安全语义通信:基础知识和挑战
摘要
语义通信允许接收者了解意图而不是比特信息本身,这是一种支持未来无线通信实时人机和机器对机器交互的新兴技术。 在语义通信中,发送方和接收方共享一些公共知识,这些知识可用于在发送方提取小尺寸信息并在接收方恢复原始信息。 由于设计目的不同,语义通信中的安全问题与标准的按位通信相比有两个独特的特征。 首先,语义通信中的攻击者不仅要考虑被盗数据的数量,还要考虑被盗数据的含义。 其次,语义通信系统中的攻击者不仅可以攻击标准通信系统中进行的语义信息传输,还可以攻击用于语义信息提取的机器学习(ML)模型,因为大多数语义信息是使用基于ML的方法生成的。 由于这些独特的特征,在本文中,我们概述了安全语义通信设计的基本原理和主要挑战。 我们首先提供各种方法来定义和提取语义信息。 然后,我们重点关注两个领域的安全语义通信技术:信息安全和语义ML模型安全。 对于每个领域,我们都确定了主要问题和挑战。 然后,我们将对这些问题进行综合处理。 简而言之,本文提供了一套关于如何在现实世界无线通信网络上设计安全语义通信系统的整体指南。
索引术语:
安全语义通信、信息安全、语义 ML 模型安全。我简介
智能手机处理器的发展使边缘设备(即手机)能够生成和处理大规模图像、视频和沉浸式扩展现实数据,这将显着增加网络拥塞[1]。 因此,有必要设计新颖的通信技术来支持如此大的数据量的数据传输和处理。 当前的研究[1]研究了利用机器学习(ML)工具,体现智能表面(RIS)、毫米波(mmWave)和边缘计算来提高网络性能。 然而,利用这些技术的网络性能将受到香农容量的限制,因为大多数这些技术都试图最大化边缘设备的数据速率,以达到香农容量限制[2] 。 因此,有必要设计新颖的通信技术,进一步提高网络性能,超越香农容量限制。
语义通信技术是克服香农容量限制的一种有前途的方法,它使得边缘设备能够提取大尺寸数据的含义,以下称为语义信息,并且仅将语义信息传输到接收器,而不是传输整个数据[3]。 因此,与当前仅关注设备数据速率最大化的工作相比,语义通信的目的不仅是最大化每个设备的数据速率,而且是最大化传输数据可以承载的含义。 由于语义通信仍处于起步阶段,它面临着语义信息定义、语义信息提取、语义通信测量、安全问题和弹性等诸多挑战。
最近,[3,4,5,6]中出现了一些与语义通信相关的调查和教程。 特别是,[3,4,5]中的作者提供了关于使用信息论进行语义信息表示和语义通信度量设计的综合教程。 [6]中的作者介绍了一种基于边缘智能的语义通信框架,并提出了其实现挑战。 然而,这些现有的调查和教程[3,4,5,6]都没有引入语义通信中的安全问题。 与标准通信系统中只考虑被盗数据量的攻击者相比,语义通信中的攻击者有两个独特的特征。 首先,语义通信中的攻击者不仅要考虑被盗数据的数量,还要考虑被盗数据的含义。 例如,如果攻击者窃取了用户的大量数据,但没有从窃取的数据中获取目标内容/含义,我们就会认为攻击者没有成功攻击用户。 其次,语义通信系统中的攻击者不仅可以像标准通信系统中那样攻击语义信息传输,还可以攻击用于语义信息提取的ML模型,因为大多数语义信息是使用基于ML的方法生成的。 由于语义通信中攻击者的这些独特特征,有必要介绍实现安全语义通信的基础知识和挑战。
