自监督学习调查:算法、应用和未来趋势
摘要
深度监督学习算法通常需要大量标记数据才能获得令人满意的性能。 然而,收集和标记此类数据的过程可能既昂贵又耗时。 自监督学习(SSL)是无监督学习的一个子集,旨在从未标记的数据中学习判别性特征,而不依赖于人工注释的标签。 SSL 最近引起了极大的关注,导致了许多相关算法的开发。 然而,缺乏全面的研究来阐明不同 SSL 变体的联系和演变。 本文回顾了各种 SSL 方法,包括算法方面、应用领域、三个关键趋势和开放研究问题。 首先,我们详细介绍了大多数 SSL 算法背后的动机,并比较了它们的共性和差异。 其次,我们探讨了 SSL 在图像处理、计算机视觉和自然语言处理等领域的代表性应用。 最后,我们讨论 SSL 研究中观察到的三个主要趋势,并强调仍然存在的悬而未决的问题。 可以通过 https://github.com/guijiejie/SSL 访问精选的有价值资源。
索引术语:
自监督学习、对比学习、生成模型、表征学习、迁移学习1 简介
深度监督学习算法在计算机视觉(CV)和自然语言处理(NLP)等各个领域都表现出了令人印象深刻的性能。 为了解决这个问题,通常采用在 ImageNet [1] 等大规模数据集上预训练的模型作为起点,然后针对特定的下游任务进行微调(表 I)。 这种做法有两个主要原因。 首先,从大规模数据集中获取的参数提供了良好的初始化,使得在其他任务上训练的模型能够更快地收敛[2]。 其次,在大规模数据集上训练的网络已经学习了判别性特征,这些特征可以很容易地转移到下游任务中,并减轻此类任务中有限训练数据引起的过拟合问题[3, 4] 。
| Pre-training | Data | Pre-training Tasks | Downstream Tasks |
|---|---|---|---|
| Supervised | extensive labeled data | image categorization[5] | detection / segmentation / |
| pose estimation / depth estimation, etc | |||
| video action categorization[6] | action recognition / object tracking, etc | ||
| SSL | extensive unlabeled data | Image: rotation [7], jigsaw [8], etc | detection / segmentation / |
| pose estimation / depth estimation, etc | |||
| Video: the order of frames [9], playing direction [10], etc | action recognition / object tracking, etc | ||
| NLP: masked language modeling[11] | question answering / textual entailment recognition / | ||
| natural language inference, etc. |
不幸的是,许多现实世界的数据挖掘和机器学习应用程序面临着一个共同的挑战,即大量未标记的训练实例与有限数量的标记实例共存。 由于需要具有足够领域专业知识的熟练人类注释者[12, 13],因此获取带标签的示例通常成本高昂、艰巨或耗时。 为了说明这一点,请考虑对网络用户配置文件的分析,其中可以轻松收集大量数据。 然而,对非盈利或盈利用户进行标记需要进行彻底的审查、判断,有时甚至需要由经验丰富的人工评估人员执行耗时的跟踪任务,从而导致大量费用。 另一个例子与医学领域有关,通过常规医学检查可以轻松获得未标记的例子。 然而,对如此大量的病例进行单独诊断给医学专家带来了沉重的负担。 例如,在乳腺癌诊断中,放射科医生必须在大量易于获得的高分辨率乳房 X 光照片中标记每个病灶。 事实证明,这个过程通常效率极低且耗时。 此外,监督学习方法容易受到虚假相关性和泛化错误的影响,并且容易受到对抗性攻击。
为了解决监督学习的上述局限性,人们引入了各种机器学习范式,包括主动学习、半监督学习和自监督学习(SSL)。 本文特别强调SSL。 SSL 算法旨在从大量未标记的实例中学习判别性特征,而不依赖于人工注释。 SSL的总体框架如图1所示。 在自监督预训练阶段,制定预定义的借口任务供深度学习算法解决。 借口任务的伪标签是根据输入数据的特定属性自动生成的。 一旦自监督预训练过程完成,获得的模型就可以转移到下游任务。
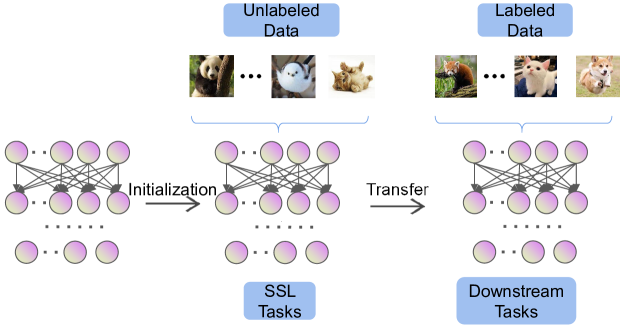
SSL 算法的一个显着优势是它们能够利用大量未标记数据,因为伪标签的生成不需要人工注释。 通过在训练过程中利用这些伪标签,自监督算法已经展现出了良好的结果,与下游任务中的监督算法相比,性能差距缩小了。 Asano 等人 [14] 证明 SSL 可以产生可泛化的特征,即使应用于单个图像,这些特征也表现出强大的泛化能力。
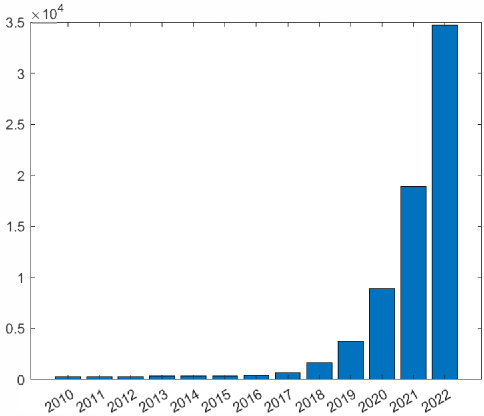
SSL [15,16,17,18,19,20,21,22,23,3,4,24]的进展迅速,引起了研究界的极大关注(图.2),并被认为是实现人类水平智能的关键要素[25]。 Google Scholar 报告了大量与 SSL 相关的出版物,仅 2021 年就发表了约 18,900 篇论文。 这相当于平均每天 52 篇论文或每小时超过 2 篇论文(图2)。 为了帮助研究人员浏览大量 SSL 论文并巩固最新的研究成果,我们的目标是针对这一主题提供及时、全面的调查。
与之前工作的差异:之前的工作提供了针对特定应用的 SSL 评论,例如推荐系统[26]、图表[27, 28]、顺序迁移学习[29]、视频[30]、自监督深度网络的对抗性预训练[31]、和视觉特征学习[32]。 此外,刘等人[4]主要关注2020年之前发表的论文,缺乏最新进展。 Jaiswal 等人[33]将他们的调查集中在对比学习(CL)上。 值得注意的是,CV 领域内 SSL 研究的最新突破具有重要意义。 因此,这篇综述主要涵盖了来自 CV 社区的最新 SSL 研究,特别是那些有影响力和经典的发现。 本次综述的主要目的是阐明 SSL 的概念、它的类别和子类别、它的区别以及与其他机器学习范式的关系,以及它的理论基础。 我们对视觉 SSL 的前沿进行了广泛且最新的回顾,将其分为四个关键领域:基于上下文、CL、生成和对比生成算法,旨在为学者概述突出的研究趋势。
2 算法
本节首先介绍 SSL,然后解释与 SSL 相关的借口任务及其与其他学习范例的集成。
2.1 什么是 SSL?
SSL 的引入归功于[34](图3),他利用这种架构在具有多种模式的自然环境中进行学习。 例如,一头牛的景象和它特有的“哞哞”声经常被同时观察到。 因此,尽管牛图像可能不需要牛标签,但它经常与“moo”实例相关联。 关键在于处理牛图像,为网络导出一个自监督标签,使其能够处理相应的“哞”声,反之亦然。
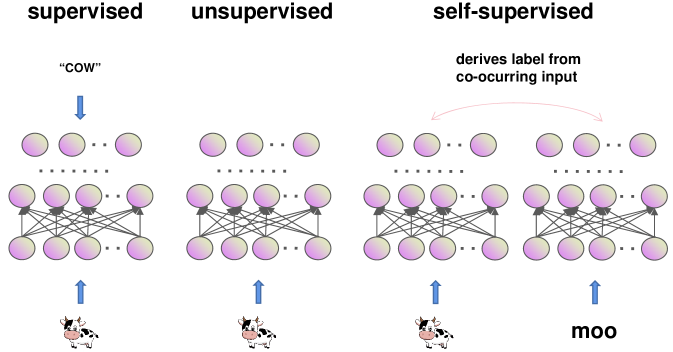
随后,机器学习社区提出了 SSL 的概念,属于无监督学习领域。 SSL 涉及通过揭示数据组件或数据的各种视图之间的关系,从输入数据示例“本质上”生成输出标签。 这些输出标签直接源自数据示例。 根据这个定义,自动编码器 (AE) 可以被视为一种 SSL 算法,其中输出标签对应于数据本身。 AE 已在多个领域得到广泛应用,包括降维和异常检测。
在 ICLR 2020 的主题演讲中,Yann LeCun 阐述了 SSL 的概念,将其视为完成缺失信息(重建)的类似过程。 他提出了以下多种变体:1)从任何其他部分预测输入的任何部分; 2)从过去预测未来; 3)从可见预测不可见; 4) 从所有可用部分中预测任何被遮挡、被遮蔽或损坏的部分。 总之,SSL 中输入的一部分是未知的,目标是预测该特定段。
Jing 等人 [32] 扩展了 SSL 的定义,以涵盖无需人工注释标签即可运行的方法。 因此,任何没有此类标签的方法都可以归类为 SSL,从而有效地将 SSL 等同于无监督学习。 此分类包括生成对抗网络 (GAN)[35],从而将它们定位在 SSL 领域内。
借口任务,也称为代理或代理任务,是 SSL 领域的基本概念。 术语“借口”表示正在解决的任务不是主要目标,而是作为生成稳健的预训练模型的手段。 借口任务的突出例子包括旋转预测和实例辨别等。 每个借口任务都需要使用不同的损失函数来实现其预期目标。 鉴于 SSL 中借口任务的重要性,我们将进一步详细介绍它们。
2.2 借口任务
本节全面概述 SSL 中使用的借口任务。 SSL 中的一种流行方法涉及为网络设计要解决的借口任务,其中通过优化与这些任务相关的目标函数来训练网络。 借口任务通常表现出两个关键特征。 首先,采用深度学习方法来学习有助于解决借口任务的特征。 其次,监督信号源自数据本身,这一过程称为自我监督。 常用的技术包括四类借口任务:基于上下文的方法、CL、生成算法和对比生成方法。 在我们的论文中,生成算法主要指掩模图像建模(MIM)方法。
2.2.1 基于上下文的方法
基于上下文的方法依赖于所提供示例之间固有的上下文关系,涵盖空间结构以及局部和全局一致性的保存等方面。 我们使用旋转作为简单示例[36]来说明基于上下文的借口任务的概念。 随后,我们逐步引入额外的任务(图4)。

旋转:利用旋转的方法涉及深度神经网络(DNN),通过识别应用于原始图像的几何变换来学习图像表示。 在他们的工作中,Gidaris 等人 [7] 为每个图像生成了三个旋转图像(、 和 旋转)原始图像(“旋转”)。 这些图像根据旋转角度分为四类(、、和),作为输出源自图像本身的标签。 具体来说,采用了一组离散几何变换,其中表示应用标记为的几何变换的运算符到图像,产生变换后的图像。
为了预测旋转,Gidaris 等人采用了表示为 的深度卷积神经网络 (CNN),它解决了四类分类任务。 CNN 采用输入图像 (其中 对于 来说是未知的)并生成潜在几何变换的概率分布,表示为
| (1) |
这里,表示标记为的几何变换的预测概率,而表示的可学习参数。
为了准确地对自然图像的 类进行分类,熟练的 CNN 应该具备这样做的能力。 因此,当提供一组训练实例时,的自监督训练目标可以表示为
| (2) |
这里,损失函数定义为
| (3) |
在[37]中,相对旋转角度被限制在区间内。 这些旋转被离散化为每个 的容器,总共 20 个类(或容器)。
着色:着色的概念最初在[38]中引入,随后的研究[39,40,41]证明了其作为SSL 的借口任务。 颜色预测的优点是需要免费提供的训练数据。 在这种情况下,模型可以利用任何彩色图像的 通道作为输入,并利用 CIE 颜色空间中相应的 颜色通道作为自身- 受监督的信号。 目标是在给定输入亮度通道 的情况下预测 颜色通道 ,其中 和 分别表示图像的高度和宽度。 在这种情况下,和分别表示真实值和预测值。 常用的目标函数旨在最小化 和 之间的 Frobenius 范数,如下所示
| (4) |
此外,[38]利用多项式交叉熵损失代替(4)来增强鲁棒性。 完成训练过程后,就可以预测任何灰度图像的 颜色通道。 因此,可以将 通道和 颜色通道连接起来,将原始灰度图像恢复为彩色表示。
拼图:拼图方法利用拼图游戏作为代理任务,假设模型通过理解示例中嵌入的上下文信息来完成这些任务。 具体来说,图像被分割成离散的块,并且它们的位置被随机重新排列,目的是重建原始顺序。 在[42]中,从数据大小、模型容量三个维度研究了缩放两种自监督方法(即拼图[8, 43]和着色)的影响,以及问题的复杂性。 结果表明,传输性能表现出与数据大小相关的对数线性增长模式。 此外,随着模型容量的增加和问题复杂性的增加,表示质量也得到了提高。
其他:[44, 45]中采用的借口任务涉及条件运动传播问题。 为了对特征表示过程施加特定的约束,Noroozi等人[46]引入了一个额外的要求,即所有图像块的特征表示之和应近似于整个图像的特征表示。 虽然许多借口任务产生的表示与图像变换表现出协方差,但[47]主张语义表示对于此类变换不变的重要性。 作为回应,他们提出了一种借口不变表示学习方法,可以通过借口任务学习不变表示。
2.2.2 对比学习
许多基于 CL 的 SSL 方法已经出现,它们建立在简单实例区分任务的基础上[48, 49]。 著名的示例包括 MoCo v1 [50]、MoCo v2 [51]、MoCo v3 [52]、SimCLR v1 [53] 和 SimCLR v2 [54]。 MoCo等开创性算法显着增强了自监督预训练的性能,达到了与监督学习相当的水平,从而使SSL对于大规模应用具有高度针对性。 早期的 CL 方法是建立在利用反例的概念之上的。 然而,随着 CL 的进步,出现了一系列消除负例需求的方法。 这些方法包含不同的想法,例如自蒸馏和特征去相关,但都遵循保持正例一致性的原则。 以下部分概述了当前可用的各种 CL 方法(图5)。
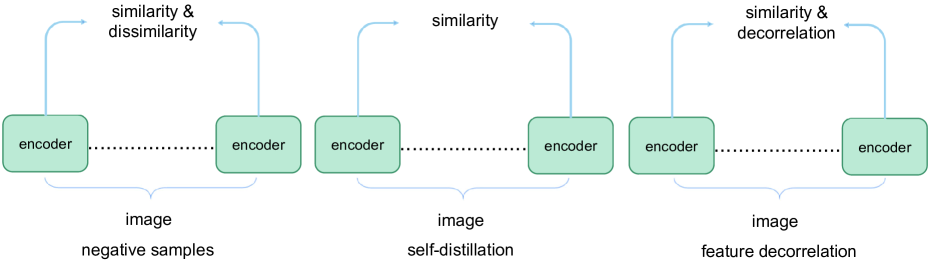
基于负例的 CL
基于负例的 CL 遵循称为实例辨别的借口任务,其中涉及生成实例的不同视图。 在基于负例的 CL 中,源自同一实例的视图被视为锚样本的正例,而来自不同实例的视图则被视为负例。 基本原则是在潜在空间内促进正例之间的接近并最大化负例之间的分离。 正面和负面例子的定义取决于所考虑的模态和具体要求等因素,包括视频理解中的空间和时间一致性或多模态学习场景中模态的共现。 在传统 2D 图像 CL 的背景下,图像增强技术用于从单个图像生成不同的视图。
MoCo:他等人[50]将CL定义为字典查找任务。 在此框架中,查询和一组编码示例充当字典中的键。 假设字典中表示为的单个键与查询匹配,则采用对比损失[55]函数。 当 与其正键 相似且与所有其他负键不同时,此函数的值较低。 在MoCo v1 [50]框架中,利用了InfoNCE损失函数[56],一种对比损失的形式,即,
| (5) |
其中表示温度超参数。 总和是根据一个正例和 个负例计算的。 InfoNCE源自噪声对比估计(NCE)[57],其特征在于以下目标:
| (6) |
其中 与正例 表现出相似性,而与负例 表现出不同性。
MoCo v2 [51] 建立在 MoCo v1 [50] 和 SimCLR v1 [53] 建立的基础上,结合了多层感知器 (MLP) )投影头和更多数据增强。
SimCLR:SimCLR v1 [53] 采用带有 实例的小批量采样策略,其中对比预测任务是在增强实例对上制定的从小批量中,总共生成 2 个实例。 值得注意的是,SimCLR v1 没有显式选择负实例。 相反,对于给定的正对,小批量中剩余的 2 增强实例将被视为负例。 让表示两个实例和之间的余弦相似度。 SimCLR v1 的正实例对 的损失函数定义为
| (7) |
