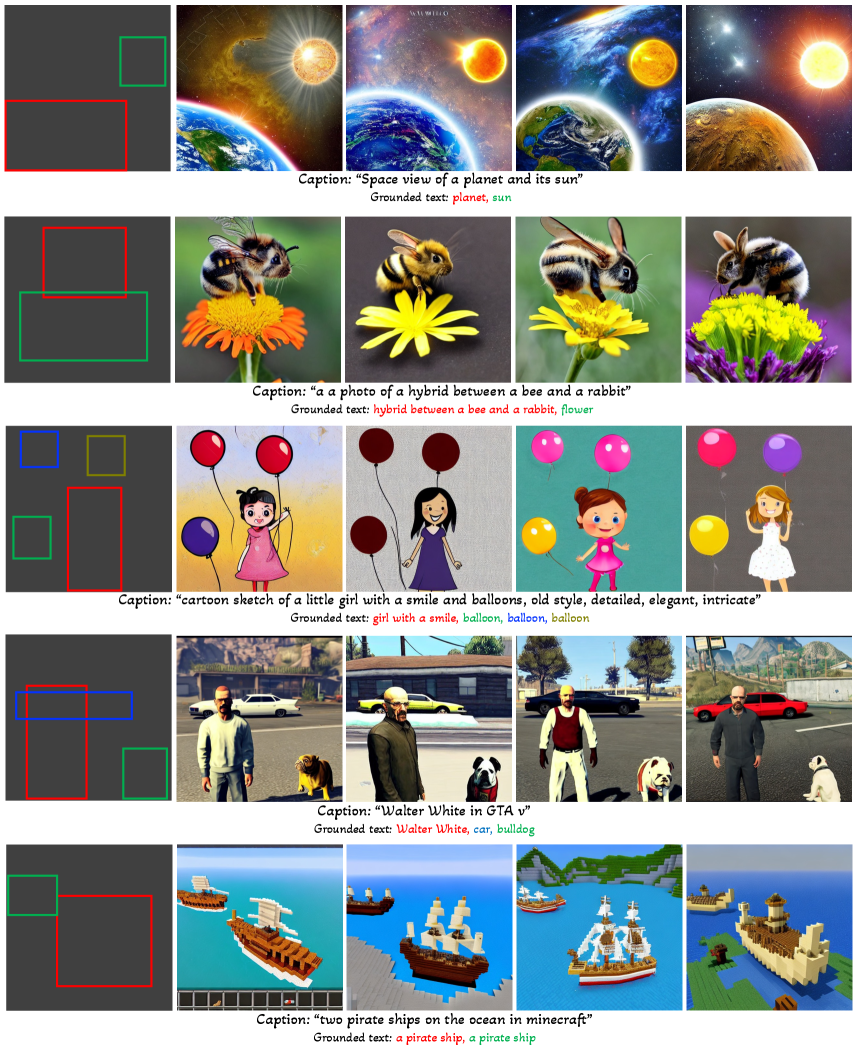
Gligen:基于开放集的文本到图像生成
摘要
大规模文本到图像的扩散模型取得了惊人的进步。 然而,现状是单独使用文本输入,这会妨碍可控性。 在这项工作中,我们建议Gligen,Grounded-Language-to-Image Gen eration,一种新颖的方法,它建立并扩展了现有预训练文本到图像扩散模型的功能,使它们也能够以接地输入为条件。 为了保留预训练模型的大量概念知识,我们冻结了其所有权重,并通过门控机制将基础信息注入到新的可训练层中。 我们的模型通过标题和边界框条件输入实现了开放世界的接地 text2img 生成,并且接地能力很好地推广到新颖的空间配置和概念。 Gligen 在 COCO 和 LVIS 上的零样本性能大幅优于现有的监督布局到图像基线。 †† 在 Microsoft 完成的部分工作; 共同资深作者
![[Uncaptioned image]](x1.png)
1简介
近年来,图像生成研究取得了巨大进步。 在过去的几年里,GAN [14] 是最先进的,其潜在空间和条件输入已被充分研究以实现可控操作[48, 60] 和一代[27,47,29,82]。 文本条件自回归 [52, 74] 和扩散 [51, 56] 模型由于其更稳定的学习目标和大规模,表现出了惊人的图像质量和概念覆盖率在网络图像-文本配对数据上进行训练。 这些模型因其实际用例(例如.、艺术设计和创作)而受到公众的关注。
尽管取得了令人兴奋的进展,但现有的大规模文本到图像生成模型不能以文本之外的其他输入方式为条件,因此缺乏精确定位概念、使用参考图像或其他条件输入来控制生成过程的能力。 当前的输入,即即.,仅自然语言就限制了信息的表达方式。 例如,使用文本很难描述物体的精确位置,而边界框/关键点可以轻松实现这一点,如图1所示。 虽然条件扩散模型 [10, 55, 53] 和 GAN [48, 37, 26, 71] 采用除文本之外的输入模式进行修复、layout2img 生成, etc.,确实存在,它们很少结合这些输入来生成可控的text2img。
此外,先前的生成模型(无论生成模型系列如何)通常是在每个特定于任务的数据集上独立训练的。 相比之下,在识别领域,长期存在的范式是从大规模图像数据预训练的基础模型开始构建识别模型[32,42,84][ 17, 4, 16] 或图像文本对 [50, 33, 75]。 由于扩散模型已经在数十亿个图像文本对 [53] 上进行了训练,一个自然的问题是: 我们能否以现有的预训练扩散模型为基础,并赋予它们新的条件输入模式? 通过这种方式,类似于识别文献,由于预训练模型拥有大量的概念知识,我们可能能够在其他生成任务上取得更好的性能,同时获得比现有文本到图像生成模型更多的可控性。
出于上述目标,我们提出了一种为预训练的文本到图像扩散模型提供新的基础条件输入的方法。 如图1所示,我们仍然保留文本标题作为输入,但也启用其他输入模式,例如基础概念的边界框、基础参考图像、基础部分关键点等。 关键的挑战是在预训练模型中保留原始的大量概念知识,同时学习注入新的基础信息。 为了防止知识遗忘,我们建议冻结原始模型权重并添加新的可训练门控 Transformer 层 [67],以接收新的基础输入(例如。 ,边界框)。 在训练过程中,我们使用门控机制[1]逐渐将新的基础信息融合到预训练模型中。 这种设计在生成过程中实现了采样过程的灵活性,从而提高了质量和可控性;例如,我们表明,在采样步骤的前半部分使用完整模型(所有层)并在后半部分仅使用原始层(没有门控 Transformer 层)可以产生准确反映接地条件的生成结果同时还具有高图像质量。
在我们的实验中,我们主要研究带有边界框的基础 text2img 生成,受到最近在 GLIP [34] 中使用框学习基础语言图像理解模型的成功扩展的启发。为了使我们的模型能够基础开放-世界词汇概念[76,34,79,32],我们使用相同的预训练文本编码器(用于编码标题)来编码与每个接地实体相关的每个短语(即.,每个边界框一个短语)并将编码的标记及其编码的位置信息馈送到新插入的层中。 由于共享文本空间,我们发现即使仅在 COCO [41] 数据集上进行训练,我们的模型也可以泛化到看不见的对象。 它在 LVIS [15] 上的泛化大大优于强大的完全监督基线。 为了进一步提高模型的接地能力,我们按照 GLIP [34] 统一了训练的目标检测和接地数据格式。 随着训练数据的增加,我们模型的泛化能力不断提高。
贡献。
1)我们提出了一种新的text2img生成方法,该方法赋予现有text2img扩散模型新的基础可控性。 2)通过保留预先训练的权重并学习逐步集成新的本地化层,我们的模型实现了带有边界框输入的开放世界的基于text2img的生成,即。,训练中未观察到的新颖本地化概念的综合。 3)我们的模型在layout2img任务上的零样本性能显着优于先前的最先进技术,展示了为下游任务构建大型预训练生成模型的能力。
2相关工作
大规模文本到图像生成模型。
该领域最先进的模型要么是自回归 [52, 13, 74, 69] 要么是扩散 [45, 51, 53, 56, 81] 。 在自回归模型中,DALL-E [52] 是展示零样本能力的突破性工作之一,而 Parti [74] 则展示了放大自回归模型的可行性。 扩散模型也显示出非常有希望的结果。 DALL-E 2 [51] 从 CLIP [50] 图像空间生成图像,而 Imagen [56] 发现使用预训练的好处语言模型。 并发Muse[6]证明了掩模建模可以以更高的推理速度实现SoTA级别的生成性能。 然而,所有这些模型通常只采用标题作为输入,这可能很难传达其他信息,例如对象的精确位置。 Make-A-Scene [13] 还将语义映射合并到其文本到图像的生成中,通过训练编码器来标记语义掩码来调节生成。 然而,它只能在封闭的集合(158 个类别)中运行,而我们的接地实体可以是开放世界。 一项并发工作 eDiff-I [3] 表明,通过更改注意力图,可以生成大致遵循语义图输入的对象。 然而,我们相信我们与盒子的接口更简单,更重要的是,我们的方法允许其他条件输入,例如关键点、边缘图、推理图像等,这些很难通过注意力来操纵。
从布局生成图像。
给定标有目标类别的边界框,任务是生成相应的图像[78,61,62,63,39,24,72],这是目标检测的逆任务。 Layout2Im [78] 阐述了该问题,并结合 VAE 对象编码器、LSTM [22] 对象融合器和图像解码器来生成图像,使用全局和对象-水平对抗性损失[14]以加强真实性和布局对应性。 LostGAN [61, 62] 受到 StyleGAN [28] 的启发,生成用于标准化特征的掩码表示。 LAMA [39] 提高了中间掩模质量以获得更好的图像质量。 还探索了基于 Transformer [66] 的方法 [24, 72]。 关键的是,现有的layout2image方法是封闭训练,即。,它们只能生成在集合中观察到的有限的局部视觉概念,例如COCO中的80个类别。 相比之下,我们的方法代表了开放集基础图像生成的第一项工作。 并行工作 ReCo [73] 还通过建立在预先训练的稳定扩散模型 [53] 的基础上展示了开放集能力。 然而,它对原始模型权重进行了微调,这有可能导致知识遗忘。 此外,它仅演示了盒子接地结果,而我们显示了更多模式的结果,如图 1 所示。
其他条件图像生成。
