大型语言模型满足 NL2Code:一项调查
摘要
从自然语言描述(NL2Code)生成代码的任务被认为是代码智能领域的一个紧迫而重大的挑战。 由于预训练技术的快速发展,越来越多的大型语言模型被提出用于代码,从而引发了 NL2Code 的进步。 为了促进该领域的进一步研究和应用,我们在本文中全面调查了现有的 NL2Code 大语言模型,并回顾了基准和衡量标准。 我们在 HumanEval 基准上对所有现有模型进行直观比较。 通过深入观察和分析,我们得出一些见解并得出结论:NL2Code 大型语言模型成功的关键因素是“大尺寸、优质数据、专家调优”。 此外,我们还讨论了模型与人类之间差距的挑战和机遇。 我们还创建了一个网站https://nl2code.github.io来通过众包跟踪最新进展。 据我们所知,这是对 NL2Code 大型语言模型的首次调查,我们相信它将有助于该领域的持续发展。
1简介
对于新手程序员来说,即使是那些没有任何编程经验的人,是否可以仅通过用自然语言描述他们的需求来创建软件? 这是一个长期存在的令人着迷的问题,对软件工程、编程语言和人工智能等研究领域提出了挑战。 实现这一场景将对我们的生活、教育、经济和劳动力市场产生前所未有的影响,因为它将改变中心化的软件开发和运营范式。 由于其前景广阔且令人着迷,自然语言到代码(NL2Code)已被提出作为一项研究任务,引起了学术界和工业界的广泛兴趣,其目标是从自然语言描述生成代码。
早期对NL2Code的研究主要基于启发式规则或专家系统,例如基于概率语法的方法Joshi and Rambow (2003); Cohn 等人 (2010); Allamanis 和 Sutton (2014) 以及那些专注于特定领域语言的de Moura 和 Bjørner (2008);古尔瓦尼(2010); Jha 等人 (2010),不灵活且不可扩展。 其他研究使用静态语言模型,例如 n-gram Nguyen 等人 (2013); Raychev 等人 (2014); Devanbu (2012) 和隐马尔可夫 Sutskever 等人 (2008),它们具有稀疏向量表示,无法对长期依赖关系进行建模。 随后是神经网络,包括 CNN Liu 等人 (2016); Sun 等人 (2018), RNN Iyer 等人 (2016); Wan 等人 (2018) 和 LSTM Eriguchi 等人 (2016); Yin和Neubig (2017)被用来对NL和代码之间的关系进行建模。 2017年,引入Transformer Vaswani 等人(2017)模型用于机器翻译,随后应用于NL2Code任务Mastropaolo 等人(2021); Shah 等人 (2021)。 然而,这些深度学习模型需要大量标记的 NL 和代码训练对,并且对于 NL2Code 任务的能力有限。
最近,越来越多的具有 Transformer 架构的大型语言模型(大语言模型)在大规模无标签代码语料库上进行了训练。 这些模型能够以零样本的方式生成代码,并在 NL2Code 任务中取得了令人印象深刻的结果。 作为一个里程碑,Codex Chen 等人 (2021) 表明,具有 十亿个参数的大语言模型能够解决 % 的具有挑战性的 Python 问题人类创造的编程问题。 更令人鼓舞的是,Codex 已被用于为商业产品提供支持111https://github.com/features/copilot并在实践中提高编码效率Sobania等人(2022a); Barke 等人 (2023)。 随着 Codex 的成功,针对 NL2Code 任务的各种大语言模型也出现了,模型大小从数百万到数十亿参数不等。 例如,旨在解决竞技级编程问题的 AlphaCode Li 等人 (2022b),以及支持在任意位置填充代码的 InCoder Fried 等人 (2023)使用双向上下文。 其他模型如 CodeGen Nijkamp 等人 (2023)、PaLM-Coder Chowdhery 等人 (2022)、PanGu-Coder Christopoulou 等人 (2022) t2>、CodeGeeX Zheng 等人 (2023) 和 SantaCoder Allal 等人 (2023) 也获得了极大关注。 随着模型规模的增加,大语言模型已被证明表现出一些新兴的能力,例如类人编程和调试Zhang 等人 (2022);桑德斯等人 (2022);康等人(2023)。
大型语言模型因其令人印象深刻的功能和潜在价值而点燃了 NL2Code 任务的希望。 尽管取得了重大进展,但仍然存在许多挑战和机遇,需要更加先进和创新的未来工作。 目前,考虑到技术和应用的多样性,越来越需要进行全面的调查,以提供该领域的系统概述并确定关键挑战。 为此,在本文中,我们仔细研究了 NL2Code 的高级大语言模型(§2),并审查了基准和指标(§4)。 我们在HumanEval基准上对现有的所有大语言模型进行了直观的比较,进行了深入的分析,最终将这些大语言模型的成功归功于“大数据、优质数据、专家调优” (§3)。 这意味着大模型和数据量、高质量的训练数据和专业的超参数调整。 我们还讨论了大语言模型与人类之间能力差距的挑战和机遇(§5)。 此外,我们还建立了一个网站https://nl2code.github.io来跟踪最新进展并支持众包更新。 据我们所知,这是针对 NL2Code 的大语言模型的首次调查 222我们在附录A中总结了相关调查。,我们希望它能为这个令人兴奋的领域的持续发展做出贡献。
| Model | Size | L. | A. | H. | P. |
| Decoder | |||||
| GPT-C (2020) | M | × | |||
| CodeGPT (2021) | M | ✓ | |||
| GPT-Neo (2021) | M~B | ✓ | |||
| GPT-J (2021) | B | ✓ | |||
| Codex (2021) | M~B | × | |||
| GPT-CC (2021) | M~B | ✓ | |||
| CodeParrot (2021) | M~B | ✓ | |||
| LaMDA (2022) | B~B | × | |||
| PolyCoder (2022) | M~B | ✓ | |||
| CodeGen (2023) | M~B | ✓ | |||
| InCoder (2023) | B~B | ✓ | |||
| GPT-NeoX (2022) | B | ✓ | |||
| PaLM-Coder (2022) | B~B | × | |||
| PanGu-Coder (2022) | M~B | × | |||
| FIM (2022) | M~B | × | |||
| PyCodeGPT (2022b) | M | ✓ | |||
| CodeGeeX (2023) | B | ✓ | |||
| BLOOM (2022) | M~B | ✓ | |||
| SantaCoder (2023) | B | ✓ | |||
| Encoder-Decoder | |||||
| PyMT5 (2020) | M | × | |||
| PLBART (2021) | M~M | ✓ | |||
| CodeT5 (2021) | M~M | ✓ | |||
| JuPyT5 (2022a) | M | × | |||
| AlphaCode (2022b) | M~B | × | |||
| CodeRL (2022) | M | ✓ | |||
| CodeT5Mix (2022) | M~M | ✓ | |||
| ERNIE-Code (2022) | M | ✓ | |||
2 NL2Code 的大型语言模型
给定自然语言问题描述,NL2Code 任务旨在自动生成所需的代码。 为了直观地说明此任务,我们在图 1 中提供了一个 Python 编程问题作为示例,而不同的 NL2Code 基准测试可能在语言或问题领域方面有所不同。 现有的NL2Code任务的大型语言模型通常基于Transformer Vaswani等人(2017),并在大规模代码相关的未标记语料库上进行训练。 为了获得更好的代码生成性能,大多数大语言模型,无论是编码器-解码器还是仅解码器模型,都采用因果语言建模目标进行训练,即预测一系列标记后的词符。 在推理过程中,大语言模型可以以零样本的方式解决NL2Code问题,而无需微调其参数。 还有研究采用少样本 Austin 等人 (2021) 或情境学习 Nijkamp 等人 (2023) 来进一步提高性能。
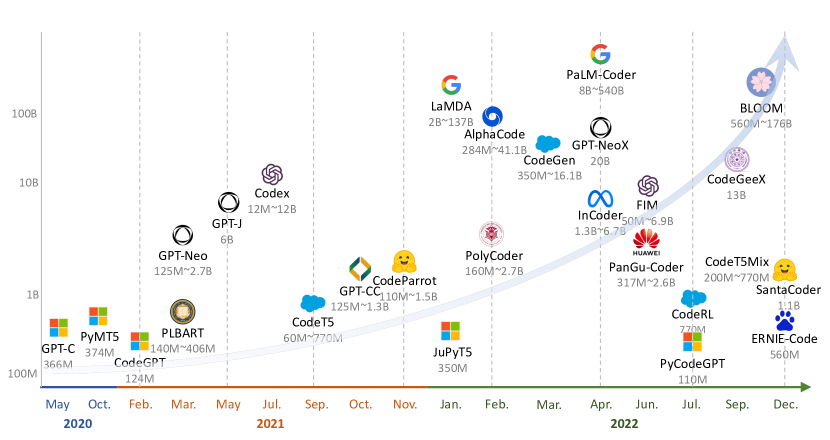
我们对NL2Code任务的代表性大语言模型进行了全面的调查。 表 1 总结了每个模型的详细信息,其中模型在架构、大小和可访问性方面有所不同。 为了更好的可视化,我们在图 2 中按时间顺序呈现这些模型,并绘制了最大的模型尺寸。 观察到的一个趋势是,随着研究领域的进步,这些大型语言模型的规模不断增长。 此外,仅解码器架构更适合尺寸较大的预训练模型。
