解码器调优:高效的语言理解作为解码
摘要
随着预训练模型 (PTM) 规模的不断增长,仅向用户提供推理 API 已成为一种新兴实践,即模型即服务 (MaaS) 设置。 为了适应模型参数冻结的 PTM,当前大多数方法都集中在输入端,寻求强大的提示来刺激模型获得正确答案。 然而,我们认为,由于缺乏梯度信号,输入端适应可能会很困难,并且通常需要数千个 API 查询,从而导致较高的计算和时间成本。 鉴于此,我们提出了解码器调整(DecT),它相反优化了输出侧的特定于任务的解码器网络。 具体来说,DecT 首先提取提示刺激的输出分数以进行初始预测。 最重要的是,我们在输出表示上训练一个额外的解码器网络,以合并后验数据知识。 通过基于梯度的优化,DecT 可以在几秒钟内完成训练,并且每个样本只需要一次 PTM 查询。 根据经验,我们进行了广泛的自然语言理解实验,结果表明 DecT 的性能显着优于最先进的算法,速度提升了 。
1简介
预训练模型 (PTM) 的最新进展展示了“预训练-微调”范式的强大功能,该范式通过单一骨干模型赋予广泛的下游 NLP 任务Devlin 等人 (2019);拉斐尔等人 (2020); Radford 等人 (2019). 考虑到数百万甚至数十亿规模的模型,模型即服务(MaaS)已成为部署大规模 PTM 的新兴实践,用户只能访问模型推理 API Brown 等人(2020);孙等人 (2022b). 在这种情况下,PTM的参数被冻结,用户无法在下游任务上调整模型进行适配。 为了找到替代方法,研究人员广泛研究了 MaaS PTM 适应方法。
该行中的大多数现有方法都基于提示,它用特定模式修改输入。 通过将输入包装成完形填空式的问题或在输入前加上一些示范性示例,PTM 可以直接产生正确的输出,并表现出强大的“上下文”学习能力Petroni 等人 (2019); Brown 等人 (2020) 没有任何参数更新。 除了启发式提示设计之外,最近的一些工作尝试在没有梯度的情况下优化输入提示。 其中,Black-box Tuning (BBT) Sun 等人 (2022b) 和 BBTv2 Sun 等人 (2022a) 应用进化算法Hansen and Ostermeier (2001) 在连续提示标记上,而RLPrompt 邓等人(2022)采用强化学习来寻找离散提示标记。 然而,无梯度优化相当困难,这些输入端方法需要查询 PTM 数千次才能优化,这导致时间和计算资源方面的巨大推理成本。 而且,他们最终的表现也不尽如人意。
考虑到输入端自适应的缺陷,我们转向输出端自适应,它在模型输出上构建可调解码器网络。 相比之下,输出侧自适应具有两个主要优点:(1)我们可以通过反向传播直接在模型输出之上调整解码器网络,而不是费力的替代方案。 (2) 我们可以将数千个模型查询减少到每个样本一次。 然而,设计解码器网络并不简单。 过去的研究表明,仅仅在输出特征上调整 MLP 或 LSTM Hochreiter and Schmidhuber (1997) 无法提供令人满意的结果 Sun 等人 (2022a, b),离开这条路尚未充分探索。
在这项工作中,我们的目标是解决输出侧自适应的性能问题,我们认为其背后有两个关键原因:(1)简单地利用 PTM 作为特征提取器忽略了 PTM 的填充能力,这是一个强大的先验能力。为了适应。 (2) MLP 和 LSTM 不是合适的网络,尤其是当训练数据不足时。
基于这些发现,我们提出了解码器调整(DecT),一种增强的输出侧自适应方法。 具体来说,DecT 有两个关键的设计选择来解决上述问题。 首先,DecT 根据提示查询 PTM,并采用模型输出分数作为初始预测,这利用了内部模型知识。 其次,在输出表示的基础上,我们选择一个原型网络(ProtoNet)Snell等人(2017)作为解码器网络,并用它来拟合训练数据,这更适合少样本学习。 通过这种方式,DecT 用后续的训练数据修改初始模型分数,从而获得更好的性能。
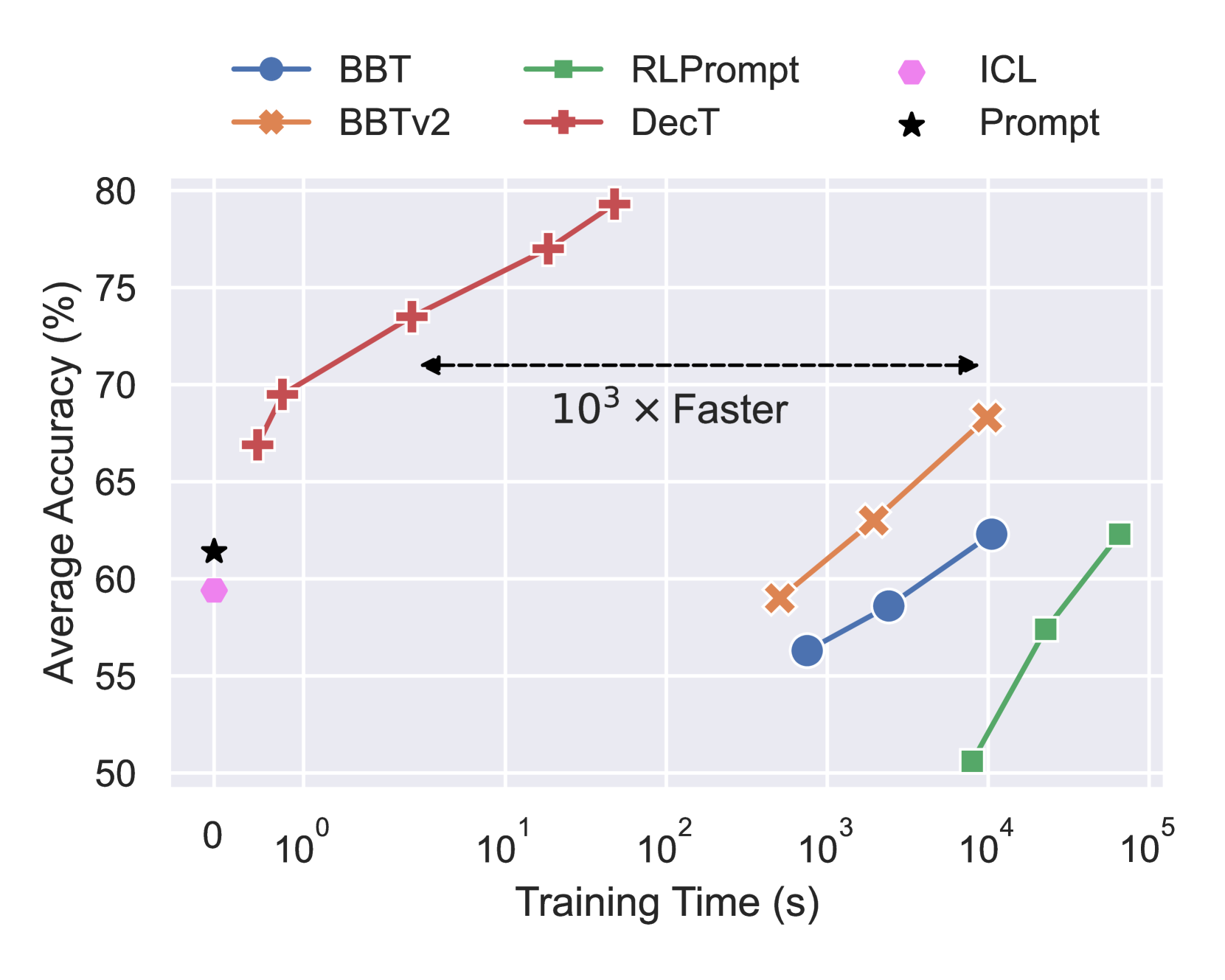