对于 GAN,已经探索了各种条件信息; 例如.,文本[70, 65, 80],框[78, 61, 62],语义掩码 [47, 36],图像 [83, 8, 38]。 对于扩散模型,LDM [53] 提出了一种通过交叉注意层注入条件来生成条件的统一方法。 Palette [55] 使用扩散模型执行图像到图像的任务。 这些模型通常是从头开始独立训练的。 在我们的工作中,我们研究如何构建基于大规模网络数据预训练的现有模型,以经济高效的方式启用新的开放集基础图像生成功能。
3 潜在扩散模型的预备知识
基于扩散的方法是文本到图像任务最有效的模型系列之一,其中潜在扩散模型(LDM)[53]及其后继者稳定扩散是研究界公开可用的最强大的模型。 为了减少普通扩散模型训练的计算成本,LDM 分两个阶段进行。 第一阶段学习双向映射网络以获得图像的潜在表示。 第二阶段在潜在上训练扩散模型。 由于第一阶段模型在 和 之间产生固定的双向映射,因此为简单起见,从这里开始,我们将重点关注 LDM 的潜在生成空间。
训练目标。
从噪声 开始,该模型会逐渐产生噪声较小的样本 ,并以每个时间步长 的字幕 为条件。为了学习这样一个以 为参数的模型 ,在每一步中,LDM 训练目标都要解决图像 的潜在表示 上的去噪问题:
| (1) |
其中是从时间步均匀采样的,是输入的步噪声变体>, 是 条件的去噪自动编码器。
网络架构。
网络架构的核心是如何对条件进行编码,并在此基础上生成更简洁的版本。 去噪自动编码器。 是通过UNet [54]实现的。 它接收嘈杂的潜在,以及来自时间步和条件的信息。 它由一系列 ResNet [19] 和 Transformer [67] 块组成。 条件编码。 在原始 LDM 中,从头开始训练类似 BERT 的 [9] 网络,将每个标题编码为文本嵌入序列 ,该序列被馈送到 (1) 来替换 。 字幕功能通过稳定扩散中的固定 CLIP [50] 文本编码器进行编码。 时间首先映射到时间嵌入,然后注入到UNet中。 标题特征用于每个 Transformer 块内的交叉注意层。 模型学习预测噪声,遵循 (1)。
通过大规模训练,模型经过良好训练,可以仅根据标题信息对进行去噪。 尽管 LDM by 预训练在互联网规模数据上显示了令人印象深刻的语言到图像生成结果,但在可以指示额外基础输入的情况下合成图像仍然具有挑战性,因此是我们论文的重点。
4 开放集接地图像生成
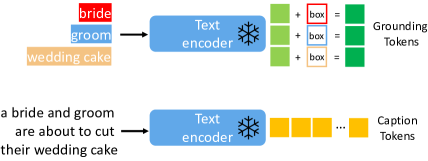
4.1 接地指令输入
对于基础文本到图像的生成,有多种方法可以通过附加条件来基础生成过程。 我们将基础实体的语义信息表示为,它可以通过文本或示例图像来描述;以及用例如边界框、一组关键点或边缘图等描述的基础空间配置。 请注意,在某些情况下,语义和空间信息都可以单独用 表示(例如边缘图),其中单个图可以表示图像中可能存在的对象以及位置。 我们将接地文本到图像模型的指令定义为标题和接地实体的组合:
| Instruction: | (2) | |||
| Caption: | (3) | |||
| Grounding: | (4) |
其中 是标题长度, 是要接地的实体数量。 在这项工作中,我们主要研究使用边界框作为基础空间配置,因为它具有很大的可用性并且易于用户标注。 对于接地实体,由于简单,我们主要关注使用文本作为其表示。 我们将标题和基础实体作为扩散模型的输入标记进行处理,如下文详细描述。
标题标记。 标题 的处理方式与 LDM 中相同。 具体来说,我们使用 获取标题特征序列(图 2 中的黄色标记),其中 是
接地 Token 。 对于用边界框表示的每个接地文本实体,我们将位置信息表示为 及其左上角和右下角坐标。 对于文本实体,我们使用相同的预训练文本编码器来获取其文本特征(图2中浅绿色词符),然后将其与其边界框信息融合以生成接地词符(图2中的深绿色词符):
| (5) |
其中 Fourier 是傅里叶嵌入 [44], 是一个多层感知器,它首先在特征维度上连接两个输入。 基础词符序列表示为
从闭集到开集。 请注意,现有的layout2img仅适用于封闭集设置(例如。,COCO类别),因为它们通常学习每个向量嵌入实体,替换 (5) 中的 。 对于具有 概念的闭集设置,学习具有 嵌入的字典,。 虽然这种非参数表示在闭集设置中效果很好,但它有两个缺点:(1) 在评估阶段,条件是通过字典查找 实现的,因此模型只能在生成的图像中对观察到的实体进行基础,缺乏概括新实体的能力; (2) 模型条件中没有使用任何单词/短语,并且缺少底层语言指令的语义结构[23]。 相反,在我们的开放集设计中,由于名词实体由用于编码标题的相同文本编码器处理,我们发现即使本地化信息仅限于基础训练数据集中的概念,我们的模型正如我们将在实验中展示的那样,仍然可以推广到其他概念。
其他接地条件的扩展。 请注意,方程 (4) 中提出的基础指令是一般形式,尽管我们到目前为止的描述重点关注使用文本作为实体 和边界框作为实体的情况(本文的主要设置)。 为了证明Gligen框架的灵活性,我们还研究了扩展方程(4)的使用场景的其他代表性案例。
-
•
图像提示。 虽然语言允许用户以开放词汇的方式描述一组丰富的实体,但有时可以通过示例图像更好地描述更多抽象和细粒度的概念。 为此,可以使用图像而不是语言来描述实体。 我们使用图像编码器获得特征 ,当 是图像时,用它来代替公式(5)中的 。
-
•
要点。 作为指定实体空间配置的简单参数化方法,边界框通过仅提供对象布局的高度和宽度来简化人机交互界面。 人们可以考虑更丰富的空间配置,例如 Gligen 的关键点,通过使用一组关键点坐标对方程 (4) 中的 进行参数化。 与编码框类似,傅立叶嵌入[44]可以应用于每个关键点位置。
-
•
空间对齐的条件。 为了实现更细粒度的可控性,可以使用空间对齐的条件图,例如边缘图、深度图、法线图和语义图。 在这些情况下,语义信息已经包含在条件图的每个空间坐标内。 网络(例如.转换层)可用于将编码为基础 Token 。 我们还注意到,将 额外输入 UNet 的第一个卷积层可以加速。 具体来说,UNet 的输入是 ,其中 是一个简单的下采样网络,用于将 降低到与 相同的空间分辨率。 在这种情况下,UNet 的第一个卷积层需要是可训练的。
图 1 显示了这些其他接地条件的生成示例。 请参阅支持以了解更多详细信息。
4.2 持续学习,打造接地气的一代
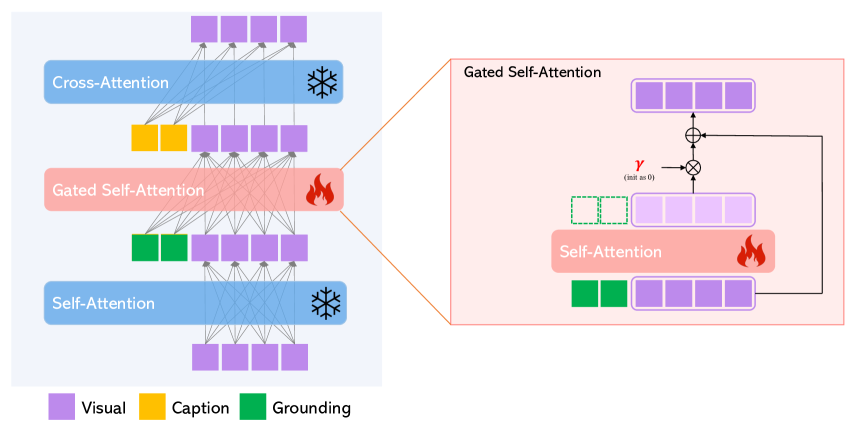
我们的目标是为现有的大型语言到图像生成模型赋予新的空间基础能力。 大型扩散模型已经在网络规模的图像文本上进行了预训练,以获得基于多样化和复杂的语言指令合成逼真图像所需的知识。 由于预训练成本高且性能优异,因此在扩展新能力的同时在模型权重中保留这些知识非常重要。 因此,我们考虑锁定原始模型权重,并通过调整新模块来逐步适应模型。
门控自我注意力。
我们将 表示为图像的视觉特征标记。 LDM 的原始 Transformer 块由两个注意力层组成:视觉标记上的自注意力,然后是来自标题标记的交叉注意力。 通过考虑残差连接,两层可以写成:
| (6) | |||
| (7) |
我们冻结这两个注意力层并添加一个新的门控自注意力层以启用空间接地能力;参见图3。 具体来说,注意力是在视觉和基础标记 的串联上执行的:
| (8) |
其中是仅考虑视觉标记的词符选择操作,是可学习标量,初始化为0。在期间设置为1整个训练过程,并且仅在推理期间的计划采样(下文介绍)中有所不同,以提高质量和可控性。 请注意,(8) 被注入到 (6) 和 (7) 之间。 直观上,(8)中的门控自注意力允许视觉特征利用条件信息,并且得到的接地特征被视为残差,其门最初设置为0(由于 被初始化为 0)。 这也使得训练更加稳定。 请注意,Flamingo [1] 中使用了类似的想法;然而,它使用门控交叉注意力,这导致我们的消融研究表现较差。
学习程序。