早期作品,如 GPT-C Svyatkovskiy 等人 (2020)、PyMT5 Clement 等人 (2020)、PLBART Ahmad 等人 (2021) t2>,参数数量相对较少,并且在零样本代码生成方面没有表现出强大的能力。 相反,诸如 GPT-Neo Black 等人 (2021) 和 GPT-J Wang and Komatsuzaki (2021) 等大规模模型,尽管参数规模达到十亿级,由于训练语料库中的代码量较少,人们发现其在 NL2Code 任务中的能力有限。 最近,针对NL2Code提出了许多强大的大语言模型,例如Codex Chen 等人 (2021)、AlphaCode Li 等人 (2022b) 和 PaLM- Coder Chowdhery 等人 (2022),拥有海量参数规模和高质量的代码训练语料库。 虽然它们在 NL2Code 上表现出令人惊讶的良好性能,但其中大多数并不容易访问。 目前也提出了一些优秀的开源模型,包括CodeParrot Huggingface (2021)、PolyCoder Xu 等人(2022)、GPT-NeoX Black 等人 (2022) 和 SantaCoder Allal 等人 (2023),为 NL2Code 大语言模型的蓬勃发展做出了贡献。 此外,最近的研究提出了各种方法来解决特定的 NL2Code 场景。 例如,JuPyT5 Chandel 等人 (2022a) 设计为在 Jupyter Notebooks 中工作,而 ERNIE-Code Chai 等人 (2022)、CodeGeeX Zheng 等人(2023) 和 BLOOM Scao 等人 (2022) 接受过支持多种自然语言或编程语言的训练。 此外,InCoder Fried 等人 (2023)、FIM Bavarian 等人 (2022) 和 SantaCoder Allal 等人 (2023) 不仅支持从左到右的代码预测,还允许填充任意代码区域。 随着 NL2Code 大语言模型的快速发展,我们创建了一个网站,通过众包的方式了解最新进展。 网站详情请参阅附录B。
这些模型不仅在学术界有吸引力 Chen 等人 (2021); Nijkamp 等人 (2023); Li 等人 (2022b),还应用于实际产品中以提高编程效率Sobania 等人 (2022a); Barke 等人 (2023)。 一个例子是 GitHub 和 OpenAI 的 Copilot,这是一种编程辅助工具,利用 Codex 提供实时代码建议。 其他著名产品包括 CodeGeeX333https://keg.cs.tsinghua.edu.cn/codegeex 和 CodeWhisperer444https://aws.amazon.com/cn/codewhisperer。 产品的摘要可以在附录表5中找到。 近期研究Sobania 等人 (2022b); Pearce 等人 (2022); Nguyen 和 Nadi (2022) 已经表明,这些产品可以提供有用的建议,同时它们也会引入可能给用户带来问题的小错误。 在大语言模型完全实用并能够像人类一样编码之前,还有改进的空间。
| Model | Size | () | ||
| k= | k= | k= | ||
| Model Size: ~M | ||||
| GPT-Neo | M | |||
| CodeParrot | M | |||
| PyCodeGPT | M | |||
| PolyCoder | M | |||
| Codex | M | |||
| Codex | M | |||
| Codex | M | |||
| Codex | M | |||
| AlphaCode(dec) | M | |||
| AlphaCode(dec) | M | |||
| AlphaCode(dec) | M | |||
| AlphaCode(dec) | M | |||
| Model Size: ~M | ||||
| CodeT5y | M | |||
| PolyCoder | M | |||
| JuPyT5 | M | |||
| BLOOM | M | |||
| Codex | M | |||
| Codex | M | |||
| AlphaCode(dec) | M | |||
| AlphaCode(dec) | M | |||
| CodeGen-Mono | M | |||
| PanGu-Coder | M | |||
| Model Size: ~B | ||||
| GPT-Neo | B | |||
| CodeParrot | B | |||
| BLOOM | B | |||
| BLOOM | B | |||
| InCodery | B | |||
| AlphaCode(dec) | B | |||
| SantaCoder | B | |||
| Model Size: ~B | ||||
| GPT-Neo | B | |||
| PolyCoder | B | |||
| Codex | B | |||
| PanGu-Coder | B | |||
| BLOOM | B | |||
| BLOOM | B | |||
| CodeGen-Mono | B | |||
| CodeGen-Mono | B | |||
| GPT-J | B | |||
| InCoder | B | |||
| Model Size: >B | ||||
| Codex | B | |||
| CodeGen-Mono | B | |||
| GPT-NeoX | B | |||
| LaMDA | B | |||
| BLOOM | B | |||
| PaLM-Coder | B | |||
| code-cushman-001 | ||||
| code-davinci-001 | ||||
| code-davinci-002 | ||||
3大语言模型成功的秘诀是什么?
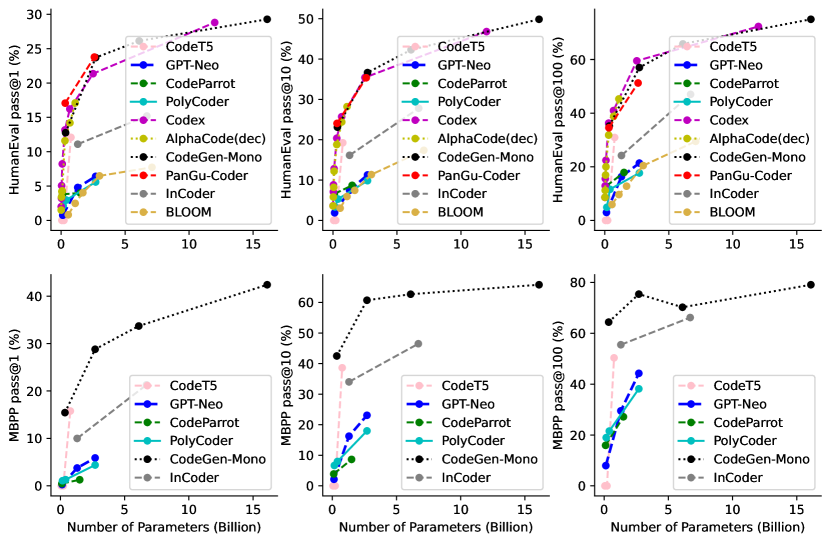
我们总结了NL2Code现有的大语言模型。 这些大语言模型在架构、规模和其他特征方面各不相同,因此很难建立完全公平的比较。 我们在HumanEval基准Chen等人(2021)上以零样本的方式评估这些大语言模型,以提供直观的比较。 HumanEval 与 Codex 一起提出,是 NL2Code 任务最流行的基准测试之一,由 手写的 Python 编程问题组成。 为每个编程问题提供测试用例来评估生成代码的正确性。 作为评估指标555的详细内容可参见附录C.1。,它计算可以通过 尝试正确回答的问题的比例。 表2显示了按模型大小组织的不同大语言模型的结果。 MBPP基准Austin等人(2021)的实施细节和评估可参见附录C.2。
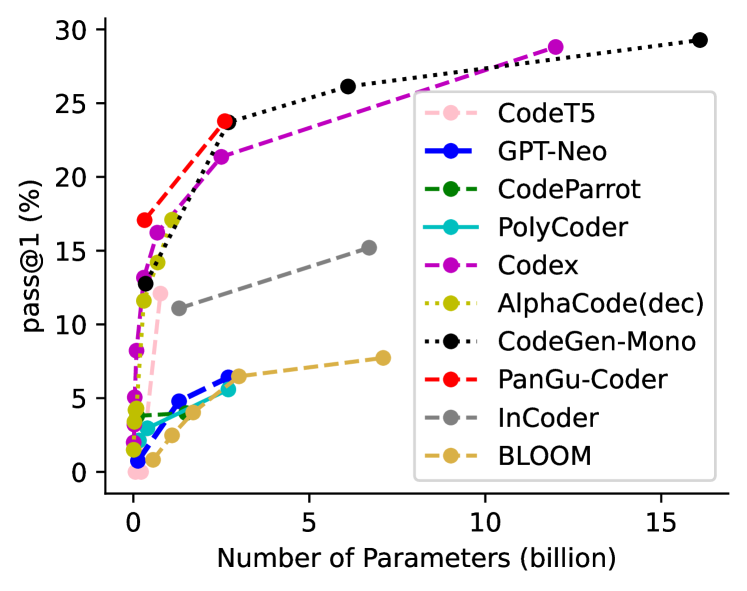
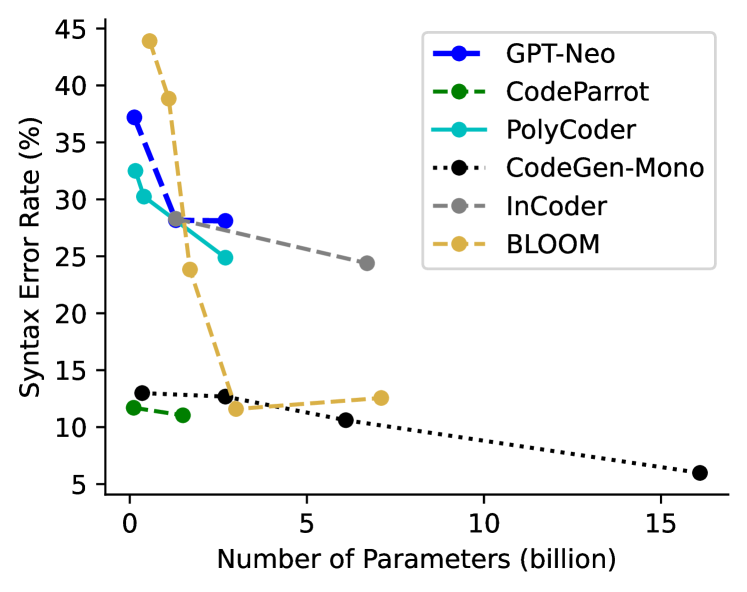
从表2可以看出,现有大语言模型在HumanEval上的性能差异很大,即使是模型大小相似的模型。 具体来说,Codex Chen 等人 (2021) 在各种模型尺寸上均处于领先地位,而相对较小的模型 PyCodeGPT M Zan 等人 (2022b),取得了与 Codex M 相当的结果。其他较大的模型,例如 AlphaCode Li 等人 (2022b)、CodeGen-Mono Nijkamp 等人 (2023) 和 PanGu-Coder Christopoulou 等人 (2022) 也表现出了令人印象深刻的表现。 值得注意的是,InCoder Fried 等人 (2023) 和 SantaCoder Allal 等人 (2023) 使用 FIM 训练方法 Bavarian 等人 (2022),在从左到右的生成设置中也获得了非常不错的结果。 性能的显着变化引出了我们的问题: 大语言模型在NL2Code中取得成功的原因是什么? 考虑到这些模型在设计选择方面的多样性,我们进行了彻底的分析并得出了答案:大尺寸、优质数据、专家调优。 也就是说,大的模型和数据量、高质量的数据和专家的超参数调优是大语言模型在NL2Code任务中成功的关键因素。 在本节中,我们将从模型、数据和调优的角度详细介绍我们的观察和见解。
3.1大模型尺寸
如图2和表2所示,最近的NL2Code大语言模型表现出更大的尺寸和更优越的性能。 这与之前的发现一致,即增加模型参数数量可以增强模型能力 Radford 等人 (2019); Thoppilan 等人 (2022); Chowdhery 等人 (2022)。 我们在图 3(a) 中进一步展示了模型大小和性能之间的相关性,该图比较了 HumanEval 基准上 代表性模型的 结果。 显然,较大的模型通常会带来更好的性能。 此外,我们还发现,当前的模型,无论尺寸如何,仍然有通过进一步增加尺寸来改进的潜力。 HumanEval 和 MBPP 基准测试的其他结果可以在附录图7中找到,这些结果也支持了这一结论。
