知识增强深度学习及其应用:调查
摘要
尽管过去几年深度学习模型在许多不同领域取得了巨大成功,但通常需要大量数据,在未见过的样本上表现不佳,并且缺乏可解释性。 目标领域中通常存在各种先验知识,它们的使用可以缓解深度学习的缺陷。 为了更好地模仿人类大脑的行为,人们提出了不同的先进方法来识别领域知识,并将其集成到深度模型中,以实现数据高效、可泛化和可解释的深度学习,我们将其称为知识增强型深度学习(KADL)。 在本次调查中,我们定义了KADL的概念,并介绍了其三个主要任务,即知识识别、知识表示和知识集成。 与现有的专注于特定类型知识的调查不同,我们提供了广泛而完整的领域知识及其表示形式的分类。 基于我们的分类法,我们对现有技术进行了系统回顾,这与调查与知识分类法无关的集成方法的现有工作不同。 这项调查包含了现有的工作,并提供了知识增强深度学习一般领域研究的鸟瞰图。 对大量论文进行彻底和批判性的评论不仅有助于了解当前的进展,还可以确定知识增强深度学习研究的未来方向。
索引术语:
领域知识、深度学习、神经符号模型、物理深度学习。我简介
尽管现有深度模型在各个领域取得了令人印象深刻的性能,但它们存在一些严重的缺陷,包括数据依赖性高和泛化性差[1]。 这些缺陷主要源于模型的数据驱动性质以及它们无法有效利用领域知识。 为了解决这些局限性,知识增强的深度学习范式开始吸引研究人员的注意,通过领域知识和可观察数据协同工作,产生数据高效、可泛化和可解释的深度学习算法。
现实世界的领域知识非常丰富。 在深度学习背景下,领域知识主要来源于两个来源:目标知识和测量知识。 目标知识控制我们想要预测的目标变量的行为和属性,而测量知识控制产生目标变量的观测数据的底层机制。 基于其表示,我们建议将深度学习中探索的领域知识分为两类:科学知识和经验知识。 科学知识代表了某个领域中控制目标变量的属性或行为的既定定律或理论。 相比之下,经验知识是指从长期观察中提取出来的众所周知的事实或规则,也可以通过人类的推理来推断。 知识可以以各种格式表示和组织。 科学知识通常用数学方程来严格地表示。 另一方面,经验知识通常以不太正式的方式表示,例如通过逻辑规则、知识图或概率依赖性。 具有不同表示形式的知识通过不同的集成方法与深度学习框架中的数据集成。
认识到当前深度学习的缺陷,最近人们对捕获先验知识并将其编码到深度学习中越来越感兴趣。 两种主流技术是神经符号集成和物理信息深度学习。 神经符号集成模型侧重于将经验知识编码到传统符号人工智能模型中,并将符号模型与深度学习模型集成。 物理信息深度学习侧重于将各种理论物理知识编码到深度学习的不同阶段。 目前该领域的调查论文范围有限,因为它们侧重于回顾神经符号模型或物理信息机器学习方法,而忽略了许多其他相关工作。 具体来说,现有的神经符号模型研究主要包括对逻辑规则或知识图谱的讨论,以及它们与深层模型的集成[2, 3]。 然而,现有的基于物理的机器学习研究仅限于特定的科学学科,并且集成方法通常是特定于任务的,例如物理学[4, 5]、网络物理系统[6]、几何[7]和化学[8]。 因此,这些调查主要集中在实验室环境下解决科学问题的方法,缺乏对实际应用的讨论。 为了解决这一局限性,我们对知识增强深度学习的现有工作进行了全面而系统的回顾。 我们的调查的贡献有三方面:
-
•
这项调查创建了一种新颖的领域知识分类法,包括科学知识和经验知识。 我们的工作包含专注于特定学科领域知识子集的现有工作[4,5,6,7,8]。
-
•
这项调查涵盖了知识表示和与系统分类整合的广泛方法。 它与现有的一般集成技术调查不同,后者与领域知识的分类不可知[9,10,11,12,13]。
-
•
这项调查涵盖的方法不仅适用于解决实验室环境下的科学问题,更重要的是适用于现实世界的应用任务。 本次调查不限于特定的应用任务,涉及从计算机视觉到自然语言处理的任务。 因此,我们的调查不仅引起了深度学习研究人员的兴趣,也引起了不同领域的深度学习从业者的兴趣。
II 知识增强深度学习
知识增强深度学习的主要任务包括知识识别、知识表示以及将知识集成到深度模型中。 在以下部分中,我们将详细介绍每项主要任务。
| Knowledge Identification | Knowledge Representation | Knowledge Integration | |||
| Data-level | Architecture-level | Training-level | Decision-level | ||
| Scientific Knowledge | Mathematical Equations | [14] | [15][16][17][18] | [19] [20][21][22] | |
| [23][24][25] | [26][27][28][29] | ||||
| [30] [31] [32][33] | [34][35] [36] [37] | ||||
| [38] [39][40][41] | [42][43][44][45] | ||||
| [46] [47] [48][49] | [50, 51, 52][53] | ||||
| [54] [55] | |||||
| Simulation Engines | [56][57][58][59] | ||||
| [60][61] [62][63] | |||||
| Experiential Knowledge | Probabilistic Relationships | [14][64][65] | [66][67][68][69] | [70][71][72][73] | [64][14] |
| [74] | |||||
| Logic Rules | [22] | [75] | [76][77] | ||
| Knowledge Graphs | [78][79][80] | [81][82] | [83][84] | ||
II-A 知识识别
知识识别涉及识别特定任务的领域知识。 对于某些任务,领域知识是容易获得的,因此很容易识别,而在其他任务中,知识则不太简单,需要领域专家的努力来识别。 在本次调查中,我们将领域知识分为科学知识和经验知识。 科学知识是规定性的,主要是指明确的数学理论或物理定律。 这些定律通过科学实验得到了广泛验证,并且在普遍情况下都是正确的(例如牛顿定律)。 这些定律明确定义了系统中涉及的不同变量之间的确定性关系。 最近基于物理的机器学习工作旨在利用不同学科的各种科学知识来增强深度学习。 经验知识是描述性的,主要指日常生活中众所周知的事实,表明一个实体的语义属性或多个实体之间的语义关系。 经验知识通常是从长期观察中提取的,但也可以从完善的研究或理论中得出。 后一类经验知识是以科学为基础的,侧重于语义和抽象层面的描述。 经验知识通常包含大量碎片信息,并且可能是不确定的、不精确的或模糊的。 神经符号模型的最新工作重点是将经验知识嵌入到深度学习中。
II-B 知识表示
知识表示涉及以组织良好和结构化的格式表示已识别的领域知识。 适当的表示取决于领域知识的类型。 科学知识通常用方程来表达。 此外,模拟引擎也被认为是科学知识的替代表示。 与科学知识相比,经验知识不太正式。 经验知识可以通过概率关系、逻辑规则或知识图来表示。
II-C 知识整合
知识集成需要将领域知识集成到深层模型中。 通过集成,深度模型可以利用现有数据集和领域知识来完成某些任务。 根据知识的类型可以采用不同的集成方法,可以分为四个层次:数据层、架构层、训练层和决策层,如图1 。
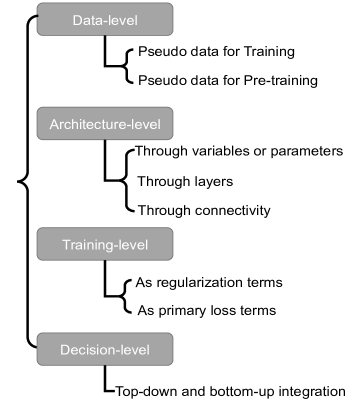
数据级集成侧重于通过使用基于知识生成的伪数据来增强原始训练数据来集成知识。 架构级集成通过修改神经网络架构来嵌入知识。 训练级集成通过从知识派生的正则化项或主要损失项来规范深度模型的训练。 最后,决策级集成将先前模型的自上而下的预测与深度模型的自下而上的预测相结合,从而在先前模型中编码的知识有助于完善深度学习管道的预测。
每种类型的集成都可以从不同的方面受益。 数据级集成可以帮助缓解许多深度模型所面临的数据匮乏问题[56,57,58,59]。 此外,与人类相比,通过自动模拟生成数据通常更便宜。 架构级集成带来的好处是使深层模型可解释和可解释,这是值得信赖的人工智能的两个关键因素[85]。 由于其简单性,训练级集成可以被视为最常见的方法。 可以灵活应用于不同的深度模型框架。 训练层面整合的灵活性也促进了知识不确定性的量化[53,54,45,55]。 决策级集成与前三种方法不同,它使用独立于深度模型训练的知识,并且现有工作相对较少进行探索。
集成方法的选择既可以依赖于任务,也可以依赖于知识。 如果知识需要以硬方式集成,那么架构级集成将是首选。 其余三种集成方法(即数据级、训练级或决策级)以软方式将知识引入深度学习管道。 其次,如果知识仅涉及目标变量(即神经网络的预测),则首选训练级集成。 为了执行其他三种类型的集成,知识预计涉及测量(例如,中间变量或观察)和目标变量。 最后,如果识别的知识由高度非线性和复杂的关系组成,那么利用成熟的引擎或模拟器进行数据级集成将是首要选择。
III 利用科学知识进行深度学习
深度学习模型在传统上由机械(例如第一原理)模型主导的先进科学和工程领域中变得越来越重要。 对于专家未能充分理解其发生机制的科学问题或在计算上无法实现精确解决方案的问题,此类模型具有特别有前途的性能。 然而,现有的深度学习需要大量带注释的数据,并且对于新数据或设置的泛化能力较差。
关于将科学和工程中的传统方法与现有的数据驱动的深度模型相结合,研究界越来越达成共识。 结合科学知识的深度学习探索了经典机械模型和现代深度模型之间的连续性。 机器学习社区一直在努力将科学知识融入深度学习(也称为基于物理的机器学习),以生成物理上一致且可解释的预测,并减少数据依赖。
下面,我们首先确定科学知识的类型及其表征。 然后,我们介绍将科学知识与深度模型相结合的不同方法。
III-A 科学知识识别
科学知识是指经过广泛科学实验验证且在普遍环境中正确的数学或物理方程(例如牛顿定律)。 这些定律明确定义了系统中涉及的不同对象之间的确定性和精确关系。
当前基于物理的深度学习试图探索经典力学模型的使用。 对于动态系统,最广泛考虑的科学知识是牛顿力学,它包括运动学和动力学。 前者指的是可观察的运动(例如运动轨迹),通常用涉及可测量属性(例如速度、加速度或位置)的多项式方程来表示。 运动学研究运动而不考虑原因。 相比之下,动力学研究运动的原因,利用偏微分方程 (PDE) 来捕获力和可测量属性之间的关系。 现有的工作探索了动力学在各种物理系统中的应用(例如气体和流体动力学[86]和蛋白质分子动力学[87, 88])。 通过对动力学的理解,可以更好地预测运动学。 因此,牛顿力学在现实世界的应用中得到了利用,例如人体行为分析[29,89,90]。 不幸的是,牛顿力学可能会导致运动方程难以求解,即使对于看似简单的系统(例如双摆系统)也是如此。 可以考虑拉格朗日力学或哈密尔顿力学。 作为牛顿力学的重新表述,拉格朗日力学和哈密顿力学都利用广义坐标,使它们能够灵活地使用哪些坐标来理解系统。 在拉格朗日力学中, 定义为系统的动能 和势能 之间的差(即 )。 哈密顿量 类似于拉格朗日量 ,定义为动能 和势能 的总和,系统的(即 )。 在拉格朗日力学中,位置的时间导数被视为广义动量,而在哈密顿力学中,则考虑动量。 对于简单的粒子系统,这种差异是微不足道的,而在更复杂的系统(例如磁场)中,动量不能再被计算为质量和速度的简单乘积。 拉格朗日系统和哈密顿系统的动力学方程随着时间的推移通过保守力守恒能量。
对称性在物理学中也得到了广泛的探索。 菲利普·安德森(Philip Anderson)有句著名的论点:“说物理学是对对称性的研究,这只是稍微夸大了这一点”[91]。 事实证明,发现对称性对于加深对物理学的理解和增强机器学习算法都很重要。 等变或不变函数保留了对称性,并且经常被用来将这些对称性合并到深度学习算法中。
