[表]capposition=顶部
AvatarGen:可动画化人体头像的 3D 生成模型
摘要
无监督地生成具有各种外观和可控几何形状的 3D 感知服装人体对于创建虚拟人体化身和其他 AR/VR 应用非常重要。 现有的方法要么仅限于刚性对象建模,要么不具有生成性,因此无法生成高质量的虚拟人并为其设置动画。 在这项工作中,我们提出了 AvatarGen,这是第一种方法,不仅能够实现具有高保真外观的几何感知服装人体合成,而且能够解开人体动画的可控性,同时只需要 2D 图像进行训练。 具体来说,我们将生成的 3D 人体合成分解为姿势引导映射和具有预定义人体姿势和形状的规范表示,以便可以在 3D 参数化人体模型 SMPL 的指导下将规范表示显式驱动为不同的姿势和形状。 AvatarGen 进一步引入了一个变形网络来学习非刚性变形,以建模细粒度的几何细节和与姿势相关的动力学。 为了提高生成的人体头像的几何质量,它利用有符号距离场作为几何代理,这允许根据 SMPL 的 3D 几何先验进行更直接的正则化。 受益于这些设计,我们的方法可以生成具有高质量外观和几何建模的可动画 3D 人体化身,其性能显着优于以前的 3D GAN。 此外,它还能够胜任许多应用,例如.、单视图重建、重新动画和文本引导合成/编辑。 我们的代码和模型将在项目页面上提供。
![[Uncaptioned image]](x1.png)
1简介
生成多样化且高质量的 3D 感知虚拟人物(化身),并精确控制其几何形状,例如.、姿势和形状,是一项基本但极具挑战性的任务。 解决此任务将使许多应用受益,例如沉浸式摄影可视化 [71]、虚拟试穿 [34]、VR/AR [63, 24] 和图像编辑[69, 21]。
传统的解决方案依赖于经典的图形建模和渲染技术[9,7,12,58]来创建虚拟化身。 尽管提供高质量,但它们通常需要预先捕获的模板、多摄像机系统、受控工作室和艺术家的长期作品。 在这项工作中,我们的目标是让虚拟人类头像以低成本被广泛使用。 为此,我们提出了第一个 3D 感知头像生成模型,可以合成 1) 高质量虚拟人 2) 各种外观和解开的几何可控性 3) 并且只能从 2D 图像中进行训练,从而大大减轻了创建化身的工作量。
在将隐式神经表示 (INR) 方法[6, 46, 38, 39]引入生成对抗网络[3, 42, 的推动下,3D 感知生成模型最近取得了快速进展。 45、17、2]。 然而,这些模型仅限于相对简单和刚性的物体,例如人脸和汽车,并且大多数无法生成穿着衣服的人体化身,由于其关节姿势和服装的巨大变化,其外观高度多样化。 此外,它们对生成过程的控制有限,因此无法对生成的对象进行动画处理,即即。,通过遵循某些指令来驱动对象移动。 另一系列作品利用 INR [39] 学习清晰的人类化身,以便从多视图图像或视频中重建单个主题[49, 43, 64, 5, 50]. 虽然可以制作动画,但这些方法不是生成性的,因此无法合成新颖的身份和外观。
针对可动画人类化身的生成建模,我们提出了 AvatarGen,这是第一个可以合成新颖人类化身的模型,并且可以对其几何形状和外观进行解开控制。 AvatarGen 基于 EG3D [2] 构建,这是一种最新方法,可以通过引入有效的三平面表示来合成 3D 感知人脸。 然而,它不能直接适用于人体化身生成,因为它无法应对复杂纹理和具有各种姿势的铰接身体结构建模的挑战。 此外,EG3D 的控制能力有限,因此很难对生成的对象进行动画处理。
为了应对这些挑战,我们建议将生成人类化身建模分解为姿势引导的规范映射和规范人类生成。 在 3D 参数化人体模型 SMPL [36] 的指导下,AvatarGen 将指定人体在观察空间中采样的每个点反扭曲为具有预定义姿势和形状的标准头像,由三平面表示[2],通过逆 LBS [22] 在规范空间中。 为了适应观察空间和规范空间之间的非刚性变形(例如衣服皱纹),我们的方法进一步训练变形模块来预测适当的残余变形。 因此,它可以通过对规范空间进行变形来生成观察空间的详细几何形状和纹理,这更容易生成并在不同实例之间共享,从而很大程度上减轻了学习困难。 同时,这种分解的设计公式解开了几何形状和外观,提供了对它们的独立控制。
虽然我们的方法可以生成具有合理几何形状的 3D 人体化身,但我们发现由于缺乏对学习几何形状(密度场)的约束,它往往会产生嘈杂的身体表面。 受最近神经隐式表面研究[60,67,45,50]的启发,我们建议使用符号距离场(SDF)来施加更强的几何感知指导对于模型训练。 这样,该模型可以利用先前的身体模型来推断合理的符号距离值,从而大大提高了人体头像生成和动画的质量。 我们还引入了局部人脸鉴别器,以减轻由于训练图像中的低分辨率人脸而导致的不良人脸生成。
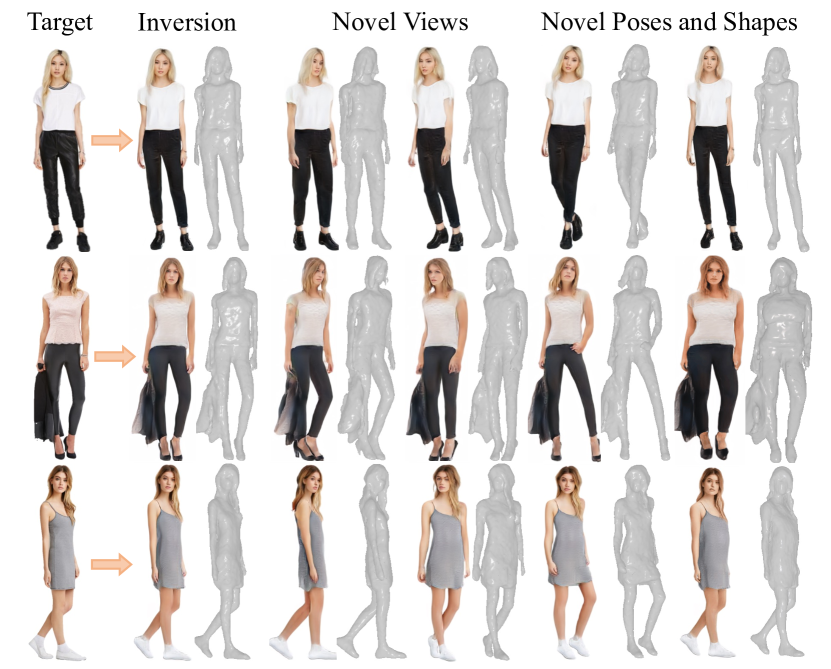
如图1所示,仅通过 2D 图像进行训练,AvatarGen 可以合成各种具有高保真外观、几何形状和解缠结可控性的穿着服装的人类化身。 我们对 AvatarGen 进行了定量和定性评估,证明它明显优于以前最先进的方法。 此外,我们的 AvatarGen 支持多种应用程序,例如单视图 3D 重建、重新动画和文本引导合成。

2相关作品
生成 3D 感知图像合成。 生成对抗网络 (GAN)[16] 最近实现了逼真的图像合成[25,27,28,26]。 将这些功能扩展到 3D 设置已开始引起人们的关注。 早期的方法将 GAN 与体素 [62, 40, 41]、网格 [59, 32] 或点云 [1, 31] 表示相结合用于 3D 感知图像合成。 最近,有几种方法通过学习隐式神经表示(INR)[55,3,42,2,45,17,10]来表示 3D 对象。 其中,一些方法使用基于INR的模型作为生成器[55, 3, 10],而另一些方法将INR生成器与2D解码器相结合以生成更高分辨率的图像[42, 17, 66、70]。 后续工作如 EG3D [2] 提出了一种用于 3D 对象建模的高效三平面表示,StyleSDF [45] 用 SDF 替换密度场以获得更好的几何质量。 然而,由于复杂的身体关节和外观变化,这种方法通常不容易扩展到非刚性人类。 此外,它们对生成过程的控制有限,使得生成的对象很难被动画化。 不同的是,我们研究了服装人类的 3D 感知生成建模问题,从而可以对几何形状和外观进行分离控制。