我们调整了预先训练的模型,以便可以在所有原始组件保持不变的情况下注入接地信息。 通过将所有新参数表示为,包括方程(8)中的所有门控自注意力层和方程(5)中的MLP,我们基于基础指令输入 ,使用 (1) 中的原始去噪目标进行模型持续学习:
| (9) |
为什么模型应该尝试使用新的接地信息? 直观上,如果模型可以利用外部知识(例如每个对象的位置),那么预测在反向扩散过程中添加到训练图像中的噪声会更容易。 因此,通过这种方式,模型学习使用附加信息,同时保留预先训练的概念知识。
推理中的预定采样。
Gligen的标准推理方案是将设置在(8)中,整个扩散过程受到接地 Token 的影响。 这种恒定的 采样方案在生成和基础方面提供了良好的整体性能,但有时与原始 text2img 模型相比生成的图像质量较低(例如,在高美学评分图像上对稳定扩散进行了微调)。 为了在Gligen的发电和接地之间取得更好的权衡,我们提出了一个预定的采样方案。 当我们冻结原始模型权重并添加新层以在训练中注入新的基础信息时,在推理过程中可以灵活地安排扩散过程以同时使用基础和语言标记或在任何时候仅使用原始模型的语言标记,通过在 (8) 中设置不同的 值。 具体来说,我们考虑一个两阶段推理过程,除以 。 对于具有步的扩散过程,可以在第一个步将设置为1,并在第一个步将设置为0剩余的 步骤:
| (10) |
计划采样的主要好处是提高视觉质量,因为在早期阶段确定粗略的概念位置和轮廓,然后在后期阶段确定细粒度的细节。 它还允许我们将在一个领域(人类关键点)训练的模型扩展到其他领域(猴子、卡通人物),如图1所示。
5实验
我们在封闭集和开放集设置中评估模型的框接地 text2img 生成,并展示对其他接地模式的扩展。 除非另有说明,我们通过在 LAION [57] 上预训练的 LDM 进行主要定量实验。
5.1 闭集接地 Text2Img 生成
我们首先在封闭环境中评估模型的发电质量和接地精度。 为此,我们在 COCO2014 [41] 数据集上进行训练和评估,该数据集是 text2img 文献 [70, 65, 82, 51, 56] 中使用的标准基准,并评估不同类型的接地指令如何影响我们模型的性能。
接地说明。
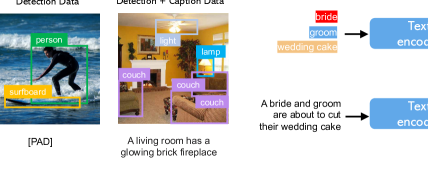
我们使用以下基础指令来训练我们的模型:1)COCO2014D:检测数据。 没有标题注释,因此我们使用空标题输入 [21]。 检测注释用作名词实体。 2)COCO2014CD:检测+字幕数据。 标题和检测注释都被使用。 请注意,名词实体可能并不总是存在于标题中。 3) COCO2014G:接地数据。 给定标题注释,我们使用 GLIP [34] 检测图像中标题的名词实体,以获取伪框标签。 关于这三类数据的更多详细信息请参阅supp。
| Model | Generation: FID | Grounding: YOLO | |
|---|---|---|---|
| Fine-tuned | Zero-shot | AP/AP50/AP75 | |
| CogView [11] | - | 27.10 | - |
| KNN-Diffusion [2] | - | 16.66 | - |
| DALL-E 2 [51] | - | 10.39 | - |
| Imagen [56] | - | 7.27 | - |
| Re-Imagen [7] | 5.25 | 6.88 | |
| Parti [74] | 3.20 | 7.23 | - |
| LAFITE [82] | 8.12 | 26.94 | - |
| LAFITE2 [80] | 4.28 | 8.42 | - |
| Make-a-Scene [13] | 7.55 | 11.84 | - |
| NÜWA [69] | 12.90 | - | - |
| Frido [12] | 11.24 | - | - |
| XMC-GAN [77] | 9.33 | - | - |
| AttnGAN [70] | 35.49 | - | - |
| DF-GAN [65] | 21.42 | - | - |
| Obj-GAN [35] | 20.75 | - | - |
| LDM [53] | - | 12.63 | - |
| LDM* | 5.91 | 11.73 | 0.6 / 2.0 / 0.3 |
| Gligen (COCO2014CD) | 5.82 | - | 21.7 / 39.0 / 21.7 |
| Gligen (COCO2014D) | 5.61 | - | 24.0 / 42.2 / 24.1 |
| Gligen (COCO2014G) | 6.38 | - | 11.2 / 21.2 / 10.7 |
基线。
表1列出了基准模型。 其中,我们还对 COCO2014 上的 LAION 400M [57] 上预训练的 LDM [53] 及其标题注释进行了微调,我们将其表示为 LDM*。
text2img 基线由于无法以框输入为条件,因此在 COCO2014C:标题数据上进行评估。
评估指标。
我们使用 30K 随机采样图像的标题和/或框注释来生成 30K 图像进行评估。 我们使用FID[20]来评估图像质量。 为了评估接地精度(即。输入边界框和生成实体之间的对应关系),我们使用YOLO分数 [40] 。 具体来说,我们使用预训练的 YOLO-v4 [5] 来检测生成图像上的边界框,并使用平均精度(AP)将它们与地面实况框进行比较。 由于之前的 text2img 方法不支持将框注释作为输入,因此在此指标上与它们进行比较是不公平的。 因此,我们仅报告微调 LDM 的数据作为参考。
结果。
表1显示了结果。 首先,我们发现,由于在预训练阶段学到了丰富的视觉知识,我们的方法的图像合成质量(通过 FID 测量)优于大多数最先进的基线。 接下来,我们发现所有三个基础指令都会产生与 LDM* 基线相当的 FID,该基线在 COCO2014 上通过标题注释进行了微调。 我们使用检测指令(COCO2014D)训练的模型具有整体最佳性能。 然而,当我们在 COCO2014CD 指令上评估这个模型时,我们发现它的性能较差(FID:8.2)——它理解真实字幕的能力可能有限,因为它只用空字幕进行训练。 对于使用 GLIP 接地指令 (COCO2014G) 训练的模型,我们实际上使用 COCO2014CD 指令对其进行评估,因为我们需要计算需要接地实况检测注释的 YOLO 分数。 它的 FID 稍差可能归因于它从 GLIP 伪标签中学习。 同样的原因可以解释其较低的 YOLO 分数(即。,模型在训练期间没有看到任何真实检测注释)。
总的来说,这个实验表明:1)我们的模型可以成功地将盒子作为附加条件,同时保持图像生成质量。 2) 所有基础指令类型都是有用的,这表明将它们的数据组合在一起可以带来互补的好处。

与 Layout2Img 生成方法的比较。
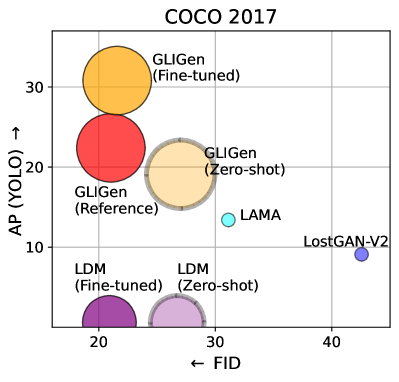
到目前为止,我们已经看到我们的模型正确地学习了使用接地条件。 但与专门为布局 2img 生成而设计的方法相比,它的准确度如何? 为了回答这个问题,我们在 COCO2017D 上训练我们的模型,它只有检测注释。 我们使用 2017 年的分割(而不是之前的 2014 年),因为它是 layout2img 文献中的标准基准。 在这个实验中,我们使用与所有layout2img基线完全相同的标注。
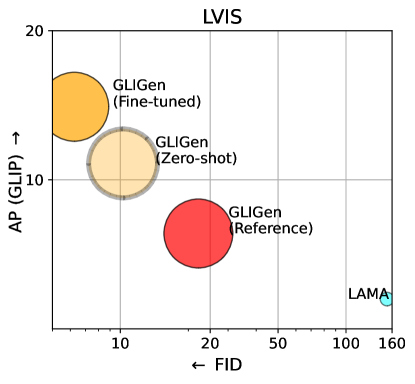