光学,另一种物理知识,也被考虑在内。 光学研究光的行为和特性。 费马原理[92]是光学的基本定律。 此外,照明模型[93]和渲染方程[94]捕获3D对象外观及其图像外观。 现有的工作探索了不同计算机视觉任务[95, 96]和计算机图形任务[97,98,99]使用各种照明模型。
除了物理知识之外,还考虑了数学理论,例如现有算法的定理(例如排序或排名)以及连续松弛[100]。 射影几何理论[101]广泛应用于各种计算机视觉任务。
III-B 科学知识的表达
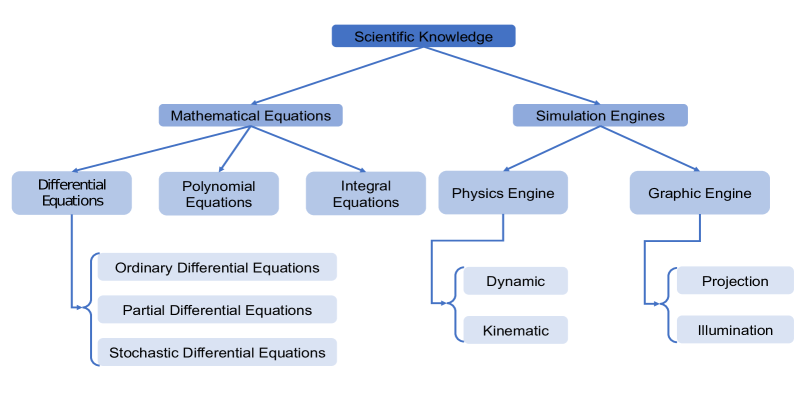
科学知识通常用方程来表示,例如微分方程。 科学知识的另一个重要的表达工具是模拟。 模拟模仿现实世界的物理系统,并被视为支配现实世界物理系统的物理原理的替代表示。 我们在图2中可视化了科学知识的分类及其表示形式。
III-B1 数学方程
方程可以包括多项式方程、微分方程和积分方程,其中微分方程在现有工作中被广泛探索。 动态规律通常用偏微分方程来表示,它表明不同变量之间的确定性关系。 一般来说,偏微分方程的形式为
| (1) |
其中是系统中涉及的变量。 是一般微分算子,是边界条件算子。 表示物理域,表示域的边界。 表示偏微分方程中涉及的物理参数。 对于简单系统,物理参数是常数(即)。 是强制项,指定边界条件,例如达西流问题的狄利克雷边界条件[54]。 是给定指定边界条件下微分方程的解。 当仅存在一个变量时,方程就变成常微分方程 (ODE)。 当项(例如,物理参数 )存在于经历随机过程的微分方程中时,方程就变成随机微分方程 (SDE)。 SDE 的一般形式类似于标准微分方程,但随机事件 除外:
| (2) |
物理参数 和强迫项 被建模为随机过程,因此解 遵循由 指定的随机过程,并且。
当我们显式设置其中一个变量对应于时间 时,微分方程描述了系统随时间的演化,这通常发生在不同的动态系统中。 例如,欧拉-拉格朗日方程定义了拉格朗日系统的动力学,
| (3) |
它连接拉格朗日 的导数相对于广义坐标 、时间 和广义动量 中的位置。 现有著作对微分方程进行了广泛的探索,例如牛顿第二定律[16, 34]、气体和流体动力学中的伯格斯方程[86]、汉密尔顿方程哈密顿动力学 [25]、拉格朗日动力学的欧拉-拉格朗日方程 [102] 以及描述用于大气对流的非线性混沌系统的洛伦兹方程 [103]。
光定律也可以用方程表示。 费马原理考虑了光路上的积分。 在[97]中,瞬态成像系统中的瞬态通过积分来表征:
| (4) |
其中 是行驶路径长度, 是可见点。 测量表面的单位面积,函数 吸收反射率和阴影。 还考虑了表示为积分方程的渲染方程[104]。 还考虑了等式代数方程。 根据反射定律,有反射的图像是玻璃反射后景与玻璃透射前景之和,即:
| (5) |
这种等式代数方程被证明有助于反射消除任务[98]。 另一个例子是马鲁斯定律,用代数方程表示,它定义了极化的影响[99]。
III-B2 模拟引擎
除了用方程明确地表示物理定律之外,通过引擎进行模拟是另一种表示方法。 模拟模仿受物理定律支配的真实物理系统,因此被认为是知识的替代表示。 物理引擎主要编码物理系统的动态控制规律,例如刚体、软体和流体。 它通过求解运动方程,根据力计算物体的加速度、速度和位移。 具体来说,物理引擎在给定某些原因的情况下,根据控制动态规则来模拟可观察的运动学。 为了模拟给定特定力的刚体物体的一系列运动,需要考虑物理引擎[61,105,62,106,36,107]。 这些模拟器大多数都是不可微分的,因此禁止在端到端深度学习框架中使用它们。 还存在对机器人操纵的运动学定律进行编码的模拟引擎。 然而,这些逆引擎使用运动学方程来估计控制动作,以便可以达到所需的位置,而与潜在的动态定律[35]无关。 图形引擎也得到了探索。 图形引擎对原则性的投影和照明模型进行编码,并按照控制原则渲染真实的 2D 观察结果。 例如,提出了一种受反射定律控制的引擎来生成忠实的图像渲染[98]。
III-C 集成到深度模型中
为了将特定领域的科学知识集成到深度模型中,现有的方法可以分为三类:数据级、架构级和训练级集成,如图1所示。 科学知识很少考虑决策级集成。 下面我们回顾一下使用这些方法将科学知识整合到深度模型中的方法。
III-C1 数据级集成
利用领域知识的一种方法是使用从传统机械模型合成的数据来训练深度模型。 捕获领域知识的基于物理的机械模型充当模拟器,并用于生成合成数据。 模拟数据可以与真实数据结合起来联合训练模型,也可以独立使用通过自监督学习来预训练模型。
模拟数据已广泛应用于整个训练,不需要额外的真实训练数据。 在计算机视觉领域,Mottaghi 等人[62]提出,在给定静态 2D 图像的情况下,通过预测查询对象在 3D 空间中的长期运动作为对力的响应来理解作用在查询对象上的力。 其过程概述如图3所示。
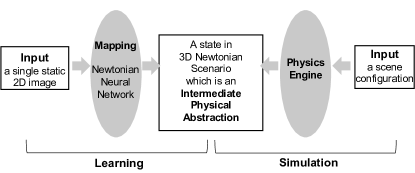
搅拌机111http://www.blender.org/游戏引擎由物理引擎和图形引擎组成,用于模拟。 具体来说,物理引擎将场景配置作为输入(例如,在幻灯片上滑动的球),并根据牛顿第二定律导出的运动方程及时模拟场景,以产生不同的牛顿场景。 物理参数(例如力大小)是随机采样的。 对于每个牛顿场景,图形引擎都会在透视投影的不同视点下渲染来自合成 3D 世界的 2D 视频。 训练中总共使用了 66 个合成视频,对应 12 种可能的物理生成场景。 同样,为了更好地理解人类与 2D 视频中的物体的交互,Ehsani 等人[61]提出了通过推断视频中的接触点和力来对动作进行物理理解。 在给定观察视频的情况下,应用正向物理模拟来监督力估计,而不需要力的 GT 标签。 特别是,通过受牛顿第二定律支配的物理模拟,在给定估计力的一段时间内估计移动物体的 3D 接触点。 然后应用投影算子将估计的 3D 关键点转换为 2D 空间。 通过随着时间的推移最小化估计的和观察到的二维接触点之间的差异,可以获得物理上一致的力。 为了执行可微的物理模拟,使用 PyBullet222https://pybullet.org/wordpress/ 模拟器,专注于遵循牛顿第二定律的刚体模拟。 同样,Tobin 等人[63]展示了机器人模拟生成的合成样本对于训练对象定位任务的深度模型的有效性,这对于机器人操作很有帮助。 通过使用 MuJoCo 物理引擎进行模拟,333https://mujoco.org/,基于其内置图形引擎[108]生成模拟2D图像。 特别是,MuJoCo 物理引擎是基于牛顿力学构建的。 内置图形引擎通过透视投影在 3D 虚拟环境中渲染给定选定摄像机的 2D 图像。 为了确保足够的仿真可变性,提出了域随机化策略,其中仿真参数(例如对象的位置和方向)在仿真过程中都是随机指定的。
深度模型训练通常从预训练阶段开始,然后进行微调。 现有研究还表明,预训练会影响深度模型的最终性能,主要是因为预训练不佳会导致模型锚定于局部最优。 通过模拟数据进行预训练已证明有助于改进参数的初始化。 Jia 等人[56, 57]引入了物理引导循环神经网络(PGRNN)来模拟湖泊温度动态。 PGRNN 根据基于物理的机械模拟器生成的合成数据进行预训练,然后使用一些观测数据进行微调。 模拟器通过偏微分方程将湖泊温度动态建模为物理参数(例如水清澈度和风遮挡)的函数。 结果表明,即使使用一组不完善的物理参数生成的合成数据,PGRNN 仍然可以获得有竞争力的性能。 这种想法也在工程学科中得到了探索。 在机器人学领域,Bousmalis 等人[58]表明,通过物理引导的初始化,精确抓取物体所需的观测数据显着减少(减少了 50 倍)。 在自动驾驶方面,Shah 等人[59]使用基于嵌入物理定律的游戏引擎构建的模拟器生成的合成样本来预训练驾驶算法。 具体地,模拟器包括车辆模型和物理引擎。 为了描述虚拟 3D 环境,需要手动指定物理参数,例如重力、空气密度、气压和磁场。 利用这些指定的参数,物理引擎可以根据牛顿第二定律推导出的运动方程来预测运动状态,以及根据车辆模型估计的力和扭矩。 这项工作表明,通过使用模拟样本进行预训练可以大大减少驾驶算法的数据需求。 除了通过物理引擎模拟来增强数据之外,还可以根据数学方程[14]生成合成数据。
III-C2 架构级集成
还可以通过神经网络架构的定制设计来集成领域知识。 架构级集成可以通过以下方式完成:1)引入特定的物理意义变量或神经网络参数,2)引入从领域知识派生的层,以及3)在神经元之间引入物理启发的连接。 我们在下面介绍每种类型的方法。
通过变量或参数进行积分
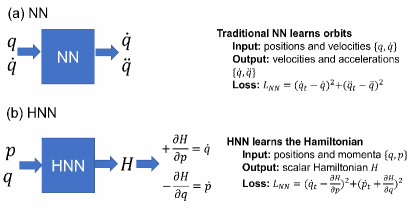
将物理原理嵌入神经网络架构的一种方法是在神经网络中引入具有物理意义的变量。 该变量可以是神经网络的输出节点。 强制能量守恒的哈密顿函数引起了广泛关注[25,24,30,31]。 物理学中的哈密顿算子是对具有守恒量的动态系统进行建模的主要工具。 在哈密顿力学中,经典物理系统由广义坐标 和共轭动量 来描述。哈密顿量然后计算系统的总能量。 定义系统动力学的哈密顿方程如下:
| (6) |
受哈密顿力学的启发,人们提出了哈密顿神经网络(HNN),其输出代表哈密顿动力学,通过该网络明确地强制执行能量守恒[24]。 传统神经网络和 HNN 之间的差异很容易理解,如图 4 所示,传统神经网络学习预测粒子轨迹,而 HNN 学习粒子的哈密顿量,据此可以预测轨迹。
Choudhary 等人[25]后来证明,HNN可以通过强制总能量守恒来更好地处理混沌系统中的高度非线性动力学。 为了证明哈密顿形式主义的实际重要性,哈密顿函数被纳入生成网络中,其中哈密顿动力学是从没有域坐标假设(例如图像)的二维观察中学习的。 所提出的哈密顿生成网络已应用于密度估计,形成神经哈密顿流[24]。 通过利用哈密顿形式主义,可以轻松守恒总概率,同时密度建模仍然具有表现力。 与 HNN 具有类似的想法,在拉格朗日神经网络 (LNN) [32, 33] 中探索了采用拉格朗日力学的广义能量守恒,其中 LNN 的输出是拉格朗日动力学。 然而,对所有这些现有提出的模型的评估仍然是概念性的,没有在实践中得到真正的应用[38]。
变量也可以是神经网络中的中间变量。 Jaques 等人[16]提出了一种称为牛顿变分自动编码器(NewtonianVAE)的潜在动力学学习框架。 受牛顿第二定律的启发,定义了隐藏空间中的线性动态系统,特别是考虑具有 自由度的刚体系统,并通过一组坐标 。 其动力学定义为
| (7) |
其中 是给定的驱动。 为了将上述动态方程合并到 VAE 中,位置 被视为随机变量,速度 为中间变量。 具体来说,速度计算为,时间间隔为。 给定 的 的条件分布现在变为
| (8) |
其中 、 和 通过神经网络 进行估计,其输入由当前系统状态组成(即})。 然后,牛顿 VAE 在给定估计的 的情况下输出 2D 图像。 这与现有方法形成鲜明对比,现有方法简单地假设 上的高斯分布,而不考虑位置、力和速度之间的潜在确定性关系,如方程式 1 所示。 (8)。 同样,为了结合平流扩散偏微分方程控制的输运动力学背后的物理原理,刘等人[15]提出了一种基于自动编码器的学习框架,其中显式结合了平流扩散方程。 编码器的两个隐藏变量输出具有物理意义,分别表示平流扩散方程中的速度场和扩散场。 为了模拟湖泊温度,Daw 等人[17]为所提出的保持单调性的长期短期记忆(LSTM)架构引入了一个物理上有意义的中间变量。 具体来说,密度值作为LSTM的中间变量,随着深度的增加而单调增加,这是湖泊温度的一个重要特征。 类似的想法适用于对作用在移动流体中每个粒子上的阻力进行建模[18]。 Muralidhar等人[18]提出了一种PhyNet,其中物理约束的中间变量被引入到卷积神经网络(CNN)架构中。 具体来说,将分别表征速度场和压力场的两个中间变量引入CNN中进行阻力预测。