3.2 大数据和优质数据
随着NL2Code训练领域大语言模型规模的增大,所使用的语料库规模也随之增大。 这凸显了选择和预处理高质量数据的重要性。 在本节中,我们将讨论训练大语言模型所必需的各种常用数据源和预处理策略。
早期模型使用人工标注的 NL 和代码数据对进行训练,数据来源包括 CodeSearchNet Husain 等人 (2019)、CoST Zhu 等人 (2022b) 和XLCoST 朱等人 (2022a)。 然而,手工标注是劳动密集型且耗时的。 还有 GPT-3 Brown 等人 (2020)、GPT-Neo Black 等人 (2021) 和 GPT-J Wang 和 Komatsuzaki ( 2021),在大规模无监督数据集 Pile Gao 等人 (2020) 上进行训练。 然而,由于训练语料库中代码文件的数量有限,这些模型尚未表现出出色的代码生成能力。 最近,随着更强大的NL2Code大语言模型的出现,更大规模的无标签代码数据集被提出,包括BigQuery Google (2016)、CodeParrot的语料库HuggingFace (2021a)、GitHub 代码 HuggingFace (2021b) 和 Stack HuggingFace (2022),这些内容是从 GitHub666https://github.com 和 Stack Overflow 72>77https://stackoverflow.com 此外,还针对不同场景提出了专门的数据集,例如使用 Jupyter Notebooks 或竞赛编程问题作为训练语料库。 已发布的数据集包括 Jupyter HuggingFace (2021c)、JuICe Agashe 等人 (2019)、APPS Hendrycks 等人 (2021) 和 CodeNet IBM (2021)。
为了保证训练语料的质量,大语言模型通常会对采集到的大量代码进行数据预处理。 我们仔细回顾了五个强大的大语言模型的数据预处理方法,包括 Codex Chen 等人 (2021)、AlphaCode Li 等人 (2022b)、CodeGen Nijkamp 等人 (2023)、InCoder Fried 等人 (2023) 和 PyCodeGPT Zan 等人 (2022b),并找出几个共性。 一是删除可能自动生成或未完成的代码文件,因为它们被认为毫无意义。 此外,还采用特定的规则来过滤掉不常见的代码文件。 这些规则包括存储库星级、文件大小、行长度和字母数字比率等因素。 综上所述,这些预处理策略的目标是获得不重复、完整、正确、干净和通用的代码语料库。
| Benchmark | Num. | P. NL | S. PL | Data Statistics | Scenario | ||||
| T.N. | P.C. | P.L. | S.C. | S.L. | |||||
| HumanEval (2021) | English | Python | Code Exercise | ||||||
| MBPP (2021) | English | Python | Code Exercise | ||||||
| APPS (2021) | English | Python | Competitions | ||||||
| CodeContests (2022b) | English | Multi. | Competitions | ||||||
| DS-1000 (2022) | English | Python | Data Science | ||||||
| DSP (2022b) | English | Python | Data Science | ||||||
| MBXP (2022) | English | Multi. | Multilingual | ||||||
| MBXP-HumanEval (2022) | English | Multi. | Multilingual | ||||||
| HumanEval-X (2023) | English | Multi. | Multilingual | ||||||
| MultiPL-HumanEval (2022) | English | Multi. | Multilingual | ||||||
| MultiPL-MBPP (2022) | English | Multi. | Multilingual | ||||||
| PandasEval (2022b) | English | Python | Public Library | ||||||
| NumpyEval (2022b) | English | Python | Public Library | ||||||
| TorchDataEval (2022a) | English | Python | Private Library | ||||||
| MTPB (2023) | English | Python | Multi-Turn | ||||||
| ODEX (2022c) | Multi. | Python | Open-Domain | ||||||
| BIG-Bench (2022) | English | Python | Code Exercise | ||||||
3.3专家调优
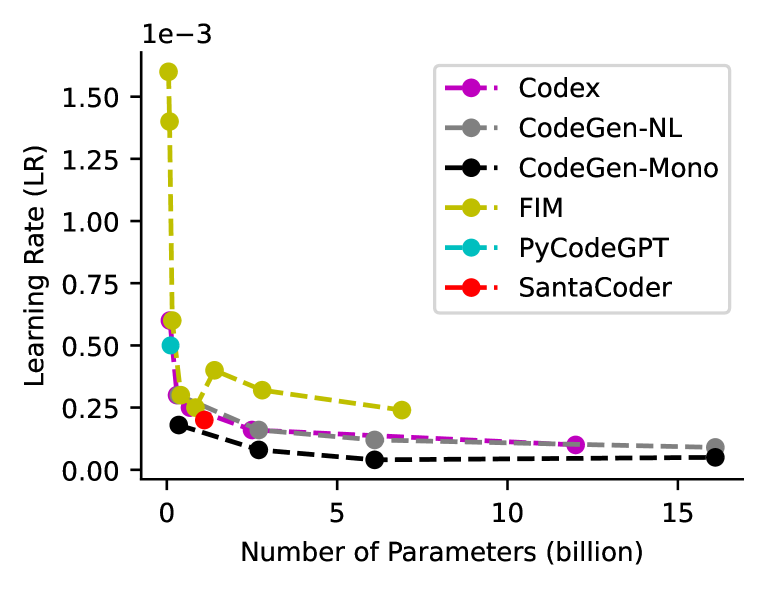
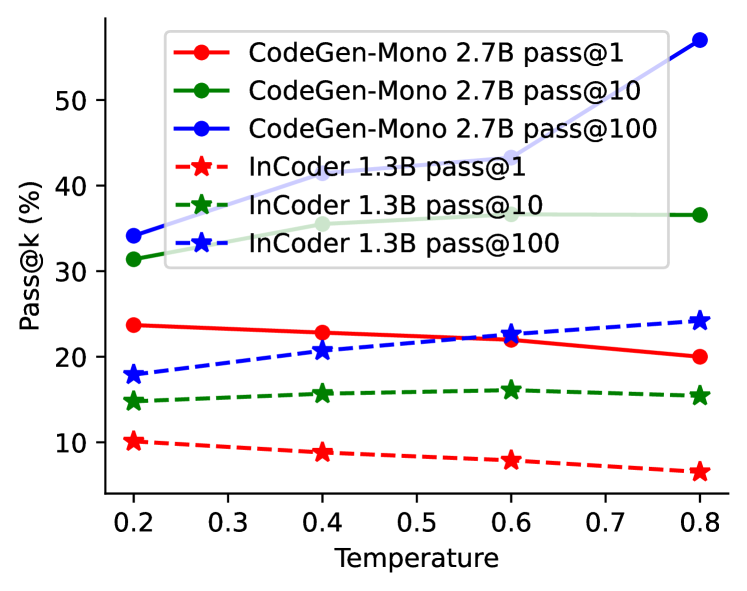
训练一个优秀的模型需要仔细考虑各种设计选择和超参数。 在回顾现有的大语言模型(摘要见附录表6)后,我们有以下发现。 首先,这些大语言模型有一些共同的设置。 例如,我们观察到当前模型的优化器几乎都是 Adam Kingma and Ba (2014) 或其变体 Loshchilov and Hutter (2017)。 我们还发现,与从头开始的训练相比,使用其他自然语言模型进行初始化并没有产生明显的增益,除了加速收敛 Chen 等人 (2021) 之外。 此外,还有一些超参数需要专家调整,例如学习率、批量大小、窗口大小、预热步骤、梯度累积步骤和采样温度。 对于学习率,我们使用六个强大的大语言模型来分析其与模型大小的相关性,如图4所示。 我们观察到,随着模型变大,学习率变小。 为了探索温度的影响,在图 5 中,我们报告了在 HumanEval 上使用多个温度的两个模型的性能。 一个观察结果是,较高的温度导致较低的和较高的,这表明较高的温度使大语言模型产生更多样的预测,反之亦然。 此外,一些研究erman Arsenovich Arutyunov and Avdoshin (2022)表明窗口大小是一个关键因素。 一个有趣的发现是,具有大窗口尺寸的小模型有时优于具有小窗口尺寸的大模型(详细信息参见附录D)。 此外,强大的大语言模型通常主要使用两种技术在代码语料库上训练新的分词器:字节级字节对编码 Radford 等人 (2019) 和 SentencePiece Kudo and Richardson ( 2018)。 新的分词器可以更有效、更准确地将代码内容拆分为标记。 这些经过验证的调优技术将为训练更强大的大语言模型提供有价值的参考。
4基准和指标
为了评估 NL2Code 任务,高质量的基准和可靠的指标是基础和必要的。 在本节中,我们简要概述了当前的基准和指标,以及我们的观察和开放挑战。
我们在表3中总结了经过深入研究的NL2Code基准,我们可以发现每个基准在大小、语言、复杂性和场景方面都有自己的特征。 我们观察到大多数基准测试包含有限数量的实例。 例如,广泛使用的 HumanEval 和 MBPP 分别具有 和 实例。 这是因为这些基准通常是手写的,以确保大语言模型在训练期间没有看到它们。 在大语言模型时代,创建新基准时避免数据泄漏至关重要。 此外,当前大多数基准测试都有英文问题描述和 Python 代码解决方案。 最近,多个多语言基准被提出,例如 MBXP Athiwaratkun 等人 (2022)、HumanEvalX Zheng 等人 (2023) 和 MultiPL Cassano 等人 (2022),涵盖多种编程语言,ODEX Wang 等人 (2022c),涵盖多种自然语言。 多语言基准的详细信息列于附录表7中。 此外,还针对其他实际场景提出了基准,例如数据科学Lai等人(2022)、公共图书馆Zan等人(2022b)、私人图书馆 Zan 等人 (2022a)、多轮程序综合 Nijkamp 等人 (2023) 以及代码安全 Siddiq 和 msiddiq (2022)。 对于基于执行的基准测试,完整覆盖生成程序的综合测试用例可以确保评估结果的可信度。 作为参考,表3还提供了每个基准测试的平均测试用例数量,以及问题描述和解决方案的长度统计。
