capbtabbox表[][]
RT-1:用于大规模现实世界控制的机器人 Transformer
摘要
通过从大型、多样化、与任务无关的数据集中转移知识,现代机器学习模型可以通过零样本或小型特定于任务的数据集来解决特定的下游任务,从而达到高水平的性能。 虽然这种能力已经在计算机视觉、自然语言处理或语音识别等其他领域得到了证明,但它仍有待在机器人技术中得到证明,由于收集现实世界的机器人数据的困难,模型的泛化能力尤其重要。 我们认为,这种通用机器人模型成功的关键之一在于开放式任务无关训练,与可以吸收所有多样化机器人数据的高容量架构相结合。 在本文中,我们提出了一个名为 Robotics Transformer 的模型类,它展现了有前途的可扩展模型属性。 我们通过对不同模型类别的研究以及它们作为数据大小、模型大小和数据多样性的函数的概括能力来验证我们的结论,这些能力基于执行现实世界任务的真实机器人的大规模数据收集。 该项目的网站和视频可以在 robotics-transformer1.github.io 找到
对应电子邮件:{keerthanapg,kanishkarao,karolhausman}@google.com。
Anthony Brohan∗, Noah Brown∗, Justice Carbajal∗、Yevgen Chebotar∗, Joseph Dabis∗, Chelsea Finn∗、Keerthana Gopalakrishnan∗, Karol Hausman∗, Alex Herzog†、Jasmine Hsu∗, Julian Ibarz∗, Brian Ichter∗, Alex Irpan∗、Tomas Jackson∗, Sally Jesmonth∗, Nikhil J Joshi∗、Ryan Julian∗, Dmitry Kalashnikov∗, Yuheng Kuang∗、Isabel Leal∗, Kuang-Huei Lee‡, Sergey Levine∗, Yao Lu∗、Utsav Malla∗, Deeksha Manjunath∗, Igor Mordatch‡、Ofir Nachum‡, Carolina Parada∗, Jodilyn Peralta∗、Emily Perez∗, Karl Pertsch∗, Jornell Quiambao∗, Kanishka Rao∗、Michael Ryoo∗, Grecia Salazar∗, Pannag Sanketi∗、Kevin Sayed∗, Jaspiar Singh∗, Sumedh Sontakke‡、Austin Stone∗, Clayton Tan∗, Huong Tran∗、Vincent Vanhoucke∗, Steve Vega∗, Quan Vuong∗、Fei Xia∗, Ted Xiao∗, Peng Xu∗、Sichun Xu∗, Tianhe Yu∗, Brianna Zitkovich∗.
1简介
端到端的机器人学习,无论是模仿还是强化,通常涉及在单任务(Kalashnikov等人,2018;Zhang等人,2018)或多任务中收集特定于任务的数据(Kalashnikov 等人,2021b;Jang 等人,2021) 针对机器人应执行的任务进行精确定制的设置。 此工作流程反映了其他领域(例如计算机视觉和 NLP)监督学习的经典方法,其中将收集、标记和部署特定于任务的数据集以解决各个任务,而任务本身之间几乎没有相互作用。 近年来,视觉、自然语言处理和其他领域发生了转变,从孤立的小规模数据集和模型转向在广泛的大型数据集上预训练的大型通用模型。 此类模型成功的关键在于与任务无关的开放式训练,与可以吸收大规模数据集中存在的所有知识的高容量架构相结合。 如果一个模型可以“吸收”经验来学习语言或感知的一般模式,那么它可以使它们更有效地承担个人任务。 虽然在监督学习中消除对大型特定任务数据集的需求通常很有吸引力,但在机器人技术中更为重要,因为数据集可能需要工程量大的自主操作或昂贵的人类演示。 因此,我们要问:我们能否在由各种机器人任务组成的数据上训练一个单一的、有能力的、大型的多任务骨干模型? 这样的模型是否享有在其他领域观察到的好处,展示对新任务、环境和对象的零样本泛化?
在机器人领域建立这样的模型并不容易。 尽管近年来文献中提出了一些大型多任务机器人策略(Reed等人,2022;Jang等人,2021),但此类模型通常对现实世界任务的广度有限,例如与 Gato (Reed 等人, 2022) 一样,或者专注于训练任务而不是泛化到新任务,就像最近遵循方法 (Shridhar 等人, 2021; 2022) 的指令一样>,或在新任务上取得相对较低的表现(Jang 等人,2021)。
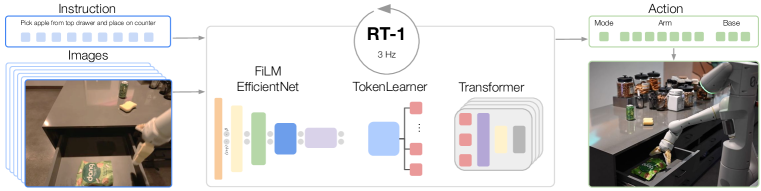

两个主要挑战在于组装正确的数据集和设计正确的模型。 虽然数据收集和管理通常是许多大型机器学习项目的“无名英雄”(Radford 等人,2021;Ramesh 等人,2021),在机器人领域尤其如此,其中数据集通常是机器人特定的并手动收集(Dasari 等人,2019;Ebert 等人,2021)。 正如我们将在评估中展示的那样,良好的泛化需要结合规模和广度的数据集,涵盖各种任务和设置。 同时,数据集中的任务应充分连接以实现泛化,以便模型可以发现结构相似任务之间的模式,并执行以新颖方式组合这些模式的新任务。 我们利用了一个由 13 个机器人组成的车队在 17 个月的时间里收集的数据集,其中包含130k 个情节和超过 700 个任务,并且我们在评估中消除了该数据集的各个方面。
第二个挑战在于模型本身的设计。 有效的机器人多任务学习需要高容量模型,而 Transformer (Vaswani 等人, 2017) 模型在这方面表现出色,特别是当需要学习许多有条件的任务时,就像我们的例子一样,关于语言说明。 然而,机器人控制器还必须足够高效才能实时运行,这对变形金刚来说尤其是一个重大挑战。 我们提出了一种称为 RT-1(机器人 Transformer 1)的新颖架构,该架构通过将高维输入和输出(包括相机图像、指令和电机命令)编码为供 Transformer 使用的紧凑词符表示,从而实现高效在运行时进行推理以使实时控制变得可行。
我们的贡献是 RT-1 模型以及在现实世界机器人任务的大型且广泛的数据集上使用该模型进行的实验。 我们的实验不仅证明 RT-1 与现有技术相比可以显着提高泛化性和鲁棒性,而且还评估和消除了模型和训练集组成中的许多设计选择。 我们的结果表明,RT-1 可以以 97% 的成功率执行超过 700 条训练指令,并且对新任务、干扰因素和背景的泛化能力分别比下一个最佳基线好 25%、36% 和 18%。 这种性能水平使我们能够在 SayCan (Ahn 等人, 2022) 框架中执行非常长的任务,阶段多达 50 个。 我们进一步表明,RT-1 可以合并来自模拟甚至其他机器人类型的数据,保留原始任务的性能并提高对新场景的泛化。 图 1(b)222Helper robots shown in Fig. 1-5 are from Everyday Robots。
2相关工作
最近的许多工作提出了基于 Transformer 的机器人控制策略。 与 RT-1 一样,一些作品使用 Transformers 处理的语言命令作为强大的框架来指定和泛化新任务 (Zhang & Chai, 2021; Pashevich 等人, 2021; Silva 等人, 2021; Jang 等人,2021;Ahn 等人,2022;Nair 等人,2022)。 我们的工作将 Transformer 的应用更进一步,将语言和视觉观察到机器人动作的映射视为序列建模问题,并使用 Transformer 来学习这种映射。 这个想法的直接灵感来自于游戏(Chen等人,2021;Lee等人,2022a)以及模拟机器人导航(Fang等人,2019)的成功>、运动(Janner 等人, 2021; Gupta 等人, 2022) 和操纵(Jiang 等人, 2022) 环境。 我们注意到,其中一些工作不仅仅局限于文本调节,还使用 Transformer 来泛化机器人形态(例如,Gupta 等人(2022))和其他任务规范模式(例如, Jang 等人 (2021); Jiang 等人 (2022))。 这些扩展为 RT-1 带来了有希望的未来方向。
除了基于 Transformer 的政策之外,我们工作的重点是大规模的可推广且强大的现实世界机器人操作。 现实世界中基于 Transformer 的机器人操作的现有工作侧重于从每个任务的一组演示中有效地学习任务(Shridhar 等人,2022)。 Behaviour Transformer (Shafiullah 等人, 2022) 和 Gato (Reed 等人, 2022) 主张在大规模机器人和非机器人数据集上训练单一模型。 然而,这些作品在现实世界的机器人任务中受到限制;例如,Gato 可以有效地学习单个任务(彩色块堆叠),而无需评估对新任务或各种现实世界设置的泛化。 在技术方面,我们的工作研究了如何构建基于 Transformer 的策略,以便将高容量和泛化性与实时控制所需的计算效率结合起来。
虽然使用大容量 Transformer 模型来学习机器人控制策略是一项相当新的创新,但机器人技术在多任务和语言条件学习方面有着悠久的历史,RT-1 建立在这些基础之上。 大量工作涉及机器人抓取的学习策略和预测模型(Saxena 等人,2006;Lenz 等人,2015;Pinto & Gupta,2016;Gupta 等人,2018;Viereck 等人,2017),目的是泛化到新对象。 之前的工作试图通过结合语言解析、视觉和机器人控制的流水线方法来解决机器人语言理解问题(MacMahon 等人,2006;Kollar 等人,2010;Tellex 等人,2011)端到端方法(Mei 等人,2016;Stepputtis 等人,2020;Lynch & Sermanet,2020;Ahn 等人,2022)。 多任务机器人学习也从学习达到目标的角度进行了探讨(Chung 等人, 2015; Raffin 等人, 2019; Jurgenson 等人, 2020; Huang 等人, 2020),以及可以以离散集或其他参数化形式执行任务的学习策略(Deisenroth 等人,2014;Devin 等人,2017;Fox 等人,2019;Kalashnikov 等人,2021a) 。 机器人领域的许多先前工作也集中于收集包含演示或试验的数据集,这些演示或试验说明了各种不同的任务(Sharma 等人,2018;Dasari 等人,2019;Yu 等人,2020;Singh 等人, 2020;詹姆斯等人,2020)。 我们的工作进一步证明了多任务、语言条件机器人学习的力量,展示了更大规模、更多样化的行为、物体和场景的实验结果,并提出了新的架构和设计选择,使机器人能够更大规模的学习。
3 预赛
机器人学习。
我们的目标是学习机器人策略来通过视觉解决语言条件任务。 形式上,我们考虑顺序决策环境。 在时间步,向策略提供语言指令和初始图像观察。 该策略生成一个动作分布 ,从中采样动作 并将其应用于机器人。 此过程继续进行,策略通过从学习的分布 中采样并将这些操作应用于机器人来迭代地生成操作 。 当达到终止条件时交互结束。 从开始步骤到终止步骤的完整交互被称为片段。 在一个回合结束时,代理将获得一个二元奖励 指示机器人是否执行了指令 。 目标是学习一种策略 ,在指令分布、起始状态 和转换动态的预期下最大化平均奖励。
变形金刚。 RT-1 使用 Transformer (Vaswani 等人, 2017) 来参数化策略 。 一般来说,Transformer 是使用自注意力层和全连接神经网络的组合将输入序列 映射到输出序列 的序列模型。 虽然 Transformers 最初是为文本序列设计的,其中每个输入 和输出 代表一个文本词符,但它们已扩展到图像 (Parmar 等人,2018) 以及其他模式(Lee 等人,2022a;Reed 等人,2022)。 如下一节所述,我们通过首先将输入 映射到序列 并将操作输出 映射到序列来参数化 在使用 Transformer 学习映射 之前。
模仿学习。 模仿学习方法在演示 的数据集 上训练策略 (Pomerleau,1988;Zhang 等人,2018;Jang 等人,2021)。 具体来说,我们假设访问剧集数据集 ,所有这些都是成功的(即最终奖励为 )。 我们使用行为克隆 (Pomerleau,1988)来学习,它通过最小化动作的负对数似然来优化 给出图像和语言说明。
4系统概述
这项工作的目标是构建并演示一个通用的机器人学习系统,该系统可以吸收大量数据并有效地进行泛化。 我们使用 Everyday Robots 的移动机械手333everydayrobots.com,它有一个7自由度的手臂、一个两指夹具和一个移动底座(见图2(d))。 为了收集数据并评估我们的方法,我们使用三个基于厨房的环境:两个真实的办公室厨房和一个模仿这些真实厨房的训练环境。 训练环境如图2(a)所示,由部分计数器组成,是为大规模数据收集而构建的。 如图 2 (b, c) 所示,两个真实环境具有与训练环境类似的台面,但在照明、背景和完整厨房几何形状方面有所不同(例如,可能有一个可能会看到橱柜而不是抽屉或水槽)。 我们评估我们的政策在这些不同环境中的表现,衡量政策的表现和泛化能力。
我们的训练数据由人类提供的演示组成,我们用机器人刚刚执行的指令的文本描述来注释每一集。 指令通常包含一个动词和一个或多个描述目标对象的名词。 为了将这些指令分组在一起,我们将它们分为许多技能(例如,“挑选”、“打开”或“直立放置”等动词)和对象(例如,“可乐罐”、“苹果”等名词,或“抽屉”)。 我们在第 2 节中大规模描述了我们的数据收集策略的细节。 5.2。 我们最大的数据集包含超过 130k 个单独的演示,这些演示使用多种对象构成了 700 多个不同的任务指令(见图 2 (f))。 我们在第 2 节中描述了收集的数据的详细信息。 5.2。
