用于医学图像分析的自监督预训练的统一视觉信息保留框架
摘要
近年来,计算机视觉中的自监督学习(SSL)取得了重大进展,其主要目标是通过比较孪生图像视图来保留潜在表示中的不变和可区分语义。 然而,保留的高级语义并不包含足够的局部信息,而局部信息在医学图像分析(例如基于图像的诊断和肿瘤分割)中至关重要。 为了缓解比较 SSL 的局部性问题,我们建议将像素恢复任务纳入,以将更多像素级信息显式地编码到高级语义中。 我们还解决了尺度信息保留问题,尺度信息是帮助图像理解的强大工具,但在 SSL 中并未受到太多关注。 结果框架可以表述为特征金字塔上的多任务优化问题。 具体而言,我们在金字塔中执行多尺度像素恢复和孪生特征比较。 此外,我们提出使用非跳跃 U-Net 来构建特征金字塔,并开发子裁剪来取代 3D 医学成像中的多裁剪。 提出的统一 SSL 框架 (PCRLv2) 在各种任务上超越了其自监督对应框架,包括脑肿瘤分割 (BraTS 2018)、胸部病理识别 (ChestX-ray、CheXpert)、肺结节检测 (LUNA) 和腹部器官分割 (LiTS),有时在有限的标注下以较大优势超过它们。 代码和模型可在 https://github.com/RL4M/PCRLv2 获取。
索引词:
医学图像分析,自监督学习,迁移学习,上下文恢复,特征金字塔。1 引言
在训练深度神经网络之前,通常需要获取大量的带人工标注的数据。 此条件在自然图像中易于满足,因为人工成本和标注难度是可以承受的。 然而,在医学图像分析中,可信的标注主要来自领域专家诊断,由于目标疾病的罕见性、保护患者隐私的需要以及医疗资源的匮乏,这些诊断很难获得。 在此背景下,自监督学习 (SSL) 作为一种可行技术被广泛接受,用于在没有专门标注的情况下学习医学图像表示。 我们通常在预训练阶段部署 SSL 以获得可迁移性好的特征,这些特征可以转移到各种下游任务中以提高性能。
SSL 的最新进展主要基于比较学习 [17, 8, 15, 10]。 其背后的原理是通过最大化一对孪生图像之间的互信息来学习具有不变性和可辨别语义的可迁移潜在表示。 这些比较方法的一个潜在问题是它们主要集中在编码表示中的高级全局语义,而忽略了像素级信息的保留。 1 11在 3D 医学图像中,我们经常使用“体素”来表示与 2D 图像中的像素相同的概念。 为简便起见,我们在本文的其余部分使用“像素”来表示 2D 和 3D 图像中最小的可寻址元素。 . 然而,在医学图像分析中,后一种类型的的信息通常起着至关重要的作用。 例如,在胸部病理检测中,放射科医生或临床医生需要根据胸部 X 光片的纹理指出小的病变。 有时,这些病理区域很难识别,即使是医学专家也必须检查像素级细节才能判断病变的位置。 另一个典型的例子是脑肿瘤分割,其中一个体素的分割错误可能会导致脑手术中不可挽回的伤害,例如在尝试切除听神经瘤时对耳蜗神经造成永久性损伤。
一种保留学习特征中像素级信息的直观方法是直接从潜在表示中恢复像素级内容。 这种方法被称为上下文恢复 [29],已被用作基于预文本的 SSL 中的替代任务,用于自然图像 [29, 23, 44] 和医学图像 [7, 49]。 具体来说,这些方法首先对给定图像应用各种数据增强策略来生成一个损坏的输入,基于此,深度模型被训练以恢复原始像素。 通过这种方式,我们明确要求潜在表示保留与像素密切相关的的信息。 尽管纯粹基于像素的特征不如来自对比性 SSL [17, 48] 的特征可迁移,但我们假设显式地保留像素级信息和全局语义仍然是有益的,尤其是在医学图像分析中,细节至关重要。
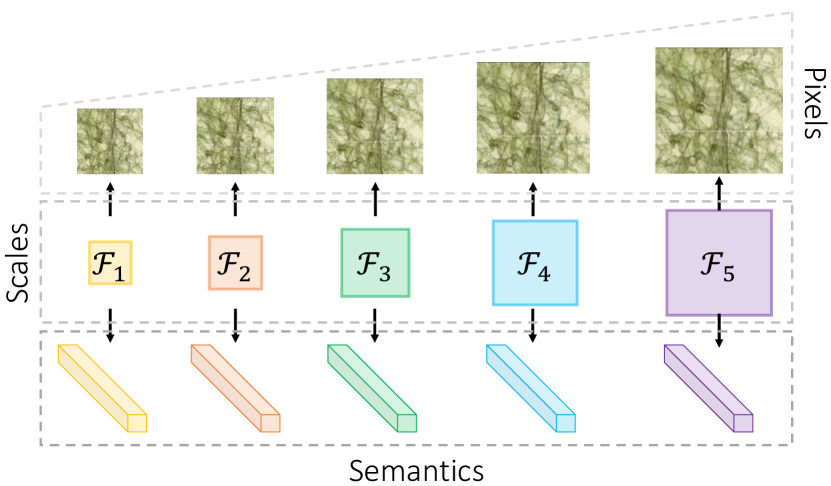
除了语义和像素之外,引入多尺度表示已被证明在帮助图像理解方面非常有用 [12, 27, 39, 24, 26, 32]。 这些方法的常见做法是在训练、测试或这两个阶段构建特征金字塔。 然后,可以在多尺度特征的基础上进行各种任务,例如检测和分割。 构建特征金字塔的目标是赋予图像表示识别不同尺度物体的能力,这与人类认知规律也相一致 [31]。 然而,SSL 中很少提及多尺度视觉信息的保留。 因此,尚不清楚引入多尺度自监督表示是否提供更强的迁移学习能力。
在图 1 中,我们说明了所提出的统一视觉信息保留框架用于 SSL 的动机。 本文提出的框架从三个方面解决自监督视觉表示中信息保存问题:像素、语义和尺度。 首先,为了在潜在表示中保留像素级信息,我们的框架在自监督模型中包含一个重建分支,以从损坏的输入中重建未损坏的图像。 具体来说,我们在训练过程中要求自监督模型从随机损坏输入的特征图中恢复像素。 因此,与像素密切相关的信息可以明确地编码到潜在表示中。 在实践中,这种类型的信息将增强自监督表示识别和区分纹理的能力。 除了像素级信息外,在视觉表示中保留不变和判别性的语义也是必要的。 为此,我们采用了现有的比较 SSL,通过比较孪生图像块的高级表示来编码不变的语义信息[10]。 我们凭经验发现,孪生 SSL 不仅产生可比较的(有时更多)可转移的医学图像表示,而且与典型的对比方式相比,更容易实现[17]。 最后但同样重要的是,提出的统一框架通过在多个尺度上进行像素恢复和特征比较,引入了多尺度潜在表示。 为了实现这一目标,我们提出了一个非跳跃 U-Net (nsUNet),它在 U 形架构之上构建了一个特征金字塔[32]。 在实践中,nsUNet 在执行上下文恢复任务时有效地避免了快捷方式解决方案的产生。 在 nsUNet 的基础上,我们在特征金字塔的每个级别(即尺度)上进行像素级上下文恢复和孪生特征比较。 通过这种方式,提出的框架有助于提高自监督表示识别不同大小和尺度的物体(例如,医学图像中的病灶和器官)的能力。
我们总结了本文的贡献如下:
-
•
我们提出了一种信息保存框架,用于推进医学图像分析中的 SSL。 在这个框架中,我们统一了从三个方面保存潜在表示中的视觉信息:像素、语义和尺度。 为此,像素恢复和特征比较在不同的特征尺度上进行。
-
•
我们引入了非跳跃U-Net(nsUNet)来构建特征金字塔。 与医学影像中典型的U形模型[32, 11]相比,nsUNet保持了更多的特征尺度,并消除了广泛采用的跳跃连接的使用,以避免对像素恢复的捷径解决方案。
-
•
受多裁剪[5]的启发,我们提出了子裁剪来比较全局体积与局部体积。 为了减轻三维空间中全局视图和局部视图之间互信息减少的问题,子裁剪限制了局部视图在全局视图的三维最小包围盒内的裁剪。 在三维医学图像上的实验发现,在各种下游任务中,子裁剪比多裁剪更有效。
-
•
我们进行了广泛而全面的实验,以验证所提出框架的有效性。 我们证明,在预训练/微调协议下,像素、语义和尺度的统一可以提供令人印象深刻的性能。 具体而言,所提出的框架在胸部病理分类、肺结节检测、腹部器官分割和脑肿瘤分割方面,显著优于自监督和监督对应方法。
本文的会议版本 (PCRLv1) 在 [47] 中展示,它展示了除了对比学习获得的不变性和判别性语义之外,结合更多像素级信息的优势。 在本文中,我们对 PCRLv1 做了重大和实质性的修改,并将改进后的框架命名为 PCRLv2(即 Preservational Comparative Representation Learning)。 PCRLv2 中的修改和改进包括但不限于 (i) 除了局部像素级和全局语义信息,尺度信息也被保留在自监督视觉表示中。 背后的动机是,尽管在各种视觉任务中已经考虑了多种特征尺度,但它们在 SSL 中并没有引起太多关注。 PCRLv2 表明,引入多尺度潜在表示可以提高 SSL 在下游任务中的迁移学习性能。 (ii) PCRLv2 将 PCRLv1 中的注意力像素恢复和混合特征对比操作简化为一个简洁的多任务优化问题。 因此,PCRLv2 更简单、更容易实现,同时性能更好,因此更实用。 (iii) 与依赖于普通 U-Net 架构 [32] 的 PCRLv1 相比,PCRLv2 在新的骨干网络上执行 SSL,即非跳跃 U-Net (nsUNet)。 nsUNet 有两个内在优势。 首先,nsUNet 的特征金字塔允许执行多尺度像素级上下文恢复和语义特征比较。 因此,像素、语义和尺度的统一产生了更多可迁移的视觉表示。 其次,nsUNet 可以有效地避免捷径解决方案的产生,与使用典型的跳跃连接相比,性能明显提高。 (iv) 我们将多裁剪的想法 [5] 集成到 PCRLv2 中。 此外,在 3D 医学图像中,我们提出子裁剪,通过在全局视图的 3D 最小包围盒内随机裁剪多个局部体积,来生成具有更高互信息的可靠局部视图。 在实践中,我们发现提出的子裁剪比多裁剪具有更好的预训练性能。 (v) 在 5 个分类/分割任务中,PCRLv2 提供了更多可转移的预训练视觉表示,不仅在所有实验中明显优于之前的自监督和监督对应方法,而且也明显优于 PCRLv1。
2 相关工作
本节回顾了比较 SSL 中的相关工作,包括对比和非对比方法,并列出了使用上下文恢复作为预训练任务的 SSL 方法。 在第三部分,我们收集了强调在 SSL 中结合多尺度特征的论文。
比较 SSL 方法。 比较 SSL 背后的核心思想之一是通过特征级比较,提取和编码不变和区分语义到表示中。 Hjelm 等人 [20] 提出 Deep InfoMax,使用 InfoNCE [28] 最大化同一输入图像的全局和局部特征向量之间的互信息。 Bachman 等人 [3] 通过对每个输入的独立增强版本的特征向量进行全局-局部比较,对 InfoMax 进行了增强。 Tian 等人 [36] 增加了每个输入的增强视图数量,并将 InfoNCE 扩展到多个视图。 He 等人 [17] 提出了 Momentum Contrast (MoCo),它包含一个动量编码器来维护正负特征向量之间的一致性。 与 [20, 3] 不同,MoCo 只在全局特征向量之上执行 InfoNCE。 与 MoCo 相比,SimCLR 去除了动量架构,并在具有一个隐藏层的 MLP 的输出上定义 InfoNCE。 受 SimCLR 的启发,Chen 等人 [9] 提出了 MoCov2,它通过添加一个额外的 MLP 头部和更多的增强来改进 MoCo。 SwAV [5] 将 InfoNCE 中的特征向量替换为聚类分配,并引入了多裁剪策略,以在可承受的计算开销下增加图像视图数量。 Grill 等人 [15] 提出了 BYOL(引导你自己的潜在模型),它通过仅从正样本中提取语义来消除 SSL 中 InfoNCE 的使用。 基于 BYOL,Chen 等人 [10] 进一步去除了动量架构的限制,并引入了一个名为 SimSiam 的简单孪生学习框架。 在实践中,SimSiam 在各种下游任务中产生的结果与 MoCov2 相当。 最近,Zbontar 等人 [42] 通过测量孪生全局特征向量之间的互相关矩阵并尝试使该矩阵接近于单位矩阵来简化 SimSiam。