3D 人体重建和动画。 传统的人体重建方法需要复杂的硬件,对于日常使用来说价格昂贵,例如深度传感器[7,12,58]或密集的相机阵列[9,18]。 为了减轻对捕获设备的要求,一些方法训练神经网络以使用可微渲染器[65, 15]从图像重建人体模型。 最近,神经辐射场(NeRF)[39]采用体积渲染来从密集的相机视图中学习密度和色场。 一些方法利用人体先验增强 NeRF,以实现从稀疏多视图数据进行 3D 人体重建[51,5,64,57]。 后续改进[49,4,33,50,61]是通过将隐式表示与 SMPL 模型相结合并利用线性混合蒙皮技术从时间数据中学习可动画的 3D 人体建模来实现的。 然而,这些方法不是生成性的,即。,它们无法合成新颖的身份和外观。 并发作品 ENARF-GAN [44] 和 EVA3D [20] 也利用 3D 人类先验来学习可动画的 3D 人类 GAN。 然而,它们仍然存在不良伪影和缺乏精确的几何控制。 相反,我们的 AvatarGen 通过解开几何可控性实现了高保真人体图像合成。
3方法论
3.1概述
我们引入了一种名为 AvatarGen 的 3D 生成模型,它可以合成高质量的多视图一致人体图像,并且对人体几何形状具有解开的可控性(例如。 ,姿势和形状)。 它只需要 2D 图像进行训练,无需使用多视图、时间信息或 3D 人体扫描注释。
图2说明了我们提出的AvatarGen 的流程。 给定来自高斯分布的随机采样潜在代码 ,调节相机 和几何参数 ,其中 和 分别指定人体姿势和形状,其生成器生成3D神经表示(即。,三平面 [2] 详见下文)并合成具有相应视点、姿势和形状的逼真人体图像 。 在这项工作中,我们使用 3D 参数模型 SMPL [36] 来表示人体几何形状 。 遵循 EG3D [2],我们将每个训练图像与一组相机 和从现成的姿态估计器估计的 SMPL 参数 相关联[29]。
我们选择三平面[2]作为人类头像的表示,因为它对于高保真图像合成来说是高效且有效的。 生成器将 和相机条件 编码到三平面特征字段。 然后给定所需的相机姿态,通过查询三平面特征并集成基于MLP的神经辐射场(颜色特征和密度) 沿着相机光线。 通过将此特征图输入超分辨率模块[28],生成器会生成高分辨率的最终图像。 我们通过对抗训练使用鉴别器模块 优化 ,从而产生视图一致的图像合成。
3.2 可动画化的 3D 感知人类 GAN
生成具有可控几何形状的 3D 感知人类化身面临两个主要挑战。 首先是如何将指定的几何条件有效地集成到生成模型中,使生成的头像可控且可动画。 第二个挑战是如何保证生成质量,考虑到学习姿势相关的服装人体外观和几何形状受到很大的约束,并且模型训练很困难。 为了应对这些挑战,受到最近动态神经渲染工作[49,47,64]的启发,我们建议将人类头像生成分解为两个步骤:姿势引导规范映射 和典型的人类一代。
姿势引导的规范映射。 我们将带有 SMPL 的人体二维图像定义为观察空间。 为了缓解学习困难,我们的模型尝试将观察空间变形为具有跨不同身份共享的预定义模板 SMPL 主体 的规范空间 。 因此,变形函数将观察空间中采样的任何空间点映射到规范空间中的以进行体积渲染。
学习这样的变形函数已被证明对于动态场景建模是有效的[47, 52]。 然而,学习以这种隐式方式变形无法处理人类的大型关节,因此很难推广到新的姿势/形状。 为了克服这个限制,我们使用 SMPL 来显式引导变形[33,49,4]。 SMPL 定义了基于顶点蒙皮的人体模型 ,其中 是 顶点的集合, 是一组为顶点分配的蒙皮权重 关节,每个关节都有 。 通过逆 LBS (IS) 变换 [23],我们可以将参数 的观察空间中的 SMPL 体映射到规范空间,如下所示:
| (1) |
其中 和 是从带有 的 SMPL 导出的每个关节 处的旋转和平移。
通过从 SMPL 体[22]表面上的最近点采用相同的变换,该公式可以扩展到观测空间中的任何空间点。 形式上,对于任何点,我们首先在SMPL体表面上找到其最近的点作为。 然后,我们使用相应的蒙皮权重在规范空间中将变形为,如下所示:
| (2) |
尽管 SMPL 引导的逆 LBS 可以帮助将刚性骨架与模板主体对齐,但它缺乏对与姿势/形状相关的变形进行建模的能力,例如布料皱纹。 为了缓解这个问题,我们进一步训练一个变形网络来学习残差变形,通过以下方式完成细粒度的几何变形
| (3) |
其中是通过MLP从输入潜在代码映射的潜在样式代码,其中包含当前生成的外观和几何细节。 我们将其与位置嵌入的 和 SMPL 连接起来,并将它们提供给 MLP 以产生残余变形。 因此,最终的规范映射 被表述为
| (4) |
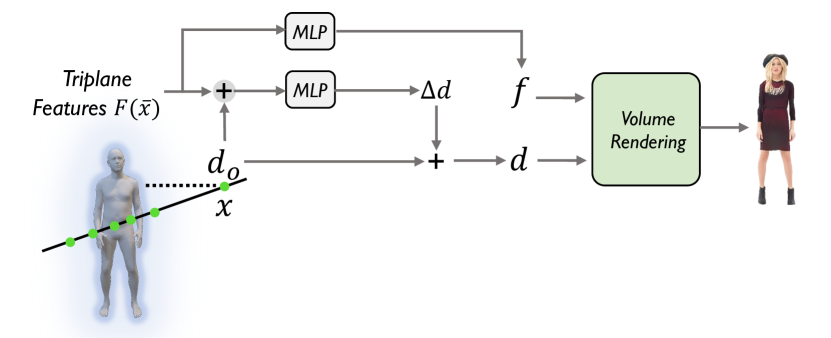
典型的人类一代。 将 中的 3D 点扭曲回 后,AvatarGen 利用三平面表示在规范空间中生成 3D 感知的着装人类。 更具体地说,它首先将潜在代码 和相机参数 作为输入,通过 StyleGAN 主干生成规范三平面。 然后,对于每个点 向后扭曲到 ,模型查询规范三平面特征,然后查询 MLP 以解码基于颜色的特征 和用于体积渲染和以下超分辨率的密度。 请注意,我们的规范三平面仅需要生成具有规范姿势和形状的外观和几何形状,这减轻了优化困难,并极大地帮助学习具有解开可控性的高质量人类生成。
3.3几何感知人体建模