我们系统的主要贡献之一是网络架构,即 Robotics Transformer 1 (RT-1),这是一种高效的模型,可以吸收大量数据,有效地概括并以实时速率输出动作,以实现实际的机器人控制。 RT-1 将一小段图像和自然语言指令作为输入,并在每个时间步输出机器人的动作。 为此,该架构(如图 1(a) 所示)利用了多个元素:首先,通过 ImageNet 预训练卷积网络处理图像和文本(Tan & Le,2019) 以通过 FiLM (Perez 等人, 2018) 预训练指令嵌入为条件,然后通过词符 Learner (Ryoo 等人, 2021) 进行计算一组紧凑的 Token ,最后是一个 Transformer (Vaswani 等人, 2017) 来处理这些 Token 并生成离散的动作 Token 。 这些动作包括手臂运动的七个维度(x、y、z、滚动、俯仰、偏航、夹具的打开)、基础运动的三个维度(x、y、偏航)以及在三种模式之间切换的离散维度:控制手臂、底座或终止情节。 RT-1 以 Hz 执行闭环控制和命令操作,直到产生“终止”操作或达到预设的时间步长限制。

5 RT-1:机器人 Transformer
在本节中,我们将描述如何标记图像、文本和动作,然后讨论 RT-1 模型架构。 然后我们描述如何获得实时控制所需的运行速度。 最后,我们描述了数据收集过程以及数据集中的技能和说明。
5.1型号
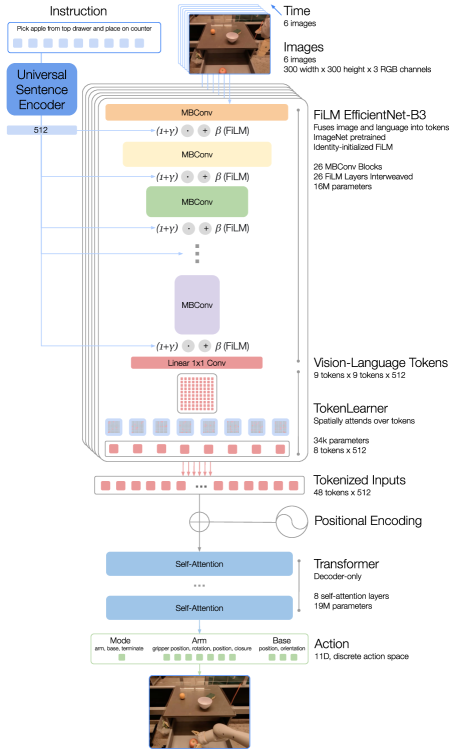
我们的模型建立在 Transformer 架构(Vaswani 等人,2017)之上,以图像历史和任务描述作为输入,直接输出标记化动作,如图 1(a),详细见图3。 下面我们按照图 3 中从上到下的顺序描述模型的组件。 附录C.3中提供了有关大规模模型选择的更多详细信息。
指令和图像标记化。 RT-1 架构依赖于图像和语言指令的数据高效且紧凑的标记化。 RT-1 通过将图像传递给 ImageNet 预训练的 EfficientNet-B3 (Tan & Le,2019) 模型来标记 6 个图像的历史记录,该模型将 6 个分辨率为 的图像作为输入并从最终的卷积层输出形状为的空间特征图。 与 Reed 等人 (2022) 不同,在将图像输入到 Transformer 主干之前,我们不会将图像修补为视觉标记。 相反,我们将 EfficientNet 的输出特征图扁平化为 视觉标记,这些标记被传递到网络的后续层。
为了包含语言指令,我们以预训练语言嵌入的形式将图像标记器设置在自然语言指令上,从而可以尽早提取与任务相关的图像特征并提高 RT-1 的性能。 该指令首先通过通用句子编码器(Cer等人,2018)嵌入。 然后,将此嵌入用作身份初始化 FiLM 层(Perez 等人,2018) 的输入,添加到预训练的 EfficientNet 中以调节图像编码器。 通常,将 FiLM 层插入预训练网络的内部会破坏中间激活并抵消使用预训练权重的好处。 为了克服这个问题,我们将密集层(和)的权重初始化为0,从而产生FiLM仿射变换为零,允许FiLM层最初充当身份并保留预训练权重的函数。 我们发现,在没有 ImageNet 预训练的情况下,使用从头初始化的 EfficientNet 进行训练时,身份初始化的 FiLM 也能产生更好的结果,但它没有超过上述初始化。 图像标记器的架构如图3所示。
RT-1 通过 FiLM EfficientNet-B3 进行的图像和指令标记化共有 16M 个参数,具有 26 层 MBConv 块和 FiLM 层,输出 81 个视觉语言标记。
TokenLearner。 为了进一步压缩 RT-1 需要参与的 token 数量,从而加快推理速度,RT-1 使用了 TokenLearner (Ryoo 等人, 2021)。 TokenLearner 是一个逐元素注意力模块,它学习将大量标记映射为更少数量的标记。 这使我们能够根据图像标记的信息来软选择图像标记,仅将重要的词符组合传递到后续的 Transformer 层。 TokenLearner 的加入将对来自预训练 FiLM-EfficientNet 层的 视觉标记进行子采样,仅生成 最终标记,然后将其传递到我们的 Transformer 层。
Transformer 。 然后,将每张图像的这 8 个标记与历史记录中的其他图像连接起来,形成总共 48 个标记(添加位置编码),并将其馈送到 RT-1 的 Transformer 主干中。 Transformer 是一个仅解码器的序列模型,具有 8 个自注意力层和 19M 个输出动作标记的总参数。
动作标记化。 为了对动作进行标记,RT-1 中的每个动作维度都被离散化为 箱。 如前所述,我们考虑的动作维度包括手臂运动的七个变量(、、、滚动、俯仰、偏航、打开抓手),三个用于底座运动的变量(,,偏航)以及一个在三种模式之间切换的离散变量:控制手臂,底座或终止情节。 对于每个变量,我们将目标映射到 256 个 bin 之一,其中 bin 均匀分布在每个变量的范围内。
损失。 我们使用先前基于 Transformer 的控制器中使用的标准分类交叉熵熵目标和因果掩蔽(Reed 等人,2022;Lee 等人,2022a)。
推理速度。 与自然语言或图像生成等大型模型的许多应用相比,需要在真实机器人上实时运行的模型的独特要求之一是快速且一致的推理速度。 考虑到人类执行本工作中考虑的指令的速度(我们测量的速度在 秒范围内),我们希望模型不会明显慢于此。 根据我们的实验,此要求至少对应于 Hz 控制频率,并且在考虑到系统中的其他延迟的情况下,模型的推理时间预算将小于 ms。
这一要求限制了我们可以使用的模型的大小。 我们在实验中进一步探讨模型大小对推理速度的影响。 我们采用两种技术来加速推理:(i) 使用 TokenLearner (Ryoo 等人,2021) 减少预训练的 EfficientNet 模型生成的 Token 数量,(ii) 仅计算这些 Token 一次并将它们重新用于以下重叠的窗口以供将来的推论。 这两者都使我们能够分别将模型推理速度加快 和 倍。 有关模型推理的更多详细信息,请参阅附录 C.1。
5.2数据
| Skill | Count | Description | Example Instruction |
| Pick Object | 130 | Lift the object off the surface | pick iced tea can |
| Move Object Near Object | 337 | Move the first object near the second | move pepsi can near rxbar blueberry |
| Place Object Upright | 8 | Place an elongated object upright | place water bottle upright |
| Knock Object Over | 8 | Knock an elongated object over | knock redbull can over |
| Open Drawer | 3 | Open any of the cabinet drawers | open the top drawer |
| Close Drawer | 3 | Close any of the cabinet drawers | close the middle drawer |
| Place Object into Receptacle | 84 | Place an object into a receptacle | place brown chip bag into white bowl |
| Pick Object from Receptacle and Place on the Counter | 162 | Pick an object up from a location and then place it on the counter | pick green jalapeno chip bag from paper bowl and place on counter |
| Section 6.3 and 6.4 tasks | 9 | Skills trained for realistic, long instructions | open the large glass jar of pistachios |
| pull napkin out of dispenser | |||
| grab scooper | |||
| Total | 744 |
我们的目标是构建一个具有高性能、对新任务的泛化性以及对干扰和背景的鲁棒性的系统。 因此,我们的目标是收集一个大型、多样化的机器人轨迹数据集,其中包括多个任务、对象和环境。 我们的主要数据集包含 130k 机器人演示,由 13 个机器人组成的车队在 17 个月的时间里收集。 我们在一系列办公室厨房部分(我们将其称为机器人教室)进行了大规模数据收集,如图2所示。 有关数据收集的更多详细信息,请参见附录C.2。
技能和说明。 虽然文献中任务的定义仍然不一致,但在这项工作中,我们计算了系统可以执行的语言指令的数量,其中一条指令对应于一个或多个名词包围的动词,例如“place水瓶直立”,“移动可乐罐到绿色薯片袋”或“打开抽屉”。 RT-1 能够在多个真实的办公室厨房环境中执行 700 多种语言指令,我们在实验中对其进行了评估和详细描述。 为了对评估进行分组并得出系统性能的结论,我们按指令中使用的动词对指令进行分组,我们将其称为技能。 表 1 显示了更详细的指令列表,其中包含示例以及每种技能的指令数量。
目前的技能包括挑选、放置、打开和关闭抽屉、将物品放入和取出抽屉、将细长物品直立放置、将其打翻、拉餐巾和打开罐子。 选择这些技能来演示多个对象的多种行为(如图 2(e) 所示),以测试 RT-1 的各个方面,例如对新指令的泛化和执行许多任务的能力。 然后,我们极大地扩展了“拾取”技能的对象多样性,以确保该技能能够泛化到不同的对象(参见图2(f)中扩展的对象集)。 当我们进行消融以包括表 1 最后一行中添加的指令时,技能得到了进一步扩展,这些指令用于第 2 节中描述的实验。 6.4 和 6.3。 这些额外技能侧重于办公室厨房中现实的、长远的指示。 添加任务和数据的整个过程在附录C.4中描述。 由于我们在添加新指令时不对特定技能做任何假设,因此系统很容易扩展,我们可以不断提供更多样化的数据来提高其能力。
6实验
我们的实验试图回答以下问题:
在本节中,我们将比较两种最先进的基线架构:Gato (Reed 等人,2022) 和 BC-Z (Jang 等人,2021)。 重要的是,这两者都是根据我们在第 2 节中详细描述的数据进行训练的。 5.2(这是我们系统的重要组成部分),因为这些出版物中的原始模型不会表现出我们评估任务所需的泛化属性。 Gato 与 RT-1 类似,基于 Transformer 架构,但在多个方面与 RT-1 有所不同。 首先,它在没有语言概念的情况下计算图像标记,并且每个图像词符嵌入是针对每个图像块单独计算的,这与我们模型中的早期语言融合和全局图像嵌入相反。 其次,它不使用预先训练的文本嵌入来对语言字符串进行编码。 它还不包括第 2 节中讨论的真实机器人所必需的推理时间考虑因素。 5.1 例如 TokenLearner 和删除自回归操作。 为了以足够高的频率在真实机器人上运行 Gato,与原始出版物相比,我们还限制了模型的大小,即 1.2B 参数(导致机器人推理时间为 s) ,与 RT-1 大小相似(Gato 为 37M 参数,RT-1 为 35M)。 BC-Z基于ResNet架构,并被用于SayCan(Ahn等人,2022)。 BC-Z 与 RT-1 的不同之处在于它是一个前馈模型,不使用先前的时间步长,并且它使用连续动作而不是离散动作标记。 除了原始 BC-Z 模型大小之外,我们还将我们的方法与 BC-Z 的较大版本进行比较,该版本具有与 RT-1 相似的参数数量,并将其称为 BC-Z XL。 我们在附录 D.4 和 D.5 部分中研究和分析了每个设计决策如何改变性能。
我们评估实验的成功率,以衡量训练指令的性能、对未见过的指令的泛化、对背景和干扰因素的鲁棒性以及长视野场景中的性能,如下所述。 在本节中,我们通过 3000 多次实际试验来评估我们的方法和基线,这是迄今为止对机器人学习系统最大规模的评估之一。
6.1 实验设置
正如 4 节中提到的,我们使用 Everyday Robots 的一组移动机械手在三个环境中评估 RT-1:两个真实的办公室厨房和模仿这些真实厨房的训练环境。 训练环境如图2(a)所示,由部分计数器组成,而两个真实环境如图2(b,c)所示,具有相似的计数器台面与训练环境不同,但在照明、背景和完整的厨房几何形状方面有所不同(例如,可能有一个柜子而不是抽屉,或者可能会看到水槽)。 这些策略的评估包括训练任务的性能、对新任务的泛化、对未见环境的鲁棒性,以及在长期任务中链接在一起时的性能,如下所述。
看到了任务表现。 为了评估所见指令的性能,我们评估从训练集中采样的指令的性能。 但请注意,此评估仍然涉及改变对象的放置和设置的其他因素(例如,一天中的时间、机器人位置),需要将技能推广到环境中的实际变化。 此次评估总共测试了 200 多个任务:拾取物体 36 个、敲击物体 35 个、将物体直立 35 个、移动物体 48 个、打开和关闭各种抽屉 18 个、取出和放置物体 36 个放进抽屉里。
未见任务概括。 为了评估对未见过的任务的泛化能力,我们测试了 21 个新颖的、未见过的指令。 这些指令分布在技能和对象中。 这确保了训练集中至少存在每个对象和技能的某些实例,但它们将以新颖的方式组合。 例如,如果发出“拿起苹果”,则还有其他包含苹果的训练指令。 所有未见过的指令的列表可以在附录D.1中找到。
稳健性。 为了评估鲁棒性,我们执行了 30 项实际任务来衡量干扰鲁棒性,并执行 22 项任务来衡量背景鲁棒性。 通过在新厨房(具有不同的照明和背景视觉效果)和不同的柜台表面(例如有图案的桌布)中进行评估来测试背景稳健性。 鲁棒性评估场景的示例配置如图4所示。
长期情景。 我们还评估了对更现实的长期场景的泛化,每个场景都需要执行一系列技能。 本次评估的目标是结合新任务、对象、环境等多个泛化轴,并在现实环境中测试整体泛化能力。 这些评估由两个真实厨房中的 15 条长视野指令组成,需要执行由 个不同步骤组成的技能序列,每个步骤的范围与训练指令大致相当。 这些步骤是从更高级别的指令自动获得的,例如“你会如何扔掉桌子上的所有物品?”通过使用 SayCan 系统(Ahn 等人,2022),如第 6.4 节和附录 D.3 中详细描述。