手动评估生成的代码是不切实际的,这需要自动度量。 上述基准测试均提供了基于执行评估的测试用例,其中的指标包括 Chen 等人 (2021)、 Li可以使用测试用例平均值 Hendrycks 等人 (2022b) 和执行精度 Rajkumar 等人 (2022)。 然而,这种方法对测试用例的质量有严格的要求,并且只能评估可执行代码。 对于非可执行代码,可以使用 BLEU Papineni 等人 (2002)、ROUGE Lin (2004) 和 CodeBLEU Ren 等人 (2020) 等指标> 被使用,但它们不能精确评估代码的正确性。 到目前为止,在设计评估代码各个方面的指标方面存在许多开放的挑战,例如脆弱性、可维护性、清晰度、执行复杂性和稳定性。
5挑战与机遇
我们的调查表明,NL2Code 大语言模型的进展对学术界和工业界都产生了相当大的影响。 尽管取得了这些进展,但仍然存在许多挑战需要解决,为进一步的研究和应用提供了充足的机会。 在本节中,我们将探讨大语言模型与人类之间的能力差距所带来的挑战和机遇。
理解能力
自然语言固有的灵活性允许使用多种表达方式来传达功能需求。 人类能够理解不同抽象层次的各种描述。 相比之下,当前的大语言模型往往对给定的上下文敏感,这可能会导致意外的性能下降Wang 等人(2022a)。 此外,大语言模型在面对条件和要求众多的复杂问题时可能会陷入困境 Barke 等人 (2022);今井(2022)。 我们认为探索大语言模型的理解能力是一个重要的研究方向。 一种可能的解决方案是将复杂问题分解为多个步骤,就像推理任务 Wei 等人 (2022) 中通常所做的那样。
判断能力
人类有能力确定他们是否能够解决编程问题。 尽管当前的模型即使没有问题的答案,也总是会返回解决方案,因为它们是通过无监督的因果语言建模目标进行训练的。 这可能会在实际应用中引起问题。 为了提高大语言模型的判断能力,研究人员采用强化学习来利用用户反馈,例如 InstructGPT Ouyang 等人 (2022) 和 ChatGPT8 等模型。 t2>88https://chat.openai.com。 然而,收集高质量的代码反馈成本高昂且具有挑战性。 还有正在进行的研究Chen 等人 (2023); Key等人(2022)探索大语言模型自我验证的可能性,这也是一个很有前景的研究方向。
解释能力
众所周知,人类开发人员拥有解释他们编写的代码含义的能力,这对于教育目的和软件维护至关重要。 最近的研究表明,大语言模型具有自动生成代码解释的潜力。 MacNeil 等人 (2022a) 提出使用大语言模型为学生在学习过程中生成代码解释,MacNeil 等人 (2022b) 提出解释给定的多个方面使用 Copilot 的代码片段。 要充分发挥大语言模型在这方面的潜力,还需要进一步的研究和探索。
适应性学习能力
当前大型语言模型与人类之间的根本区别在于它们适应新知识和更新知识的能力。 人类开发人员拥有快速搜索和学习新材料(例如编程文档)的独特能力,并相对轻松地适应 API 的变化。 然而,重新训练或微调大语言模型需要大量的努力和资源。 这个问题启发了最近的一些研究,例如 DocCoder Zhou 等人 (2023) 和 APICoder Zan 等人 (2022a),它们利用基于检索的方法来提供模型推理过程中额外或更新的知识。 尽管取得了这些进步,但赋予大语言模型人类强大的学习能力仍然是一个公开的挑战。
多任务处理能力
大型语言模型已应用于多种与代码相关的任务,例如代码修复Joshi等人(2022); Prenner 和 Robbes (2021)、代码搜索 Neelakantan 等人 (2022)、代码审查 Li 等人 (2022c) 以及非代码任务可以以类似代码的方式格式化,例如数学Drori and Verma (2021); Drori 等人 (2021) 和化学 Krenn 等人 (2022);曲棍球与怀特(2022)。 然而,大语言模型与人类在多任务处理方面的能力存在差异。 人类可以在任务之间无缝切换,而大语言模型可能需要复杂的提示工程Liu 等人(2023)。 另一个证据是,大语言模型缺乏像人类一样快速掌握多种编程语言Zheng 等人(2023)的能力。 这些局限性突出了未来研究的领域。
6结论
在本文中,我们调查了现有的 NL2Code 大型语言模型,并对其成功的根本原因进行了全面分析。 我们还提供了基准和指标的详细审查。 关于模型和人类之间的差距,我们提出了持续的挑战和机遇。 此外,我们还开发了一个网站来跟踪该领域的最新发现。 我们希望这项调查能够有助于全面概述该领域并促进其蓬勃发展。
局限性
在本文中,我们深入研究了NL2Code现有的大型语言模型,并以自己的思考从不同的角度进行了总结。 然而,由于这个领域发展如此之快,可能有一些方面我们忽略了,或者有些新的工作我们没有涵盖。 为了缓解这个问题,我们创建了一个网站来通过众包跟踪最新进展,希望它能够不断为该领域的发展做出贡献。 此外,现有的大语言模型在模型规模、架构、语料库、预处理、分词器、超参数和训练平台等方面都有自己的特点。 此外,其中一些目前尚未公开,例如 AlphaCode Li 等人 (2022b) 和 PaLM-Coder Chowdhery 等人 (2022)。 因此,进行完全公平的比较几乎是不切实际的。 我们尽力对流行的HumanEval和MBPP基准进行一种比较,希望能为不同大语言模型的性能差异提供线索。 此外,评估大语言模型的计算资源成本很高。 因此,我们在 https://nl2code.github.io 上公开了大语言模型生成的所有文件。
参考
- Agashe et al. (2019) Rajas Agashe, Srinivasan Iyer, and Luke Zettlemoyer. 2019. JuICe: A large scale distantly supervised dataset for open domain context-based code generation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5436–5446.
- Ahmad et al. (2021) Wasi Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang. 2021. Unified pre-training for program understanding and generation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2655–2668.
- aiXcoder (2018) aiXcoder. 2018. aiXcoder. https://aixcoder.com.
- Alibaba (2022) Alibaba. 2022. Alibaba. https://github.com/alibaba-cloud-toolkit/cosy.
- Allal et al. (2023) Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Muñoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alexander Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, J. Poirier, Hailey Schoelkopf, Sergey Mikhailovich Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Franz Lappert, Francesco De Toni, Bernardo Garc’ia del R’io, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luisa Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Christopher Hughes, Daniel Fried, Arjun Guha, Harm de Vries, and Leandro von Werra. 2023. SantaCoder: don’t reach for the stars! ArXiv, abs/2301.03988.
- Allamanis et al. (2018) Miltiadis Allamanis, Earl T Barr, Premkumar Devanbu, and Charles Sutton. 2018. A survey of machine learning for big code and naturalness. ACM Computing Surveys (CSUR), 51(4):1–37.