其中, 是指示函数,如果 则等于 1, 表示温度超参数。 总体损失是针对小批量内的所有正对(包括 和 )计算的。
在MoCo中,动量编码器生成的特征作为反例存储在特征队列中。 这些反例在反向传播期间不会经历梯度更新。 相反,SimCLR 利用当前小批量中的负样本,并且所有负样本在反向传播期间都会受到梯度更新。 MoCo 和 SimCLR 都依赖于数据增强技术,包括裁剪、调整大小和颜色失真。 值得注意的是,SimCLR 通过强调稳健数据增强在 CL 中的关键作用做出了重大贡献,这一发现随后被 MoCo v2 证实。 还探索了其他增强方法[58]。 例如,在[59]中,估计了图像中的前景显着性水平,并通过选择性地将图像前景复制并粘贴到不同的背景上来创建增强,例如具有随机灰度级别的灰度图像、纹理图像、和 ImageNet 图像。 此外,视图可以来自各种来源,包括不同的模式,例如照片和声音[60],以及不同图像通道之间的一致性[61]。
已知最小化对比损失可以有效地最大化变量 和 [56] 之间的互信息 的下界>。 基于这种理解,[62]提出了基于信息论设计不同视图的原则。 这些原则表明视图应旨在最大化 和 (、 和 分别表示第一个视图、第二个视图和标签),表示任务标签包含的信息量,同时最小化 ,表示包含任务相关和任务相关的输入之间的共享信息不相关的细节。 因此,最佳的数据增强方法取决于特定的下游任务。 在密集预测任务的背景下,[63]引入了一种生成不同视图的新颖方法。 这项研究表明,SimCLR 中使用的常用数据增强方法更适合分类任务,而不是对象检测和语义分割等密集预测任务。 因此,针对特定下游任务的数据增强方法的设计已成为一个重要的探索领域。
鉴于强大的数据增强在增强 CL 性能方面所观察到的好处[53],人们对利用更强大的增强技术越来越感兴趣。 然而,值得注意的是,仅仅依赖强大的数据增强实际上会导致性能下降[62]。 强数据增强引入的失真可以改变图像结构,导致与弱增强图像不同的分布。 这种差异带来了优化挑战。 为了解决强数据增强带来的过度拟合问题,[64]提出了一种替代方法。 他们建议使用弱数据增强生成的分布作为模拟,而不是采用单热分布。 通过将增强示例的分布与弱增强示例的分布对齐,可以减轻强数据增强的负面影响。
基于自蒸馏的 CL
Bootstrap Your Own Latent (BYOL) [65] 是一种著名的自蒸馏算法,专为自监督图像表示学习而设计,无需负对。 这种方法采用两个相同的 DNN(称为 Siamese 网络),具有相同的架构但权重不同。 一个作为在线网络,另一个作为目标网络。 与 MoCo [50] 类似,BYOL 通过在线网络的逐步平均来增强目标网络。 连体网络已成为当代自监督视觉表示学习模型中的流行架构,包括 SimCLR、BYOL 和 SwAV [66]。 这些模型旨在最大化单个图像的两个增强版本之间的相似性,同时结合特定条件以减轻解决方案崩溃的风险。
[67] 引入的简单暹罗 (SimSiam) 网络提供了一种简单的方法来学习 SSL 中的有效表示,而无需负例对、大批量或动量编码器。 给定一个数据点 和两个随机增强视图 和 、一个编码器 和一个 MLP 预测头 处理这些视图。 结果输出表示为 和 。 [67] 的目标是最小化它们的负余弦相似度:
| (8) |
这里,代表-范数。 与[65]类似,对称损失[67]定义为
| (9) |
这个损失是根据示例定义的,总体损失是所有示例的平均值。 值得注意的是,[67]通过修改等式来采用停止梯度()运算。 (8) 为 。 这意味着 被视为常量。 同样,等式。 (9) 被修改为
| (10) |
图6说明了 SimCLR、BYOL、SwAV 和 SimSiam 之间的区别。 将 BYOL 和 SimSiam 归类为 CL 方法是一个有争议的话题,因为它们排除了负面示例。 然而,为了与[68]保持一致,本文认为BYOL和SimSiam属于CL方法。
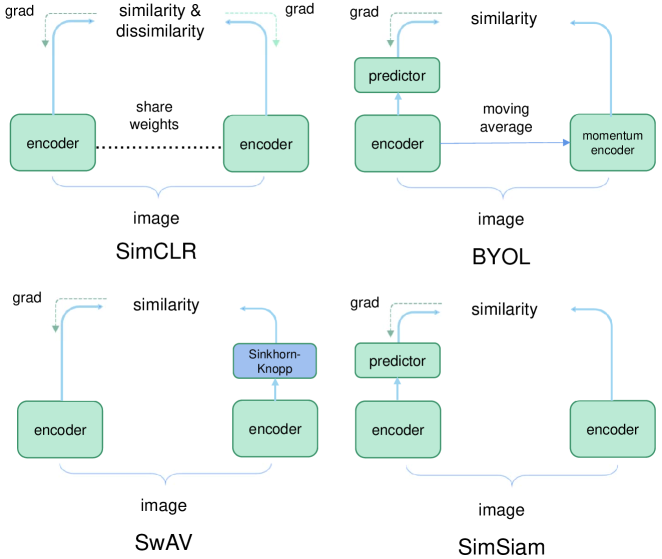
基于特征去相关的 CL
特征去相关的目标是学习去相关的特征。
巴洛双胞胎:巴洛双胞胎[69]引入了一种新颖的损失函数,该函数鼓励来自示例的扭曲版本的嵌入向量的相似性,同时最大限度地减少其组件之间的冗余。 与 MoCo [50] 和 SimCLR [53] 等其他 SSL 方法类似,Barlow twins 为采样的批次 中的每个图像生成两个视图来自数据集,产生批量嵌入 和 。 巴洛孪生的目标函数定义为
| (11) |
这里,是一个超参数,表示沿批量维度两个相同网络的输出之间计算的互相关矩阵:
| (12) |
在上式中,表示批量示例索引,表示网络输出的向量维度索引。 矩阵具有正方形形状,其大小等于网络输出的维数。
方差-不变-协方差正则化:方差-不变-协方差正则化 (VICReg) [70] 已针对 SSL 提出,类似于巴洛双胞胎 [69]. 巴洛孪生关注的是互相关矩阵,而 VICReg 同时考虑方差、不变性和协方差。 令 、 和 分别表示 中向量的维数、批量大小以及由分别是 中所有示例中维度 处的值。 VICReg 中的方差正则化项 被定义为铰链损失函数,应用于沿批量维度的嵌入的标准偏差:
| (13) |
这里,表示正则化标准差,定义为
| (14) |
常数决定标准差,在实验中设置为1,而是一个小标量,用于防止数值不稳定。 此标准鼓励当前批次内每个维度的方差等于或大于 ,从而防止所有数据映射到同一向量的崩溃情况。
VICReg 中的不变性准则 捕获 和 之间的相似性,定义为每对数据之间的均方欧氏距离,不包含任何正常化:
| (15) |
另外,VICReg中的协方差准则定义为
| (16) |
其中表示的协方差矩阵。 VICReg 的总体损失是方差、不变性和协方差的加权和:
| (19) |
其中 和 是两个超参数。
化学发光分析
尽管对比 SSL 取得了令人印象深刻的结果,但其成功的底层机制仍然有些模糊且未被完全理解。 多项研究深入研究了该领域[71,72,73,74,75,76,77,78,79,80,81,82]。 [72,77,80]的理论研究为通过 CL 生成的特征表示的价值提供了支持。 他们的研究结果表明,这些表示为下游任务提供了重要的实用性。
与主成分分析的联系:Tian [82]证明具有像InfoNCE这样的损失函数的CL可以被表述为一个最大-最小问题。 max 函数旨在最大化特征表示之间的对比度,而 min 函数则为具有相似表示的示例对分配权重。 在深度线性网络的背景下,Tian表明表示学习中的最大函数相当于主成分分析(PCA),并且大多数局部极小值对应于全局极小值,从而恢复最优PCA解。 实验结果表明,当该公式扩展到包含 InfoNCE 之外的新对比损失时,可以在 STL-10 和 CIFAR10 等数据集上实现可比甚至更优越的性能。 此外,Tian将他的理论分析扩展到2层整流线性单元(ReLU)网络,强调线性和非线性场景之间的实质性差异,并强调数据增强在训练过程中的重要作用。 值得注意的是,PCA 的目标是最大化低维子空间内的示例间距离,使其成为实例区分的特定实例。
与谱聚类的联系:Chen等人[79]建立了CL和谱聚类之间的联系,表明从CL获得的表示对应于正对图的嵌入谱聚类。 具体来说,作者引入了一个群体增强图,其中节点表示来自群体分布的增强数据,节点之间是否存在边缘取决于它们是否源自同一原始示例。 他们的关键假设是不同的类仅表现出有限数量的连接,从而导致此类图的划分更加稀疏。 经验证据证实了这一特性,说明了同一类内的数据连续性[81]。
具体来说,对邻接矩阵进行谱分解来构造矩阵,其中每一行表示一个示例的表示。 通过线性变换,他们证明了可以通过最小化非常规对比损失来检索相应的特征提取器,如下所示:
| (22) |
值得注意的是,在表示的维数超过不相交子图的最大数量的情况下,在线性分类中使用学习的表示可以保证产生最小的错误。
与监督学习的联系:最近的研究强调了使用 CL 进行自我监督预训练来完成涉及分类的下游任务的显着功效。 然而,当应用于其他任务域时,其有效性可能会有所不同。 因此,迫切需要研究对比预训练在增强监督学习方面的潜力,特别是在超越传统监督学习所实现的准确性方面。
Newell等人[83]对预训练对模型性能的潜在影响进行了全面的调查。 他们的研究探讨了以下三个关键假设。 首先,预训练是否能够持续带来性能提升。 其次,在面对有限的标记数据时,预训练是否能够实现更高的准确性,但当有足够的标记数据可用时,预训练是否最终会达到与基线相当的性能水平。 第三,在准确率达到稳定水平之前,预训练是否收敛到基线性能。 为了解决这些假设,作者在带有渲染的合成 COCO 数据集上进行了实验,从而允许使用大量标签。 结果表明,自监督预训练符合第三个假设中概述的假设。 这表明 SSL 在学习能力方面并未超越监督学习,但在处理有限的标记数据时确实表现有效。
其他的
除了上述工作之外,其他几种方法也采用了 CL。 其中,[52, 84] 研究了视觉变换器 (ViT) 作为对比 SSL 骨干的利用,采用多裁剪和交叉熵损失[84] 。 值得注意的是,[84]发现所得特征表现出作为-最近邻(-NN)分类器的卓越性能,并有效地编码了有关图像的语义分割。 这些理想的特性也激发了特定的下游任务[85]。 在另一项研究中,[86]采用从同一图像中提取的补丁作为正对,而从不同图像中提取的补丁作为负对。 RegionCL [87] 中进一步探索了混合操作,以使对比对多样化。 Yang 等人[88]利用加权目标函数将 CL 和 MIM 集成到文本识别中。 文献中提供了许多基于 CL 的方法[89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107、108、109]。 值得注意的是,CL 不仅仅限于 SSL,它还可以用于监督学习[110]。
2.2.3 生成算法
对于生成算法类别,本研究主要关注 MIM 方法。 MIM方法[111](图7)——即来自图像转换器的双向编码器表示(BEiT)[112],掩模AE( MAE) [68]、上下文 AE (CAE) [113] 和简单的 MIM 框架 (SimMIM) [114] — 有获得了巨大的人气,并对 CL 的主导地位构成了相当大的挑战。 MIM 利用图像块之间的共现关系作为监督信号。
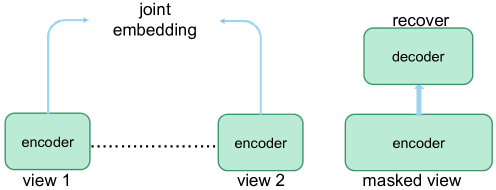
MIM 代表去噪 AE (DAE) [16] 的一种变体,强调对输入噪声保持弹性的鲁棒表示的重要性。 值得注意的是,Transformers (BERT) 的双向编码器表示[11]已成为 DAE 的著名变体,并在 NLP 领域取得了显着的成功。 研究人员希望通过采用类似 BERT 的预训练策略将这一成功扩展到 CV。 然而,必须承认的是,BERT 在 NLP 领域的成功不仅归功于其大规模的自监督预训练,还归功于其可扩展的网络架构。 NLP 和 CV 社区之间的一个显着区别是它们使用不同的主要模型,其中 Transformer 在 NLP 中普遍使用,而 CNN 在 CV 中广泛采用。
随着最初的 ViT [5] 的引入,情况发生了显着变化,这标志着一个关键时刻。 Alexey Dosovitskiy等人从BERT的蒙版图像预测范式中汲取灵感,进行了将MIM应用于CV的开创性研究。 他们的较小 ViT-B/16 模型通过自监督预训练在 ImageNet [1] 上实现了 79.9% 的准确率,比从头开始训练提高了 2%,令人印象深刻。 然而,它仍然达不到监督预训练所达到的准确性。 除了 ViT 之外,一项单独的早期研究还采用了上下文编码器[115],采用类似于 MAE 的概念,即,图像修复。
尽管结构一致,但 MAE 直到 BEiT 出现才在视觉研究中找到重要应用。 在 BEiT 之前,还有另一种尝试称为图像生成预训练 (iGPT)[116],但由于其精度和计算效率不佳而受到的关注有限。 沿着 BERT 在 NLP 领域取得成功的足迹,BEiT 引入了为视觉预训练量身定制的 MIM 任务 即,这是一种词符化方法,它将输入图像分解为视觉词符,然后随机屏蔽图像斑块的子集。 与 BERT 类似,屏蔽和未屏蔽的图像标记都被输入 ViT,旨在根据未屏蔽补丁的信息恢复屏蔽的视觉标记。 为了解决预测原始像素的挑战,作者利用离散变分自动编码器 (dVAE) [117] 来创建预定义的视觉词汇表。 一个有趣的方面是下游任务不需要显式的 [mask] 标签,导致研究人员开发不同的算法来缓解这个问题。 例如,在最初的 BERT 中,使用随机词等方法来缓解上游和下游任务之间的不一致。 在 CV 中,BEiT 和 SimMIM 都采用类似于 BERT 的范例,包括将特殊的 [mask] 标记包含到网络中。
与 BEiT 相比,MAE 不使用特殊的掩码标记,并将任务视为回归问题。 它从架构、信息密度和解码器设计三个关键方面解决了在 CV 中应用 DAE 的挑战。 MAE 的简单性和有效性使其成为 MIM 领域的重要基准。
在这里,我们定义
| (23) |
其中 表示编码器, 表示解码器, 表示在将输入馈入网络之前应用于输入的变换, 表示用于导出目标标签的转换。 值得注意的是,这种表示是为了清晰和易于理解而提供的,而不是作为严格的定义。
BEiT 和 MAE 之间的主要区别在于它们对 的选择。 BEiT 使用预训练分词器输出的词符作为目标,而 MAE 直接使用原始像素作为目标。 BEiT 采用两阶段方法,首先训练标记器将图像转换为视觉标记,然后进行 BERT 式训练。 另一方面,MAE 是一种单阶段端到端方法,结合解码器将编码器导出的表示解码为原始像素。 两种具有代表性的 MIM 方法 BEiT 和 MAE,展示了不同的架构设计,后续的 MIM 方法通常遵循其中一种技术。 MIM 的一个核心挑战在于目标表示 的选择,这导致了 MIM 方法的分类,如表 II 所示。
| Low-Level Targets | High-Level Targets | Self-Distillation | Contrastive / Multi-modal Teacher | ||||||||
| Algorithm | ViT [5] | MAE [68] | SimMIM [114] | Maskfeat [118] | BEiT [112] | CAE [113] | PeCo [119] | data2vec [120] | SdAE [121] | MimCo [122] | BEiT v2 [123] |
| Target | Raw Pixel | HOG | VQ-VAE | VQ-GAN | self | MoCo v3 | CLIP | ||||

引入 BEiT 和 MAE 后,提出了几种变体。 iBOT [111] 是 BEiT 的“在线分词器”改编版,旨在解决 dVAE 在仅捕获局部细节中的低级语义方面的局限性。 CAE 引入了对齐约束,以鼓励屏蔽补丁表示(由“潜在上下文回归器”预测)位于编码表示空间中。 表征学习任务和借口任务的这种解耦增强了模型的表征学习能力。 此外,MAE 已扩展到图像之外的其他模式[124,125,126]。