通过十个语言理解数据集的少样本学习实验,我们强调了 DecT 的三个优势(见图1)。 (1) DecT 平均绝对精度提高了,大大优于之前的工作。 (2)DecT效率高。 与主要即时工程基线相比,DecT 将平均适应时间从超过 16,000 秒 (BBTv2) 大幅缩短至 3 秒。 (3) DecT 每个示例只需要一次 PTM 查询,而其他方法需要大约 调用。 当 PTM 呼叫不免费时,这一优势至关重要。 此外,我们还进行了广泛的消融研究并验证了 DecT 每个组成部分的影响。
2 预赛
给定一组训练数据 和 PTM ,我们需要预测样本 的标签 ,其中 是类的数量。 我们假设每个类别都有相同数量的 训练样本。
在 MaaS 设置中, 是一个具有固定参数的黑盒推理 API。 因此,我们只能查询输入为的模型并得到相应的输出。 为了更好地利用 PTM,将输入样本包装到提示中已成为一种常见做法。 具体来说,我们将每个输入 封装到带有 [MASK] 词符的模板 中(这里我们假设使用屏蔽语言模型)。 然后,我们用 查询 并获取 [MASK] 位置处的最终层隐藏状态 和分数 超过标签词 。 以情感分析为例,我们可以使用
作为模板,分别作为消极和积极情绪的标签词。 这些标签词的输出分数进一步对应于类别。
3方法论
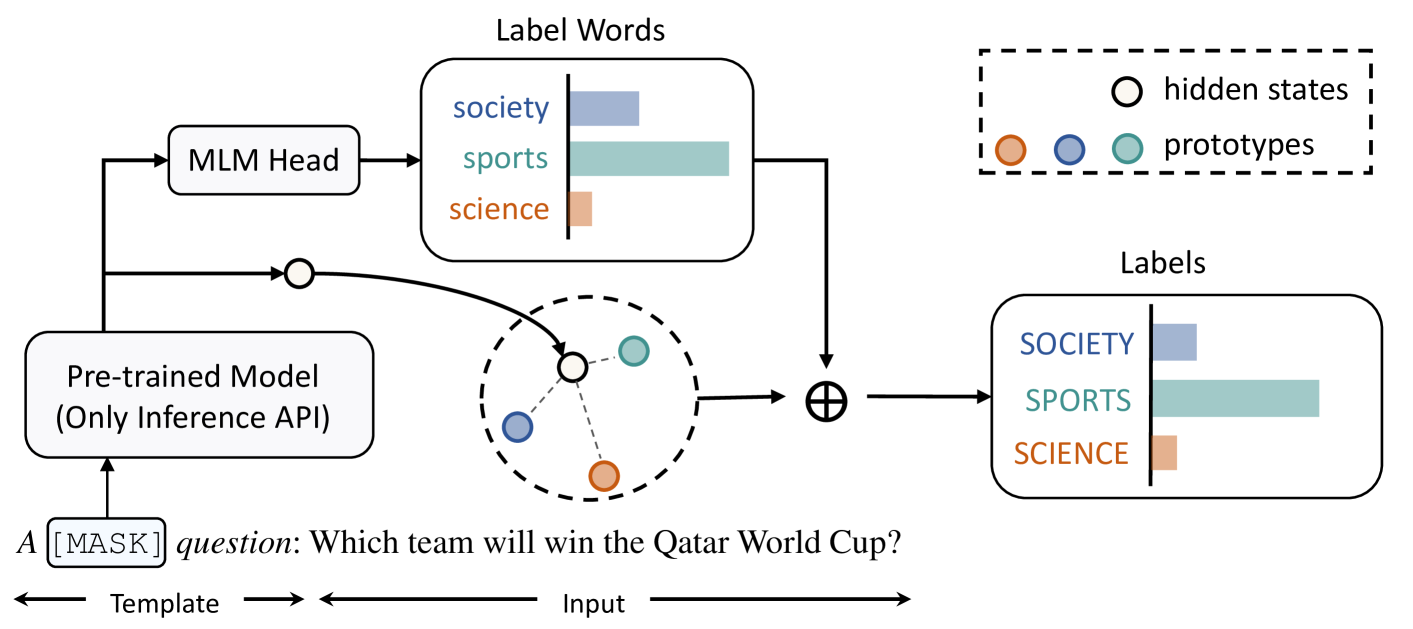
在本节中,我们将详细介绍我们提出的用于分类任务的解码器调优(DecT)方法。 我们首先回顾当前的输入端自适应方法,然后概述 DecT,最后逐步详细介绍它。
3.1 输入端适配
以前的 MaaS 适应方法寻求刺激 PTM 输出正确答案的最佳提示111BBTv2 Sun 等人 (2022a) 进一步优化了中间层的提示标记,但这里省略。. 在不失一般性的情况下,我们使用转换函数 来制定这些方法,该函数对输入 进行预处理。 可以通过添加演示 Brown 等人 (2020)、离散提示标记 Deng 等人 (2022) 或软提示标记 Sun 来进行专门化等人(2022a,b)。 将最终分数表示为 ,将概率表示为 ,这些方法定义 并优化 以实现正确的预测。 尽管在没有模型梯度的情况下优化 是可能的,但我们认为这是非常繁琐的。 通过一个大的“黑匣子”模型进行转发,在没有梯度信号引导的情况下,为特定输出找到相应的输入是相当具有挑战性的。 因此,用户可能会以昂贵的查询成本获得次优的性能。 我们在实验中凭经验验证了它。
3.2 DecT概述
为了更有效和高效的 PTM 适应,我们转向输出侧适应而不是输入侧。 总的来说,输出端自适应可以看作是模型输出的后处理,它使用另一个函数来处理模型输出,并得到最终的分数。 与输入侧不同,输出侧自适应很容易通过梯度下降进行优化,并且对于每个样本,我们只需要查询 PTM 一次。
对于DecT,如图2所示,我们将后处理建模为解码,即对初始模型预测进行后修改。 具体来说,我们首先使用提示封闭的输入查询 PTM 以获取模型输出,包括每个类别和隐藏状态的分数。 直观上,输出分数包含 PTM 内部的先验知识,因此我们将它们保留为最终分数的一部分。然后,我们在隐藏状态上调整额外的解码器函数以适应训练数据并做出最终预测。 接下来,我们描述如何查询模型,然后指定评分函数的实现。
3.3 提示查询
要获得模型输出,我们只需按照第 2 节中的过程操作,并使用手动模板包装输入查询模型。 然后我们通过校准处理分数。
校准。
正如 Zhao 等人 (2021) 中所述,PTM 倾向于为那些频繁出现的标签词分配更高的概率,从而导致输出分数有偏差。 为了消除预测偏差,我们进一步用空输入校准输出分数 “”继Zhao等人(2021)。 使用查询模型,我们可以获得校准分数并通过对其进行归一化。 然后我们通过以下方式校准
| (1) |
之后,校准分数 在各个班级之间进行平衡。
3.4 调整输出
获得隐藏状态和校准分数后,我们在 PTM 之外执行 DecT 训练,以修改适合数据的输出分数。 将类的最终分数表示为,我们通过以下函数计算它:
| (2) |
其中 是可训练的解码器函数, 是控制 PTM 分数权重的超参数, 是第 个 logit在中。 通过调整 ,最终预测将训练数据合并到 PTM 输出之上,从而有效地结合了两种知识。
的设计选择相当灵活。 在实践中,我们选择原型网络(ProtoNet)Snell 等人 (2017),因为它们简单且在少样本学习和基于提示的调优方面表现出色Cui 等人 (2022) t1>. 为此,我们使用由 参数化的线性层来投影隐藏状态并获得样本表示