除了引入物理上有意义的变量之外,另一种方法是将一些神经网络参数直接映射到物理上有意义的参数。 这些物理参数可以在训练期间不可修改,也可以通过观察学习进行微调。 在地球物理学中,神经网络已被考虑用于模拟地震波形反演的动态过程[23]。 为了模拟地震波传播,提出了一种理论引导的循环神经网络(RNN); RNN 是专门为求解控制微分方程而设计的,其中一些参数被指定为控制物理方程中的物理参数。 特别是,给定在时域中离散化的波动方程,下一个时间步长(即 )的波场是根据前两个时间步长(即 )计算的。 > 和 ) 作为
|
|
(9) |
其中是空间拉普拉斯算子,代表位置,是源函数。 给定和的的符号计算直接通过神经网络实现,其可训练参数对应于物理参数波动方程 Eq. (9)。
层层整合
通常通过神经网络层集成的最具代表性的知识类型涉及对称性。 对称通常指一组可逆变换,例如平移、旋转或缩放。
等变性和不变性作为对称性的代表类型已被广泛考虑。 不变函数是一种映射,使得输出空间不受输入空间中的对称变换的影响,而等变函数放松了不变函数。 它陈述了一种映射,使得输入空间中的对称性可以保留在输出空间中。 从数学上讲,假设有一个对称变换 和一个函数 ,从 映射到 。如果 被认为与 等价,如果
| (10) |
输入空间 上的对称变换 保留在输出空间 上。 被认为是不变的,如果
| (11) |
换句话说,输出 不受作用于输入空间 的对称变换 的影响。不变性可以是等变性的特例,反之亦然。 例如,转换 是与 的标识转换。
等变或不变神经网络旨在保持对称性。 在计算机视觉中探索了照明不变性特征[47],其中将知识引导的卷积层合并到现有的深度模型中。 考虑昼夜域适应问题,从源域到目标域的照明变化会导致分布变化。 为了解决分布偏移问题,需要对光照不变的特征,这可以从 Kubelka-Munk 理论导出。 Kubelka-Munk 理论[109] 通过定义从观察方向上的物体反射的光谱来模拟材料反射。 Kubelka-Munk理论定义的光照不变特征的计算直接通过所提出的颜色不变卷积(CIConv)层实现,如图5所示。

类似地,在湍流建模中,旋转不变性表明流体流动的物理特性不依赖于观察者坐标的方向,并且是基本物理原理。 为了将旋转不变性嵌入到神经网络中,Ling等人[41]定义了张量基神经网络(TBNN),其中通过添加高阶乘法层来修改NN架构。 特别是,TBNN 有一个额外的输入层接受张量基,并且其最后一个隐藏层使用该张量基输入层执行成对乘法以提供输出。 修改后的架构确保预测基于旋转不变张量。 通过结合旋转不变性,TBNN 提高了预测归一化雷诺应力各向异性张量的准确性。 在分子动力学应用中,Anderson等人[46]提出了一种旋转不变神经网络,名为Cormorant,通过该网络可以学习复杂多体物理系统的行为和性质。 Cormorant 中的每个神经元明确对应于原子的一个子集。 给定指定的神经元,激活层确保与旋转协变,使得所提出的鸬鹚保证旋转不变。
还对等方差进行了探索。 Wang等人[39]表明,现有的时空深度模型可以通过等变函数合并对称性来提高泛化能力。 更具体地说,他们考虑了四种类型的等方差:时间和空间平移等方差、旋转等方差、匀速运动等方差和尺度等方差。 使用定制的等变层将这些对称性合并到神经网络中。 通过层等变函数的组合,网络变得等变。
然而,在现实的物理世界中,对称性可能是脆弱的。 例如,一个小的扰动很容易导致动态系统的不连续转变或破坏摆系统的旋转对称性。 小的扰动经常发生,随着时间的推移,这些扰动的积累可能会导致显着的差异。 因此,通过定制层强制等方差作为硬归纳偏置可能会出现问题。 为了解决这个问题,Finzi等人[40]最近提出了一种施加等方差约束的软方法,其中所提出的神经网络架构由限制层和灵活层的混合组成。 限制层受到严格约束,而灵活层则不受约束。 通过混合两种类型的层,引入等方差作为灵活的归纳偏置。
通过连接进行集成
给定对象之间的物理依赖性,可以手动指定神经网络神经元之间的连接性。 为了对涉及多个对象的动力学进行建模,采用物理上合理的交互来设计神经网络连接。 神经物理引擎(NPE)是一种将符号结构与基于梯度的学习相结合的可微物理模拟器,已被提出[48]。 与基于机械模型的传统物理引擎不同,NPE 被实现为基于学习的神经网络,同时在不同场景中保持通用性。 NPE 的发展考虑了物理学在时间和空间上都是马尔可夫的这一事实。 时态马尔可夫允许 NPE 仅通过考虑当前步骤的状态来预测系统状态。 空间马尔可夫允许 NPE 将交互动态分解为成对交互。 NPE 由模仿对象之间成对交互的符号模型结构组成,并以神经网络的形式实现。 NPE 以 2D 观测结果作为输入,并执行前向动力学来预测物体未来的运动。 针对n体交互系统[49]独立开发了一项非常相似的工作。
III-C3 培训级集成
将科学知识融入深度模型的最常见技术之一是通过深度模型的训练。 特别是,对深度模型输出的约束源自科学知识,并用作训练深度模型的正则化项。 增强训练目标通常表示为
| (12) |
表示给定预测 和真实标签 的标准训练损失。 对于分类任务,通常是基于交叉熵损失来定义的。 基于物理的正则化项对应于物理约束,具有可调整的重要性系数。 当基于物理的约束独立于输入时,正则化项减少为。 通过 ,训练被引导生成具有物理一致输出的模型。 基于物理的正则化 的计算不需要观察的注释,因此允许在训练中包含未标记的数据,从而减少对数据的依赖。 基于物理的正则化 也可以以无标签的方式直接用于训练深度模型。
可以是显式的,也可以是隐式的,可以灵活地运用在不同的深度学习框架中。 显式正则化是直接在基于领域知识的深度模型的输出上定义的,而隐式正则化是由嵌入深度学习管道的基于物理的模型引起的。 接下来,我们介绍两种不同的深度模型框架下的知识引导模型正则化:判别性深度模型和生成性深度模型。
使用判别性深度模型进行正则化
科学知识的模型正则化广泛应用于判别性深度模型中。 在气候建模的背景下,源自物理系统应满足的守恒定律的约束被编码为正则化项。 特别是,神经网络 将输入 映射到输出 (即 )。 守恒约束被概括为一个线性系统(即),其中是给定的约束矩阵。 然后,这些物理约束被编码为 NN 输出上的正则化项:
| (13) |
评估结果表明,通过添加这种物理引导的正则化,模拟云过程的预测性能得到了提高[19, 20]。 类似地,Zhang等人[21]提出通过神经网络参数化分子动力学的原子能,其损失函数考虑动能和势能守恒。 还考虑了具有非保守力的物理系统的正则化[22]。 在有摩擦的双摆系统中,由于摩擦的存在,系统的总能量不断减少。 能量的减少被表述为约束,其中和分别表示系统在当前时间步长和未来时间步长的总能量。 考虑到神经网络将当前时间步的状态(即 )作为输入并输出下一个时间步的估计状态(即 ),约束可以通过正则化项集成到神经网络中
| (14) |
其中 和 分别计算当前和下一个时间步的系统能量。 根据能量的减少,预计将小于,从而导致上述约束。 类似地,[26] 中考虑了动态系统的一组常见物理属性,其中每个物理属性都表示为等式或不等式约束。 然后,这些基于物理的约束通过增强拉格朗日方法作为正则化纳入深度模型中。
偏微分方程(如方程 (1) 中所述)已被广泛视为约束,并作为正则化项集成到深度模型中。 提出了一种物理信息神经网络(PINN)[27],用于利用神经网络求解偏微分方程。 PINN 通过使用观测数据和 PDE 来学习解决方案 ,其中 PDE 充当归纳偏差。 以粘性 Burgers 方程为例 [28]:
| (15) |
在 PINN 中,前馈神经网络通过将位置 和时间 作为输入来预测 PDE 解 。 目标函数由数据损失项和 PDE 残差组成,
| (16) |
其中 测量在某些位置和时间步(即 )预测的偏微分方程解 与给定 之间的差异。 测量预测解 在位置和时间步的偏微分方程残差:
| (17) |
给定预测解,通过数值估计器计算偏导数。 数据损失的数据点 和 PDE 残差的数据点 分别收集。 是正则化项的系数。 在 PINN 中,通过测量解残差来约束模型参数,将偏微分方程直接编码为正则化项。 在人体姿态估计的背景下,采用物理力学来确保物理上合理的估计,其中推导出表示为 ODE 的欧拉-拉格朗日方程,并将其编码为模型正则化的软约束。 通过将欧拉-拉格朗日方程集成到数据驱动的深度模型中,可以确保估计的 3D 身体姿态在物理上是合理的[29]。
从领域知识派生的物理引导函数已用于以无标签的方式训练深度模型。 Stewart 和 Ermon [34] 提出了一种利用物理方程对神经网络进行无标签监督的方法。 本文的目标是通过指定应保持输出空间 的约束 来监督神经网络,而不是使用标签。 损失函数则变为
| (18) |
其中 指的是惩罚模型复杂性的附加正则化项。 论文中提供的一个例子是跟踪一个自由落体的物体。 回归网络的训练被表述为在图像序列(即)上运行的结构化预测问题。 牛顿第二万有引力定律(自由落体运动)用代数方程表示,并直接纳入训练的损失函数中。 特别是,对于自由落体的物体,其在时间间隔为 的第 时间步的高度计算为 ,其中 和 是初始高度和速度。 是物体自由落体的固定加速度。 因此,任何预测轨迹 都应该符合具有固定曲率的抛物线。 然后定义损失来测量拟合残差,
| (19) |
在哪里
| (20) |
和 a = [] 与 。 此外,基于完善的算法导出的算法监督已用于神经网络,因此不再需要来自真实注释的直接监督[100]。
对于上述所有相关工作,通用知识和数据信息之间的相对重要性是通过训练目标的设计预先确定的,并且在训练后不可调整。 然而,相对重要性可能因不同的输入而异。 例如,给定不可见的输入,基于数据的预测不太可靠,而知识在最终预测中发挥着更重要的作用。 Seo等人[22]提出了一个框架,其中通用知识相对于数据信息的相对重要性通过控制参数进行调整。 控制参数被假定为遵循预定义分布的随机变量。 从输入数据中提取的两组潜在表示和分别对应于通用知识和数据信息。 最终的潜在特征作为获得,并用于生成最终预测。 两组损失 和 分别根据下游任务的通用知识和注释定义。 是输入 和输出 的函数,测量对基于特定于目标下游任务的先验知识导出的规则的违反情况(例如,等式14)。 最终训练损失计算为 上的预期损失,即
| (21) |
其中是平衡两个损失项单位的比例参数。 通过所提出的框架,表示相对重要性的 在测试过程中成为一个变量。
上面讨论的物理引导正则化项都是在深度模型的输出空间上明确定义的。 物理引导的正则化项也可以是隐式的(即,由作为神经网络管道的一个中间原语嵌入的基于物理的模型引起)[35,36,37]。 例如,吴等人[36]构建了一个无需人工注释即可理解物理场景的系统。 该系统的核心是物理世界表示,它首先由感知模块恢复,然后由模拟引擎使用。 感知模块是一个深度神经网络,是自我监督的,没有标注。 模拟引擎由物理引擎和图形引擎组成,旨在生成物理预测。
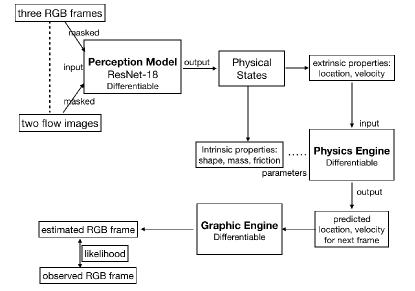
所提出的管道在合成台球桌实验上进行评估,如图6所示。 给定感知模型提取的特征,物理引擎通过遵循运动方程来预测系统的未来物理状态,并且图形引擎根据预测的物理状态渲染RGB图像。 感知模型是通过在给定观察序列的情况下最大化估计 RGB 图像的可能性来学习的。
使用生成深度模型进行正则化
除了判别模型之外,知识也被应用于深度生成模型。 为了生成现实的结果,不同的生成模型探索了领域知识的使用。 例如,为了有效地利用生成对抗网络(GAN)来生成偏微分方程治理的复杂系统的解决方案,吴等人[44]提出了一种统计约束的GAN,其中导出统计正则化项来测量训练样本和生成样本的协方差结构之间的距离,