- Allamanis and Sutton (2014) Miltiadis Allamanis and Charles Sutton. 2014. Mining idioms from source code. In Proceedings of the 22nd acm sigsoft international symposium on foundations of software engineering, pages 472–483.
- Amazon (2022) Amazon. 2022. CodeWhisperer. https://aws.amazon.com/cn/codewhisperer.
- Anonymous (2022) Anonymous. 2022. CodeT5Mix: A pretrained mixture of encoder-decoder transformers for code understanding and generation. In Submitted to The Eleventh International Conference on Learning Representations. Under review.
- Athiwaratkun et al. (2022) Ben Athiwaratkun, Sanjay Krishna Gouda, Zijian Wang, Xiaopeng Li, Yuchen Tian, Ming Tan, Wasi Uddin Ahmad, Shiqi Wang, Qing Sun, Mingyue Shang, Sujan Kumar Gonugondla, Hantian Ding, Varun Kumar, Nathan Fulton, Arash Farahani, Siddharth Jain, Robert Giaquinto, Haifeng Qian, Murali Krishna Ramanathan, Ramesh Nallapati, Baishakhi Ray, Parminder Bhatia, Sudipta Sengupta, Dan Roth, and Bing Xiang. 2022. Multi-lingual evaluation of code generation models. ArXiv, abs/2210.14868.
- Austin et al. (2021) Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie J. Cai, Michael Terry, Quoc V. Le, and Charles Sutton. 2021. Program synthesis with large language models. ArXiv, abs/2108.07732.
- Barke et al. (2022) Shraddha Barke, Michael B. James, and Nadia Polikarpova. 2022. Grounded Copilot: How programmers interact with code-generating models. Proceedings of the ACM on Programming Languages, 7:85 – 111.
- Barke et al. (2023) Shraddha Barke, Michael B James, and Nadia Polikarpova. 2023. Grounded copilot: How programmers interact with code-generating models. Proceedings of the ACM on Programming Languages, 7(OOPSLA1):85–111.
- Bavarian et al. (2022) Mohammad Bavarian, Heewoo Jun, Nikolas A. Tezak, John Schulman, Christine McLeavey, Jerry Tworek, and Mark Chen. 2022. Efficient training of language models to fill in the middle. ArXiv, abs/2207.14255.
- Black et al. (2022) Sid Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, and Samuel Weinbach. 2022. GPT-NeoX-20B: An open-source autoregressive language model. In Proceedings of the ACL Workshop on Challenges & Perspectives in Creating Large Language Models.
- Black et al. (2021) Sid Black, Leo Gao, Phil Wang, Connor Leahy, and Stella Biderman. 2021. GPT-Neo: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, T. J. Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeff Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. Neural Information Processing Systems, 33:1877–1901.
- Cassano et al. (2022) Federico Cassano, John Gouwar, Daniel Nguyen, Sy Duy Nguyen, Luna Phipps-Costin, Donald Pinckney, Ming-Ho Yee, Yangtian Zi, Carolyn Jane Anderson, Molly Q. Feldman, Arjun Guha, Michael Greenberg, and Abhinav Jangda. 2022. A scalable and extensible approach to benchmarking nl2code for 18 programming languages. ArXiv, abs/2208.08227.
- Chai et al. (2022) Yekun Chai, Shuohuan Wang, Chao Pang, Yu Sun, Hao Tian, and Hua Wu. 2022. ERNIE-Code: Beyond english-centric cross-lingual pretraining for programming languages. arXiv preprint arXiv:2212.06742.
- Chandel et al. (2022a) Shubham Chandel, Colin B. Clement, Guillermo Serrato, and Neel Sundaresan. 2022a. Training and evaluating a jupyter notebook data science assistant. ArXiv, abs/2201.12901.
- Chandel et al. (2022b) Shubham Chandel, Colin B Clement, Guillermo Serrato, and Neel Sundaresan. 2022b. Training and evaluating a jupyter notebook data science assistant. arXiv preprint arXiv:2201.12901.
- Chen et al. (2023) Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. 2023. CodeT: Code generation with generated tests. In The Eleventh International Conference on Learning Representations.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde, Jared Kaplan, Harrison Edwards, Yura Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, David W. Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William H. Guss, Alex Nichol, Igor Babuschkin, S. Arun Balaji, Shantanu Jain, Andrew Carr, Jan Leike, Joshua Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew M. Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. 2021. Evaluating large language models trained on code. ArXiv, abs/2107.03374.
- Chowdhery et al. (2022) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam M. Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Benton C. Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier García, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Díaz, Orhan Firat, Michele Catasta, Jason Wei, Kathleen S. Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. 2022. PaLM: Scaling language modeling with pathways. ArXiv, abs/2204.02311.
- Christopoulou et al. (2022) Fenia Christopoulou, Gerasimos Lampouras, Milan Gritta, Guchun Zhang, Yinpeng Guo, Zhong-Yi Li, Qi Zhang, Meng Xiao, Bo Shen, Lin Li, Hao Yu, Li yu Yan, Pingyi Zhou, Xin Wang, Yu Ma, Ignacio Iacobacci, Yasheng Wang, Guangtai Liang, Jia Wei, Xin Jiang, Qianxiang Wang, and Qun Liu. 2022. PanGu-Coder: Program synthesis with function-level language modeling. ArXiv, abs/2207.11280.
- Clement et al. (2020) Colin B. Clement, Dawn Drain, Jonathan Timcheck, Alexey Svyatkovskiy, and Neel Sundaresan. 2020. PyMT5: Multi-mode translation of natural language and python code with transformers. In Conference on Empirical Methods in Natural Language Processing.
- CodedotAl (2021) CodedotAl. 2021. GPT Code Clippy: The Open Source version of GitHub Copilot. https://github.com/CodedotAl/gpt-code-clippy.
- Cohn et al. (2010) Trevor Cohn, Phil Blunsom, and Sharon Goldwater. 2010. Inducing tree-substitution grammars. The Journal of Machine Learning Research, 11:3053–3096.
- de Moura and Bjørner (2008) Leonardo Mendonça de Moura and Nikolaj S. Bjørner. 2008. Z3: An efficient smt solver. In International Conference on Tools and Algorithms for Construction and Analysis of Systems.
- DeepGenX (2022) DeepGenX. 2022. CodeGenX. https://docs.deepgenx.com.
- Dehaerne et al. (2022) Enrique Dehaerne, Bappaditya Dey, Sandip Halder, Stefan De Gendt, and Wannes Meert. 2022. Code generation using machine learning: A systematic review. IEEE Access.
- Devanbu (2012) Premkumar T. Devanbu. 2012. On the naturalness of software. 2012 34th International Conference on Software Engineering (ICSE), pages 837–847.
- Drori and Verma (2021) Iddo Drori and Nakul Verma. 2021. Solving linear algebra by program synthesis. arXiv preprint arXiv:2111.08171.
- Drori et al. (2021) Iddo Drori, Sarah Zhang, Reece Shuttleworth, Leonard Tang, Albert Lu, Elizabeth Ke, Kevin Liu, Linda Chen, Sunny Tran, Newman Cheng, Roman Wang, Nikhil Singh, Taylor Lee Patti, J. Lynch, Avi Shporer, Nakul Verma, Eugene Wu, and Gilbert Strang. 2021. A neural network solves, explains, and generates university math problems by program synthesis and few-shot learning at human level. Proceedings of the National Academy of Sciences of the United States of America, 119.
- Eriguchi et al. (2016) Akiko Eriguchi, Kazuma Hashimoto, and Yoshimasa Tsuruoka. 2016. Tree-to-sequence attentional neural machine translation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 823–833.
- erman Arsenovich Arutyunov and Avdoshin (2022) erman Arsenovich Arutyunov and Sergey Avdoshin. 2022. Big transformers for code generation. Proceedings of the Institute for System Programming of the RAS.
- FauxPilot (2022) FauxPilot. 2022. FauxPilot. https://github.com/moyix/fauxpilot.
- Fried et al. (2023) Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Scott Yih, Luke Zettlemoyer, and Mike Lewis. 2023. InCoder: A generative model for code infilling and synthesis. In The Eleventh International Conference on Learning Representations.
- Gao et al. (2020) Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. 2020. The Pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027.
- GitHub (2021) GitHub. 2021. GitHub Copilot. https://github.com/features/copilot.
- Google (2016) Google. 2016. GitHub on BigQuery: Analyze all the open source code. https://cloud.google.com/bigquery.
- Google (2022) Google. 2022. Big-bench. https://github.com/google/BIG-bench.
- Gulwani (2010) Sumit Gulwani. 2010. Dimensions in program synthesis. In Proceedings of the 12th international ACM SIGPLAN symposium on Principles and practice of declarative programming, pages 13–24.
- Hendrycks et al. (2021) Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Xiaodong Song, and Jacob Steinhardt. 2021. Measuring coding challenge competence with apps. In Neural Information Processing Systems.
- Hocky and White (2022) Glen M Hocky and Andrew D White. 2022. Natural language processing models that automate programming will transform chemistry research and teaching. Digital discovery, 1(2):79–83.
- HuggingFace (2021a) HuggingFace. 2021a. CodeParrot Dataset. https://huggingface.co/datasets/transformersbook/codeparrot.
- HuggingFace (2021b) HuggingFace. 2021b. Github-Code. https://huggingface.co/datasets/codeparrot/github-code.
- HuggingFace (2021c) HuggingFace. 2021c. GitHub-Jupyter. https://huggingface.co/datasets/codeparrot/github-jupyter.