表 2 显示我们在图像质量和接地精度方面均实现了最先进的性能。 我们认为核心原因是因为以前的方法从头开始训练模型,而我们建立在具有丰富视觉语义的大规模预训练生成模型的基础上。 定性比较在支持中。 我们还扩大了训练数据(稍后讨论)并在此数据集上预训练了模型。 左图5显示了该模型的零样本和微调结果。
| Model | FID | YOLO score (AP/AP50/AP75) |
|---|---|---|
| LostGAN-V2 [62] | 42.55 | 9.1 / 15.3 / 9.8 |
| OCGAN [64] | 41.65 | - |
| HCSS [25] | 33.68 | - |
| LAMA [40] | 31.12 | 13.40 / 19.70 / 14.90 |
| TwFA [71] | 22.15 | - / 28.20 / 20.12 |
| Gligen-LDM | 21.04 | 22.4 / 36.5 / 24.1 |
| Model | Training data | AP | APr | APc | APf |
|---|---|---|---|---|---|
| LAMA [40] | LVIS | 2.0 | 0.9 | 1.3 | 3.2 |
| Gligen-LDM | COCO2014CD | 6.4 | 5.8 | 5.8 | 7.4 |
| Gligen-LDM | COCO2014D | 4.4 | 2.3 | 3.3 | 6.5 |
| Gligen-LDM | COCO2014G | 6.0 | 4.4 | 6.1 | 6.6 |
| Gligen-LDM | GoldG,O365 | 10.6 | 5.8 | 9.6 | 13.8 |
| Gligen-LDM | GoldG,O365,SBU,CC3M | 11.1 | 9.0 | 9.8 | 13.4 |
| Gligen-Stable | GoldG,O365,SBU,CC3M | 10.8 | 8.8 | 9.9 | 12.6 |
| Upper-bound | - | 25.2 | 19.0 | 22.2 | 31.2 |
|
|
5.2 开放集接地 Text2Img 生成

COCO-训练模型。 我们首先使用仅使用COCO(COCO2014CD)的接地注释进行训练的Gligen,并评估它是否可以生成超出COCO类别的接地实体。 图4显示了定性结果,其中Gligen可以奠定新概念,例如“冠蓝鸦”、“羊角面包”或地面物体属性,例如“棕色木桌”,超出训练类别。 我们假设这是因为 Gligen 的门控自注意力学习重新定位与随后的交叉注意力层的标题中的基础实体相对应的视觉特征,并由于以下原因获得泛化能力:这两层共享文本空间。
我们还定量评估了我们的模型在 LVIS [15] 上的零样本生成性能,其中包含 1203 个长尾对象类别。 我们使用 GLIP 从生成的图像中预测边界框并计算 AP,因此我们将其命名为 GLIP 分数。 我们与为layout2img任务设计的最先进模型进行比较:LAMA [40]。 我们使用 LVIS 训练集上的官方代码(在完全监督的环境中)训练 LAMA,而我们通过在 LVIS val 集上运行推理,以 零样本任务传输 方式直接评估我们的模型没有看到任何 LVIS 标签。 表 3(前 4 行)显示结果。 令人惊讶的是,尽管我们的模型只接受了 COCO 注释的训练,但它的表现却大大优于监督基线。 这是因为从头开始训练的基线很难从有限的注释中学习(LVIS 中的许多稀有类别的训练样本少于五个)。 相比之下,我们的模型可以利用预训练模型的大量概念知识。
扩大训练数据。
接下来,我们使用更大的训练数据来研究模型的开放集能力。 具体来说,我们遵循 GLIP [34] 并在 Object365 [58] 和 GoldG [34] 上进行训练,它结合了两个基础数据集:Flickr [49] 和 VG [31]。 我们还使用 CC3M [59] 和 SBU [46] 以及 GLIP 生成的接地伪标签。
表3显示了数据缩放结果。 当我们扩大训练数据时,我们模型的零样本性能会提高,特别是对于罕见的概念。 我们还尝试对在 LVIS 上最大的数据集上预训练的模型进行微调,并在右图 5 中展示其性能。 为了证明我们方法的通用性,我们还使用最大的数据基于稳定扩散模型检查点来训练我们的模型。 我们在图6中展示了使用该模型的一些定性示例。 与普通的稳定扩散相比,我们的模型获得了基础能力。 我们注意到,稳定扩散模型可能会忽略某些对象(第二个示例中的“umbrella”),因为它使用倾向于关注全局场景属性的 CLIP 文本编码器,并且可能会忽略对象级别详细信息[3]。 它还努力生成空间反事实概念。 通过通过接地标记显式注入实体信息,我们的模型可以通过两种方式提高接地能力:所引用的对象更有可能出现在生成的图像中,以及对象驻留在指定的空间位置。
5.3 超越文本形态基础
图像接地一代。 如前所述,我们还可以使用参考图像来表示接地实体。 图1(b)显示了定性结果,这表明视觉特征可以补充难以用语言描述的细节。
基于文本和图像的生成。
除了使用文本或图像来表示基础实体之外,人们还可以将两种表示形式保留在一个模型中,以实现更具创造性的生成。 图1(c)显示了带有风格/语气转移的文本生成。 对于样式参考图像,我们发现将其接地到图像角或其边缘就足够了。 由于模型需要为整个图像生成和谐的风格,我们假设自注意力层可以将此信息广播到所有像素,从而导致整个图像的风格一致。
关键点扎根一代。
我们还演示了使用关键点进行关节对象控制的Gligen,如图1(d)所示。 请注意,该模型仅使用人类关键点注释进行训练;但由于我们提出的预定采样技术,它可以推广到其他人形物体。 我们还在支持中定量研究了这种接地条件。
空间对齐的条件图接地生成。
图1 (e-h)展示了深度图、边缘图、法线图和语义图基础生成的结果。 这些类型的条件允许用户进行更细粒度的发电控制。 请参阅支持以获得更多定性结果。
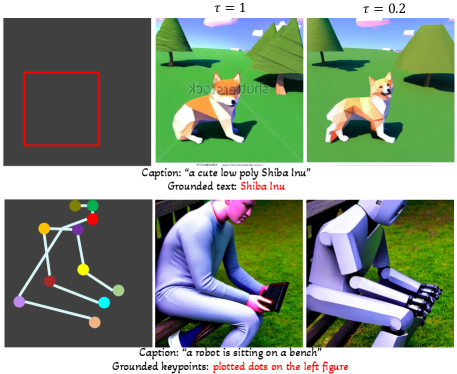
5.4预定采样
图 7 定性地显示了通过将 设置为 0.2 进行计划采样的好处。 同一行中的图像共享相同的噪声和条件输入。 第一行显示计划采样可用于提高图像质量,因为原始稳定扩散模型是使用高质量图像进行训练的。 第二行显示了使用 COCO 人类关键点注释训练的模型的生成示例。 由于该模型纯粹使用人类关键点进行训练,因此即使在标题中指定了不同的对象(即机器人),最终结果也会偏向于生成人类。 然而,通过使用计划采样,我们可以扩展该模型以生成具有类似人类形状的其他对象。
6结论
我们提出了Gligen来扩展具有接地能力的预训练text2img扩散模型,并使用边界框作为接地条件演示了开放世界泛化。 我们的方法简单有效,并且可以轻松扩展到其他条件,例如关键点、参考图像、空间对齐条件(例如边缘图、深度图等)。 Gligen 的多功能性使其成为推进文本到图像合成领域并扩展预训练模型在各种应用中的能力的有前途的方向。
致谢。
这项工作得到了 NSF CAREER IIS2150012、NASA 80NSSC21K0295 以及韩国政府 (MSIT) 资助的信息与通信技术规划与评估研究所 (IITP) 赠款的部分支持(No. 2022-0-00871,人工智能自主性的发展和人工智能代理协作的知识增强)和(No. RS-2022-00187238,用于高效预训练的大型韩语模型技术的开发),以及 Adobe 数据科学研究奖。
参考
