视觉语言预训练的过滤、蒸馏和硬阴性
摘要
在大规模噪声数据上进行对比学习训练的视觉语言模型在零样本识别问题中变得越来越受欢迎。 在本文中,我们改进了对比预训练流程的以下三个方面:数据集噪声、模型初始化和目标。 首先,我们提出了一种名为复杂性、动作和文本识别(CAT)的简单过滤策略,该策略可显着减小数据集大小,同时提高零样本视觉语言任务的性能。 接下来,我们提出了一种名为“概念蒸馏”的方法,利用强大的单峰表示进行对比训练,该方法不会增加训练复杂性,同时优于之前的工作。 最后,我们修改了传统的对比对齐目标,并提出了一种重要性采样方法,可以在不增加额外复杂性的情况下对硬负片的重要性进行上采样。 在 29 项任务的广泛零样本基准上,与基线相比,我们的蒸馏和硬负训练 (DiHT) 方法在 20 项任务上有所改进。 此外,对于少样本线性探测,我们提出了一种新颖的方法,弥合了零样本和少样本性能之间的差距,比之前的工作有了显着的改进。 模型可在 github.com/facebookresearch/diht 获取。
1简介
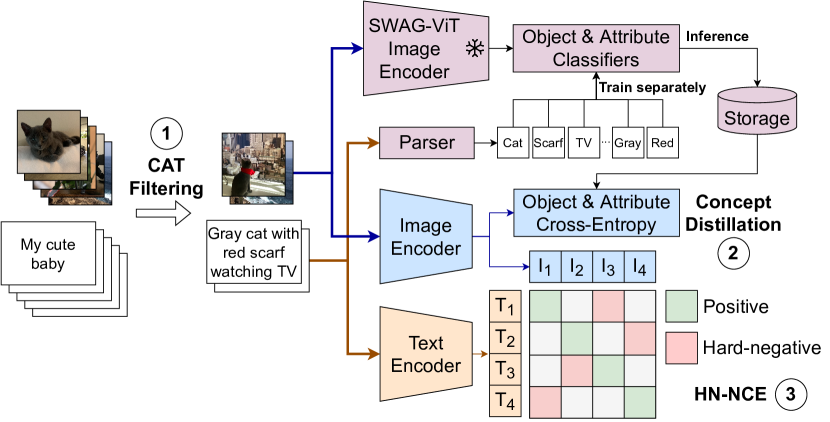
多模态学习中越来越流行的范例是对比预训练[11, 43, 62, 28, 41, 76, 85, 87],它涉及在非常大规模的噪声数据集上训练多模态模型来自网络的图像文本对。 它已被证明对于各种视觉语言任务非常有效,无需任何特定于任务的微调(即。,零样本),例如图像分类[65]、文本和图像检索[45, 59]、视觉问答[21]等等。 在本文中,我们研究了双编码器架构[62]的对比预训练问题,目的是改进零样本任务的图像文本对齐。 我们重新审视了对比预训练流程的三个重要方面——数据集中的噪声、模型初始化和对比训练,并提出了在各种零样本基准上显着提高模型性能的策略,见图1 。
大多数图像文本数据集都是嘈杂且对齐不良的。 最近的努力[27]尝试通过基于来自现有模型(如CLIP[62])的对齐分数过滤样本来清除噪声。 然而,这种方法受到模型本身的偏差和缺陷的限制。 另一方面,基于动量的方法[41]降低噪声对于大规模训练来说是不可行的,因为它们增加了计算和内存需求。 为此,我们提供了一种可扩展且有效的方法,名为Ccomplexity、Action 和Text-spotting (CAT) 过滤。 CAT 是一种过滤策略,用于从嘈杂的网络规模数据集中仅选择信息丰富的文本图像对。 我们表明,在大规模噪声数据集(例如 LAION [66])的 CAT 过滤版本上进行训练可以在视觉语言任务中提供高达 12% 的相对改进,尽管删除几乎 80% 的训练数据,请参阅第 4.2 节和表 1 了解更多详细信息。
进一步改进多模态训练的常见策略[58, 89]是使用在各自模态上大规模预训练的图像和文本模型来热启动它。 然而,由于图像文本数据中的噪声增加,对整个模型的微调会破坏热启动的好处。 人们也可以使用模型冻结策略,例如锁定图像调整[89],但它们无法适应多模态问题中存在的复杂查询(例如。 ,跨模态检索),并且模型在检索基准上表现不佳(参见第 4.2 节)。 我们提出了一种完全不同的方法,即概念蒸馏 (CD),以利用强大的预训练视觉模型。 概念蒸馏背后的关键思想是在图像编码器上训练线性分类器,以从预训练的教师模型中预测蒸馏出的概念,其灵感来自于弱监督大规模分类的结果 [49, 71]。
最后,我们重新审视训练目标:几乎所有先前的工作都通过 InfoNCE 损失[55]利用了噪声对比估计,标准 InfoNCE 公式中已经发现了缺陷[12, 30]。 我们证明,通过使用基于模型的重要性采样技术来强调更困难的否定,可以获得性能的显着提高。
图 2 提供了我们的流程摘要。 我们的组合方法在 29 项任务的详细基准上比双编码器架构的基线获得了显着改进。 具体来说,使用 ViT-B/16 [17] 架构,我们在 29 个任务中的 20 个任务上提高了零样本性能,优于 LAION-2B 数据集上的 CLIP 训练[27, 66],尽管在80%较小的子集上进行训练,请参见图4。 此外,我们证明,即使使用较小(但噪音相对较小)的预训练数据集PMD进行训练,我们在29个任务中的28个任务上的表现也比在CLIP上训练的表现更好相同的数据,通常有很大的余量,见图5。
此外,我们提出了一种简单而有效的方法,以在低数据状态下从零样本学习转向少样本学习时保持性能连续性。 之前的工作[62]显示,当从零样本转向样本学习时,性能大幅下降,这对于实际场景来说是不希望的。 我们提出了一种替代线性探测方法,该方法使用零样本文本提示初始化线性分类器,并确保最终权重不会通过投影梯度下降[5]偏离太多。 在 ImageNet1K 上,我们在较小的 值上比之前的工作有了巨大的改进。 例如,与随机线性探测的基线策略相比,我们的方法将 5-shot top-1 准确度提高了 7% 的绝对幅度(见图 6)。初始化。
2相关工作
用于对比预训练的数据集管理。
大规模对比预训练 [11, 43, 62, 28, 41, 76, 85, 87] 通常需要数亿到数十亿量级的数据集大小。 该领域的开创性工作,例如.、CLIP [62] 和 ALIGN [28] 在很大程度上依赖于从网络上爬取的图像文本对。 随后,大规模图文数据集的版本已被创建但未公开发布,包括WIT-400M [62]、ALIGN-1.8B [28]、FILIP -340M [85]、FLD-900M [87]、BASIC-6.6B [58]、PaLI-10B [10 ]。 这些数据集通常使用不明确或原始的清理策略,例如。,删除带有简短或非英语标题的样本。 最近,LAION-400M [67] 使用基于 CLIP 的分数来过滤大型数据集。 作者后来发布了来自 Common Crawl 的纯英文 LAION-2B 和 LAION-5B 未经过滤的数据集111commoncrawl.org。 除了 LAION-400M 和 BLIP [40] 使用引导图像文本编码器过滤掉噪声字幕之外,在系统管理策略上并没有进行大量投资来提高零样本对齐性能大规模预训练。 与之前的工作相比,我们使用质量驱动的过滤器来保留标题足够复杂的图像,包含语义概念(动作),并且不包含可以在图像中发现的文本[38]。
从预先训练的视觉模型中蒸馏。
知识蒸馏[25]旨在将知识从一种模型转移到另一种模型,并已在许多环境中使用,包括提高性能和效率[6,7,42,64,81,74, 68]提高泛化能力[16,44,43]。 多种方法使用自蒸馏来提高性能并降低计算开销[23,82,88]。 对于视觉和语言预训练,[2, 41, 31] 使用使用移动平均动量模型的嵌入计算的软标签,目的是减少噪声图像文本对的不利影响训练数据。 我们的概念蒸馏方法是一种更便宜、更有效的替代方案,因为它不需要我们在整个训练过程中运行昂贵的教师模型222可以预先计算和存储蒸馏目标。 同时保留视觉概念中最有用的信息。
利用预训练视觉模型的另一种方法是使用它们来初始化图像编码器,并通过锁定图像编码器 [58, 89] 或微调 [58]。 然而,这些方法缺乏将复杂文本与经过充分训练的图像编码器对齐的能力,因此在多模态任务上表现不佳,例如。跨模态检索(参见第4.3)。
与硬否定的对比训练。
噪声对比估计 (NCE) [22] 是视觉文本学习的典型目标,具有跨大规模多模态对齐的应用[62, 28, 11, 43] 和无监督视觉表示学习[53, 24]。 多项工作研究了原始 InfoNCE 目标[55]的缺点,特别是负样本的选择和重要性。 Chuang 等人. [12]提出了一种去偏方法来解决非常大的批量大小下的假阴性问题,这在大规模预训练中很常见。 Kalantidis 等人。 [30]提出了一种 MixUp 方法来提高无监督对齐的硬负样本的质量。 事实证明,在训练目标中使用特定于模型的硬负例也可以减少模型的估计偏差[90]。 与之前的半监督工作相反,我们将 Robinson et al. [63] 首次提出的基于模型的硬负目标扩展到多模式对齐。
3方法
背景。
我们考虑对比图像文本预训练的任务。 给定图像-文本对的数据集,我们想要学习双编码器模型,其中代表图像编码器, 表示文本编码器。 我们使用简写 和 分别表示图像-文本对 的编码图像和文本。 我们现在将描述我们方法的三个关键组成部分,然后是最终的训练目标。
3.1 复杂性、操作和文本 (CAT) 过滤
我们的复杂性、动作和文本发现 (CAT) 过滤是两个过滤器的组合:标题复杂性过滤器,如果标题不够复杂,则删除图像标题对;图像过滤器,如果图像包含文本匹配,则删除对。标题以防止对齐过程中出现多义现象。 我们使用使用过滤器后获得的预清洁的LAION-2B333不适合观看的图片和有毒字幕。 以 [69] 作为基础数据集。
通过复杂性和动作过滤字幕。
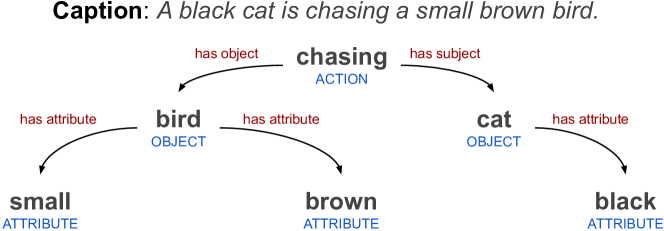
嘈杂的网络规模数据集没有任何基于语义的管理,因此标题可能不相关、不符合语法且未对齐。 我们的动机是通过简单地选择具有足够复杂性的标题来减少这种噪音,以便训练分布与目标任务相匹配。 为此,我们构建了一个基于规则的快速解析器,从文本中提取对象、属性和动作关系(参见图 3 的示例),并使用生成的语义图来估计文本的复杂性。图像标题。 具体来说,我们将标题的复杂性定义为解析图中存在的与任何对象的最大关系数。 例如,在标题“一只黑猫正在追逐一只棕色小鸟”中,对象“鸟”具有“小”、“棕色”和“一只黑猫正在追逐”属性,因此,标题的复杂性是 C。 我们只保留至少具有 C 字幕复杂度的样本。 为了进一步删除可能包含产品的对,如果标题不包含至少一个操作(从解析器获得),我们会过滤掉标题。
通过文本识别过滤图像。
网络规模数据集中的图像标题对通常将部分标题显示为图像中的文本(通过目视检查,我们发现 LAION 的此类示例高达 30% [66])。 在这些情况下,最小化目标可以对应于识别文本(例如.,光学字符识别),而不是高级视觉语义(例如.,对象,属性)我们希望模型能够对齐。 这将降低以对象为中心和以场景为中心的下游零样本任务的性能,因此我们使用现成的文本识别器[38]从集合中删除此类图像。 我们删除文本识别置信度至少为 且至少 与滑动窗口中的标题匹配的预测字符的图像文本对。 我们(通过检查)观察到,这种方法可以有效地识别带有文本的图像,并且失败案例主要是非英语文本。 使用经过培训的多语言文本识别器进行过滤可以解决此问题,但是,我们将其留作未来的工作。 过滤统计数据可以在补充中找到。