为了提高 AvatarGen 的几何建模质量,受到最近的神经隐式表面工作[60,67,45,50]的启发,我们采用有符号距离场(SDF)而不是密度场作为几何代理,因为它引入了更直接的正则化[45, 50],并允许模型充分利用 3D SMPL 模型的几何知识作为指导。
具有几何先验的 SDF 预测。 由于复杂的身体关节、姿势相关的变形以及 2D 图像的监督不足,直接采用 SDF 进行服装人体建模并非易事。
为了解决这些问题,我们提出了一种简单而有效的 SDF 预测方案,该方案充分利用 SMPL 人体模型的几何先验。 具体来说,给定所需的 SMPL 参数 ,我们在观察空间中获得其相应的身体网格为 ,其中 是 SMPL 变换函数。 然后,对于每个 3D 点 ,我们不是直接预测其有符号距离值,而是首先计算其到 最近表面点的粗略有符号距离 。然后,我们单独将从三平面采样的特征提供给 到轻量级 MLP,以预测剩余符号距离。 残差SDF对细粒度的表面细节进行建模,例如SMPL模型未表示的头发、衣服和皱纹(图2)。 每个点的最终有符号距离计算为。 在粗体网格之上预测 SDF 很大程度上减轻了几何学习的困难,从而获得更好的生成和动画效果。 详情请参阅附录。
此外,尽管管道已解开,如第 2 节所示。 3.2,没有明确的损失约束生成的几何图形与定义的人体姿势和形状一致。 因此,我们通过最小化预测的 SDF 与底层 SMPL 主体定义的 SDF 的差异来指导预测的 SDF
| (5) |
这里是体渲染的光线样本,是点先验损失的权重,是一个常数定义表面边界周围紧密度的标量。 这样的先验损失引导生成的几何图形遵循控制的几何属性。 当远离 SMPL 身体表面的点时,我们衰减几何先验损失 的权重,从而允许在生成残余几何形状(例如头发和衣服)时具有更高的自由度。
基于 SDF 的体绘制。 继[45]之后,我们采用基于SDF的体绘制来获取特征图像。 对于光线上的任何采样点 ,我们首先通过规范映射将其取消扭曲为 。 我们从规范三平面中查询 的特征 ,并将其输入两个 MLP 来预测颜色特征 和符号距离 ,其中是从SMPL查询的主体SDF。 然后,我们将每个点 单独一条射线 的有符号距离值 转换为密度值 作为 其中 是一个可学习的参数,用于控制表面边界周围的密度的紧密程度。 通过沿光线积分,我们可以得到相应的像素特征为
| (6) |
其中 和 是每条光线采样的点数。 通过聚合所有光线,我们可以获得最终的图像特征,并将其输入超分辨率模块[28]以生成最终的高分辨率合成图像。
3.4训练
我们使用非饱和 GAN 损失 [28] 和 R1 正则化 [37] 训练到我们的模型端-到结束。 我们还采用了EG3D[2]提出的双判别器。 它将渲染的原始图像和解码的高分辨率图像输入鉴别器,以提高生成的多视图图像的一致性。 此外,正如[13]中观察到的,由于与全身相比分辨率较低,大多数人类生成伪影出现在面部区域。 因此,我们通过裁剪头部区域并将其输入到与整个框架联合训练的附加鉴别器来进一步提高生成的人脸的质量。 对于 分辨率图像,使用覆盖整个头部区域的 正方形。 为了获得更好的可控性,我们将 SMPL 参数 和相机参数 作为条件提供给对手训练的判别器。 为了规范学习到的 SDF,我们将 Eikonal 损失应用于采样点,如下所示:
| (7) |
其中和分别表示采样点和预测的有符号距离值。 遵循[45],我们采用最小表面损失来鼓励模型以最小体积的过零来表示人体几何形状,这使 SDF 接近于零: 为了防止学习到的变形网络崩溃,我们使用变形正则化损失将残余变形正规化为小:。 以及方程中的几何先验损失。 (5),总体损失表示为
| (8) | ||||
其中是相应的损失权重。
| MPV | UBC | DeepFashion | SHHQ | |||||||||||||
| FID | FaceFID | Depth | PCK | FID | FaceFID | Depth | PCK | FID | FaceFID | Depth | PCK | FID | FaceFID | Depth | PCK | |
| StyleNeRF- | 10.71 | 24.32 | 1.46 | - | 20.65 | 34.30 | 1.44 | - | 15.93 | 29.22 | 1.43 | - | 13.52 | 26.21 | 1.37 | - |
| StyleSDF- | 43.79 | 69.71 | 1.79 | - | 34.12 | 39.05 | 1.80 | - | 45.06 | 41.78 | 1.77 | - | 43.24 | 47.46 | 1.78 | - |
| EG3D- | 15.44 | 33.98 | 1.31 | - | 14.55 | 20.24 | 1.28 | - | 14.36 | 34.99 | 1.44 | - | 9.33 | 35.10 | 1.43 | - |
| ENARF- | 75.10 | 57.64 | 2.32 | 58.92 | 41.75 | 36.34 | 2.10 | 54.40 | 67.96 | 51.17 | 2.57 | 55.06 | 73.53 | 49.35 | 2.43 | 53.44 |
| EVA3D- | - | - | - | - | 12.61 | - | - | 99.17 | 15.91 | - | - | 87.50 | 11.99 | - | - | 88.95 |
| AvatarGen- | 5.25 | 6.89 | .429 | 98.79 | 6.71 | 8.61 | .453 | 99.38 | 7.68 | 8.76 | .433 | 99.24 | 4.29 | 4.51 | .365 | 99.49 |
4实验