- [1] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andy Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and Karen Simonyan. Flamingo: a visual language model for few-shot learning. ArXiv, abs/2204.14198, 2022.
- [2] Oron Ashual, Shelly Sheynin, Adam Polyak, Uriel Singer, Oran Gafni, Eliya Nachmani, and Yaniv Taigman. Knn-diffusion: Image generation via large-scale retrieval. arXiv preprint arXiv:2204.02849, 2022.
- [3] Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Karsten Kreis, Miika Aittala, Timo Aila, Samuli Laine, Bryan Catanzaro, Tero Karras, and Ming-Yu Liu. ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers. ArXiv, abs/2211.01324, 2022.
- [4] Hangbo Bao, Li Dong, and Furu Wei. Beit: Bert pre-training of image transformers. arXiv preprint arXiv:2106.08254, 2021.
- [5] Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection. ArXiv, abs/2004.10934, 2020.
- [6] Huiwen Chang, Han Zhang, Jarred Barber, AJ Maschinot, Jose Lezama, Lu Jiang, Ming-Hsuan Yang, Kevin Murphy, William T Freeman, Michael Rubinstein, et al. Muse: Text-to-image generation via masked generative transformers. arXiv preprint arXiv:2301.00704, 2023.
- [7] Wenhu Chen, Hexiang Hu, Chitwan Saharia, and William W Cohen. Re-imagen: Retrieval-augmented text-to-image generator. arXiv preprint arXiv:2209.14491, 2022.
- [8] Yunjey Choi, Min-Je Choi, Mun Su Kim, Jung-Woo Ha, Sunghun Kim, and Jaegul Choo. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8789–8797, 2018.
- [9] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics.
- [10] Prafulla Dhariwal and Alex Nichol. Diffusion models beat gans on image synthesis. ArXiv, abs/2105.05233, 2021.
- [11] Ming Ding, Zhuoyi Yang, Wenyi Hong, Wendi Zheng, Chang Zhou, Da Yin, Junyang Lin, Xu Zou, Zhou Shao, Hongxia Yang, and Jie Tang. Cogview: Mastering text-to-image generation via transformers, 2021.
- [12] Wanshu Fan, Yen-Chun Chen, Dongdong Chen, Yu Cheng, Lu Yuan, and Yu-Chiang Frank Wang. Frido: Feature pyramid diffusion for complex scene image synthesis. ArXiv, abs/2208.13753, 2022.
- [13] Oran Gafni, Adam Polyak, Oron Ashual, Shelly Sheynin, Devi Parikh, and Yaniv Taigman. Make-a-scene: Scene-based text-to-image generation with human priors. ArXiv, abs/2203.13131, 2022.
- [14] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. Generative adversarial nets. In NIPS, 2014.
- [15] Agrim Gupta, Piotr Dollár, and Ross B. Girshick. Lvis: A dataset for large vocabulary instance segmentation. CVPR, pages 5351–5359, 2019.
- [16] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16000–16009, 2022.
- [17] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, 2020.
- [18] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross B. Girshick. Mask r-cnn. 2017 IEEE International Conference on Computer Vision (ICCV), pages 2980–2988, 2017.
- [19] Kaiming He, X. Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. CVPR, pages 770–778, 2016.
- [20] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In NIPS, 2017.
- [21] Jonathan Ho. Classifier-free diffusion guidance. ArXiv, abs/2207.12598, 2022.
- [22] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural Computation, 9:1735–1780, 1997.
- [23] Ray S Jackendoff. Semantic structures, volume 18. MIT press, 1992.
- [24] Manuel Jahn, Robin Rombach, and Björn Ommer. High-resolution complex scene synthesis with transformers. ArXiv, abs/2105.06458, 2021.
