juesato@deepmind.com
使用过程和结果反馈解决数学文字问题
摘要
最近的研究表明,要求语言模型生成推理步骤可以提高许多推理任务的性能。 当超越提示时,这引发了我们应该如何监督此类模型的问题:基于结果的方法,监督最终结果,还是基于过程的方法,监督推理过程本身? 这些方法之间的差异,不仅自然地体现在最终答案错误中,还体现在推理错误中,推理错误可能难以检测,并且在许多现实世界的领域(如教育)中存在问题。 我们对在自然语言任务 GSM8K 上训练的基于过程和基于结果的方法进行了首次全面比较。 我们发现,纯基于结果的监督在较少的标签监督下产生了类似的最终答案错误率。 但是,对于正确的推理步骤,我们发现有必要使用基于过程的监督或来自模仿基于过程反馈的学习奖励模型的监督。 总的来说,我们从最终答案错误率的 16.8% 12.7% 和最终答案正确的解决方案中推理错误率的 14.0% 3.4% 提高了之前最好的结果。
1 介绍
最近的研究表明,要求语言模型使用逐步推理可以提高推理任务的性能 (Shwartz 等人,2020;Nakano 等人,2021;Cobbe 等人,2021;Wei 等人,2022;Kojima 等人,2022;Lewkowycz 等人,2022)。 虽然这些工作主要集中在提示语言模型,但先前的工作表明,微调应该优于单独的提示 (Stiennon 等人,2020;Perez 等人,2021;Ouyang 等人,2022)。 这引发了如何最好地监督此类模型的问题。 两种自然的方法是基于结果的方法,监督最终结果,以及基于过程的方法,监督推理过程的每个步骤,包括输出最终结果的最后一步。
基于过程的方法强调人类理解——为了展示或选择好的推理步骤,人类标注者需要理解任务。 人类可理解性在许多领域都直接相关。 例如,在教育环境中,没有(可理解的)解释的答案往往会比解释更多地造成混淆。 从长远来看,人类可理解性还有助于检测机器学习系统何时可能使用欺骗性或不道德的行为来实现表面上吸引人的结果,例如通过微妙地操纵人员或系统来提高各种指标 (Amodei et al., 2016)。 最近的研究表明,基于结果的方法在这方面往往存在不足。 例如,最近关于基于自然语言的推理的研究 (Zelikman et al., 2022; Creswell et al., 2022) 表明,即使模型生成的推理轨迹不正确,只要模型专门针对最终答案的正确性进行优化,它们就可以生成正确的最终答案。 同样,关于人工智能安全性的研究 (Stuhlmüller and Byun, 2022; Krakovna et al., 2020) 表明,这种优化可能会导致模型执行难以理解的策略。
这表明,为具有语言化推理轨迹的语言模型 (LM) 选择监督方法可能具有重要意义。 在这项工作中,我们对针对自然语言任务训练的基于过程和基于结果的方法进行了首次全面比较。 为此,我们使用最近提出的 GSM8K 数据集 (Cobbe et al., 2021),该数据集包含数学文字题。 在所有情况下,我们都会生成一系列通向最终答案的推理步骤,但会改变是否仅对最终答案 (基于结果) 或对单个推理步骤 (基于过程) 提供监督。 虽然数据集的范围有限,无法研究某些安全问题,但它可以使基于结果和基于过程的方法之间进行清晰的比较。 对于基于过程的方法,我们考虑由 GSM8K 数据集本身提供的离线人工生成的推理轨迹,以及在线人工正确性标注,我们为模型生成的样本中的推理步骤收集这些标注。
我们在许多不同的建模和训练组件的背景下比较了这些方法,包括:少样本提示、监督微调、通过专家迭代和奖励建模进行的强化学习 (RL),用于重新排序和 RL。 我们所有的模型都基于一个大型预训练的 LM (Hoffmann et al., 2022)。
在整个过程中,我们考虑了两个主要指标:轨迹错误率,衡量模型根据人工标注者在其推理轨迹中犯错的频率;以及最终答案错误率,该指标仅考虑模型的最终答案,而不考虑推理轨迹。 “推理轨迹”是指推理的所有文本步骤,包括在 GSM8K 中为最终数字答案的最后一步。
主要结果
我们发现,我们最好的方法,它结合了监督学习和基于奖励模型的强化学习,显著提高了最先进的跟踪错误率,从 14.0% 3.4%,以及最终答案错误率,从 16.8% 12.7%。 当模型被允许在 30% 的问题上弃权时,最终答案错误率进一步降低到 2.7%。 关于过程和结果反馈的关键发现如下:
-
•
基于结果和基于过程的方法导致相似的最终答案错误率。 无论是使用奖励模型(23.5% vs. 22.3%)还是使用奖励模型(16.6% vs. 14.8%),用最终答案正确性监督的 LMs 达到了与那些训练模仿人类提供的解决方案的 LMs 几乎相同的最终答案错误率。
-
•
基于过程和基于结果的监督奖励模型都学会模拟基于过程的反馈。 有些令人惊讶的是,我们发现,即使是用基于结果的标签(指示最终答案是否正确)训练的奖励模型,也会产生与基于过程的标签(指示每个推理步骤是否正确)更一致的预测,而不是它们与基于结果的标签本身的预测。 虽然这种效果可能是特定于数据集的,如部分 3中所讨论,但它有助于解释奖励模型对于改善跟踪误差的有效性,以及我们希望在今后的工作中对此进行进一步研究。
-
•
低跟踪错误需要基于过程的反馈,或者一个模拟它的奖励模型。 所有直接针对最终答案正确性使用强化学习的模型都导致了高跟踪错误,最好的跟踪错误率为 12.4%,而我们最好的基于过程的方法只有 3.8%。 基于我们之前的发现,针对奖励模型而不是最终答案正确性进行强化学习,缩小了大部分差距,将跟踪错误率降低到 5.5%。
在本文的其余部分,我们将在 Section 2 中描述我们比较的方法,并在 Section 中描述我们的结果t4>3。 部分 4更广泛地讨论基于过程和结果的反馈的影响,部分 5讨论了相关工作,部分6进行了总结。
2 问题和方法
本节描述了数据集、评估指标和本文中评估的不同建模组件。 请参见 图 1,了解它们如何组合在一起的概述。
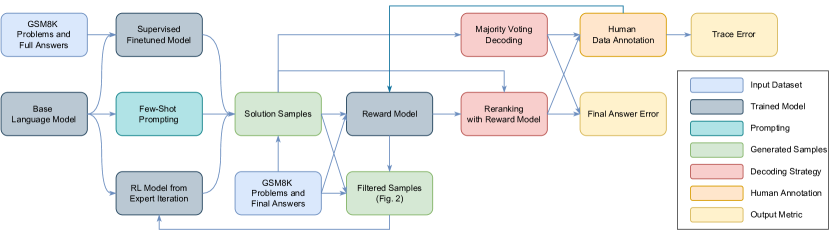
2.1 数据集和评估指标
我们在 GSM8K 数据集 (Cobbe 等人,2021) 上进行所有实验,该数据集由小学数学文字题组成。 我们选择 GSM8K 是因为它是一个有竞争力的基准,并且包含自然语言推理轨迹。 我们专注于一个单一数据集,因为招募具有领域专业知识的人类标注者以准确评估推理轨迹需要高昂的前期成本。 表 2 和 附录 A 显示了几个示例问题。 我们从原始训练集中分出一个包含 256 个示例的验证集,这让我们剩下 7118 个训练示例和 1319 个测试示例。
我们报告了在 GSM8K 测试集上评估的所有方法的两个主要指标。 最终答案错误率 是方法无法产生正确最终答案的问题的比例。 由于 GSM8K 上的所有最终答案都是整数,因此可以使用精确字符串匹配来衡量。 轨迹错误率 是具有正确最终答案但方法产生至少一个不正确的推理步骤的问题的比例。 我们通过人类对每个推理步骤的正确性进行标注来估计这一点,使用 第 2.7 节中讨论的评分界面。
2.2 训练:概述
我们的目标是训练一个系统,用于将问题的文本作为输入并生成答案文本作为输出的序列到序列任务 (Sutskever 等人,2014)。 对于数学文字问题,答案是一个完整的推理跟踪:一个换行符分隔的 步骤 序列,其中最后一步预计提供 最终答案。 对于 GSM8K,最终答案始终是整数。
我们的方法大体上遵循先前关于 RL 用于 LMs 的工作 (Ziegler 等人,2019; Nakano 等人,2021; Menick 等人,2022)。 我们使用 LM 作为 策略,将问题陈述和迄今为止的步骤映射到下一步。 在 RL 形式化中,这将每个步骤视为一个动作,观察结果由迄今为止的所有符元提供。 该策略可以通过少样本提示、监督微调 (部分 2.3) 或 RL (部分 2.6) 中的任何一种获得。 我们还训练 LM 作为 奖励模型 (部分 2.4),这些模型对策略提出的完成或部分完成进行评分,既可以用于对策略样本进行重新排序,也可以用作强化学习过程中的奖励来源。 在以下小节中,我们将描述我们如何训练和组装这些组件。
2.3 监督微调
在监督微调 (SFT) 中,我们对 LM 进行微调,以最大化给定输入符元序列的目标符元序列的对数似然。 在我们的论文中,我们使用 SFT 作为基于过程的方法,方法是将 GSM8K 数据集中提供的推理跟踪作为目标符元(而不是仅使用最终答案作为目标的基于结果的方法),并将问题陈述作为输入符元。
训练细节
我们使用 AdamW (Loshchilov 和 Hutter,2017) 进行微调,学习率为 ,批次大小为 256。 一旦语言建模损失在验证集上开始增加,我们就停止微调。 对于我们的 SFT 模型,这种情况发生在 70 步之后,相当于略多于 2 个训练集时期。
2.4 奖励模型
我们评估了两种主要的训练奖励模型 (RM) 方法 (Christiano 等人,2017; Ziegler 等人,2019; Menick 等人,2022),也称为验证器 (Cobbe 等人,2021)。 在这两种方法中,我们将 RM 实现为一个 LM,训练它在每一步之后预测一个二进制标签,表示为“正确”或“不正确”的符元。 在 结果监督 RM (ORM) 中,每一步的二进制标签指示该完整样本的最终答案是否与参考最终答案匹配,如 Cobbe 等人 (2021) 所提议。 因此,在每一步最大化 ORM 得分的策略最大化了 RM 在每一步中最终达到正确最终答案的估计概率。 对于 过程监督 RM (PRM),每一步后的二进制标签指示到目前为止的步骤是否正确。 由于我们缺乏可靠的编程方法来确定中间步骤的正确性,因此我们对这些标签使用人工注释,如部分2.7中所述。 因此,最大化 PRM 得分的策略选择每一步以最大化 RM 对到目前为止步骤正确的估计概率。 如果到目前为止的步骤是正确的,这通常意味着这种策略将最小化在当前步骤引入错误的概率。 正如 Section 3.2 中所述,我们发现这优于 Li 等人 (2022) 中的方法,即与我们的 PRM 类似,但用基于字符串匹配中间计算结果的启发式方法取代了人工评估。