| (22) |
其中和分别代表标准判别器和生成器,代表GAN的标准训练损失。 和分别表示训练数据和生成样本分布的协方差结构。 表示距离测量,例如 Frobenius 范数。 表示正则化项的系数。 在低维流形上引入统计约束(即协方差结构)有助于减少在高维中寻找所需解的搜索空间。 结果,不仅减少了数据量,而且收敛解所需的训练时间也缩短了,正如求解湍流偏微分方程所证明的那样。 在计算材料科学的应用中,Shah等人[43]提出了一种名为InvNet的深度生成模型,通过该模型生成满足期望物理性质的合成结构化样本。 InvNet 是传统 GAN 的扩展,其中引入了额外的不变性检查器以及传统的生成器和判别器。 引入不变性检查器作为中间原语,并在此基础上定义隐式知识引导正则化项。 不变性损失是基于所提出的不变性检查器定义的,测量对不变性的违反。 通过不变性损失,鼓励生成的样本满足某些不变性(例如主题不变性,在固定位置的所有合成图像中植入预定义的主题)。 除了以偏微分方程表示的知识之外,实际 3D 形状生成还考虑了物理连接性和稳定性。 Mezghanni 等人[42]提出将物理约束纳入深度生成模型,从而物理约束捕获 3D 组件的连通性和 3D 形状的物理稳定性。 然后定义完全可微的物理损失项,以将物理约束集成到神经网络中。 具体来说,提出了一种神经稳定性预测器,作为神经网络分类器实现并使用模拟数据进行预训练,以强制执行物理稳定性约束。 对于模拟数据中的每个合成 3D 形状,其稳定性由 Bullet 物理引擎标记。 稳定性约束通过预先训练的稳定性分类器进行编码,并通过稳定性损失集成到深度模型中。
变分自动编码器 (VAE) 也已与物理集成进行了探索,以实现稳健且可解释的生成建模[51, 52]。 特别是,以偏微分方程表示的物理知识被集成到 VAE 中。 VAE 的潜在变量受到偏微分方程定义的约束。 此外,在[50]中,不是假设完全访问偏微分方程的完整表达式,而是假设只有部分偏微分方程是已知的,VAE的潜变量部分地基于物理意义偏微分方程的已知部分。 其余未知的偏微分方程以数据驱动的方式建模。
利用概率框架,在基于物理的深层模型中考虑了不确定性量化[53,54,45,55]。 Zhu 等人[54]考虑了物理信息CNN通过不确定性量化求解偏微分方程。 不确定性源于物理参数的随机性,表示为随机向量,其中是可能的物理参数设置的总数并且可以非常高。 相应地,偏微分方程对于每个可能的物理参数设置的解变为。 任务是在给定一组观察值 和 的情况下对 进行建模。 表示要学习的神经网络参数。 同时,PDE 解的不确定性通过方差 进行建模。 为了训练神经网络,不使用标记数据,而是仅基于偏微分方程及其边界条件定义基于能量的模型,从中我们获得参考密度。 特别是,参考密度 遵循 Boltzmann-Gibbs 分布:
| (23) |
其中 是构建的基于能量的模型的可学习参数。 能量函数 测量偏微分方程和边界条件的违反情况。 是一个可调的超参数。 物理方程被编码到基于能量的概率模型中。 最后,通过最小化估计分布和参考分布之间的 KL 散度来训练神经网络:
| (24) |
通过训练过程,物理方程被集成到神经网络中。 同样,Yang 和 Perdikaris [53] 通过考虑方程的下界简化了目标函数。 (24)。 遵循类似的想法,Karumuri 等人[55]采用深度残差网络(ResNet)以无标签方式求解椭圆随机偏微分方程。 特别是,基于物理的损失函数被定义为随机变量概率分布上的偏微分方程残差的期望。 上面讨论的所有三项工作都集中于与时间无关的物理系统,不随时间演化。 Geneva 和 Zabaras [45] 将这一想法扩展到动态系统,其中使用自回归网络来预测给定系统状态历史的未来物理状态。
IV 利用经验知识进行深度学习
除了科学知识之外,经验知识也被广泛认为是神经符号模型知识的主要来源。 经验知识是指日常生活中众所周知的事实,描述一个对象的语义属性或多个对象之间的语义关系。 它通常是直观的,是通过长期观察或完善的研究得出的。 与科学知识不同,经验知识虽然广泛可用,但具有描述性且不精确。 包含语义信息的经验知识可以作为深度学习中预测任务(例如回归或分类任务)的强大先验知识,特别是在小数据环境中,仅训练数据不足以捕获变量之间的关系[65 ]。
IV-A 经验知识识别
根据应用领域的不同,经验知识可能表现为两种类型:实体属性和实体关系。 实体关系揭示了实体之间的语义关系。 它们可以从有关命名实体之间关系的日常事实中推断出来,也可以从成熟的研究或理论(例如解剖学)中得出。 例如,人体解剖学在人体和面部行为分析的计算机视觉中被广泛考虑[14,110,111]。 对于面部行为分析,面部解剖知识可以提供有关面部肌肉之间关系的信息,以产生自然的面部表情。 类似地,身体解剖学可以提供有关身体关节之间关系的信息,以产生稳定且物理上合理的身体姿势和运动。 语义关系可以直接给出或从现有的语义关系间接推断。 例如,根据海伦-米伦出演《墨水心》和海伦-米伦获得最佳女演员奖,我们可以推断出《墨水心》获得了奖项提名。 然而,推断的事实很容易出错。 实体属性捕获有关实体属性的知识。 它们可以引用描述人类感知的世界中概念的层次关系的本体信息[112]。 例如,雨是由水组成的,海是海洋的同义词。 [113, 114]对语言知识作为经验知识的主要来源进行了分析。 大型语言模型被认为是摘要文本推理任务[115]的归纳偏差。 文本解释等语言知识已被探索用于语言模型细化[116]。
IV-B 经验知识的表示
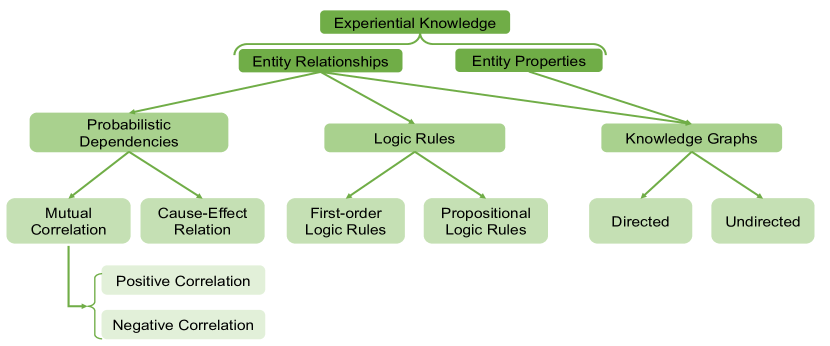
经验知识的表示因领域而异。 一般来说,经验知识的表示包括概率依赖、逻辑规则和知识图。 这些表示捕获了经验知识所揭示的实体的关系和属性。 我们在图 7 中说明了经验知识的分类及其表示形式。
IV-B1 概率依赖性
由于固有的不确定性,对象之间的语义关系广泛地通过概率依赖性来表示。 对象的状态以概率方式建模,从而通过概率依赖性捕获对象之间的关系。 关系又可以分为正相关和负相关。 我们以面部动作单元(AU)为例。 根据FACS[117],AU代表面部肌肉,一根面部肌肉可以控制一个或多个AU。 如果相应的肌肉被激活,则二元 AU 可以打开。 AU1(内提眉肌)和 AU2(外提眉肌)通常一起出现,因为它们由同一块额肌控制。 AU15(降唇肌)和 AU24(降唇肌)是正相关的另一个例子,这是因为它们的底层控制肌(即降口角肌和眼轮匝肌) oris)总是一起移动。 如果两个变量 和 呈正相关(例如,="AU1 "和 ="AU2"),其中 0, 1 和 0, 1,那么我们有
| (25) |
考虑到负相关性,AU12(唇角拉肌)和 AU15(唇角压肌)不能同时作为其对应的肌肉(即,大大肌和降口角肌一起出现) )不太可能同时激活。 负相关可以用类似的方式表示。 如果两个变量 和 负相关(例如,="AU12 "和 ="AU15"),其中 0, 1 和 0, 1,那么我们有
| (26) |
IV-B2 一阶逻辑和命题逻辑
逻辑可以分为一阶逻辑和命题逻辑。 一阶逻辑(FOL)[118]利用逻辑规则从现有的经验知识中推断出新的经验知识;它已被用作推导方法来导出不同类型的知识,例如文本解释[116]。 FOL的计算公式如下:
| (27) |
其中 表示逻辑原子。 每个原子通过谓词捕获已知的对象属性或关系。 原子通过连接(例如合取)运算符组合起来,形成逻辑规则的条件部分。 是逻辑规则隐含的结果或结论。 它代表了从逻辑规则中衍生出来的新的经验知识。 规则的条件部分和结论部分通过蕴涵运算符连接。 例如,我们有
| (28) |
是一个原子,Smokes 是谓词, 作为逻辑变量。 它捕获变量代表的人吸烟与否的实体属性知识。 是隐含的结果或派生知识,它捕获了该人是否咳嗽的知识。 该规则规定,如果条件部分 为 true,则 也为 true。
IV-B3 知识图谱
知识图谱是经验知识的另一种符号表示,主要用于捕获对象之间的语义关系,语义知识以三元组格式表示:(主语,谓语,宾语)。 这种三元组的数量通常很大。 在知识图中,这些三元组被组织为包含节点和边的图。 节点代表主题或对象,例如动物或地点,以及命名实体,例如名为Mary Kelley的人。 边代表谓词并连接节点对并描述它们之间的关系。 此外,边还可以表示实体的属性,节点表示属性。 以三元组(cat, attribute, paw)为例,节点为cat和claw,关系为attribute. 这个三元组陈述了一个事实:“猫的属性是爪子”。 边可以是有向的,也可以是无向的,例如动物之间的食物链关系或人与人之间的社会关系。 知识图可以编码大量常识、规则和领域知识,捕获实体的语义关系和属性。 因此,知识图谱是获取经验知识的重要基础资源。 例如,可以将对象语义的经验知识组织在知识图谱中以进行图像分类[119]。 Miscrosoft 概念图 [120] 是知识图的另一个示例,其中 Miscrosoft 概念图 [120] 中的顶点可以代表食物(例如水果)、哺乳动物(例如狗)和猫,或公共汽车和加油站等设施。 边缘表示基于日常事实的概念之间的关系,例如猫是哺乳动物,其中is反映了cat和哺乳动物。
IV-C 集成到深度模型中
为了将经验知识集成到深度模型中,现有方法涵盖四种类型的集成:数据级、架构级、训练级和决策级,如图1所示。 我们在以下小节中介绍每组方法。
IV-C1 数据级集成
伪训练数据通常被认为包含了表示为概率依赖性的经验知识,并用于增强现有的训练数据。 例如,Teshima和Sugiyama[65]提出将变量之间的条件独立关系纳入预测建模。 首先从先验知识中提取一组变量之间的条件独立关系。 然后通过生成满足提取的条件独立关系的合成数据来增强训练数据。 除了增强训练数据之外,伪数据还可以用于构建先验知识模型。 对于面部AU识别,Li等人[64]提出利用基于知识生成的伪数据来构建无数据先验模型,该模型捕获下游任务的目标变量的先验分布。 对参数和变量的约束首先来自通用的 AU 知识。 然后提出有效的采样方法来生成满足变量和参数约束的伪数据。 然后从伪数据中学习贝叶斯网络,作为无数据先验模型。 类似的想法已在上半身姿势估计任务[14]中得到利用。 四种约束(即连通性约束、体长约束、运动学约束和对称性约束)首先源自人体解剖学知识。 然后在给定这些约束的情况下生成合成数据,并在此基础上学习先验概率模型。
此外,合成数据可以从表示为布尔规则[22]的通用知识生成。 例如,当输入特征 大于常数 (即 )时,-类(即 )的概率会更高。 为了将此布尔规则合并到深度模型中,Seo 等人 [22] 建议用一对扰动的 来增强每个训练数据点 >。 是一个小的扰动正值。 正则化被定义为
|
|
(29) |
如果和,根据先验知识,我们应该有。 如果满足约束,我们就有。 否则,。
IV-C2 架构级集成
描述变量之间关系的领域知识可以通过架构设计集成到深层模型中。 我们讨论分别表示为概率依赖、逻辑规则和知识图的经验知识的架构级集成方法。
纳入概率依赖性的架构设计