| (3) |
在原型上,经典方法将它们建模为嵌入空间中的点,忽略了不同的类特征。 受 Ding 等人 (2022a) 的启发,我们将原型建模为具有附加半径参数的超球体。 具体来说,类的原型包含两个参数,中心位置向量和半径标量。 我们随机初始化 并将 初始化为 与类 中的实例之间的平均距离:
| (4) |
至于评分函数,我们计算实例和原型之间的欧几里得距离。
| (5) |
根据方程。 2,最终的logit为
| (6) |
从几何角度来看,得分函数计算从实例 到原型“表面”的距离,其中 是整个半径,就像偏置项一样。 有了这些分数,我们就可以通过 Softmax 函数计算预测概率:
| (7) |
我们可以通过交叉熵损失来优化和
| (8) |
4实验
| Method | SST2 | IMDB | Yelp | AG | DB | Yahoo | RTE | SNLI | MNLI-m/mm | NERD | Avg. | |
| 0 | Prompt | |||||||||||
| 1 | ICL | |||||||||||
| BBT | ||||||||||||
| BBTv2 | ||||||||||||
| RLPrompt | ||||||||||||
| DecT | ||||||||||||
| 4 | ICL | |||||||||||
| BBT | ||||||||||||
| BBTv2 | ||||||||||||
| RLPrompt | ||||||||||||
| DecT | ||||||||||||
| 16 | ICL | |||||||||||
| BBT | ||||||||||||
| BBTv2 | ||||||||||||
| RLPrompt | ||||||||||||
| DecT |
4.1实验设置
数据集。
我们对四种典型的自然语言理解任务进行了实验。 对于情感分析,我们选择 SST2 Socher 等人 (2013)、Yelp P. Zhang 等人 (2015) 和 IMDB Maas 等人 (2011) t2>。 对于文本分类,我们使用 AG 的 News、Yahoo Zhang 等人 (2015) 和 DBPedia Lehmann 等人 (2015)。 对于自然语言推理(NLI),我们采用 RTE Dagan 等人 (2005); Haim 等人 (2006); Giampiccolo 等人 (2007); Bentivogli 等人 (2009)、SNLI Bowman 等人 (2015) 和 MNLI Williams 等人 (2018)。 对于实体类型,我们在 FewNERD Ding 等人 (2021b) 上进行实验。 我们在附录A.1中报告数据集统计数据。
分裂。
我们从训练集中随机抽取每个类别的数据实例以进行少样本学习,并抽取相同数量的数据进行验证。 对于 GLUE Wang 等人 (2019) (SST2, RTE, MNLI) 和 SNLI 中的数据集,我们使用原始验证集作为 Zhang 等人 (2021) 的测试集。 对于其他数据集,我们对其原始测试集进行评估。
基线。
我们与代表性的 MaaS PTM 适应方法进行比较。 Prompt是指直接使用模板包装的样本进行零样本分类。 上下文学习(ICL) Brown 等人 (2020) 在测试样本之前进一步连接一些范例。 BBT Sun 等人 (2022b) 通过进化算法优化软提示标记,BBTv2 Sun 等人 (2022a) t3> 进一步向中间层插入深度提示以获得更好的性能。 RLPrompt Deng 等人 (2022) 是另一种最新算法,通过强化学习来优化离散提示。 我们在附录A.2中报告了基线的详细信息。
环境。
对于所有实验,我们使用 NVIDIA A100 和 RTX 2080 Ti GPU。 我们使用 PyTorch Paszke 等人 (2019)、HuggingFace Tansformers Wolf 等人 (2020) 和 OpenPrompt Ding 等人 (2022b) 实现 DecT 。
实施细节。