MIM 在预训练视觉变换器方面表现出了巨大的潜力[127,128,129,130]。 利用通用的 ViT 主干,MIM 通过屏蔽原始图像的某些块并随后恢复屏蔽信息来获取自我监督的视觉表示。 然而,在之前的工作中,图像块的随机屏蔽导致有效视觉表示学习所必需的有价值的语义信息的利用不足。 此外,骨干网络的规模相当大,导致大多数先前开发的方法需要大量的预训练时间。 为了解决这些问题,刘等人[131]引入了注意力驱动的掩蔽和抛出策略,有效地解决了上述两个挑战。
2.2.4 对比生成方法
如[132]所述,对比模型往往需要大量数据并且容易出现过度拟合问题,而生成模型则遇到数据填充挑战,并且与对比模型相比表现出较差的数据扩展能力。 虽然对比模型通常关注全局视图[84],忽略图像内的内部结构,但 MIM 主要建模局部关系。 对比自监督学习和生成自监督学习所面临的不同特征和挑战促使研究人员探索这两种方法的结合。
为了进一步阐述,让我们比较对比自监督方法和生成自监督方法所面临的挑战。 生成式自监督方法的特点是数据填充方法[133]。 对于一定规模的模型,当数据集达到一定规模时,数据的进一步缩放不会导致生成式自监督方法的性能显着提升。 相比之下,最近的研究揭示了数据扩展在增强 CL 性能方面的潜力[134]。 随着数据的增加,CL 显示出显着的性能改进,表现出显着的泛化性,而无需对下游任务进行额外的微调。 然而,在低数据情况下,情况有所不同。 对比模型可能会找到过度拟合有限数据的简单表示的捷径[50],从而导致使用预训练模型和对比自监督方法[的下游任务的泛化性能提升不一致。 132]。 另一方面,生成方法更擅长处理低数据场景,甚至在数据极其稀缺时(例如只有 10 张图像[135])可以实现显着的性能提升。
人们已经做出了一些努力来整合这两种类型的算法[136, 132]。 在[136]中,GAN被用于CL中的在线数据增强。 该研究设计了一个对比模块,该模块学习用于生成的视图不变特征,并引入视图不变损失函数以促进原始视图和生成视图之间的学习。 另一方面,[111]从BEiT和DINO [84]中汲取灵感。 它将 BEiT 的分词器修改为在线蒸馏教师,同时集成了 DINO 框架的跨视图蒸馏。 因此,与 MIM 方法相比,iBOT [111] 显着提高了线性探测精度。
尽管尝试结合两种类型的方法,但简单的组合可能并不总是能带来性能提升,甚至可能比生成模型基线表现更差,从而加剧表示过度拟合的问题[132]。 性能下降可能是由于 CL 和生成方法的不同属性造成的。 例如,CL 方法通常表现出较长的注意力距离,而生成方法则倾向于局部注意力[137]。 鉴于这一挑战,RECON [132] 作为一种解决方案出现,通过生成建模来指导 CL,从而利用这两种范式的优势。
2.2.5总结
如上所述,已经设计了许多 SSL 借口任务,其中几个重要的里程碑变体如图 8 所示。 还有其他几个借口任务可用[138, 139],包括不同的方法,例如相对补丁位置[140]、噪声预测[141] 、特征聚类[142,143,144]、跨通道预测[145]以及组合不同的线索[146]。 Kolesnikov 等人[147]对之前提出的 SSL 借口任务进行了全面调查,得出了重要的见解。 此外,Krähenbühl 等人[148]提出了一种替代借口任务的方法,并证明了从视频游戏中获取数据的简便性。
据观察,基于上下文的方法由于其性能较差而表现出有限的适用性。 在视觉 SSL 领域,两种主要的算法类型是 CL 和 MIM。 虽然视觉 CL 可能会遇到过拟合问题,但以 CLIP [2] 为代表的融合多模态的 CL 算法已经受到欢迎。
2.3 与其他学习范式的结合
必须承认 SSL 的进步并不是孤立发生的。相反,它们是随着时间的推移不断发展的结果。 在本节中,我们提供了相关学习范式的完整列表,这些范式与 SSL 结合使用,有助于更清楚地了解其集体影响。
2.3.1 GAN
GAN 代表了经典的无监督学习方法,并且是 SSL 技术兴起之前该领域最成功的方法之一。 GAN 与 SSL 的集成提供了多种途径,自监督 GAN(SS-GAN)就是这样的一个例子。 GAN 的目标函数 [35, 149] 给出为
| (26) |
SS-GAN [150]是通过将GAN的目标函数与旋转[7]的概念相结合来定义的:
| (29) |
其中 表示 GAN 的目标函数,如式(1)所示。 (26),指的是从一组可能的旋转中选择的旋转,类似于[7]中提出的概念。 这里,表示图像旋转了度,对应于鉴别器在旋转角度上的预测分布给定示例。 值得注意的是,旋转[7]是一种经典的SSL方法。 SS-GAN 通过在 期间集成旋转预测任务,将旋转不变性训练融入到 GAN 的生成过程中。
2.3.2 半监督学习
SSL 和半监督学习是可以有效结合的对比范式。 这种组合的一个著名例子是自监督半监督学习 (S4L) [151]。 在 S4L 中,目标函数由下式给出
| (30) |
where represents the labeled training dataset, is the unlabeled training dataset, denotes the classification loss computed on all labeled examples, stands for the self-supervised loss (e.g., rotation task in Eq. (3)) utilizing both and , is a free parameter used for balancing the contributions of and , and represents the parameters of the learning model.
将 SSL 纳入辅助任务是半监督学习中一种行之有效的方法。 在这种情况下利用 SSL 的另一种经典方法是在未标记数据上实施 SSL,然后在标记数据上微调生成的模型,如 SimCLR 框架中所示。
为了证明自监督对抗对抗性扰动的鲁棒性,Hendrycks等人[152]提出了一个总体损失函数,作为监督损失和自监督损失的线性组合:
| (33) |
其中代表一个例子,是ground-truth标签,表示模型参数,指交叉熵损失,代表投影梯度下降。 (33) 中的第一项和第二项分别对应于监督学习损失和 SSL 损失。
2.3.3 多实例学习(MIL)
Miech 等人[13]引入了MIL的InfoNCE损失(5)的扩展,并将其称为MIL-NCE:
| (34) |
其中 和 分别表示视频剪辑和旁白。 函数 和 分别生成 和 的嵌入。 对于由索引的特定示例,表示正视频/旁白对的集合,而对应于负视频/旁白对的集合。
2.3.4 多视图/多模态学习
观察对于婴儿获取关于世界的知识起着至关重要的作用。 值得注意的是,他们可以通过观察和比较过程来掌握苹果的概念,这将他们的学习方法与依赖于大量标记苹果数据的传统监督算法区分开来。 Orhan 等人[22]证明了这一现象,他收集了婴儿的感知数据,并采用 SSL 算法来模拟婴儿如何学习“苹果”的概念。 此外,婴儿对世界的学习延伸到多视图和多模态学习[2],涵盖视频和音频等各种感官输入。 因此,当婴儿探索和理解世界的运作方式时,SSL 和多视图/多模态学习自然地融合在婴儿的学习机制中。
多视点CL
Tian 等人[62]提出的标准多视图CL中的目标函数由下式给出
| (35) |
其中 对应于等式。 (5)。 此外,它还支持 ,其中 和 表示数据点 的两个视图。 Tian等人[62]进行了一项识别CL有效视图的研究,并介绍了无监督视图学习和半监督视图学习。 要在其通道上分割图像 ,操作表示为 。 让表示,即,,其中表示基于流的模型。 对于无监督视图学习和半监督视图学习,都采用了对抗性训练。 两个编码器 和 经过训练以最大化 ,如等式 1 所示。 (35),而 则经过训练以最小化 。 形式上,无监督视图学习的目标函数可以表示为
| (36) |
在半监督视图学习的背景下,当有多个标记示例可用时,目标函数可以表示为
| (39) |
其中表示标签,和是分类器,表示交叉熵损失。 更多相关工作可以参见[62,61,153]。 表 III 总结了不同的 SSL 丢失。
| Category | Method | Loss | Equation | |
|---|---|---|---|---|
| Pretext | Context-Based | Rotation [7] | (3) | |
| CL | MoCo v1 [50] | (5) | ||
| SimCLR v1 [53] | (7) | |||
| SimSiam [67] | (10) | |||
| Barlow twins [69] | (11) | |||
| VICReg [70] | (19) | |||
| Combinations with Other Learning Paradigms | SS-GAN [150] | (29) | ||
| S4L [151] | (30) | |||
| SSL improving robustness [152] | (33) | |||
| unsupervised view learning [62] | (36) | |||
| semi-supervised view learning [62] | (39) | |||
图片和文字
在 Gomez 等人[154]进行的研究中,作者采用主题建模框架将文章文本投影到主题概率空间中。 然后,这种语义级表示被用作图像上训练 CNN 模型的自监督信号。 类似地,CLIP [2] 利用 CL 风格的预训练任务来预测字幕和图像之间的对应关系。 受益于 CL 范例,CLIP 能够在包含从互联网收集的 4 亿图像文本对的广泛数据集上从头开始训练模型。 因此,CLIP 的进步极大地将多模式学习推向了研究关注的前沿。
点云和其他模式
人们提出了几种 SSL 方法,通过三元组和交叉熵损失利用跨模态和跨视图对应关系来联合学习 3D 点云特征和 2D 图像特征[155]。 此外,人们还努力使用 3D 数据的异构网络[156],从不同模态(例如图像、点云和网格)联合学习视图不变和模式不变特征。 SSL 也已用于点云数据集,其方法包括基于图 CNN 的 CL 和聚类[157]。 此外,AE已在[158,159,125,126]等作品中用于点云,而胶囊网络已在[160]中应用于点云数据。
2.3.5 测试时间训练
Sun等人[161]引入了“具有自我监督的测试时间训练(TTT)”,以在训练和测试数据来自不同分布时提高预测模型的性能。 TTT 将单个未标记的测试示例转换为 SSL 问题,从而在进行预测之前启用模型参数更新。 最近,Gandelsman 等人[162]将 TTT 与 MAE 结合起来以提高性能。 他们认为,通过将 TTT 视为单样本学习问题,可以使用 MAE 来解决针对每个测试输入优化模型的问题
| (40) |
| (41) |
这里,和分别指MAE的编码器和解码器,分别表示主任务头。
与经典范例相反,在训练过程中,主要任务头利用从 MAE 编码器获取的特征,而不是原始示例。 因此,在预测期间训练 时,单个示例就足够了。 此外,本文还为 TTT 的功效提供了直观的理由。 具体来说,TTT 在分布变化下实现了改进的偏差-方差权衡。 静态模型严重依赖于训练数据,这些数据可能无法准确地表示新的测试分布,从而导致偏差。 另一方面,为每个测试输入从头开始训练一个新模型,忽略所有训练数据,是不可取的。 这种方法会为每个测试输入提供无偏的表示,但由于其奇异性而表现出高方差。
2.3.6总结
SSL 的发展特点是其动态性和互连性。 对各种方法的结合进行分析可以更清楚地掌握 SSL 的发展轨迹。 这一成功的典范就是 CLIP,它有效地将 CL 与多模态学习结合起来,取得了令人瞩目的成就。 SSL 已与各种机器学习任务广泛集成,展示了其多功能性和潜力。 已与聚类[66]、半监督学习[151]、多任务学习[163, 164, 165, 166],迁移学习 [167, 168, 169],图神经网络 [170, 171, 172, 173, 174, 153, 175],强化学习 [176, 177, 178],少样本学习[179, 180],神经架构搜索[181],稳健学习[182, 183, 184, 152],以及元学习[185, 186]。 这种多样化的集成强调了 SSL 在机器学习领域的广泛适用性和影响。
3 应用
SSL 最初出现在元音类别识别[187]的背景下,随后扩展到涵盖对象提取任务[188]。 SSL 已在多个领域得到广泛应用,包括 CV、NLP、医学图像分析和遥感 (RS)。
3.1简历
Sharma 等人[189]引入了一种全卷积体积AE,用于对象形状的无监督深度嵌入学习。 此外,SSL还广泛应用于图像处理和CV的各个方面:图像修复[115]、人体解析[190, 191]、场景去遮挡 [192]、语义图像分割[193, 194]、单目视觉[195]、行人重识别(re-ID)[196, 197, 198]、视觉里程计[199]、场景流估计[200]、知识蒸馏[201]、光学流量预测[202],视觉语言导航(VLN)[203]0>,生理信号估计[204, 205]1>,图像去噪[206, 207]2>,目标检测[208, 209, 210]3>,超分辨率[211, 212]4>,2D图像的体素预测[213]5>、自我运动[214, 215]6>和掩模预测[216]7>。 这些应用凸显了 SSL 在图像处理和 CV 领域的广泛影响和相关性。
3.1.1 视频的 SSL 模型
SSL 已在各种应用中获得广泛使用,包括视频表示学习[217,218,219]和视频检索[220]。 Wang 等人[221]使用大量未标记的网络视频来学习视觉表示。 中心概念围绕利用视觉跟踪作为自我监督信号。 因此,由轨迹连接的两个补丁预计具有相似的视觉表示,因为它们可能对应于相同的对象或属于相同的对象部分。 Srivastava等人[222]提出了一种复合自监督模型,通过集成两个不同的模型:长短期记忆(LSTM)AE和基于LSTM的未来预测模型。 该复合模型具有输入重建和未来预测的双重目的。
视频中的时间信息