在本文中,我们介绍了设计安全语义通信系统的基础知识、解决方案和挑战。 在此背景下,我们首先介绍基本的语义通信过程。 然后,我们概述了定义语义信息的四种方法:a)自动编码器,b)信息瓶颈(IB),c)知识图,d)概率图,并总结了它们的优点,缺点和应用。 然后我们介绍攻击者如何攻击语义信息传输和提取,并从信息安全和机器学习安全的角度解释防御这些攻击的方法。
II 语义通信基础
在本节中,我们首先介绍语义通信的过程。 然后,我们介绍四种对从原始数据中提取的语义信息进行建模的方法,并解释它们的差异、优点、缺点和应用。
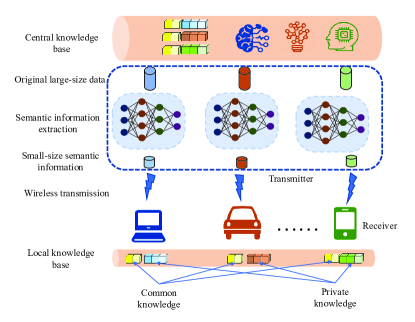
II-A 语义沟通过程
整个语义沟通过程主要包括三个阶段。 第一阶段,发送端基于中心知识库,利用机器学习工具从原始大数据中提取小数据语义信息,如图1所示。 然后,在第二阶段通过无线链路传输语义信息。 在第三阶段,接收者基于自己的本地知识库(包括公共知识和私有知识)恢复语义信息背后的预期含义。
II-B 语义信息构建
II-B1 自动编码器
语义通信传输语义消息,这些消息是指从“含义”底层源学习到的一系列格式良好的符号。 相应地,接收者的目标是充分理解编码语义符号的“含义”。 因此,有效地提取源的语义,同时忽略冗余信息,在语义通信中起着关键作用。 由于强大的表示和学习能力,神经网络通常用于从源中提取语义。 特别地,自动编码器是一种用于学习高维数据的有效表示的神经网络,它可以提取最重要的信息,因此特别适合语义通信。 特别地,自动编码器由编码器和解码器组成。 与源数据相比,编码器输出的编码符号的维度要少得多,因为它只保留关键信息,而丢弃数据的无关紧要部分。 然后,解码器用于从低维符号中恢复原始数据。
使用自动编码器提取语义信息具有以下优点。 首先,自动编码器可以基于卷积神经网络、Transformer、全连接神经网络等各种类型的神经网络来实现。 因此,它适用于文本、图像、视频和多模态数据等不同源数据的语义通信。 此外,由于编码器的输出维度少得多,因此可以显着提高语义通信的传输效率。 此外,自动编码器可以以自我监督的方式进行训练。 然而,自动编码器也存在一些关键挑战。 特别是,尽管自动编码器生成的编码可以被机器有效理解,但对于人类来说却难以理解,这似乎在某种程度上与语义通信的原理相矛盾。 表I总结了使用自动编码器对语义信息进行建模的优点、缺点和应用。
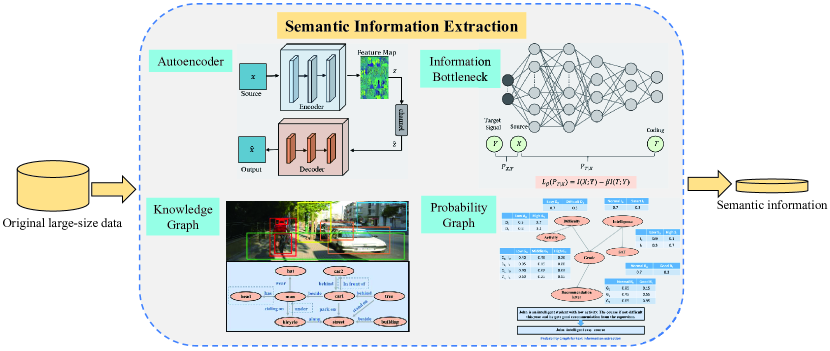
II-B2 信息瓶颈
由于语义通信的目的只是保留语义,因此语义通信的本质是有损压缩问题。 为了解决此类问题,Claude Shannon 提出了基础理论,即率失真理论,解决了压缩与保真度之间的最优权衡[7]。 特别是,速率失真理论旨在最小化给定失真下所需的训练速率,这可以用来指导语义通信系统的过程。 然而率失真理论的一个问题是它需要提前选择一个特定的失真函数,这将进一步确定提取的语义。 然而,畸变函数的选择不是理论的一部分。