训练细节
除非另有说明,对于所有包含 ORM 的方法,我们使用来自该方法策略的样本训练 ORM,并采用 个温度为 的样本。 我们遵循 Cobbe 等人 (2021) 并使用丢弃进行正则化,丢弃参数为 ,其他方面则复用 部分 2.3 中用于 SFT 的超参数。 为了加速 SFT 基于方法的学习,我们使用 SFT 模型参数初始化 ORM 训练,而对于少样本基于方法,我们从基础预训练的 LM 初始化。 对于 PRM,我们从 SFT 策略中标注 个样本,限制在 SFT 预测占多数 (见 部分 2.5) 不正确的问题,以便最大限度地利用我们的标注预算。 由于我们的人工标注数据集规模较小 (1560 个完整解决方案),我们将 PRM 参数初始化为 ORM 参数,并将学习率降低至 。 RM 损失曲线有一些波动,因此我们在 步之前选择验证损失最佳的 RM。
2.5 解码
对于所有测试时解码,我们首先生成 个完整解决方案样本,然后选择最佳样本,方法是将样本进行集成或使用 RM。 在早期实验中,我们还尝试在每个生成的步骤 (而不是完整解决方案) 后进行 RM 排名,但发现这样做会导致性能略微下降,最终答案的错误率提高了 1-2%。 我们使用温度 进行采样,并使用 Cobbe 等人 (2021) 中的语法,允许模型决定何时使用计算器。
我们使用两种方法来选择最佳样本。 当没有 RM 可用时,我们使用 多数投票。 对于这种情况,我们首先从 个样本中选择最常见的最终答案,然后从那些产生此最终答案的样本中随机选择一个样本。 这被称为 王等人 (2022) 的自一致性,与更一般的技术 (如最小贝叶斯风险解码 (Kumar 和 Byrne, 2004)) 类似。 否则,我们使用 RM 加权 解码,也被称为 李等人 (2022) 的验证者投票。 在这里,我们根据 RM 估计的正确性概率对每个样本进行加权,选择总权重最大的最终答案,然后从那些产生所选最终答案的样本中选择 RM 分数最高的样本。 更正式地说,我们选择最终答案 ,其中 是模型样本,然后根据 选择最佳样本。 与仅选择具有最高 RM 分数的样本相比,此方法效果略好(SFT 模型的最终答案错误率约为 1%,RL 模型略高)。 但是,我们注意到,多数投票和 RM 加权解码由于依赖于最终答案之间的精确字符串匹配,因此通用性略差。
2.6 通过专家迭代进行 RL
我们所有的 RL 实验都使用专家迭代 (Silver 等人,2017;Anthony 等人,2017)。 作为一种元算法,专家迭代在两个高级操作之间交替进行。 在策略改进中,我们将基本策略与搜索过程相结合,以从所谓的专家策略中生成样本。 然后,在蒸馏中,我们对这些专家样本进行监督学习,以将基本策略改进为专家策略。 我们使用 5 个时期,并根据最终答案测试错误(使用 RM 加权解码)选择 5 个时期中最好的模型,如果不存在 RM,则使用多数投票。
基于 SFT 的实现与基于少样本的实现
初始基本策略可以是 SFT 策略,也可以是我们基本 LM 的 5 个样本提示版本。 我们特别注意到,除了用于提示的 5 个随机训练示例之外,所有基于少样本的方法从未使用 GSM8K 数据集提供的中间推理步骤,我们的人工标注,或从该数据派生的任何模型。 从 SFT 模型初始化时,我们遵循 Polu 和 Sutskever (2020) 并重用每个迭代的专家样本,因此我们的训练集在每个时期都会增长。 我们不会在少样本方法中这样做,因为在这种情况下,来自早期时期的样本有许多跟踪错误,我们不希望 RL 模型模仿这些错误。 相应地,这两种情况下存在一些小的实现差异,我们在对策略改进和蒸馏过程的详细描述中都提到了这些差异。
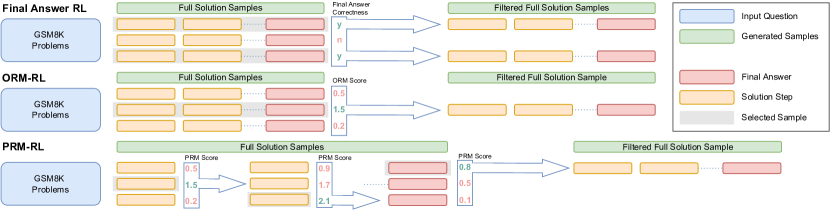
策略改进
我们考虑了三种策略改进过程的版本 (图 2)。 在 最终答案 RL 方法中,也称为自学推理器,由 Zelikman 等人 (2022) 提出,我们为每个问题生成 个完整轨迹,并根据最终答案的正确性进行过滤。 对于少样本版本,我们选择所有产生正确最终答案的轨迹,而对于基于 SFT 的版本,我们每个问题只使用一个随机选择的样本。 在 ORM-RL 方法中,我们为每个问题生成 个完整轨迹,并根据 ORM 模型选择得分最高的样本。 在 PRM-RL 方法中,我们改为将每个步骤视为一个独立的回合。 在每个步骤中,我们生成 个候选步骤,选择具有最高 PRM 得分的候选步骤,并从所选步骤继续,直到模型输出带有最终答案指示文本的步骤,或最多 15 个步骤。 我们在所有实验中设置 。 对于基于少样本的方法,我们在每次专家迭代后重新训练 RM。 对于基于 SFT 的方法,我们跳过此步骤并使用固定的 RM,因为令人惊讶的是,这在初步实验中并没有产生显著差异。
蒸馏
对于蒸馏,我们使用与 SFT 相同的超参数。 与 SFT 一样,我们通过验证损失进行提前停止,其中我们的验证集是根据验证集上的专家策略样本构建的。 对于基于 SFT 的方法,我们在每个蒸馏步骤初始化 SFT 参数,而对于基于少样本的方法,我们初始化基本模型参数。
2.7 数据标注
如第 2.4节所述,PRM 在逐步标签上进行训练,这些标签指示到目前为止的步骤是否正确。 为了收集这些数据,我们将问题陈述、GSM8K 中的参考解决方案和生成的模型解决方案呈现给人类标注者,并要求他们指出第一个出现重大错误的模型步骤(如果存在)。 我们的说明将重大错误定义为“表达的信息不正确的一步,或者在不撤消该步的情况下无法获得正确解决方案”。 从这些标注中,我们可以使用二元标签对每个步骤进行标注,以指示到目前为止的步骤是否正确:第一个重大错误之前的步骤全部标注为“正确”,而其余步骤标注为“错误”。
我们通过删除来自标注者协议低的标注者的样本(在 20% 使用重复标注的解决方案上测量),以及来自标注者标记为模棱两可的 GSM8K 问题的样本,对数据集进行了一小部分清理。 这删除了我们大约 20% 的数据,留下了 530 个训练集问题中 1560 个模型样本的标注,对应于 9856 个步骤级别的二元标签。 对于验证集,我们使用了相同的方法,但添加了重复标注,并由论文作者手动进行了一次检查,以解决标注者之间的分歧。 我们的验证集包含 162 个模型样本,总共 913 个步骤。 为了评估,我们使用了每个模型 200 个具有正确最终答案的问题。 这对于表 1中的 10 个模型中的每一个都是这样做的,同样也使用了重复标注。 我们在附录 B中详细描述了我们的数据收集过程。
3 结果
| Error rate (%) | ||||
| Approach | Base model | Trace Final-answer | ||
| Few-shot (Wang et al., 2022; Wei et al., 2022) | PaLM-540B | 14.0 | 25.6 | |
| Few-shot (Lewkowycz et al., 2022) | Minerva-540B | - | 21.5 | |
| Few-shot+Final-Answer RL (Zelikman, 2022) | GPT-J-6B | - | 89.3 | |
| Few-shot, ORM reranking (Li et al., 2022) | Codex-175B | - | 16.8 | |
| Zero-shot (Kojima et al., 2022) | InstructGPT-175B | - | 59.3 | |
| SFT, ORM reranking (Cobbe et al., 2021) | GPT-175B | - | 45.0 | |
| {44mm[ ] | Few-shot, Majority Voting | Our Base-70B | - | 41.5 |
| Few-shot+Final-Answer RL, Majority Voting | Our Base-70B | 19.8 (7.9-31.7) | 23.5 | |
| SFT+Final-Answer RL, Majority Voting | Our Base-70B | 12.1 (4.6-19.6) | 20.2 | |
| SFT, Majority Voting | Our Base-70B | 11.4 (4.8-18.0) | 22.3 | |
| {54mm[ ] | Few-shot, ORM reranking | Our Base-70B | - | 27.8 |
| Few-shot+Final-Answer RL, ORM reranking | Our Base-70B | 12.4 (2.1-22.8) | 16.6 | |
| SFT+Final-Answer RL, ORM reranking | Our Base-70B | 3.7 (0.5-6.9) | 14.2 | |
| SFT, ORM reranking | Our Base-70B | 4.4 (0.6-8.3) | 14.8 | |
| SFT, PRM reranking | Our Base-70B | 3.5 (0.5-6.5) | 14.1 | |
| {33mm[ ] | Few-shot+ORM-RL, ORM reranking | Our Base-70B | 5.5 (2.6-8.4) | 13.8 |
| SFT+ORM-RL, ORM reranking | Our Base-70B | 3.4 (0.0-6.8) | 12.7 | |
| SFT+PRM-RL, PRM reranking | Our Base-70B | 3.8 (0.5-7.1) | 12.9 | |
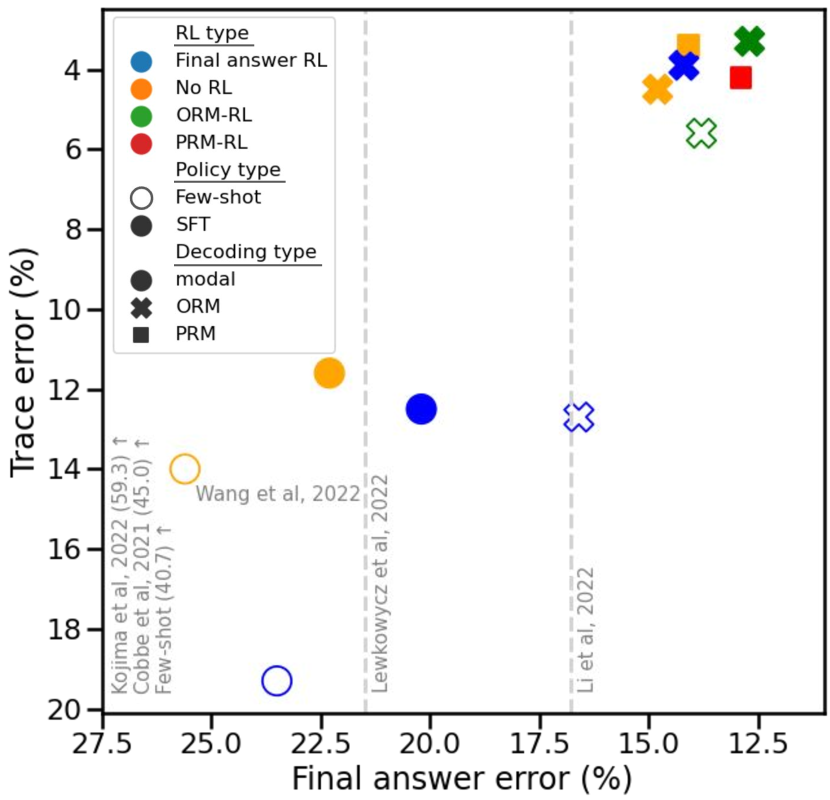