3.2概念蒸馏
识别图像中与相应标题中的对象和属性相对应的视觉概念对于对齐至关重要。 因此,我们建议将这些概念从预先训练的教师模型中提取到我们的图像编码器中。 具体来说,我们在编码图像嵌入 之上添加两个辅助线性分类器来预测 (i) 对象和 (ii) 视觉 属性并使用教师模型为它们生成伪标签。 这些分类器与对比损失一起进行训练。
我们使用语义解析器来解析图像标题,该语义解析器从文本中提取对象和属性(第3.1节)并将其用作伪标签。 然后,在对低频概念进行平方根上采样[49]之后,我们使用软目标交叉熵损失[20]在教师模型嵌入上训练线性分类器。 冻结教师模型的主干非常重要,以确保我们保留使用更强大的模型进行蒸馏的优势。 然后,对于每个图像,我们使用这些经过训练的线性分类器生成两个 softmax 概率向量 - 分别用于对象的 和用于属性的 。 为了最大限度地减少存储开销,我们通过仅保留 top- 预测类值并重新规范化它们以生成最终的伪标签来进一步稀疏它们。 在多模态训练期间,我们使用这些伪标签向量作为目标的交叉熵损失。 除非另有说明,我们使用从 SWAG [71] 预训练的 ViT-H/14 [17] 架构作为教师模型。 请参阅第 4.2 节和补充材料,了解不同骨干网影响的消融和保留 top- 预测以及更多详细信息。
我们的概念蒸馏方法有几个优点。 首先,教师的预测捕获了强视觉编码中的相关性,使它们作为标签比标题本身更具信息性。 标题仅限于一些对象和属性,而教师的预测则提供了更详尽的列表。 此外,我们的方法比其他蒸馏方法更有效地获得了最近提出的公开可用的强单峰视觉模型的好处,因为在冻结的教师模型上训练线性分类器是便宜的。 存储预测后,我们丢弃教师模型,从而绕过标准蒸馏方法 [25, 74] 中同时运行学生和教师模型的内存和计算限制,这对于大型教师模型至关重要。 我们凭经验证明(参见第 4.2 节),我们的策略比直接提取教师嵌入效果更好。 此外,与使用预训练模型热启动图像编码器的方法相比,我们的方法可以毫无困难地利用更高容量的教师模型,并且与锁定图像调整[58, 89]不同,我们的方法给出训练图像编码器以实现更好的对齐的灵活性,同时保留预先训练的视觉特征的强度。
3.3 与硬负片的多模态对齐
对比学习[55]已迅速成为多模态配准的事实方法,其中大多数先前的工作都集中在多模态 InfoNCE [55]目标上,对于任何一批特征化图像-文本对 ,给定的目标为(对于某些可学习的温度 )、
虽然这种方法在多模态对齐方面取得了巨大成功[62, 28],但当从大规模噪声数据集中学习时,噪声对比估计中应用的均匀采样通常可以提供不一定具有区分性的负样本,需要非常大的批量大小。 对于对比自监督学习的问题,Robinson 等人. [63]提出了一种重要性采样方法来重新加权负样本批量处理,以便“较难”的负片按照其难度的比例进行上采样。 我们提出了类似的多模式对齐策略。 具体来说,对于某些,我们提出以下硬负噪声对比多模态对齐目标:
其中称重函数给出为444我们通过 进行标准化,因为这是负数的数量。:
权重的设计使得困难的负对(具有更高的相似性)被强调,而更容易的负对被忽略。 此外, 使用正项重新调整标准化,以考虑数据中存在假阴性的情况。 权重的形式是具有浓度参数的非标准化von Mises-Fisher分布[50]。 观察一下,当设置 和 时,我们获得了原始目标。 与上面提出的 [63] 的原始表述和 HN-NCE 目标存在几个关键差异。 首先,我们仅使用跨模态对齐项,而不是[63]中提出的单模态目标。 接下来,我们对文本到图像和图像到文本的对齐采用单独的惩罚。 最后,我们结合了一个可学习的温度参数来协助学习过程。 我们更详细地讨论我们的设计选择,并在补充材料中提供额外的理论和实验论证。
3.4培训目标
4实验
在这里,我们评估了我们在广泛的视觉和视觉语言任务中的方法。 我们对 4.2 节中的设计选择的 29 项任务进行了广泛的消融,并与 4.3 节中流行的零样本基准的最先进方法进行了比较。 最后,我们在 4.4 节中提出了一种通过基于提示的初始化进行少样本分类的替代方法。
4.1 实验设置
训练数据集。
我们使用 LAION-5B 数据集 [66] 的 2.1B 英文字幕子集。 在训练之前,我们在[69]之后过滤掉具有NSFW图像、文本中的有毒单词或水印概率大于的图像的样本对。 这给我们留下了 1.98B 图像,我们在整篇论文中将其称为 LAION-2B 数据集。 此外,我们还在 [70] 的公共多模态数据集 (PMD) 集合上探索训练我们的模型。 PMD 包含各种公共数据集的训练分割。 下载后555已按照 huggingface.co/datasets/facebook/pmd 下载。 由于缺少样本和 SBU 字幕,我们剩下 63M 的数据(vs. [70] 中报告的 70M)图像文本对[56](最初在 PMD 中)下线。
训练细节。
对于我们的模型架构,我们严格遵循 Radford et al. [62] 的 CLIP。 我们使用视觉转换器 (ViT) [17] 处理图像,使用文本转换器 [75] 处理字幕。 我们尝试了 3 种不同的架构,分别表示为 B/32、B/16 和 L/14,其中 32、16 和 14 表示输入图像块大小。 有关架构详细信息,请参阅补充。 对于蒸馏和微调实验,我们利用公共 SWAG-ViT 模型[71],该模型在主题标签的弱监督下进行了预训练。
我们使用 Adam [33] 优化器以及解耦权重衰减 [48] 和余弦学习率计划 [47]。 输入图像大小为 224224 像素。 为了加速训练并节省内存,我们使用混合精度训练[51]。 所有超参数都在补充材料中给出。 它们由训练 B/32 在小规模设置中选择,并在所有架构中重复使用。 对于对象和属性分类器,我们发现将学习率缩放 10.0 并将权重衰减缩放 0.01 会得到更好的结果。 我们在 4B、8B、16B 和 32B 总样本上训练我们的模型。 对于 ViT-L/14,我们进一步以更高的 336px 分辨率训练 4 亿个样本,将该模型表示为 L/14@336。 我们在 512 个 A100 GPU 上对 L/14 进行了 6 天的训练,处理了 16B 个样本,总计 个 GPU 小时。
评估基准。
我们在 29 个任务的零样本基准上评估我们的模型:(i) 17 个图像分类,(ii) 10 个跨模式检索,(iii) 2 个视觉问答。 数据集详细信息在补充中提供。
4.2 零样本基准的消融
在本节中,我们取消了三个预训练贡献:数据集过滤、对象和属性预测的蒸馏以及硬负对比目标。 在 ImageNet1K [65] (IN) 验证集、文本到图像 (T2I) 和图像到文本 (I2T) 零样本 Recall@1 上对零样本 Accuracy@1 进行消融在 COCO [60] 和 Flickr [59] 测试集上。 我们还报告了我们的模型和基线之间 29 个零样本任务的准确性 (%) 变化。 为了公平比较,我们训练了本节中介绍的所有方法(包括基线)。
数据集过滤的效果。
我们应用我们的过滤器,以及基于 CLIP [62] 对齐分数 (0.35) 的过滤,并消除基线性能,无需蒸馏或硬负对比训练, ViT-B/32 模型架构的表1。 所有模型在训练期间都会看到 4B 个总样本,而每个过滤步骤后唯一样本的数量都会下降。 第 (3) 行中的复杂性过滤器 (C) 将数据集大小减少了约 270M,同时略微增加了在 T2I 任务中观察到的图像文本对齐。 接下来,第 (4) 行中的操作过滤器 (A) 将大小减少了 1B 以上,同时在对齐复杂文本方面具有很大的优势。 然而,正如预期的那样,它会损害以对象为中心的 ImageNet 的性能。 最后,第 (5) 行中的文本识别 (T) 过滤器全面增强了对齐,因为它消除了学习文本的双峰视觉表示的需要。 我们还与第 (2) 行中基于 CLIP 分数的过滤进行比较,选择该分数是为了使数据集大小与我们的数据集大小相当,并表明它过于严格并删除了大量有用的训练对,从而损害了性能。 最后,LAION-CAT 仅占原始数据集大小的 22%,显着提高了图像文本零样本性能。 我们还观察到,当我们进行更长的训练计划时,这种情况会持续下去。 详情请参阅补充。
| # | Filter | Size | IN | COCO | Flickr | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| CLIP | C | A | T | T2I | I2T | T2I | I2T | |||
| 1 | 1.98B | 60.8 | 33.7 | 52.1 | 59.3 | 77.7 | ||||
| 2 | ✓ | 440M | 52.5 | 29.8 | 46.1 | 54.8 | 72.0 | |||
| 3 | ✓ | 1.71B | 60.8 | 33.9 | 52.5 | 60.8 | 77.8 | |||
| 4 | ✓ | ✓ | 642M | 58.7 | 35.9 | 53.8 | 64.3 | 82.0 | ||
| 5 | ✓ | ✓ | ✓ | 438M | 61.5 | 37.6 | 55.9 | 66.5 | 83.2 | |
蒸馏方法的影响。
为了了解预训练 SWAG-ViT 视觉编码器[71]直接蒸馏的效果,我们研究了两种基线方法:
(1) 嵌入蒸馏 (ED) 借鉴了 SimSiam [9] 并在学生视觉编码器的图像表示和预训练的图像表示之间使用辅助负余弦相似度损失SWAG 模型。
(2) 分布蒸馏 (DD) 借鉴了 ALBEF [41] 中动量蒸馏的思想,计算 SWAG 图像表示与学生文本表示,并将它们用作学生图像表示和文本对齐的软标签。 在应用 InfoNCE [55] 损失之前,软标签与硬 标签线性组合。