我们在四个真实世界时尚数据集上评估 3D 感知服装人类生成方法:MPV [11]、UBC [68]、DeepFashion [35] 和 SHHQ [14]。 每张图像中都包含穿着衣服的人。 由于我们专注于前景人类生成,因此我们使用分割模型[8]来删除不相关的背景。 我们采用现成的姿态估计器[29]来获得近似的相机和SMPL参数。 我们过滤掉部分观察的图像和 SMPL 估计较差的图像,并分别为每个数据集获得近 13K、31K、12K 和 39K 全身图像。 我们根据估计的关键点和比例对齐和裁剪图像,并将其大小调整为 分辨率。 我们对每条射线单独采样 48 个点以进行体积渲染。 训练期间使用水平翻转增强。 我们注意到这些数据集主要由前视图图像组成,很少有从侧视图或后视图捕获的图像。 为了弥补这一点,我们采样了更多侧视图和后视图图像,以重新平衡[2]之后的视点分布。 我们的数据处理脚本和预处理数据集将被发布。
4.1比较
基线。 我们将 AvatarGen 与 3D 感知图像合成的五种最先进的方法进行比较:EG3D [2]、StyleSDF [45]、StyleNeRF [17 ]、ENARF-GAN [44] 和 EVA3D [20]。 EG3D 和 StyleNeRF 将体积渲染器与 2D 解码器相结合,用于高分辨率图像合成。 StyleSDF 使用 SDF 进行正则化几何建模。 ENARF-GAN 和 EVA3D 也利用 3D 人类先验来生成可动画的人类。
定量评价。 标签。 1 提供 AvatarGen 和基线之间的定量比较。 我们使用 50k 生成图像和所有可用真实图像之间的 Fréchet 起始距离 (FID) [19] 来测量图像质量。 我们还通过从生成的图像和真实图像中裁剪面部区域( 对于 分辨率图像)来计算 FaceFID,从而评估生成的面部的质量。 我们通过根据 [54] 生成的图像估计的伪地面实况 (GT) 深度图 (深度) 计算均方误差 (MSE) 来评估几何质量。 继[44]之后,我们使用正确关键点百分比(PCK)来评估姿态可控性的有效性。 其他评估详情请参阅附录。 从选项卡。 1,我们观察到我们的模型优于所有基线。 所有指标和数据集。 值得注意的是,它在四个数据集上显着优于基线模型(FID 中为 50.9%、51.1%、51.7%、54.0%)。 这些结果清楚地证明了其在穿着人体合成方面的优越性。 此外,它保持了最先进的几何质量和姿势精度。

定性结果。 我们在图 3 中展示了与基线的定性比较。 可以看出,与我们的方法相比,StyleSDF [45] 生成的 3D 头像具有过度平滑的几何形状。 此外,在生成的头像周围可以观察到噪音和孔洞,并且缺少面部和衣服等几何细节。 EG3D [2] 很难从 2D 图像中学习 3D 人体几何,并且质量退化。 尽管使用 3D 人类生成的姿势先验,ENARF-GAN 仍然存在渲染质量低和几何形状不理想的问题。 与它们相比,AvatarGen 生成具有高保真外观的 3D 感知头像,并且仅从 2D 图像中学习复杂的人体几何形状。 此外,AvatarGen 可以生成具有更好几何细节的不同姿势的头像。 请参阅我们的项目页面和附录以获取更多结果。
| Geo. | FID | FaceFID | Depth |
|---|---|---|---|
| Density | 7.87 | 11.21 | .652 |
| SDF | 6.54 | 8.74 | .576 |
| Deform. | FID | FaceFID | Depth |
|---|---|---|---|
| IS | 7.89 | 12.90 | .752 |
| IS+RD | 6.54 | 8.74 | .576 |
| Face Disc. | FID | FaceFID | Depth |
|---|---|---|---|
| w/o | 6.02 | 12.31 | .604 |
| w/ | 6.54 | 8.74 | .576 |
| SDF Scheme | FID | FaceFID | Depth |
|---|---|---|---|
| W/o | 7.16 | 10.63 | .689 |
| Can. | 7.09 | 9.27 | .592 |
| Obs.+raw | 7.03 | 10.23 | .602 |
| Obs. | 6.54 | 8.74 | .576 |
| Ray Steps | FID | FaceFID | Depth |
|---|---|---|---|
| 12 | 7.76 | 12.44 | .656 |
| 24 | 7.59 | 12.02 | .636 |
| 36 | 7.07 | 11.30 | .626 |
| 48 | 6.54 | 8.74 | .576 |
| KNN | FID | FaceFID | Depth |
|---|---|---|---|
| 1 | 6.54 | 8.74 | .576 |
| 2 | 6.49 | 9.55 | .583 |
| 3 | 6.20 | 9.72 | .578 |
| 4 | 6.17 | 8.88 | .575 |


4.2消融研究
我们对 DeepFashion () 进行消融研究,因为它包含更多样化的外观和姿势。
几何代理。 我们的 AvatarGen 使用 SDF 作为几何代理来促进几何学习。 为了研究其有效性,我们还以密度场为代理来评估我们的模型。 如表所示。 2(a),使用密度场会显着降低生成的头像质量——FID 和 FaceFID 分别增加 16.8% 和 22.0%,深度误差增加 11.6%。 这表明 SDF 对于模型更精确地表示穿着人体几何形状非常重要,尤其是对于面部等详细区域。
我们还在图 4 中展示了使用密度(左)或 SDF(右)作为几何代理训练的模型的定量结果。 我们观察到用密度场训练的模型可以生成具有合理几何形状的人体化身。 然而,它往往会产生嘈杂的身体表面。 此外,由于缺乏几何约束,在背景区域中观察到冗余几何结构(例如.,前两个示例)。 相比之下,由于SDF引入的几何正则化,用SDF训练的模型产生了更光滑、质量更好的人体表面。