对于所有方法,我们使用相同的 RoBERTa Liu 等人 (2019) 作为主干模型。 对于 DecT,我们将表示维度设置为 128,并使用 Adam 优化器 Kingma and Ba (2015) 优化 30 个 epoch 的参数。 学习率为0.01。 在的选择上,我们直接为大多数数据集设置,基于直觉,应该随着训练数据量的增加而减少。 在 MNLI 和 FewNERD 上,我们在验证集上调整 并分别选择 和 。 在附录A.3中,我们给出了模板和标签词。
4.2 主要结果
表1展示了主要的少样本学习结果。 从结果中,我们得到以下观察结果:(1)总体而言,DecT 大幅优于最先进的基线方法(平均超过 ),显示出其优越的性能。 在不同的任务中,DecT 和基线在一些简单的情感分析和主题分类任务上获得了相似的结果。 具体来说,我们强调 DecT 对于困难的数据集(例如 Yahoo 和 FewNERD)更有利。 虽然其他基线方法难以很好地优化,但 DecT 显着超越了它们(与 BBTv2 和 ICL 相比,在 16 次拍摄设置下,在 Yahoo 上约为 ,在 FewNERD 上约为 )。 (2) 在稳定性方面,DecT 也始终具有较低的方差,并且一些基线(ICL 和 RLPrompt)非常不稳定。 鉴于少样本PTM自适应的难度,自适应方法对随机种子的鲁棒性具有重要意义。 (3) 在基线上,无优化方法,即零样本提示和 ICL 是强基线。 然而,如表所示,ICL 在 1-shot 设置中给出了最好的结果,并且由于输入长度的限制,它很难随着更多的训练数据而改善。 与它们相比,仅优化输入提示(ICL、BBT 和 RLPrompt)显示出边际改进,显示出黑盒提示优化的局限性。 相比之下,BBTv2 在 PTM 中插入了额外的可学习提示标记,功能更强大。 凭借 DecT 的优异结果,我们认为输出端优化是 MaaS PTM 适应的一种有前途的方法。
4.3效率比较
| Method | Tr. Time (s) | # Query | # Param. (K) |
| ICL | 0 | 0 | 0 |
| BBT | 17,521 | 8,000 | 0.5 |
| BBTv2 | 16,426 | 8,000 | 12 |
| RLPrompt | 65,579 | 12,000 | 3,100 |
| DecT | 3 | 1 | 130 |
| Method | SST2 | IMDB | Yelp | AG | DB | Yahoo | RTE | SNLI | MNLI-m/mm | NERD | Avg. | |
| 64 | Fine-tuning | |||||||||||
| DecT | ||||||||||||
| 256 | Fine-tuning | |||||||||||
| DecT |
尽管性能优越,DecT 的另一大优势是其高效率。 在图 1 中,我们绘制了不同镜头下每种方法的平均准确度与训练时间的关系(-shot 表示 DecT,-shot 表示 BBT、BBTv2和 RLPprompt、Prompt 和 ICL 的 0-shot)。 我们还在表2中提供了训练时间、查询数量和参数数量的详细统计。 我们可以清楚地看到,DecT 可以快速优化,并且每个训练样本只需要一次模型查询,比大多数提示优化方法更快,查询更少. 对于 BBT、BBTv2 和 RLPrompt,即使在样本少的情况下,用户也必须查询模型近 次,并花费几个小时才能充分优化。 当推理 API 不是免费的时,例如 OpenAI API 222https://openai.com/api/,使用这些方法的成本很高,这进一步增加了它们在丰富数据和大型模型场景中的使用负担。
在可调参数方面,DecT 线性投影层需要 130K 的额外参数,小于 RoBERTa 的 (355M),大大节省了存储空间。
4.4 超越少量样本
如4.3节所示,简单的架构和高效率使DecT能够扩展更多的训练数据,而基线方法则难以在可接受的时间限制内完成训练。 为了探索 DecT 超出少样本训练设置的可扩展性,我们使用增加的数据( 和 )进行实验。 作为参考,我们将 DecT 与微调(更新完整模型参数的最强基线)进行比较。