比较 SSL,尤其是基于 InfoNCE 的方法,也已广泛应用于医学图像分析。 Zhou 等人 [48] 提议将 mixup [43] 整合到 MoCov2 中,从而增加 InfoNCE 中正样本和负样本的多样性。 Taleb 等人 [34] 开发了现有 SSL 技术的 3D 版本,并在下游任务上比较了 2D 和 3D SSL 方法。 Azizi 等人 [2] 将多实例学习融入 SimCLR,这有助于利用每个患者的多个视图。 大概在同一时间,Vu 等人 [37] 开发了一种方法来选择来自同一患者视图的正样本,并使用此策略来改进 MoCov2。 还有一些方法 [6, 40, 41] 为半监督医学图像分割量身定制了比较 SSL。
然而,上述方法未能解决将像素级信息整合到具有丰富语义的高级表示中的重要性,而这是所提出的 PCRL 的主要关注点。
上下文恢复以保留像素级信息。 恢复原始上下文一直被视为 SSL 中重要的预训练任务。 Pathak 等人 [29] 首次通过恢复掩盖的输入图像来进行自监督特征学习。 Larsson 等人 [23] 和 Zhang 等人 [44] 通过预测 RGB 颜色值在像素级别上执行 SSL。 对于医学图像,Chen 等人 [7] 扩展了 [29] 中的方法,并交换了图像块。 Zhou 等人 [49] 表明,为输入图像添加更多增强将有利于 SSL。 Tao 等人 [35] 提出了一种针对 3D 医学图像的体积上下文转换。 与上述方法不同,Henaff [19] 提出以自回归方式预测下一个上下文特征向量。
从上面我们可以看到,上下文恢复在医学成像中比在自然图像中更为普遍。 根本原因是,医学成像任务需要更多像素级信息才能做出细致入微且准确的决策。 另一方面,我们观察到比较 SSL 可以生成语义更丰富的表示。 因此,构建一个同时整合像素级和语义信息的 SSL 框架将是有益的。 就我们所知,这些基于上下文恢复的方法都没有包含这种组合。
SSL 中的多尺度特征。 尽管多尺度特征在现有的 SSL 研究中并没有引起太多关注,但它在某些方法中已被视为 SSL 的一种隐式但有效的正则化方法。 Deep InfoMax [20] 使用 InfoNCE 对比高层特征向量与低层特征图。 为了改进 Deep InfoMax,Bachman 等人 [3] 提出在多个层面上对比全局特征向量和局部特征向量。 在医学图像分析中,保留尺度信息变得至关重要,因为病理可能在不同尺度上表现出不同的特征。 在 [6] 中,引入了局部对比损失来学习局部区域的独特表示,这有助于像素级分割。 同时,全局特征向量被用于提炼用于分类任务的判别语义。 相似的想法也被用于图像配准 [25] 和单样本分割 [46],其中全局和局部特征向量分别用于提供关于语义和位置的信息。
然而,大多数这些方法仅在两个尺度上执行 SSL,即一个全局尺度和一个局部尺度,这无法完全捕获多尺度信息。 此外,虽然这些方法强调了引入局部信息到 SSL 的好处,但它们没有利用有助于编码局部性的像素级信息。 相反,本文提出了一种统一的框架,可以同时保留语义、像素级和尺度信息。
3 方法论
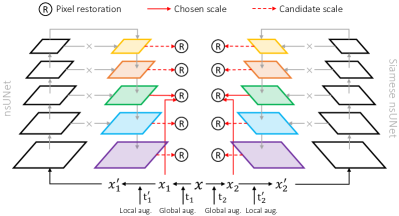
我们在图 2 中概述了 PCRLv2。 假设 表示一批输入图像。 我们引入了级联增强,分别从全局和局部角度扭曲 。 具体来说,第一阶段增强( 和 在图 2 中)主要包括全局变换,例如翻转和旋转,其目标是从全局角度扭曲输入图像的语义。 相比之下,第二阶段增强( 和 在图 2 中)包括局部像素级变换,例如随机噪声和高斯模糊,这些变换用于扰动局部语义。 在两阶段增强之后,最终增强的图像 和 被传递到 Siamese 网络以执行像素恢复和特征比较,而将 和 应用于 的结果,即 和 ,作为像素恢复任务的地面真值目标(如图 2a 所示)。
我们在特征金字塔上执行 SSL 以编码多尺度视觉表示。 遵循医学图像处理中的标准实践,我们使用名为非跳跃 U-Net(nsUNet)的 U 形模型构建特征金字塔。 与典型的 U-Net 架构 [32, 11] 相比,nsUNet 具有更多特征尺度,并完全去除了跳跃连接,这两点我们在经验上发现有助于产生更好的预训练表示。 在训练阶段,首先从所有五个特征尺度中随机选择一个尺度,然后我们在所选尺度上的 Siamese 特征图上进行像素恢复和特征比较。 在预训练阶段之后,我们在各种下游任务上微调 nsUNet 的编码器。
3.1 非跳跃 U-Net 中的特征金字塔
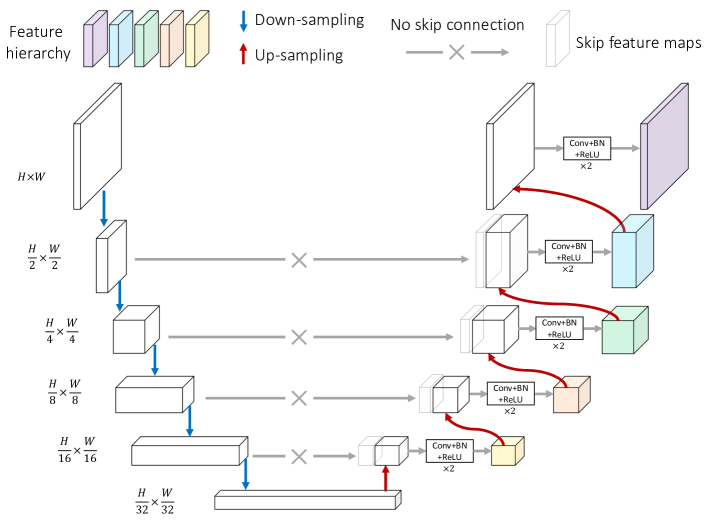
U-Net 及其系列 [32, 11, 22] 以其处理图像分割任务的能力而闻名。 这些模型最显著的特征是跳跃连接,它连接了相同分辨率的低级和高级特征图。 关键的见解是恢复编码器网络的下采样操作(如步幅池化或卷积)中丢失的空间信息。 U 形模型使用特征金字塔,通过跳跃连接将多尺度细节逐步整合到高级语义中,使 U 形架构成为进行上下文恢复的理想选择。
在本文中,我们从两个角度探讨了 U 形架构在 SSL 中的潜力:通过去除跳跃连接来深度融合语义和像素级信息,以及通过在特征金字塔上进行 SSL 来引入多尺度潜在表示。 对于第一个视角,我们通过经验发现,跳跃连接为上下文恢复提供了捷径,因为低级特征图包含丰富的、高分辨率的像素级细节。 这种特性确实有助于上下文恢复。 但是,它可能会阻止高级潜在表示(具有丰富的语义)合并更多像素级信息,因为提供像素级细节的任务被分配给了低级特征图。 为了解决这个问题,我们在 U 形架构中去除了跳跃连接,并提出了非跳跃 U-Net (nsUNet)。 nsUNet 依赖于没有任何跳跃连接的高级表示来恢复像素级细节。 通过这种方式,语义和像素级信息可以深度融合。 同时,nsUNet 的固有多尺度特征图提供了构建特征金字塔的机会,在此基础上可以同时进行多个尺度的 SSL。
图 3 展示了 nsUNet 的架构。 nsUNet 中的特征金字塔包含五个级别,从低分辨率(下采样率为 32)到全分辨率(无下采样)。 对于二维输入数据,我们使用 ResNet-18 [18] 作为编码器,而对于三维输入体积,我们则根据 [11] 构建编码器。 如图 3 所示,nsUNet 的解码器在所有金字塔级别上都保持着共享的架构,可以概括为:
| (1) | ||||
其中 。 表示瓶颈块的输出,该块具有最低的空间分辨率(降采样率 = 32)。 Up 代表上采样操作。 Conv-BN-ReLU 代表一系列操作,包括卷积(内核大小 = 3)、批归一化 (BN) 和 ReLU 激活。 因此,特征图包 随后被转发到以下与任务相关的头,分别和同时执行像素恢复和特征比较。
3.2 多尺度像素恢复
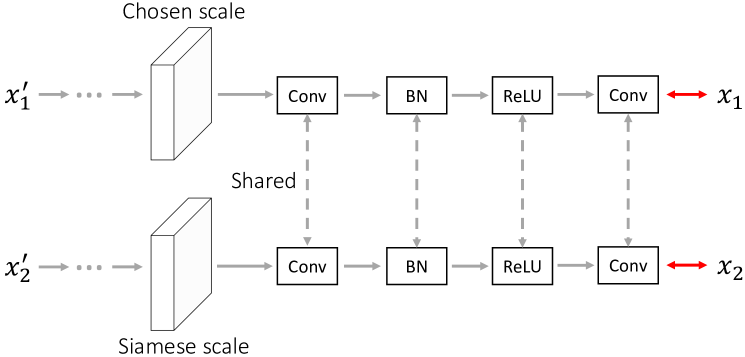
正如其名称所暗示的那样,多尺度像素恢复旨在同时在潜在视觉表示中保留像素级和尺度信息。 为实现这一目标,我们要求网络恢复跨不同尺度的精确像素级细节,其中每对孪生特征图共享一个像素恢复头。 相反,PCRLv1 仅在全分辨率下恢复像素细节,这不可避免地会丢失学习表示中的多尺度属性。
如图 4a 所示,输入图像 和 是通过各种像素级增强(如高斯模糊和随机噪声)有意地被损坏的。 对于每个训练迭代,我们首先从 中随机选择一个特征尺度 。 然后,我们将 传递给 尺度的像素恢复头 ,其内部处理过程可以总结为:
| (2) | ||||
其中所有卷积层使用 3 的内核大小和 2 的步长。 同样,我们将共享的像素恢复头应用于成对的孪生特征图 以获取预测输出 :
| (3) | ||||
最后,我们使用均方误差 (MSE) 损失来衡量 和 之间的重建误差。 对于孪生特征金字塔,我们将 MSE 损失应用于 和 。 每个训练迭代(使用小批量优化)中像素恢复任务的成本函数 如下:
| (4) | ||||
其中 表示每个特征金字塔中的尺度数量。 代表尺度索引。 是一个指示函数,当 == 为真时等于 1(否则为 0)。 的解释可以概括为:(i) 从所有五个尺度中随机选择一个特征尺度 ;(ii) 将 及其孪生特征图 传递到共享任务头 ;(iii) 计算 的输出与未被破坏的图像 之间的 MSE 损失。 通过跨不同特征尺度重建相同的目标 / , 可以将像素级信息编码为多尺度潜在视觉表示。
3.3 多尺度特征比较
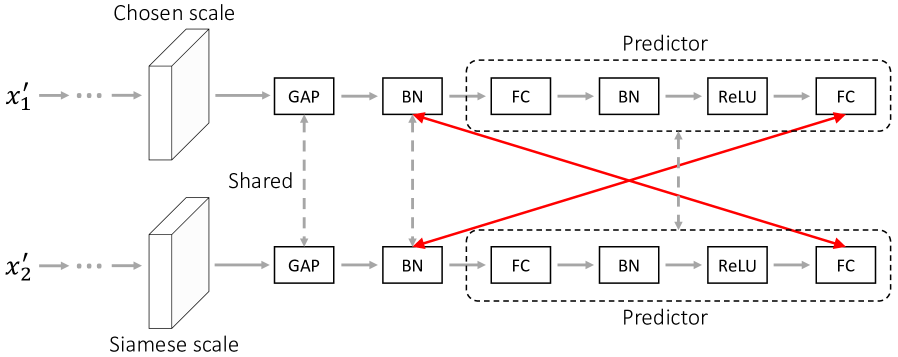
PCRLv1 利用混合方法,借助动量编码器 [17] 和 mixup [43] 来进行对比学习。 然而,这种对比部署很复杂,使 PCRLv1 变得很重,因此难以实施和改进。 为了解决这些问题,PCRLv2 将 PCRLv1 中的混合对比策略替换为多尺度比较。 受 [10] 的启发,多尺度比较使用孪生学习进行 SSL,其关键操作是吸引同一图像的孪生视图。 与 [10] 在一个尺度上进行特征比较不同,我们建议在不同的特征尺度上保留判别语义,这迫使模型保留多尺度自监督表示。 下面,我们提供执行多尺度比较的技术细节。
接下来,我们将 传递到共享预测器 ,其架构如图 4b 所示,可以概括为:
| (6) |
其中 FC 表示全连接层。 FC-BN-ReLU 代表一系列层,即全连接层、批次归一化层和 ReLU 激活。 同样,我们可以通过将传递给相同的预测器来获取。
我们用余弦相似度来测量暹罗特征向量之间的相似度:
| (7) | ||||
其中表示L2归一化。 对称地,我们计算如下:
| (8) | ||||
最后,多尺度特征比较的成本函数可以概括为:
| (9) | ||||
表示特征尺度的数量。 代表尺度索引。 遵循[10],我们在公式9中应用停止梯度操作(表示为sg),以防止网络优化器找到捷径解决方案。
最小化要求模型最大化所有特征尺度上暹罗潜在特征之间的相似度。 通过这种方式,尺度不变性可以隐式地整合到保留的潜在语义中。
3.4 从多裁剪到子裁剪
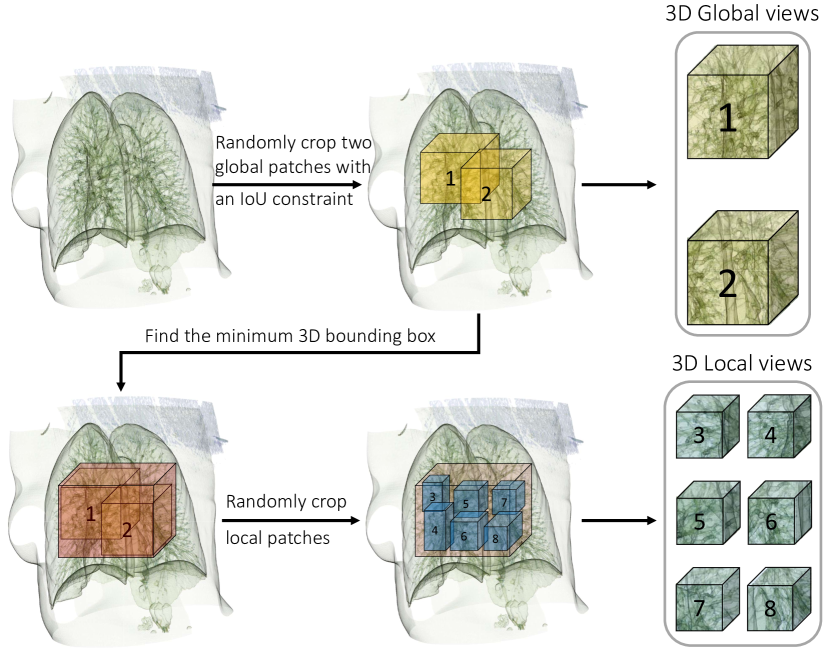
多裁剪 [5] 被认为是提高自然图像中 SSL 性能的有效策略,它通过从原始输入中采样多个标准分辨率裁剪和更多低分辨率裁剪来增加输入视图的数量。 多裁剪背后的一个关键见解是捕获场景或物体各个部分之间的关系,而低分辨率视图则确保计算成本的可控增长。