SDF 预测方案。 AvatarGen 预测 SMPL 身体网格顶部穿着衣服的人类的残留 SDF。 如表所示。 2(d),如果去掉SMPL主体引导并直接预测残余SDF(第一行),性能显着下降,即。,8.7 FID、FaceFID 和深度误差分别增加 %、17.8%、16.4%。 这表明粗略的 SMPL 身体先验对于指导 AvatarGen 更好地生成穿着人体几何体非常重要。 我们还比较了从观察 (Obs.) 和规范 (Can.) 空间查询的 SMPL 主体 SDF 之间的性能。 该模型由 Obs. 查询的身体 SDF 引导,更准确,性能更好。
此外,我们研究了两种 SDF 预测方案的效果——直接预测原始 SDF (Obs.+raw) 和从观测空间预测粗 SMPL 体顶部的 SDF 残差。 我们看到残差预测方案提供了更好的结果,因为它减轻了几何学习的困难。 此外,我们研究了等式中 SMPL 几何先验损失的影响。 (5)。 删除它会导致性能下降。 所有指标(FID:7.20 vs. 6.54,FaceFID:10.29 vs. 8.74,深度:0.645 vs. 0.576),验证其有效性用于规范几何学习。
变形方案。 我们的模型使用姿势引导变形来将空间点从观察空间恢复到规范空间。 我们还在表中评估了其他两种变形方案。 2(b):1)仅残余变形[47](RD),2)逆LBS变形[22]<仅 /t4> (IS)。 仅使用 RD 时,模型训练不会收敛,这表明隐式学习变形无法处理人类的大型发音并导致令人难以置信的结果。 仅使用 IS 时,模型获得了合理的结果(FID:7.89,FaceFID:12.9,深度:0.752),验证了显式姿势引导变形的重要性。 进一步结合 IS 和 RD(我们的模型)可大幅提升性能——FID、FaceFID 和深度分别降低 20.6%、32.2% 和 23.4%。 这些结果表明,残余变形与姿势引导逆 LSB 变换相结合,确实可以更好地表示非刚性服装人体变形,从而产生更好的外观和几何建模。
为了更好地研究拟议变形网络的效果,我们在图 5 中直观地展示了使用(左)和不使用(右)该网络训练的 AvatarGen 的生成结果(即.,典型观察空间和目标观察空间中的头像)。 从图中,我们观察到变形网络有助于学习更好的规范到观察映射,并明显提高生成的规范化身的质量,从而产生高质量的姿势化身。 值得注意的是,我们的变形网络可以帮助在规范空间与观察空间之间建立正确的对应关系,甚至对于连衣裙等宽松的衣服也是如此。
人脸鉴别器。 标签。 2(c)展示了使用人脸鉴别器的效果。 我们可以观察到,如果禁用人脸鉴别器,人脸质量会显着下降,即。,FaceFID 中的 12.31 vs. 8.74。 虽然整体 FID 略有改善,但几何质量变差。 这表明附加的面部鉴别器有助于学习几何细节并提高目标区域的质量。 请参阅附录中的定性比较。
射线步数。 标签。 2(e) 显示每条相机光线采样点数的影响。 每条光线只有 12 个采样点,AvatarGen 已经达到了可接受的结果,即。,FID、FaceFID 和深度分别为 7.76、12.44 和 0.656。 随着采样点的增加,性能单调增加,展示了 AvatarGen 在 3D 感知人体合成方面的能力。
逆蒙皮变形中的 KNN 数量。 对于任何空间点,我们使用最近邻来查找逆 LBS 变换的相应蒙皮权重(方程 1)。 (2))。 在这里,我们研究了 KNN 邻居的数量如何影响表中的模型性能。 2(f)。 我们观察到,使用更多的 KNN 邻居可以提供稍微更好的 FID 性能,但几何形状会更差,并且训练时间会更长,因为模型需要检索更多的邻居。
4.3应用
肖像图像重建和动画。 图6展示了AvatarGen在单视图3D重建中的应用。 遵循[56],我们通过使用MSE损失和感知损失优化潜在代码来拟合目标图像,以恢复外观和几何形状。 利用恢复的 3D 表示,我们可以在新颖的相机姿势下操纵图像。 由于其解缠结的设计,AvatarGen 还可以在 SMPL 控制信号指定的不同姿势和形状下,以保留的身份和高保真纹理重新激活生成的头像。

文本引导合成。 最近的工作[48, 30]探索了使用文本图像嵌入[53]来指导GAN进行可控图像合成。 我们还在图 7 中可视化了文本引导的穿着人类的合成。 具体来说,我们按照 StyleCLIP [48] 使用一系列指定不同布料样式的文本提示来优化合成图像的潜在代码。 然后我们在不同的相机姿势下合成重新打扮的人类头像。
5结论
这项工作介绍了第一个 3D 感知的穿着人类头像生成模型 AvatarGen。 通过将生成过程分解为规范的人体生成和变形阶段,它可以利用几何先验和有效的三平面表示来解决可动画人体化身生成中的挑战。 我们证明它可以生成具有解缠结几何可控性的高保真人类,并支持多种下游应用。 我们相信我们的方法将使普通用户更容易创建人类头像,为设计师提供帮助并降低手动成本。
限制。 我们提出了一种高保真可动画 3D 人类 GAN,但我们的方法仍有进一步改进的空间。 1) 它依赖于 SMPL 估计。 不准确的估计会导致发电质量下降。 2)我们的方法生成的人类头像的细粒度运动,例如面部表情变化,尚无法控制。 使用更具表现力的 3D 人体模型,例如。,SMPL-X 作为指导将是一个有前途的解决方案。
参考
- [1] Panos Achlioptas, Olga Diamanti, Ioannis Mitliagkas, and Leonidas Guibas. Learning representations and generative models for 3d point clouds. In ICML, 2018.