详细结果如图1和表3所示,我们得到以下结论。 (1)DecT以较低的成本在更多的训练数据上不断提高其性能。 从 16 个样本到 256 个样本,平均精度提高了,而平均训练时间则少于秒。 (2) 与微调相比,DecT 在 64-shot 场景中甚至与它持平,但在 256-shot 设置中逐渐落后,这是合理的,因为我们只调整了模型外的一小部分参数。 通过进一步的任务级观察,我们发现DecT在情感分析和主题分类方面仍然表现良好,但在NLI和实体打字方面无法赶上微调,这些任务被认为是较难的任务,因为它们需要复杂的推理或细粒度的语义理解。 (3) 在实验中,我们发现由于可训练参数数量巨大且损失信号相对较少,微调对少样本设置中的随机种子更加敏感,64 样本设置中的高方差证明了这一点。 因此,DecT的稳定性优势再次得到验证。
总而言之,我们迈出了第一步,将 MaaS 方法应用到少样本学习之外。 结果表明,DecT 在常规分类任务上与微调相比具有竞争力,但在困难任务上受到限制。 如何在不更新参数的情况下使 PTM 适应具有挑战性的任务仍然需要进一步探索。
5分析
5.1消融研究
| Average Accuracy | ||||
| 1 | 4 | 16 | ||
| ✗ | ✗ | |||
| ✓ | ✗ | |||
| ✗ | ✓ | |||
| ✓ | ✓ | |||
| Model | SST2 | IMDB | Yelp | AG | DB | Yahoo | RTE | SNLI | MNLI-m/mm | NERD | Avg. |
| T5 | |||||||||||
| T5 | |||||||||||
| T5 | |||||||||||
| T5 |

消融模型分数。
显然,模型分数对 DecT 的少样本训练性能有很大贡献,特别是当数据极其稀缺(1-shot)时,这说明模型分数包含对语言理解有益的先验模型知识。 此外,合并训练数据可以减少方差。 当训练数据较多时,模型分数带来的增强较小,这是合理的,因为模型和 ProtoNet 分数的相对权重发生变化。
消融半径。
同时,半径在低镜头场景下也很有帮助,它表征了类别之间的差异。 但随着训练数据数量的增加,ProtoNet 在模型预测中占据主导地位, 的影响也减弱。
消融解码器。
如前所述,解码器功能的设计选择是灵活的。 我们用两层 MLP 替换 ProtoNet 并评估性能。 在图3中我们可以看到,ProtoNet 在 1-shot 设置中显着优于 MLP,这与 ProtoNet 在少样本设置中的优势相匹配。 在 4-shot 和 16-shot 实验中,ProtoNet 仍然获得更高的分数,但差距较小。 在稳定性方面,ProtoNet 始终实现较低的标准偏差分数,这是另一个优势。 总的来说,我们发现 ProtoNet 是 DecT 的重要组成部分,简单地用 MLP 替换它会降低性能。
5.2 的影响
作为超参数, 控制模型分数和原型分数的相对重要性。 在这里我们研究一下它对 AG News 和 SST2 的影响。 在图4中,我们可以观察到:(1)很大程度上影响1-shot设置中的DecT。 随着 的增加,DecT 逐渐表现得更好、更稳定,这说明了模型知识在这种情况下的重要性。 (2)随着射击次数的增加,变化的影响减弱,最佳实践变小。 这些观察结果验证了我们在4.1节中的选择策略,该策略有效地平衡了模型和数据知识。
5.3 PTM 的影响
在本节中,我们将探讨 DecT 如何应用于不同架构和规模的 PTM。 我们选择了 T5 Raffel等人(2020),一个编码器-解码器PTM,在不同尺度上,从T5、T5、T5到T5。 表5展示了T5模型的完整结果。 首先,DecT已成功部署在生成语言模型T5上,验证了其跨PTM的可迁移性。 此外,我们可以观察到缩放效应的明显趋势,即较大的模型始终表现更好。
5.4 模板的影响
虽然DecT是输出端的自适应方法,但模板的选择也会影响最终的性能。 为了评估模板的影响,我们在AG的News和SST2上进行了实验,结果如表6所示。 总体而言,DecT 不太依赖模板。 虽然不同的模板可能会导致零样本性能波动,但 DecT 在很大程度上缩小了它们之间的差距。 此外,我们尝试了从 RLPrompt Deng 等人 (2022) 中搜索到的两个模板,它们都取得了令人满意的结果。 在SST2上,RLPrompt的模板甚至比手动设计的模板还要好。 因此,我们强调 DecT 与输入端自适应算法是互补的,它们可以协同工作以获得更好的性能。