- [25] Manuel Jahn, Robin Rombach, and Björn Ommer. High-resolution complex scene synthesis with transformers. ArXiv, abs/2105.06458, 2021.
- [26] Justin Johnson, Agrim Gupta, and Li Fei-Fei. Image generation from scene graphs. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1219–1228, 2018.
- [27] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. CVPR, pages 4396–4405, 2019.
- [28] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. CVPR, pages 4396–4405, 2019.
- [29] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8107–8116, 2020.
- [30] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. CoRR, abs/1412.6980, 2015.
- [31] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A. Shamma, Michael S. Bernstein, and Li Fei-Fei. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision, 123:32–73, 2016.
- [32] Chunyuan Li, Haotian Liu, Liunian Harold Li, Pengchuan Zhang, Jyoti Aneja, Jianwei Yang, Ping Jin, Houdong Hu, Zicheng Liu, Yong Jae Lee, and Jianfeng Gao. ELEVATER: A benchmark and toolkit for evaluating language-augmented visual models. In NeurIPS Track on Datasets and Benchmarks, 2022.
- [33] Junnan Li, Ramprasaath R Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, and Steven Hoi. Align before fuse: Vision and language representation learning with momentum distillation. arXiv preprint arXiv:2107.07651, 2021.
- [34] Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. Grounded language-image pre-training. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 10955–10965. IEEE, 2022.
- [35] Wenbo Li, Pengchuan Zhang, Lei Zhang, Qiuyuan Huang, Xiaodong He, Siwei Lyu, and Jianfeng Gao. Object-driven text-to-image synthesis via adversarial training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12174–12182, 2019.
- [36] Yuheng Li, Yijun Li, Jingwan Lu, Eli Shechtman, Yong Jae Lee, and Krishna Kumar Singh. Collaging class-specific gans for semantic image synthesis. ICCV, pages 14398–14407, 2021.
- [37] Yuheng Li, Yijun Li, Jingwan Lu, Eli Shechtman, Yong Jae Lee, and Krishna Kumar Singh. Contrastive learning for diverse disentangled foreground generation. ArXiv, abs/2211.02707, 2022.
- [38] Yuheng Li, Krishna Kumar Singh, Utkarsh Ojha, and Yong Jae Lee. Mixnmatch: Multifactor disentanglement and encoding for conditional image generation. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8036–8045, 2020.
- [39] Z. Li, Jingyu Wu, Immanuel Koh, Yongchuan Tang, and Lingyun Sun. Image synthesis from layout with locality-aware mask adaption. ICCV, pages 13799–13808, 2021.
- [40] Z. Li, Jingyu Wu, Immanuel Koh, Yongchuan Tang, and Lingyun Sun. Image synthesis from layout with locality-aware mask adaption. ICCV, pages 13799–13808, 2021.
- [41] Tsung-Yi Lin, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.
- [42] Haotian Liu, Kilho Son, Jianwei Yang, Ce Liu, Jianfeng Gao, Yong Jae Lee, and Chunyuan Li. Learning customized visual models with retrieval-augmented knowledge. CVPR, 2023.
- [43] Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
- [44] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020.
- [45] Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. In ICML, 2022.
- [46] Vicente Ordonez, Girish Kulkarni, and Tamara L. Berg. Im2text: Describing images using 1 million captioned photographs. In NIPS, 2011.
- [47] Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive normalization. CVPR, pages 2332–2341, 2019.
- [48] Deepak Pathak, Philipp Krähenbühl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros. Context encoders: Feature learning by inpainting. CVPR, pages 2536–2544, 2016.
- [49] Bryan A. Plummer, Liwei Wang, Christopher M. Cervantes, Juan C. Caicedo, J. Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. International Journal of Computer Vision, 123:74–93, 2015.
- [50] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In ICML, 2021.
- [51] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. ArXiv, abs/2204.06125, 2022.
- [52] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 8821–8831. PMLR, 18–24 Jul 2021.
- [53] Robin Rombach, A. Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. CVPR, pages 10674–10685, 2022.
- [54] O. Ronneberger, P.Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention (MICCAI), volume 9351 of LNCS, pages 234–241. Springer, 2015. (available on arXiv:1505.04597 [cs.CV]).
- [55] Chitwan Saharia, William Chan, Huiwen Chang, Chris A. Lee, Jonathan Ho, Tim Salimans, David J. Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. ACM SIGGRAPH 2022 Conference Proceedings, 2022.
- [56] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L. Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, Seyedeh Sara Mahdavi, Raphael Gontijo Lopes, Tim Salimans, Jonathan Ho, David J. Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. ArXiv, abs/2205.11487, 2022.
- [57] Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. LAION-400M: open dataset of clip-filtered 400 million image-text pairs. CoRR, abs/2111.02114, 2021.
- [58] Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. ICCV, pages 8429–8438, 2019.
- [59] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In ACL, 2018.
- [60] Yujun Shen, Jinjin Gu, Xiaoou Tang, and Bolei Zhou. Interpreting the latent space of gans for semantic face editing. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9240–9249, 2020.
- [61] Wei Sun and Tianfu Wu. Image synthesis from reconfigurable layout and style. ICCV, pages 10530–10539, 2019.
- [62] Wei Sun and Tianfu Wu. Learning layout and style reconfigurable gans for controllable image synthesis. TPAMI, 44:5070–5087, 2022.
- [63] Tristan Sylvain, Pengchuan Zhang, Yoshua Bengio, R. Devon Hjelm, and Shikhar Sharma. Object-centric image generation from layouts. ArXiv, abs/2003.07449, 2021.
- [64] Tristan Sylvain, Pengchuan Zhang, Yoshua Bengio, R. Devon Hjelm, and Shikhar Sharma. Object-centric image generation from layouts. ArXiv, abs/2003.07449, 2021.
- [65] Ming Tao, Hao Tang, Songsong Wu, N. Sebe, Fei Wu, and Xiaoyuan Jing. Df-gan: Deep fusion generative adversarial networks for text-to-image synthesis. ArXiv, abs/2008.05865, 2020.
- [66] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
- [67] Ashish Vaswani, Noam M. Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. ArXiv, abs/1706.03762, 2017.
- [68] Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8798–8807, 2018.
- [69] Chenfei Wu, Jian Liang, Lei Ji, Fan Yang, Yuejian Fang, Daxin Jiang, and Nan Duan. Nüwa: Visual synthesis pre-training for neural visual world creation. In European Conference on Computer Vision, 2022.
- [70] Tao Xu, Pengchuan Zhang, Qiuyuan Huang, Han Zhang, Zhe Gan, Xiaolei Huang, and Xiaodong He. Attngan: Fine-grained text to image generation with attentional generative adversarial networks. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1316–1324, 2018.
- [71] Zuopeng Yang, Daqing Liu, Chaoyue Wang, J. Yang, and Dacheng Tao. Modeling image composition for complex scene generation. CVPR, pages 7754–7763, 2022.
- [72] Zuopeng Yang, Daqing Liu, Chaoyue Wang, J. Yang, and Dacheng Tao. Modeling image composition for complex scene generation. CVPR, pages 7754–7763, 2022.
- [73] Zhengyuan Yang, Jianfeng Wang, Zhe Gan, Linjie Li, Kevin Lin, Chenfei Wu, Nan Duan, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Reco: Region-controlled text-to-image generation. ArXiv, abs/2211.15518, 2022.
- [74] Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, Benton C. Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge, and Yonghui Wu. Scaling autoregressive models for content-rich text-to-image generation. ArXiv, abs/2206.10789, 2022.
- [75] Lu Yuan, Dongdong Chen, Yi-Ling Chen, Noel Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xuedong Huang, Boxin Li, Chunyuan Li, et al. Florence: A new foundation model for computer vision. arXiv preprint arXiv:2111.11432, 2021.
- [76] Alireza Zareian, Kevin Dela Rosa, Derek Hao Hu, and Shih-Fu Chang. Open-vocabulary object detection using captions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14393–14402, 2021.