当应用于医学图像时,多裁剪在二维 X 射线数据中效果良好,但在三维体积数据(如 CT 和 MRI)中会导致模型不收敛。 在仔细调查后,我们发现这个问题的根源在于有限的输入大小和三维空间中众多候选裁剪之间的矛盾。 具体来说,一方面,我们无法负担大型三维输入,因为用三维深度模型处理它们通常会消耗大量的 GPU 内存。 另一方面,如果我们过度缩减三维输入的大小,采样的视图将过于分散,无法保证模型捕获局部-全局关联。
为了缓解上述问题,我们在三维医学图像中引入 子裁剪 来代替多裁剪。 子裁剪 的核心思想很简单:缩减采样空间。 如图 5 所示,子裁剪主要包括三个步骤:(i)随机裁剪两个具有 IoU 约束的扩展全局视图;(ii)在裁剪的全局补丁上找到最小三维边界框;(iii)在三维边界框内随机裁剪多个局部补丁。 子裁剪中有两个关键操作:对全局视图的 IoU 约束和在最小边界框内对局部补丁的采样。 在实践中,第一个操作通过确保大补丁之间的重叠大于固定阈值来保证全局-全局关联。 第二个操作缓解了局部视图的分散问题,并帮助模型发现局部-全局关系。
3.5 总体训练目标
将多裁剪/子裁剪应用于医学图像后,我们可以获得两个全局视图 和 个局部视图 。 为了说明,我们将相关输入用损失函数的符号表示。 例如, 表示我们在两个全局视图的提取的孪生表示之上计算 ,其中 和 可以被视为一对孪生图像。 最后,PCRLv2 的整体训练目标可以形式化如下:
| (10) | ||||
在 中有三个项:、 和 。 第一项旨在保留多尺度学习表示中的像素级细节。 第二项强调了将多尺度语义编码到潜在特征中的重要性。 最后一项旨在捕获多尺度全局-局部语义关系。
3.6 简要讨论:PCRLv2 vs. PCRLv1
更简单。 PCRLv1 通过变换条件注意和跨模型混合将上下文恢复和比较 SSL 结合在一起。 这两个组件使框架笨重,不直观,也不易于实现。 与 PCRLv1 相比,PCRLv2 利用更简单但更直观的設計通过多尺度学习将像素级和语义信息结合在一起。 如前所述,PCRLv2 可以被表述为一个简单的多任务优化问题,其目标函数最大化潜在视觉表示中多级信息的保留。 这些特点使其更易于实现和潜在扩展。
更快。 PCRLv1 在其实现中大量使用混合(对输入和特征),这被发现可以带来性能提升。 在 PCRLv2 中,我们消除了混合策略,并将训练时间缩短了一半。 此外,PCRLv2 在训练阶段需要更少的 GPU 运行内存,这使其在现实世界场景中更加实用。
4 实验
在本节中,我们首先进行彻底的消融研究,以调查 PCRLv2 中不同模块的影响。 然后,我们评估了 PCRLv2 在 2D 和 3D 医学影像任务上的有效性,包括胸部病理分类、肺结节检测、腹部器官分割和脑肿瘤分割。 对于模型评估,我们遵循 预训练(在源数据上)微调(在目标数据上) 协议,并采用两种设置,即半监督学习和迁移学习。 在第一种设置中,源数据和目标数据来自同一个数据集。 具体来说,我们首先使用所有没有标签的训练数据来预训练模型,然后使用有限的标注来微调预训练模型。 至于迁移学习(第二种设置),我们在不同的数据集上预训练和微调模型。 与半监督学习不同,我们在迁移学习中使用有限和完整的标注来微调预训练模型。
4.1 数据集
NIH 胸部 X 光片 (2D) [38] 由来自 30,805 名患者的 112,120 张 X 光片组成。 NIH 胸部 X 光片中存在 14 种不同的胸部病理,包括肺不张、心肌肥大、实变、水肿、积液、肺气肿、纤维化、疝气、浸润、肿块、结节、胸膜增厚、肺炎和气胸。 使用自然语言处理 (NLP) 技术从相关的放射学报告中自动提取射线照片的标签。 我们在实验中使用 NIH 胸部 X 光片进行半监督学习,并在迁移学习中将其视为目标数据集。
CheXpert (2D) [21] 包含来自 65,240 名患者的 224,316 张胸部 X 光片,用于检测 14 种常见的胸部 X 光观察结果:无发现、心脏扩大、心肌肥大、肺不透明、肺病灶、水肿、实变、肺炎、肺不张、气胸、胸膜积液、其他胸膜、骨折和支持设备。 与 NIH 胸部 X 光片类似,开发了一个 NLP 标注器,以自动检测放射学报告中 14 种观察结果的存在。 在实践中,CheXpert 作为迁移学习的源数据。
LUNA (3D) [33] 是为了自动检测肺结节而收集的,其中包含 888 个带标注的胸部计算机断层扫描 (CT) 图像。 LUNA 是 LIDC-IDRI [1] 的一个精心挑选的子集,它排除了切片厚度大于 3 毫米、切片间距不一致或缺少切片的扫描。 在 888 次扫描中,放射科医生总共进行了 5,855 次标注,其中只有 3 毫米的结节被归类为相关病变,并且至少有一名放射科医生检查过每个结节。 在 LUNA 上,我们进行半监督学习和迁移学习实验。 对于迁移学习,LUNA 主要用于自监督预训练。
LiTS (3D) [4] 发布了 131 个腹部 CT 体积及其相关标注,用于训练和验证。 LiTS 中有两种类型的标签:肝脏和肿瘤。 在本文中,我们只利用肝脏的真实地面掩码来评估各种 SSL 算法的有效性。 LiTS 上的任务是腹部器官分割,其中 LiTS 用于迁移学习中的微调。
BraTS (3D) 一直被认为是脑肿瘤分割的一系列挑战。 在本文中,我们对发布的 BraTS 2018 年的 351 个磁共振成像 (MRI) 扫描进行了实验。 BraTS 中有三个类别:整个肿瘤 (WT)、肿瘤核心 (TC) 和增强肿瘤 (ET)。 与 LiTS 的作用类似,BraTS 在迁移学习中充当目标数据。
4.2 基线
我们的广泛实验中包含了各种 SSL 基线,这些基线可以粗略地分为三类:2D 特定方法、3D 特定方法和通用 (2D & 3D) 方法。 以下是每个类别中基线的详细信息。
特定于二维的 SSL 方法 包括基于 ImageNet 的预训练 (IN) [14]、对比学习 (C2L) [48] 和简单孪生学习 (SimSiam) [10]。 IN 是最广泛采用的预训练方法,它在最大的自然图像数据集之一,即 ImageNet [14] 上进行监督式预训练。 C2L 是一种最近提出的基于动量对比 (即 MoCov1 [17] 和 MoCov2 [9]) 的 SSL 方法。 SimSiam 是一种简单的孪生 SSL 框架,它消除了对比学习中负样本的障碍,以及 BYOL [15] 中动量编码器的使用。 此外,我们比较了 PCLRv2 和 SimSiam,以突出显示保留的像素级信息和多尺度特征的重要性。
特定于三维的 SSL 方法 包括魔方++ [35] 和 3D-CPC [34]。 魔方++ 是最新的 SSL 方法,它建立在 3D 医学图像的上下文恢复之上。 它采用了一种体积变换来进行上下文置换。 相比之下,3D-CPC 基于对比预测编码 [19],对比学习的一种变体,并在 [34] 中研究的各种 SSL 方法中表现出最佳性能。
通用 SSL 方法 包括从头训练 (TS)、模型生成 (MG) [49]、TransVW [16] 和 PCRLv1 [47] (我们方法的会议版本)。 MG 采用激进的增强来生成损坏的输入图像,模型需要基于这些图像恢复原始输入。 TransVW 通过追加一个中间分类头来显式编码解剖模式,从而改进了 MG。 PCRLv1 首次提出在 SSL 中同时保留语义和像素级信息。
4.3 实现细节
预训练的数据集预处理。 在 NIH ChestX-ray 和 CheXpert 上,每个输入图像在随机裁剪后被调整大小为 224224。 在 LUNA 上,我们从整个 CT 扫描中随机裁剪一个体积,其大小随机从 {646432, 969664, 969696, 11211264} 中选择。 然后将每个裁剪后的体积调整大小为 646432。 裁剪中每个体素的 Hounsfield 单位 (HU) 被截断为 [-1000,1000]。 如果一个体素的 HU 低于 -150,我们将其视为背景体素。 在实践中,如果裁剪中超过 85% 的体素属于背景,我们不会在预训练中使用这个裁剪。
微调的数据集预处理。 对于 NIH ChestX-ray 和 CheXpert,我们遵循与预训练阶段相同的预处理程序。 在 LUNA 上,我们在每次训练迭代中随机裁剪一个体积,每个裁剪的大小为 484848。 在 LiTS 上,我们首先定位肝脏并在每个轴上将目标体积扩展 30 片。 随机裁剪后,每个裁剪的大小为 25625664。 与 LUNA 不同,我们将每个体素的 HU 截断为 [-200, 200]。 对于 BraTS,每个随机裁剪的大小为 1121121124。
数据增强和多裁剪/子裁剪。 如图 2 所示,增强有两种类型,即全局增强和局部增强。 具体而言,对于二维任务,全局增强包括随机裁剪、随机水平翻转和随机旋转。 局部增强包括随机灰度化、高斯模糊和裁剪。 相比之下,对于 3D 任务,全局增强包括随机翻转和随机仿射。 应用局部增强策略,包括高斯模糊、随机噪声、随机伽马和随机交换。 请注意,所有 3D 增强都是按照[30]实施的。 至于 2D 任务中的多裁剪,我们采用随机裁剪的比例因子222https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html来生成全局和局部视图。 具体来说,我们将比例范围设置为 [0.3, 1] 以生成两个全局视图。 对于六个局部视图,比例范围设置为 [0.05, 0.3]。 全局和局部视图均被调整大小为 224224。 至于 3D 任务中的子裁剪,我们从 {646432, 969664, 969696, 11211264} 中随机抽取两个全局视图。 两个全局视图之间的 IoU 约束(即阈值)为 0.3。 然后,我们找到全局视图的最小边界框,从中随机裁剪出六个局部视图,每个视图的随机大小从 {888, 161616, 323216, 323232} 中选取。 随机裁剪后,所有 3D 全局视图均调整大小为 646432,而所有局部视图均调整大小为 161616。
| Datasets | w/o skip | w/ skip | Gain |
| NIH | 76.6 | 75.4 | 1.2 |
| BraTS | 73.0 | 71.5 | 1.5 |
| LiTS | 79.0 | 77.6 | 1.4 |