可以采用视频中各种形式的时间信息,包括帧顺序、视频播放方向、视频播放速度和未来预测信息[223, 224]。 1)帧的顺序。 多项研究探讨了视频中帧顺序的重要性。 Misra 等人[9]介绍了一种从原始时空信号中学习视觉表示并确定从视频中提取的帧的正确时间序列的方法。 Fernando 等人[225]提出了一种新颖的自监督 CNN 预训练方法,称为“奇数一出学习”,其目标是识别一组相关的不相关或奇数元素元素。 该奇数元素对应于时间帧顺序不正确的视频子序列,而相关元素保持正确的时间顺序。 Lee等人[226]采用以非时间顺序呈现的时间打乱的帧作为训练CNN的输入,以预测打乱序列的正确顺序,有效地使用时间相干性作为自我受监督的信号。 在这项工作的基础上,Xu 等人 [227] 使用临时打乱的剪辑作为输入而不是单个帧,训练 3D CNN 对这些打乱的剪辑进行排序。 2)视频播放方向。 Wei 等人[10]研究的视频中的时间方向分析涉及辨别时间箭头以确定视频序列是向前还是向后进行。 3)视频播放速度。 视频播放速度已成为多项研究的调查主题。 Benaim 等人[228]专注于预测视频中移动物体的速度,确定它们的移动速度比正常速度快还是慢。 Yao 等人[229]利用播放速率及其相应的视频内容作为视频表示学习的自监督信号。 此外,Wang 等人[230]通过视频速度预测的视角解决了自监督视频表示学习的挑战。
视频中物体的运动
Diba 等人[231]专注于视频中运动的 SSL,通过使用动态运动滤波器来增强运动表示,特别是提高人类动作识别。 视频 SSL 的概念 (CoCLR) [232] 与 SimCLR [53] 相似。
视频中的多模态数据
视频中的听觉和视觉成分本质上是相互关联的。 利用这种相关性,Korbar 等人[233]采用自监督时间同步方法来学习用于视频和音频分析的全面且有效的模型。 同样,其他方法[234, 60]也建立在联合视频和音频模式的基础上,而某些研究[235,236, 237]则结合了视频和文本模式。 此外,Alayrac 等人[238]探索了一种涉及视频中视觉、音频和语言的三模态方法。 另一方面,Sermanet 等人[239]提出了一种自监督技术,用于从从不同角度捕获的未标记视频中学习表示和机器人行为。
视频中对象的时空一致性
Wang等人[240]提出了一种自监督算法,利用时间上的循环一致性作为自监督信号来学习未标记视频中的视觉对应关系。 Li 等人 [241] 和 Jabri 等人 [242] 探索了这项工作的扩展。 Lai等人[243]提出了一种记忆增强的自监督方法,可以实现可泛化且准确的像素级跟踪。 张等人[244]利用深度图的时空一致性来减少学习过程中的遗忘。 赵等人[245]提出了一种新颖的自监督算法,名为“视频完形填空过程(VCP)”,它有助于学习视频丰富的时空表示。
3.1.2 用于图像处理和 CV 的通用顺序 SSL 模型
对比预测编码 (CPC) [56] 的基本概念是使用稳健的自回归模型通过未来数据的潜在空间预测来获取信息表示。 虽然 CPC 最初应用于语音和文本等序列数据,但它也适用于图像[246]。
iGPT [116] 从 GPT [247, 248] 在 NLP 领域的成就中汲取灵感,研究类似的模型是否可以有效地学习图像的表示。 iGPT 探索了两个训练目标,即自回归预测和去噪目标,从而与 BERT [11] 具有相似之处。 在高分辨率场景中,该方法[116]与 ImageNet [1] 上的其他自监督方法相媲美。 与 iGPT 类似,ViT [5] 也采用 Transformer 架构来执行视觉任务。 通过将纯 Transformer 应用于图像块序列,ViT 在图像分类任务中展现了出色的性能。 Transformer 架构已进一步扩展到各种视觉相关应用,如[249,68,250,112,84,52]所示。
3.2 自然语言处理
在 NLP 领域,在词嵌入上执行 SSL 的开创性工作包括连续词袋模型和连续 Skip-gram 模型[251]。 SSL 方法,特别是 BERT [11] 和 GPT,在 NLP [252,253,254,255,256] 中得到了广泛的应用。 此外,SSL 已用于其他顺序数据,包括声音数据[257]。
3.3 其他字段
在医学领域[258],标记数据的可用性通常是有限的,而存在大量未标记数据。 这种自然场景使 SSL 成为一种引人注目的方法,它已被有效地应用于医学图像分割 [259] 和 3D 医学图像分析 [260] 等各种任务。 最近,SSL 还在遥感领域找到了应用,受益于大量尚未开发的大规模未标记数据。 例如,SeCo [261] 利用 RS 图像的季节性变化来构建正对并执行 CL。 另一方面,RVSA [262] 引入了一种新颖的旋转不同大小的窗口注意机制,该机制将普通视觉 Transformer 改进为各种遥感任务的基本模型。 值得注意的是,它是使用生成 SSL 方法 MAE [68] 在大规模 MillionAID 数据集上进行预训练的。
4 性能比较
一旦通过 SSL 获得预训练模型,就需要对其性能进行评估。 传统方法涉及衡量下游任务所实现的性能,以确定提取特征的质量。 然而,这个评估指标并不能深入了解网络在自监督预训练期间具体学到了什么。 为了深入研究自监督特征的可解释性,可以采用替代评估指标,例如网络剖析[263]。 最近,出现了大量 MIM 方法,与以前的方法相比,它们展示了不同的重点。 在本节中,我们的目标是清楚地展示各种方法所表现出的性能。 我们总结了典型 SSL 方法在成熟数据集上的分类和迁移学习功效。 值得注意的是,SSL 技术理论上可以应用于多种模式的数据。 然而,为了简单起见,我们将重点缩小到图像域中的 SSL。 在此领域内,我们比较了几个下游任务所取得的性能,主要包括图像分类、对象检测和语义分割。
4.1 综合比较
在本节中,我们将介绍在各个数据集上测试的不同算法所获得的结果,如表 IV 中所总结。 实验结果直接来自原始论文或带有注释的其他来源。 当结果来源于原始论文时,不提供具体说明;然而,对于替代工作的结果,会标明数据源。 如果从另一项工作复制的方法与原始论文相比具有更高的准确性,我们会始终以更高的准确性报告结果。
值得注意的是,由于比较多种算法的目的,实验设置并未严格标准化。 尽管如此,我们还是努力调整关键的超参数,而某些参数(例如训练纪元的数量)可能无法完全调整。 实验结果统一使用原论文中指定的默认backbone获得,如ResNet-50或ViT-B。 在某些实验结果缺乏相应的 ResNet-50 或 ViT-B 实现的情况下,我们提供基于其他主干的结果,并适当地标有下标。
设置。 预训练过程使用 ImageNet-1k [1] 作为主要数据集。 随后,按照表IV中概述的标准程序[50, 53],通过冻结特征的线性分类对这些方法进行比较分析。 这需要使用从预训练模型获得的特征来训练一个线性分类器,该分类器由一个全连接层和后面的 softmax 函数组成。 “微调”是指对整个模型进行微调。 报告的结果表明在 ImageNet 验证集上获得的 top-1 分类精度。
我们还展示了我们在广泛认可的数据集上的对象检测和语义分割任务的发现,包括 PASCAL VOC [264]、COCO [265] 和 ADE20k [ 266, 267]。 PASCAL VOC 数据集上的目标检测结果评估采用默认的平均精度 (mAP),具体为 。 默认情况下,PASCAL VOC 上的物体检测任务使用 VOC2007 进行训练。 然而,某些方法使用组合的07+12数据集而不是VOC2007进行训练,并且结果用上标“e”注释。 对于COCO上的对象检测和实例分割任务,我们采用边界框AP()和掩模AP()指标,根据[50 ]。
| Methods | Linear Probe | Fine-Tuning | VOC_det | VOC_seg | COCO_det | COCO_seg | ADE20K_seg | DB |
| Random: | [8] | - | [67] | [8] | [50] | [50] | - | - |
| R50 Sup | 76.5[66] | 76.5[66] | [67] | 74.4[65] | 40.6[50] | 36.8[50] | - | - |
| ViT-B Sup | 82.3[68] | 82.3[68] | - | - | 47.9[68] | 42.9[68] | 47.4[68] | - |
| Context-Based: | ||||||||
| Jigsaw[8] | [66] | [42] | - | - | - | 256 | ||
| Colorization[38] | [66] | [7] | - | - | - | - | ||
| Rotation[7] | - | - | - | 128 | ||||
| CL Based on Negative Examples: | ||||||||
| Examplar[138] | [48] | - | - | - | - | - | - | - |
| Instdisc[48] | - | - | - | - | - | 256 | ||
| MoCo v1[50] | - | - | - | 256 | ||||
| SimCLR[53] | [52] | - | [67] | - | [67] | [67] | - | 4096 |
| MoCo v2[51] | [67] | - | - | [70] | [70] | - | 256 | |
| MoCo v3[52] | 76.7 | 83.2 | - | - | 47.9[68] | 42.7[68] | 47.3[68] | 4096 |
| CL Based on Clustering: | ||||||||
| SwAV[66] | - | [70] | - | [70] | - | 4096 | ||
| CL Based on Self-distillation: | ||||||||
| BYOL[65] | - | [67] | [70] | [70] | - | 4096 | ||
| SimSiam[67] | - | [67] | - | - | 512 | |||
| DINO[84] | 78.2 | 83.6[111] | - | - | 46.8[113] | 41.5[113] | 44.1[112] | 1024 |
| CL Based on Feature Decorrelation: | ||||||||
| Barlow Twins[69] | - | [70] | - | - | 2048 | |||
| VICReg[70] | - | - | - | 2048 | ||||
| Masked Image Modeling (ViT-B by default): | ||||||||
| Context Encoder[115] | [7] | - | [7] | - | - | - | - | |
| BEiT v1[112] | 56.7[123] | 83.4[111] | - | - | 49.8[68] | 44.4[68] | 47.1[68] | 2000 |
| MAE[68] | 67.8 | 83.6 | - | - | 50.3 | 44.9 | 48.1 | 4096 |
| SimMIM[114] | 56.7 | 83.8 | - | - | [268] | - | [268] | 2048 |
| PeCo[119] | - | 84.5 | - | - | 43.9 | 39.8 | 46.7 | 2048 |
| iBOT[111] | 79.5 | 84.0 | - | - | 51.2 | 44.2 | 50.0 | 1024 |
| MimCo[122] | - | 83.9 | - | - | 44.9 | 40.7 | 48.91 | 2048 |
| CAE[113] | 70.4 | 83.9 | - | - | 50 | 44 | 50.2 | 2048 |
| data2vec[120] | - | 84.2 | - | - | - | - | - | 2048 |
| SdAE[121] | 64.9 | 84.1 | - | - | 48.9 | 43.0 | 48.6 | 768 |
| BEiT v2[123] | 80.1 | 85.5 | - | - | - | - | 53.1 | 2048 |
4.2 摘要
首先,基于CL的自监督算法的线性探测精度始终优于其他算法。 这种优越性可以归因于该算法能够生成结构良好的潜在空间,其中不同的类别被有效地分离,相似的类别被适当地聚类。
其次,据观察,使用 MIM 的预训练模型可以进行微调,以在大多数情况下实现卓越的性能。 相反,基于 CL 的预训练模型缺乏此属性。 造成这种差异的主要原因在于基于 CL 的模型更容易出现过度拟合[269,64,270]。 这一观察结果还扩展到下游任务的预训练模型的微调。 基于 MIM 的方法始终在下游任务中表现出显着的性能增强,而基于 CL 的方法提供的帮助相对有限。
第三,基于 CL 的方法往往采用动量编码器、内存队列和多裁剪等资源密集型技术,显着增加了对计算、存储和通信资源的需求。 相比之下,基于 MIM 的方法具有更有效的资源利用,这可能归因于缺少示例交互。 这一优势特性使得基于 MIM 的算法能够轻松扩展模型和数据,有效利用现代 GPU 进行高度并行计算。
5 结论、未来趋势和悬而未决的问题
总之,这篇全面的综述提供了对当代 SSL 研究的重要见解,为新手提供了该领域的整体概况。 该论文从算法、应用和未来趋势三个主要角度对 SSL 进行了全面的调查。 我们关注主流的视觉SSL算法,将其分为四大类:基于上下文的方法、生成方法、对比方法和对比生成方法。 此外,我们研究了 SSL 和其他学习范式之间的相关性,同时将早期 SSL 算法与当前主流算法进行比较。 最后,我们将深入探讨未来趋势和未解决的问题,如下所述。
主要趋势:首先,SSL的实践发展取得了显着进展,但理论分析相对滞后。 例如,人们已经对为什么 BYOL 和 SimSiam [67] 不会崩溃 [271] 进行了调查,但根本原因仍然难以捉摸。 需要进一步的理论探索来解开这个谜团并可能发现更有效的解决方案。 此外,最近的研究表明,与传统的基于 CL 的方法相比,基于 MIM 的方法可以获得相当甚至更好的性能。 这也迫切需要理论上的解释。
其次,出现了一个关键问题,即自动设计最佳借口任务以提高固定下游任务的性能。 人们提出了各种方法来解决这一挑战,包括像素到传播一致性方法[63]和密集对比学习[272]。 然而,这个问题仍然没有得到充分解决,有必要朝这个方向进行进一步的理论研究。
第三,迫切需要一个包含多种模式的统一 SSL 范式。 MIM 在视觉任务中表现出了显着的进步,类似于 NLP 中掩码语言模型的成功,这表明统一学习范式的可能性。 此外,ViT 架构弥合了视觉和语言模式之间的差距,从而能够为 CV 和 NLP 任务构建统一的 Transformer 模型。 最近的努力[273, 120]试图统一SSL模型,在下游任务中取得了令人印象深刻的结果并显示出广泛的适用性。 尽管如此,NLP 在利用 SSL 模型方面取得了进一步的进展,促使 CV 社区从 NLP 方法中汲取灵感,以有效地利用预训练模型的潜力。
开放问题:首先,SSL 能否利用几乎无限数据的优势? 考虑到大量的未标记数据,SSL 能否持续受益于额外的未标记数据,并且可以确定理论拐点吗?