- Huggingface (2021) Huggingface. 2021. Training CodeParrot from Scratch. https://huggingface.co/blog/codeparrot.
- HuggingFace (2022) HuggingFace. 2022. The Stack. https://huggingface.co/datasets/bigcode/the-stack.
- Husain et al. (2019) Hamel Husain, Hongqi Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. 2019. CodeSearchNet Challenge: Evaluating the state of semantic code search. ArXiv, abs/1909.09436.
- IBM (2021) IBM. 2021. CodeNet. https://github.com/IBM/Project_CodeNet.
- Imai (2022) Saki Imai. 2022. Is github copilot a substitute for human pair-programming? an empirical study. In Proceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings, pages 319–321.
- Iyer et al. (2016) Srini Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. 2016. Summarizing source code using a neural attention model. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).
- Jha et al. (2010) Susmit Jha, Sumit Gulwani, Sanjit A. Seshia, and Ashish Tiwari. 2010. Oracle-guided component-based program synthesis. 2010 ACM/IEEE 32nd International Conference on Software Engineering, 1:215–224.
- Joshi and Rambow (2003) Aravind Joshi and Owen Rambow. 2003. A formalism for dependency grammar based on tree adjoining grammar. In Proceedings of the Conference on Meaning-text Theory, pages 207–216. MTT Paris, France.
- Joshi et al. (2022) Harshit Joshi, José Cambronero, Sumit Gulwani, Vu Le, Ivan Radicek, and Gust Verbruggen. 2022. Repair is nearly generation: Multilingual program repair with llms. arXiv preprint arXiv:2208.11640.
- Kang et al. (2023) Sungmin Kang, Bei Chen, Shin Yoo, and Jian-Guang Lou. 2023. Explainable automated debugging via large language model-driven scientific debugging. arXiv preprint arXiv:2304.02195.
- Key et al. (2022) Darren Key, Wen-Ding Li, and Kevin Ellis. 2022. I Speak, You Verify: Toward trustworthy neural program synthesis. arXiv preprint arXiv:2210.00848.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Krenn et al. (2022) Mario Krenn, Qianxiang Ai, Senja Barthel, Nessa Carson, Angelo Frei, Nathan C Frey, Pascal Friederich, Théophile Gaudin, Alberto Alexander Gayle, Kevin Maik Jablonka, et al. 2022. Selfies and the future of molecular string representations. Patterns, 3(10):100588.
- Kudo and Richardson (2018) Taku Kudo and John Richardson. 2018. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 66–71, Brussels, Belgium. Association for Computational Linguistics.
- Lai et al. (2022) Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Scott Yih, Daniel Fried, Si yi Wang, and Tao Yu. 2022. DS-1000: A natural and reliable benchmark for data science code generation. ArXiv, abs/2211.11501.
- Le et al. (2022) Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven CH Hoi. 2022. CodeRL: Mastering code generation through pretrained models and deep reinforcement learning. arXiv preprint arXiv:2207.01780, abs/2207.01780.
- Le et al. (2020) Triet HM Le, Hao Chen, and Muhammad Ali Babar. 2020. Deep learning for source code modeling and generation: Models, applications, and challenges. ACM Computing Surveys (CSUR), 53(3):1–38.
- Li et al. (2022a) Yaoxian Li, Shiyi Qi, Cuiyun Gao, Yun Peng, David Lo, Zenglin Xu, and Michael R Lyu. 2022a. A closer look into transformer-based code intelligence through code transformation: Challenges and opportunities. arXiv preprint arXiv:2207.04285.
- Li et al. (2022b) Yujia Li, David H. Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom, Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de, Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey, Cherepanov, James Molloy, Daniel Jaymin Mankowitz, Esme Sutherland Robson, Pushmeet Kohli, Nando de, Freitas, Koray Kavukcuoglu, and Oriol Vinyals. 2022b. Competition-level code generation with alphacode. Science, 378:1092 – 1097.
- Li et al. (2022c) Zhiyu Li, Shuai Lu, Daya Guo, Nan Duan, Shailesh Jannu, Grant Jenks, Deep Majumder, Jared Green, Alexey Svyatkovskiy, Shengyu Fu, et al. 2022c. Automating code review activities by large-scale pre-training. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, pages 1035–1047.
- Lin (2004) Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text summarization branches out, pages 74–81.
- Liu et al. (2023) Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55(9):1–35.
- Liu et al. (2016) Zhiqiang Liu, Yong Dou, Jingfei Jiang, and Jinwei Xu. 2016. Automatic code generation of convolutional neural networks in fpga implementation. In 2016 International conference on field-programmable technology (FPT), pages 61–68. IEEE.
- Loshchilov and Hutter (2017) Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
- Lu et al. (2021) Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin B. Clement, Dawn Drain, Daxin Jiang, Duyu Tang, Ge Li, Lidong Zhou, Linjun Shou, Long Zhou, Michele Tufano, Ming Gong, Ming Zhou, Nan Duan, Neel Sundaresan, Shao Kun Deng, Shengyu Fu, and Shujie Liu. 2021. CodeXGLUE: A machine learning benchmark dataset for code understanding and generation. ArXiv, abs/2102.04664.
- Luhunu and Syriani (2017) Lechanceux Luhunu and Eugene Syriani. 2017. Survey on template-based code generation. In ACM/IEEE International Conference on Model Driven Engineering Languages and Systems.
- MacNeil et al. (2022a) Stephen MacNeil, Andrew Tran, Arto Hellas, Joanne Kim, Sami Sarsa, Paul Denny, Seth Bernstein, and Juho Leinonen. 2022a. Experiences from using code explanations generated by large language models in a web software development e-book. arXiv preprint arXiv:2211.02265.
- MacNeil et al. (2022b) Stephen MacNeil, Andrew Tran, Dan Mogil, Seth Bernstein, Erin Ross, and Ziheng Huang. 2022b. Generating diverse code explanations using the gpt-3 large language model. In Proceedings of the 2022 ACM Conference on International Computing Education Research-Volume 2, pages 37–39.
- Mastropaolo et al. (2021) Antonio Mastropaolo, Simone Scalabrino, Nathan Cooper, David Nader Palacio, Denys Poshyvanyk, Rocco Oliveto, and Gabriele Bavota. 2021. Studying the usage of text-to-text transfer transformer to support code-related tasks. In 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE), pages 336–347. IEEE.
- Microsoft (2019) Microsoft. 2019. IntelliCode. https://github.com/MicrosoftDocs/intellicode.
- Neelakantan et al. (2022) Arvind Neelakantan, Tao Xu, Raul Puri, Alec Radford, Jesse Michael Han, Jerry Tworek, Qiming Yuan, Nikolas Tezak, Jong Wook Kim, Chris Hallacy, et al. 2022. Text and code embeddings by contrastive pre-training. arXiv preprint arXiv:2201.10005.
- Nguyen and Nadi (2022) Nhan Nguyen and Sarah Nadi. 2022. An empirical evaluation of github copilot’s code suggestions. In Proceedings of the 19th International Conference on Mining Software Repositories, pages 1–5.
- Nguyen et al. (2013) Tung Thanh Nguyen, Anh Tuan Nguyen, Hoan Anh Nguyen, and Tien N Nguyen. 2013. A statistical semantic language model for source code. In Proceedings of the 2013 9th Joint Meeting on Foundations of Software Engineering, pages 532–542.
- Nijkamp et al. (2023) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. 2023. CodeGen: An open large language model for code with multi-turn program synthesis. In The Eleventh International Conference on Learning Representations.
- of Oxford (2020) University of Oxford. 2020. Diffblue Cover. https://www.diffblue.com.
- Ouyang et al. (2022) Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke E. Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Francis Christiano, Jan Leike, and Ryan J. Lowe. 2022. Training language models to follow instructions with human feedback. ArXiv, abs/2203.02155.
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318.
- Pawade et al. (2018) Dipti Pawade, Avani Sakhapara, Sanyogita Parab, Divya Raikar, Ruchita Bhojane, and Henali Mamania. 2018. Literature survey on automatic code generation techniques. i-Manager’s Journal on Computer Science, 6(2):34.
- Pearce et al. (2022) Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. 2022. Asleep at the keyboard? assessing the security of github copilot’s code contributions. In 2022 IEEE Symposium on Security and Privacy (SP), pages 754–768. IEEE.
- Prenner and Robbes (2021) Julian Aron Prenner and Romain Robbes. 2021. Automatic program repair with openai’s codex: Evaluating quixbugs. arXiv preprint arXiv:2111.03922.
- Radford et al. (2019) Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Rajkumar et al. (2022) Nitarshan Rajkumar, Raymond Li, and Dzmitry Bahdanau. 2022. Evaluating the text-to-sql capabilities of large language models. arXiv preprint arXiv:2204.00498.
- Raychev et al. (2014) Veselin Raychev, Martin Vechev, and Eran Yahav. 2014. Code completion with statistical language models. In Proceedings of the 35th ACM SIGPLAN Conference on Programming Language Design and Implementation, pages 419–428.
- Ren et al. (2020) Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. CodeBLEU: a method for automatic evaluation of code synthesis. arXiv preprint arXiv:2009.10297.
- Saunders et al. (2022) William Saunders, Catherine Yeh, Jeff Wu, Steven Bills, Long Ouyang, Jonathan Ward, and Jan Leike. 2022. Self-critiquing models for assisting human evaluators. arXiv preprint arXiv:2206.05802.
- Scao et al. (2022) Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, Matthias Gallé, et al. 2022. BLOOM: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100.