| Template | Prompt | DecT |
| SST2 | ||
| In summary, it was [MASK]. | 83.3 | 91.0 |
| It was [MASK]. | 73.3 | 88.4 |
| AgentMediaGrade Officials Grade [MASK]. | 90.4 | 92.2 |
| AG’s News | ||
| [ Topic : [MASK] ] | 80.9 | 86.4 |
| [ Category : [MASK] ] | 78.6 | 86.8 |
| [MASK] Alert Blog Dialogue Diary Accountability | 78.8 | 86.0 |
6相关工作
我们的工作探索如何有效地适应大型 PTM。 在本节中,我们分别回顾了基于提示的调优(数据效率)、参数高效调优(参数效率)和 MaaS 适应方法的三个研究方向。
6.1 基于提示的调整
基于提示的调整的主要做法是将文本片段包装到人工设计的模板中。 通过这种方式,基于提示的调优将下游任务转换为预训练任务(例如掩码语言建模),并大大增强了 PTM 的零/少样本学习能力。 首先应用于知识探索Petroni等人(2019),并在NLP中得到广泛采用Schick and Schütze (2021);刘等人 (2021);胡等人 (2022b);丁等人 (2021a);韩等人 (2021);崔等人(2022)。 其他作品还研究了自动或可学习的提示 Shin 等人 (2020); Hambardzumyan 等人 (2021); Schick 等人 (2020),但提示的优化是一个不小的问题。 在我们的工作中,我们采用手动模板来激发模型知识并帮助数据高效的模型适应。
6.2 参数高效调优
另一项工作探索调整一小部分模型参数以减少计算和存储预算,即参数高效调整(PET)Ding 等人(2022c)。 典型的 PET 方法包括插入可调模块 Houlsby 等人 (2019);李和梁(2021); Hu 等人 (2022a),添加软提示标记 Lester 等人 (2021) 并指定某些参数 Zaken 等人 (2022)。 尽管 PET 方法通过很少的参数更新即可实现显着的性能,但它们仍然需要模型梯度,而这在 MaaS 设置中不可用。
6.3 MaaS 适配
对于仅推理 API,还有一些无需调整任何模型参数即可调整模型的作品。 Brown 等人 (2020) 提出了上下文学习,它将测试输入与多个示例连接起来。 尽管优雅且易于使用,但研究人员也发现情境学习不稳定 Zhao 等人 (2021); Lu 等人 (2022) 并受输入长度限制。 其他方法尝试使用黑盒优化方法 Sun 等人 (2022a, b) 或强化学习 Deng 等人 (2022) 来优化提示。 然而,由于缺乏梯度信号,他们需要数千次模型查询,导致模型很大时成本很高,并且API调用不是免费的。 与上述方法不同,我们在输出侧调整模型,不需要优化远处的输入提示。 我们只需要对每个训练样本进行一次 API 调用,并在各个任务中取得更好的结果。
7结论
在本文中,我们提出了 DecT,它使用现成的 PTM 执行数据和参数高效的自适应。 通过融合先验模型知识和后验数据知识,DecT 在 10 种语言理解任务上取得了优异的性能。 同时,DecT 在训练时间和查询数量方面超出了现有基线三个数量级,凸显了其在实际部署中的优势。 在未来的工作中,我们渴望探索如何结合输入端和输出端的适应方法来实现更好的 PTM 适应,以及如何将这一研究领域扩展到更具挑战性的场景。
参考
- Bentivogli et al. (2009) Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. 2009. The fifth pascal recognizing textual entailment challenge. In TAC.