其次,探索 SSL 和多模态学习之间的相互联系是相关的,因为这两种方法与在婴儿中观察到的认知过程有相似之处。 因此,出现了一个关键的问题:如何将这两种方法协同整合以形成稳健且全面的学习模型?
第三,确定最佳或推荐的 SSL 算法是一个挑战,因为没有普遍适用的解决方案。 算法的理想选择应该与特定的问题结构保持一致,但实际情况往往使这个过程变得复杂。 因此,开发一个清单来帮助用户在特定情况下确定最合适的方法值得研究,并且应该作为未来研究的一个有希望的途径。
第四,未标记数据总是会导致结果改善的假设值得仔细审查。 我们的假设挑战了这一概念,特别是在半监督学习方法方面,因为没有免费的午餐定理开始发挥作用。 当模型假设无法有效地与潜在问题结构保持一致时,可能会出现性能下降。 例如,如果模型假设决策边界和高数据密度区域之间有很大的分离,那么当面对来自严重重叠的柯西分布的数据时,它可能会表现不佳,因为决策边界将穿过密集区域。 然而,先发制人地识别这种不匹配仍然是一个复杂且悬而未决的问题。 因此,该主题值得进一步研究以阐明这一问题。
参考
- [1] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 248–255, 2009.
- [2] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., “Learning transferable visual models from natural language supervision,” in Int. Conf. Mach. Learn., pp. 8748–8763, 2021.
- [3] L. Ericsson, H. Gouk, and T. M. Hospedales, “How well do self-supervised models transfer?,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 5414–5423, 2021.
- [4] X. Liu, F. Zhang, Z. Hou, L. Mian, Z. Wang, J. Zhang, and J. Tang, “Self-supervised learning: Generative or contrastive,” IEEE T. Knowl. Data Eng., 2022.
- [5] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” in Int. Conf. Learn. Represent., 2021.
- [6] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotemporal features with 3d convolutional networks,” in IEEE Int. Conf. Comput. Vis., pp. 4489–4497, 2015.
- [7] S. Gidaris, P. Singh, and N. Komodakis, “Unsupervised representation learning by predicting image rotations,” in Int. Conf. Learn. Represent., pp. 1–14, 2018.
- [8] M. Noroozi and P. Favaro, “Unsupervised learning of visual representations by solving jigsaw puzzles,” in Eur. Conf. Comput. Vis., pp. 69–84, 2016.
- [9] I. Misra, C. L. Zitnick, and M. Hebert, “Shuffle and learn: unsupervised learning using temporal order verification,” in Eur. Conf. Comput. Vis., pp. 527–544, 2016.
- [10] D. Wei, J. J. Lim, A. Zisserman, and W. T. Freeman, “Learning and using the arrow of time,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 8052–8060, 2018.
- [11] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [12] X. Zeng, Y. Pan, M. Wang, J. Zhang, and Y. Liu, “Realistic face reenactment via self-supervised disentangling of identity and pose,” in AAAI Conf.Artif. Intell., pp. 12154–12163, 2020.
- [13] A. Miech, J.-B. Alayrac, L. Smaira, I. Laptev, J. Sivic, and A. Zisserman, “End-to-end learning of visual representations from uncurated instructional videos,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 9879–9889, 2020.
- [14] Y. M. Asano, C. Rupprecht, and A. Vedaldi, “A critical analysis of self-supervision, or what we can learn from a single image,” in Int. Conf. Learn. Represent., 2020.
- [15] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” Science, vol. 313, no. 5786, pp. 504–507, 2006.
- [16] P. Vincent, H. Larochelle, Y. Bengio, and P.-A. Manzagol, “Extracting and composing robust features with denoising autoencoders,” in Int. Conf. Mach. Learn., pp. 1096–1103, 2008.
- [17] L. Pinto and A. Gupta, “Supersizing self-supervision: Learning to grasp from 50k tries and 700 robot hours,” in IEEE Int. Conf. Robot. Autom., pp. 3406–3413, 2016.
- [18] Y. Li, M. Paluri, J. M. Rehg, and P. Dollár, “Unsupervised learning of edges,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1619–1627, 2016.
- [19] D. Li, W.-C. Hung, J.-B. Huang, S. Wang, N. Ahuja, and M.-H. Yang, “Unsupervised visual representation learning by graph-based consistent constraints,” in Eur. Conf. Comput. Vis., pp. 678–694, 2016.
- [20] H. Lee, S. J. Hwang, and J. Shin, “Rethinking data augmentation: Self-supervision and self-distillation,” arXiv preprint arXiv:1910.05872, 2019.
- [21] B. Zoph, G. Ghiasi, T.-Y. Lin, Y. Cui, H. Liu, E. D. Cubuk, and Q. Le, “Rethinking pre-training and self-training,” in Neural Inf. Process. Syst., pp. 1–13, 2020.
- [22] A. E. Orhan, V. V. Gupta, and B. M. Lake, “Self-supervised learning through the eyes of a child,” in Neural Inf. Process. Syst., pp. 9960–9971, 2020.
- [23] J. Mitrovic, B. McWilliams, J. Walker, L. Buesing, and C. Blundell, “Representation learning via invariant causal mechanisms,” in Int. Conf. Learn. Represent., pp. 1–19, 2021.
- [24] T. Hua, W. Wang, Z. Xue, S. Ren, Y. Wang, and H. Zhao, “On feature decorrelation in self-supervised learning,” in IEEE Int. Conf. Comput. Vis., pp. 9598–9608, 2021.
- [25] VentureBeat, “Yann LeCun, Yoshua Bengio: Self-supervised learning is key to human-level intelligence.” https://cacm.acm.org/news/244720-yann-lecun-yoshua-bengio-self-supervised-learning-is-key-to-human-level-intelligence/fulltext.
- [26] J. Yu, H. Yin, X. Xia, T. Chen, J. Li, and Z. Huang, “Self-supervised learning for recommender systems: A survey,” arXiv preprint arXiv:2203.15876, 2022.
- [27] Y. Liu, M. Jin, S. Pan, C. Zhou, Y. Zheng, F. Xia, and P. Yu, “Graph self-supervised learning: A survey,” IEEE T. Knowl. Data Eng., 2022.
- [28] L. Wu, H. Lin, C. Tan, Z. Gao, and S. Z. Li, “Self-supervised learning on graphs: Contrastive, generative, or predictive,” IEEE T. Knowl. Data Eng., 2022.
- [29] H. H. Mao, “A survey on self-supervised pre-training for sequential transfer learning in neural networks,” arXiv preprint arXiv:2007.00800, 2020.
- [30] M. C. Schiappa, Y. S. Rawat, and M. Shah, “Self-supervised learning for videos: A survey,” arXiv preprint arXiv:2207.00419, 2022.
- [31] G.-J. Qi and M. Shah, “Adversarial pretraining of self-supervised deep networks: Past, present and future,” arXiv preprint arXiv:2210.13463, 2022.
- [32] L. Jing and Y. Tian, “Self-supervised visual feature learning with deep neural networks: A survey,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 43, no. 11, pp. 4037–4058, 2021.
- [33] A. Jaiswal, A. R. Babu, M. Z. Zadeh, D. Banerjee, and F. Makedon, “A survey on contrastive self-supervised learning,” Technologies, vol. 9, no. 1, pp. 1–22, 2020.
- [34] V. R. de Sa, “Learning classification with unlabeled data,” in Neural Inf. Process. Syst., pp. 112–119, 1994.
- [35] J. Gui, Z. Sun, Y. Wen, D. Tao, and J. Ye, “A review on generative adversarial networks: Algorithms, theory, and applications,” IEEE T. Knowl. Data Eng., 2022.
- [36] T. Nathan Mundhenk, D. Ho, and B. Y. Chen, “Improvements to context based self-supervised learning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 9339–9348, 2018.
- [37] P. Agrawal, J. Carreira, and J. Malik, “Learning to see by moving,” in IEEE Int. Conf. Comput. Vis., pp. 37–45, 2015.
- [38] R. Zhang, P. Isola, and A. A. Efros, “Colorful image colorization,” in Eur. Conf. Comput. Vis., pp. 649–666, 2016.
- [39] G. Larsson, M. Maire, and G. Shakhnarovich, “Learning representations for automatic colorization,” in Eur. Conf. Comput. Vis., pp. 577–593, 2016.
- [40] R. Zhang, J.-Y. Zhu, P. Isola, X. Geng, A. S. Lin, T. Yu, and A. A. Efros, “Real-time user-guided image colorization with learned deep priors,” arXiv preprint arXiv:1705.02999, 2017.
- [41] G. Larsson, M. Maire, and G. Shakhnarovich, “Colorization as a proxy task for visual understanding,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6874–6883, 2017.
- [42] P. Goyal, D. Mahajan, A. Gupta, and I. Misra, “Scaling and benchmarking self-supervised visual representation learning,” in IEEE Int. Conf. Comput. Vis., pp. 6391–6400, 2019.
- [43] U. Ahsan, R. Madhok, and I. Essa, “Video jigsaw: Unsupervised learning of spatiotemporal context for video action recognition,” in Proc. Winter Conf. Appl. Comput. Vis., pp. 179–189, 2019.
- [44] X. Zhan, X. Pan, Z. Liu, D. Lin, and C. C. Loy, “Self-supervised learning via conditional motion propagation,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1881–1889, 2019.
- [45] K. Wang, L. Lin, C. Jiang, C. Qian, and P. Wei, “3d human pose machines with self-supervised learning,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 42, no. 5, pp. 1069–1082, 2019.
- [46] M. Noroozi, H. Pirsiavash, and P. Favaro, “Representation learning by learning to count,” in IEEE Int. Conf. Comput. Vis., pp. 5898–5906, 2017.
- [47] I. Misra and L. v. d. Maaten, “Self-supervised learning of pretext-invariant representations,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6707–6717, 2020.
- [48] Z. Wu, Y. Xiong, S. X. Yu, and D. Lin, “Unsupervised feature learning via non-parametric instance discrimination,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 3733–3742, 2018.
- [49] N. Zhao, Z. Wu, R. W. Lau, and S. Lin, “What makes instance discrimination good for transfer learning?,” in Int. Conf. Learn. Represent., pp. 1–11, 2021.
- [50] K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 9729–9738, 2020.
- [51] X. Chen, H. Fan, R. Girshick, and K. He, “Improved baselines with momentum contrastive learning,” arXiv preprint arXiv:2003.04297, 2020.
- [52] X. Chen, S. Xie, and K. He, “An empirical study of training self-supervised visual transformers,” in IEEE Int. Conf. Comput. Vis., pp. 9640–9649, 2021.
- [53] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in Int. Conf. Mach. Learn., pp. 1597–1607, 2020.
- [54] T. Chen, S. Kornblith, K. Swersky, M. Norouzi, and G. Hinton, “Big self-supervised models are strong semi-supervised learners,” in Neural Inf. Process. Syst., pp. 1–13, 2020.
- [55] R. Hadsell, S. Chopra, and Y. LeCun, “Dimensionality reduction by learning an invariant mapping,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1735–1742, 2006.
- [56] A. v. d. Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” arXiv preprint arXiv:1807.03748, 2019.
- [57] M. Gutmann and A. Hyvärinen, “Noise-contrastive estimation: A new estimation principle for unnormalized statistical models,” in Int. Conf. Artif. Intell. Statist., pp. 297–304, 2010.
- [58] M. Zheng, S. You, F. Wang, C. Qian, C. Zhang, X. Wang, and C. Xu, “Ressl: Relational self-supervised learning with weak augmentation,” arXiv preprint arXiv:2107.09282, 2021.
- [59] N. Zhao, Z. Wu, R. W. Lau, and S. Lin, “Distilling localization for self-supervised representation learning,” in AAAI Conf.Artif. Intell., pp. 10990–10998, 2021.