架构级集成的一个代表性路线集中于表示为概率依赖性的经验知识,由此根据知识构建的概率模型充当先验模型并嵌入为神经网络的一层。 因此,变量之间的语义关系可以以概率的方式纳入神经网络。 通常,概率模型连接到神经网络的最后一层。 通常采用条件随机场(CRF),它将神经网络的隐藏特征作为输入,并输出满足 CRF 中编码的知识的最终预测(例如,在 AU [66] 之间)。 在[67]中,将全连接的CRF连接到CNN的最后一层,共同执行面部标志检测。 通过利用全连接的 CNN-CRF,获得面部标志点位置的概率预测,捕获标志点之间的结构依赖关系。 对于场景图生成[68],首先通过基于能量的概率模型捕获实体和关系之间的结构化关系。 基于能量的概率模型将典型场景图生成模型的输出作为输入,并通过最小化能量来对其进行细化。 通过概率模型捕获的先验知识也可以用于定义图卷积网络的邻接矩阵[69]。 对于面部动作单元(AU)密度估计任务,采用贝叶斯网络来捕获 AU 之间的固有依赖性。 然后提出了概率图卷积,其邻接矩阵由贝叶斯网络的结构定义。 此外,还可以引入概率模型作为神经网络的可学习中间层。 提出了 CausalVAE [74],其中将因果层引入到变分自动编码器(VAE)的潜在空间中。 因果层本质上描述了结构因果模型(SCM)。 通过因果层,将独立的外生因素转化为因果内生因素,进行因果表示学习。
结合逻辑规则的架构设计
通过神经网络架构进行集成是一种将符号逻辑规则集成到深层模型中的传统神经符号方法。 通过引入逻辑变量或参数,逻辑规则被集成到神经网络架构中。 这种方法可以追溯到 20 世纪 90 年代,当时基于知识的人工神经网络 (KBANN) [121] 和联结归纳学习和逻辑编程 (CILP) [122] 介绍了方法。 最近,提出了逻辑神经网络(LNN)[123],其中每个神经元代表逻辑公式中的一个元素,该元素可以是一个概念(例如,cat)或逻辑连接词(例如,AND、OR)。 然而,这些工作的重点是利用神经网络进行可微分和可扩展的逻辑推理。
很少有人提出通过逻辑规则定制架构来改进深度模型。 为了利用逻辑规则来提高深度模型性能,逻辑规则被编码到马尔可夫逻辑网络(MLN)中,并将构建的MLN作为先验模型嵌入到神经网络中作为输出层,以改进知识图完成任务[75]。 具体而言,首先确定了四种逻辑规则,用于捕捉知识图谱中的知识:(1) 组成规则:如果对于任意三个变量 有 ,则谓词 由两个谓词 和 组成;(2) 逆规则:如果对于任意两个变量 和 有 ,则谓词 是 的逆;(3) 对称规则:如果对于任意两个变量 和 我们有 ,那么谓词 是对称的;(4)子集规则:如果对于任意两个变量 和 我们有 ,那么谓词 是 的子集。 给定一组已识别的逻辑规则,马尔可夫逻辑网络(MLN)将三元组的目标变量的联合分布定义为
| (30) |
其中 是势函数,根据观察到的三元组进行计算。 然后将这样的 MLN 连接到深度模型的最后一层,从而通过给定观察到的三元组的深度模型学习置信度分数 。 通过引入 MLN,预测丢失三元组的任务被重新表述为遵循编码逻辑规则推断未见配置的后验分布。
融入知识图谱的架构设计
知识图谱还可以作为一层集成到神经网络架构中。 梁等人[78]提出了一种带有符号推理的图卷积。 知识图谱中的先验知识通过提出的符号图推理(SGR)层专门集成到神经网络中,如图8所示。
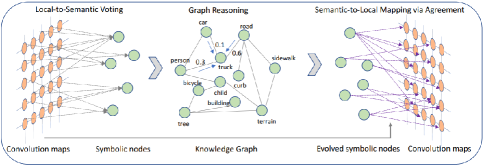
为了使所提出的SGR与卷积层配合,当前卷积层的局部隐藏特征首先被转移到SGR中相应符号节点的特征。 SGR 中符号节点之间的连接性是根据知识图谱中的先验知识定义的。 在先验知识的指导下,SGR 然后执行图形推理并更新特征。 最后,更新的特征被映射到下一个卷积层中的局部特征。 为了在跨视觉域和文本域中以无监督的方式生成医疗报告,提出了一种知识驱动的编码器-解码器模型来利用知识图[79]。 知识图被编码到编码器内的知识驱动注意力模块中。 以图像和医疗报告作为输入,编码器首先通过标准深度模型分别获得图像嵌入和报告嵌入。 然后引入注意机制,其中嵌入是查询,知识图用于定义查找矩阵。 从注意力模块中学习到的表示通过利用知识图来连接视觉和文本域。 在训练期间,通过最小化文本域中生成的医疗报告和观察到的医疗报告之间的重建误差来学习所提出的模型。 在测试过程中,知识驱动的编码器-解码器模型可以利用知识图中适用于视觉和文本领域的经验知识,从医学图像生成医学报告。
CRF 已被用来捕获知识图中的经验知识,并被集成为神经网络的一层。 罗等人[80]提出了一种上下文感知零样本识别(CA-ZSL)方法。 先验对象间关系是从知识图中提取的,并使用条件随机场(CRF)进行编码。 对于包含对象的图像,每个对象的图像区域和类分配分别表示为和,用. CRF模型则定义为
| (31) |
其中一元势 是根据每个对象相应提取的特征进行估计的。 使用提取的特征和知识图来估计成对潜力。 从知识图谱中提取的语义关系被编码在成对的势函数中,其中是一个可调的超参数。 通过最大化对数似然来训练神经网络。 在测试过程中,通过学习的 CRF 模型中的最大后验 (MAP) 推理,以上下文感知的方式推断出未见过的对象的标签。
IV-C3 培训级集成
经验知识被视为指导深度模型训练的先验偏差。 约束是基于知识获得的,并作为正则化项集成到深度模型[77,124,125,112]中。 正则化可以从概率依赖性、逻辑规则或知识图导出,我们将在下面的段落中进一步讨论。
具有概率依赖性的正则化
来自语义关系知识的概率依赖通常通过正则化集成到深度模型中。 Srinivas Kancheti 等人[70]在训练期间考虑因果域先验来正则化神经网络,从而通过正则化强制使神经网络中学到的因果效应与因果关系的先验知识相匹配。 考虑一个具有 输入和 输出的神经网络 ,对于第 个输入, 为包含先验因果知识的 矩阵(就梯度而言)。 为了强制与先验知识一致,定义了正则化
| (32) |
其中是一个二进制矩阵,表示先验知识的可用性,是训练样本的总数。 是 w.r.t 的 雅可比行列式。 第 个输入。 表示可接受的误差范围, 是逐元素乘积。 类似地,Rieger等人[71]提出通过解释损失来惩罚与先验知识不相符的模型解释。 对于 AU 检测任务,AU 之间的概率关系源自面部解剖知识。 这些概率关系中的每一个都被表述为约束。 在[72]中,相应地定义了测量每个约束的满足程度的损失函数,并将其用于学习AU检测器。 不同的是,Cui等人[73]提出学习贝叶斯网络(BN)来紧凑地捕获大量关于AU关系的约束。 然后使用 BN 构建训练深度神经网络的预期交叉熵损失以进行 AU 检测。
用逻辑规则进行正则化
逻辑知识被编码为模型正则化的约束。 通过正则化,如果深度模型的输出违反了逻辑规则导出的约束,那么深度模型就会受到惩罚。 徐等人[76]提出将命题逻辑自动推理技术与现有的深度学习模型相结合。 命题逻辑通过所提出的语义损失被编码在损失函数中。 命题逻辑中的句子是通过变量定义的。 句子是对神经网络输出施加的语义约束。 假设是概率向量,其中每个元素表示变量的预测概率,并对应于神经网络的单个输出。 语义损失 测量对给定 的 的违反:
| (33) |
表示状态满足句子。 状态满足句子的概率越大,语义损失越小。 所提出的语义损失将神经网络正则化与逻辑推理联系起来。 它对于不同的应用都很有效,例如分类和偏好排名。
针对关系预测任务,提出了一种具有语义正则化的逻辑嵌入网络(LENSR)[77],其中命题逻辑被集成到关系检测模型中。 对于给定图像,首先使用标准视觉关系检测模型来估计关系谓词的概率分布。 然后基于给定输入图像预定义的命题逻辑公式提出关系谓词的另一种概率分布。 最后,定义语义正则化来通过最小化这两个概率分布的差异来对齐它们。
利用知识图进行正则化
知识图谱是经验知识的图形表示,也被用于模型正则化。 Fang等人[81]提出从知识图谱中提取语义一致性约束,然后将其用作正则化项。 特别地,一对对象和主体之间的一致性分数是通过重新启动的随机游走来计算的
| (34) |
其中。 和表示目标对象和目标主体的总数。 是总移动步数,是重新启动概率,意味着在每个移动步,都有概率从起始节点重新启动移动到节点的邻居之一。 计算出的矩阵用作语义一致性的约束,并用于对目标检测任务的神经网络进行正则化。 同样,Gu 等人[82]提出从知识图谱中提取外部知识并应用图像重建来改进场景图生成,特别是当数据集有偏差、注释有噪声或缺失时。 对象关系作为外部领域知识从 ConceptNet 中检索,并通过对象到图像生成分支应用于细化对象特征。 对象到图像生成分支根据对象特征和关于对象的先验关系知识重建图像。 可以通过最小化重建误差来学习具有语义意义的对象特征。
IV-C4 决策级集成
来自深度模型和先验知识的预测可以通过联合自上而下和自下而上的预测策略直接组合。 通过整合两组预测,最终的预测可以更加准确和鲁棒。
对于基于开放领域知识的视觉问答,Marino等人[83]结合了隐性知识和符号知识。 隐性知识是指从数据(例如原始文本)中学到的知识。 符号知识是指在现有知识图谱中编码的基于图的知识(例如,DBpedia [126]和ConceptNet [127])。 所提出的KRISP模型包含两个子模块:隐式知识推理和显式知识推理。 然后使用后期融合策略将两个知识源结合起来生成最终输出。 通过后期融合策略,数据和符号知识的预测直接结合起来,独立于深度模型的训练。
两组预测可以按照贝叶斯规则以概率方式组合。 为了获得基于概率知识的预测,采用捕获先验知识的 PGM 模型作为先验模型,并通过概率推理获得其预测。 对于AU识别任务,Li等人[64]考虑了自上而下和自下而上的集成,其中从通用知识学习的贝叶斯网络作为自上而下的模型和数据驱动的模型作为自下而上的模型。 然后使用贝叶斯规则组合两个模型的预测以产生最终预测。 基于概率知识的预测也可以直接基于知识来定义。 对于知识图补全任务,Cui等人[84]基于类型信息推导了关系的先验分布。 然后通过贝叶斯规则将先验分布与现有基于嵌入的模型的自下而上的预测相结合以进行最终预测。
V 讨论和未来方向
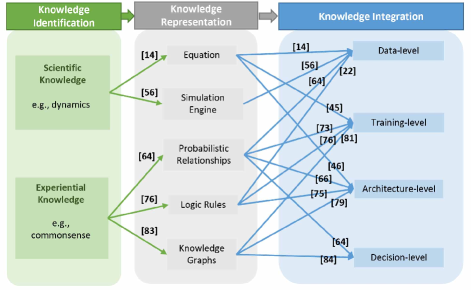
在本次调查中,我们回顾了知识增强深度学习的传统和流行技术,包括知识识别、知识表示和集成。 我们把知识分为两类:科学知识和经验知识。 在每个类别中,我们引入了知识识别、表示以及与深度学习的集成。 正如我们所讨论的,为了利用相关先验知识改进深度学习,我们已经做了很多工作,以产生数据高效、可泛化和可解释的深度学习模型。 为了帮助读者更好地理解 KADL 并将其应用到他们的工作中,我们根据现有工作的摘要提供了一个说明树(表I)。 如图9所示的规范树作为一个配方,其中包括将特定类型的先验知识纳入深度模型的不同途径。 每个路径由特定的知识类型、知识表示格式和知识集成方法组成,并附有相关著作的参考文献。
尽管做出了这些努力,现有方法仍存在一些缺点。 在以下段落中,我们讨论现有技术并强调未来有希望的发展方向。
知识类型多样
现有的知识增强深度模型探索不同类型的领域知识,包括科学知识和经验知识。 然而,所探索的知识大多是物理学中的科学知识和象征性代表的经验知识。 将成熟的算法知识注入深度模型已经开始引起研究人员的关注,深度模型是通过算法监督而不是地面实况注释来训练的[100]。 此外,现有方法通常仅限于一种特定类型的知识。 对于某个应用任务,科学知识和经验知识可能有多种来源。 因此,可以联合组合不同类型的知识以提高深度模型性能。
有效的知识整合
现有的集成方法利用合成数据、模型架构设计、正则化函数或预测细化。 其中,大部分的整合方法都是在训练过程中进行的。 因此,现有的集成技术在很大程度上依赖于特定的训练程序,通过联合考虑两个信息源来训练深度模型,而无需明确区分数据和知识。 该问题可以通过决策级融合来解决。 使用先验模型捕获领域知识的决策级知识集成方案引起的关注相对较少。 知识与先前模型的集成,将知识的自上而下的预测和数据的自下而上的估计结合起来,可以从多个方面受益。 首先,先验模型的构建独立于深度模型,深度模型是通过可观察数据初始化的。 由于先验模型和深层模型是独立于集成过程而构建的,因此自上而下和自下而上的集成过程可以灵活地应用于任何深层模型和先验模型。 其次,原则上遵循贝叶斯规则进行知识整合。 基于知识的基于数据的预测的细化变得易于处理和解释。
混合集成方法
