without 3d supervision. In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2020.
- [35] Michael Oechsle, Songyou Peng, and Andreas Geiger. Unisurf: Unifying neural implicit surfaces and radiance fields for multi-view reconstruction. In International Conference on Computer Vision (ICCV), 2021.
- [36] Keunhong Park, Utkarsh Sinha, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Steven M. Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields. In Proceedings of the IEEE International Conference on Computer Vision, pages 5865–5874, 2021.
- [37] Keunhong Park, Utkarsh Sinha, Peter Hedman, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Ricardo MartinBrualla, and Steven M. Seitz. Hypernerf: A higherdimensional representation for topologically varying neural radiance fields. ACM Trans. Graph., 40(6), 2021.
- [38] Sida Peng, Yuanqing Zhang, Yinghao Xu, Qianqian Wang, Qing Shuai, Hujun Bao, and Xiaowei Zhou. Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans. In CVPR, 2021.
- [39] Albert Pumarola, Enric Corona, and and Francesc Moreno-Noguer Gerard Pons-Moll. D-nerf: Neural radiance fields for dynamic scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 10318–10327, 2021.
- [40] René Ranftl, Vibhav Vineet, Qifeng Chen, and Vladlen Koltun. Dense monocular depth estimation in complex dynamic scenes. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4058–4066, 2016.
- [41] Chris Russell, Rui Yu, and Lourdes Agapito. Video pop-up: Monocular 3d reconstruction of dynamic scenes. In Computer Vision – ECCV 2014, pages 583–598, Cham, 2014. Springer International Publishing.
- [42] Katja Schwarz, Yiyi Liao, Michael Niemeyer, and Andreas Geiger. Graf: Generative radiance fields for 3d-aware image synthesis. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 20154–20166. Curran Associates, Inc., 2020.
- [43] Ruizhi Shao, Liliang Chen, Zerong Zheng, Hongwen Zhang, Yuxiang Zhang, Han Huang, Yandong Guo, and Yebin Liu. Floren: Real-time high-quality human performance rendering via appearance flow using sparse rgb cameras. In SIGGRAPH Asia 2022 Conference Papers, pages 1–10, 2022.
- [44] Ruizhi Shao, Hongwen Zhang, He Zhang, Mingjia Chen, Yanpei Cao, Tao Yu, and Yebin Liu. Doublefield: Bridging the neural surface and radiance fields for high-fidelity human reconstruction and rendering. In CVPR, 2022.
- [45] Ruizhi Shao, Zerong Zheng, Hongwen Zhang, Jingxiang Sun, and Yebin Liu. Diffustereo: High quality human reconstruction via diffusion-based stereo using sparse cameras. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXII, pages 702–720. Springer, 2022.
- [46] Vincent Sitzmann, Michael Zollhöfer, and Gordon Wetzstein. Scene representation networks: Continuous 3d-structure-aware neural scene representations. In Advances in Neural Information Processing Systems, 2019.
- [47] Pratul P. Srinivasan, Boyang Deng, Xiuming Zhang, Matthew Tancik, Ben Mildenhall, and Jonathan T. Barron. Nerv: Neural reflectance and visibility fields for relighting and view synthesis. In CVPR, 2021.
- [48] Jonathan Starck and Adrian Hilton. Surface capture for performance-based animation. IEEE Computer Graphics and Applications, 27(3):21–31, 2007.
- [49] Cheng Sun, Min Sun, and Hwann-Tzong Chen. Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5459–5469, 2022.
- [50] Guoxing Sun, Xin Chen, Yizhang Chen, Anqi Pang, Pei Lin, Yuheng Jiang, Lan Xu, Jingya Wang, and Jingyi Yu. Neural free-viewpoint performance rendering under complex human-object interactions. In Proceedings of the 29th ACM International Conference on Multimedia, 2021.
- [51] Jiaming Sun, Xi Chen, Qianqian Wang, Zhengqi Li, Hadar Averbuch-Elor, Xiaowei Zhou, and Noah Snavely. Neural 3D reconstruction in the wild. In SIGGRAPH Conference Proceedings, 2022.
- [52] Jingxiang Sun, Xuan Wang, Yichun Shi, Lizhen Wang, Jue Wang, and Yebin Liu.