- [2] Eric R Chan, Connor Z Lin, Matthew A Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas Guibas, Jonathan Tremblay, Sameh Khamis, et al. Efficient geometry-aware 3d generative adversarial networks. CVPR, 2022.
- [3] Eric R Chan, Marco Monteiro, Petr Kellnhofer, Jiajun Wu, and Gordon Wetzstein. pi-gan: Periodic implicit generative adversarial networks for 3d-aware image synthesis. In CVPR, 2021.
- [4] Jianchuan Chen, Ying Zhang, Di Kang, Xuefei Zhe, Linchao Bao, Xu Jia, and Huchuan Lu. Animatable neural radiance fields from monocular rgb videos. arXiv, 2021.
- [5] Mingfei Chen, Jianfeng Zhang, Xiangyu Xu, Lijuan Liu, Yujun Cai, Jiashi Feng, and Shuicheng Yan. Geometry-guided progressive nerf for generalizable and efficient neural human rendering. arXiv, 2021.
- [6] Zhiqin Chen and Hao Zhang. Learning implicit fields for generative shape modeling. In CVPR, 2019.
- [7] Alvaro Collet, Ming Chuang, Pat Sweeney, Don Gillett, Dennis Evseev, David Calabrese, Hugues Hoppe, Adam Kirk, and Steve Sullivan. High-quality streamable free-viewpoint video. In ACM Trans. on Graphics, 2015.
- [8] PaddlePaddle Contributors. Paddleseg, end-to-end image segmentation kit based on paddlepaddle. https://github.com/PaddlePaddle/PaddleSeg, 2019.
- [9] Paul Debevec, Tim Hawkins, Chris Tchou, Haarm-Pieter Duiker, Westley Sarokin, and Mark Sagar. Acquiring the reflectance field of a human face. In Computer graphics and interactive techniques, 2000.
- [10] Yu Deng, Jiaolong Yang, Jianfeng Xiang, and Xin Tong. Gram: Generative radiance manifolds for 3d-aware image generation. CVPR, 2022.
- [11] Haoye Dong, Xiaodan Liang, Xiaohui Shen, Bochao Wang, Hanjiang Lai, Jia Zhu, Zhiting Hu, and Jian Yin. Towards multi-pose guided virtual try-on network. In ICCV, 2019.
- [12] Mingsong Dou, Sameh Khamis, Yury Degtyarev, Philip Davidson, Sean Ryan Fanello, Adarsh Kowdle, Sergio Orts Escolano, Christoph Rhemann, David Kim, Jonathan Taylor, et al. Fusion4d: Real-time performance capture of challenging scenes. In ACM Trans. on Graphics, 2016.
- [13] Anna Frühstück, Krishna Kumar Singh, Eli Shechtman, Niloy J. Mitra, Peter Wonka, and Jingwan Lu. Insetgan for full-body image generation. In CVPR, 2022.
- [14] Jianglin Fu, Shikai Li, Yuming Jiang, Kwan-Yee Lin, Chen Qian, Chen-Change Loy, Wayne Wu, and Ziwei Liu. Stylegan-human: A data-centric odyssey of human generation. arXiv, 2022.
- [15] Thiago L. Gomes, Thiago M. Coutinho, Rafael Azevedo, Renato Martins, and Erickson R. Nascimento. Creating and reenacting controllable 3d humans with differentiable rendering. In WACV, 2022.
- [16] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In NeurIPS, 2014.
- [17] Jiatao Gu, Lingjie Liu, Peng Wang, and Christian Theobalt. Stylenerf: A style-based 3d-aware generator for high-resolution image synthesis. CVPR, 2022.
- [18] Kaiwen Guo, Peter Lincoln, Philip Davidson, Jay Busch, Xueming Yu, Matt Whalen, Geoff Harvey, Sergio Orts-Escolano, Rohit Pandey, Jason Dourgarian, et al. The relightables: Volumetric performance capture of humans with realistic relighting. In ACM Trans. on Graphics, 2019.
- [19] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. NeurIPS, 2017.
- [20] Fangzhou Hong, Zhaoxi Chen, Yushi Lan, Liang Pan, and Ziwei Liu. Eva3d: Compositional 3d human generation from 2d image collections. arXiv, 2022.
- [21] Fangzhou Hong, Mingyuan Zhang, Liang Pan, Zhongang Cai, Lei Yang, and Ziwei Liu. Avatarclip: Zero-shot text-driven generation and animation of 3d avatars. ACM Trans. on Graphics, 2022.
- [22] Zeng Huang, Yuanlu Xu, Christoph Lassner, Hao Li, and Tony Tung. Arch: Animatable reconstruction of clothed humans. In CVPR, 2020.
- [23] Alec Jacobson, Ilya Baran, Ladislav Kavan, Jovan Popović, and Olga Sorkine. Fast automatic skinning transformations. ACM Trans. on Graphics, 2012.
- [24] Boyi Jiang, Yang Hong, Hujun Bao, and Juyong Zhang. Selfrecon: Self reconstruction your digital avatar from monocular video. In CVPR, 2022.
- [25] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of GANs for improved quality, stability, and variation. In ICCV, 2018.
- [26] Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Alias-free generative adversarial networks. In NeurIPS, 2021.
- [27] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In CVPR, 2019.
- [28] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of StyleGAN. In CVPR, 2020.
- [29] Muhammed Kocabas, Chun-Hao P Huang, Otmar Hilliges, and Michael J Black. Pare: Part attention regressor for 3d human body estimation. In ICCV, 2021.
- [30] Gihyun Kwon and Jong Chul Ye. Clipstyler: Image style transfer with a single text condition. In CVPR, 2022.