现有的方法倾向于分别整合科学知识和经验知识。 此外,他们倾向于采用一种特定的方法来进行知识整合。 对于某些应用领域,两种类型的知识可能同时存在。 因此,应该将它们联合集成以进一步提高深度模型的性能。 此外,用户总是需要选择一种集成方式。 没有适用于所有类型知识的通用集成方案,如何以最佳方式自动将知识与数据集成仍然是一个悬而未决的问题。 因此,考虑到不同集成方法的互补性,同时采用不同的集成方法来发挥各自的优势可能是有益的。
不确定性的知识整合
现有的工作已经探索了以概率方式编码经验知识,例如使用概率图模型捕获不确定关系。 但总的来说,现有的知识整合方法都是确定性方法,忽略了潜在的知识不确定性及其对深度模型学习和推理的影响。 不确定性不仅存在于经验知识中,也存在于科学知识中。 例如,在物理学中,不确定性源于随机物理参数或未知物理参数或不完整的观察。 沿着这条线的现有工作旨在测量控制物理系统的偏微分方程解的质量,因此受到特定领域假设的影响。 概率工具,例如概率图形模型(PGM),在捕获经验知识的不确定性方面非常强大。 然而,很少有作品探讨 PGM 在科学定律不确定性建模中的使用[128, 129]。 如何有效、系统地对科学知识中的不确定性进行建模以适应现实世界的应用任务,对于深度学习界来说仍然是一个悬而未决的问题。
参考
- [1] G. Marcus, “Deep learning: A critical appraisal,” arXiv preprint arXiv:1801.00631, 2018.
- [2] T. R. Besold, A. d. Garcez, S. Bader, H. Bowman, P. Domingos, P. Hitzler, K.-U. Kühnberger, L. C. Lamb, D. Lowd, P. M. V. Lima et al., “Neural-symbolic learning and reasoning: A survey and interpretation,” arXiv preprint arXiv:1711.03902, 2017.
- [3] D. Yu, B. Yang, D. Liu, and H. Wang, “A survey on neural-symbolic systems,” arXiv preprint arXiv:2111.08164, 2021.
- [4] J. Willard, X. Jia, S. Xu, M. Steinbach, and V. Kumar, “Integrating physics-based modeling with machine learning: A survey,” arXiv preprint arXiv:2003.04919, vol. 1, no. 1, pp. 1–34, 2020.
- [5] J. Han, L. Zhang et al., “Integrating machine learning with physics-based modeling,” arXiv preprint arXiv:2006.02619, 2020.
- [6] R. Rai and C. K. Sahu, “Driven by data or derived through physics? a review of hybrid physics guided machine learning techniques with cyber-physical system (cps) focus,” IEEE Access, vol. 8, pp. 71 050–71 073, 2020.
- [7] M. Rath and A. P. Condurache, “Boosting deep neural networks with geometrical prior knowledge: A survey,” arXiv preprint arXiv:2006.16867, 2020.
- [8] P. Nowack, P. Braesicke, J. Haigh, N. L. Abraham, J. Pyle, and A. Voulgarakis, “Using machine learning to build temperature-based ozone parameterizations for climate sensitivity simulations,” Environmental Research Letters, vol. 13, no. 10, p. 104016, 2018.
- [9] C. Deng, X. Ji, C. Rainey, J. Zhang, and W. Lu, “Integrating machine learning with human knowledge,” Iscience, vol. 23, no. 11, p. 101656, 2020.
- [10] L. von Rueden, S. Mayer, K. Beckh, B. Georgiev, S. Giesselbach, R. Heese, B. Kirsch, J. Pfrommer, A. Pick, R. Ramamurthy et al., “Informed machine learning–a taxonomy and survey of integrating knowledge into learning systems,” arXiv preprint arXiv:1903.12394, 2019.
- [11] S. W. Kim, I. Kim, J. Lee, and S. Lee, “Knowledge integration into deep learning in dynamical systems: An overview and taxonomy,” Journal of Mechanical Science and Technology, vol. 35, no. 4, pp. 1331–1342, 2021.
- [12] L. von Rueden, S. Mayer, R. Sifa, C. Bauckhage, and J. Garcke, “Combining machine learning and simulation to a hybrid modelling approach: Current and future directions,” in International Symposium on Intelligent Data Analysis. Springer, 2020, pp. 548–560.
- [13] A. Sagel, A. Sahu, S. Matthes, H. Pfeifer, T. Qiu, H. Rueß, H. Shen, and J. Wörmann, “Knowledge as invariance–history and perspectives of knowledge-augmented machine learning,” arXiv preprint arXiv:2012.11406, 2020.
- [14] J. Chen, S. Nie, and Q. Ji, “Data-free prior model for upper body pose estimation and tracking,” IEEE Transactions on Image Processing, vol. 22, no. 12, pp. 4627–4639, 2013.
- [15] P. Liu, L. Tian, Y. Zhang, S. Aylward, Y. Lee, and M. Niethammer, “Discovering hidden physics behind transport dynamics,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 10 082–10 092.
- [16] M. Jaques, M. Burke, and T. M. Hospedales, “Newtonianvae: Proportional control and goal identification from pixels via physical latent spaces,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 4454–4463.
- [17] A. Daw, R. Q. Thomas, C. C. Carey, J. S. Read, A. P. Appling, and A. Karpatne, “Physics-guided architecture (pga) of neural networks for quantifying uncertainty in lake temperature modeling,” in Proceedings of the 2020 siam international conference on data mining. SIAM, 2020, pp. 532–540.
- [18] N. Muralidhar, J. Bu, Z. Cao, L. He, N. Ramakrishnan, D. Tafti, and A. Karpatne, “Phynet: Physics guided neural networks for particle drag force prediction in assembly,” in Proceedings of the 2020 SIAM International Conference on Data Mining. SIAM, 2020, pp. 559–567.
- [19] T. Beucler, S. Rasp, M. Pritchard, and P. Gentine, “Achieving conservation of energy in neural network emulators for climate modeling,” arXiv preprint arXiv:1906.06622, 2019.
- [20] T. Beucler, M. Pritchard, S. Rasp, J. Ott, P. Baldi, and P. Gentine, “Enforcing analytic constraints in neural networks emulating physical systems,” Physical Review Letters, vol. 126, no. 9, p. 098302, 2021.
- [21] L. Zhang, J. Han, H. Wang, R. Car, and E. Weinan, “Deep potential molecular dynamics: a scalable model with the accuracy of quantum mechanics,” Physical review letters, vol. 120, no. 14, p. 143001, 2018.
- [22] S. Seo, S. O. Arik, J. Yoon, X. Zhang, K. Sohn, and T. Pfister, “Controlling neural networks with rule representations,” arXiv preprint arXiv:2106.07804, 2021.