我们的结果总结在 表 1 和 图 4 中。 ORM-RL 和 PRM-RL 模型实现了低于 13% 的最终答案错误率,优于当前最先进模型的 16.8% 最终答案错误率 (Li 等人,2022)。 当模型被允许在只有 30% 的问题上弃权时,这进一步降低到 2.7%。 相应的跟踪错误分别为 3.4% 和 3.8%,这显著提高了先前最佳工作 (Wang 等人,2022;Wei 等人,2022) 中报道的 14%。 除了这些定量结果之外,我们重点介绍了三个关键要点:
仅监督最终答案的正确性就足以实现较低的最终答案错误率。
SFT 和 Few-shot+Final-Answer RL 模型在没有 RM (22.3% 对 23.5%) 和有 ORM (14.8% 对 16.6%) 的情况下都获得了相似的最终答案错误率。 值得注意的是,Few-shot+Final-Answer RL 只需要演示者提供最终答案,而不是完整的推理轨迹。 换句话说,Few-shot+Final-Answer RL 每个问题使用 1-4 个标记的标签监督,而 SFT 使用数百个。 这表明,在最终答案正确性足以的情况下,基于结果的方法可以提供一种标签高效的方法,并具有竞争力的性能。
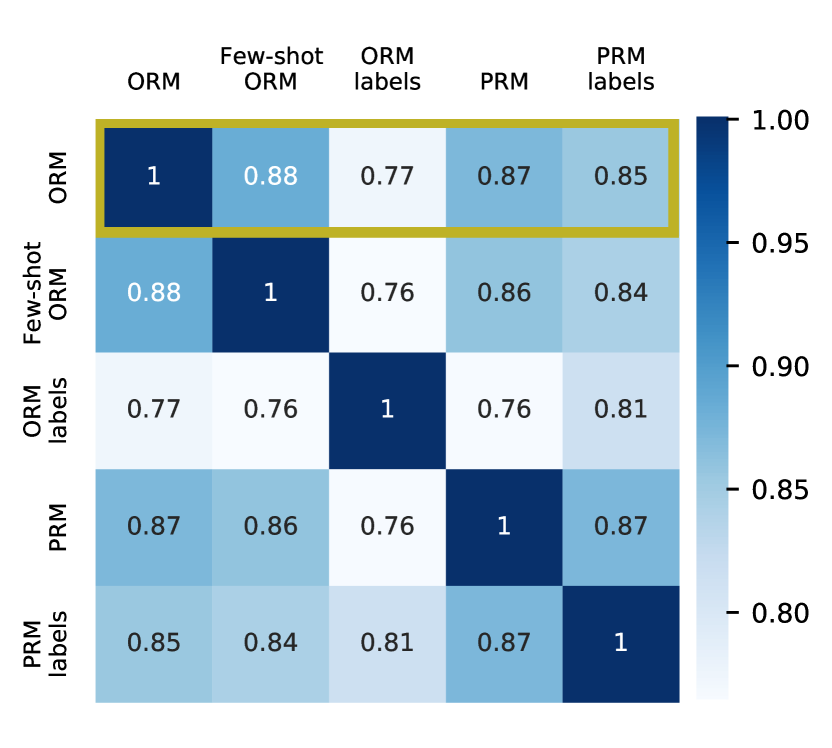
ORM 监督的奖励模型近似于 PRM 标签。
尽管 ORM 只被训练来预测最终答案是否正确,但我们在 图 4 中可以看到,ORM 预测往往比 ORM 标签本身 (85% 对 77%,在所有步骤中平均) 更符合 PRM 标签。 11 1附录 C 显示了在只考虑最后一步时类似的结果。 我们怀疑这是因为,对于 ORM 来说,学习识别步骤是否正确比通过内部计算最终答案来检查答案更简单。 这一事实进一步支持了这一观点:即使跟踪错误只在最终答案正确的样本上进行测量,RM 重新排序仍然显著提高了相对于 SFT 单独的跟踪错误 (4.4% 对 11.4%)。 这表明 RM 正在检查推理步骤,而不仅仅是最终答案。 但是,我们提醒不要过度概括:ORM 模型近似于 PRM 标签可能是特定领域的。 这可能取决于模型在有和没有推理轨迹的情况下计算正确答案的相对难度,以及数学问题中没有虚假解 (Goldman 等人,2017),在这种情况下,不正确的推理步骤不太可能导致正确的最终答案。
较低的跟踪误差需要基于过程的反馈或模拟它的奖励模型。
图 4 显示,尽管最终答案误差率相似,但基于结果的少样本+最终答案强化学习与基于过程的监督微调模型相比,跟踪误差率明显更高(19.8% 对 11.4%)。 这种差异在奖励模型重新排序时仍然存在:使用 ORM 重新排序的少样本+最终答案强化学习比使用 ORM/PRM 重新排序的监督微调表现更差(12.4% 对 4.4%/3.5%)。 然而,我们发现,当我们使用 ORM 训练少样本强化学习模型(少样本+ORM-强化学习)而不是直接针对最终答案的正确性进行训练时,跟踪误差从 12.4% 显着下降到 5.5%,缩小了大部分差距。 我们认为这是由于之前的发现,即 ORM 基本上学习模拟 PRM,使模型能够从模拟的基于过程的反馈中学习,从而导致相对较低的跟踪误差率。
3.1 不使用奖励模型
|
Problem : 每次出门,提利昂都会更换两次口罩。 如果他每天出门三次,他每两天会使用多少个口罩?
Model answer (跟踪错误,最终答案正确):提利昂每天出门 3 次,每次出门更换 2 次口罩,所以每天总共使用 3*2=<<3*2=6>>6 个口罩。 提利昂每天使用 6 个口罩,每天有 2 天,所以每两天使用 6*2=<<6*2=12>>12 个口罩。 最终答案:12 |
比较以过程为中心和以结果为中心的两种方法,SFT 和少样本 + 最终答案强化学习 (Few-shot+Final-Answer RL) 的最终答案错误率相似,但 SFT 的追踪错误率明显更低。 此外,从 SFT 模型开始,应用最终答案强化学习 (Final-Answer RL) 会降低最终答案错误率 (从 22.3% 降至 20.2%),但会增加追踪错误率 (从 11.4% 升至 12.1%,尽管我们注意到差异在统计上并不显著)。 这两者都支持这样的观点:以结果为中心的方法可以找到以错误的原因产生正确答案的方法。 表 2 提供了一个定性示例。
微调 (Finetuning) 相对于单纯的提示 (prompting) 提高了性能。
我们对监督大语言模型 (LLM) 的不同方法的关注,假设在提供足够的数据的情况下,微调 (finetuning) 的性能优于单纯的提示 (prompting)。 我们首先针对 GSM8K 验证了这一假设。 我们发现,仅 5 次提示策略 (Few-shot) 在 多数投票中实现了 41.5% 的最终答案错误(使用单个样本时,错误率为 77.7%)。 尽管考虑到少样本策略不需要额外的微调数据,这已经很令人印象深刻,但与少样本 + 最终答案强化学习 (Few-shot+Final-Answer RL) 和 SFT 模型相比,其性能仍有很大的提升空间,从而验证了我们最初的假设。
3.2 仅用于重新排序的奖励模型
总体而言,奖励模型 (RM) 对追踪和最终答案准确率都提供了显著的提升。 我们发现,RM 重新排序显著提高了追踪错误率,将 SFT 的追踪错误率从 11.4% 降低到 5% 以下。 RM 重新排序也有利于少样本 + 最终答案强化学习 (Few-shot+Final-Answer RL) 模型,尽管追踪错误率仍然明显高于 SFT 模型。 正如 Cobbe 等人 (2021) 所发现的那样,我们的结果也表明,RM 会降低最终答案错误率,从 22.3% 降低到 15% 以下。 我们也尝试了来自 Li 等人 (2022) 的“步骤级投票验证器”。 这与 PRM 方法类似,但使用基于中间数值结果的启发式方法计算标签。 这导致最终答案错误率略微恶化为 15.9%。
3.3 带有奖励模型的强化学习
| Error rate | |||
| Model | Greedy | Majority | RM-weighted |
| Few-shot | 54.3 | 41.4 | 27.8 |
| Few-shot + Final-answer RL | 36.4 | 23.8 | 16.6 |
| Few-shot + ORM-RL | 31.5 | 18.8 | 13.8 |
| SFT | 41.1 | 22.3 | 14.1 |
| SFT + Final-answer RL | 35.0 | 20.2 | 14.2 |
| SFT + ORM-RL | 31.2 | 17.8 | 12.7 |
| SFT + PRM-RL | 34.4 | 17.6 | 12.9 |
RL 显着提高了少样本性能,但在 SFT 之上提供了更适度的收益。
从 表 3 中我们可以看到,从少样本模型开始,无论解码方法如何,RL 都将最终答案错误率降低了一半。 相反,从 SFT 模型开始,RL 在使用 RM 进行解码方面几乎没有影响,但在使用贪婪解码时确实提供了显著的改进(41.1% 到 31.2%)。
针对 RM 进行优化优于直接优化最终答案的正确性。
在少样本和 SFT 设置中,ORM-RL 和 PRM-RL 在所有三种解码策略中都优于最终答案 RL。 表面上,考虑到 ORM-RL 优化了最终答案正确性的近似值(ORM 全解分数),这可能令人惊讶。 然而,我们早期的 RM 分析 (图 4) 表明 ORM 近似于基于过程的反馈,并检查推理步骤而不是直接检查最终答案。 因此,一个可能的解释是,Final-Answer RL 仅检查解决方案是否达到正确的最终答案,而 PRM-RL 和 ORM-RL 检查解决方案是否出于正确的原因得出了正确答案。
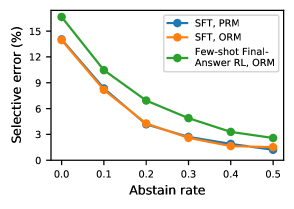
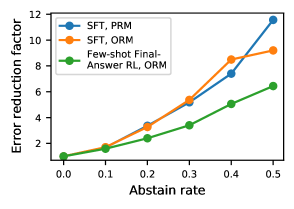
3.4 选择性预测
在许多实际应用中,可以放弃。 例如,如果使用机器学习系统向学生解释问题或协助计算,最好让模型放弃而不是产生错误的输出。 这促使了选择性预测设置 (El-Yaniv 等人,2010; Geifman 和 El-Yaniv,2017),其中模型被允许对 的输入进行放弃,并且选择性错误率是在模型不放弃的输入上进行测量的。 为了确定放弃哪些输入,我们在所选样本的 RM 分数上设置一个阈值,该阈值由 确定。
选择性预测极大地降低了最终答案错误,尤其是对于跟踪错误低的模型。
图 5 显示,通过对 % 的输入进行弃权,我们将最终答案错误率从 14.1% 降至 2.7%,在 % 时可以进一步降至 1.5%。 此外,在 ,选择性预测与 SFT 和 ORM 或 PRM 相结合,与 Few-shot+Final-Answer RL 情况下的 3 相比,产生了 5 的最终答案错误率降低。 这可能与 SFT 的跟踪错误改进有关: 当跟踪错误较低时,RM 可以更可靠地使用中间步骤正确性来确定其置信度。 但是,需要进一步调查才能真正了解这种影响。
3.5 OOD 泛化
为了评估非分布式泛化,我们在 MATH (Hendrycks 等人,2021) 数据集的预代数分割上对我们的模型进行了零样本评估。
我们将范围限制在没有渐近线图的问题,并使用简单的正则表达式删除了一些 LaTeX 格式,例如将 $
frac{3}{4}$ 转换为 3/4。
总体而言,我们看到明显的 OOD 泛化,我们的 SFT+ORM-RL 模型(使用多数投票)的最终答案错误率为 64.6%(假设模型无法回答所有带有渐近线图的问题,则过滤前错误率为 74.2%)。
这明显低于 Lewkowycz 等人 (2022) 在预代数问题上的 29% 错误率(该研究使用了更大的基础 LM 并对更多数学数据进行了训练),但明显优于 Hendrycks 等人 (2021) 对 GPT-3 的先前最佳结果 92.3% 错误率。
所有模型的最终答案错误率都在 60%-70% 的范围内,我们没有观察到基于监督类型而产生的明显趋势。
我们在 附录 D 中提供了完整的详细信息和结果。
4 讨论
4.1 何时使用基于过程的反馈与基于结果的反馈?