6.2 RT-1 能否学会执行大量指令,并泛化到新的任务、对象和环境?
为了回答我们的第一个问题,我们与之前提出的模型相比,分析了 RT-1 的整体性能、泛化性和鲁棒性能力。 具体来说,我们与 Gato (Reed 等人, 2022) 和 BC-Z (Jang 等人, 2021) 使用的模型架构以及更大的版本进行比较BC-Z,我们称之为 BC-Z XL。 但请注意,所有模型都使用与 RT-1 相同的数据进行训练,并且评估仅比较模型架构,而不是任务集、数据集或整个机器人系统。 RT-1 的能力在很大程度上取决于数据集和任务集,我们相信它比之前的工作有了显着的改进(例如 BC-Z 使用 100 个任务,原始的 Gato 模型训练了各种形状的堆叠任务),并且因此,这种比较应该被视为对先前的模型相当有利,这些模型也受益于我们收集的庞大且多样化的数据集和任务集。
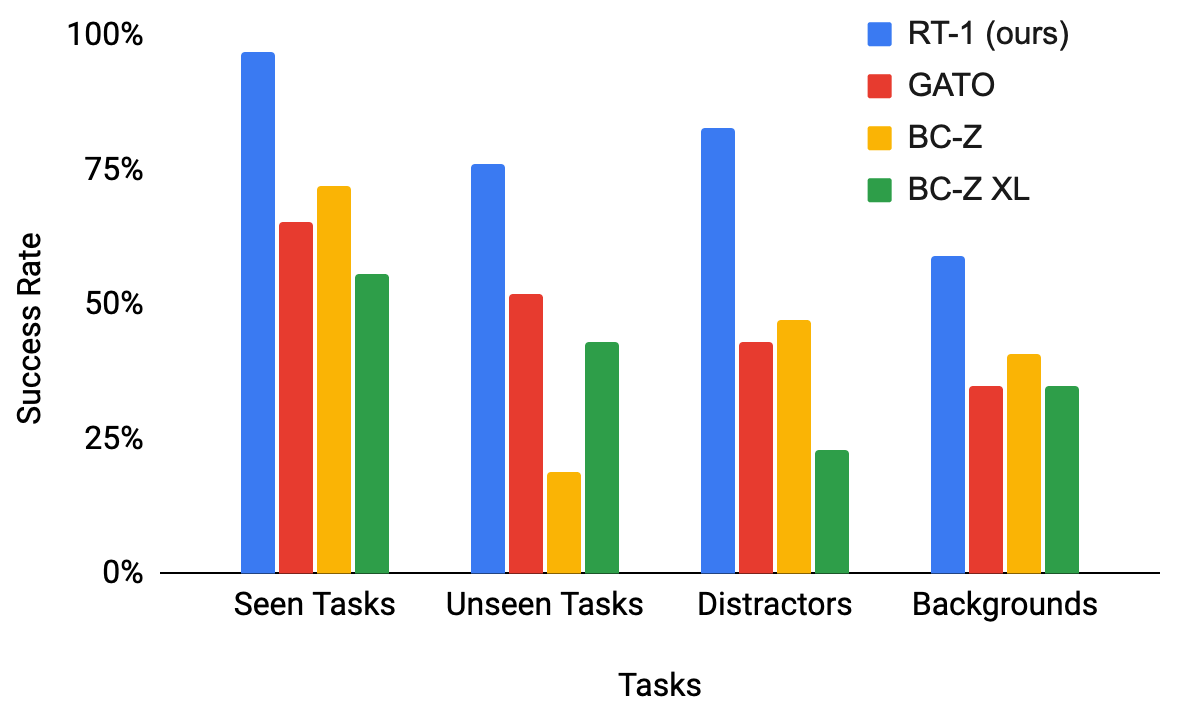
结果如表2所示。 在每个类别中,我们发现 RT-1 显着优于之前的模型。 在所见任务中,RT-1 能够成功执行 200 多条指令中的 97%,比 BC-Z 高 25%,比 Gato 高 32%。 在未见过的任务上,RT-1 表明它能够泛化为新颖的指令,执行 76% 的前所未见的指令,比下一个最佳基线多 24%。 虽然由于策略的自然语言条件使得这种对新颖指令的概括成为可能,但由于策略能够理解先前见过的概念的新组合,所以所有基线也都以自然语言为条件,并且原则上享有相同的好处。 我们在下一节中进一步消除 RT-1 的不同组成部分,以更好地理解我们方法的哪些方面对这种差异贡献最大。 在干扰物和背景上,我们发现 RT-1 非常稳健,成功执行了 83% 的干扰物鲁棒性任务和 59% 的背景鲁棒性任务(分别比下一个最佳替代方案高 36% 和 18%)。 总的来说,我们发现 RT-1 具有很高的通用性能,同时表现出令人印象深刻的泛化性和鲁棒性。 我们在图 5 中展示了 RT-1 代理的示例轨迹,包括涵盖不同技能、环境和对象的指令。 我们还在附录中提供了不同泛化测试的附加轨迹示例,其中包括背景(图10)和干扰项(图12)。
| Model | Seen Tasks | Unseen Tasks | Distractors | Backgrounds |
|---|---|---|---|---|
| Gato (Reed et al., 2022) | 65 | 52 | 43 | 35 |
| BC-Z (Jang et al., 2021) | 72 | 19 | 47 | 41 |
| BC-Z XL | 56 | 43 | 23 | 35 |
| RT-1 (ours) | 97 | 76 | 83 | 59 |

概括为现实的指令。 接下来,我们测试我们的方法是否在我们之前评估的部署在真实厨房中的所有不同轴上具有足够的泛化能力,这会同时产生多个分布变化,例如新的任务组合、物体干扰物以及新颖的环境。
为了在真实厨房的真实场景中评估我们的算法,我们构建了任务序列来实现许多现实目标。 机器人会在抽屉里补充一些零食,清理打翻的调味品瓶,关闭人类打开的抽屉,用橙子和餐巾准备零食,并从厨房的多个地方取回丢失的太阳镜和章鱼玩具。 这些场景中使用的详细说明列于附录D.1中。 办公室厨房涉及训练环境的巨大转变,我们对这些场景中的任务进行了不同概括程度的分类:概括到新的台面布局和照明条件, 用于额外泛化到看不见的干扰对象, 用于额外泛化到全新的任务设置、新任务对象或看不见的位置(例如水槽附近)的对象。 图4的最后一行描绘了与真实厨房中的补货、准备零食和取回丢失物品这三个任务相对应的三个级别。 不同级别的示例轨迹如图11中的附录所示。
我们在表 3 中报告了这些现实场景中每个任务的成功率以及不同的泛化级别,并发现 RT-1 在所有级别上都是最稳健的。 Gato 在第一级的泛化能力相当好,但对于更困难的泛化场景,它的表现会显着下降。 BC-Z 及其 XL 等效项在 级别上表现相当好,在 级别上优于 Gato,但它们仍然没有达到 RT-1 的泛化级别。
| Generalization Scenario Levels | ||||
| Models | All | L1 | L2 | L3 |
| Gato Reed et al. (2022) | 30 | 63 | 25 | 0 |
| BC-Z Jang et al. (2021) | 45 | 38 | 50 | 50 |
| BC-Z XL | 55 | 63 | 75 | 38 |
| RT-1 (ours) | 70 | 88 | 75 | 50 |
![[Uncaptioned image]](kanishka_data.png)
6.3 我们能否通过合并异构数据源(例如来自不同机器人的模拟或数据)来进一步推动生成的模型?
接下来,我们探讨 RT-1 在利用高度异构数据方面的局限性。 我们演示了 RT-1 如何整合和学习截然不同的数据源,并从这些数据中进行改进,而不会牺牲该数据固有的各种任务的原始任务性能。 为此,我们进行了两项实验:(1)RT-1 在真实数据和模拟数据上进行训练和测试;(2)RT-1 在不同任务的大型数据集上进行训练,这些数据集最初是由不同的机器人收集的。 附录D.2中提供了有关每项内容的更多信息。
吸收模拟数据。 表 4 显示了 RT-1 和基线吸收真实数据和模拟数据的能力。 为了测试这一点,我们获取了所有真实的演示数据,但我们还提供了额外的模拟数据,其中包括机器人在现实世界中从未见过的物体。 具体来说,我们指定不同的泛化场景:对于具有真实对象的可见技能,训练数据具有该指令的真实数据(即,在可见任务上的表现),对于具有模拟对象的可见技能 t1> 训练数据具有该指令的模拟数据(例如“拾取一个模拟物体”,它存在于模拟中),并且对于带有模拟物体的未见技能,训练数据具有该指令的模拟数据对象,但没有描述该对象的技能的指令示例,无论是模拟还是真实(例如,“将一个模拟对象移动到苹果”,即使机器人只练习了拾取该模拟对象而不是将其移动到附近)其他物体)。 所有评估都是在现实世界中完成的,但为了限制评估的指令数量,我们专注于选择和移动技能。
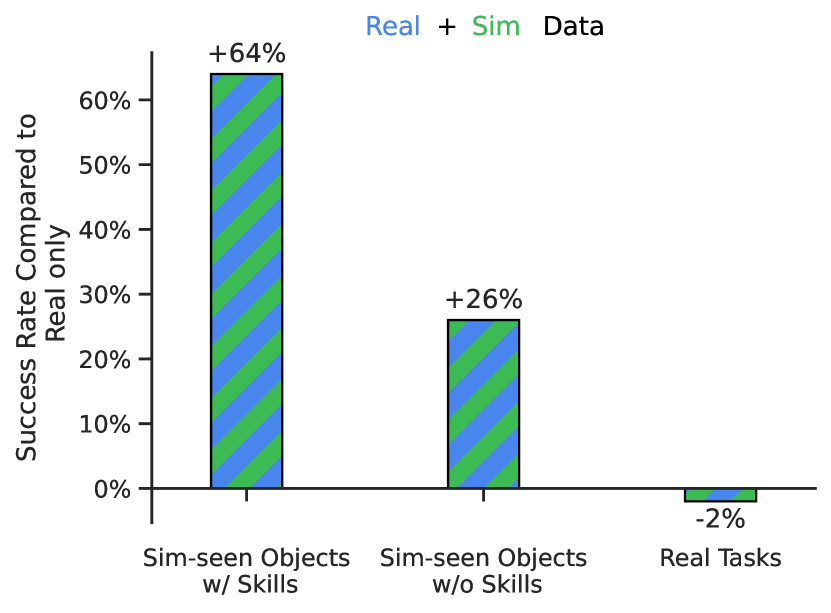
我们在表 4 中发现,对于 RT-1,与 Real Only 数据集相比,添加模拟数据不会损失性能。 然而,我们确实看到,仅在模拟中看到的对象和任务的性能显着提高(从 23% 到 87%),接近真实情况的性能,展示了令人印象深刻的领域转移程度。 我们还发现未见过的指令的性能显着提高,从 7% 提高到 33%;令人印象深刻的是,所涉及的物体从未在现实中见过,而且指令也从未见过。 总的来说,我们发现 RT-1 能够有效地吸收新数据,即使来自非常不同的领域。
| Real Objects | Sim Objects (not seen in real) | |||
| Seen Skill | Seen Skill | Unseen Skill | ||
| Models | Training Data | w/ Objects | w/ Objects | w/ Objects |
| RT-1 | Real Only | 92 | 23 | 7 |
| RT-1 | Real + Sim | 90(-2) | 87(+64) | 33(+26) |
吸收来自不同机器人的数据。 为了突破 RT-1 的数据吸收极限,我们进行了一组额外的实验,其中结合了来自不同机器人的两个数据源:Kuka IIWA 以及迄今为止实验中使用的 Everyday Robots 移动机械手。 Kuka 数据包含 QT-Opt (Kalashnikov 等人, 2018) 中收集的所有成功示例,相当于 209k 个情节,其中机器人不加区别地抓取垃圾箱中的物体(参见表中的 Kuka 情节。 5)。 为了测试 RT-1 是否可以有效地吸收这两个截然不同的数据集(我们将其称为标准“课堂评估”),以及反映 Kuka 数据中存在的分箱选取设置的新构建任务的性能,我们将其称为“Bin-picking eval”(见图6)。
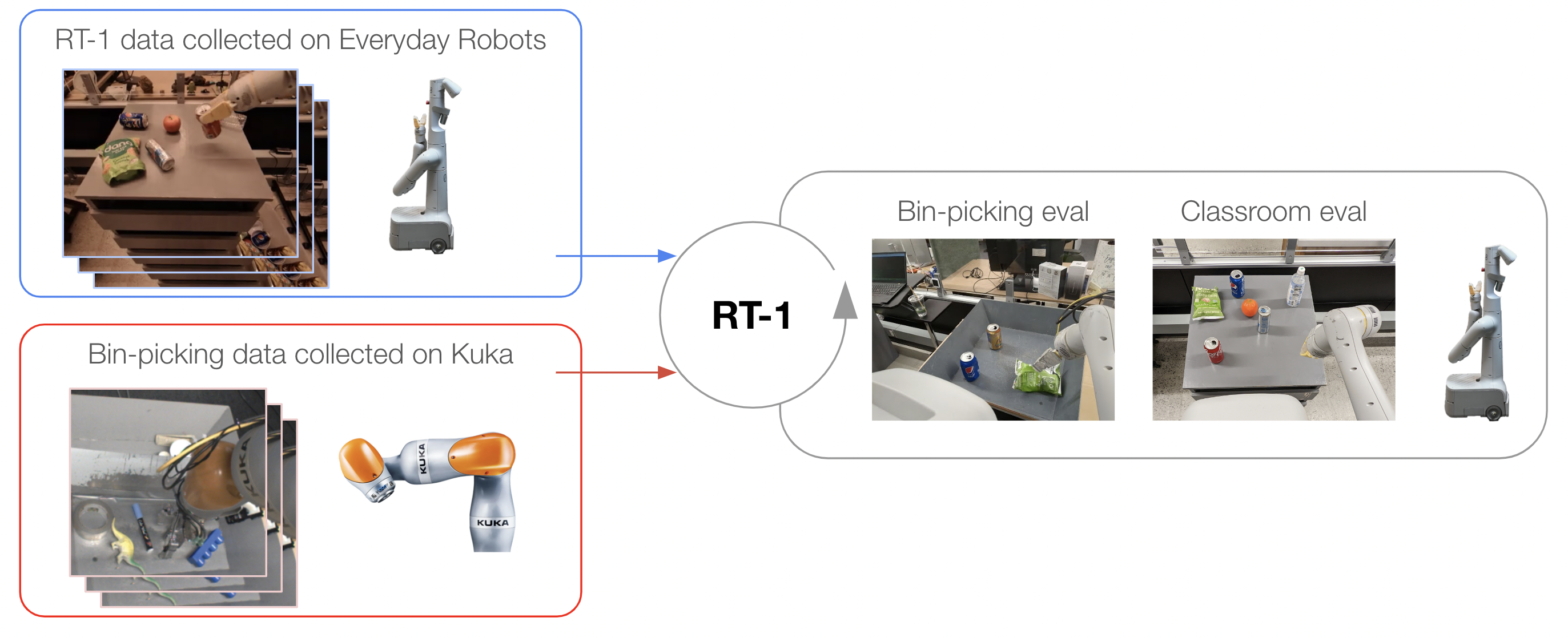
我们想通过指出数据集之间的主要差异来强调这种设置的难度。 不仅收集数据的机器人在外观和动作空间上有所不同,而且它们部署的环境也有不同的外观和动态。 此外,QT-Opt 数据呈现出完全不同的动作分布——它是由 RL 代理收集的,而不是我们数据集中存在的人类演示。
结果如表5所示。 我们观察到,混合 RT-1 数据和 Kuka 数据的模型对原始任务的性能(即课堂评估)仅略有下降,即 。 更重要的是,在 Bin-picking 评估中,我们观察到,与仅在多机器人数据上训练的模型的 相比,在多机器人数据上训练的模型的性能为 。 RT-1 数据。 这是 性能差异(几乎是 2 倍)。 此外,RT-1 在 Kuka 垃圾箱拣选数据上进行了训练,并使用 Everyday Robots (EDR) 机器人对垃圾箱拣选任务进行了评估,其性能达到了 0%,这证实了很难从另一个机器人形态转移行为。 然而,混合来自两个机器人的数据使得 RT-1 能够推断出 EDR 机器人的正确动作,即使面对 Kuka 机器人观察到的状态也是如此。 这是在没有对 EDR 机器人进行垃圾箱拣选的明确演示的情况下,通过利用 Kuka 机器人过去收集的经验来实现的。 这些结果表明,RT-1 的吸收特性还包括通过观察其他机器人的经验来获取新技能的能力,并为未来的工作提供了令人兴奋的途径,我们可以结合更多的多机器人数据集来增强机器人的能力。
| Models | Training Data | Classroom eval | Bin-picking eval |
|---|---|---|---|
| RT-1 | Kuka bin-picking data + EDR data | 90(-2) | 39(+17) |
| RT-1 | EDR only data | 92 | 22 |
| RT-1 | Kuka bin-picking only data | 0 | 0 |
![[Uncaptioned image]](x5.png)
6.4 各种方法如何泛化长视野机器人场景?