训练和评估细节。 我们使用带动量的随机梯度下降 (SGD) 作为默认优化器,其中动量设置为 0.9。 初始学习率为 1e-2,我们采用余弦退火策略进行学习率衰减。 我们将权重衰减设置为 1e-5。 训练轮数为 240。 2D 预训练和微调(在 NIH 胸部 X 光或 CheXpert 上)的批次大小分别为 256 和 512。 至于 3D 预训练,批次大小(在 LUNA 上)为 32。 对于 3D 微调任务,在 LUNA、LiTS 和 BraTS 上的批次大小分别为 32、4 和 4。 在 NIH 胸部 X 光、CheXpert 和 LUNA 上的评估指标是 AUROC(接收者操作特征曲线下面积)。 对于 LiTS 和 BraTS 上的分割任务,我们使用 Dice 相似度作为评估指标。 我们使用整个数据集的 70%、10% 和 20% 来构建训练集、验证集和测试集。 特别地,对于半监督学习,我们通过从整个训练集中删除特定数量的数据来构建预训练集。 同时,其余部分用作微调的训练集。 对于 NIH 胸部 X 光、CheXpert 和 LUNA 的微调,使用二元交叉熵损失,而对于 LiTS 和 BraTS 的微调,使用 Dice 损失。
4.4 消融研究
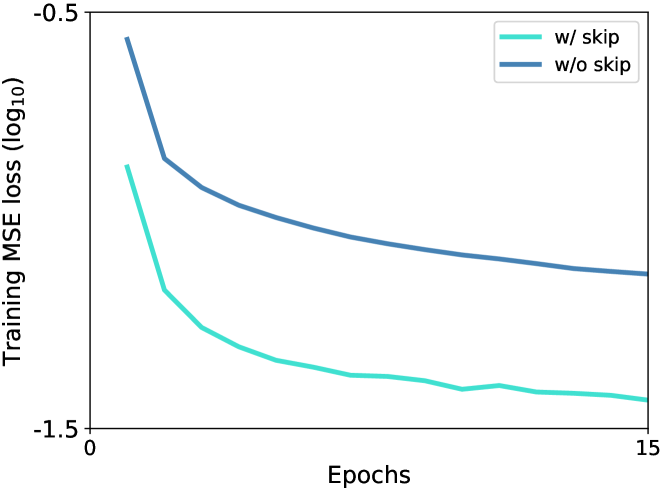
跳跃连接对像素恢复的影响。 在图 6 中,我们展示了训练阶段的均方误差 (MSE) 损失(参见等式 4)曲线。 我们看到,带有跳跃连接的 MSE 损失在前 15 个训练时期内快速下降。 相比之下,提出的 nsUNet(无跳跃)减慢了 MSE 损失的下降速度。 这些现象与跳跃连接的作用一致,跳跃连接弥合了低级像素细节和高级潜在语义之间的差距。 跳跃连接的存在使得通过结合来自低级但高分辨率特征图的像素级细节,更容易恢复像素。 然而,nsUNet 去除了跳跃连接,避免了对上下文恢复的捷径解决方案。 虽然这种设计使得恢复像素更加困难(图 6 中的损失值更高),但它有助于将像素级信息编码为高级语义表示。 表 I 中的性能增益可以验证这种优势,其中去除跳跃连接使胸部病理识别、脑肿瘤分割和腹部器官分割的性能提高了 1% 以上。
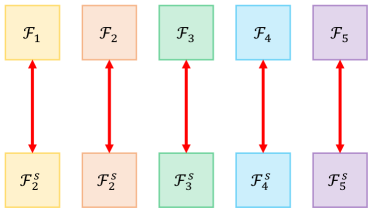
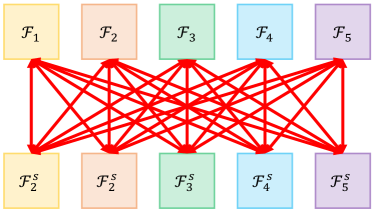
如何对多个特征尺度进行孪生特征比较? 我们在图 7 中说明了两种直观的选项。 除了采用的成对比较方式(图 7a)之外,另一个明显的选项是按照交叉方式比较孪生特征(类似的策略在 [3] 中使用)。 如图 7b 所示,跨尺度比较在所有特征尺度上积极地比较孪生特征。 背后的动机是通过耦合不同尺度上的特征来引入多尺度潜在表示。 表 II 报告了成对和跨尺度 Siamese 特征比较的实验结果。 我们发现跨尺度特征比较使半监督病理识别的性能略微下降了 0.6%。 其根本原因可能是每个尺度的特征都保持着独特的特性,忽略这些差异会导致特征表示退化。
PCRLv2 中不同模块的调查。 在表 III 中,我们研究并报告了不同模块对 BraTS 中的整个肿瘤 (WT) 和增强肿瘤 (ET) 类别的影响。 请注意,在实践中,大多数 WT 实例比 ET 实例大得多,这使得 ET 实例更难以分割。 此外,我们还介绍了在 NIH 胸部 X 光上的迁移学习结果。
| Pairwise | Crossed [3] | Gain | |
| Mean AUROC | 76.6 | 76.0 | 0.6 |
| # | Res. | Comp. | S (3) | S (5) | MC | SC | WT (BraTS) | ET (BraTS) | NIH |
| 0 | ✓ | 74.2 | 64.9 | 78.2 | |||||
| 1 | ✓ | 76.4 | 63.8 | 78.5 | |||||
| 2 | ✓ | ✓ | 76.2 | 64.6 | 80.9 | ||||
| 3 | ✓ | ✓ | ✓ | 76.9 | 66.1 | 81.5 | |||
| 4 | ✓ | ✓ | ✓ | 77.2 | 66.8 | 82.0 | |||
| 5 | ✓ | ✓ | ✓ | ✓ | fail | fail | 82.5 | ||
| 6 | ✓ | ✓ | ✓ | ✓ | 77.7 | 67.2 | 82.7 |
首先,我们分别研究像素恢复(第 0 行)和特征比较(第 1 行)的影响。 对于像素恢复任务,我们直接重建全分辨率的未损坏图像,而孪生特征比较则在编码器的最后一层输出上进行。 比较第 0 行和第 1 行,我们看到上下文恢复任务在分割小肿瘤区域(即 ET)方面更具优势,而比较 SSL 在处理大肿瘤区域(即 WT)和胸部病理方面更有能力。 这种比较表明,语义信息保留可能对大对象的检测更有帮助,而分割小对象则需要结合像素级信息。 在第 2 行,我们已经可以通过直接结合像素恢复和特征比较来获得明显的性能提升。
|
Labeling ratio |
Methodology |
Mean |
Atelectasis |
Cardiomegaly |
Effusion |
Infiltration |
Mass |
Nodule |
Pneumonia |
Pneumothorax |
Consolidation |
Edema |
Emphysema |
Fibrosis |
Pleural Thick. |
Hernia |
| 5% | TS | 61.8 | 58.8 | 72.0 | 68.8 | 51.5 | 63.8 | 49.2 | 57.4 | 67.4 | 61.5 | 71.0 | 62.7 | 58.1 | 60.0 | 63.1 |
| MG [49] | 66.4 | 63.4 | 74.1 | 72.9 | 53.5 | 67.2 | 54.3 | 59.9 | 71.3 | 66.5 | 77.0 | 65.8 | 64.5 | 62.8 | 76.2 | |
| TransVW [16] | 66.5 | 64.2 | 72.9 | 72.2 | 54.8 | 69.4 | 55.7 | 59.6 | 71.0 | 64.8 | 77.4 | 66.6 | 63.6 | 62.8 | 75.6 | |
| C2L [48] | 71.7 | 69.9 | 77.9 | 76.2 | 59.1 | 73.4 | 60.0 | 64.5 | 76.2 | 71.4 | 80.3 | 76.1 | 69.9 | 68.4 | 80.4 | |
| SimSiam [10] | 71.7 | 68.9 | 79.3 | 77.8 | 58.7 | 73.0 | 61.0 | 65.4 | 76.2 | 72.1 | 81.7 | 75.1 | 69.6 | 68.1 | 76.8 | |
| PCRLv1 [47] | 74.1 | 70.1 | 80.3 | 79.3 | 61.8 | 76.8 | 64.6 | 68.6 | 77.2 | 72.8 | 83.7 | 77.4 | 71.3 | 72.7 | 80.8 | |
| PCRLv2 | 76.6 | 75.7 | 81.0 | 80.3 | 64.0 | 76.8 | 68.7 | 70.7 | 83.2 | 77.5 | 87.8 | 79.2 | 72.5 | 73.2 | 81.8 | |
| 10% | TS | 68.1 | 65.8 | 77.6 | 74.4 | 57.1 | 69.4 | 54.8 | 63.0 | 72.9 | 68.3 | 78.8 | 68.2 | 64.3 | 66.4 | 72.5 |
| MG [49] | 70.0 | 67.1 | 78.1 | 76.1 | 57.2 | 72.8 | 57.5 | 63.3 | 75.5 | 70.9 | 79.5 | 68.8 | 67.4 | 68.0 | 77.6 | |
| TransVW [16] | 70.2 | 66.6 | 78.9 | 74.9 | 58.4 | 71.2 | 59.5 | 64.8 | 72.6 | 70.4 | 79.4 | 70.7 | 67.2 | 68.3 | 79.5 | |
| C2L [48] | 74.1 | 72.3 | 81.7 | 79.9 | 60.2 | 74.6 | 62.7 | 67.6 | 78.7 | 73.9 | 83.5 | 78.2 | 72.8 | 69.8 | 81.4 | |
| SimSiam [10] | 74.0 | 71.2 | 81.4 | 78.9 | 60.2 | 75.5 | 63.2 | 67.3 | 78.7 | 73.2 | 83.5 | 77.7 | 72.5 | 71.8 | 80.8 | |
| PCRLv1 [47] | 76.2 | 73.6 | 82.9 | 81.2 | 64.7 | 77.1 | 66.7 | 69.7 | 79.8 | 74.5 | 86.9 | 78.8 | 75.6 | 74.2 | 81.1 | |
| PCRLv2 | 78.2 | 77.2 | 84.3 | 84.4 | 67.4 | 77.5 | 68.9 | 71.6 | 84.4 | 77.8 | 89.0 | 79.3 | 76.1 | 74.0 | 82.4 | |
| 20% | TS | 71.5 | 68.9 | 80.7 | 77.5 | 60.2 | 73.6 | 58.7 | 66.2 | 76.1 | 71.7 | 82.9 | 72.2 | 69.0 | 68.7 | 74.7 |
| MG [49] | 73.9 | 71.9 | 83.0 | 80.0 | 62.3 | 75.2 | 62.2 | 67.5 | 79.0 | 73.3 | 83.6 | 73.4 | 71.0 | 70.6 | 81.4 | |
| TransVW [16] | 74.3 | 71.6 | 82.5 | 80.1 | 62.3 | 76.7 | 62.8 | 69.2 | 78.2 | 73.5 | 83.8 | 75.4 | 72.2 | 71.2 | 80.3 | |
| C2L [48] | 76.4 | 74.2 | 83.9 | 81.7 | 63.8 | 77.3 | 64.7 | 70.3 | 81.5 | 75.5 | 86.0 | 80.2 | 75.2 | 73.4 | 81.8 | |