基于过程的反馈和基于结果的反馈各有优劣,适当的选择通常取决于上下文。 通常情况下,当有可靠且完整的评估指标可用时,基于结果的反馈往往更合适,而当没有可靠且完整的评估指标时,基于过程的反馈更合适。 这里我们将讨论导致我们得出这种观点的考虑因素。 我们首先讨论了关于最终答案和追踪错误的相对优势和劣势,然后再讨论过程性反馈的动机,这些动机尚未得到实证验证。
4.1.1 最终答案与追踪错误
我们的结果表明,当低最终答案错误就足够时,基于结果的方法提供了一种标签效率高的方法来获得这个结果,而当需要低追踪错误时,使用基于过程的反馈或其近似值是有帮助的。 这些指标的相对重要性取决于上下文。 在一个期望的结果易于评估且评估过程健壮的上下文中,最终答案错误是合适的。 例如,如果最终答案可以快速验证,无论是通过编程还是通过快速的用户检查,那么低最终答案错误就是一个相当完整的性能指标。 相反,Menick 等人 (2022) 以问答为例,其中需要低追踪错误,因为即使最终答案正确,也很难让用户在没有看到导致该答案的来源的情况下依赖该答案。 在教育等其他领域,推理步骤本身也可能具有直接的兴趣。
4.1.2 基于过程的方法既需要人类理解,也有助于人类理解
相对于基于结果的方法,基于过程的方法往往需要更深的人类理解 (Krakovna 等人,2020)。 例如,基于功耗、芯片面积和其他指标的基于结果的反馈可以用来优化计算机芯片布局 (Mirhoseini 等人,2021),而基于过程的方法将需要详细的芯片布局设计专家知识。 为了在一般情况下具有竞争力,基于过程的方法要求我们提高人类的理解能力,无论是通过 ML 系统(如增强或辩论)(Christiano 等人,2018; Irving 等人,2018),还是通过更广泛的方式,例如与专家合作 (Rauh 等人,2022),培训人员 (Stiennon 等人,2020),或为他们提供辅助工具。
其次,基于过程的方法可能促进人类理解,因为它们选择人类理解的推理步骤。 相反,基于结果的优化可能会找到难以理解的策略,并导致系统可理解性降低,如果这些策略是实现高评分结果的最简单方法。 例如,在 GSM8K 中,从 SFT 开始,添加最终答案 RL 会降低最终答案错误,但会增加(虽然不显著)追踪错误。
4.1.3 基于过程的方法避免操纵激励
在人工智能安全文献中,一个常见的担忧来自篡改(Everitt 等人,2017)的 RL 代理,即腐败其反馈机制以获得正面反馈。 作为一个假设的例子,考虑一个与用户反复交互的辅助代理。 如果为了用户的整体满意度而优化,这样的代理可能会影响用户,让他们偏向于更容易满足的偏好(例如,更容易预测,或者普遍更容易接受机器学习生成的建议),以便提高用户报告的满意度(Kenton 等人,2021)。 一个类似的长期担忧是,代理可能会获得权力并完全控制其反馈程序,以确保获得正面反馈(Cotra,2022)。
相比之下,考虑从基于过程的反馈中训练,使用用户对单个行动的评估,而不是对整体满意度的评估。 2 22请注意,基于结果的与基于过程的频谱通常适用于监督任何基于结果的行动序列,或基于每个行动的单独监督。 由于 GSM8K 中唯一的行动是推理步骤,因此我们在本文中通常直接引用推理步骤,但不同的监督方法更普遍地适用。 虽然这并不能直接阻止影响未来用户偏好的行动,但这些未来的变化不会影响对应行动的奖励,因此不会被基于过程的反馈优化。 我们参考Kumar 等人 (2020) 和 Uesato 等人 (2020) 来正式展示这个论点。 他们的解耦算法呈现了基于过程的反馈的特别纯净的版本,它防止反馈直接依赖于结果。
避免篡改的另一种方法是不断改进基于结果的指标,方法是监控导致篡改的行动序列,并对这些序列进行惩罚。 然而,这种方法只适用于我们可以检测到的篡改:在其他情况下,影响可能难以观察或衡量(例如,我们如何确定系统是否影响了用户偏好?)。 或者理解(例如,看起来无害的决定仍然可能产生重大影响,尤其是在总体上)。 从广义上讲,增量式基于结果的方法的风险在于解决最容易注意到的问题,而没有解决根本原因或更微妙的情况。
4.2 我们结果的泛化限制
我们通常预期基于过程的和基于结果的反馈在数学方面比在其他领域更紧密地一致。 对于数学问题,错误的步骤通常不利于得出正确的最终答案。 这与我们之前的发现相符,即结果监督的推理模型(RM)近似于基于过程的反馈。 相反,在其他领域,不良行为可能对高度评价的结果有帮助,例如,操纵可能提高报告的用户满意度。 因此,我们认为,针对数学问题优化结果(最终答案的正确性)对诱导正确过程的影响比在其他领域更强。
4.3 与基于过程和结果的反馈相关的概念
在这项工作中,我们关注了可用于训练大型语言模型的不同形式的监督,并讨论了这些形式的监督,以区分基于过程和基于结果的方法。 这种框架已在博客文章 (Stuhlmüller and Byun, 2022) 和非正式讨论中使用,但据我们所知,这是第一篇讨论它的实证论文。 在这里,我们将讨论与整个文献中使用的其他相关区分的异同。
监督学习 vs. 强化学习
广义而言,监督方法往往更倾向于基于过程,而强化学习方法往往更倾向于基于结果。 事实上,我们考虑的最基于过程的方法纯粹是监督的 (SFT),而最基于结果的方法是纯强化学习 (少样本 + 最终答案强化学习)。 然而,强化学习方法可以或多或少地基于过程,例如,当比较基于过程的强化学习 (PRM-RL) 与基于结果的强化学习 (ORM-RL) 或最终答案强化学习时。 相反,对由结果过滤的推理轨迹进行监督模仿(例如,导致高度评价的用户交互的轨迹)与基于监督学习的高回报轨迹的强化学习方法相融合 (Silver et al., 2017; Anthony et al., 2017; Abdolmaleki et al., 2018)。 因此,基于过程和结果的分类承认,得到的模型取决于更广泛的数据提供过程,该过程通常不会完全由代码描述。
强监督 vs. 弱监督
虽然强监督和弱监督的含义会根据上下文而有所不同,但监督中间步骤的方法通常被称为强监督 (Yang et al., 2018; Perez et al., 2020)。 与上述类似,虽然基于过程的方法倾向于强监督,而基于结果的方法倾向于弱监督,但强监督方法可以是基于过程的或基于结果的。 例如,评估中间推理步骤的人,要么直接评估这些推理步骤,要么推迟到评估其产生的结果。
言语化的推理
言语化的推理轨迹并不一定意味着基于过程的方法。 事实上,虽然本工作中的所有方法都使用言语化的推理轨迹,但它们使用基于过程和基于结果的反馈。 此外,言语化的推理轨迹并不一定代表模型的内部推理过程,大部分推理发生在大型神经网络激活内部,除非在严格的模块化方法中 (Creswell 等人,2022)。 这种谨慎尤其适用于存在欺骗潜力的领域 (Kenton 等人,2021)。
尽管如此,言语化的推理仍然有助于实现基于过程的反馈。 与基于激活空间中执行的迭代计算的方法 (Guez 等人,2019;Dehghani 等人,2018;Graves,2016;Schrittwieser 等人,2020) 形成对比,人类可以直接监督自然语言中的迭代推理步骤。
5 相关工作
用 LMs 解决数学问题
数学文字题一直是研究 LMs 中推理的热门领域 (Kushman 等人,2014;Ling 等人,2017;Amini 等人,2019;Miao 等人,2020;Hendrycks 等人,2021;Cobbe 等人,2021)。 最近几篇论文表明,仅少样本提示就能在 GSM8K 上取得令人印象深刻的性能 (Chowdhery 等人,2022;Lewkowycz 等人,2022;Wei 等人,2022;Wang 等人,2022)。 所有这些论文都将推理轨迹包含在少样本提示中,这鼓励模型生成言语化的推理步骤(也称为自言自语 (Shwartz 等人,2020) 和思维链提示 (Wei 等人,2022))。 提示从在大型数学内容数据集上进行训练中获益良多 (Lewkowycz 等人,2022),以及从指令遵循的微调中获益良多 (Ouyang 等人,2022)。 Kojima 等人 (2022) 和 Li 等人 (2022) 证明了最终答案错误率的改进,从 GPT-3 的 (Brown 等人,2020) 提高到 InstructGPT 的 (Ouyang 等人,2022),并进一步提高到 Codex 的 23.3% (Chen 等人,2021)。
我们专注于微调,因为我们对不同反馈程序的影响感兴趣,并且因为对于我们的基础语言模型而言,它明显优于单独提示。 原始的 GSM8K 论文 (Cobbe 等人,2021) 证明了奖励模型或验证器的显著益处,我们使用他们的 ORM 方法。 Li 等人 (2022) 也研究了 RM 并提出了一种基于启发式算法的逐步感知 RM,该算法在 GSM8K 上略微降低了性能,但在各种其他基准测试中提升了性能。 我们发现,对每个步骤的人工评估都提供了改进。 我们还使用 STaR (Zelikman 等人,2022)(在本文中称为 Few-shot+Final-Answer RL),并表明通过使用更好的基础模型 (Hoffmann 等人,2022),其 GSM8K 最终答案错误率可以从他们报告的 89% 降低到 23.5%,并通过使用基于 RM 的 RL 而不是他们的最终答案 RL 程序,进一步降低到 13.8%。 与上述先前工作形成对比的是,我们不仅展示了改进的性能,而且还对不同类型的反馈进行了全面的比较,重点关注跟踪错误率和最终答案错误率。
语言模型中的多步推理
除了数学问题,大量研究研究了语言模型的多步推理。 虽然全面回顾超出了本文的范围,但我们讨论了一些代表性的方法类别。 先前的工作建议对基础模型进行改进 (Lewkowycz 等人,2022;Ouyang 等人,2022),以及基于提示的方法 (Perez 等人,2020;Shwartz 等人,2020;Wei 等人,2022;Kojima 等人,2022;Dohan 等人,2022)。 我们对微调的监督技术的关注是对这类改进的补充。
其他工作只专注于基于结果的方法或基于过程的方法。 例如,在基于过程的一侧,Wu 等人 (2021) 通过监督个别摘要来总结整本书,这些摘要是递归组成的。 这提供了一个例子,其中基于结果的方法(直接使用人类对整本书摘要的认可)将是极其昂贵的,因为这种反馈的成本和稀疏性,但对每个步骤单独进行基于过程的监督是可能的。 Creswell 等人 (2022) 和 Nye 等人 (2021) 在推理轨迹可以以编程方式合成的合成环境中使用基于过程的 SFT,而我们则专注于推理轨迹和反馈必须由人类生成的自然语言环境。 在基于结果的一侧,Zelikman 等人 (2022) 将基于结果的方法应用于多步推理问题。 然而,与所有这些工作形成对比的是,我们直接比较了基于结果和基于过程的技术,并对跟踪错误率进行了详细分析。