在下一组实验中,我们评估我们的方法是否具有足够的泛化能力,可以在长期的现实厨房环境中使用。 为了回答这个问题,我们在两个不同的真实厨房中执行 RT-1 和 SayCan (Ahn 等人,2022) 框架内的各种基线。 由于 SayCan 结合了许多低级指令来执行高级指令,因此可能的高级指令数量随着技能的增加而组合增加,因此可以充分看到 RT-1 的技能广度(有关 SayCan 算法的更多详细信息,请参阅参考Ahn 等人 (2022))。 长视野任务的成功率也会随着任务长度的延长而呈指数下降,因此操作技巧的高成功率尤为重要。 此外,由于移动操纵任务需要导航和操纵,因此策略对基础位置的鲁棒性至关重要。 附录D.3提供了更多详细信息。
表 6 显示了我们的结果(根据附录表 12 中的说明)。 除了原始的 SayCan 之外,所有方法的计划成功率均为 87%,其中 RT-1 表现最好,在 Kitchen1 中执行成功率为 67%。 Kitchen2 构成了一个更具挑战性的泛化场景,因为机器人教室训练场景是根据 Kitchen1 建模的(参见图 2 中厨房的图片)。 由于这种泛化困难,带有 Gato 的 SayCan 无法完成任何长期任务,而带有 BC-Z 的 SayCan 能够达到 13% 的成功率。 最初的 SayCan 论文没有评估新厨房的性能。 令人惊讶的是,对于我们的方法,从 Kitchen1 到 Kitchen2 的操作性能没有明显下降。 在补充视频中,我们展示了这使我们能够操作 Kitchen2 中看不见的抽屉,并且我们可以使用 SayCan-RT1 来规划和执行超长范围的任务,最多有 50 个步骤。
| SayCan tasks in Kitchen1 | SayCan tasks in Kitchen2 | ||||
|---|---|---|---|---|---|
| Planning | Execution | Planning | Execution | ||
| Original SayCan (Ahn et al., 2022)∗ | 73 | 47 | - | - | |
| SayCan w/ Gato (Reed et al., 2022) | 87 | 33 | 87 | 0 | |
| SayCan w/ BC-Z (Jang et al., 2021) | 87 | 53 | 87 | 13 | |
| SayCan w/ RT-1 (ours) | 87 | 67 | 87 | 67 | |
6.5 泛化指标如何随着数据量和数据多样性的变化而变化?
虽然之前的工作已经展示了基于 Transformer 的模型(Lee 等人,2022a;Reed 等人,2022;Jiang 等人,2022)随着模型参数数量的扩展能力,但在许多机器人工作中模型大小通常不是主要瓶颈,最大大小受到在真实机器人上运行此类模型的延迟要求的限制。 相反,在本研究中,我们专注于消除数据集大小和多样性的影响,因为它们在传统数据有限的机器人学习领域中发挥着重要作用。 由于数据收集对于真实的机器人来说特别昂贵,因此量化我们的模型需要什么样的数据才能实现一定的性能和泛化非常重要。 因此,我们的最后一个问题重点关注 RT-1 具有不同数据属性的缩放属性。
| Generalization | ||||||||
| Models | % Tasks | % Data | Seen Tasks | All | Unseen Tasks | Distractors | Backgrounds | |
| Smaller Data | ||||||||
| RT-1 (ours) | 100 | 100 | 97 | 73 | 76 | 83 | 59 | |
| RT-1 | 100 | 51 | 71 | 50 | 52 | 39 | 59 | |
| RT-1 | 100 | 37 | 55 | 46 | 57 | 35 | 47 | |
| RT-1 | 100 | 22 | 59 | 29 | 14 | 31 | 41 | |
| Narrower Data | ||||||||
| RT-1 (ours) | 100 | 100 | 97 | 73 | 76 | 83 | 59 | |
| RT-1 | 75 | 97 | 86 | 54 | 67 | 42 | 53 | |
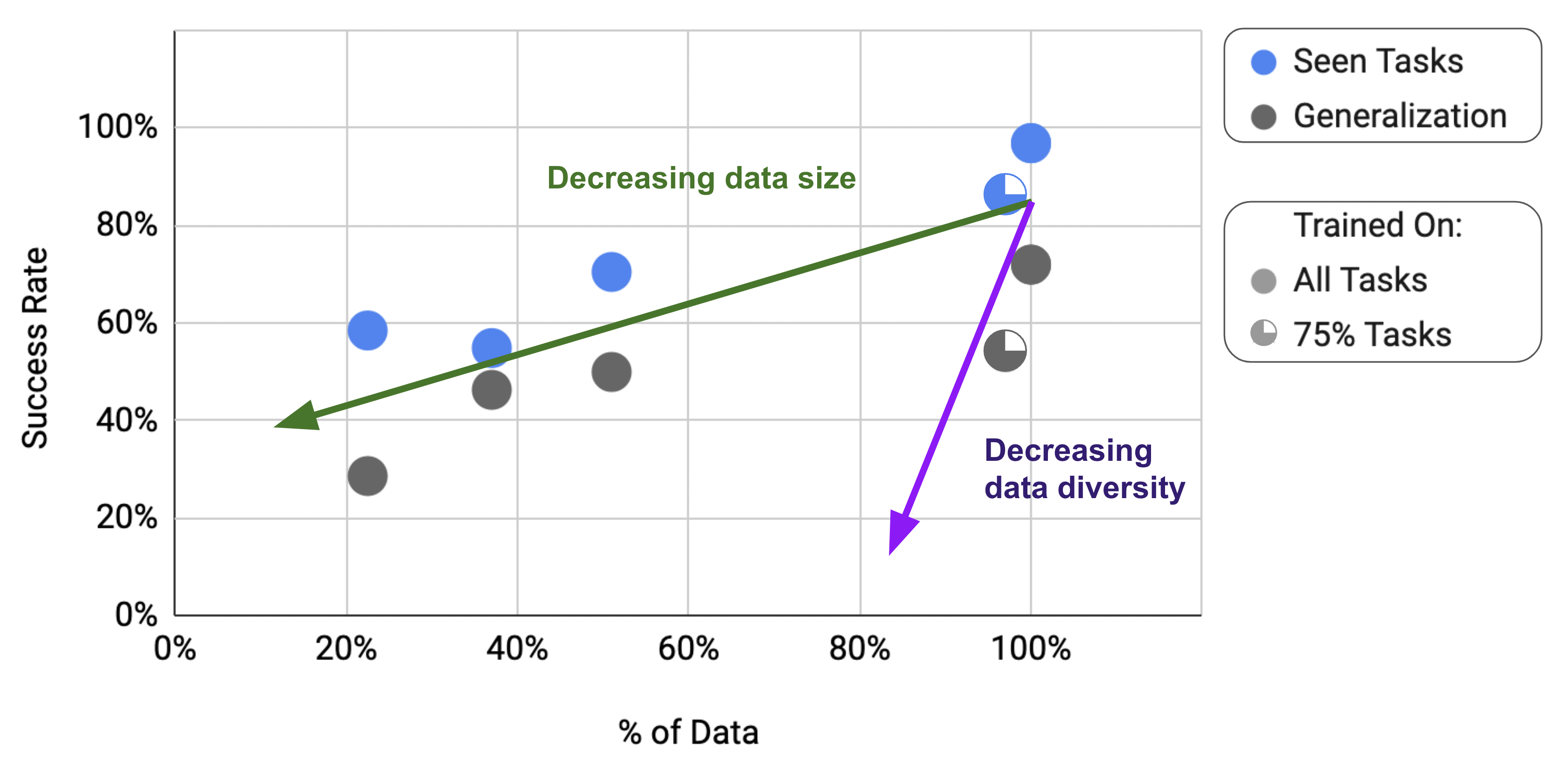
在表 7 中,我们展示了当我们减小数据集大小(% 数据)和数据集多样性(% 任务)时 RT-1 的性能、泛化和鲁棒性。 为了分离数据集大小和多样性的轴,我们通过从具有最大数据的任务中删除数据来创建具有相同任务多样性的较小数据集,将每个任务的示例数量限制为 200(导致数据的 51%)、100 (占数据的 37%)和 50(占数据的 22.5%)。 为了创建一个狭窄的数据集,我们删除了数据最少的任务,从而保留了 97% 的总体数据,但只保留了 75% 的任务。 当我们减小数据集大小时,我们会看到性能下降的总体趋势和泛化能力下降的更陡峭的趋势。 当我们使数据集变得更窄时,我们看到性能下降得更厉害,特别是在泛化方面。 事实上,删除 25% 的任务同时保留 97% 的数据可以实现相当于将数据集大小减少 49% 的泛化性能。 因此,我们的主要结论是,数据多样性比数据数量更重要。
7 结论、局限性和未来的工作
我们提出了 Robotics Transformer 1,RT-1,一种机器人学习方法,可以有效地吸收大量数据,并且具有数据量和多样性。 我们在一个大型演示数据集上对 RT-1 进行了训练,该数据集包含 13 个机器人在 17 个月的时间里收集的超过 13 万个片段。 在我们广泛的实验中,我们证明了我们的方法可以以 97% 的成功率执行 700 多个指令,并且比之前发布的基线更好地有效地推广到新任务、对象和环境。 我们还证明,RT-1 可以成功地吸收来自模拟和其他机器人形态的异构数据,而不牺牲原始任务性能,同时提高对新场景的泛化。 最后,我们展示了这种水平的性能和泛化如何使我们能够在 SayCan (Ahn 等人,2022) 框架中执行非常长的任务,步骤多达 50 个。
虽然 RT-1 通过数据吸收模型向大规模机器人学习迈出了有希望的一步,但它也存在一些局限性。 首先,它是一种模仿学习方法,它继承了此类方法的挑战,例如它可能无法超越演示者的表现。 其次,对新指令的推广仅限于以前见过的概念的组合,RT-1 尚无法推广到以前从未见过的全新运动。 最后,我们的方法是在大量但不是很灵巧的操作任务上提出的。 我们计划继续扩展 RT-1 支持和推广的指令集来应对这一挑战。
当我们探索这项工作的未来方向时,我们希望通过开发允许非专家通过定向数据收集和模型提示来训练机器人的方法来更快地扩展机器人技能的数量。 虽然 RT-1 的当前版本相当稳健,尤其是对于干扰对象而言,但通过大幅增加环境多样性,可以进一步提高其对背景和环境的稳健性。 我们还希望通过可扩展的注意力和记忆来提高 RT-1 的反应速度和上下文保留。
为了让研究社区能够在这项工作的基础上进行构建,我们开源了 RT-1 444http://github.com/google-research/robotics_transformer,我们希望能为研究人员提供宝贵的资源,用于未来放大机器人的研究学习。
致谢
感谢 Aleksandra Faust、Andy Christiansen、Chuyuan Fu、Daniel Kappler、David Rendleman、Eric Jang、Jessica Gomez、Jessica Lin、Jie Tan、Josh Weaver、Justin Boyd、Krzysztof Choromanski、Matthew Bennice、Mengyuan Yan、Mrinal Kalakrishnan、感谢 Nik Stewart、Paul Wohlhart、Peter Pastor、Pierre Sermanet、Wenlong Lu、Zhen Yu Song、Zhuo Xu 以及 Google 和 Everyday Robots 机器人技术团队的反馈和贡献。
参考
- Ahn et al. (2022) Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, et al. Do as I can, not as I say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022.