- [31] Ruihui Li, Xianzhi Li, Chi-Wing Fu, Daniel Cohen-Or, and Pheng-Ann Heng. Pu-gan: a point cloud upsampling adversarial network. In ICCV, 2019.
- [32] Yiyi Liao, Katja Schwarz, Lars Mescheder, and Andreas Geiger. Towards unsupervised learning of generative models for 3D controllable image synthesis. In CVPR, 2020.
- [33] Lingjie Liu, Marc Habermann, Viktor Rudnev, Kripasindhu Sarkar, Jiatao Gu, and Christian Theobalt. Neural actor: Neural free-view synthesis of human actors with pose control. ACM Trans. on Graphics, 2021.
- [34] Ting Liu, Jianfeng Zhang, Xuecheng Nie, Yunchao Wei, Shikui Wei, Yao Zhao, and Jiashi Feng. Spatial-aware texture transformer for high-fidelity garment transfer. In IEEE Trans. on Image Processing, 2021.
- [35] Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In CVPR, 2016.
- [36] Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. ACM Trans. on Graphics, 2015.
- [37] Lars Mescheder, Andreas Geiger, and Sebastian Nowozin. Which training methods for gans do actually converge? In ICML, 2018.
- [38] Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. Occupancy networks: Learning 3d reconstruction in function space. In CVPR, 2019.
- [39] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020.
- [40] Thu Nguyen-Phuoc, Chuan Li, Lucas Theis, Christian Richardt, and Yong-Liang Yang. HoloGAN: Unsupervised learning of 3D representations from natural images. In ICCV, 2019.
- [41] Thu Nguyen-Phuoc, Christian Richardt, Long Mai, Yong-Liang Yang, and Niloy Mitra. BlockGAN: Learning 3D object-aware scene representations from unlabelled images. In NeurIPS, 2020.
- [42] Michael Niemeyer and Andreas Geiger. Giraffe: Representing scenes as compositional generative neural feature fields. In CVPR, 2021.
- [43] Atsuhiro Noguchi, Xiao Sun, Stephen Lin, and Tatsuya Harada. Neural articulated radiance field. In ICCV, 2021.
- [44] Atsuhiro Noguchi, Xiao Sun, Stephen Lin, and Tatsuya Harada. Unsupervised learning of efficient geometry-aware neural articulated representations. In ECCV, 2022.
- [45] Roy Or-El, Xuan Luo, Mengyi Shan, Eli Shechtman, Jeong Joon Park, and Ira Kemelmacher-Shlizerman. Stylesdf: High-resolution 3d-consistent image and geometry generation. CVPR, 2022.
- [46] Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. Deepsdf: Learning continuous signed distance functions for shape representation. In CVPR, 2019.
- [47] Keunhong Park, Utkarsh Sinha, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Steven M Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields. In ICCV, 2021.
- [48] Or Patashnik, Zongze Wu, Eli Shechtman, Daniel Cohen-Or, and Dani Lischinski. Styleclip: Text-driven manipulation of stylegan imagery. In ICCV, 2021.
- [49] Sida Peng, Junting Dong, Qianqian Wang, Shangzhan Zhang, Qing Shuai, Hujun Bao, and Xiaowei Zhou. Animatable neural radiance fields for human body modeling. ICCV, 2021.
- [50] Sida Peng, Shangzhan Zhang, Zhen Xu, Chen Geng, Boyi Jiang, Hujun Bao, and Xiaowei Zhou. Animatable neural implicit surfaces for creating avatars from videos. arXiv, 2022.
- [51] Sida Peng, Yuanqing Zhang, Yinghao Xu, Qianqian Wang, Qing Shuai, Hujun Bao, and Xiaowei Zhou. Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans. In CVPR, 2021.
- [52] Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-nerf: Neural radiance fields for dynamic scenes. In CVPR, 2021.
- [53] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, 2021.
- [54] Shunsuke Saito, Tomas Simon, Jason Saragih, and Hanbyul Joo. Pifuhd: Multi-level pixel-aligned implicit function for high-resolution 3d human digitization. In CVPR, 2020.
- [55] Katja Schwarz, Yiyi Liao, Michael Niemeyer, and Andreas Geiger. Graf: Generative radiance fields for 3d-aware image synthesis. NeurIPS, 2020.
- [56] Guoxian Song, Linjie Luo, Jing Liu, Wan-Chun Ma, Chunpong Lai, Chuanxia Zheng, and Tat-Jen Cham. Agilegan: stylizing portraits by inversion-consistent transfer learning. ACM Trans. on Graphics, 2021.
- [57] Shih-Yang Su, Frank Yu, Michael Zollhöfer, and Helge Rhodin. A-nerf: Articulated neural radiance fields for learning human shape, appearance, and pose. In NeurIPS, 2021.
- [58] Zhuo Su, Lan Xu, Zerong Zheng, Tao Yu, Yebin Liu, and Lu Fang. Robustfusion: Human volumetric capture with data-driven visual cues using a rgbd camera. In ECCV, 2020.
- [59] Attila Szabó, Givi Meishvili, and Paolo Favaro. Unsupervised generative 3D shape learning from natural images. arXiv, 2019.
- [60] Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. NeurIPS, 2021.
- [61] Chung-Yi Weng, Brian Curless, Pratul P. Srinivasan, Jonathan T. Barron, and Ira Kemelmacher-Shlizerman. HumanNeRF: Free-viewpoint rendering of moving people from monocular video. CVPR, 2022.
- [62] Jiajun Wu, Chengkai Zhang, Tianfan Xue, William T. Freeman, and Joshua B. Tenenbaum. Learning a probabilistic latent space of object shapes via 3D generative-adversarial modeling. In NeurIPS, 2016.
- [63] Donglai Xiang, Fabian Prada, Timur Bagautdinov, Weipeng Xu, Yuan Dong, He Wen, Jessica Hodgins, and Chenglei Wu. Modeling clothing as a separate layer for an animatable human avatar. ACM Trans. on Graphics, 2021.
- [64] Hongyi Xu, Thiemo Alldieck, and Cristian Sminchisescu. H-nerf: Neural radiance fields for rendering and temporal reconstruction of humans in motion. NeurIPS, 2021.
- [65] Xiangyu Xu and Chen Change Loy. 3D human texture estimation from a single image with transformers. In ICCV, 2021.