| SimSiam [10] | 76.5 | 73.8 | 84.0 | 81.4 | 63.2 | 78.2 | 64.7 | 69.6 | 82.1 | 76.2 | 86.4 | 80.7 | 75.0 | 73.9 | 81.7 | |
| PCRLv1 [47] | 78.8 | 75.4 | 86.2 | 83.6 | 65.1 | 79.9 | 69.6 | 72.0 | 82.3 | 79.9 | 88.3 | 82.6 | 76.5 | 75.9 | 81.9 | |
| PCRLv2 | 79.9 | 78.1 | 87.2 | 85.9 | 68.2 | 80.5 | 69.9 | 72.5 | 85.3 | 80.4 | 89.2 | 83.1 | 77.5 | 77.0 | 83.5 | |
| 30% | TS | 73.4 | 70.6 | 81.9 | 79.1 | 61.6 | 75.5 | 60.7 | 68.8 | 78.3 | 72.7 | 84.3 | 74.1 | 70.3 | 70.9 | 78.9 |
| MG [49] | 76.1 | 74.3 | 84.4 | 82.1 | 63.6 | 78.3 | 64.4 | 69.6 | 81.2 | 75.8 | 85.6 | 75.9 | 73.6 | 73.6 | 82.8 | |
| TransVW [16] | 76.7 | 74.9 | 84.1 | 81.9 | 64.9 | 79.0 | 65.3 | 70.9 | 80.3 | 76.2 | 86.5 | 78.6 | 74.5 | 74.2 | 82.1 | |
| C2L [48] | 77.5 | 74.3 | 84.8 | 82.6 | 64.6 | 78.3 | 66.3 | 71.5 | 83.0 | 76.8 | 87.6 | 81.3 | 76.5 | 74.4 | 82.9 | |
| SimSiam [10] | 78.0 | 75.4 | 85.1 | 82.9 | 65.0 | 79.4 | 67.0 | 71.4 | 83.4 | 77.4 | 87.8 | 82.8 | 76.1 | 75.5 | 82.7 | |
| PCRLv1 [47] | 79.0 | 75.5 | 86.6 | 83.8 | 65.9 | 80.7 | 70.2 | 72.8 | 82.9 | 80.4 | 88.9 | 83.3 | 76.6 | 76.5 | 81.9 | |
| PCRLv2 | 81.1 | 78.4 | 87.6 | 86.6 | 69.6 | 82.8 | 72.0 | 74.0 | 86.2 | 81.0 | 89.9 | 84.4 | 79.5 | 79.0 | 84.6 | |
| 40% | TS | 75.4 | 72.6 | 83.6 | 81.5 | 62.9 | 77.3 | 63.3 | 70.1 | 80.3 | 74.9 | 85.5 | 76.4 | 72.5 | 73.0 | 81.8 |
| MG [49] | 77.3 | 75.4 | 86.0 | 83.3 | 65.1 | 79.0 | 65.1 | 70.8 | 82.1 | 77.0 | 87.3 | 76.7 | 74.8 | 74.9 | 83.5 | |
| TransVW [16] | 77.6 | 75.0 | 85.1 | 82.7 | 65.2 | 79.7 | 66.5 | 72.0 | 81.0 | 76.7 | 87.2 | 79.2 | 75.5 | 76.5 | 83.7 | |
| C2L [48] | 79.0 | 76.0 | 86.1 | 84.3 | 66.0 | 80.0 | 67.9 | 72.5 | 84.1 | 78.5 | 88.5 | 83.7 | 77.9 | 76.6 | 83.8 | |
| SimSiam [10] | 79.4 | 76.7 | 86.7 | 84.7 | 67.0 | 80.9 | 69.0 | 73.1 | 84.4 | 78.9 | 88.9 | 83.5 | 77.7 | 76.6 | 83.4 | |
| PCRLv1 [47] | 79.9 | 76.7 | 87.1 | 84.9 | 67.1 | 82.7 | 72.2 | 73.3 | 83.6 | 80.6 | 89.2 | 83.8 | 77.3 | 76.9 | 83.2 | |
| PCRLv2 | 81.5 | 78.7 | 87.8 | 87.0 | 69.8 | 83.2 | 72.5 | 74.7 | 86.3 | 81.2 | 90.2 | 84.9 | 80.0 | 79.4 | 85.0 |
| Methodology | Labeling ratio | |||
| 10% | 20% | 30% | 40% | |
| TS | 78.4 | 83.0 | 85.7 | 87.5 |
| MG [49] | 80.2 | 85.0 | 87.5 | 90.3 |
| TransVW [16] | 79.3 | 84.5 | 87.9 | 90.5 |
| Cube++ [35] | 81.4 | 85.2 | 87.9 | 90.0 |
| 3D-CPC [34] | 80.2 | 85.2 | 88.3 | 90.6 |
| PCRLv1 [47] | 84.4 | 87.5 | 89.8 | 92.2 |
| PCRLv2 | 85.5 | 88.3 | 90.3 | 93.1 |
接下来,我们证明多尺度表示有利于像素恢复和特征比较任务。 通过在 3 个尺度上执行这两个任务,我们观察到 WT 上提高了 0.7%,ET 上提高了 1.5%,以及胸部病理分类提高了 0.6%。 这些结果表明,引入多个尺度对小区域的分割更有帮助。 此外,通过将尺度数量从 3 个增加到 5 个,我们可以持续提高所有三个任务的准确性。 毫不奇怪,ET 从引入多个尺度中获益最多,表明在医学图像分割中利用多尺度表示的必要性。
|
Labeling ratio |
Methodology |
Mean |
Atelectasis |
Cardiomegaly |
Effusion |
Infiltration |
Mass |
Nodule |
Pneumonia |
Pneumothorax |
Consolidation |
Edema |
Emphysema |
Fibrosis |
Pleural Thick. |
Hernia |
| 10% | TS | 68.1 | 67.6 | 63.3 | 76.8 | 57.5 | 71.5 | 61.8 | 64.2 | 76.2 | 69.8 | 80.2 | 72.4 | 62.8 | 68.0 | 61.1 |
| IN [28] | 73.5 | 73.3 | 68.7 | 81.6 | 63.0 | 76.6 | 67.3 | 70.0 | 81.3 | 75.6 | 85.9 | 78.5 | 68.6 | 72.5 | 65.9 | |
| MG [49] | 70.1 | 69.9 | 65.6 | 79.2 | 59.4 | 72.9 | 64.3 | 67.0 | 77.9 | 72.0 | 82.3 | 75.8 | 65.9 | 69.6 | 59.4 | |
| TransVW [16] | 69.7 | 69.4 | 64.3 | 78.2 | 59.5 | 72.6 | 63.1 | 67.2 | 77.2 | 70.9 | 83.0 | 75.3 | 65.8 | 68.9 | 60.2 | |
| C2L [48] | 73.1 | 72.5 | 68.0 | 81.3 | 62.4 | 75.8 | 67.2 | 70.2 | 80.6 | 74.8 | 85.4 | 78.4 | 68.3 | 72.2 | 66.1 | |
| SimSiam [10] | 72.5 | 71.9 | 67.5 | 81.2 | 61.7 | 75.9 | 66.6 | 69.6 | 79.8 | 74.2 | 84.8 | 77.6 | 67.7 | 71.8 | 64.5 | |
| PCRLv1 [47] | 75.8 | 75.4 | 70.6 | 84.2 | 65.5 | 78.9 | 69.6 | 72.7 | 83.5 | 77.6 | 88.5 | 80.8 | 71.3 | 74.8 | 67.6 | |
| PCRLv2 | 77.2 | 76.8 | 72.0 | 85.6 | 66.8 | 80.2 | 71.0 | 74.0 | 84.8 | 78.9 | 89.8 | 82.2 | 72.6 | 76.2 | 69.7 | |
| 20% | TS | 71.4 | 71.8 | 73.1 | 78.4 | 59.6 | 72.5 | 64.5 | 66.6 | 77.7 | 71.7 | 82.0 | 75.5 | 69.8 | 68.9 | 68.2 |
| IN [14] | 76.2 | 75.9 | 78.3 | 82.9 | 64.2 | 77.8 | 68.8 | 70.7 | 83.0 | 76.4 | 87.2 | 80.0 | 75.3 | 73.9 | 73.1 | |
| MG [49] | 73.8 | 73.9 | 75.4 | 80.2 | 61.9 | 74.9 | 66.5 | 68.3 | 80.0 | 74.0 | 85.1 | 78.1 | 72.8 | 71.5 | 71.3 | |
| TransVW [16] | 73.8 | 73.0 | 75.5 | 80.1 | 62.3 | 75.6 | 66.7 | 68.6 | 80.2 | 74.0 | 85.2 | 77.5 | 72.9 | 71.5 | 69.4 | |
| C2L [48] | 77.0 | 76.5 | 78.9 | 83.4 | 65.0 | 78.6 | 69.8 | 71.8 | 83.5 | 77.2 | 88.1 | 80.8 | 76.0 | 74.2 | 73.5 | |
| SimSiam [10] | 76.6 | 76.6 | 78.7 | 83.3 | 64.6 | 77.9 | 69.2 | 71.6 | 83.1 | 76.9 | 87.8 | 80.5 | 75.5 | 73.8 | 73.6 | |
