UniKGQA:解决知识图谱多跳问答的统一检索和推理
摘要
知识图谱多跳问答(KGQA)旨在在大规模知识图谱(KG)上找到距离自然语言问题中提到的主题实体多跳的答案实体。 为了应对巨大的搜索空间,现有的工作通常采用两阶段的方法:首先检索与问题相关的相对较小的子图,然后对子图进行推理以准确地找到答案实体。 尽管这两个阶段高度相关,但以前的工作采用了截然不同的技术解决方案来开发检索和推理模型,忽略了它们在任务本质上的相关性。 在本文中,我们提出了 UniKGQA,这是一种用于多跳 KGQA 任务的新方法,通过统一模型架构和参数学习中的检索和推理。 对于模型架构,UniKGQA 由用于问题关系语义匹配的基于预训练语言模型(PLM)的语义匹配模块和沿着 KG 上的有向边传播匹配信息的匹配信息传播模块组成。 对于参数学习,我们为检索和推理模型设计了基于问题关系匹配的共享预训练任务,然后提出面向检索和推理的微调策略。 与以前的研究相比,我们的方法更加统一,检索和推理阶段紧密相关。 对三个基准数据集的大量实验证明了我们的方法在多跳 KGQA 任务上的有效性。 我们的代码和数据可在 https://github.com/RUCAIBox/UniKGQA 上公开获取。
1简介
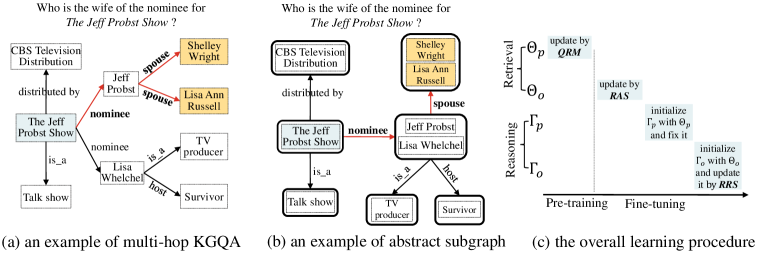
随着大规模知识图谱(KG)的出现,例如 Freebase (Bollacker 等人,2008) 和 Wikidata (Tanon 等人,2016),知识图谱问题回答(KGQA)已成为一个重要的研究课题,旨在从KG中找到自然语言问题的答案实体。 最近的研究(Lan等人,2021)主要集中在多跳KGQA,这是一种更复杂的场景,需要对边缘(或关系)进行复杂的多跳推理在 KG 上推断出正确答案。 我们在图1(a)中展示了一个示例。 给定问题“The Jeff Probst Show 提名者的妻子是谁”,任务目标是从主题实体“The Jeff Probst Show”中找到推理路径”到答案实体“Shelley Wright”和“Lisa Ann Russell”。
面对大规模知识图谱中巨大的搜索空间,之前的工作(Sun等人,2018;2019)通常采用检索-然后-推理的做法,实现了很好的权衡。 一般来说,检索阶段的目标是从大规模知识图谱中提取相关的三元组,组成相对较小的问题相关子图,而推理阶段的重点是从检索到的子图中准确地找到答案实体。 虽然两个阶段的目的不同,但两个阶段都需要评估候选实体相对于问题的语义相关性(用于移除或重新排序),这本质上可以认为是语义匹配问题。 为了测量实体相关性,基于关系的特征,无论是直接关系(Miller等人,2016)还是复合关系路径(Sun等人,2018),都被示出对于构建语义匹配模型特别有用。 如图1(a)所示,给定问题,识别知识图谱中语义匹配的关系和组合关系路径是关键(例如,“被提名人 配偶”)用于查找正确的答案实体。 由于这两个阶段处理 KG 上不同规模的搜索空间(例如数百万v.s. 数千),他们通常采用特定的技术解决方案:前者更喜欢更有效的专注于召回性能的方法(Sun等人,2018),而后者更喜欢更强大的方法来建模细粒度的匹配信号(何等人,2021)。
考虑到两个阶段的本质相同,本文旨在通过研究以下问题来推动多跳 KGQA 的研究:我们能否为两个阶段设计一个统一的模型架构以获得更好的性能? 为多跳 KGQA 开发统一的模型架构,一个主要优点是我们可以紧密联系两个阶段并增强相关信息的共享。 尽管这两个阶段高度相关,但之前的研究通常在模型学习中分开对待它们:只有检索到的三元组从检索阶段传递到推理阶段,而其余的用于语义匹配的有用信号在管道框架中被忽略了。 这种方法可能会导致性能次优或较差,因为多跳 KGQA 是一项非常具有挑战性的任务,需要精心设计的解决方案,充分利用两个阶段的各种相关信息。
然而,为多跳 KGQA 开发统一的模型架构存在两个主要问题:(1)如何应对两个阶段的搜索空间规模差异很大? (2)如何跨两个阶段有效共享或传递有用的相关信息? 对于第一个问题,我们没有让相同的模型架构直接拟合非常不同的数据分布,而是提出了一种新的子图形式来减少检索阶段的节点规模,即通过合并组成的摘要子图来自KG的具有相同关系的节点(见图1(b))。 对于第二个问题,基于相同的模型架构,我们为两个阶段设计了有效的学习方法,以便我们可以共享相同的预训练参数并使用学习到的检索模型来初始化推理模型(见图1(c))。
为此,在本文中,我们提出了 UniKGQA,一种用于多跳 KGQA 任务的统一模型。 具体来说,UniKGQA 由基于 PLM 的用于问题关系语义匹配的语义匹配模块和沿着 KG 上的有向边传播匹配信息的匹配信息传播模块组成。 为了学习这些参数,我们设计了预训练(即问题关系匹配)和微调(即面向检索和推理的学习)基于统一架构的策略。 与之前的多跳 KQGA 工作相比,我们的方法更加统一和简化,与检索和推理阶段紧密相关。
据我们所知,这是第一个将多跳 KGQA 任务的模型架构和学习中的检索和推理相结合的工作。 为了评估我们的方法,我们对三个基准数据集进行了广泛的实验。 在困难的数据集 WebQSP 和 CWQ 上,我们的性能大大优于现有的最先进的基线(例如 WebQSP 上的 Hits@1 提高了 8.1%,Hits@ 提高了 2.0% 1 CWQ)。
2 初步
在本节中,我们介绍将在整篇论文中使用的符号,然后正式定义多跳 KGQA 任务。
知识图谱(KG)。 知识图谱通常由一组三元组组成,用表示,其中和分别表示实体集和关系集。 三元组描述了头实体和尾实体之间存在关系这一事实。 此外,我们用表示实体所属的邻域三元组集合。 令表示的逆关系,我们可以通过其逆三元组来表示三元组。 这样,我们就可以将实体的邻域三元组的定义简化为。 我们进一步使用和分别表示KG中实体和关系的嵌入矩阵。
多跳知识图问答(Multi-hop KGQA)。 给定一个自然语言问题和一个知识图谱,KGQA的任务旨在通过知识图谱找到该问题的答案实体,由答案集。 继之前的工作(Sun等人,2018;2019)之后,我们假设问题中提到的实体(例如,图1(a))被标记并与KG上的实体链接,即主题实体,记为。 在这项工作中,我们专注于解决多跳 KGQA 任务,其中答案实体与 KG 上的主题实体有多个跳的距离。 考虑到效率和准确性之间的权衡,我们遵循现有的工作(Sun等人,2018;2019),使用检索-then-来解决此任务推理框架。 在两阶段框架中,给定问题和主题实体,检索模型旨在从大规模输入中检索小子图 KG ,而推理模型通过对检索到的子图进行推理来搜索答案实体。
3方法
在本节中,我们提出了我们提出的 UniKGQA,它统一了多跳 KGQA 的检索和推理。 主要的新颖之处在于,我们为两个阶段引入了统一的模型架构(第 3.1 节),并设计了一种有效的学习方法,涉及特定的预训练和微调策略(第 3.2 节)。 接下来,我们详细介绍这两部分。
3.1统一模型架构
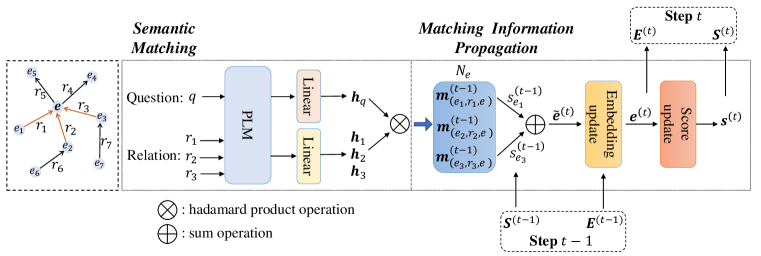
我们考虑用于检索和推理的通用输入形式,并通过集成两个主要模块来开发基本架构:(1)语义匹配(SM)模块,它采用 PLM 来执行之间的语义匹配问题和关系; (2)匹配信息传播(MIP)模块,传播知识图谱上的语义匹配信息。 我们在图2中展示了模型架构的概述。 接下来我们对这三个部分进行详细的介绍。