- Bowman et al. (2015) Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. 2015. A large annotated corpus for learning natural language inference. In Proceedings of EMNLP.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Proceedings of NeurIPS.
- Cui et al. (2022) Ganqu Cui, Shengding Hu, Ning Ding, Longtao Huang, and Zhiyuan Liu. 2022. Prototypical verbalizer for prompt-based few-shot tuning. In Proceedings of ACL.
- Dagan et al. (2005) Ido Dagan, Oren Glickman, and Bernardo Magnini. 2005. The pascal recognising textual entailment challenge. In Machine learning challenges workshop.
- Deng et al. (2022) Mingkai Deng, Jianyu Wang, Cheng-Ping Hsieh, Yihan Wang, Han Guo, Tianmin Shu, Meng Song, Eric P Xing, and Zhiting Hu. 2022. Rlprompt: Optimizing discrete text prompts with reinforcement learning. In Proceedings of EMNLP.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT.
- Ding et al. (2022a) Ning Ding, Yulin Chen, Ganqu Cui, Xiaobin Wang, Hai-Tao Zheng, Zhiyuan Liu, and Pengjun Xie. 2022a. Few-shot classification with hypersphere modeling of prototypes. arXiv preprint arXiv:2211.05319.
- Ding et al. (2021a) Ning Ding, Yulin Chen, Xu Han, Guangwei Xu, Pengjun Xie, Hai-Tao Zheng, Zhiyuan Liu, Juanzi Li, and Hong-Gee Kim. 2021a. Prompt-learning for fine-grained entity typing. arXiv preprint arXiv:2108.10604.
- Ding et al. (2022b) Ning Ding, Shengding Hu, Weilin Zhao, Yulin Chen, Zhiyuan Liu, Hai-Tao Zheng, and Maosong Sun. 2022b. Openprompt: An open-source framework for prompt-learning. In Proceedings of ACL.
- Ding et al. (2022c) Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, Jing Yi, Weilin Zhao, Zhiyuan Liu, Hai-Tao Zheng, Jianfei Chen, Yang Liu, Jie Tang, Juanzi Li, and Maosong Sun. 2022c. Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models. In arXiv.
- Ding et al. (2021b) Ning Ding, Guangwei Xu, Yulin Chen, Xiaobin Wang, Xu Han, Pengjun Xie, Haitao Zheng, and Zhiyuan Liu. 2021b. Few-nerd: A few-shot named entity recognition dataset. In Proceedings of ACL, pages 3198–3213.
- Giampiccolo et al. (2007) Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and William B Dolan. 2007. The third pascal recognizing textual entailment challenge. In Proceedings of the ACL-PASCAL workshop on textual entailment and paraphrasing.
- Haim et al. (2006) R Bar Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. 2006. The second pascal recognising textual entailment challenge. In Proceedings of the Second PASCAL Challenges Workshop on Recognising Textual Entailment, volume 7.
- Hambardzumyan et al. (2021) Karen Hambardzumyan, Hrant Khachatrian, and Jonathan May. 2021. WARP: word-level adversarial reprogramming. In Proceedings of ACL, pages 4921–4933.
- Han et al. (2021) Xu Han, Weilin Zhao, Ning Ding, Zhiyuan Liu, and Maosong Sun. 2021. Ptr: Prompt tuning with rules for text classification. arXiv preprint arXiv:2105.11259.
- Hansen and Ostermeier (2001) Nikolaus Hansen and Andreas Ostermeier. 2001. Completely derandomized self-adaptation in evolution strategies. Evolutionary computation, 9(2):159–195.
- Hochreiter and Schmidhuber (1997) Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory. Neural computation, 9(8):1735–1780.
- Houlsby et al. (2019) Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for NLP. In Proceedings of ICML.
- Hu et al. (2022a) Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022a. Lora: Low-rank adaptation of large language models. In Proceedings of ICLR.
- Hu et al. (2022b) Shengding Hu, Ning Ding, Huadong Wang, Zhiyuan Liu, Juanzi Li, and Maosong Sun. 2022b. Knowledgeable prompt-tuning: Incorporating knowledge into prompt verbalizer for text classification. In Proceedings of ACL.
- Kingma and Ba (2015) Diederik P. Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In Proceedings of ICLR.
- Lehmann et al. (2015) Jens Lehmann, Robert Isele, Max Jakob, Anja Jentzsch, Dimitris Kontokostas, Pablo N Mendes, Sebastian Hellmann, Mohamed Morsey, Patrick Van Kleef, Sören Auer, et al. 2015. Dbpedia–a large-scale, multilingual knowledge base extracted from wikipedia. Semantic web, 6(2):167–195.
- Lester et al. (2021) Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. In Proceedings of EMNLP.
- Li and Liang (2021) Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of ACL-IJCNLP.
- Liu et al. (2021) Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2021. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- Loshchilov and Hutter (2019) Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regularization. In Proceedings of ICLR.
- Lu et al. (2022) Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In Proceedings of ACL.
- Maas et al. (2011) Andrew Maas, Raymond E Daly, Peter T Pham, Dan Huang, Andrew Y Ng, and Christopher Potts. 2011. Learning word vectors for sentiment analysis. In Proceedings of ACL.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Z. Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of NeurIPS, pages 8024–8035.