- Cer et al. (2018) Daniel Cer, Yinfei Yang, Sheng-yi Kong, Nan Hua, Nicole Limtiaco, Rhomni St John, Noah Constant, Mario Guajardo-Cespedes, Steve Yuan, Chris Tar, et al. Universal sentence encoder. arXiv preprint arXiv:1803.11175, 2018.
- Chen et al. (2021) Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. Advances in neural information processing systems, 34:15084–15097, 2021.
- Chung et al. (2015) Michael Jae-Yoon Chung, Abram L Friesen, Dieter Fox, Andrew N Meltzoff, and Rajesh PN Rao. A bayesian developmental approach to robotic goal-based imitation learning. PloS one, 10(11):e0141965, 2015.
- Dasari et al. (2019) Sudeep Dasari, Frederik Ebert, Stephen Tian, Suraj Nair, Bernadette Bucher, Karl Schmeckpeper, Siddharth Singh, Sergey Levine, and Chelsea Finn. Robonet: Large-scale multi-robot learning. In Conference on Robot Learning, 2019.
- Deisenroth et al. (2014) Marc Peter Deisenroth, Peter Englert, Jan Peters, and Dieter Fox. Multi-task policy search for robotics. In 2014 IEEE international conference on robotics and automation (ICRA), pp. 3876–3881. IEEE, 2014.
- Devin et al. (2017) Coline Devin, Abhishek Gupta, Trevor Darrell, Pieter Abbeel, and Sergey Levine. Learning modular neural network policies for multi-task and multi-robot transfer. In 2017 IEEE international conference on robotics and automation (ICRA), pp. 2169–2176. IEEE, 2017.
- Dudík et al. (2011) Miroslav Dudík, John Langford, and Lihong Li. Doubly robust policy evaluation and learning. arXiv preprint arXiv:1103.4601, 2011.
- Ebert et al. (2021) Frederik Ebert, Yanlai Yang, Karl Schmeckpeper, Bernadette Bucher, Georgios Georgakis, Kostas Daniilidis, Chelsea Finn, and Sergey Levine. Bridge data: Boosting generalization of robotic skills with cross-domain datasets. arXiv preprint arXiv:2109.13396, 2021.
- Fang et al. (2019) Kuan Fang, Alexander Toshev, Li Fei-Fei, and Silvio Savarese. Scene memory transformer for embodied agents in long-horizon tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 538–547, 2019.
- Fox et al. (2019) Roy Fox, Ron Berenstein, Ion Stoica, and Ken Goldberg. Multi-task hierarchical imitation learning for home automation. In 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), pp. 1–8. IEEE, 2019.
- Gupta et al. (2018) Abhinav Gupta, Adithyavairavan Murali, Dhiraj Prakashchand Gandhi, and Lerrel Pinto. Robot learning in homes: Improving generalization and reducing dataset bias. Advances in neural information processing systems, 31, 2018.
- Gupta et al. (2022) Agrim Gupta, Linxi Fan, Surya Ganguli, and Li Fei-Fei. Metamorph: Learning universal controllers with transformers. arXiv preprint arXiv:2203.11931, 2022.
- Hanna et al. (2017) Josiah P Hanna, Peter Stone, and Scott Niekum. Bootstrapping with models: Confidence intervals for off-policy evaluation. In Thirty-First AAAI Conference on Artificial Intelligence, 2017.
- Ho et al. (2020) Daniel Ho, Kanishka Rao, Zhuo Xu, Eric Jang, Mohi Khansari, and Yunfei Bai. RetinaGAN: An object-aware approach to sim-to-real transfer, 2020. URL https://arxiv.org/abs/2011.03148.
- Huang et al. (2020) De-An Huang, Yu-Wei Chao, Chris Paxton, Xinke Deng, Li Fei-Fei, Juan Carlos Niebles, Animesh Garg, and Dieter Fox. Motion reasoning for goal-based imitation learning. In 2020 IEEE International Conference on Robotics and Automation (ICRA), pp. 4878–4884. IEEE, 2020.
- Irpan et al. (2019) Alexander Irpan, Kanishka Rao, Konstantinos Bousmalis, Chris Harris, Julian Ibarz, and Sergey Levine. Off-policy evaluation via off-policy classification. Advances in Neural Information Processing Systems, 32, 2019.
- James et al. (2020) Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J Davison. RLBench: The robot learning benchmark & learning environment. IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020.
- Jang et al. (2021) Eric Jang, Alex Irpan, Mohi Khansari, Daniel Kappler, Frederik Ebert, Corey Lynch, Sergey Levine, and Chelsea Finn. Bc-z: Zero-shot task generalization with robotic imitation learning. In Conference on Robot Learning, pp. 991–1002. PMLR, 2021.
- Janner et al. (2021) Michael Janner, Qiyang Li, and Sergey Levine. Reinforcement learning as one big sequence modeling problem. In ICML 2021 Workshop on Unsupervised Reinforcement Learning, 2021.
- Jiang et al. (2022) Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, and Linxi Fan. Vima: General robot manipulation with multimodal prompts. arXiv preprint arXiv:2210.03094, 2022.
- Jurgenson et al. (2020) Tom Jurgenson, Or Avner, Edward Groshev, and Aviv Tamar. Sub-goal trees a framework for goal-based reinforcement learning. In International Conference on Machine Learning, pp. 5020–5030. PMLR, 2020.
- Kalashnikov et al. (2018) Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, et al. Scalable deep reinforcement learning for vision-based robotic manipulation. In Conference on Robot Learning, pp. 651–673. PMLR, 2018.
- Kalashnikov et al. (2021a) Dmitry Kalashnikov, Jacob Varley, Yevgen Chebotar, Benjamin Swanson, Rico Jonschkowski, Chelsea Finn, Sergey Levine, and Karol Hausman. Mt-opt: Continuous multi-task robotic reinforcement learning at scale. arXiv preprint arXiv:2104.08212, 2021a.
- Kalashnikov et al. (2021b) Dmitry Kalashnikov, Jake Varley, Yevgen Chebotar, Ben Swanson, Rico Jonschkowski, Chelsea Finn, Sergey Levine, and Karol Hausman. MT-opt: Continuous multi-task robotic reinforcement learning at scale. arXiv, 2021b.
- Kollar et al. (2010) Thomas Kollar, Stefanie Tellex, Deb Roy, and Nicholas Roy. Toward understanding natural language directions. In 2010 5th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pp. 259–266. IEEE, 2010.
- Lee et al. (2022a) Kuang-Huei Lee, Ofir Nachum, Mengjiao Yang, Lisa Lee, Daniel Freeman, Winnie Xu, Sergio Guadarrama, Ian Fischer, Eric Jang, Henryk Michalewski, et al. Multi-game decision transformers. arXiv preprint arXiv:2205.15241, 2022a.
- Lee et al. (2022b) Kuang-Huei Lee, Ted Xiao, Adrian Li, Paul Wohlhart, Ian Fischer, and Yao Lu. PI-QT-Opt: Predictive information improves multi-task robotic reinforcement learning at scale. arXiv preprint arXiv:2210.08217, 2022b.
- Lenz et al. (2015) Ian Lenz, Honglak Lee, and Ashutosh Saxena. Deep learning for detecting robotic grasps. The International Journal of Robotics Research, 34(4-5):705–724, 2015.
- Lynch & Sermanet (2020) Corey Lynch and Pierre Sermanet. Language conditioned imitation learning over unstructured data. arXiv preprint arXiv:2005.07648, 2020.
- MacMahon et al. (2006) Matt MacMahon, Brian Stankiewicz, and Benjamin Kuipers. Walk the talk: Connecting language, knowledge, and action in route instructions. Def, 2(6):4, 2006.
- Mei et al. (2016) Hongyuan Mei, Mohit Bansal, and Matthew R Walter. Listen, attend, and walk: Neural mapping of navigational instructions to action sequences. In Thirtieth AAAI Conference on Artificial Intelligence, 2016.
- Nair et al. (2022) Suraj Nair, Eric Mitchell, Kevin Chen, Silvio Savarese, Chelsea Finn, et al. Learning language-conditioned robot behavior from offline data and crowd-sourced annotation. In Conference on Robot Learning, pp. 1303–1315. PMLR, 2022.
- Parmar et al. (2018) Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. Image transformer. In International conference on machine learning, pp. 4055–4064. PMLR, 2018.
- Pashevich et al. (2021) Alexander Pashevich, Cordelia Schmid, and Chen Sun. Episodic transformer for vision-and-language navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 15942–15952, 2021.
- Perez et al. (2018) Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), Apr. 2018. doi: 10.1609/aaai.v32i1.11671. URL https://ojs.aaai.org/index.php/AAAI/article/view/11671.
- Pinto & Gupta (2016) Lerrel Pinto and Abhinav Gupta. Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours. In 2016 IEEE international conference on robotics and automation (ICRA), pp. 3406–3413. IEEE, 2016.
- Pomerleau (1988) Dean A Pomerleau. Alvinn: An autonomous land vehicle in a neural network. Advances in neural information processing systems, 1, 1988.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pp. 8748–8763. PMLR, 2021.
- Raffin et al. (2019) Antonin Raffin, Ashley Hill, René Traoré, Timothée Lesort, Natalia Díaz-Rodríguez, and David Filliat. Decoupling feature extraction from policy learning: assessing benefits of state representation learning in goal based robotics. arXiv preprint arXiv:1901.08651, 2019.
- Ramesh et al. (2021) Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In International Conference on Machine Learning, pp. 8821–8831. PMLR, 2021.
- Reed et al. (2022) Scott Reed, Konrad Zolna, Emilio Parisotto, Sergio Gomez Colmenarejo, Alexander Novikov, Gabriel Barth-Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, et al. A generalist agent. arXiv preprint arXiv:2205.06175, 2022.
- Ryoo et al. (2021) Michael Ryoo, AJ Piergiovanni, Anurag Arnab, Mostafa Dehghani, and Anelia Angelova. Tokenlearner: Adaptive space-time tokenization for videos. Advances in Neural Information Processing Systems, 34:12786–12797, 2021.
- Saxena et al. (2006) Ashutosh Saxena, Justin Driemeyer, Justin Kearns, and Andrew Ng. Robotic grasping of novel objects. Advances in neural information processing systems, 19, 2006.
- Shafiullah et al. (2022) Nur Muhammad Mahi Shafiullah, Zichen Jeff Cui, Ariuntuya Altanzaya, and Lerrel Pinto. Behavior transformers: Cloning modes with one stone. arXiv preprint arXiv:2206.11251, 2022.
- Sharma et al. (2018) Pratyusha Sharma, Lekha Mohan, Lerrel Pinto, and Abhinav Gupta. Multiple interactions made easy (mime): Large scale demonstrations data for imitation. In Conference on robot learning, pp. 906–915. PMLR, 2018.
- Shridhar et al. (2021) Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Cliport: What and where pathways for robotic manipulation. In Proceedings of the 5th Conference on Robot Learning (CoRL), 2021.
- Shridhar et al. (2022) Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. arXiv preprint arXiv:2209.05451, 2022.
- Silva et al. (2021) Andrew Silva, Nina Moorman, William Silva, Zulfiqar Zaidi, Nakul Gopalan, and Matthew Gombolay. Lancon-learn: Learning with language to enable generalization in multi-task manipulation. IEEE Robotics and Automation Letters, 7(2):1635–1642, 2021.
- Singh et al. (2020) Avi Singh, Eric Jang, Alexander Irpan, Daniel Kappler, Murtaza Dalal, Sergey Levinev, Mohi Khansari, and Chelsea Finn. Scalable multi-task imitation learning with autonomous improvement. In 2020 IEEE International Conference on Robotics and Automation (ICRA), pp. 2167–2173. IEEE, 2020.
- Stepputtis et al. (2020) Simon Stepputtis, Joseph Campbell, Mariano Phielipp, Stefan Lee, Chitta Baral, and Heni Ben Amor. Language-conditioned imitation learning for robot manipulation tasks. Advances in Neural Information Processing Systems, 33:13139–13150, 2020.
- Tan & Le (2019) Mingxing Tan and Quoc Le. EfficientNet: Rethinking model scaling for convolutional neural networks. In Kamalika Chaudhuri and Ruslan Salakhutdinov (eds.), Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp. 6105–6114. PMLR, 09–15 Jun 2019. URL https://proceedings.mlr.press/v97/tan19a.html.