- Shah et al. (2021) Meet Shah, Rajat Shenoy, and Radha Shankarmani. 2021. Natural language to python source code using transformers. In 2021 International Conference on Intelligent Technologies (CONIT), pages 1–4. IEEE.
- Sharma et al. (2021) Tushar Sharma, Maria Kechagia, Stefanos Georgiou, Rohit Tiwari, and Federica Sarro. 2021. A survey on machine learning techniques for source code analysis. arXiv preprint arXiv:2110.09610.
- Shin and Nam (2021) Jiho Shin and Jaechang Nam. 2021. A survey of automatic code generation from natural language. Journal of Information Processing Systems, 17(3):537–555.
- Siddiq and msiddiq (2022) Mohammed Latif Siddiq and msiddiq. 2022. SecurityEval dataset: mining vulnerability examples to evaluate machine learning-based code generation techniques. Proceedings of the 1st International Workshop on Mining Software Repositories Applications for Privacy and Security.
- Sobania et al. (2022a) Dominik Sobania, Martin Briesch, and Franz Rothlauf. 2022a. Choose your programming copilot: a comparison of the program synthesis performance of github copilot and genetic programming. In Proceedings of the Genetic and Evolutionary Computation Conference, pages 1019–1027.
- Sobania et al. (2022b) Dominik Sobania, Martin Briesch, and Franz Rothlauf. 2022b. Choose your programming copilot: a comparison of the program synthesis performance of github copilot and genetic programming. In Proceedings of the Genetic and Evolutionary Computation Conference, pages 1019–1027.
- Sun et al. (2018) Zeyu Sun, Qihao Zhu, Lili Mou, Yingfei Xiong, Ge Li, and Lu Zhang. 2018. A grammar-based structural cnn decoder for code generation. In AAAI Conference on Artificial Intelligence.
- Sutskever et al. (2008) Ilya Sutskever, Geoffrey E Hinton, and Graham W Taylor. 2008. The recurrent temporal restricted boltzmann machine. Neural Information Processing Systems, 21.
- Svyatkovskiy et al. (2020) Alexey Svyatkovskiy, Shao Kun Deng, Shengyu Fu, and Neel Sundaresan. 2020. IntelliCode compose: code generation using transformer. Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering.
- Syriani et al. (2018) Eugene Syriani, Lechanceux Luhunu, and Houari Sahraoui. 2018. Systematic mapping study of template-based code generation. Computer Languages, Systems & Structures, 52:43–62.
- tabnine (2018) tabnine. 2018. TabNine. https://www.tabnine.com.
- Thoppilan et al. (2022) Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. 2022. LAMDA: Language models for dialog applications. arXiv preprint arXiv:2201.08239.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Neural Information Processing Systems, 30.
- Wan et al. (2018) Yao Wan, Zhou Zhao, Min Yang, Guandong Xu, Haochao Ying, Jian Wu, and Philip S Yu. 2018. Improving automatic source code summarization via deep reinforcement learning. In Proceedings of the 33rd ACM/IEEE international conference on automated software engineering, pages 397–407.
- Wang and Komatsuzaki (2021) Ben Wang and Aran Komatsuzaki. 2021. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/kingoflolz/mesh-transformer-jax.
- Wang et al. (2022a) Shiqi Wang, Zheng Li, Haifeng Qian, Cheng Yang, Zijian Wang, Mingyue Shang, Varun Kumar, Samson Tan, Baishakhi Ray, Parminder Bhatia, Ramesh Nallapati, Murali Krishna Ramanathan, Dan Roth, and Bing Xiang. 2022a. ReCode: Robustness evaluation of code generation models. arXiv preprint arXiv:2212.10264.
- Wang et al. (2021) Yue Wang, Weishi Wang, Shafiq Joty, and Steven CH Hoi. 2021. CodeT5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 8696–8708.
- Wang et al. (2022b) Zhiruo Wang, Grace Cuenca, Shuyan Zhou, Frank F Xu, and Graham Neubig. 2022b. MCoNaLa: a benchmark for code generation from multiple natural languages. arXiv preprint arXiv:2203.08388.
- Wang et al. (2022c) Zhiruo Wang, Shuyan Zhou, Daniel Fried, and Graham Neubig. 2022c. Execution-based evaluation for open-domain code generation. arXiv preprint arXiv:2212.10481.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903.
- Xu et al. (2022) Frank F. Xu, Uri Alon, Graham Neubig, and Vincent J. Hellendoorn. 2022. A systematic evaluation of large language models of code. Proceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming.
- Xu and Zhu (2022) Yichen Xu and Yanqiao Zhu. 2022. A survey on pretrained language models for neural code intelligence. arXiv preprint arXiv:2212.10079.
- Yin et al. (2018) Pengcheng Yin, Bowen Deng, Edgar Chen, Bogdan Vasilescu, and Graham Neubig. 2018. Learning to mine aligned code and natural language pairs from stack overflow. 2018 IEEE/ACM 15th International Conference on Mining Software Repositories (MSR), pages 476–486.
- Yin and Neubig (2017) Pengcheng Yin and Graham Neubig. 2017. A syntactic neural model for general-purpose code generation. arXiv preprint arXiv:1704.01696.
- Zan et al. (2022a) Daoguang Zan, Bei Chen, Zeqi Lin, Bei Guan, Yongji Wang, and Jian-Guang Lou. 2022a. When language model meets private library. In Conference on Empirical Methods in Natural Language Processing.
- Zan et al. (2022b) Daoguang Zan, Bei Chen, Dejian Yang, Zeqi Lin, Minsu Kim, Bei Guan, Yongji Wang, Weizhu Chen, and Jian-Guang Lou. 2022b. CERT: Continual pre-training on sketches for library-oriented code generation. In International Joint Conference on Artificial Intelligence.
- Zhang et al. (2022) Jialu Zhang, José Cambronero, Sumit Gulwani, Vu Le, Ruzica Piskac, Gustavo Soares, and Gust Verbruggen. 2022. Repairing bugs in python assignments using large language models. arXiv preprint arXiv:2209.14876.
- Zheng et al. (2023) Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shanshan Wang, Yufei Xue, Zi-Yuan Wang, Lei Shen, Andi Wang, Yang Li, Teng Su, Zhilin Yang, and Jie Tang. 2023. CodeGeeX: A pre-trained model for code generation with multilingual evaluations on humaneval-x. ArXiv, abs/2303.17568.
- Zhou et al. (2023) Shuyan Zhou, Uri Alon, Frank F Xu, Zhengbao JIang, and Graham Neubig. 2023. DocCoder: Generating code by retrieving and reading docs. In The Eleventh International Conference on Learning Representations.
- Zhu et al. (2022a) Ming Zhu, Aneesh Jain, Karthik Suresh, Roshan Ravindran, Sindhu Tipirneni, and Chandan K. Reddy. 2022a. XLCoST: A benchmark dataset for cross-lingual code intelligence.
- Zhu et al. (2022b) Ming Zhu, Karthik Suresh, and Chandan K Reddy. 2022b. Multilingual code snippets training for program translation.