- Petroni et al. (2019) Fabio Petroni, Tim Rocktäschel, Sebastian Riedel, Patrick S. H. Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander H. Miller. 2019. Language models as knowledge bases? In Proceedings of EMNLP-IJCNLP.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J Liu, et al. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140):1–67.
- Schick et al. (2020) Timo Schick, Helmut Schmid, and Hinrich Schütze. 2020. Automatically identifying words that can serve as labels for few-shot text classification. In Proceedings of COLING.
- Schick and Schütze (2021) Timo Schick and Hinrich Schütze. 2021. Exploiting cloze-questions for few-shot text classification and natural language inference. In Proceedings of EACL.
- Shin et al. (2020) Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, and Sameer Singh. 2020. Autoprompt: Eliciting knowledge from language models with automatically generated prompts. In Proceedings of EMNLP.
- Snell et al. (2017) Jake Snell, Kevin Swersky, and Richard S. Zemel. 2017. Prototypical networks for few-shot learning. In Proceedings of NIPS.
- Socher et al. (2013) Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of EMNLP.
- Sun et al. (2022a) Tianxiang Sun, Zhengfu He, Hong Qian, Yunhua Zhou, Xuanjing Huang, and Xipeng Qiu. 2022a. BBTv2: Towards a gradient-free future with large language models. In Proceedings of EMNLP.
- Sun et al. (2022b) Tianxiang Sun, Yunfan Shao, Hong Qian, Xuanjing Huang, and Xipeng Qiu. 2022b. Black-box tuning for language-model-as-a-service. In Proceedings of ICML.
- Wang et al. (2019) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of ICLR.
- Williams et al. (2018) Adina Williams, Nikita Nangia, and Samuel R. Bowman. 2018. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of NAACL-HLT.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of EMNLP, pages 38–45, Online.
- Zaken et al. (2022) Elad Ben Zaken, Yoav Goldberg, and Shauli Ravfogel. 2022. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. In Proceedings of ACL.
- Zhang et al. (2021) Tianyi Zhang, Felix Wu, Arzoo Katiyar, Kilian Q Weinberger, and Yoav Artzi. 2021. Revisiting few-sample bert fine-tuning. In Proceedings of ICLR.
- Zhang et al. (2015) Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text classification. In Proceedings of NIPS.
- Zhao et al. (2021) Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021. Calibrate before use: Improving few-shot performance of language models. In Proceedings of ICML.
附录A实验细节
A.1 数据集统计
我们在表7中提供了数据集统计数据。
| Task | Dataset | # Class | # Test |
| Sentiment Analysis | SST2 | 2 | 872 |
| Yelp | 2 | 38,000 | |
| IMDB | 2 | 25,000 | |
| Topic Classification | AG’s News | 4 | 7,600 |
| Yahoo | 10 | 60,000 | |
| DBPedia | 14 | 70,000 | |
| NLI | RTE | 2 | 277 |
| SNLI | 3 | 9,842 | |
| MNLI-m/mm | 3 | 9,815/9,832 | |
| Entity Typing | FewNERD | 66 | 96,853 |
A.2基线
情境学习(ICL)。
为了保证有意义的结果,我们随机排列演示并将它们放在输入提示之前。 由于输入长度限制,我们截断超出输入长度的演示。
BBT 和 BBTv2。
我们使用官方代码重现 BBT 和 BBTv2。 对于他们工作中采用的数据集,我们遵循原始实现,包括模板、标签词和超参数。 对于其他数据集,我们使用模板、标签词和默认超参数进行重现。 我们从论文中获取现有的 16 次实验结果,并使用 5 个随机种子进行其他实验,以进行公平比较。
RL 提示。
我们还使用官方代码进行复制,并从他们的原始论文中获取一些实验结果。 值得注意的是,RLPrompt 采用 SST2 的测试集,而我们使用验证集,因此我们报告了 SST2 验证集上的重现结果。
微调。
我们采用基于提示的微调,使用与 DecT 相同的模板和标签词。 我们使用 AdamW 优化器 Loshchilov 和 Hutter (2019) 使用 学习率将整个模型调整了 5 个周期。
A.3 模板和标签词
我们在表8中报告了使用的提示模板和标签词。 其中大部分摘自OpenPrompt Ding 等人(2022b)。
| Dataset | Template | Label Words |
| SST2 | In summary, it was [MASK]. | bad, great |
| Yelp | ||
| IMDB | ||
| AG’s News | [ Topic : [MASK] ] | politics, sports, business, technology |
| Yahoo | [ Topic : [MASK] ] | society, science, health, education, computers, sports, business, entertainment, family, politics |
| DBPedia | The category of is [MASK]. | company, school, artist, athlete, politics, transportation, building, river, village, animal, plant, album, film, book |
| RTE | ? [MASK], | No, Yes |
| SNLI | No, Maybe, Yes | |
| MNLI-m/mm | No, Maybe, Yes | |
| FewNERD | [ENT] is [MASK]. | actor, director, artist, athlete, politician, scholar, soldier, person, show, religion, company, team, school, government, media, party, sports, organization, geopolitical, road, water, park, mountain, island, location, software, food, game, ship, train, plane, car, weapon, product, theater, facility, airport, hospital, library, hotel, restaurant, building, championships, attack, disaster, election, protest, event, music, written, film, painting, broadcast, art, biology, chemical, living, astronomy, god, law, award, disease, medical, language, currency, educational |