| PCRLv1 [47] | 77.5 | 77.3 | 79.7 | 84.3 | 65.7 | 78.9 | 70.3 | 72.8 | 83.8 | 77.6 | 88.6 | 81.1 | 76.5 | 74.8 | 74.3 | |
| PCRLv2 | 79.4 | 79.0 | 81.3 | 85.9 | 67.3 | 80.8 | 72.1 | 74.0 | 86.0 | 79.4 | 90.3 | 83.1 | 78.4 | 76.7 | 76.6 | |
| 30% | TS | 73.5 | 71.7 | 79.7 | 79.9 | 60.5 | 76.5 | 68.4 | 66.8 | 79.2 | 72.8 | 83.4 | 76.9 | 71.4 | 70.5 | 71.3 |
| IN [14] | 78.5 | 77.2 | 84.6 | 84.3 | 66.2 | 80.8 | 73.0 | 72.3 | 84.0 | 78.0 | 88.5 | 82.0 | 76.8 | 75.3 | 76.0 | |
| MG [49] | 75.6 | 74.1 | 81.8 | 81.0 | 63.3 | 77.9 | 70.1 | 69.0 | 80.9 | 74.8 | 85.4 | 79.7 | 73.6 | 72.6 | 74.2 | |
| TransVW [16] | 75.7 | 74.8 | 81.4 | 81.0 | 63.6 | 77.7 | 69.9 | 69.8 | 80.9 | 75.4 | 86.0 | 79.3 | 73.9 | 72.3 | 73.8 | |
| C2L [48] | 78.6 | 77.1 | 84.5 | 84.5 | 66.1 | 81.1 | 73.0 | 72.5 | 84.0 | 78.1 | 88.3 | 82.1 | 76.8 | 75.5 | 76.8 | |
| SimSiam [10] | 78.3 | 77.0 | 84.4 | 84.1 | 65.7 | 80.7 | 72.7 | 72.2 | 83.9 | 77.9 | 88.1 | 82.1 | 76.6 | 75.2 | 75.6 | |
| PCRLv1 [47] | 79.9 | 78.5 | 85.8 | 85.6 | 67.4 | 82.3 | 74.2 | 73.8 | 85.5 | 79.4 | 89.7 | 83.5 | 78.1 | 76.7 | 78.1 | |
| PCRLv2 | 80.5 | 79.1 | 86.4 | 86.2 | 68.0 | 82.8 | 74.8 | 74.3 | 86.0 | 80.0 | 90.3 | 84.1 | 78.6 | 77.2 | 79.2 | |
| 40% | TS | 75.4 | 72.6 | 80.0 | 81.0 | 62.5 | 76.9 | 69.2 | 68.0 | 80.7 | 74.7 | 85.1 | 79.5 | 74.0 | 71.0 | 79.8 |
| IN [14] | 79.0 | 76.7 | 84.2 | 84.3 | 66.3 | 80.7 | 73.6 | 72.3 | 84.7 | 78.5 | 88.6 | 83.4 | 77.4 | 75.0 | 79.7 | |
| MG [49] | 76.5 | 74.1 | 81.3 | 81.7 | 63.9 | 77.9 | 71.1 | 70.1 | 82.5 | 76.1 | 85.6 | 80.6 | 74.5 | 73.1 | 77.9 | |
| TransVW [16] | 77.3 | 75.2 | 82.4 | 82.4 | 64.4 | 79.0 | 71.4 | 70.5 | 83.2 | 76.7 | 86.6 | 82.0 | 75.8 | 73.6 | 78.4 | |
| C2L [48] | 79.1 | 76.9 | 84.3 | 84.5 | 66.4 | 80.8 | 73.4 | 72.2 | 84.8 | 78.3 | 88.6 | 83.4 | 77.2 | 75.4 | 80.6 | |
| SimSiam [10] | 78.9 | 76.7 | 83.9 | 84.1 | 66.6 | 80.4 | 73.1 | 72.1 | 84.7 | 78.1 | 88.4 | 83.4 | 77.2 | 74.8 | 80.5 | |
| PCRLv1 [47] | 80.8 | 78.5 | 86.0 | 86.2 | 68.2 | 82.4 | 75.2 | 74.0 | 86.6 | 80.2 | 90.2 | 85.1 | 79.0 | 76.9 | 82.1 | |
| PCRLv2 | 81.5 | 79.2 | 86.6 | 86.9 | 68.9 | 83.0 | 75.8 | 74.6 | 87.2 | 80.8 | 90.9 | 85.8 | 79.7 | 77.6 | 83.4 | |
| 50% | TS | 77.5 | 75.2 | 82.0 | 82.0 | 64.5 | 79.6 | 71.8 | 71.3 | 82.9 | 75.8 | 86.6 | 80.9 | 76.1 | 75.5 | 80.3 |
| IN | 79.5 | 77.2 | 84.5 | 84.4 | 66.6 | 81.4 | 73.6 | 73.0 | 84.6 | 78.2 | 89.1 | 82.7 | 77.9 | 77.3 | 82.0 | |
| MG [49] | 77.6 | 75.0 | 82.8 | 82.8 | 64.8 | 79.5 | 71.8 | 71.6 | 82.3 | 75.7 | 86.7 | 81.5 | 76.2 | 75.7 | 79.5 | |
| TransVW [16] | 77.3 | 74.5 | 81.9 | 82.4 | 64.8 | 78.8 | 71.5 | 71.3 | 82.4 | 75.7 | 86.8 | 80.4 | 75.7 | 74.9 | 80.6 | |
| C2L [48] | 79.8 | 77.6 | 84.7 | 84.5 | 67.0 | 81.6 | 73.6 | 73.4 | 84.7 | 78.5 | 89.0 | 83.1 | 78.4 | 78.0 | 82.6 | |
| SimSiam [10] | 80.0 | 77.7 | 84.9 | 84.8 | 67.1 | 81.7 | 74.0 | 73.5 | 84.7 | 78.3 | 89.5 | 83.6 | 78.8 | 77.7 | 83.2 | |
| PCRLv1 [47] | 81.2 | 78.7 | 86.1 | 86.3 | 68.3 | 82.8 | 75.4 | 74.5 | 86.8 | 80.4 | 90.5 | 85.3 | 79.5 | 78.2 | 83.5 | |
| PCRLv2 | 82.5 | 80.0 | 87.4 | 87.3 | 69.6 | 84.1 | 76.4 | 76.1 | 87.4 | 81.0 | 91.8 | 85.9 | 81.0 | 80.4 | 86.1 | |
| 100% | TS | 80.9 | 77.7 | 86.1 | 85.1 | 67.7 | 84.2 | 73.3 | 73.9 | 84.9 | 78.7 | 89.4 | 85.4 | 79.4 | 78.5 | 87.6 |
| IN | 80.8 | 77.8 | 86.3 | 84.7 | 67.3 | 83.6 | 73.0 | 74.1 | 84.9 | 78.8 | 89.5 | 85.7 | 79.6 | 78.2 | 87.0 | |
| MG [49] | 80.8 | 77.8 | 86.3 | 84.7 | 67.3 | 83.6 | 73.0 | 74.1 | 84.9 | 78.8 | 89.5 | 85.7 | 79.6 | 78.2 | 87.0 | |
| TransVW [16] | 81.2 | 77.9 | 86.4 | 85.3 | 67.6 | 84.3 | 73.8 | 74.4 | 85.1 | 79.3 | 89.8 | 86.2 | 80.0 | 78.6 | 88.8 | |
| C2L [48] | 81.4 | 78.2 | 87.0 | 85.3 | 68.3 | 84.8 | 73.7 | 74.8 | 85.5 | 79.6 | 90.1 | 86.3 | 80.0 | 78.6 | 88.1 | |
| SimSiam [10] | 81.6 | 78.3 | 87.2 | 85.5 | 68.3 | 84.9 | 74.2 | 74.7 | 85.7 | 79.6 | 90.1 | 86.2 | 80.2 | 79.1 | 89.1 | |
| PCRLv1 [47] | 83.0 | 79.8 | 88.5 | 87.1 | 69.7 | 86.1 | 75.6 | 76.1 | 87.0 | 81.2 | 91.6 | 87.7 | 81.7 | 80.4 | 90.2 | |
| PCRLv2 | 84.0 | 80.7 | 89.3 | 87.9 | 70.5 | 87.0 | 76.4 | 77.0 | 87.9 | 82.0 | 92.5 | 88.6 | 82.6 | 81.3 | 91.6 |
最后但并非最不重要,我们调查了多裁剪(第 4 行)和子裁剪(第 5 行)的意义。 我们通过实验证明,直接将多裁剪应用于 3D 医学体积会导致模型训练失败。 潜在的原因可能是,在 3D 空间中,裁剪后的全局和局部视图很难像在 2D 空间中那样保持清晰的空间关系。 相反,子裁剪可以通过成功地保留潜在表示中的空间关系,在两种类型的肿瘤区域上提供一致的性能提升。 当将子裁剪应用于 2D X 光片时,我们观察到比多裁剪略有改善。 潜在的原因是,子裁剪被提出来处理 3D 空间中分散的采样视图,以确保模型捕捉到局部-全局关系。 然而,在 2D 空间中,采样视图通常(部分地)重叠。
4.5 半监督胸部病理识别