- [23] J. Sun, Z. Niu, K. A. Innanen, J. Li, and D. O. Trad, “A theory-guided deep-learning formulation and optimization of seismic waveform inversion,” Geophysics, vol. 85, no. 2, pp. R87–R99, 2020.
- [24] P. Toth, D. J. Rezende, A. Jaegle, S. Racanière, A. Botev, and I. Higgins, “Hamiltonian generative networks,” arXiv preprint arXiv:1909.13789, 2019.
- [25] A. Choudhary, J. F. Lindner, E. G. Holliday, S. T. Miller, S. Sinha, and W. L. Ditto, “Physics-enhanced neural networks learn order and chaos,” Physical Review E, vol. 101, no. 6, p. 062207, 2020.
- [26] F. Djeumou, C. Neary, E. Goubault, S. Putot, and U. Topcu, “Neural networks with physics-informed architectures and constraints for dynamical systems modeling,” arXiv preprint arXiv:2109.06407, 2021.
- [27] M. Raissi, P. Perdikaris, and G. E. Karniadakis, “Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations,” Journal of Computational Physics, vol. 378, pp. 686–707, 2019.
- [28] G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, and L. Yang, “Physics-informed machine learning,” Nature Reviews Physics, vol. 3, no. 6, pp. 422–440, 2021.
- [29] Z. Li, J. Sedlar, J. Carpentier, I. Laptev, N. Mansard, and J. Sivic, “Estimating 3d motion and forces of person-object interactions from monocular video,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 8640–8649.
- [30] S. J. Greydanus, M. Dzumba, and J. Yosinski, “Hamiltonian neural networks,” 2019.
- [31] Y. D. Zhong, B. Dey, and A. Chakraborty, “Symplectic ode-net: Learning hamiltonian dynamics with control,” arXiv preprint arXiv:1909.12077, 2019.
- [32] M. Cranmer, S. Greydanus, S. Hoyer, P. Battaglia, D. Spergel, and S. Ho, “Lagrangian neural networks,” arXiv preprint arXiv:2003.04630, 2020.
- [33] C. Allen-Blanchette, S. Veer, A. Majumdar, and N. E. Leonard, “Lagnetvip: A lagrangian neural network for video prediction,” arXiv preprint arXiv:2010.12932, 2020.
- [34] R. Stewart and S. Ermon, “Label-free supervision of neural networks with physics and domain knowledge,” in Thirty-First AAAI Conference on Artificial Intelligence, 2017.
- [35] F. Xie, A. Chowdhury, M. Kaluza, L. Zhao, L. L. Wong, and R. Yu, “Deep imitation learning for bimanual robotic manipulation,” arXiv preprint arXiv:2010.05134, 2020.
- [36] J. Wu, E. Lu, P. Kohli, B. Freeman, and J. Tenenbaum, “Learning to see physics via visual de-animation,” Advances in Neural Information Processing Systems, vol. 30, pp. 153–164, 2017.
- [37] Y.-L. Qiao, J. Liang, V. Koltun, and M. Lin, “Differentiable simulation of soft multi-body systems,” in Thirty-Fifth Conference on Neural Information Processing Systems, 2021.
- [38] A. Botev, A. Jaegle, P. Wirnsberger, D. Hennes, and I. Higgins, “Which priors matter? benchmarking models for learning latent dynamics,” 2021.
- [39] R. Wang, R. Walters, and R. Yu, “Incorporating symmetry into deep dynamics models for improved generalization,” arXiv preprint arXiv:2002.03061, 2020.
- [40] M. Finzi, G. Benton, and A. G. Wilson, “Residual pathway priors for soft equivariance constraints,” Advances in Neural Information Processing Systems, vol. 34, 2021.
- [41] J. Ling, A. Kurzawski, and J. Templeton, “Reynolds averaged turbulence modelling using deep neural networks with embedded invariance,” Journal of Fluid Mechanics, vol. 807, pp. 155–166, 2016.
- [42] M. Mezghanni, M. Boulkenafed, A. Lieutier, and M. Ovsjanikov, “Physically-aware generative network for 3d shape modeling,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 9330–9341.
- [43] V. Shah, A. Joshi, S. Ghosal, B. Pokuri, S. Sarkar, B. Ganapathysubramanian, and C. Hegde, “Encoding invariances in deep generative models,” arXiv preprint arXiv:1906.01626, 2019.
- [44] J.-L. Wu, K. Kashinath, A. Albert, D. Chirila, H. Xiao et al., “Enforcing statistical constraints in generative adversarial networks for modeling chaotic dynamical systems,” Journal of Computational Physics, vol. 406, p. 109209, 2020.
- [45] N. Geneva and N. Zabaras, “Modeling the dynamics of pde systems with physics-constrained deep auto-regressive networks,” Journal of Computational Physics, vol. 403, p. 109056, 2020.
- [46] B. Anderson, T.-S. Hy, and R. Kondor, “Cormorant: Covariant molecular neural networks,” arXiv preprint arXiv:1906.04015, 2019.
- [47] A. Lengyel, S. Garg, M. Milford, and J. C. van Gemert, “Zero-shot day-night domain adaptation with a physics prior,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 4399–4409.
- [48] M. B. Chang, T. Ullman, A. Torralba, and J. B. Tenenbaum, “A compositional object-based approach to learning physical dynamics,” arXiv preprint arXiv:1612.00341, 2016.
- [49] P. W. Battaglia, R. Pascanu, M. Lai, D. Rezende, and K. Kavukcuoglu, “Interaction networks for learning about objects, relations and physics,” arXiv preprint arXiv:1612.00222, 2016.
- [50] N. Takeishi and A. Kalousis, “Physics-integrated variational autoencoders for robust and interpretable generative modeling,” arXiv preprint arXiv:2102.13156, 2021.
- [51] Y. Yin, V. Le Guen, J. Dona, E. de Bézenac, I. Ayed, N. Thome, and P. Gallinari, “Augmenting physical models with deep networks for complex dynamics forecasting,” Journal of Statistical Mechanics: Theory and Experiment, 2021.
- [52] O. Linial, N. Ravid, D. Eytan, and U. Shalit, “Generative ode modeling with known unknowns,” in Proceedings of the Conference on Health, Inference, and Learning, 2021, pp. 79–94.
- [53] Y. Yang and P. Perdikaris, “Adversarial uncertainty quantification in physics-informed neural networks,” Journal of Computational Physics, vol. 394, pp. 136–152, 2019.
- [54] Y. Zhu, N. Zabaras, P.-S. Koutsourelakis, and P. Perdikaris, “Physics-constrained deep learning for high-dimensional surrogate modeling and uncertainty quantification without labeled data,” Journal of Computational Physics, vol. 394, pp. 56–81, 2019.
- [55] S. Karumuri, R. Tripathy, I. Bilionis, and J. Panchal, “Simulator-free solution of high-dimensional stochastic elliptic partial differential equations using deep neural networks,” Journal of Computational Physics, vol. 404, p. 109120, 2020.
- [56] X. Jia, J. Willard, A. Karpatne, J. Read, J. Zwart, M. Steinbach, and V. Kumar, “Physics guided rnns for modeling dynamical systems: A case study in simulating lake temperature profiles,” in Proceedings of the 2019 SIAM International Conference on Data Mining. SIAM, 2019, pp. 558–566.
- [57] X. Jia, J. Willard, A. Karpatne, J. S. Read, J. A. Zwart, M. Steinbach, and V. Kumar, “Physics-guided machine learning for scientific discovery: An application in simulating lake temperature profiles,” ACM/IMS Transactions on Data Science, vol. 2, no. 3, pp. 1–26, 2021.
- [58] K. Bousmalis, A. Irpan, P. Wohlhart, Y. Bai, M. Kelcey, M. Kalakrishnan, L. Downs, J. Ibarz, P. Pastor, K. Konolige et al., “Using simulation and domain adaptation to improve efficiency of deep robotic grasping,” in 2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018, pp. 4243–4250.
- [59] S. Shah, D. Dey, C. Lovett, and A. Kapoor, “Airsim: High-fidelity visual and physical simulation for autonomous vehicles,” in Field and service robotics. Springer, 2018, pp. 621–635.
- [60] E. Coumans and Y. Bai, “Pybullet, a python module for physics simulation for games, robotics and machine learning,” 2016.
- [61] K. Ehsani, S. Tulsiani, S. Gupta, A. Farhadi, and A. Gupta, “Use the force, luke! learning to predict physical forces by simulating effects,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 224–233.
- [62] R. Mottaghi, H. Bagherinezhad, M. Rastegari, and A. Farhadi, “Newtonian scene understanding: Unfolding the dynamics of objects in static images,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 3521–3529.
- [63] J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain randomization for transferring deep neural networks from simulation to the real world,” in 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2017, pp. 23–30.
- [64] Y. Li, J. Chen, Y. Zhao, and Q. Ji, “Data-free prior model for facial action unit recognition,” IEEE Transactions on affective computing, vol. 4, no. 2, pp. 127–141, 2013.
- [65] T. Teshima and M. Sugiyama, “Incorporating causal graphical prior knowledge into predictive modeling via simple data augmentation,” in Uncertainty in Artificial Intelligence. PMLR, 2021, pp. 86–96.
- [66] C. Corneanu, M. Madadi, and S. Escalera, “Deep structure inference network for facial action unit recognition,” in Proceedings of European Conference on Computer Vision, 2019.
- [67] L. Chen, H. Su, and Q. Ji, “Deep structured prediction for facial landmark detection,” Advances in neural information processing systems, vol. 32, 2019.
- [68] M. Suhail, A. Mittal, B. Siddiquie, C. Broaddus, J. Eledath, G. Medioni, and L. Sigal, “Energy-based learning for scene graph generation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 13 936–13 945.
- [69] T. Song, Z. Cui, W. Zheng, and Q. Ji, “Hybrid message passing with performance-driven structures for facial action unit detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 6267–6276.
- [70] S. Srinivas Kancheti, A. Gowtham Reddy, V. N. Balasubramanian, and A. Sharma, “Matching learned causal effects of neural networks with domain priors,” arXiv e-prints, pp. arXiv–2111, 2021.
- [71] L. Rieger, C. Singh, W. Murdoch, and B. Yu, “Interpretations are useful: penalizing explanations to align neural networks with prior knowledge,” in International conference on machine learning. PMLR, 2020, pp. 8116–8126.
- [72] Y. Zhang, W. Dong, B.-G. Hu, and Q. Ji, “Classifier learning with prior probabilities for facial action unit recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 5108–5116.
- [73] Z. Cui, T. Song, Y. Wang, and Q. Ji, “Knowledge augmented deep neural networks for joint facial expression and action unit recognition,” Advances in Neural Information Processing Systems, vol. 33, 2020.
- [74] M. Yang, F. Liu, Z. Chen, X. Shen, J. Hao, and J. Wang, “Causalvae: Disentangled representation learning via neural structural causal models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 9593–9602.
- [75] M. Qu and J. Tang, “Probabilistic logic neural networks for reasoning,” arXiv preprint arXiv:1906.08495, 2019.
- [76] J. Xu, Z. Zhang, T. Friedman, Y. Liang, and G. Broeck, “A semantic loss function for deep learning with symbolic knowledge,” in International conference on machine learning. PMLR, 2018, pp. 5502–5511.
- [77] Y. Xie, Z. Xu, M. S. Kankanhalli, K. S. Meel, and H. Soh, “Embedding symbolic knowledge into deep networks,” arXiv preprint arXiv:1909.01161, 2019.
- [78] X. Liang, Z. Hu, H. Zhang, L. Lin, and E. P. Xing, “Symbolic graph reasoning meets convolutions,” Advances in Neural Information Processing Systems, vol. 31, pp. 1853–1863, 2018.
- [79] F. Liu, C. You, X. Wu, S. Ge, X. Sun et al., “Auto-encoding knowledge graph for unsupervised medical report generation,” Advances in Neural Information Processing Systems, vol. 34, 2021.
- [80] R. Luo, N. Zhang, B. Han, and L. Yang, “Context-aware zero-shot recognition,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 11 709–11 716.
- [81] Y. Fang, K. Kuan, J. Lin, C. Tan, and V. Chandrasekhar, “Object detection meets knowledge graphs.” International Joint Conferences on Artificial Intelligence, 2017.