通用输入公式。 为了支持检索和推理阶段,我们考虑一种评估实体相关性的通用形式,其中给出了候选实体的问题和子图。 对于检索阶段,是一个摘要子图,它合并摘要节点以合并来自同一关系的实体。 对于推理阶段,是基于检索阶段检索到的子图构建的,没有摘要节点。 这种通用的输入公式使得能够为两个不同阶段开发统一的模型架构。 接下来,我们将以一般方式描述该方法,而不考虑具体阶段。
语义匹配(SM)。 SM 模块旨在生成问题 与给定子图 中的三元组 之间的语义匹配特征。 考虑到PLM出色的建模能力,我们利用PLM生成文本编码作为问题和关系的表示。具体来说,我们首先利用PLM对和的文本进行编码,并使用[CLS]词符的输出表示作为它们的表示:
| (1) |
基于和,受NSM模型(何等人,2021)的启发,我们得到了捕获语义匹配特征的向量 在第 步的问题 和三元组 之间,采用相应的投影层:
| (2) |
其中,是步投影层的参数,,是隐藏层分别为 PLM 和特征向量的维度, 为 sigmoid 激活函数, 为 hadamard 乘积。
匹配信息传播(MIP)。 基于生成的语义匹配特征,MIP模块首先聚合它们以更新实体表示,然后利用它来获得实体匹配分数。 为了初始化匹配分数,给定问题 和子图 ,对于每个实体 ,我们将匹配分数设置在 之间> 和 如下:如果 是主题实体,则为 ,否则为 。 在第步,我们利用最后一步计算出的头实体的匹配分数作为权重,并聚合相邻三元组的匹配特征以获得以下表示:尾部实体:
| (3) |
其中 是第 步骤中实体 的表示, 是可学习矩阵。 第一步,由于没有匹配分数,遵循 NSM (He 等人, 2021) 模型,我们直接聚合其单跳关系的表示作为实体表示: ,其中是一个可学习的矩阵。 基于所有实体的表示,我们使用softmax函数更新它们的实体匹配分数:
| (4) |
其中 是一个可学习的向量。
经过步迭代后,我们可以获得最终的实体匹配分数,它是子图中所有实体的概率分布。 这些匹配分数可用于衡量实体作为给定问题的答案的可能性,并将用于检索和推理阶段。
3.2 模型训练
在我们的方法中,我们同时拥有多跳 KGQA 两个阶段的检索模型和推理模型。 由于两个模型采用相同的架构,因此我们引入 和 分别表示用于检索和推理阶段的模型参数。 如3.1节所示,我们的架构包含两组参数,即底层PLM和用于匹配和传播的其他参数。 因此,和可以分解为:和,其中下标和分别表示我们架构中的PLM参数和其他参数。 为了学习这些参数,我们设计了预训练(即问题关系匹配)和微调(即面向检索和推理的学习)基于统一架构的策略。 接下来,我们描述模型训练方法。
使用问题关系匹配 (QRM) 进行预训练。 对于预训练,我们主要关注学习底层 PLM 的参数(即和)。 在实现中,我们让两个模型共享相同的 PLM 参数副本,即 。 如3.1节所示,语义匹配模块的基本能力是对问题和单个关系之间的相关性进行建模(方程2),其基于来自底层 PLM 的文本编码。 因此,我们设计了基于问题关系匹配的对比预训练任务。 具体来说,我们采用对比学习目标(Hadsell等人,2006)来对齐相关问题关系对的表示,同时推开其他对。 为了收集相关的问题关系对,给定一个由问题 、主题实体 和答案实体 组成的示例,我们提取所有最短的整个KG中和之间的路径,并将这些路径内的所有关系视为与相关,表示为。 这样,我们就可以获得一些弱监督的例子。 在预训练过程中,对于每个问题,我们随机采样相关关系,并利用对比学习损失进行预训练:
| (5) |
其中是温度超参数,是随机采样的负关系,是余弦相似度,, 是 PLM 从 SM 模块编码的问题和关系(等式1)。 这样,通过预训练PLM参数可以增强问题-关系匹配能力。 请注意,PLM 参数将在预训练后固定。
摘要子图 (RAS) 检索的微调。 预训练后,我们首先根据检索任务对整个模型进行参数的学习。 回想一下,我们将子图转换为摘要子图的形式,其中合并摘要节点用于合并来自相同关系的实体。 由于我们的 MIP 模块(第 3.1 节)可以生成子图中节点的匹配分数 (方程 4),其中下标 表示节点来自摘要子图。 此外,我们利用标记的答案来获取真实向量,用 表示。 如果中的摘要节点包含答案实体,我们将其设置为1。 然后我们最小化学习到的匹配分数向量和真实匹配分数向量之间的 KL 散度,如下所示:
| (6) |
对RAS损失进行微调后,可以有效地学习检索模型。 我们进一步利用它来检索给定问题 的子图,根据匹配分数选择排名靠前的 节点。 请注意,只有与主题实体距离合理的节点才会被选择到子图中,这确保了后续推理阶段找到答案实体时有一个相对较小但相关的子图。
对检索子图 (RRS) 的推理进行微调。 对检索模型进行微调后,我们继续通过学习参数来调整推理模型。 通过微调的检索模型,我们可以获得每个问题的较小子图。 在推理阶段,我们专注于进行准确的推理,找到答案实体,从而恢复出摘要节点中的原始节点以及它们之间的原始关系。 由于检索和推理阶段高度依赖,我们首先使用检索模型中的参数初始化推理模型的参数:。 然后,遵循等式。 4,我们采用类似的方法根据以下公式将学习到的匹配分数(由 表示)与真实向量(由 表示)进行拟合吉隆坡损失:
| (7) |
其中下标 表示节点来自检索的子图。 利用 RRS 损失进行微调后,我们就可以利用学习到的推理模型,根据匹配分数选择排名靠前的实体作为答案列表。
如图1(c)所示,整个训练过程由以下部分组成:(1)预训练和问题关系匹配,(2)固定并微调以检索摘要子图,以及(3)修复由初始化的并微调 由 初始化,用于子图推理。
我们的工作为检索和推理阶段提供了一种新颖的统一模型,以共享推理能力。 在表1中,我们总结了我们的方法与多跳KGQA的几种流行方法之间的差异,包括GraphfNet (Sun等人,2018),PullNet (孙等人,2019),NSM (何等人,2021),SR+NSM (张等人,2022)。 正如我们所看到的,现有的方法通常在检索和推理阶段采用不同的模型,而我们的方法更加统一。 一个主要好处是,两个阶段之间的信息可以有效地共享和重用:我们用学习到的检索模型初始化推理模型。
4实验
4.1 实验设置
| Methods | Retrieval | Reasoning |
|
||
|---|---|---|---|---|---|
| GraftNet | PPR | GraftNet | ✗ | ||
| PullNet | LSTM | GraftNet | ✗ | ||
| NSM | PPR | NSM | ✗ | ||
| SR+NSM | PLM | NSM | ✗ | ||
| UniKGQA | UniKGQA | UniKGQA | ✓ |
| Datasets | #Train | #Valid | #Test | Max #hop |
|---|---|---|---|---|
| MetaQA-1hop | 96,106 | 9,992 | 9,947 | 1 |
| MetaQA-2hop | 118,980 | 14,872 | 14,872 | 2 |
| MetaQA-3hop | 114,196 | 14,274 | 14,274 | 3 |
| WebQSP | 2,848 | 250 | 1,639 | 2 |
| CWQ | 27,639 | 3,519 | 3,531 | 4 |