针对这一问题,从信息论的角度提出了信息瓶颈(IB)原理,它可以看作是率失真理论[8]的推广。 一方面,IB原理中的失真是通过编码的语义符号和目标变量之间的互信息来衡量的。 在语义通信中,目标变量随着应用的不同而变化。 例如,对于图像分类任务,目标变量是源图像的标签,因为我们试图正确地对源图像进行分类。 另一方面,IB原理中的速率通过源和编码符号之间的互信息来表征,其指示编码符号用于表示源的比特数。
IB 的优点在于它提供了在给定失真下最小化速率的特定理论界限。 然而,在实践中,信息位的联合分布和边缘分布很难获得,因此原始IB不能直接用于指导语义通信的训练过程。 表I总结了使用信息瓶颈来建模语义信息的优点、缺点和应用。
II-B3 知识图谱
由于自动编码器的输出所表示的语义信息对于人类来说是不可理解的,并且没有任何物理意义,接下来,我们介绍使用知识图谱进行语义信息表示。 由于知识图谱由节点和边组成,因此我们用节点来表示原始数据中的某个对象或概念,用边来表示每对节点之间的关系。 每对节点及其关系由三元组定义。 因此,知识图建模的语义信息由多个三元组组成。 与其他图模型不同,知识图谱中的三元组是由用户想要传输的原始数据和该用户必须理解原始数据的知识决定的。 因此,具有不同知识的不同用户从相同的原始数据中提取的语义信息可能是不同的。
使用知识图来建模语义信息有几个关键优势。 首先,提取的语义信息是人类可以理解的。 因此,接收器在接收到语义信息时可以不需要恢复原始数据,因为语义信息表示原始数据的相似含义。 其次,可以根据网络状况和资源情况,对由多个三元组组成的语义信息的数据大小进行管理。 具体地,当网络资源(即带宽)有限时,可以限制语义信息中的三元组的数量以满足通信服务要求(即延迟)。 然而,利用知识图谱获取语义信息也面临着一些挑战。 首先,通过基于神经网络的方法提取语义信息中的所有三元组。 因此,在将知识图用于能源有限设备(即物联网设备)时,必须考虑并减少训练这些神经网络的复杂性和时间。 其次,当前大多数研究假设所有用户都具有相同的三元组提取知识,这可能不切实际。 因此,有必要设计新颖的方法来为每个用户建模和生成独特的知识库。 表I总结了使用知识图谱来建模语义信息的优点、缺点和应用。
II-B4 概率图
方向概率图还可以用来表征传输信息[9]的固有信息。 在有向概率图中,每个顶点代表语义实体,边代表这两个顶点之间连接的概率。 由于彼此之间具有高连接概率的多个顶点可以融合成单个顶点,因此新生成的顶点可以包含比原始顶点更高级别的语义信息。 概率图展示了不同实体之间的概率,可以用来提取概率图中整体概率较高的玉米语义信息。
用概率图提取语义信息有一些优点。 首先,将评价较高的低级语义实体组合成高级语义实体,利用概率生成不同级别的语义信息。 其次,概率图可以用来预测接收者的传入信息。 通过预测和推理,接收方可以提前调整其行动。 然而,使用概率图仍然存在一些挑战。 由于概率图可以通过神经网络来学习,而多级语义信息的提取需要额外的计算,因此构造多级语义信息的复杂度较高。 此外,为了确保接收方能够精确预测发送方的未来信息,发送方和接收方都需要共享一些高度相关的共同知识。 表I总结了使用概率图来建模语义信息的优点、缺点和应用。 因此,图2说明了上述四种方法的语义提取过程。