据我们所知,最直接比较多步骤 LM 推理中基于过程和基于结果的反馈的先前工作是 WebGPT (Nakano 等人,2021)。 在 WebGPT 中,中间步骤是网页浏览器交互,它们通过 SFT 或通过对结果答案进行基于结果的 RL 来进行监督。 与我们类似,他们观察到,与基于结果的 RM 重新排序相比,SFT 有显著改进,但添加完全解决方案 RL 影响最小。 然而,我们更全面地探索了基于过程和基于结果的监督,此外还评估了基于过程的 RM、PRM-RL 方法以及纯粹基于结果的 RL 策略(没有 SFT)。 这使我们能够就监督对最终答案与跟踪错误的影响得出比先前工作更广泛的结论。
对基于过程和基于结果的算法任务方法的比较。
大多数关于基于过程和基于结果方法的正面比较的先前工作都是关于算法任务,例如对数字列表进行排序,这些任务避免使用人类数据。 早期的基于结果的方法,例如神经图灵机 (Graves 等人,2014),是端到端训练的,以预测最终答案。 相反,神经程序员解释器 (Reed 和 De Freitas,2015;Li 等人,2016;Cai 等人,2017) 是为了模仿执行跟踪中的每个步骤而训练的,这些步骤可以串联在一起。 这需要更强的监督,但能提高泛化能力。 迭代放大 (Christiano 等人,2018) 使用引导程序来训练模型以逼近潜在的指数大小的推理步骤树,假设一个无法直接回答难题但可以将难题分解成更简单问题的预言机。 我们的工作将这些结果扩展到自然语言,其中既没有程序性执行跟踪,也没有分解过程,这些都需要从人类反馈中学习。
相关数据集
在这项工作中,我们选择使用 GSM8K 数据集,因为它提供了自然语言推理跟踪,允许在不让我们自己收集跟踪的情况下,对基于过程和基于结果的方法进行详细比较。 包含完整推理跟踪的替代数据集包括 EntailmentBank (Dalvi 等人,2021)、StrategyQA (Geva 等人,2021)、ProofWriter (Tafjord 等人,2020) 以及 CLUTTR (Gontier 等人,2020)。 然而,与 GSM8K 相比,这些数据集要么包含模板化问题(ProofWriter 和 CLUTTR),要么规模明显更小(EntailmentBank 和 StrategyQA)。 此外,使用多个数据集将非常昂贵,因为需要为每项任务训练人类标注者,并为每个数据集收集大量的人类反馈标注。
6 结论
在这项工作中,我们在自然语言任务上进行了首次针对过程和结果监督的全面比较。 我们发现,两种类型的监督都导致了类似的最终答案错误率,使用结果监督时,我们最好的模型将 GSM8K 的最终答案错误率从 16.8% 提高到 13.8%,而使用过程监督时,则提高到 12.9%。 相反,我们发现,要获得较低的轨迹错误率,要么需要过程监督,要么需要模仿它的奖励模型。 纯粹的过程方法(SFT 加 PRM 排序)将最先进的轨迹错误率从 14.0% 降低到 3.4%,而其结果方法的模拟实现了 12.7% 的轨迹错误率。 然而,有点令人惊讶的是,我们发现,使用结果标签训练的奖励模型产生的预测结果与过程标签更一致,而不是与结果标签本身更一致。 通过在强化学习训练过程中使用此奖励模型,我们缩小了大部分差距,将轨迹错误率从 12.7% 降低到 5.5%。 虽然其中一些结论可能特定于我们对数学文字问题的设置,但我们希望未来工作能探索这些结论在多大程度上能够推广到其他领域。
参考文献
- Abdolmaleki et al. (2018) A. Abdolmaleki, J. T. Springenberg, Y. Tassa, R. Munos, N. Heess, and M. Riedmiller. Maximum a posteriori policy optimisation. arXiv preprint arXiv:1806.06920, 2018.
- Amini et al. (2019) A. Amini, S. Gabriel, P. Lin, R. Koncel-Kedziorski, Y. Choi, and H. Hajishirzi. Mathqa: Towards interpretable math word problem solving with operation-based formalisms. arXiv preprint arXiv:1905.13319, 2019.
- Amodei et al. (2016) D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Mané. Concrete problems in ai safety. arXiv preprint arXiv:1606.06565, 2016.
- Anthony et al. (2017) T. Anthony, Z. Tian, and D. Barber. Thinking fast and slow with deep learning and tree search. Advances in Neural Information Processing Systems, 30, 2017.
- Brown et al. (2020) T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Cai et al. (2017) J. Cai, R. Shin, and D. Song. Making neural programming architectures generalize via recursion. arXiv preprint arXiv:1704.06611, 2017.
- Chen et al. (2021) M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Herbert-Voss, W. H. Guss, A. Nichol, A. Paino, N. Tezak, J. Tang, I. Babuschkin, S. Balaji, S. Jain, W. Saunders, C. Hesse, A. N. Carr, J. Leike, J. Achiam, V. Misra, E. Morikawa, A. Radford, M. Knight, M. Brundage, M. Murati, K. Mayer, P. Welinder, B. McGrew, D. Amodei, S. McCandlish, I. Sutskever, and W. Zaremba. Evaluating large language models trained on code. CoRR, abs/2107.03374, 2021. URL https://arxiv.org/abs/2107.03374.
- Chowdhery et al. (2022) A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Christiano et al. (2018) P. Christiano, B. Shlegeris, and D. Amodei. Supervising strong learners by amplifying weak experts. arXiv preprint arXiv:1810.08575, 2018.
- Christiano et al. (2017) P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017.
- Cobbe et al. (2021) K. Cobbe, V. Kosaraju, M. Bavarian, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- Cotra (2022) A. Cotra. Without specific countermeasures, the easiest path to transformative ai likely leads to ai takeover, 2022. URL https://www.alignmentforum.org/posts/pRkFkzwKZ2zfa3R6H/without-specific-countermeasures-the-easiest-path-to.
- Creswell et al. (2022) A. Creswell, M. Shanahan, and I. Higgins. Selection-inference: Exploiting large language models for interpretable logical reasoning. arXiv preprint arXiv:2205.09712, 2022.
- Dalvi et al. (2021) B. Dalvi, P. A. Jansen, O. Tafjord, Z. Xie, H. Smith, L. Pipatanangkura, and P. Clark. Explaining answers with entailment trees. ArXiv, abs/2104.08661, 2021.
- Dehghani et al. (2018) M. Dehghani, S. Gouws, O. Vinyals, J. Uszkoreit, and Ł. Kaiser. Universal transformers. arXiv preprint arXiv:1807.03819, 2018.
- Dohan et al. (2022) D. Dohan, W. Xu, A. Lewkowycz, J. Austin, D. Bieber, R. G. Lopes, Y. Wu, H. Michalewski, R. A. Saurous, J. Sohl-dickstein, et al. Language model cascades. arXiv preprint arXiv:2207.10342, 2022.
- El-Yaniv et al. (2010) R. El-Yaniv et al. On the foundations of noise-free selective classification. Journal of Machine Learning Research, 11(5), 2010.
- Everitt et al. (2017) T. Everitt, V. Krakovna, L. Orseau, M. Hutter, and S. Legg. Reinforcement learning with a corrupted reward channel. arXiv preprint arXiv:1705.08417, 2017.