- [82] J. Gu, H. Zhao, Z. Lin, S. Li, J. Cai, and M. Ling, “Scene graph generation with external knowledge and image reconstruction,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 1969–1978.
- [83] K. Marino, X. Chen, D. Parikh, A. Gupta, and M. Rohrbach, “Krisp: Integrating implicit and symbolic knowledge for open-domain knowledge-based vqa,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 14 111–14 121.
- [84] Z. Cui, P. Kapanipathi, K. Talamadupula, T. Gao, and Q. Ji, “Type-augmented relation prediction in knowledge graphs,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 8, 2021, pp. 7151–7159.
- [85] D. Kaur, S. Uslu, K. J. Rittichier, and A. Durresi, “Trustworthy artificial intelligence: a review,” ACM Computing Surveys (CSUR), vol. 55, no. 2, pp. 1–38, 2022.
- [86] Z. Wang, W. Xing, R. Kirby, and S. Zhe, “Physics informed deep kernel learning,” 2020.
- [87] M. M. Sultan, H. K. Wayment-Steele, and V. S. Pande, “Transferable neural networks for enhanced sampling of protein dynamics,” Journal of chemical theory and computation, vol. 14, no. 4, pp. 1887–1894, 2018.
- [88] O. T. Unke, M. Bogojeski, M. Gastegger, M. Geiger, T. Smidt, and K.-R. Müller, “Se (3)-equivariant prediction of molecular wavefunctions and electronic densities,” arXiv preprint arXiv:2106.02347, 2021.
- [89] Y. Yuan, S.-E. Wei, T. Simon, K. Kitani, and J. Saragih, “Simpoe: Simulated character control for 3d human pose estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 7159–7169.
- [90] S. Shimada, V. Golyanik, W. Xu, P. Pérez, and C. Theobalt, “Neural monocular 3d human motion capture with physical awareness,” ACM Transactions on Graphics (TOG), vol. 40, no. 4, pp. 1–15, 2021.
- [91] P. W. Anderson, “More is different,” Science, vol. 177, no. 4047, pp. 393–396, 1972.
- [92] M. Born and E. Wolf, Principles of optics: electromagnetic theory of propagation, interference and diffraction of light. Elsevier, 2013.
- [93] M. Oren and S. K. Nayar, “Generalization of the lambertian model and implications for machine vision,” International Journal of Computer Vision, vol. 14, no. 3, pp. 227–251, 1995.
- [94] J. T. Kajiya, “The rendering equation,” in Proceedings of the 13th annual conference on Computer graphics and interactive techniques, 1986, pp. 143–150.
- [95] X. Cao, Z. Chen, A. Chen, X. Chen, S. Li, and J. Yu, “Sparse photometric 3d face reconstruction guided by morphable models,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 4635–4644.
- [96] H. Wang, S. Z. Li, Y. Wang, and W. Zhang, “Illumination modeling and normalization for face recognition,” in 2003 IEEE International SOI Conference. Proceedings (Cat. No. 03CH37443). IEEE, 2003, pp. 104–111.
- [97] S. Xin, S. Nousias, K. N. Kutulakos, A. C. Sankaranarayanan, S. G. Narasimhan, and I. Gkioulekas, “A theory of fermat paths for non-line-of-sight shape reconstruction,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 6800–6809.
- [98] S. Kim, Y. Huo, and S.-E. Yoon, “Single image reflection removal with physically-based training images,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 5164–5173.
- [99] C. Zhou, M. Teng, Y. Han, C. Xu, and B. Shi, “Learning to dehaze with polarization,” in Thirty-Fifth Conference on Neural Information Processing Systems, 2021.
- [100] F. Petersen, C. Borgelt, H. Kuehne, and O. Deussen, “Learning with algorithmic supervision via continuous relaxations,” in Thirty-Fifth Conference on Neural Information Processing Systems, 2021.
- [101] R. Hartley and A. Zisserman, Multiple view geometry in computer vision. Cambridge university press, 2003.
- [102] M. Lutter, C. Ritter, and J. Peters, “Deep lagrangian networks: Using physics as model prior for deep learning,” arXiv preprint arXiv:1907.04490, 2019.
- [103] V. G. Satorras, Z. Akata, and M. Welling, “Combining generative and discriminative models for hybrid inference,” 2019.
- [104] Y. Zhang, J. Sun, X. He, H. Fu, R. Jia, and X. Zhou, “Modeling indirect illumination for inverse rendering,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 18 643–18 652.
- [105] A. Zeng, S. Song, J. Lee, A. Rodriguez, and T. Funkhouser, “Tossingbot: Learning to throw arbitrary objects with residual physics,” IEEE Transactions on Robotics, 2020.
- [106] R. Mottaghi, M. Rastegari, A. Gupta, and A. Farhadi, ““what happens if…” learning to predict the effect of forces in images,” in European conference on computer vision. Springer, 2016, pp. 269–285.
- [107] J. Wu, I. Yildirim, J. J. Lim, B. Freeman, and J. Tenenbaum, “Galileo: Perceiving physical object properties by integrating a physics engine with deep learning,” Advances in neural information processing systems, vol. 28, pp. 127–135, 2015.
- [108] E. Todorov, T. Erez, and Y. Tassa, “Mujoco: A physics engine for model-based control,” in 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2012, pp. 5026–5033.
- [109] P. Kubelka and F. Munk, “An article on optics of paint layers,” Z. Tech. Phys, vol. 12, no. 593-601, pp. 259–274, 1931.
- [110] M. Haker, M. Böhme, T. Martinetz, and E. Barth, “Self-organizing maps for pose estimation with a time-of-flight camera,” in Workshop on Dynamic 3D Imaging. Springer, 2009, pp. 142–153.
- [111] T. Chen, C. Fang, X. Shen, Y. Zhu, Z. Chen, and J. Luo, “Anatomy-aware 3d human pose estimation with bone-based pose decomposition,” IEEE Transactions on Circuits and Systems for Video Technology, 2021.
- [112] A. Li, T. Luo, Z. Lu, T. Xiang, and L. Wang, “Large-scale few-shot learning: Knowledge transfer with class hierarchy,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 7212–7220.
- [113] R. Yu, A. Li, V. I. Morariu, and L. S. Davis, “Visual relationship detection with internal and external linguistic knowledge distillation,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 1974–1982.
- [114] A. Akula, V. Jampani, S. Changpinyo, and S.-C. Zhu, “Robust visual reasoning via language guided neural module networks,” Advances in Neural Information Processing Systems, vol. 34, 2021.
- [115] C. Rytting and D. Wingate, “Leveraging the inductive bias of large language models for abstract textual reasoning,” Advances in Neural Information Processing Systems, vol. 34, 2021.
- [116] H. Yao, Y. Chen, Q. Ye, X. Jin, and X. Ren, “Refining language models with compositional explanations,” Advances in Neural Information Processing Systems, vol. 34, 2021.
- [117] P. Ekman and W. V. Friesen, “Facial action coding system,” Environmental Psychology & Nonverbal Behavior, 1978.
- [118] H. B. Enderton, A mathematical introduction to logic. Elsevier, 2001.
- [119] C. Menglong, J. Detao, Z. Ting, Z. Dehai, X. Cheng, C. Zhibo, and X. Xiaoqiang, “Image classification based on image knowledge graph and semantics,” in 2019 IEEE 23rd International Conference on Computer Supported Cooperative Work in Design (CSCWD), 2019, pp. 81–86.
- [120] L. Ji, Y. Wang, B. Shi, D. Zhang, Z. Wang, and J. Yan, “Microsoft concept graph: Mining semantic concepts for short text understanding,” Data Intelligence, vol. 1, no. 3, pp. 238–270, 2019.
- [121] G. G. Towell and J. W. Shavlik, “Knowledge-based artificial neural networks,” Artificial intelligence, vol. 70, no. 1-2, pp. 119–165, 1994.
- [122] A. S. A. Garcez and G. Zaverucha, “The connectionist inductive learning and logic programming system,” Applied Intelligence, vol. 11, no. 1, pp. 59–77, 1999.
- [123] R. Riegel, A. Gray, F. Luus, N. Khan, N. Makondo, I. Y. Akhalwaya, H. Qian, R. Fagin, F. Barahona, U. Sharma et al., “Logical neural networks,” arXiv preprint arXiv:2006.13155, 2020.
- [124] I. Donadello, L. Serafini, and A. D. Garcez, “Logic tensor networks for semantic image interpretation,” arXiv preprint arXiv:1705.08968, 2017.
- [125] M. Diligenti, M. Gori, and C. Sacca, “Semantic-based regularization for learning and inference,” Artificial Intelligence, vol. 244, pp. 143–165, 2017.
- [126] J. Lehmann, R. Isele, M. Jakob, A. Jentzsch, D. Kontokostas, P. N. Mendes, S. Hellmann, M. Morsey, P. Van Kleef, S. Auer et al., “Dbpedia–a large-scale, multilingual knowledge base extracted from wikipedia,” Semantic web, vol. 6, no. 2, pp. 167–195, 2015.
- [127] R. Speer, J. Chin, and C. Havasi, “Conceptnet 5.5: An open multilingual graph of general knowledge,” in Thirty-First AAAI Conference on Artificial Intelligence, 2017.
- [128] C. G. Enright, M. G. Madden, and N. Madden, “Bayesian networks for mathematical models: techniques for automatic construction and efficient inference,” International Journal of Approximate Reasoning, vol. 54, no. 2, pp. 323–342, 2013.
- [129] S. Evers and P. J. Lucas, “Constructing bayesian networks for linear dynamic systems,” BMAW-11 Preface, 2011.
| Zijun Cui received the B.S. degree from the Department of Physics, University of Science and Technology of China, Hefei, China, in 2015, and received the M.S. degree from the School of Engineering, Brown University, Rhode Island, USA, in 2017. She is currently pursuing the Ph.D. degree with the Rensselaer Polytechnic Institute, NY, USA. She has broad experiences with deep learning and probabilistic graphical models. Her current research interests include knowledge-augmented deep learning, learning and inference on probabilistic graphical models, and their applications to computer vision and natural language processing. |
| Tian Gao received the Ph.D and B.S degrees both from the Department of Electrical, Computer, and System Engineering, Rensselaer Polytechnic Institute, Troy, NY, USA. He is currently a research staff member of IBM Research AI at T. J. Watson Research Center. His research focuses on machine learning and its application in computer vision and natural language processing. He has worked on probabilistic graphical models, knowledge extraction, causal discovery, and other aspects of machine learning. From 2010 to 2012, he was a National Science Foundation Triple Helix Program Fellow. |
| Kartik Talamadupula is a Senior Research Scientist and Research Manager at IBM Research AI. His background is in automated planning and sequential decision making. He has applied decision-making techniques to human-in-the-loop AI, data-driven dialog, and human-agent collaboration. |
| Qiang Ji received his Ph.D degree in Electrical Engineering from the University of Washington. He is currently a Professor with the Department of Electrical, Computer, and Systems Engineering at Rensselaer Polytechnic Institute (RPI). From 2009 to 2010, he served as a program director at the National Science Foundation (NSF), Arlington, VA, USA, where he managed NSF’s computer vision and machine learning programs. He also held teaching and research positions with the Beckman Institute at University of Illinois at Urbana-Champaign, Urbana, IL, USA; the Robotics Institute at Carnegie Mellon University, Pittsburgh, PA, USA; the Dept. of Computer Science at University of Nevada, Reno, Nevada, USA; and the Air Force Research Laboratory, Rome, NY, USA. Prof. Ji currently serves as the director of the Intelligent Systems Laboratory (ISL) at RPI. Prof. Ji’s research interests are in human-centered computer vision, probabilistic graphical models, probabilistic deep learning, and their applications in various fields. He has published over 300 papers in peer-reviewed journals and conferences, and has received multiple awards for his work. Prof. Ji is has served as an editor on several related IEEE and international journals and as a general chair, program chair, technical area chair, and program committee member for numerous international conferences/workshops. Prof. Ji is a fellow of the IEEE and the IAPR. |