数据集。 继多跳 KGQA 的现有工作(Sun 等人,2018;2019;He 等人,2021;Zhang 等人,2022),我们采用三个基准数据集,即 MetaQA (Zhang 等人, 2018)、WebQuestionsSP (WebQSP) (Zhang 等人, 2018; Yih 等人, 2015), 以及Complex WebQuestions 1.1 (CWQ) (Talmor & Berant,2018) 用于评估我们的模型。 表2显示了三个数据集的统计数据。 由于之前的工作在 MetaQA 上几乎取得了满分,因此 WebQSP 和 CWQ 是我们主要评估的数据集。 我们在附录A中提供了这些数据集的详细描述。
评估协议。 对于检索性能,我们遵循Zhang 等人(2022),通过答案覆盖率(%)来评估模型。 它是检索到的子图包含至少一个答案的问题的比例。 对于推理性能,我们遵循Sun等人(2018;2019),将推理视为排序任务进行评估。 给定每个测试问题,我们依靠评估模型的预测概率对所有候选实体进行排名,然后使用 Hits@1 评估 top-1 答案是否正确。 由于一个问题可能对应多个答案,因此我们还采用广泛使用的F1指标。
基线。 我们考虑以下性能比较基准:(1)以推理为中心的方法:KV-Mem (Miller 等人,2016),GraftNet (Sun 等人, 2018), EmbedKGQA (Saxena 等人, 2020), NSM (何等人, 2021), TransferNet (石等人, 2021); (2)检索增强方法:PullNet0> (Sun 等人, 2019)1>、SR+NSM2> (Zhang 等人, 2022 )3>、SR+NSM+E2E4> (张等人, 2022)5>。 我们在附录 B 中提供了这些基线的详细描述。
| Models | WebQSP | CWQ | MetaQA-1 | MetaQA-2 | MetaQA-3 | ||
| Hits@1 | F1 | Hits@1 | F1 | Hits@1 | Hits@1 | Hits@1 | |
| KV-Mem | 46.7 | 34.5 | 18.4 | 15.7 | 96.2 | 82.7 | 48.9 |
| GraftNet | 66.4 | 60.4 | 36.8 | 32.7 | 97.0 | 94.8 | 77.7 |
| PullNet | 68.1 | - | 45.9 | - | 97.0 | 99.9 | 91.4 |
| EmbedKGQA | 66.6 | - | - | - | 97.5 | 98.8 | 94.8 |
| NSM | 68.7 | 62.8 | 47.6 | 42.4 | 97.1 | 99.9 | 98.9 |
| TransferNet | 71.4 | - | 48.6 | - | 97.5 | 100 | 100 |
| SR+NSM | 68.9 | 64.1 | 50.2 | 47.1 | - | - | - |
| SR+NSM+E2E | 69.5 | 64.1 | 49.3 | 46.3 | - | - | - |
| UniKGQA | 75.1 | 70.2 | 50.7 | 48.0 | 97.5 | 99.0 | 99.1 |
| w QU | 77.0 | 71.0 | 50.9 | 49.4 | 97.6 | 99.9 | 99.5 |
| w QU,RU | 77.2 | 72.2 | 51.2 | 49.0 | 98.0 | 99.9 | 99.9 |
4.2评估结果
表3显示了不同方法在5个多跳KGQA数据集上的结果。 可见:
首先,大多数基线在三个 MetaQA 数据集上表现良好(100% Hits@1)。 这是因为这些数据集基于一些手工制作的问题模板,并且对于给定的知识图谱只有九种关系类型。 因此,该模型可以轻松捕获问题和关系之间的相关语义来执行推理。 为了进一步研究这一点,我们对 MetaQA 数据集进行了额外的一次性实验,并在附录 E 中介绍了详细信息。其次,在相同的检索方法下,TransferNet 的性能优于 GraftNet、EmbedKGQA 和 NSM。 它关注疑问词来计算关系的分数,并将实体分数与关系一起传输。 这种方式可以有效捕获问题路径匹配语义。 此外,SR+NSM和SR+NSM+E2E大幅优于NSM和PullNet。 原因是它们都利用基于PLM的关系路径检索器来提高检索性能,然后降低后期推理阶段的难度。
最后,在 WebQSP 和 CWQ 上,我们提出的 UniKGQA 明显优于所有其他竞争基线。 与其他依赖独立模型来执行检索和推理的基线不同,我们的方法可以利用统一的架构来完成它们。 这种统一的架构可以预先学习两个阶段的问题相关语义匹配的基本能力,还能有效地将相关性信息从检索阶段转移到推理阶段,即用检索模型的参数初始化推理模型。
在我们的方法中,我们修复了基于 PLM 的编码器的参数以提高效率。 实际上,更新它的参数可以进一步提高我们的性能。 这种方式使研究人员能够在实际应用中采用我们的方法时权衡效率和有效性。 在这里,我们通过提出 UniKGQA 的两种变体来研究它:(1) w QU 仅在编码问题时更新 PLM 编码器的参数,(2) w QU, RU 在对问题和关系进行编码时更新 PLM 编码器的参数。 事实上,这两种变体都可以提高我们 UniKGQA 的性能。 并且只有在编码问题时更新 PLM 编码器才能获得与更新两者相当的甚至更好的性能。 一个可能的原因是,在对问题和关系进行编码时更新 PLM 编码器可能会导致下游任务过度拟合。 因此,我们的 UniKGQA 在编码问题时仅更新 PLM 编码器是有希望的,因为它可以以相对较少的额外计算成本实现更好的性能。
4.3进一步分析
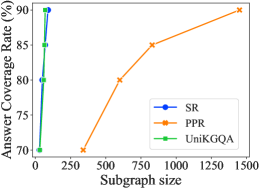
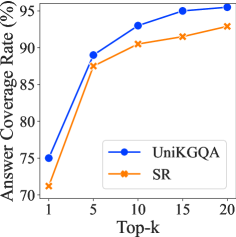
检索评估。 我们评估 UniKGQA 的有效性,以检索给定问题的更小但更好的答案覆盖率子图。 遵循SR(张等人,2022)的评估原则,我们从直接子图大小、答案覆盖率和最终QA性能三个方面来衡量这种能力。 具体来说,我们首先根据答案覆盖率曲线将 UniKGQA 与 SR (Zhang 等人,2022) 和基于 PPR 的启发式检索方法 (Sun 等人,2018) 进行比较w.r.t. 图节点的数量。 然后,我们根据最终的 QA 性能将 UniKGQA 与 SR+NSM (Zhang 等人,2022) 和 PPR+NSM (He 等人,2021) 进行比较。 为了进一步研究我们方法的有效性,我们添加了 UniKGQA 的额外变体,即 UniKGQA+NSM,它依赖 UniKGQA 进行检索,而 NSM 进行推理。 图3左侧和中间显示了上述方法的比较结果。 我们可以看到,在相同大小的检索子图下,UniKGQA 和 SR 的答案覆盖率明显高于 PPR。 它证明了训练可学习检索模型的有效性和必要性。 此外,虽然UniKGQA和SR的曲线非常相似,但我们的UniKGQA可以获得比SR+NSM更好的最终推理性能。 原因是UniKGQA可以基于统一的架构将相关信息从检索阶段转移到推理阶段,学习更有效的推理模型。 通过将我们的 UniKGQA 与 UniKGQA+NSM 进行比较可以进一步验证这一发现。
| Models | WebQSP | CWQ | ||
|---|---|---|---|---|
| Hits@1 | F1 | Hits@1 | F1 | |
| UniKGQA w QU | 77.0 | 71.0 | 50.9 | 49.4 |
| w/o Pre | 75.4 | 70.6 | 49.2 | 48.8 |