表 2(上半部分)列出了我们从预测概念 (CD) 中进行的蒸馏与上述蒸馏方法的比较。 请注意,为了公平比较,我们在这些实验中没有使用硬阴性对比损失。 我们的蒸馏方法表现最好,尽管它几乎没有训练开销,因为预测的概念是预先计算的,而例如。,ED 的速度慢了 60%由于需要运行视觉塔的额外副本,GPU 内存增加 8%。 我们也可以预先计算 ED 和 DD 的嵌入,但这会使数据集大小增加 1.2TB 并产生数据加载瓶颈,而我们的预先计算的预测在保存前 10 个预测时仅需要 32.6GB 的额外存储空间(请参阅补充)。 我们还表明,我们的方法对于所使用的 top- 预测的数量是稳健的,详细信息见补充材料。
人们还可以使用外部单峰图像模型,并在图像文本对齐任务中对其进行调整,而不是使用蒸馏。 我们遵循[89]并探索三个微调选项作为基线:(i)锁定图像调整(LiT),其中图像编码器被锁定,并且仅训练文本编码器,(ii)微调(FT),其中图像编码器以与文本编码器相比缩放 0.01 的学习率进行训练,(iii)延迟微调(FT-延迟),其中图像编码器被锁定预编码器的一半。 (i) 之后的训练周期,然后对 (ii) 之后的其余部分进行微调。 这些设置的结果如表2(下半部分)所示。 LiT vs. FT 是图像识别任务的强大性能(通过 ImageNet1K 测量)与更好的图像文本对齐(通过 COCO 和 Flickr 测量)之间的权衡。 锁定图像编码器使得对齐很难实现,但对其进行微调会损害其原始图像识别能力。 另一方面,我们表明我们的概念蒸馏是两全其美的,它在 5 个指标中有 4 个超过了 LiT 或 FT。 FT 的另一个缺点是它在最终设置中需要相同的架构,而 CD 可以通过使用存储的预测作为元数据轻松地与任何架构或训练设置相结合。 总而言之,与相关方法不同,我们提出的蒸馏:(i)训练几乎没有成本,(ii)与架构无关,(iii)改进图像识别和复杂的图像文本对齐。
| Init | Method | SWAG | IN | COCO | Flickr | ||
| (teacher) | T2I | I2T | T2I | I2T | |||
| Random | Baseline | — | 68.7 | 42.8 | 60.5 | 72.8 | 89.7 |
| ED | B/16 | 69.2 | 42.6 | 59.4 | 72.8 | 86.8 | |
| DD | B/16 | 68.6 | 41.8 | 57.4 | 71.7 | 87.0 | |
| CD (ours) | B/16 | 71.0 | 42.8 | 59.5 | 72.3 | 86.5 | |
| CD (ours) | H/14 | 72.3 | 43.4 | 60.4 | 73.8 | 87.6 | |
| SWAG | LiT | — | 73.0 | 32.5 | 50.6 | 60.8 | 79.6 |
| FT | — | 71.2 | 43.1 | 60.3 | 73.1 | 87.7 | |
| FT-delay | — | 72.0 | 42.7 | 60.7 | 72.5 | 86.2 | |
硬负对比训练的效果。
我们在表3中展示了使用硬阴性对比物镜(HN-NCE)时的消融。 性能表明,与普通的 InfoNCE 相比,使用新提出的损失是有益的,并且其积极效果与从对象和属性预测中提出的蒸馏所获得的收益是互补的。 请参阅补充说明,了解超参数 和 效果的消融。
| # | Method | IN | COCO | Flickr | |||
|---|---|---|---|---|---|---|---|
| CD | HN | T2I | I2T | T2I | I2T | ||
| 1 | 68.7 | 42.8 | 60.5 | 72.8 | 89.7 | ||
| 2 | ✓ | 72.3 | 43.4 | 60.4 | 73.8 | 87.6 | |
| 3 | ✓ | ✓ | 72.0 | 43.7 | 62.0 | 73.2 | 89.5 |
对 PMD 进行预训练时的效果。
最后,我们在更小的数据集(i.e. PMD)上使用 63M 训练样本训练视觉语言模型时,分析了我们提出的方案。 结果如表4所示。 所有贡献都显着提高了基线的性能,因此我们得出结论,使用建议的管道在低资源训练制度中非常有益666与 LAION 相比,PMD 数据集更小且相对干净得多。 因此,我们观察到它不需要我们的过滤步骤。. 请注意,PMD 数据集包含 COCO 和 Flickr 训练样本,因此,它不是严格的零样本评估。 因此,我们不会在下一节中将在 PMD 数据集上训练的模型与最先进的模型进行比较。 然而,我们相信这些强有力的发现也将激励我们在更小、更干净的数据集上使用我们的方法。
| Arch. | # | Method | IN | COCO | Flickr | ||||
| CD-O | CD-A | HN | T2I | I2T | T2I | I2T | |||
| B/32 | 1 | 49.0 | 28.9 | 50.2 | 62.0 | 80.3 | |||
| 2 | ✓ | 57.8 | 32.2 | 54.0 | 65.6 | 85.7 | |||
| 3 | ✓ | ✓ | 59.7 | 34.4 | 55.7 | 68.3 | 87.8 | ||
| 4 | ✓ | ✓ | ✓ | 62.4 | 37.3 | 60.4 | 71.8 | 89.9 | |
| B/16 | 5 | 54.6 | 33.1 | 55.7 | 67.4 | 85.5 | |||
| 6 | ✓ | ✓ | 65.5 | 37.4 | 59.9 | 72.4 | 88.7 | ||
| 7 | ✓ | ✓ | ✓ | 67.8 | 42.7 | 65.5 | 77.6 | 92.5 | |
零样本基准。
我们将使用我们提出的概念蒸馏和硬负损失训练的模型表示为 DiHT。 为了更详细地展示我们模型的性能,我们报告了在 LAION-CAT 上训练的 DiHT-B/16,具有 438M 样本与。我们训练的 CLIP-B/16 基线LAION-2B 上的 2B 样本如图 4 所示。 此外,我们报告了 DiHT-B/16 vs。 CLIP-B/16 基线,其中两个模型均在具有 63M 样本的 PMD 数据集上进行训练,如图 5. 当分别在 LAION-CAT 或 LAION-2B 上进行训练时,DiHT 在 29 项基准任务中赢得了 20 项。 令人印象深刻的是,当在 PMD 上进行训练时,DiHT 在 29 项基准任务中的 28 项中获胜,通常具有很大的优势。
对分布变化的稳健性。
我们在表5中评估了 DiHT-B/16 与不同数据集上与 ImageNet 相关的鲁棒性。 CLIP-B/16 基线,由我们在 PMD 和 LAION 数据集上进行训练。 我们提出的方法比普通 CLIP 提高了鲁棒性,在某些情况下提高了很大的幅度,例如。 ImageNet-A 和 ObjectNet。
| Method | Train Data | #D |
IN |
IN-V2 |
IN-A |
IN-R |
IN-Sketch |
ObjectNet |
|---|---|---|---|---|---|---|---|---|
| CLIP | PMD | 63M | 54.6 | 47.9 | 35.5 | 56.3 | 30.8 | 38.5 |
| DiHT | PMD | 63M | 67.8 | 61.5 | 54.3 | 74.4 | 44.7 | 52.8 |
| CLIP | LAION-2B | 1.98B | 70.3 | 62.7 | 39.3 | 81.0 | 57.1 | 56.2 |
| DiHT | LAION-CAT | 438M | 72.2 | 64.3 | 49.2 | 85.1 | 58.3 | 62.3 |
4.3 与最先进的零样本比较
我们将我们的 DiHT 模型与表 6 中最先进的双编码器模型进行了比较。 鉴于所有模型都使用不同的架构、输入图像分辨率、训练数据库和训练时处理的样本数量,我们在表中概述了这些详细信息,以便于比较。
我们的方法与 CLIP [62] 和 OpenCLIP [27] 最相似,并且具有相同的训练复杂度和推理复杂度。 即使我们的训练数据集小得多,我们的性能也明显优于具有相同架构的模型。 我们最好的模型 DiHT-L/14 和 DiHT-L/14@336 在更高的 px 分辨率下进行额外 400M 样本的训练,在流行的文本图像 COCO 和 Flickr 基准测试中,其性能优于具有明显更高复杂性的模型。 ALIGN [28]的参数数量大约是我们的 DiHT-L/14 模型的两倍,并且是在 4 倍大的数据上训练的,与之相比,我们在所有检索基准上的性能都有大幅提高。 我们的模型也比 FILIP [85] 性能更好,后者利用词符相似性来计算最终对齐,因此明显提高了训练速度和内存成本。 我们在所有 检索基准上也优于 Florence [87]。 请注意,Florence [87] 使用了更新且更强大的 Swin-H Vision Transformer 架构 [46] 和卷积嵌入 [78],并且统一的对比目标[84]。 我们提出的贡献是对 FILIP [85] 和 Florence [87] 的补充,我们相信结合起来可以获得额外的收益。 最后,LiT [89] 和 BASIC [58] 首先在具有交叉熵的大规模图像标注数据集上预训练模型,然后在图像文本数据集。 尽管该策略在 ImageNet1K [65] 和图像分类基准上实现了最先进的性能,但它在跨模态检索等多模态任务上具有严重的缺点。 我们在4.2节中的消融也证实了这个问题。 另一方面,我们的方法不会受到这种负面影响。
| Method | px | #P | #D | #S | IN | COCO | Flickr | ||
| T2I | I2T | T2I | I2T | ||||||
| ViT-B/32 | |||||||||
| CLIP [62] | 224 | 151M | 400M | 12.8B | 63.4 | 31.4 | 49.0 | 59.5 | 79.9 |
| OpenCLIP [27] | 224 | 151M | 400M | 12.8B | 62.9 | 34.8 | 52.3 | 61.7 | 79.2 |