- Geifman and El-Yaniv (2017) Y. Geifman and R. El-Yaniv. Selective classification for deep neural networks. Advances in neural information processing systems, 30, 2017.
- Geva et al. (2021) M. Geva, D. Khashabi, E. Segal, T. Khot, D. Roth, and J. Berant. Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies. Transactions of the Association for Computational Linguistics (TACL), 2021.
- Goldman et al. (2017) O. Goldman, V. Latcinnik, U. Naveh, A. Globerson, and J. Berant. Weakly-supervised semantic parsing with abstract examples. arXiv preprint arXiv:1711.05240, 2017.
- Gontier et al. (2020) N. Gontier, K. Sinha, S. Reddy, and C. Pal. Measuring systematic generalization in neural proof generation with transformers. Advances in Neural Information Processing Systems, 33:22231–22242, 2020.
- Graves (2016) A. Graves. Adaptive computation time for recurrent neural networks. arXiv preprint arXiv:1603.08983, 2016.
- Graves et al. (2014) A. Graves, G. Wayne, and I. Danihelka. Neural turing machines. arXiv preprint arXiv:1410.5401, 2014.
- Guez et al. (2019) A. Guez, M. Mirza, K. Gregor, R. Kabra, S. Racanière, T. Weber, D. Raposo, A. Santoro, L. Orseau, T. Eccles, et al. An investigation of model-free planning. In International Conference on Machine Learning, pages 2464–2473. PMLR, 2019.
- Hendrycks et al. (2021) D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021.
- Hoffmann et al. (2022) J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. d. L. Casas, L. A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. v. d. Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, J. W. Rae, O. Vinyals, and L. Sifre. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
- Irving et al. (2018) G. Irving, P. Christiano, and D. Amodei. Ai safety via debate. arXiv preprint arXiv:1805.00899, 2018.
- Kenton et al. (2021) Z. Kenton, T. Everitt, L. Weidinger, I. Gabriel, V. Mikulik, and G. Irving. Alignment of language agents. arXiv preprint arXiv:2103.14659, 2021.
- Kojima et al. (2022) T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa. Large language models are zero-shot reasoners. arXiv preprint arXiv:2205.11916, 2022.
- Krakovna et al. (2020) V. Krakovna, J. Uesato, V. Mikulik, M. Rahtz, T. Everitt, R. Kumar, Z. Kenton, J. Leike, and S. Legg. Specification gaming: the flip side of ai ingenuity, 2020. URL https://deepmindsafetyresearch.medium.com/specification-gaming-the-flip-side-of-ai-ingenuity-c85bdb0deeb4.
- Kumar et al. (2020) R. Kumar, J. Uesato, R. Ngo, T. Everitt, V. Krakovna, and S. Legg. REALab: An embedded perspective on tampering. arXiv preprint arXiv:2011.08820, 2020.
- Kumar and Byrne (2004) S. Kumar and W. Byrne. Minimum bayes-risk decoding for statistical machine translation. Technical report, JOHNS HOPKINS UNIV BALTIMORE MD CENTER FOR LANGUAGE AND SPEECH PROCESSING (CLSP), 2004.
- Kushman et al. (2014) N. Kushman, Y. Artzi, L. Zettlemoyer, and R. Barzilay. Learning to automatically solve algebra word problems. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 271–281, 2014.
- Lewkowycz et al. (2022) A. Lewkowycz, A. Andreassen, D. Dohan, E. Dyer, H. Michalewski, V. Ramasesh, A. Slone, C. Anil, I. Schlag, T. Gutman-Solo, Y. Wu, B. Neyshabur, G. Gur-Ari, and V. Misra. Solving quantitative reasoning problems with language models, 2022. URL https://arxiv.org/abs/2206.14858.
- Li et al. (2016) C. Li, D. Tarlow, A. L. Gaunt, M. Brockschmidt, and N. Kushman. Neural program lattices. 2016.
- Li et al. (2022) Y. Li, Z. Lin, S. Zhang, Q. Fu, B. Chen, J.-G. Lou, and W. Chen. On the advance of making language models better reasoners. arXiv preprint arXiv:2206.02336, 2022.
- Ling et al. (2017) W. Ling, D. Yogatama, C. Dyer, and P. Blunsom. Program induction by rationale generation: Learning to solve and explain algebraic word problems. arXiv preprint arXiv:1705.04146, 2017.
- Loshchilov and Hutter (2017) I. Loshchilov and F. Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- Menick et al. (2022) J. Menick, M. Trebacz, V. Mikulik, J. Aslanides, F. Song, M. Chadwick, M. Glaese, S. Young, L. Campbell-Gillingham, G. Irving, et al. Teaching language models to support answers with verified quotes. arXiv preprint arXiv:2203.11147, 2022.
- Miao et al. (2020) S.-y. Miao, C.-C. Liang, and K.-Y. Su. A diverse corpus for evaluating and developing english math word problem solvers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 975–984, 2020.
- Mirhoseini et al. (2021) A. Mirhoseini, A. Goldie, M. Yazgan, J. W. Jiang, E. Songhori, S. Wang, Y.-J. Lee, E. Johnson, O. Pathak, A. Nazi, et al. A graph placement methodology for fast chip design. Nature, 594(7862):207–212, 2021.
- Nakano et al. (2021) R. Nakano, J. Hilton, S. Balaji, J. Wu, L. Ouyang, C. Kim, C. Hesse, S. Jain, V. Kosaraju, W. Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021.
- Nye et al. (2021) M. Nye, A. J. Andreassen, G. Gur-Ari, H. Michalewski, J. Austin, D. Bieber, D. Dohan, A. Lewkowycz, M. Bosma, D. Luan, et al. Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114, 2021.
- Ouyang et al. (2022) L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe. Training language models to follow instructions with human feedback, 2022. URL https://arxiv.org/abs/2203.02155.
- Perez et al. (2020) E. Perez, P. Lewis, W.-t. Yih, K. Cho, and D. Kiela. Unsupervised question decomposition for question answering. arXiv preprint arXiv:2002.09758, 2020.
- Perez et al. (2021) E. Perez, D. Kiela, and K. Cho. True few-shot learning with language models. Advances in Neural Information Processing Systems, 34:11054–11070, 2021.
- Polu and Sutskever (2020) S. Polu and I. Sutskever. Generative language modeling for automated theorem proving, 2020. URL https://arxiv.org/abs/2009.03393.
- Rauh et al. (2022) M. Rauh, J. Mellor, J. Uesato, P.-S. Huang, J. Welbl, L. Weidinger, S. Dathathri, A. Glaese, G. Irving, I. Gabriel, et al. Characteristics of harmful text: Towards rigorous benchmarking of language models. arXiv preprint arXiv:2206.08325, 2022.
- Reed and De Freitas (2015) S. Reed and N. De Freitas. Neural programmer-interpreters. arXiv preprint arXiv:1511.06279, 2015.
- Schrittwieser et al. (2020) J. Schrittwieser, I. Antonoglou, T. Hubert, K. Simonyan, L. Sifre, S. Schmitt, A. Guez, E. Lockhart, D. Hassabis, T. Graepel, et al. Mastering atari, go, chess and shogi by planning with a learned model. Nature, 588(7839):604–609, 2020.
- Shwartz et al. (2020) V. Shwartz, P. West, R. L. Bras, C. Bhagavatula, and Y. Choi. Unsupervised commonsense question answering with self-talk. arXiv preprint arXiv:2004.05483, 2020.
- Silver et al. (2017) D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, et al. Mastering the game of go without human knowledge. nature, 550(7676):354–359, 2017.
- Stiennon et al. (2020) N. Stiennon, L. Ouyang, J. Wu, D. Ziegler, R. Lowe, C. Voss, A. Radford, D. Amodei, and P. F. Christiano. Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 33:3008–3021, 2020.
- Stuhlmüller and Byun (2022) A. Stuhlmüller and J. Byun. Supervise process, not outcomes. 2022. URL https://ought.org/updates/2022-04-06-process.
- Sutskever et al. (2014) I. Sutskever, O. Vinyals, and Q. V. Le. Sequence to sequence learning with neural networks. Advances in neural information processing systems, 27, 2014.
- Tafjord et al. (2020) O. Tafjord, B. D. Mishra, and P. Clark. Proofwriter: Generating implications, proofs, and abductive statements over natural language. arXiv preprint arXiv:2012.13048, 2020.
- Uesato et al. (2020) J. Uesato, R. Kumar, V. Krakovna, T. Everitt, R. Ngo, and S. Legg. Avoiding tampering incentives in deep RL via decoupled approval. arXiv preprint arXiv:2011.08827, 2020.
- Wang et al. (2022) X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, and D. Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
- Wei et al. (2022) J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. Chi, Q. Le, and D. Zhou. Chain of thought prompting elicits reasoning in large language models, 2022.
- Wu et al. (2021) J. Wu, L. Ouyang, D. M. Ziegler, N. Stiennon, R. Lowe, J. Leike, and P. Christiano. Recursively summarizing books with human feedback. arXiv preprint arXiv:2109.10862, 2021.
- Yang et al. (2018) Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. arXiv preprint arXiv:1809.09600, 2018.
- Zelikman et al. (2022) E. Zelikman, Y. Wu, and N. D. Goodman. Star: Bootstrapping reasoning with reasoning. arXiv preprint arXiv:2203.14465, 2022.
- Ziegler et al. (2019) D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
附录 A GSM8K 示例问题和解决方案
我们提供了一些示例,以提供对任务和学习模型行为的定性理解。 LABEL:tab:random_samples 包含 10 个随机采样的问题,以及使用 ORM 排序的 SFT+ORM-RL 模型的输出。 LABEL:tab:trace_errors 包含 5 个轨迹错误,其中最终答案正确,但至少有一步有错误。
| Table 4 |
|---|
|
Problem : Glee Club 订购了 20 个披萨,吃了其中的 70%。 足球队订购了原来数量的两倍的披萨,并且吃了其中 80%。 还剩下多少披萨?
Model answer (最终答案正确): 足球队订购了 20*2=<<20*2=40>>40 个披萨。 因此,订购的披萨总数是 40+20=<<40+20=60>>60 个。 歌唱俱乐部吃了 20*0.7=<<20*0.7=14.0>>14 个披萨。 足球队吃了 40*0.8=<<40*0.8=32.0>>32 个披萨。 因此,吃掉的披萨总数是 32+14=<<32+14=46>>46 个。 所以,剩下的披萨数量是 60- 46=<<60-46=14>>14 个。 最终答案:14 |
|
Problem : 约翰尼拿了他的 20 美元的零用钱,并且又加了 10 美元。 然后他投资了这笔钱,在一年内翻了三倍。 一年后他拥有多少钱?