| w/o Trans | 75.8 | 70.6 | 49.8 | 49.3 |
| w/o Pre, Trans | 72.5 | 60.0 | 48.1 | 48.4 |
消融研究。 我们的 UniKGQA 包含两个重要的训练策略来提高性能:(1)使用问题关系匹配进行预训练,(2)使用检索模型初始化推理模型的参数。 在这里,我们进行消融研究以验证其有效性。 我们提出了三种变体:(1)w/o Pre删除预训练过程,(2)w/o Trans删除检索模型参数的初始化, (3) w/o Pre, Trans 删除预训练和初始化过程。 我们在表 4 中显示了消融研究的结果。 我们可以看到,所有这些变体的表现都低于完整的 UniKGQA,这表明这两种训练策略对于最终表现都很重要。 此外,这样的观察也验证了我们的 UniKGQA 确实能够迁移和重用学到的知识来提高最终的性能。

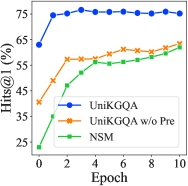
微调效率。 由于我们的 UniKGQA 模型可以迁移从预训练阶段和检索任务中学到的知识,因此它可以很容易地适应下游推理任务。 这样,我们就可以通过几个微调步骤对推理任务进行更高效的微调。 为了探索它,我们将 UniKGQA 的性能变化与强大的基线 NSM w.r.t. 进行比较 基于相同检索子图的微调纪元的增加。 结果显示在图3右侧。 首先,我们可以看到,在微调之前(即当纪元为零时),我们的 UniKGQA 已经达到了与 NSM 在上一个纪元的最佳结果相当的性能。 这表明推理模型已根据检索模型初始化的参数成功地利用了先前任务的知识。 经过两个 epoch 的微调,我们的 UniKGQA 已经取得了良好的性能。 它验证了我们的模型可以在很少的时期内以有效的方式进行微调。 为了进一步研究我们的 UniKGQA 模型,我们进行了参数敏感性分析w.r.t. 预训练步骤、隐藏维度和检索节点数,如附录H所示。
5相关工作
多跳知识图问答。 多跳 KGQA 旨在寻找距离大规模 KG 中的主题实体多跳的答案实体。 考虑到效率和准确性,现有工作(Sun等人,2018;2019;Zhang等人,2022)通常首先检索与问题相关的子图以减少搜索空间,然后进行多跳推理在上面。 这种检索推理范式比直接在整个 KG 上进行推理表现出优越性(Chen 等人,2019;Saxena 等人,2020)。
检索阶段的重点是提取涉及答案实体的相对较小的子图。 常用的方法是收集围绕主题实体的跳数较近的实体来组成子图,并过滤个性化 PageRank 分数较低的实体以减小图大小 (Sun 等人,2018;He 等人,2021) 。 尽管简单,但这种方式忽略了问题语义,限制了检索效率和准确性。 为了解决这个问题,一些工作(Sun等人,2019;Zhang等人,2022)使用神经网络(例如LSTM或PLM)设计了基于语义匹配的检索器。 从主题实体开始,这些检索器迭代地测量问题与相邻实体或关系之间的语义相关性,并将适当的实体或关系添加到子图中。 通过这种方式,将构建一个更小但更与问题相关的子图。
推理阶段的目的是通过从主题实体开始沿着关系走,准确地找到给定问题的答案实体。 早期工作(Miller 等人,2016;Sun 等人,2018;2019;Jiang 等人,2022)依赖于特殊的网络架构(例如键值存储)网络或图卷积网络)来建模多跳推理过程。 最近的工作从中间监督信号(He等人,2021)、知识转移(Shi等人,2021)等角度进一步增强了上述网络的推理能力, ETC。 然而,所有这些方法分别为检索和推理阶段设计了不同的模型架构和训练方法,忽略了两个阶段的相似性和内在联系。
最近,一些工作将问题解析为结构化查询语言(例如, SPARQL)(Lan 等人, 2021; Das 等人, 2021; Huang 等人, 2021) 和通过查询引擎执行它以获得答案。 这样,通常采用编码器-解码器架构(即 T5 (Raffel 等人, 2020))来产生结构化查询,其中带注释的结构化查询是也需要训练。
密集检索。 给定一个查询,密集检索任务旨在从大规模文档池中选择相关文档。 与传统的基于稀疏术语的检索方法不同,例如 TF-IDF (Chen 等人, 2017) 和 BM25 (Robertson & Zaragoza, 2009),稠密检索方法(Karpukhin 等人,2020;Zhou 等人,2022a;b) 依靠双编码器架构将查询和文档映射到低维稠密向量。 然后,可以使用向量距离度量(例如,余弦相似度)来衡量它们的相关性得分,从而支持高效的近似近邻(ANN)搜索算法。 在多跳KGQA中,从主题实体开始,我们需要从大规模KG中选择相关的相邻三元组,以归纳出一条到达答案实体的路径,这可以看作是一个约束密集检索任务。 因此,在这项工作中,我们还采用了双编码器架构,将问题和关系映射到密集向量中,然后根据它们的向量距离进行检索或推理。
6结论
在这项工作中,我们提出了一种用于多跳 KGQA 任务的新方法。 作为主要技术贡献,UniKGQA 为检索和推理阶段引入了基于 PLM 的统一模型架构,由语义匹配模块和匹配信息传播模块组成。 为了应对两个阶段不同规模的搜索空间,我们提出为检索阶段生成摘要子图,这可以显着减少要搜索的节点数量。 此外,我们设计了一种有效的模型学习方法,具有预训练(即问题关系匹配)和微调(即面向检索和推理的学习) )基于统一架构的策略。 通过统一的架构,所提出的学习方法可以有效地增强两个阶段之间相关信息的共享和传递。 我们对三个基准数据集进行了广泛的实验,实验结果表明,我们提出的统一模型优于竞争方法,特别是在更具挑战性的数据集(即 WebQSP 和 CWQ)上。
致谢
该工作得到了国家自然科学基金委的部分资助,批准号为: 62222215,北京市自然科学基金,批准号: 北京市杰出青年科学家计划,批准号:4222027 BJJWZYJH012019100020098。 该工作也得到了中国人民大学2022年杰出创新人才培养资助计划的部分支持。 赵鑫是通讯作者。
参考
- Bollacker et al. (2008) Kurt D. Bollacker, Colin Evans, Praveen K. Paritosh, Tim Sturge, and Jamie Taylor. Freebase: a collaboratively created graph database for structuring human knowledge. In Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2008, Vancouver, BC, Canada, June 10-12, 2008, pp. 1247–1250. ACM, 2008.
- Chen et al. (2017) Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. Reading wikipedia to answer open-domain questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, Volume 1: Long Papers, pp. 1870–1879. Association for Computational Linguistics, 2017.