| OpenCLIP [27] | 224 | 151M | 2.3B | 34B | 66.6 | 39.0 | 56.7 | 65.7 | 81.7 |
| DiHT | 224 | 151M | 438M | 16B | 67.5 | 40.3 | 56.3 | 67.9 | 83.8 |
| DiHT | 224 | 151M | 438M | 32B | 68.0 | 40.6 | 59.3 | 68.6 | 84.4 |
| ViT-B/16 | |||||||||
| CLIP [62] | 224 | 150M | 400M | 12.8B | 68.4 | 33.7 | 51.3 | 63.3 | 81.9 |
| OpenCLIP [27] | 224 | 150M | 400M | 12.8B | 67.1 | 37.8 | 55.4 | 65.2 | 84.1 |
| OpenCLIP [27] | 240 | 150M | 400M | 12.8B | 69.2 | 40.5 | 57.8 | 67.7 | 85.3 |
| DiHT | 224 | 150M | 438M | 16B | 71.9 | 43.7 | 62.0 | 73.2 | 89.5 |
| DiHT | 224 | 150M | 438M | 32B | 72.2 | 43.3 | 60.3 | 72.9 | 89.8 |
| ViT-L/14 | |||||||||
| CLIP [62] | 224 | 428M | 400M | 12.8B | 75.6 | 36.5 | 54.9 | 66.1 | 84.5 |
| CLIP [62] | 336 | 428M | 400M | 13.2B | 76.6 | 37.7 | 57.1 | 68.6 | 86.6 |
| OpenCLIP [27] | 224 | 428M | 400M | 12.8B | 72.8 | 42.1 | 60.1 | 70.4 | 86.8 |
| OpenCLIP [27] | 224 | 428M | 2.3B | 32B | 75.2 | 46.2 | 64.3 | 75.4 | 90.4 |
| DiHT | 224 | 428M | 438M | 16B | 77.0 | 48.0 | 65.1 | 76.7 | 92.0 |
| DiHT | 336 | 428M | 438M | 16.4B | 77.9 | 49.3 | 65.3 | 78.2 | 91.1 |
| Other | |||||||||
| ALIGN [28] EfficientNet-L2 | 289 | 820M | 1.8B | 19.7B | 76.4 | 45.6 | 58.6 | 75.7 | 88.6 |
| FILIP [85]∗ ViT-L/14 | 224 | 428M | 340M | 10.2B | 77.1 | 45.9 | 61.3 | 75.0 | 89.8 |
| OpenCLIP [27] ViT-H/14 | 224 | 986M | 2.3B | 32B | 77.9 | 49.0 | 67.5 | 76.8 | 91.3 |
| Florence [87] CoSwin-H | 384 | 893M | 900M | 31B | 83.7 | 47.2 | 64.7 | 76.7 | 90.9 |
| LiT [89] ViT-g/14 | 288 | 2.0B | 3.6B | 18.2B | 85.2 | 41.9 | 59.3 | — | — |
| BASIC [58] CoAtNet-7 | 224 | 3.1B | 6.6B | 32.8B | 85.7 | — | — | — | — |
4.4 少样本线性探测
利用零样本识别模型的理想场景是在没有训练数据的情况下热启动任务,然后随着看到越来越多的数据,通过少样本学习来提高性能(通过训练线性探针)。 然而,实际上,在低数据情况下,少样本模型的表现明显比零样本模型差。
我们提出了一种替代方法,通过基于提示的初始化来进行少样本分类。 我们方法的关键思想是使用每个类的 零样本 文本提示来初始化分类器,但也要确保最终权重不会使用投影梯度下降的提示偏离太多(PGD)[5]。 虽然过去已经使用提示先验对少样本模型进行了初始化,并使用天真的权重惩罚来防止灾难性遗忘[34],但这些方法并不能提高性能,并且模型只是简单地无视监督。 相反,对于任何目标数据集,其中表示来自训练的图像塔的图像特征,我们解决以下优化问题,对于某些:
这里表示来自文本编码器的提示初始化。 为了优化目标,可以使用投影梯度下降[5]。 我们观察到,我们的方法能够弥合零样本和单样本分类之间的差距,这是先前线性探针评估中的常见问题。
图 6 显示了 ImageNet1K [65] -shot 分类任务结果的完整摘要。 我们的方法的超参数 和 以及从头开始训练线性探针的基线方法的权重衰减是使用网格搜索找到的。 请注意,与基线相比,我们的方法在非常低的 值下表现得更好,并保持从零样本到 1-shot 等的性能连续体。 在较大的 值下,两种方法的性能相似,因为有足够的数据样本使零样本初始化无效。 为了进一步展示我们方法的优势,我们还将我们的性能与在强大的 SWAG [71] 模型上训练的线性探针进行了比较,这些模型特别适合此任务。 请注意,我们的方法在高达 25 个样本的分类方面优于更大的 SWAG ViT-H/14 模型。 我们想强调的是,这种虽然简单的方法是解决零样本和少样本学习之间不连续性问题的第一个方法。
5结论和未来工作
在本文中,我们证明,通过仔细的数据集过滤和简单但有效的建模更改,可以通过大规模预训练在检索和分类任务上实现零样本性能的实质性改进。 我们的 CAT 过滤方法可以普遍应用于任何大型数据集,以较小的训练计划提高性能。 此外,我们的概念蒸馏方法提出了一种利用非常大容量的预训练图像模型进行多模态的有效计算和存储训练方法。 最后,我们简单的投影梯度方法涵盖了零样本和少样本学习之间的关键性能差距。
未来,我们希望将我们的方法扩展到多模态编码器/解码器 [1, 86, 10, 41, 83] 架构,虽然价格昂贵,但与双编码器相比具有更好的零样本性能。 我们还观察到,与 PMD 相比,在噪声较大的 LAION 数据集上,我们的硬阴性损失带来的好处更少。 探索如何使其在这些非常嘈杂的环境中更有效,将会很有趣。 我们希望我们的改进和广泛的大规模消融将进一步推进视觉语言研究。
参考
- [1] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and Karen Simonyan. Flamingo: a visual language model for few-shot learning. arXiv:2204.14198, 2022.
- [2] Alex Andonian, Shixing Chen, and Raffay Hamid. Robust cross-modal representation learning with progressive self-distillation. In CVPR, 2022.
- [3] Thomas Berg, Jiongxin Liu, Seung Woo Lee, Michelle L Alexander, David W Jacobs, and Peter N Belhumeur. Birdsnap: Large-scale fine-grained visual categorization of birds. In CVPR, 2014.
- [4] Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative components with random forests. In ECCV, 2014.
- [5] Stephen Boyd, Stephen P Boyd, and Lieven Vandenberghe. Convex optimization. Cambridge University, 2004.
- [6] Cristian Buciluǎ, Rich Caruana, and Alexandru Niculescu-Mizil. Model compression. In SIGKDD, 2006.
- [7] Guobin Chen, Wongun Choi, Xiang Yu, Tony Han, and Manmohan Chandraker. Learning efficient object detection models with knowledge distillation. In NeurIPS, 2017.
- [8] Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost. arXiv:1604.06174, 2016.
- [9] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In CVPR, 2021.
- [10] Xi Chen, Xiao Wang, Soravit Changpinyo, AJ Piergiovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, Alexander Kolesnikov, Joan Puigcerver, Nan Ding, Keran Rong, Hassan Akbari, Gaurav Mishra, Linting Xie, Ashish Thapliyal, James Bradbury, Weicheng Kuo, Mojtaba Seyedhosseini, Chao Jia, Burcu K Ayan, Carlos Riquelme, Andreas Steiner, Anelia Angelova, Xiaohua Zhai, Neil Houlsby, and Radu Soricut. PaLI: A jointly-scaled multilingual language-image model. arXiv:2209.06794, 2022.