Model answer (最终答案正确): 约翰尼有 20 美元 + 10 美元 = $<<20+10=30.00>>30。 然后他有 30 美元 x 3 = $<<30*3=90.00>>90。 所以,一年后他有 90 美元。 最终答案:90 |
|
Problem : 一个水母缸里有许多水母。 五分之一的水母很大,三分之一的大水母在紫外线下会从绿色变成蓝色。 其他水母都很小,并且始终保持蓝色。 当紫外线灯打开时,有 6 只水母变色了。 水族箱里有多少只水母?
Model answer (最终答案正确): 如果三分之一的大水母变色,并且所有水母中五分之一是大的,那么所有水母中 1/3*1/5=1/15 会变色。 如果 6 只水母在灯光下变色,而所有水母的 1/15 会变色,那么水族箱中有 15/(1/15)=90 只水母。 最终答案: 90 |
|
Problem : 布朗农民的农场有 200 英亩,史密斯农民的农场是布朗农民农场面积的两倍还多 100 英亩。 两个农场加起来有多少英亩?
Model answer (最终答案正确): 布朗农民 200 英亩农场的两倍是 2*200=<<2*200=400>>400 英亩。 史密斯农民的农场比布朗农民农场面积的两倍多 100 英亩,也就是 100+400=<<100+400=500>>500 英亩。 因此,两个农场加起来共有 500+200=<<500+200=700>>700 英亩。 最终答案: 700 |
|
Problem : 凯斯尔这周买了 3 盒可可脆和 5 盒水果环。 上周她买了 4 盒麦片。 她这周比上周多买了多少盒麦片?
Model answer (最终答案正确): 上周,卡斯尔买了 4 盒。 这周,她买了 3 + 5 = <<3+5=8>>8 盒。 所以,她这周比上周多买了 8 - 4 = <<8-4=4>>4 盒麦片。 最终答案:4 |
|
Problem : 一篮绿色食物售价 25 美元,一篮红色食物售价 18 美元。 如果你购买 3 篮绿色食物和红色食物,如果你每篮红色食物减免 2 美元,你需要支付多少钱?
Model answer (最终答案正确): 如果你购买 3 篮绿色食物,你将支付 25 美元 x 3 = $<<25*3=75.00>>75.00 如果你购买 3 篮红色食物,原价为 18 美元 x 3 = $<<18*3=54.00>>54.00 由于你每篮红色食物减免 2 美元,你的总节省为 2 美元 x 3 = $<<2*3=6.00>>6.00 3 篮红色食物的新价格为 54 美元 - 6 美元 = $<<54-6=48.00>>48.00 所以,你将总共支付 75 美元 + 48 美元 = $<<75+48=123.00>>123.00。 最终答案:123 |
|
Problem : 一只鸟决定离开它在北方的夏季住所,前往它在南方的冬季住所。 为了完成旅程,这只鸟离开家,以每小时 30 英里的速度向南飞行 10 小时。 然后,这只鸟改变方向,以每小时 18 英里的速度向北飞行 2 小时。 最后,这只鸟改变方向,以每小时 22 英里的速度向南飞行 5 小时,然后降落在它南方的家。 这只鸟的北方家和南方家之间的距离是多少英里?
Model answer (最终答案不正确): 这只鸟向南飞行 10 * 30 = <<10*30=300>>300 英里。 然后它转向,以每小时 18 英里的速度向北飞行 2 * 18 = <<2*18=36>>36 英里。 最后她再次转身,朝南飞了 5*22=<<5*22=110>>110 英里。 因此,这只鸟总共飞行了 300+36+110=<<300+36+110=446>>446 英里,从她的北方家飞到南方家。 最终答案:446 |
|
Problem : 金已经开始了自己的家政服务,并且正在计算他将从他的客户那里获得多少利润。 他已经拥有 3 个客户,但正在与另外 5 个潜在客户交谈,并且有足够的信心将他们纳入他的计算。 每个客户的家需要 2 瓶漂白剂和一包抹布来清洁。 每瓶漂白剂售价 2 美元,每包抹布售价 5 美元。 这些是他唯一的开销。 他计算出他每周的总收入将为 92 美元。 利润是总收入和总支出之间的差额,那么卢卡斯每周将获得多少利润(美元)?
Model answer (最终答案正确): 他每周将需要总共 2 瓶漂白剂/客户 * 8 个客户 = <<2*8=16>>16 瓶漂白剂。 这将花费 16 瓶 * 2 美元/瓶 = $<<16*2=32.00>>32。 他每周还需要 8 个客户 * 1 包抹布 = <<8*1=8>>8 包抹布。 这将花费 8 包 * 5 美元/包 = $<<8*5=40.00>>40。 所以他每周的总支出将为 32 美元 + 40 美元 = $<<32+40=72.00>>72。 这意味着他每周的利润将为 92 美元 - 72 美元 = $<<92-72=20.00>>20。 最终答案:20 |
|
Problem : 一家医院每天接诊 500 人。 每位患者的平均就诊时间为 24 分钟。 医生向医院收取每小时 150 美元的费用,医院向患者收取每小时 200 美元的费用。 医院从这些就诊中获得了多少利润?
Model answer (最终答案正确): 每天医生看诊 500*24=<<500*24=12000>>12000 分钟的患者 所以他们获得了 12000/60=<<12000/60=200.0>>200 小时的报酬 所以他们获得了 200*150=$<<200*150=30000.00>>30000 的报酬 所以医院赚取了 200*200=$<<200*200=40000.00>>40000 所以他们赚取了 40000-30000=$<<40000-30000=10000.00>>10000 的利润 最终答案:10000 |
|
Problem : Lorraine 和 Colleen 正在用贴纸交换纽扣。 每张大贴纸可以换一个大纽扣或三个小纽扣。 一张小贴纸可以换一个小纽扣。 一个大纽扣可以换三张小贴纸。 Lorraine 开始时有 30 张小贴纸和 40 张大贴纸。 她用 90% 的小贴纸换大纽扣。 她用 50% 的大贴纸换大纽扣,并将剩下的贴纸换成小纽扣。 她最后有多少个纽扣?
Model answer (最终答案不正确): Lorraine 一共有 30 + 40 = <<30+40=70>>70 张贴纸。 她用 .90 * 30 张小贴纸 = <<90*.01*30=27.0>>27 张小贴纸换大纽扣。 因此,她还剩下 30 - 27 = <<30-27=3>>3 个小贴纸。 她用 .50 * 40 个大贴纸 = <<50*.01*40=20.0>>20 个大贴纸换了大纽扣。 因此,她还剩下 40 - 20 = <<40-20=20>>20 个大贴纸可以用来换小纽扣。 这意味着她用 20 * 3 个小贴纸 = <<20*3=60>>60 个小贴纸价值的大贴纸换了小纽扣。 因此,她最终总共有 3 + 20 + 60 = <<3+20+60=83>>83 个纽扣。 最终答案:83 |
| Table 5 |
|---|
|
Problem : 茱莉亚的船在湖上行驶时漏水。 这艘船每划向岸边十英尺就会进水两升。 她划二十英尺需要十六秒。 岸边距离她六十四秒。 当茱莉亚到达岸边时,船进了多少水?
Model answer: 茱莉亚在十六秒内划了二十英尺。 所以她的划船速度为 20 /16 = <<20 /16=1.25>>1.25 英尺/秒。 海岸距离64秒。 所以到海岸的距离是64*1.25 = <<64*1.25=80.0>>80.0英尺。 船每10英尺进水2升。 –> 所以每10英尺,船进水2 /10 = <<2 /10=0.2>>0.2升。 船以0.2升/秒的速度进水。 所以对于80英尺,船将进水80*0.2 = <<80*.02=1.6>>1.6升水。 当茱莉亚到达岸边时,她的船已经进水1.6升。 最终答案:16 |
|
Problem : 卡尔买了10包饼干。 每包饼干里面有六块饼干。 每块饼干价格为0.10美元。 如果卡尔用10美元支付,他会得到多少找零?
Model answer: 卡尔买了10包饼干,这意味着他买了60块饼干,因为6 x 10=<<6*10=60>>60 –> 卡尔花了60 x 0.10美元=<<60*.10000000000000002=6.000000000000001>>6 卡尔支付了10美元,所以找零是10美元 - 6美元 = <<10-6=4>>4 卡尔收到了4美元的找零。 最终答案:4 |
|
Problem : 安纳金和洛克辛今天去海滩了。 安纳金抓了10只海星,6只海马和3只小丑鱼。 虽然洛辛抓的 starfish 比阿纳金少 5 个,比阿纳金少 3 个海马,但比阿纳金多 2 个小丑鱼。 他们能抓多少条鱼?
Model answer: 阿纳金抓了 10 个 starfish,而洛辛抓了少 5 个,所以洛辛抓了 5 个 starfish。 阿纳金抓了 6 个海马,而洛辛抓了少 3 个,所以洛辛抓了 3 个海马。 阿纳金抓了 3 个小丑鱼,而洛辛抓了多 2 个,所以洛辛抓了 5 个小丑鱼。 因此,阿纳金抓了 10+6+3=<<10+6+3=19>>19 条鱼,洛辛抓了 5+3+5=<<5+3+5=13>>13 条鱼,总共 19+13=<<19+13=32>>32 条鱼。 –> 最终答案:32 |
|
Problem : 萨姆卖面包。 他每周的目标是卖出 120 箱面包。 有一周他在周一和周五关门。 在周末他卖了 20 箱。 周二他卖了 15 箱,周三卖了 12 箱,周四卖了 18 箱。 萨姆这一周离他的目标差多少箱?
Model answer: 周一他关门,所以是 120 箱 - 20 箱 - 15 箱 - 12 箱 - 18 箱 –> 120 箱 - 55 箱 = <<120-55=65>>65 箱 他需要卖 120 箱,但只卖了 65 箱,所以他差 120 - 65 = <<120-65=55>>55 箱。 最终答案:55 |
|
Problem : 如果一个教室里的女生人数是男生人数的 3 倍,而无性别儿童的人数是男生人数的 1/10,并且教室里有 30 个男生。 它总共有多少个孩子?