- Chen et al. (2019) Yu Chen, Lingfei Wu, and Mohammed J. Zaki. Bidirectional attentive memory networks for question answering over knowledge bases. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pp. 2913–2923. Association for Computational Linguistics, 2019.
- Das et al. (2021) Rajarshi Das, Manzil Zaheer, Dung Thai, Ameya Godbole, Ethan Perez, Jay Yoon Lee, Lizhen Tan, Lazaros Polymenakos, and Andrew McCallum. Case-based reasoning for natural language queries over knowledge bases. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pp. 9594–9611. Association for Computational Linguistics, 2021.
- Hadsell et al. (2006) Raia Hadsell, Sumit Chopra, and Yann LeCun. Dimensionality reduction by learning an invariant mapping. 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), 2:1735–1742, 2006.
- He et al. (2021) Gaole He, Yunshi Lan, Jing Jiang, Wayne Xin Zhao, and Ji-Rong Wen. Improving multi-hop knowledge base question answering by learning intermediate supervision signals. In WSDM ’21, The Fourteenth ACM International Conference on Web Search and Data Mining, Virtual Event, Israel, March 8-12, 2021, pp. 553–561. ACM, 2021.
- Huang et al. (2021) Xin Huang, Jung-Jae Kim, and Bowei Zou. Unseen entity handling in complex question answering over knowledge base via language generation. In Findings of the Association for Computational Linguistics: EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 16-20 November, 2021, pp. 547–557. Association for Computational Linguistics, 2021.
- Hudson & Manning (2019) Drew A. Hudson and Christopher D. Manning. Learning by abstraction: The neural state machine. In Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pp. 5901–5914, 2019.
- Jiang et al. (2022) Jinhao Jiang, Kun Zhou, Ji-Rong Wen, and Xin Zhao. $great truths are always simple: $ A rather simple knowledge encoder for enhancing the commonsense reasoning capacity of pre-trained models. In Findings of the Association for Computational Linguistics: NAACL 2022, Seattle, WA, United States, July 10-15, 2022, pp. 1730–1741. Association for Computational Linguistics, 2022.
- Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick S. H. Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, pp. 6769–6781. Association for Computational Linguistics, 2020.
- Lan et al. (2021) Yunshi Lan, Gaole He, Jinhao Jiang, Jing Jiang, Wayne Xin Zhao, and Ji-Rong Wen. A survey on complex knowledge base question answering: Methods, challenges and solutions. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event / Montreal, Canada, 19-27 August 2021, pp. 4483–4491. ijcai.org, 2021.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized BERT pretraining approach. CoRR, abs/1907.11692, 2019.
- Miller et al. (2016) Alexander H. Miller, Adam Fisch, Jesse Dodge, Amir-Hossein Karimi, Antoine Bordes, and Jason Weston. Key-value memory networks for directly reading documents. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP 2016, Austin, Texas, USA, November 1-4, 2016, pp. 1400–1409. The Association for Computational Linguistics, 2016.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21:140:1–140:67, 2020.
- Robertson & Zaragoza (2009) Stephen E. Robertson and Hugo Zaragoza. The probabilistic relevance framework: BM25 and beyond. Found. Trends Inf. Retr., 3(4):333–389, 2009.