- [11] Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. UNITER: UNiversal Image-TExt Representation Learning. In ECCV, 2020.
- [12] Ching-Yao Chuang, Joshua Robinson, Yen-Chen Lin, Antonio Torralba, and Stefanie Jegelka. Debiased contrastive learning. In NeurIPS, 2020.
- [13] Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. In CVPR, 2014.
- [14] Google Cloud. Using bfloat16 with tensorflow models. cloud.google.com/tpu/docs/bfloat16, 2022.
- [15] Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. In AISTATS, 2011.
- [16] Qianggang Ding, Sifan Wu, Hao Sun, Jiadong Guo, and Shu-Tao Xia. Adaptive regularization of labels. arXiv:1908.05474, 2019.
- [17] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2020.
- [18] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. IJCV, 2010.
- [19] Li Fei-Fei, Rob Fergus, and Pietro Perona. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In CVPR, 2004.
- [20] Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep learning. MIT press, 2016.
- [21] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In CVPR, 2017.
- [22] Michael Gutmann and Aapo Hyvärinen. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In AISTATS, 2010.
- [23] Sangchul Hahn and Heeyoul Choi. Self-knowledge distillation in natural language processing. In RANLP, 2019.
- [24] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, 2020.
- [25] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in neural network. arXiv:1503.02531, 2015.
- [26] Matthew Honnibal, Ines Montani, Sofie Van Landeghem, and Adriane Boyd. spaCy. github.com/explosion/spaCy, 2020.
- [27] Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. OpenCLIP. github.com/mlfoundations/open_clip, 2021.
- [28] Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In ICML, 2021.
- [29] Dhiraj Kalamkar, Dheevatsa Mudigere, Naveen Mellempudi, Dipankar Das, Kunal Banerjee, Sasikanth Avancha, Dharma Teja Vooturi, Nataraj Jammalamadaka, Jianyu Huang, Hector Yuen, Jiyan Yang, Jongsoo Park, Alexander Heineckel, Evangelos Georganas, Sudarshan Srinivasan, Abhisek Kundu, Misha Smelyanskiy, Bharat Kaul, and Pradeep Dubey. A study of bfloat16 for deep learning training. arXiv:1905.12322, 2019.
- [30] Yannis Kalantidis, Mert Bulent Sariyildiz, Noe Pion, Philippe Weinzaepfel, and Diane Larlus. Hard negative mixing for contrastive learning. In NeurIPS, 2020.
- [31] Zaid Khan, BG Vijay Kumar, Xiang Yu, Samuel Schulter, Manmohan Chandraker, and Yun Fu. Single-stream multi-level alignment for vision-language pretraining. In ECCV, 2022.
- [32] Douwe Kiela, Hamed Firooz, Aravind Mohan, Vedanuj Goswami, Amanpreet Singh, Pratik Ringshia, and Davide Testuggine. The hateful memes challenge: Detecting hate speech in multimodal memes. In NeurIPS, 2020.
- [33] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
- [34] James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural networks. PNAS, 2017.
- [35] Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. In ICCVW, 2013.
- [36] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, Michael S Bernstein, and Li Fei-Fei. Visual genome: Connecting language and vision using crowdsourced dense image annotations. IJCV, 2017.
- [37] Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Canada, 2009.
- [38] Zhanghui Kuang, Hongbin Sun, Zhizhong Li, Xiaoyu Yue, Tsui Hin Lin, Jianyong Chen, Huaqiang Wei, Yiqin Zhu, Tong Gao, Wenwei Zhang, Kai Chen, Wayne Zhang, and Dahua Lin. Mmocr: A comprehensive toolbox for text detection, recognition and understanding. In MM, 2021.
- [39] Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, Tom Duerig, and Vittorio Ferrari. The open images dataset v4. IJCV, 2020.
- [40] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In ICML, 2022.
- [41] Junnan Li, Ramprasaath Selvaraju, Akhilesh Gotmare, Shafiq Joty, Caiming Xiong, and Steven Chu Hong Hoi. Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021.
- [42] Tianhong Li, Jianguo Li, Zhuang Liu, and Changshui Zhang. Few sample knowledge distillation for efficient network compression. In CVPR, 2020.
- [43] Xiujun Li, Xi Yin, Chunyuan Li, Pengchuan Zhang, Xiaowei Hu, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, Yejin Choi, and Jianfeng Gao. Oscar: Object-semantics aligned pre-training for vision-language tasks. In ECCV, 2020.