Model answer: –> 1/10 的男孩与说每 10 个男孩中有 1 个男孩相同,所以每 10 个男孩中有 1 个男孩 有 30 个男孩,所以有 30/10 = <<30 / 10=3.0>>3 个男孩 女孩人数是男孩人数的 3 倍,所以女孩人数是男孩人数的 3 倍 有 3 个男孩,所以女孩人数是男孩人数的 3 倍 有 3 个男孩,所以女孩人数是男孩人数的 3 倍 女孩人数是男孩人数的 3 倍,所以女孩人数是男孩人数的 3 倍 有 3 个男孩,所以女孩人数是男孩人数的 3 倍 有 3 个男孩,所以女孩人数是男孩人数的 3 倍 有 3 个男孩,所以女孩人数是男孩人数的 3 倍 女孩人数是男孩人数的 3 倍,所以每个男孩有 3 个女孩 有 3 个男孩,所以每个男孩有 3 个女孩 每个男孩有 3 个女孩,所以每个男孩有 3 个女孩 每个男孩有 3 个女孩,所以有 3*30=<<3*30=90>>90 个女孩 有 90 个女孩和 30 个男孩以及 3 个非性别儿童,所以教室里共有 90+30+3 = <<90+30+3=123>>123 个孩子 最终答案:123 |
附录 B 数据注释详细信息
参与者和薪酬
我们研究设计的所有详细信息,包括补偿率,都经过了 DeepMind 的独立伦理审查委员会的审查和批准。 所有参与者在完成任务之前都提供了知情同意,并获得了时间报酬。 我们的政策是,研究人员必须至少支付与其工作地点的最低生活工资相等的工资给工人/参与者。
训练数据集问题
为了构建 PRM 训练数据集,我们使用了来自 SFT 模型的样本。 由于注释预算有限,我们只注释 SFT 多数投票预测不正确的问题,因为这将训练重点放在困难问题上,并且由于对每个问题注释 3 个模型解决方案,仍然包括正确和不正确样本的混合。
质量保证
由于评估数学问题解决方案的准确性是一项特殊技能,因此我们在使用参与者的标注进行训练或评估之前进行了一项初步资格研究。 对于资格标注任务,我们选择了三个作者一致同意第一个主要错误的模型解决方案,并要求参与者正确标注至少 4 个此类解决方案中的 3 个。 总共,91 名候选人中有 21 名被纳入我们的标注者池。
此外,我们对 20% 的训练问题使用了重复标注。 我们删除了标注者在双重评级问题上的标注者间一致性率低于 75% 的评级。 在手动检查中,我们发现这些标注者通常在这些不一致的情况下犯了错误。 这删除了 21 名标注者中的 4 名标注者的数据,占我们最初标记的训练数据的 21%,剩下 530 个标注问题(而最初有 675 个)。
在质量保证步骤之后,使用同一组重复问题,我们测量了预测第一个错误步骤任务的标注者间一致性率为 92%,Cohen's 为 。 请注意,此估计值会略微向上偏差,因为我们根据同一组过滤了评分者,但由于评分者之间的标注者间一致性率相当双峰,因此这种影响应该相对较小。
对于评估,标注者间一致性率为 87%,Cohen's 为 ,用于将完整跟踪标记为正确的二元任务。 标注者间一致性率明显低于训练集。 我们将其归因于以下观察结果:对于最终答案错误的解决方案,通常有一个非常明确的错误步骤,但对于最终答案正确的案例,中间步骤是否错误可能更加微妙。
附录 C 附加 RM 分析
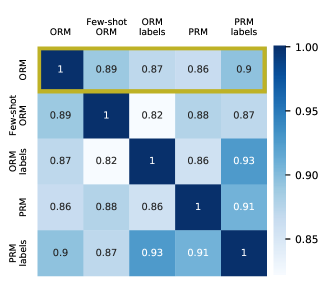
图 6 显示了 RM 和 RM 标签在最后一步上的协议矩阵。 与 图 4(对所有步骤进行平均,而不是仅对最后一步进行平均)类似,我们看到 ORM 与 PRM 标签具有更高的一致性,尽管 ORM 经过训练来预测 ORM 标签。 请注意,在最后一步,ORM 和 PRM 标签将完全一致,除了最终答案正确但跟踪错误的情况(根据构造,跟踪不可能在最终答案错误的情况下正确)。 因此,这个结果表明 ORM 更倾向于预测整个轨迹是否正确,而不仅仅是最终答案是否正确。
附录 D OOD 评估细节
|
Problem : 约翰和加里正在玩游戏。 约翰转动一个标有 1 到 20 的整数的转盘。 然后加里写下转出的数字的所有正因数的列表,除了数字本身。 然后加里用他列表中的所有数字创建一个新的转盘。 然后约翰转动这个转盘,这个过程继续进行。 当转盘上没有数字时,游戏结束。 如果约翰在第一次转动时转出了 20,那么约翰在游戏结束之前可以进行的最大总转动次数是多少(包括他已经进行的一次)?
Solution 如果约翰转出了 20,那么加里的列表将包含数字 1、2、4、5、10。 因此,这些是第二个转盘上的数字。 约翰转出了 1,然后加里的列表将为空,因为除了它本身之外,1 没有正因数。 因此,游戏将结束。 这将最多产生 1 次额外的旋转。 如果 John 旋转了 2,那么 Gary 的列表中将只包含数字 1。 然后在 John 下一次旋转时,我们将遇到与上面相同的场景。 这将最多产生 2 次额外的旋转。 如果 John 旋转了 4,那么 Gary 的列表中将包含数字 1 和 2。 正如我们上面已经发现的那样,旋转 2 比旋转 1 产生更多的额外旋转,因此在这种情况下,最大的额外旋转次数为 3 次。 如果 John 旋转了 5,那么 Gary 的列表中将只包含数字 1。 与上面一样,这将最多产生 2 次额外的旋转。 最后,如果 John 旋转了 10,那么 Gary 的列表中将包含数字 1、2 和 5。 在这些数字中,2 和 5 具有最大的额外旋转次数,因此这种情况最多有 3 次额外旋转。 因此,在所有可能性中,接下来旋转 4 或 10 可能导致 3 次额外旋转,因此最大的总旋转次数为 。 这些可以通过旋转 20、10、2、1 或 20、10、5、1 或 20、4、2、1 来实现。 |
| Model | Final-answer error |
|---|---|
| Few-shot+Final-Answer RL | 65.7 |
| SFT | 67.6 |
| SFT, ORM reranking | 65.4 |
| SFT, PRM reranking | 67.7 |
| SFT+Final-Answer RL | 63.3 |
| SFT+ORM-RL | 63.2 |
为了衡量分布外泛化,我们在 MATH (Hendrycks 等人,2021) 数据集的预代数拆分上对我们的模型进行了零样本评估。 我们在 表 7 中包含了更多模型的结果,展示了明显的 OOD 泛化。 数据集中的一个示例问题和答案可以在 表 6 中看到。 我们限制了没有图表的问题,保留了最初 871 个问题中的 633 个,并删除了一些 LaTeX 格式,如下所述。
Before Regex Transformation:
We are given that $$54+(98\div14)+(23\cdot 17)-200-(312\div 6)=200$$
Now, let’s remove the parentheses: $$54+98\div14+23\cdot 17-200-312\div 6.$$
What does this expression equal?
After Regex Transformation:
We are given that 54+(98/14)+(23*17)-200-(312/6)=200.
Now, let’s remove the parentheses: 54+98/14+23*17-200-312/6.
What does this expression equal?
|
/ (第 2 个捕获组)
| Regex Pattern for Latex Command | Replacement |
|---|---|
| Simple Replacements | |
(\\geq|\\ge)
|
>= |
(\\geq|\\ge)
|
>= |
(\\leq|\\le)
|
<= |
(\\neq|\\ne)
|
!= |
\\implies
|
-> |
(\\ldots|\\cdots|\\dots)
|
… |
\\times
|
* |
\\rightarrow
|
-> |
\\cdot
|
* |
\\div
|
/ |
\\pi
|
pi |
\\quad
|
None |
| Remove text formatting: | |
(\\text|\\textnormal|\\textrm|\\textit|
|
|
\\textbf)\{\s?(\d*\.?\d+|[a-zA-Z\s\,]*)\}’,
|
|
r’ \2’, inp)
|
|
(\\emph|\\mbox|\\mathrm|\\bf|\\small)
|
|
\{\s?(\d*\.?\d+|[a-zA-Z\s\,]*)\}’,
|
|
r’ \2’, inp)
|
|
| Remove whitespace: | |
\s?([*\-+\/])\s?
|
\1 (1st capture group) |
\\allowbreak
|
None |
\\hspace\{.*\}
|
None |
| Remove math mode: | |
\$\$?([^\$]*)\$\$?
|
\1 (1st capture group) |
\\\[([^\$]*)\\\]
|
\1 (1st capture group) |
| Convert fractions: | |
(\\frac|\\tfrac|\\dfrac)
|
|
{([a-z0-9+-]*)}{([a-z0-9+-]*)}
|
|
(\\frac|\\tfrac|\\dfrac)([0-9])([0-9])
|
Latex 转换
提取最终答案
在 MATH 数据集中,最终答案始终在一个方框中,通过使用“\boxed”命令格式化答案,例如 。 为了从解题文本中获取最终答案,我们找到带框的表达式并提取其参数。
附录 E 负面和初步结果
在这里,我们包含了我们在运行实验时做出的各种观察。 这些结果的检查远不如主论文中报告的结果仔细,并且其中一些结果可能与训练设置的细节有关。 但是,我们还是将它们包含进来,因为我们认为它们可能对未来的研究人员有所帮助:
-
•
训练 ORM 所需的步骤大约是 SFT 训练的 20 倍。 我们认为,这可能是由于 token 监督更稀疏(每一步一个 token,而不是每一步数百个 token)、需要 dropout 正则化以及能够针对每个问题训练多个生成的样本等因素的综合结果。
-
•
我们通过在每一步对 选项应用 argmax,而不是解决方案级重新排序,来实验步级重新排序。 但是,我们发现这增加了 PRM 的最终答案误差约 1%,增加了 ORM 的最终答案误差约 3%。 从第一作者对通过解决方案级重新排序但未通过步级重新排序解决的问题进行的人工检查来看,这似乎主要归因于策略中熵不足。 在这些失败案例中,通常会出现一个步骤,其中存在有效的下一步,但没有一个 延续找到它(而且通常,所有 延续都会犯同样的错误)。 相反,使用解决方案级重新排序,早期生成的步骤中的细微变化将导致相应的完成结果之间产生更多差异。 例如,可以通过将模型条件化到由 RM 拒绝的步骤来解决这个问题,但为了简单起见,我们在本文中始终使用解决方案级别的重新排序。
-
•
在预备实验中,在 SFT+ORM-RL 训练期间,在专家迭代之间重新训练 ORM 并没有帮助。 相反,对于基于少样本的专家迭代实现,我们确实在每次迭代中重新训练 ORM,部分原因是为了避免模仿早期阶段的跟踪错误。
-
•
在训练集收集期间,我们最初要求标注者提供对错误步骤的更正版本。 但是,很难以足够的精确度传达这项任务:例如,更正后的步骤会在计算之前包含计算输出(这对于自回归语言模型来说很难处理),或者即使早期模型步骤是不同(但仍然有效)方法的一部分,也会试图过于接近参考解决方案。 此外,与标注任务不同,我们无法轻松计算评估者之间或研究者与评估者之间的协议率。