从表 IV 可以看出,与从头开始训练(TS)相比,自监督预训练可以显著提高性能,这验证了在医学影像中进行预训练的必要性。 将 MG 与 TransVW 进行比较,它们在不同的标记比率中显示出类似的性能。 这种比较很容易解释,因为 TransVW 是建立在 MG 之上的,并且两者都是基于上下文恢复的。 TransVW 性能略优于 MG,因为它包含了一个额外的分类头来编码更多的语义。 与基于上下文恢复的方法相比,对比方法(C2L 和 SimSiam)显示出更好的整体和类别特定结果,特别是在较小的标记比率下。 胸部病理检测中,语义信息可能比像素级信息更重要。 至于 C2L 和 SimSiam,当标记数据量非常有限时,C2L 的表现更好。 但是,随着标记比例的增加,SimSiam 逐渐产生更好的诊断结果。
通过将语义、像素级和尺度信息整合到一个统一的框架中,PCRLv2 在不同的标记比例下显著优于各种 SSL 基线。 它明显优于之前的会议版本,即 PCRLv1。 尤其是在标记比例较小时,PCRLv2 似乎更有优势。 例如,当标记比例为 5% 时,PCRLv2 的平均性能比 PCRLv1 高出 2.5%,这验证了多尺度潜在表示的重要性。
| Methodology | 10% | 20% | 30% | 40% | 100% | |||||||||||||||
| Mean | WT | TC | ET | Mean | WT | TC | ET | Mean | WT | TC | ET | Mean | WT | TC | ET | Mean | WT | TC | ET | |
| TS | 66.6 | 71.2 | 66.7 | 62.1 | 72.7 | 78.5 | 74.3 | 65.5 | 76.7 | 81.8 | 77.9 | 70.6 | 77.1 | 82.3 | 78.3 | 70.9 | 81.5 | 86.8 | 82.8 | 75.1 |
| MG [49] | 69.6 | 72.4 | 71.4 | 65.1 | 75.5 | 80.4 | 77.3 | 68.9 | 79.6 | 84.2 | 80.6 | 74.1 | 80.4 | 85.3 | 82.0 | 74.0 | 82.4 | 87.1 | 83.6 | 76.6 |
| TransVW [16] | 70.3 | 74.6 | 71.7 | 64.6 | 75.6 | 79.9 | 75.4 | 71.5 | 79.1 | 83.8 | 79.9 | 73.6 | 80.8 | 85.8 | 82.1 | 74.5 | 82.3 | 87.1 | 83.3 | 76.5 |
| Cube++ [35] | 69.0 | 74.5 | 70.6 | 61.9 | 74.9 | 80.7 | 75.9 | 68.1 | 79.3 | 84.0 | 79.4 | 74.5 | 79.7 | 84.5 | 80.0 | 74.6 | 82.2 | 87.2 | 82.4 | 77.0 |
| 3D-CPC [34] | 70.1 | 76.7 | 70.5 | 63.1 | 75.9 | 81.6 | 75.6 | 70.5 | 79.4 | 84.6 | 79.9 | 73.7 | 81.2 | 86.5 | 81.8 | 75.3 | 82.9 | 88.0 | 83.3 | 77.4 |
| PCRLv1 [47] | 71.6 | 76.9 | 73.1 | 65.2 | 77.6 | 81.4 | 79.1 | 72.7 | 81.1 | 84.9 | 82.2 | 76.6 | 83.3 | 87.5 | 84.6 | 78.2 | 85.0 | 89.0 | 86.2 | 80.2 |
| PCRLv2 | 73.0 | 77.7 | 74.3 | 67.2 | 78.8 | 83.2 | 79.4 | 74.0 | 82.1 | 85.1 | 82.7 | 78.7 | 84.1 | 87.9 | 84.5 | 80.1 | 85.6 | 89.4 | 85.9 | 81.7 |
| Methodology | Labeling ratio | ||||
| 10% | 20% | 30% | 40% | 100% | |
| TS | 71.1 | 77.2 | 84.1 | 87.3 | 90.7 |
| MG [49] | 73.3 | 79.5 | 84.3 | 87.9 | 91.3 |
| TransVW [16] | 73.8 | 79.3 | 85.5 | 88.2 | 91.4 |
| Cube++ [35] | 74.2 | 79.3 | 84.5 | 88.2 | 91.8 |
| 3D-CPC [34] | 74.8 | 80.2 | 85.6 | 88.9 | 91.9 |
| PCRLv1 [47] | 77.3 | 83.5 | 87.8 | 90.1 | 93.7 |
| PCRLv2 | 79.0 | 86.5 | 89.3 | 90.9 | 94.5 |
4.6 半监督肺结节检测
在表 V中,我们报告了半监督肺结节检测的实验结果。 值得注意的是,我们观察到 TS 和 SSL 基线之间的性能差距比表 IV中报告的差距更小。 一个可能的解释是,检测肺结节的任务对标记数据的数量不太敏感。 在所有 SSL 基线中,Cube++ 在使用少量标记数据时表现出更好的性能,而 3D-CPC 在较大的标记比例中更具优势。 此外,我们看到 TransVW 随着标记比例的增加,快速赶上 MG 和 Cube++。
PCRLv1 在不同的标记比例下,以较大优势优于之前的 SSL 方法。 在合并多尺度潜在表示后,PCRLv2 在一系列标记比例中始终优于 PCRLv1。 当基线 SSL 方法随着标记比例的增加表现出相似的性能时,PCRLv2 仍然可以提供比 PCRLv1 和以前的 SSL 方法更令人印象深刻的改进。
4.7 胸部病理识别中的迁移学习
在表 VI中,我们验证了不同预训练方法提供的视觉表示的可迁移能力。 具体来说,我们将 PCRLv2 与从头开始训练、基于 ImageNet 的预训练 (IN)、不同的 SSL 基线和 PCRLv1 进行比较。
将 MG/TransVW 与 IN 进行比较,我们看到基于上下文恢复的 SSL 保持了有限的可迁移能力。 当目标域只有很少的标注时,这种现象变得更加明显。 根本原因是语义信息在迁移学习中起着至关重要的作用。 相反,C2L 和 SimSiam 带来的显著性能提升再次验证了对比 SSL 的有效性。 C2L 和 SimSiam 仍然无法显著超越 IN,尤其是在标注率为 10% 时,IN 更具优势。
通过整合基于上下文恢复和对比 SSL 的优点,PCRLv1 已经能够显著超越之前的 SSL 方法。 此外,通过利用多尺度语义和像素级信息,PCRLv2 在不同标注率下的整体和特定类别结果方面,都比 PCRLv1 取得了持续的改进。
4.8 脑肿瘤分割的迁移学习
我们在表 VII 中报告了将迁移学习应用于脑肿瘤分割的实验结果,其中我们使用 LUNA 数据集进行自监督预训练,并使用不同数量的标记数据对预训练模型进行微调。
4.9 肝脏分割的迁移学习
4.10 视觉分析
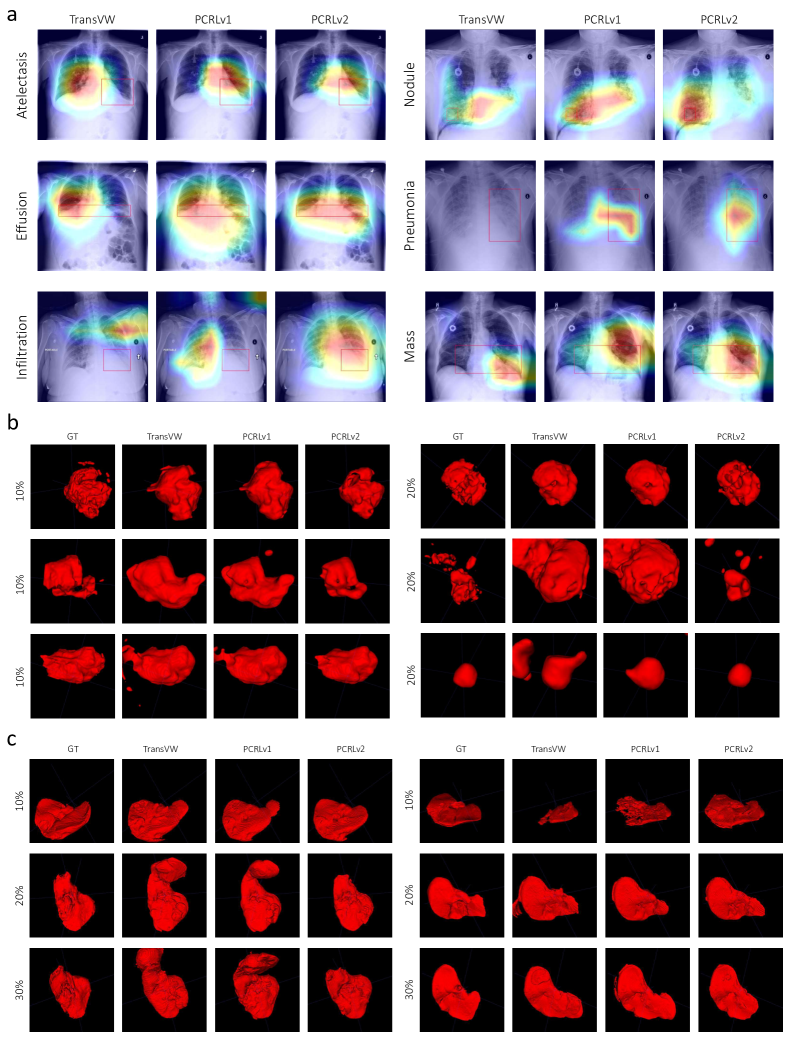
图 8 视觉分析了在胸部病理识别 (10%)、脑肿瘤分割 (10% 和 20%) 和肝脏分割 (10%,20% 和 30%) 上使用有限标注进行迁移学习的实验结果。 在这里,我们将 PCRLv2 与通用 SSL 方法进行比较。 考虑到 TransVW 是在 MG 之上开发的,我们排除了 MG,并将 PCRLv2 与 PCRLv1 和 TransVW 进行比较。
图 8a 展示了使用 CAM [45] 对六种不同病理进行胸部病理诊断的视觉解释。 我们发现 TransVW 无法准确地捕捉到肺不张、浸润、结节和肺炎病灶的正确位置。 相比之下,PCRLv1 可以生成更可解释的诊断结果,但仍然在浸润和结节方面产生不一致的预测。 通过整合多尺度潜在表征,PCRLv2 可以捕捉到浸润和结节上的小病灶区域,从而得到集中且准确的诊断结果。
在图 8b 和图 8c 中,我们可视化了 BraTS 上增强型肿瘤 (ET) 和 LiTS 上肝脏的分割结果。 与 TransVW 和 PCRLv1 相比,PCRLv2 减少了误报预测,并包含更丰富的细粒度细节。 我们认为 PCRLv2 的优越性可以归因于多尺度像素级和语义信息的整合。
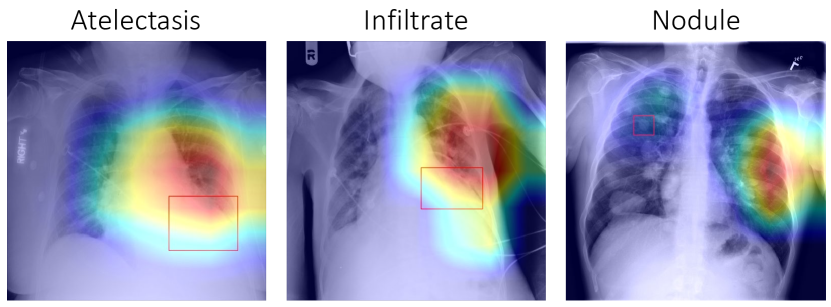
我们还在图 9 中提供了一些失败的示例。 这些检测结果的一个共同特征是它们包含了肺部区域之外的高置信度预测。 然而,在日常临床实践中,这种异常不应该位于肺部区域之外。 类似的现象已在 [13] 中报道,作者将它们总结为在基于神经网络的学习系统中常见的“捷径”。 为了缓解自监督学习中的这个问题,我们可以将常识知识添加到预训练模型中。 此外,还需要开发更强大的机器学习工具来解释各种下游任务中的模型。
5 结论
我们提出了一个统一的视觉信息保留框架,用于医学影像的自监督学习。 该框架旨在将像素级、语义和尺度信息同时编码到潜在表征中。 为了实现这一目标,我们在非跳跃 U-Net 支持的特征金字塔上进行多尺度像素恢复和特征比较。 提出的 PCRLv2 在四个公认的数据集上,无论是定量还是定性验证,都以大幅优势超越了之前的自监督预训练方法,并在其会议版本 (PCRLv1) 上取得了一致的改进。 我们将继续探索如何在未来将不同类型的信息最佳地整合到 SSL 中。
参考文献
- [1] Samuel G Armato III, Geoffrey McLennan, Luc Bidaut, Michael F McNitt-Gray, Charles R Meyer, Anthony P Reeves, Binsheng Zhao, Denise R Aberle, Claudia I Henschke, Eric A Hoffman, et al. The lung image database consortium (lidc) and image database resource initiative (idri): a completed reference database of lung nodules on ct scans. Medical Physics, 38(2):915–931, 2011.