- [44] Yuncheng Li, Jianchao Yang, Yale Song, Liangliang Cao, Jiebo Luo, and Li-Jia Li. Learning from noisy labels with distillation. In ICCV, 2017.
- [45] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.
- [46] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In CVPR, 2021.
- [47] Ilya Loshchilov and Frank Hutter. SGDR: Stochastic gradient descent with warm restarts. In ICLR, 2017.
- [48] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In ICLR, 2019.
- [49] Dhruv Kumar Mahajan, Ross B. Girshick, Vignesh Ramanathan, Kaiming He, Manohar Paluri, Yixuan Li, Ashwin Bharambe, and Laurens van der Maaten. Exploring the limits of weakly supervised pretraining. In ECCV, 2018.
- [50] Kanti V Mardia and Peter E Jupp. Directional statistics. Wiley Online Library, 2000.
- [51] Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. Mixed precision training. In ICLR, 2018.
- [52] George A Miller. WordNet: An electronic lexical database. MIT press, 1998.
- [53] Ishan Misra and Laurens van der Maaten. Self-supervised learning of pretext-invariant representations. In CVPR, 2020.
- [54] Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In ICVGIP, 2008.
- [55] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv:1807.03748, 2018.
- [56] Vicente Ordonez, Girish Kulkarni, and Tamara Berg. Im2text: Describing images using 1 million captioned photographs. In NeurIPS, 2011.
- [57] Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In CVPR, 2012.
- [58] Hieu Pham, Zihang Dai, Golnaz Ghiasi, Kenji Kawaguchi, Hanxiao Liu, Adams Wei Yu, Jiahui Yu, Yi-Ting Chen, Minh-Thang Luong, Yonghui Wu, Mingxing Tan, and Quoc V Le. Combined scaling for open-vocabulary image classification. arXiv:2111.10050, 2021.
- [59] Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. In ICCV, 2015.
- [60] Jordi Pont-Tuset, Jasper Uijlings, Soravit Changpinyo, Radu Soricut, and Vittorio Ferrari. Connecting vision and language with localized narratives. In ECCV, 2020.
- [61] Filip Radenovic, Animesh Sinha, Albert Gordo, Tamara Berg, and Dhruv Mahajan. Large-scale attribute-object compositions. arXiv:2105.11373, 2021.
- [62] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In ICML, 2021.
- [63] Joshua Robinson, Ching-Yao Chuang, Suvrit Sra, and Stefanie Jegelka. Contrastive learning with hard negative samples. ICLR, 2021.
- [64] Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets. arXiv:1412.6550, 2014.
- [65] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge. IJCV, 2015.
- [66] Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Ludwig Scmidth, Robert Kaczmarcyk, and Jitsev Jenia. LAION-5B: An open large-scale dataset for training next generation image-text models. arXiv:2210.08402, 2022.
- [67] Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. LAION-400M: Open dataset of clip-filtered 400 million image-text pairs. arXiv:2111.02114, 2021.
- [68] Zhiqiang Shen and Eric Xing. A fast knowledge distillation framework for visual recognition. In ECCV, 2022.
- [69] Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, and Yaniv Taigman. Make-a-video: Text-to-video generation without text-video data. arXiv:2209.14792, 2022.
- [70] Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela. FLAVA: A foundational language and vision alignment model. In CVPR, 2022.
- [71] Mannat Singh, Laura Gustafson, Aaron Adcock, Vinicius de Freitas Reis, Bugra Gedik, Raj Prateek Kosaraju, Dhruv Mahajan, Ross Girshick, Piotr Dollár, and Laurens van der Maaten. Revisiting weakly supervised pre-training of visual perception models. In CVPR, 2022.
- [72] Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv:1212.0402, 2012.
- [73] Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. Winoground: Probing vision and language models for visio-linguistic compositionality. In CVPR, 2022.
- [74] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In ICML, 2021.
- [75] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017.
- [76] Zirui Wang, Jiahui Yu, Adams Wei Yu, Zihang Dai, Yulia Tsvetkov, and Yuan Cao. SimVLM: Simple visual language model pretraining with weak supervision. arXiv:2108.10904, 2021.
- [77] Bichen Wu, Ruizhe Cheng, Peizhao Zhang, Peter Vajda, and Joseph E Gonzalez. Data efficient language-supervised zero-shot recognition with optimal transport distillation. arXiv:2112.09445, 2021.
- [78] Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, and Lei Zhang. Cvt: Introducing convolutions to vision transformers. In ICCV, 2021.
- [79] Jianxiong Xiao, Krista A Ehinger, James Hays, Antonio Torralba, and Aude Oliva. Sun database: Exploring a large collection of scene categories. IJCV, 2016.
- [80] Ning Xie, Farley Lai, Derek Doran, and Asim Kadav. Visual entailment: A novel task for fine-grained image understanding. arXiv:1901.06706, 2019.
- [81] Qizhe Xie, Minh-Thang Luong, Eduard Hovy, and Quoc V Le. Self-training with noisy student improves imagenet classification. In CVPR, 2020.
- [82] Ting-Bing Xu and Cheng-Lin Liu. Data-distortion guided self-distillation for deep neural networks. In AAAI, 2019.
- [83] Jinyu Yang, Jiali Duan, Son Tran, Yi Xu, Sampath Chanda, Liqun Chen, Belinda Zeng, Trishul Chilimbi, and Junzhou Huang. Vision-language pre-training with triple contrastive learning. In CVPR, 2022.
- [84] Jianwei Yang, Chunyuan Li, Pengchuan Zhang, Bin Xiao, Ce Liu, Lu Yuan, and Jianfeng Gao. Unified contrastive learning in image-text-label space. In CVPR, 2022.
- [85] Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. FILIP: Fine-grained interactive language-image pre-training. arXiv:2111.07783, 2021.
- [86] Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners are image-text foundation models. arXiv:2205.01917, 2022.
- [87] Lu Yuan, Dongdong Chen, Yi-Ling Chen, Noel Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xuedong Huang, Boxin Li, Chunyuan Li, Ce Liu, Mengchen Liu, Zicheng Liu, Yumao Lu, Yu Shi, Lijuan Wang, Jianfeng Wang, Bin Xiao, Xiao Zhen, Jianwei Yang, Michael Zeng, Luowei Zhou, and Pengchuan Zhang. Florence: A new foundation model for computer vision. arXiv:2111.11432, 2021.
- [88] Sukmin Yun, Jongjin Park, Kimin Lee, and Jinwoo Shin. Regularizing class-wise predictions via self-knowledge distillation. In CVPR, 2020.
- [89] Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. LiT: Zero-shot transfer with locked-image text tuning. In CVPR, 2022.
- [90] Wenzheng Zhang and Karl Stratos. Understanding hard negatives in noise contrastive estimation. In NAACL, 2021.