- [60] R. Arandjelovic and A. Zisserman, “Objects that sound,” in Eur. Conf. Comput. Vis., pp. 435–451, 2018.
- [61] Y. Tian, D. Krishnan, and P. Isola, “Contrastive multiview coding,” in Eur. Conf. Comput. Vis., pp. 776–794, 2020.
- [62] Y. Tian, C. Sun, B. Poole, D. Krishnan, C. Schmid, and P. Isola, “What makes for good views for contrastive learning,” in Neural Inf. Process. Syst., pp. 1–13, 2020.
- [63] Z. Xie, Y. Lin, Z. Zhang, Y. Cao, S. Lin, and H. Hu, “Propagate yourself: Exploring pixel-level consistency for unsupervised visual representation learning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 16684–16693, 2021.
- [64] X. Wang and G.-J. Qi, “Contrastive learning with stronger augmentations,” IEEE Trans. Pattern Anal. Mach. Intell., pp. 1–12, 2022.
- [65] J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. H. Richemond, E. Buchatskaya, C. Doersch, B. A. Pires, Z. D. Guo, M. G. Azar, et al., “Bootstrap your own latent: A new approach to self-supervised learning,” in Neural Inf. Process. Syst., pp. 1–14, 2020.
- [66] M. Caron, I. Misra, J. Mairal, P. Goyal, P. Bojanowski, and A. Joulin, “Unsupervised learning of visual features by contrasting cluster assignments,” in Neural Inf. Process. Syst., 2020.
- [67] X. Chen and K. He, “Exploring simple siamese representation learning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 15750–15758, 2021.
- [68] K. He, X. Chen, S. Xie, Y. Li, P. Dollár, and R. Girshick, “Masked autoencoders are scalable vision learners,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 16000–16009, 2022.
- [69] J. Zbontar, L. Jing, I. Misra, Y. LeCun, and S. Deny, “Barlow twins: Self-supervised learning via redundancy reduction,” in Int. Conf. Mach. Learn., 2021.
- [70] A. Bardes, J. Ponce, and Y. LeCun, “Vicreg: Variance-invariance-covariance regularization for self-supervised learning,” in Int. Conf. Learn. Represent., pp. 1–12, 2022.
- [71] M. Tschannen, J. Djolonga, P. K. Rubenstein, S. Gelly, and M. Lucic, “On mutual information maximization for representation learning,” in Int. Conf. Learn. Represent., pp. 1–12, 2020.
- [72] N. Saunshi, O. Plevrakis, S. Arora, M. Khodak, and H. Khandeparkar, “A theoretical analysis of contrastive unsupervised representation learning,” in Int. Conf. Mach. Learn., pp. 5628–5637, 2019.
- [73] Y. Yang and Z. Xu, “Rethinking the value of labels for improving class-imbalanced learning,” in Neural Inf. Process. Syst., 2020.
- [74] Y.-H. H. Tsai, Y. Wu, R. Salakhutdinov, and L.-P. Morency, “Self-supervised learning from a multi-view perspective,” arXiv preprint arXiv:2006.05576, 2020.
- [75] T. Wang and P. Isola, “Understanding contrastive representation learning through alignment and uniformity on the hypersphere,” in Int. Conf. Mach. Learn., pp. 9929–9939, 2020.
- [76] C.-Y. Chuang, J. Robinson, L. Yen-Chen, A. Torralba, and S. Jegelka, “Debiased contrastive learning,” in Int. Conf. Learn. Represent., 2020.
- [77] J. D. Lee, Q. Lei, N. Saunshi, and J. Zhuo, “Predicting what you already know helps: Provable self-supervised learning,” arXiv preprint arXiv:2008.01064, 2020.
- [78] S. Chen, G. Niu, C. Gong, J. Li, J. Yang, and M. Sugiyama, “Large-margin contrastive learning with distance polarization regularizer,” in Int. Conf. Mach. Learn., pp. 1673–1683, 2021.
- [79] J. Z. HaoChen, C. Wei, A. Gaidon, and T. Ma, “Provable guarantees for self-supervised deep learning with spectral contrastive loss,” in Neural Inf. Process. Syst., pp. 5000–5011, 2021.
- [80] C. Tosh, A. Krishnamurthy, and D. Hsu, “Contrastive learning, multi-view redundancy, and linear models,” in Algorithmic Learning Theory, pp. 1179–1206, 2021.
- [81] C. Wei, K. Shen, Y. Chen, and T. Ma, “Theoretical analysis of self-training with deep networks on unlabeled data,” in Int. Conf. Learn. Represent., pp. 1–15, 2021.
- [82] Y. Tian, “Deep contrastive learning is provably (almost) principal component analysis,” arXiv preprint arXiv:2201.12680, 2022.
- [83] A. Newell and J. Deng, “How useful is self-supervised pretraining for visual tasks?,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 7345–7354, 2020.
- [84] M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” in IEEE Int. Conf. Comput. Vis., pp. 9650–9660, 2021.
- [85] Y. Wang, X. Shen, S. X. Hu, Y. Yuan, J. L. Crowley, and D. Vaufreydaz, “Self-supervised transformers for unsupervised object discovery using normalized cut,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 14543–14553, 2022.
- [86] E. Hoffer, I. Hubara, and N. Ailon, “Deep unsupervised learning through spatial contrasting,” arXiv preprint arXiv:1610.00243, 2016.
- [87] Y. Xu, Q. Zhang, J. Zhang, and D. Tao, “Regioncl: exploring contrastive region pairs for self-supervised representation learning,” in European Conference on Computer Vision, pp. 477–494, Springer, 2022.
- [88] M. Yang, M. Liao, P. Lu, J. Wang, S. Zhu, H. Luo, Q. Tian, and X. Bai, “Reading and writing: Discriminative and generative modeling for self-supervised text recognition,” arXiv preprint arXiv:2207.00193, 2022.
- [89] H. Wu, Y. Qu, S. Lin, J. Zhou, R. Qiao, Z. Zhang, Y. Xie, and L. Ma, “Contrastive learning for compact single image dehazing,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 10551–10560, 2021.
- [90] R. Zhu, B. Zhao, J. Liu, Z. Sun, and C. W. Chen, “Improving contrastive learning by visualizing feature transformation,” in IEEE Int. Conf. Comput. Vis., pp. 10306–10315, 2021.
- [91] M. Yang, Y. Li, Z. Huang, Z. Liu, P. Hu, and X. Peng, “Partially view-aligned representation learning with noise-robust contrastive loss,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1134–1143, 2021.
- [92] L. Xiong, C. Xiong, Y. Li, K.-F. Tang, J. Liu, P. Bennett, J. Ahmed, and A. Overwijk, “Approximate nearest neighbor negative contrastive learning for dense text retrieval,” in Int. Conf. Learn. Represent., pp. 1–12, 2021.
- [93] J. Li, P. Zhou, C. Xiong, and S. C. Hoi, “Prototypical contrastive learning of unsupervised representations,” in Int. Conf. Learn. Represent., pp. 1–12, 2021.
- [94] K. Kotar, G. Ilharco, L. Schmidt, K. Ehsani, and R. Mottaghi, “Contrasting contrastive self-supervised representation learning pipelines,” in IEEE Int. Conf. Comput. Vis., pp. 9949–9959, 2021.
- [95] S. Liu, H. Fan, S. Qian, Y. Chen, W. Ding, and Z. Wang, “Hit: Hierarchical transformer with momentum contrast for video-text retrieval,” in IEEE Int. Conf. Comput. Vis., pp. 11915–11925, 2021.
- [96] A. Islam, C.-F. Chen, R. Panda, L. Karlinsky, R. Radke, and R. Feris, “A broad study on the transferability of visual representations with contrastive learning,” in IEEE Int. Conf. Comput. Vis., pp. 8845–8855, 2021.
- [97] J. Li, C. Xiong, and S. C. Hoi, “Learning from noisy data with robust representation learning,” in IEEE Int. Conf. Comput. Vis., pp. 9485–9494, 2021.
- [98] H. Cha, J. Lee, and J. Shin, “Co2l: Contrastive continual learning,” in IEEE Int. Conf. Comput. Vis., pp. 9516–9525, 2021.
- [99] O. J. Hénaff, S. Koppula, J.-B. Alayrac, A. v. d. Oord, O. Vinyals, and J. Carreira, “Efficient visual pretraining with contrastive detection,” in IEEE Int. Conf. Comput. Vis., pp. 10086–10096, 2021.
- [100] D. Dwibedi, Y. Aytar, J. Tompson, P. Sermanet, and A. Zisserman, “With a little help from my friends: Nearest-neighbor contrastive learning of visual representations,” in IEEE Int. Conf. Comput. Vis., pp. 9588–9597, 2021.
- [101] J. Cui, Z. Zhong, S. Liu, B. Yu, and J. Jia, “Parametric contrastive learning,” in IEEE Int. Conf. Comput. Vis., pp. 715–724, 2021.
- [102] A. Shah, S. Sra, R. Chellappa, and A. Cherian, “Max-margin contrastive learning,” in AAAI Conf.Artif. Intell., 2022.
- [103] L. Jing, P. Vincent, Y. LeCun, and Y. Tian, “Understanding dimensional collapse in contrastive self-supervised learning,” in Int. Conf. Learn. Represent., pp. 1–11, 2022.
- [104] J. Zhang, X. Xu, F. Shen, Y. Yao, J. Shao, and X. Zhu, “Video representation learning with graph contrastive augmentation,” in ACM Int. Conf. Multimedia, pp. 3043–3051, 2021.
- [105] S. Lal, M. Prabhudesai, I. Mediratta, A. W. Harley, and K. Fragkiadaki, “Coconets: Continuous contrastive 3d scene representations,” in IEEE Conf. Comput. Vis. Pattern Recognit., 2021.
- [106] Q. Hu, X. Wang, W. Hu, and G.-J. Qi, “Adco: Adversarial contrast for efficient learning of unsupervised representations from self-trained negative adversaries,” in IEEE Conf. Comput. Vis. Pattern Recognit., 2021.
- [107] Y. Kalantidis, M. B. Sariyildiz, N. Pion, P. Weinzaepfel, and D. Larlus, “Hard negative mixing for contrastive learning,” in Neural Inf. Process. Syst., pp. 1–12, 2020.
- [108] G. Bukchin, E. Schwartz, K. Saenko, O. Shahar, R. Feris, R. Giryes, and L. Karlinsky, “Fine-grained angular contrastive learning with coarse labels,” in IEEE Conf. Comput. Vis. Pattern Recognit., 2021.
- [109] S. Purushwalkam and A. Gupta, “Demystifying contrastive self-supervised learning: Invariances, augmentations and dataset biases,” in Neural Inf. Process. Syst., pp. 1–12, 2020.
- [110] P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y. Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, “Supervised contrastive learning,” in Neural Inf. Process. Syst., pp. 18661–18673, 2020.
- [111] J. Zhou, C. Wei, H. Wang, W. Shen, C. Xie, A. Yuille, and T. Kong, “ibot: Image bert pre-training with online tokenizer,” in Int. Conf. Learn. Represent., pp. 1–12, 2022.
- [112] H. Bao, L. Dong, S. Piao, and F. Wei, “Beit: Bert pre-training of image transformers,” in Int. Conf. Learn. Represent., pp. 1–13, 2022.
- [113] X. Chen, M. Ding, X. Wang, Y. Xin, S. Mo, Y. Wang, S. Han, P. Luo, G. Zeng, and J. Wang, “Context autoencoder for self-supervised representation learning,” arXiv preprint arXiv:2202.03026, 2022.
- [114] Z. Xie, Z. Zhang, Y. Cao, Y. Lin, J. Bao, Z. Yao, Q. Dai, and H. Hu, “Simmim: A simple framework for masked image modeling,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 9653–9663, 2022.
- [115] D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros, “Context encoders: Feature learning by inpainting,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 2536–2544, 2016.
- [116] M. Chen, A. Radford, R. Child, J. Wu, H. Jun, P. Dhariwal, D. Luan, and I. Sutskever, “Generative pretraining from pixels,” in Int. Conf. Mach. Learn., pp. 1691–1703, 2020.
- [117] A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,” in Int. Conf. Mach. Learn., pp. 8821–8831, 2021.
- [118] C. Wei, H. Fan, S. Xie, C.-Y. Wu, A. Yuille, and C. Feichtenhofer, “Masked feature prediction for self-supervised visual pre-training,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 14668–14678, 2022.
- [119] X. Dong, J. Bao, T. Zhang, D. Chen, W. Zhang, L. Yuan, D. Chen, F. Wen, and N. Yu, “Peco: Perceptual codebook for bert pre-training of vision transformers,” arXiv preprint arXiv:2111.12710, 2021.
- [120] A. Baevski, W.-N. Hsu, Q. Xu, A. Babu, J. Gu, and M. Auli, “Data2vec: A general framework for self-supervised learning in speech, vision and language,” arXiv preprint arXiv:2202.03555, 2022.
- [121] Y. Chen, Y. Liu, D. Jiang, X. Zhang, W. Dai, H. Xiong, and Q. Tian, “Sdae: Self-distillated masked autoencoder,” in Eur. Conf. Comput. Vis., pp. 108–124, 2022.
- [122] Q. Zhou, C. Yu, H. Luo, Z. Wang, and H. Li, “Mimco: Masked image modeling pre-training with contrastive teacher,” in ACM Int. Conf. Multimedia, pp. 4487–4495, 2022.
- [123] Z. Peng, L. Dong, H. Bao, Q. Ye, and F. Wei, “Beit v2: Masked image modeling with vector-quantized visual tokenizers,” arXiv preprint arXiv:2208.06366, 2022.
- [124] C. Feichtenhofer, H. Fan, Y. Li, and K. He, “Masked autoencoders as spatiotemporal learners,” arXiv preprint arXiv:2205.09113, 2022.
- [125] Y. Liang, S. Zhao, B. Yu, J. Zhang, and F. He, “Meshmae: Masked autoencoders for 3d mesh data analysis,” in Eur. Conf. Comput. Vis., pp. 37–54, 2022.
- [126] Y. Pang, W. Wang, F. E. Tay, W. Liu, Y. Tian, and L. Yuan, “Masked autoencoders for point cloud self-supervised learning,” in Eur. Conf. Comput. Vis., pp. 604–621, 2022.
- [127] Z. Liu, H. Hu, Y. Lin, Z. Yao, Z. Xie, Y. Wei, J. Ning, Y. Cao, Z. Zhang, L. Dong, et al., “Swin transformer v2: Scaling up capacity and resolution,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 12009–12019, 2022.