- [77] Han Zhang, Jing Yu Koh, Jason Baldridge, Honglak Lee, and Yinfei Yang. Cross-modal contrastive learning for text-to-image generation, 2021.
- [78] Bo Zhao, Lili Meng, Weidong Yin, and Leonid Sigal. Image generation from layout. CVPR, pages 8576–8585, 2019.
- [79] Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. RegionCLIP: Region-based language-image pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16793–16803, 2022.
- [80] Yufan Zhou, Chunyuan Li, Changyou Chen, Jianfeng Gao, and Jinhui Xu. Lafite2: Few-shot text-to-image generation. arXiv preprint arXiv:2210.14124, 2022.
- [81] Yufan Zhou, Bingchen Liu, Yizhe Zhu, Xiao Yang, Changyou Chen, and Jinhui Xu. Shifted diffusion for text-to-image generation. arXiv preprint arXiv:2211.15388, 2022.
- [82] Yufan Zhou, Ruiyi Zhang, Changyou Chen, Chunyuan Li, Chris Tensmeyer, Tong Yu, Jiuxiang Gu, Jinhui Xu, and Tong Sun. Towards language-free training for text-to-image generation. CVPR, 2022.
- [83] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Computer Vision (ICCV), 2017 IEEE International Conference on, 2017.
- [84] Xueyan Zou*, Zi-Yi Dou*, Jianwei Yang*, Zhe Gan, Linjie Li, Chunyuan Li, Xiyang Dai, Jianfeng Wang, Lu Yuan, Nanyun Peng, Lijuan Wang, Yong Jae Lee,̂ and Jianfeng Gao.̂ Generalized decoding for pixel, image and language. arXiv, 2022.
附录
在本补充材料中,我们提供了更多实施和训练细节,然后呈现更多结果和讨论。
附录A实施和训练细节
我们以稳定扩散模型[53]为例来说明我们的实现细节。
带文本的盒子接地标记。
每个接地文本首先被输入文本编码器以获得文本嵌入(例如.,稳定扩散中 CLIP 文本嵌入的 768 维)。 由于稳定扩散使用从 Transformer 主干输出的 77 个文本标记的特征,因此我们在这一层选择“EOS”词符特征作为我们的接地文本嵌入。 这是因为在CLIP训练中,选择了这个“EOS”词符特征,并应用了线性变换(一个FC层)来与视觉特征进行比较,因此这个词符特征应该包含关于输入文本描述。 我们还尝试直接使用 CLIP 文本嵌入(在线性投影之后),但是,我们注意到经验上的收敛缓慢可能是由于基础文本嵌入和标题嵌入之间的空间未对齐。 遵循 NeRF [44],我们使用输出维度 64 的傅立叶嵌入对边界框坐标进行编码。 正如主论文中的方程 5 中所述,我们首先连接这两个特征并将它们输入多层感知器。 MLP由三个隐藏层组成,隐藏维度为512,输出接地词符维度设置为与文本嵌入维度相同(e.g.,768稳定扩散情况)。 在边界框情况下,我们将接地标记的最大数量设置为 30。
带图像的盒子接地 Token 。
我们用类似的方式来获取图像的基础词符。 我们使用 CLIP 图像编码器(ViT-L-14 用于稳定扩散)来获得图像嵌入。 我们将 CLIP 训练目标表示为最大化 (我们省略标准化),其中 是来自文本编码器的“EOS”词符嵌入, 是来自图像编码器的“CLS”词符嵌入, 和 分别是文本和图像嵌入的线性变换。 由于是用于基础文本特征的文本特征空间,为了简化我们的训练,我们选择通过将图像特征投影到文本特征空间中,并将其归一化为28.7,这是我们根据经验发现的 的平均范数。 我们还将接地 Token 的最大数量设置为 30。 因此,如果同时保留图像和文本作为接地实体的表示,则总共有 60 个标记。
关键点接地 Token 。
关键点注释的基础词符以相同的方式处理,除了我们还学习 人词符嵌入向量 来在语义上链接属于同一个人的关键点。 这是为了处理我们要生成的同一张图像中有多个人的情况,以便模型知道哪个关键点对应于哪个人。 每个关键点语义嵌入都是一个可学习的向量;每个人词符的维度设置为与关键点嵌入维度相同。 接地词符的计算公式为:
| (11) |
其中是每个关键点的位置,是第人的人称词符。 实际中,我们将设置为10,这是每张图像中允许生成的最大人数。 因此,COCO 数据集中有 170 个标记(即.,10*17;每个人有 17 个关键点注释)。
空间对齐条件的标记。
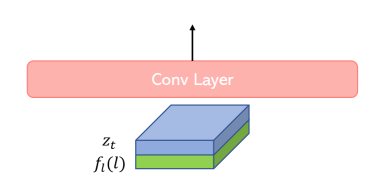
此类条件包括边缘图、深度图、语义图、法线图等;它们可以表示为 张量。 我们将空间大小调整为 ,并使用 convnext-tiny [43] 作为主干,输出空间大小为 的特征,然后是扁平化为 64 个接地 Token 。 我们注意到,如果我们还在 Unet 输入中提供接地条件 ,它可以帮助更快地训练。 如图8所示,在本例中,输入为,其中是一个简单的下采样网络,用于减少进入与 相同的空间维度,这是时间步 处的噪声潜在代码( 表示稳定扩散)。 在这种情况下,Unet 的第一个卷积层需要是可训练的。
门控自注意力层。
我们插入的自注意力层与每个 Transformer 块处的原始扩散模型自注意力层相同,只是我们添加了一个线性投影层,该线性投影层将基础词符转换为与视觉词符相同的维度。 例如,UNet下行分支第一层[54],投影层将768维的接地词符转换为320(即本层图像特征维度),视觉标记与基础标记连接起来,作为门控注意力层的输入。
训练详情。
数据详细信息。
在主要论文第5.1中,我们研究了盒接地的三种不同类型的数据。 训练数据需要文本 和基础实体 作为完整条件。 在实践中,我们可以考虑更灵活的输入来放宽数据要求,即即.图9所示的三种类型的数据。 接地数据。 每个图像都与描述整个图像的标题相关联;名词实体从标题中提取,并用边界框标记。 由于名词实体直接取自自然语言标题,因此它们可以涵盖更丰富的词汇,这将有利于基于开放世界的词汇生成。 检测数据。 名词实体是预定义的封闭集类别(例如.,COCO [41]中的80个对象类)。 在这种情况下,我们选择使用无分类器指南 [21] 中介绍的空标题词符作为标题。 探测数据的数量(百万)比落地数据(数千)大,因此可以大大增加整体训练数据。 检测和字幕数据。 名词实体与检测数据中的相同,并且用文本标题单独描述图像。 在这种情况下,名词实体可能与标题中的名词实体不完全匹配。 例如,在图9中,标题仅给出了客厅的高级描述,而没有提及场景中的对象,而检测标注提供了更细粒度的对象级细节。
附录 B消融研究
门控自注意力的消融。
空标题上的消融。
当我们只有检测注释时,我们选择使用空标题(COCO2014D)。 另一种方案是简单地将所有名词实体组合成一个句子; 例如.,如果图像中有两只猫和一只狗,则伪标题可以是:“猫,猫,狗” 。 在这种情况下,FID 变得更差,从 5.61 增加到 7.40(空标题,参见主论文表 1)。 这可能是因为预训练的文本编码器在 LDM 训练期间从未遇到过这种类型的不自然的标题。 解决方案是微调文本编码器或设计更好的提示,但这不是我们工作的重点。
傅里叶嵌入的消融。