- Saxena et al. (2020) Apoorv Saxena, Aditay Tripathi, and Partha P. Talukdar. Improving multi-hop question answering over knowledge graphs using knowledge base embeddings. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pp. 4498–4507. Association for Computational Linguistics, 2020.
- Shi et al. (2021) Jiaxin Shi, Shulin Cao, Lei Hou, Juanzi Li, and Hanwang Zhang. Transfernet: An effective and transparent framework for multi-hop question answering over relation graph. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pp. 4149–4158. Association for Computational Linguistics, 2021.
- Sun et al. (2018) Haitian Sun, Bhuwan Dhingra, Manzil Zaheer, Kathryn Mazaitis, Ruslan Salakhutdinov, and William W. Cohen. Open domain question answering using early fusion of knowledge bases and text. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, pp. 4231–4242. Association for Computational Linguistics, 2018.
- Sun et al. (2019) Haitian Sun, Tania Bedrax-Weiss, and William W. Cohen. Pullnet: Open domain question answering with iterative retrieval on knowledge bases and text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, pp. 2380–2390. Association for Computational Linguistics, 2019.
- Talmor & Berant (2018) Alon Talmor and Jonathan Berant. The web as a knowledge-base for answering complex questions. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, Louisiana, USA, June 1-6, 2018, Volume 1 (Long Papers), pp. 641–651. Association for Computational Linguistics, 2018.
- Tanon et al. (2016) Thomas Pellissier Tanon, Denny Vrandecic, Sebastian Schaffert, Thomas Steiner, and Lydia Pintscher. From freebase to wikidata: The great migration. In Proceedings of the 25th International Conference on World Wide Web, WWW 2016, Montreal, Canada, April 11 - 15, 2016, pp. 1419–1428. ACM, 2016.
- Yih et al. (2015) Wen-tau Yih, Ming-Wei Chang, Xiaodong He, and Jianfeng Gao. Semantic parsing via staged query graph generation: Question answering with knowledge base. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, ACL 2015, July 26-31, 2015, Beijing, China, Volume 1: Long Papers, pp. 1321–1331. The Association for Computer Linguistics, 2015.
- Zhang et al. (2022) Jing Zhang, Xiaokang Zhang, Jifan Yu, Jian Tang, Jie Tang, Cuiping Li, and Hong Chen. Subgraph retrieval enhanced model for multi-hop knowledge base question answering. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pp. 5773–5784. Association for Computational Linguistics, 2022. doi: 10.18653/v1/2022.acl-long.396. URL https://doi.org/10.18653/v1/2022.acl-long.396.
- Zhang et al. (2018) Yuyu Zhang, Hanjun Dai, Zornitsa Kozareva, Alexander J. Smola, and Le Song. Variational reasoning for question answering with knowledge graph. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2-7, 2018, pp. 6069–6076. AAAI Press, 2018.
- Zhou et al. (2022a) Kun Zhou, Yeyun Gong, Xiao Liu, Wayne Xin Zhao, Yelong Shen, Anlei Dong, Jingwen Lu, Rangan Majumder, Ji-Rong Wen, Nan Duan, et al. Simans: Simple ambiguous negatives sampling for dense text retrieval. In EMNLP, 2022a.
- Zhou et al. (2022b) Kun Zhou, Xiao Liu, Yeyun Gong, Wayne Xin Zhao, Daxin Jiang, Nan Duan, and Ji-Rong Wen. Master: Multi-task pre-trained bottlenecked masked autoencoders are better dense retrievers. 2022b.
参考
- Bollacker et al. (2008) Kurt D. Bollacker, Colin Evans, Praveen K. Paritosh, Tim Sturge, and Jamie Taylor. Freebase: a collaboratively created graph database for structuring human knowledge. In Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2008, Vancouver, BC, Canada, June 10-12, 2008, pp. 1247–1250. ACM, 2008.
- Chen et al. (2017) Danqi Chen, Adam Fisch, Jason Weston, and Antoine Bordes. Reading wikipedia to answer open-domain questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, Volume 1: Long Papers, pp. 1870–1879. Association for Computational Linguistics, 2017.
- Chen et al. (2019) Yu Chen, Lingfei Wu, and Mohammed J. Zaki. Bidirectional attentive memory networks for question answering over knowledge bases. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pp. 2913–2923. Association for Computational Linguistics, 2019.
- Das et al. (2021) Rajarshi Das, Manzil Zaheer, Dung Thai, Ameya Godbole, Ethan Perez, Jay Yoon Lee, Lizhen Tan, Lazaros Polymenakos, and Andrew McCallum. Case-based reasoning for natural language queries over knowledge bases. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pp. 9594–9611. Association for Computational Linguistics, 2021.
- Hadsell et al. (2006) Raia Hadsell, Sumit Chopra, and Yann LeCun. Dimensionality reduction by learning an invariant mapping. 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), 2:1735–1742, 2006.
- He et al. (2021) Gaole He, Yunshi Lan, Jing Jiang, Wayne Xin Zhao, and Ji-Rong Wen. Improving multi-hop knowledge base question answering by learning intermediate supervision signals. In WSDM ’21, The Fourteenth ACM International Conference on Web Search and Data Mining, Virtual Event, Israel, March 8-12, 2021, pp. 553–561. ACM, 2021.
- Huang et al. (2021) Xin Huang, Jung-Jae Kim, and Bowei Zou. Unseen entity handling in complex question answering over knowledge base via language generation. In Findings of the Association for Computational Linguistics: EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 16-20 November, 2021, pp. 547–557. Association for Computational Linguistics, 2021.
- Hudson & Manning (2019) Drew A. Hudson and Christopher D. Manning. Learning by abstraction: The neural state machine. In Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pp. 5901–5914, 2019.
- Jiang et al. (2022) Jinhao Jiang, Kun Zhou, Ji-Rong Wen, and Xin Zhao. $great truths are always simple: $ A rather simple knowledge encoder for enhancing the commonsense reasoning capacity of pre-trained models. In Findings of the Association for Computational Linguistics: NAACL 2022, Seattle, WA, United States, July 10-15, 2022, pp. 1730–1741. Association for Computational Linguistics, 2022.
- Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick S. H. Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, pp. 6769–6781. Association for Computational Linguistics, 2020.
- Lan et al. (2021) Yunshi Lan, Gaole He, Jinhao Jiang, Jing Jiang, Wayne Xin Zhao, and Ji-Rong Wen. A survey on complex knowledge base question answering: Methods, challenges and solutions. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI 2021, Virtual Event / Montreal, Canada, 19-27 August 2021, pp. 4483–4491. ijcai.org, 2021.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized BERT pretraining approach. CoRR, abs/1907.11692, 2019.
- Miller et al. (2016) Alexander H. Miller, Adam Fisch, Jesse Dodge, Amir-Hossein Karimi, Antoine Bordes, and Jason Weston. Key-value memory networks for directly reading documents. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP 2016, Austin, Texas, USA, November 1-4, 2016, pp. 1400–1409. The Association for Computational Linguistics, 2016.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21:140:1–140:67, 2020.