- [128] Q. Zhang, Y. Xu, J. Zhang, and D. Tao, “Vitaev2: Vision transformer advanced by exploring inductive bias for image recognition and beyond,” Int. J. Comput. Vis., pp. 1–22, 2023.
- [129] Y. Li, H. Mao, R. Girshick, and K. He, “Exploring plain vision transformer backbones for object detection,” in Eur. Conf. Comput. Vis., pp. 280–296, 2022.
- [130] Y. Xu, J. Zhang, Q. Zhang, and D. Tao, “Vitpose: Simple vision transformer baselines for human pose estimation,” in Neural Inf. Process. Syst., pp. 38571–38584, 2022.
- [131] Z. Liu, J. Gui, and H. Luo, “Good helper is around you: Attention-driven masked image modeling,” in AAAI Conf.Artif. Intell., pp. 1799–1807, 2023.
- [132] Z. Qi, R. Dong, G. Fan, Z. Ge, X. Zhang, K. Ma, and L. Yi, “Contrast with reconstruct: Contrastive 3d representation learning guided by generative pretraining,” arXiv preprint arXiv:2302.02318, 2023.
- [133] Z. Xie, Z. Zhang, Y. Cao, Y. Lin, Y. Wei, Q. Dai, and H. Hu, “On data scaling in masked image modeling,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 10365–10374, 2023.
- [134] M. Oquab, T. Darcet, T. Moutakanni, H. Vo, M. Szafraniec, V. Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, et al., “Dinov2: Learning robust visual features without supervision,” arXiv preprint arXiv:2304.07193, 2023.
- [135] X. Kong and X. Zhang, “Understanding masked image modeling via learning occlusion invariant feature,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6241–6251, 2023.
- [136] H. Chen, Y. Wang, B. Lagadec, A. Dantcheva, and F. Bremond, “Joint generative and contrastive learning for unsupervised person re-identification,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 2004–2013, 2021.
- [137] Z. Xie, Z. Geng, J. Hu, Z. Zhang, H. Hu, and Y. Cao, “Revealing the dark secrets of masked image modeling,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 14475–14485, 2023.
- [138] A. Dosovitskiy, J. T. Springenberg, M. Riedmiller, and T. Brox, “Discriminative unsupervised feature learning with convolutional neural networks,” in Neural Inf. Process. Syst., pp. 766–774, 2014.
- [139] A. Dosovitskiy, P. Fischer, J. T. Springenberg, M. Riedmiller, and T. Brox, “Discriminative unsupervised feature learning with exemplar convolutional neural networks,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 38, no. 9, pp. 1734–1747, 2015.
- [140] C. Doersch, A. Gupta, and A. A. Efros, “Unsupervised visual representation learning by context prediction,” in IEEE Int. Conf. Comput. Vis., pp. 1422–1430, 2015.
- [141] P. Bojanowski and A. Joulin, “Unsupervised learning by predicting noise,” in Int. Conf. Mach. Learn., 2017.
- [142] J. Xie, R. Girshick, and A. Farhadi, “Unsupervised deep embedding for clustering analysis,” in Int. Conf. Mach. Learn., pp. 478–487, 2016.
- [143] J. Yang, D. Parikh, and D. Batra, “Joint unsupervised learning of deep representations and image clusters,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 5147–5156, 2016.
- [144] M. Caron, P. Bojanowski, A. Joulin, and M. Douze, “Deep clustering for unsupervised learning of visual features,” in Eur. Conf. Comput. Vis., pp. 132–149, 2018.
- [145] R. Zhang, P. Isola, and A. A. Efros, “Split-brain autoencoders: Unsupervised learning by cross-channel prediction,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1058–1067, 2017.
- [146] X. Wang, K. He, and A. Gupta, “Transitive invariance for self-supervised visual representation learning,” in IEEE Int. Conf. Comput. Vis., pp. 1329–1338, 2017.
- [147] A. Kolesnikov, X. Zhai, and L. Beyer, “Revisiting self-supervised visual representation learning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1920–1929, 2019.
- [148] P. Krähenbühl, “Free supervision from video games,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 2955–2964, 2018.
- [149] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Neural Inf. Process. Syst., pp. 2672–2680, 2014.
- [150] T. Chen, X. Zhai, M. Ritter, M. Lucic, and N. Houlsby, “Self-supervised gans via auxiliary rotation loss,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 12154–12163, 2019.
- [151] X. Zhai, A. Oliver, A. Kolesnikov, and L. Beyer, “S4l: Self-supervised semi-supervised learning,” in IEEE Int. Conf. Comput. Vis., pp. 1476–1485, 2019.
- [152] D. Hendrycks, M. Mazeika, S. Kadavath, and D. Song, “Using self-supervised learning can improve model robustness and uncertainty,” in Neural Inf. Process. Syst., pp. 15663–15674, 2019.
- [153] K. Hassani and A. H. Khasahmadi, “Contrastive multi-view representation learning on graphs,” in Int. Conf. Mach. Learn., 2020.
- [154] L. Gomez, Y. Patel, M. Rusiñol, D. Karatzas, and C. Jawahar, “Self-supervised learning of visual features through embedding images into text topic spaces,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 4230–4239, 2017.
- [155] L. Jing, Y. Chen, L. Zhang, M. He, and Y. Tian, “Self-supervised feature learning by cross-modality and cross-view correspondences,” arXiv preprint arXiv:2004.05749, 2020.
- [156] L. Jing, Y. Chen, L. Zhang, M. He, and Y. Tian, “Self-supervised modal and view invariant feature learning,” arXiv preprint arXiv:2005.14169, 2020.
- [157] L. Zhang and Z. Zhu, “Unsupervised feature learning for point cloud understanding by contrasting and clustering using graph convolutional neural networks,” in International Conference on 3D Vision, pp. 395–404, 2019.
- [158] Y. Yang, C. Feng, Y. Shen, and D. Tian, “Foldingnet: Point cloud auto-encoder via deep grid deformation,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 206–215, 2018.
- [159] M. Gadelha, R. Wang, and S. Maji, “Multiresolution tree networks for 3d point cloud processing,” in Eur. Conf. Comput. Vis., pp. 103–118, 2018.
- [160] Y. Zhao, T. Birdal, H. Deng, and F. Tombari, “3d point capsule networks,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1009–1018, 2019.
- [161] Y. Sun, X. Wang, Z. Liu, J. Miller, A. A. Efros, and M. Hardt, “Test-time training with self-supervision for generalization under distribution shifts,” in Int. Conf. Mach. Learn., 2020.
- [162] Y. Gandelsman, Y. Sun, X. Chen, and A. A. Efros, “Test-time training with masked autoencoders,” arXiv preprint arXiv:2209.07522, 2022.
- [163] J. J. Sun, A. Kennedy, E. Zhan, D. J. Anderson, Y. Yue, and P. Perona, “Task programming: Learning data efficient behavior representations,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 2876–2885, 2021.
- [164] Z. Ren and Y. Jae Lee, “Cross-domain self-supervised multi-task feature learning using synthetic imagery,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 762–771, 2018.
- [165] K. Hassani and M. Haley, “Unsupervised multi-task feature learning on point clouds,” in IEEE Int. Conf. Comput. Vis., pp. 8160–8171, 2019.
- [166] A. Piergiovanni, A. Angelova, and M. S. Ryoo, “Evolving losses for unsupervised video representation learning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 133–142, 2020.
- [167] K. Saito, D. Kim, S. Sclaroff, and K. Saenko, “Universal domain adaptation through self supervision,” in Neural Inf. Process. Syst., pp. 1–11, 2020.
- [168] Y. Sun, E. Tzeng, T. Darrell, and A. A. Efros, “Unsupervised domain adaptation through self-supervision,” arXiv preprint arXiv:1909.11825, 2019.
- [169] M. Noroozi, A. Vinjimoor, P. Favaro, and H. Pirsiavash, “Boosting self-supervised learning via knowledge transfer,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 9359–9367, 2018.
- [170] W. Hu, B. Liu, J. Gomes, M. Zitnik, P. Liang, V. Pande, and J. Leskovec, “Strategies for pre-training graph neural networks,” arXiv preprint arXiv:1905.12265, 2019.
- [171] Y. You, T. Chen, Z. Wang, and Y. Shen, “When does self-supervision help graph convolutional networks?,” arXiv preprint arXiv:2006.09136, 2020.
- [172] J. Qiu, Q. Chen, Y. Dong, J. Zhang, H. Yang, M. Ding, K. Wang, and J. Tang, “Gcc: Graph contrastive coding for graph neural network pre-training,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1150–1160, 2020.
- [173] Z. Hu, Y. Dong, K. Wang, K.-W. Chang, and Y. Sun, “Gpt-gnn: Generative pre-training of graph neural networks,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1857–1867, 2020.
- [174] Y. Rong, Y. Bian, T. Xu, W. Xie, Y. Wei, W. Huang, and J. Huang, “Self-supervised graph transformer on large-scale molecular data,” in Neural Inf. Process. Syst., 2020.
- [175] Y. Zhu, Y. Xu, F. Yu, Q. Liu, S. Wu, and L. Wang, “Deep graph contrastive representation learning,” arXiv preprint arXiv:2006.04131, 2020.
- [176] U. Buchler, B. Brattoli, and B. Ommer, “Improving spatiotemporal self-supervision by deep reinforcement learning,” in Eur. Conf. Comput. Vis., pp. 770–786, 2018.
- [177] D. Guo, B. A. Pires, B. Piot, J.-b. Grill, F. Altché, R. Munos, and M. G. Azar, “Bootstrap latent-predictive representations for multitask reinforcement learning,” arXiv preprint arXiv:2004.14646, 2020.
- [178] N. Hansen, Y. Sun, P. Abbeel, A. A. Efros, L. Pinto, and X. Wang, “Self-supervised policy adaptation during deployment,” arXiv preprint arXiv:2007.04309, 2020.
- [179] S. Gidaris, A. Bursuc, N. Komodakis, P. Pérez, and M. Cord, “Boosting few-shot visual learning with self-supervision,” in IEEE Int. Conf. Comput. Vis., pp. 8059–8068, 2019.
- [180] J.-C. Su, S. Maji, and B. Hariharan, “Boosting supervision with self-supervision for few-shot learning,” arXiv preprint arXiv:1906.07079, 2019.
- [181] C. Li, T. Tang, G. Wang, J. Peng, B. Wang, X. Liang, and X. Chang, “Bossnas: Exploring hybrid cnn-transformers with block-wisely self-supervised neural architecture search,” in IEEE Int. Conf. Comput. Vis., 2021.
- [182] L. Fan, S. Liu, P.-Y. Chen, G. Zhang, and C. Gan, “When does contrastive learning preserve adversarial robustness from pretraining to finetuning?,” in Neural Inf. Process. Syst., 2021.
- [183] M. Kim, J. Tack, and S. J. Hwang, “Adversarial self-supervised contrastive learning,” in Neural Inf. Process. Syst., pp. 1–12, 2020.
- [184] T. Chen, S. Liu, S. Chang, Y. Cheng, L. Amini, and Z. Wang, “Adversarial robustness: From self-supervised pre-training to fine-tuning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 699–708, 2020.
- [185] Y. Lin, X. Guo, and Y. Lu, “Self-supervised video representation learning with meta-contrastive network,” in IEEE Int. Conf. Comput. Vis., pp. 8239–8249, 2021.
- [186] Y. An, H. Xue, X. Zhao, and L. Zhang, “Conditional self-supervised learning for few-shot classification,” in Int. Joint Conf. Artif. Intell., pp. 2140–2146, 2021.
- [187] S. Pal, A. Datta, and D. D. Majumder, “Computer recognition of vowel sounds using a self-supervised learning algorithm,” Journal of the Anatomical Society of India, pp. 117–123, 1978.
- [188] A. Ghosh, N. R. Pal, and S. K. Pal, “Self-organization for object extraction using a multilayer neural network and fuzziness mearsures,” IEEE Transactions on Fuzzy Systems, pp. 54–68, 1993.
- [189] A. Sharma, O. Grau, and M. Fritz, “Vconv-dae: Deep volumetric shape learning without object labels,” in Eur. Conf. Comput. Vis., pp. 236–250, 2016.
- [190] K. Gong, X. Liang, D. Zhang, X. Shen, and L. Lin, “Look into person: Self-supervised structure-sensitive learning and a new benchmark for human parsing,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 932–940, 2017.
- [191] X. Liang, K. Gong, X. Shen, and L. Lin, “Look into person: Joint body parsing & pose estimation network and a new benchmark,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, no. 4, pp. 871–885, 2018.
- [192] X. Zhan, X. Pan, B. Dai, Z. Liu, D. Lin, and C. C. Loy, “Self-supervised scene de-occlusion,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 3784–3792, 2020.
- [193] D. Pathak, R. Girshick, P. Dollár, T. Darrell, and B. Hariharan, “Learning features by watching objects move,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 2701–2710, 2017.
- [194] Y. Wang, J. Zhang, M. Kan, S. Shan, and X. Chen, “Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 12275–12284, 2020.
- [195] Z. Chen, X. Ye, L. Du, W. Yang, L. Huang, X. Tan, Z. Shi, F. Shen, and E. Ding, “Aggnet for self-supervised monocular depth estimation: Go an aggressive step furthe,” in ACM Int. Conf. Multimedia, pp. 1526–1534, 2021.
- [196] H. Chen, B. Lagadec, and F. Bremond, “Ice: Inter-instance contrastive encoding for unsupervised person re-identification,” in IEEE Int. Conf. Comput. Vis., pp. 14960–14969, 2021.
- [197] T. Isobe, D. Li, L. Tian, W. Chen, Y. Shan, and S. Wang, “Towards discriminative representation learning for unsupervised person re-identification,” in IEEE Int. Conf. Comput. Vis., pp. 8526–8536, 2021.
- [198] Z. Wang, J. Zhang, L. Zheng, Y. Liu, Y. Sun, Y. Li, and S. Wang, “Cycas: Self-supervised cycle association for learning re-identifiable descriptions,” in Eur. Conf. Comput. Vis., 2020.
- [199] S. Li, X. Wang, Y. Cao, F. Xue, Z. Yan, and H. Zha, “Self-supervised deep visual odometry with online adaptation,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6339–6348, 2020.
- [200] W. Wu, Z. Y. Wang, Z. Li, W. Liu, and L. Fuxin, “Pointpwc-net: Cost volume on point clouds for (self-) supervised scene flow estimation,” in Eur. Conf. Comput. Vis., 2020.
- [201] G. Xu, Z. Liu, X. Li, and C. C. Loy, “Knowledge distillation meets self-supervision,” arXiv preprint arXiv:2006.07114, 2020.
- [202] J. Walker, A. Gupta, and M. Hebert, “Dense optical flow prediction from a static image,” in IEEE Int. Conf. Comput. Vis., pp. 2443–2451, 2015.