- [53] Jingxiang Sun, Xuan Wang, Yong Zhang, Xiaoyu Li, Qi Zhang, Yebin Liu, and Jue Wang. Fenerf: Face editing in neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7672–7682, 2022.
- [54] Aparna Taneja, Luca Ballan, and Marc Pollefeys. Modeling dynamic scenes recorded with freely moving cameras. Computer Vision – ACCV 2010, page 613–626, 2011.
- [55] Edgar Tretschk, Ayush Tewari, Vladislav Golyanik, Michael Zollhofer, Christoph Lassner, and Christian Theobalt. Non-rigid neural radiance fields: Reconstruction and novel view synthesis of a dynamic scene from monocular video. In Proceedings of the IEEE International Conference on Computer Vision, pages 12959–12970, 2021.
- [56] Chaoyang Wang, Ben Eckart, Simon Lucey, and Orazio Gallo. Neural trajectory fields for dynamic novel view synthesis. In arXiv preprint, arXiv:2105.05994, 2021.
- [57] Liao Wang, Ziyu Wang, Pei Lin, Yuheng Jiang, Xin Suo, Minye Wu, Lan Xu, and Jingyi Yu. IButter: Neural Interactive Bullet Time Generator for Human Free-Viewpoint Rendering, page 4641–4650. Association for Computing Machinery, New York, NY, USA, 2021.
- [58] Liao Wang, Jiakai Zhang, Xinhang Liu, Fuqiang Zhao, Yanshun Zhang, Yingliang Zhang, Minye Wu, Jingyi Yu, and Lan Xu. Fourier plenoctrees for dynamic radiance field rendering in real-time. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 13524–13534, 2022.
- [59] Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. NeurIPS, 2021.
- [60] Chung-Yi Weng, Brian Curless, Pratul P. Srinivasan, Jonathan T. Barron, and Ira Kemelmacher-Shlizerman. HumanNeRF: Free-viewpoint rendering of moving people from monocular video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16210–16220, June 2022.
- [61] Liwen Wu, Jae Yong Lee, Yu-Xiong Wang Anand Bhattad, and David Forsyth. Diver: Real-time and accurate neural radiance fields with deterministic integration for volume rendering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 16200–16209, 2022.
- [62] Wenqi Xian, Jia-Bin Huang, Johannes Kopf, and Changil Kim. Space-time neural irradiance fields for free-viewpoint video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9421–9431, 2021.
- [63] Lior Yariv, Jiatao Gu, Yoni Kasten, and Yaron Lipman. Volume rendering of neural implicit surfaces. In Thirty-Fifth Conference on Neural Information Processing Systems, 2021.
- [64] Lior Yariv, Yoni Kasten, Dror Moran, Meirav Galun, Matan Atzmon, Basri Ronen, and Yaron Lipman. Multiview neural surface reconstruction by disentangling geometry and appearance. Advances in Neural Information Processing Systems, 33, 2020.
- [65] Alex Yu, Ruilong Li, Matthew Tancik, Hao Li, Ren Ng, and Angjoo Kanazawa. Plenoctrees for real-time rendering of neural radiance fields. In Proceedings of the IEEE International Conference on Computer Vision, pages 5752–5761, 2021.
- [66] Tao Yu, Zerong Zheng, Kaiwen Guo, Pengpeng Liu, Qionghai Dai, and Yebin Liu. Function4d: Real-time human volumetric capture from very sparse consumer rgbd sensors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5746–5756, 2021.
- [67] Xiuming Zhang, Pratul P. Srinivasan, Boyang Deng, Paul Debevec, William T. Freeman, and Jonathan T. Barron. Nerfactor: Neural factorization of shape and reflectance under an unknown illumination. ACM Trans. Graph., 40(6), dec 2021.
- [68] Fuqiang Zhao, Wei Yang, Jiakai Zhang, Pei Lin, Yingliang Zhang, Jingyi Yu, and Lan Xu. Humannerf: Efficiently generated human radiance field from sparse inputs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7743–7753, June 2022.
- [69] Zerong Zheng, Han Huang, Tao Yu, Hongwen Zhang, Yandong Guo, and Yebin Liu. Structured local radiance fields for human avatar modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15893–15903, 2022.
- [70] Tinghui Zhou, Shubham Tulsiani, Weilun Sun, Jitendra Malik, and Alexei A Efros. View synthesis by appearance flow. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14, pages 286–301. Springer, 2016.