附录A附录
A.1方法详细信息
A.1.1 语义解析器
为了实现丰富的复杂性和语义过滤,我们构建了一个快速的自定义语义解析器,它将给定的文本标题转换为类似于 Visual Genome[36] 中的语义图。 特别是,我们提取对象、它们的部分、它们的属性以及它们所涉及的操作(例如参见图 3)。 该解析器构建在 Spacy[26] 的英语依存解析器之上,并结合多种规则来推断公共对象关系。 解析器的目标是高速、高精度地处理常见对象关系,例如“has_attribute”和“has_part”以及基本的“action”支持。 下面,我们描述从自然语言文本中提取的结构化关系。
我们支持以下语义关系:
对象(_obj)。
我们提取图像中应该呈现的对象。 我们考虑的名词不是另一个名词的属性(不是名词短语的一部分)。 例如.生日蛋糕和婴儿车中的,名词蛋糕和stroller 被解析为对象,名词 birthday 和 baby 被视为属性。 我们不考虑专有名词。
属性(has_attr)。
表示表征对象或其他属性的属性。 例如,深绿色会导致事实绿色 - has_attr - 深色,而黄色蜡烛会导致蜡烛 - has_attr -黄色。
部分(has_part)。
表征对象的视觉部分。 例如。 蛋糕有 21 根黄色蜡烛 将导致部分事实 蛋糕 - has_part - 蜡烛。
行动(_act)。
不包含属性或部分的动词(例如。形式的be、looks、seems 和 have 被排除)被视为操作。 对于动作,我们还解析主语和宾语参数。
操作的主题(act_has_subj、is_act_subj)。
我们使用 act_has_subj 和 is_act_subj 关系来表示作为动作主题的参数(名词)。 例如.对于文本a person is eat an apple,我们添加以对象为中心和相应的以动作为中心的对称事实:人 - is_subj_act - 吃和吃 act_has_subj 人。
操作的对象(act_has_obj、is_act_obj)。
我们还包括指定操作的对象参数的关系。 例如.对于文本a person is eat an apple,我们添加以对象为中心和相应的以动作为中心的对称事实:苹果 - is_obj_act - 吃 和吃 act_has_obj 苹果。
我们认识到我们的方法存在以下局限性:
语义属性。
在这项工作中,我们专注于以对象为中心的视觉和动作特征,我们不处理空间关系(X 旁边的 Y)或其他动作参数(*在*图书馆阅读一本书)。 动词的空间关系和附加参数通常涉及更复杂的语义推理,并且需要更强大的方法和特定于任务的模型,例如经过语义角色标签训练的模型,这些模型通常需要大量计算。 我们把这些留到以后的工作中。
依赖性解析器错误。
在当前版本的解析器中,我们还将潜在的属性解析为动作,这不太可能总是可见的。 例如。 在“跑步者”这个短语中,跑步是一个动作,也是一个属性,我们这样解析它们。 然而,有时底层解析器也会将“striped mug”等短语中的属性解析为动词,其中我们将属性“striped”处理为属性和操作(不带参数)。
A.1.2概念蒸馏
教师模型是通过在冻结的 SWAG [71] 主干网络之上训练线性分类器(预测对象和属性)构建的。 SWAG 通过预测 Instagram 图像中的主题标签以弱监督方式进行训练。 我们使用公开可用的权重,并采用类似于 SWAG 的训练过程来学习线性分类器。 训练对象分类器的过程如下。 首先,我们解析标题以提取名词。 接下来,我们通过 WordNet [52] 同义词集对名词进行规范化,并删除数据集中出现次数少于 250 次的名词。 生成的词汇表包含10K 个独特的同义词集。 最后,我们通过交叉熵损失优化线性层的权重。 交叉熵目标分布中的每个条目是 或 ,具体取决于相应的同义词集是否存在,其中 是数字该图像的同义词集。 我们应用图像的逆平方根重采样来对 [71] 之后的尾部类进行上采样。 重采样时数据集的目标长度设置为 5000 万个样本。 我们使用 SGD 来训练线性层,动量为 0.9,权重衰减为 1e-4。 学习率按照线性缩放规则设置:lr0.001。 为了加速训练,我们使用 64 个 GPU,每个 GPU 的批量大小为 256。 属性分类器的构建方式类似,但 WordNet 形容词同义词集需要额外的过滤来删除非视觉属性,例如。、幽闭恐惧症 ,经验丰富。 在[61]之后,我们根据属性的共享性和可视性来选择属性。 我们根据上述分数对属性进行排序,并保留1200个属性。
A.2培训细节
对于我们的模型架构,我们严格遵循 Radford et al. [62] 的 CLIP。 我们使用视觉转换器 (ViT) [17] 处理图像,使用文本转换器 [75] 处理字幕。 我们尝试了 3 种不同的架构,分别表示为 B/32、B/16 和 L/14,其中 32、16 和 14 表示输入图像块大小。 其他架构扩展参数见表A.1。 对于蒸馏和微调实验,我们利用公共 SWAG-ViT 模型[71],该模型在主题标签的弱监督下进行了预训练。
| Model | Dim | Vision | Language | ||||
|---|---|---|---|---|---|---|---|
| layers | width | heads | layers | width | heads | ||
| B/32 | 512 | 12 | 768 | 12 | 12 | 512 | 8 |
| B/16 | 512 | 12 | 768 | 12 | 12 | 512 | 8 |
| L/14 | 768 | 24 | 1024 | 16 | 12 | 768 | 12 |
我们使用 Adam [33] 优化器以及解耦权重衰减 [48] 和余弦学习率计划 [47]。 输入图像大小为 224224 像素,用于预训练运行。 所有超参数均显示在表A.2中。 它们是通过小规模设置的训练选择的,并重复用于其他实验。 对于概念蒸馏 (CD) 中的对象和属性分类器,我们发现将学习率缩放 10.0 并将权重衰减缩放 0.01 会得到更好的结果。
| Shared | |||
| Learning rate (LR) | 1e-3 | ||
| Warm-up | 1% | ||
| Vocabulary size | 49408 | ||
| Temperature (init, max) | (, 100.0) | ||
| Adam (, ) | (0.9, 0.98) | ||
| Adam | 1e-6 | ||
| High resolution LR | 1e-4 | ||
| Dataset specific | LAION | PMD | |
| CD learning rate scale | 10.0 | 1.0 | |
| CD weight decay scale | 0.01 | 1.0 | |
| HN-NCE | 1.0 | 0.999 | |
| HN-NCE | 0.25 | 0.5 | |
| LAION | PMD | ||
| Model specific | L/14 | B/16,B/32 | B/16,B/32 |
| Batch size | 98304 | 49152 | 32768 |
| Weight decay | 0.2 | 0.1 | 0.1 |
我们根据实验在 4B、8B、16B 或 32B 处理样本上预训练模型。 对于 L/14,我们以更高的 336px 分辨率训练额外的 4 亿个样本,将此模型表示为 L/14@336。 我们在 512 个 A100 GPU 上对 L/14 进行了 6 天的训练,处理了 16B 个样本,总共花费了 个 GPU 小时。
为了加速训练并节省内存,我们使用混合精度训练[51]。 对于 L/14,我们使用梯度检查点 [8] 和 BFLOAT16 [14, 29] 格式,所有其他模型均使用 FP16 [51] 进行训练t2> 格式。 对比损失是根据成对相似度[62]的局部子集计算的。
A.3评估详情
我们在 24 个数据集的零样本基准上评估我们的模型:(i) 17 图像分类:Birdsnap [3]、CIFAR10 [37] 、CIFAR100 [37]、Caltech101 [19]、Country211 [62]、DTD [13]、Flowers102 [54]、Food101 [4]、ImageNet1K [65]、OxfordPets [57]0>、STL10 [15]1>、SUN397 [79]2>、StanfordCars [35]3>、UCF101 [72]4>、HatefulMemes [ 32]5>、PascalVOC2007 [18]6>、OpenImages [39]7>; (ii) 5种跨模态检索8>(文本到图像T2I、图像到文本I2T):COCO [45]9>、Flickr [59] 0>、LN-COCO [60]1>、LN-Flickr [60]2>、Winoground [73]3>; (iii) 2 视觉问答4>:SNLI-VE [80]5>、VQAv2 [21]6>。 请注意,跨模式检索数据集有 2 个任务(T2I 和 I2T),因此我们总共评估 29 个任务。
我们遵循零样本 CLIP 基准777github.com/LAION-AI/CLIP_benchmark 实现大多数数据集,并实现缺少的数据集。 对于大多数图像分类任务,我们计算 Accuracy@1,除了 HatefulMemes,我们计算 AUROC,因为它是二元分类;OpenImages,我们计算 [77] 之后的 FlatHit@1;PascalVOC2007,我们计算平均精度(mAP),因为它是多标签分类。 我们使用与 CLIP [62] 相同的提示集成方法来改进零样本图像分类。 对于跨模态检索(T2I 和 I2T),我们计算 Recall@1。 对于 COCO 和 Flickr,我们应用一个简单的提示借口“{caption} 的照片”,对于 LN-COCO、LN-Flickr 和 Winoground 不应用提示。 我们将视觉问答(VQA)作为二元预测任务,并根据图像和文本(假设或问题)之间的余弦相似度计算 AP。 对于SNLI-VE,我们采用注释者之间达成一致的子集,我们使用“蕴含”和“矛盾”作为二元类,并删除“中性”类。 对于 VQAv2,我们采用带有是/否问题的子集。 SNLI-VE 和 VQAv2 不会应用任何提示。
A.4 额外的消融
数据集过滤的效果。
在图 A.1 中,我们观察到,当我们进行更长的训练计划时,我们提出的复杂性、操作和文本识别 (CAT) 数据集过滤所带来的收益仍然有效。 我们使用多个复杂度过滤器进行了小规模实验(参见表A.3),我们发现具有最小复杂度 C1 的 CAT 表现最好。
| Filter | # examples | % of full | |||||
|---|---|---|---|---|---|---|---|
| [69] | C0 | C1 | C2 | A | T | ||
| 2,121,505,329 | 100.00 | ||||||
| ✓ | 1,983,345,180 | 93.49 | |||||