- [203] F. Zhu, Y. Zhu, X. Chang, and X. Liang, “Vision-language navigation with self-supervised auxiliary reasoning tasks,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 10012–10022, 2020.
- [204] X. Niu, S. Shan, H. Han, and X. Chen, “Rhythmnet: End-to-end heart rate estimation from face via spatial-temporal representation,” IEEE Trans. Image Process., vol. 29, pp. 2409–2423, 2020.
- [205] X. Niu, Z. Yu, H. Han, X. Li, S. Shan, and G. Zhao, “Video-based remote physiological measurement via cross-verified feature disentangling,” in Eur. Conf. Comput. Vis., 2020.
- [206] Y. Xie, Z. Wang, and S. Ji, “Noise2same: Optimizing a self-supervised bound for image denoising,” in Neural Inf. Process. Syst., 2020.
- [207] T. Huang, S. Li, X. Jia, H. Lu, and J. Liu, “Neighbor2neighbor: Self-supervised denoising from single noisy images,” in IEEE Conf. Comput. Vis. Pattern Recognit., 2021.
- [208] C. Yang, Z. Wu, B. Zhou, and S. Lin, “Instance localization for self-supervised detection pretraining,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 3987–3996, 2021.
- [209] I. Croitoru, S.-V. Bogolin, and M. Leordeanu, “Unsupervised learning from video to detect foreground objects in single images,” in IEEE Int. Conf. Comput. Vis., pp. 4335–4343, 2017.
- [210] E. Xie, J. Ding, W. Wang, X. Zhan, H. Xu, Z. Li, and P. Luo, “Detco: Unsupervised contrastive learning for object detection,” arXiv preprint arXiv:2102.04803, 2021.
- [211] G. Wu, J. Jiang, X. Liu, and J. Ma, “A practical contrastive learning framework for single image super-resolution,” arXiv preprint arXiv:2111.13924, 2021.
- [212] S. Menon, A. Damian, S. Hu, N. Ravi, and C. Rudin, “Pulse: Self-supervised photo upsampling via latent space exploration of generative models,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 2437–2445, 2020.
- [213] R. Girdhar, D. F. Fouhey, M. Rodriguez, and A. Gupta, “Learning a predictable and generative vector representation for objects,” in Eur. Conf. Comput. Vis., pp. 484–499, 2016.
- [214] D. Jayaraman and K. Grauman, “Learning image representations tied to ego-motion,” in IEEE Int. Conf. Comput. Vis., pp. 1413–1421, 2015.
- [215] Z. Yin and J. Shi, “Geonet: Unsupervised learning of dense depth, optical flow and camera pose,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 1983–1992, 2018.
- [216] Y. Zhao, G. Wang, C. Luo, W. Zeng, and Z.-J. Zha, “Self-supervised visual representations learning by contrastive mask prediction,” in IEEE Int. Conf. Comput. Vis., 2021.
- [217] L. Huang, Y. Liu, B. Wang, P. Pan, Y. Xu, and R. Jin, “Self-supervised video representation learning by context and motion decoupling,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 13886–13895, 2021.
- [218] K. Hu, J. Shao, Y. Liu, B. Raj, M. Savvides, and Z. Shen, “Contrast and order representations for video self-supervised learning,” in IEEE Int. Conf. Comput. Vis., pp. 7939–7949, 2021.
- [219] M. Tschannen, J. Djolonga, M. Ritter, A. Mahendran, N. Houlsby, S. Gelly, and M. Lucic, “Self-supervised learning of video-induced visual invariances,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 13806–13815, 2020.
- [220] X. He, Y. Pan, M. Tang, Y. Lv, and Y. Peng, “Learn from unlabeled videos for near-duplicate video retrieval,” in International Conference on Research on Development in Information Retrieval, pp. 1–10, 2022.
- [221] X. Wang and A. Gupta, “Unsupervised learning of visual representations using videos,” in IEEE Int. Conf. Comput. Vis., pp. 2794–2802, 2015.
- [222] N. Srivastava, E. Mansimov, and R. Salakhudinov, “Unsupervised learning of video representations using lstms,” in Int. Conf. Mach. Learn., pp. 843–852, 2015.
- [223] T. Han, W. Xie, and A. Zisserman, “Video representation learning by dense predictive coding,” in ICCV Workshops, 2019.
- [224] T. Han, W. Xie, and A. Zisserman, “Memory-augmented dense predictive coding for video representation learning,” in Eur. Conf. Comput. Vis., 2020.
- [225] B. Fernando, H. Bilen, E. Gavves, and S. Gould, “Self-supervised video representation learning with odd-one-out networks,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 3636–3645, 2017.
- [226] H.-Y. Lee, J.-B. Huang, M. Singh, and M.-H. Yang, “Unsupervised representation learning by sorting sequences,” in IEEE Int. Conf. Comput. Vis., pp. 667–676, 2017.
- [227] D. Xu, J. Xiao, Z. Zhao, J. Shao, D. Xie, and Y. Zhuang, “Self-supervised spatiotemporal learning via video clip order prediction,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 10334–10343, 2019.
- [228] S. Benaim, A. Ephrat, O. Lang, I. Mosseri, W. T. Freeman, M. Rubinstein, M. Irani, and T. Dekel, “Speednet: Learning the speediness in videos,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 9922–9931, 2020.
- [229] Y. Yao, C. Liu, D. Luo, Y. Zhou, and Q. Ye, “Video playback rate perception for self-supervised spatio-temporal representation learning,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6548–6557, 2020.
- [230] J. Wang, J. Jiao, and Y.-H. Liu, “Self-supervised video representation learning by pace prediction,” in Eur. Conf. Comput. Vis., 2020.
- [231] A. Diba, V. Sharma, L. V. Gool, and R. Stiefelhagen, “Dynamonet: Dynamic action and motion network,” in IEEE Int. Conf. Comput. Vis., pp. 6192–6201, 2019.
- [232] T. Han, W. Xie, and A. Zisserman, “Self-supervised co-training for video representation learning,” in Neural Inf. Process. Syst., pp. 1–12, 2020.
- [233] B. Korbar, D. Tran, and L. Torresani, “Cooperative learning of audio and video models from self-supervised synchronization,” in Neural Inf. Process. Syst., pp. 7763–7774, 2018.
- [234] R. Arandjelovic and A. Zisserman, “Look, listen and learn,” in IEEE Int. Conf. Comput. Vis., pp. 609–617, 2017.
- [235] C. Sun, A. Myers, C. Vondrick, K. Murphy, and C. Schmid, “Videobert: A joint model for video and language representation learning,” in IEEE Int. Conf. Comput. Vis., pp. 7464–7473, 2019.
- [236] A. Nagrani, C. Sun, D. Ross, R. Sukthankar, C. Schmid, and A. Zisserman, “Speech2action: Cross-modal supervision for action recognition,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 10317–10326, 2020.
- [237] J. C. Stroud, D. A. Ross, C. Sun, J. Deng, R. Sukthankar, and C. Schmid, “Learning video representations from textual web supervision,” arXiv preprint arXiv:2007.14937, 2020.
- [238] J.-B. Alayrac, A. Recasens, R. Schneider, R. Arandjelović, J. Ramapuram, J. De Fauw, L. Smaira, S. Dieleman, and A. Zisserman, “Self-supervised multimodal versatile networks,” arXiv preprint arXiv:2006.16228, 2020.
- [239] P. Sermanet, C. Lynch, Y. Chebotar, J. Hsu, E. Jang, S. Schaal, and S. Levine, “Time-contrastive networks: Self-supervised learning from video,” in IEEE Int. Conf. Robot. Autom., pp. 1134–1141, 2018.
- [240] X. Wang, A. Jabri, and A. A. Efros, “Learning correspondence from the cycle-consistency of time,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 2566–2576, 2019.
- [241] X. Li, S. Liu, S. De Mello, X. Wang, J. Kautz, and M.-H. Yang, “Joint-task self-supervised learning for temporal correspondence,” in Neural Inf. Process. Syst., pp. 318–328, 2019.
- [242] A. Jabri, A. Owens, and A. A. Efros, “Space-time correspondence as a contrastive random walk,” in Neural Inf. Process. Syst., pp. 19545–19560, 2020.
- [243] Z. Lai, E. Lu, and W. Xie, “Mast: A memory-augmented self-supervised tracker,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6479–6488, 2020.
- [244] Z. Zhang, S. Lathuiliere, E. Ricci, N. Sebe, Y. Yan, and J. Yang, “Online depth learning against forgetting in monocular videos,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 4494–4503, 2020.
- [245] D. Luo, C. Liu, Y. Zhou, D. Yang, C. Ma, Q. Ye, and W. Wang, “Video cloze procedure for self-supervised spatio-temporal learning,” in AAAI Conf.Artif. Intell., pp. 11701–11708, 2020.
- [246] O. J. Hénaff, A. Srinivas, J. De Fauw, A. Razavi, C. Doersch, S. Eslami, and A. v. d. Oord, “Data-efficient image recognition with contrastive predictive coding,” in Int. Conf. Mach. Learn., 2020.
- [247] A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,” 2018.
- [248] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al., “Language models are few-shot learners,” arXiv preprint arXiv:2005.14165, 2020.
- [249] C. Li, J. Yang, P. Zhang, M. Gao, B. Xiao, X. Dai, L. Yuan, and J. Gao, “Efficient self-supervised vision transformers for representation learning,” arXiv preprint arXiv:2106.09785, 2021.
- [250] Z. Li, Z. Chen, F. Yang, W. Li, Y. Zhu, C. Zhao, R. Deng, L. Wu, R. Zhao, M. Tang, and J. Wang, “Mst: Masked self-supervised transformer for visual representation,” in Neural Inf. Process. Syst., pp. 1–12, 2021.
- [251] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” in Neural Inf. Process. Syst., pp. 3111–3119, 2013.
- [252] L. Kong, C. d. M. d’Autume, W. Ling, L. Yu, Z. Dai, and D. Yogatama, “A mutual information maximization perspective of language representation learning,” arXiv preprint arXiv:1910.08350, 2019.
- [253] J. Wu, X. Wang, and W. Y. Wang, “Self-supervised dialogue learning,” arXiv preprint arXiv:1907.00448, 2019.
- [254] K. Clark, M.-T. Luong, Q. V. Le, and C. D. Manning, “Electra: Pre-training text encoders as discriminators rather than generators,” in Int. Conf. Learn. Represent., 2020.
- [255] X. Qiu, T. Sun, Y. Xu, Y. Shao, N. Dai, and X. Huang, “Pre-trained models for natural language processing: A survey,” arXiv preprint arXiv:2003.08271, 2020.
- [256] H. Wang, X. Wang, W. Xiong, M. Yu, X. Guo, S. Chang, and W. Y. Wang, “Self-supervised learning for contextualized extractive summarization,” in Annual Meeting of the Association for Computational Linguistics, pp. 2221–2227, 2019.
- [257] Y. Aytar, C. Vondrick, and A. Torralba, “Soundnet: Learning sound representations from unlabeled video,” in Neural Inf. Process. Syst., pp. 892–900, 2016.
- [258] H.-Y. Zhou, C. Lu, S. Yang, X. Han, and Y. Yu, “Preservational learning improves self-supervised medical image models by reconstructing diverse contexts,” in IEEE Int. Conf. Comput. Vis., pp. 3499–3509, 2021.
- [259] K. Chaitanya, E. Erdil, N. Karani, and E. Konukoglu, “Contrastive learning of global and local features for medical image segmentation with limited annotations,” in Neural Inf. Process. Syst., 2020.
- [260] J. Zhu, Y. Li, Y. Hu, K. Ma, S. K. Zhou, and Y. Zheng, “Rubik’s cube+: A self-supervised feature learning framework for 3d medical image analysis,” Medical Image Analysis, p. 101746, 2020.
- [261] O. Manas, A. Lacoste, X. Giró-i Nieto, D. Vazquez, and P. Rodriguez, “Seasonal contrast: Unsupervised pre-training from uncurated remote sensing data,” in IEEE Int. Conf. Comput. Vis., pp. 9414–9423, 2021.
- [262] D. Wang, Q. Zhang, Y. Xu, J. Zhang, B. Du, D. Tao, and L. Zhang, “Advancing plain vision transformer toward remote sensing foundation model,” IEEE Trans. Geoscience and Remote Sensing, vol. 61, pp. 1–15, 2022.
- [263] D. Bau, B. Zhou, A. Khosla, A. Oliva, and A. Torralba, “Network dissection: Quantifying interpretability of deep visual representations,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 6541–6549, 2017.
- [264] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes (voc) challenge,” Int. J. Comput. Vis., vol. 88, pp. 303–338, 2010.
- [265] T.-Y. Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, C. L. Zitnick, and P. Dollár, “Microsoft coco: Common objects in context,” 2015.
- [266] B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, and A. Torralba, “Scene parsing through ade20k dataset,” in IEEE Conf. Comput. Vis. Pattern Recognit., 2017.
- [267] B. Zhou, H. Zhao, X. Puig, T. Xiao, S. Fidler, A. Barriuso, and A. Torralba, “Semantic understanding of scenes through the ade20k dataset,” Int. J. Comput. Vis., vol. 127, no. 3, pp. 302–321, 2019.
- [268] J. Liu, X. Huang, Y. Liu, and H. Li, “Mixmim: Mixed and masked image modeling for efficient visual representation learning,” arXiv preprint arXiv:2205.13137, 2022.
- [269] J. Robinson, L. Sun, K. Yu, K. Batmanghelich, S. Jegelka, and S. Sra, “Can contrastive learning avoid shortcut solutions?,” in Neural Inf. Process. Syst., pp. 4974–4986, 2021.
- [270] Y. Wei, H. Hu, Z. Xie, Z. Zhang, Y. Cao, J. Bao, D. Chen, and B. Guo, “Contrastive learning rivals masked image modeling in fine-tuning via feature distillation,” arXiv preprint arXiv:2205.14141, 2022.
- [271] Y. Tian, X. Chen, and S. Ganguli, “Understanding self-supervised learning dynamics without contrastive pairs,” in Int. Conf. Mach. Learn., pp. 10268–10278, 2021.
- [272] X. Wang, R. Zhang, C. Shen, T. Kong, and L. Li, “Dense contrastive learning for self-supervised visual pre-training,” in IEEE Conf. Comput. Vis. Pattern Recognit., pp. 3024–3033, 2021.
- [273] W. Wang, H. Bao, L. Dong, J. Bjorck, Z. Peng, Q. Liu, K. Aggarwal, O. K. Mohammed, S. Singhal, S. Som, et al., “Image as a foreign language: Beit pretraining for all vision and vision-language tasks,” arXiv preprint arXiv:2208.10442, 2022.