- Tellex et al. (2011) Stefanie Tellex, Thomas Kollar, Steven Dickerson, Matthew Walter, Ashis Banerjee, Seth Teller, and Nicholas Roy. Understanding natural language commands for robotic navigation and mobile manipulation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 25, pp. 1507–1514, 2011.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Viereck et al. (2017) Ulrich Viereck, Andreas Pas, Kate Saenko, and Robert Platt. Learning a visuomotor controller for real world robotic grasping using simulated depth images. In Conference on robot learning, pp. 291–300. PMLR, 2017.
- Xiao et al. (2020) Ted Xiao, Eric Jang, Dmitry Kalashnikov, Sergey Levine, Julian Ibarz, Karol Hausman, and Alexander Herzog. Thinking while moving: Deep reinforcement learning with concurrent control. arXiv preprint arXiv:2004.06089, 2020.
- Yu et al. (2020) Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on robot learning, pp. 1094–1100. PMLR, 2020.
- Zhang et al. (2018) Tianhao Zhang, Zoe McCarthy, Owen Jow, Dennis Lee, Xi Chen, Ken Goldberg, and Pieter Abbeel. Deep imitation learning for complex manipulation tasks from virtual reality teleoperation. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pp. 5628–5635. IEEE, 2018.
- Zhang & Chai (2021) Yichi Zhang and Joyce Chai. Hierarchical task learning from language instructions with unified transformers and self-monitoring. arXiv preprint arXiv:2106.03427, 2021.
附录
附录 A作者贡献
-
•
评估(消融、设计过程、实现和运行消融):Yevgen Chebotar、Keerthana Gopalakrishnan、Karol Hausman、Julian Ibarz、Brian Ichter、Alex Irpan、Isabel Leal、Kuang-Huei Lee、Yao Lu、 Ofir Nachum、Kanishka Rao、Sumedh Sontakke、Austin Stone、Quan Vuong、Fei Xia、Ted Shaw 和 Tianhe Yu。
-
•
网络架构(分词器、训练、推理):Yevgen Chebotar、Keerthana Gopalakrishnan、Julian Ibarz、Alex Irpan、Kuang-Huei Lee、Yao Lu、Karl Pertsch、Kanishka Rao、Michael Ryoo、Sumedh Sontakke、Austin斯通、Quan Vuong。
-
•
开发基础设施(数据、训练、收集、模拟、评估、存储和操作):Anthony Brohan、Keerthana Gopalakrishnan、Karol Hausman、Alex Herzog、Jasmine Hsu、Alex Irpan、Nikhil Joshi、Ryan Julian、 Dmitry Kalashnikov、Yuheng Kuang、Isabel Leal、Yao Lu、Fei Xia、Ted Shaw、Peng Xu、Sichun Xu 和 Tianhe Yu。
-
•
领导层(项目管理或建议):Chelsea Finn、Karol Hausman、Julian Ibarz、Sally Jesmonth、Sergey Levine、Yao Lu、Igor Mordatch、Carolina Parada、Kanishka Rao、Pannag Sanketi、Vincent Vanhoucke。
-
•
论文(图形、可视化、写作):Keerthana Gopalakrishnan、Karol Hausman、Brian Ichter、Sergey Levine、Ofir Nachum、Karl Pertsch、Kanishka Rao、Austin Stone、Fei Xia 和 Ted Shaw。
-
•
数据收集和评估:Noah Brown、Justice Carbajal、Joseph Dabis、Tomas Jackson、Utsav Malla、Deeksha Manjunath、Jodily Peralta、Emily Perez、Jornell Quiambao、Grecia Salazar、Kevin Sayed、Jaspiar Singh、Clayton Tan 、Huong Tran、Steve Vega 和 Brianna Zitkovich。
附录B型号卡
我们在图 7 中展示了 RT-1 的模型卡。
Model Card for RT-1 (Robotics Transformer)
Model Details
-
•
Developed by researchers at Robotics at Google and Everyday Robots, 2022, v1.
-
•
Transformer-based model, built upon a FiLM-conditioned EfficientNet (Tan & Le, 2019), a TokenLearner (Ryoo et al., 2021), and a Transformer (Vaswani et al., 2017).
-
•
Trained with imitation learning with inputs of natural language tasks and images and output robot actions.
Intended Use
-
•
Intended to be used for controlling an Everyday Robot for manipulation tasks.
-
•
Unclear suitability as a learned representation for different robotic embodiments, environments, or significantly varied downstream tasks.
-
•
Not suitable for interaction with humans.
Factors
-
•
Factors include varying backgrounds, lighting, scenes, base position, and novel natural language tasks. Hardware factors include camera and robot embodiment.
Metrics
-
•
Evaluation metrics include seen task performance, unseen task performance, robustness to backgrounds and distractors, and performance in long-horizon scenarios. Each measures the success rate of the model performing natural language specified tasks with randomized objects and object locations and varying scenes.
Training Data
-
•
Trained on 130k tele-operation demonstrations over 13 robots and 744 tasks.
| Skill | Count | Description | Example Instruction |
|---|---|---|---|
| Pick Object | 130 | Lift the object off the surface | pick iced tea can |
| Move Object Near Object | 337 | Move the first object near the second | move pepsi can near rxbar blueberry |
| Place Object Upright | 8 | Place an elongated object upright | place water bottle upright |
| Knock Object Over | 8 | Knock an elongated object over | knock redbull can over |
| Open / Close Drawer | 6 | Open or close any of the cabinet drawers | open the top drawer |
| Place Object into Receptacle | 84 | Place an object into a receptacle | place brown chip bag into white bowl |
| Pick Object from Receptacle and Place on the Counter | 162 | Pick an object up from a location and then place it on the counter | pick green jalapeno chip bag from paper bowl and place on counter |
| Additional tasks | 9 | Skills trained for realistic, long instructions | pull napkin out of dispenser |
| Total | 744 |
Evaluation Data
-
•
Evaluated on real-world randomized scenes and over 3000 total rollouts in the environment it was trained on as well as two new office kitchen environments.
Quantitative Analyses
-
•
RT-1 shows high-performance and robustness and can learn from heterogenous data.

Ethical Considerations
-
•
Early research, model has not yet been evaluated for suitability to use outside of its current research setting.
Caveats and Recommendations
-
•
While the current model covers only a small portion of possible robotic manipulation tasks, it presents a recipe for scalable robotic learning and an architecture that shows favorable generalization and data absorption properties.
附录C模型和数据
C.1 模型推理
除了推理速度要求之外,我们还需要确保我们的系统以一致的频率输出动作,避免抖动。 为了实现这一点,我们引入了一种固定时间等待机制,该机制在状态之后等待一定的时间(ms,所有组件的最大观察到的延迟),用于计算下一个操作,已被捕获,但在应用操作之前,类似于 Xiao 等人 (2020) 描述的过程。
C.2 大规模数据收集。
每个机器人在剧集开始时都会自主接近其站点,并向操作员传达他们应该向机器人演示的指令。 为了确保数据集的平衡以及场景的随机化,我们创建了一个软件模块,负责对要演示的指令进行采样以及背景配置的随机化。 每个机器人都会告诉演示者如何随机化场景以及演示哪些指令。
使用 2 个虚拟现实遥控器通过操作员和机器人之间的直接视线收集演示。 我们将远程控制映射到我们的政策行动空间,以保持过渡动态的一致性。 遥控器的 3D 位置和旋转位移映射到机器人工具的 6d 位移。 摇杆的x、y位置映射为移动底座的转动角度和行驶距离。 我们计算并跟踪从操纵杆命令获得的目标姿势的轨迹。
C.3 大规模模型选择
随着机器人学习系统的能力越来越强,可以处理的指令数量不断增加,对这些模型的评估变得困难(Kalashnikov 等人,2021a;Jang 等人,2021)。 这不仅对于在开发过程中评估不同的模型类和数据分布来说是一个重要的考虑因素,而且对于为特定的训练运行选择性能最佳的模型检查点也是一个重要的考虑因素。 虽然针对这个问题已经提出了许多解决方案(Dudík等人,2011;Irpan等人,2019;Hanna等人,2017),大多数在离线强化学习文献中被称为“off -政策评估”,大规模评估多任务机器人学习系统仍然是一个开放的研究挑战。
在这项工作中,我们建议利用“真实到模拟”传输的模拟作为可扩展工具,在许多实际任务的训练过程中提供模型性能的近似估计。 我们在模拟器中运行根据真实数据训练的策略来测试完整的部署性能。 请注意,我们所有的训练数据都来自现实世界(除了6.3节中的实验),模拟器仅用于模型选择。 为了实现这一目标,我们扩展了 Lee 等人 (2022b) 提出的模拟环境,以支持 5.2 节中描述的 551 项任务。 对于每个任务,我们定义了一组场景设置随机化、机器人姿势随机化和成功检测标准。 为了弥合现实世界和模拟之间的视觉分布变化,我们训练了一个 RetinaGAN (Ho 等人, 2020) 模型,将模拟图像转换为逼真的图像。 然后,我们通过在每个时间步应用 RetinaGAN 视觉转换并测量推出模拟任务的成功率,将根据真实数据训练的策略直接部署到这些模拟环境中。
虽然仅根据现实世界数据训练的模型在现实世界中的表现比在模拟中表现更好,但我们发现高性能现实世界政策的模拟成功率高于低绩效现实世界政策的模拟成功率。 换句话说,模拟政策成功率的排序对于预测现实世界政策成功率的排序提供了信息。 我们注意到,在这种从真实到模拟的评估设置中,与从模拟到真实的设置相比,我们对模拟精度的要求不太严格;只要模拟成功率与真实成功率呈方向相关,我们就可以接受真实成功率和模拟成功率之间适度甚至较高的差距。
我们在图 8 中展示了模拟中的示例相机图像及其基于 RetinaGAN 的转换。

C.4数据收集过程
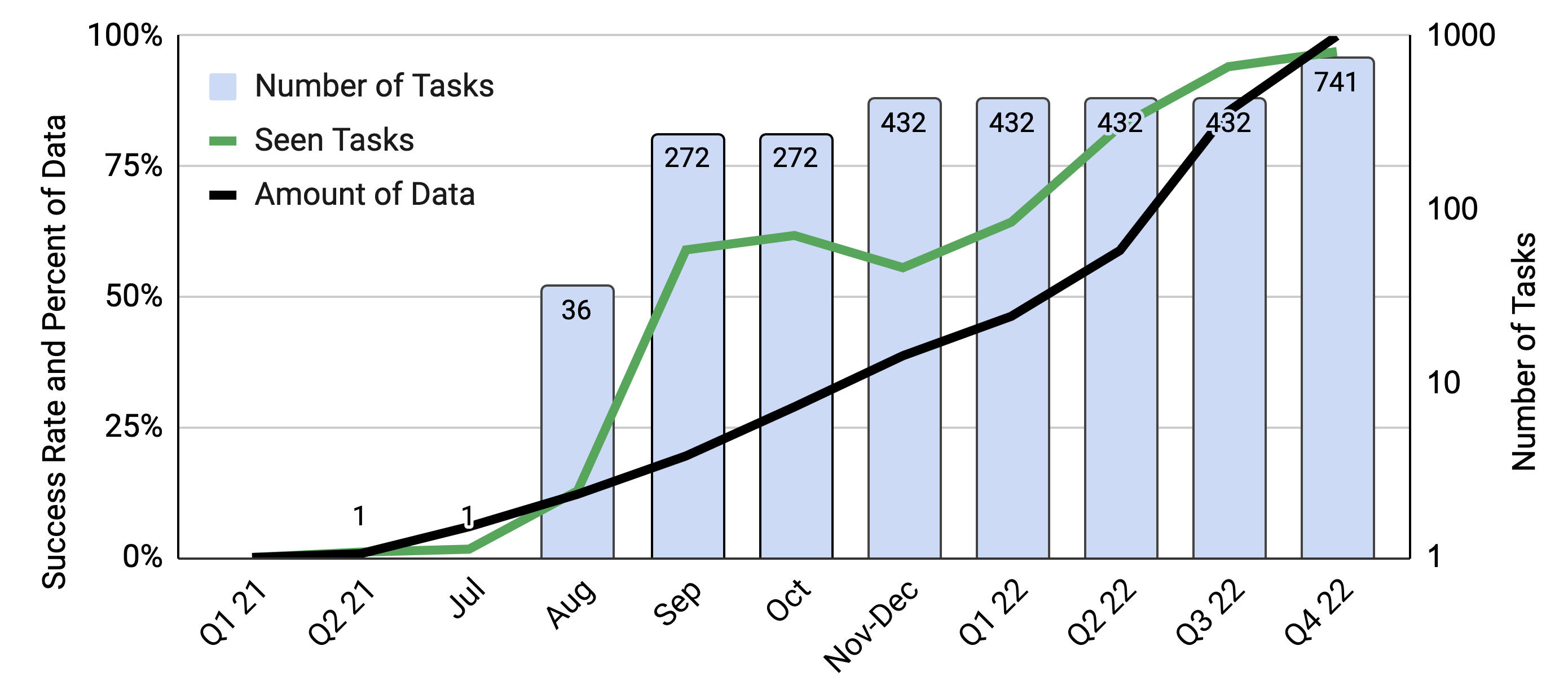
图9显示了数据、任务数量以及策略的成功率随时间的增长情况。 随着收集的数据越来越多,我们的系统能够处理的任务/指令的数量也会随着时间的推移而增加。 已见任务的表现也是如此。 未来工作的重要方面之一是开发技术,使我们能够以更快的速度增长数据以及机器人的性能和一般能力。
附录D实验
D.1 评估详细信息
在6.2节中,我们研究了RT-1对训练数据集中不存在的困难场景的零样本泛化能力。 为了公平评估 RT-1 的不同消融以及基线政策,我们设计了涵盖一系列增量难度级别的标准化评估程序。
见过任务。 我们对训练数据集中存在的 744 个任务进行评估。 12 种技能之间的细分如表1所示。 对于所有“Seen”评估,我们使用与 5.2 节中所述的数据收集相同的教室设置。 对于每项政策,我们都会报告一个具有代表性的指标,该指标采用个人技能评估的技能加权平均值。
看不见的任务。 我们评估了训练期间执行的 53 项任务的政策绩效。 虽然在训练期间看不到看不见的指令的技能和对象的特定组合,但相同技能和对象的其他组合存在于训练集中。 我们在与已见任务相同的环境和相同的随机化过程中评估这些未见的任务。 表 8 显示了这些看不见的任务的完整列表。
干扰器的鲁棒性。 我们测试了三个任务(“拾取可乐罐”、“将可乐罐直立放置”、“将可乐罐移动到绿色米片袋附近”),并向场景中添加了越来越多的干扰对象。 简单的设置包括 0、2 或 5 个干扰对象。 中等设置包括 9 个干扰对象,但可乐罐永远不会被遮挡。 硬设置包括 9 个干扰对象,但场景更加拥挤,可乐罐被部分遮挡。 两种中等难度设置都比训练数据集中的场景更困难,训练数据集中包含 0 到 4 个干扰项。 这些难度设置和策略评估推出的示例如图12所示。
背景稳健性。 我们测试了六个任务(“挑选可乐罐”、“将蓝色筹码袋移到橙色附近”、“将红牛罐打翻”、“挑选绿色墨西哥胡椒筹码袋”、“将海绵移动到棕色筹码袋附近”、“将红牛罐直立放置” )具有逐渐更具挑战性的背景和柜台纹理。 在简单设置中,我们利用与训练数据集相同的背景环境和计数器纹理。 在中等设置中,我们使用相同的背景环境,但添加有图案的桌布来改变柜台纹理。 在硬环境中,我们采用全新的厨房环境和新的台面;这会改变柜台纹理、抽屉材料和颜色以及背景视觉效果。 这些难度设置和策略评估推出的示例如图10所示。