| Classifications | Advantages | Disadvantages | Applications |
|---|---|---|---|
| Autoencoder | • Autoecnoder is applicable to data of different modalities • Autoencoder can be trained in an self-supervised way | • The extracted semantic information is incomprehensible for humans | • Deep joint source-channel coding • Multi-modal semantic transmission |
| Information Bottleneck | • IB provides a specific theoretical bound for minimizing the rate under given distortion | • The mutual information is challenging to be obtained • The extracted semantic information is incomprehensible for humans | • Task-oriented semantic transmission |
| Knowledge Graph | • Modeled semantic information has physical meanings • Receivers do not need to recover original data | • Senders need to generate knowledge library for ML model training • Token selection is implemented by complex neural networks | • Machine to machine communications • Human to machine communications |
| Probability Graph | • Probability graph can be utilized to conduct inference • Different levels of semantic information can be extracted | • High computation complexity • Both the transmitter and receiver need to share some common knowledge | • Multi-level semantic information • Information prediction and inference |
三信息安全
接下来介绍语义信息传输中的安全问题。 我们特别讨论了信息瓶颈、转换通信和物理层的安全问题,并总结了在这些场景中实现安全语义通信的挑战。
III-A 信息安全瓶颈
在本小节中,我们将介绍使用 IB 进行安全语义通信。 如前所述,IB利用源符号与编码符号之间以及编码符号与目标变量之间的互信息来分别表示语义通信系统的速率和失真。 遵循这一原则,我们可以进一步将 IB 扩展到安全语义通信。 特别地,当存在攻击者试图在语义通信过程中检测合法用户的敏感语义信息时,可以通过最小化敏感信息与编码语义符号之间的互信息来降低敏感语义信息泄漏概率。 这样,IB同时考虑了语义通信的速率、失真和安全性,因此其目标变成在给定失真和信息泄露危险的情况下最小化速率。
此外,IB还可以用于分析安全语义通信系统的训练过程。 特别是,我们可以使用 IB 作为损失函数来训练语义通信系统。 在训练过程中,我们可以估计三个互信息项的值,从而可以分析训练每个阶段的速率、失真和安全性的性能权衡过程。 这样,我们可以更好地理解安全语义通信系统的训练过程,并进一步选择合适的超参数来优化系统的性能。
然而,应用 IB 来指导安全语义通信仍然面临一些关键挑战。 特别是,与 IB 的原始形式类似,互信息的计算具有挑战性,因为编码符号和敏感信息的联合分布和边缘分布通常是未知的。 因此,需要对互信息术语进行严格的、可训练的界限来有效地训练语义通信。
III-B 转换语义通信
在本小节中,我们介绍使用转换通信进行语义信息传输。 在语义通信中,我们不仅考虑攻击者检测到的数据量,还考虑检测到的原始数据的含义。 因此,我们可以使用两种方法来保护发送者的数据隐私。 首先,我们可以使用传统的转换通信技术来保护发送者的数据隐私。 特别是可以向攻击者想要攻击的用户发送干扰信号,从而保护用户的数据隐私。 其次,可以修改语义信息中的三元组,以避免携带攻击者想要检测的三元组。 还可以共同考虑采用传统的转换通信方式和三重选择方式来保护用户的数据安全。
然而,使用转换通信进行安全语义通信也面临着一些挑战。 首先,发送者需要估计攻击者想要检测的三元组以及接收者想要接收的三元组,因为发送者在语义信息传输之前不会与攻击者和接收者进行通信。 其次,需要分析实现这两种数据保护方法的能耗、数据传输延迟以及其他成本。 为此,可以根据不同的网络情况决定采用传统的转换通信方式还是三重选择方式。 例如,当发送方用于语义信息传输的发射功率有限时,我们可能无法使用传统的转换通信方法来保护用户的数据安全,因为接收方可能无法检测到发送方的原始信号。 最后,研究发送者和接收者之间的合作以进一步提高数据安全性是另一个有趣的研究方向。
III-C 物理层安全
语义通信的物理层安全[10, 11]包括公共知识库安全和语义信息安全两个方面。
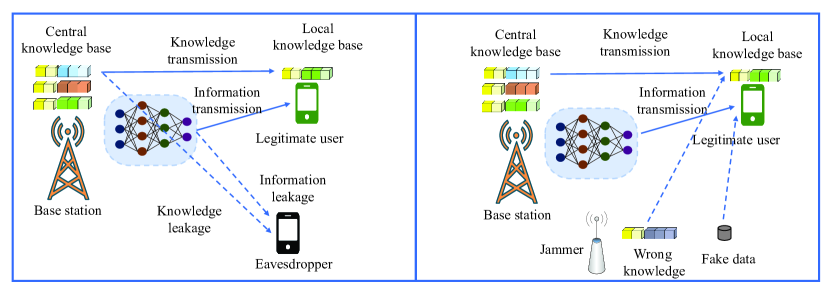
III-C1 知识库安全