- Robertson & Zaragoza (2009) Stephen E. Robertson and Hugo Zaragoza. The probabilistic relevance framework: BM25 and beyond. Found. Trends Inf. Retr., 3(4):333–389, 2009.
- Saxena et al. (2020) Apoorv Saxena, Aditay Tripathi, and Partha P. Talukdar. Improving multi-hop question answering over knowledge graphs using knowledge base embeddings. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020, pp. 4498–4507. Association for Computational Linguistics, 2020.
- Shi et al. (2021) Jiaxin Shi, Shulin Cao, Lei Hou, Juanzi Li, and Hanwang Zhang. Transfernet: An effective and transparent framework for multi-hop question answering over relation graph. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pp. 4149–4158. Association for Computational Linguistics, 2021.
- Sun et al. (2018) Haitian Sun, Bhuwan Dhingra, Manzil Zaheer, Kathryn Mazaitis, Ruslan Salakhutdinov, and William W. Cohen. Open domain question answering using early fusion of knowledge bases and text. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, pp. 4231–4242. Association for Computational Linguistics, 2018.
- Sun et al. (2019) Haitian Sun, Tania Bedrax-Weiss, and William W. Cohen. Pullnet: Open domain question answering with iterative retrieval on knowledge bases and text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, pp. 2380–2390. Association for Computational Linguistics, 2019.
- Talmor & Berant (2018) Alon Talmor and Jonathan Berant. The web as a knowledge-base for answering complex questions. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, Louisiana, USA, June 1-6, 2018, Volume 1 (Long Papers), pp. 641–651. Association for Computational Linguistics, 2018.
- Tanon et al. (2016) Thomas Pellissier Tanon, Denny Vrandecic, Sebastian Schaffert, Thomas Steiner, and Lydia Pintscher. From freebase to wikidata: The great migration. In Proceedings of the 25th International Conference on World Wide Web, WWW 2016, Montreal, Canada, April 11 - 15, 2016, pp. 1419–1428. ACM, 2016.
- Yih et al. (2015) Wen-tau Yih, Ming-Wei Chang, Xiaodong He, and Jianfeng Gao. Semantic parsing via staged query graph generation: Question answering with knowledge base. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, ACL 2015, July 26-31, 2015, Beijing, China, Volume 1: Long Papers, pp. 1321–1331. The Association for Computer Linguistics, 2015.
- Zhang et al. (2022) Jing Zhang, Xiaokang Zhang, Jifan Yu, Jian Tang, Jie Tang, Cuiping Li, and Hong Chen. Subgraph retrieval enhanced model for multi-hop knowledge base question answering. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pp. 5773–5784. Association for Computational Linguistics, 2022. doi: 10.18653/v1/2022.acl-long.396. URL https://doi.org/10.18653/v1/2022.acl-long.396.
- Zhang et al. (2018) Yuyu Zhang, Hanjun Dai, Zornitsa Kozareva, Alexander J. Smola, and Le Song. Variational reasoning for question answering with knowledge graph. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2-7, 2018, pp. 6069–6076. AAAI Press, 2018.
- Zhou et al. (2022a) Kun Zhou, Yeyun Gong, Xiao Liu, Wayne Xin Zhao, Yelong Shen, Anlei Dong, Jingwen Lu, Rangan Majumder, Ji-Rong Wen, Nan Duan, et al. Simans: Simple ambiguous negatives sampling for dense text retrieval. In EMNLP, 2022a.
- Zhou et al. (2022b) Kun Zhou, Xiao Liu, Yeyun Gong, Wayne Xin Zhao, Daxin Jiang, Nan Duan, and Ji-Rong Wen. Master: Multi-task pre-trained bottlenecked masked autoencoders are better dense retrievers. 2022b.
| Dataset | # of templates |
|
|
||||
|---|---|---|---|---|---|---|---|
| MetaQA-1 | 161 | 597 | 9 | ||||
| MetaQA-2 | 210 | 567 | 9 | ||||
| MetaQA-3 | 150 | 761 | 9 |
附录A数据集
我们在这项工作中采用了三个广泛使用的多跳 KGQA 数据集:
MetaQA (Zhang 等人, 2018) 包含超过 40 万个电影领域的问题,答案实体距离最多 3 个跃点主题实体。 根据跳数,该数据集被分成三个子数据集:即 MetaQA-1hop、MetaQA-2hop 和 MetaQA-3hop 。
WebQuestionsSP (WebQSP) (Yih 等人, 2015) 包含 4,737 个问题,答案实体需要在 KG Freebase 上进行最多 2 跳推理(Bollacker等人,2008)。 我们使用与 GraftNet (Sun 等人, 2018) 相同的训练/有效/测试分割。