附录A相关调查
以往关于代码智能主题的调查Allamanis 等人 (2018);乐等人 (2020);李等人 (2022a); Xu 和 Zhu (2022) 和代码生成 Pawade 等人 (2018);申和南 (2021); Dehaerne 等人 (2022) 主要关注早期方法,例如编程模板的使用 Syriani 等人 (2018); Luhunu 和 Syriani (2017),基于 CNN、RNN 和 LSTM 架构的神经模型Allamanis 等人 (2018); Sharma 等人 (2021),以及需要标记数据进行训练 Mastropaolo 等人 (2021) 的小型 Transformer 模型; Shah 等人 (2021)。 然而,随着模型尺寸的提高,基于 Transformer 的模型在 NL2Code 任务中表现出了卓越的性能,并促进了功能更强大的代码生成模型的开发。 有鉴于此,显然需要对 NL2Code 任务的大型语言模型进行全面调查,以弥补这一知识差距。 本研究致力于通过对成功的大语言模型进行全面分析以及对 NL2Code 基准和指标进行详细审查来满足这一需求。 我们还提出了大语言模型与人类之间的能力差距所面临的持续挑战和机遇。
最后,我们想强调一下我们调查的一些标准。 首先,我们仅参考官方论文来调查模型的大小。 例如,Codex 在论文中报告了最大尺寸为 B 的模型,但后来训练了更大的模型。 在这种情况下,我们只考虑B模型作为最大的模型。 另外,图2中模型的发表日期取自官方论文或博客。
附录 B 在线网站
为了及时跟踪NL2Code大语言模型的最新进展,我们开发了在线实时更新网站https://nl2code.github.io。 我们在这个网站上收集了尽可能多的最新研究成果。 每个人都可以通过在 GitHub 上拉取请求来为网站做出贡献。 该网站还包括模糊搜索和自定义标签类别等功能,这将方便研究人员快速找到他们想要的论文。 我们希望本网站能够为相关领域的研究人员和开发人员提供帮助,并为其进步做出贡献。
| Model | Size | |||
| k= | k= | k= | ||
| Model Size: ~M | ||||
| GPT-Neoy | M | |||
| CodeParroty | M | |||
| PyCodeGPTy | M | |||
| PolyCodery | M | |||
| Model Size: ~M | ||||
| CodeT5y | M | |||
| PolyCodery | M | |||
| BLOOMy | M | |||
| CodeGen-Monoy | M | |||
| Model Size: ~B | ||||
| GPT-Neoy | B | |||
| CodeParroty | B | |||
| BLOOMy | B | |||
| BLOOMy | B | |||
| InCodery | B | |||
| SantaCodery | B | |||
| Model Size: ~B | ||||
| GPT-Neoy | B | |||
| PolyCodery | B | |||
| BLOOMy | B | |||
| BLOOMy | B | |||
| CodeGen-Monoy | B | |||
| CodeGen-Monoy | B | |||
| GPT-Jy | B | |||
| InCoder | B | |||
| Model Size: >B | ||||
| CodeGen-Mono | B | |||
| cushman-001 | ||||
| davinci-001 | ||||
| davinci-002 | ||||
附录 C实验设置
在本节中,我们将首先介绍 的定义,然后详细介绍在两个基准上进行的实验的详细信息,即 HumanEval Chen 等人 (2021)(结果见表2)和MBPP Austin 等人(2021)(结果见表4)。
C.1
我们使用 作为评估指标。 对于每个编程问题,我们都会对 个候选代码解决方案进行采样,然后随机选择其中的 个。 如果任何代码解决方案通过了给定的测试用例,则可以认为问题已经解决。 所以是基准Chen等人(2021)中已解决问题的比例。 形式上,假设样本中正确的个数为、、 if ;否则, 。 我们选择 作为我们的主要评估指标,因为它通过执行测试用例提供了对代码准确性的完全精确的评估,而第 4 节中提到的其他指标要么源自 或精度较低。
C.2实施细节
对于 HumanEval,我们使用原始基准999https://github.com/openai/human-eval/blob/master/data/HumanEval.jsonl.gz。
表2中的大部分结果取自原始论文,而我们严格遵循相同的实验设置重现了GPT-CC、PLBART、CodeT5和InCoder B的结果和其他型号一样。
具体来说,我们将样本数量设置为,将新生成的 Token 的最大长度设置为,将top_p设置为 。
我们将温度设置为从 到 ,间隔为 ,并报告这些温度下的最佳性能。
对于 MBPP,我们使用 Chen 等人 (2023)101010https://github.com/microsoft/CodeT/blob/main/CodeT/data/dataset/mbpp_sanitized_for_code_generation.jsonl。 表4中,InCoder B和大于B的模型的结果取自Chen 等人(2023),同时我们重现了其他结果。 具体来说,我们将样本数量设置为,新生成的 Token 的最大长度设置为,top_p设置为,并且温度至。
对于上述两个基准,我们采用相同的后处理策略。 遵循 Codex Chen 等人 (2021),当生成的代码中遇到以下序列之一时,我们终止采样过程: '\nclass', ' \ndef'、'\n#'、'\n@'、'\nif' 和 '\n打印'。 在我们的实验中,CodeT5 M 指的是版本111111https://huggingface.co/Salesforce/codet5-large-ntp-py 具有因果语言建模目标。 为了良好的重现性和进一步的研究,我们在我们的网站上公开了 HumanEval 和 MBPP 上的大语言模型的代码和生成结果。
附录 D 上下文窗口与上下文窗口 表现
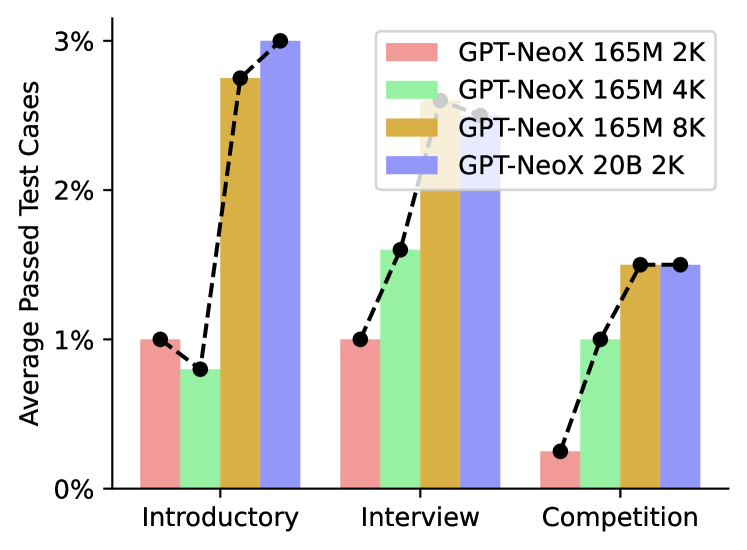
最近的研究erman Arsenovich Arutyunov and Avdoshin (2022)声称上下文窗口的大小对于增强NL2Code大语言模型的性能起着至关重要的作用。 具体来说,我们在 APPS 基准 Hendrycks 等人 (2021) 和 GPT-NeoX Black 等人 (2022) 上进行实验,我们将结果可视化如图 6 发现具有上下文窗口的M版本模型与具有上下文的B版本模型相当窗户。 这一观察结果表明,在训练模型时也需要考虑上下文窗口。
| Products | Model | Supported PLs | Supported IDEs | |||||||||||
| tabnine (2018) |
|
|
||||||||||||
| aiXcoder (2018) |
|
|
||||||||||||
| IntelliCode (2019) |
|
VS Code, Visual Studio | ||||||||||||
| Diffblue Cover (2020) | Java | IntelliJ IDEA, CLI Tool | ||||||||||||
| Copilot (2021) | Codex |
|
|
|||||||||||
| Cosy (2022) | Java | IntelliJ IDEA | ||||||||||||
| CodeWhisperer (2022) |
|
|
||||||||||||
| CodeGenX (2022) | GPT-J | Python | VS Code | |||||||||||
| CodeGeeX (2023) | CodeGeeX |
|
|
|||||||||||
| FauPilot (2022) | CodeGen | Python, Java, Javascript, Go, C, C++ |
| Data | Model Hyper-parameters | Training | |||||||||||||
| Model | de. | token. | opti. | betas | eps | bs | ws | gss | wp | lr | wd | decay | pr | init. | m. |
| Decoder | |||||||||||||||
| GPT-C M | × | BBPE | Adam | e- | Cosine | Scratch | → | ||||||||
| CodeGPT M | × | BBPE | Adam | e- | GPT-2 | → | |||||||||
| GPT-Neo B | BBPE | Adam | , | e- | Cosine | Scratch | → | ||||||||
| GPT-J B | BBPE | Adam | BF16 | → | |||||||||||
| Codex B | ✓ | BBPE | Adam | , | e- | M | e- | Cosine | GPT-3 | → | |||||
| GPT-CC B | ✓ | BBPE | AdaFa | e- | Linear | GPT-Neo | → | ||||||||
| CodeParrot B | ✓ | BBPE | AdamW | , | e- | K | e- | Cosine | Scratch | → | |||||
| LaMDA B | SP | K | → | ||||||||||||
| PolyCoder B | ✓ | BBPE | AdamW | , | e- | K | e- | Cosine | Scratch | → | |||||
| CodeGen B | ✓ | BBPE | Adam | , | e- | M | e- | Cosine | → | ||||||
| InCoder B | ✓ | BBPE | Adam | , | PN | Scratch | |||||||||
| GPT-NeoX B | ✓ | BBPE | ZeRo | , | e- | M | e- | Cosine | FP16 | Scratch | → | ||||
| PaLM-Coder B | ✓ | SP | Adafa. | e- | PaLM | → | |||||||||
| PanGu-Coder B | ✓ | SP | Adam | , | Cosine | Scratch | → | ||||||||
| FIM B | ✓ | BBPE | Adam | M | e- | Scratch | |||||||||
| PyCodeGPT M | ✓ | BBPE | AdamW | , | e- | K | e- | Cosine | FP16 | Scratch | → | ||||
| CodeGeeX B | BBPE | ZeRo | , | Cosine | FP16 | → | |||||||||
| BLOOM B | ✓ | BBPE | Adam | , | e- | Cosine | BF16 | Scratch | → | ||||||
| SantaCoder B | ✓ | BBPE | Adam | , | e- | e- | Cosine | FP16 | Scratch | ||||||
| Encoder-Decoder | |||||||||||||||
| PyMT5 M | ✓ | BBPE | Adam | , | e- | e- | IS | FP16 | → | ||||||
| PLBART M | × | SP | Adam | , | e- | e- | Linear | FP16 | → | ||||||
| CodeT5 M | × | BBPE | AdamW | e- | Linear | FP16 | Scratch | → | |||||||
| JuPyT5 M | ✓ | BBPE | Adam | , | e- | e- | IS | FP16 | PyMT5 | → | |||||
| AlphaCode B | ✓ | SP | AdamW | , | e- | Cosine | BF16 | → | |||||||
| CodeRL M | BBPE | AdamW | PN | CodeT5 | → | ||||||||||
| CodeT5Mix M | ✓ | BBPE | AdamW | Linear | FP16 | Scratch | → | ||||||||
| ERNIE-Code M | × | SP | AdaFa | e- | Linear | BF16 | mT5 | → | |||||||
| Benchmark | Originate From | Multilingual | |||
| MCoNaLa (2022b) | CoNaLa (2018) | English, Spanish, Japanese, Russian | |||
| ODEX (2022c) |
|
English, Spanish, Japanese, Russian | |||
| MBXP (2022) | MBPP (2021) |
|
|||
| MBXP-HumanEval (2022) | HumanEval (2021) |
|
|||
| MultiPL-MBPP (2022) | MBPP (2021) |
|
|||
| MultiPL-HumanEval (2022) | HumanEval (2021) |
|
|||
| HumanEval-X (2023) | HumanEval (2021) | Python, Java, JavaScript, Go, C++ |