公共知识库在发送器和接收器之间共享,这有助于发送器提取语义信息并允许接收器恢复接收比特的背后信息。 因此,保护公共知识库非常重要。 如图3所示,语义通信的物理层安全包括两种情况。 对于窃听情况,发射机的知识可能会被泄露。 对于干扰情况,干扰者可以发送错误的知识,这可以导致合法用户从接收到的语义信息中恢复出错误的消息。 为了保护知识安全,可以应用波束成形设计和安全密钥分发方法。
III-C2 语义信息安全
语义信息基于发送器和接收器之间的共享知识,这表明语义信息与条件信息相关。 根据语义信息的构建过程,除了常规的干扰和噪声之外,还存在语义干扰和噪声。 语义干扰包括信息的歧义。 例如,一个单词或短语在不同场景下可以具有不同的含义。 由于背景信息有限,很难区分特定语义信息的真实含义,从而造成语义干扰。 由于原始信息被映射到语义空间,因此引入了语义噪声,这会引入额外的噪声,因为多个信息可以被映射到相同或相似的语义信息。 因此,安全语义信息速率应考虑语义干扰和噪声,这就需要新的设计来保护语义信息安全。 一种可能的方式是联合学习和通信设计[12]来保证语义通信的安全。
IV 语义机器学习安全
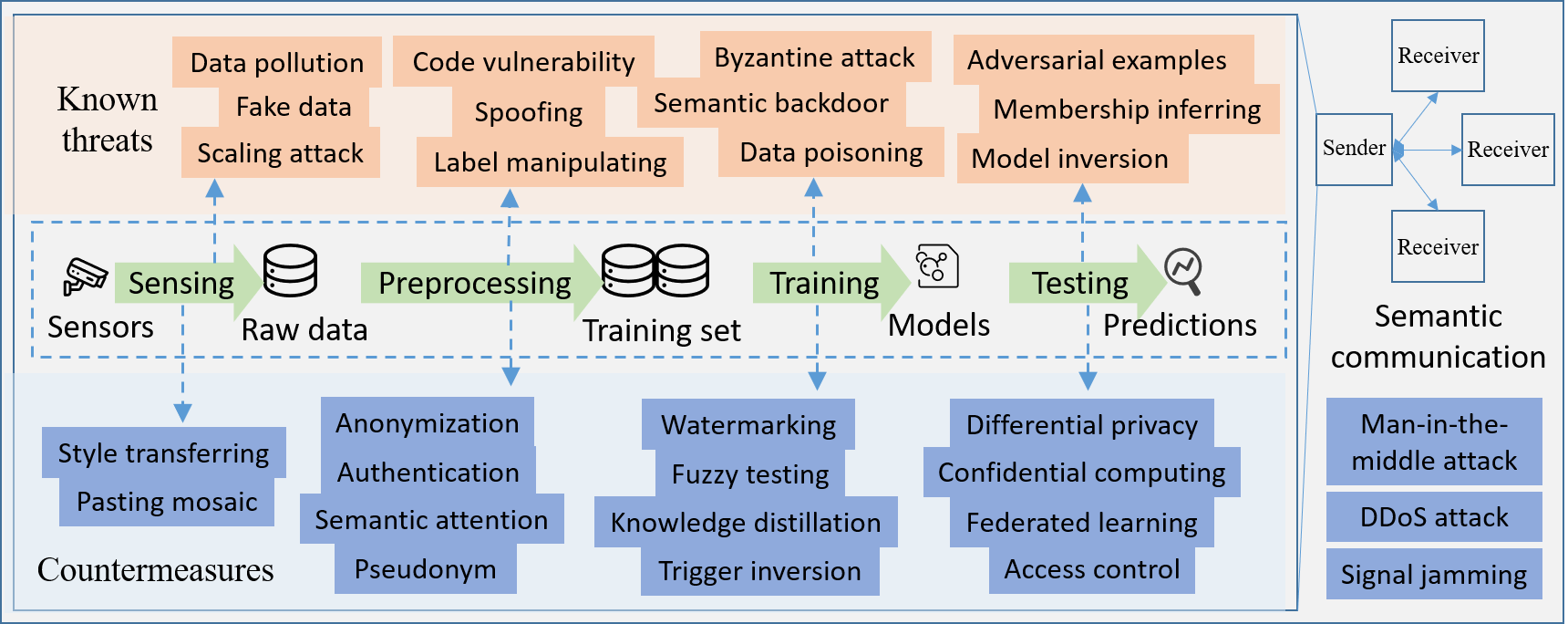
正如第二部分提到的,许多机器学习技术,如知识图谱、编码器/解码器和深度神经网络,被认为是构建语义通信系统基本组件的重要推动者。 在本节中,我们将这些推动因素称为“语义 ML”。 提前预测、建模和分析语义机器学习新兴的安全风险对于未来语义通信系统的发展和普及具有重要意义。 例如,上传到知识库的所有语义特征都应该具有复杂的审查机制,以防止被恶意用户修改。 在本节中,我们首先分析语义机器学习的漏洞和已知威胁。 然后,我们还讨论了针对这些威胁的有希望的对策。 最后,我们展望了可信赖且可解释的技术为语义通信系统构建安全语义 ML 模型的潜力。
IV-A 安全风险
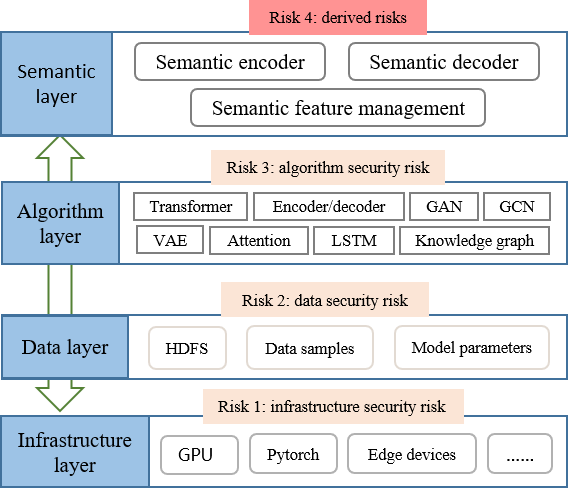
语义机器学习的主要安全风险可以概括为内生风险和衍生风险,如图4所示。
IV-A1 内生风险
对于语义ML来说,数据是重要驱动,算法是核心技术,基础设施是底层支撑。 内生风险可能导致数据安全威胁、算法安全威胁、基础设施安全威胁。
风险一:数据安全风险。 已知的数据安全风险[13]包括隐私泄露、数据中毒、数据污染、数据伪造等。 在语义通信系统中,我们可以使用机器学习来提取语义特征,生成知识库,并将传输的语义特征解析为原始数据。 在各个语义通信节点的模型训练过程中,如果对手通过投毒、污染等方式篡改了部分原始数据样本,则数据传输的准确性将大幅下降。 此外,如果在语义通信的ML模型中注入特定的后门,即迫使ML模型对特定的触发器(具有特定语义的内容)极其敏感,那么整个语义通信系统将容易受到恶意操纵。 此外,随着模型反演、梯度泄漏和隶属推理的出现,黑盒和白盒数据重构都可能威胁到机器学习在语义通信系统中的实用性,这是很难预防的。