Complex WebQuestions 1.1 (CWQ) (Talmor & Berant, 2018) 基于 WebQSP,通过扩展问题实体或对答案添加约束来构建。 这些问题需要在 KG Freebase 上进行最多 4 跳推理(Bollacker 等人,2008)。
现有工作表明,MetaQA 的训练数据绰绰有余 (Shi 等人, 2021; He 等人, 2021),因此我们实验中的所有比较方法可以达到非常高的性能。 我们对三个 MetaQA 数据集的模板数量、每个模板的平均训练案例数量以及用于构建问题的关系数量进行了进一步分析,并将其显示在表 5 中。 综上所述,更多的训练案例和更简单的问题使得 MetaQA 更容易解决。
附录 B基线
我们考虑以下基线方法进行性能比较:
KV-Mem (Miller 等人, 2016) 维护一个键值内存表来存储 KG 事实,并通过以下方式进行多跳推理对内存执行迭代读取操作。
GraftNet (Sun 等人, 2018) 首先通过启发式方法分别从知识图谱和维基百科中检索与问题相关的子图和文本句子。 然后采用图神经网络对基于子图和文本句子构建的异构图进行多跳推理。
PullNet (Sun 等人, 2019) 训练由 LSTM 和图神经网络组成的图检索模型,而不是 GraftNet 中的启发式方式进行检索任务,然后利用GraftNet进行多跳推理。
EmbedKGQA (Saxena 等人, 2020) 通过将预训练的实体嵌入与问题来自 PLM 的表示。
NSM (He 等人, 2021) 首先按照 GraftNet 进行检索,然后调整神经状态机 (Hudson & Manning, 2019 )用于视觉推理,在KG上进行多跳推理。
TransferNet (Shi 等人, 2021) 首先按照 GraftNet 进行检索,然后对 KG 或文本形式进行多跳推理透明框架中的关系图。 推理模型由用于问题编码的 PLM 和用于更新实体与问题之间的相关性分数的图神经网络组成。
SR+NSM (Zhang 等人, 2022) 首先学习基于 PLM 的关系路径检索器进行有效检索,然后利用 NSM 推理器执行多跳推理。
SR+NSM+E2E (Zhang 等人, 2022) 进一步对 SR+NSM 进行微调端到端的方式。
附录C知识图谱预处理详细信息
我们按照现有工作(Sun等人,2018;He等人,2021)对完整的Freebase进行预处理。 对于 MetaQA,我们直接使用数据集提供的 WikiMovies 子集,大小约为 134,741。 对于WebQSP和CWQ数据集,我们将检索和推理的最大跳数分别设置为2和4。 基于原始数据集中标记的主题实体,我们为每个样本保留由主题实体的四跳内的实体组成的邻域子图。 经过这样简单的预处理后,我们使用的KG大小对于WebQSP来说是147,748,092,对于CWQ来说是202,358,414。 基于预处理的知识图谱,我们使用我们提出的方法进行检索和推理。
附录 D实施细节。
在预训练过程中,我们根据主题实体和答案实体之间的最短关系路径收集问题关系对,然后使用这些对来预训练 RoBERTa 库 (Liu 等人, 2019) 具有对比学习目标的模型。 我们将温度设置为0.05,并通过在验证集上评估Hits@1来选择最佳模型。 为了进行检索和推理,我们使用对比学习预训练的 RoBERTa 来初始化 UniKGQA 模型的 PLM 模块,并将其他线性层的隐藏大小设置为 768。 我们使用 AdamW 优化器来优化参数,其中 PLM 模块的学习率为 0.00001,其他参数的学习率为 0.0005。 批量大小设置为 40。 对于 CWQ 数据集,推理步骤设置为 4,对于 WebQSP 和 MetaQA-3 数据集,推理步骤设置为 3,对于 MetaQA-2 数据集,推理步骤设置为 2,对于 MetaQA-1 数据集,推理步骤设置为 1。 我们按照现有工作(Sun等人,2018;He等人,2021)对每个数据集的KG进行预处理。
附录EMetaQA 的一次性实验
| Model | MetaQA-1 | MetaQA-2 | MetaQA-3 |
|---|---|---|---|
| NSM | 94.8 | 97.0 | 91.0 |
| TransferNet | 96.5 | 97.5 | 90.1 |
| UniKGQA | 97.1 | 98.2 | 92.6 |
由于MetaQA中的样本绰绰有余,因此我们实验中的所有比较方法都取得了非常高的性能。 例如,我们的方法和之前的工作(例如, TransferNet 和 NSM)在 MetaQA 上实现了超过 98% Hits@1,这表明该数据集的性能可能已经饱和。 为了检验这个假设,我们考虑进行少样本实验来验证不同方法的性能。 特别地,我们遵循NSM论文(He等人,2021)进行了一次性实验。 我们从原始训练集中为每个问题模板随机抽取一个训练案例,以形成一次性训练数据集。 这样,MetaQA-1、MetaQA-2和MetaQA-3的训练样本数分别为161、210和150。 我们评估了我们的方法的性能以及使用这个新训练数据集训练的一些强大的基线(即 TrasnferNet 和 NSM)。 如表 6 所示,我们的方法在所有三个子集中始终优于这些基线。
附录 F我们的统一模型架构的消融研究
| Models | WebQSP (Hits@1) | CWQ (Hits@1) |
|---|---|---|
| PPR+NSM | 68.7 | 47.6 |
| SR+NSM | 68.9 | 50.2 |
| SR+UniKGQA | 70.5 | 48.0 |
| UniKGQA+NSM | 69.1 | 49.2 |
| UniKGQA+UniKGQA | 75.1 | 50.7 |
统一的模型架构是我们方法的关键。 一旦去除统一的模型架构,检索和推理阶段就很难共享通过预训练增强的问题关系匹配能力,也很难将检索阶段学习到的多跳KGQA的相关信息传递到模型中。推理阶段。 为了验证这一点,我们进行了额外的消融研究,以探讨仅采用统一模型架构作为推理模型或检索模型的效果。 我们选择现有的强检索模型(即 SR)和推理模型(即 NSM),并比较与我们的 UniKGQA 集成时的性能。 正如我们在表 7 中看到的,所有变体的表现都低于我们的 UniKGQA。 这表明检索和推理阶段同时使用的统一模型确实是改进的关键原因。
附录G预训练策略分析
| Models | WebQSP (Hits@1) | CWQ (Hits@1) |
|---|---|---|
| UniKGQA | 75.1 | 50.7 |
| w QU | 77.0 | 50.9 |
| w/o Pre, w QU | 75.4 | 49.2 |
| w/o Pre | 67.3 | 48.1 |
我们进行分析实验来研究预训练策略 (Pre) 在更新或不更新 PLM (QU) 的情况下如何影响性能。 我们在表 8 中显示结果。 一旦删除预训练策略,修复(不修复)PLM 时,WebQSP 中的模型性能将下降 10.4%(2.1%),CWQ 中的模型性能将下降 5.1%(3.3%)。 这表明预训练策略是我们方法的重要组成部分。 预训练后,可以修复 PLM,以便在微调过程中更有效地优化参数。
附录H参数敏感性分析
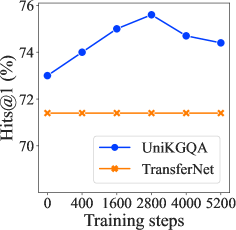
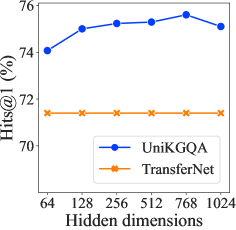
预训练步骤虽然预训练策略在我们的方法中显示出有效的效果,但太多的预训练步骤将非常耗时且成本高昂。 在这里,我们研究不同预训练步骤的性能。 如图4左侧所示,我们可以看到,与最佳方法相比,我们的方法只需很少的预训练步骤(即 2800)即可达到最佳性能基线 TransferNet。 这表明我们的方法不需要太多的预训练步骤。 相反,我们可以看到太多的预训练步骤会损害模型的性能。 原因可能是 PLM 过度适应对比学习目标。
参数调整。 在我们的方法中,我们需要调整两个超参数:(1) 线性层 的隐藏大小和 (2) 检索的节点 的数量。在这里,我们调整 {64, 128, 256, 512, 768, 1024} 中的 和 {1, 5, 10, 15, 20} 中的 。 我们在图4的中间和右侧展示了与推理阶段和检索阶段的最佳结果进行比较的结果。 由于是UniKGQA和SR中一致的超参数,因此我们还描述了具有不同的SR的各种结果,以进行公平的比较。 首先,我们可以看到我们的方法对于不同的隐藏大小具有鲁棒性,因为性能始终在 77.0 附近。 由于PLM采用768作为嵌入大小,我们可以看到768也比其他数字稍好一些。 此外,我们可以看到,随着的增加,答案覆盖率也不断提高。 然而,当增加到15甚至20时,性能增益变得相对较小。 这意味着检索到的子图可能已经饱和,进一步增加 只能带来边际改进。