附录C接地修复

| 1%-3% | 5%-10% | 30%-50% | |
|---|---|---|---|
| LDM [53] | 25.9 | 23.4 | 14.6 |
| Gligen-LDM | 29.7 | 30.9 | 25.6 |
| Upper-bound | 41.7 | 43.4 | 45.0 |

C.1 基于文本的修复
与其他扩散模型一样,Gligen 也可以通过在每个采样步骤后用 中的样本替换已知区域来完成修复任务,其中 是图像[53]的潜在表示。 我们可以根据缺失区域进行文本描述,如图10所示。 然而,在这种情况下,人们可能想知道,我们是否可以简单地使用普通文本到图像扩散模型(例如稳定扩散或 DALLE2)通过提供对象名称作为标题来填充缺失区域? 在这种情况下,额外的接地输入有什么好处? 为了回答这个问题,我们在 COCO 数据集上进行了以下实验:对于每张图像,我们随机屏蔽一个对象。 然后我们让模型修复缺失的区域。 我们选择相对于图像具有三种不同尺寸比例的缺失对象:小(1%-3%)、中值(5%-10%)和大(30%-50%)。 每个案例使用 5000 张图像。
表 4 表明,与基线相比,我们的修复对象更紧密地占据了缺失区域(框)。 图10提供了直观比较修复结果的示例(我们使用稳定扩散以获得更好的质量)。 第一行显示基线生成的对象不遵循提供的框。 第二行显示,当图像中已经存在缺失的类别时,他们可能会忽略标题。 这是可以理解的,因为基线经过训练可以在标题后面生成整个图像。 我们的方法可能更适合编辑应用程序,其中用户可能希望生成完全适合缺失区域的对象或添加图像中已存在的类的实例。

| Model | Pre-training data | Traing data | FID | AP | APr | APc | APf |
|---|---|---|---|---|---|---|---|
| LAMA [40] | – | LVIS | 151.96 | 2.0 | 0.9 | 1.3 | 3.2 |
| Gligen-LDM | COCO2014CD | – | 22.17 | 6.4 | 5.8 | 5.8 | 7.4 |
| Gligen-LDM | COCO2014D | – | 31.31 | 4.4 | 2.3 | 3.3 | 6.5 |
| Gligen-LDM | COCO2014G | – | 13.48 | 6.0 | 4.4 | 6.1 | 6.6 |
| Gligen-LDM | GoldG,O365 | – | 8.45 | 10.6 | 5.8 | 9.6 | 13.8 |
| Gligen-LDM | GoldG,O365,SBU,CC3M | – | 10.28 | 11.1 | 9.0 | 9.8 | 13.4 |
| Gligen-LDM | GoldG,O365,SBU,CC3M | LVIS | 6.25 | 14.9 | 10.1 | 12.8 | 19.3 |
| Upper-bound | – | – | – | 25.2 | 19.0 | 22.2 | 31.2 |
C.2 基于图像的修复
正如我们之前所演示的,可以将文本接地到缺失区域进行修复,也可以将参考图像接地到缺失区域。 图13显示了基于参考图像的修复结果。 为了消除边界伪影,我们遵循 GLIDE [45],并通过添加 5 个额外通道(4 个用于 和 1 个用于修复掩模)来修改第一个卷积层,并使它们可训练随着新添加的层。

| Model | FID | AP | AP50 | AP75 |
|---|---|---|---|---|
| pix2pixHD [68] | 142.4 | 15.8 | 33.7 | 13.0 |
| Gligen (w/o caption) | 31.02 | 31.8 | 53.5 | 31.0 |
| Gligen (w caption) | 27.34 | 31.5 | 52.9 | 31.0 |
| Upper-bound | - | 62.4 | 75.0 | 65.9 |
附录D关键点接地研究
尽管到目前为止我们已经展示了边界框的结果,但我们的方法在可用于生成的接地条件方面具有灵活性。 为了证明这一点,我们接下来使用另一种基础条件来评估我们的模型:人类关键点。 我们使用 COCO2017 数据集。 我们与经典的图像到图像翻译模型 pix2pixHD [68] 进行比较。 由于 pix2pixHD 不将字幕作为输入,因此我们训练模型的两种变体:一种使用 COCO 字幕,另一种则不使用。 在后一种情况下,空标题用作交叉注意层的输入以进行公平比较。
附录E其他定量结果
在本节中,我们将展示使用我们最大的数据(GoldG、O365、CC3M、SBU)的预训练模型的更多研究。 我们在主论文表3中报告了该模型在 LVIS [15] 上的零样本性能。 在这里,我们在 LVIS 上微调该模型,并在表 5 中报告其 GLIP 分数。 显然,经过微调,我们显示了更准确的生成结果,大大超过了监督基线 LAMA [40]。
同样,我们也在 COCO2017 val-set 上测试了该模型的零样本性能,其微调结果如表7所示。 结果表明预训练的好处可以大大提高布局对应性能。
| YOLO score | ||||
| Model | FID | AP | AP50 | AP75 |
| LostGAN-V2 [62] | 42.55 | 9.1 | 15.3 | 9.8 |
| OCGAN [64] | 41.65 | – | ||
| HCSS [25] | 33.68 | – | ||
| LAMA [40] | 31.12 | 13.40 | 19.70 | 14.90 |
| TwFA [71] | 22.15 | – | 28.20 | 20.12 |
| Gligen-LDM | 21.04 | 22.4 | 36.5 | 24.1 |
| After pretrain on GoldG,O365,SBU,CC3M | ||||
| Gligen-LDM (zero-shot) | 27.03 | 19.1 | 30.5 | 20.8 |
| Gligen-LDM (finetuned) | 21.58 | 30.8 | 42.3 | 35.3 |
附录FGligen分析
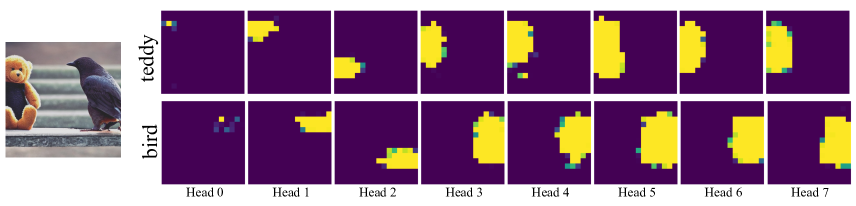
为了更好地理解Gligen,我们选择研究盒接地模型。 具体来说,我们尝试可视化门控训练自注意力层中的注意力图,以及方程 8 中的可学习 在此过程中如何变化。
在图14中,我们首先显示使用两个接地 Token (泰迪熊;鸟)的生成结果。 接下来,我们可视化在视觉特征之间添加的层的注意力图,以及 UNet 中一个中间层的所有 8 个头的两个接地标记。 即使对于第一个采样步骤(输入是高斯噪声),视觉特征也开始关注具有正确空间对应的基础标记。 这种对应关系在后面的采样步骤中逐渐消失(这与我们的“计划采样技术”一致,我们发现粗略布局是在早期采样步骤中决定的)。
我们还发现 UNet 开始层的注意力图对于所有样本步骤来说都难以解释。 我们假设这是由于缺乏视觉标记的位置嵌入,而位置信息可以通过Conv层通过零填充泄漏到后面的层中。 这可能表明为扩散模型预训练(例如稳定扩散模型训练)添加位置嵌入可能有利于下游适应。
附录 G更多定性结果
我们在图11中展示了与layout2img基线的定性比较,它补充了主论文第5.1中的结果。 结果表明,我们的模型在 LDM 上构建时具有可比的图像质量,但在稳定扩散模型上构建时具有更多的视觉吸引力和细节。
最后,我们在图 16 中展示了带有边界框的更接地的 text2img 结果,并在图 17 18 19 20 21 22 中展示了其他模态的接地结果。 请注意,我们的关键点模型仅使用来自 COCO [41] 的关键点注释,与个人身份无关,但它可以成功地利用和结合在 text2img 训练阶段学到的知识来控制特定的关键点人。 出于好奇,我们还测试了在人类身上学到的关键点接地信息是否可以转移到其他非人形类别(例如猫或灯)以进行关键点接地生成,但我们发现即使采用预定采样,我们的模型在这种情况下也会遇到困难。 与边界框相比,边界框仅指定图像中对象的粗略位置和大小,因此可以在所有对象类别之间共享,关键点(即对象部分)并不总是可以在不同类别之间共享。 因此,虽然关键点比框能够实现更细粒度的控制,但它们的通用性较差。