风险2:算法安全。 黑盒和公平是算法安全风险的两大来源。 一方面,基于神经网络的机器学习算法通过复杂的计算过程提取输入数据的特征,然后将其分类到校准的类别中,但现有的科学知识和原理无法对分类结果给出合理的解释。这是攻击难以有效防御的根本原因。 例如,当基于神经网络的语义通信系统中的接收器输出错误结果时,很难定位故障所在。 另一方面,在从海量数据中提取知识的过程中,通常会使用排序、分类、关联、过滤、注意力机制等算法来处理数据项。 如果算法在不同性别或种族设置下表现出不公平的输出,使用语义通信系统的信息传输将遭受复杂的社会问题。
风险3:基础设施安全。 为了训练语义ML模型并提供智能通信服务,需要构建各种开发库、连接异构计算设备并构建云平台。 一旦这些语义机器学习基础设施中的漏洞被攻击者利用,通过这些基础设施生成的语义机器学习模型可能会表现出异常行为。 例如,Tensorflow和PyTorch上的恶意软件可能会修改模型结构,而一些黑客会试图非法占用深度学习节点的计算资源(例如GPU、CPU和虚拟机)进行挖矿。
IV-A2 衍生风险
除了现有的内生风险外,在语义通信中部署ML模型还面临着许多由于实际应用场景的开放性而衍生的风险。 衍生风险主要包括语义对抗样本和语义后门。 例如,可用于构建实时语义通信的视觉 Transformer 很容易受到对抗性示例[14]的影响。 此外,衍生的风险还包括中间人攻击、DDoS攻击和信号干扰攻击,因为语义通信的发送者和接收者的ML模型需要跨域训练。
IV-B 对策
为了展示如何攻击语义通信系统中存在上述安全风险的机器学习模型,图5说明了大多数已知的攻击。 根据已知攻击的特点,相应的对策主要分为三个分支: 1)防中毒; 2)提高对抗性例子的鲁棒性; 3)防止隐私泄露。 至于反中毒方法,存在三种不同的设计范式,包括a)删除中毒数据,b)平滑异常激活值,c)擦除隐藏后门。 a) 和 b) 都需要访问模型训练过程,这对于服务提供商来说通常是不切实际的。 触发反演和无数据知识蒸馏作为黑盒防御技术越来越多地被考虑。
为了模型的鲁棒性,最流行的对策是对抗性训练和差分隐私。 然而,对抗性训练往往需要更多的数据样本,而差分隐私可能会降低模型的准确性,因此结合模型可解释性来探究对抗性样本的原因成为当前的热点。 为了防止攻击者从机器学习模型中恢复原始数据和语义,人们正在研究机密计算、差分隐私[15]和联邦学习等隐私保护框架,以满足不同领域的个性化需求。场景。 在不同的应用场景中,用户需要根据自己的个性化需求选择合适的隐私保护方式。 此外,许多人工智能服务提供商非常重视模型水印和认证技术,以保护自己的知识产权。
V 结论
在本文中,我们提供了四种表示语义信息的方法。 基于语义信息的构建,我们指出语义信息的主要安全问题有两个方面:信息安全和机器学习安全。 针对每个方面,我们都指出了存在的主要问题以及相应的处理措施。 未来的方向包括用于安全语义通信性能分析和优化的联合通信和计算设计。
参考
- [1] W. Saad, M. Bennis, and M. Chen, “A vision of 6G wireless systems: Applications, trends, technologies, and open research problems,” IEEE Network, vol. 34, no. 3, pp. 134–142, May/June 2020.