- [66] Yang Xue, Yuheng Li, Krishna Kumar Singh, and Yong Jae Lee. Giraffe hd: A high-resolution 3d-aware generative model. In CVPR, 2022.
- [67] Lior Yariv, Jiatao Gu, Yoni Kasten, and Yaron Lipman. Volume rendering of neural implicit surfaces. In NeurIPS, 2021.
- [68] Polina Zablotskaia, Aliaksandr Siarohin, Bo Zhao, and Leonid Sigal. Dwnet: Dense warp-based network for pose-guided human video generation. BMVC, 2019.
- [69] Jiakai Zhang, Xinhang Liu, Xinyi Ye, Fuqiang Zhao, Yanshun Zhang, Minye Wu, Yingliang Zhang, Lan Xu, and Jingyi Yu. Editable free-viewpoint video using a layered neural representation. ACM Trans. on Graphics, 2021.
- [70] Jichao Zhang, Enver Sangineto, Hao Tang, Aliaksandr Siarohin, Zhun Zhong, Nicu Sebe, and Wei Wang. 3d-aware semantic-guided generative model for human synthesis. In ECCV, 2022.
- [71] Jiakai Zhang, Liao Wang, Xinhang Liu, Fuqiang Zhao, Minzhang Li, Haizhao Dai, Boyuan Zhang, Wei Yang, Lan Xu, and Jingyi Yu. Neuvv: Neural volumetric videos with immersive rendering and editing. ACM Trans. on Graphics, 2022.
附录A实施细节
本节我们详细介绍 AvatarGen 各个模块的实现以及超参数的选择。
主干。 我们采用 StyleGAN2 [28] 主干作为三平面生成器,并采用两块 StyleGAN2 调制的卷积层作为超分辨率模块,遵循 EG3D [2]。 输出三平面分辨率设置为,具有96个通道,然后将其分割为三个平面以进行特征采样。 我们在 StyleGAN2 中使用基于 MLP 的映射网络来编码潜在代码和相机条件。 我们采用 EG3D 中使用的类似双判别器架构来规范生成器训练。 与 EG3D 不同的是,我们进一步将头部区域的额外上采样图像提供给鉴别器,以提高人脸的生成质量。 对于 分辨率图像,裁剪覆盖整个头部区域的 方形图像以进行人脸识别。
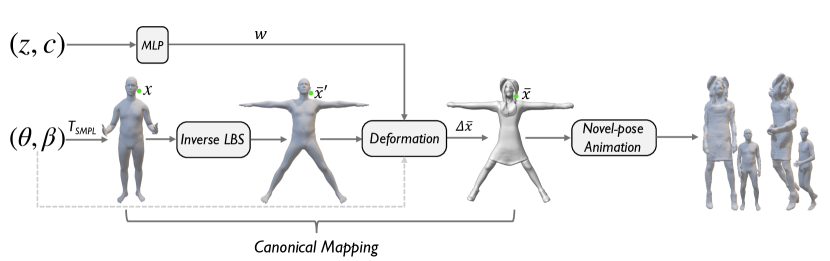
规范映射。 图S8显示了规范映射模块的详细信息。 对于点,我们首先在SMPL体表面上找到其最近的点:。 然后,我们使用其相应的蒙皮权重在规范空间中将变形为,如下所示:
| (9) |
对于细粒度的几何变形,我们进一步训练变形网络来学习残差变形:
| (10) |
其中是通过MLP从输入潜在代码映射的潜在样式代码,其中包含当前生成的外观和几何细节。 我们将其与位置嵌入的 和 SMPL 连接起来,并将它们提供给 MLP 以产生残余变形 。 因此,最终的规范映射 被表述为
| (11) |
在推理过程中,给定潜在代码 和相机 ,AvatarGen 利用预先训练的三平面来合成规范化身的相应外观和几何形状,然后通过以下方式对其进行动画处理:根据所需的 SMPL 控制信号对规范进行变形。
基于 SDF 的体积渲染器。 我们基于SDF的体积渲染器的详细架构如图S9所示。 对于光线上的任何采样点,我们首先通过规范映射将其反扭曲为(图S8)。 我们从规范三平面中查询 的特征 ,并将其输入两个 MLP 来预测颜色特征 和符号距离 ,其中是从SMPL查询的主体SDF。 然后,我们将沿着射线 的每个点 的有符号距离值 转换为密度值 作为 其中 是一个可学习的参数,用于控制表面边界周围的密度的紧密程度。 通过沿光线积分,我们可以得到相应的像素特征为
| (12) |
其中 和 是每条光线采样的点数。 通过聚合所有光线,我们可以获得后续超分辨率模块的高维特征图像。
超参数。 生成器的学习率设置为,鉴别器的学习率设置为。 对于损失函数,我们设置,,,,。 该模型在 8 个 NVIDIA V100 GPU 上进行训练,批量大小为 16。 与 EG3D 类似,我们采用渐进式增长策略,即。,我们首先使用 分辨率体积渲染训练模型,然后逐步增长它到 -分辨率。 整个训练过程大约需要4天时间才能收敛。
附录 B 更多结果
B.1 人脸鉴别器
我们在图 S10 中展示了使用和不使用面部识别训练的模型的比较。 我们可以观察到,我们提出的面部识别明显提高了面部区域的质量。 如果我们禁用面部识别,模型往往会产生扭曲的面部,尤其是从不同的相机姿势渲染时。

B.2 几何形状和外观之间的解开
在图S11中,我们可视化了更多具有相同姿势和形状条件但具有不同潜在代码的合成人类化身。 我们观察到 AvatarGen 可以根据输入 SMPL 信号的指定合成具有所需形状和姿势的不同化身。 这清楚地表明所提出的分解管道可以很好地将几何生成与外观分开,从而使可动画化身的生成成为可能。

B.3与 2D GAN 的比较
我们在图 S12 中展示了 2D StyleGAN2 与我们的生成结果的比较。 两个模型均在 DeepFashion 上以 分辨率进行训练。 虽然StyleGAN2的FID比我们的低很多(即., 3.07 vs. 7.68),但它是StyleGAN2 很难捕捉人体结构,因此会出现不自然姿势和扭曲身体部位的伪影。 然而,我们的方法利用几何先验和学习的 3D 感知表示,可以有效地捕获人体结构并在给定所需条件的情况下生成高质量图像。

B.4 更多可视化结果