现实的指示。 为了研究 RT-1 在更现实的场景中的表现,我们提出了在真实的办公室厨房中进行评估的设置,这与原始的训练教室环境发生了巨大的转变。 我们提出了多种技能,结合了之前的零样本评估的各个方面,包括添加新的干扰因素,包括新的背景以及对象与技能的新组合。 我们将最简单的场景称为概括,它引入了新的台面和照明条件,但保持技能和对象相同。 接下来,泛化还添加了新颖的干扰对象,例如厨房罐子容器。 最后,泛化添加新对象或新位置,例如水槽附近。 虽然其中一些分布偏移在第 6.2 节中进行了测试,但这些实际说明旨在同时测试多个维度。 这些指令的示例如图11所示。
| Instruction |
|---|
| pick coke can from top drawer and place on counter |
| pick green can from top drawer and place on counter |
| pick green rice chip bag from middle drawer and place on counter |
| pick redbull can from top drawer and place on counter |
| place 7up can into bottom drawer |
| place brown chip bag into top drawer |
| place green can into middle drawer |
| move 7up can near redbull can |
| move apple near green rice chip bag |
| move apple near paper bowl |
| move apple near redbull can |
| move blue chip bag near blue plastic bottle |
| move blue chip bag near pepsi can |
| move blue chip bag near sponge |
| move brown chip bag near apple |
| move brown chip bag near green rice chip bag |
| move brown chip bag near redbull can |
| move coke can near green jalapeno chip bag |
| move coke can near water bottle |
| move green can near 7up can |
| move green can near apple |
| move green can near coke can |
| move green jalapeno chip bag near blue chip bag |
| move green rice chip bag near orange |
| move green rice chip bag near orange can |
| move green rice chip bag near paper bowl |
| move orange can near brown chip bag |
| move pepsi can near orange can |
| move redbull can near coke can |
| move rxbar blueberry near blue plastic bottle |
| move rxbar blueberry near orange can |
| move rxbar chocolate near paper bowl |
| move rxbar chocolate near rxbar blueberry |
| move sponge near apple |
| move water bottle near 7up can |
| move water bottle near sponge |
| move white bowl near orange can |
| pick blue plastic bottle |
| pick green rice chip bag |
| pick orange |
| pick rxbar chocolate |
| pick sponge |
| place pepsi can upright |
| knock orange can over |
| pick blue plastic bottle from paper bowl and place on counter |
| pick brown chip bag from white bowl and place on counter |
| pick green can from paper bowl and place on counter |
| pick green jalapeno chip bag from white bowl and place on counter |
| pick orange can from white bowl and place on counter |
| pick redbull can from white bowl and place on counter |
| place blue plastic bottle into paper bowl |
| place coke can into paper bowl |
| place orange can into paper bowl |



D.2 异构数据
我们还探讨了 RT-1 在利用高度异构数据方面的局限性。 我们演示了 RT-1 如何整合和学习截然不同的数据源,并从这些数据中进行改进,而不会牺牲该数据固有的各种任务的原始任务性能。 为此,我们进行了两项实验:(1)RT-1 在真实数据和模拟数据上进行训练和测试;(2)RT-1 在不同任务的大型数据集上进行训练,这些数据集最初是由不同的机器人收集的。
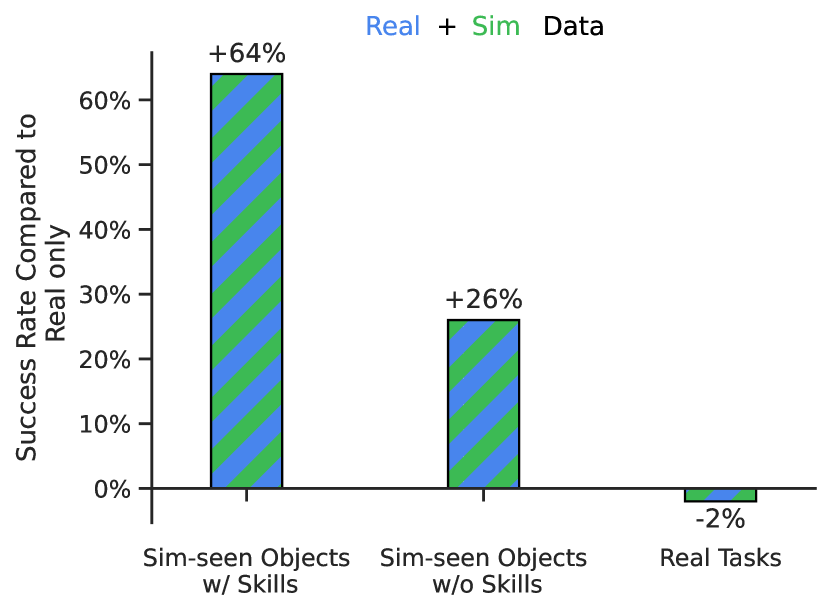
吸收模拟数据。 表 9 显示了 RT-1 和基线吸收真实数据和模拟数据的能力。 为了测试这一点,我们获取了所有真实的演示数据,但我们还提供了额外的模拟数据,其中包括机器人在现实世界中从未见过的物体。 我们添加一组模拟对象,并仅在模拟中的任务子集(特别是拾取任务)上显示它们。 为了实现这一点,我们运行第 2 节中描述的 real2sim 方法。 C.3 从现实世界策略引导模拟策略,然后使用多任务 RL (Kalashnikov 等人,2021a) 以及模拟中的其他对象进行训练。 从这个过程中,我们提取了 518k 条成功挑选新对象的轨迹,并将它们与之前实验中使用的真实数据混合。 本实验的目的是证明,通过扩展模拟轨迹数据集,我们可以在不牺牲原始训练性能(吸收模型所需的属性)的情况下受益于 RT-1 的泛化能力。
为了评估该模型的属性,我们指定了不同的泛化场景:对于 seen 技能与真实对象,训练数据具有该指令的真实数据(即,在所见任务上的性能),对于 seen使用模拟对象的技能训练数据具有该指令的模拟数据(例如“拾取一个模拟对象”,它存在于模拟中),而对于使用模拟对象的未见过的技能训练数据具有该对象的 sim 数据,但没有描述该对象的技能的指令示例,无论是在 sim 中还是在现实中(例如,“将 sim 对象移动到苹果”,即使机器人只练习过挑选该 sim)物体,并且不要将其移动到其他物体附近)。 所有评估都是在现实世界中完成的,但为了限制评估的指令数量,我们专注于选择和移动技能。
我们在表 9 中发现,对于 RT-1,与仅真实数据集相比,添加模拟数据不会损失性能。 然而,我们确实看到,仅在模拟中看到的对象和任务的性能显着提高(从 23% 到 87%),接近真实情况的性能,展示了令人印象深刻的领域转移程度。 我们还发现未见过的指令的性能显着提高,从 7% 提高到 33%;令人印象深刻的是,所涉及的物体从未在现实中见过,而且指令也从未见过。 总的来说,我们发现 RT-1 能够有效地“吸收”新数据,即使来自非常不同的领域。
| Real Objects | Sim Objects (not seen in real) | |||
| Seen Skill | Seen Skill | Unseen Skill | ||
| Models | Training Data | w/ Objects | w/ Objects | w/ Objects |
| RT-1 | Real Only | 92 | 23 | 7 |
| RT-1 | Real + Sim | 90 | 87 | 33 |
吸收来自不同机器人的数据。 为了突破 RT-1 的数据吸收极限,我们进行了一组额外的实验,其中结合了来自不同机器人的两个数据源:Kuka IIWA 以及迄今为止实验中使用的 Everyday Robots 移动机械手。 Kuka 数据包含 QT-Opt (Kalashnikov 等人, 2018) 中收集的所有成功示例,相当于 209k 个情节,其中机器人不加区别地抓取垃圾箱中的物体(参见表中的 Kuka 情节。 10)。 我们在此实验中的目标是分析在添加额外数据时 RT-1 任务的性能是否会下降,更重要的是,我们是否可以观察到不同机器人形态收集的数据的任何传输。
我们想通过指出数据集之间的主要差异来强调这种设置的难度。 不仅收集数据的机器人在外观和动作空间上有所不同,而且它们部署的环境也有不同的外观和动态。 此外,QT-Opt 数据呈现出完全不同的动作分布——它是由 RL 代理收集的,而不是我们数据集中存在的人类演示。
为了将Kuka数据与RT-1数据混合在一起,我们首先将原始Kuka 4-DOF动作空间转换为与RT-1相同的动作空间,即我们将roll和pitch设置为,同时保留原始 Kuka 数据中存在的偏航值。 此外,我们将二进制 gripper-close 命令转换为 RT-1 数据中存在的连续夹具闭合命令。 我们还需要与所执行的任务相对应的文本指令,并且由于 Kuka 数据不包含所抓取的对象的名称,因此我们将所有数据重新标记为“拾取任何内容”指令。 通过这些修改,我们以 2:1(RT-1 数据:Kuka 数据)比例混合两个数据集并训练 RT-1 以获得最终模型。
为了测试 RT-1 是否能够有效吸收这两个截然不同的数据集,我们评估了原始 RT-1 任务的性能(在这种情况下,我们还关注“pick”和“move to”技能),我们将其称为作为标准的“课堂评估”,以及反映 Kuka 数据中存在的垃圾箱选取设置的新构建任务的性能,我们将其称为“垃圾箱选取评估”。 为了使箱式拾取评估接近原始数据集,我们将物体放入相同的箱中,并通过添加额外的电线并将夹具着色为灰色来修改机器人,使其与 Kuka 机械臂相似。 对于所有评估,我们使用具有拾取命令的 Everyday Robots 机器人,并根据 72 次抓取试验对其进行评估。
结果如表10所示。 我们观察到,混合 RT-1 数据和 Kuka 数据的模型对原始任务的性能(即课堂评估)仅略有下降,即 。 更重要的是,在 Bin-picking 评估中,我们观察到,与仅在多机器人数据上训练的模型的 相比,在多机器人数据上训练的模型的性能为 。 RT-1 数据。 这是 性能差异(几乎是 2 倍)。 此外,RT-1 在 Kuka 垃圾箱拣选数据上进行了训练,并使用 Everyday Robots (EDR) 机器人对垃圾箱拣选任务进行了评估,其性能达到了 0%,这证实了很难从另一个机器人形态转移行为。 然而,混合来自两个机器人的数据使得 RT-1 能够推断出 EDR 机器人的正确动作,即使面对 Kuka 机器人观察到的状态也是如此。 这是在没有对 EDR 机器人进行垃圾箱拣选的明确演示的情况下,通过利用 Kuka 机器人过去收集的经验来实现的。 这些结果表明,RT-1 的吸收特性还包括通过观察其他机器人的经验来获取新技能的能力,并为未来的工作提供了令人兴奋的途径,我们可以结合更多的多机器人数据集来增强机器人的能力。
| Models | Training Data | Classroom eval | Bin-picking eval |
|---|---|---|---|
| RT-1 | Kuka bin-picking data + EDR data | 90 | 39 |
| RT-1 | EDR only data | 92 | 22 |
| RT-1 | Kuka bin-picking only data | 0 | 0 |
![[Uncaptioned image]](x11.png)
D.3 长期评估详细信息
除了前面部分中显示的短期个人技能评估之外,我们还评估了 RT-1 在长期现实厨房环境中的表现,该环境链接多种操作和导航技能以在 SayCan 框架内完成自然语言指令 ( Ahn 等人,2022)。 表 12 列出了用于这些评估的长范围指令列表。
长视野任务的成功率随着任务长度的延长而呈指数下降,因此操作技能的高成功率尤为重要。 此外,由于移动操纵任务需要导航和操纵,因此策略对基础位置的鲁棒性至关重要。 由于SayCan结合了许多低级指令来执行高级指令,因此可能的高级指令的数量随着指令的组合而增加,因此可以充分看到RT-1的技能广度。
SayCan 的工作原理是在机器人可供性中建立语言模型,并利用少样本提示将用自然语言表达的长期任务分解为一系列低级技能。 长期任务的一个例子是“给我两种不同的苏打水”,一个可行的计划是“1. 找到一瓶可乐,2. 拿起可乐,3. 带给你,4. 放下可乐,5. 找到一杯百事可乐,6. 拿起百事可乐,7. 带给你,8. 放下百事可乐,9。完成。”为了获得可供性函数,我们使用经过 MT-OPT 训练的价值函数(Kalashnikov 等人,2021a)。 SayCan算法的详细描述请参考(Ahn等人,2022)。
由于本文的重点是获得许多通用技能,因此我们将评估重点放在 Ahn 等人 (2022) 中提出的任务子集上。 它是长视野系列任务,涉及 15 条指令,每条指令平均需要 9.6 个步骤才能完成,每条指令平均涉及 2.4 种操作技能。 完整的指令列表可以在表12中找到。
我们与 3 个基线进行比较。 1) SayCan with BC-Z,使用 SayCan 规划算法,以 BC-Z 作为操作策略,2) SayCan with Gato,使用 SayCan 规划算法,以 Gato 作为操作策略,3) 最初报告的 SayCan 结果,使用 SayCan 规划算法与 BC-Z 相同,但由于它使用的提示略有不同,因此计划成功率较低。 为了公平比较,我们在 1) 中重新实现了 3)。
如表11所示,除了原始的SayCan之外,所有方法的规划成功率均为87%,其中RT-1表现最好,在Kitchen1中执行成功率为67%。 Kitchen2 构成了一个更具挑战性的泛化场景,因为机器人教室训练场景是根据 Kitchen1 建模的(参见图 2 中厨房的图片)。 由于这种泛化困难,带有 Gato 的 SayCan 无法完成任何长期任务,而带有 BC-Z 的 SayCan 能够达到 13% 的成功率。 最初的 SayCan 论文没有评估新厨房的性能。 令人惊讶的是,对于我们的方法,从 Kitchen1 到 Kitchen2 的操作性能没有明显下降。 在补充视频中,我们展示了这使我们能够操作 Kitchen2 中看不见的抽屉,并且我们可以使用 SayCan-RT1 来规划和执行超长范围的任务,最多有 50 个步骤。
| SayCan tasks in Kitchen1 | SayCan tasks in Kitchen2 | ||||
|---|---|---|---|---|---|
| Planning | Execution | Planning | Execution | ||
| Original SayCan (Ahn et al., 2022)∗ | 73 | 47 | - | - | |
| SayCan w/ Gato (Reed et al., 2022) | 87 | 33 | 87 | 0 | |
| SayCan w/ BC-Z (Jang et al., 2021) | 87 | 53 | 87 | 13 | |
| SayCan w/ RT-1 (ours) | 87 | 67 | 87 | 67 | |
| Instruction |
|---|
| How would you put an energy bar and water bottle on the table |
| How would you bring me a lime soda and a bag of chips |
| Can you throw away the apple and bring me a coke |
| How would you bring me a 7up can and a tea? |
| How would throw away all the items on the table? |
| How would you move an multigrain chips to the table and an apple to the far counter? |
| How would you move the lime soda, the sponge, and the water bottle to the table? |
| How would you bring me two sodas? |
| How would you move three cokes to the trash can? |
| How would you throw away two cokes? |
| How would you bring me two different sodas? |
| How would you bring me an apple, a coke, and water bottle? |
| I spilled my coke on the table, how would you throw it away and then bring me something to help clean? |
| I just worked out, can you bring me a drink and a snack to recover? |
| How would you bring me a fruit, a soda, and a bag of chips for lunch |
D.4 模型消融
模型设计中有哪些重要且实用的决策以及它们如何影响性能和泛化?