- [2] C. E. Shannon and W. Weaver, The Mathematical Theory of Communication. The University of Illinois Press, 1949.
- [3] Z. Qin, X. Tao, J. Lu, and G. Y. Li, “Semantic communications: Principles and challenges,” arXiv preprint arXiv:2201.01389, 2021.
- [4] Q. Lan, D. Wen, Z. Zhang, Q. Zeng, X. Chen, P. Popovski, and K. Huang, “What is semantic communication? a view on conveying meaning in the era of machine intelligence,” Journal of Communications and Information Networks, vol. 6, no. 4, pp. 336–371, 2021.
- [5] W. Yang, H. Du, Z. Liew, W. Y. B. Lim, Z. Xiong, D. Niyato, X. Chi, X. S. Shen, and C. Miao, “Semantic communications for 6G future internet: Fundamentals, applications, and challenges,” arXiv preprint arXiv:2207.00427, 2022.
- [6] G. Shi, Y. Xiao, Y. Li, and X. Xie, “From semantic communication to semantic-aware networking: Model, architecture, and open problems,” IEEE Communications Magazine, vol. 59, no. 8, pp. 44–50, Aug. 2021.
- [7] C. E. Shannon, “Coding theorems for a discrete source with a fidelity criterion,” IRE Conv. Rec., vol. 7, no. 9, pp. 56–83, 1959.
- [8] Z. Goldfeld and Y. Polyanskiy, “The information bottleneck problem and its applications in machine learning,” IEEE J. Sel. Areas Commun., vol. 1, no. 1, pp. 19–38, 2020.
- [9] T. L. Griffiths and M. Steyvers, “A probabilistic approach to semantic representation,” in Pro. Twenty-Fourth Annual Conf. Cognitive Science Society. Routledge, 2019, pp. 381–386.
- [10] Y.-S. Shiu, S. Y. Chang, H.-C. Wu, S. C.-H. Huang, and H.-H. Chen, “Physical layer security in wireless networks: A tutorial,” IEEE Wireless Commun., vol. 18, no. 2, pp. 66–74, 2011.
- [11] A. Mukherjee, S. A. A. Fakoorian, J. Huang, and A. L. Swindlehurst, “Principles of physical layer security in multiuser wireless networks: A survey,” IEEE Commun. Surveys & Tutor., vol. 16, no. 3, pp. 1550–1573, 2014.
- [12] M. Chen, Z. Yang, W. Saad, C. Yin, H. V. Poor, and S. Cui, “A joint learning and communications framework for federated learning over wireless networks,” IEEE Trans. Wireless Commun., vol. 20, no. 1, pp. 269–283, Jan. 2021.
- [13] M. Goldblum, D. Tsipras, C. Xie, X. Chen, A. Schwarzschild, D. Song, A. Madry, B. Li, and T. Goldstein, “Dataset security for machine learning: Data poisoning, backdoor attacks, and defenses,” IEEE Trans. Pattern Analysis and Machine Intelligence, pp. 1–1, 2022.
- [14] K. Mahmood, R. Mahmood, and M. van Dijk, “On the robustness of vision transformers to adversarial examples,” in Proc. IEEE/CVF Int. Conf. Computer Vision (ICCV), 2021, pp. 7818–7827.
- [15] T. Zhu, D. Ye, W. Wang, W. Zhou, and P. S. Yu, “More than privacy: Applying differential privacy in key areas of artificial intelligence,” IEEE Transactions on Knowledge and Data Engineering, vol. 34, no. 6, pp. 2824–2843, 2022.