| ✓ | ✓ | 1,891,725,045 | 89.17 | ||||
| ✓ | ✓ | 1,709,522,548 | 80.58 | ||||
| ✓ | ✓ | 1,143,660,096 | 53.91 | ||||
| ✓ | ✓ | 691,535,901 | 32.60 | ||||
| ✓ | ✓ | ✓ | 642,162,957 | 30.27 | |||
| ✓ | ✓ | ✓ | 487,493,190 | 22.98 | |||
| ✓ | ✓ | ✓ | ✓ | 438,358,791 | 20.66 | ||
top-k 预测对象和属性的影响。
在表A.4中,我们表明我们的概念蒸馏方法对于预测对象和属性数量的选择非常稳健。 对于 ,只需少量增加数据集内存即可实现较高的准确性。
| top-k | Memory | IN | COCO | Flickr | ||
|---|---|---|---|---|---|---|
| T2I | I2T | T2I | I2T | |||
| 5 | 16.3GB | 71.4 | 42.9 | 59.4 | 72.2 | 86.5 |
| 10 | 32.6GB | 71.9 | 42.9 | 60.3 | 73.3 | 87.0 |
| 25 | 81.6GB | 71.4 | 43.1 | 60.0 | 72.9 | 87.9 |
和对HN-Nce的影响。
从直觉上可以看出,项控制损失函数中正对齐项的质量,项控制负对齐项的难度。 对术语 的需求可归因如下。 如果数据集中存在假阴性,则抑制正对齐项可以防止模型对真阳性和假阳性对进行过度区分。 因此,随着误报可能性的增加,我们希望减少 (例如.、更小的数据集、更少噪音的训练)。 对 的需求很简单: 越高,称重函数就越“尖锐”,最难的底片上的质量就越大。 表A.5显示了和不同值对LAION-CAT的影响。
| IN | COCO | Flickr | ||||
|---|---|---|---|---|---|---|
| T2I | I2T | T2I | I2T | |||
| 1 | 0 | 68.7 | 42.8 | 60.5 | 72.8 | 87.6 |
| 1 | 0.25 | 69.2 | 42.9 | 61.2 | 72.6 | 87.8 |
| 1 | 0.5 | 66.5 | 40.3 | 59.7 | 71.4 | 84.9 |
| 0.999 | 0.25 | 69.0 | 42.6 | 60.9 | 72.3 | 87.9 |
| 0.9 | 0.25 | 68.6 | 42.1 | 59.2 | 71.2 | 85.5 |
少样本探测的附加结果。
我们使用 ImageNet1K [65] 的完整训练集检查模型在线性探测方面的性能。 我们在表 A.6 中比较了 DiHT-L/14 和 CLIP-L/14 [62] 架构对于 224px 和 336px 输入大小的性能。 我们观察到 DiHT 模型的 PGD 方法优于之前的工作,并且还发现 SGD 训练的模型和 PGD 训练的模型之间的性能没有显着差异,因为在使用完整数据集训练时不需要正则化。 我们重现了 CLIP [62] 的报告数据,并以 24 的学习率、无权重衰减和 96,000 的批量大小训练我们的模型,持续 160 个时期。
| Model | Optimizer | ImageNet-1K Accuracy (%) |
|---|---|---|
| CLIP-L/14 @ 224px | SGD | 83.60 |
| DiHT-L/14 @ 224px | SGD | 85.40 |
| DiHT-L/14 @ 224px | PGD | 85.41 |
| CLIP-L/14 @ 336px | SGD | 85.40 |
| DiHT-L/14 @ 336px | SGD | 85.87 |
| DiHT-L/14 @ 336px | PGD | 85.89 |
| Method |
Birdsnap |
CIFAR10 |
CIFAR100 |
Caltech101 |
Country211 |
DTD |
Flowers102 |
Food101 |
ImageNet1K |
OxfordPets |
STL10 |
SUN397 |
StanfordCars |
UCF101 |
HatefulMemes |
PascalVOC |
OpenImages |
COCO T2I |
COCO I2T |
Flickr T2I |
Flickr I2T |
LN-COCO T2I |
LN-COCO I2T |
LN-Flickr T2I |
LN-Flickr I2T |
Winoground T2I |
Winoground I2T |
SNLI-VE |
VQAv2 |
| ViT-B/32 @ 224 | |||||||||||||||||||||||||||||
| CLIP | 40.3 | 89.8 | 65.1 | 83.9 | 17.2 | 43.8 | 66.6 | 83.9 | 63.4 | 87.4 | 97.2 | 62.3 | 59.7 | 64.2 | 58.1 | 84.2 | 27.8 | 31.4 | 49.0 | 59.5 | 79.9 | 16.8 | 24.6 | 30.2 | 38.1 | 28.1 | 27.4 | 77.6 | 57.3 |
| OpenCLIP | 50.5 | 93.6 | 75.8 | 86.4 | 16.7 | 56.1 | 71.7 | 82.7 | 66.6 | 90.6 | 96.6 | 68.5 | 86.0 | 66.1 | 53.4 | 85.4 | 34.6 | 39.0 | 56.7 | 65.7 | 81.7 | 29.5 | 35.1 | 44.0 | 51.4 | 32.0 | 30.2 | 78.6 | 59.3 |
| DiHT | 46.5 | 92.0 | 73.6 | 80.4 | 16.3 | 55.3 | 69.8 | 84.1 | 68.0 | 91.7 | 97.2 | 66.5 | 79.6 | 68.3 | 53.5 | 78.9 | 32.4 | 40.6 | 59.3 | 68.6 | 84.4 | 29.8 | 35.7 | 46.1 | 54.0 | 30.9 | 33.0 | 79.1 | 59.9 |
| ViT-B/16 @ 224 | |||||||||||||||||||||||||||||
| CLIP | 43.2 | 90.8 | 68.3 | 84.7 | 22.8 | 44.9 | 71.2 | 88.7 | 68.4 | 89.1 | 98.3 | 64.4 | 64.7 | 69.5 | 59.3 | 85.3 | 29.3 | 33.7 | 51.3 | 63.3 | 81.9 | 18.7 | 25.2 | 31.3 | 37.4 | 31.0 | 30.2 | 77.9 | 57.7 |
| OpenCLIP | 52.1 | 91.7 | 71.4 | 86.2 | 18.1 | 50.8 | 69.3 | 86.1 | 67.1 | 89.4 | 97.0 | 69.6 | 83.8 | 67.7 | 55.7 | 84.2 | 35.2 | 37.8 | 55.4 | 65.2 | 84.1 | 26.1 | 33.1 | 43.5 | 46.9 | 30.5 | 30.2 | 78.4 | 59.3 |
| DiHT | 54.5 | 92.7 | 77.5 | 81.2 | 19.1 | 59.4 | 70.5 | 89.1 | 72.2 | 92.7 | 98.2 | 68.4 | 86.0 | 70.3 | 56.2 | 79.5 | 34.6 | 43.3 | 60.3 | 72.9 | 89.8 | 32.4 | 38.2 | 52.9 | 57.7 | 32.0 | 33.4 | 80.8 | 60.3 |
| ViT-L/14 @ 224 | |||||||||||||||||||||||||||||
| CLIP | 52.5 | 95.6 | 78.2 | 86.7 | 31.9 | 55.5 | 79.1 | 93.1 | 75.6 | 93.5 | 99.4 | 67.6 | 77.8 | 77.0 | 60.4 | 85.5 | 30.6 | 36.5 | 54.9 | 66.1 | 84.5 | 20.8 | 28.6 | 36.2 | 44.2 | 31.9 | 32.0 | 78.2 | 58.4 |
| OpenCLIP | 62.9 | 96.6 | 83.4 | 88.0 | 26.3 | 62.9 | 75.5 | 91.0 | 75.2 | 93.2 | 98.9 | 74.3 | 92.6 | 75.2 | 55.1 | 87.5 | 38.0 | 46.2 | 64.3 | 75.4 | 90.4 | 34.6 | 39.9 | 50.9 | 57.7 | 33.4 | 36.4 | 80.8 | 60.0 |
| DiHT | 60.4 | 91.7 | 81.3 | 81.6 | 26.0 | 60.3 | 77.6 | 92.7 | 77.0 | 93.8 | 98.0 | 70.2 | 91.1 | 77.9 | 56.5 | 79.3 | 35.0 | 48.0 | 65.1 | 76.7 | 92.0 | 35.6 | 40.7 | 52.7 | 60.3 | 31.8 | 33.4 | 81.3 | 61.0 |
| ViT-L/14 @ 336 | |||||||||||||||||||||||||||||
| CLIP | 53.7 | 95.0 | 77.0 | 87.2 | 34.4 | 56.0 | 78.6 | 93.8 | 76.6 | 93.8 | 99.5 | 68.7 | 79.2 | 77.6 | 61.6 | 86.2 | 31.8 | 37.7 | 57.1 | 68.6 | 86.6 | 20.2 | 28.6 | 38.1 | 45.7 | 32.3 | 21.4 | 78.7 | 58.5 |
| DiHT | 62.0 | 92.2 | 81.2 | 82.4 | 27.8 | 61.1 | 77.0 | 92.9 | 77.9 | 94.0 | 98.2 | 71.2 | 91.5 | 77.7 | 56.3 | 81.0 | 36.5 | 49.3 | 65.3 | 78.2 | 91.1 | 36.7 | 41.2 | 54.5 | 61.6 | 35.0 | 38.5 | 81.7 | 61.4 |
零样本基准的其他结果。
我们在表 A.7 中报告了 CLIP [62]、OpenCLIP [27] 和 DiHT 在所有 29 个零样本任务上的性能。
A.5 与硬负片的对比对齐
收敛保证
Proposition 1。
让。 然后对于任何可测量的和,我们观察到收敛为。
证明。
遵循[63]的命题6,对于任何,损失函数定义如下。
∎