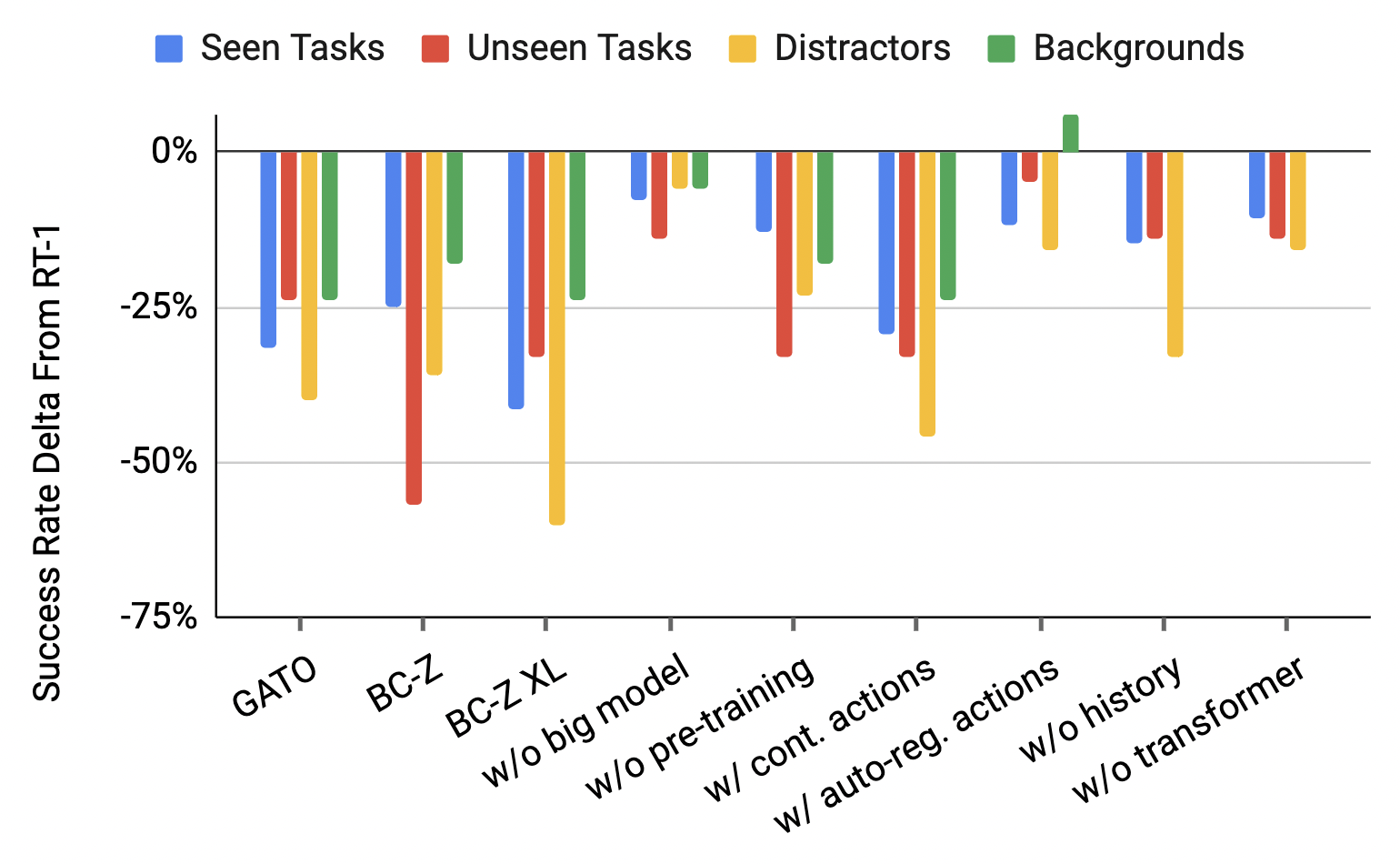
为了回答这个问题,我们对 RT-1 中的不同设计决策进行了一组消融。 我们的目标是测试一些假设,这些假设将帮助我们澄清我们的方法的好处来自何处。 关于改进来源的可能假设包括:(i)我们模型的容量和表达能力,我们通过消除模型大小、尝试其他架构(例如,通过删除 Transformer 组件)来验证这一点; (ii) 特定的动作表示,这使得表示复杂的多模式动作分布变得容易,我们通过切换到连续(正态分布)动作以及消除自回归动作表示来测试它; (iii) ImageNet 预训练的组件初始化,我们通过随机初始化模型的权重来测试; (iv)访问短历史,我们通过排除观察历史来测试短历史。 更具体地说,我们通过 (1) 减小模型大小(从 35M 到 21M 参数)、(2) 删除 Transformer 架构(使用预先训练的 EfficientNet 代替)、(3) 使用连续而不是离散动作来消除模型空间(使用 MSE 损失和多元正态输出),(4) 对动作进行自动回归调节,(5) 删除 FiLM EfficientNet 的 ImageNet 预训练,以及 (6) 删除历史记录(减少作为输入的六张图像的序列)到单个图像)。 对于每个消融,我们在已见任务的性能、未见任务的性能以及推理速度和对干扰物和背景的鲁棒性方面进行比较(在 6.1 节中对每个类别进行了更详细的描述)附录D.1)。
表 13 显示了每次消融的结果以及与完整 RT-1 相比的增量性能。 RT-1 在任务和新环境中取得了令人印象深刻的性能,特别是在最具挑战性的鲁棒性问题上优于基线。 我们还发现每个设计决策都很重要,尽管程度不同。 我们首先评估一个模型,该模型用更标准的连续高斯分布替换模型中的每维离散动作表示。 我们观察到此修改导致性能显着下降。 每维离散化使我们的模型能够表示复杂的多模态分布,而高斯分布仅捕获单个模态。 这些结果表明,对于我们的系统使用的更复杂和多样化的演示数据,这种标准和流行的选择是非常次优的。 ImageNet 预训练对于模型泛化和鲁棒性尤为重要,由于 ImageNet 数据集的视觉效果庞大且多样化,未见任务的执行率降低了 33%。 添加历史记录主要对干扰因素的泛化产生影响,而删除 Transformer 组件对已见任务、未见任务和干扰因素产生统一但较小的负面影响。 为了保持 ImageNet 预训练的同时减小模型尺寸,我们仅将参数数量减少了 40%(从 31M 减少到 25M)。 训练和泛化任务中的性能下降,但没有其他消融中那么严重。 最后,(Reed 等人,2022;Chen 等人,2021;Lee 等人,2022a)中使用的对动作进行自回归调节并没有提高性能,而且推理速度减慢了 2 倍以上。
如第 2 节所述。 5.1,为了在真实的机器人上运行大型 Transformer 模型,我们需要一个支持快速推理以进行实时操作的模型。 请注意,为了实现 Hz 的目标控制速率(第 5.1 节中描述),我们还需要考虑管道中的其他延迟源,例如相机延迟和通信开销。 然而,这些因素对于所有模型都是恒定的,因此我们将评估重点放在网络推理时间上。 表13的最后一列显示了所有模型的推理速度。 在参数数量相似的情况下,RT-1 几乎比 Gato 快一个数量级,但它也比基于 ResNet 的 BC-Z 慢得多。 就我们模型的不同消融而言,我们观察到最大的减慢是由包含自回归操作引起的(2x减慢),并且由于这不会显着影响性能, RT-1 的最终版本不会自动生成动作。
| Distractors | Backgrounds | |||||||
| Model | Seen Tasks | Unseen Tasks | All | Easy | Medium | Hard | All | Inference Time (ms) |
| Gato (Reed et al., 2022) | 65 (-32) | 52 (-24) | 43 (-40) | 71 | 44 | 29 | 35 (-24) | 129 |
| BC-Z (Jang et al., 2021) | 72 (-25) | 19 (-57) | 47 (-36) | 100 | 67 | 7 | 41 (-18) | 5.3 |
| BC-Z XL | 56 (-41) | 43 (-33) | 23 (-60) | 57 | 33 | 0 | 35 (-24) | 5.9 |
| RT-1 (ours) | 97 | 76 | 83 | 100 | 100 | 64 | 59 | 15 |
| RT-1 w/o big model | 89 (-8) | 62 (-14) | 77 (-6) | 100 | 100 | 50 | 53 (-6) | 13.5 |
| RT-1 w/o pre-training | 84 (-13) | 43 (-33) | 60 (-23) | 100 | 67 | 36 | 41 (-18) | 15 |
| RT-1 w/ continuous actions | 68 (-29) | 43 (-33) | 37 (-46) | 71 | 67 | 0 | 35 (-24) | 16 |
| RT-1 w/ auto-regressive actions | 85 (-12) | 71 (-5) | 67 (-16) | 100 | 78 | 43 | 65 (+6) | 36 |
| RT-1 w/o history | 82 (-15) | 62 (-14) | 50 (-33) | 71 | 89 | 14 | 59 (+0) | 15 |
| RT-1 w/o Transformer | 86 (-13) | 62 (-14) | 67 (-16) | 100 | 100 | 29 | 59 (+0) | 26 |
D.5总结与分析
在本节中,我们总结了一些发现,并对 RT-1 的高性能、泛化性和鲁棒性提出了直觉。 首先,ImageNet 预训练(以及 Universal Sentence Encoder 语言嵌入)具有很大的影响,特别是对看不见的任务。 我们观察到 RT-1 继承了一些来自这些模型训练数据集的通用性和多样性的知识。 其次,持续的行动对绩效的各个方面都有很大的影响。 这之前已经被观察到,可能是由于能够表示更复杂的动作分布——每维度离散化使我们的模型能够表示复杂的多模态分布,而高斯分布仅捕获单一模式。 第三,考虑到这种富有表现力的多任务模型,数据多样性比数据大小具有更大的影响。 事实上,即使是在模拟环境中或从不同机器人实施例中收集的数据集也可以被 RT-1 利用,为新的数据收集机制开辟途径。
最后,与 Gato 的后期融合相比,RT-1 通过 FiLM 条件早期将语言融合到图像管道中。 这使得图像标记仅关注手头指令的相关特征,这可能是 Gato 干扰性能不佳的原因。 图13直观地展示了 RT-1 推出期间的注意力。 我们看到注意力集中在相关特征上,特别是抓手和感兴趣的物体之间的交互上。 诸如此类的注意力层瓶颈会导致紧凑的表示,从而有效地忽略干扰因素和变化的背景。