- [2] Shekoofeh Azizi, Basil Mustafa, Fiona Ryan, Zachary Beaver, Jan Freyberg, Jonathan Deaton, Aaron Loh, Alan Karthikesalingam, Simon Kornblith, Ting Chen, et al. Big self-supervised models advance medical image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3478–3488, 2021.
- [3] Philip Bachman, R Devon Hjelm, and William Buchwalter. Learning representations by maximizing mutual information across views. Advances in neural information processing systems, 32, 2019.
- [4] Patrick Bilic, Patrick Ferdinand Christ, Eugene Vorontsov, Grzegorz Chlebus, Hao Chen, Qi Dou, Chi-Wing Fu, Xiao Han, Pheng-Ann Heng, Jürgen Hesser, et al. The liver tumor segmentation benchmark (lits). arXiv preprint arXiv:1901.04056, 2019.
- [5] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. Advances in Neural Information Processing Systems, 33:9912–9924, 2020.
- [6] Krishna Chaitanya, Ertunc Erdil, Neerav Karani, and Ender Konukoglu. Contrastive learning of global and local features for medical image segmentation with limited annotations. Advances in Neural Information Processing Systems, 33:12546–12558, 2020.
- [7] Liang Chen, Paul Bentley, Kensaku Mori, Kazunari Misawa, Michitaka Fujiwara, and Daniel Rueckert. Self-supervised learning for medical image analysis using image context restoration. Medical Image Analysis, 58:101539, 2019.
- [8] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International Conference on Machine Learning, pages 1597–1607. PMLR, 2020.
- [9] Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297, 2020.
- [10] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15750–15758, 2021.
- [11] Özgün Çiçek, Ahmed Abdulkadir, Soeren S Lienkamp, Thomas Brox, and Olaf Ronneberger. 3d u-net: learning dense volumetric segmentation from sparse annotation. In International Conference on Medical Image Computing and Computer-assisted Intervention, pages 424–432. Springer, 2016.
- [12] Navneet Dalal and Bill Triggs. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, volume 1, pages 886–893, 2005.
- [13] Alex J DeGrave, Joseph D Janizek, and Su-In Lee. Ai for radiographic covid-19 detection selects shortcuts over signal. Nature Machine Intelligence, 3(7):610–619, 2021.
- [14] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009.
- [15] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning. Advances in Neural Information Processing Systems, 33:21271–21284, 2020.
- [16] Fatemeh Haghighi, Mohammad Reza Hosseinzadeh Taher, Zongwei Zhou, Michael B Gotway, and Jianming Liang. Transferable visual words: Exploiting the semantics of anatomical patterns for self-supervised learning. IEEE Transactions on Medical Imaging, 40(10):2857–2868, 2021.
- [17] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9729–9738, 2020.
- [18] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016.
- [19] Olivier Henaff. Data-efficient image recognition with contrastive predictive coding. In International Conference on Machine Learning, pages 4182–4192. PMLR, 2020.
- [20] R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual information estimation and maximization. In International Conference on Learning Representations, 2018.
- [21] Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. CheXpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 590–597, 2019.
- [22] Fabian Isensee, Paul F Jaeger, Simon AA Kohl, Jens Petersen, and Klaus H Maier-Hein. nnu-net: a self-configuring method for deep learning-based biomedical image segmentation. Nature Methods, 18(2):203–211, 2021.
- [23] Gustav Larsson, Michael Maire, and Gregory Shakhnarovich. Learning representations for automatic colorization. In European Conference on Computer Vision, pages 577–593. Springer, 2016.
- [24] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2117–2125, 2017.
- [25] Fengze Liu, Ke Yan, Adam P Harrison, Dazhou Guo, Le Lu, Alan L Yuille, Lingyun Huang, Guotong Xie, Jing Xiao, Xianghua Ye, et al. SAME: Deformable image registration based on self-supervised anatomical embeddings. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 87–97. Springer, 2021.
- [26] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3431–3440, 2015.
- [27] David G Lowe. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 60(2):91–110, 2004.
- [28] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- [29] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A Efros. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2536–2544, 2016.
- [30] Fernando Pérez-García, Rachel Sparks, and Sebastien Ourselin. Torchio: a python library for efficient loading, preprocessing, augmentation and patch-based sampling of medical images in deep learning. Computer Methods and Programs in Biomedicine, 208:106236, 2021.
- [31] Bart M Haar Romeny. Front-end vision and multi-scale image analysis: multi-scale computer vision theory and applications, written in mathematica, volume 27. Springer Science & Business Media, 2008.
- [32] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer, 2015.
- [33] Arnaud Arindra Adiyoso Setio, Alberto Traverso, Thomas De Bel, Moira SN Berens, Cas Van Den Bogaard, Piergiorgio Cerello, Hao Chen, Qi Dou, Maria Evelina Fantacci, Bram Geurts, et al. Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: the luna16 challenge. Medical Image Analysis, 42:1–13, 2017.
- [34] Aiham Taleb, Winfried Loetzsch, Noel Danz, Julius Severin, Thomas Gaertner, Benjamin Bergner, and Christoph Lippert. 3D self-supervised methods for medical imaging. Advances in Neural Information Processing Systems, 33:18158–18172, 2020.
- [35] Xing Tao, Yuexiang Li, Wenhui Zhou, Kai Ma, and Yefeng Zheng. Revisiting rubik’s cube: self-supervised learning with volume-wise transformation for 3d medical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 238–248. Springer, 2020.
- [36] Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive multiview coding. In European Conference on Computer Vision, pages 776–794. Springer, 2020.
- [37] Yen Nhi Truong Vu, Richard Wang, Niranjan Balachandar, Can Liu, Andrew Y Ng, and Pranav Rajpurkar. Medaug: Contrastive learning leveraging patient metadata improves representations for chest x-ray interpretation. In Machine Learning for Healthcare Conference, pages 755–769. PMLR, 2021.
- [38] Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M Summers. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2097–2106, 2017.
- [39] Songfan Yang and Deva Ramanan. Multi-scale recognition with dag-cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1215–1223, 2015.
- [40] Chenyu You, Ruihan Zhao, Lawrence Staib, and James S Duncan. Momentum contrastive voxel-wise representation learning for semi-supervised volumetric medical image segmentation. arXiv preprint arXiv:2105.07059, 2021.
- [41] Chenyu You, Yuan Zhou, Ruihan Zhao, Lawrence Staib, and James S Duncan. Simcvd: Simple contrastive voxel-wise representation distillation for semi-supervised medical image segmentation. IEEE Transactions on Medical Imaging, 2022.
- [42] Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and Stéphane Deny. Barlow twins: Self-supervised learning via redundancy reduction. In International Conference on Machine Learning, pages 12310–12320. PMLR, 2021.
- [43] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. Mixup: Beyond empirical risk minimization. International Conference on Learning Representations, 2017.
- [44] Richard Zhang, Phillip Isola, and Alexei A Efros. Split-brain autoencoders: Unsupervised learning by cross-channel prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1058–1067, 2017.
- [45] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discriminative localization. In IEEE Conference on Computer Vision and Pattern Recognition, pages 2921–2929, 2016.
- [46] Hong-Yu Zhou, Hualuo Liu, Shilei Cao, Dong Wei, Chixiang Lu, Yizhou Yu, Kai Ma, and Yefeng Zheng. Generalized organ segmentation by imitating one-shot reasoning using anatomical correlation. In International Conference on Information Processing in Medical Imaging, pages 452–464. Springer, 2021.
- [47] Hong-Yu Zhou, Chixiang Lu, Sibei Yang, Xiaoguang Han, and Yizhou Yu. Preservational learning improves self-supervised medical image models by reconstructing diverse contexts. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3499–3509, 2021.
- [48] Hong-Yu Zhou, Shuang Yu, Cheng Bian, Yifan Hu, Kai Ma, and Yefeng Zheng. Comparing to learn: Surpassing imagenet pretraining on radiographs by comparing image representations. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 398–407. Springer, 2020.
- [49] Zongwei Zhou, Vatsal Sodha, Jiaxuan Pang, Michael B Gotway, and Jianming Liang. Models genesis. Medical Image Analysis, 67:101840, 2021.